
Research and Application of a Novel Hybrid Model Based on Data Selection and Artificial Intelligence Algorithm for Short Term Load Forecasting


Abstract
:1. Introduction
- (1)
- A novel hybrid model is successfully developed for multi-step short-term load forecasting; it comprises data selection, signal processing, SVR, the advanced optimization algorithm and the multi-step forecasting strategy. Its effectiveness is validated in New South Wales and Singapore.
- (2)
- A new intelligent optimization algorithm is initially utilized to obtain the optimal parameters of the SVR model, while the signal processing approach effectively identifies and extracts the main feature of power load series, and it is proven that these methods can improve the forecasting performance.
- (3)
- The data structure of the forecasting model is effectively constructed by the data selection, which ensures that the datasets have the same properties to achieve abundant forecasting performance.
- (4)
- A more comprehensive evaluation of the proposed model is conducted in this paper. Two testing methods, i.e., the Diebold–Mariano (DM) test and forecasting effectiveness, are employed to evaluate the proposed hybrid model, in addition to four common metric rules, i.e., the mean absolute error (MAE), root mean square of error (RMSE), normalized mean square of error (NMSE) and mean absolute percentage error (MAPE).
2. Methodology
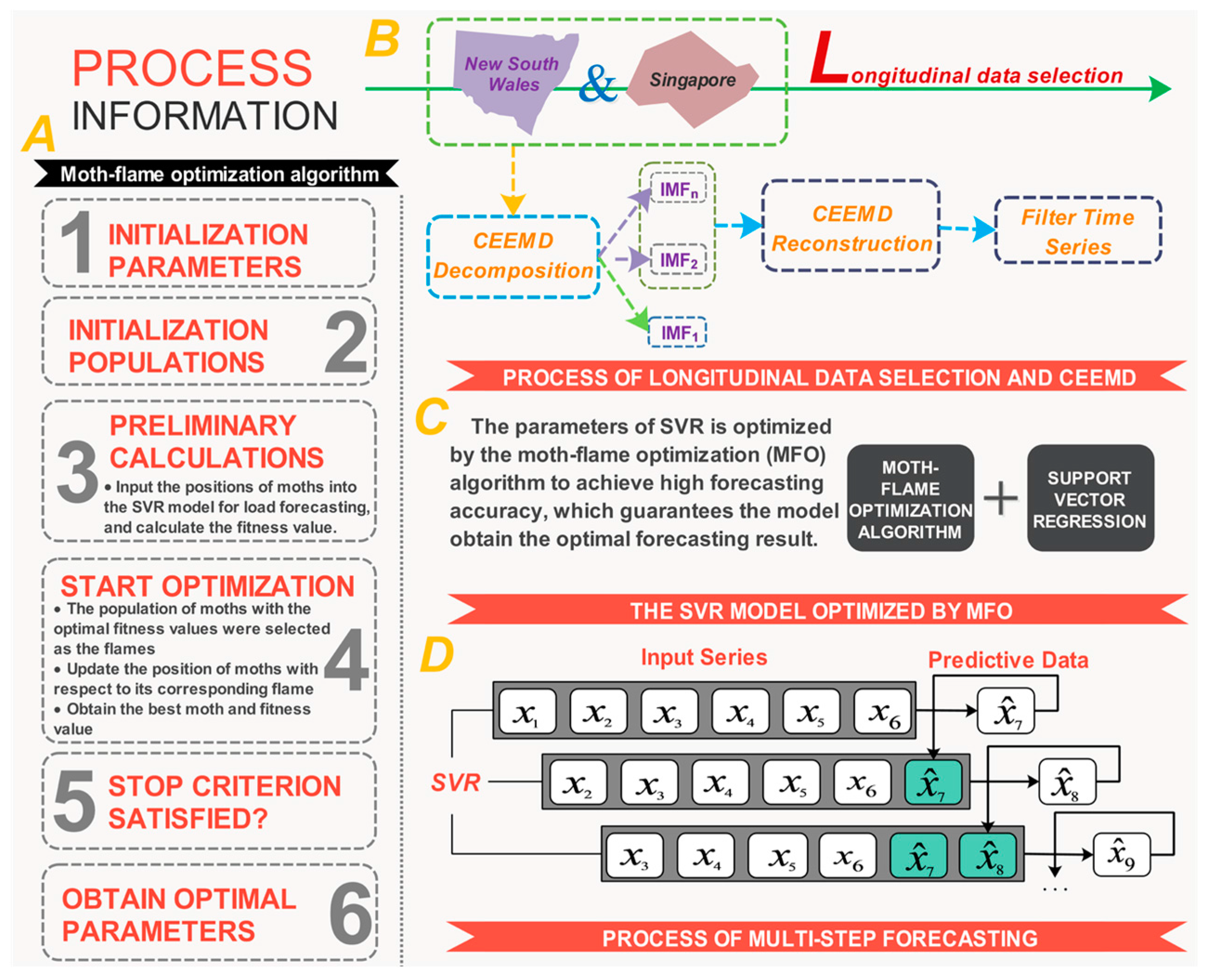
2.1. The Decomposition Approach for Signal Processing
2.2. Support Vector Regression (SVR)
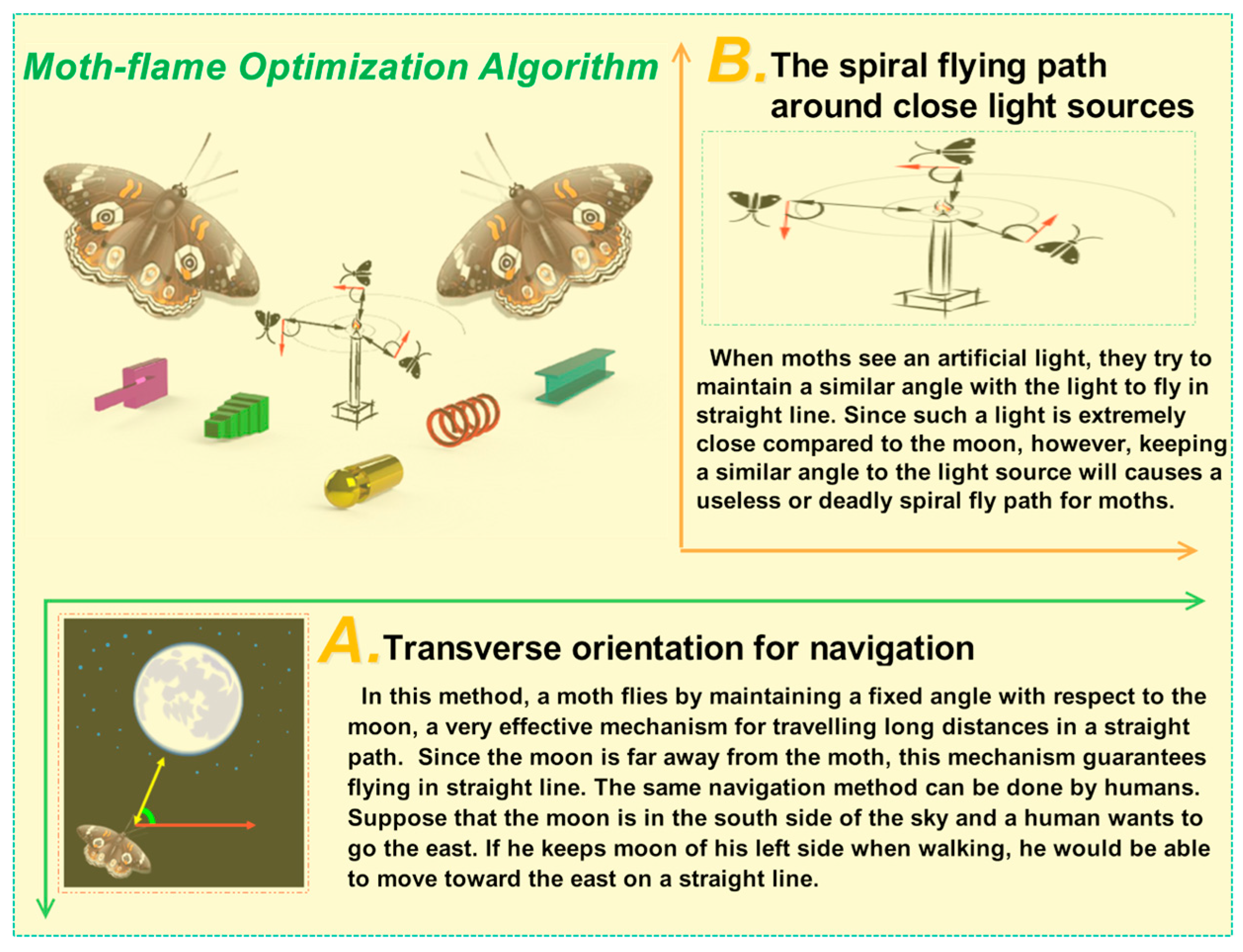
2.3. Brief Overview of Moth-Flame Optimization Algorithm
| Algorithm 1 Moth-Flame Optimization Algorithm. | |
| Input: —a sequence of training data —a sequence of test data Output: —the value can satisfy the best fitness after global searching | |
| Parameters: n—the number of moths and flames d—the number of variables Max_iter—the maximum iteration number fi—the fitness function of moth i iter—the current iteration number lb/ub—the lower/upper bound of variables | |
| 1 | /*Set the parameters of MFO.*/ |
| 2 | /*Initialize the position of moth Mi (i = 1, 2, ..., n) randomly.*/ |
| 3 | FOR EACH i: 1 ≤ i ≤ n DO |
 | |
| 27 | END WHILE |
| 28 | RETURN gbest |
