Capacity Region of a New Bus Communication Model

1
School of Information Science and Technology, Southwest JiaoTong University, Northbound Section Second Ring Road 111, Chengdu, 610031, China
2
Computer Science and Engineering Department, Shanghai Jiao Tong University, Dongchuan road 800, Shanghai, 200240, China
3
Institute for Experimental Mathematics, Duisburg-Essen University, Ellernstr.29, Essen, 45326, Germany
*
Author to whom correspondence should be addressed.
Entropy 2013, 15(2), 678-697; https://doi.org/10.3390/e15020678
Submission received: 11 November 2012
/
Revised: 17 November 2012
/
Accepted: 7 February 2013
/
Published: 18 February 2013
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:In this paper, we study a new bus communication model, where two transmitters wish to send their corresponding private messages and a common message to a destination, while they also wish to send the common message to another receiver connected to the same wire. From an information-theoretical point of view, we first study a general case of this new model (with discrete memoryless channels). The capacity region composed of all achievable triples is determined for this general model, where and are the transmission rates of the private messages and is the transmission rate of the common message. Then, the result is further explained via the Gaussian example. Finally, we give the capacity region for the new bus communication model with additive Gaussian noises and attenuation factors. This new bus communication model captures various communication scenarios, such as the bus systems in vehicles, and the bus type of communication channel in power line communication (PLC) networks.
1. Introduction
The bus communication model has been widely studied for many years. It captures various communication scenarios, such as the bus systems in vehicles, and the bus type of communication channel in power line communication (PLC) networks (see [1,2,3,4,5]).
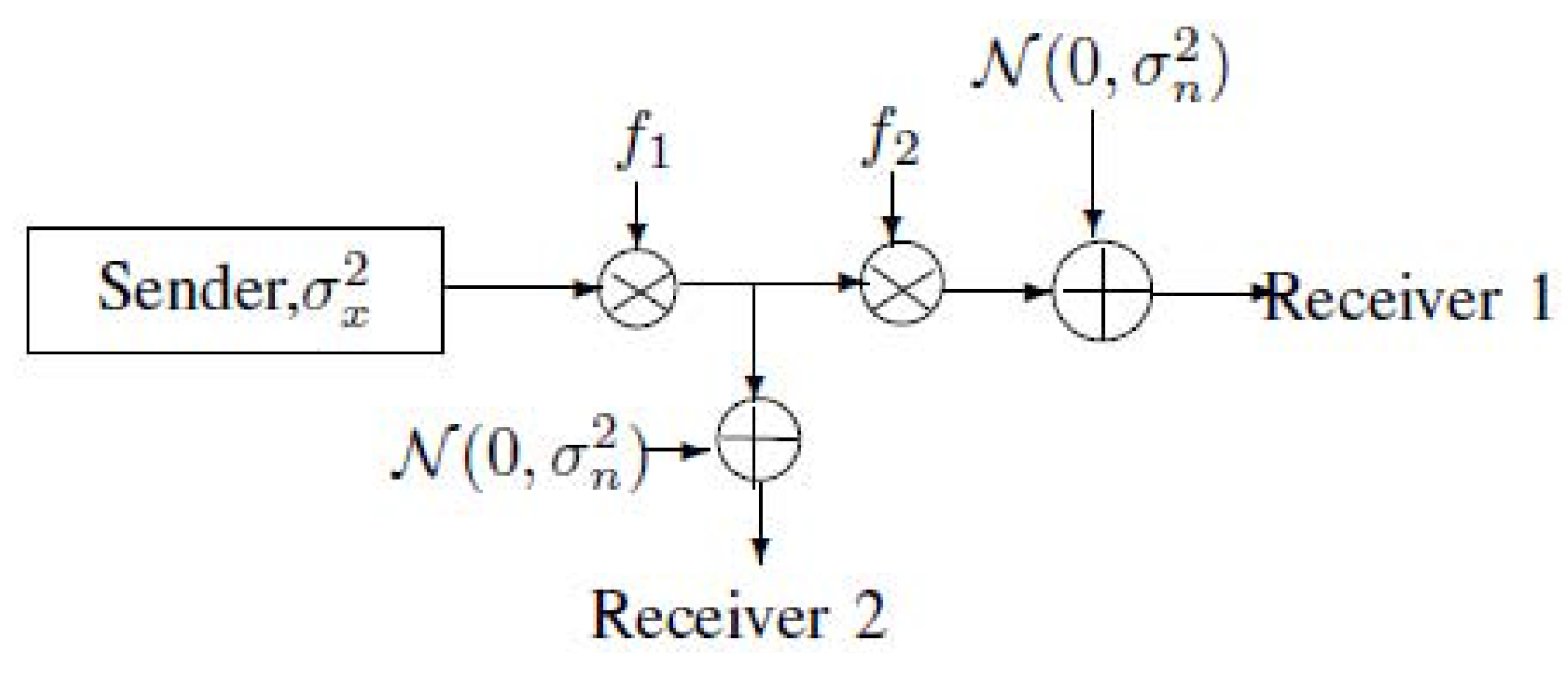
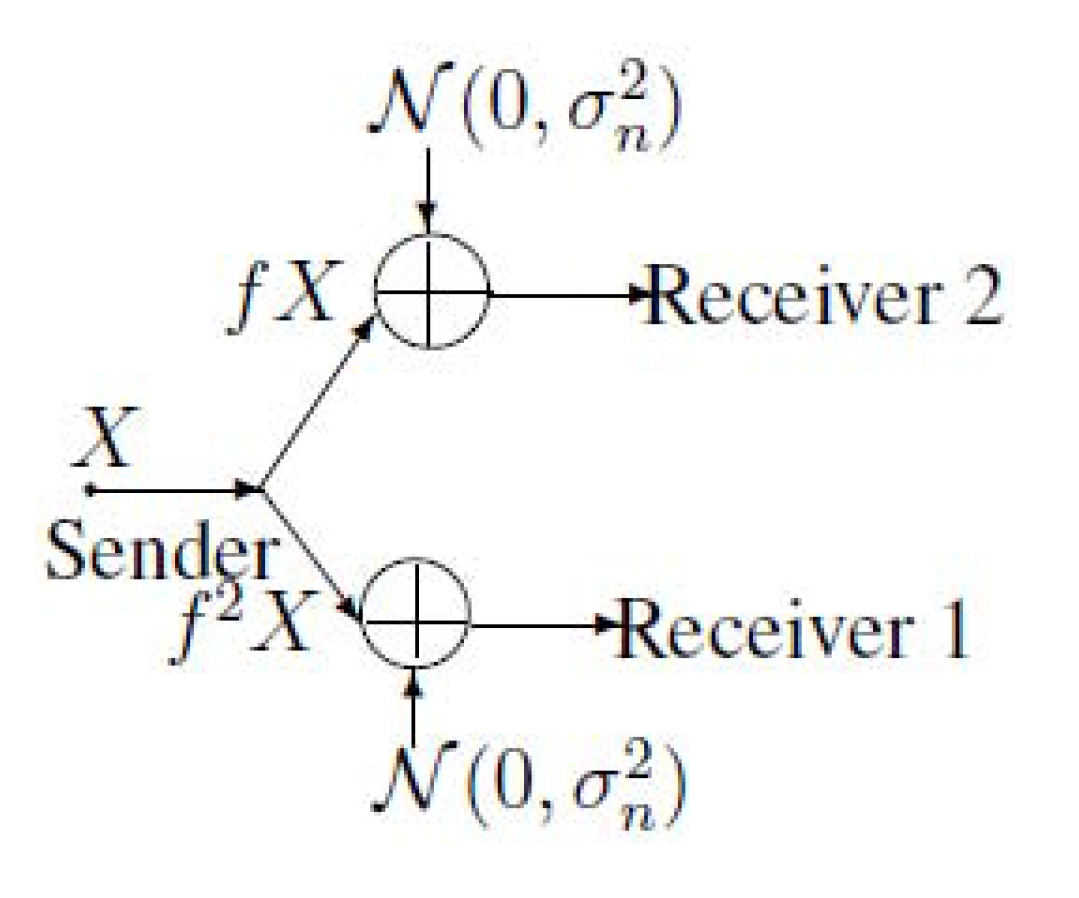
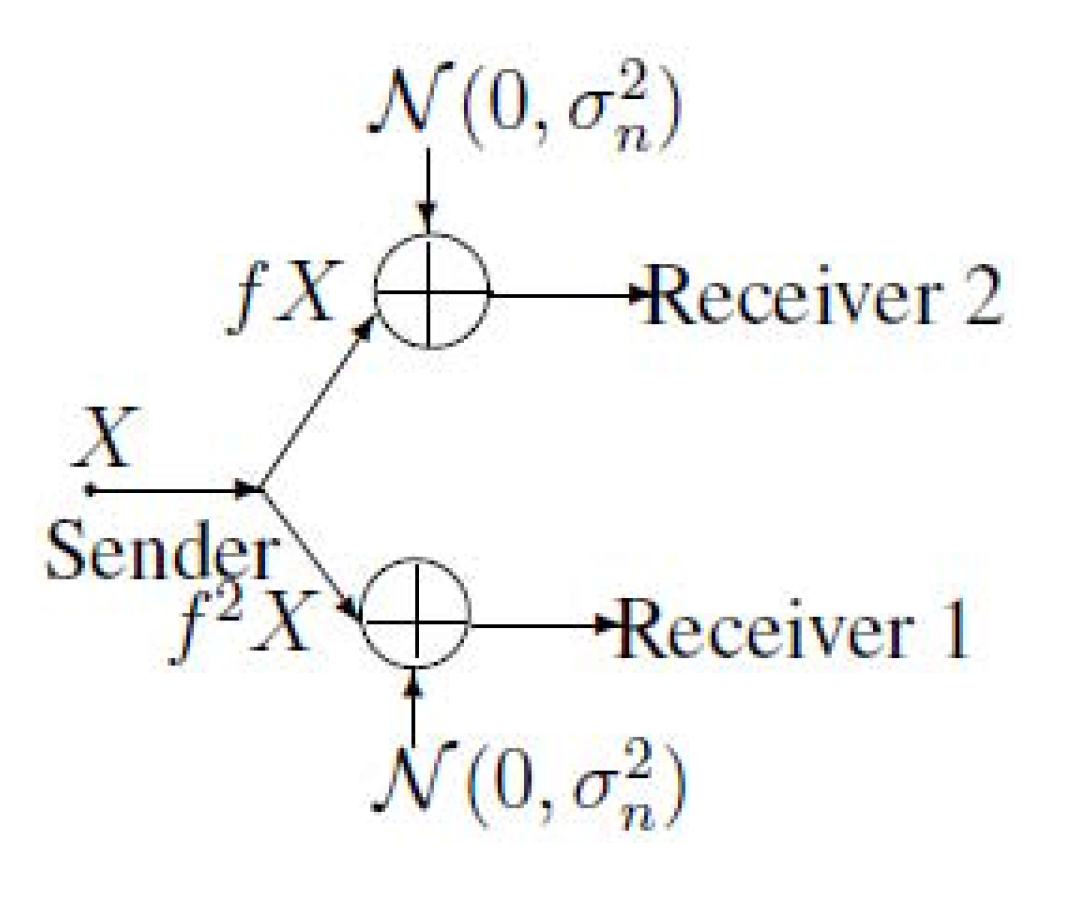
Let us consider the bus communication model of Figure 1 from an information-theoretical point of view. Figure 1 can be equivalent to the model of the broadcast channel (see Figure 2). Note that Figure 2 implies that .
