
Research on Communication Signal Modulation Recognition Based on a CCLDNN
College of Electrical Engineering, Sichuan University, Chengdu 610065, China
*
Author to whom correspondence should be addressed.
Electronics 2024, 13(9), 1604; https://doi.org/10.3390/electronics13091604
Submission received: 26 March 2024
/
Revised: 18 April 2024
/
Accepted: 19 April 2024
/
Published: 23 April 2024
(This article belongs to the Section Microwave and Wireless Communications)
Abstract
:In this paper, a new automatic modulation recognition (AMR) method named CCLDNN (complex-valued convolution long short-term memory deep neural network) is proposed. It is designed to significantly improve the recognition accuracy of modulation modes in low signal-to-noise ratio (SNR) environments. The model integrates the advantages of existing mainstream neural networks. The phase and amplitude information of complex signals is effectively captured through a complex module in the input layer. The Squeeze-and-Excitation (SE) attention mechanism, Bi-LSTM layer, and deep convolutional layer are introduced in the feature extraction layer to gradually enhance feature expression. Among these, the introduction of LSTM enables the model to capture the sequence dependence of signals, and the application of the SE attention mechanism further improves the model’s ability to focus on key features. Tests using the RadioML2016.10a dataset show that the model performs well at multiple SNR levels, achieving an average recognition accuracy of more than 80% over an SNR range of 0 dB to 18 dB. However, under the condition of a low SNR from −20 dB to −2 dB, the model still maintains a high recognition ability. The advanced CCLDNN method shows great deep learning potential in solving practical communication problems.
1. Introduction
Radio signal automatic modulation recognition [1,2,3,4] (AMR) is a key technology in the field of signal processing and pattern recognition. It has important application value and scientific significance in both military and civilian fields, such as radio management [5], wireless signal monitoring [6], and electronic information warfare [7]. Due to AMR’s strong robustness and high accuracy, it is often used for wireless source identification and shielding from surrounding interference to improve spectral efficiency. Many scholars have conducted a lot of research on this technology. After decades of development, radio signal modulation technologies are mainly divided into two categories: those that use the decision theory modulation method based on maximum likelihood (LB) [8,9,10] and those that use the pattern recognition method based on feature extraction (FB) [11,12,13].
In recent years, with the development of deep learning, neural network models have been applied extensively in intelligent speech recognition, computer image processing, and other fields. Tim O’Shea et al. [14] applied convolutional neural networks (CNNs) to signal modulation recognition and generated radio machine learning datasets using GNU radio. Zhao et al. [15] added a Bi-LSTM model to a CNN to generate a CBLSTM model, which showed better results than RNN, LSTM, and other models in signal fault diagnosis. A generative adversarial network (GAN) model has also been combined with CNNs to effectively reduce the interference of noise on time–frequency image signals [5]. At the same time, some researchers have proposed a CLDNN structure by combining a CNN with a long short-term memory (LSTM) network and achieved a better recognition effect than CNNs on the same dataset [16]. Sun et al. [17] introduced the CLDNN model into the recognition of radiation source signals and replaced the short-term memory layer with a bidirectional gated cycle unit layer to achieve a balance between recognition speed and accuracy.
Compared with a traditional CNN, although the signal recognition accuracy of the one-dimensional convolutional long-term deep neural network (1CLDNN) is better, the effect is still limited in an environment with a low signal-to-noise ratio [16]. Based on this, Zou et al. used a short-link layer that could recognize modulated signals more efficiently, and they established an attention mechanism short-link convolution long short-term memory deep neural network (ASCLDNN) model to improve the recognition effect. Qi et al. [18] proposed several AMC methods based on a prototype and variants of the convolutional neural network (CNN). A waveform spectrum multimode fusion (WSMF) method based on a deep residual network (Resnet) was used to implement AMC, and the feature fusion strategy was used to fuse the multimodal features of the signal to obtain more distinguishing features. Simulation results showed that, compared with the traditional CNN-based single-mode information AMC method, the proposed method performed better, and it could distinguish 16 types of modulation signals and work well in higher-order digital modulation types. Wang et al. [19] proposed an AMC based on federated learning and introduced balanced cross-entropy to solve the class imbalance problem. Tests showed that the average accuracy difference between FedeAMC and CentAMC was less than 2%. Additionally, the risk of data breaches was low, and it did not result in significant performance losses. Zhang et al. [20] proposed an AMC feature fusion scheme based on a convolutional neural network (CNN). The scheme aims to extract more distinguishing features by combining various images and hand-made signal features. Firstly, it extracts eight manual features and different image features, and then it combines the image features and manual features to produce joint features. The multimodal fusion model is used to fuse the joint features. The results showed that the scheme had excellent performance, and a classification accuracy of 92.5% could still be achieved when the SNR was −4 dB. In 2023, Xu et al. [21] proposed an automatic signal modulation classification and recognition algorithm based on a neural network autoencoder to solve the problem of traditional noise reduction algorithms damaging signals with high SNR. The results showed that the accuracy of automatic modulation classification and recognition improved and became stable with the increase in modulation signals. In the same year, Zheng et al. [22] first tried to regularize deep learning models based on sample SNR distribution to improve AMC accuracy, and they proposed a prior regularization method in deep learning (DL-PR) to guide loss optimization during model training. This method retains the original information of the received signal as much as possible, and it makes full use of prior knowledge in the signal transmission process, finally helping the deep learning model to obtain good generalization on various signal to noise ratio (SNR) signals. In 2024, Jang et al. [23] proposed a scalable AMC scheme called Meta-Transformer, a meta-learning framework based on small sample learning (FSL) to acquire general knowledge and learning methods for AMC tasks. This approach enables the model to identify new unseen modulations using only a very small number of samples, eliminating the need to completely retrain the model.
In order to further improve the signal recognition rate and recognition effect, based on the CLDNN model, this study adds a complex number module, introduces a bidirectional and multilayer long short-term memory network, and integrates an attention mechanism, thus establishing the CCLDNN model. The signal recognition effect of the new model is compared with that of several typical models, and the results show better performance.
The inclusion of a complex number module in the CCLDNN framework is a strategic enhancement aimed at capturing the intricate properties of signals, especially those inherent in electromagnetic waves and signals that are naturally represented in a complex number format. Complex numbers enable the model to handle phase information and amplitude in a unified framework, providing a more comprehensive analysis of signals than traditional real-valued models. This capability is particularly advantageous in environments where phase information is critical for accurate signal recognition.
