Variational Characterization of Free Energy: Theory and Algorithms

1
Institut für Mathematik, Brandenburgische Technische Universität Cottbus-Senftenberg, D-03046 Cottbus, Germany
2
Institut für Mathematik, Freie Universität Berlin, D-14195 Berlin, Germany
3
Zuse Institute Berlin, D-14195 Berlin, Germany
*
Author to whom correspondence should be addressed.
Entropy 2017, 19(11), 626; https://doi.org/10.3390/e19110626
Submission received: 25 September 2017
/
Revised: 7 November 2017
/
Accepted: 15 November 2017
/
Published: 20 November 2017
(This article belongs to the Special Issue Understanding Molecular Dynamics via Stochastic Processes)
{kind=link}
Abstract
:The article surveys and extends variational formulations of the thermodynamic free energy and discusses their information-theoretic content from the perspective of mathematical statistics. We revisit the well-known Jarzynski equality for nonequilibrium free energy sampling within the framework of importance sampling and Girsanov change-of-measure transformations. The implications of the different variational formulations for designing efficient stochastic optimization and nonequilibrium simulation algorithms for computing free energies are discussed and illustrated.
1. Introduction
It is one of the standard problems in statistical physics and its computational applications, e.g., in molecular dynamics, that one desires to compute expected values of an observable f with respect to a given (equilibrium) probability density ,
Even if samples from the density are available, the simplest Monte Carlo estimator, the mean value, may suffer from a large variance (compared to the quantity that one tries to estimate), such that the accurate estimation of requires an unreasonably large sample size. Various approaches to circumvent this problem and to reduce the variance of an estimator are available, one of the most prominent representatives being importance sampling where samples are drawn from another probability density and reweighted with the likelihood ratio [1,2]. It is well-known that theoretically (and under certain assumptions) there exists an optimal importance sampling density such that the resulting estimator has variance zero. By a clever choice of the importance sampling proposal density, it is thus possible to completely remove the stochasticity from the problem and to obtain what is sometimes called certainty equivalence. Yet, drawing samples from the optimal density (or an approximation of it) is a difficult problem in itself, so that the striking variance-reduction due to importance sampling often does not pay off in practice.
The zero variance property of importance sampling and the challenge to utilize it algorithmically is the starting point of this article where the focus is on its generalization to path sampling problems and its algorithmic realization. Regarding the former, we will show that the Donsker–Varadhan variational principle, a well-known measure-theoretic characterization of the cumulant generating functions [3] that gives rise to a variational characterization of the thermodynamic free energy [4,5] permits several stunning utilizations of the importance sampling framework for path sampling problems; examples involve trajectory-dependent expectations like expected hitting times or free energy differences [6,7]. We will see that finding the optimal change of measure in path space is equivalent to solving an optimal control problem for the underlying dynamical system in which the dynamics is controlled by external driving forces and thus driven out of equilibrium [8,9].
One of the central contributions of this paper is that we prove that the resulting path space importance sampling scheme features zero variance estimators under quite general assumptions. We furthermore elaborate on the connection between optimized importance sampling and the famous Jarzynski fluctuation relation for the thermodynamic free energy [10]. In particular we will explore this connection and describe how to devise better non-equilibrium free energy algorithms, and hopefully obtain a better understanding of Jarzynski-based estimators; cf. [11,12,13,14].
Regarding the algorithmic realization, the theoretical insight into the relation between (adaptive) importance sampling and optimal control leads to novel algorithms that aim at utilizing the zero variance property without having to sample from the optimal importance sampling density. We will demonstrate how this can be achieved by discretizing the optimal control problem, using ideas from stochastic approximation and stochastic optimization [9,15]; see [16,17,18] for an alternative approach using ideas from the theory of large deviations. The examples we present are mainly pedagogical and admittedly very simple, but they highlight important features of the importance sampling scheme, such as the exponential tilting of the (path space) probability measure or the uniqueness of the solution to the stochastic approximation problem within a certain parametric family of trial probability measures, and this is why we confine our attention to such low-dimensional examples. Regarding the application of our approach to molecular dynamics simulation, we allude to the relevant literature.
Outline
The article is organized as follows: Firstly, in Section 2 we review certainty equivalence and the zero variance property of optimized importance sampling in state space, starting from the Donsker–Varadhan principle and its relation to importance sampling, and comment on some algorithmic issues. Then, in Section 3, we consider the generalization to path space, discuss the relation to stochastic optimal control and revisit Jarzynski-based estimators for thermodynamic free energies. Section 4 surveys and discusses novel algorithms that are exploiting the theoretical properties of the control-based importance sampling scheme. We briefly discuss some of these algorithms with simple toy examples in Section 5, before the article concludes in Section 6 with a brief summary and a discussion of open issues. The article contains four appendices that record various technical identities, including a brief derivation of Girsanov’s change of measure formula, and the proof of the main theorem: the zero-variance property of optimized importance sampling on path space.
2. Certainty Equivalence
In mathematical finance, the guaranteed payment that an investor would accept instead of a potentially higher, but uncertain return on an asset is called a certainty equivalent. In physics, certainty equivalence amounts to finding a deterministic surrogate system that reproduces averages of certain fluctuating thermodynamic quantities with probability one. One such example is the thermodynamic free energy difference between two equilibrium states that can be either computed by an exponential average over the fluctuating nonequilibrium work done on the system or by measuring the work of an adiabatic transformation between these states.
2.1. Donsker–Varadhan Variational Principle
Before getting into the technical details, we briefly review the classical Donsker–Varadhan variational principle for the cumulant generating function of a random variable. To this end, let X be a real-valued, n-dimensional random variable with smooth probability density and call
the expectation with respect to for any integrable function .
Definition 1.
Let be a bounded random variable. The quantity
is called the free energy of the random variable with respect to π, where is the set of bounded and measurable, real-valued functions on (“If you can write it down, it’s measurable!”, S. R. Srinivasa Varadhan).
Definition 2.
Let ρ be another probability density on . Then
is called the relative entropy of ρ with respect to π (or: Kullback–Leibler divergence), provided that implies that for every . Otherwise, we set .
The requirement that must not be zero without being zero is known as absolute continuity and guarantees that the likelihood ratio is well defined. In what follows, we may assume without loss of generality that . (Otherwise we may exclude those states for which .)
A well-known thermodynamic principle states that the free energy is the Legendre transform of the entropy. The following variant of this principle is due to Donsker and Varadhan and says that (e.g., see [3] and the references therein)
where the minimum is over all probability density functions on . The last equality easily follows from Jensen’s inequality by noting that
Additionally, it can be readily seen that equality is attained if and only if
which defines a probability measure with given in Equation (2).
Importance Sampling
The relevance of Equations (4) and (5) lies in the fact that, by sampling X from the probability distribution with density , one removes the stochasticity from the problem, since the random variable
is almost surely (a.s.) constant. As a consequence, the Monte Carlo scheme for computing the free energy on the left hand side of Equation (4) based on the empirical mean of the independent draws of with , will have a zero variance. This zero-variance property is a consequence of Jensen’s inequality and the strict concavity of the logarithmic function which implies that equality is attained if and only if the random variable inside the expectation is almost surely constant. The next statement makes this precise.