Figure 1.
The bus communication model (Gains and , the power of the sender , and the power of the noise ).
Figure 1.
The bus communication model (Gains and , the power of the sender , and the power of the noise ).
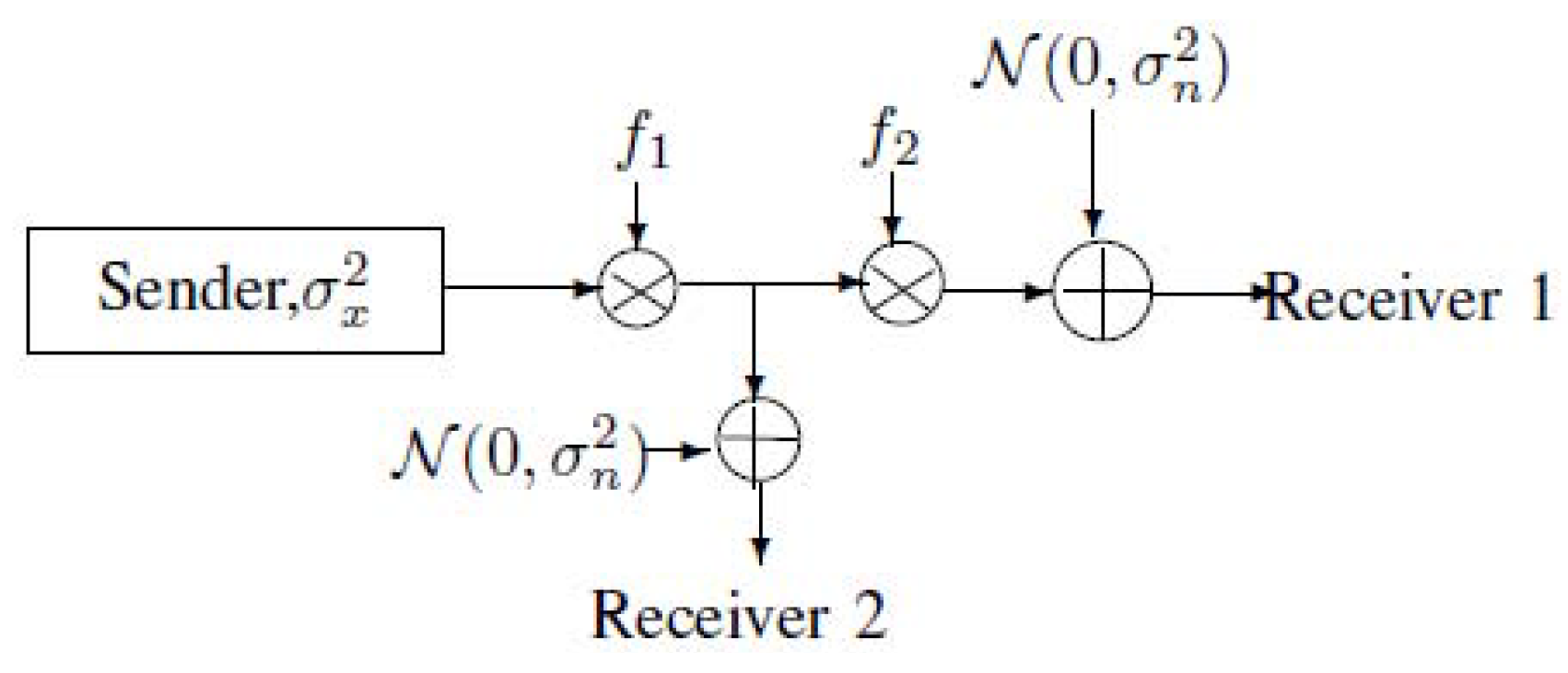
Figure 2.
The broadcast presentation of the bus communication model.
The model of the boradcast channel was first investigated by Cover [6], and the capacity region of the general case (two private messages and one common message) is still not known. After the publication of Cover’s work, Körner and Marton [7] studied the broadcast channel with degraded message set (one private and one common message), and found its capacity region. For the degraded broadcast channel, the capacity region is totally determined, (see [8,9,10]). In addition, Gamal and Cover [11] showed that the Gaussian broadcast channel is a kind of degraded broadcast channel, and therefore, the capacity region for the Gaussian case can be directly obtained from the result of the degraded broadcast channel.
The following Theorem 1 shows the capacity region of the model of Figure 2, which is a kind of Gaussian broadcast channel.
Theorem 1
The capacity region of the model of Figure 2 is the set of rate pairs , such that
for some . Note that is the power constraint of the channel input, X, f and are channel gains () and is the power of the noise.
Theorem 1 is directly obtained from the capacity region of the Gaussian broadcast channel [11], and therefore, the proof is omitted here.
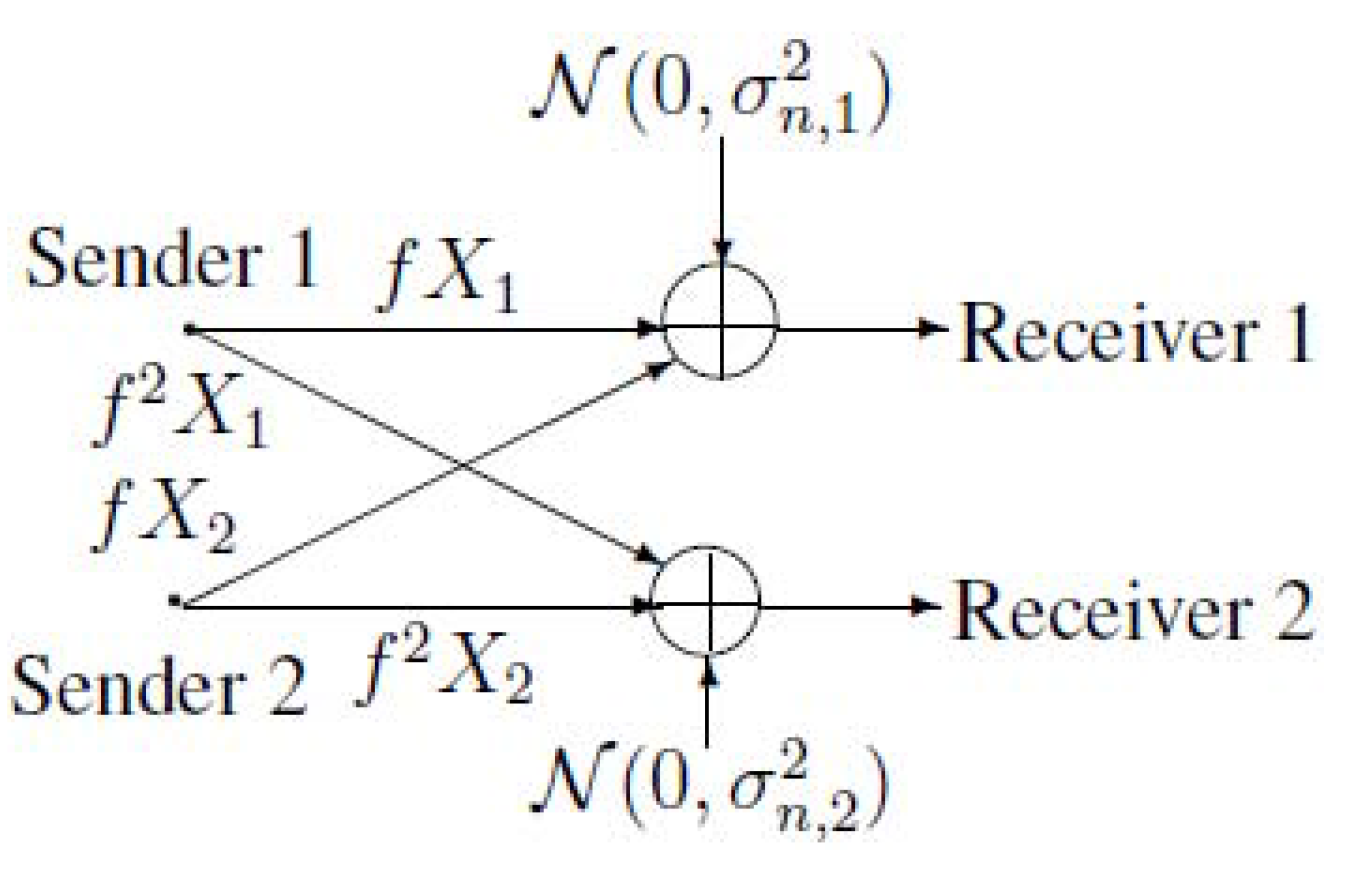
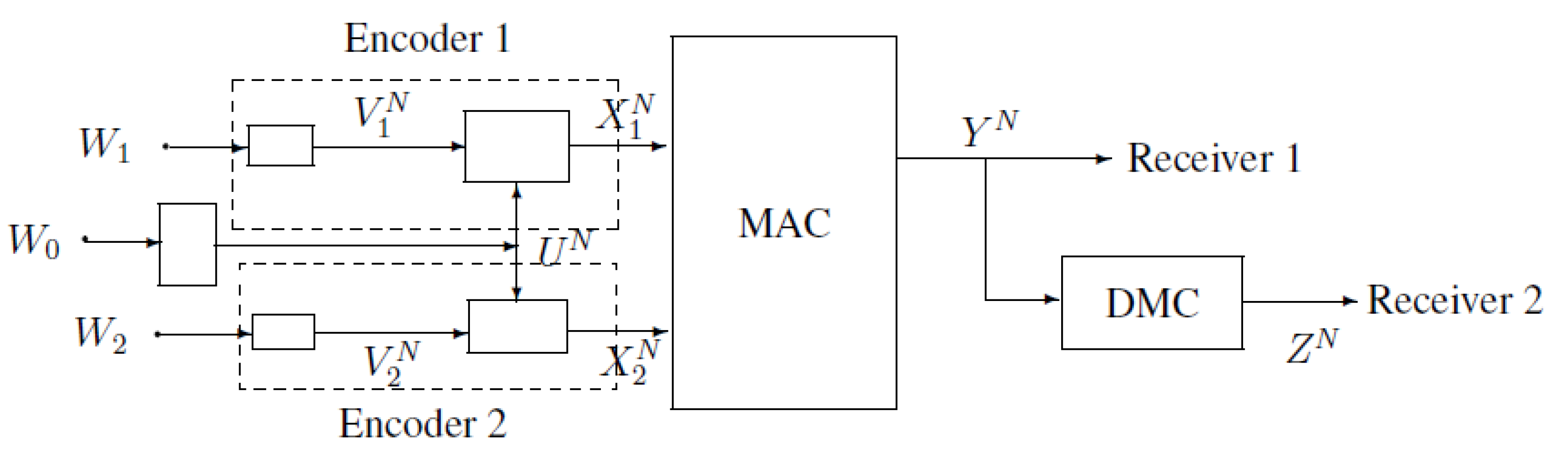
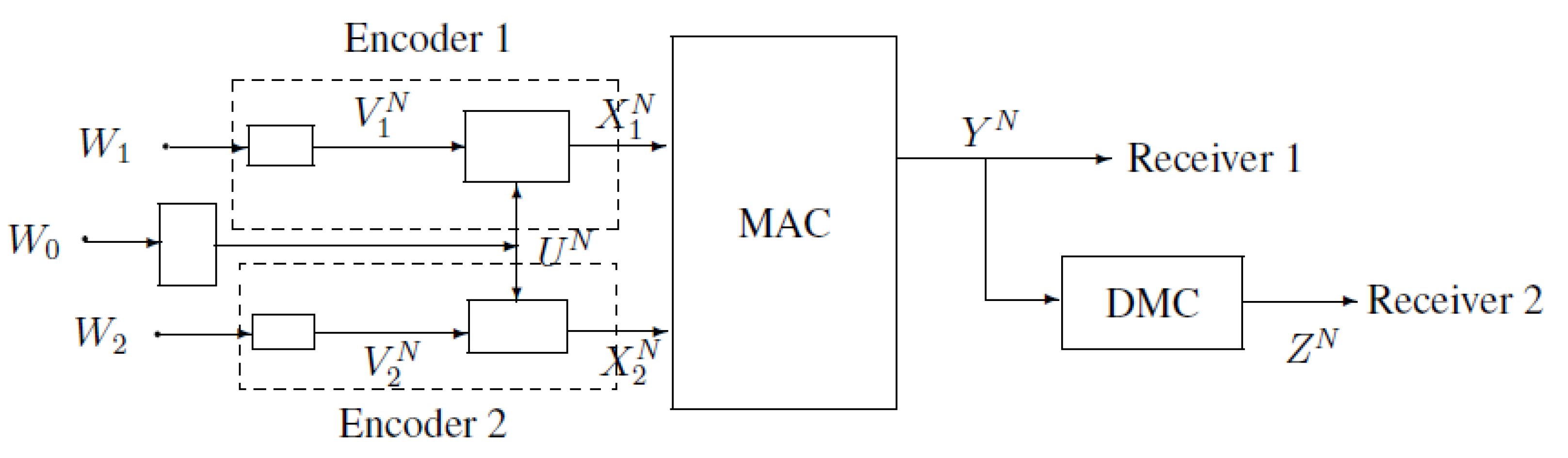
In this paper, we study a two-sender bus communication model (see Figure 3). Two transmitters wish to send their corresponding private messages and a common message to receiver 1, while they also wish to send the common message to receiver 2.
Figure 3.
A new bus communication model with two transmitters.
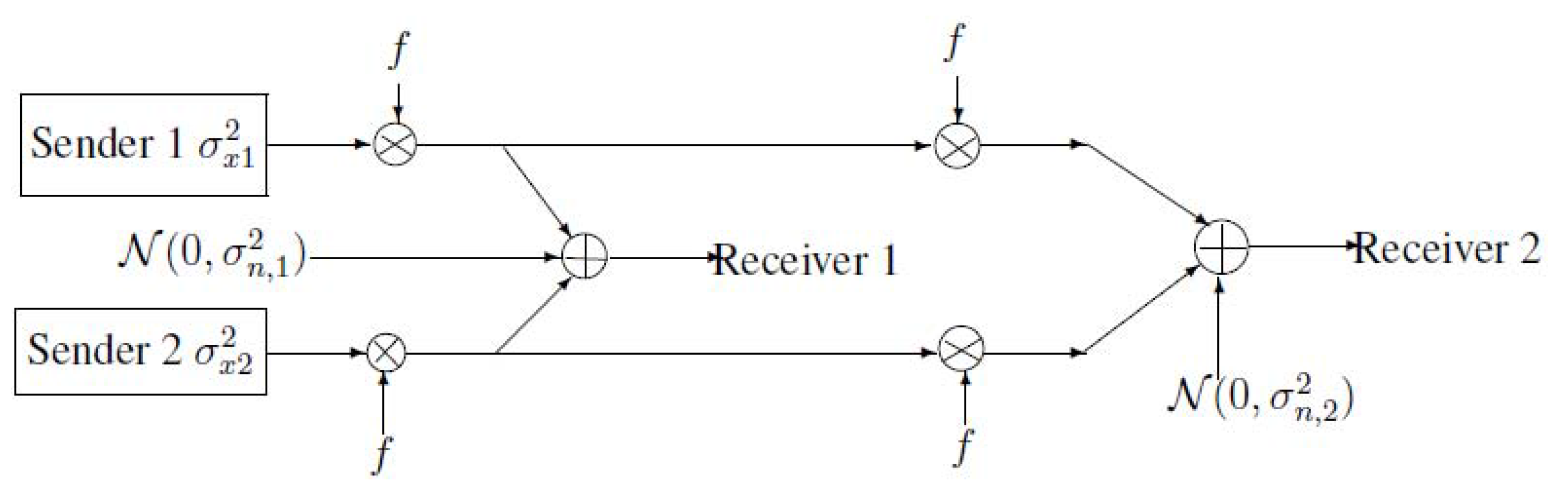
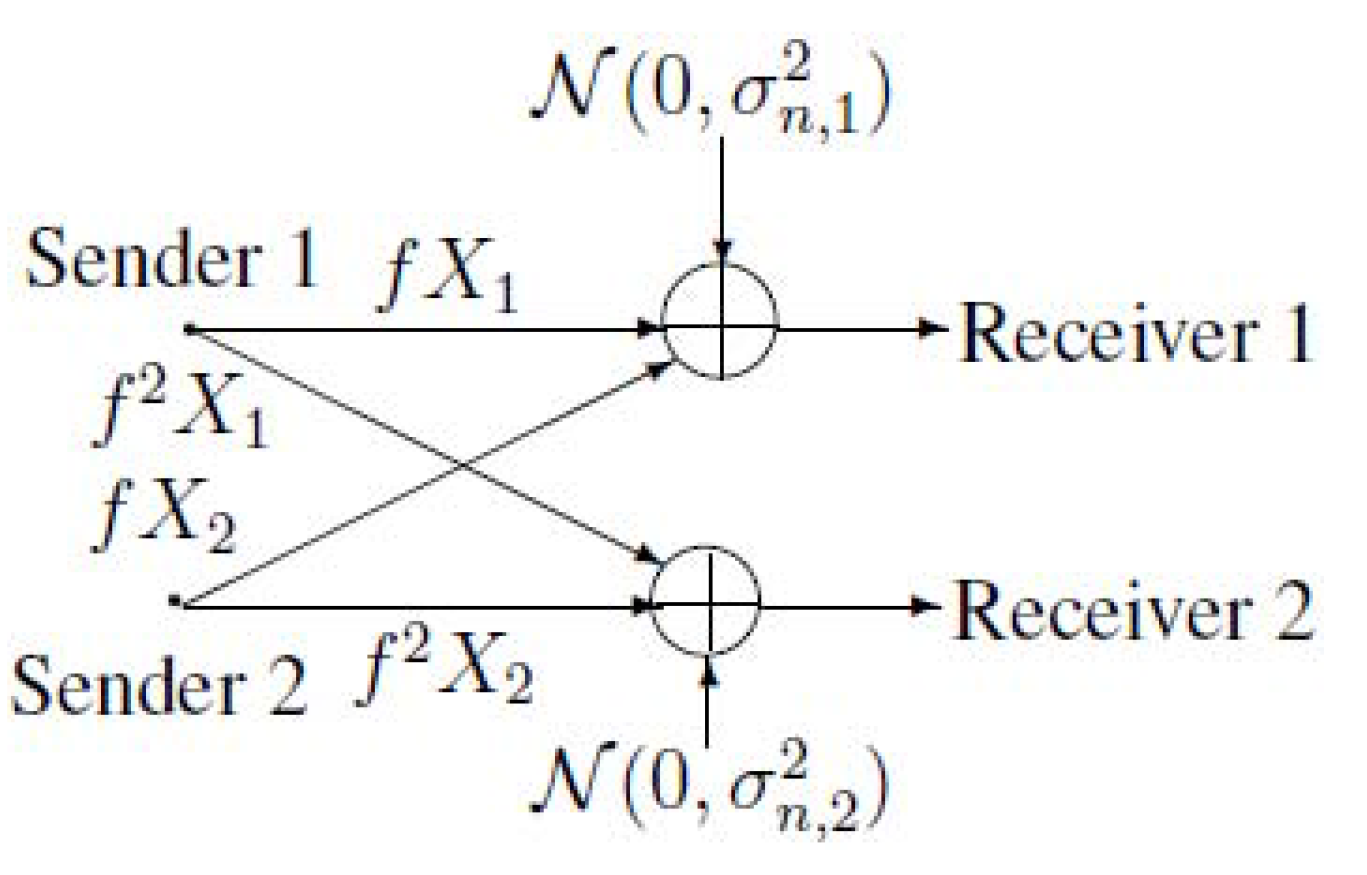
Figure 3 can be equivalent to the following Figure 4. Note that the capacity region of the Gaussian broadcast channel (BC) can be obtained from the capacity region of the discrete memoryless degraded broadcast channel. Therefore, first, we study the discrete memoryless case of the model of Figure 4, where two transmitters wish to send their private messages, and , and a common message, to receiver 1, and meanwhile, they also wish to send the common message, to receiver 2. Receiver 2 can receive a degraded version of the output of the multiple-access channel (MAC) via a discrete memoryless channel (DMC) (see Figure 5). This model can be viewed as a combination of multiple-access channel and degraded broadcast channel. For convenience, we call it MAC-DBC in this paper.
