
Near-Infrared Spectroscopy Combined with Fuzzy Improved Direct Linear Discriminant Analysis for Nondestructive Discrimination of Chrysanthemum Tea Varieties



Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Preparation
2.2. NIR Spectra Collection
2.3. Preprocessing
2.4. Data Processing Algorithms
2.4.1. Principal Component Analysis
2.4.2. LDA
2.4.3. IDLDA
| Algorithm 1: The Steps of IDLDA Algorithm |
| Step 1. Build the matrices , , and ; Step 2. Singular value decomposition of as ; Step 3. Find and build ; Step 4. Use and to diagonalize , as , where such that corresponds to the range space of and corresponds to the null space of ; Step 5. Calculate the transformation matrix , and project samples into the feature space. |
2.4.4. FIDLDA
| Algorithm 2: The Steps of FIDLDA Algorithm |
| Step 1. Build the matrices , , and ; Step 2. Singular value decomposition of as ; Step 3. Find and build ; Step 4. Use and to diagonalize , as , where such that corresponds to the range space of and corresponds to the null space of ; Step 5. Calculate the transformation matrix , and project samples into the feature space. |
2.4.5. KNN
2.5. Software
3. Results
3.1. NIR Spectral Analysis
3.2. Spectral Preprocessing
3.3. Dimensionality Reduction by PCA
3.4. Extraction of Features by LDA
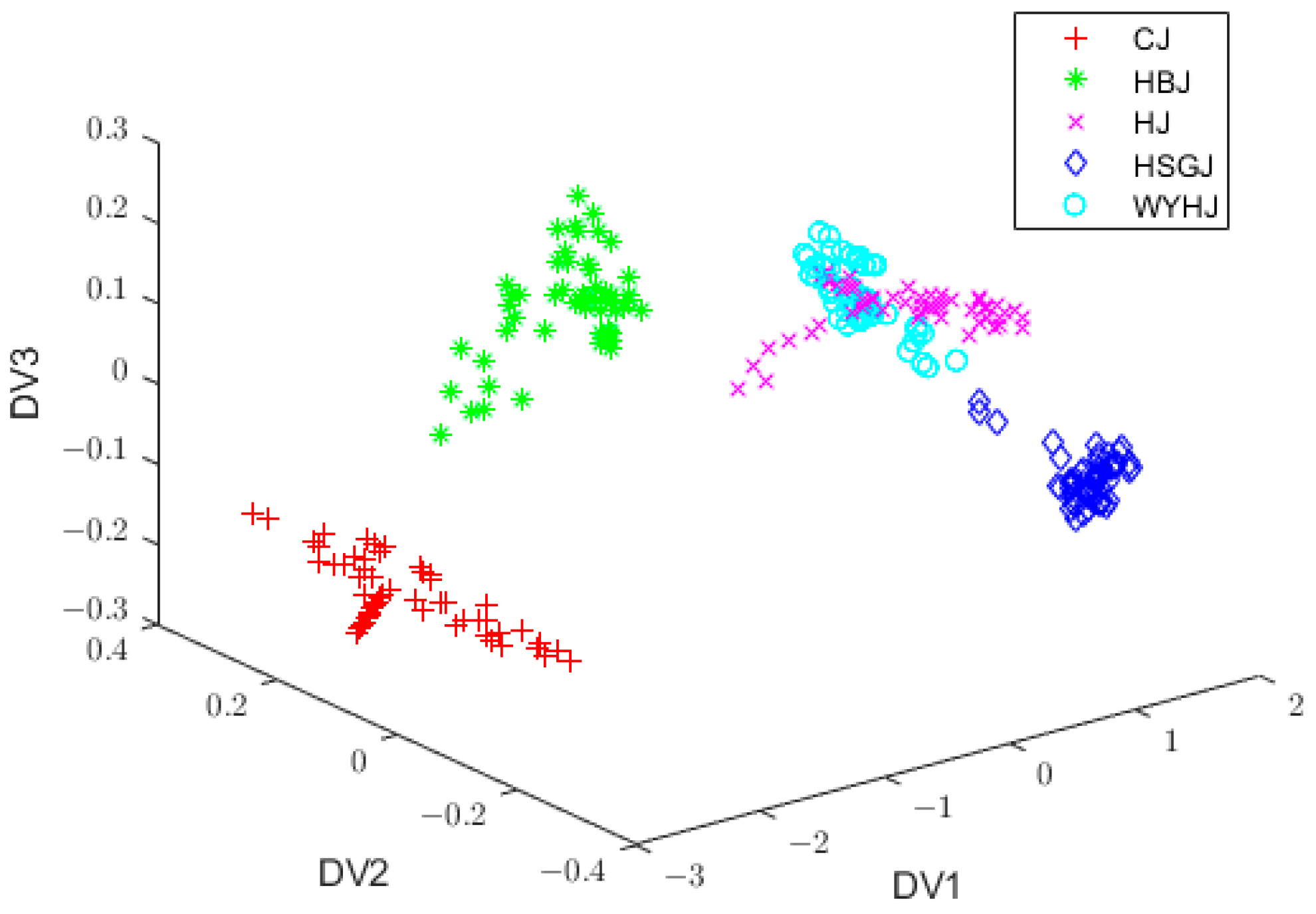
3.5. Discriminant Feature Extraction by IDLDA
3.6. Feature Extraction by FIDLDA
3.7. Classification Results of KNN
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, L.; Liu, Y.; Huang, X.J.; Zhu, Y.Y.; Li, J.X.; Miao, Y.H.; Du, H.Z.; Liu, D.H. Comparison of chemical constituents and pharmacological effects of different varieties of Chrysanthemum Flos in China. Chem. Biodivers. 2021, 18, e2100206. [Google Scholar] [CrossRef]
- Hadizadeh, H.; Samiei, L.; Shakeri, A. Chrysanthemum, an ornamental genus with considerable medicinal value: A comprehensive review. S. Afr. J. Bot. 2022, 144, 23–43. [Google Scholar] [CrossRef]
- Sun, J.H.; Wang, Z.D.; Lin, C.; Xia, H.; Yang, L.G.; Wang, S.K.; Sun, G.J. The hypolipidemic mechanism of chrysanthemum flavonoids and its main components, luteolin and luteoloside, based on the gene expression profile. Front. Nutr. 2022, 9, 952588. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y.Y.; Guo, W.; Yang, X.; Qu, J.M.; Gao, M.; Chen, S.T.; Dong, J.R.; Li, Q.; Wang, T.J. Comparison of the chemical components, efficacy and mechanisms of action of chrysanthemum morifolium flower and its wild relative chrysanthemum indicum flower against liver-fire hyperactivity syndrome of hypertension via integrative analyses. Int. J. Mol. Sci. 2022, 23, 13767. [Google Scholar] [CrossRef]