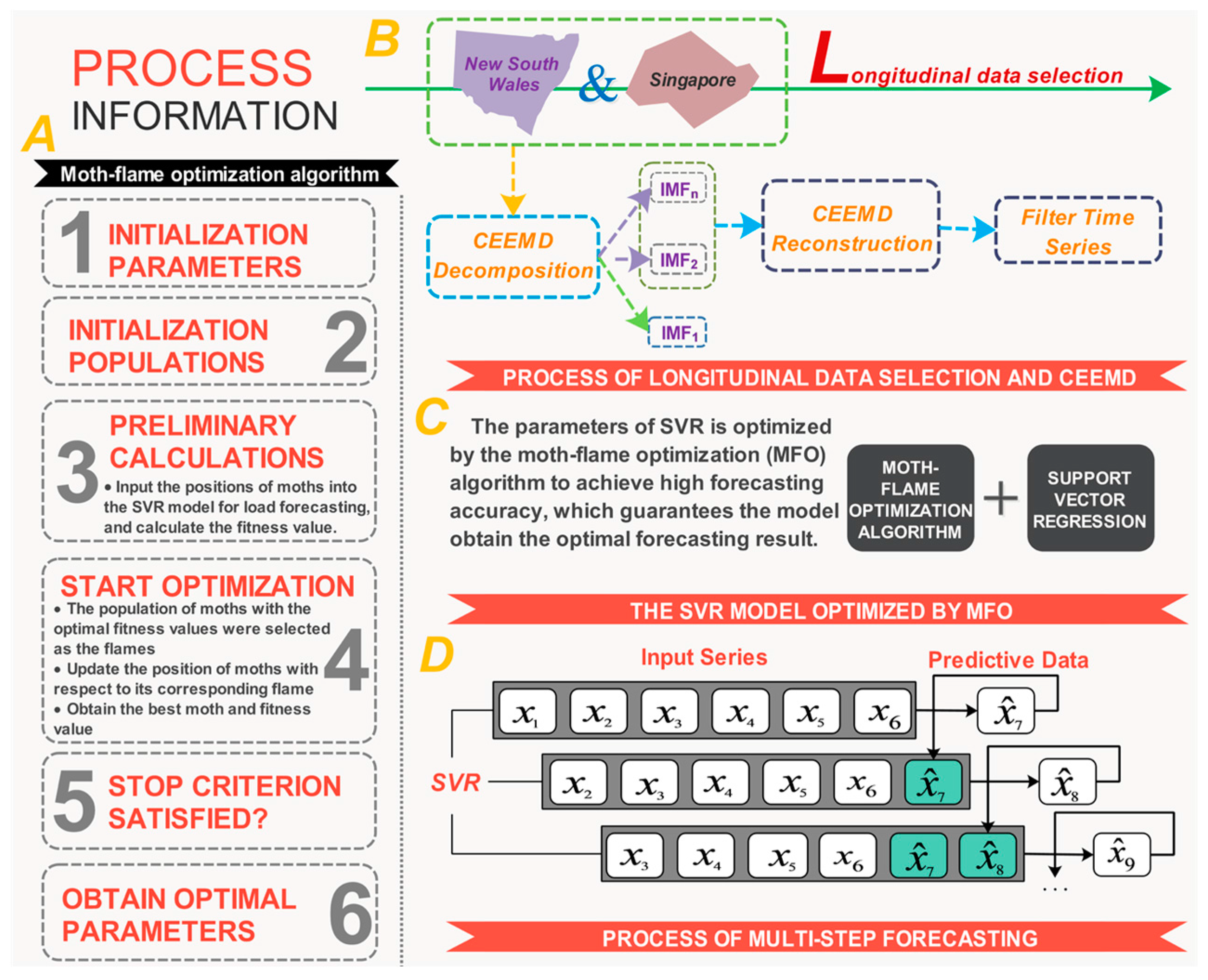
3. The Innovative Hybrid Model for Short-Term Load Forecasting
4. Materials and Methods
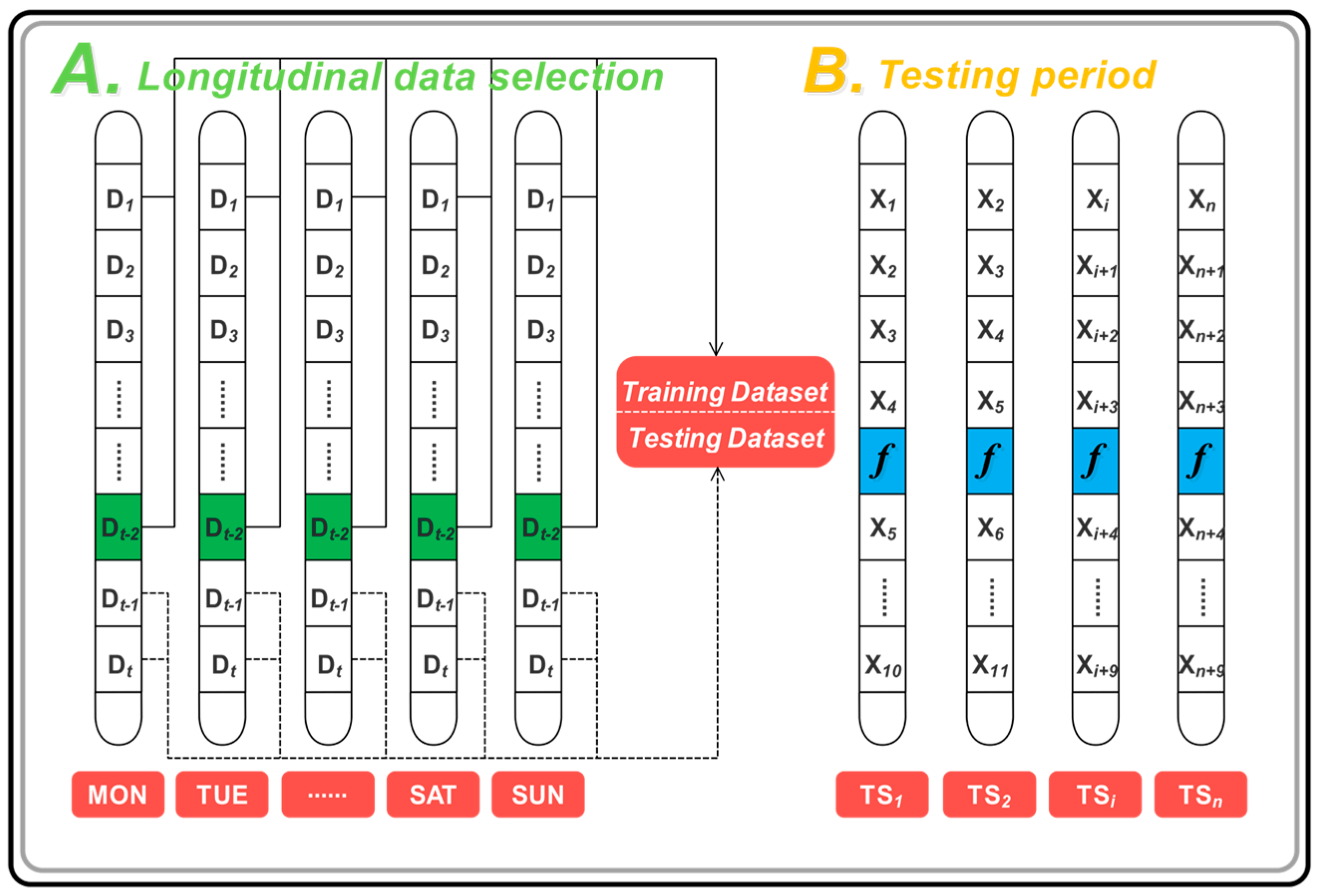
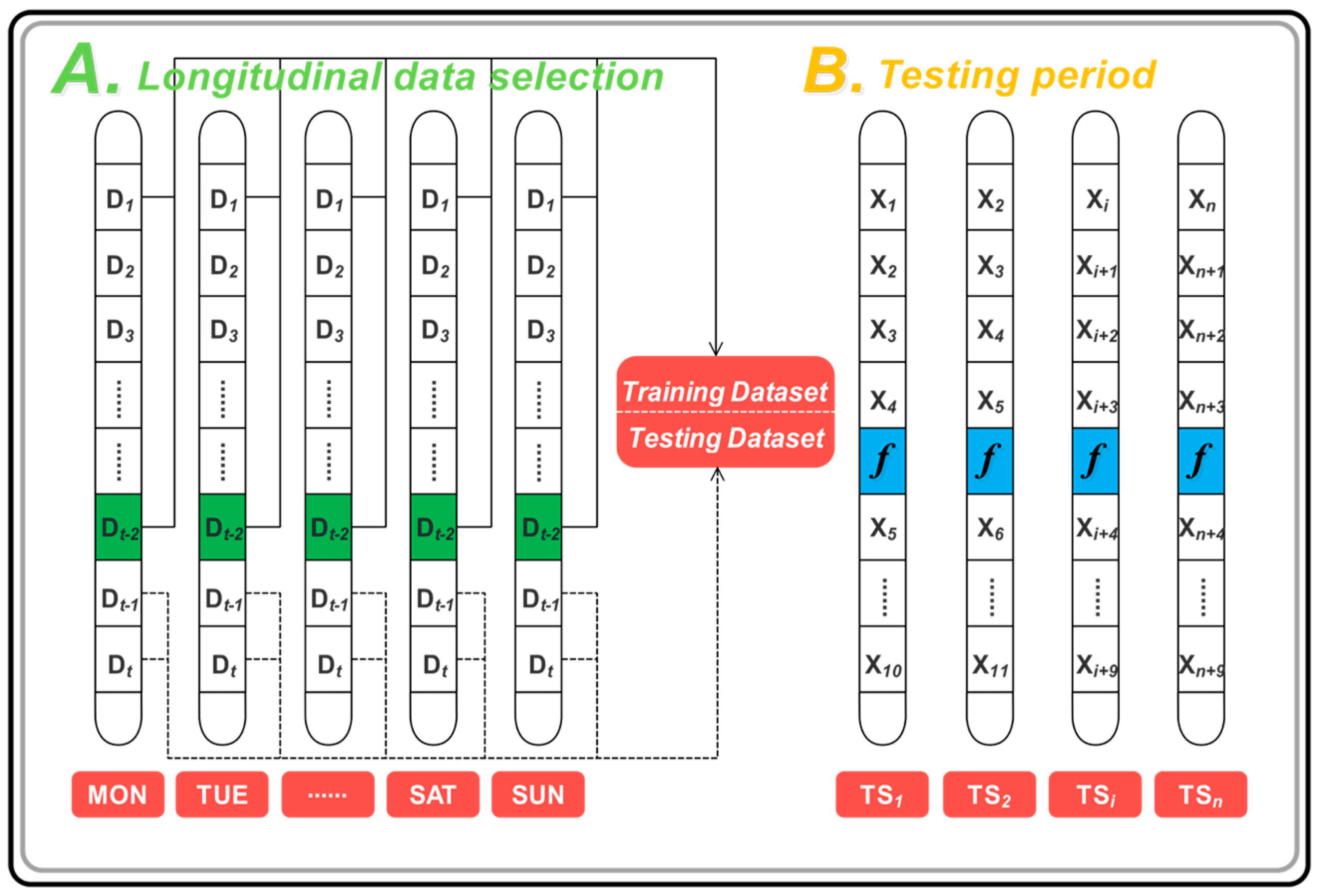
4.1. Data Selection
4.2. The Performance Metric
4.3. Testing Method
4.3.1. DM Test
4.3.2. Forecasting Effectiveness
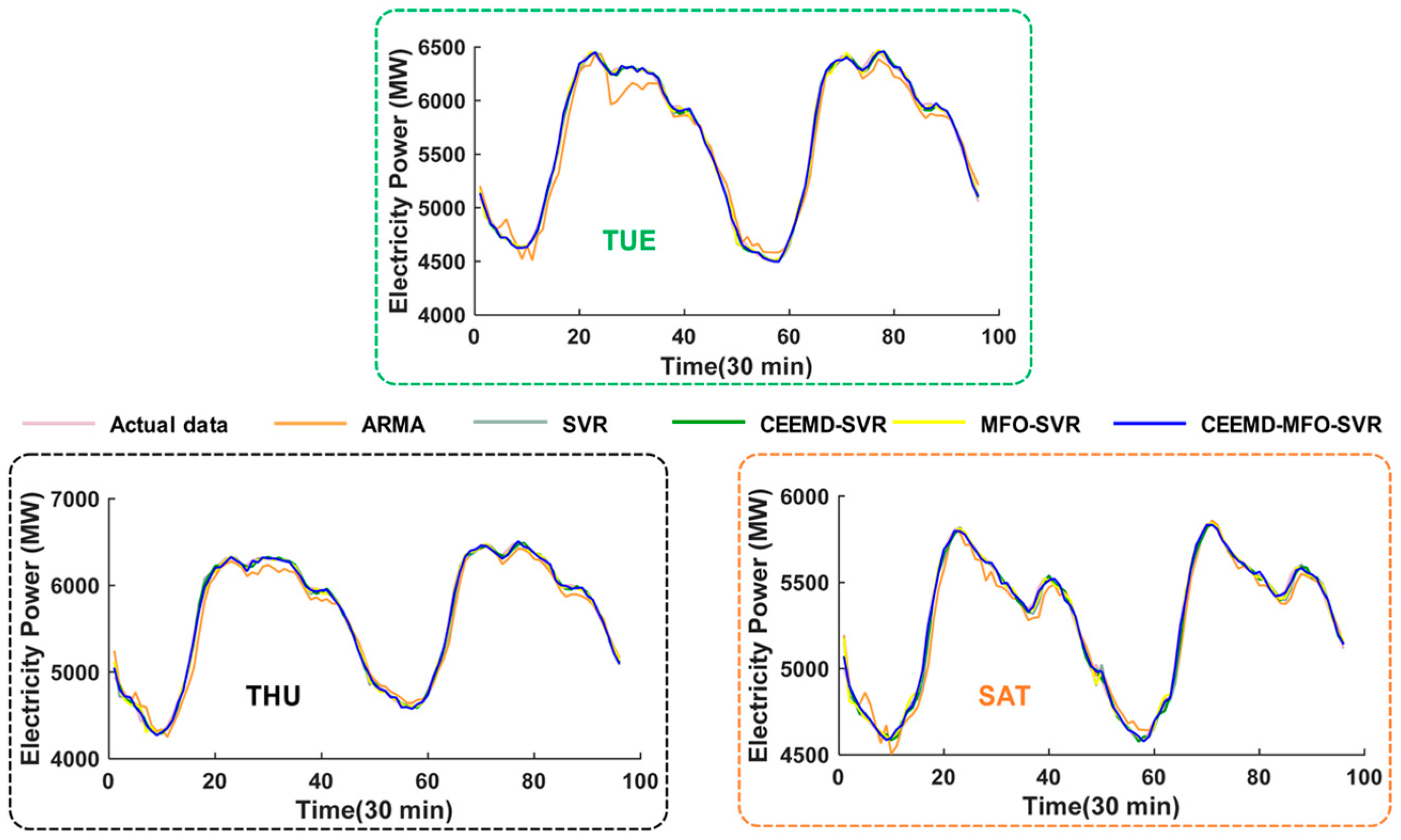
4.4. Experiment I: The Case of New South Wales
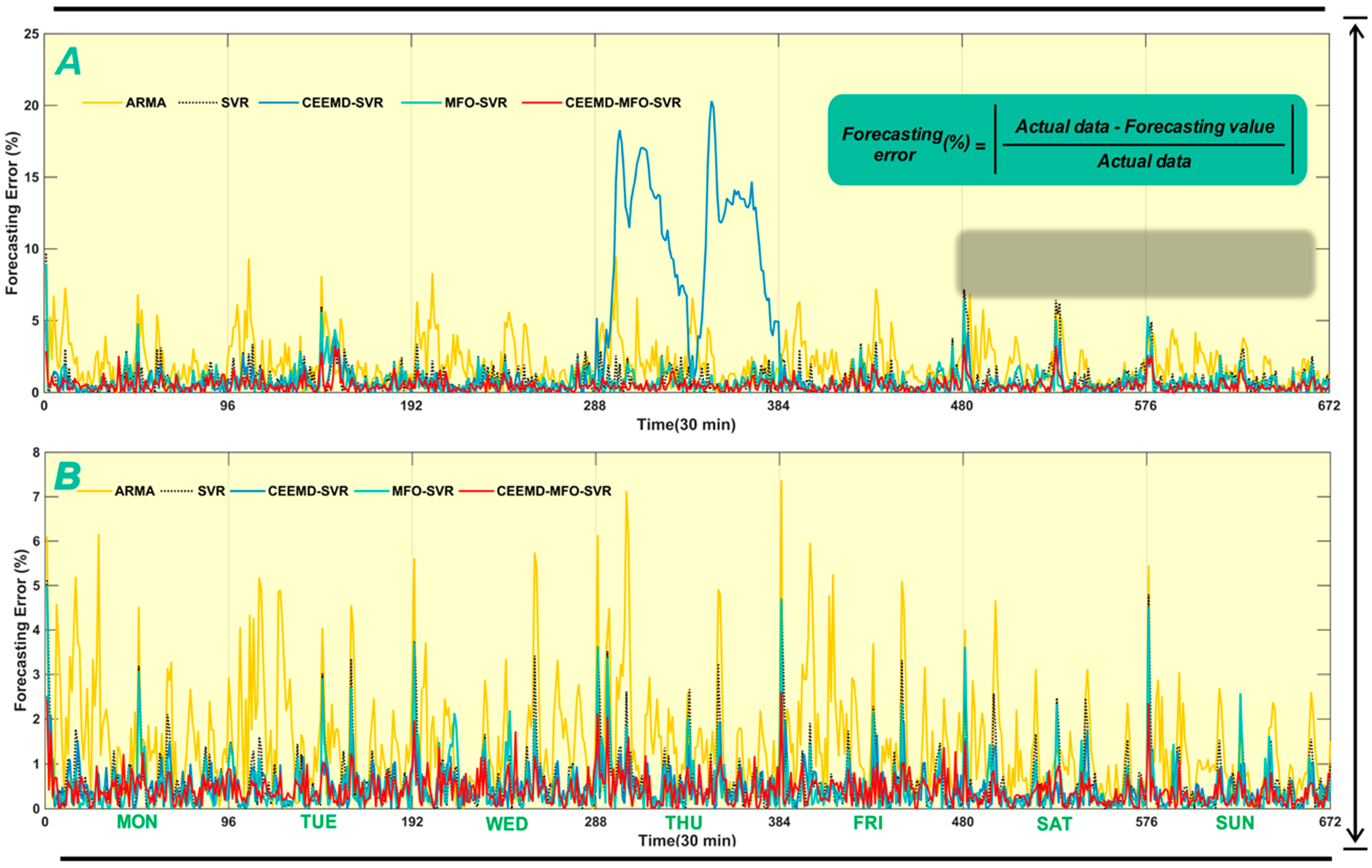
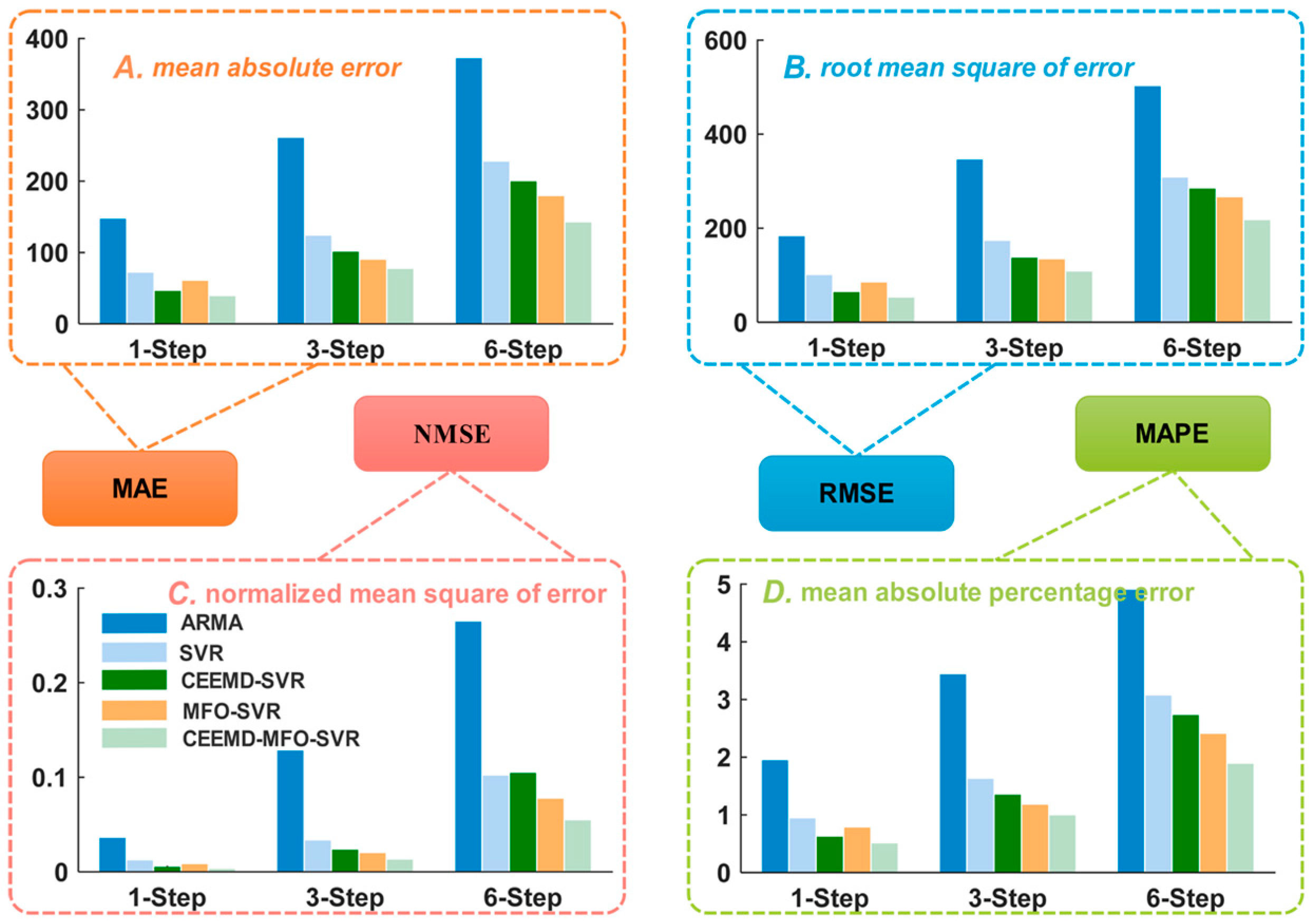
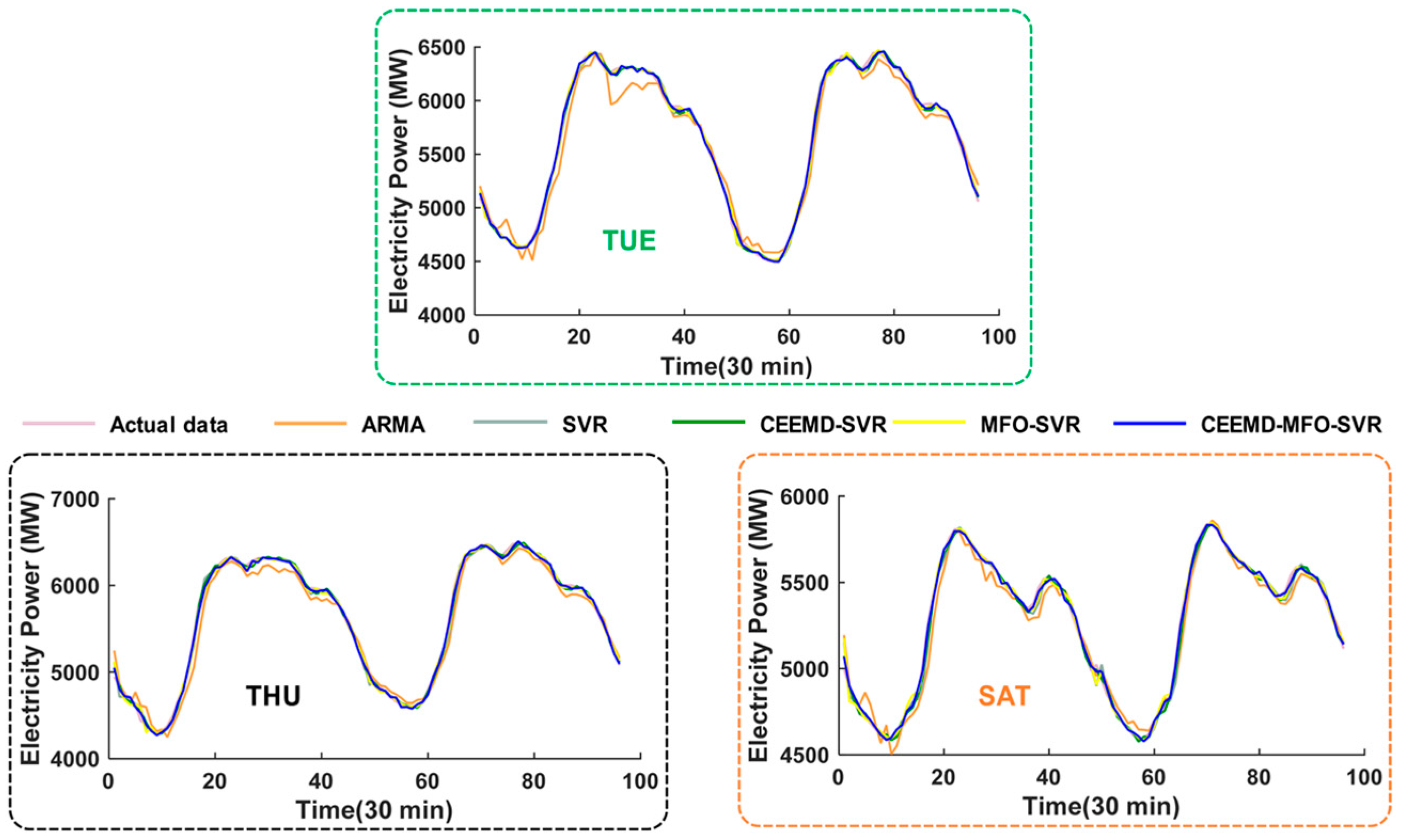
4.4.1. Analysis for One-Step Forecasting
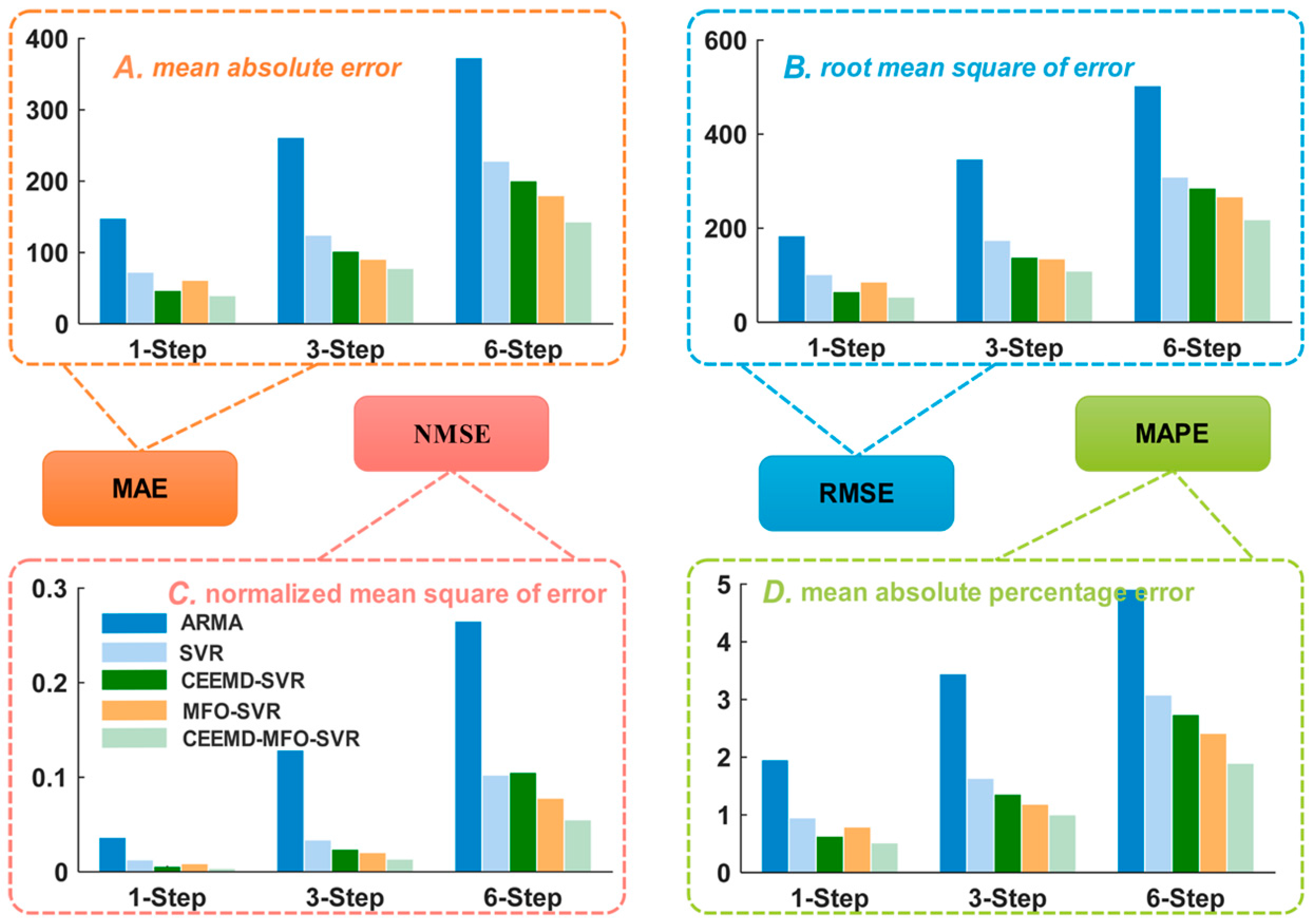
- (a)
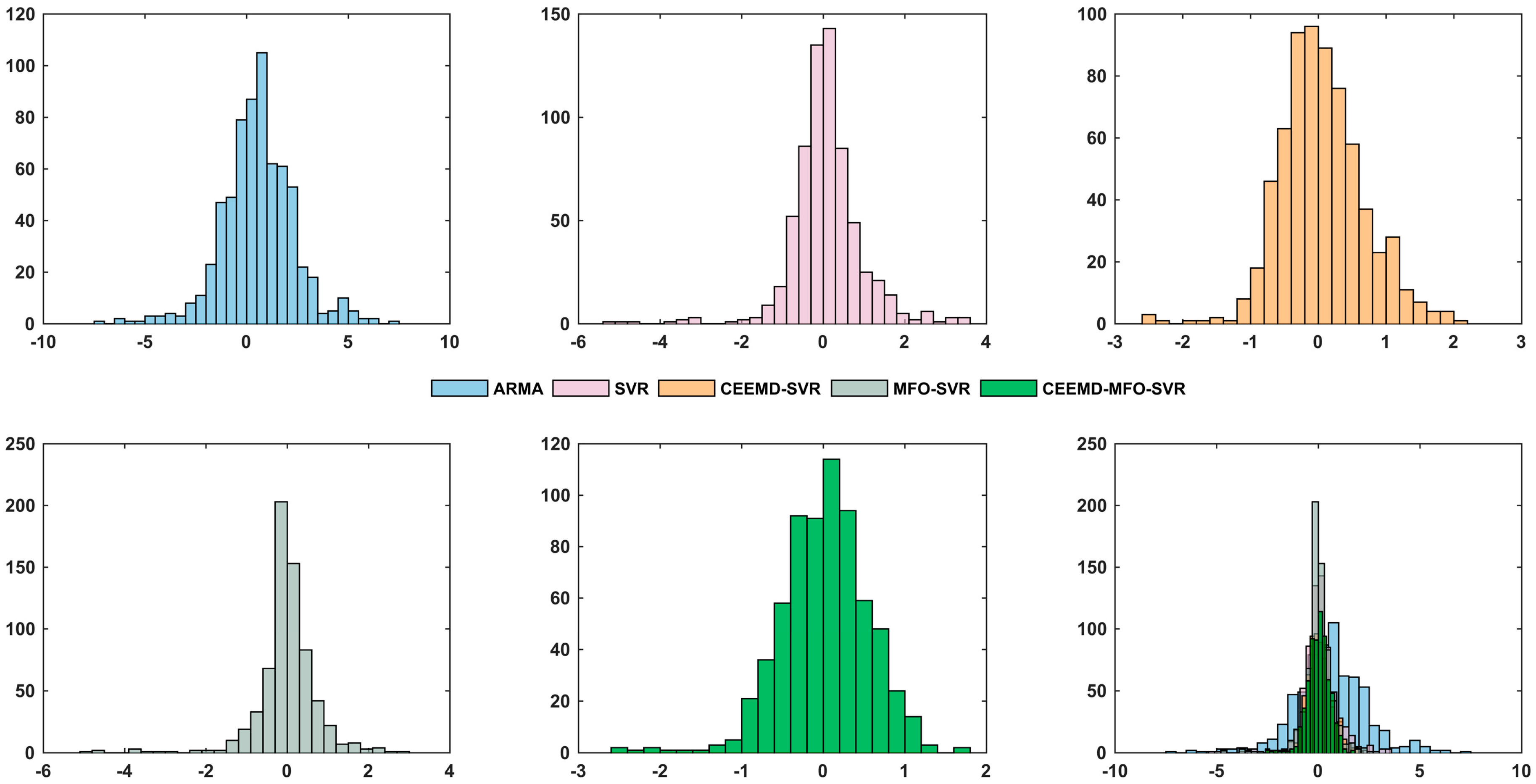
- When comparing the traditional time series model ARMA with the individual artificial intelligence model SVR, regarding the MAE, NMSE, RMSE and MAPE, the SVR model is superior to the ARMA model. The results indicate that the artificial intelligent algorithms are powerful forecasting tools with strong robustness and fault tolerance to solve the STLF problem influenced by several factors, being able to achieve better performance compared with the traditional time series model.