Theorem 1 (Optimal importance sampling).
Let be the probability density given in Equation (5). Then the random variable has zero variance under , and we have:
Proof.
We need to show that . Using Equation (5) and noting that since W is bounded and , it follows that Z has finite second moment and
where we have used that . ☐
The above theorem asserts that -almost surely (-a.s.)
which means that the importance sampling scheme based on estimating using draws from the density is a zero-variance estimator of . We will discuss the problem of drawing from an approximation of the optimal distribution later on in Section 4.
Remark 1.
Equation (4) furnishes the famous relation for the Helmholtz free energy F, with U being the internal energy, T the temperature and S denoting the Gibbs entropy. If we modify the previous assumptions by setting and where with being Boltzmann’s constant and E denoting a smooth potential energy function that is bounded from below and growing at infinity, then
with the unique minimizer being the Gibbs-Boltzmann density with normalization constant . In the language of statistics, is a probability distribution from the exponential family with sufficient statistic and parameter .
An alternative variational characterization of expectations is discussed in Appendix A.
2.2. Computational Issues
In practice, the above result is of limited use because the optimal importance sampling distribution is only known up to the normalizing constant C where the latter is just the sought quantity . Clearly we can resort to Markov Chain Monte Carlo (MCMC) to generate samples that are asymptotically distributed according to (see, e.g., [19])
However, in the situation at hand, we wish estimate in Equation (6), where is given in Theorem 1, and the problem is that the likelihood ratio is only known up to the normalizing factor. In this case, the self-normalized importance sampling estimator must be used (see, e.g., [20]):
which is a consistent estimator for . Note that unlike in the case of the importance sampling estimators with known likelihood ratio, the self-normalized estimator is only asymptotically unbiased, even if we can draw exactly from (see Appendix B for details.)
To avoid the bias due to the self-normalization, it is helpful to note that holds -a.s. As a consequence,
is an unbiased estimator of , provided that we can generate i.i.d. samples from . Taking the logarithm, it follows that
is a consistent estimator for , which by Jensen’s inequality and the strict concavity of the logarithm will again be only asymptotically unbiased.
Comparison with the Standard Monte Carlo Estimator
In most cases, the samples from will be generated by MCMC or the like. If we consider the advantages of as compared to the plain vanilla Monte Carlo estimator
with being a sample that is drawn from the reference distribution , there are two aspects that will influence the efficiency of Equation (9) relative to Equation (10), namely:
- (a)
- the speed of convergence towards the stationary distribution and
- (b)
- the (asymptotic) variance of the estimator.
By construction, the asymptotic variance of the importance sampling estimator is zero or close to zero if we take numerical discretization errors into account, hence the efficiency of the estimator (9) is solely determined by the speed of convergence of the corresponding MCMC algorithm to the stationary distribution , which, depending on the problem at hand, may be larger or smaller than the speed of convergence to . It may even happen that is unimodal, whereas is multimodal and hence difficult to generate, for example when is the standard Gaussian density and with is a bistable (energy) function. We refrain from going into details here and instead refer to the review article [21] for an in-depth discussion of the asymptotic properties of reversible diffusions.
In Section 4 and Section 5, we discuss alternatives to Monte Carlo sampling based on stochastic optimization and approximation algorithms that are feasible even for large-scale systems.
Remark 2.
The comparison of Equations (9) and (10) suggests that the importance sampling estimator (9) is an instance of Bennett’s bidirectional estimator for a positive random variable, called “weighting function” in Bennett’s language [22]. As a consequence, Theorem 1 implies that Bennett’s bidirectional estimator has zero variance when the negative logarithm of the weighting function equals the bias potential.
3. Certainty Equivalence in Path Space
The previous considerations nicely generalize from the case of real-valued random variables to time-dependent problems and path functionals.
3.1. Donsker–Varadhan Variational Principle in Path Space
Let with be the solution of the stochastic differential equation (SDE)
where is a smooth, possibly time-dependent vector field, is a smooth matrix field and B is an m-dimensional Brownian motion. Our standard example will be an SDE with for a smooth potential energy function V and , so that satisfies a gradient dynamics. We assume throughout this paper that the functions are such that Equation (11) or the corresponding gradient dynamics have unique strong solutions for all .
Now, suppose that we want to compute the free energy (2) where W is now considered to be a functional of the paths for some bounded stopping time :
for some bounded and sufficiently smooth, real valued functions . We assume throughout the rest of the paper that are bounded from below and that W is integrable.
We define P to be the probability measure on the space of continuous trajectories that is induced by the Brownian motion that drives the SDE (11). We call P a path space measure, and we denote the expectation with respect to P by .
Definition 3 (Path space free energy).
Note that Equation (13) simply is the path space version of Equation (2) which now implicitly depends on the initial condition . The Donsker–Varadhan variational principle now reads
where stands for absolute continuity of Q with respect to P, which means that implies that for any measurable set , as a consequence of which
exists. Note that Equation (15) is just the generalization of the relative entropy (3) from probability densities on to probability measures on the measurable space , with being a -algebra containing measurable subsets of , where we again declare that when Q is not absolutely continuous with respect to P. Therefore it is sufficient that the infimum in Equation (14) is taken over all path space measures .
If , it is again a simple convexity argument (see, e.g., [4]), which shows that the minimum in Equation (14) is attained at given by:
where denotes the restriction of the path space density to trajectories of length . More precisely, is understood as the restriction of the measure defined by to the -algebra that contains all measurable sets , with the property that for every the set is an element of the -algebra that is generated by all trajectories of length t. In other words, is a -algebra that contains the history of the trajectories of (the random) length .
Even though Equation (16) is the direct analogue of Equation (5), this result is not particularly useful if we do not know how to sample from . Therefore, let us first characterize the admissible path space measures and discuss the practical implications later on.
3.1.1. Likelihood Ratio of Path Space Measures
It turns out that the only admissible change of measure from P to Q such that results in a change of the drift in Equation (11). Let be an -valued stochastic process that is adapted, in that depends only on the Brownian motion up to time , and that satisfies the Novikov condition (see, e.g., [23]):
Now, define the auxiliary process
Using the definition of , we may write Equation (11) as
Note that Equations (11) and (18) govern the same process , because the extra drift is absorbed by the shifted mean of the process . By construction, is not a Brownian motion under P, because its expectation with respect to P is not zero in general. On the other hand, is a Brownian motion under the measure P, and our aim is to find a measure under which is a Brownian motion. To this end, let be the process defined by
or, equivalently,
Girsanov’s theorem (see, e.g., [23], Theorem 8.6.4, or Appendix C) now states that is a standard Brownian motion under the probability measure Q with likelihood ratio
with respect to P where the Novikov condition (17) guarantees that , i.e., that Q is a probability measure. Inserting Equations (20) and (21) into the Donsker–Varadhan formula Equation (14), using that is Brownian motion with respect to Q, it follows that the term in in the expression of the relative entropy, which is linear in u, drops out, and what remains is (cf. [4,6]):
with being the solution of Equation (18). Since the distribution of under Q is the same as the distribution of B under P, an equivalent representation of the last equation is
where is the solution of the controlled SDE
with being our standard, m-dimensional Brownian motion (under P). See Appendix C for a sketch of derivation of Girsanov’s formula.
