
Generating Synthetic Sperm Whale Voice Data Using StyleGAN2-ADA

 , , , and
, , , and 
Abstract
:1. Introduction
- We introduce an approach to reduce the scarcity of whale audio data by analyzing its spectral characteristics.
- We describe a method for producing synthetic acoustic data for sperm whales using the StyleGAN2-ADA network.
- Several experiments conducted on authentic sperm whale audio datasets show the high resemblance between the augmented and synthetically created data derived using the proposed approach, in contrast to other considered data augmentation methods.
2. Related Works
- Time warping the sparse image. A logarithmic spectrogram is viewed as an image, where the time axis is horizontal and the frequency axis is vertical. A random point along the horizontal line passing through the center of the image within a certain range is warped either to the left or right by a randomly chosen distance.
- Frequency masking involves masking a range of consecutive mel-frequency channels. The number of channels to be masked is first chosen randomly, and then the starting point for the masking is selected.
- Time masking involves masking a range of sequential time steps. Similar to frequency masking, the number of time steps and the starting point for the masking are chosen randomly. Additionally, there is an upper bound on the width of the time mask.
- Problems with training neural networks with small sizes of training samples.
- The limited number of methods for augmenting sound data.
- The area of generation of sound signals (including bio-similar ones) has been poorly studied in small samples.
3. Materials and Methods
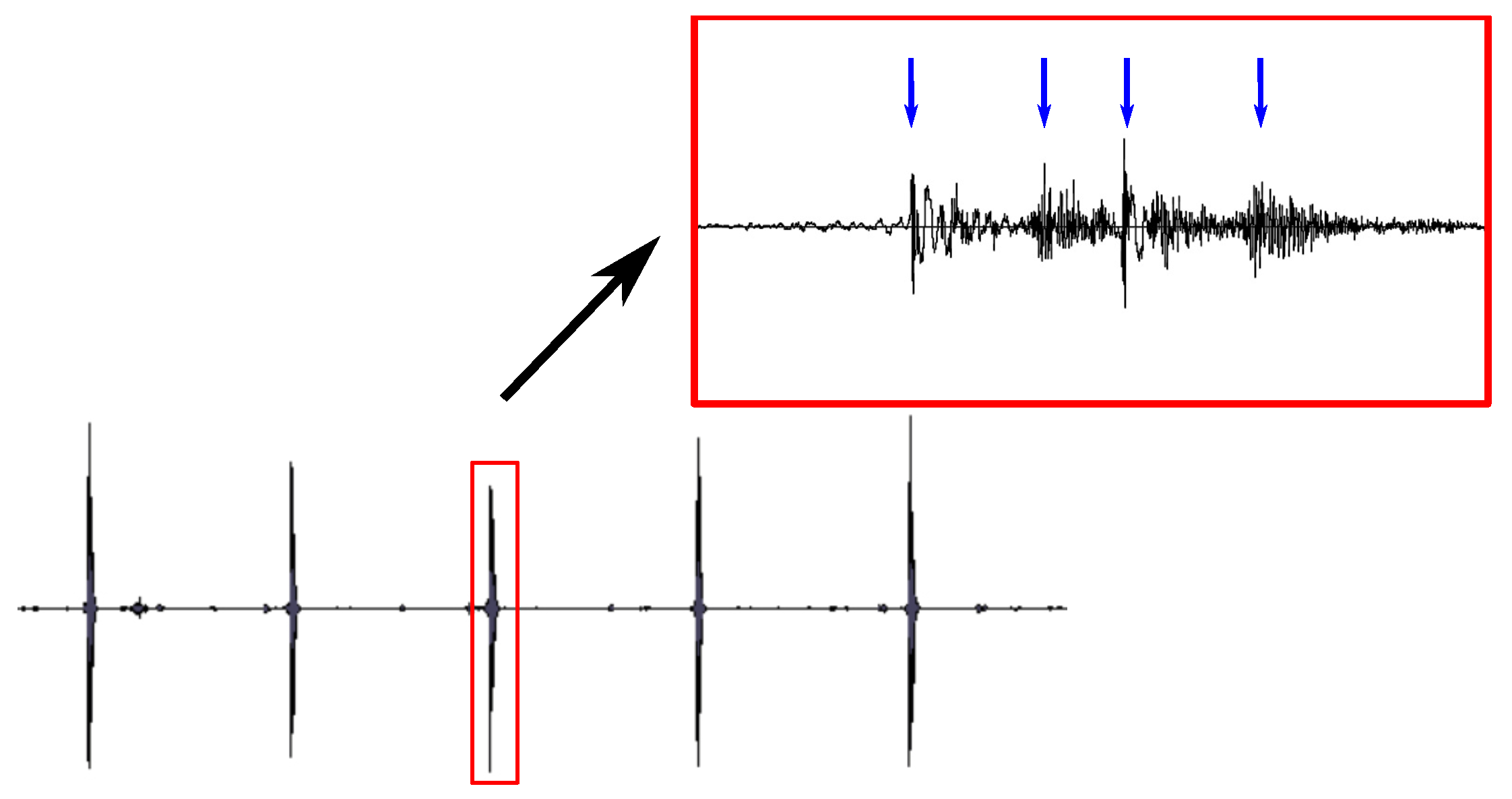
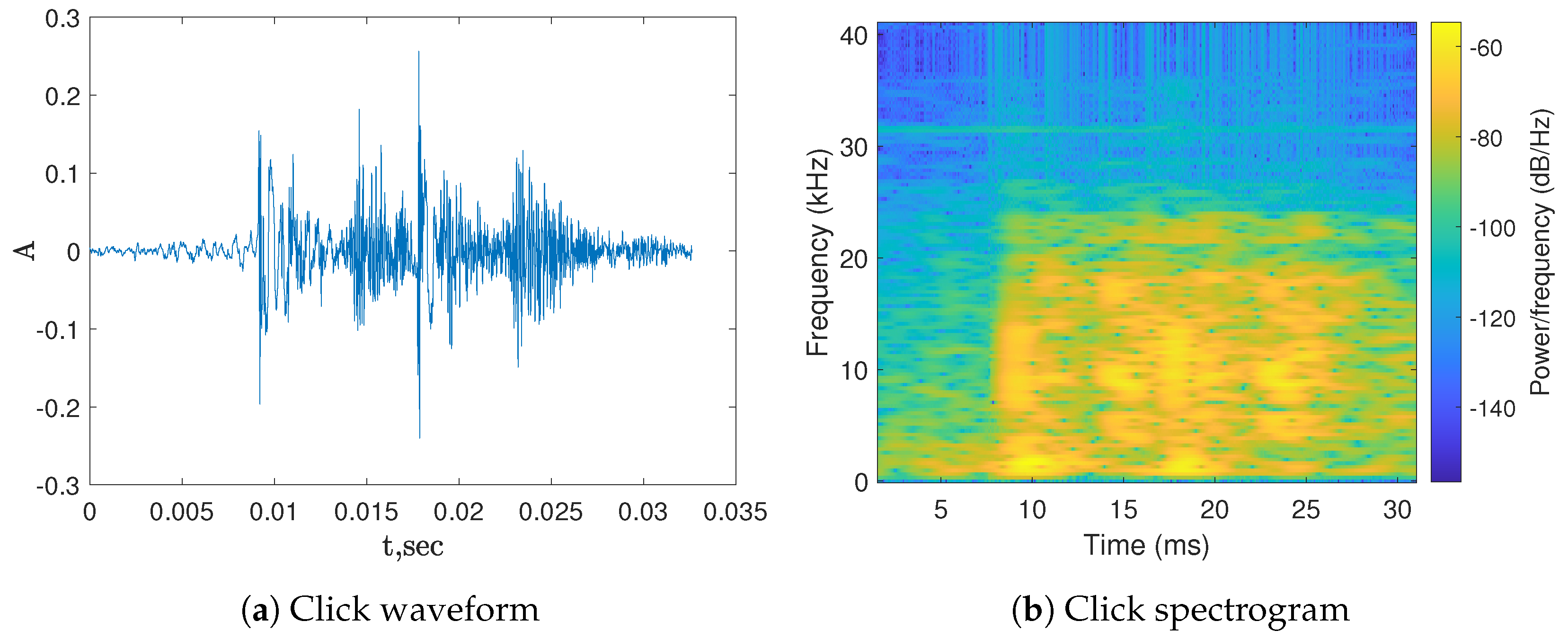
3.1. Sperm Whale Clicks
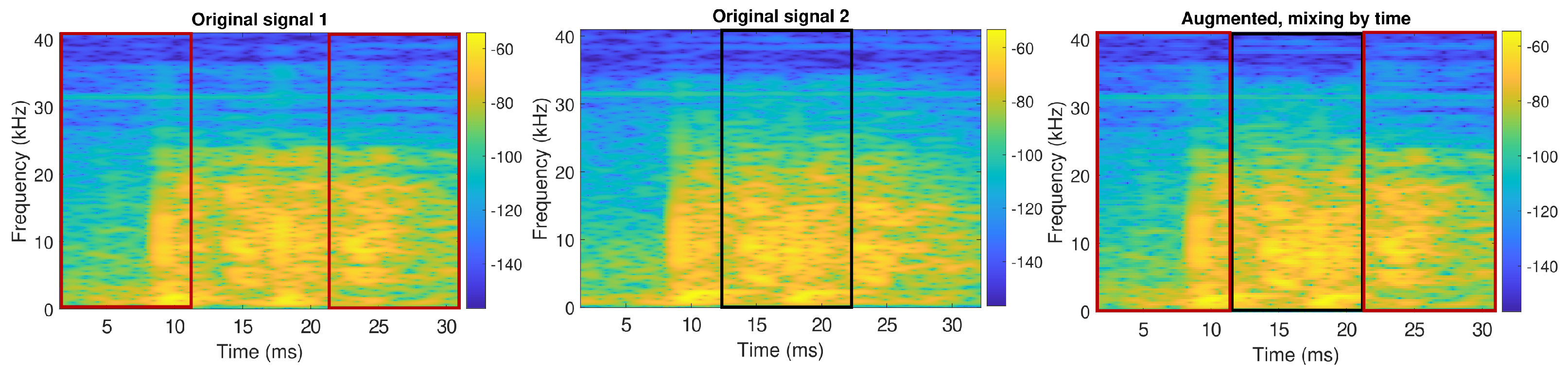
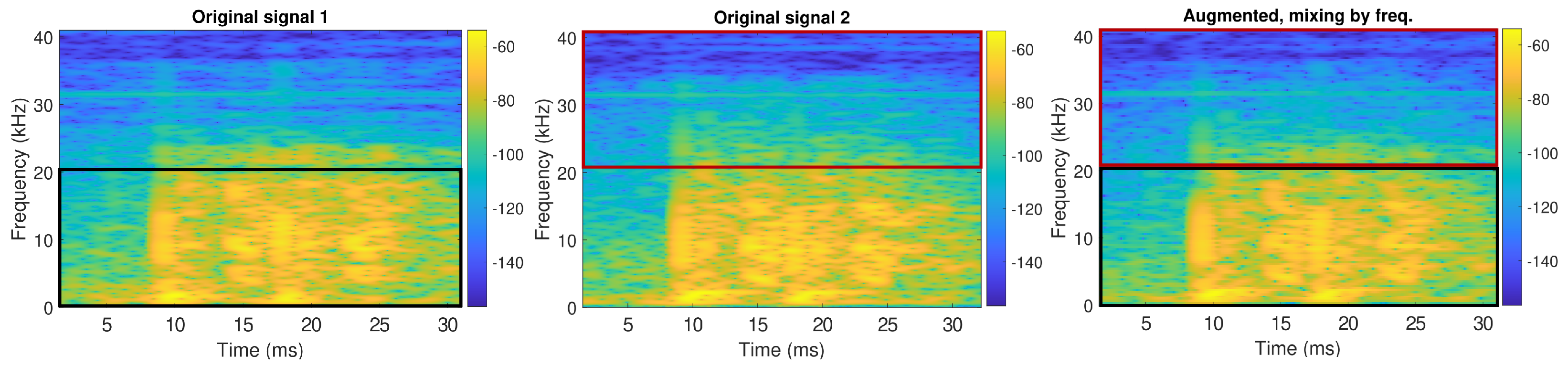
3.2. Augmentation of Sperm Whale Clicks
- Changing the signal speed within the range of 0.8 to 1.2 compared to the original signal, implemented using the MATLAB function stretchaudio(S,k). The initial signal (S), its length, and the parameter for changing the audio speed (k) are transmitted as parameters.
- Shifting the signal pitch within the range of − 3 to 3 semitones, implemented using the MATLAB function shiftpich(S,k). As parameters, the initial signal and the number of semitones for the shift (k) are passed to the function.
- Changing the signal volume within the range of −3 to 3 dB. The new signal is obtained from the original signal S multiplied by the amplification factor, where k is the required amount of dB: .
