1. Introduction
Maritime transportation represents approximately 90% of global trade by volume, placing safety and security challenges as a high priority for nations across the globe. Maritime surveillance data are collected at different scales and are increasingly used to achieve higher levels of situational awareness.
Automatic Identification System (AIS) technology provides a vast amount of near-real time information, calling for an ever increasing degree of automation in transforming data into meaningful information to support operational decision makers. As an example, the Centre for Maritime Research and Experimentation (CMRE) is currently receiving an average rate of 600 Million AIS messages per month from multiple sources, and the rate is increasing [
1]. AIS is a self-reporting messaging system originally conceived for collision avoidance (AIS is mandatory for ships of 300 gross tonnage and upwards in international voyages, 500 and upwards for cargoes not in international waters and passenger vessels [
2]. In addition, fishing vessels greater than 15 m sailing in water under the jurisdiction of the European Union Member States shall also be required to be fitted with AIS [
3].) to broadcast information on their location (positional, identification and other information) at a variable refresh rate, which depends on their motion (vessels at anchor transmit their position every two minutes and increase the broadcast rate up to two seconds when maneuvering or sailing at high speed; every five minutes, vessels transmit other data (static and voyage related information) containing identifiers, such as International Maritime Organization (IMO) number, call sign, ship name and Maritime Mobile Service Identity (MMSI), used as a primary key to link the message to position information. Static information also includes size, type of vessel and cargo, whereas voyage related data, such as Estimated Time of Arrival (ETA) and destination, are manually set and not fully reliable [
4].) Over the last several years, the AIS data received by ships and coastal stations have been transmitted to regional or national data centers. When multiple receivers are connected into networks, certain challenges arise with data intermittency, resolving data redundancy received by multiple receivers, correcting errors in timestamps assigned by varying receivers and identifying tracks of vessels that erroneously share the message identifier. This level of pre-processing is necessary to extract maritime motion patterns, especially at a global scale.
Receiving AIS messages from space [
5] is becoming increasingly commonplace. As opposed to terrestrial networks of AIS receivers, whose performance is characterized by high persistence, but limited coverage, satellite-based systems can pick up messages in the open sea, far away from the coastline. Space-based receivers tend to be mounted on Low Earth Orbit (LEO) satellites, so the AIS coverage is global at the expense of persistence, due to the orbiting platform revisit time. It is clear that when integrating such systems with data received by terrestrial receivers, there are additional issues to resolve with variable frequency update, coverage and persistence.
In this work, a methodology is presented that aims to convert the large amount of AIS data into decision support elements, independently of the number of receivers, their performance, the platform of origin and the scale of the area of interest. The knowledge is extracted via an incremental learning approach, in order to dynamically adapt to evolving situations (e.g., maritime seasonal patterns, operational conditions or changing routing schemes). This allows maritime traffic to be characterized following a fully unsupervised learning strategy with no a priori information needed (i.e., using only raw AIS data).
The proposed
traffic route extraction methodology can be used to provide up-to-date high level contextual information (e.g., Level 2 processing in the Joint Directors of Laboratories (JDL) model [
6]). Knowledge of traffic routes is a useful input to situational awareness and helps in understanding seasonal variations in traffic patterns. Besides traffic densities, the extracted routes provide useful information on daily patterns and transit duration differentiated by vessel types. Further, extracted routes enable realistic simulations of traffic, which are useful to test and evaluate target tracking performance, the effectiveness of surveillance technologies and other decision support frameworks.
Generated contextual maritime knowledge can also be used to perform rule-based and low-likelihood
anomaly detection. Rule-based anomaly detection approaches refer to the generation of alerts based on a set of rules [
7], such as maximum speed allowed in a port, presence in areas restricted to navigation or inconsistencies between ship claimed and actual activity. Conversely, low-likelihood anomaly detection aims at detecting deviations from “normality” of vessel traffic patterns derived in the learning phase (see, e.g., [
8] and references therein) and is illustrated via an example provided in the present work. Behaviors that differ from “normality” do not necessarily mean they are “anomalies” in an operational context, but they are highlighted as
unusual for further analysis.
The vessel traffic and motion information, once extracted, can be alternatively exploited to perform ship route prediction at a given time. This is the process of predicting ship movements well beyond any available positioning data, based on behaviors of past vessels on the same route. This is useful, for example, in counter piracy applications to identify risk areas associated with the joint predicted presence of white shipping density (e.g., commercial merchant traffic) and Pirates Action Groups (PAG) [
9]. Backward and forward tracking of vessels can also be significantly improved using the learned maritime traffic patterns, which are particularly useful when attempting to fuse AIS and space-based optical or Synthetic Aperture Radar (SAR) information (e.g., [
10]).
The distribution and characterization of traffic can also be used for augmenting remote sensing tracking and classification performance, enabling knowledge-based tracking and classification (e.g., [
11]). Specifically, the knowledge of vessel patterns can be used for (i) connecting tracks originated by the same target and broken by gaps in coverage or reduced observability and/or (ii) providing
a priori knowledge about the vessel type for classification purposes.
In
Section 2, we give a brief review of related work on traffic characterization and route knowledge extraction. We discuss the traffic knowledge discovery methodology in
Section 3. This is followed by some examples of route knowledge exploitation in
Section 4: the route classification is given in
Section 4.1. Two specific applications (
i.e., route prediction and anomaly detection) are provided in
Section 4.2 and
Section 4.3, respectively, to illustrate the potential of the derived knowledge. Finally, concluding remarks are given in
Section 5.
2. Related Work
The application of statistical methodologies to derive motion patterns from a collection of trajectories in an unsupervised way is a challenging task. Several methods have been proposed as applied in video surveillance and image processing (e.g., [
12,
13,
14,
15,
16]). In [
17], a probabilistic model to track human behavior over time is presented. The papers [
18,
19,
20,
21] specifically deal with maritime applications, although using image processing techniques. Reference [
12] presented an extensive model to statistically learn motion patterns without any prior knowledge in traffic scenes where the traffic flows are constrained to stay in specific areas. The application of such techniques in maritime situational awareness has gained an increasing acceptance during recent years. One possible approach is to subdivide the area of interest into a spatial grid whose cells are characterized by the motion properties of the crossing vessels (e.g., [
10,
22,
23]). Although effective for small area surveillance, the main limitations of the “grid”-based approach resides in the required computational burden when increasing the scale, as well as the need for
a priori selection of the optimal cell size. In areas characterized by complex traffic, like intersecting sea lanes, the resulting multi-modal behavioral description would lead to complex algorithms to perform anomaly detection. A new trend in the field of maritime anomaly detection is to adopt a “vectorial” representation of traffic, where trajectories are thought of as a set of straight paths connecting waypoints; this allows a compact representation of vessel motions that can be implemented at a global scale. In the works reported in [
24,
25], the waypoints are nodes in the proximity of land masses, and Great Circle routes are formed to represent ocean journeys. In areas characterized by complex routing systems, it is necessary to further introduce intermediate nodes (
i.e., turning points) to more accurately describe routes. For [
26,
27], turning points are detected in areas where changes in the Course Over Ground (COG) of vessels are consistently observed. One of the limitations of “vectorial” approaches is the detection of turning points in unregulated areas, where the behavior of vessels is much more complex and, therefore, difficult to categorize. The present paper addresses this practical issue: the representation of maritime traffic is still “vectorial”, but in contrast to previous research, the route objects are directly formed by the flow vectors of the vessels whose paths connect the derived waypoints (
i.e., stationary areas, as well as entry and exit points). Specifically, the approach introduced here is based on a preliminary clustering of waypoints. Trajectories are, then, identified between such waypoints. Differently from other “vectorial” representations, the route objects include directional changes without explicitly deriving turning points. As will be seen, it is still possible to consistently capture maritime patterns in a compact and accurate way. It is also feasible to extract temporal information, like route travel time distributions and daily patterns, as well as to associate historical route patterns to vessels. These features enable the discovery of maritime traffic knowledge that can be used to implement higher level anomaly detection tools. Additionally, the distance-based approach, adopted in [
26,
27], was not always effective in distinguishing waypoints close to each other. In order to overcome this difficulty, a density-based algorithm (
i.e., DBSCAN—Density-Based Spatial Clustering of Applications with Noise) was selected and adapted to the specific maritime application.
Dealing with potential applications of the derived framework, anomaly detection in trajectory data is one of the most interesting. Within this field, a great number of papers recently appeared. Some of them classify a trajectory as anomalous based on the distance to the closest set of trajectories, grouped using similarity metrics. When the distance between trajectories is expressed in terms of a likelihood, we speak of probabilistic anomaly detection [
28]. In [
17,
29,
30,
31], some probabilistic methods for anomaly detection are presented. Many methods tend to first pre-process the trajectories, since commonly used similarity measures, such as the Euclidean distance, require equally spaced and properly aligned trajectories. To overcome these difficulties, some alternative metrics have been proposed, such as the Dynamic Time Warping (DTW) (see, e.g., [
14]) which finds the minimum Euclidean distance when the data points of the two trajectories are shifted arbitrarily in time). However, most of the available approaches are thought to work with complete trajectories,
i.e., they need the points of the whole trajectory before classifying the trajectory as anomalous. That is a problem in areas where positional data are received only intermittently and complete trajectories are not observed. Moreover, when applied for surveillance purposes, the detection of anomalies needs to be performed on-line. In this context, it is crucial to reduce delays between the start of the anomalous behavior and the alarm raised by the monitoring system. Sequential process control techniques aim at shortening the average time required to signal a change in the normal process. In this paper, we apply point-based incremental algorithms both in maritime knowledge discovery and exploitation. The provided example of anomaly detection is performed by using a sliding time window, similarly to video surveillance techniques (see, e.g., [
15]). A similar approach is proposed in [
32], where sequential motion anomaly detection is performed, assuming that AIS training data are already extracted to form clusters of common paths. In the present paper, the pre-processing, transformation and validation of AIS data is integrated into the functional architecture, which generates the traffic pattern framework.
3. Traffic Model and Knowledge Discovery
The proposed methodology, called Traffic Route Extraction and Anomaly Detection (TREAD), automatically learns a statistical model for maritime traffic from AIS data in an unsupervised way,
i.e., without assuming any prior knowledge on the monitored scene. Building on the work in [
26,
27,
33], the traffic knowledge used here is shaped by vessel objects, created and updated from the sequence of input AIS messages. A bounding box is selected and corresponds to the specific area under surveillance. The series of vessel state vectors can originate as discontinuous events, such as a break in observation updates. The clustering of such events, initiated by different vessels objects,
, enables us to form waypoint objects,
, which identify either stationary points,
, entry points,
, and exit points,
, within the selected bounding box. The linking of such waypoints ultimately leads to the detection and statistical characterization of route objects,
. Anomalies can then be detected on the basis of the discovered knowledge and its interaction with real-time vessel traffic. The general assumption of the statistical model is that the feature values of the data points come from a stable (
i.e., stationary) distribution of normal traffic, estimated using training data. The feature data points are considered as single trajectory points. In the literature, such an approach is referred to as a point-based approach (see, e.g., [
8]), in contrast to trajectory-based approaches, where the traffic representation is based on complete trajectories (see, e.g., [
14]).
The approach presented here is a practical compromise to get a reliable traffic representation without increasing the model complexity: (i) it uses a point-based traffic representation and (ii) it integrates time information into the knowledge exploitation to include the relationship between successive data points. A practical advantage is that the TREAD methodology can easily handle trajectories of unequal length or with gaps. As a matter of fact, incomplete and segmented trajectories are frequent in maritime traffic, due to the refresh rate of AIS messages being highly variable for a number of legitimate reasons (since it was conceived for collision avoidance, AIS Class A units change the messages transmission rate depending on the need to refresh information, ranging from three minutes (ship at anchor) up to two seconds (fast and/or maneuvering vessel). Similarly, Class B devices for non-SOLAS (Safety of Life at Sea) vessels report at variable intervals, although transmitting at lower rates than Class A equipment [
34].). This occurs when AIS tracks are “lost”, because of (i) terrestrial coverage gaps in the network of receivers, (ii) intermittent AIS [
35] or (iii) long time intervals between subsequent overpasses or low probability of detection of satellite-based receivers [
36]. A vessel transponder could also be switched off intentionally, but that is a separate issue.