3.1.2. Importance Sampling in Path Space
Similarly to the finite dimensional case considered in the last section, we can derive optimal importance sampling strategies from the Donsker–Varadhan principle. To this end, we consider the case that is a random stopping time, which is a case that is often relevant in applications (e.g., when computing transition rates or committor functions [7]), but that is rarely considered in the importance sampling literature. Let and be an open and bounded set with smooth boundary . We define
as the first exit time of the set O and define the stopping time
to be the minimum of and T, i.e., the exit from the set O or the end of the maximum time interval, whatever comes first. For the ease of notation, we will use the same symbol to denote the stopping time under the controlled or uncontrolled process (i.e., for ) throughout the article. Unless otherwise noted, it should be clear from the context whether is understood with respect to or . Here, satisfies the controlled SDE (23).
We will argue that the optimal , which yields zero variance in the reweighting scheme
via , can be generated by a feedback control of the form
with a suitable function . Finding turns the Donsker–Varadhan variational principle (14) into an optimal control problem by virtue of Equations (22) and (23). The following statement characterizes the optimal control by which the infimum in Equation (14) is attained and which, as a consequence, provides a zero variance reweighting scheme (or: change of measure).
Theorem 2.
Let
be the exponential of the negative free energy, considered as a function of the initial condition with . Then, the path space measure induced by the feedback control
yields a zero variance estimator, i.e.,
Proof.
See Appendix D. ☐
Remark 3.
We should mention that Theorem 2 covers also the special cases that either is a deterministic stopping time (see, e.g., [24], Proposition 5.4.4) or, by sending , that is the first exit time of the set O, assuming that the stopping time is a.s. finite (but not necessarily bounded).
3.2. Revisiting Jarzynski’s Identity
The Donsker–Varadhan variational principle shares some features with the nonequilibrium free energy formula of Jarzynski [10], and, in fact, the variational form makes this formula amenable to the analysis of the previous paragraphs, with the aim of improving the quality of the corresponding statistical estimators. Jarzynski’s identity relates the Helmholtz equilibrium free energy to averages that are taken over an ensemble of non-equilibrium trajectories generated by forcing the dynamics.
We discuss a possible application of importance sampling to free energy calculation à la Jarzynski with a simple standard example, but we stress that all considerations easily generalize to more general situations than the one treated below.
As an example, let be a parametric family of smooth potential energy functions and define the free energy difference between the two equilibrium densities and as the log-ratio
(Often and are called thermodynamic states.) Defining the energy difference and the equilibrium probability density
the Helmholtz free energy is seen to be an exponential average of the familiar form (2):
Jarzynski’s formula [10] states that the last equation can be represented as an exponential average over non-stationary realizations of a parameter-dependent process . Specifically, letting denote the nonequilibrium work done on the system by varying the parameter from to within time , Jarzynski’s equality states that
where will be specified below. In the last equation the expectation is taken over all realizations of , with initial conditions distributed according to the equilibrium density . To be specific, we assume that the parametric process is the solution of the SDE
with being a differentiable parameter process (called: protocol) that interpolates between and . Further, let the work exerted by the protocol be given by
where is the interpolated potential, and denotes the time derivative of . Note that is a path functional of the standard form (12), with bounded deterministic stopping time and cost functions
Letting now P denote the path space measure that is generated by the Brownian motion in the parameter dependent SDE (31), we can express Jarzynski’s equality (30) by
where the (conditional) expectation is understood over all realizations of (31) with initial condition .
Optimized Protocols by Adaptive Importance Sampling
The applicability of Jarzynski’s formula heavily depends on the choice of the protocol . The observation that an uneducated choice of a protocol may render the corresponding statistical estimator virtually useless because of a dramatic increase of its variance is in accordance with what one observes in importance sampling. An attempt to optimize the protocol by minimizing the variance of the estimator has been carried out in [12], but here, we shall follow an alternative route, exploiting the fact that Jarzynski’s formula has the familiar exponential form considered in this paper; cf. also [11,13,14].
Having this said and recalling Theorem 2, it is plausible that there exists a zero variance estimator for which appeared in the integrand of Jarzynski’s equality (33), under certain assumptions on the functional . For simplicity, we confine the following considerations to the above example of a diffusion process of the form (31) with a deterministic protocol . To make the idea of optimizing the protocol more precise, we introduce the shorthand for the solution of Equation (31) and define
with and the expectation taken over all realizations of . The process solves a controlled variant of the SDE (31), specifically,
Here, we have used the shorthand . Theorem 2 that specifies the zero-variance importance sampling estimator in terms of a feedback control policy can be adapted to our situation (see, e.g., [7,18]) by letting so that a.s. The zero-variance estimator is generated by the feedback control
with given by Equation (34), and thus, by the SDE
Specifically, given N independent draws from the equilibrium distribution and corresponding N independent trajectories of the SDE (36) with initial conditions , an asymptotically unbiased, the minimum variance estimator of the free energy is given by
where with given by Equation (19) and being the nonequilibrium work (32) under the controlled process (36).
Remark 4.
Generally, the discretization of the work requires some care, because the discretization error may introduce some “shadow work” that may spoil the properties of the importance sampling estimator [25]. Further note that, even if time-discretization errors are ignored, the estimator (37) is not a zero-variance estimator because we have minimized only the conditional estimator (for fixed initial condition). Moreover the estimator is only asymptotically unbiased by Jensen’s inequality and the strict concavity of the logarithm.
Further notice that the estimator hinges on the availability of which is typically difficult to compute. An idea, inspired by the adaptive biasing force (ABF) algorithm [26,27,28] is to estimate γ on the fly and then iteratively refine the estimate in the course of the simulation using a suitable parametric representation [29,30]. If good collective variables or reaction coordinates are known, it is further possible to choose a representation that depends only on these variables and still obtain low variance estimators [31,32].
4. Algorithms: Gradient Descent, Cross Entropy Minimization and beyond
According to Theorem 2 designing reweighting (importance sampling) schemes on path space that feature zero variance estimators comes at the price of solving an optimal control problem of the following form: minimize the cost functional
over all admissible controls and subject to the dynamics
Here, admissible controls are Markovian feedback controls such that Equation (39) has a unique strong solution. Leaving all technical details aside see Section IV.3 in [8], it can be shown that the value function (or: optimal cost-to-go)
with being the unique optimal control given by Equation (26), is the solution of a nonlinear partial differential equation of Hamilton–Jacobi–Bellman type. Solving this equation numerically is typically even more difficult than solving the original sampling problem by brute-force Monte Carlo (especially when the state space dimension n is large).