- (b)
- Statistics of single SVR and our proposed model show that the integrated method leads to reductions of 29.9310 in MAE, 52.1163 in RMSE, 0.0073 in NMSE, and 0.4055% in MAPE. Moreover, the results between the individual SVR and CEEMD-SVR model reveal that the technique contributes to performance improvements of 26.1722 in MAE, 43.3798 in RMSE, 0.0064 in NMSE, and 0.3365% in MAPE. Furthermore, the results between the single SVR and MFO-SVR models demonstrate that the moth-flame optimization algorithm leads to reductions of 7.2622 in MAE, 11.4700 in RMSE, 0.0020 in NMSE, and 0.0971% in MAPE.
- (c)
- Statistics of different models show that the proposed model has a lower MAPE value of 0.5395% compared to the MAPEs of 1.9765%, 0.9450%, 0.6085% and 0.8479% for the ARMA, SVR, CEEMD-SVR and MFO-SVR models, respectively, which show that the integrated method leads to reductions of 1.4370%, 0.4055%, 0.0690% and 0.3084% in MAPE when compared with the ARMA, SVR, CEEMD-SVR and MFO-SVR model, respectively.
- (d)
- The comparison between the SVR, CEEMD-SVR, MFO-SVR and the proposed model proves that the single SVR model is inferior to the benchmark models, which proves that the signal processing and moth-flame optimization algorithm are effective in improving the forecasting accuracy. Therefore, to solve the short-term load forecasting problem, an increasing number of studies have proposed the signal processing technique and artificial intelligence optimization algorithm.
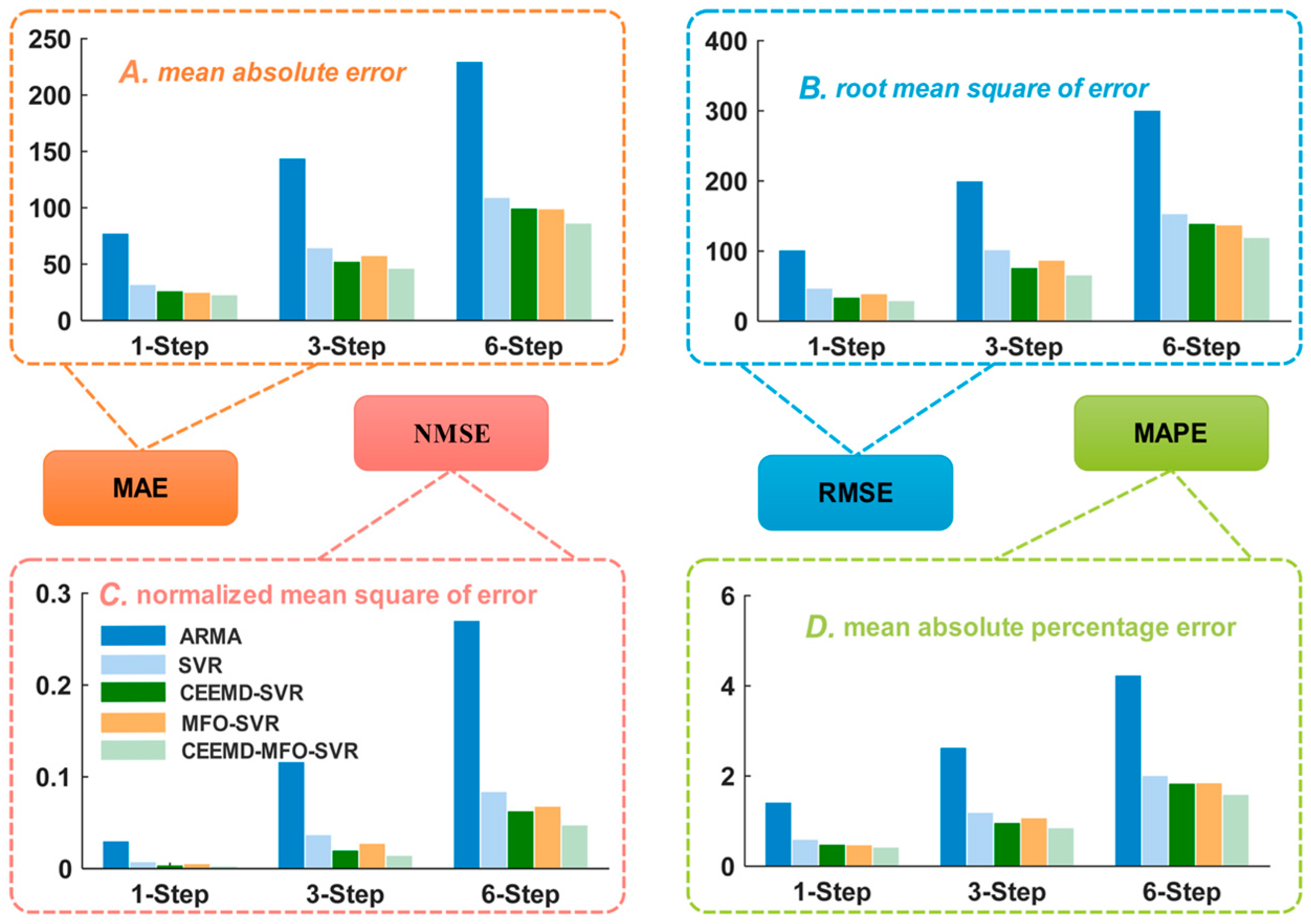
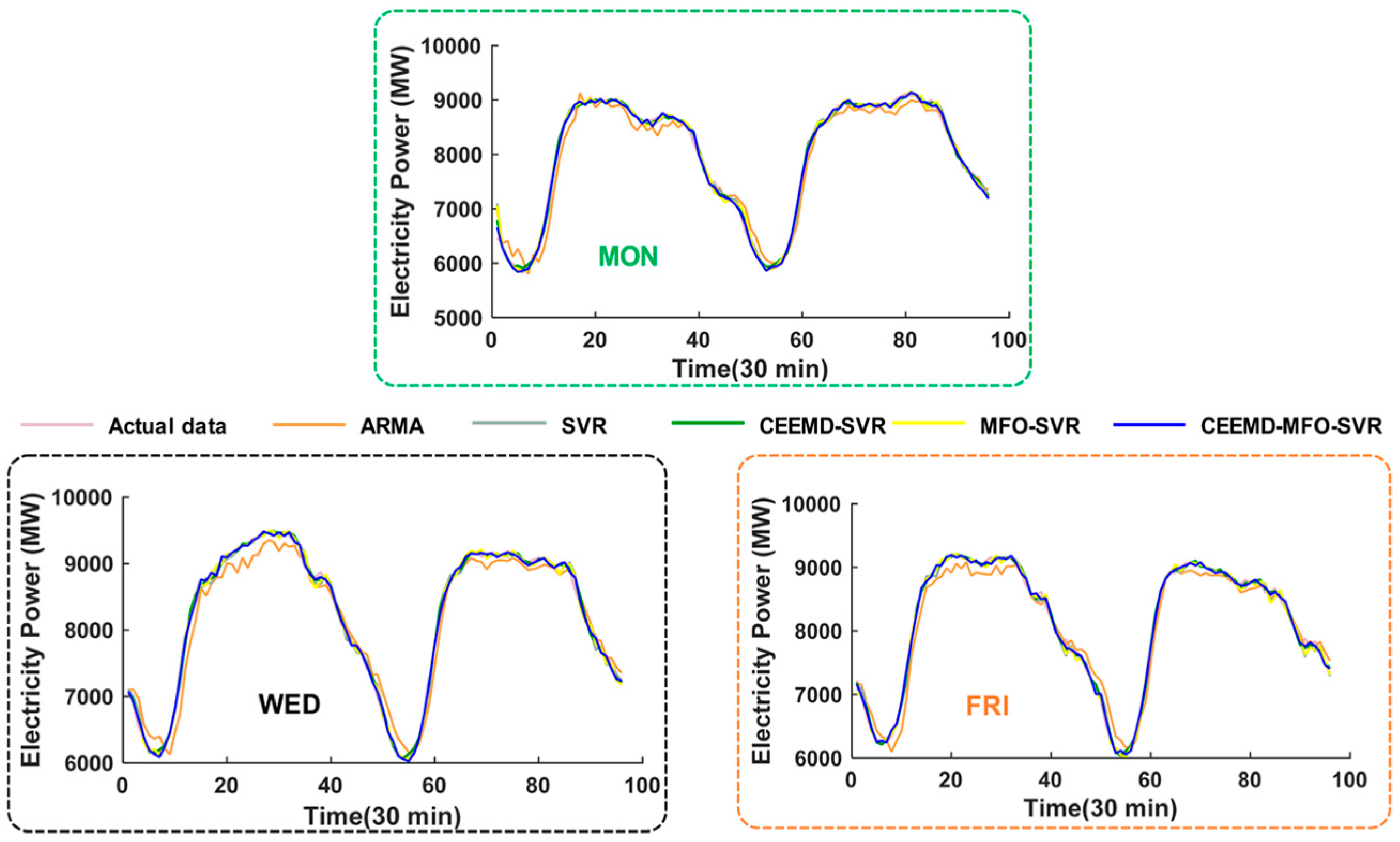
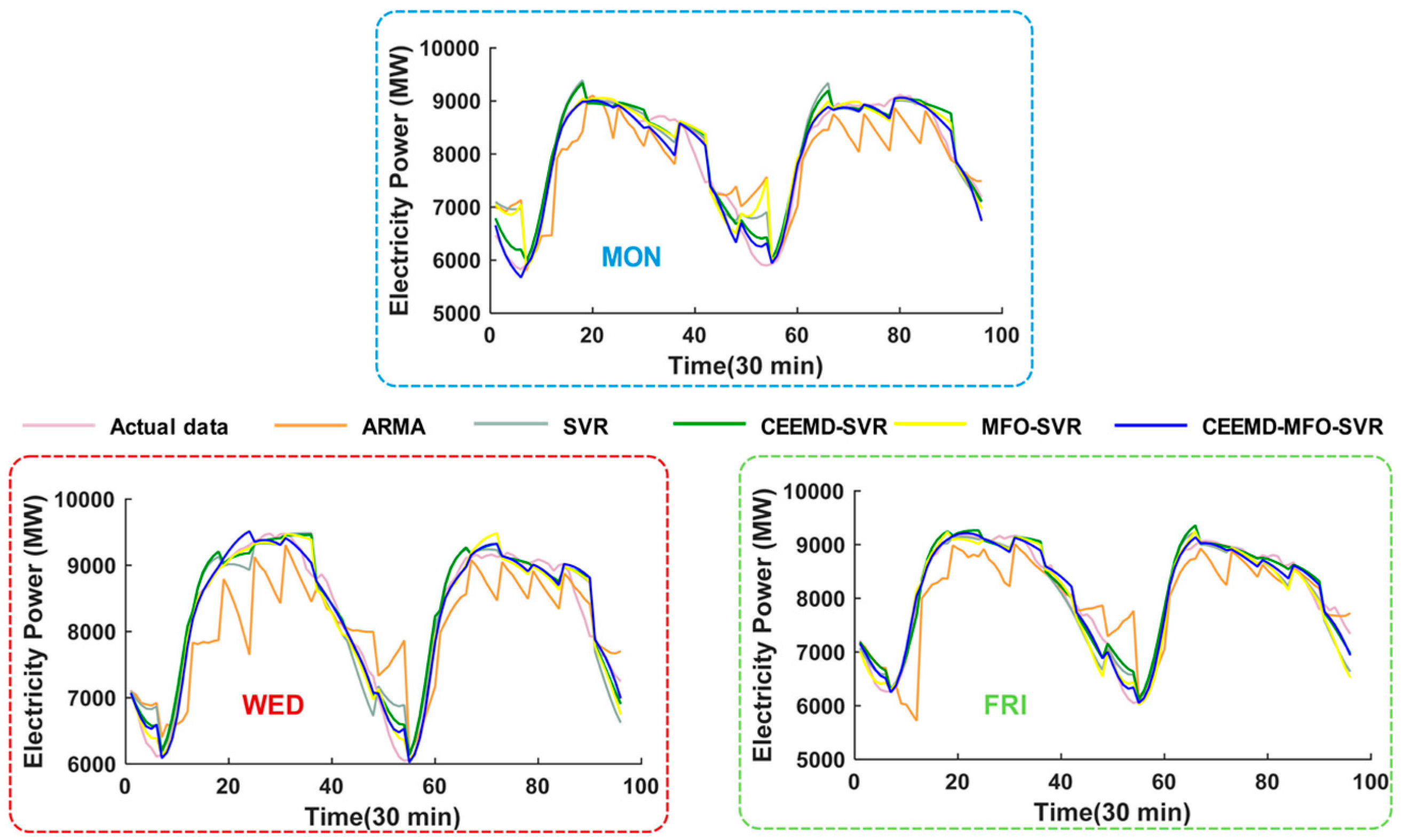
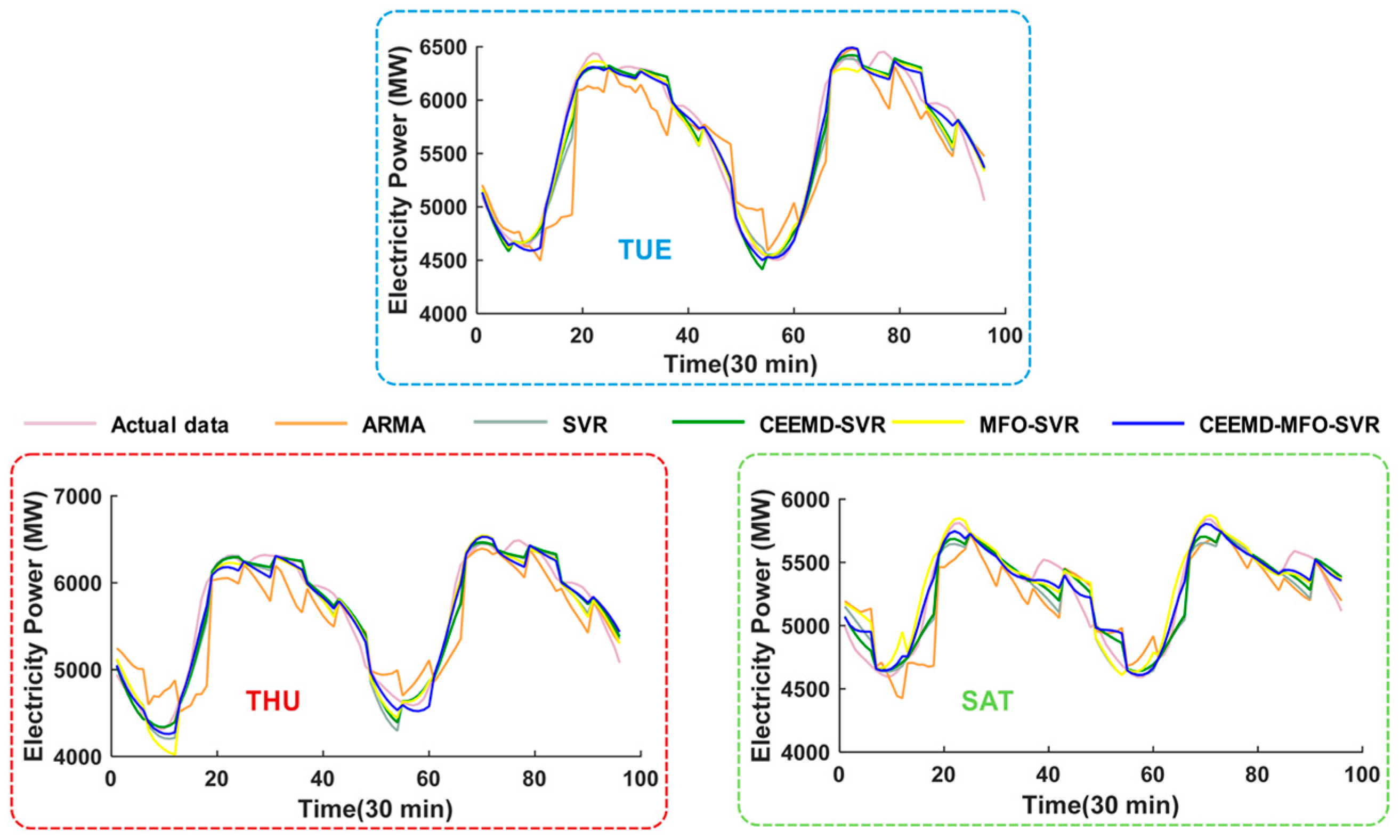
4.4.2. Analysis for Multi-Step Forecasting
- (a)
- The comparison results between the ARMA model and single SVR model indicate that the SVR model can achieve better performance compared with the traditional time series model. For instance, the decreased error of MAPE for three-step forecasting is 1.6310%, 1.4136%, 2.2192%, 2.0912%, 2.1447%, 1.5024% and 1.6789%, corresponding to reductions for six-step forecasting of 1.7858%, 0.9612%, 2.5612%, 2.1654%, 2.4864%, 1.3612% and 1.5038% from Monday to Sunday, respectively.