Figure 4.
An equivalent model for the model of Figure 3.
Figure 4.
An equivalent model for the model of Figure 3.
Then, we study the model of Figure 4, which is a Gaussian example of the MAC-DBC in Figure 5. The capacity regions of the MAC-DBC and the model of Figure 4 are totally determined.
The study of MAC-DBC from an information-theoretical point of view is due to the fact that the network information theory has recently become an active research area. Both MAC and BC play an important role in the network information theory, and they have been extensively studied separately. However, the cascade of MAC and BC (MAC-BC) has seldom drawn people’s attention. To investigate the capacity region and the capacity-achieving coding scheme for the MAC-BC is the motivation of this work.
Figure 5.
A combination of multiple-access channel and degraded broadcast channel (MAC-DBC).

In this paper, random variab1es, sample values and alphabets are denoted by capital letters, lower case letters and calligraphic letters, respectively. A similar convention is applied to the random vectors and their sample values. For example, denotes a random N-vector , and is a specific vector value in that is the Nth Cartesian power of . denotes a random -vector , and is a specific vector value in . Let denote the probability mass function . Throughout the paper, the logarithmic function is to the base 2.
The remainder of this paper is organized as follows. In Section 2, we present the basic definitions and the main result on the capacity region of MAC-DBC. In Section 3, we provide the capacity region of the model of Figure 4. Final conclusions are presented in Section 4. The proofs are provided from Section A to Section E.
2. Notations, Definitions and the Main Results of MAC-DBC
In this section, a description of the MAC-DBC is given by Definition 1 to Definition 3. The capacity region, , composed of all achievable triples is given in Theorem 2, where the achievable triple is defined in Definition 4.
Definition 1
(Encoders) The private messages, and , take values in and , respectively. The common message, , takes values in . , and are independent and uniformly distributed over their ranges. The channel encoders are two mappings:
where , , and .
where , , and . Note that and are independent, and is independent of .
The transmission rates of the private messages and the common message are , , and , respectively.
Definition 2
(Channels) The MAC is a DMC with finite input alphabet , finite output alphabet and transition probability , where . . The inputs of the MAC are and , while the output is .
Receiver 2 has access to the output of the MAC via a discrete memoryless channel (DMC). The input of this DMC is , and the output is . The transition probability satisfies that
where and .
Definition 3
(Decoders) The decoder for receiver 1 is a mapping, , with input and outputs , , . Let be the error probability of the receiver 1 , and it is defined as .
The decoder for receiver 2 is a mapping, , with input and output . Let be the error probability of the receiver 2 , and it is defined as .
Definition 4
(Achievable triple in the model of Figure 5) A triple (where ) is called achievable if, for any (where ϵ is an arbitrary small positive real number and ), there exists channel encoders-decoders , such that
Theorem 2 gives a single-letter characterization of the set , which is composed of all achievable triples in the model of Figure 5, and it is proved in Section A and Section B.
Theorem 2
A single-letter characterization of the region is as follows,
where
Remark 1
There are some notes on Theorem 2; see the following.
3. A Gaussian Example of MAC-DBC and the Capacity Region of the Model of Figure 4
In this section, we first study a Gaussian example of Figure 5, where the channel input-output relationships at each time instant i () are given by
and
where and . The random vectors, , and , are independent with i.i.d. components. The channel inputs, and , are subject to the average power constraints, and , respectively, i.e.,
Theorem 3
Then, we will show that the capacity region of the model of Figure 4 can be obtained from the above Theorem 3. The channel input-output relationships of Figure 4 at each time instant i () are given by
and
, where , and . The channel inputs and , are subject to the average power constraints and , respectively.
Note that the additive Gaussian noise, , can be viewed as a cascade of and , where . Moreover, Equations (11) and (12) are equivalent to Equations (13) and (14), respectively, where
and
Therefore, the model of Figure 4 is analogous to the above Gaussian example of MAC-DBC. The capacity region is as follows.
Theorem 4
The proof is directly obtained from Theorem 3, and it is omitted here.