Note that Equations (38) and (39) is simply the concrete form of the Donsker–Varadhan principle when the path space measure is generated by a diffusion. Therefore the equivocation with the path space free energy (13) or (34) is not a coincidence, because by definition the value function is the free energy, considered as a function of the initial conditions. In other words and in view of Theorem 2, there is no need for further sampling once the value function is known.
We will now discuss concrete numerical algorithms to minimize Equations (38) and (39) without resorting to the associated Hamilton–Jacobi–Bellman equation.
4.1. Gradient Descent
The fact that solving the optimal control problem can be as difficult as solving the sampling problem suggests to combine the two in an iterative fashion using a parametric representation of the value function (or: free energy). To this end, notice that the optimal control is essentially a gradient force that can be approximated by
based on a finite-dimensional approximation
of the value function with suitable smooth basis functions that span an N-dimensional subspace of the space of classical solutions of the associated Hamilton–Jacobi–Bellman equation. Here we denote by the Banach space of functions that are r and s times continuously differentiable in their first and second arguments, respectively, and for continuous functions. Plugging the above representation into Equations (38) and (39) yields the following finite-dimensional optimization problem: minimize
over the controls where is the solution of the SDE (23) with control .
Let us define , with the shorthand . Because of the dependence of the process and the random stopping time on the parameter , the functional is not quadratic in , but it has been shown [33] that it is strongly convex if the basis functions are non-overlapping. In this case has a unique minimum, which suggests to do a gradient descent in the parameter :
Here, is a sequence of step sizes that goes to zero as , and the gradient must be interpreted in the sense of a functional derivative:
for suitable test functions (i.e., square-integrable and adapted to the Brownian motion). Then, the gradient has the components
Introducing the shorthand
for the cost and the convention for the expectation with respect to P, the derivative (45) can again be found by means of Girsanov’s formula: there exists a measure that is absolutely continuous with respect to the reference measure P, such that
with the likelihood ratio
Assuming that the derivative and the expectation in Equation (47) commute, we can differentiate inside the expectation which is independent of the parameter and then switch back to the controlled process under the reference measure P, by which we obtain (see [33]):
Hence, using Equation (46), we find
where the last expression can be estimated by Monte Carlo, possibly in combination with variance minimizing strategies to improve the convergence of the gradient estimation in the course of the gradient descent [33,34]. Before we conclude, we shall briefly explain why the gradient vanishes when the variance is zero.
Lemma 1.
Under the optimal control , it holds that:
Proof.
We summarize the above considerations in Algorithm 1 below.
| Algorithm 1 Gradient descent |
|
Remark 5.
The step size control in Algorithm 1 follows the Barzilai-Borwein procedure that guarantees convergence as when the functional is convex. Another alternative is to do a line search after each iterate in the descent direction and then determine so that it satisfies the Wolfe condition; see [35] for further details.
Remark 6.
In practice, it may be advantageous to pick the basis functions so that they are not explicitly time-dependent (e.g., Gaussians, Chebyshev polynomials or the alike). If the associated control problem is stationary, as is for example the case when the SDE is homogeneous and the stopping time is a hitting time, the value function will be stationary too and, as a consequence, the control policy will be stationary. If, however, the problem is explicitly time-dependent, one may change the ansatz (42) to have stationary basis functions, but time-dependent coefficients , where the time-dependence is mediated by the initial data; see [29] for a discussion.
4.2. Cross-Entropy Minimization
Another algorithm for minimizing is based on an entropy representation of , namely,
where u is any admissible control for Equations (38) and (39), is the optimal control, and and are the corresponding path space measures. Equation (51) is a consequence of the zero-variance property of the optimal change of measure, since Equation (27) implies that
and hence
Taking the expectation with respect to Q and using that both Q and are absolutely continuous with respect to P and vice versa yields Equation (51).
The idea now is to seek a minimizer of in the set of probability measures that are generated by the discretized controls , i.e., one would like to minimize
over , such that is absolutely continuous with respect to . By Equation (16) the optimal change of measure is only known up to the normalizing factor , which enters Equation (54) only as an additive constant; note that we call or a normalizing factor, even though it is clearly a function of the initial conditions or . Nevertheless minimizing is not easily possible since the functional may have several local minima. With a little trick, however, we can turn the minimization of Equation (54) into a feasible minimization problem, simply by flipping the arguments. To this end, we define:
Clearly, Equation (51) does not hold with arguments in the Kullback-Leibler (or: KL) divergence term reversed, since is not symmetric; nevertheless, it holds that
where the minimum is attained if and only if . Hence, by continuity of the relative entropy, we may expect that by minimizing the “wrong” functional we get close to the optimal change of measure, provided that the optimal can be approximated by our parametric family . We have the following handy result (see [15]).
Lemma 2 (Cross-entropy minimization).
The minimization of (55) is equivalent to the minimization of the cross-entropy functional
where the log likelihood ratio between controlled and uncontrolled trajectories is quadratic in the unknown and can be computed via Girsanov’s theorem.
Proof.
By definition of the KL divergence, we have
since all measures are mutually absolutely continuous. The first term in the last equation is independent of , and the second term is proportional to the cross-entropy functional up to the unknown normalizing factor . ☐
The fact that the cross-entropy functional is quadratic in implies that the necessary optimality condition is of the form
where and are given by:
Note that the average in Equation (59) is over the uncontrolled realizations X. It is easy to see that the matrix S is positive definite if the basis functions are linearly independent, which implies that Equation (58) has a unique solution and our necessary condition is in fact sufficient. Nevertheless it may happen in practice that the coefficient matrix S is badly conditioned, in which case it may be advisable to evaluate the coefficients using importance sampling or a suitable annealing strategy; see [15,29] for further details.
A simple, iterative variant of the cross-entropy algorithm is summarized in Algorithm 2.
| Algorithm 2 Simple cross-entropy method |
|
4.3. Other Monte Carlo-Based Methods
We refrain from listing all possibilities to compute the optimal change of measure or the optimal control, and mention only two more possibilities that are functional in situations in which grid-based discretization methods (e.g., for solving the nonlinear Hamilton–Jacobi–Bellman equation) are unfeasible. The strength of the methods described below is that they can be combined with model reduction methods such as averaging, homogenization or Markov state modeling if either suitable collective variables, a reaction coordinate or some dominant metastable sets are known; see, e.g., [7,15,29,32,36,37] for the general approach and the application to molecular dynamics.
4.3.1. Approximate Policy Iteration
The first option is based on successive linearization of the Hamilton–Jacobi–Bellman equation of the underlying optimal control problem. The idea is the following: Given any admissible control , the Feynman–Kac theorem [23] (Theorem 8.2.1) states that the cost functional , considered as a function of the initial data of the controlled process with , solves a linear boundary value problem of the form
where is a linear differential operator that depends on the chosen control policy and which precise form (e.g., parabolic, elliptic or hypoelliptic) depends on the problem at hand. Clearly, is the value function (or free energy), i.e., the solution we seek. For an arbitrary initial choice of a control policy we have , and a successive improvement of the policy can be obtained by iterating
Under suitable assumptions on the drift and diffusion coefficients, iteration of Equations (60) and (61) yields a convergent series of control policies that converges to the unique optimal control, hence the name of the method is policy iteration. Clearly, solving the linear partial differential Equation (60) by any grid-based method will be unfeasible if the state space dimension is larger than, say, three or four. In this case, it is possible to approximate the infinitesimal generators by a sparse and grid-free Markov State Model (MSM) that captures the underlying dynamics ; see, e.g., [36] for the error analysis of the corresponding nonequilibrium MSM and an application to molecular dynamics. In this case, one speaks of an approximate policy iteration. For further details on approximate policy iteration algorithms we refer to the article [38] and the references therein.
