Bayesian Testing of a Point Null Hypothesis Based on the Latent Information Prior

1
Department of Mathematical Informatics, Graduate School of Information Science and Technology, the University of Tokyo, 7-3-1 Hongo, Bunkyo-ku, Tokyo 113-8656, Japan
2
RIKEN Brain Science Institute, 2-1 Hirosawa, Wako City, Saitama 351-0198, Japan
Entropy 2013, 15(10), 4416-4431; https://doi.org/10.3390/e15104416
Submission received: 9 August 2013
/
Revised: 16 September 2013
/
Accepted: 10 October 2013
/
Published: 17 October 2013
Abstract
:Bayesian testing of a point null hypothesis is considered. The null hypothesis is that an observation, x, is distributed according to the normal distribution with a mean of zero and known variance . The alternative hypothesis is that x is distributed according to a normal distribution with an unknown nonzero mean, μ, and variance . The testing problem is formulated as a prediction problem. Bayesian testing based on priors constructed by using conditional mutual information is investigated.
1. Introduction
We investigate a problem of testing a point null hypothesis from the viewpoint of prediction. The null hypothesis, , is that an observation, x, is distributed according to the normal distribution, , with a mean of zero and variance , and the alternative hypothesis, , is that x is distributed according to a normal distribution with unknown nonzero mean μ and variance . The variance, , is assumed to be known. This simple testing problem has various essential aspects in common with more general testing problems and has been discussed by many researchers. An essential part of our discussion in the present paper holds for other testing problems based on more general models.
The assumption that the sample size is one is not essential. When we have N observations from or , then the sufficient statistic is distributed according to under or under , respectively. Then, the null hypothesis is that is distributed according to , and the alternative hypothesis is that is distributed according to , where and . Thus, the testing problem with sample size N is essentially equal to that with the sample size one. From now on, the variance, , is set to be one without loss of generality.
We formulate the testing problem as a prediction problem. Let if is true and if is true. Let w be the probability that , and let be the prior probability measure of μ. The probability, w, is set to be in many previous studies, and the choice of is discussed; see, e.g., [1] and the references therein. The objective is to predict m by using a Bayesian predictive distribution, , depending on the prior and the observation, x.
Common choices of π are the Normal prior and the Cauchy prior , recommended by Jeffreys [2]. Sometimes, it is considered that large values of scale parameters τ and γ represent “ignorance” about μ. However, such a naive choice of scale parameter values could cause a serious problem known as the Jeffreys–Lindley paradox [3].
We choose from the viewpoint of prediction and construct a Bayesian predictive distribution to predict m based on an objectively chosen prior In the testing problem, the variable, m, is predicted, the variable, x, is observed and the parameter, μ, is neither observed nor predicted. The latent information prior [4] is defined as a prior maximizing the conditional mutual information:
between m and μ given x.
The latent information prior introduced in [4] is an objective Bayes prior. An outline of the method based on it is as follows. First, a statistical problem is formulated as a prediction problem, in which x is the observed random variable, y is the random variable to be predicted and θ is the unknown parameter. Then, a prior that maximizes the conditional mutual information between y and θ given x is adopted.
In Section 2, we consider for Kullback-Leibler loss for prediction corresponding to Bayesian testing. In Section 3, we obtain the latent information prior and discuss properties of Bayesian testing based on it. In Section 4, we compare the proposed testing based on the latent information prior with Bayesian testing based on the normal prior and the Cauchy prior.
2. Kullback-Leibler Loss of Predictive Densities
We consider Kullback-Leibler loss of prediction corresponding to Bayesian testing. The Bayesian predictive density with respect to w and π is given by:
and
where:
and is the density function of the normal distribution, .
If the value of μ is known, then the alternative hypothesis, : , becomes a simple hypothesis, and the predictive distribution is given by the posterior:
and:
To evaluate the performance of predictive densities, we adopt the Kullback-Leibler divergence:
from and to as a loss function.
The risk function is given by:
where and . Here, and are denoted by and , respectively, because they do not depend on π. The distribution of x does not depend on μ if , because .
It is not fruitful to discuss decision theoretic properties, such as the minimaxity of the risk defined by:
because it is easy to distinguish between and when is very large.
The Kullback-Leibler risk in Equation (8) corresponds to the regret type quantity:
which means the loss by not knowing the value of μ. By considering the minimaxity of the regret type risk in Equation (8), several reasonable results are obtained.
Lemma 1.
The risk function in Equation (11) is a continuous function of μ for every w and π.
The Bayes risk with respect to a prior π of a Bayesian predictive density based on is:
3. Latent Information Priors
We obtain the latent information prior defined as a prior maximizing the conditional mutual information, . We restrict the original parameter space, , of μ to a compact subset, , for mathematical convenience. A typical choice is a bounded closed interval . If b is large enough, the testing problem versus , is close to the original problem.
Let and be the spaces of all probability measures on K and , respectively, endowed with the weak convergence topology. Then, is compact, since the K is compact. It is easy to verify that the conditional mutual information, , is a continuous function of and . Therefore, there exists that attains the maximum of Equation (1) for fixed , since is compact. In the following, is denoted as by omitting the subscript, w, when there is no confusion.
The Bayesian testing based on the latent information prior, , has the following minimax property.
Theorem 1.
Let be the latent information prior. Then:
Proof.
It is sufficient to show the relations:
In the previous section, we have seen the equalities and , corresponding to the first and second equalities in Equation (15). Thus, it is enough to show the last inequality, , since the relations, except for the first and second equalities and the last inequality, are obvious.
We prove the inequality by contradiction. Assume that there exists a value, , such that:
Let , where is the delta measure concentrated at ξ. Then, . From Equations (12) and (16):
where we put . However, , because of the definition of and the fact that . This is a contradiction. Thus, we have proven the desired result. ☐
The discussion in the proof is parallel to that for submodels of multinomial models in [4], although the testing problem is not included in the class considered there. Closely related discussion on the unconditional mutual information is given in Csiszár [6]. See also, [7,8].
