Robust-BD Estimation and Inference for General Partially Linear Models

Department of Statistics, University of Wisconsin-Madison, Madison, WI 53706, USA
*
Author to whom correspondence should be addressed.
Entropy 2017, 19(11), 625; https://doi.org/10.3390/e19110625
Submission received: 10 October 2017
/
Revised: 15 November 2017
/
Accepted: 16 November 2017
/
Published: 20 November 2017
(This article belongs to the Special Issue New Developments in Statistical Information Theory Based on Entropy and Divergence Measures)
Abstract
:The classical quadratic loss for the partially linear model (PLM) and the likelihood function for the generalized PLM are not resistant to outliers. This inspires us to propose a class of “robust-Bregman divergence (BD)” estimators of both the parametric and nonparametric components in the general partially linear model (GPLM), which allows the distribution of the response variable to be partially specified, without being fully known. Using the local-polynomial function estimation method, we propose a computationally-efficient procedure for obtaining “robust-BD” estimators and establish the consistency and asymptotic normality of the “robust-BD” estimator of the parametric component . For inference procedures of in the GPLM, we show that the Wald-type test statistic constructed from the “robust-BD” estimators is asymptotically distribution free under the null, whereas the likelihood ratio-type test statistic is not. This provides an insight into the distinction from the asymptotic equivalence (Fan and Huang 2005) between and in the PLM constructed from profile least-squares estimators using the non-robust quadratic loss. Numerical examples illustrate the computational effectiveness of the proposed “robust-BD” estimators and robust Wald-type test in the appearance of outlying observations.
1. Introduction
Semiparametric models, such as the partially linear model (PLM) and generalized PLM, play an important role in statistics, biostatistics, economics and engineering studies [1,2,3,4,5]. For the response variable Y and covariates , where and , the PLM, which is widely used for continuous responses Y, describes the model structure according to:
where is a vector of unknown parameters and is an unknown smooth function; the generalized PLM, which is more suited to discrete responses Y and extends the generalized linear model [6], assumes:
where F is a known link function. Typically, the parametric component is of primary interest, while the nonparametric component serves as a nuisance function. For illustration clarity, this paper focuses on . An important application of PLM to brain fMRI data was given in [7] for detecting activated brain voxels in response to external stimuli. There, corresponds to the part of hemodynamic response values, which is the object of primary interest to neuroscientists; is the slowly drifting baseline of time. Determining whether a voxel is activated or not can be formulated as testing for the linear form of hypotheses,
where is a given full row rank matrix and is a known vector.
Estimation of the parametric and nonparametric components of PLM and generalized PLM has received much attention in the literature. On the other hand, the existing work has some limitations: (i) The generalized PLM assumes that follows the distribution in (3), so that the likelihood function is fully available. From the practical viewpoint, results from the generalized PLM are not applicable to situations where the distribution of either departs from (3) or is incompletely known. (ii) Some commonly-used error measures, such as the quadratic loss in PLM for Gaussian-type responses (see for example [7,8]) and the (negative) likelihood function used in the generalized PLM, are not resistant to outliers. The work in [9] studied robust inference based on the kernel regression method for the generalized PLM with a canonical link, based on either the (negative) likelihood or (negative) quasi-likelihood as the error measure, and illustrated numerical examples with the dimension . However, the quasi-likelihood is not suitable for the exponential loss function (defined in Section 2.1), commonly used in machine learning and data mining. (iii) The work in [8] developed the inference of (4) for PLM, via the classical quadratic loss as the error measure, and demonstrated that the asymptotic distributions of the likelihood ratio-type statistic and Wald statistic under the null of (4) are both . It remains unknown whether this conclusion holds when the tests are constructed based on robust estimators.
Without completely specifying the distribution of , we assume:
with a known functional form of . We refer to a model specified by (2) and (5) as the “general partially linear model” (GPLM). This paper aims to develop robust estimation of GPLM and robust inference of , allowing the distribution of to be partially specified. To introduce robust estimation, we adopt a broader class of robust error measures, called “robust-Bregman divergence (BD)” developed in [10], for a GLM, in which BD includes the quadratic loss, the (negative) quasi-likelihood, the exponential loss and many other commonly-used error measures as special cases. We propose the “robust-BD estimators” for both the parametric and nonparametric components of the GPLM. Distinct from the explicit-form estimators for PLM using the classical quadratic loss (see [8]), the “robust-BD estimators” for GPLM do not have closed-form expressions, which makes the theoretical derivation challenging. Moreover, the robust-BD estimators, as numerical solutions to non-linear optimization problems, pose key implementation challenges. Our major contributions are given below.
- The robust fitting of the nonparametric component is formulated using the local-polynomial regression technique [11]. See Section 2.3.
- We develop a coordinate descent algorithm for the robust-BD estimator of , which is computationally efficient particularly when the dimension d is large. See Section 3.
- Theorems 1 and 2 demonstrate that under the GPLM, the consistency and asymptotic normality of the proposed robust-BD estimator for are achieved. See Section 4.
- For robust inference of , we propose a robust version of the Wald-type test statistic , based on the robust-BD estimators, and justify its validity in Theorems 3–5. It is shown to be asymptotically (central) under the null, thus distribution free, and (noncentral) under the contiguous alternatives. Hence, this result, when applied to the exponential loss, as well as other loss functions in the wider class of BD, is practically feasible. See Section 5.1.
- For robust inference of , we re-examine the likelihood ratio-type test statistic , constructed by replacing the negative log-likelihood with the robust-BD. Our Theorem 6 reveals that the asymptotic null distribution of is generally not , but a linear combination of independent variables, with weights relying on unknown quantities. Even in the particular case of using the classical-BD, the limit distribution is not invariant with re-scaling the generating function of the BD. Moreover, the limit null distribution of (in either the non-robust or robust version) using the exponential loss, which does not belong to the (negative) quasi-likelihood, but falls in BD, is always a weighted , thus limiting its use in practical applications. See Section 5.2.
Simulation studies in Section 6 demonstrate that the proposed class of robust-BD estimators and robust Wald-type test either compare well with or perform better than the classical non-robust counterparts: the former is less sensitive to outliers than the latter, and both perform comparably well for non-contaminated cases. Section 7 illustrates some real data applications. Section 8 ends the paper with brief discussions. Details of technical derivations are relegated to Appendix A.
2. Robust-BD and Robust-BD Estimators
This section starts with a brief review of BD in Section 2.1 and “robust-BD” in Section 2.2, followed by the proposed “robust-BD” estimators of and in Section 2.3 and Section 2.4.
2.1. Classical-BD
To broaden the scope of robust estimation and inference, we consider a class of error measures motivated from the Bregman divergence (BD). For a given concave q-function, [12] defined a bivariate function,
We call the BD and call q the generating q-function of the BD. For example, a function for some constant a yields the quadratic loss . For a binary response variable Y, gives the misclassification loss , where is an indicator function; gives the Bernoulli deviance loss log-likelihood ; results in the hinge loss of the support vector machine; yields the exponential loss used in AdaBoost [13]. Moreover, [14] showed that if:
with a finite constant a such that the integral is well defined, then matches the “classical (negative) quasi-likelihood” function.
2.2. Robust-BD
Let denote the Pearson residual, which reduces to the standardized residual for linear models. In contrast to the “classical-BD”, denoted by in (6), the “robust-BD” developed in [10] for a GLM [6], is formed by:
where is chosen to be a bounded, odd function, such as the Huber -function [15], , and the bias-correction term, , entails the Fisher consistency of the parameter estimator and satisfies:
with
We make the following discussions regarding features of the “robust-BD”. To facilitate the discussion, we first introduce some necessary notation. Assume that the quantities:
exist finitely up to any order required. Then, we have the following expressions,
where ,
and . Particularly, contains ; contains , and ; contains , , , , , and , where denotes the Pearson residual. Accordingly, depend on y through and its derivatives coupled with r. Then, we observe from (9) and (11) that:
In the particular choice of , it is clearly noticed from (9) that , and thus, . In such a case, the proposed “robust-BD” reduces to the “classical-BD” .
2.3. Local-Polynomial Robust-BD Estimator of
Let be observations of captured by the GPLM in (2) and (5), where the dimension is a finite integer. From (2), it is directly observed that if the true value of is known, then estimating becomes estimating a nonparametric function; conversely, if the actual form of is available, then estimating amounts to estimating a vector parameter.
To motivate the estimation of at a fitting point t, a proper way to characterize is desired. For any given value of , define:
where a is a scalar, is the “robust-BD” defined in (8), which aims to guard against outlying observations in the response space of Y, and is a given bounded weight function that downweights high leverage points in the covariate space of . See Section 6 and Section 7 for an example of . Set:
Theoretically, will be assumed (in Condition A3) for obtaining asymptotically unbiased estimators of . Such property indeed holds, for example, when a classical quadratic loss combined with an identity link is used in (14). Thus, we call the “surrogate function” for .
The characterization of the surrogate function in (14) enables us to develop its robust-BD estimator based on nonparametric function estimation. Assume that is -times continuously differentiable at the fitting point t. Denote by the vector consisting of along with its (re-scaled) derivatives. For observed covariates close to the point t, the Taylor expansion implies that:
where . For any given value of , let be the minimizer of the criterion function,
with respect to , where is re-scaled from a kernel function K and is termed a bandwidth parameter. The first entry of supplies the local-polynomial robust-BD estimator of , i.e.,
where denotes the j-th column of a identity matrix.
It is noted that the reliance of on does not guarantee its consistency to . Nonetheless, it is anticipated from the uniform consistency of in Lemma 1 that will offer a valid estimator of , provided that consistently estimates . Section 2.4 will discuss our proposed robust-BD estimator . Furthermore, Lemma 1 will assume (in Condition A1) that is the unique minimizer of with respect to a.
2.4. Robust-BD Estimator of
For any given value of , define:
where is as defined in (14) and plays the same role as in (13). Theoretically, it is anticipated that:
which holds for example in the case where a classical quadratic loss combined with an identity link is used. To estimate , it is natural to replace (20) by its sample-based criterion,
where is as defined in (17). Hence, a parametric estimator of is provided by:
Finally, the estimator of is given by:
3. Two-Step Iterative Algorithm for Robust-BD Estimation
In a special case of using the classical quadratic loss combined with an identity link function, the robust-BD estimators for parametric and nonparametric components have explicit expressions,
where , , , with being an identity matrix, , the design matrix,
and:
In other cases, robust-BD estimators from (17) and (23) do not have closed-form expressions and need to be solved numerically, which are computationally challenging and intensive. We now discuss a two-step robust proposal for iteratively estimating and . Let and denote the estimates in the -th iteration, where . The k-th iteration consists of two steps below.
The algorithm terminates provided that is below some pre-specified threshold value, and all stabilize.
3.1. Step 1
For the above two-step algorithm, we first elaborate on the procedure of acquiring in Step 1, by extending the coordinate descent (CD) iterative algorithm [17] designed for penalized estimation to our current robust-BD estimation, which is computationally efficient. For any given value of , by Taylor expansion, around some initial estimate (for example, ), we obtain the weighted quadratic approximation,
where is a constant not depending on ,
with defined in (10). Hence,
Thus it suffices to conduct minimization of with respect to , using a coordinate descent (CD) updating procedure. Suppose that the current estimate is , with the current residual vector , where is the vector of pseudo responses. Adopting the Newton–Raphson algorithm, the estimate of the j-th coordinate based on the previous estimate is updated to:
As a result, the residuals due to such an update are updated to:
Cycling through , we obtain the estimate . Now, we set and . Iterate the process of weighted quadratic approximation followed by the CD updating, for a number of times, until the estimate stabilizes to the solution .
The validity of in Step 1 converging to the true parameter is justified as follows. (i) Standard results for M-estimation [16] indicate that the minimizer of is consistent with . (ii) According to our Theorem 1 (ii) in Section 4.1, for a compact set , where stands for convergence in probability. Using derivations similar to those of (A4) gives for any compact set . Thus, minimizing is asymptotically equivalent to minimizing . (iii) Similarly, provided that is close to , minimizing is asymptotically equivalent to minimizing . Assembling these three results with the definition of yields:
3.2. Step 2
In Step 2, obtaining for any given values of and t is equivalent to minimizing in (16). Notice that the dimension of is typically low, with degrees or being the most commonly used in practice. Hence, the minimizer of can be obtained by directly applying the Newton–Raphson iteration: for ,
where denotes the estimate in the k-th iteration, and:
The iterations terminate until the estimate stabilizes.
Our numerical studies of the robust-BD estimation indicate that (i) the kernel regression method can be both faster and stabler than the local-linear method; (ii) to estimate the nonparametric component , the local-linear method outperforms the kernel method, especially at the edges of points ; (iii) for the performance of the robust estimation of , which is of major interest, there is a relatively negligible difference between choices of using the kernel and local-linear methods in estimating nonparametric components.
