Information Anatomy of Stochastic Equilibria


1
Department of Physics, University of California at Berkeley, Berkeley, CA 94720, USA
2
Complexity Sciences Center, Department of Physics, University of California at Davis, One Shields Avenue, Davis, CA 95616, USA
*
Authors to whom correspondence should be addressed.
Entropy 2014, 16(9), 4713-4748; https://doi.org/10.3390/e16094713
Submission received: 17 March 2014
/
Revised: 3 August 2014
/
Accepted: 19 August 2014
/
Published: 25 August 2014
(This article belongs to the Special Issue Information in Dynamical Systems and Complex Systems)
Abstract
:A stochastic nonlinear dynamical system generates information, as measured by its entropy rate. Some—the ephemeral information—is dissipated and some—the bound information—is actively stored and so affects future behavior. We derive analytic expressions for the ephemeral and bound information in the limit of infinitesimal time discretization for two classical systems that exhibit dynamical equilibria: first-order Langevin equations (i) where the drift is the gradient of an analytic potential function and the diffusion matrix is invertible and (ii) with a linear drift term (Ornstein–Uhlenbeck), but a noninvertible diffusion matrix. In both cases, the bound information is sensitive to the drift and diffusion, while the ephemeral information is sensitive only to the diffusion matrix and not to the drift. Notably, this information anatomy changes discontinuously as any of the diffusion coefficients vanishes, indicating that it is very sensitive to the noise structure. We then calculate the information anatomy of the stochastic cusp catastrophe and of particles diffusing in a heat bath in the overdamped limit, both examples of stochastic gradient descent on a potential landscape. Finally, we use our methods to calculate and compare approximations for the time-local predictive information for adaptive agents.
1. Introduction
If we track the position of a particle diffusing on an unchanging potential long enough, we can estimate the probability of observing a sequence of positions [1]. From that, we can quantitatively answer questions about the process’s behavior using a range of information statistics that answer specific questions:
- How random is it? The entropy rate hμ, which is the entropy in the present observation conditioned on all past observations [2].
- How much memory is required to store these causal states? The statistical complexity Cμ, or the entropy of the causal states [3].
- How much of the future is predictable from the past? The excess entropy E, which is the mutual information between the past and the future [5].
- How much of the generated information (hμ) is relevant to predicting the future? The bound information bμ, which is the mutual information between the present and future observations conditioned on all past observations [6].
- How much of the generated information is useless (neither affects future behavior nor contains information about the past)? The ephemeral information rμ, which is the entropy in the present observation conditioned on all past and future observations [6].
These informational quantities usually cannot be deduced from a bifurcation diagram, so we see them as providing a complementary view of a process’s structure and behavior.
In applications, such informational characterizations of a time series are useful for monitoring good sensory coding [7], cognitive modalities [8], brain coherence [9], hidden Markov model structural inference [10], action policies of autonomous agents [11,12], structure in disordered materials [13,14], dynamical phase transitions [15,16] and intrinsic information processing in deterministic chaos [17,18] and cellular automata [19,20].
Here, we focus on continuous stochastic nonlinear dynamical systems, the theory for which has a long and venerable history, has met with a number of successful predictions, and has identified a number of principles describing how noise interacts with nonlinearity [21]. For nonlinear systems transitioning to chaos, to take just one example, noise plays the role of a “disordering” field, just as the magnetic field is an ordering field for spin systems at critical transitions [22,23]. Though their history substantially predates that of the wide range of complex systems applications just cited, relatively fewer analyses of their information processing components—their information anatomy—have been carried out. As a start, we demonstrate how to calculate the quantities above for continuous-time, continuous-state stochastic nonlinear systems exhibiting dynamical equilibria, yielding intuition for the properties these measures capture in simpler, and perhaps more familiar, physical models.
Throughout, we focus on a ubiquitous and simple nonlinear generative model: stochastic gradient descent or, in other words, diffusion on a potential surface. We assume infinite precision in our observation of the state space. The first calculation assumes that the diffusion matrix is invertible and drift is analytic; the second assumes that the drift term is linear, but allows for a noninvertible diffusion matrix. All calculations assume that the time between measurements is nonzero, but arbitrarily small, and that all derived information anatomy quantities are finite at finite temporal coarse-graining.
There are alternative ways to frame information analyses of continuous stochastic processes [24]. The one we take is rather prosaic, paralleling the “physics” approach laid out by Gaspard and Wang [25], who coarse-grain time at a finite, but small, time scale τ and state-space at a similar spatial scale ε. This discretizes the calculations and then one takes the limits τ → 0 and ε → 0. Crucially, the limits often reveal divergences in the informational quantities. For example, it is well known that the (ε, τ )-entropy of a broad family of continuous stochastic processes diverges [25]. However, as Gaspard and Wang demonstrate and as is familiar in other fundamental physics domains, the form of the divergences captures important structural properties. The main deviation here from their approach is that we employ the Shannon differential entropy to side-step state-space (ε) coarse-graining.
An alternative, and insightful, framing considers the divergences to be unnatural; in particular, with naive coarse-graining, it is difficult to establish ergodic theorems key to information theory. In this view, the main concern translates into a search for tractable definitions of information measures that finitely quantify information processing in continuous stochastic systems. To address divergences, one investigates a given stochastic process relative to Brownian motion. In a crude sense, the known Brownian base case carries the divergences. To factor them out of the given process, one employs Girsanov’s theorem to transform the given process to a canonical Brownian motion with the same diffusion [26]. Properties of the transformation then characterize the given process’s informational properties; for example, giving a relative entropy rate. This strikes us as an important avenue for future investigation; one that, to be clear, is not yet completed, as far as we know, and one that eventually will be related to the more prosaic, physics framing that we address here.
To get started, background is given in Section 2. Results are presented in Section 3 and stated more succinctly in Table 1. To illustrate how to apply those formulae, we calculate the information anatomy of the stochastic cusp catastrophe in Section 4.1 and of coupled particles diffusing in a heat bath in Section 4.2.
We provide a suite of appendices that are home to technical details necessary for completeness, but that would otherwise distract. Several appendices also draw out implications of information anatomy analysis. Appendix A shows that the information anatomy of a Markov system requires looking only one time step into the future and past, as expected from a similar calculation in [6]. Appendix B establishes that the causal states of a first-order Langevin equation with an analytic drift are isomorphic to the present position. Appendix C justifies why, given an infinitesimal time resolution τ, the conditional entropy of the measurement at a future time step given the present measurement can be approximated arbitrarily well by using a linearized drift term when the diffusion matrix is invertible. Appendix D then demonstrates that the entropy of the Green’s function of a linear Langevin equation with a noninvertible diffusion matrix differs from that when the diffusion matrix is invertible. Finally, Appendix E applies the formulae in Appendices A–C to explore estimates of the time-local predictive information and related alternatives, used as optimization principles to choose action policies for adaptive autonomous agents [12].
2. Background
Let us first recall the information anatomy analysis of discrete-time, discrete-state processes introduced in [6]. The main object of study is a process ℘: the list of all of a system’s behaviors or realizations {… x−2, x−1, x0, x1, …} and their probabilities, specified by the joint distribution Pr(…X−2, X−1, X0, X1, …). We denote a contiguous chain of random variables as X0:L = X0X1 · · ·XL−1. We assume the process is ergodic and stationary (Pr(X0:L) = Pr(Xt:L+t) for all t ∈ ℤ) and the measurement symbols range over a finite alphabet: x ∈
![Entropy 16 04713f4]() . In this setting, the present X0 is the random variable measured at t = 0, the past is the chain X:0 = …X−2X−1 leading up the present and the future is the chain following the present X1: = X1X2 · · ·. (We suppress the infinite index in these.)
. In this setting, the present X0 is the random variable measured at t = 0, the past is the chain X:0 = …X−2X−1 leading up the present and the future is the chain following the present X1: = X1X2 · · ·. (We suppress the infinite index in these.)
 . In this setting, the present X0 is the random variable measured at t = 0, the past is the chain X:0 = …X−2X−1 leading up the present and the future is the chain following the present X1: = X1X2 · · ·. (We suppress the infinite index in these.)
. In this setting, the present X0 is the random variable measured at t = 0, the past is the chain X:0 = …X−2X−1 leading up the present and the future is the chain following the present X1: = X1X2 · · ·. (We suppress the infinite index in these.)Shannon’s various information quantities—entropy, conditional entropy, mutual information, and the like—when applied to time series are functions of the joint distributions Pr(X0:L). Importantly, they define an algebra of information measures for a given set of random variables [27]. James et al. [6] used this to show that the past and future partition the single-measurement entropy H(X0) into several measure-theoretic atoms. These include the ephemeral information:
which measures the uncertainty of the present knowing the past and future; the bound information:
which is the information shared between present, and future conditioned on past; and the enigmatic information:
which is the co-information between past, present and future.