We set with and consider two values, and , of w. The latent information priors, , for two values and are numerically obtained by using a generalized Arimoto-Blahut algorithm, the details of which will be discussed in another place. Here, is the setting adopted in many previous studies, and is the value maximizing .
The Arimoto-Blahut algorithm [9,10] is widely used in information theory to obtain the capacity of channels. A channel is defined to be a conditional distribution, , of y given θ, where y and θ are random variables taking values in finite sets, and Θ, respectively. If a channel, , is given, then the mutual information, , between y and θ is a function of the distribution, , of θ. The maximum value, , of the mutual information as a function of π is called the capacity of the channel . The Arimoto-Blahut algorithm is an iterative algorithm to obtain the capacity and the corresponding distribution , attaining the maximum value. The original Arimoto-Blahut algorithm cannot be directly applied to our problem, since we need to maximize the conditional mutual information, , where x and θ are not discrete random variables, to obtain the latent information prior.
Figure 1.
Latent information priors for (a) and for (b) .
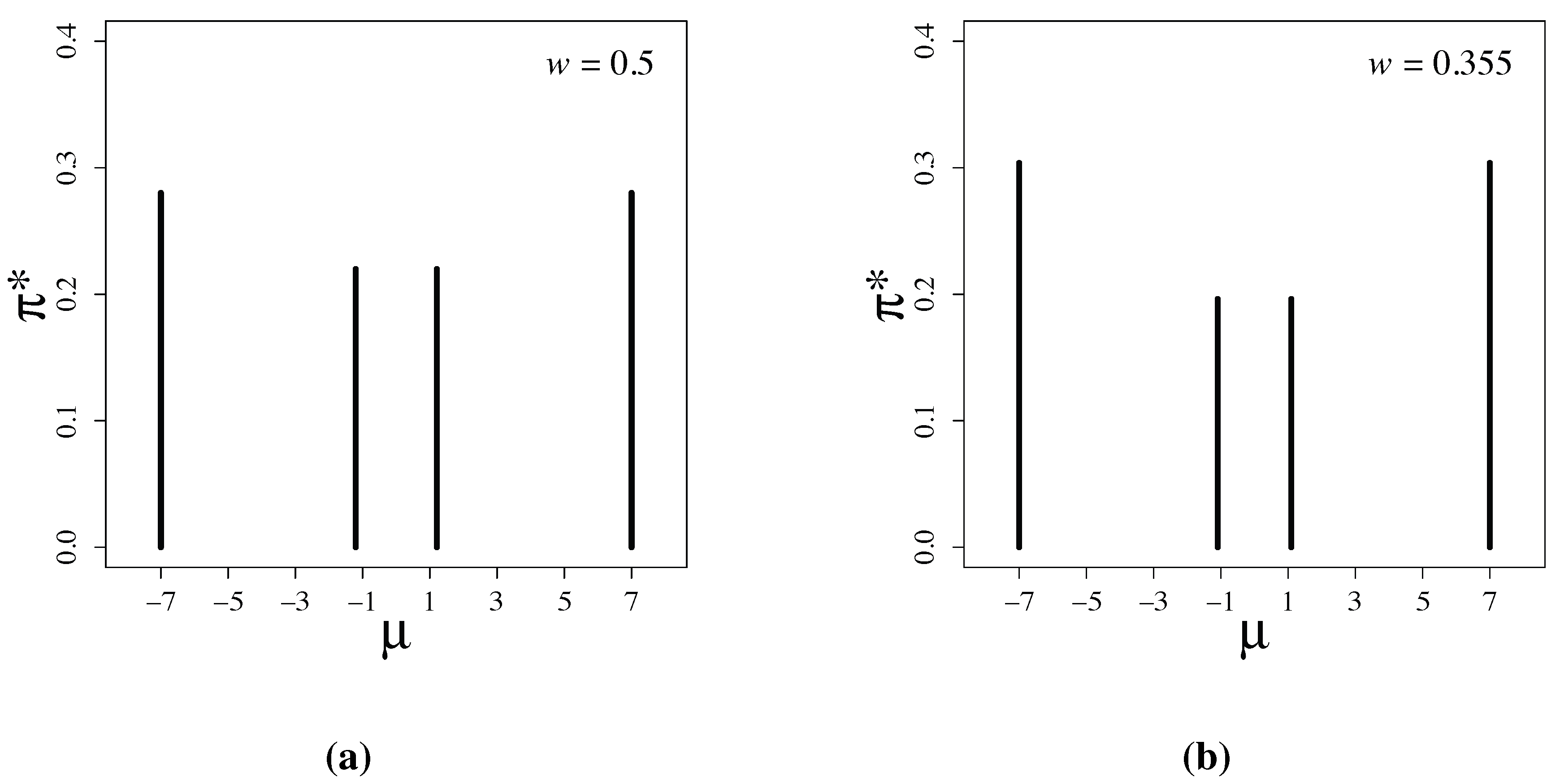
Figure 1 shows the numerically-obtained latent information priors. The priors have the form:
The parameter values are , and , when , and , and , when .
Lemma 2 below gives the risk of Bayesian testing based on the prior in Equation (18).
Lemma 2.
Let:
where and . Then, the risk in Equation (8) is given by:
and the conditional mutual information in Equation (1) is given by:
The first and second terms in Equation (20) do not depend on π. The third term in Equation (20) does not depend on μ.