4. Asymptotic Property of the Robust-BD Estimators
This section investigates the asymptotic behavior of robust-BD estimators and , under regularity conditions. The consistency of to and uniform consistency of to are given in Theorem 1; the asymptotic normality of is obtained in Theorem 2. For the sake of exposition, the asymptotic results will be derived using local-linear estimation with degree . Analogous results can be obtained for local-polynomial methods with lengthier technical details and are omitted.
We assume that , and let be a compact set. For any continuous function , define and . For a matrix M, the smallest and largest eigenvalues are denoted by , and , respectively. Let be the matrix norm. Denote by convergence in probability and convergence in distribution.
4.1. Consistency
We first present Lemma 1, which states the uniform consistency of to the surrogate function . Theorem 1 gives the consistency of and .
Lemma 1
(For the non-parametric surrogate ). Let and be compact sets. Assume Condition and Condition in the Appendix. If , , , , then
Theorem 1
(For and ). Assume conditions in Lemma 1.
- (i)
- If there exists a compact set such that and Condition holds, then .
- (ii)
- Moreover, if Condition holds, then .
4.2. Asymptotic Normality
The asymptotic normality of is provided in Theorem 2.
Theorem 2
(For the parametric part βo). Assume Conditions A and Condition B in the Appendix. If , and , then:
where:
and:
with:
From Condition , (13) and (14), we can show that if for some constant , then . In that case, , where:
Consider the conventional PLM in (1), estimated using the classical quadratic loss, identity link and . If , then , and thus, the result of Theorem 2 agrees with that in [18].
Remark 2.
Theorem 2 implies the root-n convergence rate of . This differs from , which converges at some rate incorporating both the sample size n and the bandwidth h, as seen in the proofs of Lemma 1 and Theorem 2.
5. Robust Inference for Based on BD
In many statistical applications, we will check whether or not a subset of explanatory variables used is statistically significant. Specific examples include:
These forms of linear hypotheses for can be more generally formulated as: (4).
5.1. Wald-Type Test
We propose a robust version of the Wald-type test statistic,
based on the robust-BD estimator proposed in Section 2.4, where and are estimates of and satisfying . For example,
and:
fulfill the requirement, where:
Again, we can verify that if for some constant and is obtained from kernel estimation method, then , and hence, , where:
Theorem 3 justifies that under the null, would for large n be distributed as , thus asymptotically distribution-free.
Theorem 3
Theorem 4 indicates that has a non-trivial local power detecting contiguous alternatives approaching the null at the rate :
where .
Theorem 4
To appreciate the discriminating power of in assessing the significance, the asymptotic power is analyzed. Theorem 5 manifests that under the fixed alternative , at the rate n. Thus, has the power approaching to one against fixed alternatives.
Theorem 5
For the conventional PLM in (1) estimated using the non-robust quadratic loss, [8] showed the asymptotic equivalence between the Wald-type test and likelihood ratio-type test. Our results in the next Section 5.2 reveal that such equivalence is violated when estimators are obtained using the robust loss functions.
5.2. Likelihood Ratio-Type Test
This section explores the degree to which the likelihood ratio-type test is extended to the “robust-BD” for testing the null hypothesis in (4) for the GPLM. The robust-BD test statistic is:
where is the robust-BD estimator for developed in Section 2.4.
Theorem 6 indicates that the limit distribution of under is a linear combination of independent chi-squared variables, with weights relying on some unknown quantities, thus not distribution free.
Theorem 6
(Likelihood ratio-type test based on robust-BD under H0). Assume conditions in Theorem 2.
Theorem 7 states that has non-trivial local power for identifying contiguous alternatives approaching the null at rate and that at the rate n under , thus having the power approaching to one against fixed alternatives.
5.3. Comparison between and
In summary, the test has some advantages over the test . First, the asymptotic null distribution of is distribution-free, whereas the asymptotic null distribution of in general depends on unknown quantities. Second, is invariant with re-scaling the generating q-function of the BD, but is not. Third, the computational expense of is much more reduced than that of , partly because the integration operations for are involved in , but not in , and partly because requires both unrestricted and restricted parameter estimates, while is useful in cases where restricted parameter estimates are difficult to compute. Thus, will be focused on in numerical studies of Section 6.
6. Simulation Study
We conduct simulation evaluations of the performance of robust-BD estimation methods for general partially linear models. We use the Huber -function with . The weight functions are chosen to be , where , and denote the sample median and sample median absolute deviation of respectively, . As a comparison, the classical non-robust estimation counterparts correspond to using and . Throughout the numerical work, the Epanechnikov kernel function is used. All these choices (among many others) are for feasibility; the issues on the trade-off between robustness and efficiency are not pursued further in the paper.
The following setup is used in the simulation studies. The sample size is , and the number of replications is 500. (Incorporating a nonparametric component in the GPLM desires a larger n when the number of covariates increases for better numerical performance.) Local-linear robust-BD estimation is illustrated with the bandwidth parameter h to be of the interval length of the variable T. Results using other data-driven choices of h are similar and are omitted.
6.1. Bernoulli Responses
We generate observations randomly from the model,
where with , and is independent of T. The link function is , where and . Both the deviance and exponential loss functions are employed as the BD.
For each generated dataset from the true model, we create a contaminated dataset, where 10 data points are contaminated as follows: they are replaced by , where , ,
with .
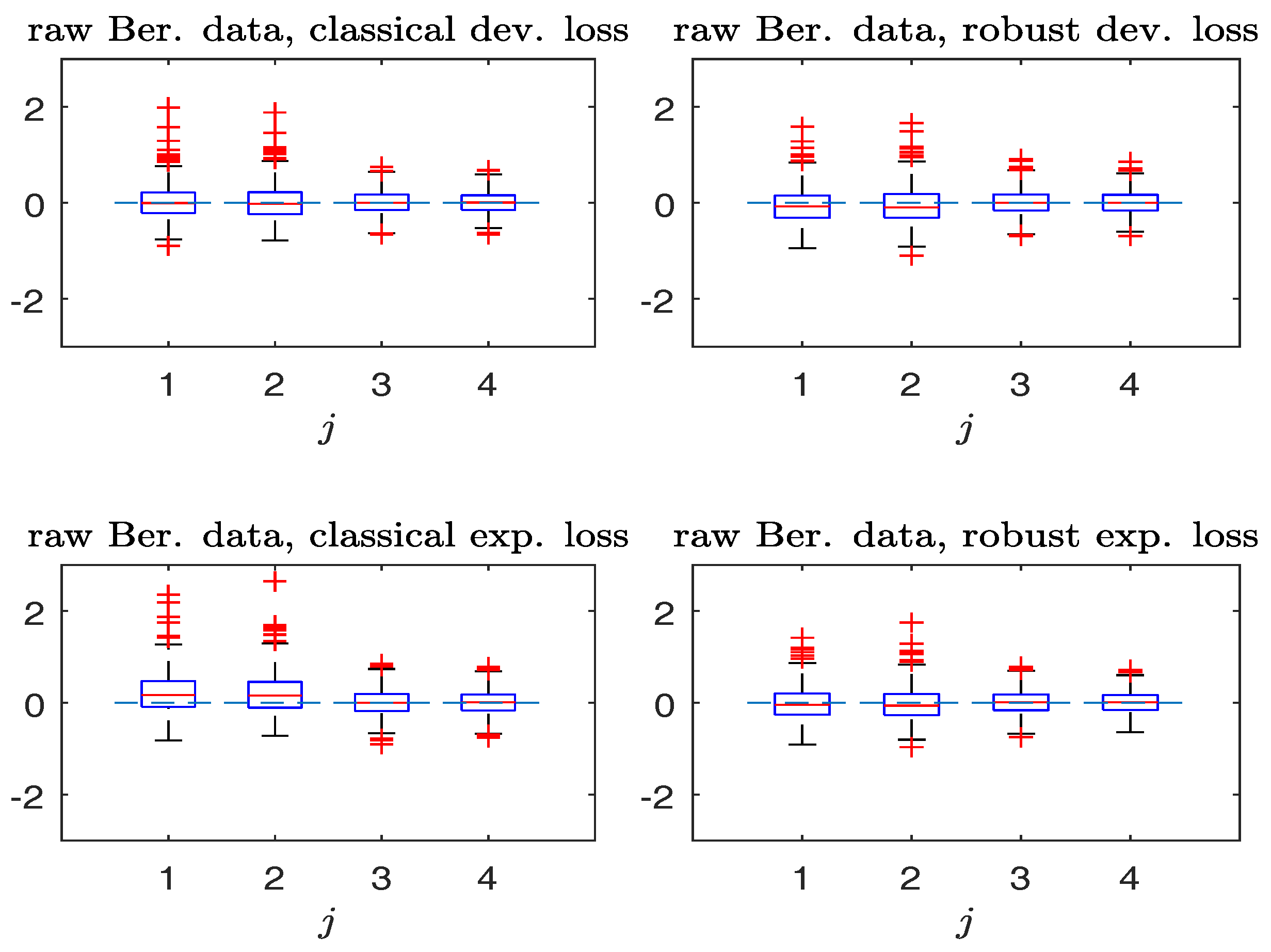
Figure 1 and Figure 2 compare the boxplots of , , based on the non-robust and robust-BD estimates, where the deviance loss and exponential loss are used as the BD in the top and bottom panels respectively. As seen from Figure 1 in the absence of contamination, both non-robust and robust methods perform comparably well. Besides, the bias in non-robust methods using the exponential loss (with unbounded) is larger than that of the deviance loss (with bounded). In the presence of contamination, Figure 2 reveals that the robust method is more effective in decreasing the estimation bias without excessively increasing the estimation variance.