For a stationary time series, the bound information is also the shared information between present and past conditioned on the future:
One can also consider the amount of predictable information not captured by the present:
which is called the elusive information. It measures the amount of past-future correlation not contained in the present. It is nonzero if the process has “hidden states” and is therefore quite sensitive to how the state space is “observed” or coarse-grained.
The total information in the future predictable from the past (or vice versa) is the excess entropy:
The process’s Shannon entropy rate hμ can also be written as a sum of atoms:
Thus, a portion of the information (hμ) a process spontaneously generates is thrown away (rμ) and a portion is actively stored (bμ). Putting these observations together gives the information anatomy of a single measurement:
These quantities were originally defined for stationary processes, but easily carry over to a nonstationary process of finite Markov order. (See Appendix A.)
The burden of the following is to analyze the limit from the discrete-time, discrete-value processes just discussed to continuous-time, continuous-value processes. Suppose that observations are made at very small intervals of duration τ. Then, the observation at time tn = nτ is now labeled Xnτ, and the past X:0 is now denoted …X−2τX−τ instead of …X−2X−1. Rather than entropy or mutual information per observed symbol, as in the discrete time setting, we define an entropy or mutual information per elapsed time unit; that is, informational rates. A step in this direction is to normalize the information measures defined above by the observation interval:
and
We normalize the entropy H[X0] of a single symbol by the time resolution τ to preserve the form of the information-theoretic relationship given in Equation (1). In doing so, we no longer interpret H0(τ ) as the entropy of a single measurement symbol, but rather as the number of bits per unit time required to encode the time series in a model-free manner.
In contrast with the original information anatomy interpretation given in [6], we think of hμ(τ) as the minimal achievable coding rate, were we to build a maximally predictive model. In this time normalization, terms of order τ or higher are ignored. These definitions then lead to the τ-entropy rate familiar in the discrete-time, continuous-value setting [2,25,28]:
More natural definitions of these quantities might involve a fully continuous-time development that avoids the log τ divergences of the τ entropy rate [29]. As noted in the Introduction, however, we leave alternative developments for the future. When considering continuous-value processes, we use the differential entropy, thereby regularizing away the log ε divergences seen in the (ε, τ )-entropy rate [25].
Figures 1(a) and 1(b) give information diagrams that illustrate the algebra of the information measure atoms just defined. There, the entropy of a set is the sum of the entropy of its atoms. This reveals several useful linear dependencies that were originally noted in [6]:
and
For a Markov process, illustrated in Figure 1b, the elusive information vanishes:
Therefore, in this case, if we find expressions for H0(τ), hμ(τ) and bμ(τ), then we can find rμ(τ), qμ(τ) and E/τ via:
and
3. Information Anatomy of Stochastic Dynamical Systems
To determine a process’s information anatomy, one must calculate entropies and conditional entropies of the joint probability distribution of the entire past, the present, and the entire future. In the general case, this is challenging. However, since the first-order Langevin equations we consider are Markov, we have:
and
(Appendix A provides the derivation.) Therefore, to calculate a Markov process’s information anatomy, we need only the joint probability distribution of three successive measurements instead of the joint probability distribution of the present and semi-infinite past and future. To further simplify the calculation of conditional entropies, we assume that τ is small enough that the entropy of the Green’s function—i.e., the transition probabilities P(x′, t + τ |x, t)—is well approximated by the entropy of a corresponding Gaussian. This is exactly true for a linear Langevin equation. For a nonlinear Langevin equation, the Gaussian approximation is valid in the limit of infinitesimal τ. (Appendix C calculates small-τ approximations for the variance of this Gaussian.) We do not approximate the stationary distribution of a nonlinear Langevin equation by a Gaussian, however, and this means that the joint probability distribution over successive measurements is in general highly non-Gaussian. Finally, we assume that all derived information anatomy quantities are finite (at finite τ) and that there is a normalizable stationary probability distribution.
Appendix B shows that, for first-order Langevin dynamics, the single-measurement entropy H[X0] is the process’s statistical complexity Cμ [3,4]. The result is that the information anatomy analysis decomposes this causal-state information into:
- that useful for prediction or retrodiction beyond the information provided by the causal states at the previous time step—the bound information bμ;
- that useful for both prediction and retrodiction—the co-information qμ; and
- that useless for both prediction and retrodiction—the ephemeral information rate rμ.
This is a similar, but finer Cμ decomposition than considered in [30]. There, and more generally, Cμ = E + χ. That is, the state information consists of that shared with the future (E) and information not shared with the future, but that must be stored to implement optimal prediction—the crypticity χ [31]. Together with these observations, Equation (4) reminds us that χ = hμ for Markov processes, as originally noted for finite-range one-dimensional spin systems [32].
3.1. Nonlinear Langevin Dynamics
Consider an n-dimensional nonlinear Langevin equation:
where x ∈ ℝn, U(x) is an analytic potential function and η(t) is zero-mean white noise with diffusion matrix D: 〈ηi(t)〉 = 0 and 〈ηi(t)ηj(t′)〉 = Dijδ(t−t′). The diffusion coefficients Dij = Dji are assumed to be independent of x and such that det D ≠ 0. The following (well known) stationary distribution is derived by converting the stochastic differential equation into its Fokker–Planck equation form:
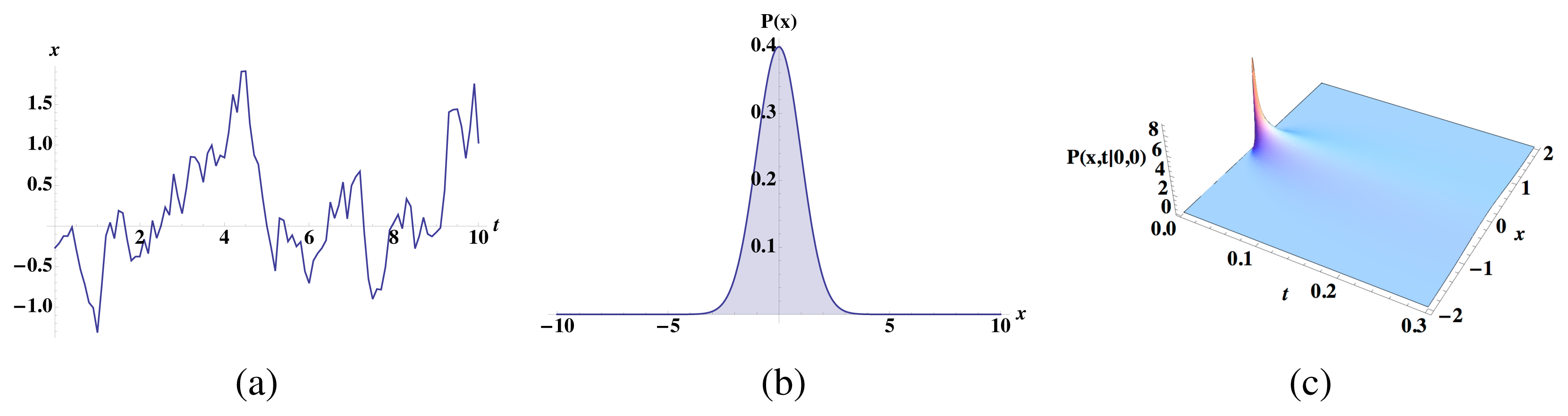
where Z = ∫ e−2U(x)dx. We assume that this is the stationary probability distribution experienced by the particle and that it is normalizable: Z < ∞. (See Figure 2 for simulation results in one dimension.)
The time-discretization normalized entropy of a measurement is:
The conditional entropies H[Xτ |X0] and H[Xτ |X−τ] in Equations (5) and (6) can be calculated, simplifying if the conditional probabilities Pr(Xτ |X0) and Pr(Xτ |X−τ) are Gaussians, using:
and
This yields:
and
Appendix C gives a plausibility proof that the conditional distributions Pr(Xτ |X0) and Pr(Xτ |X−τ ) are Gaussian to o(τ) over a region of ℝn with measure arbitrarily close to one. The entropies of these Gaussians are calculable to leading and subleading order in τ using a linearized version of the nonlinear Langevin equation about the initial position:
where A(x′) is a matrix with entries (A(x′))ij = ∂(D∇U)j/∂xi. (This is similar, but not identical to the approximation used in [12]. Appendix E comments on the differences.) From Appendix C, we have that:
and, similarly,
Substituting Equations (11) and (12) into Equations (9) and (10), respectively, gives, with some algebra:
and:
Substituting Equation (14) into Equation (5), we find that:
The leading order term is recognizable as an (ε, τ)-entropy rate of the Ornstein–Uhlenbeck process [25], except that the ε has been regularized away, since we used Shannon’s differential entropy. Substituting Equations (13) and (14) into Equation (6), we find the bound information rate:
Thus, the rate of active information storage depends on the dimension of the state space to leading order in τ, but its nondivergent part depends on the average curvature of the potential.