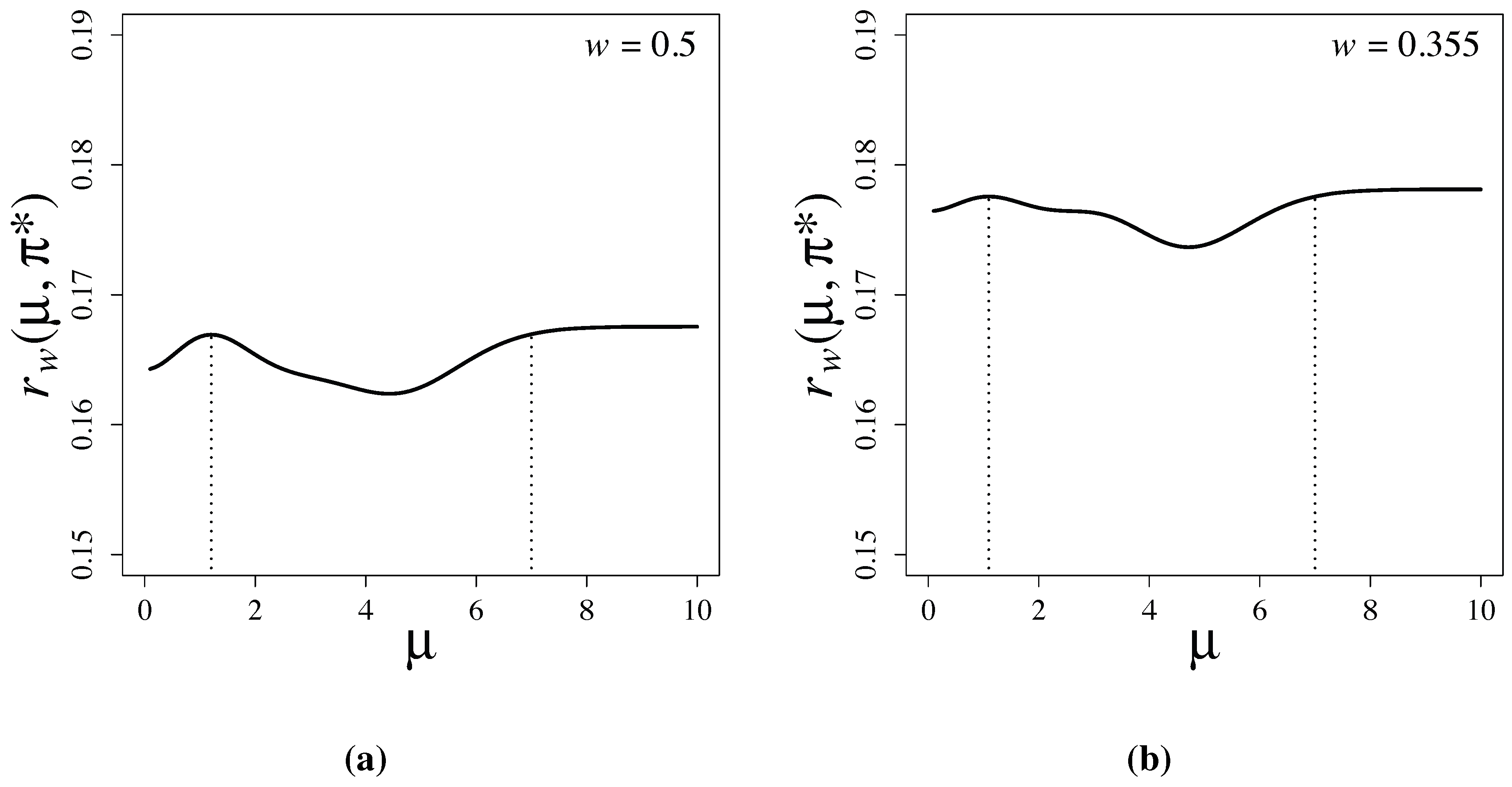
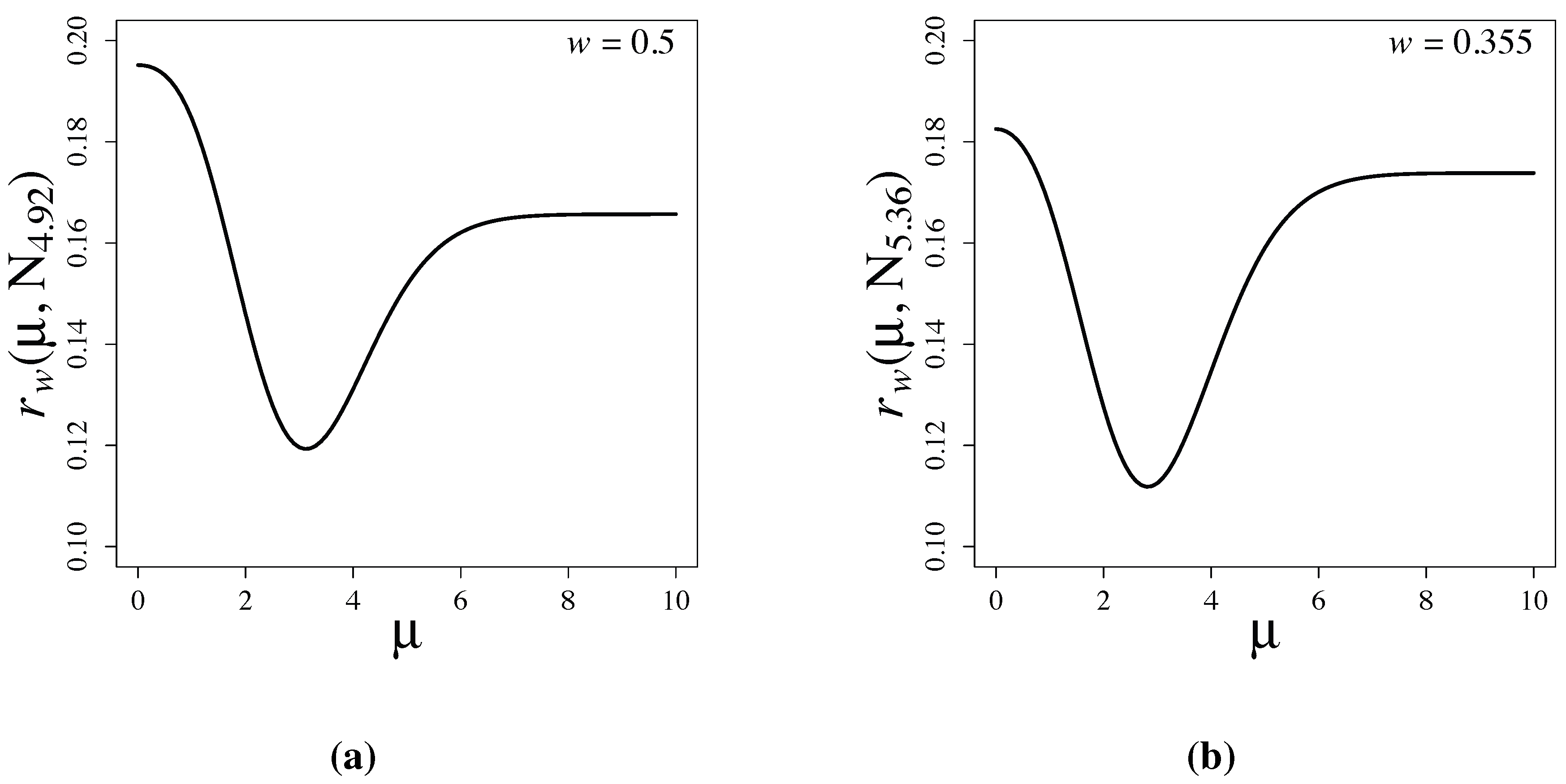
Figure 2 shows the risk functions of the latent information priors when and , respectively. Note that is attained at and b in both examples. This is consistent with the proof of Theorem 1, and it is numerically verified that the prior maximizes the conditional mutual information. Furthermore, we observe that the supremum value, , of the risk without restriction is only slightly larger than the maximum value, , with the restriction . The risk functions rapidly converge as μ exceeds seven.
Figure 2.
Risk functions of Bayesian testing based on latent information priors for (a) and for (b) . When , and . When , and . The vertical dotted lines indicate the locations of a and b.
Figure 2.
Risk functions of Bayesian testing based on latent information priors for (a) and for (b) . When , and . When , and . The vertical dotted lines indicate the locations of a and b.
Since:
and is small in our problem when , the supremum value, , of the risk function of the latent information prior, , under the parameter restriction, , is only slightly larger than the minimax value, without the restriction. We see in the next section that the supremum, , of the risk functions of commonly used priors are much larger than those of .
The discreteness of latent information priors shown in Figure 1 is a remarkable feature. In Bayesian statistics, k-reference priors have been known to be discrete measures in many examples; see [11,12,13]. The k-reference prior is defined to be a prior maximizing the mutual information between and θ when we have a set, , of k-independent observations, , from in a parametric model, . However, such discrete priors have not been widely used. Instead of k-reference priors, reference priors introduced by Bernardo [14] have been used for many problems. Reference priors are not discrete and are defined by considering the limit that the sample size k goes to infinity. One main reason why discrete priors are not popular is that discrete priors are totally unacceptable form the viewpoint of subjective Bayes in which priors are considered to represent prior belief on parameters.
Although they have not been widely used, discrete priors, such as latent information priors, are reasonable from the viewpoint of prediction and objective Bayes. Various statistical problems, including estimation and testing, can be formulated from the viewpoint of prediction, and priors can be constructed by considering the conditional mutual information. Thus, latent information priors depending on the choice of variables to be predicted could play important roles in many statistical applications. Conditional mutual information is essential in information theory and naturally appeared in several studies in statistics; see e.g., [15,16]. Priors based on conditional mutual information and those based on unconditional mutual information are often quite different; see [4].
