Geometry of q-Exponential Family of Probability Distributions

1
Laboratory for Mathematical Neuroscience, RIKEN Brain Science Institute, Hirosawa 2-1, Wako-shi, Saitama 351-0198, Japan
2
Department of Electrical and Electronics Engineering, Graduate School of Engineering, University of Fukui, Bunkyo 3-9-1, Fukui-shi, Fukui 910-8507, Japan
*
Authors to whom correspondence should be addressed.
Entropy 2011, 13(6), 1170-1185; https://doi.org/10.3390/e13061170
Submission received: 11 February 2011
/
Revised: 1 June 2011
/
Accepted: 2 June 2011
/
Published: 14 June 2011
(This article belongs to the Special Issue Distance in Information and Statistical Physics Volume 2)
Abstract
:The Gibbs distribution of statistical physics is an exponential family of probability distributions, which has a mathematical basis of duality in the form of the Legendre transformation. Recent studies of complex systems have found lots of distributions obeying the power law rather than the standard Gibbs type distributions. The Tsallis q-entropy is a typical example capturing such phenomena. We treat the q-Gibbs distribution or the q-exponential family by generalizing the exponential function to the q-family of power functions, which is useful for studying various complex or non-standard physical phenomena. We give a new mathematical structure to the q-exponential family different from those previously given. It has a dually flat geometrical structure derived from the Legendre transformation and the conformal geometry is useful for understanding it. The q-version of the maximum entropy theorem is naturally induced from the q-Pythagorean theorem. We also show that the maximizer of the q-escort distribution is a Bayesian MAP (Maximum A posteriori Probability) estimator.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
Statistical physics is founded on the Gibbs distribution for microstates, which forms an exponential family of probability distributions known in statistics. Important macro-quantities such as energy, entropy, free energy, etc. are connected with it. However, recent studies show that there are non-standard complex systems which are subject to the power law instead of the exponential law of the Gibbs type distributions. See [1,2] as well as extensive literatures cited in them.
Tsallis [3] defined the q-entropy to elucidate various physical phenomena of this type, followed by many related research works on this subject (see, [1]). The concept of the q-Gibbs distribution or q-exponential family of probability distributions is naturally induced from this framework (see also [4]). However, its mathematical structure has not yet been explored enough [2,5,6], while the Gibbs type distribution has been studied well as the exponential family of distributions [7]. We need a mathematical (geometrical) foundation to study the properties of the q-exponential family. This paper presents a geometrical foundation for the q-exponential family based on information geometry [8], giving geometrical definitions of the q-potential function, q-entropy and q-divergence in a unified way.
We define the q-geometrical structure consisting of a Riemannian metric and a pair of dual affine connections. By using this framework, we prove that a family of q-exponential distributions is dually flat, in which the q-Pythagorean theorem holds. This naturally induces the corresponding q-maximum entropy theorem similarly to the case of the Tsallis q-entropy [1,9,10]. The q-structure is ubiquitous since the family of all discrete probability distributions can always be endowed with the structure of the q-exponential family for arbitrary q. It is possible to generalize the q-structure to any family of probability distributions. Further, it has a close relation with the α-geometry [8], which is one of information geometric structure of constant curvature. This new dually flat structure, different from the old one given rise to from the invariancy in information geometry, can be also obtained by conformal flattening of the α-geometry [11,12], using a technique in the conformal and projective geometry [13,14,15].
The present framework prepares mathematical tools for analyzing physical phenomena subject to the power law. The Legendre transformation again plays a fundamental role for deriving the geometrical dual structure. There exist lots of applications of q-geometry to information theory ([16] and others) and statistics, including Bayes q-statistics.
2. q-Gibbs or q-Exponential Family of Distributions
2.1. q-Logarithm and q-Exponential Function
It is the first step to generalize the logarithm and exponential functions to include a family of power functions, where the logarithm and exponential functions are included as the limiting case [1,5,21]. This was also used for defining the α-family of distributions in information geometry [8]. We define the q-logarithm by
and its inverse function, the q-exponential, by
for a positive q with . The limiting case reduces to
so that and are defined for .
2.2. q-Exponential Family
The standard form of an exponential family of distributions is written as
with respect to an adequate measure , where is a set of random variables and are the canonical parameters to describe the underlying system. The Gibbs distribution is of this type. Here, is called the free energy, which is the cumulant generating function.
The power version of the Gibbs distribution is written as
where . This is the q-Gibbs distribution or q-exponential family [4], which we denote by S, where the domain of x is restricted such that holds. The function , called the q-free energy or q-potential function, is determined from the normalization condition:
where we replaced by for brevity’s sake. The function depends on q, but we hereafter neglect suffix q in most cases. Research on the q-exponential family can be found, for example, in [2,4,19]. The q-Gaussian distribution is given by
and is studied in [22,23,24,25] in detail. Here, we need to introduce a vector random variable and a new parameter , which is a vector-valued function of μ and σ, to represent it in the standard form (7). It is an interesting observation that the domain of x in the q-Gaussian case depends on q if . Hence, that q- and -Gaussian are in general not absolutely continuous when .
It should be remarked that the q-exponential family itself is the same as the α-family of distributions in information geometry [8]. Here, we introduce a different geometrical structure, generalizing the result of [24].
We mainly use the family of discrete distributions over elements , although we can easily extend the results to the case of continuous random variables. Here, random variable x takes values over X. We also treat the case of , and the limiting cases of or 1 give the well-known ones.
