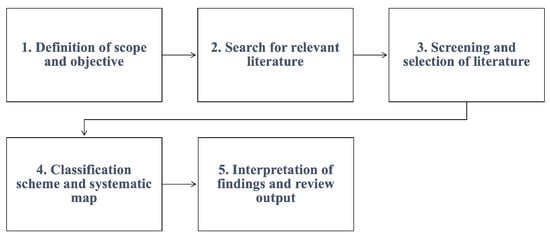
A web-based
Java programming learning assistant system (JPLAS) has been developed for novice students to study
Java programming by themselves while enhancing
code reading and
code writing skills. One type of the implemented exercise problem is
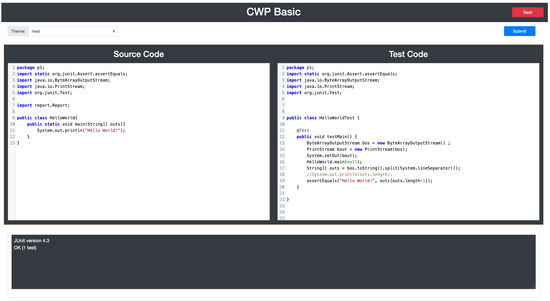
code writing problem (CWP), which asks
[...] Read more.
A web-based
Java programming learning assistant system (JPLAS) has been developed for novice students to study
Java programming by themselves while enhancing
code reading and