- (b)
- Taking Monday as an example, the MAPE of the individual SVR model is 1.8508% in three-step forecasting and 3.7417% in six-step forecasting, while the corresponding MAPE of the proposed hybrid model is 1.0160% and 1.9835%. Moreover, compared with the CEEMD-SVR model and MFO-SVR model, the proposed model leads to reductions of 0.3510% and 0.4755% in MAPE for three-step forecasting and reductions of 0.8506% and 1.6513% for six-step forecasting, respectively, which proves that these two methods can improve the multi-step forecasting accuracy of short-term load forecasting.
- (c)
- When comparing the different forecasting horizons, we can conclude that the forecasting error will increase with increasing number of rolling processes. Nevertheless, the negative influence of accumulated error can be reduced due to the SVR model’s excellent performance for one-step forecasting; thus, the proposed integrated model obtains the optimal results.
- (d)
- Taking Wednesday as an example, for the three-step forecasting, the proposed model has a lower MAPE value of 0.9527% compared to the MAPEs of 3.7744%, 1.5552%, 1.2362% and 1.0060% for the ARMA, SVR, CEEMD-SVR and MFO-SVR models, respectively, while also having a lower MAPE value of 1.6581% compared to the MAPEs of 5.8298%, 3.2686%, 2.5270% and 1.9699% for the ARMA, SVR, CEEMD-SVR and MFO-SVR models for six-step forecasting, respectively. The corresponding difference between three-step and six step forecasting is 0.7054%, 2.0554%, 1.7134%, 1.2908% and 0.9639%, which indicates that the proposed hybrid model is superior to other benchmark models for multi-step forecasting.
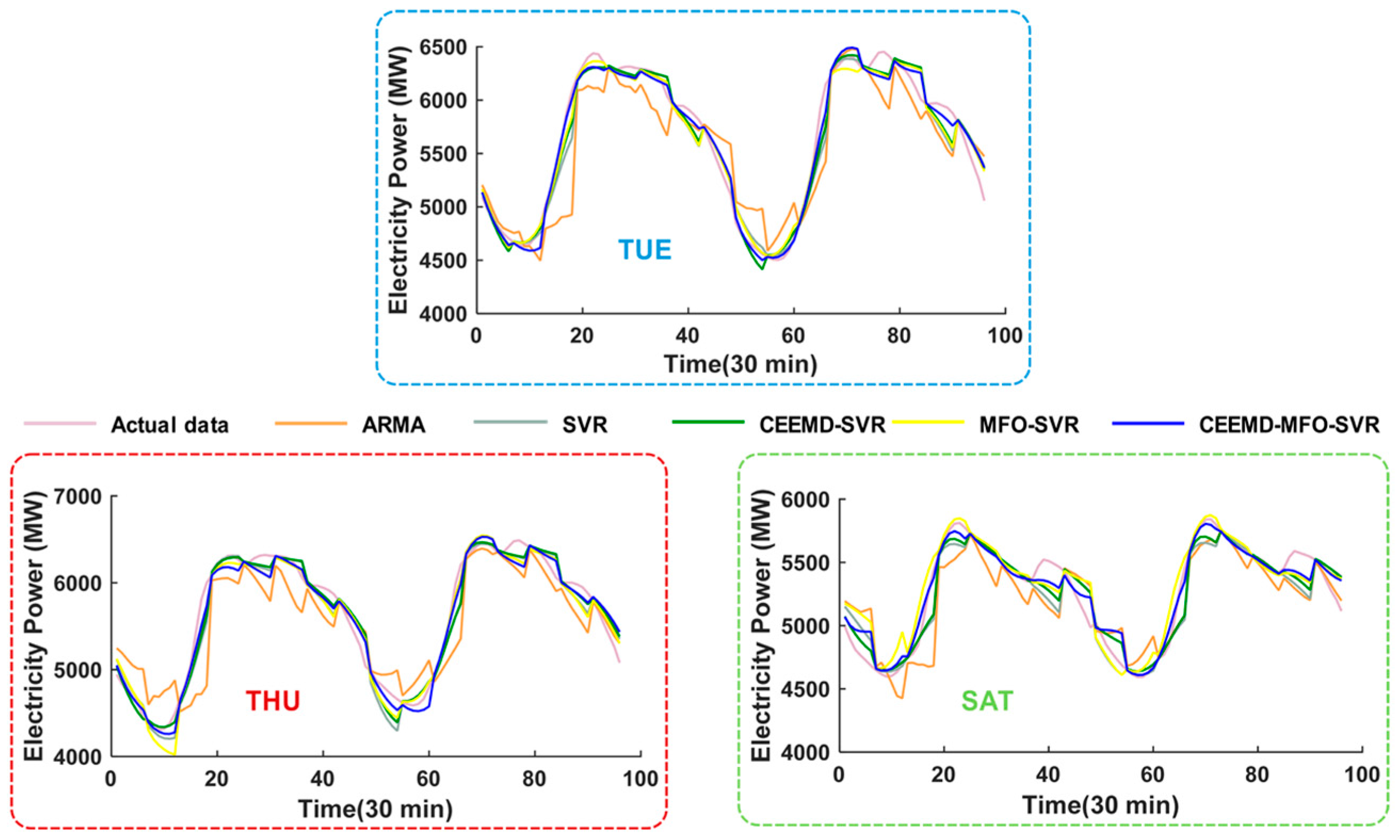
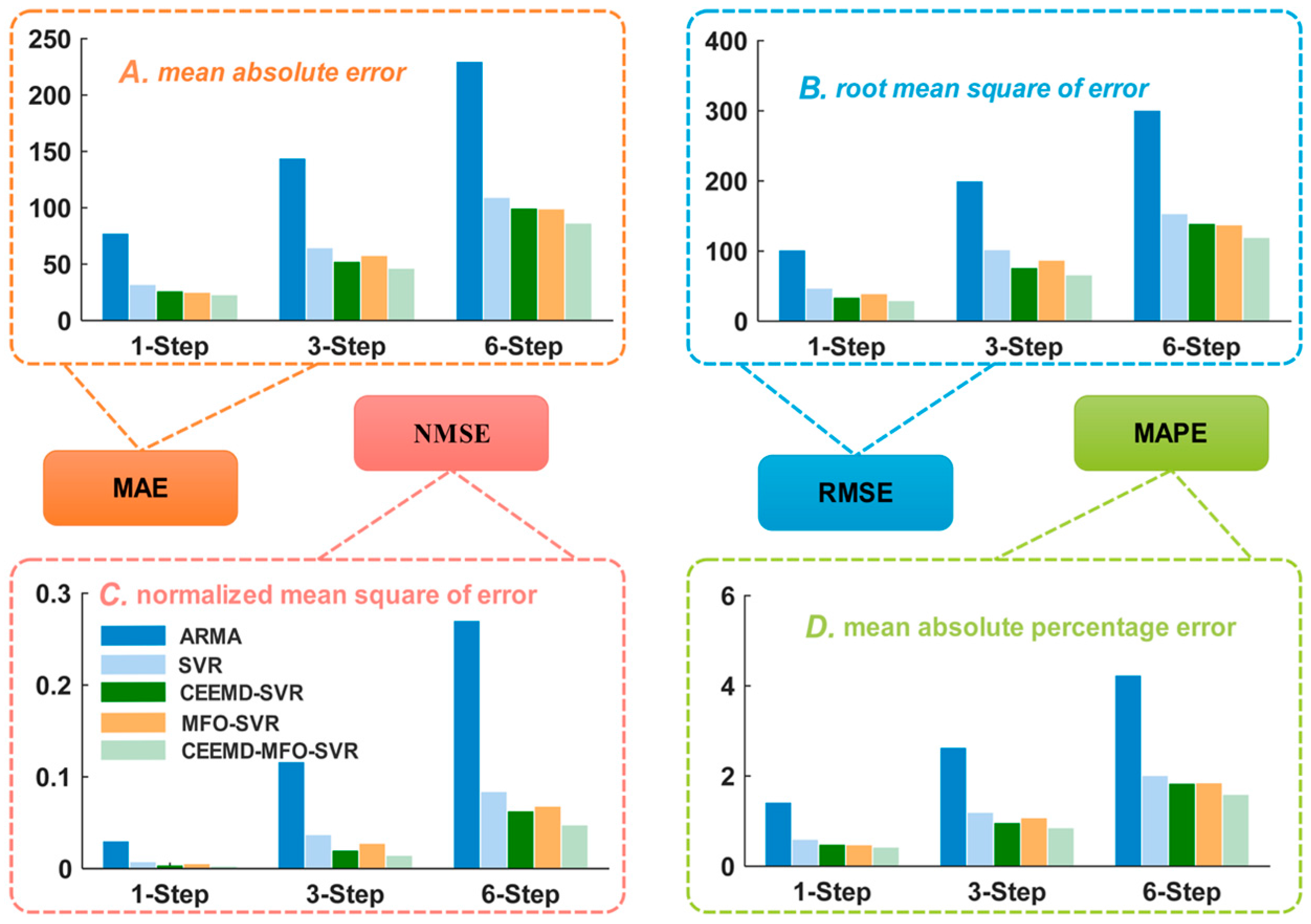
4.5. Experiment II: The Case of Singapore
4.6. Experiment III: Testing Based on DM Test and Forecasting Effectiveness
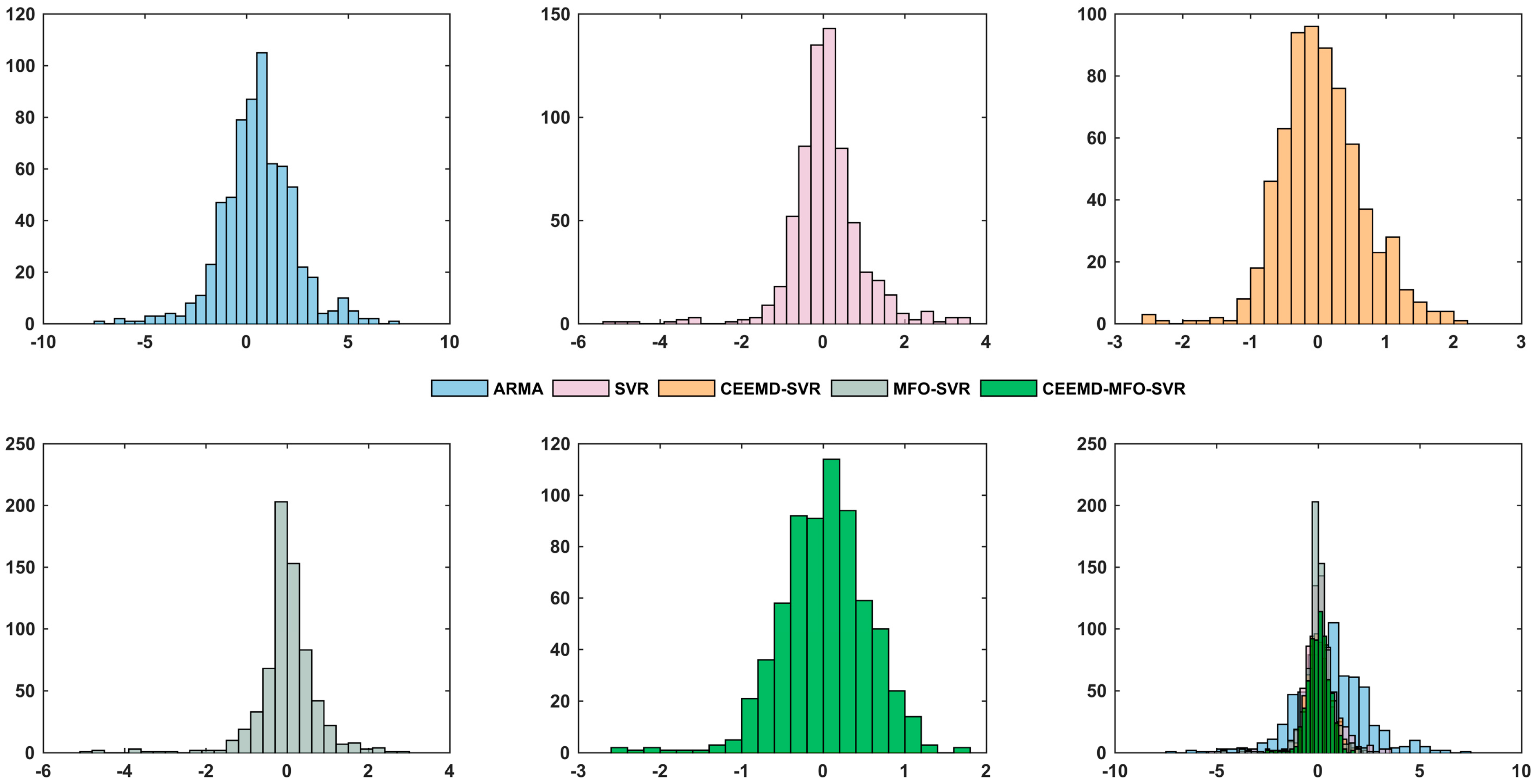
5. Discussion
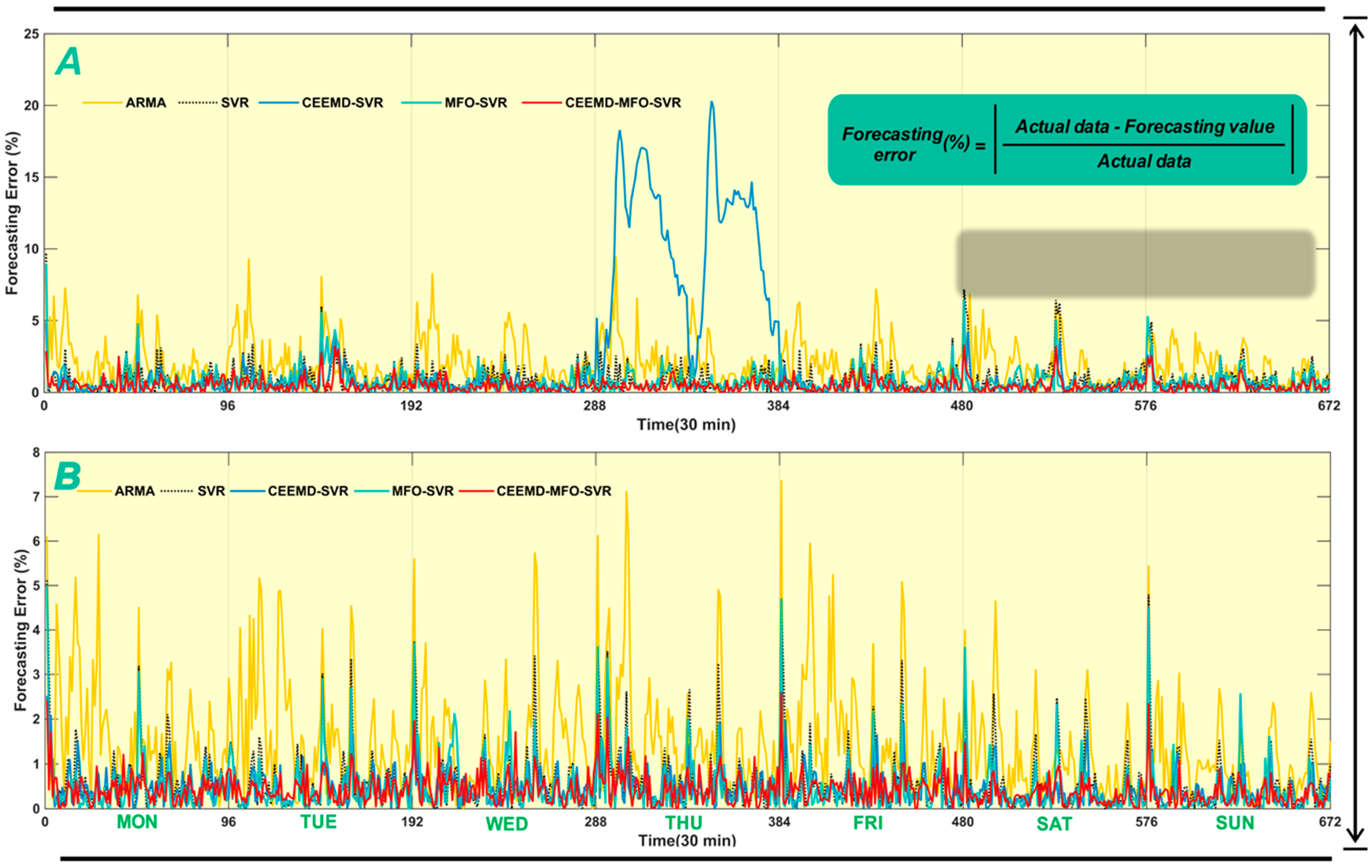
5.1. Discussion of the Effectiveness of Data Processing and Optimization
5.2. Steps of Forecasting
5.3. Performance Time
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Shu, F.; Luonan, C. Short-term load forecasting based on an adaptive hybrid method. IEEE Trans. Power Syst. 2006, 21, 392–401. [Google Scholar]
- Önkal, D.; Zeynep Sayim, K.; Lawrence, M. Wisdom of group forecasts: Does role-playing play a role? Omega 2012, 40, 693–702. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, D.; Jia, H.; Djilali, N. Power system operation risk analysis considering charging load self-management of plug-in hybrid electric vehicles. Appl. Energy 2014, 136, 662–670. [Google Scholar] [CrossRef]
- Xiao, L.; Shao, W.; Liang, T.; Wang, C. A combined model based on multiple seasonal patterns and modified firefly algorithm for electrical load forecasting. Appl. Energy 2016, 167, 135–153. [Google Scholar] [CrossRef]
- Pai, P.F. Hybrid ellipsoidal fuzzy systems in forecasting regional electricity loads. Energy Convers. Manag. 2006, 47, 2283–2289. [Google Scholar] [CrossRef]
- Hobbs, B.F. Analysis of the value for unit commitment of improved load forecasts. IEEE Trans. Power Syst. 1999, 14, 1342–1348. [Google Scholar] [CrossRef]
- The 12 Biggest Blackouts in History. Available online: http://www.msn.com/en-za/news/offbeat/the-12-biggest-blackouts-in-history/ar-CCeNdC#page=1 (accessed on 23 January 2017).
- Available online: http://finance.qq.com/a/20120801/003975.htm (accessed on 23 January 2017). (In Chinese)
- Wang, Y.; Wang, J.; Zhao, G.; Dong, Y. Application of residual modification approach in seasonal ARIMA for electricity demand forecasting: A case study of China. Energy Policy 2012, 48, 284–294. [Google Scholar] [CrossRef]
- Fischer, J.; Wilfert, H.-H. Updating of Daily Load Prediction in Power Systems Using AR-Models. In Proceedings of the 2nd IFAC Symposium on Stochastic Control, Vilnius, Lithuanian, 19–23 May 1986.
- Pappas, S.S.; Ekonomou, L.; Karampelas, P.; Karamousantas, D.C.; Katsikas, S.K.; Chatzarakis, G.E.; Skafidas, P.D. Electricity demand load forecasting of the Hellenic power system using an ARMA model. Electr. Power Syst. Res. 2010, 80, 256–264. [Google Scholar] [CrossRef]
- Ling, Y.; Shantz, C.; Mahadevan, S.; Sankararaman, S. Stochastic prediction of fatigue loading using real-time monitoring data. Int. J. Fatigue 2011, 33, 868–879. [Google Scholar] [CrossRef]
- Lee, C.M.; Ko, C.N. Short-term load forecasting using lifting scheme and ARIMA models. Expert Syst. Appl. 2011, 38, 5902–5911. [Google Scholar] [CrossRef]
- Al-Hamadi, H.M.; Soliman, S.A. Long-term/mid-term electric load forecasting based on short-term correlation and annual growth. Electr. Power Syst. Res. 2005, 74, 353–361. [Google Scholar] [CrossRef]
- Mohamed, Z.; Bodger, P. Forecasting electricity consumption in New Zealand using economic and demographic variables. Energy 2005, 30, 1833–1843. [Google Scholar] [CrossRef]
- Christiaanse, W.R. Short-Term Load Forecasting Using General Exponential Smoothing. IEEE Trans. Power Appar. Syst. 1971, PAS-90, 900–911. [Google Scholar] [CrossRef]
- Zhang, M.; Bao, H.; Yan, L.; Cao, J.P.; Jian-Guang, D.U. Research on processing of short-term historical data of daily load based on Kalman filter. Power Syst. Technol. 2003, 9, 39–42. [Google Scholar]