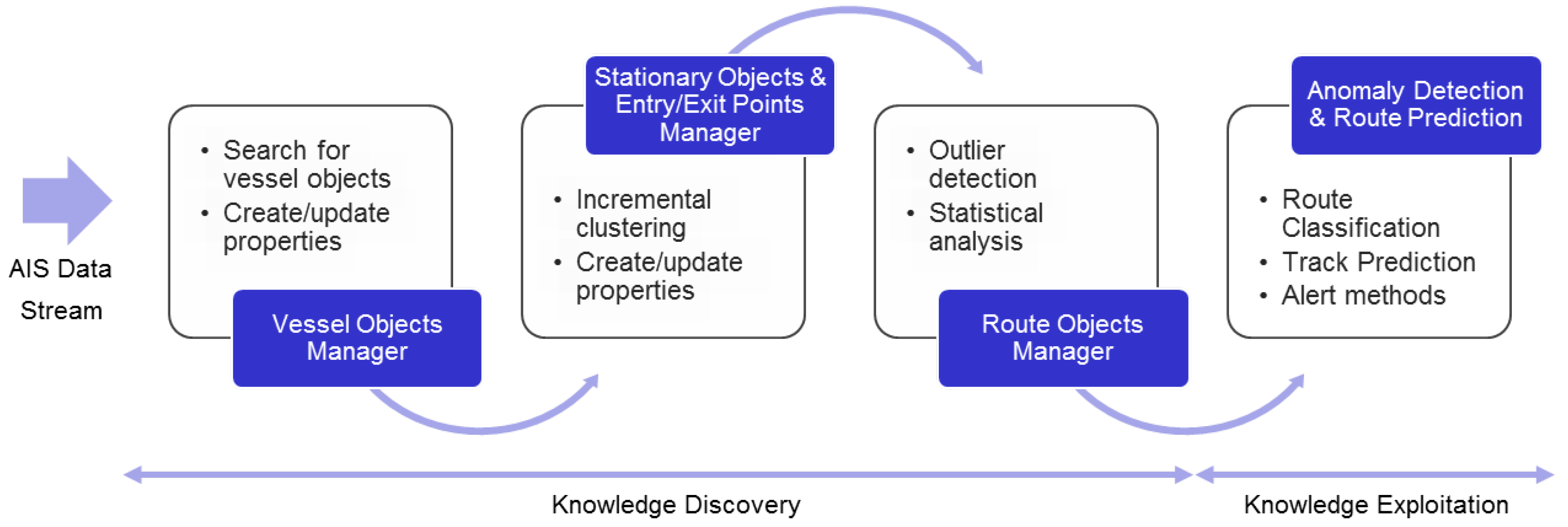
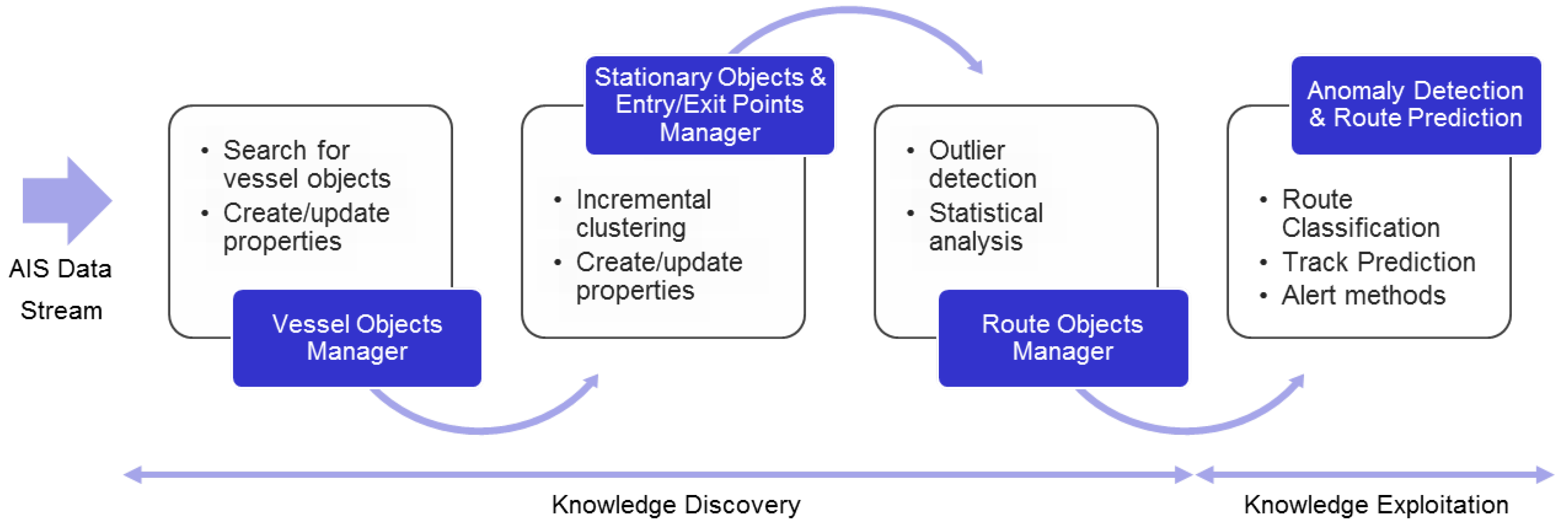
TREAD Functional Architecture Manager: the discovery and exploitation of maritime traffic knowledge-based on AIS information follows the functional architecture shown in
Figure 1; the stream of AIS messages is processed to incrementally learn maritime motion patterns through the “Vessel Objects Manager” activated by relevant events based on the temporal and spatial characterization of vessel behavior. The clustering of such events leads to the discovery of waypoints (stationary objects and entry/exit points). The knowledge discovery process is followed by potential exploitation, such as in route classification, prediction and anomaly detection.
Figure 1.
Knowledge discovery functional architecture: historical database or real-time data stream of Automatic Identification System (AIS) messages is sequentially processed to incrementally learn maritime motion patterns through processes (“managers”) activated by relevant events. The knowledge discovery process is followed by on-line exploitation, such as route classification, prediction and anomaly detection.
Figure 1.
Knowledge discovery functional architecture: historical database or real-time data stream of Automatic Identification System (AIS) messages is sequentially processed to incrementally learn maritime motion patterns through processes (“managers”) activated by relevant events. The knowledge discovery process is followed by on-line exploitation, such as route classification, prediction and anomaly detection.
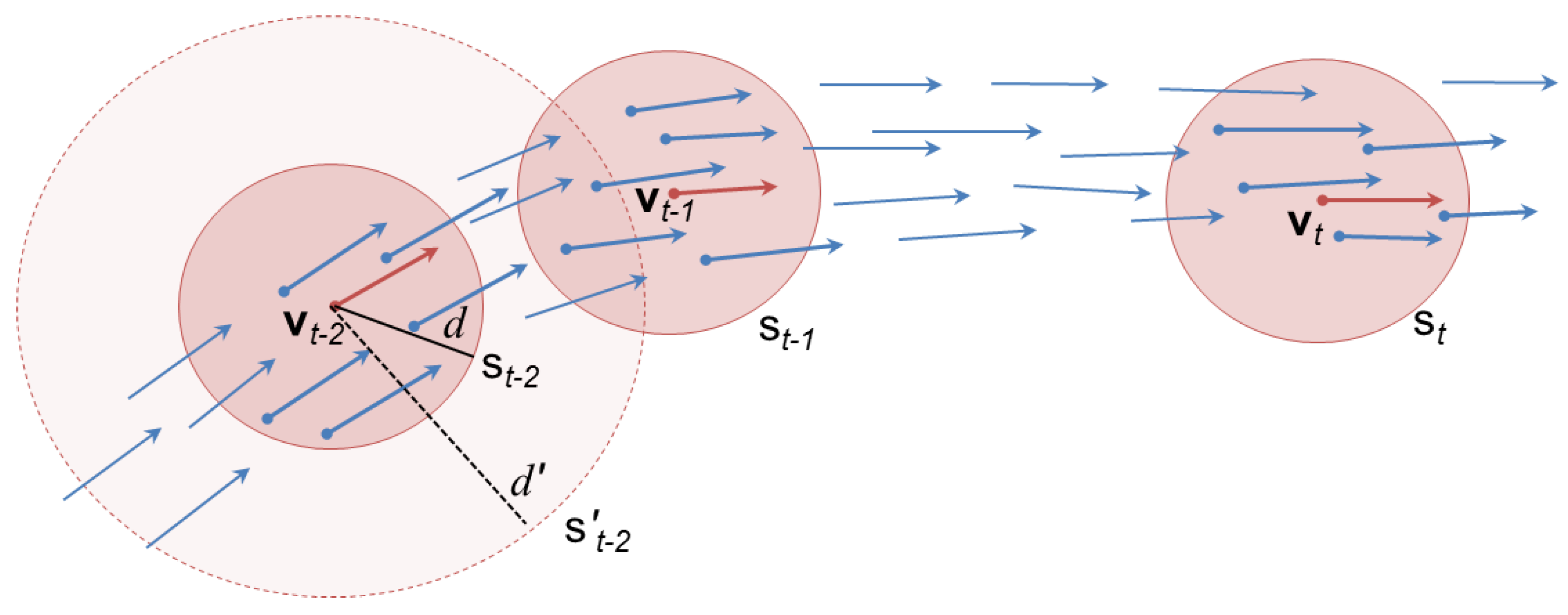
Vessel Objects Manager: As soon as a new vessel enters the monitored scene, a detection occurs, and the management of vessel objects is initialized (see Algorithm 1-Unsupervised Route Extraction, Annex A). The list of vessel objects, , is updated according to the information content of each decoded AIS message (or database record when performing historical data analysis). Every vessel object, , is identified by the MMSI number and contains both static and dynamic properties. While the former are linked to the identification of the vessel (e.g., type, call sign, name, International Maritime Organization (IMO) number, size), the latter are related to the state vector (e.g., position, Course Over Ground (COG), Speed Over Ground (SOG)) and to historical and current route patterns). These properties are progressively updated when new data become available. With reference to Algorithm 1—Unsupervised Route Extraction in Annex A—the refers to the timestamped history of observed state vector information (i.e., position and velocity parameters) for the vessel object, .
| Algorithm 1 |
| Require: // AIS messages containing static and dynamic info, e.g., , , , x, y, |
| Require: τ // time needed before labeling the vessel as being ‘lost’ |
| Require: // list of vessel, waypoint and route objects |
| Require: // clustering parameters (see Algorithm 2) |
- 1:
for all do - 2:
if then - 3:
// the vessel object identified by does not exist: it is added to the list, its status initialized as ‘sailing’, an entry event generated to be analyzed for objects clustering and the routes list updated - 4:
- 5:
‘sailing’) - 6:
- 7:
// see Algorithm 2 - 8:
// (see Algorithm 3) - 9:
else - 10:
// the vessel exists: its parameters are updated and tested - 11:
- 12:
// observed average speed shown by the vessel - 13:
if and ‘sailing’ then - 14:
// the vessel has stopped and a stationary event generated that is considered for POs (ports and offshore platforms) object clustering - 15:
‘stationary’) - 16:
- 17:
- 18:
end if - 19:
if ‘lost’ then - 20:
// the vessel is observed again after having been lost (e.g., exited the bounding box area) - 21:
‘sailing’) - 22:
- 23:
- 24:
end if - 25:
end if - 26:
// every , look for vessels not having been updated in the last τ time interval and update the list - 27:
if mod then - 28:
for all do - 29:
if and ‘lost’) then - 30:
// the last recorded position of the vessel is used to modify the list, to update the list of vessel waypoints and to create/update the routes, - 31:
‘lost’) - 32:
- 33:
- 34:
end if - 35:
end for - 36:
end if - 37:
end for - 38:
return
|
From the AIS data stream, the status of vessel objects is derived and updated. Changes of the status of vessel objects are events of interest, such as “lost” when not observed for a time
τ, which is a multiple of the maximum AIS message refresh rate in the area of interest. Additional vessel statuses are “stationary”/“sailing”, and their transitions identify other events of interest, such as when the vessel stops or starts sailing again from a stoppage. Such events create or update waypoint objects,
, as shown in Annex A, Algorithm 1—Unsupervised Route Extraction—and Algorithm 2—On-Line WPs Clustering.