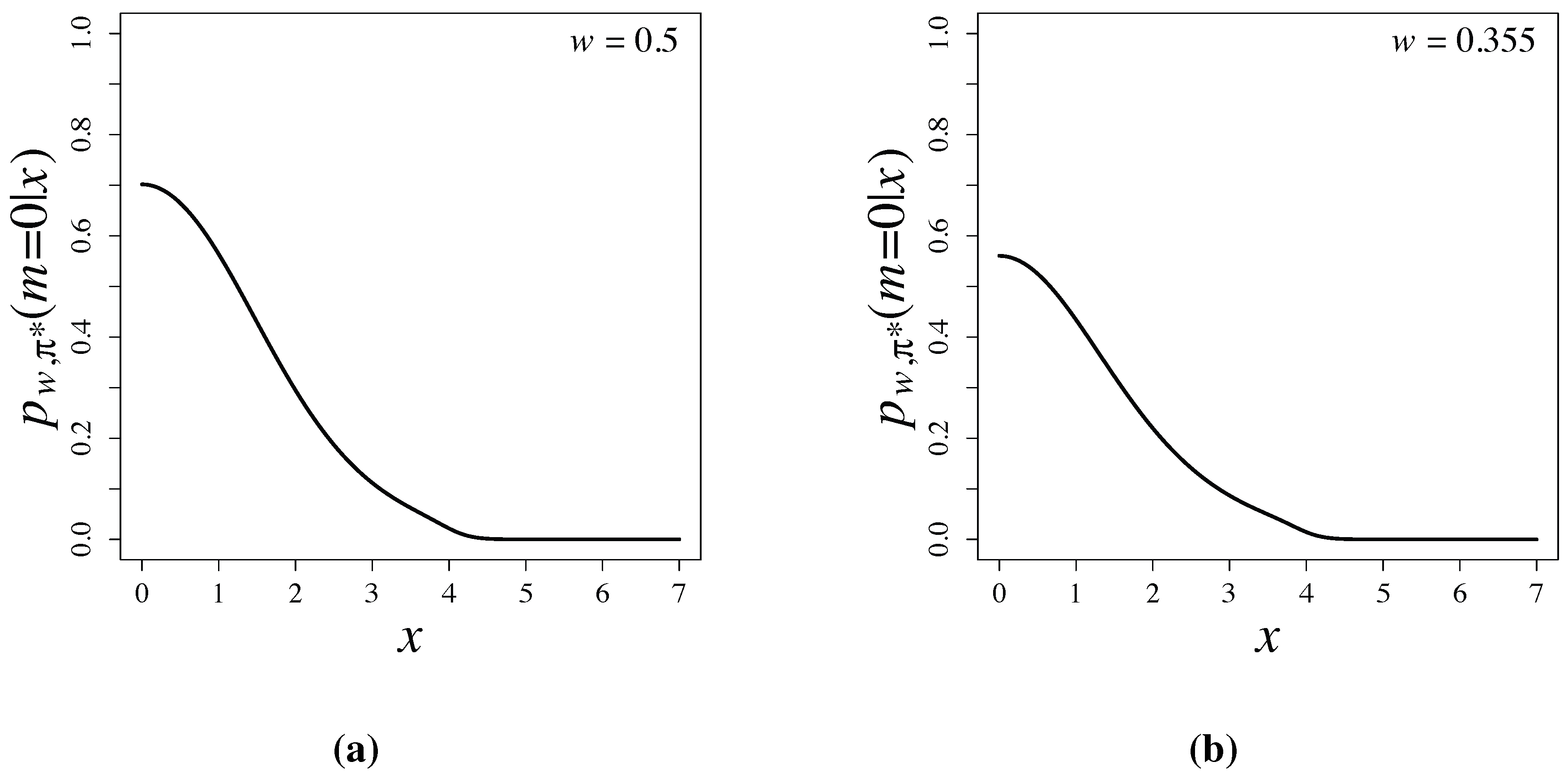
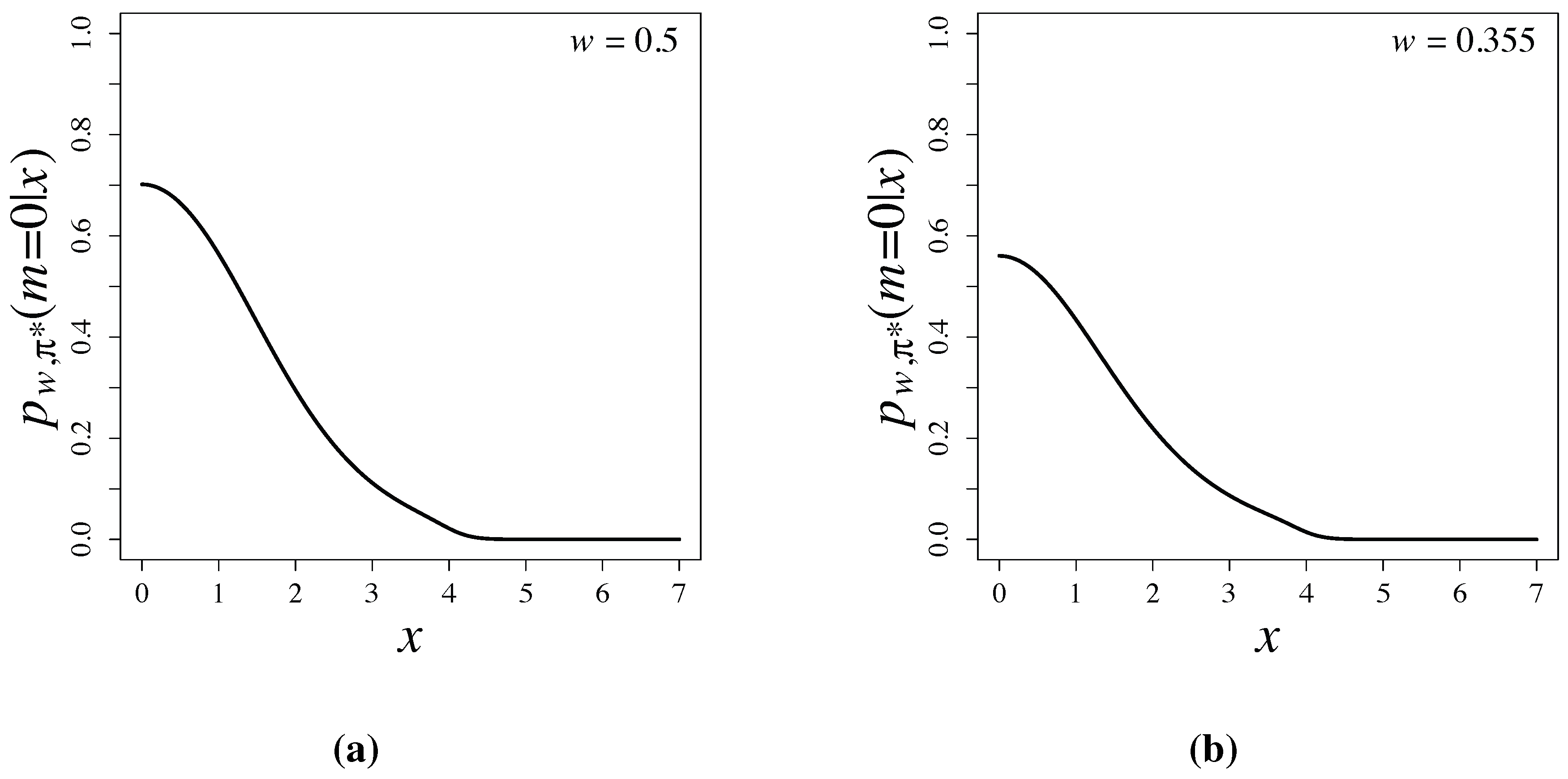
Bayesian testing based on latent information priors is free from the Jeffreys-Lindley paradox [3], since the priors are constructed by using conditional mutual information and depend properly on sample sizes. Posterior probabilities, , are shown in Figure 3 and are compared with p-values of the two-sided test in Table 1. When and 4, posterior probabilities are much smaller than p-values of the two-sided test. Large differences of posterior probabilities and p-values have been widely observed and discussed in [1,17,18].
