1. Introduction
As an important field of computer vision, object detection can recognize the category of objects and determine their location in images and videos, which is very valuable in autonomous driving [
1], security monitoring [
2], drone aerial photography [
3], medical image diagnosis [
4], and industrial quality inspection [
5]. Therefore, object detection has become a research hotspot in the field of computer vision.
The significance of object detection, particularly in the realm of remote sensing images, has increased with the rapid advancements in remote sensing technology [
6]. Deep learning, renowned for its adept feature extraction and semantic information fusion capabilities, has recently gained widespread application in computer vision research [
7,
8]. This technological evolution has birthed a novel approach to object detection in remote sensing images, proving invaluable in applications such as satellite monitoring [
9] and the deployment of unmanned aerial vehicles [
10] for law enforcement. However, these applications pose formidable challenges, necessitating the development of swift and precise detection algorithms. The ongoing research in object detection algorithms for remote sensing images can be broadly categorized into two streams [
11]: one prioritizes the precision of detection algorithms, while the other concentrates on optimizing the execution speed.
The intricacy of object detection in remote sensing images surpasses that of natural scenes. These images present intricate scenes and backgrounds, with significant variations in object scales induced by incongruent spatial resolutions among diverse sensors [
12] or substantial differences in object sizes [
13]. To illustrate, a single image may encompass both expansive cargo ships and diminutive fishing boats, posing considerable hurdles for the object detection algorithm [
14]. Furthermore, remote sensing images exhibit densely packed objects, where objects of the same class often manifest in aggregations (such as numerous cars in a parking lot), complicating the precise localization of objects [
15,
16].
Recently, various object detection datasets, such as ImageNet [
17], COCO [
18], and PASCOL VOC [
19], have been continuously updated and improved. Based on these detection models, such as Fast-RCNN [
20], YOLOv3 [
21], and FCOS [
22], these models have been applied to other sub-level detection tasks. Various datasets display distinct characteristics, encompassing variations in image scenes, image quality, spatial resolution, and object categories. These open detection datasets comprise high-quality, high-resolution images where target objects are prominently visible, rich in color details, and substantial in size. Consequently, these datasets serve as relatively straightforward examples for detection models that are currently in existence.
However, these open datasets also contain a large number of images with both large-scale and small-scale objects, which are examples that are difficult for existing detection models to detect, such as Fast-RCNN [
20], YOLOv3 [
21], and FCOS [
22]. Insufficient generation proposals and poor proposal classification performance have resulted in the poor detection performance for these difficult samples. In addition, due to the complexity of actual application scenarios such as multiple scenes, multiple qualities, multiple scales, etc., actual object detection contains more difficult samples, and most scenarios contain various irregular objects. There are large-sized targets in actual application scenarios that occupy a large area of image space. Traditional object detection algorithms may have high computational complexity and may not be able to accurately identify them. Moreover, some feature information of large-target objects may be obscured or lost due to low resolution, which increases the difficulty of feature extraction. Another common scenario is to detect small target objects. The reduced size of the feature information due to the small size can reduce the accuracy of the object detection algorithm. In addition, small targets occupy a relatively small area in the image, making them susceptible to interference and difficult to detect accurately.
Figure 1 shows some examples of actual application scenarios. The dataset contains images of pedestrians collected for pedestrian detection. Different pedestrians have different sizes in images of different scales. Due to the different positions of pedestrians and collectors, pedestrians can be roughly divided into three different scales, where small-scale pedestrians have a pixel scale of 10 × 20, which is a difficult point in detection problems. A medium pedestrian has a size of 40 × 60 pixels. A large-scale pedestrian has a size of 100 × 60 pixels. In addition, there may be some interference, blurry outlines, and inadequate color in actual application scenarios.
To address these limitations, we have developed a multi-scale fusion module, which is a component of the MFIL-FCOS algorithm that optimizes the feature extraction strategy, establishes pixel-level correspondences, and enhances feature representation. By integrating feature information from different scales into the feature extractor through the multi-scale fusion module, the interrelationships between pixels can be understood in a nuanced way, thus improving the accuracy of detection. This approach enables the model to incorporate not just the immediate local context but also the broader global context, enhancing its ability to model ambiguous entities and extract intricate features. The integration of multi-scale fusion within our approach offers several benefits. This improves feature representation and equips the model to detect nuances and intricate structures in both 2D inspection images and remote sensing imagery at a finer level. Additionally, this module reinforces the model’s capacity to capture global dependencies through a cascading feature fusion mechanism. This, in turn, enables the model to discern spatial interrelationships among objects, facilitating accurate detection.