| Algorithm 2 |
- Require:
// list of all vessels, , and vessel, v, that generated the event of interest to be clustered - Require:
// list of waypoints to be clustered, i.e., either , or , and routes to be modified - Require:
// minimum number of points, N, in the neighborhood of the event located in that is required to generate a cluster
|
- 1:
// see Incremental DBSCAN in [ 37]. - 2:
if ‘none’ then - 3:
// the event is not clustered and is considered as noise - 4:
‘Unclassified Waypoint’ - 5:
else - 6:
// the operation performed in the WPs space is either the generation of a new waypoint, the absorption into an existing one or the merge of multiple waypoints: - 7:
if ‘new cluster’ then - 8:
//the event has created a new cluster, , the vessel list of waypoints is updated together with the time, , of information, as extracted from - 9:
‘WP’) - 10:
‘WP’) - 11:
- 12:
// info regarding the of the vessel and its last position is recorded into - 13:
- 14:
end if - 15:
if ‘cluster expanded’ then - 16:
// the event is absorbed into the cluster, : - 17:
‘WP’) - 18:
- 19:
- 20:
end if - 21:
if ‘clusters merged’ then - 22:
// the new event causes the merging of two clusters, and , into , the event is clustered, updated and, finally, deleted. - 23:
‘WP’) - 24:
- 25:
- 26:
- 27:
for all do - 28:
‘WP’‘WP’) - 29:
end for - 30:
// merge the affected routes and update the relevant list - 31:
for all ‘WP’‘WP’) do - 32:
‘WP’) = ‘WP’) - 33:
- 34:
- 35:
end for - 36:
‘WP’) - 37:
end if - 38:
end if - 39:
return
|
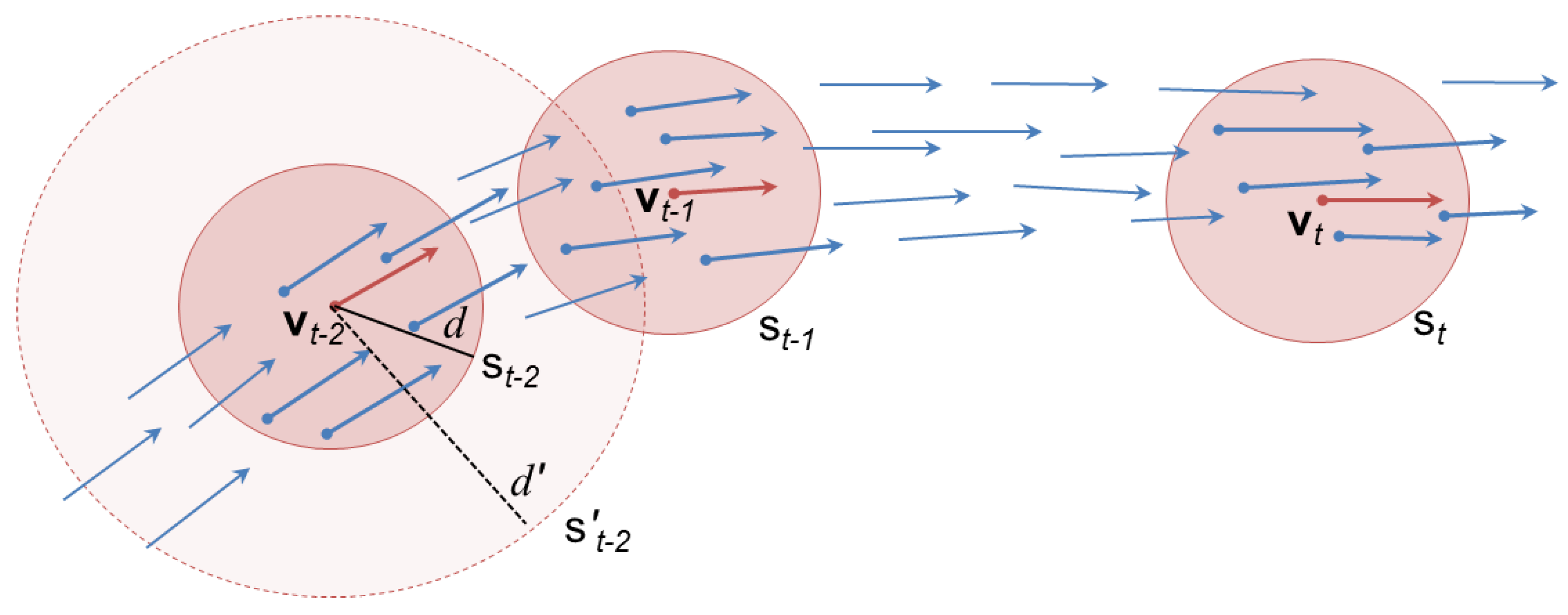
Stationary Objects Manager: A special class of waypoints is represented by stationary points, such as ports and offshore platforms,
. This class of objects consists of vessels having a speed lower than a given threshold. In particular, as can be seen in Annex A, Algorithm 1—Unsupervised Route Extraction—stationary events are detected by speed gating based on the last observations related to the vessel of interest: the parameters,
and
(
i.e., the last observed time interval and the resulting displacement in position), are computed to empirically derive the average vessel speed. This is implemented, since the field,
, in the AIS messages is unreliable to be used in detecting stationary events. Port and offshore platforms are learned by clustering the stationary behavior of vessels, and their areas are progressively shaped by vessels following the same behavior. Waypoints clustering is based on DBSCAN (
i.e., Density-Based Spatial Clustering of Applications with Noise) methodology ([
38]). DBSCAN forms clusters of elements on the basis of the density of points in their neighborhood. In other words, given a specific point,
p, if the cardinality of the neighborhood of a given radius,
Eps, is greater than a certain threshold of the minimum number of points, then such points are density-reachable from
p and belong to the same cluster. Moreover, two points,
p and
q, are density-connected if there is a third point,
o, such that
p and
q are density-reachable from
o. Points that are density-connected to each other belong to the same cluster, and points that are density-connected to any point of the cluster are also part of the cluster. In this framework, those points that are not density-connected to other points do not belong to any cluster and are considered noise.
| Algorithm 3 |
| Require: v, , |
- 1:
// if the vessel has passed through at least two waypoints - 2:
if then - 3:
- 4:
if then - 5:
//the route from to does not exist: it is added to the list - 6:
- 7:
end if - 8:
// update the relevant route by adding the track portion between and - 9:
- 10:
- 11:
- 12:
// update the vessel list of routes - 13:
‘’) - 14:
end if - 15:
return
|
Differently from centroid-based clustering, DBSCAN does not require the number of clusters
a priori, while arbitrarily shaped clusters can be easily found as often observed within the maritime traffic context. For instance, centroid-based methods can fail in discriminating different ports whose centroids are close to each other, when they are located along the coast line, as shown in
Figure 2. Moreover, DBSCAN introduces a way to classify noise points, which can be used to detect and filter outliers, as will be shown hereafter.
The on-line learning enables an incremental density-based clustering of waypoints. The waypoints clusters are either created, expanded and merged, following the typical procedure of incremental DBSCAN, as introduced in [
37]. In Algorithm 2, the on-line clustering of
is illustrated, showing how the vessel object features are updated accordingly. The cluster parameters (
i.e., the radius,
, of the neighborhood of the event of interest and the minimum number,
N, of points to be detected in the
-neighborhood of the vessel) are tuned, based on the specific nature of the
(
i.e., whether they are
or
/
objects) and on the specific features of the monitored area.
Topographically, port and offshore platform objects are represented via a spatial distribution given by the coordinates of the vessels, which contribute to create or update them. As a consequence, such objects are automatically described via a list of vessel objects and a volume of traffic. In this way, a frequency plot based on the type of vessels can be associated to each port and offshore platform object in order to help characterize the activities in the stop zones.
Figure 2.
Stationary points (green dots) incrementally detected during a two-week period over the Strait of Gibraltar, an area characterized by intense traffic. Stationary points are then clustered using incremental Density-Based Spatial Clustering of Applications with Noise (DBSCAN) into port and offshore platform objects, whose concave hulls (right) consistently capture areas where vessels anchor outside ports.
Figure 2.
Stationary points (green dots) incrementally detected during a two-week period over the Strait of Gibraltar, an area characterized by intense traffic. Stationary points are then clustered using incremental Density-Based Spatial Clustering of Applications with Noise (DBSCAN) into port and offshore platform objects, whose concave hulls (right) consistently capture areas where vessels anchor outside ports.
Entry and Exit Points Manager: Another class of waypoints useful for describing the motion patterns within a selected area is represented by entry (
) and exit (
) points. Whenever a vessel object enters (leaves) the area under analysis, it generates “birth”/“death” events (corresponding to vessel status transition “transmitting”/“lost” and
vice versa), and the relevant entry/exit point is created or updated. As in image processing and visual surveillance (see, e.g., [
16]), entry and exit points are related to the monitored scene and may change depending on the bounding box area, while port or offshore platform objects are fixed reference points. Similarly to the stationary points, entry and exit points are learned through the incremental DBSCAN method and described with a list of transiting vessel objects and a volume of traffic. Algorithm 2—
On-Line WPs Clustering in Annex A summarizes the main steps.
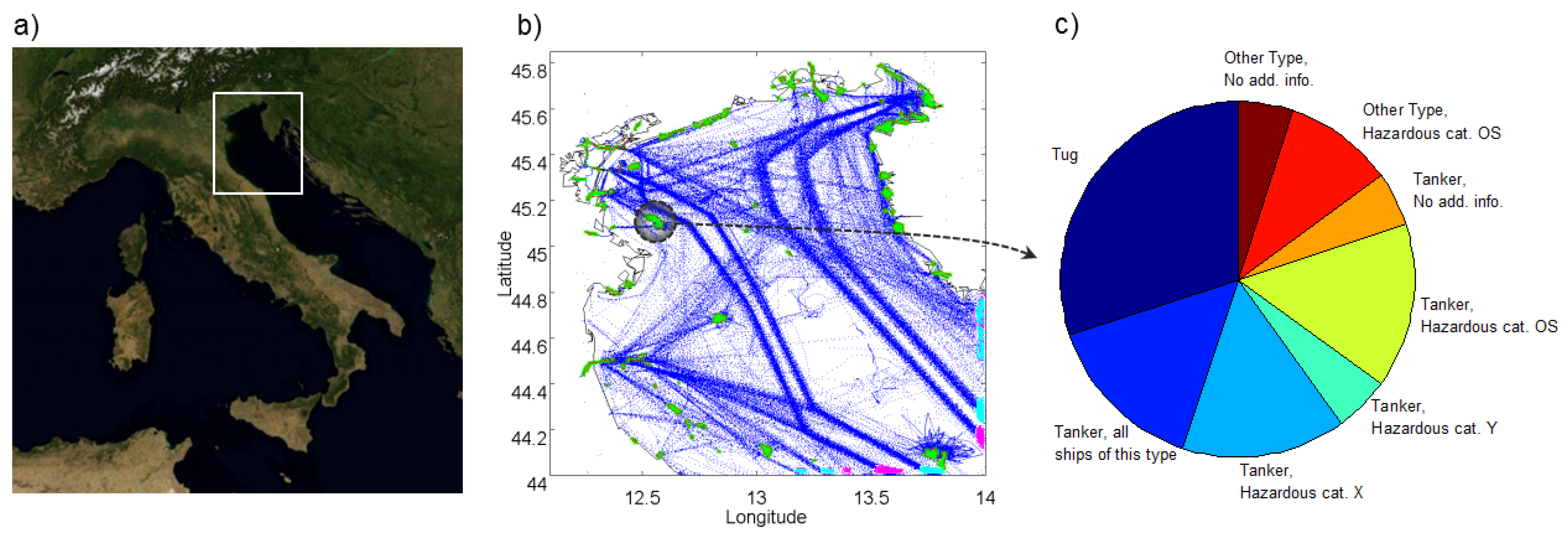
Figure 3 shows the results of the unsupervised waypoints detection and characterization over the North Adriatic Sea, where many routing systems are present (such as traffic separation schemes), because of the intense traffic and oil drilling activities.
Route Objects Manager: Once the waypoints are learned, route objects, , can be built by clustering the extracted vessel flows, which connect two ports (i.e., local routes), an entry point to a port, a port and an exit point or an entry point and an exit point (i.e., transit routes). Route objects do not merely count the registered transiting vessels, but are also statistically described by the static and kinematic features of the vessels that created or updated them.
Specifically, the Route Objects Manager, whose main steps are reported in Algorithm 3—Route Objects Manager in Annex A—deals with the creation of new route objects and with the dynamic management of their features and labels, as resulting from the incremental clustering of the relevant described in Algorithm 2—On-Line WPs Clustering, Annex A.
Figure 3.
Waypoints detection and characterization over a
km area in the North Adriatic Sea (
a) from March 1 to May 15, 2012. The unsupervised analysis leads to the detection of entry (cyan), exit (magenta) and stationary areas (green) (
b), one of them being an offshore regasification gateway as confirmed by the ship type distribution analysis (
c), following the categorization in [
39], performed on the Maritime Mobile Service Identity (MMSI) list of registered vessels.
Figure 3.
Waypoints detection and characterization over a
km area in the North Adriatic Sea (
a) from March 1 to May 15, 2012. The unsupervised analysis leads to the detection of entry (cyan), exit (magenta) and stationary areas (green) (
b), one of them being an offshore regasification gateway as confirmed by the ship type distribution analysis (
c), following the categorization in [
39], performed on the Maritime Mobile Service Identity (MMSI) list of registered vessels.