Let us put and denote the probability distribution by vector , where
The probability of x is also written as
where
Theorem 1
The family of discrete probability distributions has the structure of a q-exponential family for any q.
Proof
We take of distribution of (11). For any function , we have
By taking
into account, discrete distribution (11) can be rewritten in the form (8) as
where
is treated as a function of . Hence, is q-exponential family (6) for any q, with the following q-canonical parameters, random variables and q-potential function:
This completes the proof. □
Note that the q-potential and the canonical parameter depend on q as is seen in (17) and (19). It should also be remarked that Theorem 1 does not contradict to the theorem 1 in [19] stating that a parametrized family of probability distributions can belong to at most one q-exponential family. The author considers an m-dimensional parametrized submanifold in with where the canonical parameter depending on q is given via the variational principle. Therefore, by denoting the q-canonical parameter by , we can restate his theorem in terms of geometry that a linear submanifold parametrized by is not a linear submanifold parametrized by when . On the other hand, the present theorem states that there exists the q-canonical parameter on whole for any q and the manifold has linear structure with respect to any . This is a surprising new finding.
2.3. q-Potential Function
We study the q-geometrical structure of S. The q-log-likelihood is a linear form defined by
By differentiating it with respect to , with the abbreviated notation , we have
From this we have the following important theorem.
Theorem 2
The q-free energy or q-potential is a convex function of .
Proof
We omit the suffix q for simplicity’s sake. We have
The following identities hold:
Here, we define an important functional
in particular for discrete ,
for . This function plays a key role in the following. From (25) and (26), by using (23) and (24), we have
The latter shows that is positive-definite, and hence ψ is convex. □
2.4. q-Divergence
A convex function makes it possible to define a divergence of the Bregman-type between two probability distributions and [8,26,27]. It is given by using the gradient ,
satisfying the non-negativity condition
with equality when and only when . This gives a q-divergence in different from the invariant divergence of [28]. The divergence is canonical in the sense that it is uniquely determined in accordance with dually flat structure of q-exponential family in Section 3 and Section 4. The canonical divergence is different from the α-divergence or conventional Tsallis relative entropy used in information geometry (See the discussion in the end of this subsection). Note that it is used in [16].
Theorem 3
For two discrete distributions and , the q-divergence is given by
It is useful to consider a related probability distribution,
for defining the q-expectation. This is called the q-escort probability distribution [1,4,29]. Introducing the q-expectation of random variable by
we can rewrite the q-divergence (31) for as
because of the relations (20) and (29). The expression (38) is also valid on the exterior of when it is integrable. This is different from the definition of the Tsallis relative entropy [30,31]
which is equal to the well-known α-divergence up to a constant factor where (see [8,28]), satisfying the invariance criterion. We have
This is a conformal transformation of divergence, as we see in the following. See also the derivation based on affine differential geometry [12].
2.5. q-Riemannian Metric
When is infinitesimally close to , by putting , and using the Taylor expansion, we have
where
is a positive-definite matrix. We call the q-Fisher information matrix. When , this reduces to the ordinary Fisher information matrix given by
The positive-definite matrix defines a Riemannian metric on , giving it the q-Riemannian structure.
When a metric tensor is transformed to
by a positive function , we call it a conformal transformation. See, e.g., [13,14,15,32]. The conformal transformation of divergence induces that of the Riemannian metric.
Theorem 4
The q-Fisher information metric is given by a conformal transformation of the Fisher information metric as
A Riemannian metric defines the length of a tangent vector at by
Similarly, for two tangent vectors X and Y, their inner product is defined by
When vanishes, X and Y are said to be orthogonal. The orthogonality, or more generally the angle, of two vectors X and Y does not change by a conformal transformation, although their magnitudes change.
3. Dually Flat Structure of q-Exponential Family
3.1. Legendre Transformation and q-Entropy
Given a convex function , the Legendre transformation is defined by
where is the gradient. Since the correspondence between and is one-to-one, we may consider as another coordinate system of S.
The dual potential function is defined by
which is convex with respect to . The original coordinates are recovered from the inverse transformation given by
where , so that and are in dual correspondence.
The following theorem gives explicit relations among these quantities.
Theorem 5
The dual coordinates are given by
and the dual potential is given by
We call the q-dual potential
the negative q-entropy, because it is the Legendre-dual of the q-free energy . There are various definitions of q-entropy. The Tsallis q-entropy [3] is originally defined by
while the Rényi q-entropy [33] is
They are mutually related by monotone functions. When , all of them reduce to the Shannon entropy.
3.2. q-Dually Flat Structure
There are two dually coupled coordinate systems and in q-exponential family S with two potential functions and for each q. Two affine structures are introduced by the two convex functions ψ and φ. See information geometry of dually flat space [8]. Although S is a Riemannian manifold given by the q-Fisher information matrix (45), we may nevertheless regard S as an affine manifold where is an affine coordinate system. They represent intensive quantities of a physical system. Dually, we introduce a dual affine structure to S, where is another affine coordinate system. They represent extensive quantities. We can define two types of straight lines or geodesics in S due to the q-affine structures.
For two distributions and in S, a curve is said to be a q-geodesic connecting them, when
where t is the parameter of the curve. Dually, in terms of dual coordinates , when
holds, the curve is said to be a dual q-geodesic.
