In stock market forecasting, we argue that two issues for statistical time-series models are considered imperfect in forecasting algorithms: (1) some mathematic distribution assumptions are made for stock market data, but sometimes the observations do not follow these assumptions; and (2) basic indexes (time, open index, high index, low index, close index and volume) cannot provide enough of the stock information hidden in history for statistical time-series models to predict stock market movements accurately because the basic indexes can only exhibit the daily static conditions of the past, which cannot express the dynamic trends of a stock market.
For the systems based on genetic algorithms, two disadvantages are found: (1) computing costs, such as time consumption and computer resources, is higher than other statistical forecasting systems; and (2) the optimal forecast is not easily certifiable.
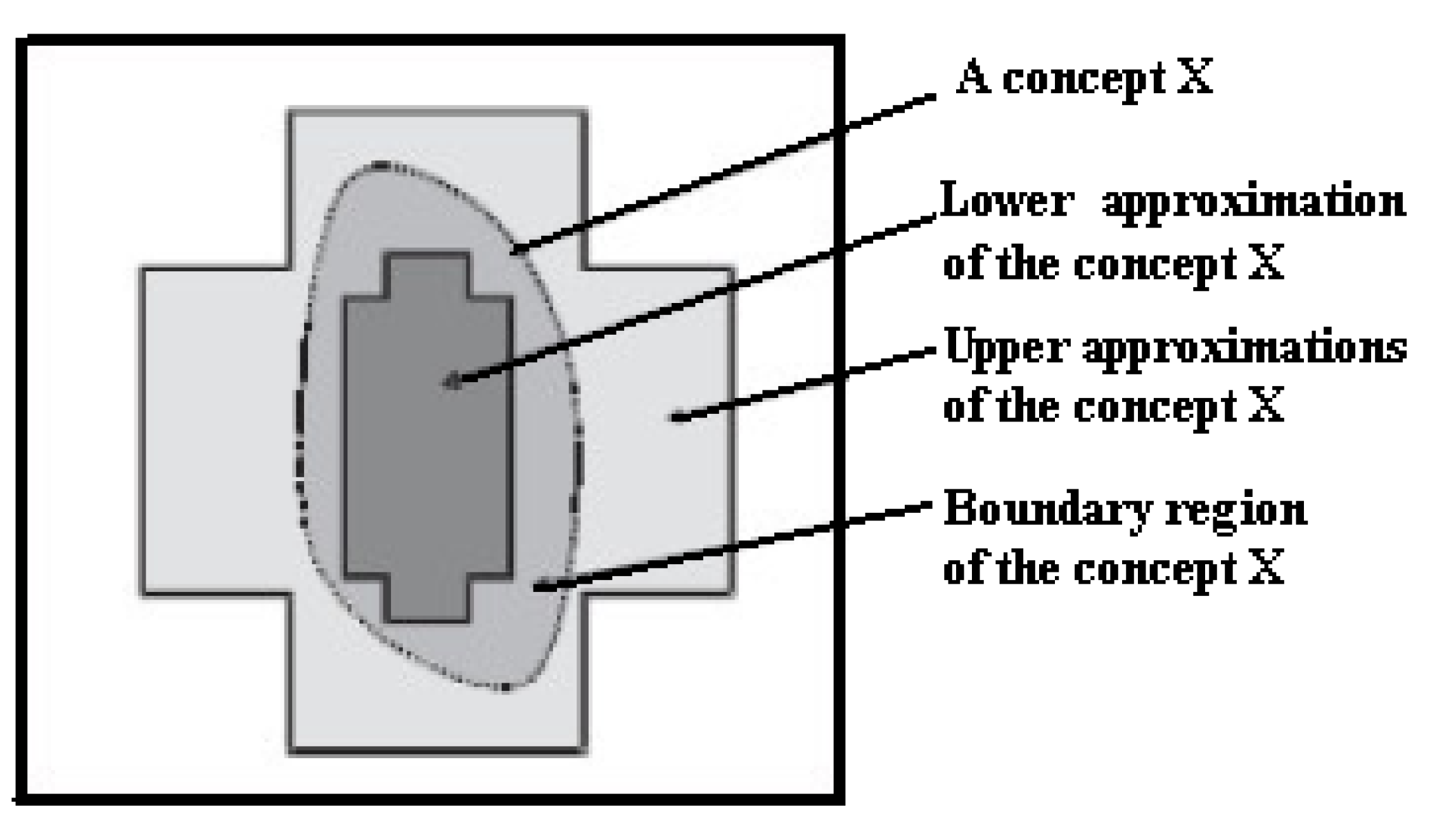
3.1. Proposed Concepts
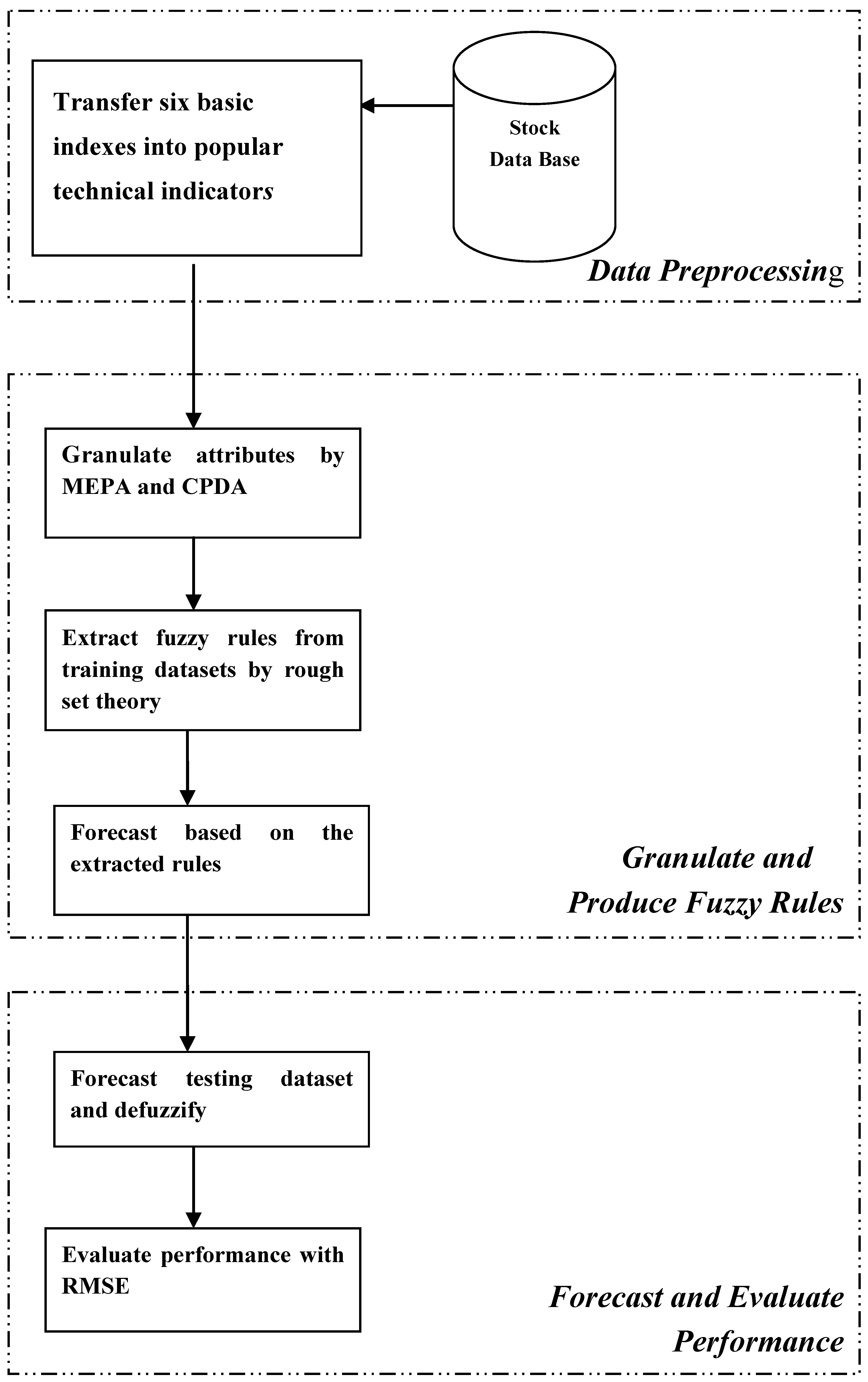
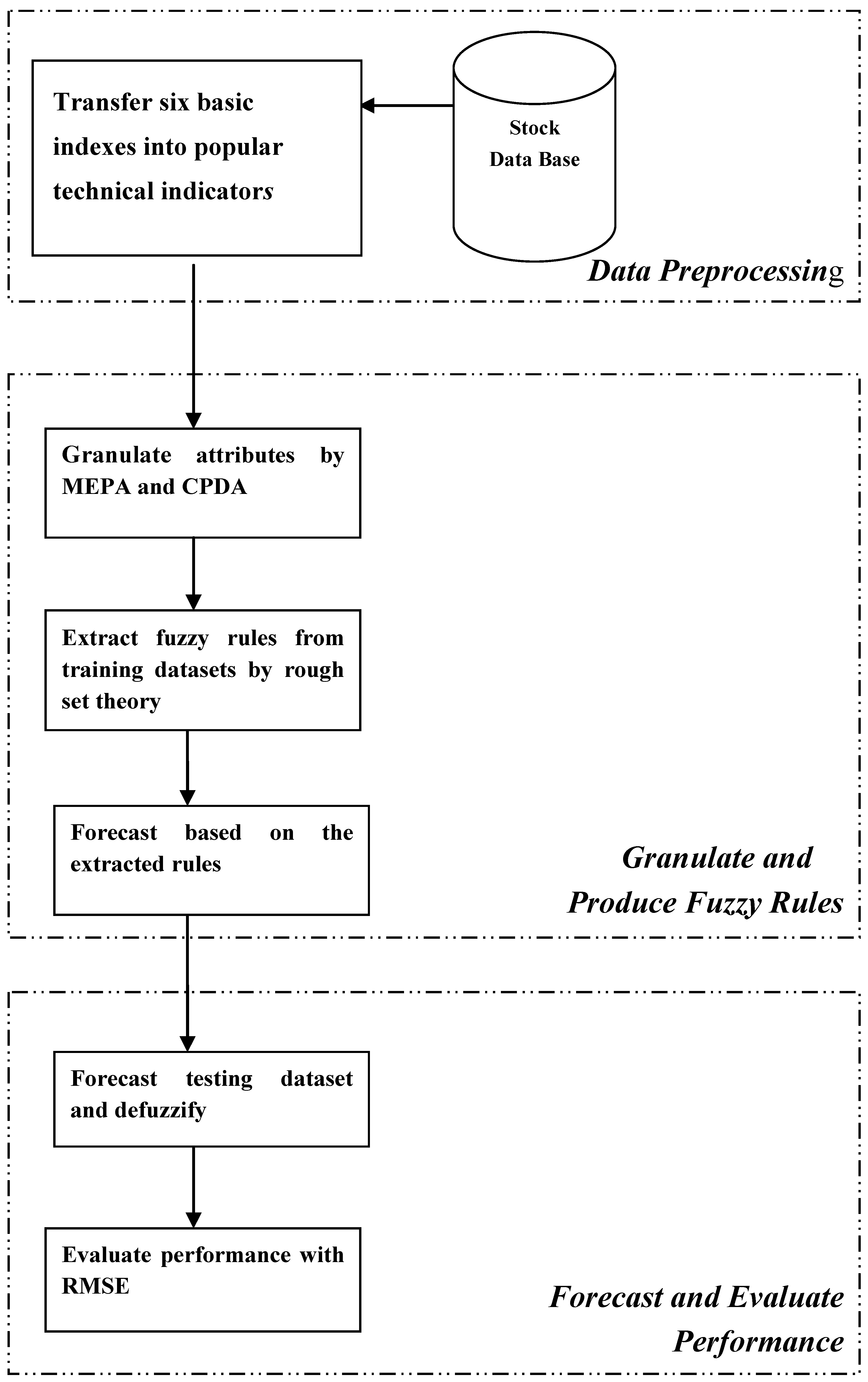
To overcome the problems mentioned above, a novel forecasting model (the framework of the proposed model is illustrated in
Figure 3), which integrates two advanced data granulating approaches (CDPA and MEPA) and a data mining method (rough set theory) in forecasting processes, is proposed in this paper. The three main procedures of the proposed model are described, as follows:
(1)
Data preprocess. Convert six basic indexes of the stock database (time, open index, high index, low index, close index, and volume) into nine useful technical indicators (RSI, MA, DIS, STOD, ROC, OBV, VR, PSY and AR, defined in
Table 5), which are highly related to stock price fluctuation [
2], in order to compose the attributes of experimental datasets.