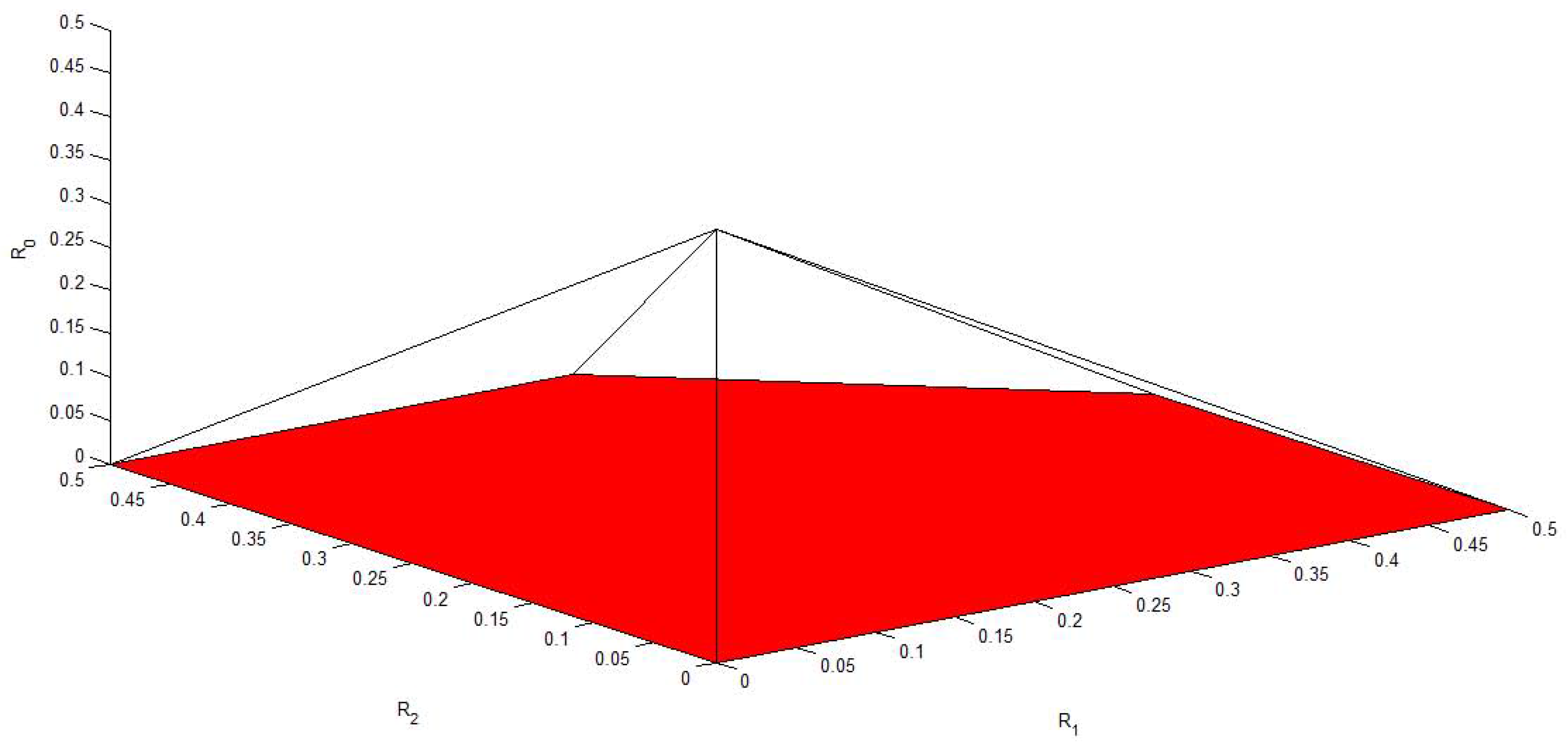
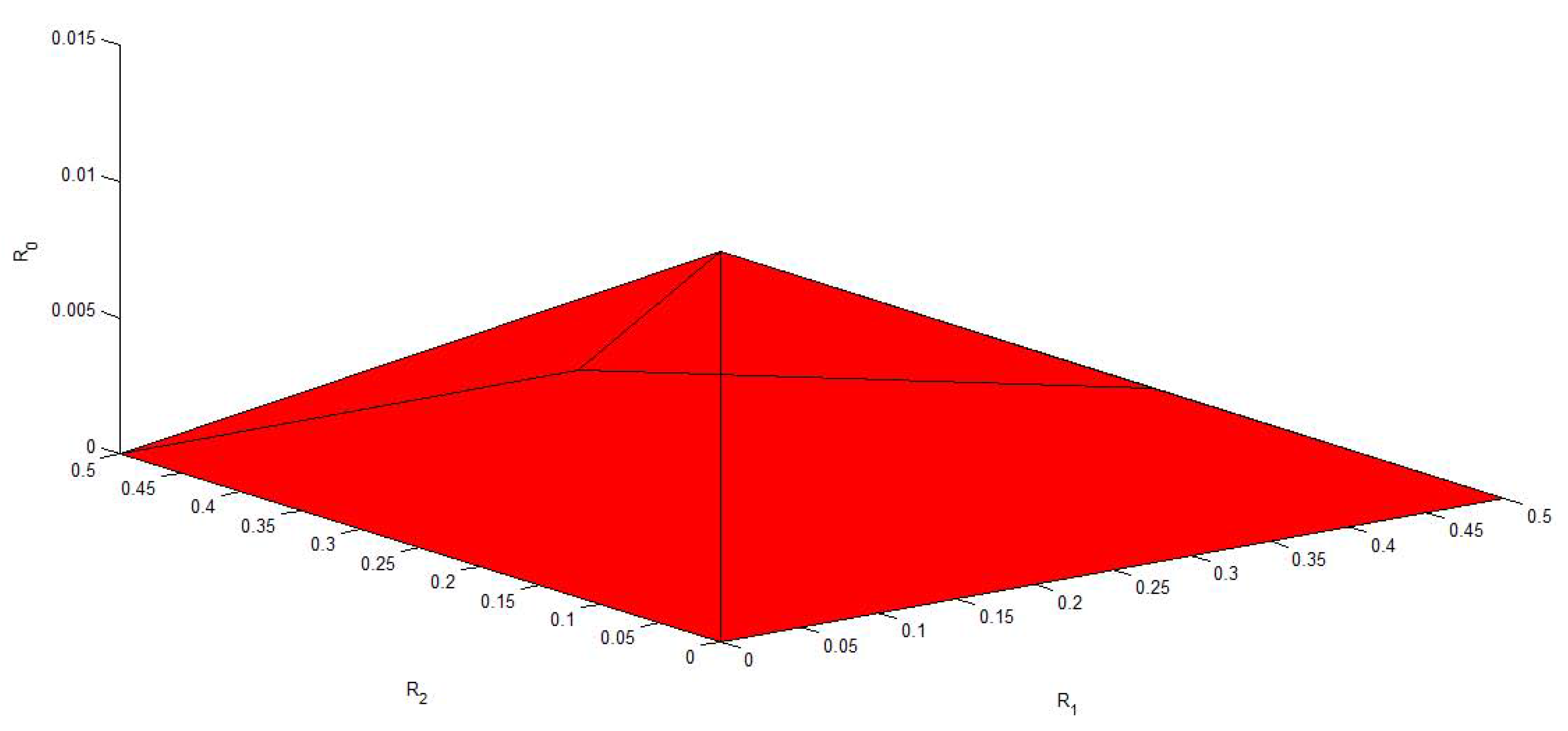
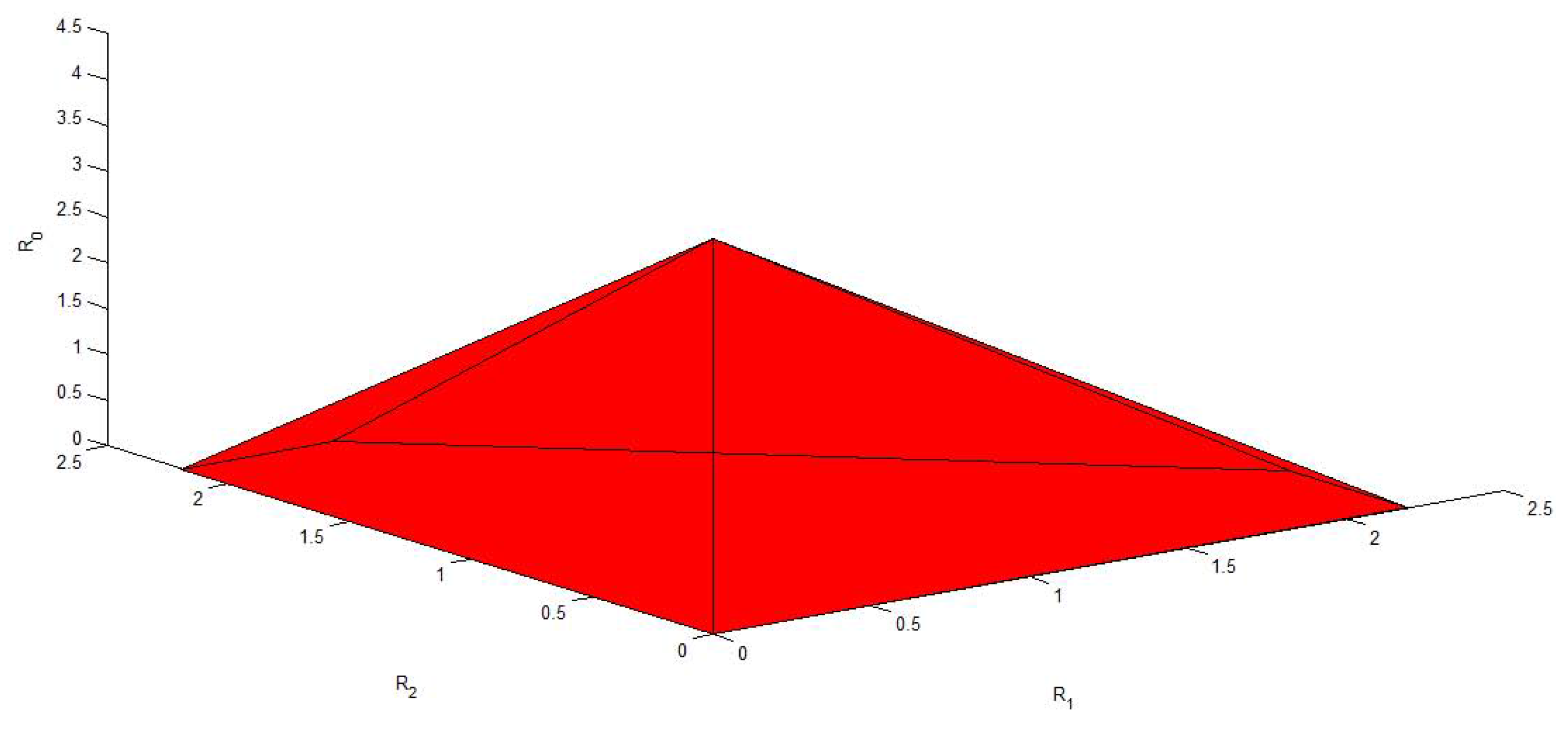
Figure 6, Figure 7, Figure 8, Figure 9 and Figure 10 plot the capacity region, , with different values of f, , , and . It is easy to see that reduces to the capacity region of the Gaussian MAC when . From these figures, we can see that enlarges as and decrease. Moreover, for fixed f, and , enlarges as and increase.
Figure 6.
The capacity region of Figure 4 with , , and .
Figure 6.
The capacity region of Figure 4 with , , and .