From these quantities, all other anatomy measures follow. Substituting Equations (15) and (16) into Equation (3), we find that the ephemeral information is:
Unsurprisingly, the dissipated information—that entropy created in the present useful for neither predicting nor retrodicting—depends only on the noisiness of the dynamics and not on the drift.
Finally, the enigmatic information—that shared between past, future, and present—follows by substituting Equations (8)–(16) into Equation (2):
It is interesting to consider how qμ changes as the stochasticity of the system increases: the stationary distribution ρeq(x) flattens out, leading to an unbounded increase in H0. This is counteracted by an unbounded increase in the entropy rate.
We can also bound the bound information rate when ∇U grows more slowly than e−2U with ||x||. Then, integration by parts applied to Equation (16) gives:
When D is positive semidefinite, with D = v⊤ v for some vector v, then:
Therefore, bμ(τ) is maximized when the potential well is as flat as possible, while maintaining Z < ∞.
3.2. Linear Langevin Equation with Noninvertible Diffusion
What if the invertibility of the diffusion matrix is relaxed? In particular, do we still have qualitatively the same information anatomy if a subsystem of the stochastic dynamical system evolves deterministically? How does this affect the information generation and storage properties? To this end, suppose
with x ∈ ℝk and m = dim(xd), where xd evolves deterministically and xn stochastically:
Again, η(t) is white noise with 〈η(t)〉 = 0 and 〈η(t)η(t′)⊤ 〉 = Dδ(t − t′), where D is invertible. Taken together, though, this is a linear Langevin equation for x with a noninvertible diffusion matrix. Naively assuming that the deterministic subsystem evolves with a small amount of noise, Equation (16) would apply and give, for example, to O(τ):
However, this assumption is incorrect; the noiseless limit is singular.
Since Equations (18) and (19) specify a linear Langevin equation for x, its Green’s function is Gaussian. For simplicity’s sake, we assume that
is invertible, though it is certainly possible to derive more complicated expressions for information anatomy quantities if this does not hold. From Appendix D, to O(τ) the entropy rate is:
and the bound information is:
These answers are very different from those derived assuming that x’s deterministic subsystem xd evolves with an infinitesimal amount of noise. The bound information in Equation (20) differs from that found from naive application of Equation (16), because the pre-factor for the log 2/τ divergence is (n + m)/2+m rather than (n+m)/2. That is, the difference counts the dimension m of the deterministically evolving state space xd. Thus, the deterministic subsystem allows for the active storage of more of the spontaneously generated stochasticity.
The ephemeral information in Equation (21) differs from a naive application of Equation (17) in two new ways. First, the expression in Equation (21) has an additional O(1/τ) factor that is linearly proportional to the dimension m of the deterministic subsystem. Second, the term
can be interpreted by supposing that
is the effective diffusion matrix felt by the deterministically evolving states.
These information anatomy quantities are therefore sensitive to the process’s underlying noise architecture.
4. Examples
To illustrate how the information measures are helpful and interesting summaries of nonlinear Langevin dynamics, let us consider several examples.
4.1. Stochastic Gradient Descent in One Dimension
Consider a first-order nonlinear Langevin dynamics for x ∈ ℝ in which:
where 〈η(t)〉 = 0 and 〈η(t)η(t′)〉 = 2Dδ(t − t′). The stationary distribution is:
with Z a normalization factor:
We require that Z < ∞.
This process’s elusive information is zero, and the ephemeral information rate is the strength of the noise. However, the bound information is:
Using integration by parts, this can be rewritten:
Therefore, bμ is sensitive to the average curvature of the potential or, equivalently, to the average squared drift normalized by the diffusion constant.
In the deterministic limit, this expression simplifies. Suppose that
are the global minima of the potential function:
, for i = 1, …, m. It follows that
. Applying this limit to Equation (22), we have:
This limit is a little strange. If D = 0 exactly, so that we have deterministic gradient descent, then the stationary time series consists of a single measurement. The information anatomy becomes rather trivial. There is no uncertainty in the present measurement, and the past, present, and future share no information. If D is nonzero, no matter how small, however, then there is finite uncertainty in a measurement, and the past, present and future share information with one another.
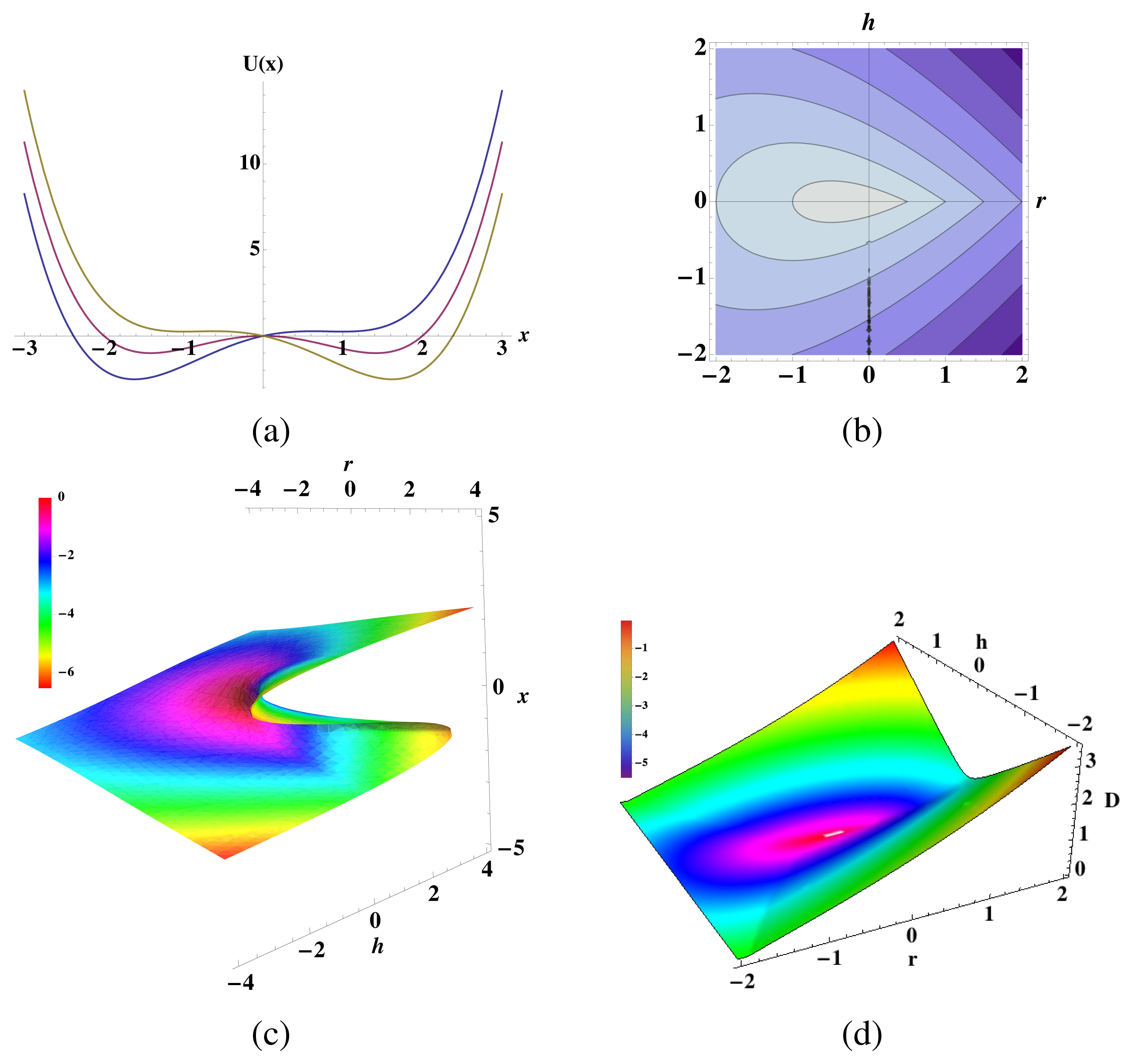
As a concrete example, consider the canonical form for the cusp catastrophe [33]:
with additive noise where 〈η(t)η(t′)〉 = 2Dδ(t− t′). The potential function is
, and the corresponding bound information in the noiseless limit is:
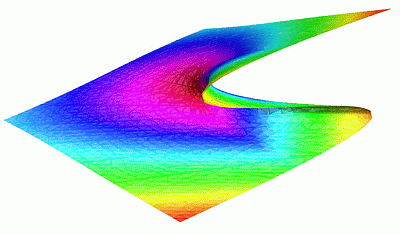
The global minimum x*(r, h) is not everywhere differentiable in r and h, and this appears also in bμ(τ, r, h). See Figure 3. The contour of nondifferentiability is h = 0 for r > 0. Along the contour, the potential is symmetric, there are suddenly two global minima of U(x) with
, and so, the sign of x* changes discontinuously across h = 0.