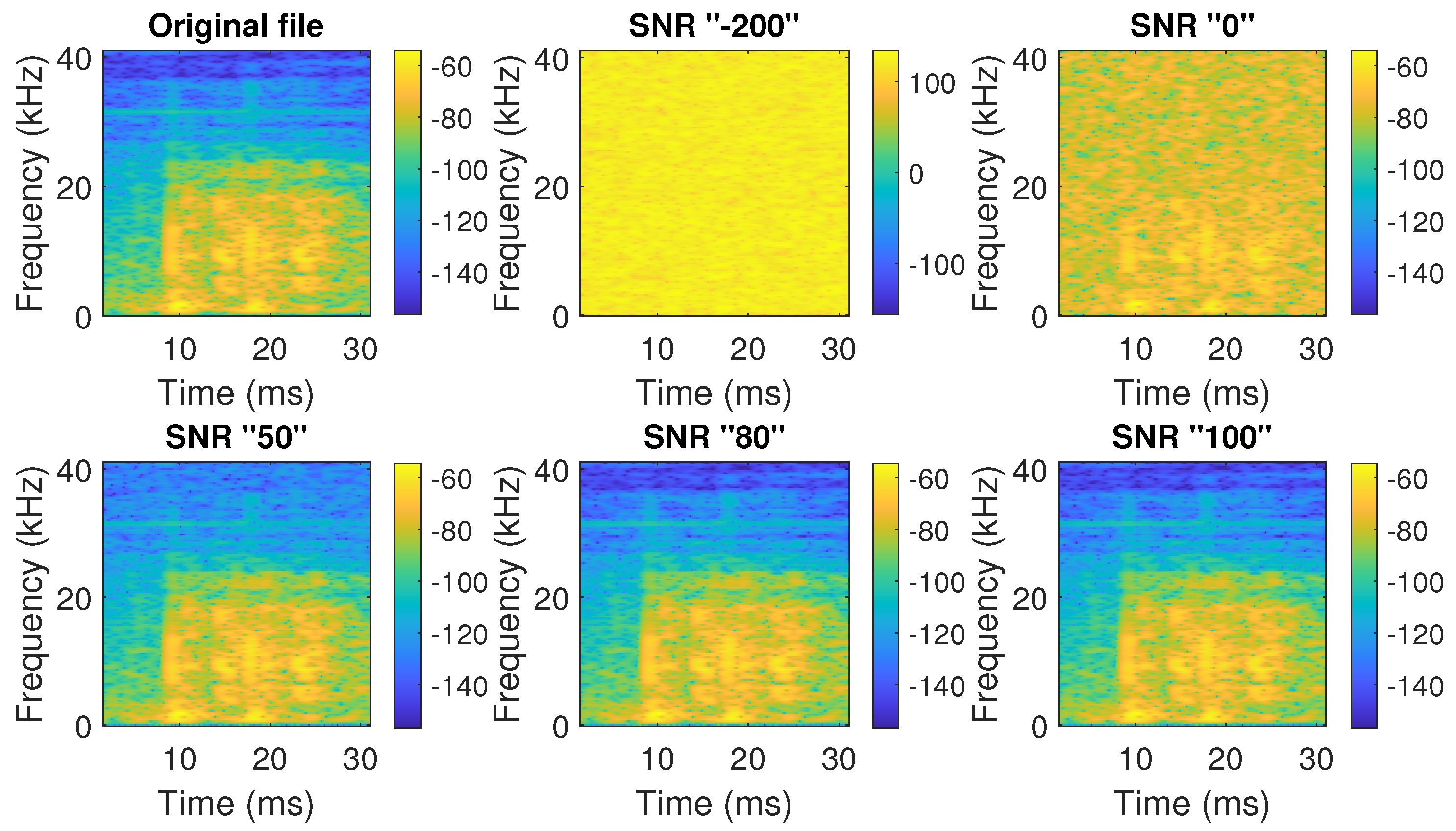
- Addition of random noise to the signal, with a signal-to-noise ratio (SNR) between 50 and 100, implemented using the MATLAB function awgn(S,snr). The parameters include the original signal (to which noise is to be added) and the signal-to-noise ratio (SNR) (to modulate the intensity of the added noise). The SNR parameter was selected to ensure that the operation did not distort the original signal. Sometimes, it is necessary to adjust the SNR parameter in such a way that it does not distort the original signal. Figure 2 shows an example of adding noise to the original signal with different original signal-to-noise ratios.
- Time shifting of certain elements within the range of −0.0001 to 0.0001 s. To implement this augmentation approach, some elements of the original signal are swapped with neighboring ones that are within a range satisfying the conditions of a given interval.
| Algorithm 1: Augmentation approach used in classical methods |
 |