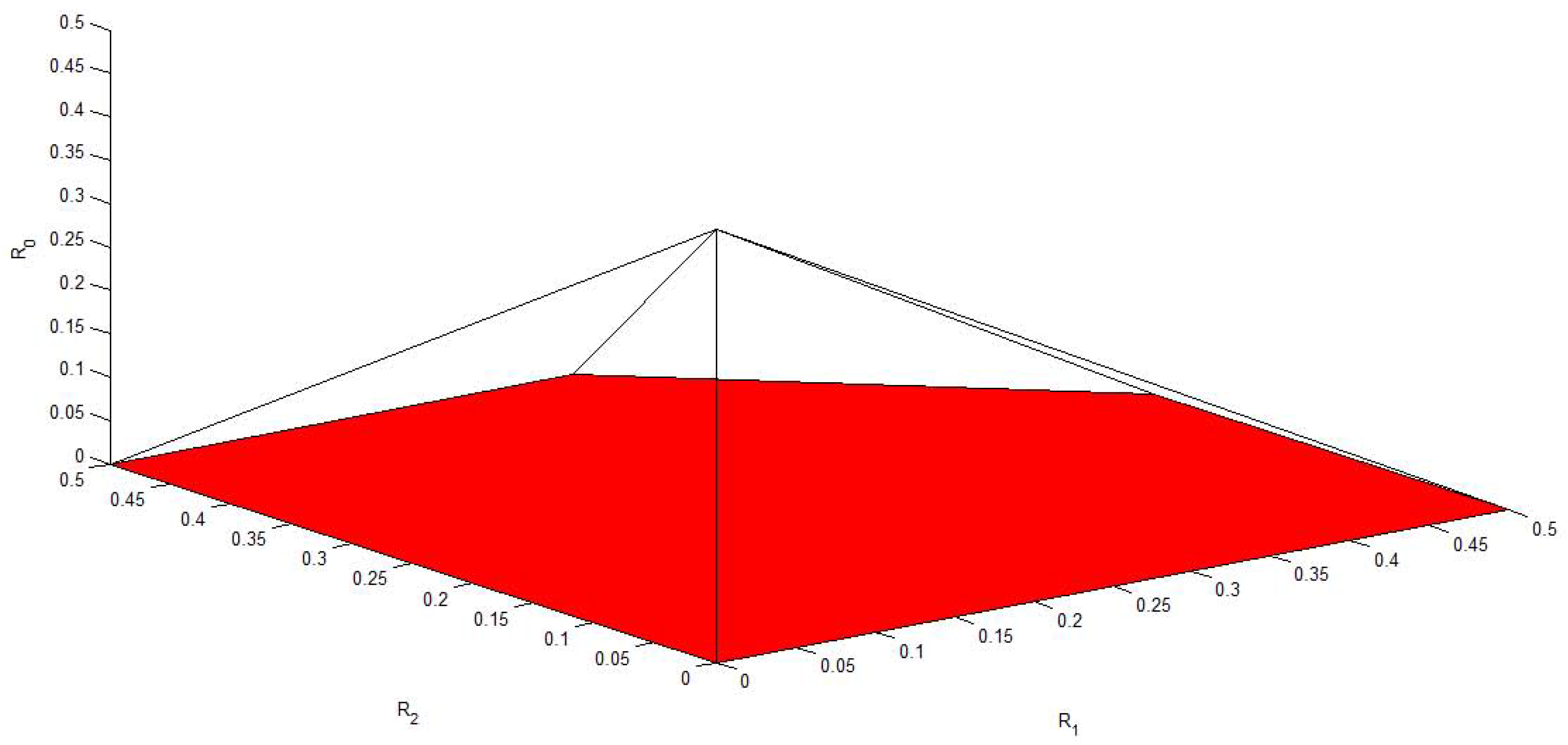
Figure 7.
The capacity region of Figure 4 with , , and .
Figure 7.
The capacity region of Figure 4 with , , and .
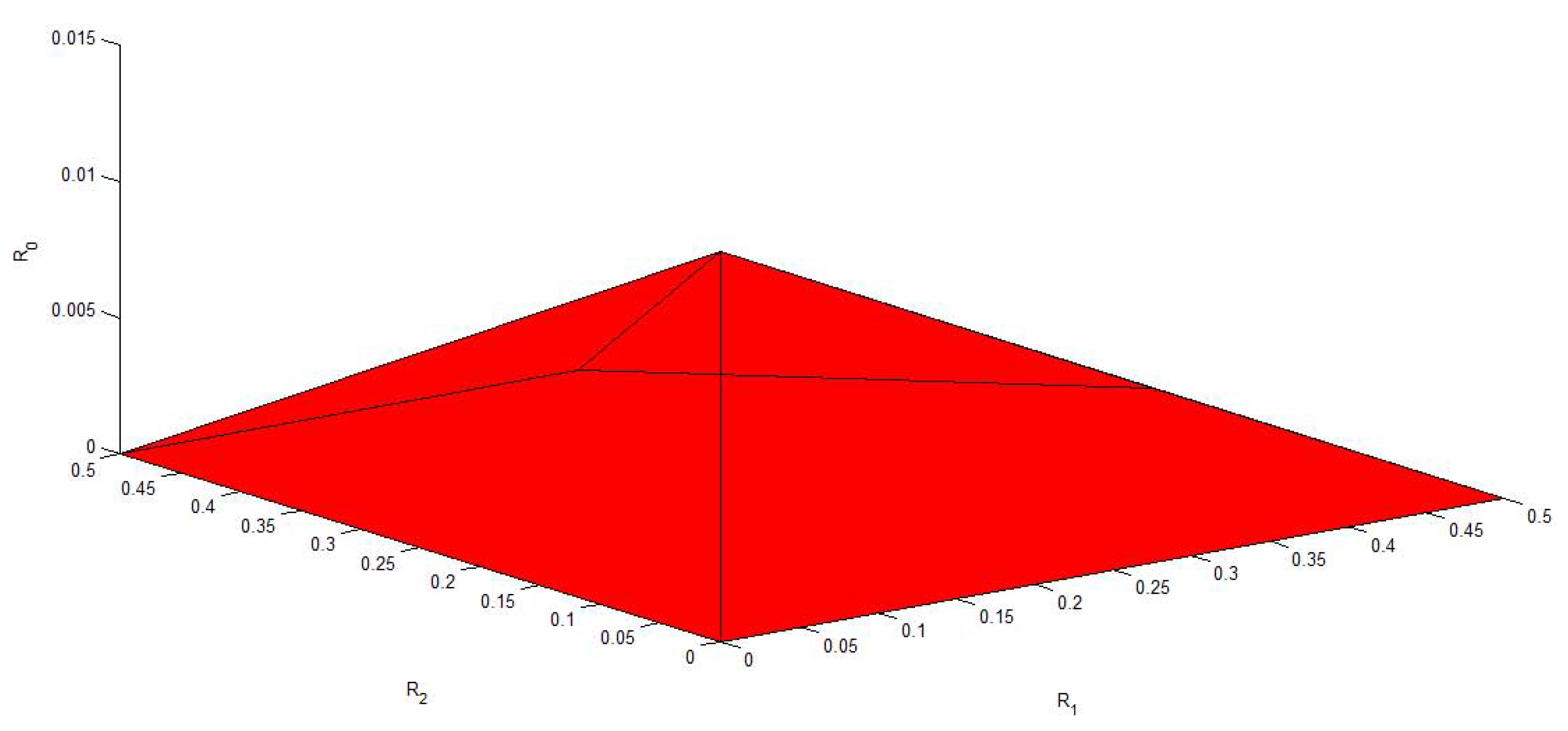
Figure 8.
The capacity region of Figure 4 with , , and .
Figure 8.
The capacity region of Figure 4 with , , and .
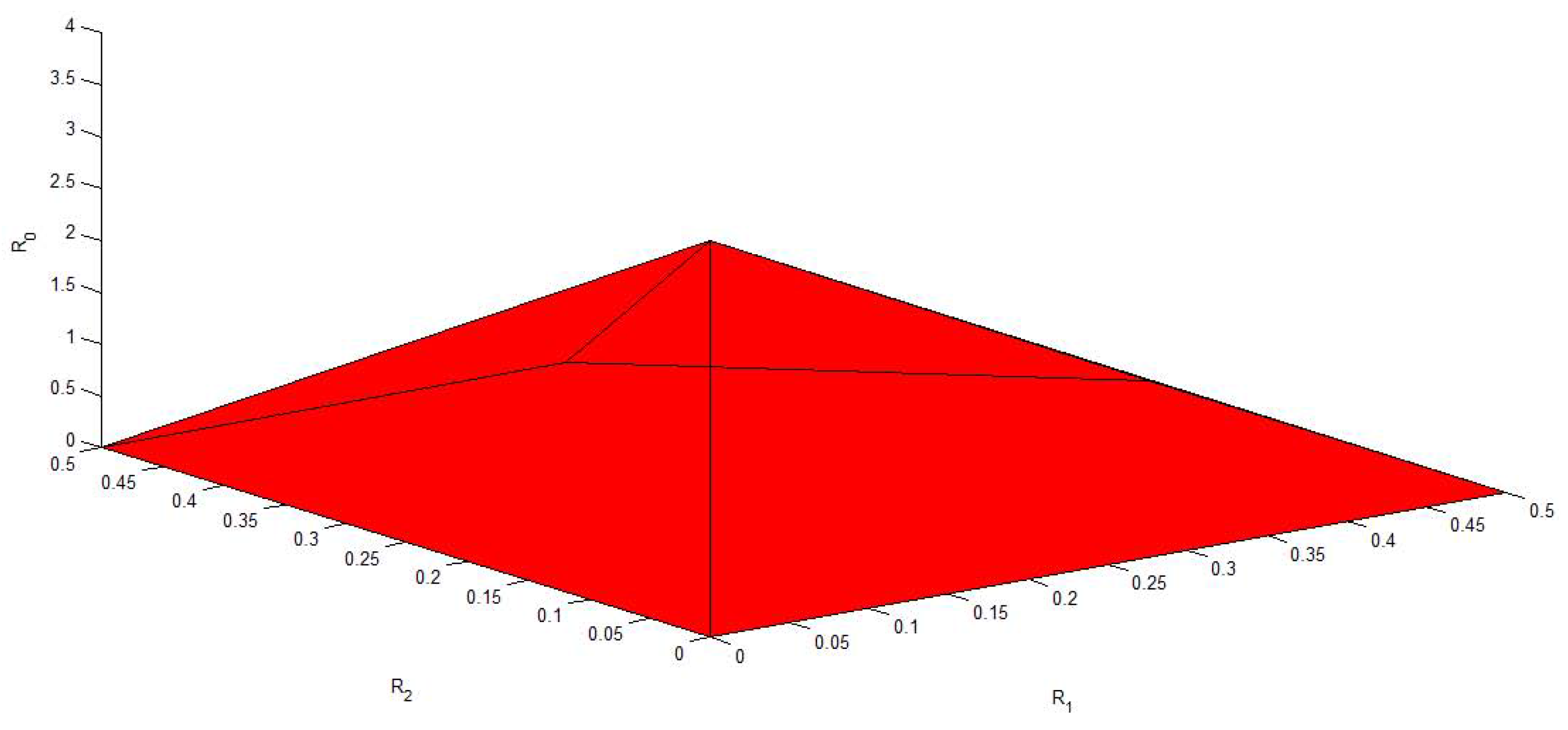
Figure 9.