More generally, the q-geodesic connecting two distribution and is given by
where is a normalizing term. This is rewritten as
Dually, the dual q-geodesic connecting and is given by using the escort distributions as
Since the manifold S has a q-Riemannian structure, the orthogonality of two tangent vectors is defined by the Riemannian metric. We rewrite the orthogonality of two geodesics in terms of the affine coordinates. Let us consider two small deviations and of , that is, from to and , which are regarded as two (infinitesimal) tangent vectors of S at .
Lemma 1
The inner product of two deviations and is given by
Proof
By simple calculations, we have
of which the right-hand side is the Riemannian inner product in the form of (46). □
Corollary.
Two curves and , intersecting at , are orthogonal when . Here, and denote derivatives of and by t, respectively.
The two geodesics and the orthogonality play a fundamental role in S as will be seen in the following.
4. q-Pythagorean and q-Max-Ent Theorems
A dually flat Riemannian manifold admits the generalized Pythagorean theorem and the related projection theorem [8]. We state them in our case.
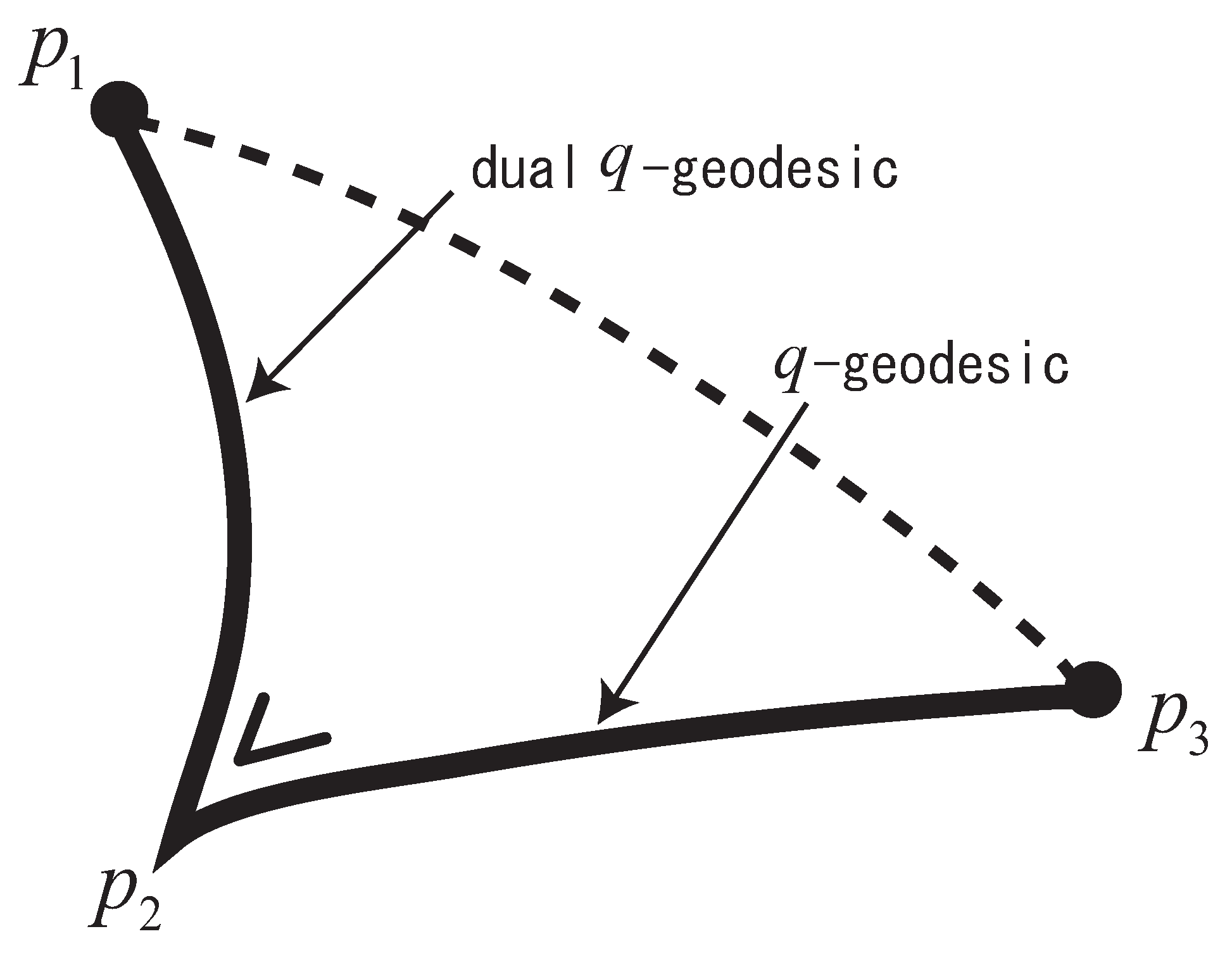
q-Pythagorean Theorem.
For three distributions and in S, it holds that
when the dual geodesic connecting and is orthogonal at to the geodesic connecting and (see Figure 1).
Figure 1.
q-Pythagorean theorem.