By integrating bidirectional and multilayer LSTM networks, the CCLDNN model gains a profound ability to capture temporal dependencies in both forward and backward directions across multiple layers. This structure enhances the capacity of the model to learn from the temporal context of signals, significantly improving the recognition of patterns that span across various time intervals. The multilayer aspect allows for a hierarchical processing of features, where higher-level abstractions of the input data can be learned at deeper layers, thus contributing to a more nuanced understanding of complex signal dynamics.
The incorporation of an attention mechanism into the CCLDNN model aims to meet the evolving need for models to discern and prioritize relevant features within a vast array of signal data. This mechanism enables the model to focus on the parts of the signal that are the most informative for the task at hand, thereby enhancing the efficiency and accuracy of signal recognition. The attention mechanism is especially beneficial in scenarios where signals are corrupted by noise or when dealing with signals of varying lengths and intensities, which are very important in practical use.
2. Materials and Methods
2.1. The Data
The RadioML2016.10a dataset is used to evaluate the performance of the proposed model after processing. The dataset contains 11 modulated signals, of which 8 are digitally modulated and 3 are analog-modulated. The eight digital signals are composed of BPSK, QPSK, 8PSK, 16QAM, 64QAM, BFSK, CPFSK, and PAM4, and the three analog signals are composed of WB-FM, AM-SS, and AM-DSB.
2.2. Methods
2.2.1. Data Preprocessing and Dataset
To evaluate the performance of the proposed automatic modulation recognition (AMR) model, we use the RadioML2016.10a dataset, which is widely used in modulation recognition studies. It contains 11 modulation types of signals with different signal-to-noise ratios (SNRs), covering both analog and digital modulation. Each sample is a time series with 128 complex sampling points, which can be represented as a two-dimensional array (2, 128). The sample group can be represented as (X, 2, 128), where X is the number of samples, 2 represents the real and imaginary parts of the complex number, and 128 is the length of each sample. We preprocess these complex signals, including normalization, to prepare the data for input to the model.
2.2.2. CCLDNN Model Architecture
A complex-valued convolutional neural network (CV-CNN) is a type of neural network specifically designed to handle data with complex forms. It is particularly suitable for processing data such as radio signals that naturally exist in the complex domain. Compared with traditional real-valued networks, a CV-CNN can effectively capture the phase information of data by maintaining the complex-valued form of the data, which is crucial for many applications. For example, in wireless communication, the phase of a signal carries important timing and modulation information. By processing the signal directly in the complex domain, a CV-CNN can model the physical properties of the signal more accurately, improving processing efficiency and performance. In addition, complex-valued networks also show superior performance in processing image phase information, which indicates that they have a wide range of applications in image processing and computer vision tasks. In radio modulation, I/Q data have a complex structure consisting of real and imaginary parts, and standard CLDNNs cannot use this structural property to achieve outputs that preserve I and Q structures. Complex-valued convolutional network linear transformations, by zero-filling the input and performing standard convolution without activation functions, can change tensors of size three via linear combinations, resulting in outputs that preserve I and Q structures. Therefore, compared to CNN and CNN2 models, complex-valued convolutional networks can take full advantage of the complex structure of data and learn features that associate real channels with complex channels.
Consequently, the complex processing unit is the core module of the CCLDNN model, and it allows the model to directly process signals in the complex form without converting the complex signals into the real form. This ability to directly process complex signals preserves all the information of the signal; avoids information loss; and allows the model to more accurately capture the phase and amplitude information of the signal, which is particularly important for the identification of modulation types. In addition, the model can independently learn the features of the real and imaginary parts of the signal by performing a convolution operation on them, thus improving the efficiency and accuracy of feature extraction. The deep convolutional network used in the model can abstract and extract the features of the signal layer by layer, and the convolution operation of each layer further refines and strengthens the signal features based on the features of the previous layer. Combined with the SE attention mechanism, the model can adaptively adjust the feature responses of each channel, strengthen the features beneficial for classification, and suppress irrelevant interference. This mechanism enables the model to accurately identify modulation types under low SNR conditions, because the model can focus on key, identifiable features, even when the signal is heavily disturbed by noise. At the same time, the bidirectional LSTM that we introduce here can simultaneously include the forward and backward information of the signal and capture the dependence of the signal on the time series. This is especially important for modulation recognition because different modulation types show different characteristics over time series. Through two-way LSTM, the model can not only learn the current state information of the signal but can also comprehensively consider the history and future information of the signal, which greatly enhances the ability of the model to understand and capture the characteristics of time series.
The attention mechanism is inspired by the human visual attention system, and it allows models to mimic human focus shifts when processing information. In deep learning, this mechanism is used to dynamically adjust the focus of a neural network, prioritizing the parts of information that are more important to the task at hand. In the field of natural language processing (NLP), the Transformer model has revolutionized sequence modeling with its self-attention mechanism, significantly improving the performance of tasks such as machine translation, text summarization, and language understanding. In the field of image recognition, the attention mechanism enables the network to focus on the key areas of the image, thus improving the accuracy and efficiency of recognition.