(2)
Granulate observations and produce rules. Utilize two advanced data granulating approaches, CPDA and MEPA, to granulate the observations of the nine technical indicators (defined in
Table 5), and stock price fluctuation (defined in equation (17)) into linguistic values. The technical indicators are defined as conditional attributes and price fluctuation is defined as a decision attribute. Use a rough set algorithm (LEM2, Learning from Examples Module, version 2 [
37]) to extract a training dataset to produce forecasting rules of linguistic values.
(3) Forecast and evaluate performance. Produce linguistic forecasts for testing a dataset with the extracted rules from a training dataset, and defuzzify the linguistic forecasts into numeric forecasts. Use root mean square error (RMSE) as a forecasting performance indicator for the proposed model. We argue that the proposed model can produce effective rules for forecasting stock market prices, based on three reasons, as follows:
Firstly, we employ technical indicators as forecasting factors instead of daily basic indexes; they are practical tools for stock analysts and fund managers to use in forecasting stock market prices Also, it has been proven that some technical indicators are highly related to future stock prices [
2].
Secondly, from past literature related to rough set theory, three advantages have been found: (1) the rough set algorithms can process data without making any assumptions about the dataset; (2) rough set theory has powerful algorithms which can deal with a dataset that contains both quantitative and qualitative attributes; and (3) rough set algorithms can discover non-linear relations between observations hidden in multi-dimensional datasets, and produce understandable rules in an If-Then format that are meaningful to the average stock investor.
Lastly, the advantages to using data granulating methods to preprocess raw data are that the data dimension of a database can be reduced and simplified, and the use of discrete features is usually more compact and shorter than the use of continuous ones [
38]. We argue that data granulating approaches can use linguistic values to represent observations in order to reduce the data complexity when using a high-dimension of a numeric dataset as an experimental dataset. Therefore, the proposed model can promote efficiency in data preprocess by employing CPDA and MEPA.
Figure 3.
Framework of the proposed model.
Figure 3.
Framework of the proposed model.
Table 5.
Defined equations for popular technical indicators.
Table 5.
Defined equations for popular technical indicators.
| Technical Indicator | Mathematical Formula and Economical Meaning |
|---|
| MA | |
| ● MA is a popular way of defining where recent price trend line |
| RSI | |
| ● RSI, moving on a scale from 0–100, highlights overbought (70 and above) and oversold (30 and below) conditions |
| PSY | |
| ● PSY measures psychological stability of investors |
| STOD | |
| ● STOD gives buy (30 and below) or sell (70 and above) signals |
| VR | |
| ● VR measures trend stability |
| OBV | |
| ● OBV is a running cumulative total which should confirm the price trend |
| DIS | |
| ● DIS shows the stability of the most recent closing prices |
| AR | |
| ● AR shows stock momentum |
| ROC | |
| ● ROC gives buy (130 and above) and sell (70 and below) signals |
3.2. The Proposed Algorithm
The proposed algorithm consists of six forecasting processes. Using the 2001 TAIEX (Taiwan Stock Exchange Capitalization Weighted Stock Index) as demonstration data, each process is introduced, step by step, in the following manner:
Step 1: Transfer basic indexes into popular technical indicators. In this step, the stock database, which contains six basic indexes (time, open index, high index, low index, close index and volume) is selected as an experimental dataset. Each experimental dataset record (see
Table 6) is transformed into a record of nine technical indicators (RSI, MA, DIS, STOD, ROC, OBV, VR, PSY and AR, see
Table 7) by using the formulas in
Table 5.
Table 6.
Basic indexes of the TAIEX dataset.
Table 6.
Basic indexes of the TAIEX dataset.
| Time | Open | High | Low | Close | Volume |
|---|
| 2001/01/02 | 4,717.49 | 4,945.09 | 4,678.00 | 4,935.28 | 2,292,485 |
| 2001/01/03 | 4,843.54 | 4,970.45 | 4,831.12 | 4,20004.79 | 2,542,050 |
| 2001/01/04 | 5,028.32 | 5,169.13 | 5,028.32 | 5,136.13 | 3,146,064 |
![Entropy 12 02397 i004]() |
| 2001/12/27 | 5,464.52 | 5,505.19 | 5,293.54 | 5,332.98 | 4,951,334 |
| 2001/12/28 | 5,372.85 | 5,408.15 | 5,307.38 | 5,398.28 | 4,035,088 |
| 2001/12/31 | 5,481.07 | 5,583.82 | 5,477.53 | 5,551.24 | 4,396,515 |
Table 7.