| Algorithm 2: Augmentation approach used in mixing methods |
 |
3.3. Deep Learning Models for Sperm Whale Audio Data Generation
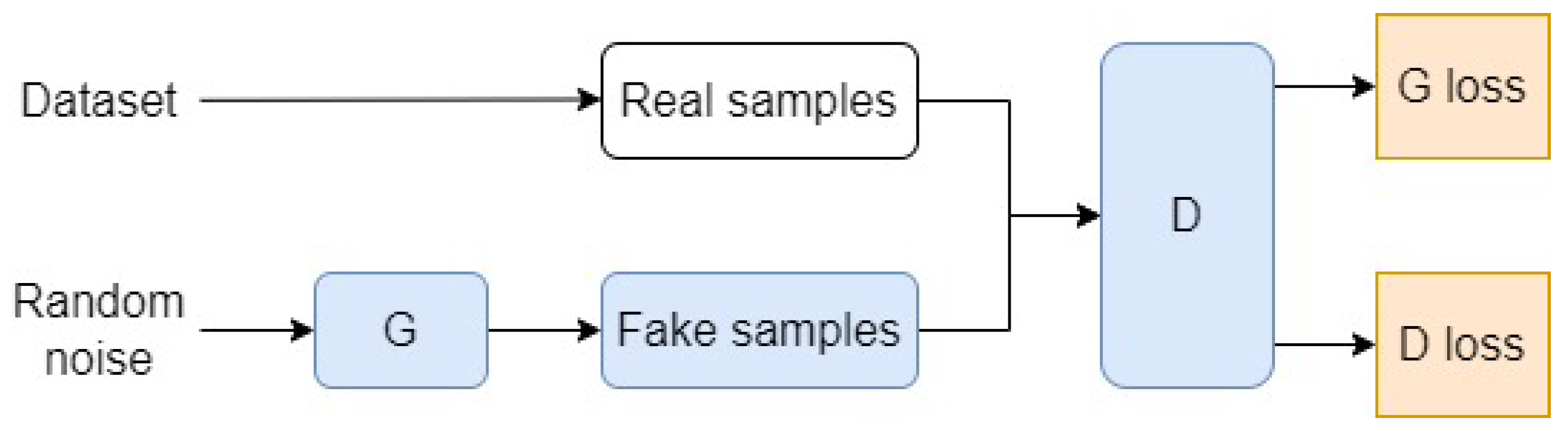
3.3.1. WaveGAN
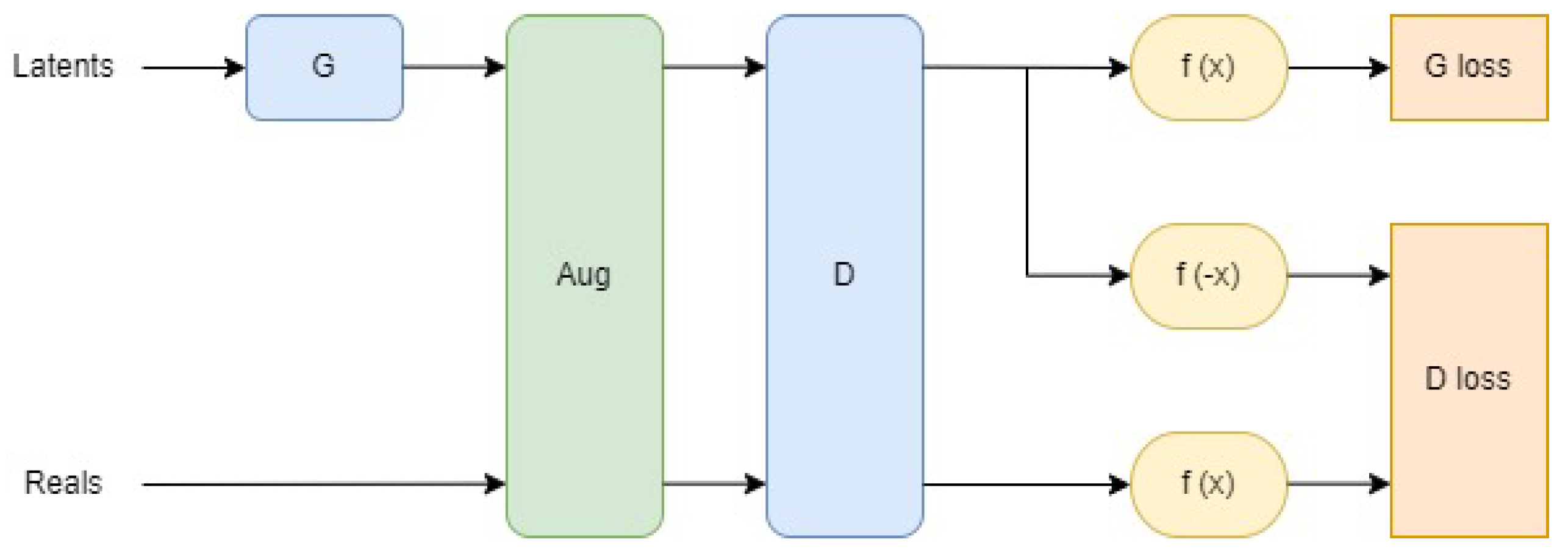
3.3.2. StyleGAN2-ADA
3.4. Metrics for Audio Data Evaluation
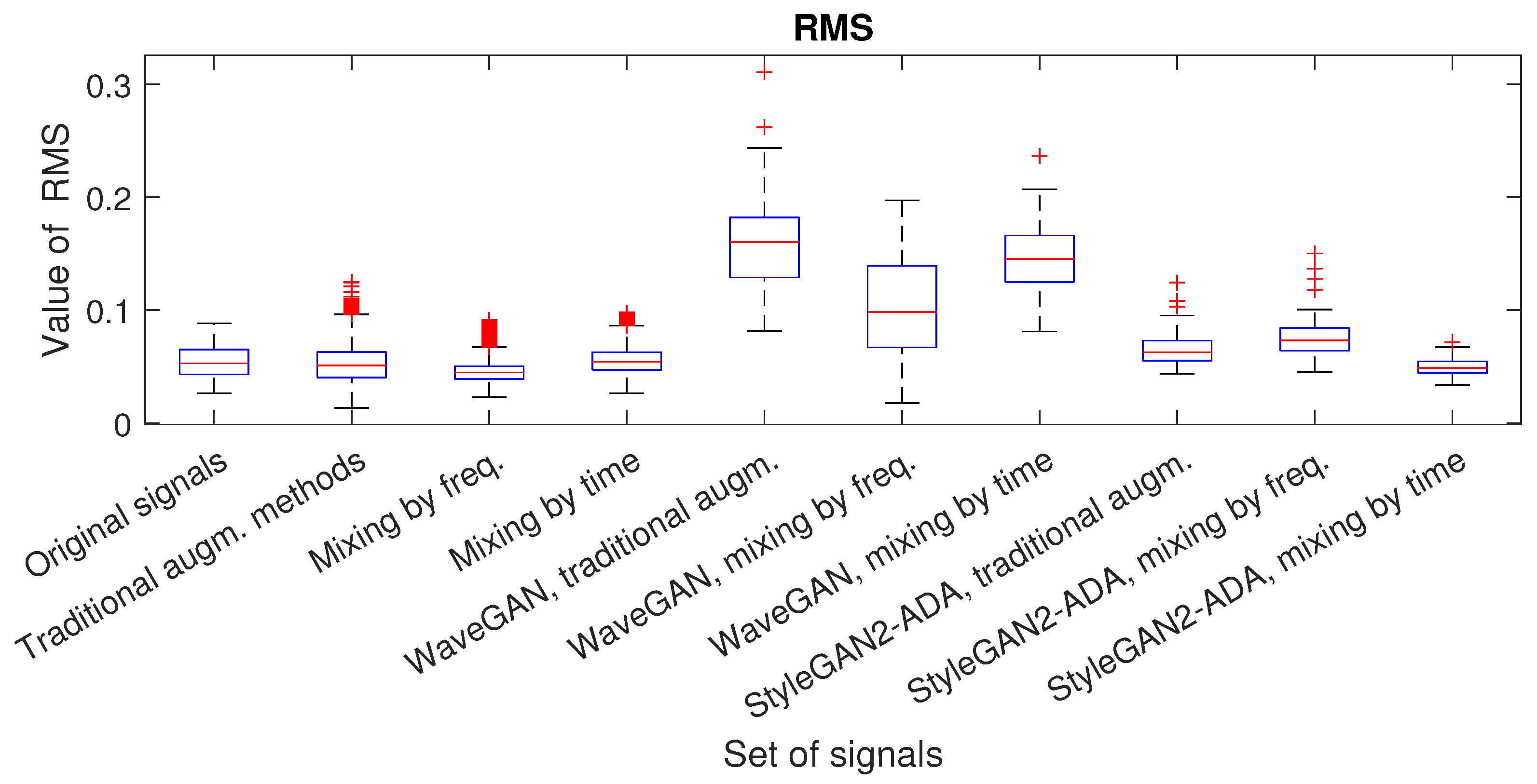
- RMS: The root-mean-square value of the signal. This metric provides information about the effective signal energy and is more representative than a simple average amplitude value. The RMS is calculated using the following formula:where is the value of the signal at the N-th point and N is the number of points in the signal.
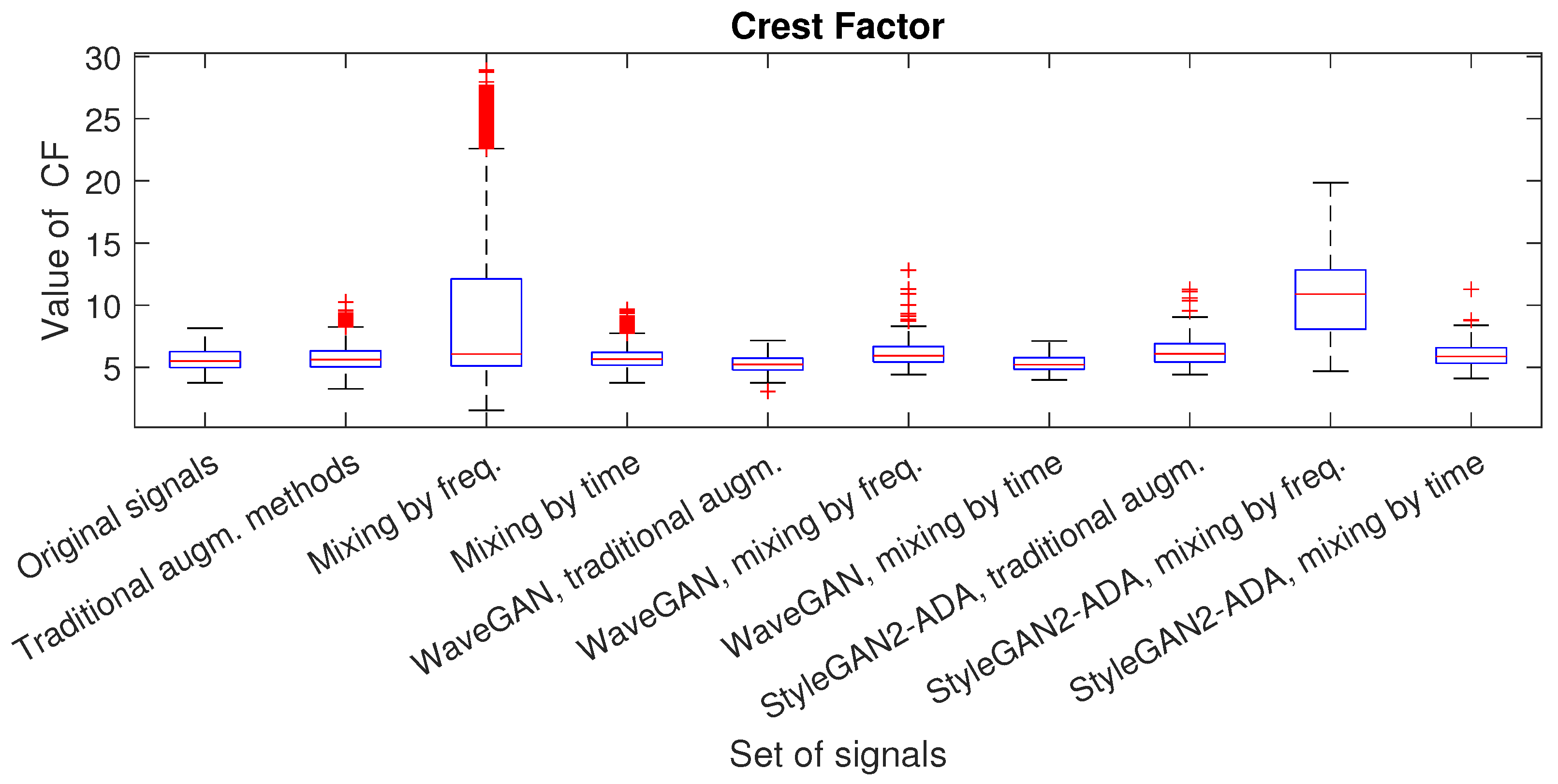
- Crest factor: This metric allows one to detect failures that manifest themselves in changes in the peak frequency of the signal. High values of this metric mean that the signal contains short-term peaks or high-frequency pulses. The crest factor is calculated using the following formula:where is the maximum value of the signal.