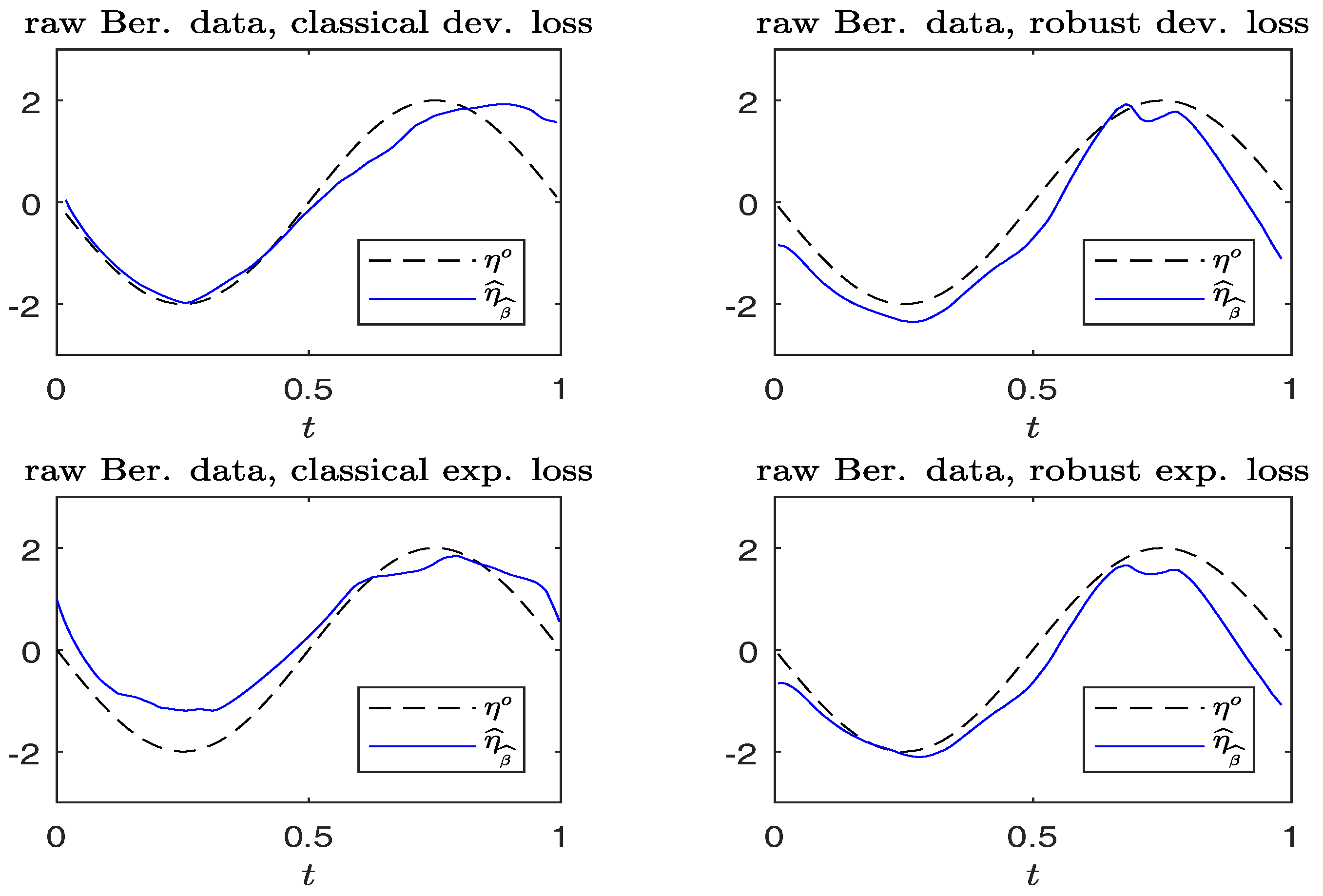
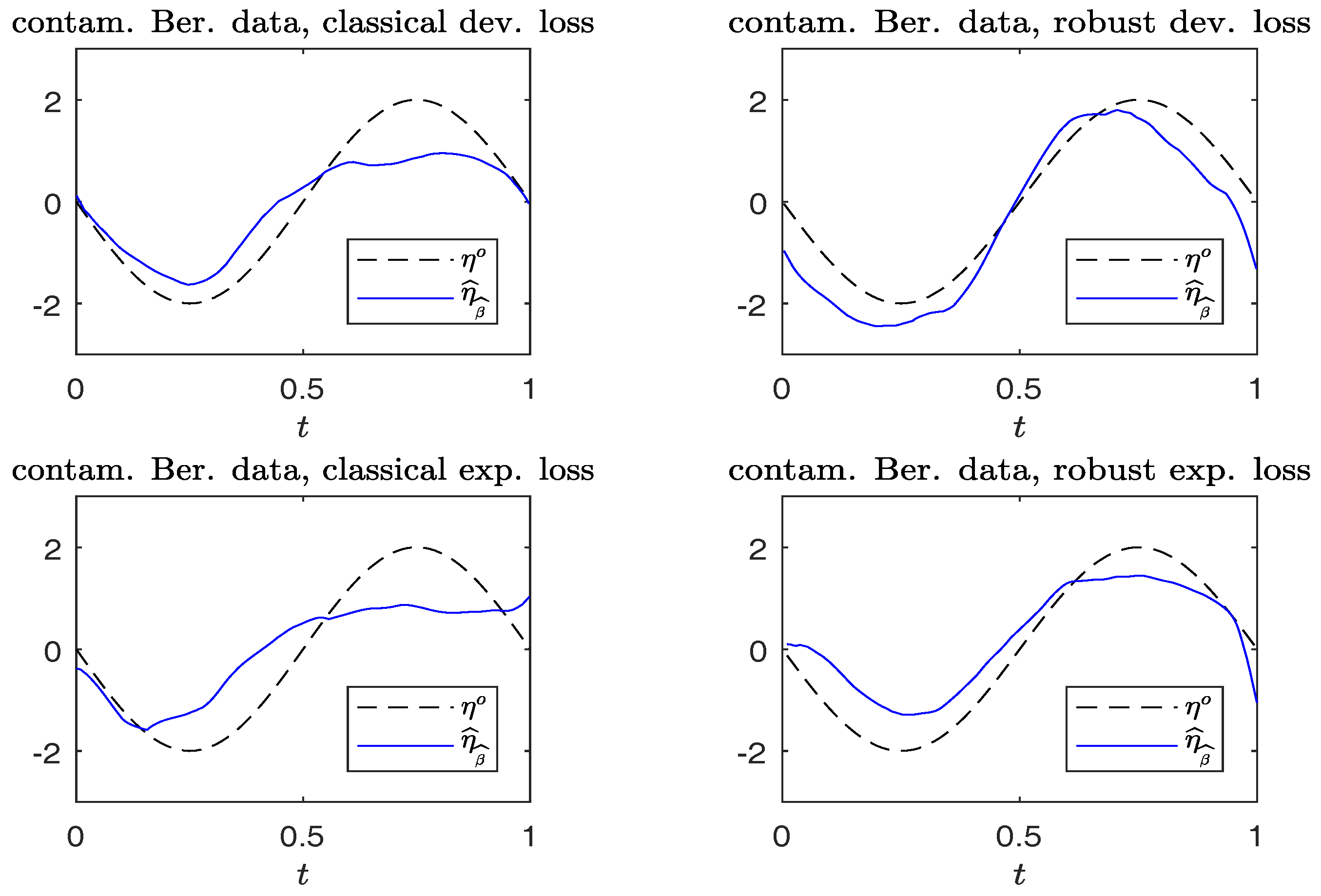
For each replication, we calculate . Figure 3 and Figure 4 compare the plots of from typical samples, using non-robust and robust-BD estimates, where the deviance loss and exponential loss are used as the BD in the top and bottom panels, respectively. There, the typical sample in each panel is selected in a way such that its MSE value corresponds to the 50-th percentile among the MSE-ranked values from 500 replications. These fitted curves reveal little difference between using the robust and non-robust methods, in the absence of contamination. For contaminated cases, robust estimates perform slightly better than non-robust estimates. Moreover, the boundary bias issue arising from the curve estimates at the edges using the local constant method can be ameliorated by using the local-linear method.
6.2. Gaussian Responses
We generate independent observations from satisfying:
where , with , denotes the CDF of the standard normal distribution. The link function is , where and . The quadratic loss is utilized as the BD.
For each dataset simulated from the true model, a contaminated data-set is created, where 10 data points are subject to contamination. They are replaced by , where , ,
with .
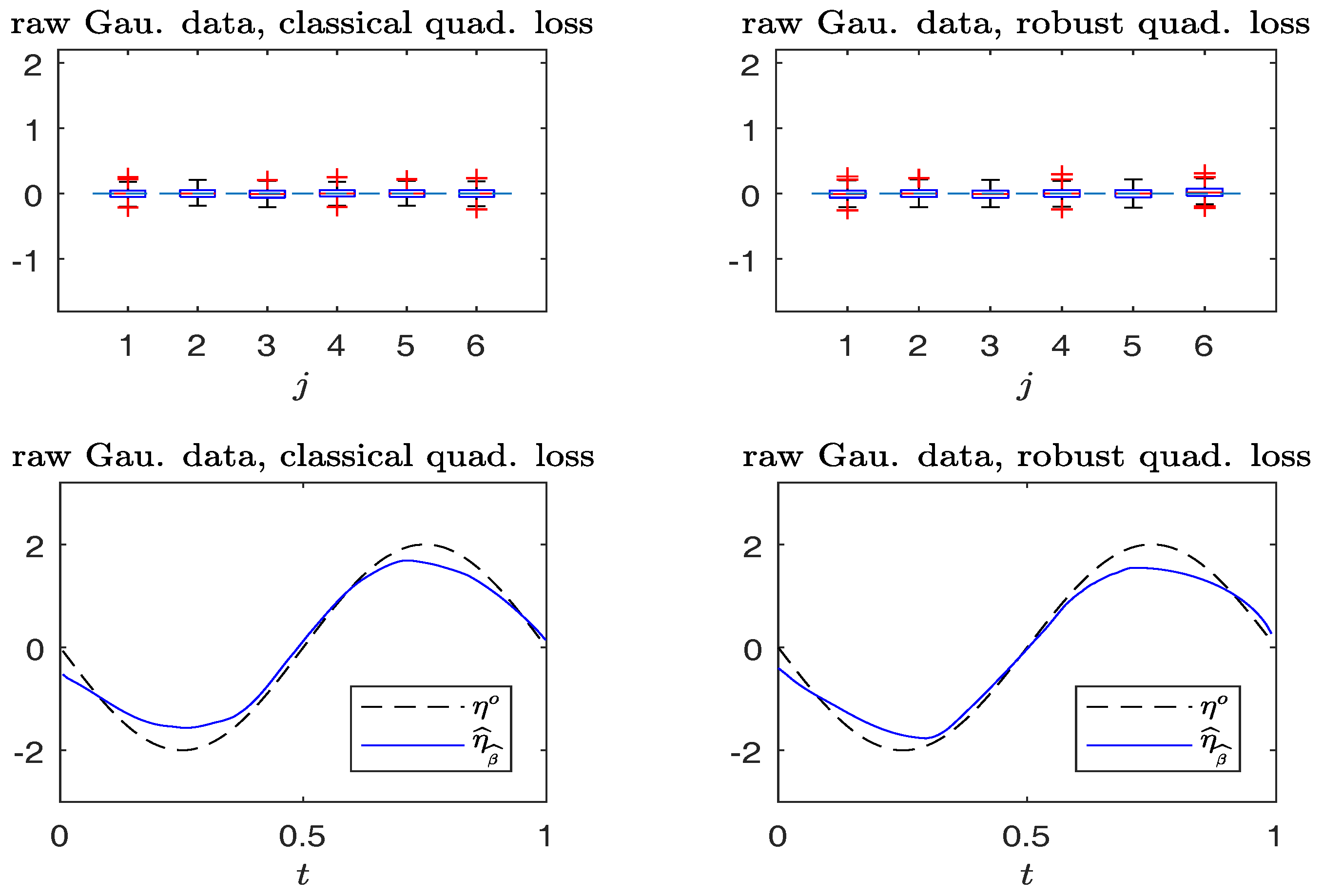
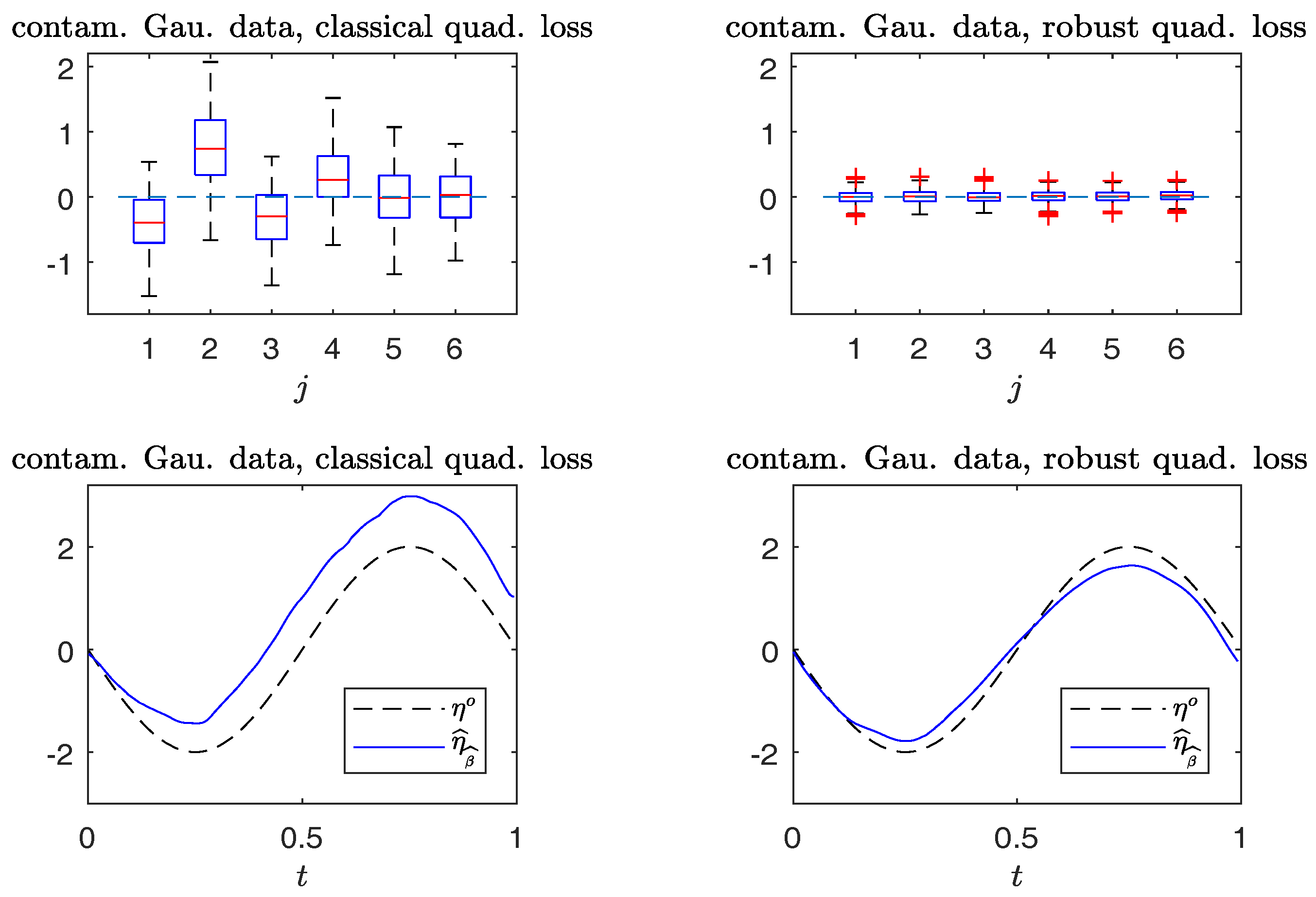
Figure 5 and Figure 6 compare the boxplots of , , on the top panels, and plots of from typical samples, on the bottom panels, using the non-robust and robust-BD estimates. The typical samples are selected similar to those in Section 6.1. The simulation results in Figure 5 indicate that the robust method performs, as well as the non-robust method for estimating both the parameter vector and non-parametric curve in non-contaminated cases. Figure 6 reveals that the robust estimates are less sensitive to outliers than the non-robust counterparts. Indeed, the non-robust method yields a conceivable bias for parametric estimation, and non-parametric estimation is worse than that of the robust method.