Original data of conditional attributes and decision attribute.
Table 7.
Original data of conditional attributes and decision attribute.
| Time | RSI | MA | DIS | STOD | ROC | OBV | VR | PSY | AR |
|---|
| 2001/1/2 | 55.71 | 4737.20 | 100.03 | −0.45 | 0.05 | 2335735.00 | 0.26 | 0.50 | 1.12 |
| 2001/1/3 | 55.89 | 4758.57 | 103.71 | 1.27 | 0.06 | 5941448.00 | 0.56 | 0.58 | 1.13 |
| 2001/1/4 | 60.40 | 4787.48 | 102.24 | 4.62 | 0.07 | 9906469.00 | 0.77 | 0.67 | 1.29 |
![Entropy 12 02397 i005]() |
| 2001/12/27 | 49.82 | 5261.71 | 102.48 | 0.90 | 0.00 | −2794502.00 | −0.12 | 0.50 | 0.96 |
| 2001/12/28 | 51.92 | 5280.22 | 101.00 | 0.14 | 0.06 | −2324048.00 | −0.10 | 0.50 | 0.98 |
| 2001/12/31 | 52.29 | 5295.08 | 101.95 | 1.67 | 0.07 | 5669238.00 | 0.23 | 0.58 | 1.01 |
Step 2: Granulate conditional and decision attributes by MEPA and CPDA. In the experimental dataset, nine technical indicators are used as conditional attributes, and stock price fluctuations, defined in equation (17), is employed as a decision attribute:
where
price fluctuation (
t) denotes the price change from time
t − 1 to time
t;
P (
t) denotes closing price at time
t; and
P(
t − 1) denotes closing price at time
t − 1.
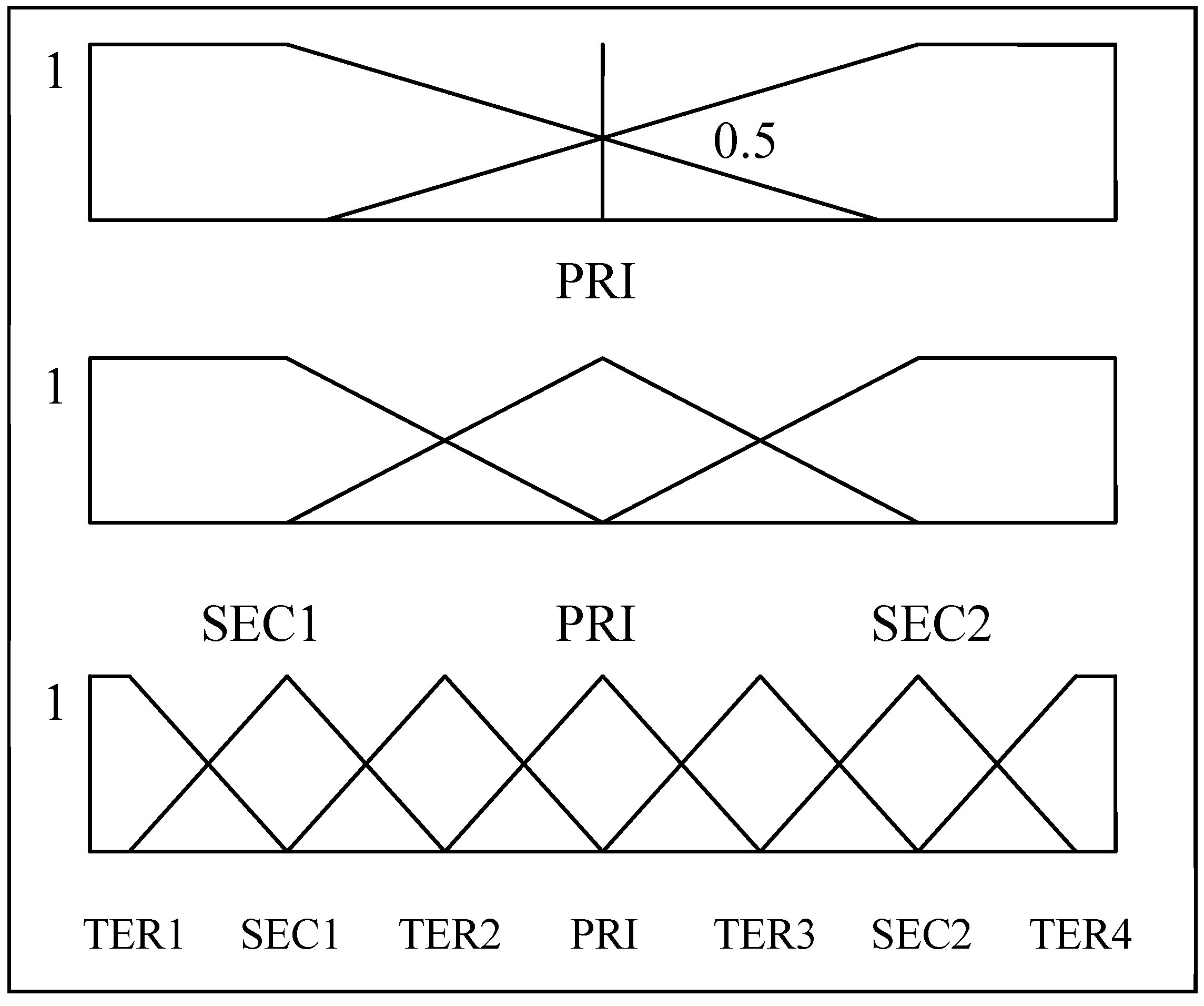
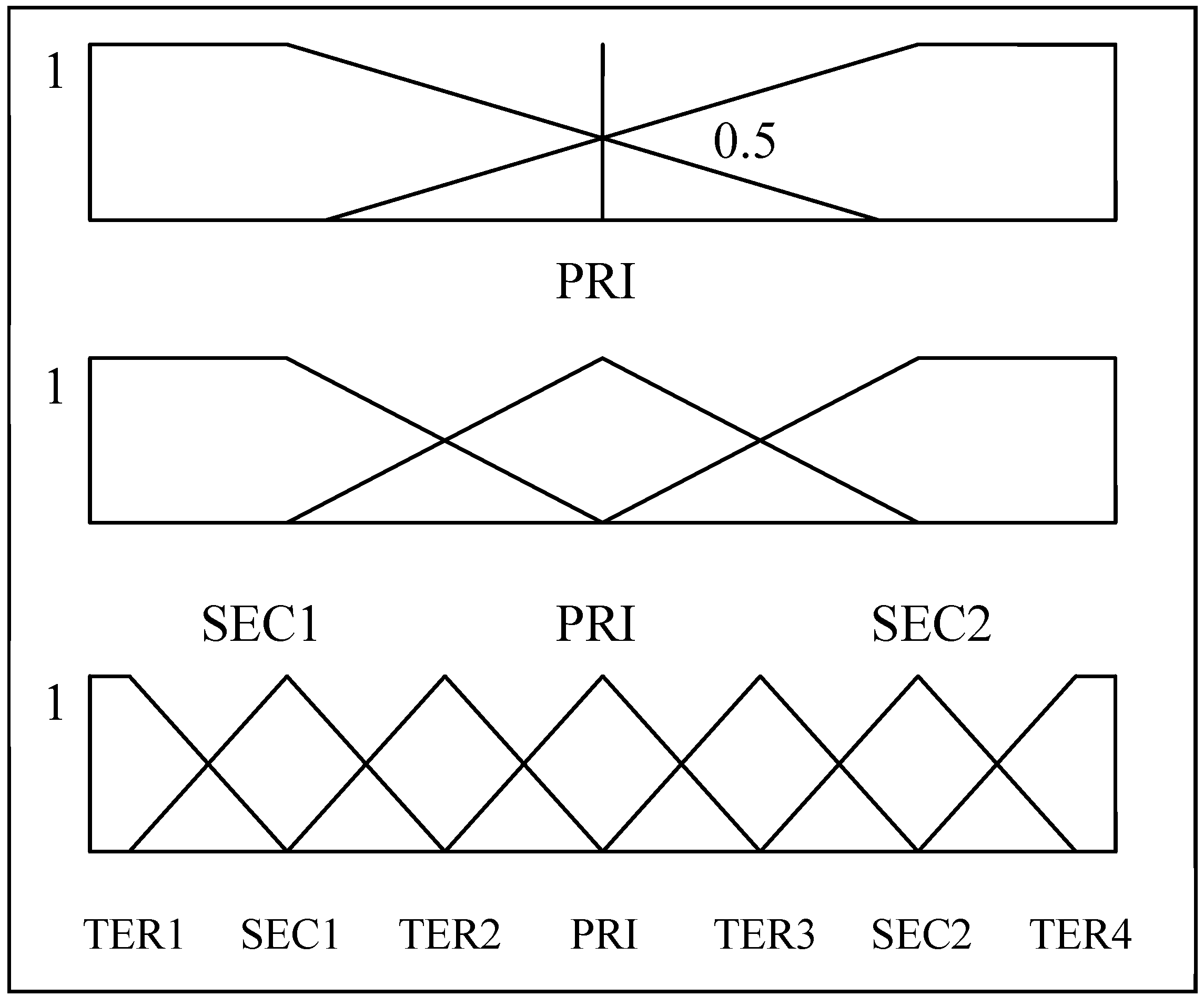