code writing skills. One type of the implemented exercise problem is
code writing problem (CWP), which asks students to create a
source code that can pass the given
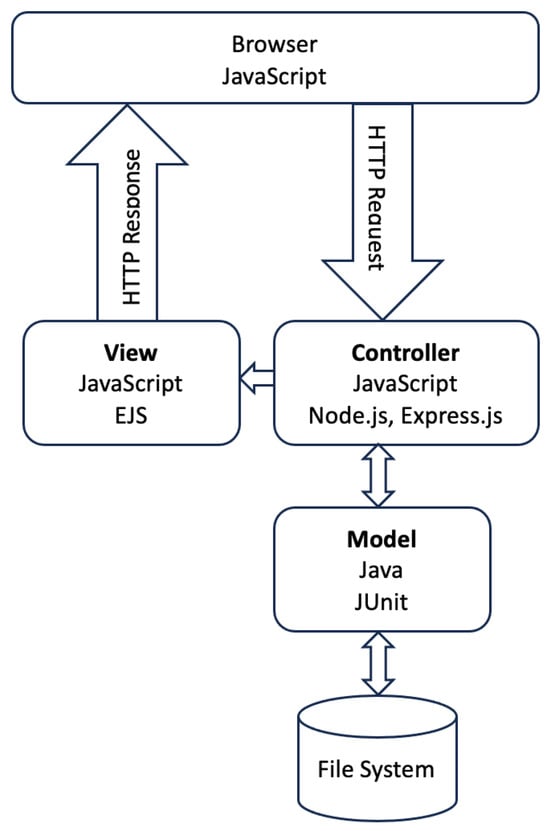
test code. The correctness of this answer code is validated by running them on
JUnit. In previous works, a Python-based
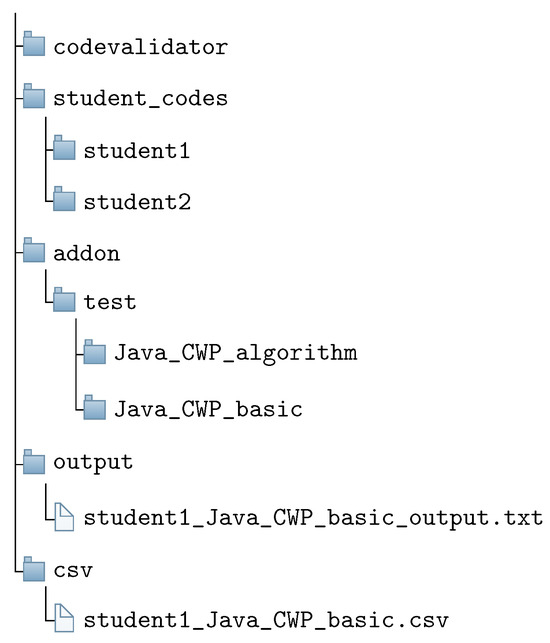
answer code validation program was implemented to assist teachers. It automatically verifies the source codes from all the students for one test code, and reports the number of passed test cases