- Mei, H.; Nie, J.; Wang, S.; Zhang, Y.; Li, C.; Shao, S.; Shao, S.; Rogers, K.M.; Yuan, Y. Geographical origin authentication of edible chrysanthemum morifolium Ramat. (Hangbaiju) using stable isotopes. Separations 2023, 10, 287. [Google Scholar] [CrossRef]
- Luo, D.S.; Chen, J.; Gao, L.; Liu, Y.P.; Wu, J.H. Geographical origin identification and quality control of Chinese chrysanthemum flower teas using gas chromatography–mass spectrometry and olfactometry and electronic nose combined with principal component analysis. Int. J. Food Sci. Technol. 2017, 52, 714–723. [Google Scholar] [CrossRef]
- Chen, F.R.; Wang, T.; Guo, Q.S.; Zhu, Z.B.; Yang, F.; Zou, Q.J.; Zhang, Y.J. Identification of chrysanthemum indicum in different geographical populations and Ch. morifolium based on DNA barcodes of psbA-trnH, matK and trnL. China J. Chin. Mater. Med. 2019, 44, 660–665. [Google Scholar]
- Hao, N.; Gao, X.; Zhao, Q.; Miao, P.Q.; Cheng, J.W.; Li, Z.; Liu, C.Q.; Li, W.L. Rapid origin identification of chrysanthemum morifolium using laser-induced breakdown spectroscopy and chemometrics. Postharvest Biol. Technol. 2023, 197, 112116. [Google Scholar] [CrossRef]
- Bec, K.B.; Grabska, J.; Huck, C.W. Principles and applications of miniaturized near-infrared (NIR) spectrometers. Chem. Eur. J 2020, 27, 1514–1532. [Google Scholar] [CrossRef]
- Jiang, H.; Chen, Q.S. Chemometric models for the quantitative descriptive sensory properties of green tea (Camellia sinensis L.) using Fourier transform near infrared (FT-NIR) spectroscopy. Food Anal. Methods 2015, 8, 954–962. [Google Scholar] [CrossRef]
- Zhang, Y.M.; Guo, W.C. Moisture content detection of maize seed based on visible/near-infrared and near-infrared hyperspectral imaging technology. Int. J. Food Sci. Technol. 2019, 55, 631–640. [Google Scholar] [CrossRef]
- Zhang, H.; Jiang, H.; Liu, G.H.; Mei, C.L.; Huang, Y.H. Identification of radix puerariae starch from different geographical origins by FT-NIR spectroscopy. Int. J. Food Prop. 2017, 20, 1567–1577. [Google Scholar] [CrossRef]
- Ripoll, G.; Lobón, S.; Joy, M. Use of visible and near infrared reflectance spectra to predict lipid peroxidation of light lamb meat and discriminate dam’s feeding systems. Meat Sci. 2018, 143, 24–29. [Google Scholar] [CrossRef]
- Biswas, A.; Chaudhari, S.R. Exploring the role of NIR spectroscopy in quantifying and verifying honey authenticity: A review. Food Chem. 2024, 445, 138712. [Google Scholar] [CrossRef]
- Lapcharoensuk, R.; Jirawat, P.; Wongpromrat, P. Classification of saline water for irrigated agriculture using near infrared spectroscopy coupled with pattern recognition techniques. E3S Web Conf. 2019, 116, 00043. [Google Scholar] [CrossRef]
- Zhan, Y.; Peng, Y.F.; Peng, H.G.; Luo, H.P. Application of near-infrared spectroscopy nondestructive testing of jujube in south xinjiang sugar content. J. Agric. Mech. Res. 2014, 36, 179–183. [Google Scholar]