This step granulates the numeric experimental dataset, which consists of two types of attributes (conditional and decision) into a granulated dataset of linguistic values for rule mining. The experimental dataset is preprocessed by two different approaches: CPDA is used to granulate the records of the decision attribute (stock price fluctuation), and MEPA is employed to granulate the records of the conditional attributes (nine technical indicators). The appropriate number of categories, based on human short-term memory function, is seven, and seven, plus or minus two [
39]. Therefore, from the researchers’ perspective, the decision attribute is granulated with five linguistic values and the conditional attribute is granulated with seven linguistic values. The five linguistic values used to present stock price fluctuations are introduced, as follows: L1 denotes
going up sharply; L2 denotes
going up; L3 denotes
remaining flat; L4 denotes
going down; and L5 denotes
down s
harply. Because a technical indicator value cannot be defined in meaningful terms, the seven linguistic values to represent a technical indicator are defined as seven labeled numbers (L1 through L7).
Table 8 demonstrates five parameterized triangle fuzzy numbers for five linguistic values of stock price fluctuations.
Table 9 demonstrates the seven linguistic values (fuzzy numbers) and their corresponding numeric ranges for the conditional attribute of MA.
Table 10 lists some observations for conditional and decision attributes for the experimental datasets.
Table 8.
Parameterized fuzzy numbers for decision attributes (price fluctuation).
Table 8.