by each code in the CSV file. While this program plays a crucial role in checking the correctness of code behaviors, it cannot detect
code plagiarism that can often happen in programming courses. In this paper, we implement a
code plagiarism checking function in the
answer code validation program, and present its application results to a Java programming course at Okayama University, Japan. This function first removes the whitespace characters and the comments using the
regular expressions. Next, it calculates the
Levenshtein distance and
similarity score for each pair of source codes from different students in the class. If the score is larger than a given threshold, they are regarded as
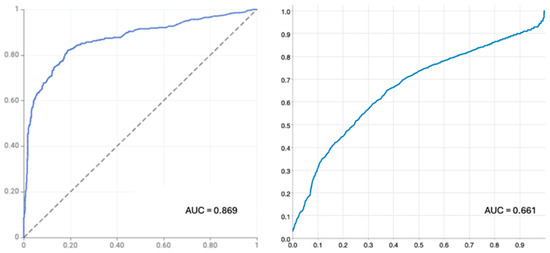
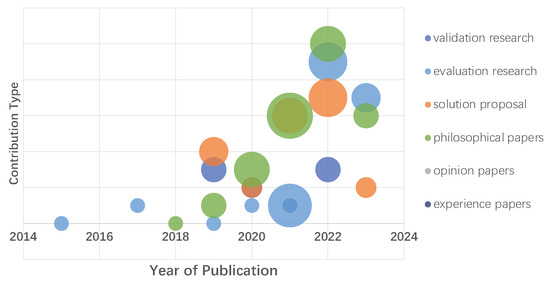
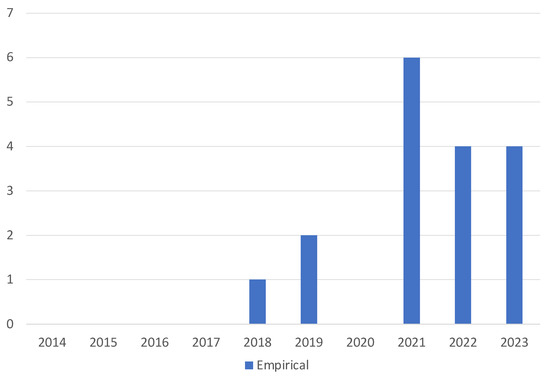
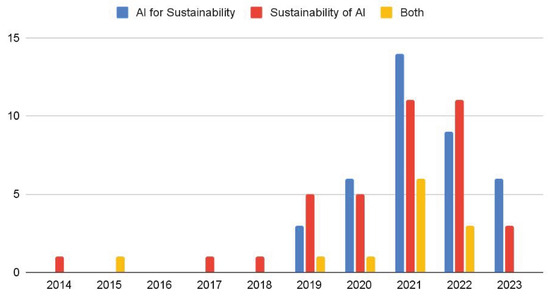
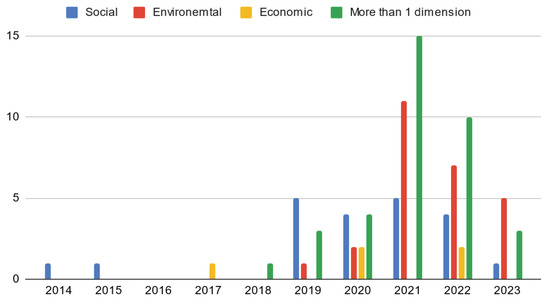
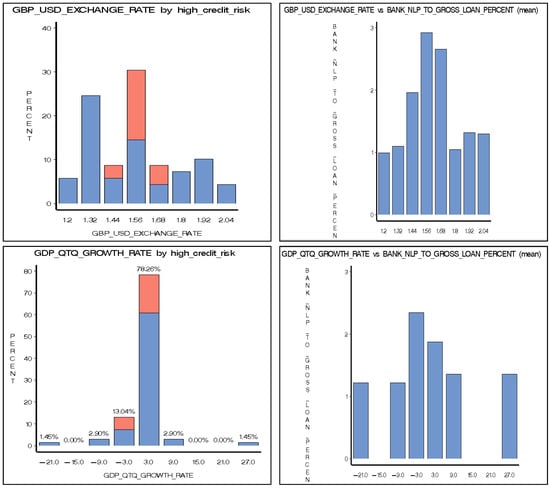
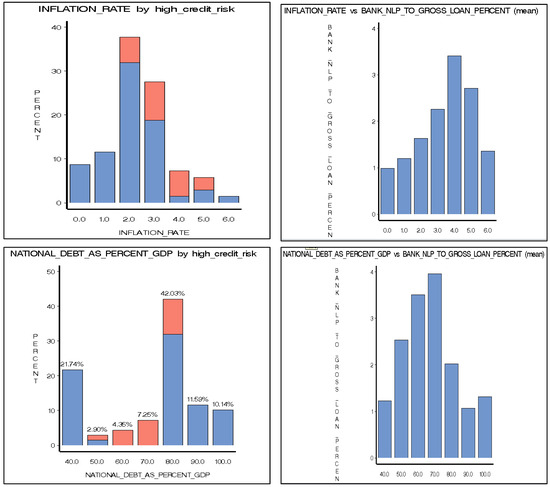
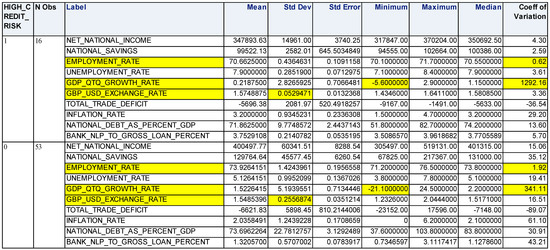
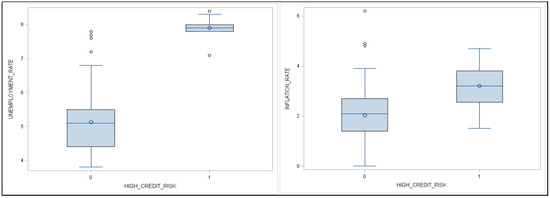
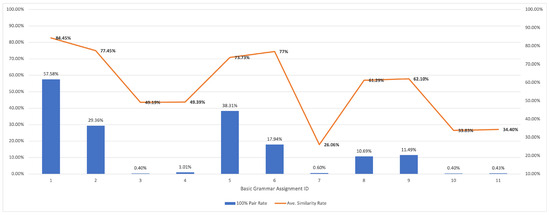