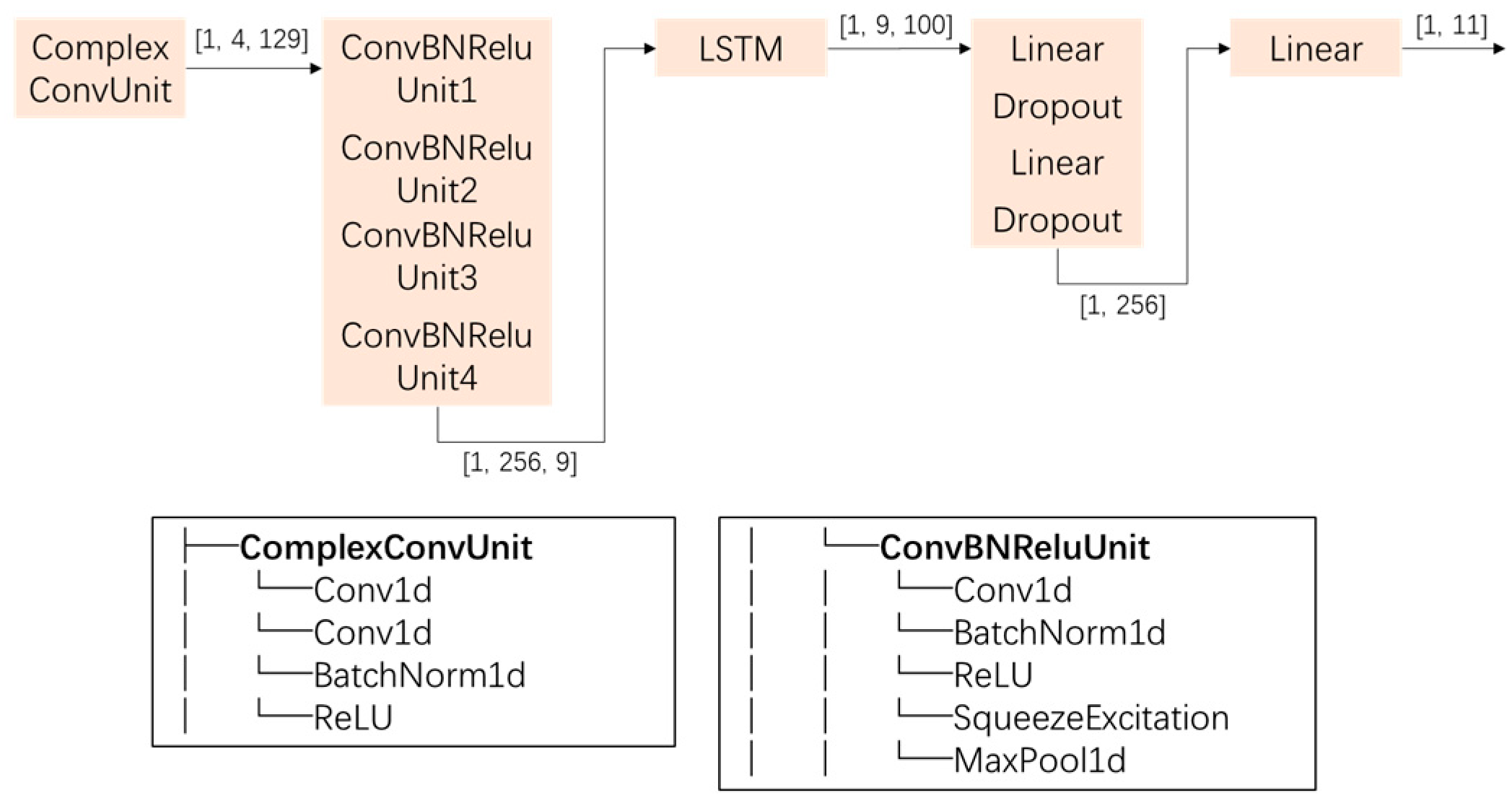
The overall architecture of the model is shown in Figure 1. Since the input data are in a complex form, we first design a ComplexConvUnit, which consists of two parallel one-dimensional convolution layers that process the real and imaginary parts of the input signal. The unit can effectively capture the characteristics of complex signals and provide more abundant information for the subsequent feature extraction and recognition. Next, we use a multilayer convolutional neural network (CNN) structure, with each layer consisting of a convolutional layer, batch normalization, a ReLU activation function, and an optional Squeeze-and-Excitation (SE) attention module. The SE module can enhance the response of the network to important features and improve recognition performance. In addition, we introduce residual connections to increase network depth while avoiding gradient disappearance or explosion problems.
At the same time, we introduce bidirectional and multilayer long short-term memory (LSTM) networks after the CNN to capture signal dependence on sequence. By increasing the hidden layer size of the LSTM, we strengthen the memory of the model and make it better able to handle long-term dependencies.
Finally, after a series of fully connected layers, the model outputs the probability that each input sample belongs to 1 of 11 modulation classes. In the fully connected layer, we use the GELU activation function and dropout regularization strategy to improve the generalization of the model ability and prevent overfitting.
In the overall architecture, the ComplexConvUnit is the key factor in the processing of complex inputs of the model. By feeding the real and imaginary parts separately into two parallel convolution layers and maintaining this separation in subsequent processing, the model is able to capture the properties of complex signals in more detail. The strategy of introducing multilayer CNNs and LSTM networks not only enhances the ability of the model to learn spatial features but also improves the understanding of time series data dependencies, which is crucial for dynamic signal processing. The use of residual connections greatly deepens the network structure without introducing additional difficulties in training, ensuring the training stability and efficiency of deep networks. The introduction of the Squeeze-and-Excitation (SE) module further enhances the emphasis of the model on important features and improves recognition accuracy. Finally, through a series of fully connected layers and a well-designed activation function and regularization strategy, the model can effectively output the probability that each sample belongs to a specific modulation class while ensuring good generalization and robustness.
Ablation experiments were conducted on the three primary modules depicted in Figure 1: the Complex Convolution Module, the Attention Mechanism Convolution ReLU Module, and the LSTM Module. To ensure unchanged input and output characteristics, we utilized fundamental operations such as convolution or pooling to bridge the dimensional disparities in arrays resulting from the ablation. The outcomes of these ablation studies, as illustrated in Figure 2, reveal that the removal of the LSTM Module has the least impact on the neural network, while the elimination of the Complex Convolution Module exerts the most significant effect. The performance of individual modules was found to be suboptimal, with accuracy rates ranging between 0.6 and 0.7 when SNR > 0.