Once a vessel enters the scene, its features are compared with the existing set of routes. If a route already exists, whose positional features are compatible to the vessel features, both the vessel is added to the route list of vessels and, mutually, the route is added to the list of the
transited by the vessel. Otherwise, the vessel contributes to the initialization of a new route, and, when a minimum number of detections (
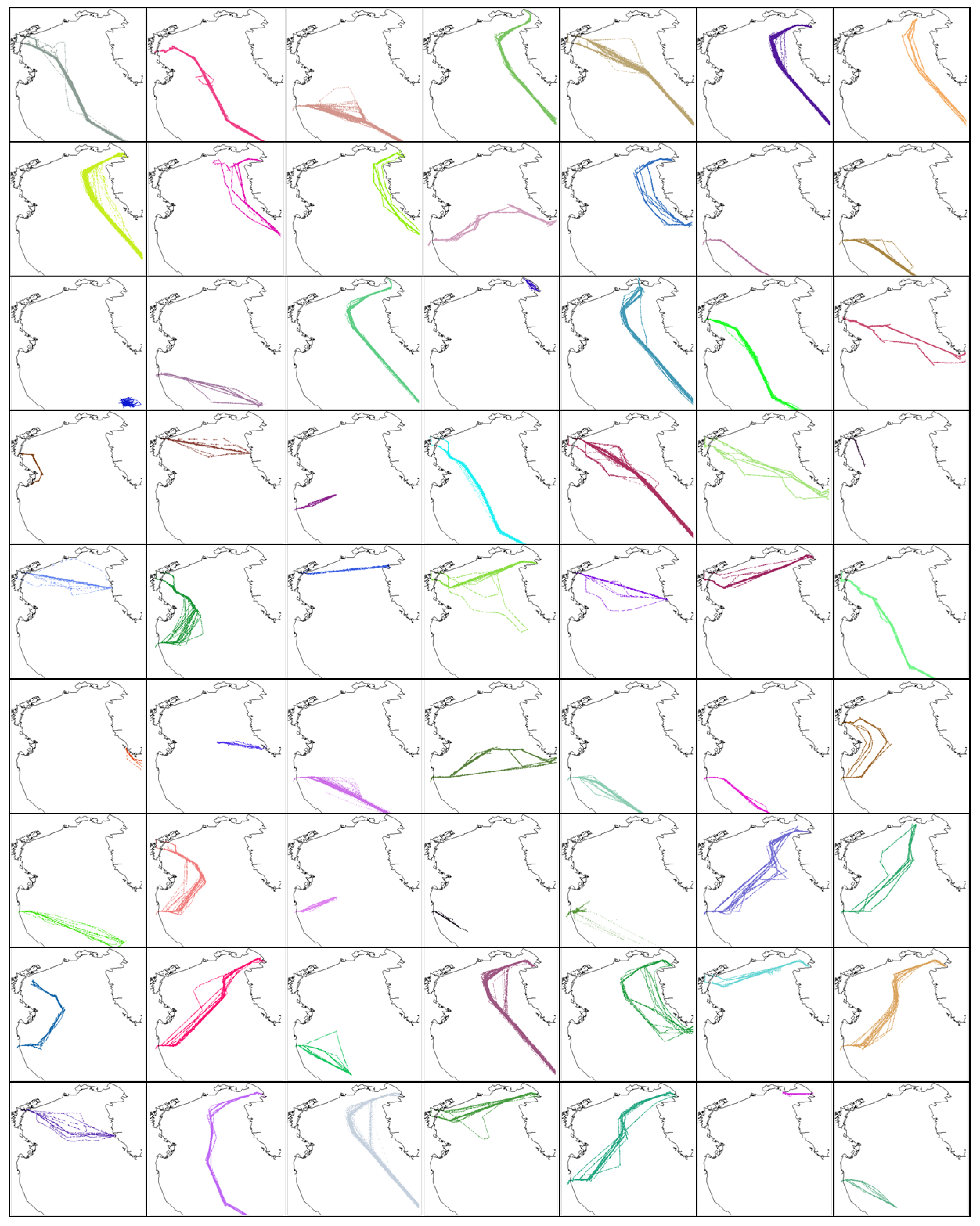
i.e., number of transits along the route) is reached, the new route is activated. Each route object has a spatio-temporal sequence of state vectors, facilitating the analysis and classification of activities. The detected routes can be organized in historical atlases, which summarize the maritime traffic in the considered area. As an example, we report the route codebook learned in the North Adriatic Sea in
Figure 4. Some of the derived routes are not easy to explain by glancing at the AIS traffic messages reported in
Figure 3b. The methodology shows a significant agreement with the traffic schemes in use on nautical charts.
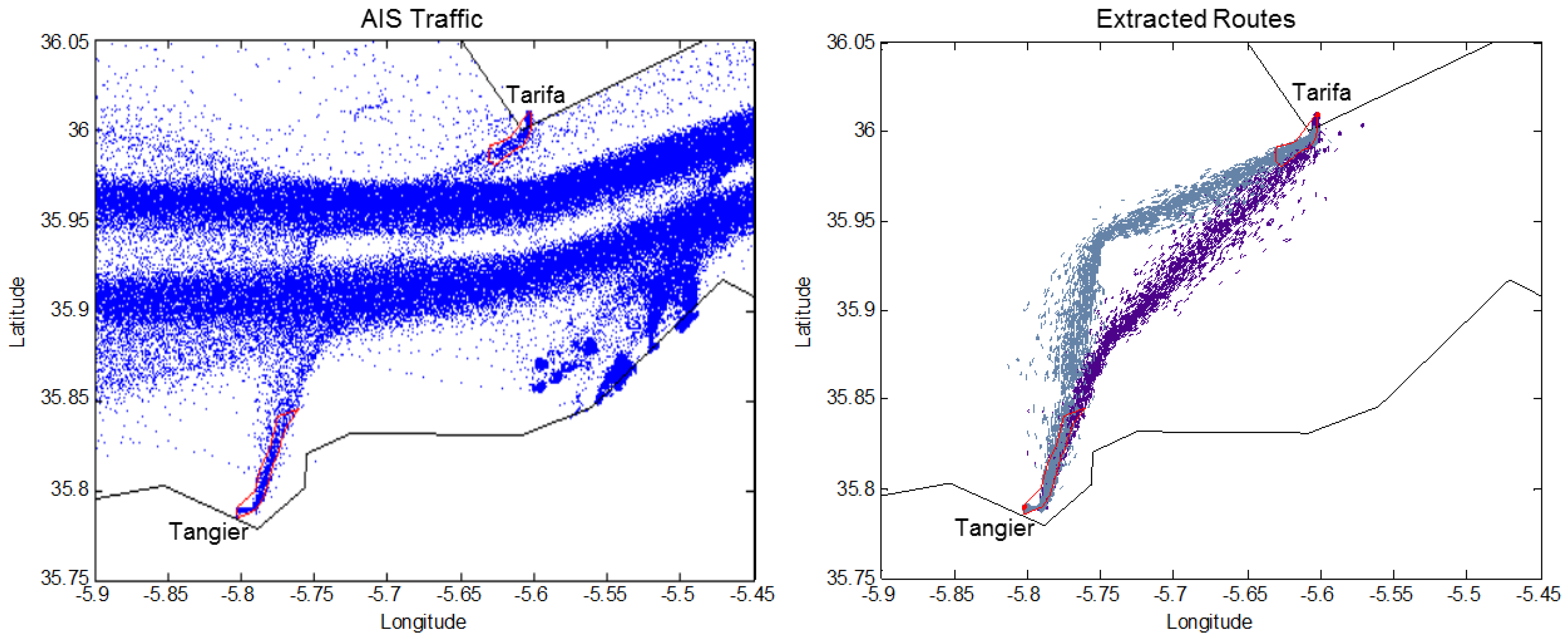
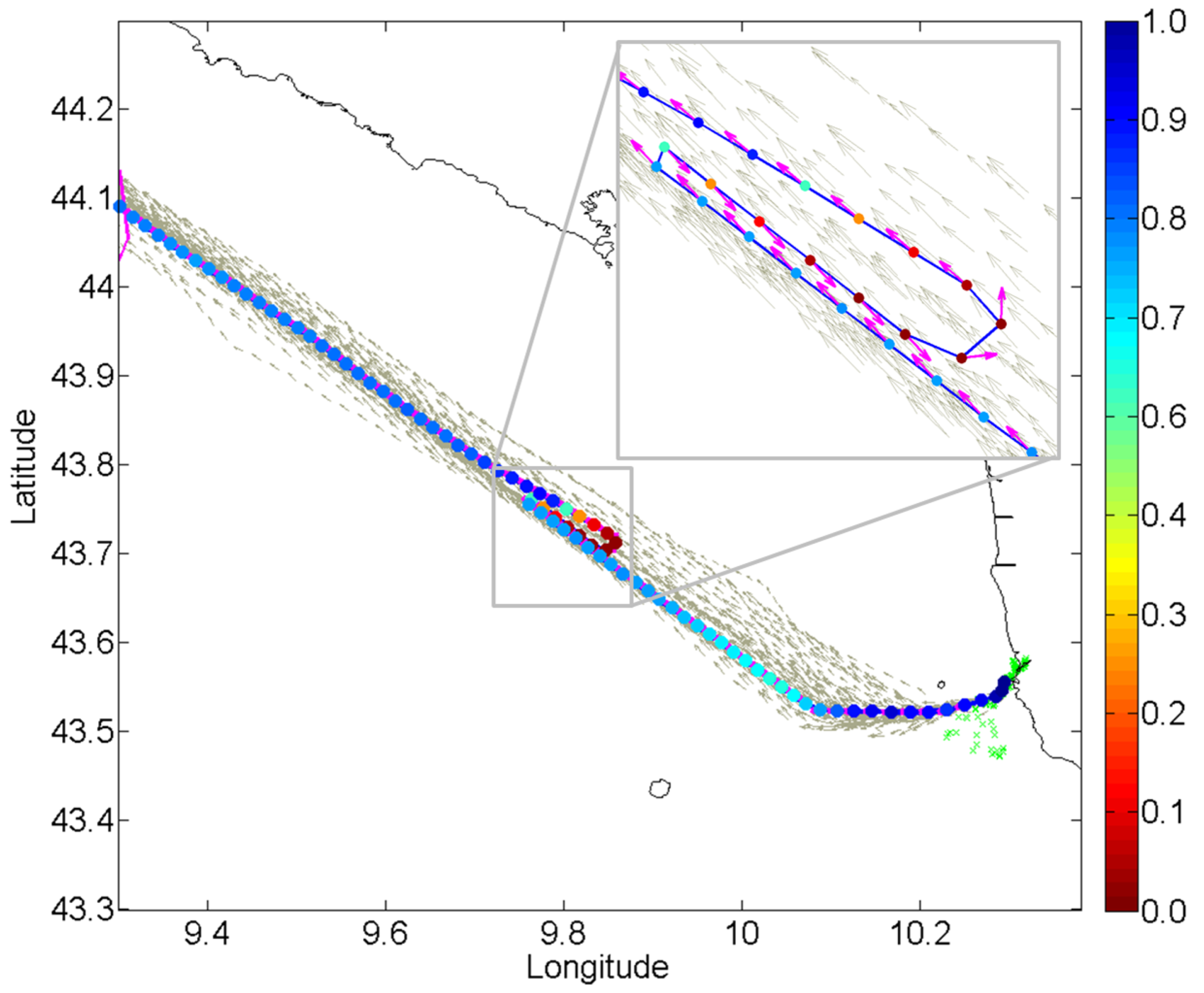
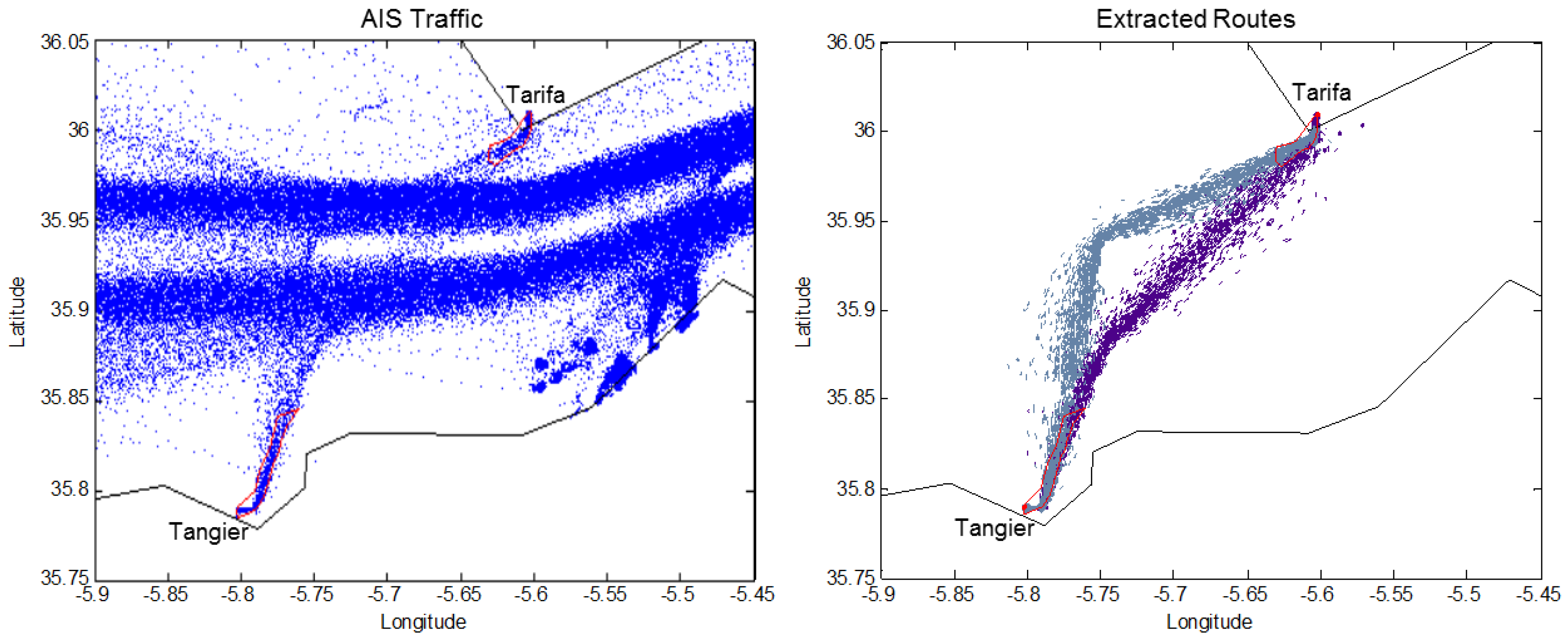
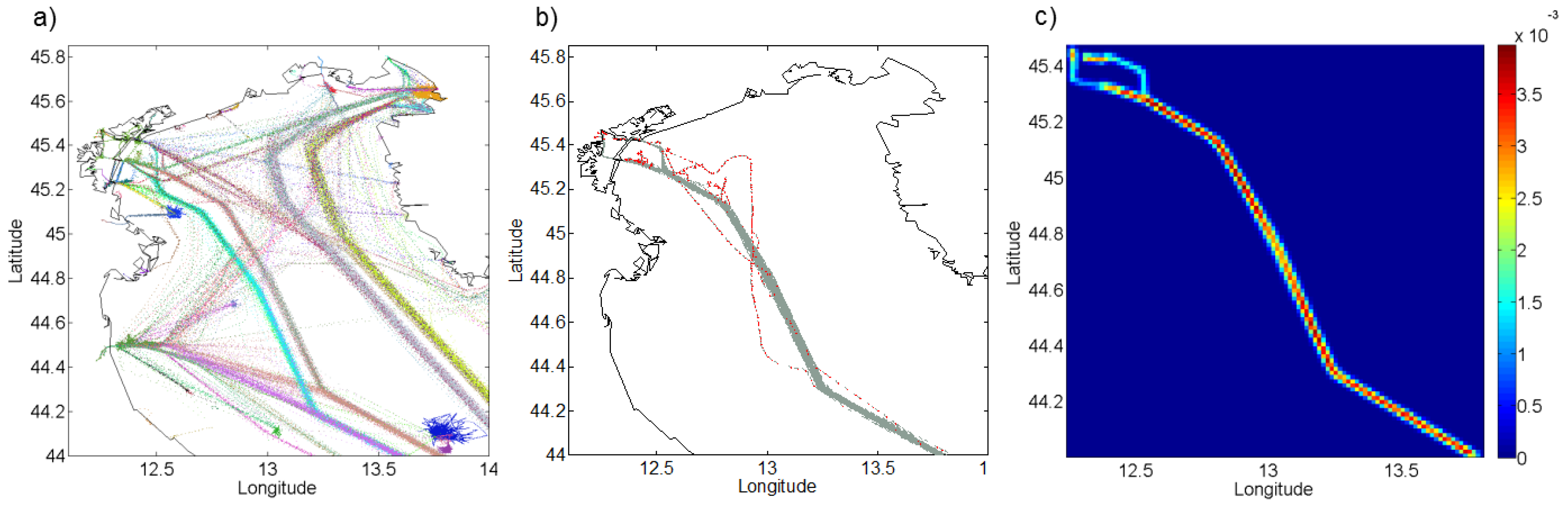
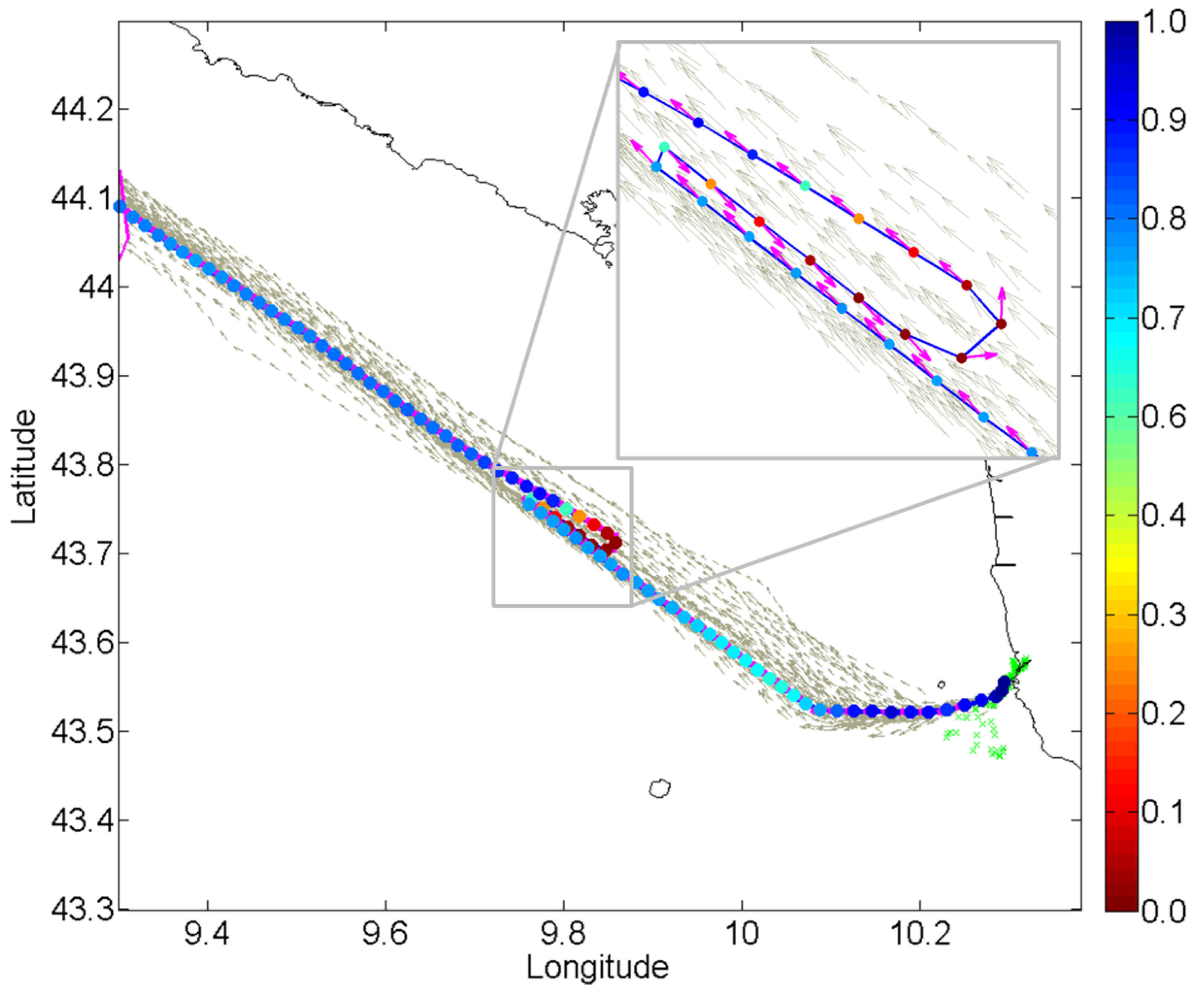
In
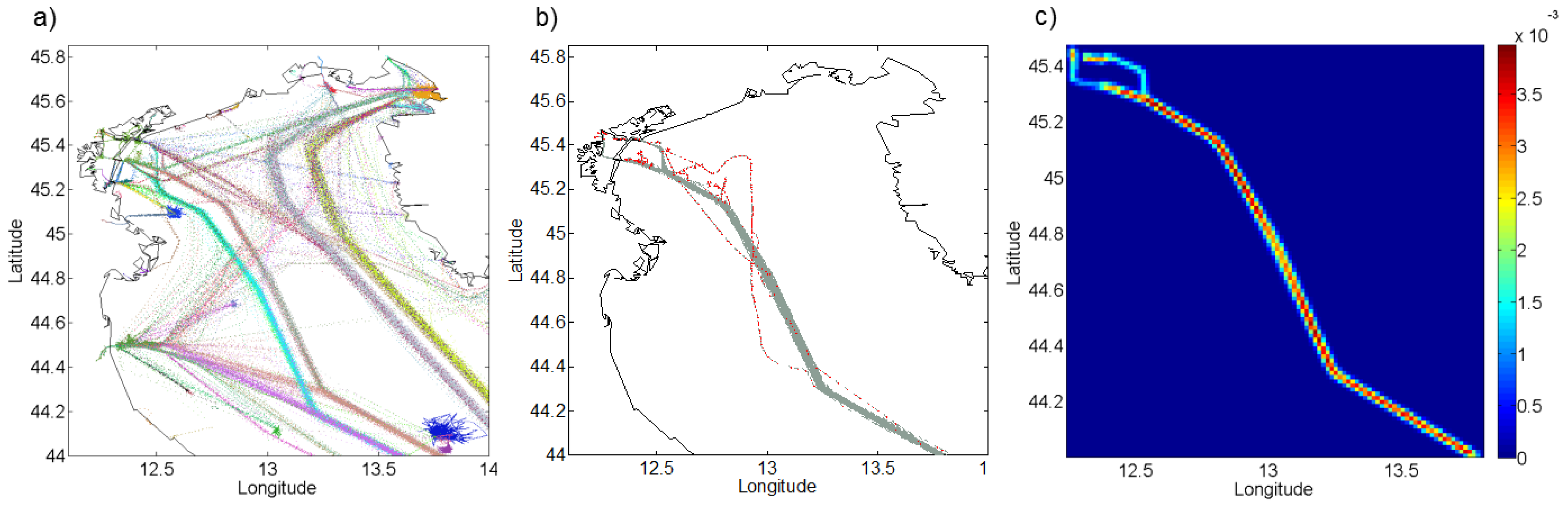
Figure 5, an example of two routes extracted between two detected stationary areas in the Strait of Gibraltar is illustrated. The major east and westbound traffic volumes significantly exceed the traffic flow between the selected ports, making the routes’ visual isolation difficult.
The two routes adhere to the maritime rules of the road when crossing the main traffic flows: the main traffic in the same direction flow is crossed at a shallow angle (
i.e.,
–
), while the opposing traffic flow in each route is cut across at broad angles (
i.e.,
). The second portion of each route is, therefore, more diffuse, as the ferries maneuver more when crossing the opposing sea lanes compared to overtaking traffic in the same direction. The extracted routes, whose number is not assumed
a priori, but automatically learned, are characterized also by the information of the entering and exiting time of the registered vessels together with their ship type. Different from live video analysis applications, this allows the extraction of higher level information, such as the ship type, distribution of the route, its average travel time and the daily/weekly patterns, as shown in
Figure 6.
Figure 4.
Set of highly dense routes into which the traffic in