Interestingly, for double-well potentials and asymmetric single-well potentials, bμ(τ) is maximized at a nonzero noise level D > 0. This is counterintuitive: adding noise only serves to decrease the process’s predictability. However, adding noise in the present affects the future in a way that cannot be predicted from the past. Since bμ(τ) measures the amount of information shared between the present and future not shared with the past, there is a level of stochasticity that maximizes bμ(τ) for some values of r and h. This is shown in Figure 3c.
4.2. Particles Diffusing in a Heat Bath
Suppose N particles with positions x1, …, xN and masses m1, …, mN diffuse according to the potential function U(x1, …, xN) in a heat bath of temperature T. Let x denote the vector of concatenated particle positions. When the inertial terms mid2xi/dt2 are negligible, an overdamped Langevin equation can be used to approximate the particles’ trajectories:
M is a diagonal matrix whose entries are the particle masses, and the parameter γ is a friction coefficient that controls how strongly the particles couple to the heat bath. The stationary distribution of positions x is the Boltzmann distribution:
where Z is the partition function:
From Equation (8), the normalized single-measurement entropy is:
where:
which is simply proportional to the familiar definition of entropy in physics.
For notational ease, let m̄ denote the geometric mean of the masses:
ki the effective “spring constant” for the ith particle:
and ωi the effective “oscillation frequency” for the ith particle:
From Equation (15), the entropy rate is:
From Equation (16), the bound information is to similar order:
From Equation (17), the ephemeral information rate is:
Several information measures appear dimensionally incorrect. This is a perennial concern when calculating the differential entropy of random variables that themselves have units. The probability density over those variables also has a dimension, and this leads to differential entropies that involve the log of a value with dimension. Implicitly, however, we chose a standard unit system, such that all quantities are dimensionless.
All of these quantities are extensive in N. The normalized entropy per measurement H0 is proportional to the Boltzmann entropy by a factor of kB/τ. The entropy rate hμ(τ) and ephemeral information rμ(τ) increase logarithmically with the mean squared velocity
. The bound information bμ(τ) increases when there is a larger γ. That is, it increases when there is stronger coupling between the particles and the heat bath or when there is a smaller average oscillation frequency
. Since γ ≥ 0 and
, the bound information is bounded above by
. To achieve this upper bound, the potential U(x) must be “flattened out” to decrease ki, as described in Section 3.
There are alternative models for coupled particles diffusing in a heat bath, and there is no guarantee that even the qualitative conclusions here hold true when particle trajectories are modeled according to a second-order Langevin equation, for instance.
5. Conclusions
Our calculations led to general formulae for the information anatomy of stochastic equilibria in simple, familiar systems when the time discretization was very small. We considered a first-order nonlinear Langevin equation with a normalizable stationary distribution, invertible diffusion matrix, and analytic drift. We do not expect the expressions in Section 3 to hold for larger time discretizations, though Gaussian approximations could be used to upper bound conditional entropies more generally. We also considered first-order linear Langevin equations with normalizable stationary distribution and a noninvertible diffusion matrix in Section 3.2.
An important technical consideration is that the information anatomy of Langevin stochastic dynamics is likely not unique, just as the pre-factors for the (ε, τ)-entropy rate of an Ornstein–Uhlenbeck process depend on definition and approximation procedure [25,28]. However, further calculations give us reason to believe that the qualitative scaling seen with drift and diffusion holds regardless of the approximation method. This parallels the way that the (ε, τ)-entropy rate estimates for an Ornstein–Uhlenbeck process all increase with the diffusion coefficient. That said, a complete understanding of how information anatomy estimates vary with technique requires further study; alternatives to which the Introduction alluded. We hope that our results are sufficiently compelling to motivate further efforts.
With this caveat in mind, let us focus on qualitative rather than quantitative conclusions. Even though the entropy rate is typically viewed as a measure of randomness, some of that randomness is useful for prediction, that is, the bound information (shared between present and future, but not contained in the past), and we showed that it is sensitive to drift and the diffusion matrix. In contrast, we showed that the ephemeral information—information in the present useless for predicting or retrodicting—is sensitive only to the diffusion and not the drift. In short, for stochastic equilibria, the entropy rate consists of a quantity (ephemeral information) that has to do with a process’s inherent noisiness and a quantity (bound information) that has only to do with the underlying process regularities.
A key lesson is that information anatomy measures are sensitive to process organization. Section 3.2 showed that the divergent components of the information anatomy of linear Langevin dynamics changes discontinuously whenever one of the diffusion coefficients vanishes. This sensitivity to underlying process structure could also be a feature rather than a defect. For instance, if we know that the underlying process is a first-order linear Langevin equation, then one could infer the dimension of the deterministically evolving state space by comparing known τ-scaling relations in Section 3 with empirically determined scaling relations.
This brings us to discuss what was learned from the several example applications. Section 4.1 showed that the bound information picks up different features than one finds in a bifurcation diagram. In the noiseless limit, the cusp catastrophe bμ is nondifferentiable on the line h = 0 for r ≥ 0, because the location of the global minimum of the potential function changes discontinuously across that contour. Moreover, this is not related to the bifurcation contour
[33] where the number of equilibria changes from two to one or vice versa, which has no apparent signature in the bound information. However, in these calculations, we did not avoid the “ultraviolet catastrophe”. We embraced it, since we could then evaluate the information anatomy for general nonlinear Langevin equations by linearizing. If one evaluates the information anatomies of these types of stochastic dynamics when the time discretization is not infinitesimal, however, then signatures of bifurcations should show up in the bound information as they do for the finite-time predictable information or excess entropy [16,34].
Section 4.2 calculated the information anatomy of coupled particles in a heat bath. Historically, statistical physics has been primarily concerned with H0, the entropy of a single measurement symbol, since its changes are proportional to heat loss [35]. However, the point of this example is that alternative information-theoretic quantities capture other behavioral properties of particles diffusing in a heat bath. As an application of this analysis, it will be worth exploring how the information anatomy measures reflect the trade-off between stable information storage and heat loss in the context of Maxwell-like demons [36].
To close our discussion of applications, we briefly mention the use of information measures to express optimization principles that guide adaptive agents. A Markov process’s bound information has been used as an optimization measure called the time-local predictive information (TiPi) [12]. Moreover, the class of systems used there and for which TiPi was calculated are exactly the first-order nonlinear Langevin dynamics analyzed here. Due to the similarities in setup and approach, Appendix E compares alternative TiPi measures. Generally, an agent that wishes to maximize its TiPi will be driven into unstable regions of the potential landscape on which it diffuses. However, Appendix E shows that the similarly motivated, but alternative, optimization measures lead to different adaptive strategies. More investigation is required to compare such strategies to those seen in biological agents before general principles of adaptive behavior will be understood.
Acknowledgments
The authors are indebted to one of the anonymous reviewers for a particularly detailed critique and also for pointing them to Girsanov transformations. The authors thank the Santa Fe Institute for its hospitality during visits. J.P.C. is a Santa Fe Institute External Faculty member. This material is based upon work supported by, or in part by, the U. S. Army Research Laboratory and the U. S. Army Research Office under contracts W911NF-13-1-0390 and W911NF-12-1-0234. S.M. was funded by a National Science Foundation Graduate Student Research Fellowship and the U.C. Berkeley Chancellor’s Fellowship.
Appendix
A. Information Anatomy of a Markov Process
If the system at hand is Markov, then the information anatomy simplifies tremendously since one need only consider single time steps into the future and into the past. As a result, many of the Markov formulae are special cases of those developed in [6] for more complex processes, but are derived here for completeness.