2.3. Training and Optimization Strategy
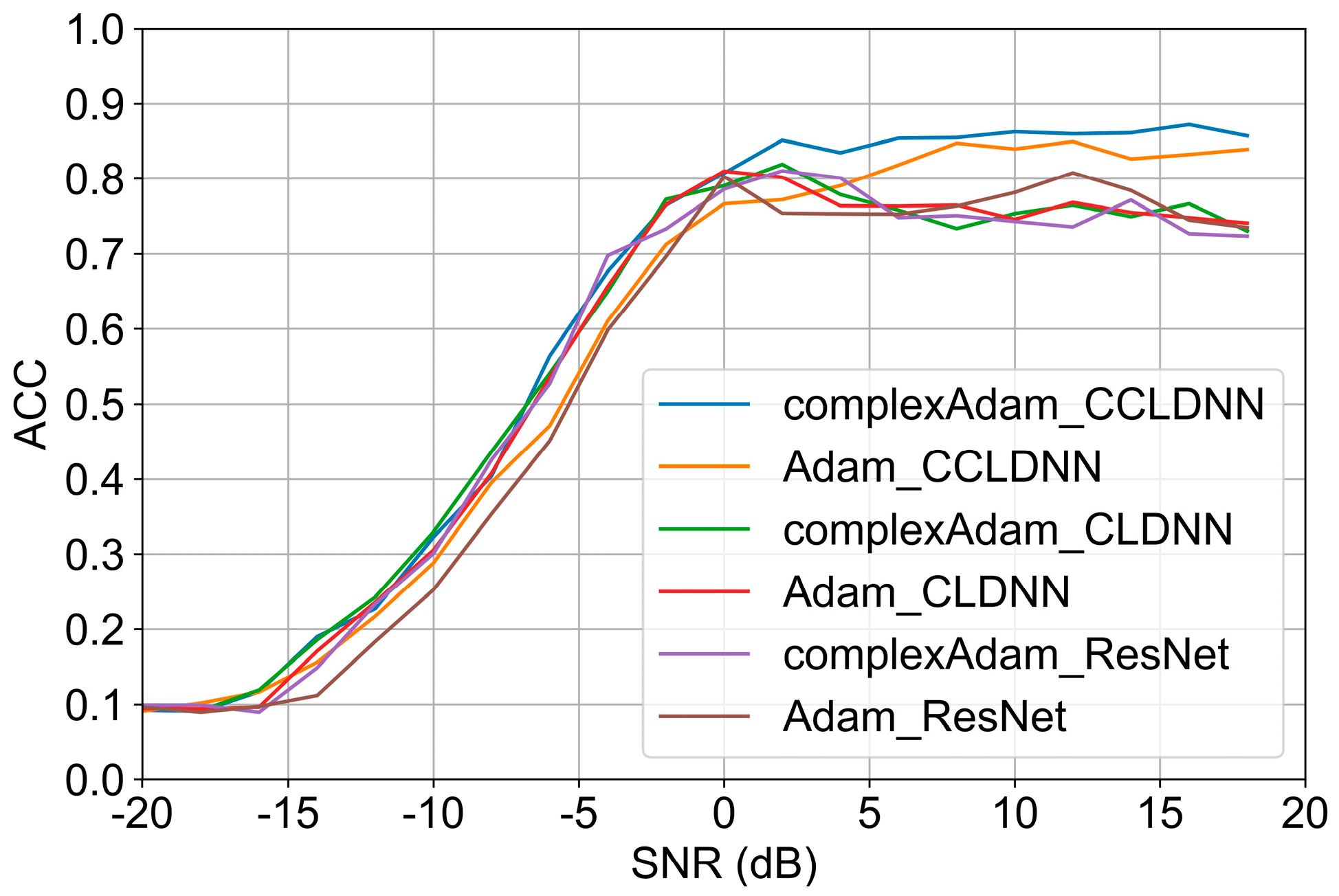
We use a complex Adam [24] as the optimizer, which combines the adaptive learning rate adjustment and weight decay strategy of the Adam optimizer, and we adjust for the complex input to help improve the training efficiency and final performance of the model. The calculation in a traditional Adam assumes that the parameters being optimized are real-valued; thus, we need to modify it before actual use when using a complex input. The crucial improvement lies in the handling of gradients during the update step, particularly in the calculation of the second moment v, where the conjugate of the gradient is multiplied by the gradient itself. This aspect is especially significant for dealing with complex parameters, as it takes into account the nature of complex numbers, which comprise both real and imaginary parts. The performance of the main three deep learning networks with Adam and the complex Adam optimizer is shown in Figure 3. It is clear that, with the complex Adam, the CCLDNN’s accuracy increases significantly at roughly all SNRs. However, the improvement from the complex Adam seems insignificant in the other two networks.
During training, we independently trained the model at multiple SNR levels and record the accuracy at each SNR level to evaluate the generalization ability under different noise conditions of the model.
We used the Microsoft Neural Network Intelligence [25] (NNI) tool for hyperparameter tuning. NNI is an open-source toolkit that supports automatic feature engineering, hyperparameter tuning, neural architecture search, and model compression. We utilized several mainstream tuning algorithms provided by NNI, including but not limited to grid search, random search, Bayesian optimization, and evolutionary algorithms. When tuning the hyperparameters with NNI, we mainly used the following techniques in parentheses to determine the optimal values of the parameters: the learning rate (grid search), batch size (random search), and dropout rate (Bayesian optimization). Overall, our approach to hyperparameter tuning was systematic and tailored to the specific characteristics of each method, which allowed us to find the optimal set of hyperparameters, thereby maximizing the performance of our models.
3. Results and Analysis
The purpose of this study is to improve the performance of neural networks under different signal-to-noise ratio (SNR) conditions by introducing complex processing units, deep feature extraction, sequence feature processing, advanced classification, and regularization strategies. This study adopts the RadioML2016.10a modulation dataset [14] published by O’Shea in 2016, which contains 220,000 samples. It covers eight digital modulation types (BPSK, QPSK, 8PSK, 16QAM, 64QAM, BFSK, CPFSK, and PAM4) and three analog modulation types (WBFM, AM-SSB, and TheDSB). The SNRs of the samples range from −20 dB to 18 dB, with a total of 20 levels, 1 level for every 2 dB. The dataset simulates various influencing factors of electromagnetic environments to truly reflect the signal transmission process, so it has high research and application value.
3.1. Model Performance Evaluation
After rigorous training and verification, it was found that our model showed excellent performance on the RadioML2016.10a and HisarMod2019.1 datasets (Figure 4). On the RadioML2016.10a dataset, the model showed high recognition accuracy at medium-to-high SNR levels (0 dB to 18 dB), with an average accuracy of more than 80%. Under low SNR conditions (−20 dB to −2 dB), the accuracy of the model remained relatively high despite performance degradation, and it was higher than that of traditional methods and unoptimized deep learning models. By comparing the performance at different SNR levels, we found that the complex processing unit and SE attention mechanism significantly improved the recognition ability of the model under low SNR conditions. On the HisarMod2019.1 dataset, the CCLDNN also performed better than Resnet at all SNRs. This shows that the model can effectively extract key features from complex signals and enhance the learning of important features through the attention mechanism.