Figure 3 was decomposed.
Figure 4.
Set of highly dense routes into which the traffic in
Figure 3 was decomposed.
Anomalies in the traffic schedule can therefore be modeled on vessels that are fully compliant with the route directions, but use them at low-likelihood times. Detected route objects often show trajectories that share the same entering and exiting waypoints, but their path considerably deviates from other vessel paths within the same route. It is necessary to discard those outliers, so that anomaly detection can be performed based on a more representative picture of the vessel normal traffic, as is commonly done in statistical process control and change detection practice. Thus, anomaly detection is related to, but differs from, noise removal in the data: noise works as an obstruction to data analysis and is not of primary interest to the analyst. Undesired outliers must be removed before further knowledge exploitation can be performed. This pre-processing phase is implemented by using the DBSCAN method. Specifically, it includes the classification of route points as core points, border points and noise points. Noise points are not considered representative of historical patterns and are filtered out. An example of a pre-processed route is reported in
Figure 7b. As highlighted in [
8], vessels typically follow traffic sea lanes that are sequences of straight lines. The Gaussian Mixture Models (GMM), very popular in the pattern recognition literature, can be used to fit the distribution of position data points. Along the minor axis perpendicular to the lane, the Gaussian models can capture the vessel position variability and displacements. However, along the major axis, the vessel distribution is assumed to be approximately uniform, and thus, the Gaussian distribution is a sub-optimal spatial density model. So, a non-parametric approach can be more appropriate to model the two-dimensional traffic density distribution and has been adopted in the present work. Among the non-parametric approaches, Kernel Density Estimation (KDE) is a common technique for estimating the unknown probability density function (pdf) of the random variable “vessel position”. Compared to GMM, KDE makes no assumption about the parametric model of the underlying pdf, whose form is estimated using historical data samples. Moreover, KDE does not need to specify the number of components of the mixture model, which is one of the main drawbacks of GMM. For these reasons, KDE has shown a superior ability to accurately model traffic lanes.