- Kelo, S.; Dudul, S. A wavelet Elman neural network for short-term electrical load prediction under the influence of temperature. Int. J. Electr. Power Energy Syst. 2012, 43, 1063–1071. [Google Scholar] [CrossRef]
- Metaxiotis, K.; Kagiannas, A.; Askounis, D.; Psarras, J. Artificial intelligence in short term electric load forecasting: A state-of-the-art survey for the researcher. Energy Convers. Manag. 2003, 44, 1525–1534. [Google Scholar] [CrossRef]
- Li, P.; Li, Y.; Xiong, Q.; Chai, Y.; Zhang, Y. Application of a hybrid quantized Elman neural network in short-term load forecasting. Int. J. Electr. Power Energy Syst. 2014, 55, 749–759. [Google Scholar] [CrossRef]
- Liao, G.C. Hybrid improved differential evolution and wavelet neural network with load forecasting problem of air conditioning. Int. J. Electr. Power Energy Syst. 2014, 61, 673–682. [Google Scholar] [CrossRef]
- Zhao, H.; Guo, S. An optimized grey model for annual power load forecasting. Energy 2016, 107, 272–286. [Google Scholar] [CrossRef]
- Hu, Z.; Bao, Y.; Xiong, T.; Chiong, R. Hybrid filter-wrapper feature selection for short-term load forecasting. Eng. Appl. Artif. Intell. 2015, 40, 17–27. [Google Scholar] [CrossRef]
- Xiao, L.; Shao, W.; Wang, C.; Zhang, K.; Lu, H. Research and application of a hybrid model based on multi-objective optimization for electrical load forecasting. Appl. Energy 2016, 180, 213–233. [Google Scholar] [CrossRef]
- Niu, M.; Sun, S.; Wu, J.; Yu, L.; Wang, J. An innovative integrated model using the singular spectrum analysis and nonlinear multi-layer perceptron network optimized by hybrid intelligent algorithm for short-term load forecasting. Appl. Math. Model. 2016, 40, 4079–4093. [Google Scholar] [CrossRef]
- Xiong, T.; Li, C.; Bao, Y.; Hu, Z.; Zhang, L. A combination method for interval forecasting of agricultural commodity futures prices. Knowl. Based Syst. 2015, 77, 92–102. [Google Scholar] [CrossRef]
- Xiong, T.; Bao, Y.; Hu, Z. Multiple-output support vector regression with a firefly algorithm for interval-valued stock price index forecasting. Knowl. Based Syst. 2014, 55, 87–100. [Google Scholar] [CrossRef]
- Ming, W.; Bao, Y.; Hu, Z.; Xiong, T. Multistep-ahead air passengers traffic prediction with hybrid ARIMA-SVMs models. Sci. World J. 2014, 2014, 567246. [Google Scholar] [CrossRef] [PubMed]
- Chen, R.; Liang, C.Y.; Hong, W.C.; Gu, D.X. Forecasting holiday daily tourist flow based on seasonal support vector regression with adaptive genetic algorithm. Appl. Soft Comput. 2015, 26, 435–443. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, W.; Wang, J. Air quality early-warning system for cities in China. Atmos. Environ. 2017, 148, 239–257. [Google Scholar] [CrossRef]
- Hong, W.C. Electric load forecasting by support vector model. Appl. Math. Model. 2009, 33, 2444–2454. [Google Scholar] [CrossRef]
- Chen, Y.; Hong, W.-C.; Shen, W.; Huang, N. Electric Load Forecasting Based on a Least Squares Support Vector Machine with Fuzzy Time Series and Global Harmony Search Algorithm. Energies 2016, 9, 70. [Google Scholar] [CrossRef]
- Ju, F.Y.; Hong, W.C. Application of seasonal SVR with chaotic gravitational search algorithm in electricity forecasting. Appl. Math. Model. 2013, 37, 9643–9651. [Google Scholar] [CrossRef]
- Fan, G.F.; Peng, L.L.; Hong, W.C.; Sun, F. Electric load forecasting by the SVR model with differential empirical mode decomposition and auto regression. Neurocomputing 2016, 173, 958–970. [Google Scholar] [CrossRef]
- Huang, M.-L. Hybridization of Chaotic Quantum Particle Swarm Optimization with SVR in Electric Demand Forecasting. Energies 2016, 9, 426. [Google Scholar] [CrossRef]
- Lee, C.-W.; Lin, B.-Y. Application of Hybrid Quantum Tabu Search with Support Vector Regression (SVR) for Load Forecasting. Energies 2016, 9, 873. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Congedo, P.M.; Malvoni, M.; Laforgia, D. Error analysis of hybrid photovoltaic power forecasting models: A case study of mediterranean climate. Energy Convers. Manag. 2015, 100, 117–130. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Malvoni, M.; Congedo, P.M. Comparison of strategies for multi-step ahead photovoltaic power forecasting models based on hybrid group method of data handling networks and least square support vector machine. Energy 2016, 107, 360–373. [Google Scholar] [CrossRef]
- Dong, Y.; Ma, X.; Ma, C.; Wang, J. Research and Application of a Hybrid Forecasting Model Based on Data Decomposition for Electrical Load Forecasting. Energies 2016, 9, 1050. [Google Scholar] [CrossRef]
- Jiang, P.; Ma, X. A hybrid forecasting approach applied in the electrical power system based on data preprocessing, optimization and artificial intelligence algorithms. Appl. Math. Model. 2016, 40, 10631–10649. [Google Scholar] [CrossRef]
- Velazquez, S.; Carta, J.A.; Matias, J.M. Influence of the input layer signals of ANNs on wind power estimation for a target site: A case study. Renew. Sustain. Energy Rev. 2011, 15, 1556–1566. [Google Scholar] [CrossRef]
- Gao, Y.; Qu, C.; Zhang, K. A Hybrid Method Based on Singular Spectrum Analysis, Firefly Algorithm, and BP Neural Network for Short-Term Wind Speed Forecasting. Energies 2016, 9, 757. [Google Scholar] [CrossRef]
- Flandrin, P.; Torres, E.; Colominas, M.A. A complete ensemble empirical mode decomposition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Prague, Czech Republic, 22–27 May 2011; pp. 4144–4147.