The capacity region of Figure 4 with , , and .
Figure 9.
The capacity region of Figure 4 with , , and .
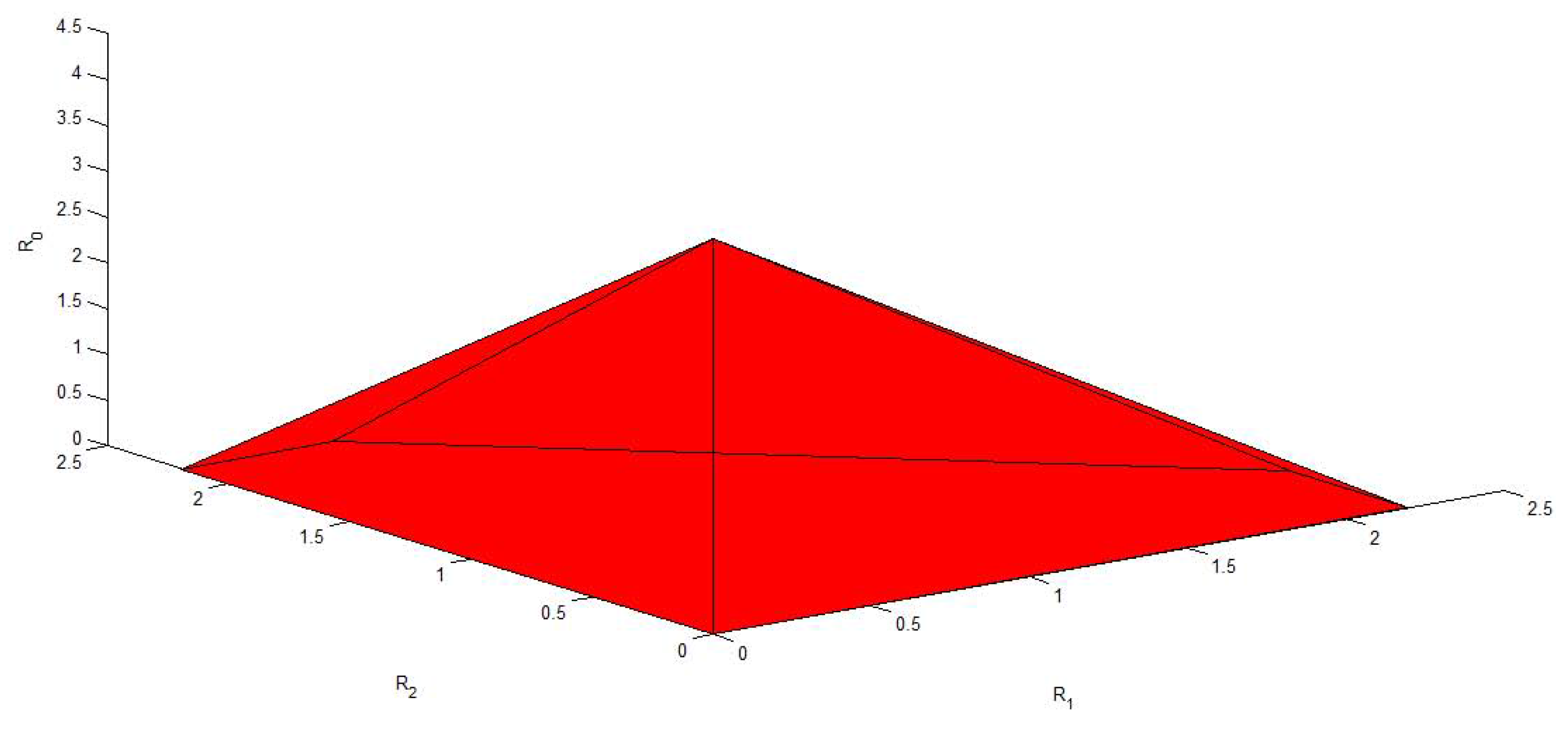
Figure 10.
The capacity region of Figure 4 with , , and .
Figure 10.
The capacity region of Figure 4 with , , and .
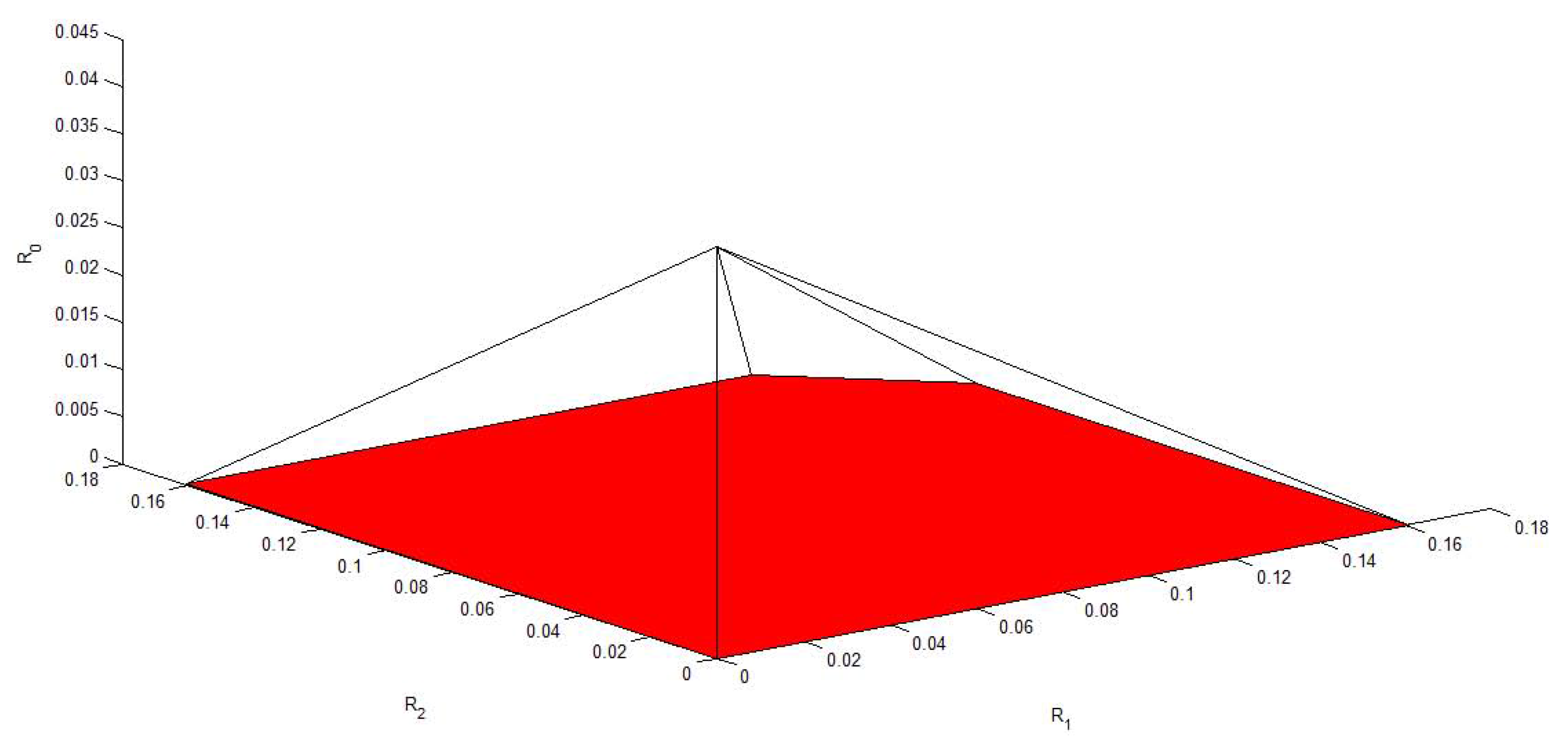
4. Conclusions
Acknowledgement
The authors would like to thank N. Cai for his help to improve this paper. This work was supported by a sub-project in National Basic Research Program of China under Grant 2012CB316100 on Broadband Mobile Communications at High Speeds, the National Natural Science Foundation of China under Grant 61271222, and the Research Fund for the Doctoral Program of Higher Education of China (No. 20100073110016).