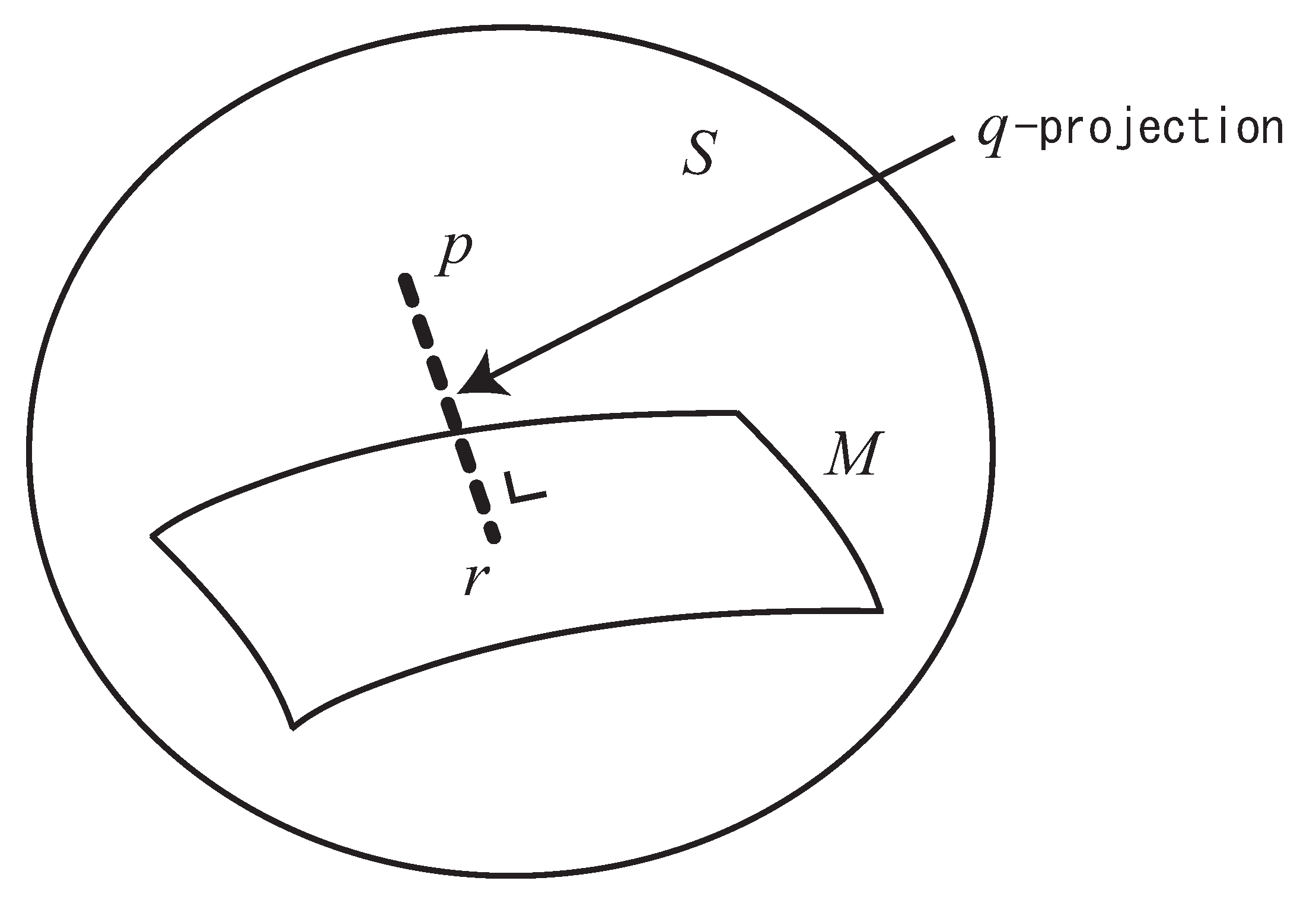
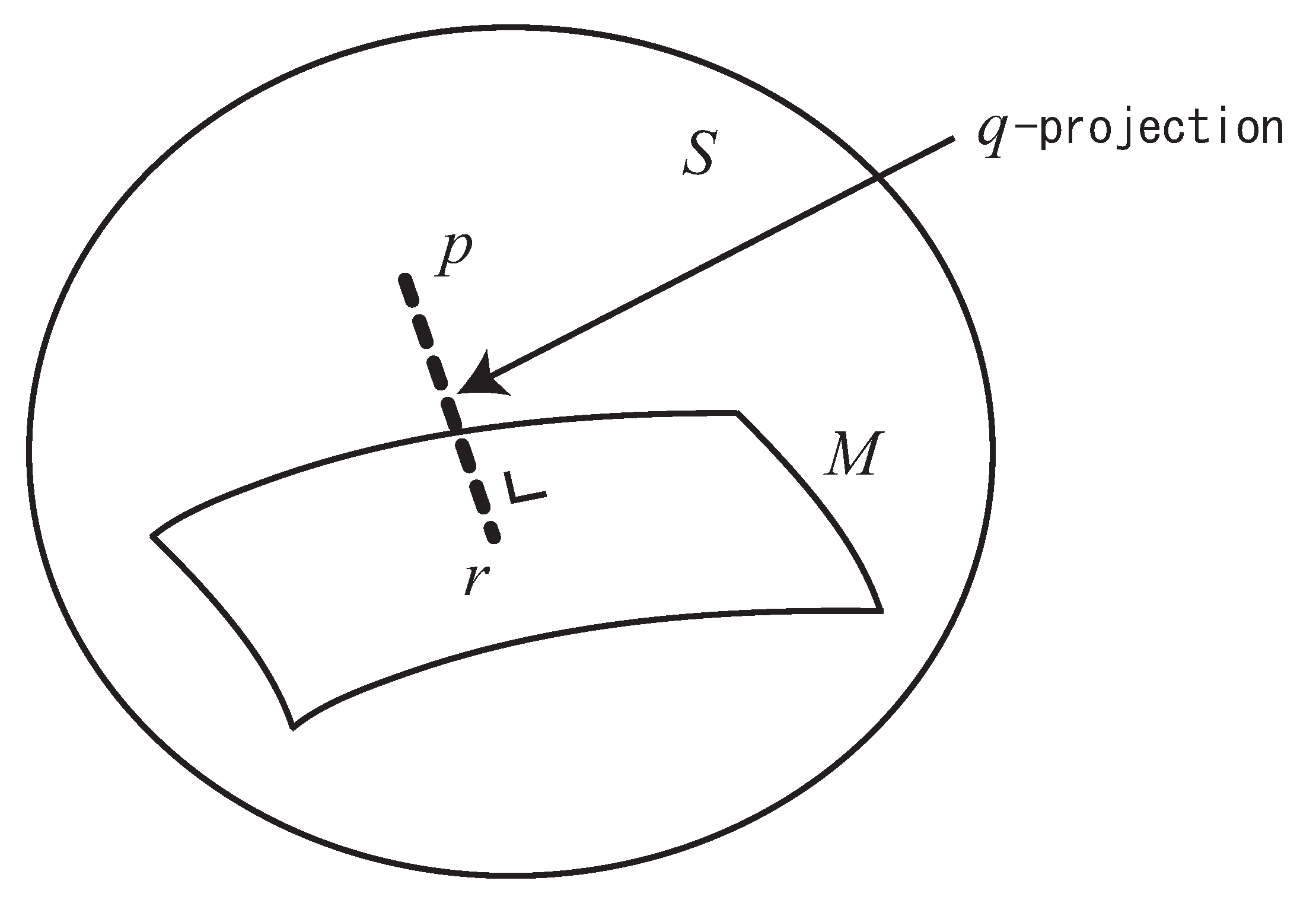
Given a distribution and a submanifold , a distribution is said to be the q-projection (dual q-projection) of to M, when the q-geodesic (dual q-geodesic) connecting and is orthogonal to M at (Figure 2).
Figure 2.
q-projection of p to M.
q-Projection Theorem.
Let M be a submanifold of S. Given , the point that minimizes is given by the dual q-projection of to M. The point that minimizes is given by the q-projection of to M.