Figure 7c reports the KDE representation of a refined route, adopting a Gaussian kernel with an optimized bandwidth selection based on the Minimization of a Cost function.
Figure 5.
AIS traffic data in proximity of the Strait of Gibraltar (left) collected over two months, and (right) extracted routes between the learned port of Tarifa and the old port of Tangier, both highlighted in red.
Figure 5.
AIS traffic data in proximity of the Strait of Gibraltar (left) collected over two months, and (right) extracted routes between the learned port of Tarifa and the old port of Tangier, both highlighted in red.
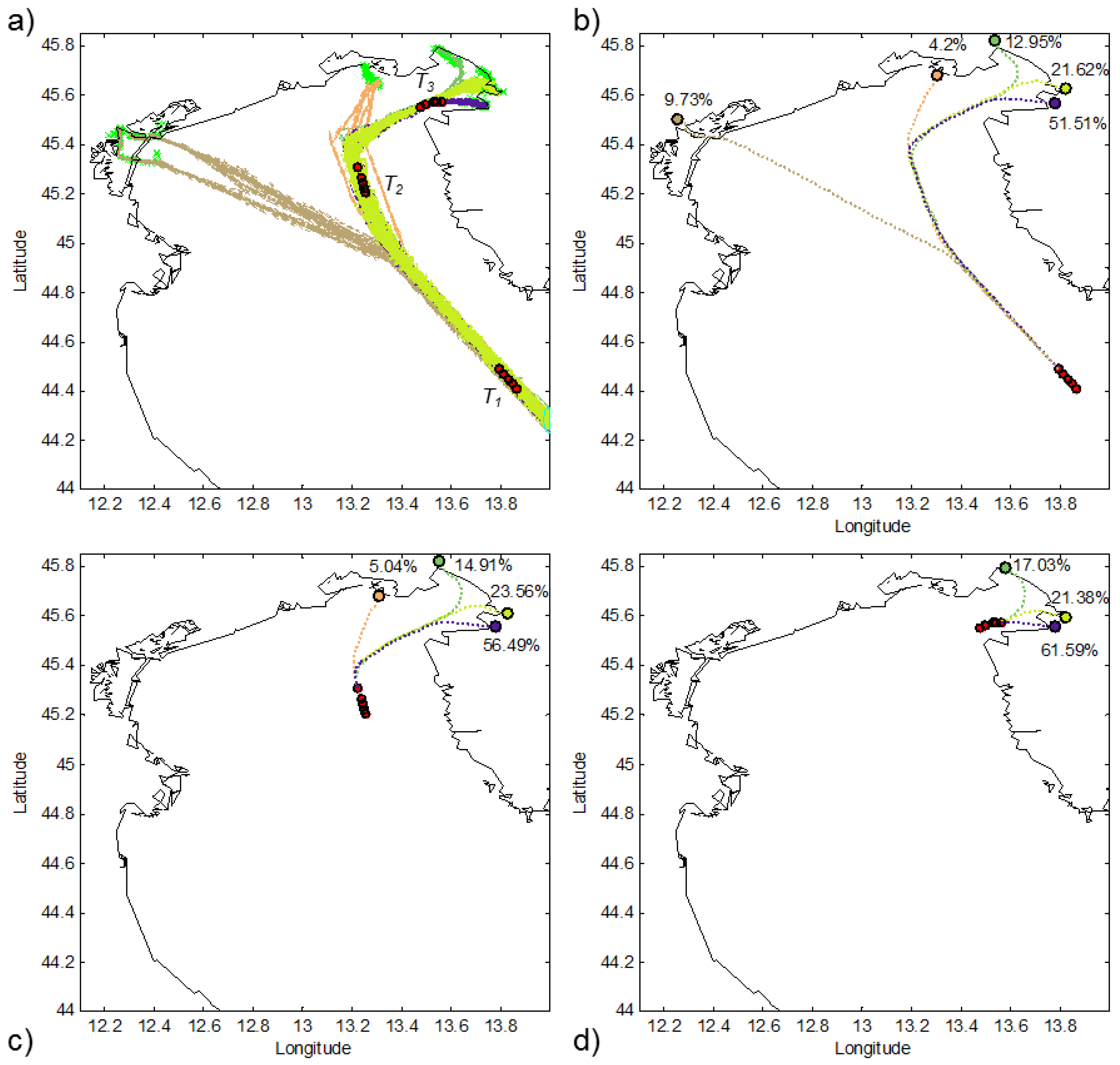
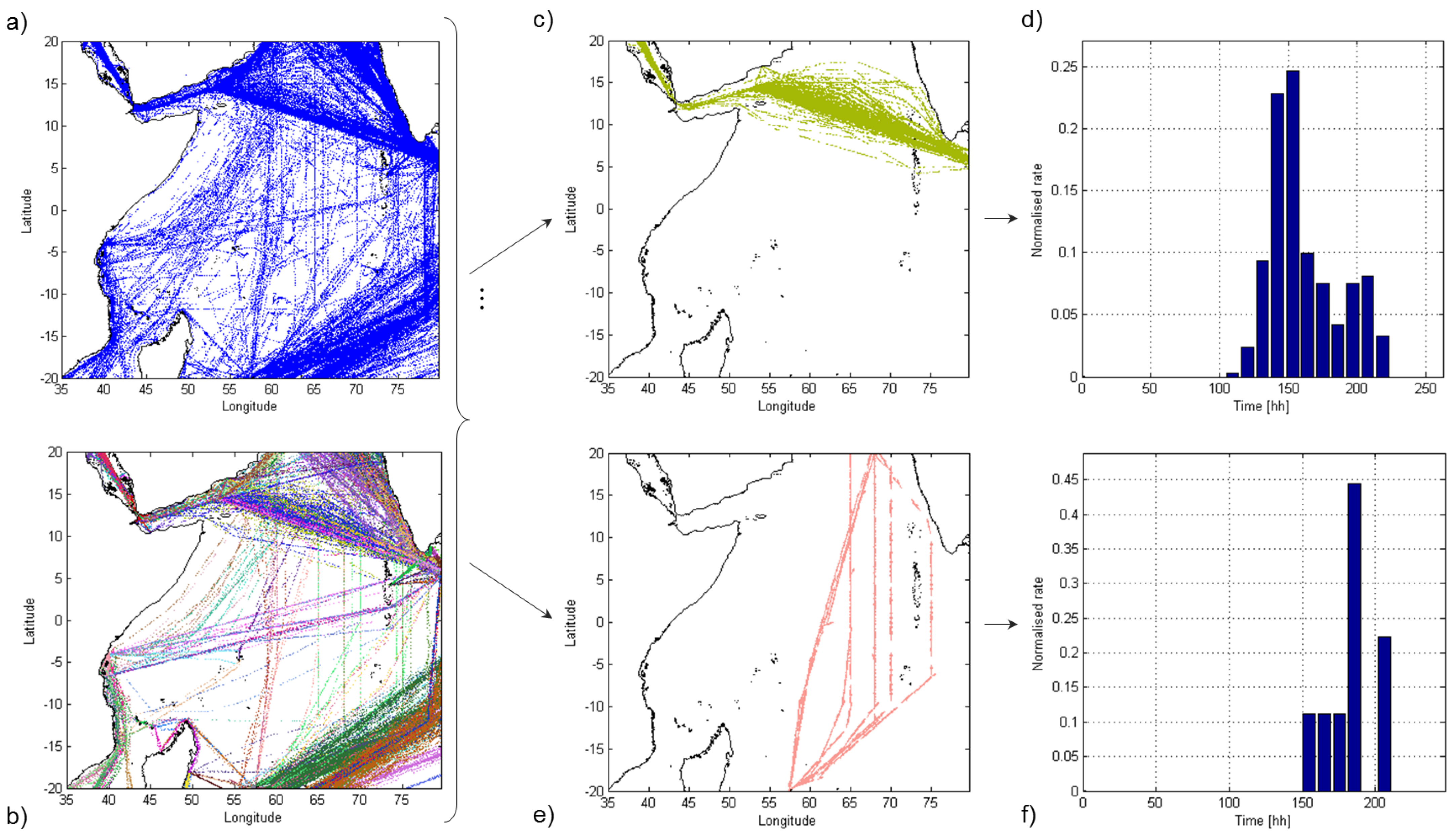
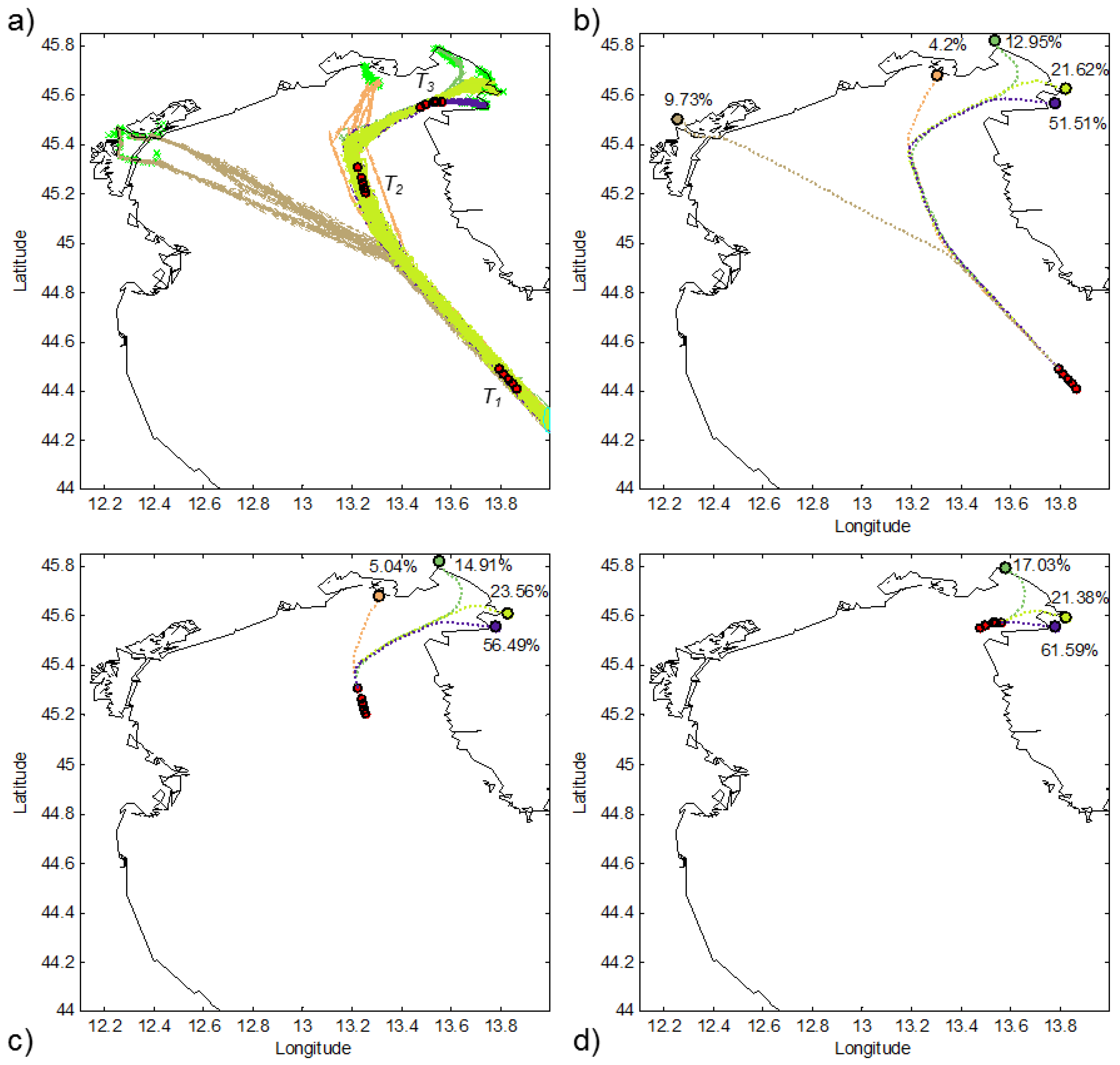
TREAD was tested in different areas and using data from different AIS sources (
i.e., terrestrial and satellite AIS).