- Shape factor: This metric evaluates the shape of a signal regardless of its size. The shape factor is calculated using the following formula:
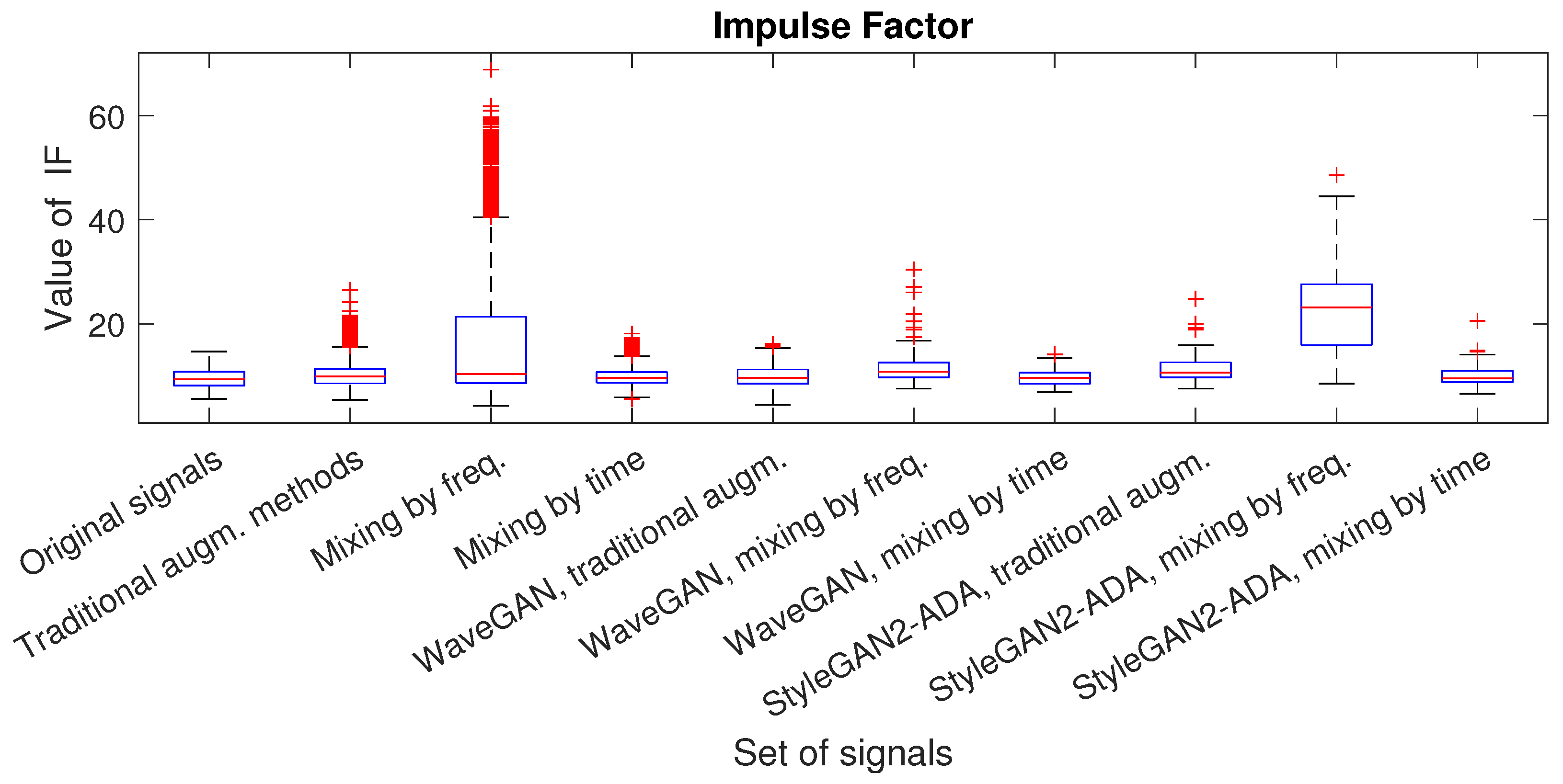
- Impulse factor: This metric evaluates the sharpness of pulses or peaks in a signal. The impulse factor is calculated using the following formula:
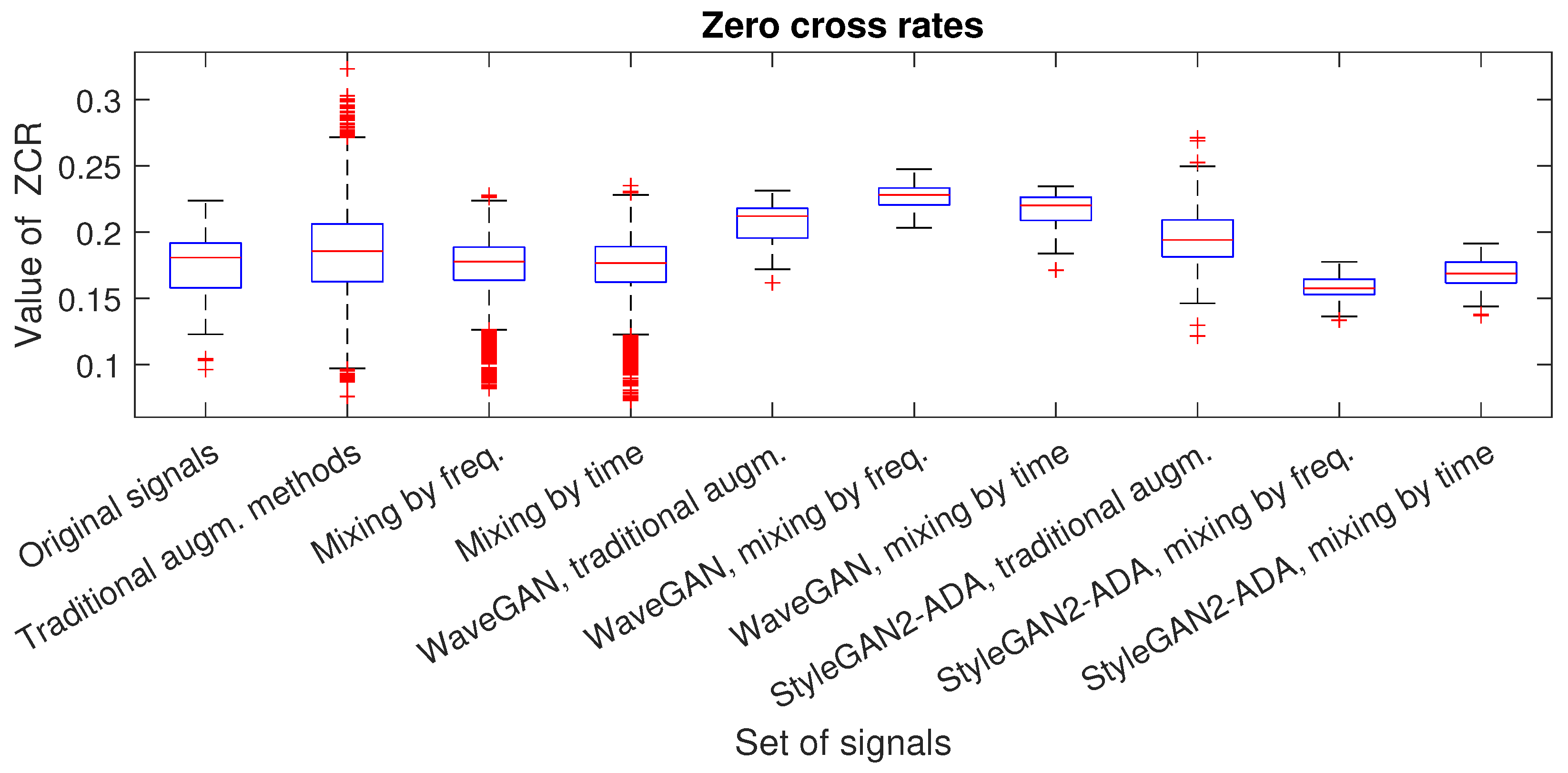
- Zero-crossing rate: This metric shows how many times the signal crosses the amplitude value of “0” during the shown period, which indicates the smoothness of the signal.
4. Results
4.1. Dataset Description
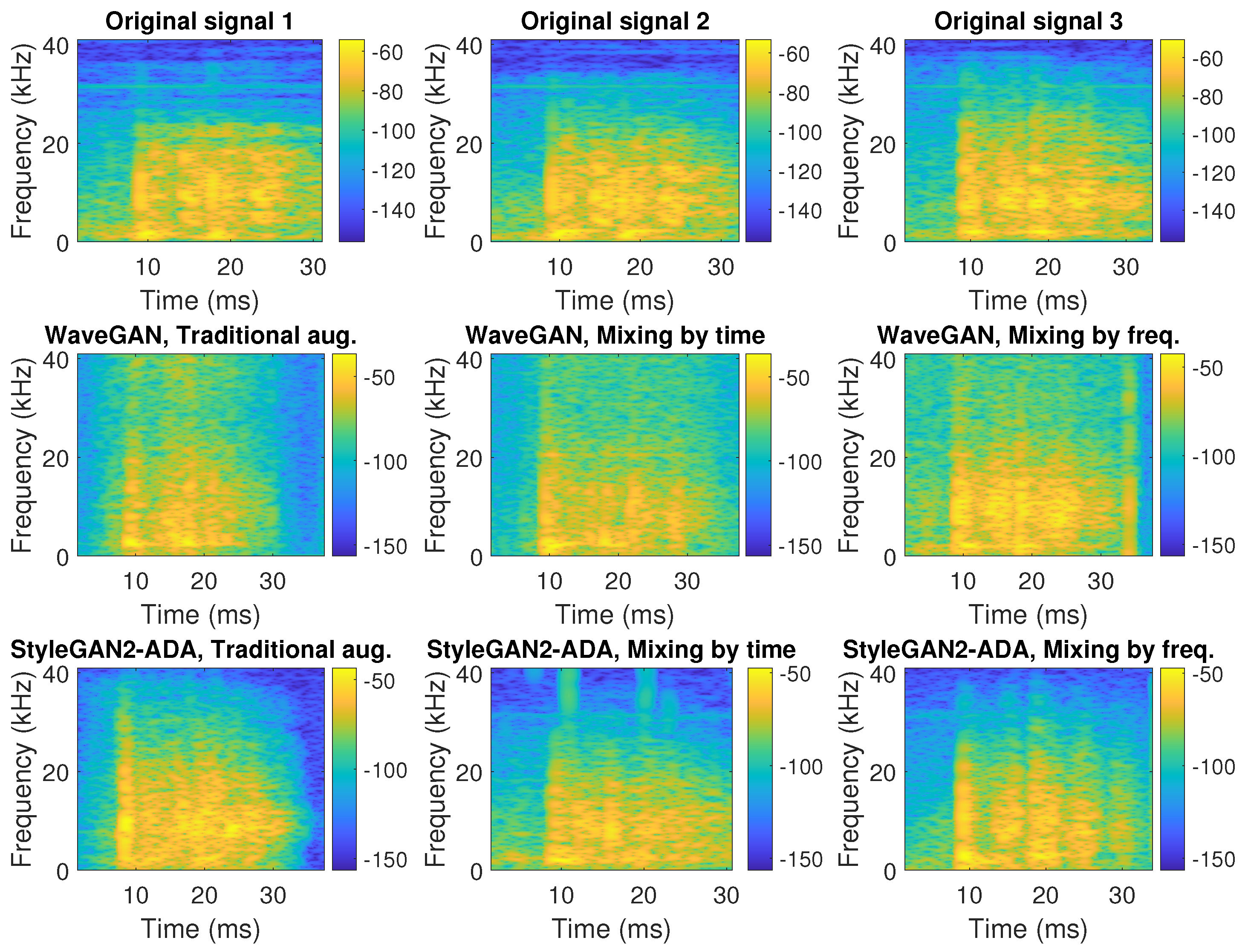
4.2. Data Augmentation and Generation Results with WaveGAN and StyleGAN2-ADA
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Hertzmann, A. Non-photorealistic rendering and the science of art. In Proceedings of the 8th International Symposium on Non-Photorealistic Animation and Rendering, New York, NY, USA, 7–10 June 2010; pp. 147–157. [Google Scholar]
- Scalera, L.; Seriani, S.; Gasparetto, A.; Gallina, P. Non-photorealistic rendering techniques for artistic robotic painting. Robotics 2019, 8, 10. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Floridi, L.; Chiriatti, M. GPT-3: Its nature, scope, limits, and consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Min, B.; Ross, H.; Sulem, E.; Veyseh, A.P.B.; Nguyen, T.H.; Sainz, O.; Agirre, E.; Heintz, I.; Roth, D. Recent advances in natural language processing via large pre-trained language models: A survey. ACM Comput. Surv. 2023, 56, 1–40. [Google Scholar] [CrossRef]