Figure 7 gives the QQ plots of the (first to 95-th) percentiles of the Wald-type statistic versus those of the distribution for testing the null hypothesis:
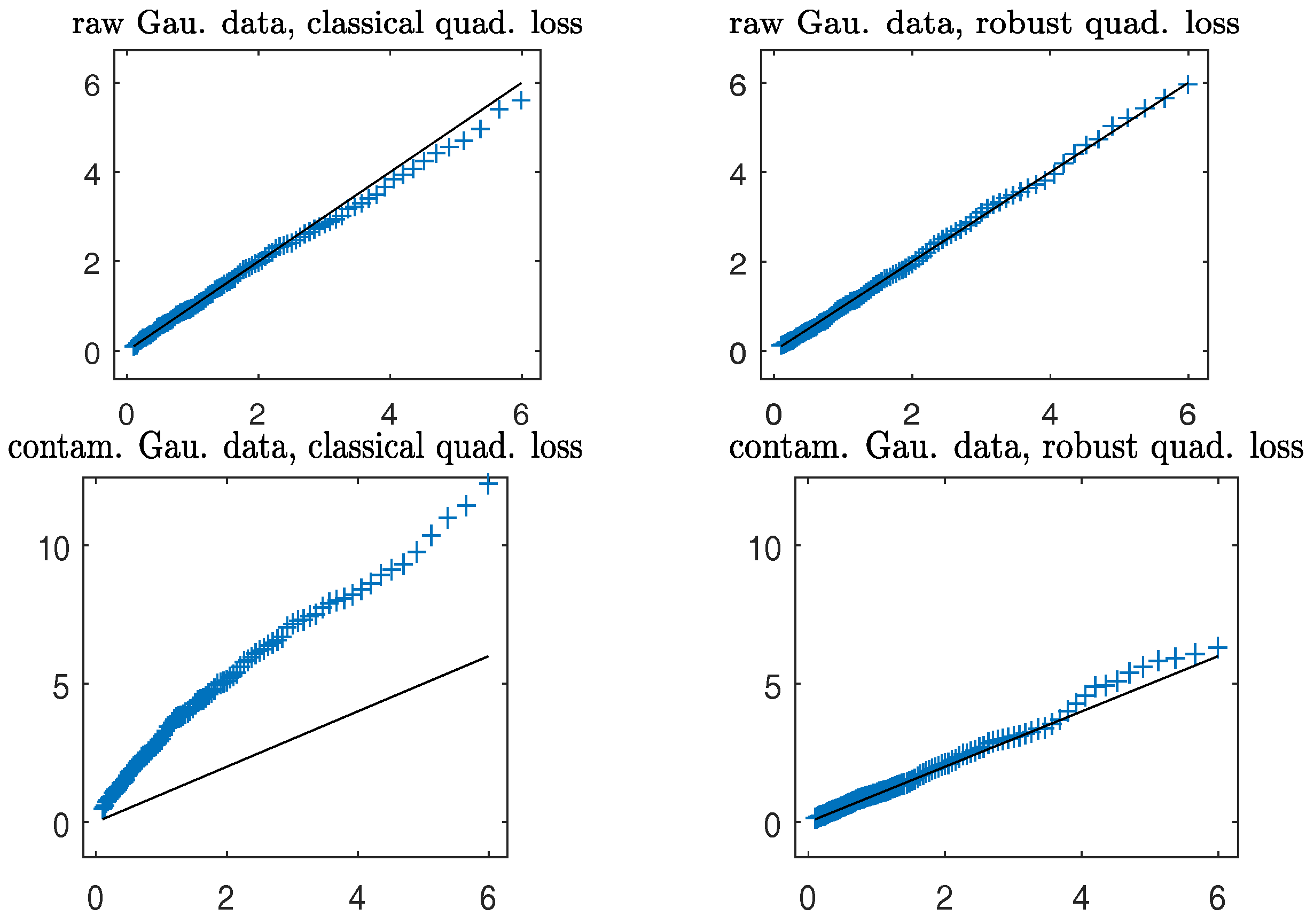
The plots depict that in both clean and contaminated cases, the robust (in right panels) closely follows the distribution, lending support to Theorem 3. On the other hand, the non-robust agrees well with the distribution in clean data; the presence of a small number of outlying data points severely distorts the sampling distribution of the non-robust (in the bottom left panel) from the distribution, yielding inaccurate levels of the test.
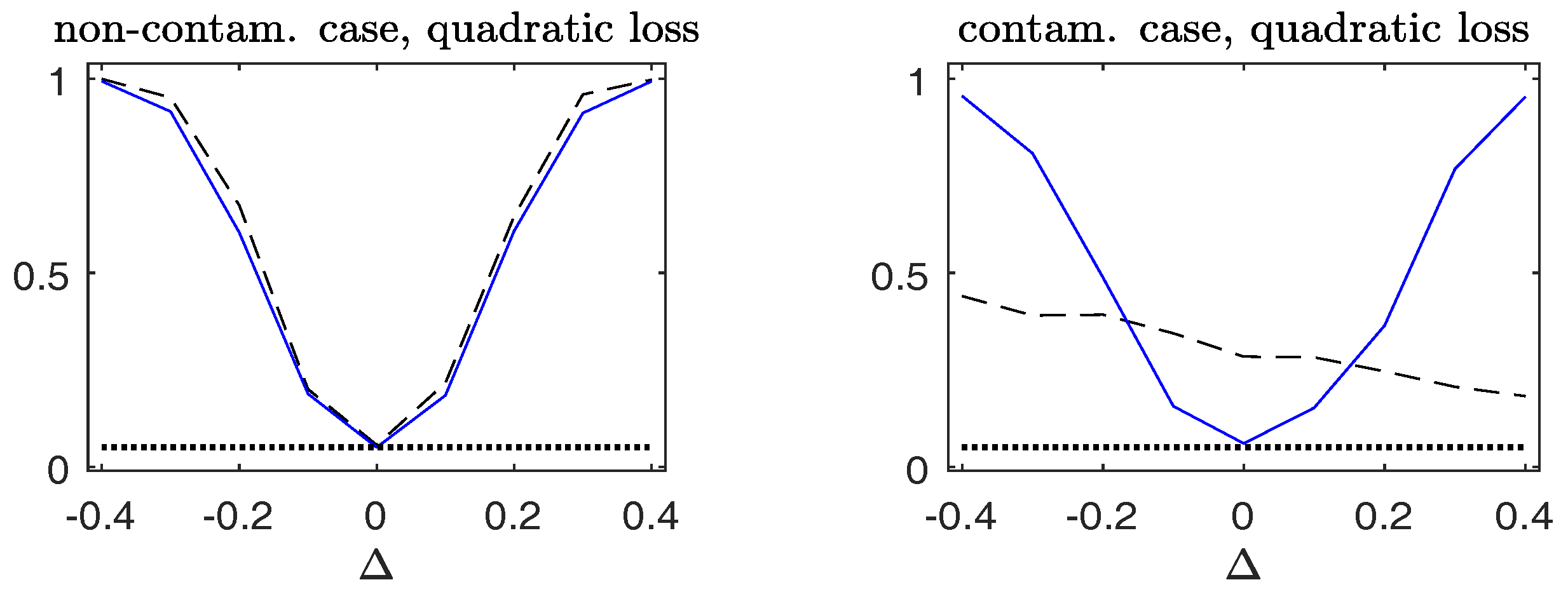
To assess the stability of the power of the Wald-type test for testing the hypothesis (32), we evaluate the power in a sequence of alternatives with parameters for each given , where . Figure 8 plots the empirical rejection rates of the null model in the non-contaminated case and the contaminated case. The price to pay for the robust is a little loss of power in the non-contaminated cases. However, under contamination, a very different behavior is observed. The observed power curve of the robust is close to those attained in the non-contaminated case. On the contrary, the non-robust is less informative, since its power curve is much lower than that of the robust against the alternative hypotheses with , but higher than the nominal level at the null hypothesis with .
7. Real Data Analysis
Two real datasets are analyzed. In both cases, the quadratic loss is set to be the BD, and the nonparametric function is fitted via local-linear regression method, where the bandwidth parameter is chosen to be 25% of the interval length of the variable T. Choices of the Huber -function and weight functions are identical to those in Section 6.
7.1. Example 1
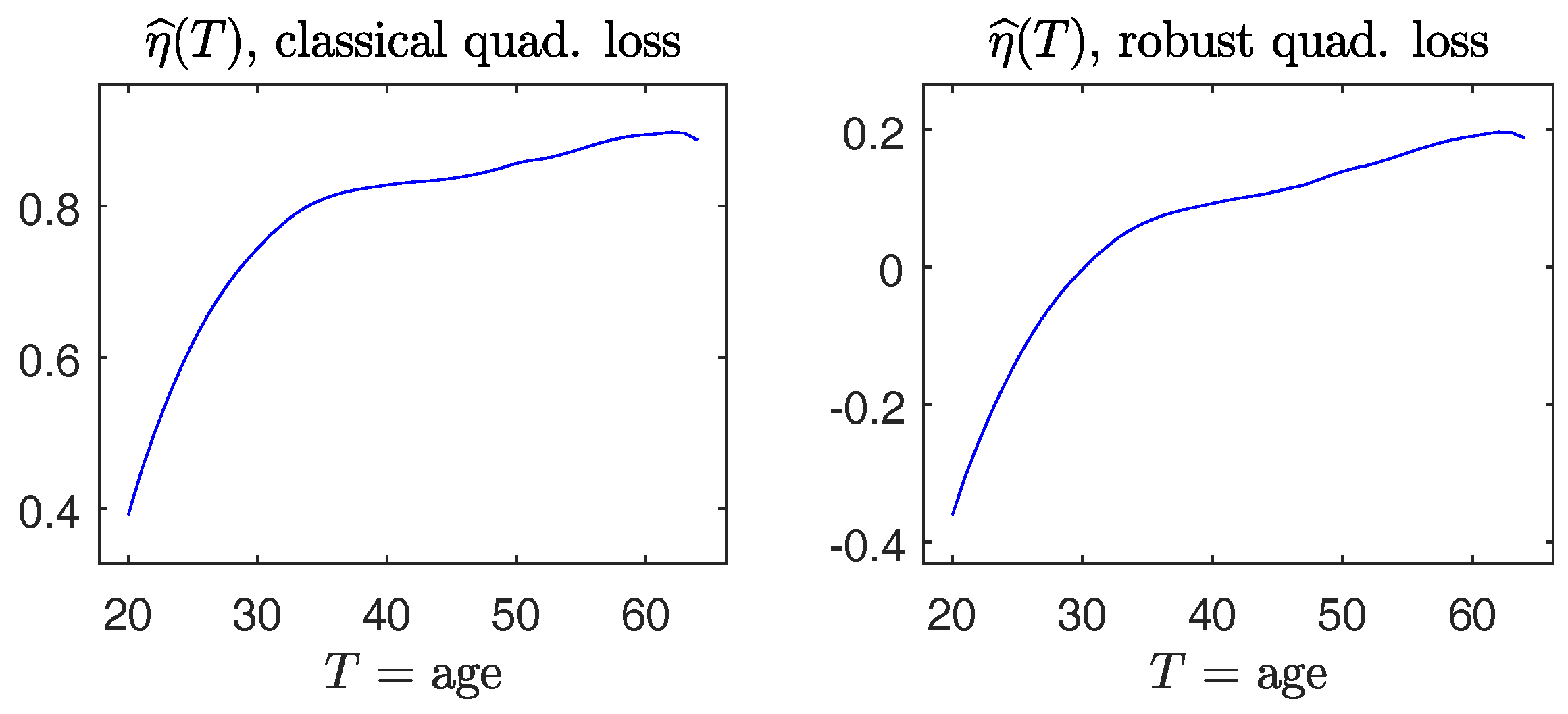
The dataset studied in [19] consists of 2447 observations on three variables, , and , for women. It is of interest to learn how wages change with years of age and years of education. It is anticipated to find an increasing regression function of in as well as in . We fit a partially linear model . Profiles of the fitted nonparametric functions in Figure 9 indeed exhibit the overall upward trend in . The coefficient estimate is with standard error 0.0042 using the non-robust method, and is with standard error 0.0046 by means of the robust method. It is seen that robust estimates are similar to the non-robust counterparts. Our evaluation, based on both the non-robust and robust methods, supports the predicted result in theoretical and empirical literature in socio-economical studies.