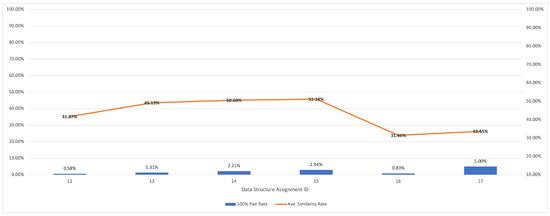
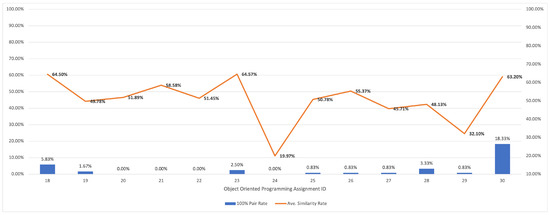
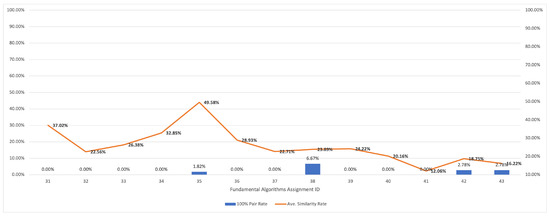
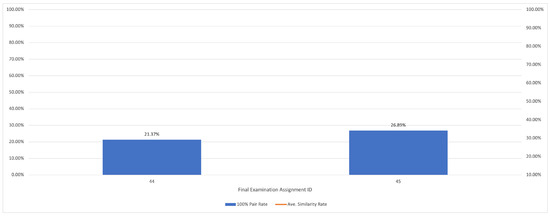
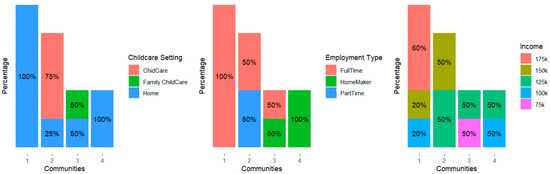
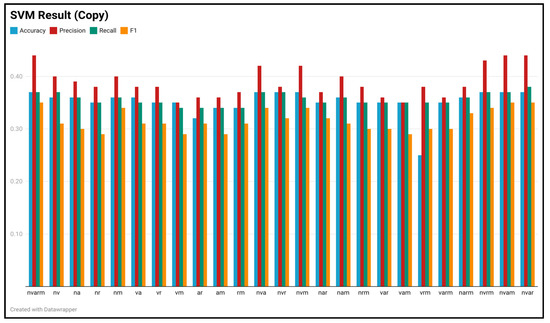
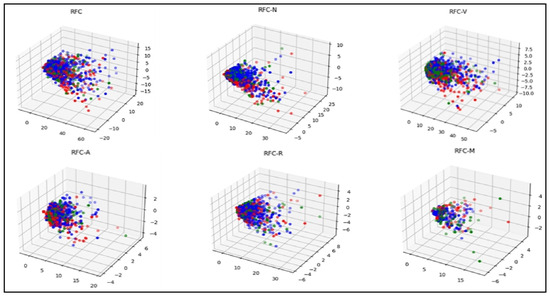
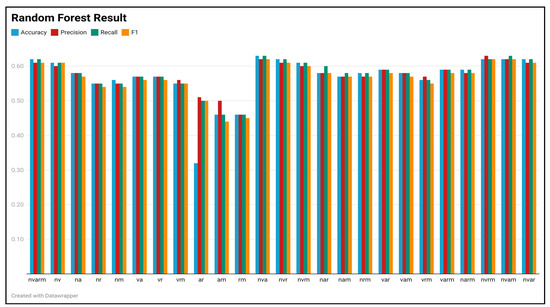
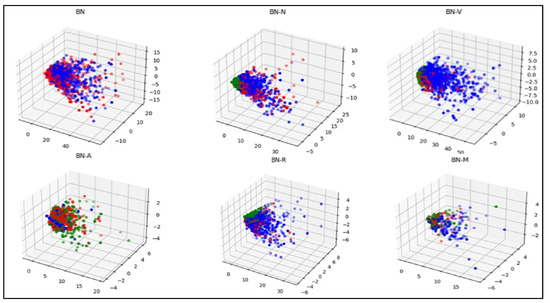
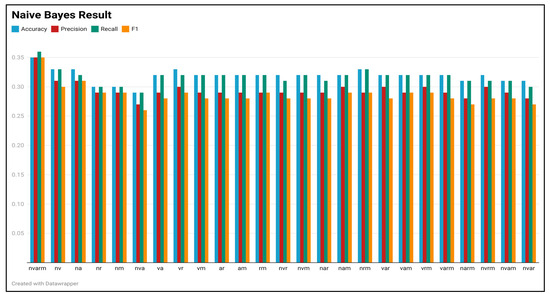
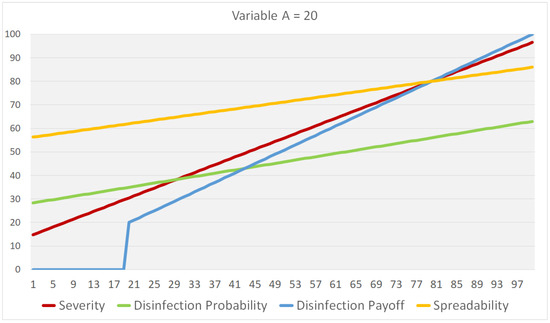
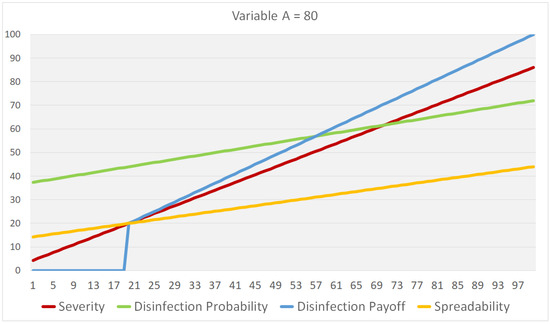
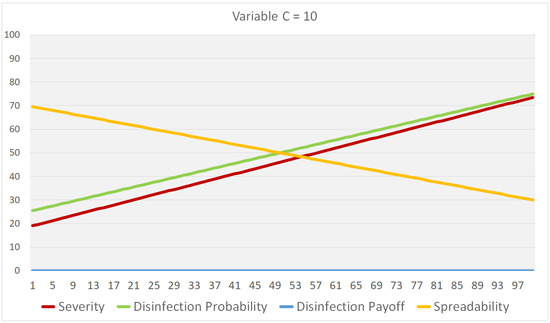
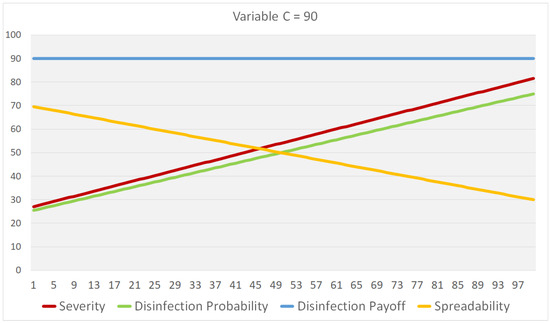