We show that the well-known q-max-ent theorem in the case of Tsallis q-entropy [1,4,9,11] is a direct consequence of the above q-Pythagorean and q-projection theorems.
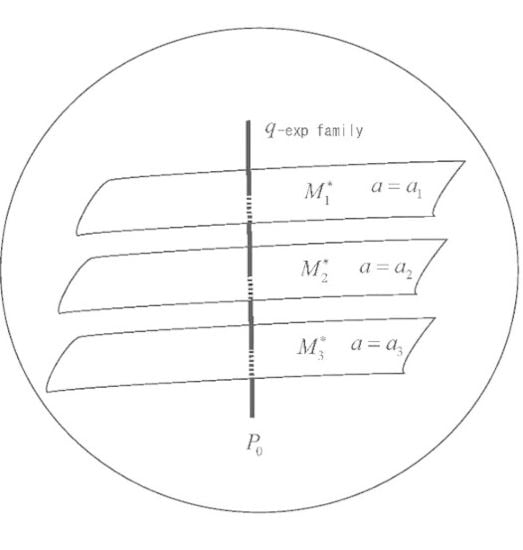
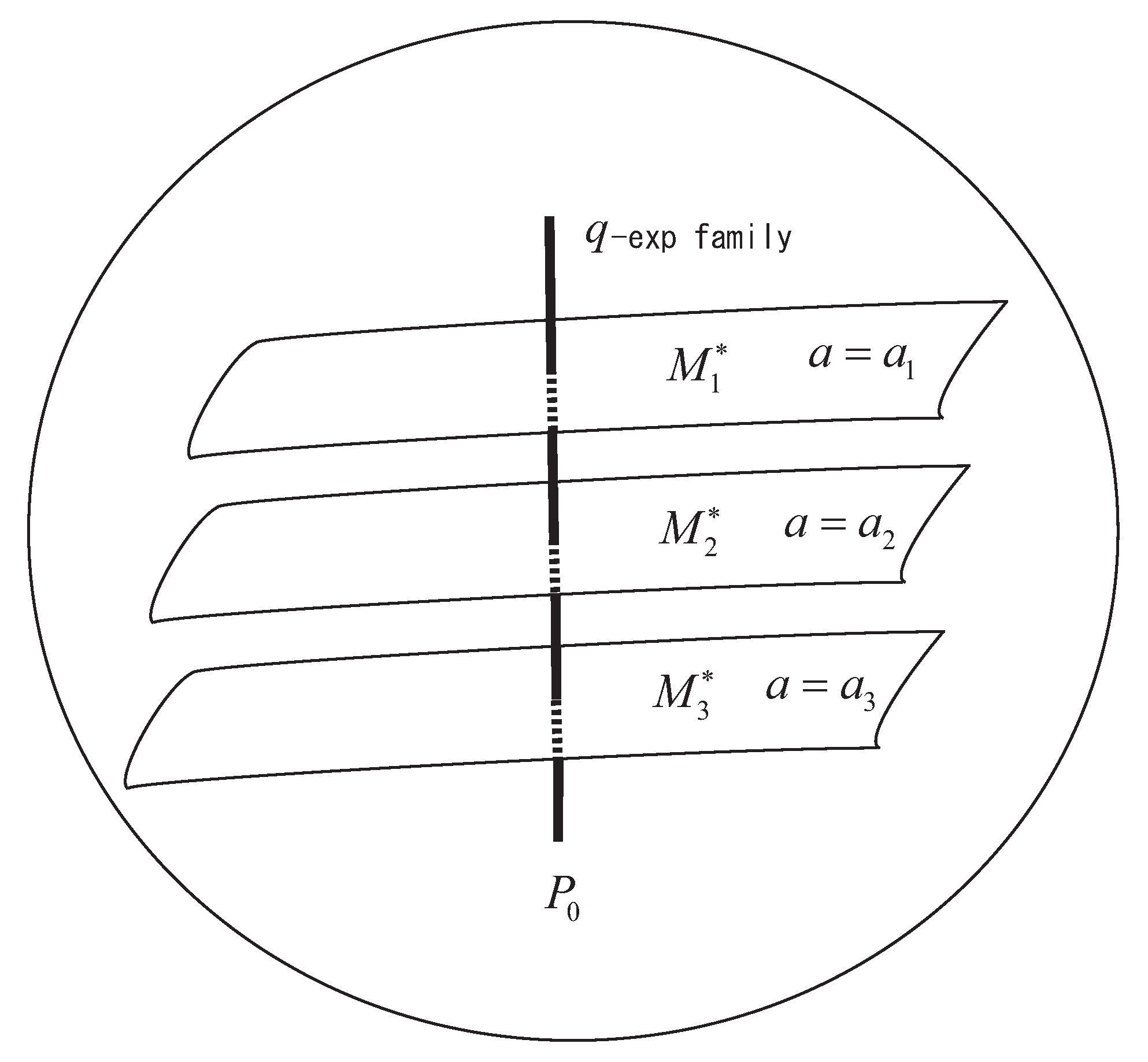
q-Max-Ent Theorem.
Probability distributions maximizing the q-entropies and under q-linear constraints for m random variables and various values of
form a q-exponential family
The proof is easily obtained by the standard analytical method. Here, we give a geometrical proof. Let us consider the subspace whose member satisfies the m constraints