4.3.2. Least-Squares Monte Carlo
If is a finite stopping time, another alternative is to exploit that the value function of the control problem Equations (38) and (39) can be computed as the solution to a forward-backward stochastic differential equation (FBSDE) of the form
where and the second equation must be interpreted as an equation that runs backwards in time. A solution of the FBSDE (62) is a triplet , with the property that and at time depend only on the history of the forward process up to time . In particular, since , the backward process is a deterministic function of the initial data only, and it holds that (e.g., [39])
The specific structure of the control problem Equations (38) and (39) implies that the forward equation is decoupled from the backward equation and that the backward process can be expressed by
where is the uncontrolled forward process. Since we can simulate the forward process and we know the functional dependence of on , the idea here is again to use the representation Equation (42) of in terms of a finite basis. It turns out that the coefficient vector can be computed by solving a least-squares problem in every time step of the time-discretized backward SDE, which is why methods for solving an FBSDE like Equation (62) are termed least squares Monte Carlo; for the general approach we refer to [40,41]; details for the situation at hand will be addressed in a forthcoming paper [42].
5. Illustrative Examples
From a measure-theoretic viewpoint, changing the drift of an SDE (also known as Girsanov transformation) is an exponential tilting of a Gaussian measure on an infinite-dimensional space. Here, for illustration purposes, we consider a one-dimensional paradigm that is in the spirit of Section 2 and that illustrates the basic features of Gaussian measure changes, Girsanov transformations and the cross-entropy method.
To this end, let the density of the standard Gaussian distribution on , and define an exponential family of “tilted” probability densities by
It can be readily checked that is the density of the normal distribution with mean and unit variance, in other words, the exponential tilting results in a shift of the mean, which represents a change of the drift in the case of an SDE (compare Equations (19) and (21)).
5.1. Example 1 (Moment Generating Function)
Let and define
By Jensen’s inequality, it follows that
where denotes the expectation with respect to . A simple calculation shows that the inequality is sharp where equality is attained for , i.e., when , with
As a consequence, the Donsker–Varadhan variational principle (4) holds when the minimum is taken over the exponential family (64) with sufficient statistic X.
We will now show that can be computed by the cross-entropy method. To this end, let
As we have just argued, there exists a unique minimizer of J that by Theorem 1 has the zero variance property, which implies that
The associated cross-entropy functional has the form (see Section 4.2):
Using Equation (64), it is easily seen that the cross-entropy functional is quadratic,
with unique minimizer:
where the second equality follows from Equation (65), using the fact that the derivative and the expectation commute because is Gaussian and hence the moment-generating function exists for all . Rearranging the terms in the last equation, we obtain
showing that:
The above consideration readily generalize to the multidimensional Gaussian case, and hence this simple example illustrates that the cross-entropy method yields the same result as direct minimization of the functional (68)—at least in the finite-dimensional case.
5.2. Example 2 (Rare Event Probabilities)
The following example illustrates that the cross-entropy method can be used and produces meaningful results, even though the Donsker–Varadhan principle does not hold. To this end consider again the case of a real-valued random variable with density and with . Then
is a small probability that is difficult to compute by brute-force Monte Carlo. In this case, a zero-variance change of measure exists, but it is not of the form (64). As a consequence, equality in Equation (66) cannot be attained within the exponential family given by Equation (64). Instead, the optimal density in this case would be the conditional density
where the normalization constant is of course the quantity we want to compute (cf. Section 2.1). Note that this expression formally agrees with the optimal density (5), which was derived under different assumptions though.
The idea now is to minimize the distance between and in the sense of relative entropy, i.e., we seek a minimizer of the Kullback–Leibler divergence in the exponential family . The associated cross-entropy functional is given by
with unique minimizer
Comparing Equations (77) and (75), we observe that both densities and have the same mean (namely ), hence the suboptimal density is concentrated around the typical values that the optimal density would produce when samples were drawn from it.
Clearly, the optimal tilting parameter (77) is probably as difficult to compute by brute-force Monte Carlo as the probability since is a rare event when is far away from the mean. The strength of both gradient descent and cross-entropy method is, however, that the optimal tilting parameter can be computed iteratively. This is illustrated numerically in Figure 1 for the choice , where we use Algorithm 1 with a constant stepsize and Algorithm 2 as specified. In each iteration m we draw a sample of size from the density , and estimate the mean,
and the sample variance in each sample. The latter is proportional to the normalized variance of an estimator that has been estimated K times.