3.2. Performance Comparison
To further examine network performance, we compare the performance of the CCLDNN with that of several existing representative modulation recognition methods. Figure 5 quantifies the improvement level of classification accuracy at each SNR level. On the RadioML2016.10a dataset, the model has the greatest performance improvement at a high SNR, compared with the CNN2 and CNN2-260 models, of nearly 20%. Compared with the CLDNN, the improvement is not obvious when the SNR < 0, and the improvement is about 10% when the SNR > 0. Compared with Resnet, the overall improvement is between 10% and 20% when the SNR < 0. The results show that the CCLDNN model proposed in this study is superior to the comparison methods under most SNR conditions, especially under SNR conditions above 0 dB. On the HisarMod2019.1 dataset, the distribution of improvements is different, characterized by less improvement than Resnet and more improvement than the CLDNN. This demonstrates the adaptability and robustness of our model to complex electromagnetic environments and its excellent performance in conventional electromagnetic environments.
3.3. Confusion Matrix Analysis
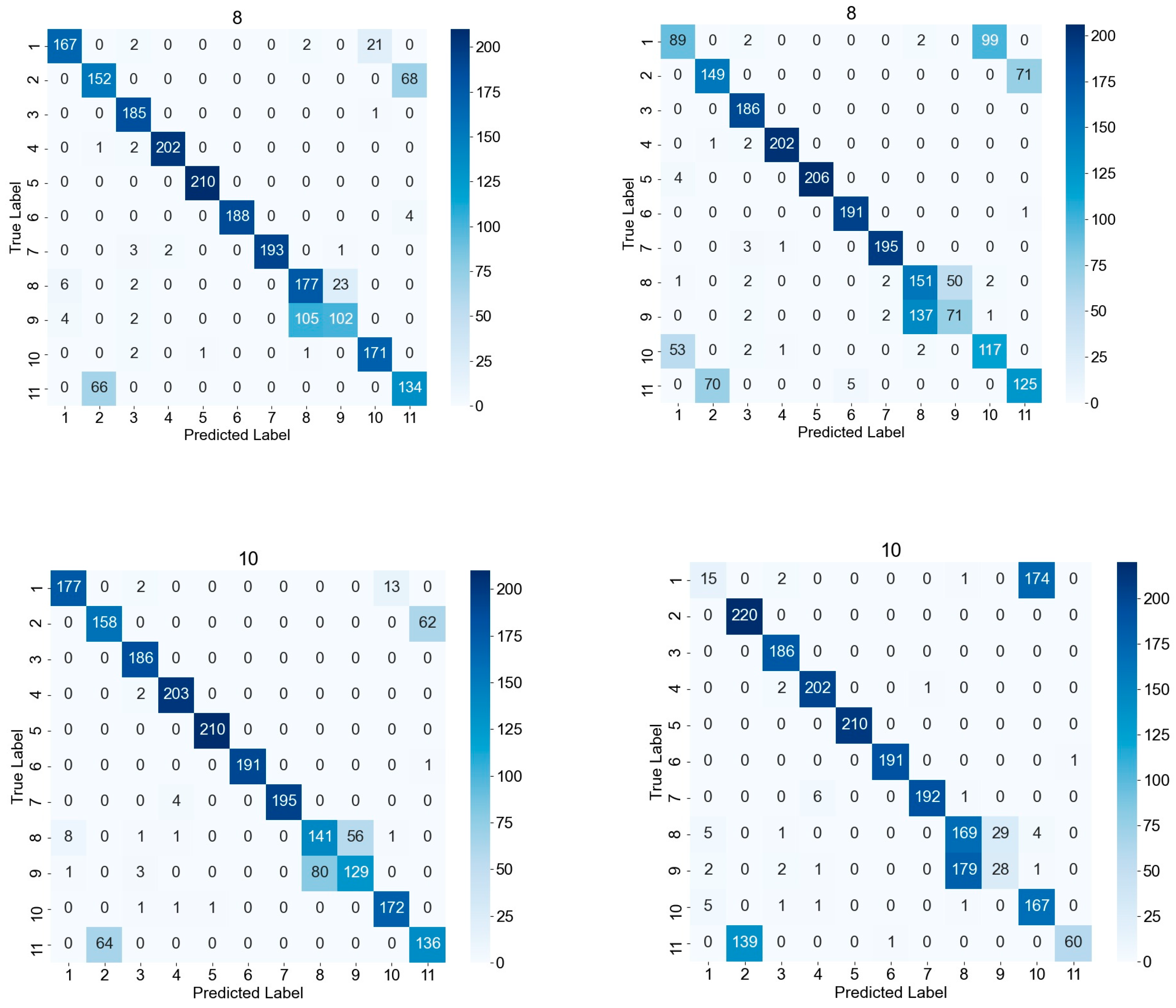
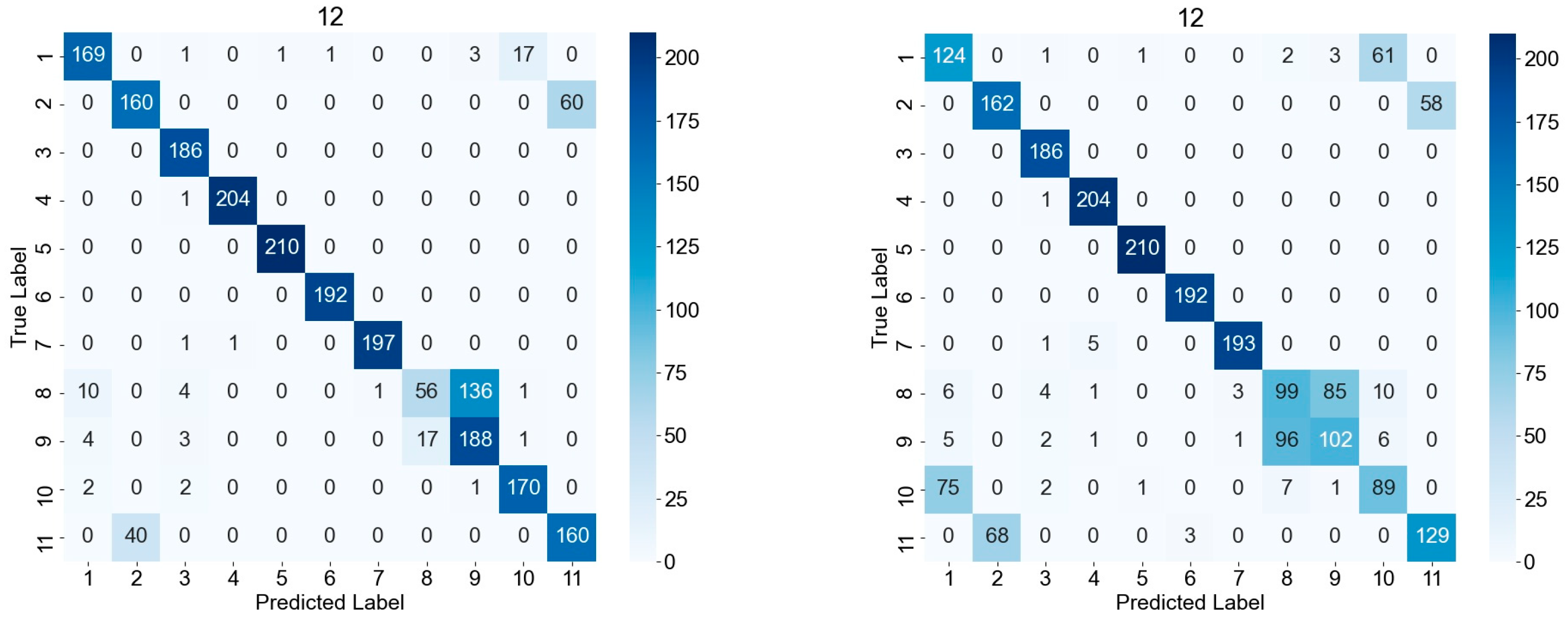
In order to better understand the performance of the model, we analyze the confusion matrix at different SNR levels. By comparing the performance of the CCLDNN and CLDNN in Figure 6, we can see that the CCLDNN has less non-diagonal noise, indicating better performance, especially in the case of a high SNR, and thus improved classification. However, both networks have more errors in distinguishing between QAM16 and QAM64 modulations because the two have very similar structures. The results show that the model can accurately distinguish most modulation types under the condition of a high SNR, with a low error identification rate. Under low SNR conditions, although the overall accuracy is decreased, the model still maintains a high accuracy for some modulation types (such as CPFSK, GFSK, and PAM4), which indicates that the model has a strong discrimination ability for these modulation types.
In a comparative analysis of Table 1, we carefully examined the performance of the CCLDNN model and the other network architectures (Resnet, CNN2, and CNN2-260) in terms of accuracy, the number of parameters, and training efficiency. Notably, the CCLDNN model, while reducing the number of parameters, not only reduced the time required for each training cycle but also achieved an average accuracy improvement of 57.3%, compared to the lower accuracy of Resnet, CNN2, and CNN2-260. This result confirms that the improvement of model performance does not simply depend on an increase in parameters but on the efficient use of data complexity and the enhancement of the feature extraction capability of the model structure. By introducing complex processing units and attention mechanisms, the CCLDNN captures the intrinsic structure and features of the data more precisely, especially when processing complex signals, and it can understand the information of the signal more comprehensively, thus improving its recognition accuracy.
Also, the validation and test time for the proposed model is given in Table 2.
However, it is undeniable that the convergence of the CCLDNN model requires more training cycles (nearly 60) than networks such as the CLDNN, which requires only 30 training cycles. This is because the increase in the upper learning limit of the model is accompanied by an increase in the training period required for convergence. In the training process of the CLDNN, Resnet, CNN2, and other networks, we found that when the network converged in about 30 rounds, the recognition accuracy rate of the continuous training model did not continue to improve, and the training loss did not continue to decrease. However, the performance of the CCLDNN model still improved steadily after 30 rounds of training.