For notational ease, we use the discrete-time notation in which Xt:t′ is the random variable of measurements Xt, Xt+1,..., Xt′−1. For a Markov process the immediately preceding observation “shields” the future from the past:
Additionally, it becomes relatively easy to calculate the information anatomy measures, since the sequence probabilities simplify:
For example, the entropy rate becomes:
Moreover, all information shared between the past and future goes through the present:
Finally, the mutual information between the present and the future conditioned on the past (bound information) is:
This equality is evident from the information diagram of Figure 1b. The other information anatomy measures follow from bμ and hμ via identities given in Section 2:
and
The excess entropy follows as the sum:
As stated in Section 2, to normalize these measures as rates (entropies per unit time rather than per measurement), we simply divide the above by the time discretization τ:
If the system is Markov, one only needs the joint distribution of three successive measurements to calculate the information anatomy. Thus, the formulae derived here also can be used as time-local measures for nonstationary dynamics despite the subtleties of defining a measure over bi-infinite time series in general [37]. Similar manipulations can be applied more generally to find the information anatomy of finite-order Markov processes.
B. Statistical Complexity is the Entropy of a Measurement
The statistical complexity Cμ is the entropy of the probability distribution over causal states. Causal states themselves are groupings of pasts that are partitioned according to the predictive equivalence relation ~ε [4]:
Although causal states can be difficult to determine for complex processes, they are particularly easy for Markov processes (and finite-order Markov processes). Recall that a Markov process is defined by single-time step shielding:
It follows that:
Therefore, for a Markov process, groupings of pasts in which only the last measurement is recorded constitute at least a prescient partition. If:
then we can conclude that the causal states are simply groupings of pasts with the same last measurement: ε(x:0) = x−1. In that case, the causal state space
![Entropy 16 04713f5]() is isomorphic to the alphabet of the process
is isomorphic to the alphabet of the process
![Entropy 16 04713f4]() and the statistical complexity is the entropy of a single measurement: Cμ = H[X0].
and the statistical complexity is the entropy of a single measurement: Cμ = H[X0].
 is isomorphic to the alphabet of the process
and the statistical complexity is the entropy of a single measurement: Cμ = H[X0].
is isomorphic to the alphabet of the process
and the statistical complexity is the entropy of a single measurement: Cμ = H[X0].First-order Langevin equations generate Markov time series. Our claim, then, is that the stochastic differential equations considered here produce time series for which:
Therefore, the causal states are isomorphic to the present measurement X0, and the statistical complexity is Cμ = H[X0]. Implicit in these calculations is an assumption that the transition probabilities Pr(X0|X−τ) for a given stochastic differential equation exist and are unique, which is satisfied, since the drift term is analytic [38].
For intuition, consider linear Langevin dynamics for an Ornstein–Uhlenbeck process:
As described in Appendix D and many other places (e.g., [21]), the transition probability density Pr(Xt|X0 = x) is a Gaussian:
For Pr(Xt|X0 = x) = Pr(Xt|X0 = x′), the means and variances of the above probability distribution must match, meaning that eBtx = eBtx′ ⇒ x = x′. Therefore, for an Ornstein–Uhlenbeck process, the causal states are indeed isomorphic to the present measurement and the statistical complexity is H[X0]. The key here is that although Pr(Xt|X0 = x) may quickly forget its initial condition x, for any finite-time discretization, the transition probability Pr(Xt|X0 = x) still depends on x.
In the more general case, we have a nonlinear Langevin equation:
where the stationary distribution ρeq exists and is normalizable. Our goal is to show that if Pr(Xt|X0 = x) = Pr(Xt|X0 = x′), then x = x′. The transition probability Pr(Xt = x|X0 = x′) is a solution to the corresponding Fokker–Planck equation:
with initial condition ρ(x, 0) = δ(x − x′). As in [38], we can use an eigenfunction expansion to show that ρ(x, t|x′, 0) cannot equal ρ(x, t|x″, 0) unless x′ = x″ for finite time t. Therefore, Pr(Xt|X0 = x′) = Pr(Xt|X0 = x″) ⇒ x′ = x″. This implies that the causal states are again isomorphic to the present measurement and the statistical complexity is Cμ = H[X0].
To summarize, this application of computational mechanics [3,4] to Langevin stochastic dynamics shows that the entropy of a single measurement is also the process’s statistical complexity Cμ. Recall that the latter is the entropy of the probability distribution over the causal states which, in turn, are groupings of pasts that lead to equivalent predictions of future behavior. Therefore, for the stochastic differential equations considered here, causal states simply track the last measured position.
What the information anatomy analysis reveals, then, is that not all of the information required for optimal prediction is predictable information about the future. In other words, Langevin stochastic dynamics are inherently cryptic [30,31]. Unfortunately, as is so often the case, the necessary and the apparent come packaged together and cannot be teased apart without effort.
C. Approximating the Short-Time Propagator Entropy
The study of stochastic differential equations and short-time propagator approximations is mathematically rich and, as noted in the introduction, the application to nonlinear diffusion has a long history [21]. What follows is a brief sketch, not a rigorous proof, that glosses over important pathological cases.
Consider the nonlinear Langevin equation:
with driving noise satisfying 〈η(t)〉 = 0 and 〈η(t)η⊤ (t′)〉 = Dδ(t − t′), where det D ≠ 0. Let p(x|x′) be the transition probability Pr(Xt = x|X0 = x′) for the system in Equation (A1). From arguments in [38], it exists and is uniquely defined. Let q(x|x′) be a Gaussian with the same mean and variance as p(x′|x).
We show that H[p] = H[q] + o(τ) where H[p] = −∫ p(x|x′) log p(x|x′)dx and H[q] = −∫ q(x|x′) log q(x|x′)dx. Note that here, and in the following, we suppress notation for the dependence of these quantities on x′, using the shorthand H[p] ≡ H[X|X′ = x′] and the like. First, consider:
Since q(x|x′) is the maximum entropy distribution consistent with the mean and the variance of p(x|x′), averages of log q(x|x′) with respect to p are the same as those with respect to q. Specifically, if x̄ is the mean:
and if C(x′) is the variance:
then q is the normal distribution consistent with that mean and variance:
From this, we derive:
Since the mean and variance for p and q are consistent, we have:
and, thus:
We wish to show that DKL[p||q] is at least of o(τ). Then, we also want to show that H[q] can be determined to o(τ) from the linearized Langevin equation:
Then, we would be able to approximate H[p] to o(τ) by H[qlinearized], where qlinearized is the transition probability that results when we locally linearize the drift.
Our strategy is to construct a series expansion for the moments of p in the timescale τ, as in [39]. Immediately, with that statement, we run into a problem. Moments do not uniquely specify a distribution unless an additional condition (e.g., Carleman’s condition) is satisfied. We will address this issue at the end of this Appendix. The second issue we find is that the sum of higher-order terms in the moment expansion is often divergent, but we have circumvented this limitation by working with infinitesimal time discretizations.
The Kullback–Leibler divergence is invariant to changes in the coordinate system and, for reasons that become apparent later, it is useful to move to the parametrization
. In a slight abuse of notation, p(z|x′) and q(z|x′) will be used to denote the re-parametrized distributions p(x|x′) and q(x|x′). Our moment expansion will show that all moments of p(z|x′) and q(z|x′) differ by a quantity that is at most of O(τ3/2), which implies that p(z|x′) = q(z|x′) + τ3/2δq, where δq is at most of O(1) in τ. From that, it would follow that DKL[q + τ3/2δq||q] = (τ3/2)2[q], where [q] is the Fisher information of a Gaussian (and hence bounded) and that H[p] = H[q] to O(τ3). That same moment expansion will show that the covariance and mean of p differ from the covariance and mean of qlinearized by a correction term of at most O(τ2). From this, it follows that H[q] is H[qlinearized] to o(τ). The bottleneck in this approximation scheme is not approximating the transition probability as a Gaussian, but rather approximating the covariance of that Gaussian by the covariance of the locally linearized stochastic differential equation.