7.2. Example 2
We analyze an employee dataset (Example 11.3 of [20]) of the Fifth National Bank of Springfield, based on year 1995 data. The bank, whose name has been changed, was charged in court with that its female employees received substantially smaller salaries than its male employees. For each of its 208 employees, the dataset consists of seven variables, (education level), (job grade), (year that an employee was hired), (year that an employee was born), (indicator of being female), (years of work experience at another bank before working at the Fifth National bank), and (current annual salary in thousands of dollars).
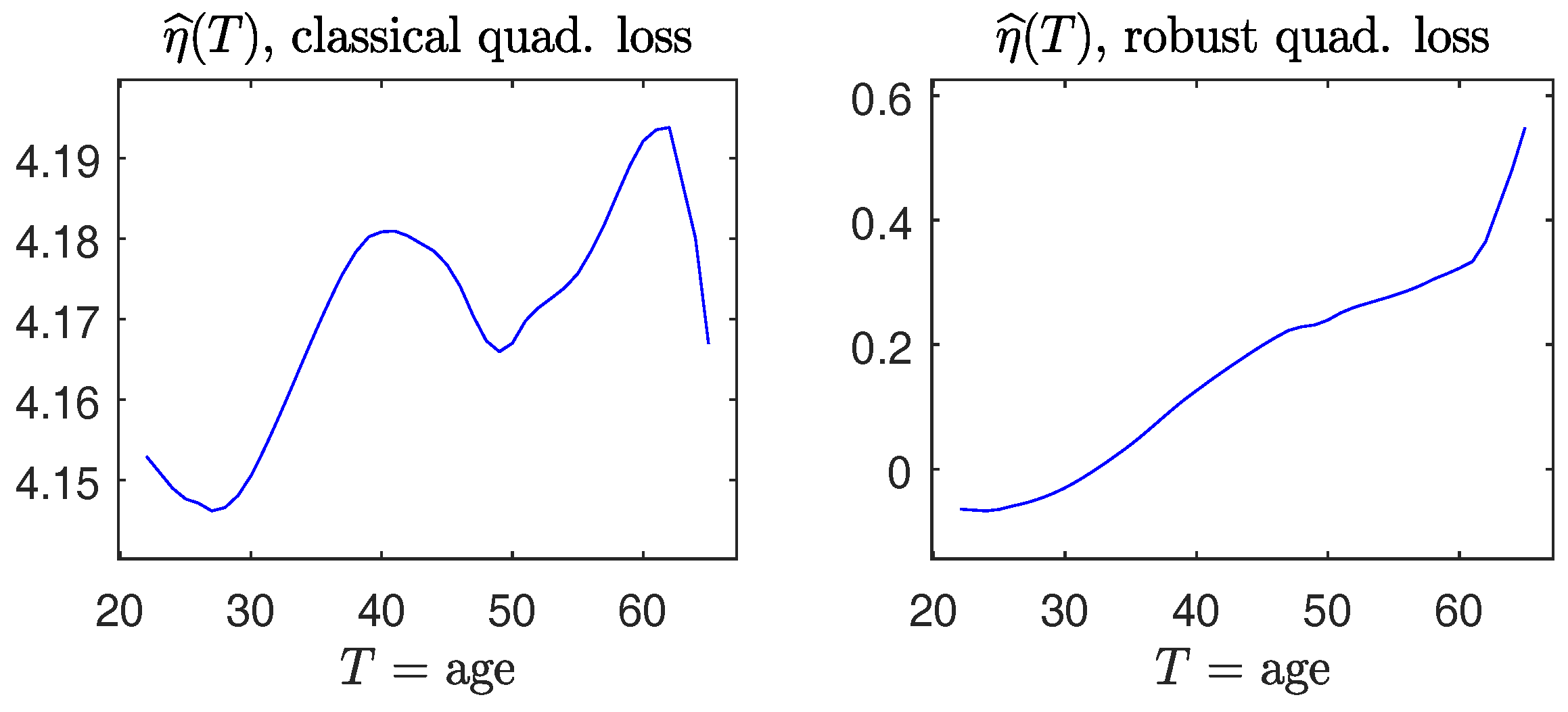
To explain variation in salary, we fit a partial linear model, , for , , , , , and , where is age. Table 1 presents parameter estimates and their standard errors (given within brackets), along with p-values calculated from the Wald-type test . Figure 10 depicts the estimated nonparametric functions.
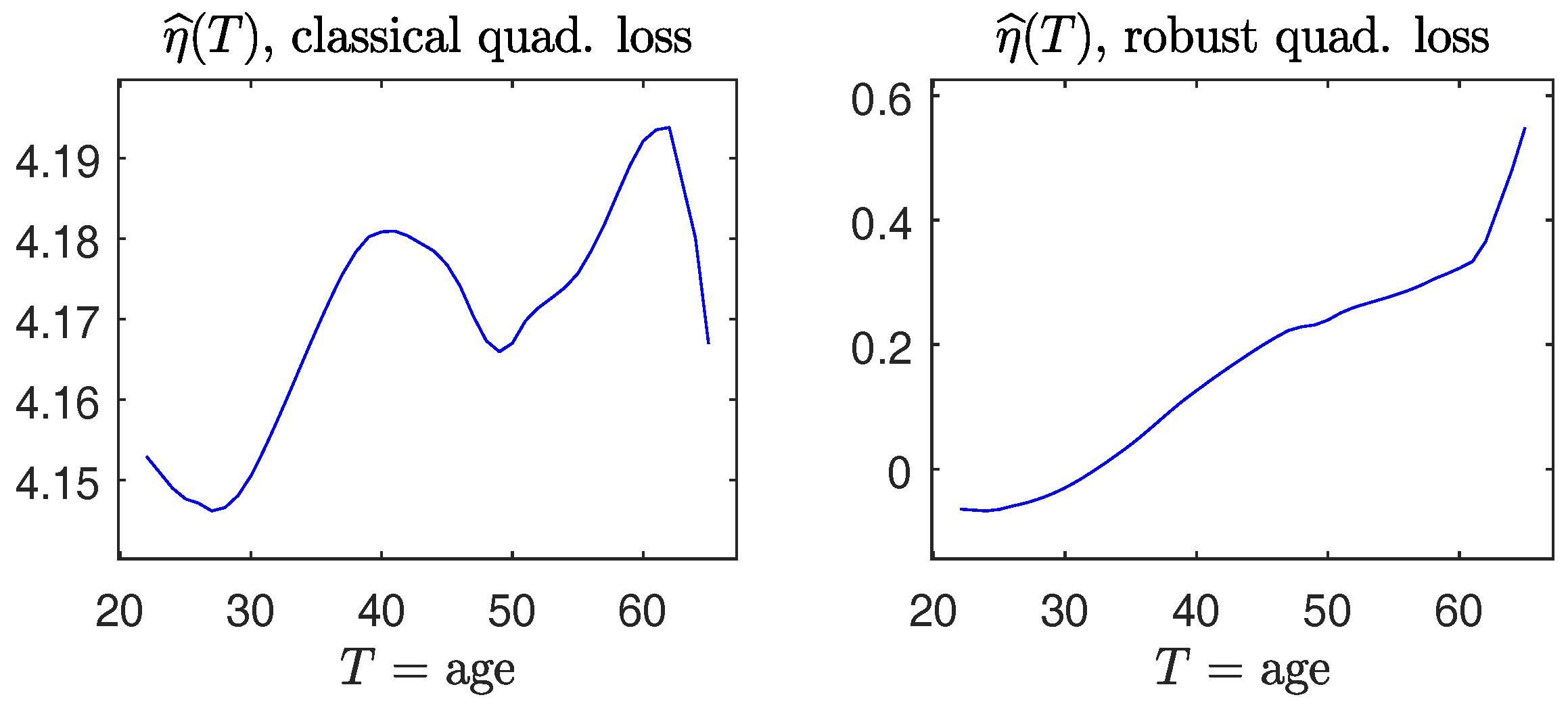
It is interesting to note that for this dataset, results from using the robust and non-robust methods make a difference in drawing conclusions. For example, from Table 1, the non-robust method gives the estimate of parameter for gender to be below zero, which may be interpreted as the evidence of discrimination against female employees in salary and lends support to the plaintiff. In contrast, the robust method yields , which does not indicate that gender has an adverse effect. (A similar conclusion made from penalized-likelihood was obtained in Section 4.1 of [21]). Moreover, the estimated nonparametric functions obtained from non-robust and robust methods are qualitatively different: the former method does not deliver a monotone increasing pattern with Age, whereas the latter method does. Whether or not the difference was caused by outlying observations will be an interesting issue to be investigated.
8. Discussion
Over the past two decades, nonparametric inference procedures for testing hypotheses concerning nonparametric regression functions have been developed extensively. See [22,23,24,25,26] and the references therein. The work on the generalized likelihood ratio test [24] offers light into nonparametric inference, based on function estimation under nonparametric models, using the quadratic loss function as the error measure. These works do not directly deal with the robust procedure. Exploring the inference on nonparametric functions, such as in GPLM associated with a scalar variable T and the additive structure as in [27] with a vector variable , estimated via the “robust-BD” as the error measure, when there are possible outlying data points, will be the future work.
This paper utilizes the class BD of loss functions, the optimal choice of which depends on specific settings and criteria. For e.g., regression and classification will utilize different loss functions, and thus further study on optimality is desirable.
Acknowledgments
The authors thank the two referees for insightful comments and suggestions. The research is supported by the U.S. NSF Grants DMS–1712418, DMS–1505367, CMMI–1536978, DMS–1308872, the Wisconsin Alumni Research Foundation and the National Natural Science Foundation of China, grants 11690014.
Author Contributions
C.Z. conceived and designed the experiments; C.Z. analyzed the data; Z.Z. contributed to discussions and analysis tools; C.Z. wrote the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proofs of Main Results
Throughout the proof, C represents a generic finite constant. We impose some regularity conditions, which may not be the weakest, but facilitate the technical derivations.
Notation:
For integers , ; ; . Define: ; . Set ; ; .
Condition A:
- A1.
- is the unique minimizer of with respect to .
- A2.
- is the unique minimizer of with respect to , where .
- A3.
- .
Condition B:
- B1.
- The function is continuous and bounded. The functions , , , and are bounded; is continuous in .
- B2.
- The kernel function K is Lipschitz continuous, a symmetric probability density function with bounded support. The matrix is positive definite.
- B3.
- The marginal density of T is a continuous function, uniformly bounded away from zero and ∞ for .
- B4.
- The function is continuous and is a continuous function of .
- B5.
- Assume is continuous in ; is continuous in .
- B6.
- Functions and are -times continuously differentiable at t.
- B7.
- The link function is monotone increasing and a bijection, is continuous, and . The matrix is positive definite for a.e. t.
- B8.
- B9.
- and are continuously differentiable with respect to , and twice continuously differentiable with respect to such that for any , is bounded. Furthermore, for any , satisfies the equicontinuity condition:
Note that Conditions A, B2–B5 and B8–B9 were similarly used in [9]. Conditions B1 and B7 follow [10]. Condition B6 is due to the local p-th-degree polynomial regression estimation.
Proof of Lemma 1:
From Condition A1, we obtain and , i.e.,
Define by the vector of along with re-scaled derivatives with respect to t up to the order p. Note that:
where and denotes the re-scaled . Then:
Hence, we rewrite (16) as:
Therefore, minimizing is equivalent to the one minimizing:
with respect to . It follows that , defined by , minimizes:
with respect to , where . Note that for any fixed , . By Taylor expansion,
where is located between and . We notice that:
where:
also, Lemma A1 implies:
where:
by (A2), Condition B2 and B5; and (by using ):
Then:
where is continuous in by B3 and B5.
We now examine . Note that:
To evaluate , it is easy to see that for each ,
Note that by Taylor expansion,
This combined with the facts (A1) and (A2) give that:
Thus, using the continuity of and in t, we obtain:
uniformly in . Thus, we conclude that when .
By Lemma A2,
This along with Lemma A.1 of [18] yields:
the first entry of which satisfies:
namely, . By [31], . Furthermore,
uniformly in . Therefore,
This yields:
Note that for , . This completes the proof. ☐
Lemma A1.
Assume Condition in the Appendix. If , and , then for given an ,
where with and , .
Proof.
Recall the matrix Set for . We observe that:
using the continuity of in and in t. Similarly,
This completes the proof. ☐
Lemma A2.
Assume Condition . If , , , , then , with a compact set .
Proof.
Let . Note that:
where and is between and . Then:
The proof completes by applying [31]. ☐
Proof of Theorem 1.
Before showing Theorem 1, we need Proposition A1 (whose proof is omitted), where the following notation will be used. Denote by the set of continuously differentiable functions in . Let denote the neighborhood of . Let denote the neighborhood of such that and
Proposition A1.
Let be independent observations of modeled by (2) and (5). Assume that a random variable T is distributed on . Let and be compact sets, be a continuous and bounded function, be such that and be a continuous function of . Then:
- (i)
- as ;
- (ii)
- as ;
- (iii)
- if, in addition, is compact and , thenas .