The loss curve in Figure 7 further compares the performance of the CCLDNN and CLDNN architectures under different SNR conditions. The CCLDNN showed a lower loss value at all SNR levels, which means that the model has a better fit under a variety of conditions, especially under high SNR conditions, where CCLDNN’s loss value (<0.5) was significantly lower than that of the CLDNN architecture (always greater than 0.5). This result once again highlights the CCLDNN’s advantages in high-quality signal processing and its efficient use of data features.
4. The Discussion
The CCLDNN model is an advanced automatic modulation recognition technology for radio signals, and it is a significant innovation and improvement on the existing CLDNN framework. The key innovations in the CCLDNN model include the following:
- Complex modules: A complex module was added to the CCLDNN model, and it allows the model to process complex signals directly instead of splitting them into real and imaginary parts. This method allows the phase information of the signal to be retained more accurately, which is a key factor for modulation recognition.
- Bidirectional long short-term memory (Bi-LSTM) network: By introducing bidirectional LSTM, the CCLDNN model can more effectively capture forward and backward dependencies in time series data. This structure enables the model to consider both past and future information when processing signals, thus improving signal recognition accuracy in complex dynamic environments.
- Multilayer LSTM structure: By stacking multiple layers of LSTM, the model is able to learn more complex feature representations, which is particularly important for distinguishing highly similar modulated signals. The multilayer structure helps to extract deeper features, thus improving the discrimination ability of the model.
- Attention mechanism: The CCLDNN model incorporates an attention mechanism, which enables the model to automatically identify and focus on the most informative part of the signal. The introduction of the attention mechanism helps improve the performance of the model in a low SNR environment because it helps the model distinguish between noise and useful signals.
Compared with other typical modulation recognition models, the CCLDNN model shows better performance. For example, compared with the traditional CNN model, the CCLDNN model, by combining LSTM and the attention mechanism, can process time series data more efficiently and achieve a higher recognition accuracy. Compared with the CBLSTM model proposed by Zhao et al. [14], the CCLDNN model achieves a stronger temporal feature learning ability by introducing bidirectional and multilayer structures. Compared with the WSMF method based on a deep residual network [17], the CCLDNN model can better handle signals with complexity and diversity through the complex number module and attention mechanism. In addition, the CCLDNN model is more robust than 1CLDNN and other traditional methods when processing signals in low SNR environments. This is because the CCLDNN model is better able to distinguish between signal and noise, thus maintaining a high recognition rate under low SNR conditions.
For future research, comparing the accuracy of the CCLDNN with the optimal theoretical limits of SNRs, such as the Chernoff bound [26] or tighter complex bounds, represents an intriguing and valuable direction. Such comparisons can provide profound insights into the performance of the CCLDNN when processing data under various SNR conditions, particularly in the fields of communications, signal processing, and related areas. In a comparison with theoretical limits, the performance of the CCLDNN model in noisy environments can be more accurately assessed, especially its robustness and accuracy. This comparison can highlight potential areas for improvement in model performance, thereby guiding future research efforts towards optimizing the model structure or training process and, thus, deepening the understanding of the gap between the model’s theoretical potential and its performance in practical applications.