Figure 3.
Posterior probabilities based on latent information priors for (a) and for (b) .

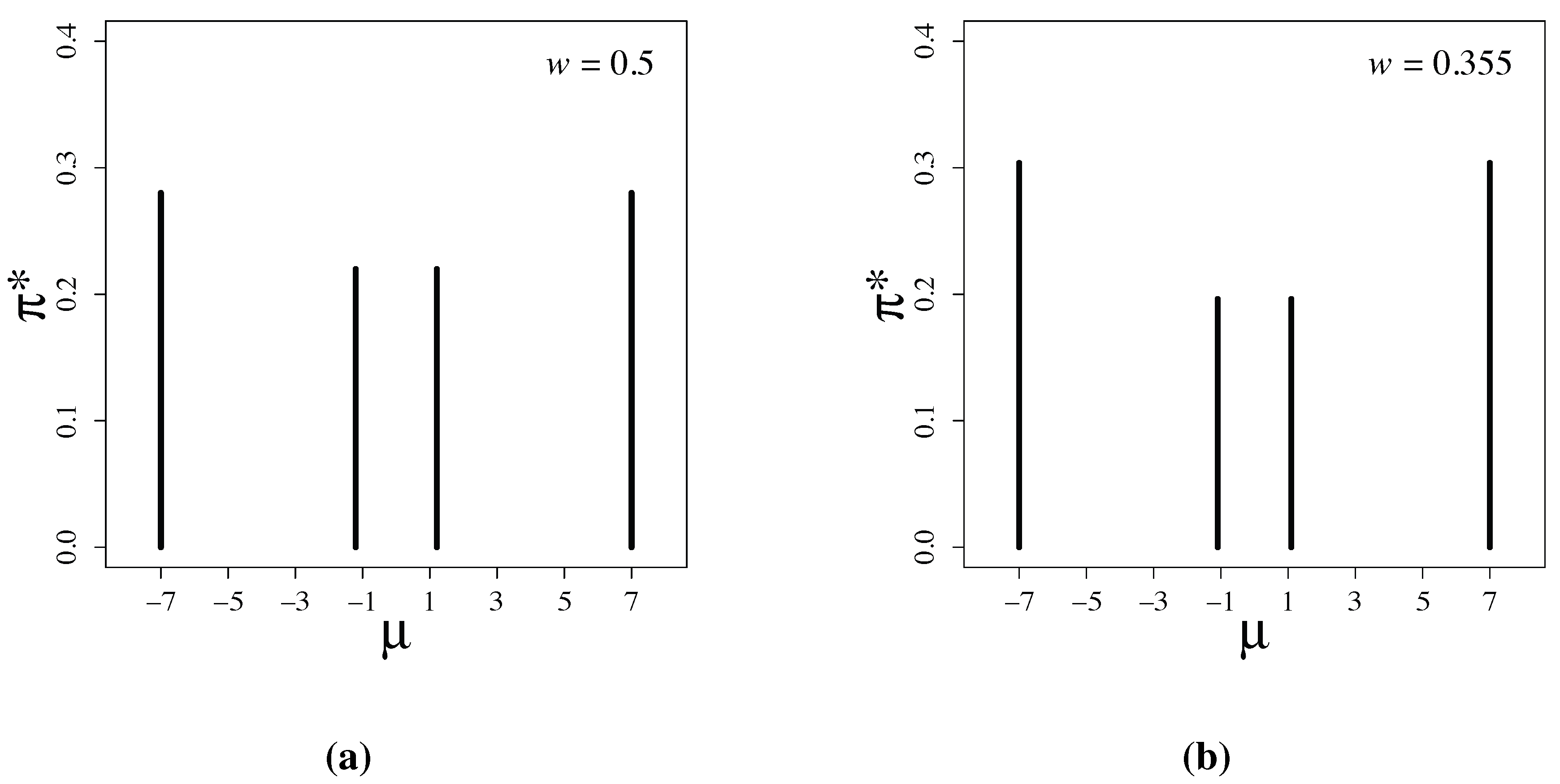{kind=link}
{kind=link}
{kind=link}
{kind=link}
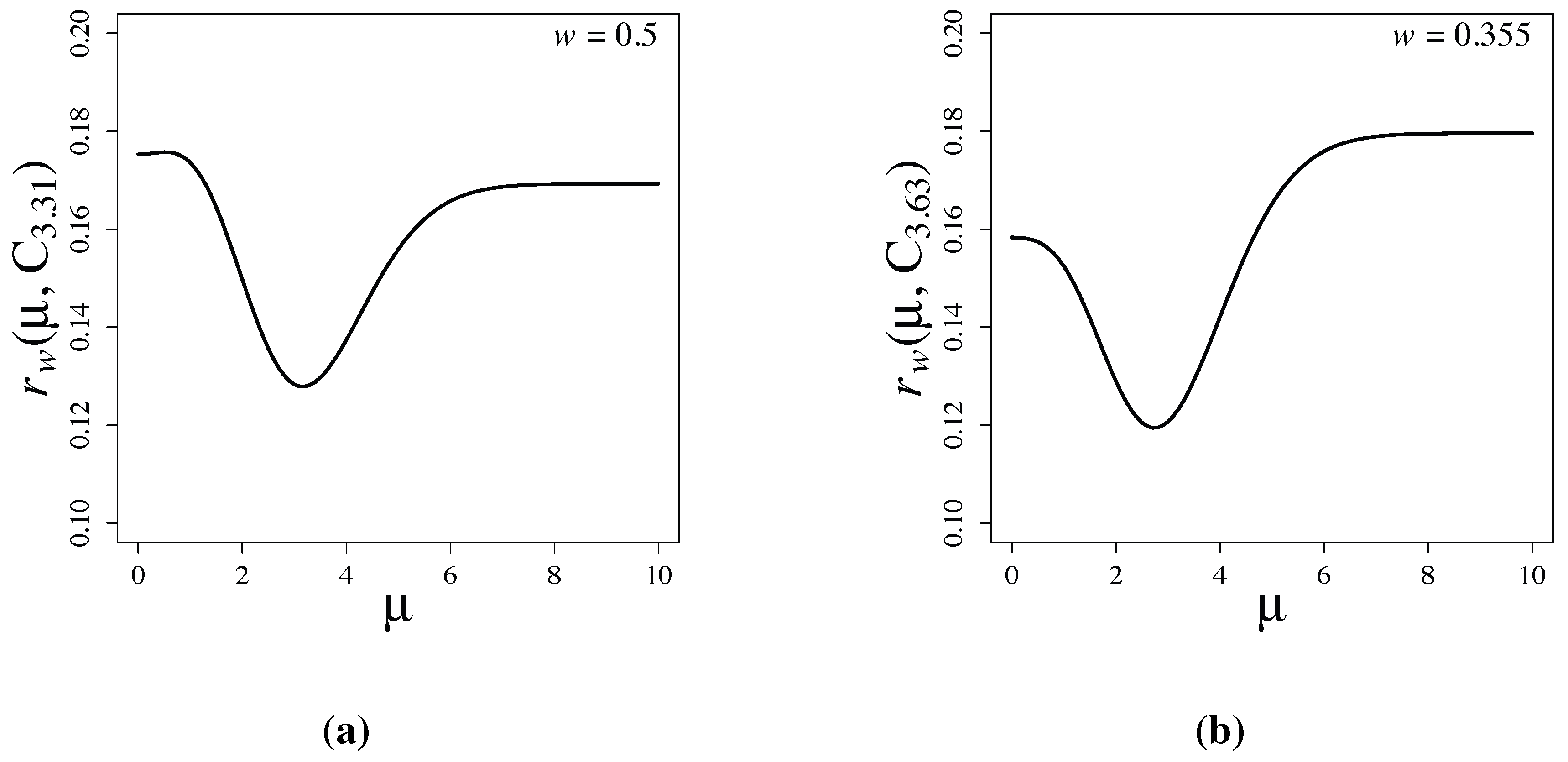{kind=link}
| x | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 0.702 | 0.564 | 0.295 | 0.112 | 0.0217 | |
| 0.560 | 0.434 | 0.220 | 0.0867 | 0.0145 | |
| p-value (two-sided test) | 1 | 0.317 | 0.0455 | 0.00267 |
4. Other Common Priors
Discrete priors, including latent information priors discussed in the previous section, have not been widely used in Bayesian statistics. Common priors for the testing are the normal prior and the Cauchy prior. It seems to have been believed by many statisticians that the Cauchy prior is slightly better than the normal prior; see, e.g., [1,2]. In this section, we evaluate the conditional mutual information for the priors and compare the performance of them to that of the latent information prior.
4.1. The Normal Prior
The normal prior, , is denoted by . From Lemma 1, we have:
Thus, the conditional mutual information is given by:
The conditional mutual information is evaluated by numerical integration. When and , the maximum values:
of Equation (24) are attained at and , respectively. The variation of the risk functions, and , shown in Figure 4 are much larger than those of the risk functions of the latent information priors shown in Figure 2. Thus, the performance of the Bayesian testing based on the normal prior is worse than that based on the latent information prior if we adopt the Kullback-Leibler loss.
Figure 4.