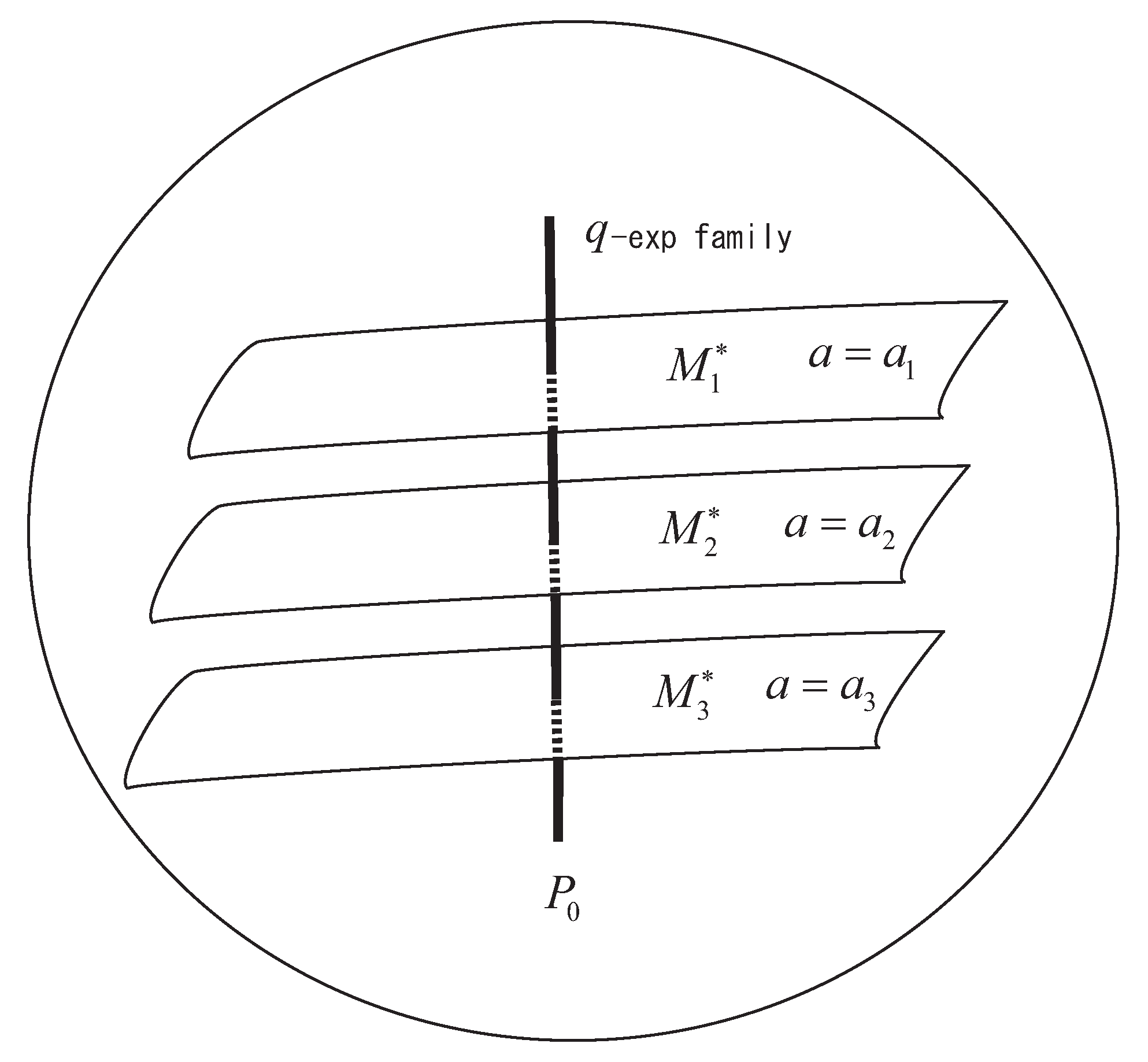
Since the constraints are linear in the dual affine coordinates or , is a linear subspace of S with respect to the dual affine connection. Let be the uniform distribution defined by , which implies from (6). Let be the q-projection of to (Figure 3). Then, the divergence from to is decomposed as
Let be the dual coordinates of . Since the divergence is written as
the minimizer of among is just , which is also the maximizer of the entropy .