For intuition and simplicity, we start with the one-dimensional example. This is similar in flavor to the approach in [39], but our point differs: we wish to understand how well we can approximate the full system with a linearized drift term. The stochastic differential equation for x ∈ ℝ is:
with noise as above. The mean 〈x〉 evolves according to:
Using an Ito discretization scheme:
where dη(t) ~
![Entropy 16 04713f6]() (0, DΔt), we have:
(0, DΔt), we have:
 (0, DΔt), we have:
(0, DΔt), we have:From these, we derive evolution equations for the moments 〈(x − 〈x〉)n〉 for n ≥ 2:
Substituting Equation (A2) into the above and simplifying leads to:
Now, we re-express:
where δ is at most O(1) in x − x′. Then:
When μ′(x′) = 0 and δ = 0 the Green’s function is a Gaussian with zero mean and variance Dt, so that 〈(x − 〈x〉)n〉 ∝ (Dt)n/2. Inspired by this base case, we consider the moments of the variable
:
We expand 〈zn〉 in terms of t, since we are interested in the small-t limit:
In terms of these coefficients, we have:
Substituting Equations (A6) and (A7) into Equation (A5) and matching O(1/t) terms,
terms, and so on, yields:
and
for O(1/t),
, and O(1), respectively. Note that none of Cn, αn, or βn have information about δ, which encapsulates higher-order drift nonlinearities. The
term finally has information about δ:
Interestingly, this implies that any dependencies of the moments on δ are O(t3/2), at most. Equations (A8)–(A10) can be solved with the following initial conditions:
and, by construction:
Then, Cn = αn = βn = 0 for n odd, and αn = 0 for n even, as well. Some algebra shows that:
A Gaussian with mean zero and variance
would also have Cn = αn = βn = 0 for n odd, αn = 0 for n even, and
. Thus, the moments zn of p(z|x′) are consistent with the moments of q(z|x′) to O(t3/2). Additionally, as described earlier, those moments are consistent with the moments of the linearized Langevin equation to o(t). From prior logic, H[p] can be approximated to o(t) by
.
The n-dimensional case follows the same principle, but the calculations are more arduous. We start with the stochastic differential equation for x ∈ ℝn:
with the noise as before. The initial condition is x(t = 0) = x′. Since we are interested not only in whether the distribution is effectively Gaussian, but also in how important the nonlinearities of μ(x) are, we re-express μ(x) as:
where Aij(x′) = ∂μj/∂xi:
and δijk is at most of O(1) in ||x − x′||. The evolution equation for the means is:
Using an Ito discretization scheme with time step Δt:
where dη(t) ~
![Entropy 16 04713f6]() (0, DΔt). From this, we find evolution equations for the moments of x. As before, we subtract the mean:
(0, DΔt). From this, we find evolution equations for the moments of x. As before, we subtract the mean:
(0, DΔt). From this, we find evolution equations for the moments of x. As before, we subtract the mean:For notational ease, let σ(1),..., σ(m) be a list of integers in the set {1,..., n} where n is the dimension of x; repeats are allowed. We want an evolution equation for Cov(xσ(1),..., xσ(m)):
Cov(xσ(k):k≠i,j) denotes the covariance of the variables xσ(k) for all k in the integer list 1,..., m with the restriction that we ignore k = i and k = j. We have a base case: when f = 0, A = 0 and Dij = Dδi,j, the Green’s function is a Gaussian with variance
. Therefore, again, we switch to variable
and calculate its covariance evolution, similarly to Equation (A7), where we employ Equation (A11) to find the appropriate t scaling of the nonlinear f term:
We expand the covariances as a series in
, assuming that they are indeed expressible for short times using such an expansion:
As before, we substitute the above series expansion into Equation (A14) and match terms of
, and O(1) to get:
and
The base case is that, by definition, 〈z〉 = 0 and 〈z0〉 = 1. This implies that βσ(1),...,σ(m) = 0 for all lists {σ(i): i = 1,..., m}. Since all moments are determined to at least O(t) by just the linearized version of the nonlinear Langevin equation and since linear Langevin equations have Gaussian Green’s functions, it follows that the Green’s function for the nonlinear Langevin equation is Gaussian to O(t). Some algebra shows that the variance of the linearized Langevin equation’s Green’s function is:
If D is invertible, the conditional entropy is then:
If the matrix D is not invertible because det D = 0, then we only have the leading order term in t of the entropy H[p] and we cannot draw any conclusions about the O(1) term in any of the information anatomy quantities. This becomes very clear by example in Appendix D.
Now, we return to the question of whether or not we can circumvent the issue of using a moment expansion to approximate entropies of a probability distribution function whose support is not bounded. The key idea is that we are only interested in potential functions U(x) that grow quickly enough with ||x||, such that the partition function Z = ∫ e−U(x)dx is normalizable. This suggests that we can approximate the potential function arbitrarily well by a potential function whose support is bounded such that transition probabilities are uniquely determined by moments. Consider, for instance, the sequence of potentials UL(x) defined by:
By construction, the transition probabilities have support over the bounded region ||x|| ≤ L. For any of these potentials, the moment expansion above uniquely determines the transition probability distribution. Therefore, the manipulations above give a corresponding sequence of conditional entropies:
where:
If limL→∞ H(L)[Xt+τ|Xt] = H[Xt+τ|Xt] to o(τ), then we can claim that the formulae in the main text applies, even when the support of the transition probability distribution function is unbounded. To o(τ), we see that:
Thus, we want to know the conditions under which the latter limit converges. In the main text, we limited ourselves to certain types of potential functions, stipulating that Z = ∫ℝn e−U(x)dx < ∞, so that there is a normalizable equilibrium probability distribution. We also stipulate that
, so that the bound information rate would be finite. Hence, both limL→∞ ∫||x||≤L e−U(x)dx = Z < ∞and limL→∞ ∫||x||≤L e−U(x)tr(A(x))dx = ∫ℝn e−U(x)tr(A(x))dx < ∞. Since both of these converge to finite, nonzero values, the ratio of the limit is the limit of the ratios, and we have:
Therefore, this sketch suggests that we can circumvent concerns about using moment expansions. Again, we require that the stationary probability distribution and bound information rate exist and are finite.
D. Linear Langevin Dynamics with Noninvertible Diffusion Matrix
If the stochastic differential equation is linear:
where η(t) is white noise 〈η(t)〉 = 0 and 〈η(t)η(t′)⊤ 〉 = Dδ(t−t′), then we can solve it in terms of η(t) as follows:
yielding:
Since η(t) is white, x(t) is a Gaussian random variable with mean:
and variance:
Since the Green’s function is Gaussian for all time (not approximately in the short time limit) and since the variance of this Gaussian does not depend on the initial state, we can calculate the conditional entropies H[Xt|X0] via:
The goal here is to calculate this quantity for small t when the matrix D is not invertible. We assume that it has the block matrix form:
where
. Let B have the corresponding block matrix form:
(Recall subscript d stands for deterministic and subscript n for noisy.) We can rewrite the variance in Equation (A21) as a power series in t:
Since we are concerned about the small-t limit, we consider only the first few terms of this power series and, for reasons that will become clear, we write all steps in block-matrix form. The first term, which is of O(t), is the usual:
The second term, of O(t2), has the form:
The third term, of O(t3), has the form:
We place a dash in the lower right block matrix entry, since, as it turns out, it does not matter for this calculation. The fourth term, of O(t4), has the form:
Similar to the Q3 calculation, we care only about the upper left hand entry, and so, every other matrix entry can be ignored. Substituting Equations (A24)–(A27) into Equation (A23), we find that:
where:
To find the determinant of the matrix in Equation (A28), we use:
Since det Dnn ≠ 0, Dnn is invertible:
Again, we have used the fact that:
Additionally, since Dnn is invertible and symmetric, we can also write:
Then:
With some algebra, this becomes:
We assume that
is invertible; i.e.,
. Therefore:
where:
and:
so that:
Liberal application of several identities—tr(XY ) = tr(Y X), tr(X) = tr(X⊤ ) and tr(X +Y ) = tr(X)+ tr(Y )—reveals:
Substituting Equations (A30) and (A31) into Equation (A29) and substituting that into Equation (A22), we have the conditional entropy:
E. Time-Local Predictive Information
Information anatomy measures should have a broad application to monitoring and guiding the behavior of adaptive autonomous agents. Practically, information anatomy gives a suite of semantically distinct kinds of information [6,40] that is substantially richer and structurally more incisive than simple uses of Shannon mutual information that implicitly assume there is only a single kind of (correlational) information. For example, it is reasonable to hypothesize that biological sensory systems are optimized to transmit with high fidelity information that is predictively useful about stimuli or environmental organization. In such a setting, the bound information quantifies how much predictability is lost if one has extracted the full predictable information E from the past, but chooses to ignore the present H[X0]. Along these lines, the time-local predictive information (TiPi) was recently proposed as a quantity that agents maximize in order to access different behavioral modes when adapting to their environment [12].
(For clarity, we must address a persistently misleading terminology at use here, since it is critical to correctly interpreting the benefits of information-theoretic analyses. The proposed measure is a special case of bound information bμ. Recall that both bμ and the excess entropy E capture the amount of information in the future that is predictable [5,6] and not that which is predictive. The latter is the amount of information that must be stored to optimally predict, and this is given by the statistical complexity Cμ. Therefore, when we use the abbreviation, TiPi, we mean the time-local predictable information: information the agent immediately sees as advantageous.)