- Kasneci, E.; Seßler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for good? On opportunities and challenges of large language models for education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Ruff, Z.J.; Lesmeister, D.B.; Appel, C.L.; Sullivan, C.M. Workflow and convolutional neural network for automated identification of animal sounds. Ecol. Indic. 2021, 124, 107419. [Google Scholar] [CrossRef]
- Davis, N.; Suresh, K. Environmental sound classification using deep convolutional neural networks and data augmentation. In Proceedings of the 2018 IEEE Recent Advances in Intelligent Computational Systems (RAICS), Thiruvananthapuram, India, 6–8 December 2018; pp. 41–45. [Google Scholar]
- Amoh, J.; Odame, K. Deep neural networks for identifying cough sounds. IEEE Trans. Biomed. Circuits Syst. 2016, 10, 1003–1011. [Google Scholar] [CrossRef]
- Göğüş, F.Z.; Karlik, B.; Harman, G. Classification of asthmatic breath sounds by using wavelet transforms and neural networks. Int. J. Signal Process. Syst. 2015, 3, 106–111. [Google Scholar] [CrossRef]
- Li, N.; Liu, S.; Liu, Y.; Zhao, S.; Liu, M. Neural speech synthesis with transformer network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6706–6713. [Google Scholar]
- Wu, Z.; Watts, O.; King, S. Merlin: An Open Source Neural Network Speech Synthesis System. In Proceedings of the SSW; 2016; pp. 202–207. Available online: http://ssw9.talp.cat/papers/ssw9_PS2-13_Wu.pdf (accessed on 7 February 2024).