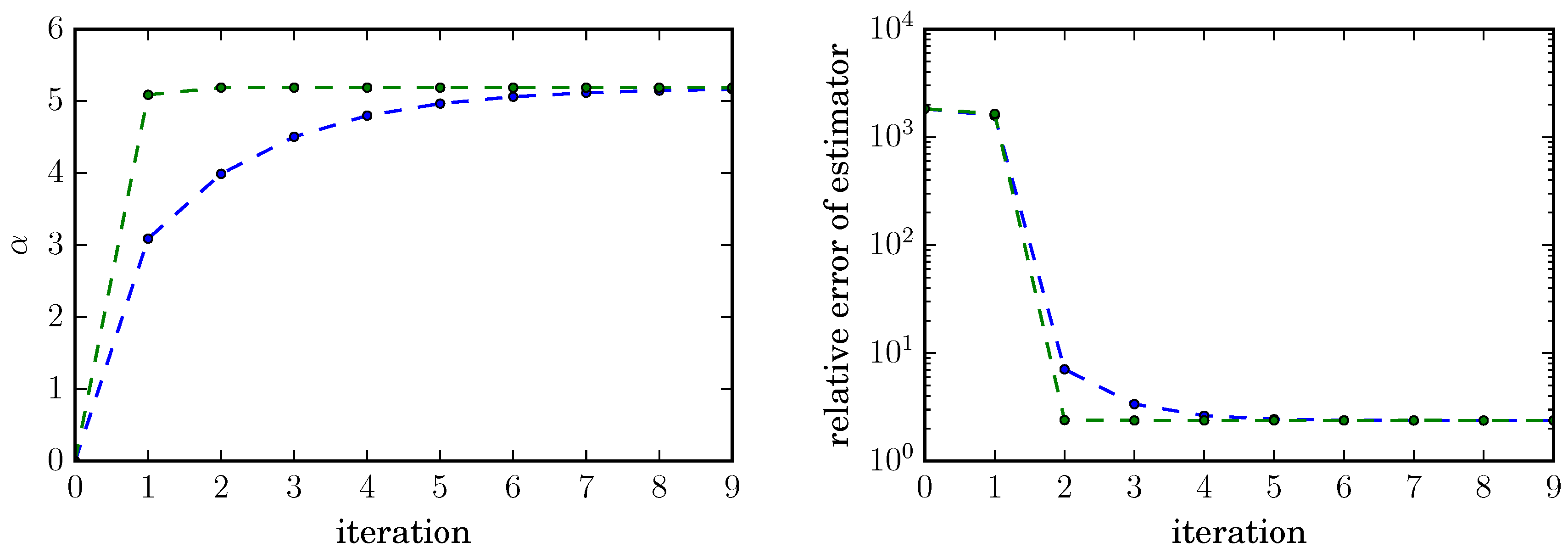
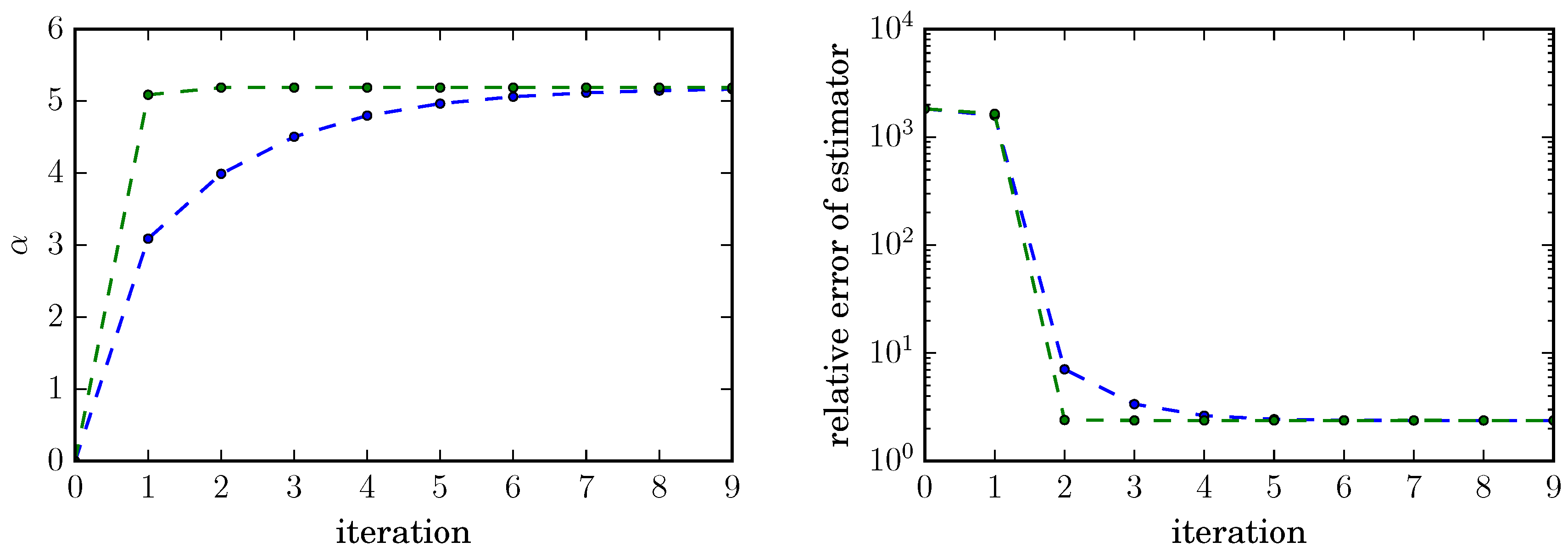
For this (admittedly simple) example both gradient descent and cross-entropy method converge well and lead to a drastic reduction of the normalized relative error of the estimator by a factor of about 1000, from about 2000 without importance sampling to about under (suboptimal) importance sampling with exponential tilting, indicating that both methods can handle situations in which the optimal (i.e., ) change of measure is not available within the set of trial densities.
6. Conclusions
We have presented a method for constructing minimum-variance importance sampling estimators. The method is based on a variational characterization of the thermodynamic free energy and essentially replaces a Monte Carlo sampling problem by a stochastic approximation problem for the optimal importance sampling density. For path sampling, the stochastic approximation problem boils down to a Markov control problem, which again can be solved by stochastic optimization techniques. We have proved that for a large class of path sampling problems that are relevant in, e.g., molecular dynamics or rare events simulation, the (unique) solution to the optimal control problem can yield zero-variance importance sampling schemes.
The computational gain when replacing the sampling problem by a variational principle is, besides improved convergence due to the variance reduction and often a higher hitting rate of the relevant events, due to the fact that the variational problem can be solved iteratively, which makes it amenable to multilevel approaches. The cross-entropy method as an example of such an approach has been presented in some detail. A substantial difficulty still is a clever choice of basis functions that is highly problem-specific, and hence, future research should address non-parametric approaches, as well as model reduction methods in combination with the stochastic optimization/approximation tools that can be used to solve the underlying variational problems.
Acknowledgments
This work was funded by the Einstein Center for Mathematics (ECMath) and by the Deutsche Forschungsgemeinschaft (DFG) under Frant DFG-SFB 1114 “Scaling Cascades in Complex Systems”.
Author Contributions
C.H. and W.Z. conceived and designed the research; L.R. performed the numerical experiments; C.H. and C.S. wrote the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Yet Another Certainty Equivalence
A similar variational characterization of expected values as in Equation (4), based on convexity arguments and Jensen’s inequality, can be formulated for non-negative random variables . For simplicity and as in Section 2.1, we assume W to be bounded and measurable and . Then, for all , it holds that
where is any non-negative probability density. If we exclude the somewhat pathological case a.s., it follows that and the supremum is attained for
The proof is along the lines of the proof of the Donsker–Varadhan principle Equation (4). Indeed, applying Jensen’s inequality and noting that is non-zero -a.s. it readily follows that
and it is easy to verify that the supremum in Equation (A1) is attained at given by Equation (A2).
Similar as in Section 2.1, the above discussions can be applied to study the importance sampling schemes for the p-th moment of random variable W. We have:
Theorem A1 (Optimal importance sampling, cont’d).
Let and be defined in Equation (A2). Then the random variable has zero variance under , and we have:
Again, Theorem A1 implies that drawing random variable X from and then estimating the reweighted expectation provides a zero variance estimator for the quantity .
Appendix B. Ratio Estimators
We shall briefly discuss the properties of the self-normalized importance sampling estimator (7) that is based on estimating a ratio of expected values
where and are i.i.d. random variables living on a joint probability space and having finite variances and and covariance . Further assume that , then, by the strong law of large numbers, the ratio converges a.s. to where .
Appendix B.1. The Delta Method
We can apply the delta method (e.g., [20] (Section 4.1)) to analyze the behavior of the ratio estimator in more detail. Roughly speaking, the delta method says that for a sum , of square-integrable, i.i.d. random variables with mean , covariance matrix and a sufficiently smooth function which can be Taylor expanded about , the central limit theorem applies. Specifically, using mean value theorem, it is easily seen that
for some lying component-wise in the half open interval between and . By the continuity of at , the fact that a.s. as and that is approximately Gaussian with mean zero and covariance , we have
where “” denotes convergence in law (or: convergence in distribution), and denotes a Gaussian distribution with mean m and covariance C.