Risk functions of Bayesian testing based on normal priors for (a) and ; and for (b) and . The functions have symmetry about the origin.
Figure 4.
Risk functions of Bayesian testing based on normal priors for (a) and ; and for (b) and . The functions have symmetry about the origin.

4.2. The Cauchy Prior
The Cauchy prior, , is denoted by . Since the characteristic functions of and are and , respectively, the characteristic function of the marginal density:
with respect to the Cauchy prior, , is given by:
The expression:
where is the complementary error function defined by:
obtained by the inverse transform of Equation (27) is useful for numerical computation; see [19] (p. 183) and [20]. From Lemma 1, we have:
We numerically evaluate the conditional mutual information:
by the Monte-Carlo method. When and , the maximum values:
of Equation (31) are attained at and , respectively. The risk functions and are shown in Figure 5. The variation of the risk function is milder than that of the risk function based on the normal prior, and the inequality holds. Thus, the Cauchy prior is preferable to the normal prior from the viewpoint of the Kullback-Leibler loss. However, the variation of the risk function shown in Figure 2 based on the latent information prior is much smaller than that of . Similar relations also hold when .
Figure 5.
Risk functions of Bayesian testing based on Cauchy priors for (a) and ; and for (b) and . The functions have symmetry about the origin.
Figure 5.
Risk functions of Bayesian testing based on Cauchy priors for (a) and ; and for (b) and . The functions have symmetry about the origin.