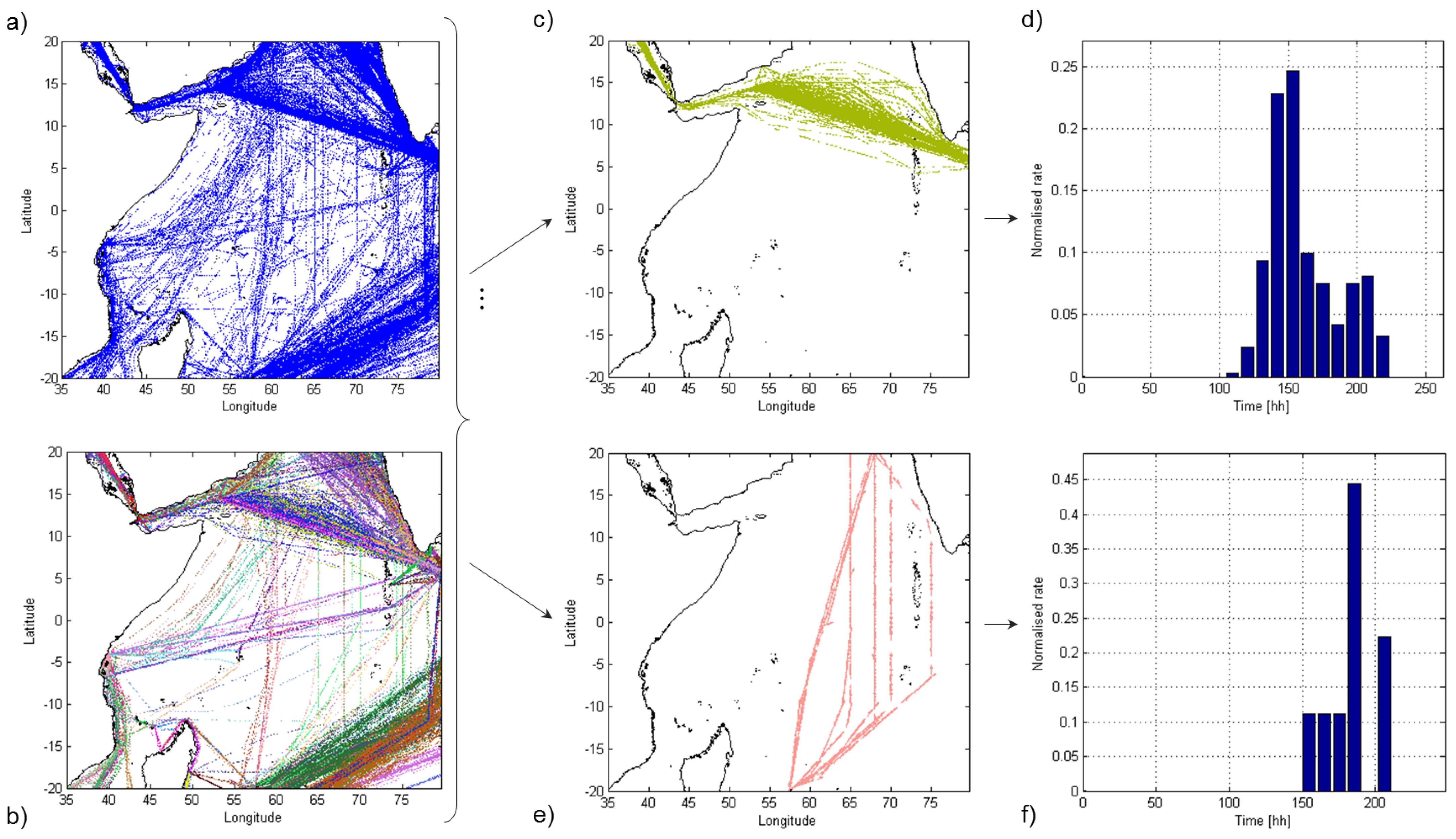
Figure 8 shows an example of the traffic knowledge learned using satellite AIS data in the Indian Ocean. It is noteworthy that some of the routes displayed in
Figure 8b are not easily anticipated by simply looking at the raw AIS traffic data in
Figure 8a. As an example, the route from the Suez Canal to the Laccadive Sea (
Figure 8c) is firstly constrained by the Internationally Recommended Transit Corridor (IRTC) and easily isolated. Then, it becomes more disperse outside the routing system and more difficult to be identified. The spatial spread of the second route in
Figure 8e shows how the effects of piracy have modified the common routes over the Indian Ocean near Somalia, due to high-risk areas.
Figure 6.
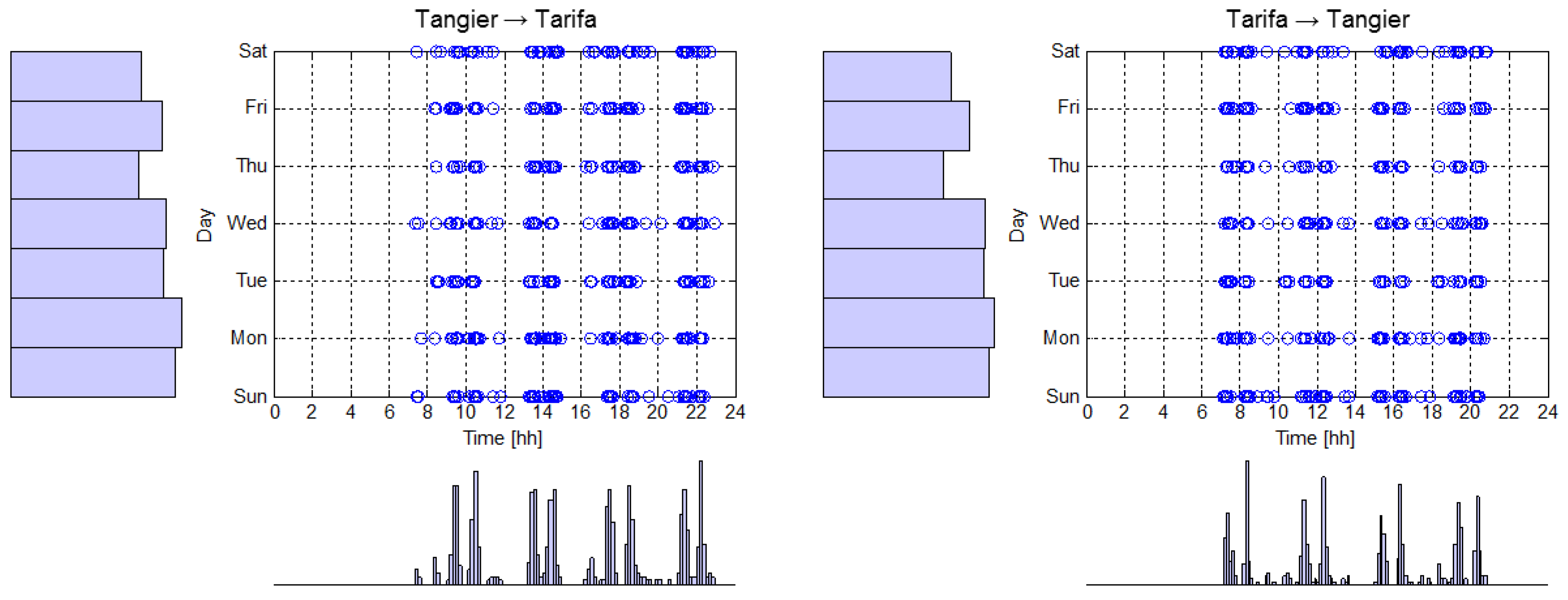
Daily patterns between northbound (left) and southbound (right) routes covered by four ferries whose schedule can be derived by the multiple peaks of the time histograms on the bottom.
Figure 6.
Daily patterns between northbound (left) and southbound (right) routes covered by four ferries whose schedule can be derived by the multiple peaks of the time histograms on the bottom.
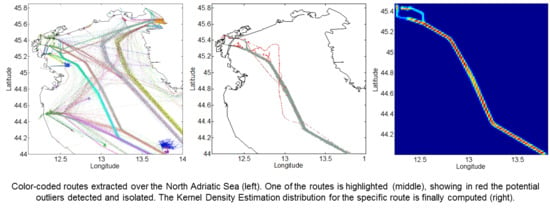
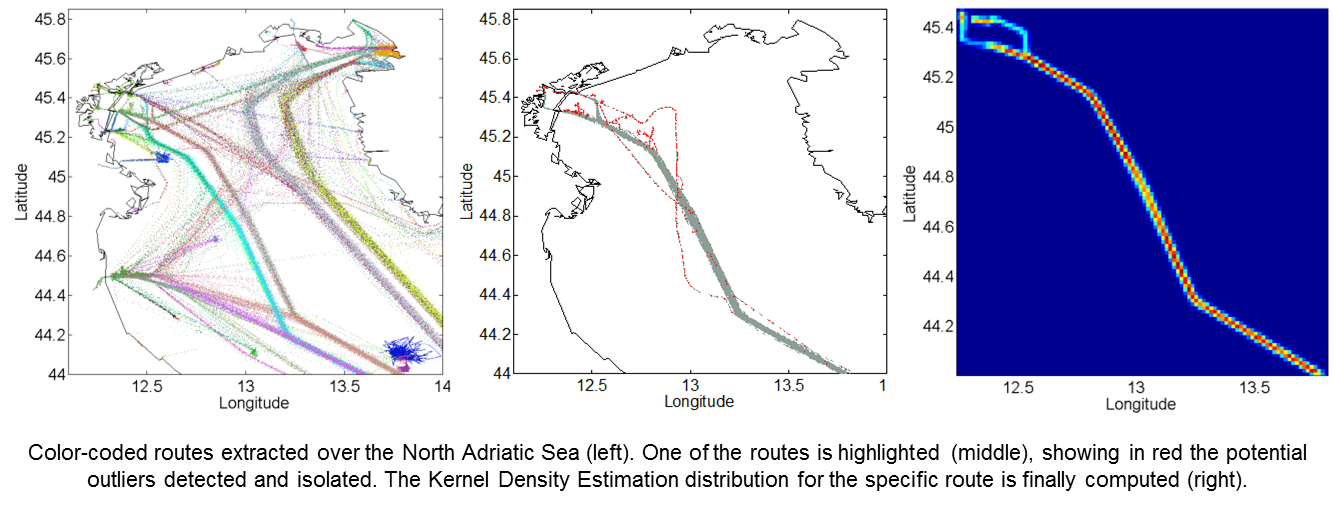
Figure 7.
Color-coded routes (
a) extracted over the area in
Figure 3, showing patterns not clearly visible by analyzing traffic density data (see
Figure 3b); one of them (
b) is highlighted, showing in red the potential outliers detected and isolated using density-based clustering on the route points. The Kernel Density Estimation (KDE) distribution for the specific route is finally computed (
c).
Figure 7.
Color-coded routes (
a) extracted over the area in
Figure 3, showing patterns not clearly visible by analyzing traffic density data (see
Figure 3b); one of them (
b) is highlighted, showing in red the potential outliers detected and isolated using density-based clustering on the route points. The Kernel Density Estimation (KDE) distribution for the specific route is finally computed (
c).
At last, each route can be decomposed into the elementary trajectories followed by all the vessels belonging to that route, thus facilitating the search for tracks that deviate from “normality”. When a vessel object is instantiated, its features are compared with all the routes already present in the database performing Route Classification (see
Section 4.1).
Figure 8.
Three-month satellite AIS positioning data over the Indian Ocean (a); superposition of detected routes (b). Two of them are further analyzed in terms of spatial (c and e) and travel times distribution (d and f).
Figure 8.
Three-month satellite AIS positioning data over the Indian Ocean (a); superposition of detected routes (b). Two of them are further analyzed in terms of spatial (c and e) and travel times distribution (d and f).