- Guo, Z.; Barimah, A.O.; Shujat, A.; Zhang, Z.; Chen, Q. Simultaneous quantification of active constituents and antioxidant capability of green tea using NIR spectroscopy coupled with swarm intelligence algorithm. LWT Food Sci. Technol. 2020, 129, 109510. [Google Scholar] [CrossRef]
- Sun, F.; Chen, Y.; Wang, K.Y.; Wang, S.M.; Liang, S.W. Identification of genuine and adulterated pinellia ternata by mid-infrared (MIR) and near-infrared (NIR) spectroscopy with partial least squares-discriminant analysis (PLS-DA). Anal. Lett. 2020, 53, 937–959. [Google Scholar] [CrossRef]
- Wu, J.Z.; Zareef, M.; Chen, Q.S.; Quyuan, Q. Application of visible-near infrared spectroscopy in tandem with multivariate analysis for the rapid evaluation of matcha physicochemical indicators. Food Chem. 2023, 421, 136185. [Google Scholar] [CrossRef]
- Ouyang, Q.; Rong, Y.N.; Wu, J.Q.; Wang, Z.; Lin, H.; Chen, Q.S. Application of colorimetric sensor array combined with visible near-infrared spectroscopy for the matcha classification. Food Chem. 2023, 420, 136078. [Google Scholar] [CrossRef]
- Lin, H.; Kang, W.C.; Han, E.; Chen, Q.S. Quantitative analysis of colony number in mouldy wheat based on near infrared spectroscopy combined with colorimetric sensor. Food Chem. 2021, 354, 129545. [Google Scholar] [CrossRef] [PubMed]
- Liu, T.; He, J.; Yao, W.; Jiang, H.; Chen, Q. Determination of aflatoxin B1 value in corn based on Fourier transform near-infrared spectroscopy: Comparison of optimization effect of characteristic wavelengths. LWT Food Sci. Technol. 2022, 164, 113657. [Google Scholar] [CrossRef]
- Larrechi, M.S.; Callao, M.P. Strategy for introducing NIR spectroscopy and multivariate calibration techniques in industry. TrAC Trends Anal. Chem. 2003, 22, 634–640. [Google Scholar] [CrossRef]
- Alaoui Mansouri, M.; Ziemons, E.; Sacré, P.Y.; Kharbach, M.; Barra, I.; Cherrah, Y.; Hubert, P.; Marini, R.D.; Bouklouze, A. Classification of polymorphic forms of fluconazole in pharmaceuticals by FT-IR and FT-NIR spectroscopy. J. Pharmaceut. Biomed. Anal. 2021, 196, 113922. [Google Scholar] [CrossRef] [PubMed]
- Ma, F.M.; Wang, M.Y.; Yan, N.; Adnan, M.; Jiang, F.H.; Hu, Q.; He, G.Y.; Shen, Y.J.; Wan, Y.; Yang, Y.X.; et al. A fast and efficient phenotyping method to estimate sugarcane stalk bending properties using near-infrared spectroscopy. Eur. J. Agron. 2024, 154, 127107. [Google Scholar] [CrossRef]
- Wu, X.H.; He, F.; Wu, B.; Zeng, S.P.; He, C.Y. Accurate classification of chunmee tea grade ssing NIR spectroscopy and fuzzy maximum uncertainty linear discriminant analysis. Foods 2023, 12, 541. [Google Scholar] [CrossRef]