In fact, [12] does a calculation very similar to the ones above, considering discrete-time stochastic dynamics of the form:
and calculating the TiPi:
with fixed T > 1. The motivation being that, whatever the history prior to t − T, the agent knows the environment state xt−T then. However, from that time forward, the agent, making no further observations, is ignorant. The stochastic dynamics then models the evolution of that ignorance from the given state to a distribution of states at t − 1 and then at t, taking into account only the model φ the agent has learned or is given. They report that TiPi is the difference between state information and noise entropy:
where:
and:
with L(0) = I.
Since ∑ depends on the states between times t − T and t − 1, the TiPi expression in Equation (A33) also depends on the states between times t − T and t − 1. The TiPi definition in Equation (A32) does not. Thus, even though the numerical results of [12] are quite interesting, the quantity that the behavioral agents there were maximizing was not the stated conditional mutual information.
To address this concern and explore informational adaptation hypotheses, let us consider alternatives. If desired, for example, one could define an averaged TiPi as:
or one could define TiPi to be:
so that it depends on both xt−T and xt−1.
Even with these modifications, Equation (A33) still cannot be a general expression for TiPi, since it depends on measurements at intermediate times that must be marginalized out of the conditional probability distribution with which we are calculating the mutual information.
Moving to discrete time with a small discretization time, let us find expressions for all three:
Suppose that the underlying dynamical system is a nonlinear Langevin equation with invertible diffusion matrix and an analytic potential function Uθ parametrized by θ:
with white noise: 〈η(t)〉 = 0 and 〈η(t)η(t′)⊤ 〉 = Dδ(t − t′). Following the argument used in Section 3:
and
These formulae lead to the following expressions for the TiPi alternatives:
and
Maximizing these with respect to θ has a different effect on the action policy. Maximizing the original TiPi IN[Xt;Xt−τ] leads the agent to alter the landscape, so that it is driven into unstable regions. Maximizing the averaged TiPi
leads to a flattening of the potential landscape. Additionally, the effect of maximizing
is not yet clear.
Not surprisingly, when N is small, we recover the result that maximizing IN[Xt;Xt−τ] has the same effect on the potential landscape as maximizing the TiPi in [12] when T = 2. Though the model there is set up for a discrete-time analysis, it is natural to suppose that adaptive agents in an environment move according to a continuous-time dynamic, but receive sensory signals in a discrete-time manner. Equating notation used here and there:
gives:
This then gives, upon substitution into Equation (A33):
The above expression is identical to that in Equation (A35) for all practical purposes, as derivatives of the two with respect to θ are identical up to an unimportant multiplicative constant to subleading order in τ. Therefore, for T = 2, many of the qualitative conclusions from numerical simulations are likely to carry over when Equation (A35) is used as the objective function.
Finally, the difference in how these quantities were calculated is interesting to us. For instance, was the series expansion for the coefficients of the moments of the Green’s function in Appendix C actually necessary? Could we have used an Ito discretization scheme to write xt+Δt in terms of xt−Δt and noise terms and use that expression to evaluate bμ? This is related to the approach taken in [12]. However, the answer obtained using the moment series expansions is a factor of two different than what would have been obtained with such a discretization scheme. Additionally, by keeping track of the order of the approximation errors in Appendix C, we found that these formulae for both bound information and TiPi would only hold for invertible diffusion matrices. As suggested by Appendix D, our estimates for such conditional mutual information change qualitatively when the diffusion matrix is not invertible. That, in turn, may be relevant to environments that are hidden Markov, settings for which the agent’s sensorium does not directly report the environmental states.
Author Contributions
Both authors contributed equally to conception and writing. S.M. performed the bulk of the calculations and numerical computation. Both authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Walters, P. An Introduction to Ergodic Theory; Graduate Texts in Mathematics, Volume 79; Springer-Verlag: New York, NY, USA, 1982. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed; Wiley-Interscience: New York, NY, USA, 2006. [Google Scholar]
- Crutchfield, J.P.; Young, K. Inferring Statistical Complexity. Phys. Rev. Lett 1989, 63, 105–108. [Google Scholar]
- Shalizi, C.R.; Crutchfield, J.P. Computational Mechanics: Pattern and Prediction, Structure and Simplicity. J. Stat. Phys 2001, 104, 817–879. [Google Scholar]
- Crutchfield, J.P.; Feldman, D.P. Regularities Unseen, Randomness Observed: Levels of Entropy Convergence. Chaos 2003, 13, 25–54. [Google Scholar]
- James, R.G.; Ellison, C.J.; Crutchfield, J.P. Anatomy of a Bit: Information in a Time Series Observation. Chaos 2011, 21, 037109. [Google Scholar]
- Palmer, S.E.; Marre, O.; Berry, M.J., II; Bialek, W. Predictive Information in a Sensory Population 2013. arXiv:1307.0225.
- Beer, R.D.; Williams, P.L. Information Processing and Dynamics in Minimally Cognitive Agents. Cogn. Sci 2014, in press. [Google Scholar]
- Tononi, G.; Edelman, G.M.; Sporns, O. Complexity and Coherency: Integrating Information in the Brain. Trends Cogn. Sci 1998, 2, 474–484. [Google Scholar]
- Strelioff, C.C.; Crutchfield, J.P. Bayesian Structural Inference for Hidden Processes. Phys. Rev. E 2014, 89, 042119. [Google Scholar]
- Sato, Y.; Akiyama, E.; Crutchfield, J.P. Stability and Diversity in Collective Adaptation. Physica D 2005, 210, 21–57. [Google Scholar]
- Martius, G.; Der, R.; Ay, N. Information driven self-organization of complex robotics behaviors. PLoS One 2013, 8, e63400. [Google Scholar]
- Varn, D.P.; Canright, G.S.; Crutchfield, J.P. Discovering Planar Disorder in Close-Packed Structures from X-Ray Diffraction: Beyond the Fault Model. Phys. Rev. B 2002, 66, 174110–174113. [Google Scholar]
- Varn, D.P.; Canright, G.S.; Crutchfield, J.P. ε-Machine spectral reconstruction theory: A direct method for inferring planar disorder and structure from X-ray diffraction studies. Acta. Cryst. Sec. A 2013, 69, 197–206. [Google Scholar]
- Crutchfield, J.P.; Young, K. Computation at the Onset of Chaos. In Entropy, Complexity, and the Physics of Information; Zurek, W., Ed.; Volume VIII, SFI Studies in the Sciences of Complexity; Addison-Wesley: Reading, MA, USA, 1990; pp. 223–269. [Google Scholar]
- Tchernookov, M.; Nemenman, I. Predictive Information in a Nonequilibrium Critical Model. J. Stat. Phys 2013, 153, 442–459. [Google Scholar]
- Atmanspracher, H.A.; Scheingraber, H. Information Dynamics; Plenum: New York, NY, USA, 1991; pp. 45–60. [Google Scholar]
- James, R.G.; Burke, K.; Crutchfield, J.P. Chaos Forgets and Remembers: Measuring Information Creation and Storage. Phys. Lett. A 2014. [Google Scholar]
- Lizier, J.; Prokopenko, M.; Zomaya, A. Information modification and particle collisions in distributed computation. Chaos 2010, 20, 037109. [Google Scholar]
- Flecker, B.; Alford, W.; Beggs, J.M.; Williams, P.L.; Beer, R.D. Partial Information Decomposition as a Spatiotemporal Filter. Chaos 2011, 21, 037104. [Google Scholar]
- Moss, F.; McClintock, P.V.E. Noise in Nonlinear Dynamical Systems; Cambridge University Press: Cambridge, UK, 1989; Volume 1. [Google Scholar]
- Shraiman, B.; Wayne, C.E.; Martin, P.C. Scaling Theory for Noisy Period-Doubling Transitions to Chaos. Phys. Rev. Lett 1981, 46, 935. [Google Scholar]
- Crutchfield, J.P.; Nauenberg, M.; Rudnick, J. Scaling for External Noise at the Onset of Chaos. Phys. Rev. Lett 1981, 46, 933. [Google Scholar]
- Girardin, V. On the Different Extensions of the Ergodic Theorem of Information Theory. In Recent Advances in Applied Probability Theory; Baeza-Yates, R., Glaz, J., Gzyl, H., Husler, J., Palacios, J.L., Eds.; Springer: New York, NY, USA, 2005; pp. 163–179. [Google Scholar]