References
- Lampe, L.; Schober, R.; Yiu, S. Distributed space-time block coding for multihop transmission in power line communication networks. IEEE J. Select. Areas Commun. 2006, 24, 1389–1400. [Google Scholar] [CrossRef]
- Bumiller, G.; Lampe, L.; Hrasnica, H. Power line communications for large-scale control and automation systems. IEEE Commun. Mag. 2010, 48, 106–113. [Google Scholar] [CrossRef]
- Lampe, L.; Han Vinck, A.J. On cooperative coding for narrow band PLC networks. Int. J. Electron. Commun. (AEÜ) 2011, 8, 681–687. [Google Scholar] [CrossRef]
- Balakirsky, V.; Vinck, A. Potential performance of PLC systems composed of several communication links. Intl. Symp. Power Line Commun. Appl. Vancouver 2005, 10, 12–16. [Google Scholar]
- Johansson, M.; Nielsen, L. Vehicle applications of controller area network. Tech. Rep. 2003, 7, 27–52. [Google Scholar]
- Cover, T.M. Broadcast channels. IEEE Trans. Inf. Theory 1972, 18, 2–14. [Google Scholar] [CrossRef]
- Körner, J.; Marton, K. General broadcast channels with degraded message sets. IEEE Trans. Inf. Theory 1977, 23, 60–64. [Google Scholar] [CrossRef]
- Gallager, R.G. Capacity and coding for degraded broadcast channels. Probl. Inf. Transm. 1974, 10, 3–14. [Google Scholar]
- Bergmans, P.P. A simple converse for broadcast channels with additive white Gaussian noise. IEEE Trans. Inf. Theory 1974, 20, 279–280. [Google Scholar] [CrossRef]
- Bergmans, P.P. Random coding theorem for broadcast channels with degraded components. IEEE Trans. Inf. Theory 1973, 19, 197–207. [Google Scholar] [CrossRef]
- El Gamal, A.; Cover, T.M. Multiple user information theory. Proc. IEEE 1980, 68, 1466–1483. [Google Scholar] [CrossRef]
- Ahlswede, R. Multiway Communication Channels. In Proceedings of the 2nd International Symposium Information Theory, Tsahkadsor, Armenia, /hlconference date, day and month 1971; pp. 23–52.
- Liao, H.H.J. Multiple access channels. Ph.D. Thesis, University of Hawaii, Honolulu, 1972. [Google Scholar]
- Csisza´r, I.; Körner, J. Information Theory. Coding Theorems for Discrete Memoryless Systems; Academic: London, UK, 1981. [Google Scholar]
- El Gamal, A.; Kim, Y. Lecture notes on network information theory. Available online: http://arxiv.org/abs/1001.3404 (accessed on 20 January 2010).
- Yeung, R.W. Information Theory and Network Coding; Springer: New York, NY, USA, 1981. [Google Scholar]
- Liang, Y.; Poor, H.V. Multiple-access channels with confidential messages. IEEE Trans. Inf. Theory 2008, 54, 976–1002. [Google Scholar] [CrossRef]
Appendix
A. Proof of the Converse Part of Theorem 2
In this section, we establish the converse part of Theorem 2: all the achievable triples are contained in the set , i.e., for any achievable triple, there exists random variables U, , , , , Y and Z such that the inequalities in Theorem 2 hold, and forms a Markov chain. We will prove the inequalities of Theorem 2 in the remainder of this section.
(Proof of ) The proof of this inequality is as follows:
where (a) is from the Fano’s inequality, (b) is from , (c) is from the definition that , (d) is from J as a random variable (uniformly distributed over ), and J is independent of and , (e) is from J as uniformly distributed over , and (f) is from the definitions that and .
Letting and note that , , it is easy to see that .
(Proof of ) The proof of this inequality is as follows:
where (1) is from the Fano’s inequality and the fact that is independent of and ; (2) is from ; (3) is from the discrete memoryless property of the channel; (4) is from ; and (5) is from the definitions that , , , , where J is a random variable (uniformly distributed over ), and is independent of , , , and .
Letting and note that , , it is easy to see that .
(Proof of ) The proof is similar to the proof of , and it is omitted here.
(Proof of )
where (a) is from the Fano’s inequality and the fact that is independent of and ; (b) is from ; (c) is from the discrete memoryless property of the channel; (d) is from ; and (e) is from the definitions that , , and .
Letting and note that , , and is independent of , it is easy to see that .
(Proof of ) The proof is obtained by the following Equation (A4).
where (a) is from the Fano’s inequality and the fact that is independent of and ; (b) is from ; (c) is from the discrete memoryless property of the channel; (d) is from ; and (e) is from the definitions that , , and .
Letting and note that , , and is independent of , it is easy to see that .
(Proof of ) The proof is analogous to the proof of , and it is omitted here.
(Proof of )
where (a) is from the Fano’s inequality; (b) is from ; (c) is from the discrete memoryless property of the channel; and (d) is from the definitions that , , .
Letting and note that , , , , it is easy to see that .
The Markov chain, , is directly obtained from the definitions , , , , and .
The proof of the converse part of Theorem 2 is completed.
B. Proof of the Direct Part of Theorem 2
In this section, we establish the direct part of Theorem 2 (about existence). Suppose , we will show that is achievable.
The coding scheme for Theorem 2 is in the following Figure A1. Now, the remainder of this section is organized as follows. Some preliminaries about typical sequences are introduced in Subsection B.1. The construction of the code is introduced in Subsection B.2. For any given , the proofs of , , , and are given in Subsection B.3.
Figure A1.
Coding scheme for MAC-DBC.
B.1. Preliminaries
- Given a probability mass function, , for any , let be the strong typical set of all , such that for all , where is the number of occurences of the letter v in the . We say that the sequences, , are V-typical.
- Analogously, given a joint probability mass function, , for any , let be the joint strong typical set of all pairs , such that for all and , where is the number of occurences of in the pair of sequences . We say that the pairs of sequences, are -typical.
- Moreover, is called -generated by iff is V- typical and . For any given , define .
- Lemma 1 For any ,where as .
B.2. Coding Construction
Given a triple , choose a joint probability mass function, , such that
The message sets, , and , satisfy the following conditions:
Code-book generation:
- For a given , generate a corresponding i.i.d., according to the probability mass function .
- For a given , generate a corresponding i.i.d., according to the probability mass function .
- For a given , generate a corresponding i.i.d., according to the probability mass function .
- is generated according to a new discrete memoryless channel (DMC), with inputs and , and output . The transition probability of this new DMC is .Similarly, is generated according to a new discrete memoryless channel (DMC), with inputs and , and output . The transition probability of this new DMC is .
Decoding scheme:
- (Receiver 1) Receiver 1 declares that messages, , and , are sent if they are the unique messages, such that , otherwise, it declares an error.
- (Receiver 2) Receiver 2 declares that a message is sent if it is the unique message, such that ; otherwise it declares an error.
B.3. Achievability Proof
By using the above Equation (A6), it is easy to verify that , and . It remains to show that and ; see the following.
Without loss of generality, assume that , and are sent.
2.3.1.
For receiver 2, define the events:
The probability of error for receiver 2 is then upper bounded by
By using LLN, the first term as . On the other hand, by using the packing lemma [15, p. 53-54], as if .
Therefore, by choosing sufficiently large N, we have .
2.3.2.
The proof of is as follows.
Define the sets
The probability of error for receiver 1 is then upper bounded by:
By using LLN, the first term, as .
For the second term, by using the packing lemma ([15][p. 53–54]), as if
where (1) is from and .
Analogously, for the third term, by using the packing lemma, as if .
For the fourth term, by using the packing lemma, as if .
where (2) is from .
For the fifth term, as if .
For the sixth term, by using the packing lemma, as if
where (3) is from .
Analogously, the seventh term, as if .
For the eighth term, by using the packing lemma, as if .
Therefore, by choosing sufficiently large N, we have .
The proof of the direct part of Theorem 2 is completed.
C. Proof of the Convexity of
Let , i.e., , satisfy the following conditions:
Let , i.e., , satisfy the following conditions:
Let Q be a switch function, such that and , where . Q is independent of all the random variables.
Define , , , , , , . Then we have
D. Size Constraints of the Auxiliary Random Variables in Theorem 2
By using the support lemma (see [14], p.310), it suffices to show that the random variables U, A and K can be replaced by new ones, preserving the Markovity and the characters , , , , , , and furthermore, the range of the new U, A and K satisfies:
The proof of which is in the reminder of this section.
Let
Define the following continuous scalar functions of :
Since there are functions of , the total number of the continuous scalar functions of is +2.
Let . With these distributions , we have
According to the support lemma ([14], p.310), the random variable, U, can be replaced by new ones, such that the new U takes at most different values and the expressions (A20)–(A23) are preserved.
Similarly, we can prove that and . The proof is omitted here.
E. Proof of Theorem 3
E.1. Proof of the Achievability
The achievability proof follows by computing the mutual information terms in Theorem 2 with the following joint distributions:
U is independent of and .
E.2. Proof of the Converse
The proof of and are from the proof of the Gaussian broadcast channel [15], and it is omitted here.
The proof of , and are from the proof of the Gaussian multiple-access channel [16], and it is omitted here.
Then, it remains to show that and . The proof of these two inequalities are analogous to ([17] [p. 1000–1001]), and therefore, we omit the proof here.
The proof of Theorem 3 is completed.
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
MDPI and ACS Style
Dai, B.; Vinck, A.J.H.; Luo, Y.; Zhuang, Z. Capacity Region of a New Bus Communication Model. Entropy 2013, 15, 678-697. https://doi.org/10.3390/e15020678
AMA Style
Dai B, Vinck AJH, Luo Y, Zhuang Z. Capacity Region of a New Bus Communication Model. Entropy. 2013; 15(2):678-697. https://doi.org/10.3390/e15020678
Chicago/Turabian StyleDai, Bin, A. J. Han Vinck, Yuan Luo, and Zhuojun Zhuang. 2013. "Capacity Region of a New Bus Communication Model" Entropy 15, no. 2: 678-697. https://doi.org/10.3390/e15020678