- Wang, Y.J.; Li, M.H.; Li, L.Q.; Ning, J.M.; Zhang, Z.Z. Green analytical assay for the quality assessment of tea by using pocket-sized NIR spectrometer. Food Chem. 2021, 345, 128816. [Google Scholar] [CrossRef]
- Chen, G.K.; Zhang, X.C.; Wu, Z.B.; Su, J.H.; Cai, G.R. An efficient tea quality classification algorithm based on near infrared spectroscopy and random Forest. J. Food Process Eng. 2021, 44, e13604. [Google Scholar] [CrossRef]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D. Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef]
- Liu, J.; Chen, S.C.; TAN, X.Y.; Zhang, D.Q. Efficient pseudoinverse linear discriminant analysis and its nonlinear form for face recognition. Int. J. Pattern Recognit. Artif. Intell. 2007, 21, 1265–1278. [Google Scholar] [CrossRef]
- Ye, J.P. Characterization of a family of algorithms for generalized discriminant analysis on undersampled problems. J. Mach. Learn. Res. 2005, 6, 483–502. [Google Scholar]
- Yu, H.; Yang, J. A direct LDA algorithm for high-dimensional data—With application to face recognition. Pattern Recognit. 2001, 34, 2067–2070. [Google Scholar] [CrossRef]
- Thomaz, C.E.; Kitani, E.C.; Gillies, D.F. A maximum uncertainty LDA-based approach for limited sample size problems—With application to face recognition. J. Braz. Comput. Soc. 2006, 12, 7–18. [Google Scholar]
- Kuldip, K.; Sharma, P.A. Improved direct LDA and its application to DNA microarray gene expression data. Pattern Recognit. Lett. 2010, 31, 2489–2492. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Wu, X.H.; Fang, Y.H.; Wu, B.; Liu, M. Application of near-infrared spectroscopy and fuzzy improved null linear discriminant analysis for rapid discrimination of milk brands. Foods 2023, 12, 3929. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Wu, X.H.; Wu, B.; Dai, C.; Fu, H. Rapid authentication of the geographical origin of milk using portable near-infrared spectrometer and fuzzy uncorrelated discriminant transformation. J. Food Process Eng. 2022, 45, e14040. [Google Scholar] [CrossRef]
- Huang, Z.; Ci, H.; Liu, Z.; Xue, Y.; Ren, X.; Xue, J.; Zhang, X. Comprehensive evaluation on yield and quality of medicinal chrysanthemum morifolium varieties based on principal component analysis and cluster analysis. Sci. Technol. Food Ind. 2024, 45, 271–280. (In Chinese) [Google Scholar]
- Rao, G.; Shao, L.; Tong, J. Optimization of ultrasonic-assisted extraction of total flavonoids from Wuyuan imperial chrysanthemum and evaluation of their Antioxidant activity. Food Res. Dev. 2021, 42, 98–103. (In Chinese) [Google Scholar]
- Jin, X.; Wang, L.L.; Zheng, W.J.; Zhang, X.D.; Liu, L.; Li, S.W.; Rao, Y.; Xuan, J.X. Predicting the nutrition deficiency of fresh pear leaves with a miniature near-infrared spectrometer in the laboratory. Measurement 2022, 188, 110553. [Google Scholar] [CrossRef]