Parameterized fuzzy numbers for decision attributes (price fluctuation).
| Linguistic Value | Fuzzy Number(a, b, c) |
|---|
| a | b | c |
|---|
| L1 | −560.2145 | −323.297 | −86.3797 |
| L2 | −126.9697 | −79.5363 | −32.1029 |
| L3 | −57.1115 | −21.2323 | 14.647 |
| L4 | −8.728 | 30.0979 | 68.9238 |
| L5 | 39.6556 | 349.08 | 658.5045 |
| Standard Derivation = 92.26; Mean = −8.73 |
Table 9.
Parameterized fuzzy numbers for conditional attributes (MA).
Table 9.
Parameterized fuzzy numbers for conditional attributes (MA).
| Linguistic Value | Fuzzy Number(a,b,c) |
|---|
| a | b | c |
|---|
| L1 | 8706.911 | 6617.774 | 4528.637 |
| L2 | 4003.256 | 4597.310 | 5191.364 |
| L3 | 4893.189 | 5297.220 | 5701.251 |
| L4 | 5455.389 | 5816.147 | 6176.905 |
| L5 | 5939.078 | 6312.935 | 6686.792 |
| L6 | 6422.766 | 6886.143 | 7349.519 |
| L7 | 6984.966 | 9151.448 | 11317.93 |
| Standard Derivation =1321.17; Mean = 5939.08 |
Table 10.
Observations for conditional and decision attributes (TAIEX).
Table 10.
Observations for conditional and decision attributes (TAIEX).
| Time | RSI | MA | DIS | STOD | ROC | OBV | VR | PSY | AR | Price Fluctuation |
|---|
| 2001/01/02 | L4 | L1 | L5 | L7 | L6 | L7 | L7 | L5 | L2 | L1 |
| 2001/01/03 | L4 | L1 | L6 | L7 | L7 | L7 | L7 | L5 | L3 | L3 |
| 2001/01/04 | L4 | L1 | L6 | L7 | L7 | L7 | L7 | L5 | L4 | L5 |
![Entropy 12 02397 i007]() |
| 2001/12/27 | L3 | L2 | L6 | L7 | L5 | L7 | L3 | L5 | L1 | L3 |
| 2001/12/28 | L3 | L2 | L6 | L7 | L7 | L7 | L3 | L5 | L1 | L3 |
| 2001/12/31 | L3 | L2 | L6 | L7 | L7 | L7 | L7 | L5 | L1 | L3 |
Step 3: Extracted fuzzy rules from training datasets by Rough Set Theory. In this step, the experimental dataset of linguistic values is split into two datasets, training and testing. The training dataset is extracted by a rough set algorithm (LEM2, Learning from Examples Module, version 2 [
37]) to produce rules for forecasting the future price.
Table 11 lists some raw rules extracted from the training dataset
. The rules can be expressed in the format of “
If-Then” (
Table 12 demonstrates three rules).
Table 11.
Examples of rules extracted from training dataset using rough set algorithm.
Table 11.
Examples of rules extracted from training dataset using rough set algorithm.
| Conditional Attribute | Decision Attribute |
|---|
| Rule 1 | (OBV=L7) | (PSY=L5) | (MA=L1) | (STOD=L7) | (DIS=L6) | (ROC=L6) | (AR=L1) | (RSI=L2) | (VR=L4) | (decision=L3) |
| Rule 2 | (OBV=L7) | (PSY=L5) | (MA=L1) | (DIS=L5) | (AR=L1) | (RSI=L1) | (STOD=L1) | N.A | N.A | (decision=L3) |
| Rule 3 | (OBV=L7) | (PSY=L5) | (STOD=L7) | (MA=L1) | (RSI=L4) | (VR=L7) | (DIS=L6) | (ROC=L7) | (AR=L3) | (decision=L3) |
![Entropy 12 02397 i008]() |
| Rule n-2 | (OBV=L7) | (STOD=L7) | (PSY=L5) | (MA=L1) | (RSI=L4) | (VR=L7) | (DIS=L6) | (ROC=L6) | (AR=L6) | (decision=L4) |
| Rule n-1 | (OBV=L7) | (AR=L1) | (MA=L1) | (PSY=L5) | (DIS=L5) | (ROC=L5) | (RSI=L2) | (STOD=L2) | (VR=L3) | (decision=L2) |
| Rule n | (OBV=L7) | (AR=L1) | (MA=L1) | (PSY=L5) | (DIS=L5) | (ROC=L5) | (RSI=L2) | (VR=L4) | (STOD=L2) | (decision=L2) |
Step 4: Forecast based on the extracted rules. This step maps the conditional attributes of every record in the testing dataset with the extracted rules from the training dataset (see
Table 11) in order to generate a linguistic forecast for future price trends. If the conditional attributes of a record satisfy the “
If” criteria of a specific rule, the linguistic forecast for this instance is defined as the “
Then” part of the rule. Whenever no rule can be found for the conditional attributes of a record, the
naïve forecast [
40] is employed as the forecast for the future price trend.
Table 13 demonstrates the linguistic conditional attributes of some records and their corresponding linguistic forecasts for a testing dataset.
Table 12.
IF-THEN rules.
| Rules No. | If-Then Rules |
|---|
| Rule 1. | If (OBV=L7)& (PSY=L5) & (MA=L1) & (STOD=L7)& (DIS=L6) & (ROC=L6) & (AR=L1) & (RSI=L2)&(VR=L4)
Then (Decision=L3) |
| Rule 2. | If (OBV=L7)& (PSY=L5) & (MA=L1) & (DIS=L5) & (AR=L1) & (RSI=L1)& (STOD=L1)
Then (Decision=L3) |
| Rule 3. | If (OBV=L7)& (PSY=L5)&(STOD=L7)&(MA=L1)&(RSI=L4) &(VR=L7) & (DIS=L6) & (ROC=L7) & (AR=L3)
Then (Decision=L3) |
Table 13.