Compared with object detection in a single scene or a single category, object detection in different scenes, different qualities, different scales, and different categories faces the following challenges. Firstly, there are obstacles in proposal generation in different application scenarios. Objects in diverse scenarios exhibit disparities in quantity, clarity, color, and spatial resolution. The amalgamation of images featuring distinct quality, grades, and spatial resolutions across various scenarios renders the pre-established anchor points employed in the detection model incapable of generating an adequate number of proposals for object detection. Consequently, this leads to a subpar detection performance. Moreover, the substantial variations in spatial resolution among images result in objects within different scenes manifesting considerable variations in size. Tiny objects often cluster closely together, posing challenges for detection via pre-determined anchor points, as used in Fast-RCNN [
20]. Anchor-free detection models, exemplified by FCOS [
22] and CenterNet [
23], address this issue by generating anchors from each point on the feature map without relying on predefined anchor parameters. This approach proves highly effective for detecting small objects within diverse image contexts.
Another pivotal challenge affecting object detection pertains to the precision of edge or boundary delineation. The intricacy of specific datasets, such as those comprising remotely sensed images, is frequently amplified by the aerial perspective characterizing many images within the dataset. These perspectives tend to obscure the distinct boundaries between objects, resulting in imprecise detection outcomes, particularly in the proximity of object perimeters. Recognizing the pivotal role of precise boundary detection in enhancing the overall accuracy and applicability of the detection task, it becomes imperative to tackle this limitation. To address this concern, we incorporated an interactive learning module as a refinement tool, which notably enhances the boundary demarcation. In addition, object detection in different scenes, qualities, scales, and categories faces the following challenges compared to object detection in a single scene or a single category. Firstly, there are obstacles in generating suggestions for the different application scenarios. Objects in different scenes differ in number, clarity, color, and spatial resolution. Owing to the amalgamation of images characterized by diverse quality, classes, and spatial resolutions across different scenes, the predefined anchors employed in the detection model fall short in generating an adequate number of proposals for object detection. This deficiency adversely impacts the overall detection performance. Furthermore, the substantial disparities in spatial resolution among the images contribute to significant variations in the sizes of objects within various scenes. The presence of densely packed tiny objects exacerbates the challenge of detection using pre-established anchors, as employed in Fast-RCNN [
20]. To address this issue, we adopt an anchor-free detection method that generates anchors from each point on the feature map without relying on predefined anchor parameters. This approach proves highly adept at object detection within a diverse range of complex scenes.
In summary, our work has the following contributions:
We propose an anchor-free object detection architecture that can improve the detector performance in multi-scale scenes.
We introduced a multi-scale feature fusion module to enhance the detector’s learning ability for different scale features and improve the robustness of the detector.
We propose a branch interaction learning module that enhances object localization capability and bounding box regression accuracy by introducing a regression–prediction weight to enhance the regression branch and the predicted centerness.
Our proposed module achieves good experimental results on the detection task and our method can also be used in remote sensing image detection.
3. Methods
3.1. Overview
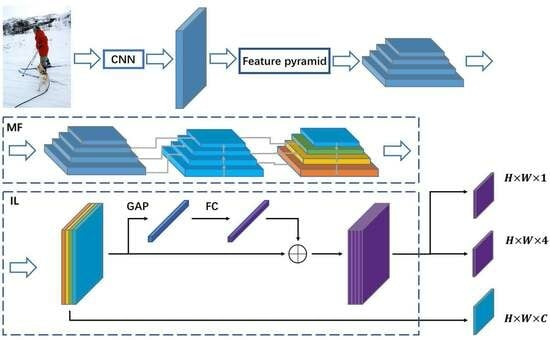
Figure 3 shows the overall structure of MFIL-FCOS, which consists of a feature extraction stage and a candidate box generation and classification stage. Backbone and FPN modules are used in the feature extraction stage. FCOS is applied to produce an ample set of candidate boxes originating from every point within the feature map, encompassing three integral branches: centerness, classification, and regression. Before performing candidate box generation and classification, the feature maps obtained through feature extraction will be inputted into the MF module for weighted integration of features at different scales. MF is designed to enhance sampling for large-scale and small-scale targets. The IL module strengthens the interaction between the regression branch and the centrality prediction branch through a special regression-prediction weight. IL is designed to achieve a more accurate regression performance.