5. Conclusions
The automatic modulation recognition model proposed in this study demonstrated excellent performance under different SNR conditions, both theoretically and experimentally, especially in terms of complex signal processing, depth feature extraction, and sequence feature processing. Under medium and high SNR conditions (0 dB to 18 dB), the model achieved an average recognition accuracy of more than 80%. Under low SNR conditions (−20 dB to −2 dB), the model still maintained a high discrimination ability, with a percentage improvement over the traditional neural network of up to more than 60%. Through a comparison with existing methods, it was found that the performance of the proposed model exceeded that of other advanced modulation recognition methods at most SNR levels; in particular, under low SNR conditions, the performance improvement was more significant, and the average accuracy improved by 10% to 20%. With the rapid development of wireless communication technology, automatic modulation identification technology will play an important role in more fields. The results of this study provide a solid foundation and a new perspective for further research and application.
From a theoretical point of view, the high performance of the CCLDNN model is attributed to the following key factors: Firstly, the complex number processing unit of the model can directly manipulate the complex number signal and effectively retain all the information of the signal, including amplitude and phase information, making comparisons with traditional real number processing methods difficult. Secondly, the introduction of an attention mechanism enables the model to automatically recognize and strengthen important features while suppressing irrelevant information, thus improving the recognition accuracy and generalization ability of the model. Finally, the CCLDNN efficiently learns complex data structures by optimizing the network structure and parameter configuration. Therefore, the reason why the CCLDNN model can achieve excellent results in modulation recognition tasks is not only because of its low parameter number and efficient calculation performance but also, more importantly, because of its advanced ability in understanding and utilizing complex signals and time series data. This research provides a new perspective and method for future signal processing and pattern recognition tasks.
To sum up, the CCLDNN model, combining a complex number module, bidirectional LSTM, and an attention mechanism, is not only an innovative step in theory, but also shows superior performance in practical applications, especially in processing signal recognition tasks in complex dynamic environments and low SNR conditions.
Author Contributions
Conceptualization, Z.H. and X.Z.; methodology, Z.H.; validation, X.Z.; formal analysis, Z.H.; data curation, Z.H.; writing—original draft preparation, Z.H.; writing—review and editing, Z.H. and X.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
All the necessary information to reproduce the results of this paper is self contained. In case of further information is required please contact the first author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Leblebici, M.; Çalhan, A.; Cicioğlu, M. CNN-based automatic modulation recognition for index modulation systems. Expert Syst. Appl. 2024, 240, 122665. [Google Scholar] [CrossRef]
- Li, Y.; He, X.; Zhou, C. Automatic Modulation Recognition Based on a New Deep K-SVD Denoising Algorithm. J. Data Sci. Intell. Syst. 2023, 1–8. [Google Scholar] [CrossRef]
- Shi, J.; Yang, X.; Ma, J.; Yue, G. CFCS: A Robust and Efficient Collaboration Framework for Automatic Modulation Recognition. J. Commun. Inf. Netw. 2023, 8, 283–294. [Google Scholar] [CrossRef]
- Yan, S.; Zhang, X.; Wang, S. Research on Automatic Modulation Recognition Method Based on Deep Learning; Springer Nature: Singapore, 2024; pp. 287–295. [Google Scholar]
- Liu, M.Q.; Li, B.; Cao, C.F.; Li, Z. Recognition method of digital modulation signals over non-Gaussian noise in cognitive radio. Tongxin Xuebao/J. Commun. 2014, 35, 82–88. [Google Scholar] [CrossRef]
- Song, G.; Jang, M.; Yoon, D. CNN-Based Automatic Modulation Classification in OFDM Systems. In Proceedings of the 2022 International Conference on Computer, Information and Telecommunication Systems (CITS), Athens, Greece, 13–15 July 2022; pp. 1–4. [Google Scholar]
- Tian, X.; Sun, X.; Yu, X.; Li, X. Modulation Pattern Recognition of Communication Signals Based on Fractional Low-Order Choi-Williams Distribution and Convolutional Neural Network in Impulsive Noise Environment. In Proceedings of the 2019 IEEE 19th International Conference on Communication Technology (ICCT), Xi’an, China, 16–19 October 2019; pp. 188–192. [Google Scholar]
- Maroto, J.; Bovet, G.; Frossard, P. Maximum Likelihood Distillation for Robust Modulation Classification. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar]
- Pulugu, D.; Singla, A.; Das, D.; Bora, P. Deep Learning-Based Automatic Modulation Classification Over MIMO Keyhole Channels. IEEE Access 2022, 10, 119566–119574. [Google Scholar] [CrossRef]
- Patra, T.; Mitra, S. Performance Evaluation of a Maximum-Likelihood Optimum Receiver. Appl. Math. Model. Comput. Simul. 2023. Available online: https://ebooks.iospress.nl/doi/10.3233/ATDE231063 (accessed on 18 April 2024).