For part (i), we first show that for any compact set in ,
It suffices to show , which follows from Proposition A1 (ii), and:
To show (A4), we note that for any , let be a compact set such that . Then:
For , by the mean-value theorem,
where is located between and . For , it follows that:
Hence,
where the last inequality is entailed by Lemma 1 and the law of large numbers for . This completes the proof of (A3). The proof of follows from combining Lemma A-1 of [1] with (A3) and Condition A2.
Part (ii) follows from Lemma 1, Part (i) and Condition B5 for . ☐
Proof of Theorem 2.
Similar to the proof of Lemma 1, it can be shown that Note that for ,
Thus:
Consider defined in (23). Note that:
where . Then, minimizes:
with respect to . By Taylor expansion,
where is located between and ,
with located between and , and following Lemma 1, Condition A3 and Proposition A1. Thus:
where . Note that:
where is between and ,
with:
Therefore,
By the central limit theorem,
where:
From (A5) and (A6), . This implies that . ☐
Proof of Theorem 3.
Denote and . Note that . Thus:
which implies that . Arguments for Theorem 2 give . Under in (4), and thus , which completes the proof. ☐
Proof of Theorem 4.
Follow the notation and proof in Theorem 3. Under in (29), and thus . This completes the proof. ☐
Proof of Theorem 5.
Following the notation and proof in Theorem 3, . We see that . Under in (4), , which means and thus . Hence, . This completes the proof. ☐
Proof of Theorem 6.
Denote . For the matrix in (4), there exists a matrix B satisfying and . Therefore, is equivalent to for some vector and . Then, minimizing subject to is equivalent to minimizing with respect to , and we denote by the minimizer. Furthermore, under in (4), we have for , and .
For Part (i), using the Taylor expansion around , we get:
where is between and . We now discuss . From the proof in Theorem 2, , where . Similar arguments deduce Thus, under in (4),
and thus by (A6),
where . Combining the fact , (A7) and (A8) gives:
This proves Part (i).
For Part (ii), using , and (31), we obtain , and thus, . Thus, (A9) , which completes the proof. ☐
Proof of Theorem 7.
The proofs are similar to those used in Theorem 4 and Theorems 5 and 6. The lengthy details are omitted. ☐
References
- Andrews, D. Asymptotics for semiparametric econometric models via stochastic equicontinuity. Econometrica 1994, 62, 43–72. [Google Scholar] [CrossRef]
- Robinson, P.M. Root-n consistent semiparametric regression. Econometrica 1988, 56, 931–954. [Google Scholar] [CrossRef]
- Speckman, P. Kernel smoothing in partial linear models. J. R. Statist. Soc. B 1988, 50, 413–436. [Google Scholar]
- Yatchew, A. An elementary estimator of the partial linear model. Econ. Lett. 1997, 57, 135–143. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. New estimation and model selection procedures for semiparametric modeling in longitudinal data analysis. J. Am. Stat. Assoc. 2004, 99, 710–723. [Google Scholar] [CrossRef]
- McCullagh, P.; Nelder, J.A. Generalized Linear Models, 2nd ed.; Chapman & Hall: London, UK, 1989. [Google Scholar]
- Zhang, C.M.; Yu, T. Semiparametric detection of significant activation for brain fMRI. Ann. Stat. 2008, 36, 1693–1725. [Google Scholar] [CrossRef]
- Fan, J.; Huang, T. Profile likelihood inferences on semiparametric varying-coefficient partially linear models. Bernoulli 2005, 11, 1031–1057. [Google Scholar] [CrossRef]
- Boente, G.; He, X.; Zhou, J. Robust estimates in generalized partially linear models. Ann. Stat. 2006, 34, 2856–2878. [Google Scholar] [CrossRef]
- Zhang, C.M.; Guo, X.; Cheng, C.; Zhang, Z.J. Robust-BD estimation and inference for varying-dimensional general linear models. Stat. Sin. 2014, 24, 653–673. [Google Scholar] [CrossRef]
- Fan, J.; Gijbels, I. Local Polynomial Modeling and Its Applications; Chapman and Hall: London, UK, 1996. [Google Scholar]
- Brègman, L.M. A relaxation method of finding a common point of convex sets and its application to the solution of problems in convex programming. USSR Comput. Math. Math. Phys. 1967, 7, 620–631. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2001. [Google Scholar]
- Zhang, C.M.; Jiang, Y.; Shang, Z. New aspects of Bregman divergence in regression and classification with parametric and nonparametric estimation. Can. J. Stat. 2009, 37, 119–139. [Google Scholar] [CrossRef]
- Huber, P. Robust estimation of a location parameter. Ann. Math. Statist. 1964, 35, 73–101. [Google Scholar] [CrossRef]
- Van der Vaart, A.W. Asymptotic Statistics; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization paths for generalized linear models via coordinate descent. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Carroll, R.; Fan, J.; Gijbels, I.; Wand, M. Generalized partially linear single-index models. J. Am. Stat. Assoc. 1997, 92, 477–489. [Google Scholar] [CrossRef]
- Mukarjee, H.; Stern, S. Feasible nonparametric estimation of multiargument monotone functions. J. Am. Stat. Assoc. 1994, 89, 77–80. [Google Scholar] [CrossRef]
- Albright, S.C.; Winston, W.L.; Zappe, C.J. Data Analysis and Decision Making with Microsoft Excel; Duxbury Press: Pacific Grove, CA, USA, 1999. [Google Scholar]
- Fan, J.; Peng, H. Nonconcave penalized likelihood with a diverging number of parameters. Ann. Stat. 2004, 32, 928–961. [Google Scholar]
- Dette, H. A consistent test for the functional form of a regression based on a difference of variance estimators. Ann. Stat. 1999, 27, 1012–1050. [Google Scholar] [CrossRef]
- Dette, H.; von Lieres und Wilkau, C. Testing additivity by kernel-based methods. Bernoulli 2001, 7, 669–697. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, C.M.; Zhang, J. Generalized likelihood ratio statistics and Wilks phenomenon. Ann. Stat. 2001, 29, 153–193. [Google Scholar] [CrossRef]
- Hong, Y.M.; Lee, Y.J. A loss function approach to model specification testing and its relative efficiency. Ann. Stat. 2013, 41, 1166–1203. [Google Scholar] [CrossRef]
- Zheng, J.X. A consistent test of functional form via nonparametric estimation techniques. J. Econ. 1996, 75, 263–289. [Google Scholar] [CrossRef]
- Opsomer, J.D.; Ruppert, D. A root-n consistent backfitting estimator for semiparametric additive modeling. J. Comput. Graph. Stat. 1999, 8, 715–732. [Google Scholar] [CrossRef]
- Belloni, A.; Chernozhukov, V.; Hansen, C. Inference on treatment effects after selection amongst high-dimensional controls. Rev. Econ. Stud. 2014, 81, 608–650. [Google Scholar] [CrossRef]
- Cattaneo, M.D.; Jansson, M.; Newey, W.K. Alternative asymptotics and the partially linear model with many regressors. Econ. Theory 2016, 1–25. [Google Scholar] [CrossRef]
- Cattaneo, M.D.; Jansson, M.; Newey, W.K. Treatment effects with many covariates and heteroskedasticity. arXiv, 2015; arXiv:1507.02493. [Google Scholar]
- Mack, Y.P.; Silverman, B.W. Weak and strong uniform consistency of kernel regression estimates. Z. Wahrsch. Verw. Gebiete 1982, 61, 405–415. [Google Scholar] [CrossRef]
Figure 1.
Simulated Bernoulli response data without contamination. Boxplots of , (from left to right). (Left panels): non-robust method; (right panels): robust method.
Figure 1.
Simulated Bernoulli response data without contamination. Boxplots of , (from left to right). (Left panels): non-robust method; (right panels): robust method.
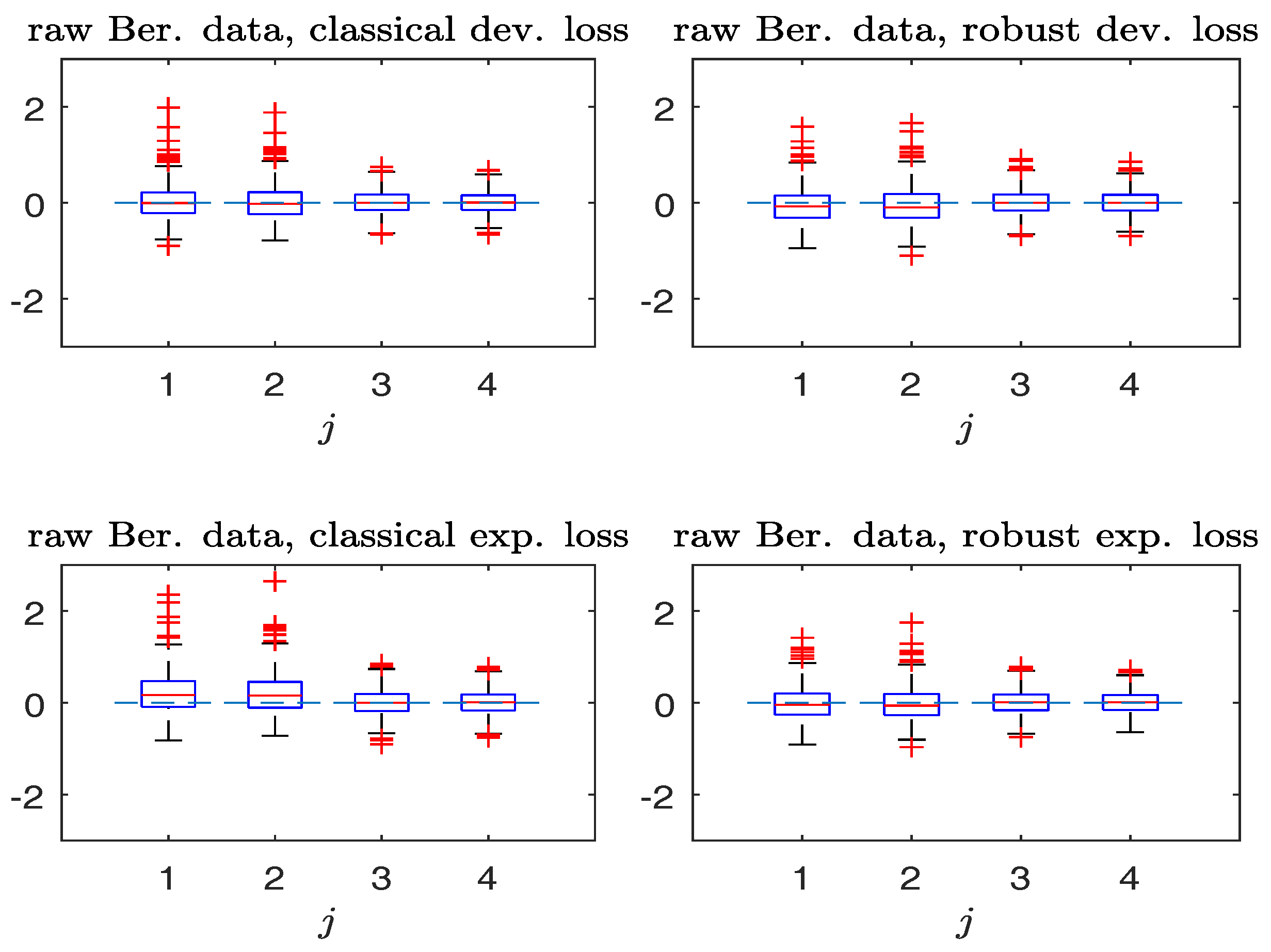
Figure 2.
Simulated Bernoulli response data with contamination. The captions are identical to those in Figure 1.
Figure 2.
Simulated Bernoulli response data with contamination. The captions are identical to those in Figure 1.

Figure 3.
Simulated Bernoulli response data without contamination. Plots of and . (Left panels): non-robust method; (right panels): robust method.
Figure 3.
Simulated Bernoulli response data without contamination. Plots of and . (Left panels): non-robust method; (right panels): robust method.