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Yen, N.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. A Math. Phys. Eng. Sci. 1996, 454, 903–995. [Google Scholar] [CrossRef]
- Flandrin, P.; Rilling, G.; Goncalves, P. Empirical mode decomposition as a filter bank. IEEE Signal Process. Lett. 2004, 11, 112–114. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble Empirical Mode Decomposition. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Hu, J.; Wang, J.; Zeng, G. A hybrid forecasting approach applied to wind speed time series. Renew. Energy 2013, 60, 185–194. [Google Scholar] [CrossRef]
- Mukherjee, S.; Osuna, E.; Girosi, F. Nonlinear prediction of chaotic time series using support vector machines. In Proceedings of the 1997 IEEE Workshop on Neural Networks for Signal Processing VII, Amelia Island, FL, USA, 24–26 September 1997.
- Wu, X.; Kumar, V.; Ross, Q.J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 Algorithms in Data Mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Zhao, H.; Zhao, H.; Guo, S. Using GM (1,1) Optimized by MFO with Rolling Mechanism to Forecast the Electricity Consumption of Inner Mongolia. Appl. Sci. 2016, 6, 20. [Google Scholar] [CrossRef]
- Gemperline, P.; Long, J.; Gregoriou, V. Nonlinear Multivariate Calibration Using Principal Components Regression and Artificial Neural Networks. Anal. Chem. 1991, 63, 2313–2323. [Google Scholar] [CrossRef]
- Diebold, F.X.; Mariano, R.S. Comparing predictive accuracy. J. Bus. Econ. Stat. 1995, 13, 25–63. [Google Scholar] [CrossRef]
- Chen, H.; Hou, D. Research on superior combination forecasting model based on forecasting effective measure. J. Univ. Sci. Technol. China 2002, 2, 172–180. [Google Scholar]
- Ma, X.; Liu, D. Comparative Study of Hybrid Models Based on a Series of Optimization Algorithms and Their Application in Energy System Forecasting. Energies 2016, 9, 640. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Week | Region | Mean Value (MW) | Std. Dev. (MW) | Maximum Value (MW) | Minimum Value (MW) | Median Value (MW) |
|---|---|---|---|---|---|---|
| MON. | New South Wales | 8270.0208 | 1220.6354 | 10,621.8300 | 5692.5600 | 8571.6300 |
| Singapore | 5407.2164 | 742.9222 | 6553.9290 | 3850.9450 | 5611.6020 | |
| TUE. | New South Wales | 8469.4371 | 1217.0708 | 11,313.9900 | 5797.8500 | 8716.4100 |
| Singapore | 5469.3661 | 703.0311 | 6594.3200 | 4067.8360 | 5602.9195 | |
| WED. | New South Wales | 8461.4985 | 1181.7534 | 10,724.8600 | 5890.3100 | 8775.5750 |
| Singapore | 5458.0263 | 725.8797 | 6615.5320 | 3951.9800 | 5558.4580 | |
| THU. | New South Wales | 8472.2550 | 1169.9212 | 10,620.7600 | 5993.0700 | 8858.1650 |
| Singapore | 5503.4093 | 720.7056 | 6605.4680 | 3893.7420 | 5683.4410 | |
| FRI. | New South Wales | 8236.6968 | 1144.1726 | 10,584.6400 | 5728.4000 | 8486.0100 |
| Singapore | 5462.0146 | 713.9701 | 6559.1230 | 3959.9520 | 5575.0105 | |
| SAT. | New South Wales | 7502.7387 | 829.6106 | 9528.0100 | 5449.5900 | 7658.9200 |
| Singapore | 5057.6897 | 463.4318 | 5972.7020 | 3961.5620 | 5105.3080 | |
| SUN. | New South Wales | 7323.2883 | 919.6963 | 9960.3000 | 5455.5700 | 7444.1350 |
| Singapore | 4816.5295 | 415.4188 | 5612.7050 | 3763.7360 | 4832.8800 |
| Model | Experimental Parameter | Default Value |
|---|---|---|
| CEEMD | Noise standard deviation | 0.2 |
| The number of realizations | 200 | |
| The removed intrinsic mode functions | IMF1 | |
| Maximum number of sifting iterations | 5000 | |
| MFO | The number of search agents | 30 |
| Maximum number of iterations | 300 | |
| The lower bounds of variables | 0.01 | |
| The upper bounds of variables | 100 | |
| The number of variables | 2 | |
| The convergence constant r | −1 to −2 | |
| SVR | The number of the input layer | 4 |
| The number of the output layer | 1 | |
| The kernel function’s name | RBF | |
| The cost c of original the SVR | 1 | |
| The gamma g of original the SVR | 0.25 |
| Metric | Definition | Equation |
|---|---|---|
| MAE | The mean absolute error of N forecasting results | |
| RMSE | The square root of average of the error squares | |
| NMSE | The normalized average of the squares of the errors | |
| MAPE | The average of N absolute percentage error |
| Week | Metric | ARMA | SVR | CEEMD-SVR | MFO-SVR | CEEMD-MFO-SVR | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 3-Step | 6-Step | 1-Step | 3-Step | 6-Step | 1-Step | 3-Step | 6-Step | 1-Step | 3-Step | 6-Step | 1-Step | 3-Step | 6-Step | ||
| MON. | MAE | 149.3168 | 264.3664 | 414.2613 | 72.0154 | 136.3824 | 268.4663 | 45.8432 | 101.7635 | 211.1696 | 64.7532 | 109.1297 | 252.7814 | 42.0844 | 78.7812 | 150.1316 |
| RMSE | 189.2493 | 361.0766 | 555.7324 | 109.0032 | 206.5667 | 380.2364 | 65.6234 | 136.8509 | 275.2133 | 97.5332 | 180.4214 | 401.6520 | 56.8869 | 108.8300 | 227.2187 | |
| NMSE | 0.0301 | 0.1097 | 0.2599 | 0.0100 | 0.0359 | 0.1217 | 0.0036 | 0.0158 | 0.0637 | 0.0080 | 0.0274 | 0.1358 | 0.0027 | 0.0100 | 0.0434 | |
| MAPE | 1.9765 | 3.4818 | 5.5275 | 0.9450 | 1.8508 | 3.7417 | 0.6085 | 1.3670 | 2.8341 | 0.8479 | 1.4915 | 3.6348 | 0.5395 | 1.0160 | 1.9835 | |
| TUE. | MAE | 155.7903 | 273.7074 | 416.3040 | 82.4250 | 168.1516 | 345.1775 | 62.6412 | 154.0930 | 310.9179 | 74.8796 | 128.7659 | 211.1475 | 45.2562 | 97.7580 | 153.5884 |
| RMSE | 197.0058 | 366.0849 | 578.0620 | 109.7363 | 234.6780 | 439.8573 | 82.8290 | 213.9505 | 424.9461 | 101.7121 | 184.8466 | 293.0550 | 62.0565 | 136.4468 | 222.9660 | |
| NMSE | 0.0364 | 0.1257 | 0.3135 | 0.0113 | 0.0517 | 0.1815 | 0.0064 | 0.0429 | 0.1694 | 0.0097 | 0.0321 | 0.0806 | 0.0036 | 0.0175 | 0.0466 | |
| MAPE | 2.0502 | 3.6205 | 5.5876 | 1.0651 | 2.2069 | 4.6264 | 0.8354 | 2.0455 | 4.1823 | 0.9940 | 1.7304 | 2.8821 | 0.5975 | 1.2716 | 2.1002 | |
| WED. | MAE | 164.0952 | 299.0298 | 464.1855 | 68.9116 | 123.8473 | 249.4280 | 44.4607 | 97.5785 | 193.3782 | 55.3373 | 82.1219 | 157.8759 | 36.5947 | 76.2369 | 129.8791 |
| RMSE | 201.2296 | 382.5640 | 592.0291 | 88.4652 | 162.6603 | 319.5566 | 57.1206 | 131.0734 | 256.0120 | 72.4172 | 114.9260 | 216.5579 | 49.0040 | 107.0317 | 194.0142 | |
| NMSE | 0.0342 | 0.1235 | 0.2957 | 0.0066 | 0.0223 | 0.0862 | 0.0028 | 0.0145 | 0.0553 | 0.0044 | 0.0111 | 0.0396 | 0.0020 | 0.0097 | 0.0318 | |
| MAPE | 2.0936 | 3.7744 | 5.8298 | 0.8628 | 1.5552 | 3.2686 | 0.5619 | 1.2362 | 2.5270 | 0.6848 | 1.0060 | 1.9699 | 0.4598 | 0.9527 | 1.6581 | |
| THU. | MAE | 167.7732 | 288.0813 | 406.8082 | 69.7697 | 121.9849 | 227.0328 | 46.5032 | 90.8335 | 175.0757 | 61.7127 | 75.8345 | 170.5123 | 38.2440 | 79.3382 | 150.2177 |
| RMSE | 207.8787 | 385.7540 | 539.3338 | 90.6257 | 169.2368 | 312.8293 | 68.0893 | 121.3090 | 274.4343 | 79.6795 | 108.7897 | 264.7262 | 47.4928 | 114.1213 | 247.6543 | |
| NMSE | 0.0373 | 0.1283 | 0.2508 | 0.0071 | 0.0247 | 0.0844 | 0.0089 | 0.0282 | 0.1442 | 0.0055 | 0.0102 | 0.0604 | 0.0019 | 0.0112 | 0.0529 | |
| MAPE | 2.1296 | 3.6411 | 5.1752 | 0.8621 | 1.5499 | 3.0098 | 0.6555 | 1.2672 | 2.5200 | 0.7390 | 0.9029 | 2.0826 | 0.4680 | 0.9604 | 1.8132 | |
| FRI. | MAE | 151.8488 | 265.2930 | 370.4275 | 65.8305 | 99.9089 | 174.9614 | 40.6910 | 90.9959 | 163.8359 | 56.5212 | 84.0547 | 176.1757 | 39.7423 | 65.0562 | 132.6612 |
| RMSE | 181.5484 | 362.8613 | 525.1881 | 90.2945 | 148.2388 | 250.2056 | 53.0908 | 122.9946 | 221.1164 | 78.4528 | 131.1631 | 255.4916 | 52.8244 | 86.6114 | 173.2087 | |
| NMSE | 0.0338 | 0.1352 | 0.2833 | 0.0084 | 0.0226 | 0.0643 | 0.0029 | 0.0155 | 0.0502 | 0.0063 | 0.0177 | 0.0670 | 0.0029 | 0.0077 | 0.0308 | |
| MAPE | 1.9485 | 3.4052 | 4.7655 | 0.8377 | 1.2605 | 2.2791 | 0.5203 | 1.1610 | 2.1590 | 0.7121 | 1.0669 | 2.2727 | 0.5100 | 0.8091 | 1.7047 | |
| SAT. | MAE | 125.8284 | 219.3056 | 248.4333 | 78.5700 | 116.2084 | 147.3141 | 41.5799 | 84.2632 | 163.6957 | 51.6702 | 76.7323 | 137.7728 | 36.3863 | 71.8198 | 132.2958 |
| RMSE | 160.6073 | 290.5429 | 353.8855 | 123.6085 | 159.9216 | 210.5417 | 65.4166 | 112.5968 | 271.2540 | 81.5617 | 113.0028 | 213.9510 | 52.1449 | 97.1539 | 202.4365 | |
| NMSE | 0.0494 | 0.1616 | 0.2398 | 0.0293 | 0.0490 | 0.0849 | 0.0082 | 0.0243 | 0.1409 | 0.0127 | 0.0244 | 0.0876 | 0.0052 | 0.0181 | 0.0785 | |
| MAPE | 1.7764 | 3.1003 | 3.4207 | 1.0970 | 1.5979 | 2.0595 | 0.5844 | 1.1630 | 2.3551 | 0.7032 | 1.0436 | 1.9500 | 0.5030 | 0.9768 | 1.8558 | |
| SUN. | MAE | 116.2149 | 214.7425 | 285.9453 | 64.3232 | 97.9753 | 178.3560 | 40.7161 | 87.7273 | 179.1373 | 56.4753 | 72.0519 | 146.0067 | 33.2267 | 69.1963 | 146.1253 |
| RMSE | 141.1563 | 272.2281 | 368.7920 | 89.1827 | 129.8764 | 241.5235 | 55.8503 | 121.1988 | 265.7823 | 80.2555 | 102.0070 | 213.8716 | 45.7782 | 102.7112 | 251.3388 | |
| NMSE | 0.0305 | 0.1135 | 0.2083 | 0.0122 | 0.0258 | 0.0893 | 0.0048 | 0.0225 | 0.1082 | 0.0099 | 0.0159 | 0.0701 | 0.0032 | 0.0162 | 0.0968 | |
| MAPE | 1.6447 | 3.0340 | 4.0101 | 0.9087 | 1.3551 | 2.5063 | 0.5767 | 1.2119 | 2.5345 | 0.7959 | 0.9927 | 2.0366 | 0.4703 | 0.9570 | 2.0863 | |
| Week | Metric | ARMA | SVR | CEEMD-SVR | MFO-SVR | CEEMD-MFO-SVR | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 3-Step | 6-Step | 1-Step | 3-Step | 6-Step | 1-Step | 3-Step | 6-Step | 1-Step | 3-Step | 6-Step | 1-Step | 3-Step | 6-Step | ||