5. Conclusions
We discussed the use of latent information priors for Bayesian testing of a point null hypothesis. The testing problem was formulated as a prediction problem, and latent information priors were numerically obtained. The variations of the risk functions of latent information priors are much smaller than those of normal and Cauchy priors. Although the testing problem treated in the present paper is simple, the results may indicate that latent information priors could be useful for various problems, since many statistical problems can be formulated from the viewpoint of prediction.
When the parameter space is multidimensional, it becomes difficult to numerically obtain latent information priors, and some approximations need to be used. One possible approach is to use asymptotic methods, and another possible approach is to choose an approximating prior from a tractable subset of the set of all probability measures on the parameter space. These approaches require further investigation.
Acknowledgments
This research was partially supported by a Grant-in-Aid for Scientific Research (23300104, 23650144) and by the Aihara Innovative Mathematical Modelling Project, the Japan Society for the Promotion of Science (JSPS) through the “Funding Program for World-Leading Innovative R&D on Science and Technology (FIRST Program),” initiated by the Council for Science and Technology Policy (CSTP).
Conflicts of Interest
The author declares no conflict of interest.
References
- Berger, J.O.; Sellke, T. Testing a point null hypothesis: The irreconcilability of p values and evidence. J. Am. Stat. Assoc. 1987, 82, 112–122. [Google Scholar] [CrossRef]
- Jeffreys, H. Theory of Probability, 3rd ed.; Oxford University Press: Oxford, UK, 1961. [Google Scholar]
- Lindley, D.V. A statistical paradox. Biometrika 1957, 44, 187–192. [Google Scholar] [CrossRef]
- Komaki, F. Bayesian predictive densities based on latent information priors. J. Stat. Plan. Inference 2011, 141, 3705–3715. [Google Scholar] [CrossRef]
- Aitchison, J. Goodness of prediction fit. Biometrika 1975, 62, 547–554. [Google Scholar] [CrossRef]
- Csiszár, I. I-divergence geometry of probability distributions and minimization problems. Ann. Probab. 1975, 3, 146–158. [Google Scholar] [CrossRef]
- Haussler, D. A general minimax result for relative entropy. IEEE Trans. Inf. Theory 1997, 43, 1276–1280. [Google Scholar] [CrossRef]
- Grünwald, P.D.; Dawid, A.P. Game theory, maximum entropy, minimum discrepancy and robust Bayesian decision theory. Ann. Stat. 2004, 32, 1367–1433. [Google Scholar]
- Arimoto, S. An algorithm for computing the capacity of arbitrary discrete memoryless channels. IEEE Trans. Inf. Theory 1972, 18, 14–20. [Google Scholar] [CrossRef]
- Blahut, R. Computation of channel capacity and rate-distortion functions. IEEE Trans. Inf. Theory 1972, 18, 460–473. [Google Scholar] [CrossRef]
- Hartigan, J.A. Bayes Theory; Springer: New York, NY, USA, 1983. [Google Scholar]
- Berger, J.; Bernardo, J.M.; Mendoza, M. On Priors that Maximize Expected Information. In Recent Developments in Statistics and Their Applications; Klein, J.P., Lee, J.C., Eds.; Freedom Press: Seoul, Korea, 1989; pp. 1–20. [Google Scholar]
- Zhang, Z. Discrete Noninformative Priors. Ph.D. Dissertation, Department of Statistics, Yale University, New Haven, CT, USA, 1994. [Google Scholar]
- Bernardo, J.M. Reference posterior distributions for Bayesian inference. J. R. Stat. Soc. B 1979, 41, 113–147. [Google Scholar]
- Clarke, B.; Yuan, A. Partial information reference priors: Derivation and interpretations. J. Stat. Plan. Inference 2004, 123, 313–345. [Google Scholar] [CrossRef]
- Ebrahimi, N.; Soofi, E.S.; Soyer, R. On the sample information about parameter and prediction. Stat. Sci. 2010, 25, 348–367. [Google Scholar] [CrossRef]
- Edwards, W.; Lindman, H.; Savage, L.J. Bayesian statistical inference for psychological research. Psychol. Rev. 1963, 70, 193–242. [Google Scholar] [CrossRef]
- Dickey, J.M. Is the tail area useful as an approximate Bayes factor? J. Am. Stat. Assoc. 1977, 72, 138–142. [Google Scholar] [CrossRef]
- Temme, N.M. Error Functions, Dawson’s and Fresnel Integrals. In NIST Handbook of Mathematical Functions; Olver, F.W.J., Lozier, D.W., Boisvert, R.F., Clark, C.W., Eds.; Cambridge University Press: Cambridge, UK, 2010; pp. 159–171. [Google Scholar]
- Poppe, G.P.M.; Wijers, C.M.J. Algorithm 680: Evaluation of the complex error function. ACM Trans. Math. Softw. (TOMS) 1990, 16. [Google Scholar] [CrossRef]
Appendix. Proofs of Lemmas
Proof of Lemma 1. From Equation (8), we have:
because m and μ are independent. Since:
and:
we have:
Proof of Lemma 2. Since:
we have:
From Lemma 1, we have:
The conditional mutual information is:
From Equations (38) and (39), we obtain the desired result. ☐
© 2013 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
MDPI and ACS Style
Komaki, F. Bayesian Testing of a Point Null Hypothesis Based on the Latent Information Prior. Entropy 2013, 15, 4416-4431. https://doi.org/10.3390/e15104416
AMA Style
Komaki F. Bayesian Testing of a Point Null Hypothesis Based on the Latent Information Prior. Entropy. 2013; 15(10):4416-4431. https://doi.org/10.3390/e15104416
Chicago/Turabian StyleKomaki, Fumiyasu. 2013. "Bayesian Testing of a Point Null Hypothesis Based on the Latent Information Prior" Entropy 15, no. 10: 4416-4431. https://doi.org/10.3390/e15104416