3.2. One-Stage Anchor-Free Object Detector
Given an input image, the CNN backbone network processes it to produce feature map , where the value of i represents the number of feature map layers, annotated ground-truth bounding boxes indexed as . Each is defined as , where the pairs , and , identify the ground-truth bounding box’s upper left and lower right corners. tags the annotated object category, where MS-COCO and VOC datasets include 80 and 20 categories, respectively.
Each point on feature map F can be mapped to a location on the input image represented by . Here, s represents the total step size of the feature map scaled with respect to the input image. Our proposed anchor-free detector diverges from the anchor-based detector since the former lacks predefined anchors. In contrast, the detector regression offset represents the result of the anchor-based detector. In our regression approach, we consider the distance from pixel points on the feature map to the four bounding boxes, effectively leveraging the four distances of the regression directly as training samples, rather than as anchor boxes.
We consider a location (x,y) to be a positive sample if it lies within the ground-truth bounding box and its classification prediction
c aligns with the category present in the ground truth. Conversely, we classify a location as negative if it does not lie within the ground-truth bounding box or if the classification result does not match. Our method’s regression result is a 4D vector
, where
,
,
, and
represent the distances from the location to the four boundaries. When a location (x,y) is associated with a ground-truth bounding box (
), the training process’s regression distance can be expressed as:
3.3. Multi-Scale Feature Fusion
Feature fusion from different scales is a crucial technique for enhancing the detection performance. Lower-level feature maps offer higher resolution and include more precise positional information. However, due to less convolution involvement, lower-layer feature maps are less semantic and more noisy. Meanwhile, higher-layer feature maps provide stronger semantic information but have a lower resolution and worse detail perception. Fusing low-level feature maps onto the high-level feature maps helps alleviate the information loss in high-dimensional feature maps to improve the classification score for small object prediction.
Object detection should concern both the deep semantic and shallow information of the image. As such, it is vital to fuse feature maps that encompass both attributes. In light of this, we propose a multi-scale feature fusion module, integrating a bottom–up feature fusion layer and an adaptive pooling layer after FPN to generate four feature maps:
,
,
, and
. Our methodology combines the layer-by-layer convolution and feature splicing of the original feature map to obtain the MF. To produce
,
first undergoes 3 × 3 convolution up-sampling with a stride of 1, resulting in
. Subsequently,
and
are concatenated to achieve
.
,
, and
all adopt the above fusion method outlined in
Figure 4. Each FPN feature map provides a prediction result because its receptive field is relative to network depth. While deeper feature maps have larger receptive fields, they can lose shallow semantic information. To counteract this, we perform global average pooling on the feature maps after multi-scale fusion, suppressing the overfitting and strengthening connections between categories and feature maps. Our proposed MF can be defined as follows:
3.4. Interactive Learning Method
When all feature points on the feature map are regressed, the quality of the resulting predicted bounding boxes is often suboptimal for locations away from the center of the object. To address this, we introduce a new centrality prediction branch alongside the regression branch. The purpose of this branch is to compute the distance from any location to the center of the predicted bounding box. Values closer to 1 indicate that the location is close to the center while values close to 0 indicate that the location is further away from the center. It is evident that bounding box regression is closely related to centrality prediction. Accordingly, for a location with bounding box regression targets of
,
,
,
, the centerness target is defined as follows:
Object detection is often viewed as a multivariate learning challenge that jointly optimizes target classification and regression. The anchor-free detector employs a centerness estimation branch that identifies low-quality points located far from the center of the target to suppress. The independent nature of the regression branch and centerness estimation branch in existing single-stage methods may result in inconsistencies in prediction, as the key point chosen is often inconsistent in both branches. While the center point relates to the characteristics and morphology of the target, this inconsistency can lead to high centerness estimation prediction scores but inaccurate bounding box regression. To address this issue and improve the interaction between the two branches, we propose an interactive learning mechanism that enables closer collaboration and more accurate predictions. We define this mechanism as the interactive learning module. The interactive learning module is shown in
Figure 5.