- Schafer, R.W. What is a Savitzky-Golay Filter. IEEE Signal Proc. Mag. 2011, 28, 111–117. [Google Scholar] [CrossRef]
- Rima, H.; Arip, M.A.; Endang, L.; Nanda, E.; Taufiq, K.; Rinaldi, I. Combination of PCA with LDA and SVM classifiers: A model for determining the geographical origin of coconut in the coastal plantation, Aceh Province, Indonesia. Case Stud. Chem. Environ. Eng. 2024, 9, 100552. [Google Scholar]
- Long, W.J.; Zhang, Q.; Wang, S.R.; Suo, Y.X.; Chen, H.Y.; Bai, X.Y.; Yang, X.L.; Zhou, Y.P.; Yang, J.; Fu, H.Y. Fast and non-destructive discriminating the geographical origin of Hangbaiju by hyperspectral imaging combined with chemometrics. Spectrochim. Acta Part A 2023, 284, 121786. [Google Scholar] [CrossRef] [PubMed]
- He, C.Y.; Ji, Y.; Wu, B.; Wu, X.H.; Fu, H.J. Non-destructive classification of chrysanthemum tea using near-infrared spectroscopy (NIRS) and fuzzy improved pseudoinverse linear discriminant analysis (FIPLDA). Anal. Lett. 2023, 57, 905–919. [Google Scholar] [CrossRef]
- Kim, N.; Jang, M.; Jo, J.; Park, J.; Kim, A.; Hwang, I. Application of energy dispersive X-ray fluorescence spectrometry and near-infrared reflectance spectroscopy combined with multivariate statistical analysis for discriminating the geographical origin of soybeans. Food Control 2022, 140, 109140. [Google Scholar] [CrossRef]
- Hollingsworth, S.A.; Dror, R.O. Molecular dynamics simulation for all. Neuron 2018, 99, 1129–1143. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CJ | HBJ | HJ | HSGJ | WYHJ | |
|---|---|---|---|---|---|
| Flavone | 16.08 | 14.22 | 10.25 | 13.39 | 4.13 |
| Soluble sugar | 23.18 | 16.35 | 19.04 | 23.05 | 15.01 |
| Chlorogenic acid | 3.75 | 3.47 | 2.16 | 1.09 | - |
| n_training | n_test | LDA | IDLDA | FIDLDA |
|---|---|---|---|---|
| 250 | 150 | 87.33 | 94.00 | 95.33 |
| 275 | 125 | 87.20 | 94.40 | 99.20 |
| 300 | 100 | 90.00 | 91.00 | 95.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Wu, X.; He, C.; Wu, B.; Zhang, S.; Sun, J. Near-Infrared Spectroscopy Combined with Fuzzy Improved Direct Linear Discriminant Analysis for Nondestructive Discrimination of Chrysanthemum Tea Varieties. Foods 2024, 13, 1439. https://doi.org/10.3390/foods13101439
Zhang J, Wu X, He C, Wu B, Zhang S, Sun J. Near-Infrared Spectroscopy Combined with Fuzzy Improved Direct Linear Discriminant Analysis for Nondestructive Discrimination of Chrysanthemum Tea Varieties. Foods. 2024; 13(10):1439. https://doi.org/10.3390/foods13101439
Chicago/Turabian StyleZhang, Jiawei, Xiaohong Wu, Chengyu He, Bin Wu, Shuyu Zhang, and Jun Sun. 2024. "Near-Infrared Spectroscopy Combined with Fuzzy Improved Direct Linear Discriminant Analysis for Nondestructive Discrimination of Chrysanthemum Tea Varieties" Foods 13, no. 10: 1439. https://doi.org/10.3390/foods13101439