Appendix B.2. Asymptotic Properties of Ratio Estimators
Applying the delta method to the function , and assuming that is bounded away from zero, we find that the ratio estimator satisfies a central limit theorem too. Specifically, assuming that so that is asymptotically bounded away from zero, the delta method yields
with variance
In particular, the estimator is asymptotically unbiased.
Appendix C. Finite-Dimensional Change of Measure Formula
We will explain the basic idea behind Girsanov’s theorem and the change of measure Formula (21). To keep the presentation easily accessible, we present only a vanilla version of the theorem based on finite-dimensional Gaussian measures, partly following an idea in [43].
Appendix C.1. Gaussian Change of Measure
Let P be a probability measure on a measurable space , on which an m-dimensional random variable is defined. Further suppose that B has standard Gaussian distribution . Given a (deterministic) vector and a matrix , we define a new random variable by
The similarity to the SDE (11) is no coincidence. Since B is Gaussian, so is X, with mean b and covariance . Now, let and define the shifted Gaussian random variable
and consider the alternative representation
of X that is equivalent to Equation (A4) if and only if
has a solution (that may not be unique though). Following the line of Section 3.1, we seek a probability measure such that is standard Gaussian under Q, and we claim that such a Q should have the property:
or, equivalently,
in accordance with Equations (19)–(21). To show that is indeed standard Gaussian under the above defined measure Q, it is sufficient to check that for any measurable (Borel) set , the probability is given by the integral against the standard Gaussian density:
Indeed, since B is standard Gaussian under P, it follows that:
showing that has a standard Gaussian distribution under Q.
Appendix C.2. Reweighting
Clearly, by the definition of Q, it holds that:
for any bounded and measurable function , where denotes the expectation with respect to the reference measure P. Now, let
Since the distribution of the pair under P is the same as the distribution of the pair with under Q, the reweighting identity Equation (A8) entails that
with . Equation (A9) is the finite dimensional analogue of the reweighting identity that has been used to convert the Donsker–Varadhan Formula (14) into its final form (22).
Appendix D. Proof of Theorem 2
The proof is based on the Feynman–Kac formula and Itô’s lemma. Here, we give only a sketch of the proof and leave aside all technical details regarding the regularity of solutions of partial differential equations, for which we refer to [8] (Section VI.5). Recall the definition
By the Feynman–Kac formula, function solves the parabolic boundary value problem
on the domain where denotes the terminal set of the augmented (control-free) process and
is its infinitesimal generator under the probability measure P.
By construction, the stopping time is bounded, and we assume that is of class on D, and continuous and uniformly bounded away from zero on the closure . Now, let us define the process
with given by Equation (18). Then, using Itô’s lemma (e.g., [23] (Theorem 4.2.1)) and introducing the shorthands
we see that satisfies the SDE
In the last equation, we have used that the first equality in Equation (A10) holds in the interior of the bounded domain D, i.e., for . Choosing for to be the optimal control
as in Equation (26), the last equation can be recast as
As a consequence, using the continuity of the process as ,
By definition of , the initial value is deterministic. Moreover , which in combination with Equation (A11) yields:
Rearranging the terms in the last equation, we find
with probability one, which yields the assertion of Theorem 2.
Remark A3.
Letting in the proof of the theorem it follows that a.s. where is the first exit time of the set O. As a consequence, the zero variance property of the importance sampling estimator carries over to the case of a.s. finite (but not necessarily bounded) hitting times or first exit times.
References
- Hammersely, J.M.; Morton, K.W. Poor Man’s Monte Carlo. J. R. Stat. Soc. Ser. B 1954, 16, 23–38. [Google Scholar]
- Rosenbluth, M.N.; Rosenbluth, A.W. Monte Carlo Calculations of the Average Extension of Molecular Chains. J. Chem. Phys. 1955, 23, 356–359. [Google Scholar] [CrossRef]
- Deuschel, J.D.; Stroock, D.W. Large Deviations; Academic Press: New York, NY, USA, 1989. [Google Scholar]
- Dai Pra, P.; Meneghini, L.; Runggaldier, W.J. Connections between stochastic control and dynamic games. Math. Control Signals Syst. 1996, 9, 303–326. [Google Scholar] [CrossRef]
- Delle Site, L.; Ciccotti, G.; Hartmann, C. Partitioning a macroscopic system into independent subsystems. J. Stat. Mech. Theory Exp. 2017, 2017, 83201. [Google Scholar] [CrossRef]
- Boué, M.; Dupuis, P. A variational representation for certain functionals of Brownian motion. Ann. Probab. 1998, 26, 1641–1659. [Google Scholar]
- Hartmann, C.; Banisch, R.; Sarich, M.; Badowski, T.; Schütte, C. Characterization of rare events in molecular dynamics. Entropy 2014, 16, 350–376. [Google Scholar] [CrossRef]
- Fleming, W.H.; Soner, H.M. Controlled Markov Processes and Viscosity Solutions; Springer: New York, NY, USA, 2006. [Google Scholar]
- Hartmann, C.; Schütte, C. Efficient rare event simulation by optimal nonequilibrium forcing. J. Stat. Mech. Theory Exp. 2012, 2012. [Google Scholar] [CrossRef]
- Jarzynski, C. Nonequilibrium equality for free energy differences. Phys. Rev. Lett. 1997, 78, 2690–2693. [Google Scholar] [CrossRef]
- Sivak, D.A.; Crooks, G.A. Thermodynamic Metrics and Optimal Paths. Phys. Rev. Lett. 2012, 109, 190602. [Google Scholar] [CrossRef] [PubMed]
- Oberhofer, H.; Dellago, C. Optimum bias for fast-switching free energy calculations. Comput. Phys. Commun. 2008, 179, 41–45. [Google Scholar] [CrossRef]
- Rotskoff, G.M.; Crooks, G.E. Optimal control in nonequilibrium systems: Dynamic Riemannian geometry of the Ising model. Phys. Rev. E 2015, 92, 60102. [Google Scholar] [CrossRef] [PubMed]
- Vaikuntanathan, S.; Jarzynski, C. Escorted Free Energy Simulations: Improving Convergence by Reducing Dissipation. Phys. Rev. Lett. 2008, 100, 109601. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Wang, H.; Hartmann, C.; Weber, M.; Schütte, C. Applications of the cross-entropy method to importance sampling and optimal control of diffusions. SIAM J. Sci. Comput. 2014, 36, A2654–A2672. [Google Scholar] [CrossRef]