Here, N refers to the feature map obtained after MF while Bmm represents the weighted feature map used for matrix multiplication.
3.5. Sim Box Refine
The box-refine structure used in DW [
41] significantly enhances the bounding box regression ability. In this paper, a simplified method is introduced whereby a new branch is introduced for regressing the four boundary points of the bounding box, and a box refinement operation is proposed based on the predicted point offset map
to refine the bounding box. Here, (a,b) =
represent the distance from the object’s detected center point to its four edges. The predicted distance can then be used in fine-tuning the boundary points, and a prediction module is designed to determine the boundary point at each predicted bounding box edge as shown in
Figure 6. By calculating the distances from each bounding box’s center point to its four boundaries under the feature maps of differing scales, the position of the original bounding box’s center point is adjusted using the coordinate points of the offset map as follows:
where
,
,
, and
denote the coordinates of the four bounding box boundary points.
3.6. Network Outputs
In the COCO dataset, our network generates a 80-dimensional vector p to predict the object category and a four-dimensional vector t for boundary box regression. By utilizing the anchor-free prediction method, the number of detection frames can be significantly reduced in comparison to the number generated using anchor-based detection algorithms. In the DIOR dataset, our network generates a 20-dimensional vector p to predict the object category and a four-dimensional vector t for boundary box regression.
3.7. Loss Function
Being an anchor-free detection algorithm, MFIL-FCOS incorporates a unique detection head onto the FPN model’s output. This detection head introduces three branches. Both the classification and centerness branches share the feature map. The branch of classification incorporates a loss function for point classification, while the branch of centerness employs a loss function for point centerness to determine whether the point represents the central region of the target. Additionally, a dedicated regression branch exists for target position regression.
MFIL-FCOS utilizes three distinct loss functions. In particular, the loss function of the point classification is implemented as follows:
The term denotes the focal loss. represents the count of positive samples, while signifies the classification score associated with points . Additionally, pertains to the fundamental aspect of classifying the point .
The centerness loss function is defined as follows:
corresponds to the cross-entropy loss. Here, denotes the score of centerness for the point , while represents the ground truth centerness value for the same point . Notably, centerness calculations are exclusively performed for positive samples.
The regression loss function is defined as follows:
represents the IOU loss. Here, denotes the regression outcomes for the point , while is the indicator function, taking the value of 1 for and 0 otherwise. It is essential to note that the location regression computations are exclusively applied to positive samples.
The total loss function is defined as follows:
4. Experiment
4.1. Datasets
Our research underwent validation using two distinct types of datasets. Initially, we utilized the COCO dataset, renowned for its diversity and comprehensive feature collection. The COCO dataset provides a vast array of annotations for everyday objects, aiding in the initial stages of acquiring distinctive features. Next, we employed the DIOR dataset, a benchmark dataset of significant scale designed for detecting targets in optical remote sensing images.
4.1.1. COCO Dataset
The COCO dataset, short for “Common Objects in Context”, is a widely used benchmark dataset in the field of computer vision and object detection. It is designed to support various computer vision tasks, such as object recognition, object detection, image segmentation, and captioning. The COCO dataset is notable for its large and diverse collection of images, making it a valuable resource for training and evaluating computer vision models.
4.1.2. DIOR Dataset
The DIOR dataset comprises 213,463 images covering 192,472 instances across 20 categories, including airports, dams, ships, and bridges. Each image measures 800 × 800 pixels, with a spatial resolution ranging from 0.5 to 30 m. The reasons for selecting DIOR for object detection lies in several factors: (1) DIOR exhibits the attributes of multi-category, multi-image, and multiple-instance scenarios; (2) Both image spatial resolution and object scales exhibit variability; (3) Due to diverse imaging conditions, encompassing different weather, seasons, and sensor sources, the dataset offers rich and varied samples; (4) The heightened intra-class diversity and diminished inter-class distinctions amplify the detection challenge and enhance the adaptability of the training model.
Figure 7 visually presents the assorted samples from each category within the DIOR dataset.
4.2. Implementation Details
Data augmentation strategy. Data augmentation plays a critical role in achieving scale and rotation invariance during training. To achieve this, we apply several techniques, such as image resizing, flipping, image normalization and padding, and other augmentation methods. Specifically, we augment the size of the initial image, ensuring that the longer side is equal to or smaller than 1333 pixels, while the shorter side is equal to or smaller than 800 pixels. These methods help our models learn essential image features and prevent overfitting to the dataset.