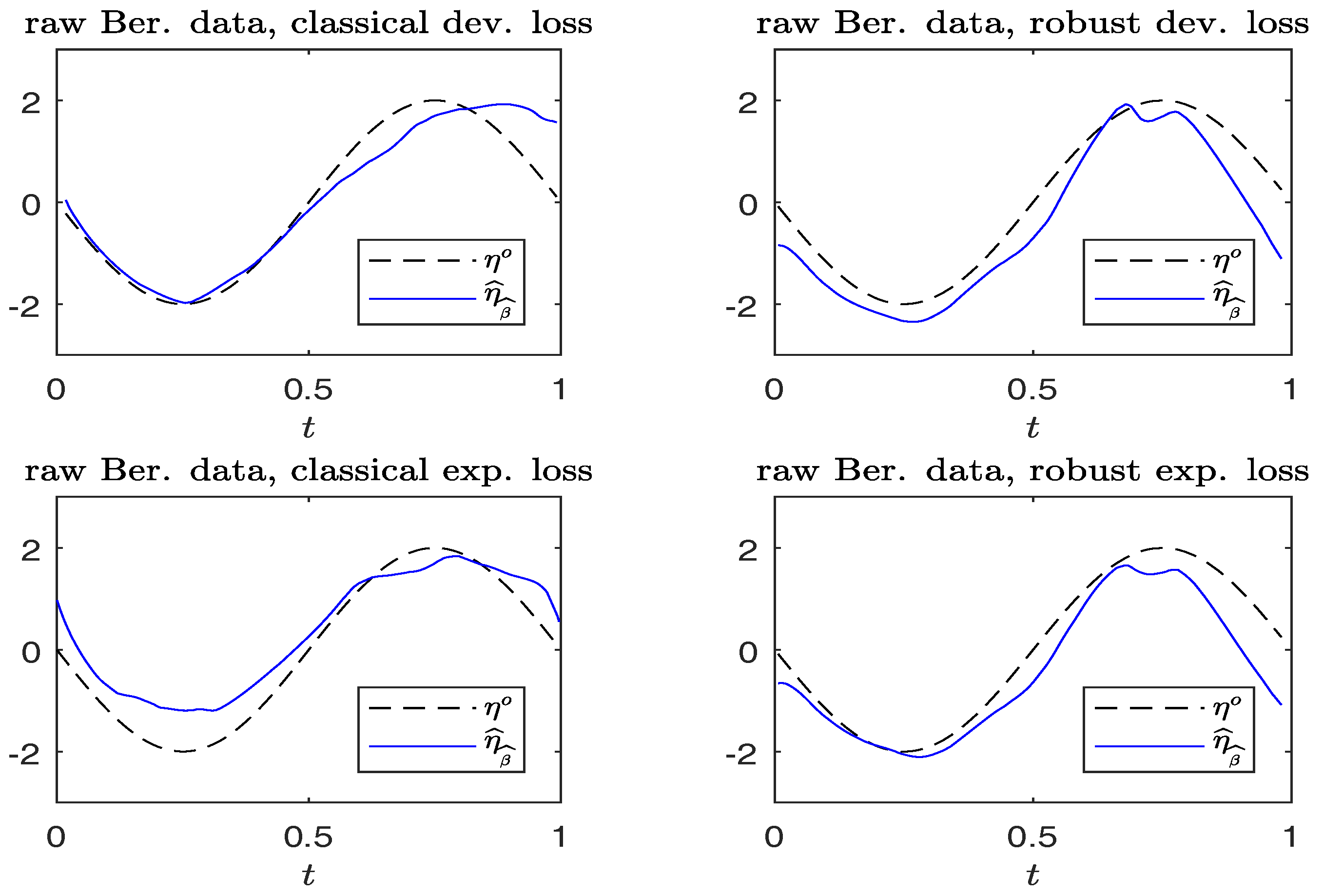
Figure 4.
Simulated Bernoulli response data with contamination. Plots of and . (Left panels): non-robust method; (right panels): robust method.
Figure 4.
Simulated Bernoulli response data with contamination. Plots of and . (Left panels): non-robust method; (right panels): robust method.
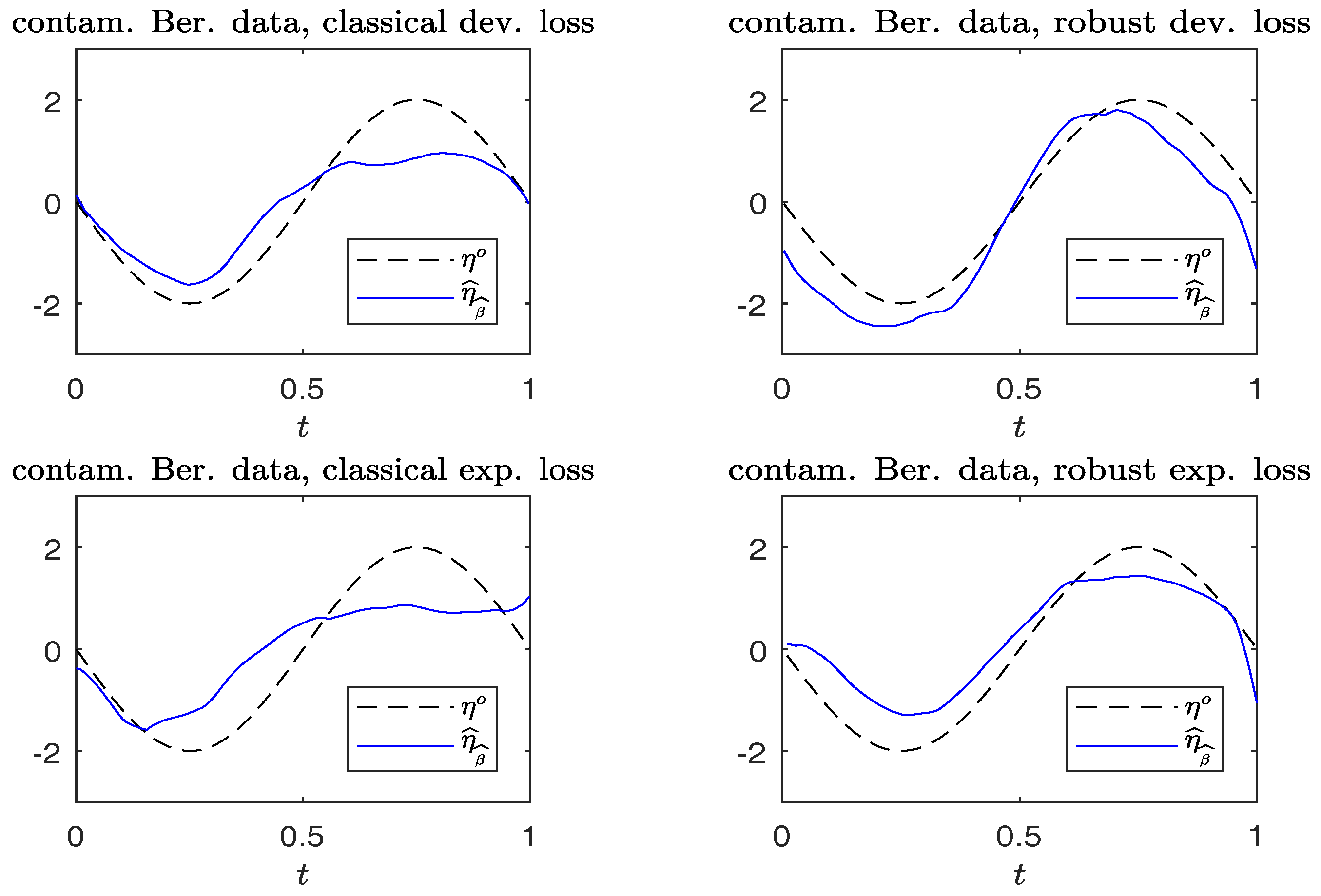
Figure 5.
Simulated Gaussian response data without contamination. Top panels: boxplots of , (from left to right). Bottom panels: plots of and . (Left panels): non-robust method; (right panels): robust method.
Figure 5.
Simulated Gaussian response data without contamination. Top panels: boxplots of , (from left to right). Bottom panels: plots of and . (Left panels): non-robust method; (right panels): robust method.
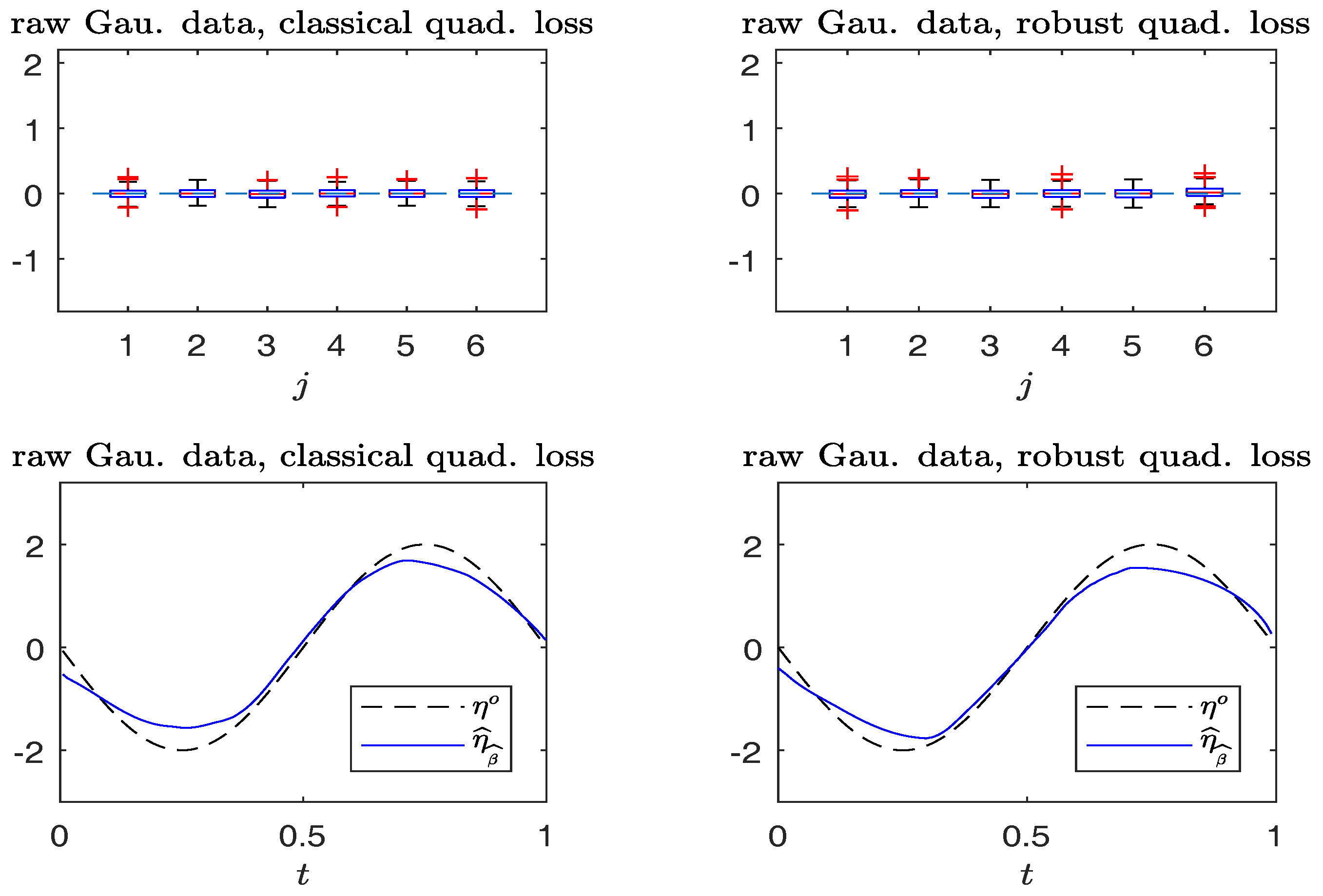
Figure 6.
Simulated Gaussian response data with contamination. Top panels: boxplots of , (from left to right). Bottom panels: plots of and . (Left panels): non-robust method; (right panels): robust method.
Figure 6.
Simulated Gaussian response data with contamination. Top panels: boxplots of , (from left to right). Bottom panels: plots of and . (Left panels): non-robust method; (right panels): robust method.