- Qian, L.; Wu, H.; Zhang, T.; Yang, X. Research and implementation of modulation recognition based on cascaded feature fusion. IET Commun. 2023, 17, 1037–1047. [Google Scholar] [CrossRef]
- Sun, Y.; Wu, W. Survey of Research on Application of Deep Learning in Modulation Recognition. Wirel. Pers. Commun. 2024, 133, 1483–1515. [Google Scholar] [CrossRef]
- Zhou, S.; Li, T.; Li, Y. Recursive Feature Elimination Based Feature Selection in Modulation Classification for MIMO Systems. Chin. J. Electron. 2023, 32, 785–792. [Google Scholar] [CrossRef]
- O’Shea, T.J.; Corgan, J.; Clancy, T.C. Convolutional Radio Modulation Recognition Networks. In Proceedings of the 17th International Conference, EANN 2016, Aberdeen, UK, 2–5 September 2016; Springer: Cham, Switzerland, 2016; Volume 629, pp. 213–226. [Google Scholar]
- Zhao, R.; Yan, R.; Wang, J.; Mao, K. Learning to Monitor Machine Health with Convolutional Bi-Directional LSTM Networks. Sensors 2017, 17, 273. [Google Scholar] [CrossRef]
- Liu, R.; Guo, Y.; Zhu, S. Modulation Recognition Method of Complex Modulation Signal Based on Convolution Neural Network. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–13 December 2020; pp. 1179–1184. [Google Scholar]
- Sun, Y.C.; Tian, R.L.; Wang, X.F.; Dong, H.; Dai, P. Emitter signal recognition based on improved CLDNN. Syst. Eng. Electron. 2021, 43, 42–47. [Google Scholar] [CrossRef]
- Qi, P.; Zhou, X.; Zheng, S.; Li, Z. Automatic Modulation Classification Based on Deep Residual Networks With Multimodal Information. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 21–33. [Google Scholar] [CrossRef]
- Wang, Y.; Gui, G.; Gacanin, H.; Adebisi, B.; Sari, H.; Adachi, F. Federated Learning for Automatic Modulation Classification Under Class Imbalance and Varying Noise Condition. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 86–96. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, C.; Gan, C.; Sun, S.; Wang, M. Automatic Modulation Classification Using Convolutional Neural Network With Features Fusion of SPWVD and BJD. IEEE Trans. Signal Inf. Process. Netw. 2019, 5, 469–478. [Google Scholar] [CrossRef]
- Xu, T.; Ma, Y. Signal Automatic Modulation Classification and Recognition in View of Deep Learning. IEEE Access 2023, 11, 114623–114637. [Google Scholar] [CrossRef]
- Zheng, Q.; Tian, X.; Yu, Z.; Wang, H.; Elhanashi, A.; Saponara, S. DL-PR: Generalized automatic modulation classification method based on deep learning with priori regularization. Eng. Appl. Artif. Intell. 2023, 122, 106082. [Google Scholar] [CrossRef]
- Jang, J.; Pyo, J.; Yoon, Y.I.; Choi, J. Meta-Transformer: A Meta-Learning Framework for Scalable Automatic Modulation Classification. IEEE Access 2024, 12, 9267–9276. [Google Scholar] [CrossRef]
- Sarroff, A.M. Complex neural networks for audio. Ph.D. Thesis, Dartmouth College, Hanover, NH, USA, 2018. [Google Scholar]
- Gridin, I. Automated Deep Learning Using Neural Network Intelligence: Develop and Design PyTorch and TensorFlow Models Using Python; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Dubhashi, D.P.; Panconesi, A. Chernoff–Hoeffding Bounds. In Concentration of Measure for the Analysis of Randomized Algorithms; Dubhashi, D.P., Panconesi, A., Eds.; Cambridge University Press: Cambridge, UK, 2009; pp. 1–15. [Google Scholar]
Figure 1.
Model structure.

Figure 2.
Ablation study.

Figure 3.
Comparison of results with Adam and complex Adam.

Figure 4.
Classification accuracy of the CCLDNN architecture compared to the CLDNN, CNN2, and CNN2-260 architectures, based on the RadioML2016.10a and HisarMod2019.1 datasets.
Figure 4.
Classification accuracy of the CCLDNN architecture compared to the CLDNN, CNN2, and CNN2-260 architectures, based on the RadioML2016.10a and HisarMod2019.1 datasets.

Figure 5.
Classification improvement of the complex architecture compared to the CLDNN, CNN2, and CNN2-260 architectures as a function of the SNR, based on the RadioML2016.10a and HisarMod2019.1 datasets.
Figure 5.
Classification improvement of the complex architecture compared to the CLDNN, CNN2, and CNN2-260 architectures as a function of the SNR, based on the RadioML2016.10a and HisarMod2019.1 datasets.

Figure 6.
Confusion matrices at (up) 8 dB, (middle) 10 dB, and (down) 12 dB for the CCLDNN (left) and CLDNN (right) architectures. The respective classification accuracies are 79.27%, 82.14%, and 84.09% for the CCLDNN and 74.18%, 73.68%, and 69.14% for the CLDNN. The 11 labels correspond to 8PSK, AM-DSB, AM-SSB, BPSK, CPFSK, GFSK, PAM4, QAM16, QAM64, QPSK, and WBFM, respectively.
Figure 6.
Confusion matrices at (up) 8 dB, (middle) 10 dB, and (down) 12 dB for the CCLDNN (left) and CLDNN (right) architectures. The respective classification accuracies are 79.27%, 82.14%, and 84.09% for the CCLDNN and 74.18%, 73.68%, and 69.14% for the CLDNN. The 11 labels correspond to 8PSK, AM-DSB, AM-SSB, BPSK, CPFSK, GFSK, PAM4, QAM16, QAM64, QPSK, and WBFM, respectively.


Figure 7.
Loss at (up) 8 dB, (middle) 10 dB, and (down) 12 dB for the CCLDNN (left) and CLDNN (right) architectures.
Figure 7.
Loss at (up) 8 dB, (middle) 10 dB, and (down) 12 dB for the CCLDNN (left) and CLDNN (right) architectures.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Training performance.
| Model | ACC (%) | Params | Epochs | Avg Epoch Duration (s) |
|---|---|---|---|---|
| CCLDNN | 59.9 | 754,459 | 30 | 4 |
| CLDNN | 52.7 | 926,363 | 30 | 2.3 |
| CNN2-260 | 50.0 | 2,707,547 | 28 | 6.3 |
| CNN2 | 48.2 | 2,749,195 | 20 | 6.2 |
| Resnet | 54.7 | 3,849,483 | 30 | 3.1 |
Table 2.
Validation and testing of running time.
| Model | Validation Times | Avg Duration (s) | Testing Times | Avg Duration (s) |
|---|---|---|---|---|
| CCLDNN | 30 | 0.4 | 1 | 0.5 |
| CLDNN | 30 | 0.3 | 1 | 0.3 |
| CNN2-260 | 28 | 0.5 | 1 | 0.5 |
| CNN2 | 20 | 0.6 | 1 | 0.6 |
| Resnet | 30 | 0.4 | 1 | 0.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
He, Z.; Zeng, X. Research on Communication Signal Modulation Recognition Based on a CCLDNN. Electronics 2024, 13, 1604. https://doi.org/10.3390/electronics13091604
AMA Style
He Z, Zeng X. Research on Communication Signal Modulation Recognition Based on a CCLDNN. Electronics. 2024; 13(9):1604. https://doi.org/10.3390/electronics13091604
Chicago/Turabian StyleHe, Zijin, and Xiaodong Zeng. 2024. "Research on Communication Signal Modulation Recognition Based on a CCLDNN" Electronics 13, no. 9: 1604. https://doi.org/10.3390/electronics13091604
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.