Training details. Stochastic gradient descent (SGD) with a momentum algorithm is utilized to train all object detection models. The SGD algorithm employs an initial learning rate of 0.01 coupled with a momentum of 0.9. Under the 1× scheduler at 12 epochs, our learning rate undergoes a warm-up strategy, and its decay is triggered at epochs 8 and 11. A weight decay of 0.0001 and a training batch size of 4 are utilized. Batch normalization is utilized throughout our network’s layers. We initialized our models’ weight using publicly available ImageNet pre-trained models. Firstly, we pre-trained our model using the COCO dataset, and subsequently, fine-tuned the model on the remote sensing dataset. The model parameters are derived from the pre-training to accommodate the simple characteristics of remotely sensed images. This customized strategy guarantees the model’s competence in effectively managing diverse occlusion scenarios and intricate object characteristics inherent to remote sensing applications. A ResNet-50-based model usually requires 1.5 days to be trained on four NVIDIA 3090 GPUs.
4.3. Ablation Experiment
This study necessitates that ablation experiments are performed using the COCO dataset. These experiments are essential to confirm the method’s validity and to ascertain the significance of each module in the process.
The amount of network parameters.
Table 1 presents a comparison of our network’s performance with respect to traditional network structures. Using ResNet-50 as the backbone network, our proposed architecture maintains comparable accuracies with fewer parameters, validating the effectiveness of our design.
Feature fusion methods. Detectors utilizing feature fusion hold promise in enhancing detection performance, especially for small and irregular objects. This capability stems from their capacity to integrate the semantic information from higher-level features with the image data from lower-level feature maps. In this research, we introduce a multi-scale feature fusion approach and conduct a comparative analysis against existing methods. The PaFPN model utilizes a bi-directional fusion technique from deep to shallow and then from shallow to deep, and is the first to propose a bottom–up secondary fusion model. The BiFPN model builds on this concept with a more complex bottom–up secondary fusion process. In contrast, the RFPN model utilizes a cyclic structured feature pyramid network. We propose a simpler and more efficient lightweight module, the MF module, which yields an improved accuracy and more significant performance gains for small object detection compared to these other methods. The results of a comparative analysis of our method and others are presented in
Table 2.
Task interaction. Target detection is frequently formulated as a joint optimization problem in which distinct learning mechanisms for classification and localization lead to feature space distributions with differing properties. Consequently, utilizing separate branches for prediction can result in misalignment. However, these misalignments can be mitigated by enhancing the interactivity between the distinct branches. To improve this interactivity between the classification and location branches, we propose an anchor-free detector with three branches: classification, regression, and centrality prediction. We use the product of the classification score and centrality prediction score when classifying positive and negative samples. Although the classification and centrality prediction branches interact on a task-by-task basis, there is a lack of interaction between the localization and centrality prediction branches. To address this issue and enhance the network training effects, we develop a new approach to improve the interaction between the localization and centrality prediction branches. In comparison to the method proposed by TOOD, our approach is more effective, as demonstrated in
Table 3.
MFIL-FCOS. In order to attribute the contribution of each component, we progressively integrated MF, IL, Sim Box Refine, and CBAM with the ResNet-50-FPN FCOS baseline, improving the detector by adding modules. The introduction of MF in the COCO dataset improves the performance from 40.4 mAP to 40.9 mAP. The introduction of IL further improves the performance from 40.9 mAP to 41.3 mAP. The use of Sim Box Refine increases the mAP by 0.1, and the results are shown in
Table 4. CBAM is a lightweight general-purpose module for generating the feature map notation diagrams, spatial and channel dimension matrix multiplication and adaptive feature learning, the integration of which increases the mAP by 0.2. In the DIOR dataset, the introduction of MF improves the performance from 0.684 mAP to 0.699 mAP, and the introduction of IL improves the performance from 0.699 mAP to 0.711 mAP, and the results are shown in
Table 5.