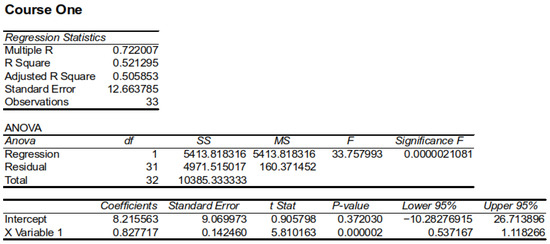
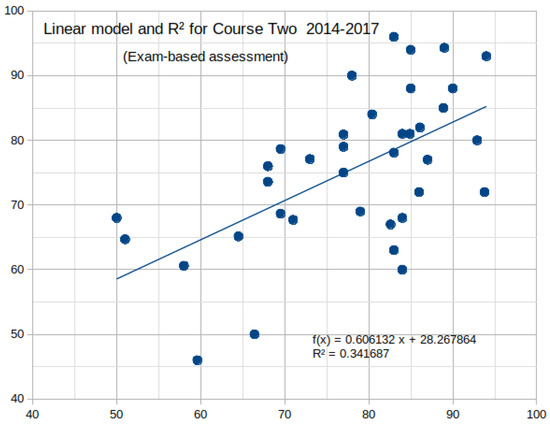
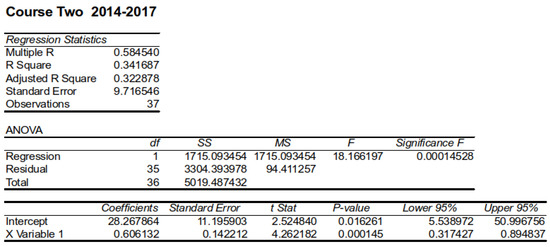
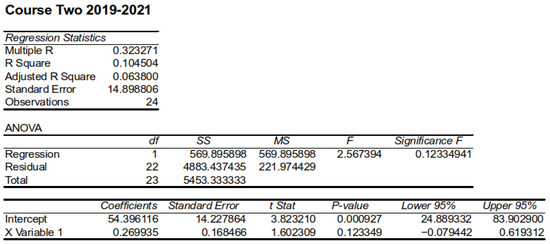
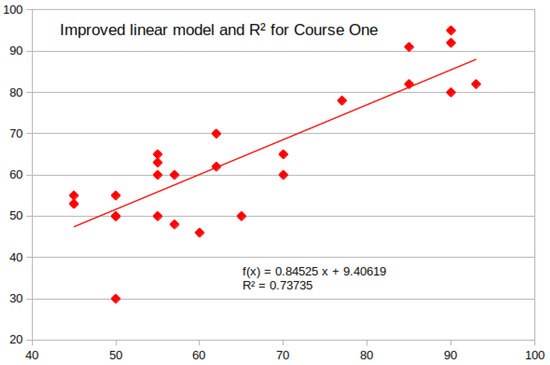
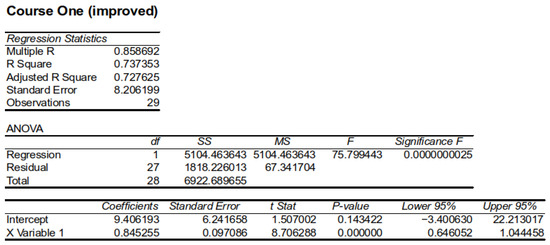
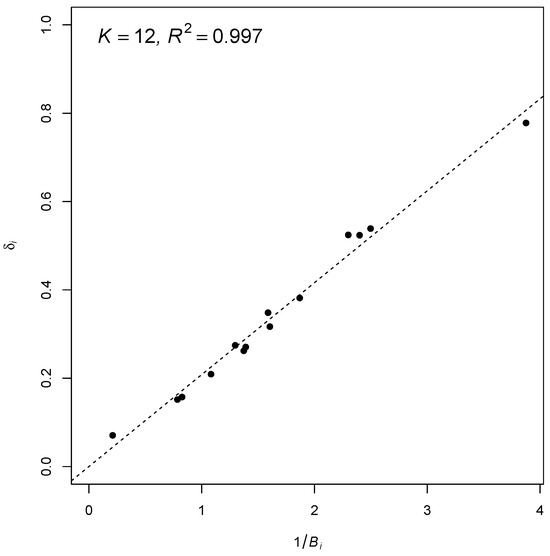
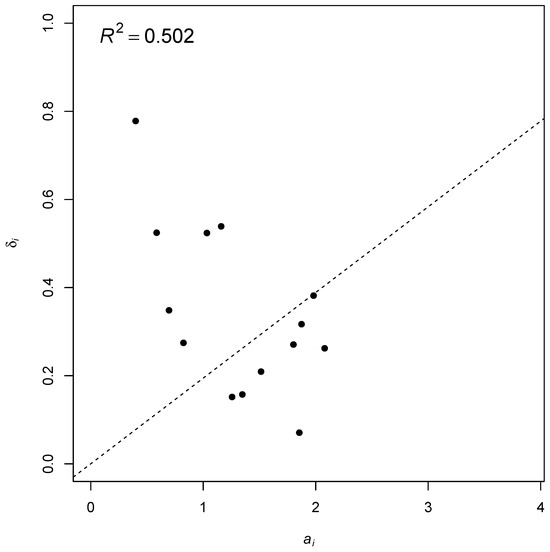
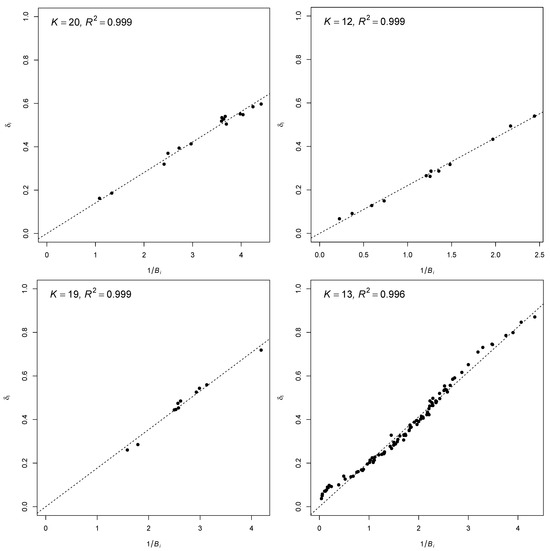
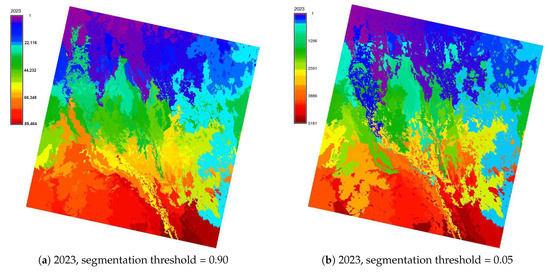
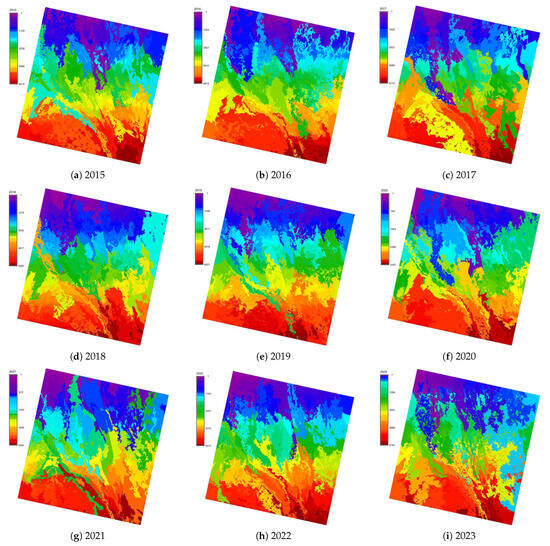
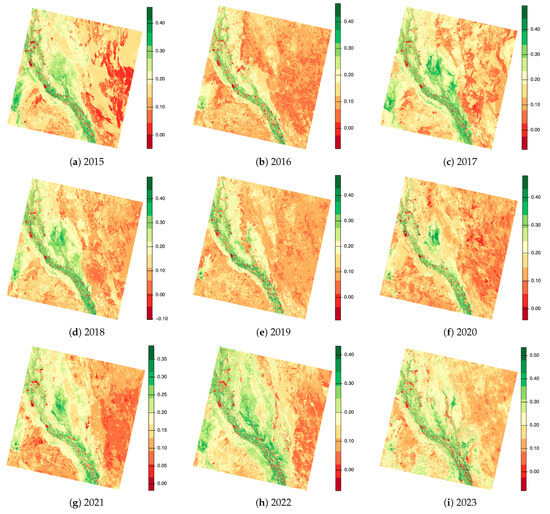
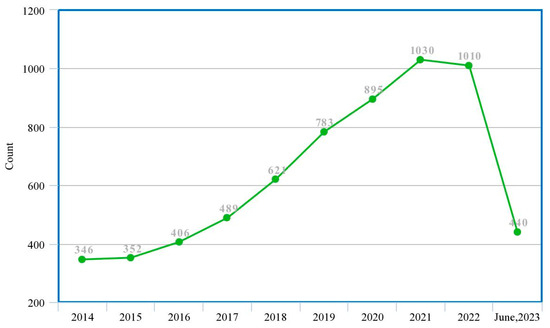
plagiarism. Finally, it outputs the scores as a CSV file with the student IDs. For evaluations, we applied the proposed function to a total of 877 source codes for 45 CWP assignments submitted from 9 to 39 students and analyzed the results. It was found that (1) CWP assignments asking for shorter source codes generate higher scores than those for longer codes due to the use of test codes, (2) proper thresholds are different by assignments, and (3) some students often copied source codes from certain students.
Full article





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}