- Dupuis, P.; Wang, H. Importance sampling, large deviations, and differential games. Stoch. Int. J. Probab. Stoch. Proc. 2004, 76, 481–508. [Google Scholar] [CrossRef]
- Dupuis, P.; Wang, H. Subsolutions of an Isaacs equation and efficient schemes for importance sampling. Math. Oper. Res. 2007, 32, 723–757. [Google Scholar] [CrossRef]
- Vanden-Eijnden, E.; Weare, J. Rare Event Simulation of Small Noise Diffusions. Commun. Pure Appl. Math. 2012, 65, 1770–1803. [Google Scholar] [CrossRef]
- Roberts, G.O.; Tweedie, R.L. Exponential convergence of Langevin distributions and their discrete approximations. Bernoulli 1996, 2, 341–363. [Google Scholar] [CrossRef]
- Glasserman, P. Monte Carlo Methods in Financial Engineering; Springer: New York, NY, USA, 2004. [Google Scholar]
- Lelièvre, T.; Stolz, G. Partial differential equations and stochastic methods in molecular dynamics. Acta Numer. 2016, 25, 681–880. [Google Scholar] [CrossRef]
- Bennett, C.H. Efficient estimation of free energy differences from Monte Carlo data. J. Comput. Phys. 1976, 22, 245–268. [Google Scholar] [CrossRef]
- Øksendal, B. Stochastic Differential Equations: An Introduction with Applications; Springer: Berlin, Germany, 2003. [Google Scholar]
- Lapeyre, B.; Pardoux, E.; Sentis, R. Méthodes de Monte Carlo Pour les Équations de Transport et de Diffusion; Springer: Berlin, Germany, 1998. (In French) [Google Scholar]
- Sivak, D.A.; Chodera, J.D.; Crooks, G.A. Using Nonequilibrium Fluctuation Theorems to Understand and Correct Errors in Equilibrium and Nonequilibrium Simulations of Discrete Langevin Dynamics. Phys. Rev. X 2013, 3, 11007. [Google Scholar] [CrossRef]
- Darve, E.; Rodriguez-Gomez, D.; Pohorille, A. Adaptive biasing force method for scalar and vector free energy calculations. J. Chem. Phys. 2008, 128, 144120. [Google Scholar] [CrossRef] [PubMed]
- Lelièvre, T.; Rousset, M.; Stoltz, G. Computation of free energy profiles with parallel adaptive dynamics. J. Chem. Phys. 2007, 126, 134111. [Google Scholar] [CrossRef] [PubMed]
- Lelièvre, T.; Rousset, M.; Stoltz, G. Long-time convergence of an adaptive biasing force methods. Nonlinearity 2008, 21, 1155–1181. [Google Scholar] [CrossRef]
- Hartmann, C.; Schütte, C.; Zhang, W. Model reduction algorithms for optimal control and importance sampling of diffusions. Nonlinearity 2016, 29, 2298–2326. [Google Scholar] [CrossRef]
- Zhang, W.; Hartmann, C.; Schütte, C. Effective dynamics along given reaction coordinates, and reaction rate theory. Faraday Discuss. 2016, 195, 365–394. [Google Scholar] [CrossRef] [PubMed]
- Hartmann, C.; Latorre, J.C.; Pavliotis, G.A.; Zhang, W. Optimal control of multiscale systems using reduced-order models. J. Comput. Nonlinear Dyn. 2014, 1, 279–306. [Google Scholar] [CrossRef]
- Hartmann, C.; Schütte, C.; Weber, M.; Zhang, W. Importance sampling in path space for diffusion processes with slow-fast variables. Probab. Theory Relat. Fields 2017. [Google Scholar] [CrossRef]
- Lie, H.C. On a Strongly Convex Approximation of a Stochastic Optimal Control Problem for Importance Sampling of Metastable Diffusions. Ph.D. Thesis, Department of Mathematics and Computer Science, Freie Universität Berlin, Berlin, Germany, 2016. [Google Scholar]
- Richter, L. Efficient Statistical Estimation Using Stochastic Control and Optimization. Master’s Thesis, Department of Mathematics and Computer Science, Freie Universität Berlin, Berlin, Germany, 2016. [Google Scholar]
- Nocedal, J.; Wright, S.J. Numerical Optimization; Springer: New York, NY, USA, 1999. [Google Scholar]
- Banisch, R.; Hartmann, C. A sparse Markov chain approximation of LQ-type stochastic control problems. Math. Control Relat. Fields 2016, 6, 363–389. [Google Scholar] [CrossRef]
- Schütte, C.; Winkelmann, S.; Hartmann, C. Optimal control of molecular dynamics using Markov state models. Math. Program. Ser. B 2012, 134, 259–282. [Google Scholar] [CrossRef]
- Bertsekas, D.P. Approximate policy iteration: A survey and some new methods. J. Control Theory Appl. 2011, 9, 310–355. [Google Scholar] [CrossRef] [Green Version]
- El Karoui, N.; Hamadène, S.; Matoussi, A. Backward stochastic differential equations and applications. Appl. Math. Optim. 2008, 27, 267–320. [Google Scholar]
- Bender, C.; Steiner, J. Least-Squares Monte Carlo for BSDEs. In Numerical Methods in Finance; Carmona, R., Del Moral, P., Hu, P., Oudjane, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 257–289. [Google Scholar]
- Gobet, E.; Turkedjiev, P. Adaptive importance sampling in least-squares Monte Carlo algorithms for backward stochastic differential equations. Stoch. Proc. Appl. 2005, 127, 1171–1203. [Google Scholar] [CrossRef]
- Hartmann, C.; Kebiri, O.; Neureither, L. Importance sampling of rare events using least squares Monte Carlo. 2018; under preparation. [Google Scholar]
- Papaspiliopoulos, O.; Roberts, G.O. Importance sampling techniques for estimation of diffusions models. In Centre for Research in Statistical Methodology; Working Papers, No. 28; University of Warwick: Coventry, UK, 2009. [Google Scholar]
Figure 1.
Comparison of the cross-entropy (green) and the gradient descent method (blue) for a rare event with probability for fixed sample size . Both algorithms quickly converge to the optimal tilting parameter for the family of importance sampling distributions (left panel) and lead to a drastic reduction of the normalized relative error by a factor of 1000, from about 2000 to 2.38 after few iterations (right panel).
Figure 1.
Comparison of the cross-entropy (green) and the gradient descent method (blue) for a rare event with probability for fixed sample size . Both algorithms quickly converge to the optimal tilting parameter for the family of importance sampling distributions (left panel) and lead to a drastic reduction of the normalized relative error by a factor of 1000, from about 2000 to 2.38 after few iterations (right panel).
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hartmann, C.; Richter, L.; Schütte, C.; Zhang, W. Variational Characterization of Free Energy: Theory and Algorithms. Entropy 2017, 19, 626. https://doi.org/10.3390/e19110626
AMA Style
Hartmann C, Richter L, Schütte C, Zhang W. Variational Characterization of Free Energy: Theory and Algorithms. Entropy. 2017; 19(11):626. https://doi.org/10.3390/e19110626
Chicago/Turabian StyleHartmann, Carsten, Lorenz Richter, Christof Schütte, and Wei Zhang. 2017. "Variational Characterization of Free Energy: Theory and Algorithms" Entropy 19, no. 11: 626. https://doi.org/10.3390/e19110626
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.