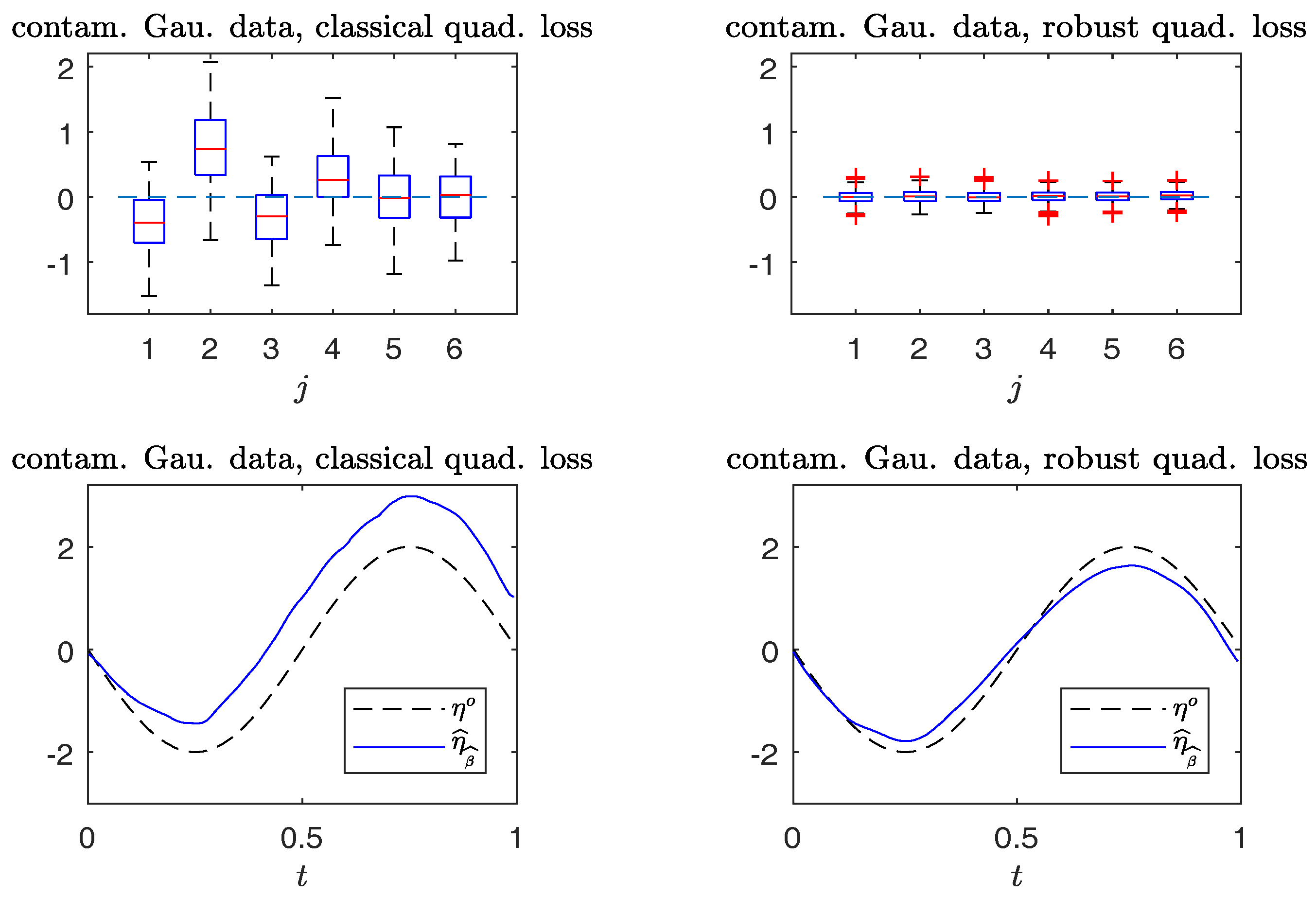
Figure 7.
Simulated Gaussian response data with contamination. Empirical quantiles (on the y-axis) of the Wald-type statistics versus quantiles (on the x-axis) of the distribution. Solid line: the 45 degree reference line. (Left panels): non-robust method; (right panels): robust method.
Figure 7.
Simulated Gaussian response data with contamination. Empirical quantiles (on the y-axis) of the Wald-type statistics versus quantiles (on the x-axis) of the distribution. Solid line: the 45 degree reference line. (Left panels): non-robust method; (right panels): robust method.
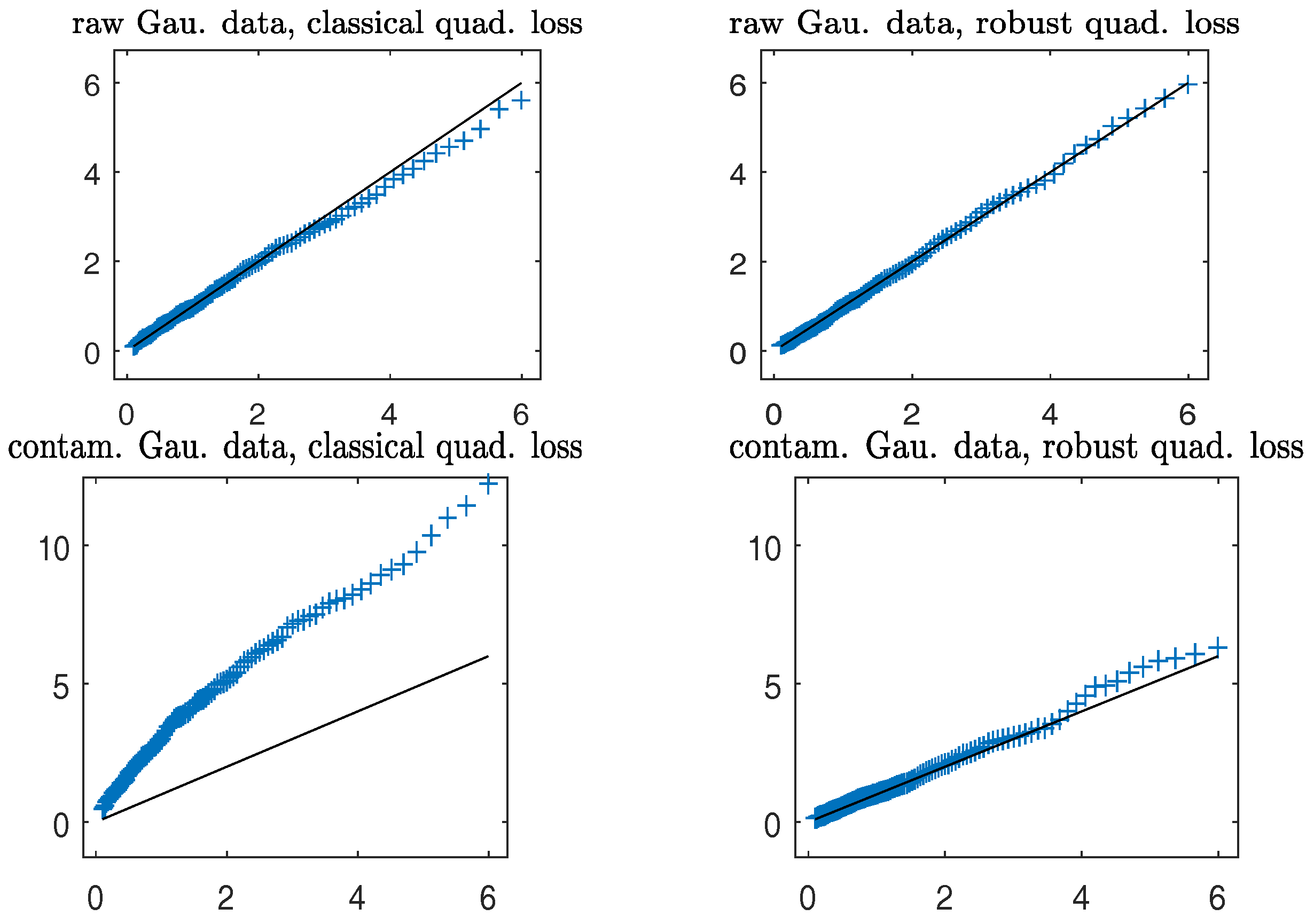
Figure 8.
Observed power curves of tests for the Gaussian response data. The dashed line corresponds to the non-robust Wald-type test ; the solid line corresponds to the robust ; the dotted line indicates the 5% nominal level. (Left panels): non-contaminated case; (right panels): contaminated case.
Figure 8.
Observed power curves of tests for the Gaussian response data. The dashed line corresponds to the non-robust Wald-type test ; the solid line corresponds to the robust ; the dotted line indicates the 5% nominal level. (Left panels): non-contaminated case; (right panels): contaminated case.

Figure 9.
The dataset in [19]. (Left panels): estimate of via the non-robust quadratic loss; (right panels): estimate of via the robust quadratic loss.
Figure 9.
The dataset in [19]. (Left panels): estimate of via the non-robust quadratic loss; (right panels): estimate of via the robust quadratic loss.
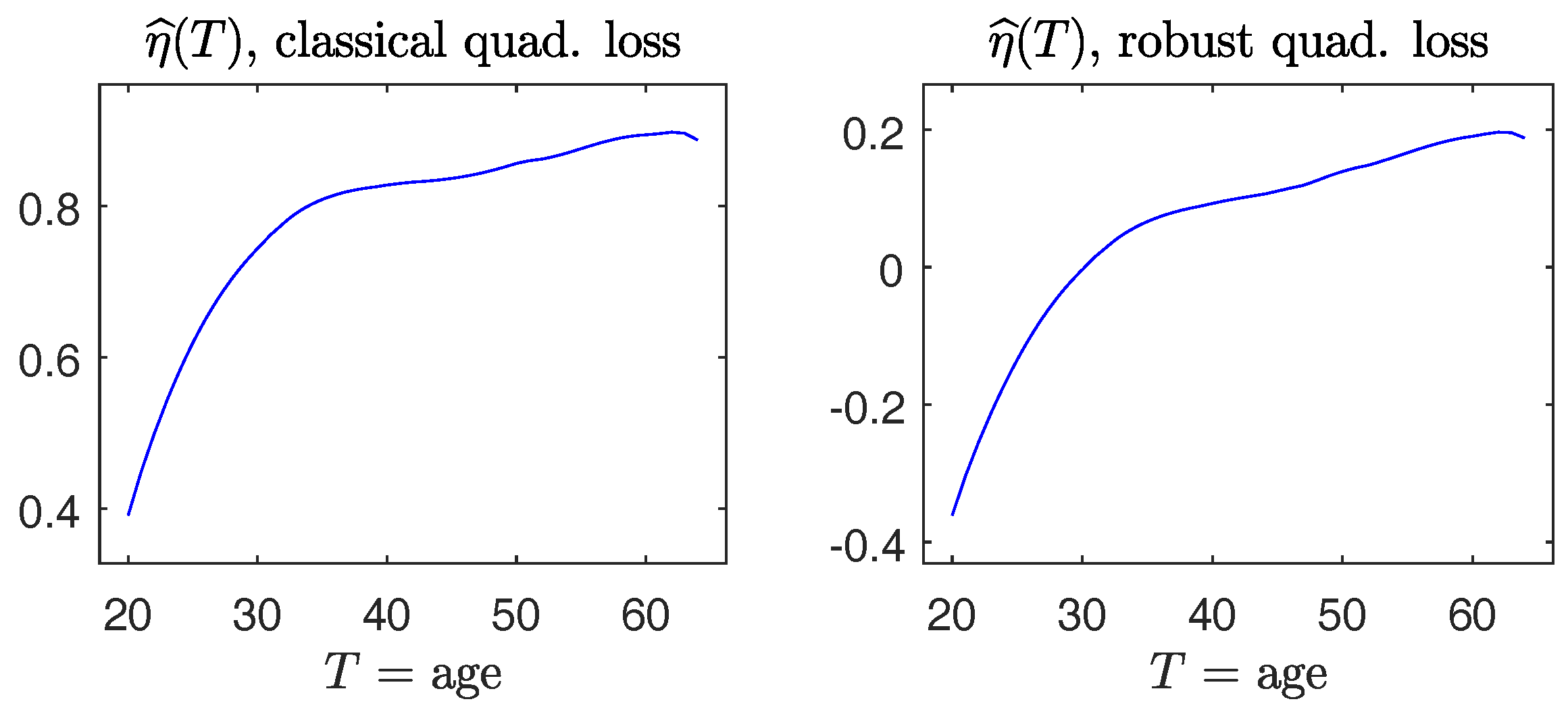
Figure 10.
The dataset in [20]. (Left panel): estimate of via the non-robust quadratic loss; (right panel): estimate of via the robust quadratic loss.
Figure 10.
The dataset in [20]. (Left panel): estimate of via the non-robust quadratic loss; (right panel): estimate of via the robust quadratic loss.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Parameter estimates and p-values for partially linear model of the dataset in [20].
Table 1.
Parameter estimates and p-values for partially linear model of the dataset in [20].
| Variable | Classical-BD Estimation | Robust-BD Estimation | ||||
|---|---|---|---|---|---|---|
| Estimate (s.e.) | p-Value of | Estimate (s.e.) | p-Value of | |||
| −0.0491 | (0.0232) | 0.0339 | 0.0530 | (0.0323) | 0.1010 | |
| −0.0093 | (0.0026) | 0.0005 | 0.0359 | (0.0086) | 0.0000 | |
| 0.0179 | (0.0079) | 0.0228 | −0.0133 | (0.0131) | 0.3103 | |
| 0.0899 | (0.0075) | 0.0000 | 0.1672 | (0.0168) | 0.0000 | |
| 0.0033 | (0.0023) | 0.1528 | −0.0050 | (0.0061) | 0.4104 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhang, C.; Zhang, Z. Robust-BD Estimation and Inference for General Partially Linear Models. Entropy 2017, 19, 625. https://doi.org/10.3390/e19110625
AMA Style
Zhang C, Zhang Z. Robust-BD Estimation and Inference for General Partially Linear Models. Entropy. 2017; 19(11):625. https://doi.org/10.3390/e19110625
Chicago/Turabian StyleZhang, Chunming, and Zhengjun Zhang. 2017. "Robust-BD Estimation and Inference for General Partially Linear Models" Entropy 19, no. 11: 625. https://doi.org/10.3390/e19110625
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.