- Gaspard, P.; Wang, X.J. Noise Chaos (ε, τ)-Entropy Per Unit Time. Phys. Rep 1993, 235, 291–343. [Google Scholar]
- Oksendal, B. Stochastic Differential Equations: An Introduction with Applications, 6th ed; Springer: New York, NY, USA, 2013. [Google Scholar]
- Yeung, R.W. Information Theory and Network Coding; Springer: New York, NY, USA, 2008. [Google Scholar]
- Gaspard, P. Brownian Motion, Dynamical Randomness, and Irreversibility. New J. Phys 2005, 7, 77–90. [Google Scholar]
- Lecomte, V.; Appert-Rolland, C.; van Wijland, F. Thermodynamic Formalism for Systems with Markov Dynamics. J. Stat. Phys 2007, 127, 51–106. [Google Scholar]
- Ellison, C.J.; Mahoney, J.R.; Crutchfield, J.P. Prediction, Retrodiction, and the Amount of Information Stored in the Present. J. Stat. Phys 2009, 136, 1005–1034. [Google Scholar]
- Crutchfield, J.P.; Ellison, C.J.; Mahoney, J.R. Time’s Barbed Arrow: Irreversibility, Crypticity, and Stored Information. Phys. Rev. Lett 2009, 103, 094101. [Google Scholar]
- Crutchfield, J.P.; Feldman, D.P. Statistical Complexity of Simple One-Dimensional Spin Systems. Phys. Rev. E 1997, 55, R1239–R1243. [Google Scholar]
- Poston, T.; Stewart, I. Catastrophe Theory and Its Applications; Pitman: London, UK, 1978. [Google Scholar]
- Feldman, D.P.; Crutchfield, J.P. Structural Information in Two-Dimensional Patterns: Entropy Convergence and Excess Entropy. Phys. Rev. E 2003, 67, 051103. [Google Scholar]
- Kittel, C.; Kroemer, H. Thermal Physics, 2nd ed; W. H. Freeman: New York, NY, USA, 1980. [Google Scholar]
- Landauer, R. Dissipation and Noise Immunity in Computation, Measurement, and Communication. J. Stat. Phys 1989, 54, 1509–1517. [Google Scholar]
- Lohr, W. Properties of the Statistical Complexity Functional and Partially Deterministic HMMs. Entropy 2009, 11, 385–401. [Google Scholar]
- Risken, H. The Fokker-Planck Equation: Methods of Solution and Applications, 2nd ed; Springer: Berlin, Germany, 1996. [Google Scholar]
- Drozdov, A.N.; Morillo, M. Expansion for the Moments of a Nonlinear Stochastic Model. Phys. Rev. Lett 1996, 77, 3280. [Google Scholar]
- Crutchfield, J.P.; Ellison, C.J.; Mahoney, J.R.; James, R.G. Synchronization and Control in Intrinsic and Designed Computation: An Information-Theoretic Analysis of Competing Models of Stochastic Computation. Chaos 2010, 20, 037105. [Google Scholar]
Figure 1.
Information anatomy of a stationary continuous-time process graphically depicted using information diagrams. Although the past entropy H[X:0] and the future entropy H[Xτ:] typically are infinite, space limitations constrain us to draw them with finite areas. (a) Information diagram for the anatomy of a process’s single observation X0 in the context of its past X:0 and its future Xτ: (after [6], with permission). (b) Information diagram for the anatomy of a Markov process, in which the present X0 causally shields the past from future. The elusive information σμ(τ) vanishes.
Figure 1.
Information anatomy of a stationary continuous-time process graphically depicted using information diagrams. Although the past entropy H[X:0] and the future entropy H[Xτ:] typically are infinite, space limitations constrain us to draw them with finite areas. (a) Information diagram for the anatomy of a process’s single observation X0 in the context of its past X:0 and its future Xτ: (after [6], with permission). (b) Information diagram for the anatomy of a Markov process, in which the present X0 causally shields the past from future. The elusive information σμ(τ) vanishes.

Figure 2.
(a) Particle diffusing according to ẋ = −x+η(t) with diffusion coefficient D = 1. A finite-time trajectory x(t) followed by the diffusing particle. (b) Over infinite time, the particle experiences positions distributed according to the probability density function ρeq(x) in Equation (7), calculated as a normalized histogram of particle positions. (c) If the previous particle position is known, a future position can be determined with less uncertainty than if no previous particle position is known. The probability Pr(x, t|0, 0) of being in position x at a time t differs from the equilibrium probability distribution ρeq(x), if we know the position of the particle at a previous time; e.g., x(0) = 0.
Figure 2.
(a) Particle diffusing according to ẋ = −x+η(t) with diffusion coefficient D = 1. A finite-time trajectory x(t) followed by the diffusing particle. (b) Over infinite time, the particle experiences positions distributed according to the probability density function ρeq(x) in Equation (7), calculated as a normalized histogram of particle positions. (c) If the previous particle position is known, a future position can be determined with less uncertainty than if no previous particle position is known. The probability Pr(x, t|0, 0) of being in position x at a time t differs from the equilibrium probability distribution ρeq(x), if we know the position of the particle at a previous time; e.g., x(0) = 0.

Figure 3.
Information anatomy of the stochastic cusp catastrophe: (a) Shifting from a double-well to single-well potentials as r and h are varied. Example potentials U(x) for various r and h: blue/dark line, r = 2 and h = −1; purple/medium line, r = 2 and h = 0; and yellow/light line, r = 2 and h = 1. (b) Contour plot of the system-dependent part of the bound information rate bμ(τ) as a function of r and h, highlighting the global minimum x* changing discontinuously as h moves through zero.
as a function of r and h: bμ(τ) is nondifferentiable with respect to h along h = 0 when r ≥ 0. (c) Bound information bμ(τ) as it varies over the cusp catastrophe equilibria surface: Height gives the fixed points as a function of r and h. Color hue is proportional to the deterministic limit
at each r and h. (d) The bound information rate is maximized at nonzero stochasticity D for double-well potentials and asymmetric single-well potentials. D maximizing
as a function of r and h: the surface is colored by
at that value of D.
Figure 3.
Information anatomy of the stochastic cusp catastrophe: (a) Shifting from a double-well to single-well potentials as r and h are varied. Example potentials U(x) for various r and h: blue/dark line, r = 2 and h = −1; purple/medium line, r = 2 and h = 0; and yellow/light line, r = 2 and h = 1. (b) Contour plot of the system-dependent part of the bound information rate bμ(τ) as a function of r and h, highlighting the global minimum x* changing discontinuously as h moves through zero.
as a function of r and h: bμ(τ) is nondifferentiable with respect to h along h = 0 when r ≥ 0. (c) Bound information bμ(τ) as it varies over the cusp catastrophe equilibria surface: Height gives the fixed points as a function of r and h. Color hue is proportional to the deterministic limit
at each r and h. (d) The bound information rate is maximized at nonzero stochasticity D for double-well potentials and asymmetric single-well potentials. D maximizing
as a function of r and h: the surface is colored by
at that value of D.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Information anatomy of first-order, n-dimensional nonlinear Langevin dynamics: ẋ = −D∇U(x) + η(t), where U(x) is analytic in x and η(t) is zero-mean white noise with invertible diffusion matrix D, 〈η(t)η(t′)⊤ 〉 = Dδ(t − t′). Stationary distribution ρeq(x) ∝ exp(−2U(x)) is assumed normalizable.
| Information Rates | Definition | Terms | ||
|---|---|---|---|---|
| O(τ−1 log τ) | O(τ−1) | O(1) | ||
| Stored H0 = Cμ(τ) | 0 | −∫ ρeq(x) log ρeq(x)dx | 0 | |
| τ-Entropy hμ(τ) | ||||
| Bound bμ(τ) | 0 | |||
| Ephemeral rμ(τ) | 0 | |||
| Enigmatic qμ(τ) | ∫ ∇ · (D∇U(x))ρeq(x)dx | |||
| Elusive σμ(τ) | 0 | 0 | 0 | |
© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
MDPI and ACS Style
Marzen, S.; Crutchfield, J.P. Information Anatomy of Stochastic Equilibria. Entropy 2014, 16, 4713-4748. https://doi.org/10.3390/e16094713
AMA Style
Marzen S, Crutchfield JP. Information Anatomy of Stochastic Equilibria. Entropy. 2014; 16(9):4713-4748. https://doi.org/10.3390/e16094713
Chicago/Turabian StyleMarzen, Sarah, and James P. Crutchfield. 2014. "Information Anatomy of Stochastic Equilibria" Entropy 16, no. 9: 4713-4748. https://doi.org/10.3390/e16094713