Linguistic forecasts for testing dataset.
Table 13.
Linguistic forecasts for testing dataset.
| Time | RSI | MA | DIS | STOD | ROC | OBV | VR | PSY | AR | Linguistic Forecast |
|---|
| 2001/11/01 | L3 | L1 | L5 | L7 | L5 | L7 | L4 | L5 | L1 | L3 |
| 2001/11/02 | L4 | L1 | L5 | L7 | L5 | L7 | L2 | L5 | L3 | L3 |
| 2001/11/05 | L4 | L1 | L6 | L7 | L5 | L7 | L2 | L5 | L3 | L3 |
![Entropy 12 02397 i009]() |
| 2000/12/28 | L3 | L2 | L6 | L7 | L7 | L7 | L3 | L5 | L3 | L3 |
| 2000/12/31 | L3 | L2 | L6 | L7 | L7 | L7 | L7 | L5 | L3 | L3 |
Step 5: Defuzzify and forecast testing datasets. Max membership principle [
25] (see equation (16)) is employed to defuzzify the linguistic forecast from Step 4. After a linguistic forecast has been defuzzified to a numeric value, a numeric forecast (see
Table 14) for a future stock price is generated by equation (18):
where
P(
t − 1) denotes the stock price at time
t − 1;
f (
t) denotes the numeric value defuzzified from the linguistic forecast for the future price trend at time
t; and
F(
t) denotes the numeric forecast for the future stock price at time
t.
Step 6: Evaluate performance with RMSE. In this step, RMSE (defined in equation (19)) is used as a performance indicator for the proposed model.
Table 15 demonstrates some forecasts produced from the proposed model and how to compute RMSE as a performance datum:
where
P(