- Kalchbrenner, N.; Elsen, E.; Simonyan, K.; Noury, S.; Casagrande, N.; Lockhart, E.; Stimberg, F.; Oord, A.; Dieleman, S.; Kavukcuoglu, K. Efficient neural audio synthesis. In Proceedings of the International Conference on Machine Learning, PMLR; 2018; pp. 2410–2419. Available online: https://proceedings.mlr.press/v80/kalchbrenner18a.html (accessed on 7 February 2024).
- Donahue, C.; McAuley, J.; Puckette, M. Adversarial audio synthesis. arXiv 2018, arXiv:1802.04208. [Google Scholar]
- Engel, J.; Agrawal, K.K.; Chen, S.; Gulrajani, I.; Donahue, C.; Roberts, A. Gansynth: Adversarial neural audio synthesis. arXiv 2019, arXiv:1902.08710. [Google Scholar]
- Nanni, L.; Maguolo, G.; Paci, M. Data augmentation approaches for improving animal audio classification. Ecol. Inform. 2020, 57, 101084. [Google Scholar] [CrossRef]
- Hidayat, A.A.; Cenggoro, T.W.; Pardamean, B. Convolutional neural networks for scops owl sound classification. Proc. Comput. Sci. 2021, 179, 81–87. [Google Scholar] [CrossRef]
- Dhariwal, P.; Jun, H.; Payne, C.; Kim, J.W.; Radford, A.; Sutskever, I. Jukebox: A generative model for music. arXiv 2020, arXiv:2005.00341. [Google Scholar]
- Oord, A.V.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Şaşmaz, E.; Tek, F.B. Animal sound classification using a convolutional neural network. In Proceedings of the 2018 3rd International Conference on Computer Science and Engineering (UBMK), Sarajevo, Bosnia and Herzegovina, 20–23 September 2018; pp. 625–629. [Google Scholar]
- Guei, A.C.; Christin, S.; Lecomte, N.; Hervet, É. ECOGEN: Bird sounds generation using deep learning. Methods Ecol. Evol. 2023, 15, 69–79. [Google Scholar] [CrossRef]
- Kim, E.; Moon, J.; Shim, J.; Hwang, E. DualDiscWaveGAN-Based Data Augmentation Scheme for Animal Sound Classification. Sensors 2023, 23, 2024. [Google Scholar] [CrossRef] [PubMed]
- Andreas, J.; Beguš, G.; Bronstein, M.M.; Diamant, R.; Delaney, D.; Gero, S.; Goldwasser, S.; Gruber, D.F.; de Haas, S.; Malkin, P.; et al. Toward understanding the communication in sperm whales. Iscience 2022, 25, 104393. [Google Scholar] [CrossRef]
- Malinka, C.E.; Atkins, J.; Johnson, M.P.; Tønnesen, P.; Dunn, C.A.; Claridge, D.E.; de Soto, N.A.; Madsen, P.T. An autonomous hydrophone array to study the acoustic ecology of deep-water toothed whales. Deep. Sea Res. Part I Oceanogr. Res. Pap. 2020, 158, 103233. [Google Scholar] [CrossRef]
- Griffiths, E.T.; Barlow, J. Cetacean acoustic detections from free-floating vertical hydrophone arrays in the southern California Current. J. Acoust. Soc. Am. 2016, 140, EL399–EL404. [Google Scholar] [CrossRef]
- Mate, B.R.; Irvine, L.M.; Palacios, D.M. The development of an intermediate-duration tag to characterize the diving behavior of large whales. Ecol. Evol. 2017, 7, 585–595. [Google Scholar] [CrossRef]
- Fish, F.E. Bio-inspired aquatic drones: Overview. Bioinspir. Biomim. 2020, 6, 060401. [Google Scholar] [CrossRef] [PubMed]
- Torres, L.G.; Nieukirk, S.L.; Lemos, L.; Chandler, T.E. Drone up! Quantifying whale behavior from a new perspective improves observational capacity. Front. Mar. Sci. 2018, 5, 319. [Google Scholar] [CrossRef]
- Maharana, K.; Mondal, S.; Nemade, B. A review: Data pre-processing and data augmentation techniques. Glob. Transit. Proc. 2022, 3, 91–99. [Google Scholar] [CrossRef]
- Yang, S.; Xiao, W.; Zhang, M.; Guo, S.; Zhao, J.; Shen, F. Image data augmentation for deep learning: A survey. arXiv 2022, arXiv:2204.08610. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Fong, R.; Vedaldi, A. Occlusions for effective data augmentation in image classification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 4158–4166. [Google Scholar]
- Lemley, J.; Bazrafkan, S.; Corcoran, P. Smart augmentation learning an optimal data augmentation strategy. IEEE Access 2017, 5, 5858–5869. [Google Scholar] [CrossRef]
- Akbiyik, M.E. Data augmentation in training CNNs: Injecting noise to images. arXiv 2023, arXiv:2307.06855. [Google Scholar]
- Rahman, A.A.; Angel Arul Jothi, J. Classification of urbansound8k: A study using convolutional neural network and multiple data augmentation techniques. In Proceedings of the Soft Computing and Its Engineering Applications: Second International Conference, icSoftComp 2020, Changa, Anand, India, 11–12 December 2020; pp. 52–64. [Google Scholar]
- Eklund, V.V. Data Augmentation Techniques for Robust Audio Analysis. Master’s Thesis, Tampere University, Tampere, Finland, 2019. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Seltzer, M.L.; Khudanpur, S. A study on data augmentation of reverberant speech for robust speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5220–5224. [Google Scholar]
- Yun, D.; Choi, S.H. Deep Learning-Based Estimation of Reverberant Environment for Audio Data Augmentation. Sensors 2022, 22, 592. [Google Scholar] [CrossRef]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Wei, S.; Xu, K.; Wang, D.; Liao, F.; Wang, H.; Kong, Q. Sample mixed-based data augmentation for domestic audio tagging. arXiv 2018, arXiv:1808.03883. [Google Scholar]
- Jaitly, N.; Hinton, G.E. Vocal tract length perturbation (VTLP) improves speech recognition. In Proceedings of the ICML Workshop on Deep Learning for Audio, Speech and Language; 2013; Volume 117, p. 21. Available online: https://www.cs.toronto.edu/~ndjaitly/jaitly-icml13.pdf (accessed on 7 February 2024).