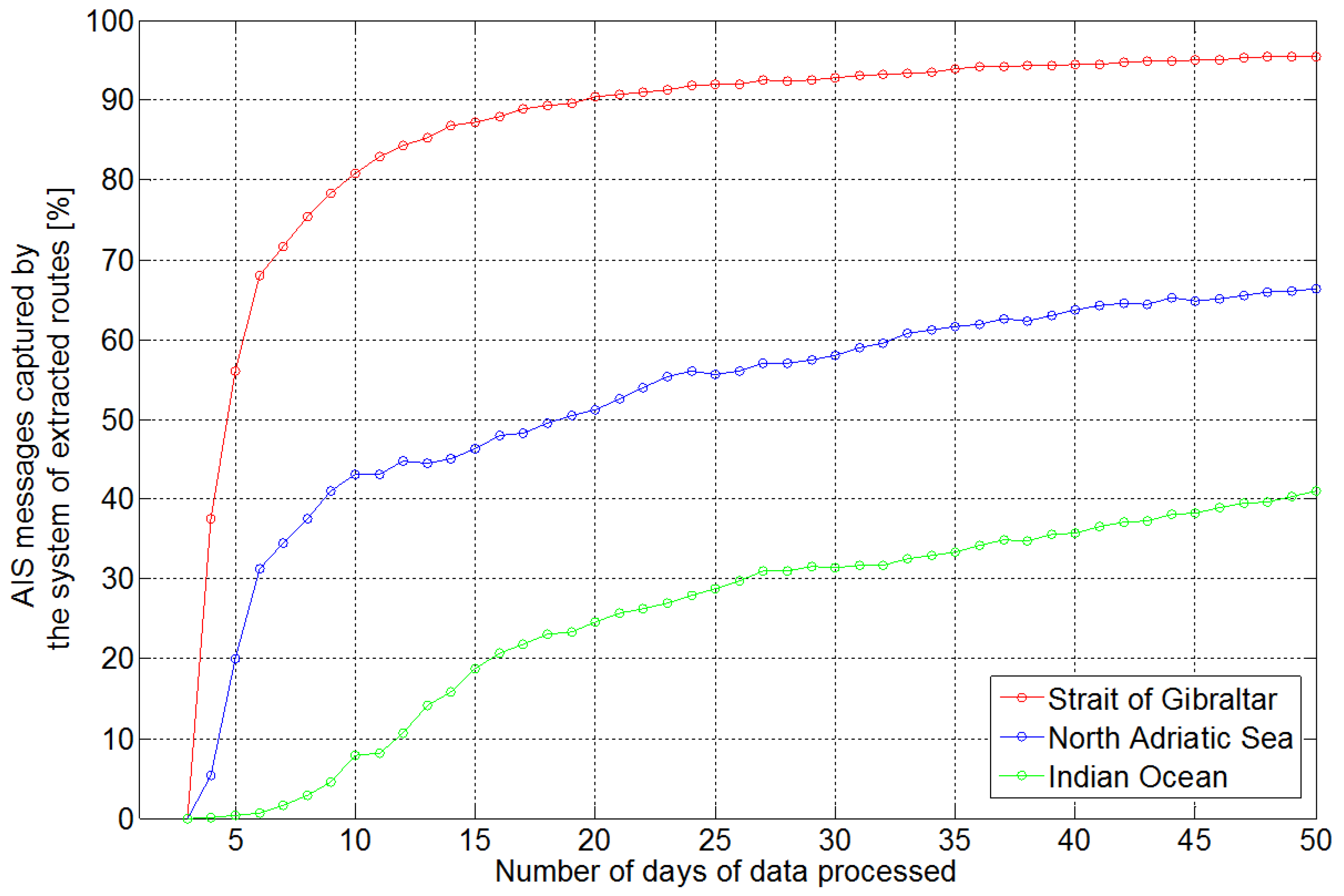
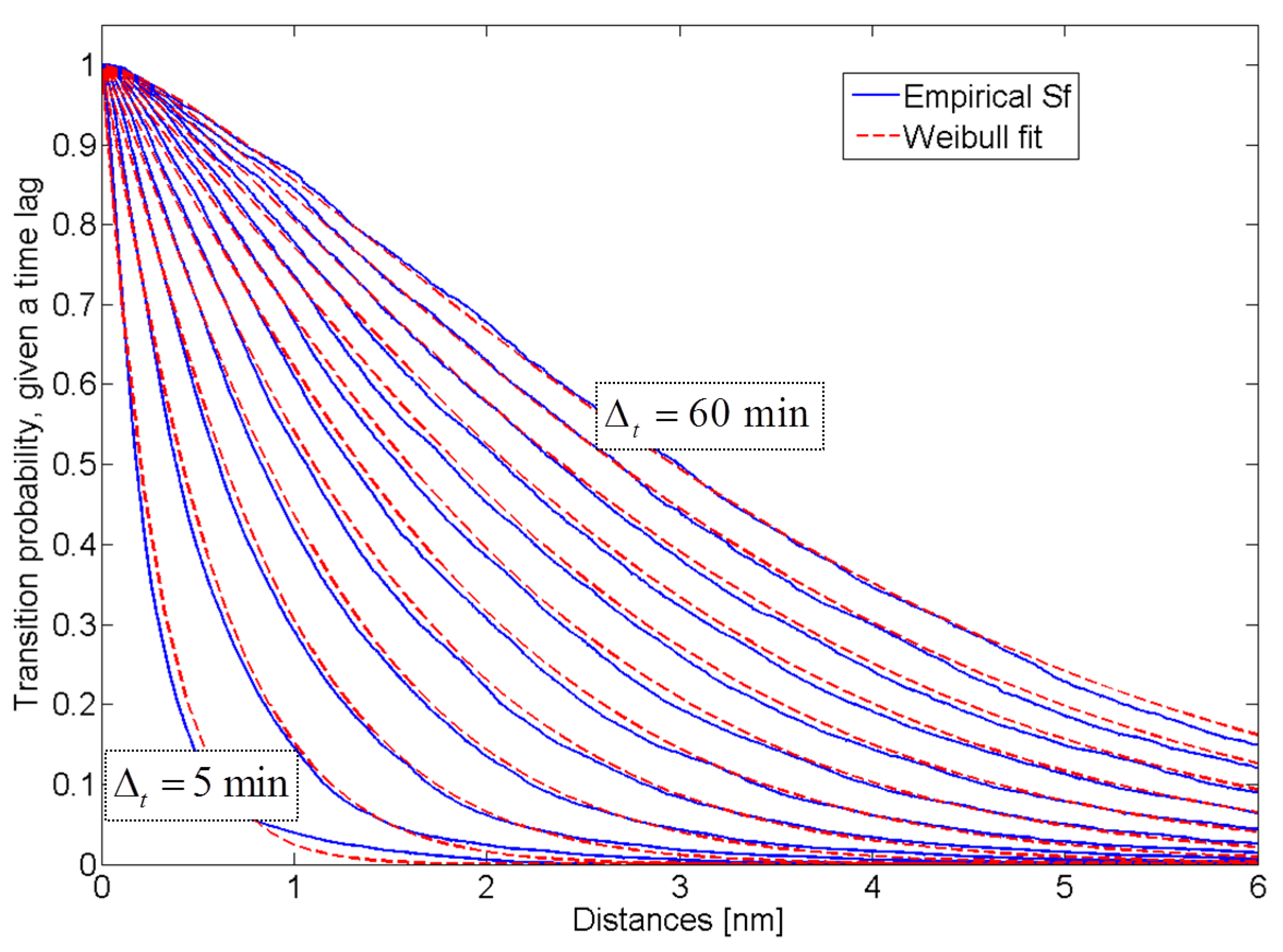
3.1. Learning Performance and Traffic Entropy
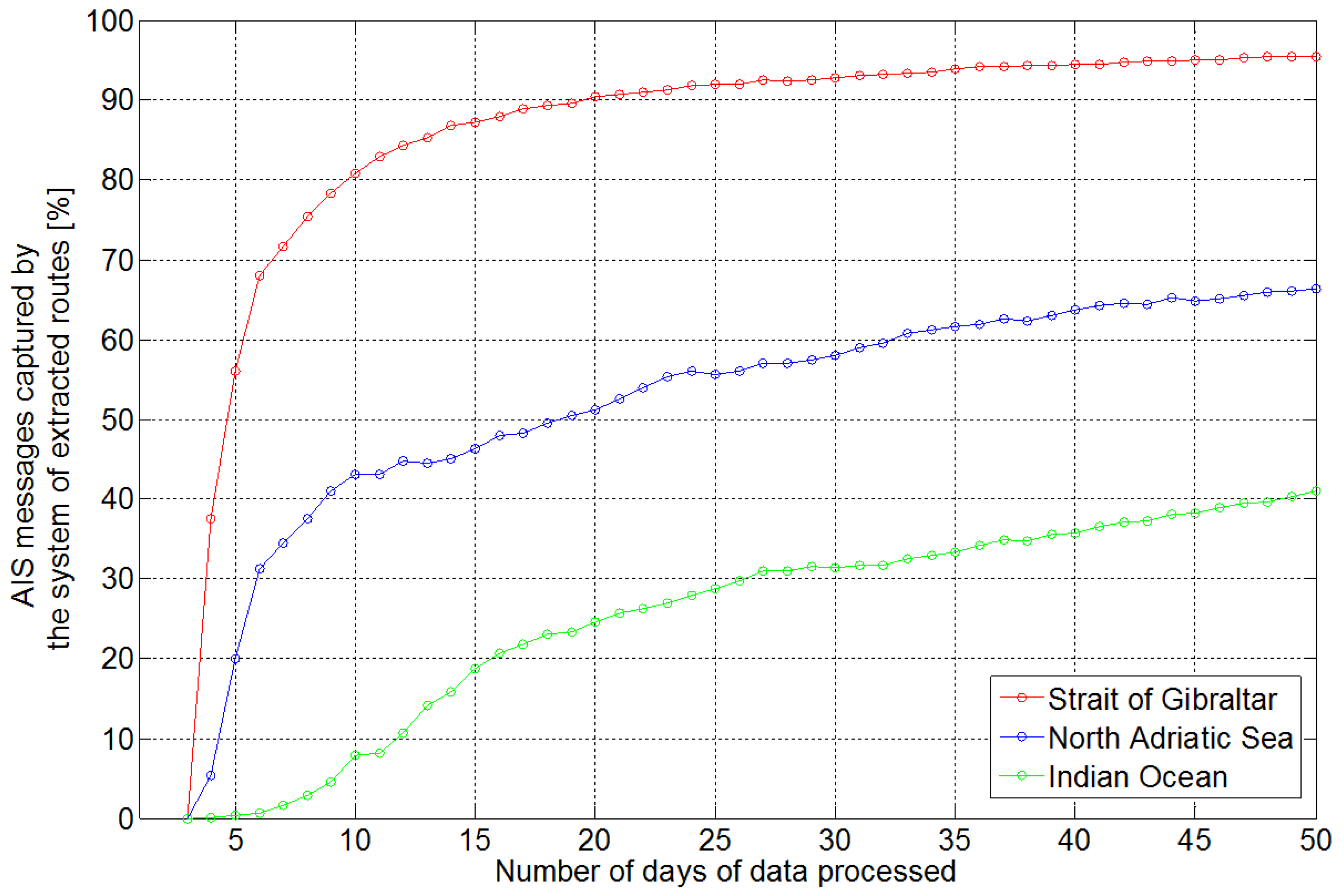
The learning performance of TREAD methodology was analyzed in terms of the ratio between the number of AIS messages mapped into the extracted system of routes and the number of processed positioning messages.
Figure 9 shows the learning results on 50-day ground based data over the Strait of Gibraltar and the North Adriatic Sea and satellite-based data over the Indian Ocean as introduced by
Figure 3b,
Figure 5a and
Figure 8, respectively. After a common preliminary phase when the system constructs the entry/exit and stationary point objects, the learning accuracy performance stabilizes at different levels, depending on traffic density and constraints. Thus, the more the traffic is constrained or regulated, the more accurate the unsupervised learning results. The extremely high traffic density and rigid routing system allowed the Strait of Gibraltar to be learned relatively quickly and consistently, capturing up to 95% of the processed messages. Lower accuracy performance can be seen in the North Adriatic Sea, where, despite the relatively constrained traffic, there are opportunities for many routes to be followed within the time window. As a result, only 70% of the traffic is learned. This aspect is even more pronounced in the Indian Ocean, where merely 40% of the traffic can be clustered, due to a lack of traffic constraints over a large area combined with the low update rates of satellite-based AIS data.
The curves in
Figure 9 represent the portion of the information that contributes to the historical traffic pattern model
versus the amount of processed information. The amount of information that does not contribute to the traffic knowledge discovery is discarded. There is a certain point of diminishing returns, or an upper threshold, for the number of data points, which are included into the learned system of routes, beyond which the additional data do not provide further useful information to the historical route system. The traffic pattern knowledge discovery process can therefore be linked to the notion of entropy, which measures the degree of disorder in a system. Information Theory entropy is widely employed to predict human mobility, Asynchronous Transfer Mode (ATM) traffic streams and cellular network traffic [
40]. Entropy clearly provides a measure of the extent to which the traffic can be predicted on the basis of the historical patterns over the area. Within this framework, entropy can be used to quantify the information gain that the derived traffic patterns will provide for prediction [
41]. In geographical clustering studies, the notion of entropy has been suggested in [
42] and recently applied to detect abnormal activities in video surveillance in [
43]. As a consequence, the detection of potential anomalies can be linked to the traffic entropy: the capability to successfully recognize low-likelihood behaviors is enhanced in areas where the traffic patterns are highly regular and, therefore, the associated level of disorder is low.
Figure 9.
Portion of AIS messages captured by the learned system of routes over the reported areas of interest.
Figure 9.
Portion of AIS messages captured by the learned system of routes over the reported areas of interest.
Thus, while the learning rate depends on the traffic density, the end state knowledge discovery performance is affected by the different levels of traffic entropy over the area of interest and will vary from region to region.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}