t) denotes the actual stock price at time
t;
F(
t) denotes the forecast at time
t; and
n is the total amount of forecasts.
Table 14.
Numeric forecasting value for testing dataset.
Table 14.
Numeric forecasting value for testing dataset.
| Date | RSI | MA | DIS | STOD | ROC | OBV | VR | PSY | AR | Linguistic Forecast | Numeric Forecast |
|---|
| 2001/11/01 | L3 | L1 | L5 | L7 | L5 | L7 | L4 | L5 | L1 | L3 | 3,882.49 |
| 2001/11/02 | L4 | L1 | L5 | L7 | L5 | L7 | L2 | L5 | L3 | L3 | 3,882.00 |
| 2001/11/05 | L4 | L1 | L6 | L7 | L5 | L7 | L2 | L5 | L3 | L3 | 3,908.69 |
![Entropy 12 02397 i010]() |
| 2001/12/28 | L3 | L2 | L6 | L7 | L7 | L7 | L3 | L5 | L1 | L3 | 5,371.43 |
| 2001/12/31 | L3 | L2 | L6 | L7 | L7 | L7 | L7 | L5 | L1 | L3 | 5,311.98 |
Table 15.
Forecasting value and performance with RMSE.
Table 15.
Forecasting value and performance with RMSE.
| Time | Actual Stock Index | Forecast Value | SE(square error) |
|---|
| 2001/11/01 | 3,929.69 | 3,882.00 | 2227.84 |
| 2001/11/02 | 3,998.48 | 3,908.69 | 8062.24 |
| 2001/11/05 | 4,080.51 | 3,977.48 | 10615.18 |
![Entropy 12 02397 i011]() |
| 2001/12/28 | 5,398.28 | 5,311.98 | 7447.69 |
| 2001/12/31 | 5,551.24 | 5,377.28 | 30262.08 |
| Mean of SE | 14884 |
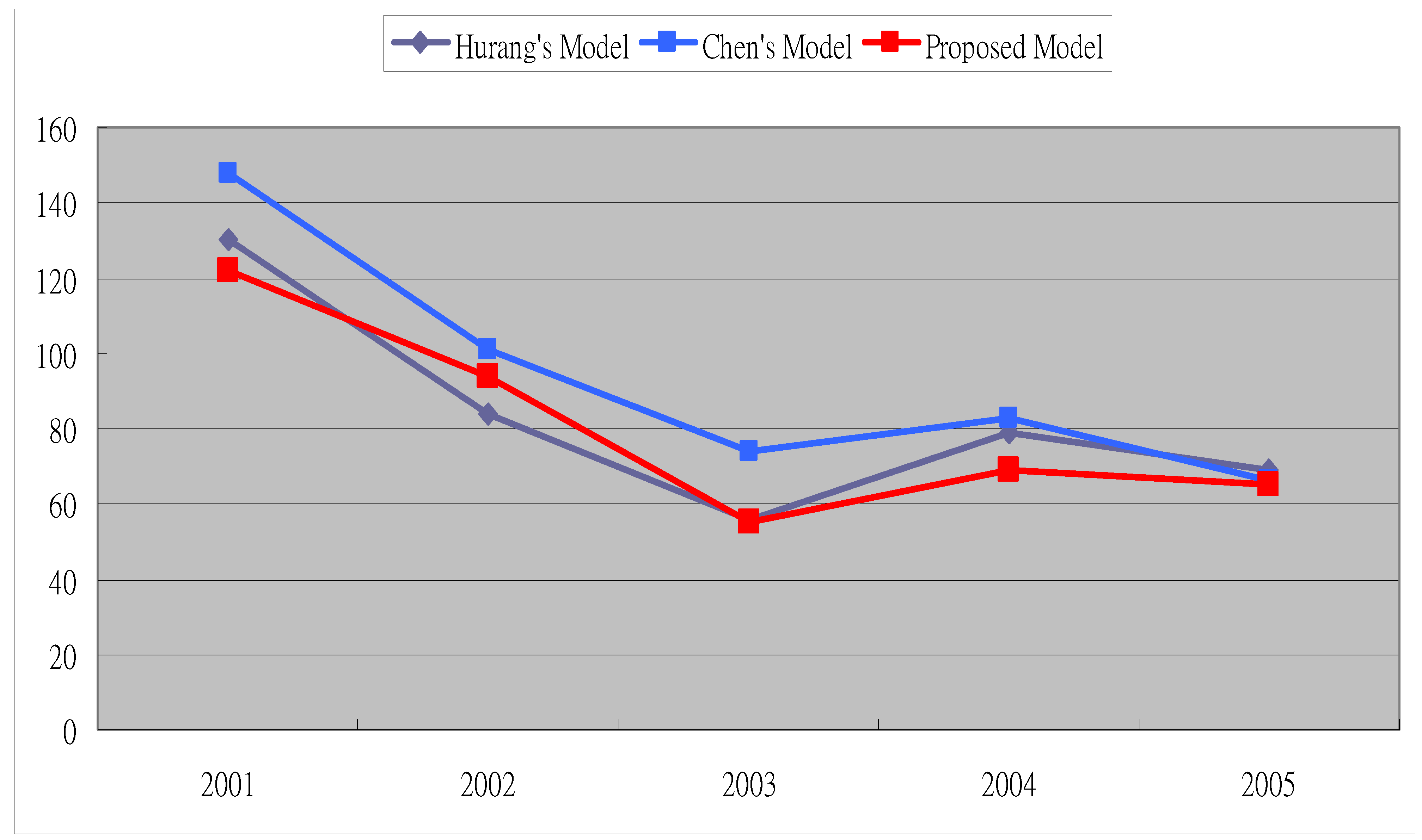
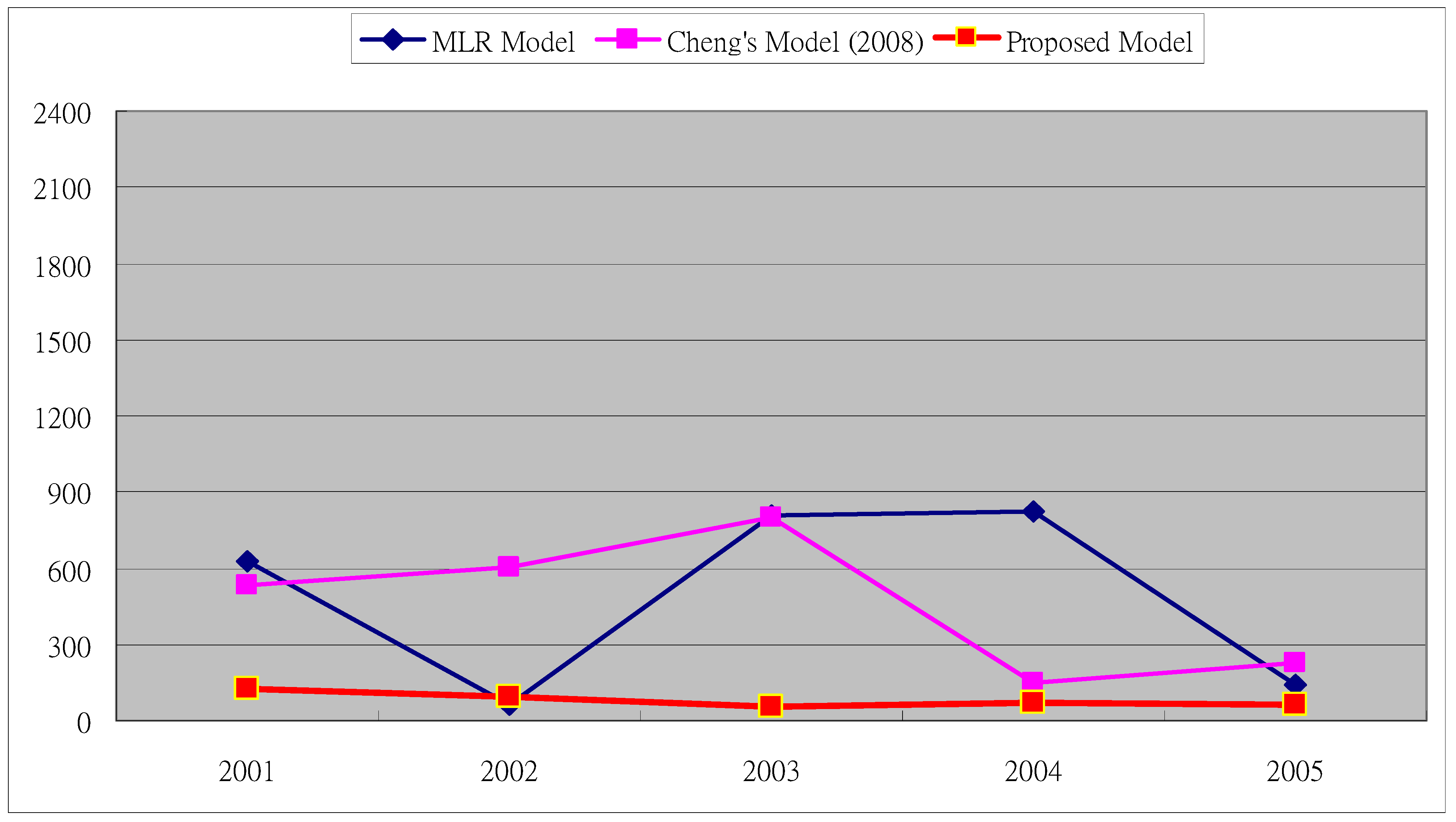
| RMSE | 122 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}