- Goldbogen, J.; Madsen, P. The evolution of foraging capacity and gigantism in cetaceans. J. Exp. Biol. 2018, 221, jeb166033. [Google Scholar] [CrossRef] [PubMed]
- Tønnesen, P.; Oliveira, C.; Johnson, M.; Madsen, P.T. The long-range echo scene of the sperm whale biosonar. Biol. Lett. 2020, 16, 20200134. [Google Scholar] [CrossRef] [PubMed]
- Zimmer, W.M.; Tyack, P.L.; Johnson, M.P.; Madsen, P.T. Three-dimensional beam pattern of regular sperm whale clicks confirms bent-horn hypothesis. J. Acoust. Soc. Am. 2005, 117, 1473–1485. [Google Scholar] [CrossRef]
- Møhl, B.; Wahlberg, M.; Madsen, P.T.; Heerfordt, A.; Lund, A. The monopulsed nature of sperm whale clicks. J. Acoust. Soc. Am. 2003, 114, 1143–1154. [Google Scholar] [CrossRef]
- Whitehead, H. Sperm whale clans and human societies. R. Soc. Open Sci. 2024, 11, 231353. [Google Scholar] [CrossRef]
- Rendell, L.E.; Whitehead, H. Vocal clans in sperm whales (Physeter macrocephalus). Proc. R. Soc. Lond. Ser. Biol. Sci. 2003, 270, 225–231. [Google Scholar] [CrossRef]
- Amorim, T.O.S.; Rendell, L.; Di Tullio, J.; Secchi, E.R.; Castro, F.R.; Andriolo, A. Coda repertoire and vocal clans of sperm whales in the western Atlantic Ocean. Deep. Sea Res. Part Oceanogr. Res. Pap. 2020, 160, 103254. [Google Scholar] [CrossRef]
- Karras, T.; Aittala, M.; Hellsten, J.; Laine, S.; Lehtinen, J.; Aila, T. Training generative adversarial networks with limited data. Adv. Neural Inf. Process. Syst. 2020, 33, 12104–12114. [Google Scholar]
- Watkins Marine Mammal Sound Database. Available online: https://cis.whoi.edu/science/B/whalesounds/index.cfm (accessed on 18 January 2024).
- Press, W.H.; Teukolsky, S.A. Savitzky-Golay smoothing filters. Comput. Phys. 1990, 4, 669–672. [Google Scholar] [CrossRef]
- Haider, N.S.; Periyasamy, R.; Joshi, D.; Singh, B. Savitzky-Golay filter for denoising lung sound. Braz. Arch. Biol. Technol. 2018, 61. [Google Scholar] [CrossRef]
- Agarwal, S.; Rani, A.; Singh, V.; Mittal, A.P. EEG signal enhancement using cascaded S-Golay filter. Biomed. Signal Process. Control. 2017, 36, 194–204. [Google Scholar] [CrossRef]
- Gajbhiye, P.; Mingchinda, N.; Chen, W.; Mukhopadhyay, S.C.; Wilaiprasitporn, T.; Tripathy, R.K. Wavelet domain optimized Savitzky–Golay filter for the removal of motion artifacts from EEG recordings. IEEE Trans. Instrum. Meas. 2020, 70, 4002111. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| WaveGAN | StyleGAN2-ADA | |
|---|---|---|
| OS: | Microsoft Windows 10 | Linux |
| CPU: | Intel Core i7-7700HQ, 2.8 GHz, 8 cores | Intel(R) Xeon(R) CPU @ 2.30 GHz, 1 core |
| GPU: | Nvidia GeForce GTX 1050, 2 GB | NVIDIA Tesla T4 |
| RAM: | 16 GB | 12 GB |
| Dataset | Number of Signals | RMS | Shape Factor | Crest Factor | Impulse Factor | Zero-Crossing Rate |
|---|---|---|---|---|---|---|
| Original signals | 81 | 0.0543 | 1.6820 | 5.7537 | 9.6390 | 0.1736 |
| Traditional augm. methods | 6561 | 0.0522 (3.8%) | 1.7431 (3.6%) | 5.0029 (13%) | 10.1507 (5.3%) | 0.1838 (5.8%) |
| Mixing by freq. | 6561 | 0.0459 (15.5%) | 1.7778 (5.7%) | 9.0402 (57.1%) | 16.4973 (71.1%) | 0.1744 (0.46%) |
| Mixing by time | 6561 | 0.0554 (2%) | 1.6922 (0.6%) | 5.7844 (0.5%) | 9.7607 (1.2%) | 0.1745 (0.52%) |
| midrule StyleGAN2-ADA, traditional augm. | 100 | 0.0651 (19.9%) | 1.7678 (5.1%) | 6.461 (12.3%) | 11.3792 (18.1%) | 0.1962 (13%) |
| StyleGAN2-ADA, mixing by freq. | 100 | 0.0753 (38.7%) | 2.0565 (22.3%) | 10.8663 (88.8%) | 22.84 (136.9%) | 0.1584 (8.7%) |
| StyleGAN2-ADA, mixing by time | 100 | 0.0497 (8.5%) | 1.6382 (2.6%) | 6.0567 (5.3%) | 9.9445 (3.2%) | 0.1685 (2.9%) |
| WaveGAN, traditional augm. | 100 | 0.1589 (192.6%) | 1.863 (10.7%) | 5.3400 (7.2%) | 9.945 (3.2%) | 0.2071 (19.3%) |
| WaveGAN, mixing by freq. | 100 | 0.1014 (86.7%) | 1.8546 (10.3%) | 6.3401 (10.2%) | 11.9535 (24%) | 0.226 (30.2%) |
| WaveGAN, mixing by time | 100 | 0.1464 (169.6%) | 1.8058 (7.4%) | 5.3474 (7.1%) | 9.686 (0.48%) | 0.2165 (24.7%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kopets, E.; Shpilevaya, T.; Vasilchenko, O.; Karimov, A.; Butusov, D. Generating Synthetic Sperm Whale Voice Data Using StyleGAN2-ADA. Big Data Cogn. Comput. 2024, 8, 40. https://doi.org/10.3390/bdcc8040040
Kopets E, Shpilevaya T, Vasilchenko O, Karimov A, Butusov D. Generating Synthetic Sperm Whale Voice Data Using StyleGAN2-ADA. Big Data and Cognitive Computing. 2024; 8(4):40. https://doi.org/10.3390/bdcc8040040
Chicago/Turabian StyleKopets, Ekaterina, Tatiana Shpilevaya, Oleg Vasilchenko, Artur Karimov, and Denis Butusov. 2024. "Generating Synthetic Sperm Whale Voice Data Using StyleGAN2-ADA" Big Data and Cognitive Computing 8, no. 4: 40. https://doi.org/10.3390/bdcc8040040