The trajectories of for various values of form a flat subspace orthogonal to , implying that they form a q-exponential family of the form (6) (see Figure 3). The tangent directions of satisfies
Hence, a q-exponential family of the form
is orthogonal to , when
This implies that . Hence, we have the q-exponential family (72) that maximizes the q-entropies.
Figure 3.
q-Max-Ent theorem.
5. q-Bayesian MAP Estimator
Given N iid observations from a statistical model , we have
Since is a monotonically increasing function, the maximizer of the q-likelihood
is the same as the ordinary maximum likelihood estimator (mle). However, the maximizer of the q-escort distribution that maximizes the q-escort log-likelihood,
is different from this. We show that the q-mle is a Bayesian MAP (maximum a posteriori probability) estimator. This clarifies the meaning of the q-escort mle.
The q-escort mle is the maximizer of the q-escort distribution,
Theorem 6
The q-escort mle is the Bayesian MAP estimator with the prior distribution
Proof
The Bayesian MAP is the maximizer of the posterior distribution with prior
which also maximizes
On the other hand, the q-escort mle is the maximizer of
Hence, when
the two estimators are identical. □
The theorem shows that the Bayesian prior has a peak at the maximizer of our q-entropy .
6. Conclusions
Much attention has been recently paid to the probability distributions subject to the power law, instead of the exponential law, since Tsallis proposed the q-entropy and related theories. The power law is also found in various communication networks. It is now a hot topic of research.
However, we do not have a geometrical foundation while that for the ordinary family of probability distributions is given by information geometry [8]. The present paper tried to give a geometrical foundation to the q-family of probability distributions. We introduced a new notion of the q-geometry. The q-structure is ubiquitous in the sense that the family of all the discrete probability distributions (and the family of all the continuous probability distributions, if we neglect delicate problems involved in the infinite dimensionality) belongs to the q-exponential family of distributions for any q. That is, we can introduce the q-geometrical structure to an arbitrary family of probability distributions, because any parametrized family of probability distributions forms a submanifold embedded in the entire manifold.
The q-structure consists of a Riemannian metric together with a pair of dually coupled affine connections, which sits in the framework of the standard information geometry. However, the q-structure is essentially different from the standard one derived by the invariance criterion of the manifold of probability distributions. We have a novel look on the theory related to the q-entropy from a viewpoint of conformal transformation. This leads us to unified definitions of various quantities such as the q-entropy, q-divergence, q-potential function and their duals, as well as new interpretations of known quantities.
This is a geometrical foundation and we expect that the paper contributes to provide further developments in this field.
References
- Tsallis, C. Introduction to Nonextensive Statistical Mechanics; Springer: New York, NY, USA, 2009. [Google Scholar]
- Naudts, J. Generalised Thermostatistics; Springer: London, UK, 2011. [Google Scholar]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Naudts, J. The q-exponential family in statistical Physics. Cent. Eur. J. Phys. 2009, 7, 405–413. [Google Scholar] [CrossRef]
- Suyari, H. Mathematical structures derived from the q-multinomial coefficient in Tsallis statistics. Physica A 2006, 368, 63–82. [Google Scholar] [CrossRef]
- Suyari, H.; Wada, T. Multiplicative duality, q-triplet and μ, ν, q-relation derived from the one-to-one correspondence between the (μ, ν)-multinomial coefficient and Tsallis entropy Sq. Physica A 2008, 387, 71–83. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, O.E. Information and Exponential Families in Statistical Theory; Wiley: New York, NY, USA, 1978. [Google Scholar]
- Amari, S.; Nagaoka, H. Methods of Information Geometry (Translations of Mathematical Monographs); Oxford University Press: Oxford, UK, 2000. [Google Scholar]
- Ohara, A. Geometry of distributions associated with Tsallis statistics and properties of relative entropy minimization. Phys. Lett. A 2007, 370, 184–193. [Google Scholar] [CrossRef]
- Furuichi, S. On the maximum entropy principle and the minimization of the Fisher information in Tsallis statistics. J. Math. Phys. 2009, 50, 013303. [Google Scholar] [CrossRef]
- Ohara, A. Geometric study for the Legendre duality of generalized entropies and its application to the porous medium equation. Eur. Phys. J. B 2009, 70, 15–28. [Google Scholar] [CrossRef]