4.4. Comparison Experiment
4.4.1. Verified on COCO Dataset
Table 6 and
Table 7 present a comparison between MFIL-FCOS and other one-stage detectors using the COCO dataset. Our model training follows the same resolution and 1× learning schedule as employed by the majority of other methods to ensure a fair comparison. We present results based on a single model and a single testing scale. When using the ResNet50 network, our model reaches 41.6 with the same accuracy as DRKD, and the DRKD method has a higher accuracy in some detection scenarios because of the use of knowledge distillation. On the ResNet-101 and ResNet-101-64x4d architectures, MFIL-FCOS demonstrates the outstanding performance with an AP of 46.9 and 48.4, respectively. This surpasses the performance of other one-stage detectors such as ATSS (by 3 AP) and GFL (by 2 AP). The introduction of ResNet-101-DCN results in an even larger improvement for MFIL-FCOS, relative to other detectors on this architecture. For instance, while GFL has an improvement of 2.3 AP (45.0 → 47.3 AP), MFIL-FCOS obtains an improvement of 2.6 AP (46.9 → 49.5 AP) instead. This demonstrates the remarkable efficiency of MFIL-FCOS in collaboration with deformable convolutional networks (DCN), as it dynamically adapts the spatial distribution of learned features to align with the task. It is important to note that DCN is specifically employed in the initial two layers of the head tower within MFIL-FCOS. When using other backbone networks, our method further improves the detection accuracy as the backbone network deepens. The DRKD method does not show a significant improvement in accuracy after using other backbone networks and may require the tuning optimization of the network. In summary,
Table 7 clearly illustrates that MFIL-FCOS surpasses other one-stage object detection methods, achieving a result with an AP of 49.5.
4.4.2. Analysis of the Detection Results and Convergence
Figure 8 shows the examples of the object detection results produced by FCOS and the method proposed in this paper. The top of each image is FCOS and the bottom is the detection result of this paper. Our method has a higher detection score when detecting the same object and fewer misses and false detections when detecting dense scenes. We performed additional assay experiments using MFIL-FCOS and the results are shown in
Figure 9.
Figure 10 shows a comparison of the convergence curves of FCOS and the method proposed in this paper during the training process. The training is performed on the COCO dataset using a training period of 12 epochs, and the other settings are kept consistent for fairness. During the training process, the convergence curve of our method is smoother and produces less fluctuation during the training process.
4.4.3. Verified on DIOR Dataset
To evaluate the efficacy of our model, we perform a comparative analysis with cutting-edge models. The analysis of the experimental data shows that our method is better than the above methods in detecting objects such as airplanes and airports, but due to the problems of uneven light and darkness in remote sensing images and the poor color differentiation of the images, the accuracy obtained is lower in detecting some of the scenes. There are differences between the different methods, such as LO-Det having a lower detection accuracy when detecting storage tanks, MFPNet having a lower detection accuracy when detecting dams, and HakwNet having a lower detection accuracy when detecting airplanes. A comprehensive analysis of
Table 8 shows that our method outperforms other methods in terms of average AP 0.722. This indicates that our method has excellent overall accuracy and achieves an excellent balance between precision and recall. In addition, our method also performs well in terms of AP 0.908 for chimneys, which is significantly better than other methods. As for the AP scores for stadiums and storage tanks, our method achieves 0.891 and 0.716, respectively, showing a competitive performance.
In
Figure 11, we illustrate the detection results of our proposed approach using diverse representative objects, specifically the harbor, tennis court, and track field. Distinctly colored bounding frames signify different object categories. The integration of our proposed MFIL-FCOS enhances the extraction of features, providing more comprehensive and targeted feature representations. Furthermore, the utilization of Sim Box Refine contributes to improved outcomes in box regression. This collaborative approach empowers our model to effectively handle the recognition and localization of objects across various scales, resulting in predicted bounding boxes closely aligned with the ground truth. Nevertheless, it is important to highlight that instances of misdetection and false detection predominantly occur in scenarios with small scales and indistinct boundaries.
4.5. Discussions
Limitation of MFIL-FCOS. Although our approach has achieved satisfactory results in object detection in multi-scale scenes, there has been limited exploration of the problems that arise during the detection of real objects. In addition to detecting small objects and dense scene objects, we also need to consider the occlusion problem in the detected scene and the leakage problem in low-light detection scenarios. In addition to this, we found that some complex objects also appear frequently in other tasks, such as 3D object detection and text detection, which leaves a lot of room for further exploration. Our work combines multi-scale feature integration with interactive learning to solve multi-scale detection problems in real detection scenarios. We hope to attract more researchers to focus on the problems that arise in real detection scenarios.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}