| MON. | MAE | 90.8506 | 177.8643 | 298.7605 | 36.1058 | 70.3113 | 114.0703 | 29.8413 | 59.6216 | 113.5754 | 25.5246 | 50.6785 | 81.4193 | 25.0462 | 46.6848 | 88.0659 |
| RMSE | 116.6122 | 235.4940 | 382.2163 | 51.6419 | 100.9278 | 157.6169 | 37.9260 | 80.3783 | 154.3141 | 40.8566 | 75.3779 | 117.7296 | 31.5145 | 66.2984 | 129.6388 | |
| NMSE | 0.0274 | 0.1118 | 0.2944 | 0.0054 | 0.0205 | 0.0501 | 0.0029 | 0.0130 | 0.0480 | 0.0034 | 0.0115 | 0.0279 | 0.0020 | 0.0089 | 0.0339 | |
| MAPE | 1.6244 | 3.1825 | 5.4467 | 0.6575 | 1.2677 | 2.0517 | 0.5328 | 1.0736 | 2.0887 | 0.4747 | 0.9354 | 1.4828 | 0.4499 | 0.8310 | 1.5995 | |
| TUE. | MAE | 90.0534 | 156.0882 | 230.2655 | 31.5554 | 62.3240 | 105.6896 | 28.0266 | 50.5870 | 93.9458 | 23.9893 | 51.9725 | 90.2592 | 23.7795 | 43.9501 | 76.1427 |
| RMSE | 116.9971 | 214.4720 | 304.2786 | 44.2051 | 99.3649 | 149.7291 | 34.8524 | 71.0920 | 126.3075 | 35.0084 | 81.0353 | 119.6260 | 28.3290 | 60.9403 | 101.6079 | |
| NMSE | 0.0309 | 0.1039 | 0.2092 | 0.0044 | 0.0223 | 0.0507 | 0.0027 | 0.0114 | 0.0360 | 0.0028 | 0.0148 | 0.0323 | 0.0018 | 0.0084 | 0.0233 | |
| MAPE | 1.6081 | 2.7657 | 4.1177 | 0.5647 | 1.1037 | 1.8564 | 0.4973 | 0.8970 | 1.6590 | 0.4341 | 0.9204 | 1.5912 | 0.4227 | 0.7722 | 1.3345 | |
| WED. | MAE | 75.8072 | 146.4575 | 243.4885 | 31.2881 | 65.5748 | 118.0987 | 26.5597 | 53.9255 | 122.3793 | 30.0861 | 74.0752 | 130.3961 | 24.2925 | 54.2744 | 106.6510 |
| RMSE | 100.4353 | 201.8140 | 317.6453 | 45.7135 | 103.8682 | 165.4857 | 32.9656 | 79.8731 | 172.3282 | 43.2920 | 111.8104 | 200.0023 | 30.8272 | 76.5508 | 153.3729 | |
| NMSE | 0.0249 | 0.1006 | 0.2492 | 0.0052 | 0.0266 | 0.0676 | 0.0027 | 0.0158 | 0.0733 | 0.0046 | 0.0309 | 0.0988 | 0.0023 | 0.0145 | 0.0581 | |
| MAPE | 1.3857 | 2.6743 | 4.4604 | 0.5831 | 1.2086 | 2.1834 | 0.4933 | 0.9957 | 2.2921 | 0.5726 | 1.3896 | 2.4450 | 0.4598 | 1.0141 | 1.9760 | |
| THU. | MAE | 84.2323 | 162.8808 | 260.7049 | 36.7486 | 69.1145 | 124.4287 | 30.2405 | 55.6085 | 101.6196 | 30.3294 | 62.2568 | 116.7772 | 26.0944 | 51.1396 | 99.2455 |
| RMSE | 112.8961 | 231.7337 | 337.2167 | 52.1014 | 107.0442 | 168.4231 | 38.3211 | 79.1465 | 143.0002 | 43.6659 | 83.9015 | 148.8143 | 34.1613 | 72.2945 | 129.8003 | |
| NMSE | 0.0257 | 0.1084 | 0.2296 | 0.0055 | 0.0231 | 0.0573 | 0.0030 | 0.0126 | 0.0413 | 0.0038 | 0.0142 | 0.0447 | 0.0024 | 0.0106 | 0.0340 | |
| MAPE | 1.5349 | 2.9529 | 4.7696 | 0.6787 | 1.2629 | 2.2944 | 0.5469 | 1.0128 | 1.8428 | 0.5679 | 1.1415 | 2.1601 | 0.4775 | 0.9220 | 1.7725 | |
| FRI. | MAE | 93.7558 | 164.1123 | 242.0319 | 35.6067 | 62.9099 | 90.4895 | 29.4234 | 55.0429 | 98.3395 | 24.0077 | 57.6159 | 82.4145 | 26.2520 | 50.4998 | 82.5722 |
| RMSE | 122.2762 | 237.3645 | 324.8348 | 51.5711 | 100.0427 | 130.1977 | 38.4653 | 77.4244 | 141.6382 | 39.1546 | 85.0135 | 111.3450 | 33.1148 | 67.0101 | 112.8754 | |
| NMSE | 0.0298 | 0.1123 | 0.2103 | 0.0053 | 0.0200 | 0.0338 | 0.0029 | 0.0119 | 0.0400 | 0.0031 | 0.0144 | 0.0247 | 0.0022 | 0.0090 | 0.0254 | |
| MAPE | 1.6684 | 2.9542 | 4.4239 | 0.6466 | 1.1238 | 1.6105 | 0.5288 | 0.9795 | 1.7646 | 0.4336 | 1.0281 | 1.4682 | 0.4682 | 0.8971 | 1.4722 | |
| SAT. | MAE | 54.4423 | 97.7853 | 166.7009 | 24.9204 | 63.0766 | 105.8425 | 17.9275 | 46.5558 | 86.8615 | 19.8955 | 51.1122 | 103.2263 | 16.0642 | 39.9372 | 68.3689 |
| RMSE | 71.2142 | 138.6945 | 215.8981 | 39.9705 | 106.8964 | 151.3951 | 25.0724 | 75.3149 | 125.1431 | 32.4203 | 83.4907 | 140.1891 | 20.7835 | 61.6914 | 98.5601 | |
| NMSE | 0.0322 | 0.1223 | 0.2964 | 0.0102 | 0.0727 | 0.1457 | 0.0040 | 0.0361 | 0.0996 | 0.0067 | 0.0443 | 0.1250 | 0.0027 | 0.0242 | 0.0618 | |
| MAPE | 1.0471 | 1.8696 | 3.1879 | 0.4783 | 1.2007 | 1.9987 | 0.3425 | 0.8869 | 1.6487 | 0.3877 | 1.0019 | 2.0288 | 0.3087 | 0.7771 | 1.3341 | |
| SUN. | MAE | 50.3933 | 100.1250 | 164.2336 | 24.4459 | 55.8543 | 102.6142 | 19.4632 | 42.9000 | 78.5588 | 18.7082 | 52.5313 | 86.0579 | 15.4955 | 34.6784 | 80.5646 |
| RMSE | 65.8844 | 135.3373 | 218.6276 | 40.3635 | 91.5260 | 146.4708 | 26.4746 | 66.6591 | 108.4774 | 34.7743 | 83.9519 | 119.1154 | 21.7158 | 52.4386 | 105.9001 | |
| NMSE | 0.0362 | 0.1529 | 0.3991 | 0.0136 | 0.0699 | 0.1791 | 0.0059 | 0.0371 | 0.0982 | 0.0101 | 0.0588 | 0.1185 | 0.0039 | 0.0230 | 0.0936 | |
| MAPE | 0.9997 | 1.9792 | 3.1899 | 0.4850 | 1.1087 | 2.0045 | 0.3860 | 0.8489 | 1.5255 | 0.3740 | 1.0447 | 1.6950 | 0.3088 | 0.6925 | 1.5907 | |
| Test | Average Value | 1-Step | 3-Step | 6-Step |
|---|---|---|---|---|
| DM-test | ARMA | 5.871782 *** | 4.633155 *** | 4.448907 *** |
| SVR | 3.411107 *** | 3.047358 *** | 2.849780 *** | |
| CEEMD-SVR | 2.843565 *** | 2.934584 *** | 3.069878 *** | |
| MFO-SVR | 2.520546 ** | 1.876395 * | 1.941112 * | |
| CEEMD-MFO-SVR | - | - | - | |
| Average Value | 1st-Order | |||
| Forecasting effectiveness 1 | ARMA | 0.983223 | 0.969689 | 0.954089 |
| SVR | 0.992377 | 0.985963 | 0.974295 | |
| CEEMD-SVR | 0.987446 | 0.981848 | 0.971156 | |
| MFO-SVR | 0.993770 | 0.988789 | 0.978419 | |
| CEEMD-MFO-SVR | 0.995397 | 0.990822 | 0.982607 | |
| Average Value | 2nd-Order | |||
| Forecasting effectiveness 2 | ARMA | 0.969691 | 0.942151 | 0.913896 |
| SVR | 0.984246 | 0.970631 | 0.950189 | |
| CEEMD-SVR | 0.979584 | 0.967833 | 0.947045 | |
| MFO-SVR | 0.986808 | 0.975962 | 0.956125 | |
| CEEMD-MFO-SVR | 0.991312 | 0.981715 | 0.964019 |
| Metric | Definition | Equation |
|---|---|---|
| REMAE | The decreased relative error of MAE | |
| RERMSE | The decreased relative error of RMSE | |
| REMAPE | The decreased relative error of MAPE |
| Metric | CEEMD-SVR vs. SVR | CEEMD-MFO-SVR vs. MFO-SVR | ||||
| 1-Step | 3-Step | 6-Step | 1-Step | 3-Step | 6-Step | |
| REMAE | 27.0219 | 18.6139 | 9.3127 | 22.1393 | 15.9649 | 14.7683 |
| RERMSE | 32.1014 | 22.9231 | 7.0789 | 31.8898 | 20.1550 | 13.1947 |
| REMAPE | 26.4222 | 17.9821 | 8.4273 | 22.6320 | 16.7065 | 15.3012 |
| Metric | MFO-SVR vs. SVR | CEEMD-MFO-SVR vs. CEEMD-SVR | ||||
| 1-Step | 3-Step | 6-Step | 1-Step | 3-Step | 6-Step | |
| REMAE | 18.7047 | 19.0036 | 14.0487 | 14.2606 | 17.2792 | 19.6106 |
| RERMSE | 16.0846 | 18.8714 | 11.4159 | 15.9736 | 16.9289 | 17.9369 |
| REMAPE | 18.4993 | 18.7970 | 13.8638 | 15.1657 | 18.6323 | 21.0086 |
| Metric | 1-Step | 3-Step | Improvement | 6-Step | Improvement |
|---|---|---|---|---|---|
| The Worst Condition | |||||
| MAE | 33.2267 | 69.1963 | 35.9696 | 146.1253 | 112.8986 |
| RMSE | 45.7782 | 102.7112 | 56.933 | 251.3388 | 205.5606 |
| NMSE | 0.0032 | 0.0162 | 0.0130 | 0.0968 | 0.0936 |
| MAPE | 0.4703 | 0.9570 | 0.4867 | 2.0863 | 1.6160 |
| The Best Condition | |||||
| MAE | 23.7795 | 43.9501 | 20.1706 | 76.1427 | 52.3632 |
| RMSE | 28.3290 | 60.9403 | 32.6113 | 101.6079 | 73.2789 |
| NMSE | 0.0018 | 0.0084 | 0.0066 | 0.0233 | 0.0215 |
| MAPE | 0.4227 | 0.7722 | 0.3495 | 1.3345 | 0.9118 |
| The Average Condition | |||||
| MAE | 30.6114 | 61.3822 | 30.7709 | 114.0364 | 83.4251 |
| RMSE | 40.4738 | 86.4379 | 45.9640 | 167.8995 | 127.4256 |
| NMSE | 0.0028 | 0.0135 | 0.0107 | 0.0508 | 0.0480 |
| MAPE | 0.4603 | 0.9178 | 0.4576 | 1.7344 | 1.2741 |
| Week | Region | ARMA | SVR | CEEMD-SVR | MFO-SVR | CEEMD-MFO-SVR |
|---|---|---|---|---|---|---|
| MON. | New South Wales | 2988.4327 | 2.6517 | 22.8111 | 36,273.5017 | 33,365.3239 |
| Singapore | 2171.3310 | 2.9814 | 20.4886 | 26,287.0722 | 30,981.8506 | |
| TUE. | New South Wales | 3896.0770 | 2.8452 | 22.1512 | 15,035.1159 | 50,738.5207 |
| Singapore | 2161.3349 | 2.9230 | 21.6295 | 29,783.6256 | 22,643.3096 | |
| WED. | New South Wales | 4037.3465 | 2.4868 | 22.9666 | 36,980.7584 | 21,574.4685 |
| Singapore | 4440.7009 | 2.8414 | 23.6145 | 22,121.6782 | 15,928.8826 | |
| THU. | New South Wales | 3658.7555 | 2.7870 | 23.0914 | 42,269.4998 | 10,439.6901 |
| Singapore | 4330.3255 | 2.8108 | 22.0941 | 40,950.2446 | 31,348.9129 | |
| FRI. | New South Wales | 3716.1698 | 2.6855 | 22.8007 | 36,980.7584 | 25,324.6323 |
| Singapore | 4428.5174 | 2.8974 | 22.6533 | 25,286.8452 | 20,982.2042 | |
| SAT. | New South Wales | 4004.7119 | 2.3885 | 23.0886 | 6509.0816 | 37,218.6057 |
| Singapore | 3622.7196 | 2.9257 | 22.1307 | 36,716.0380 | 17,889.1014 | |
| SUN. | New South Wales | 3814.1602 | 2.8924 | 22.9327 | 23,829.3685 | 31,144.1004 |
| Singapore | 3290.8024 | 3.0355 | 21.6872 | 6840.2093 | 9914.5042 | |
| AVE. | - | 3611.5275 | 2.7966 | 22.4386 | 27,561.6998 | 25,678.1505 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, W.; Wang, J.; Wang, R. Research and Application of a Novel Hybrid Model Based on Data Selection and Artificial Intelligence Algorithm for Short Term Load Forecasting. Entropy 2017, 19, 52. https://doi.org/10.3390/e19020052
Yang W, Wang J, Wang R. Research and Application of a Novel Hybrid Model Based on Data Selection and Artificial Intelligence Algorithm for Short Term Load Forecasting. Entropy. 2017; 19(2):52. https://doi.org/10.3390/e19020052
Chicago/Turabian StyleYang, Wendong, Jianzhou Wang, and Rui Wang. 2017. "Research and Application of a Novel Hybrid Model Based on Data Selection and Artificial Intelligence Algorithm for Short Term Load Forecasting" Entropy 19, no. 2: 52. https://doi.org/10.3390/e19020052