- Ohara, A.; Matsuzoe, H.; Amari, S. A dually flat structure with escort probability and its application to alpha-Voronoi diagrams. In arXiv; 2010; arXiv:cond-mat/1010.4965. [Google Scholar]
- Kurose, T. On the Divergence of 1-conformally Flat Statistical Manifolds. Tôhoku Math. J. 1994, 46, 427–433. [Google Scholar] [CrossRef]
- Matsuzoe, H. Geometry of contrast functions and conformal geometry. Hiroshima Math. J. 1999, 29, 175–191. [Google Scholar]
- Kurose, T. Conformal-projective geometry of statistical manifolds. Interdisciplinary Information Sciences 2002, 8, 89–100. [Google Scholar] [CrossRef]
- Yamano, T. Information theory based on non-additive information content. Phys. Rev. E 2001, 63, 046105. [Google Scholar] [CrossRef]
- Naudts, J. Estimators, escort probabilities, and phi-exponential families in statistical physics. J. Ineq. Pure Appl. Math. 2004, 5, 102. [Google Scholar]
- Pistone, G. kappa-exponential models from the geometrical viewpoint. Eur. Phys. J. B 2009, 70, 29–37. [Google Scholar] [CrossRef]
- Naudts, J. Generalized exponential families and associated entropy functions. Entropy 2008, 10, 131–149. [Google Scholar] [CrossRef]
- Kaniadakis, G.; Lissia, M.; Scarfone, A.M. Deformed logarithms and entropies. Physica A 2004, 340, 41–49. [Google Scholar] [CrossRef]
- Yamano, T. Some properties of q-logarithmic and q-exponential functions in Tsallis statistics. Physica A 2002, 305, 486–496. [Google Scholar] [CrossRef]
- Tsallis, C.; Levy, S.V.F.; Souza, A.M.C.; Maynard, R. Statistical-mechanical foundation of the ubiquity of Levy distributions in nature. Phys. Rev. Lett. 1995, 75, 3589–3593, Erratum Phys. Rev. Lett. 1996, 77, 5442.. [Google Scholar] [CrossRef]
- Tanaka, M. A consideration on the family of q-Gaussian distributions. IEICE (Japan) 2002, J85–D2, 161–173. (in Japanese). [Google Scholar]
- Zhang, Z.; Zhong, F.; Sun, H. Information geometry of the power inverse Gaussian distribution. Appl. Sci. 2007, 9, 194–203. [Google Scholar]
- Ohara, A.; Wada, T. Information geometry of q-Gaussian densities and behaviors of solutions to related diffusion equations. J. Phys. A: Math. Theor. 2010, 43, 035002. [Google Scholar] [CrossRef]
- Wada, T. Generalized log-likelihood functions and Bregman divergences. J. Math. Phys. 2009, 50, 113301. [Google Scholar] [CrossRef]
- Cichocki, A.; Cruces, S.; Amari, S. Generalized alpha-beta divergences and their application to robust nonnegative matrix factorization. Entropy 2011, 13, 134–170. [Google Scholar] [CrossRef]
- Amari, S. α-divergence is unique, belonging to both f-divergence and Bregman divergence classes. IEEE Trans. Inform. Theor. 2009, 55, 4925–4931. [Google Scholar] [CrossRef]
- Beck, C.; Schlögl, F. Thermodynamics of Chaotic Systems; Cambridge University Press: Cambridge, UK, 1993. [Google Scholar]
- Borland, L.; Plastino, A.R.; Tsallis, C. Information gain within nonextensive thermostatistics. J. Math. Phys. 1998, 39, 6490–6501. [Google Scholar] [CrossRef]
- Furuichi, S. Fundamental properties of Tsallis relative entropy. J. Math. Phys. 2004, 45, 4868–4877. [Google Scholar] [CrossRef]
- Okamoto, I.; Amari, S.; Takeuchi, K. Asymptotic theory of sequential estimation procedures for curved exponential families. Ann. Stat. 1991, 19, 961–981. [Google Scholar] [CrossRef]
- Rényi, A. On measures of entropy and information. In Proceedings of the 4th Berkeley Symposium on Mathematics, Statistics and Probability, Berkeley, CA, USA, 20 June–30 July 1960; pp. 547–561.
- Landsberg, P.T.; Vedral, V. Distributions and channel capacities in generalized statistical mechanics. Phys. Lett. A 1998, 247, 211–217. [Google Scholar] [CrossRef]
- Rajagopal, A.K.; Abe, S. Implications of form invariance to the structure of nonextensive entropies. Phys. Rev. Lett. 1999, 83, 1711–1714. [Google Scholar] [CrossRef]
- Yamano, T. Source coding theorem based on a nonadditive information content. Physica A 2002, 305, 190–195. [Google Scholar] [CrossRef]
- Wada, T.; Scarfone, A.M. Connections between Tsallis’ formalisms employing the standard linear average energy and ones employing the normalized q-average energy. Phys. Lett. A 2005, 335, 351–362. [Google Scholar] [CrossRef]
© 2011 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
MDPI and ACS Style
Amari, S.-i.; Ohara, A. Geometry of q-Exponential Family of Probability Distributions. Entropy 2011, 13, 1170-1185. https://doi.org/10.3390/e13061170
AMA Style
Amari S-i, Ohara A. Geometry of q-Exponential Family of Probability Distributions. Entropy. 2011; 13(6):1170-1185. https://doi.org/10.3390/e13061170
Chicago/Turabian StyleAmari, Shun-ichi, and Atsumi Ohara. 2011. "Geometry of q-Exponential Family of Probability Distributions" Entropy 13, no. 6: 1170-1185. https://doi.org/10.3390/e13061170