1. Introduction
Nonlinear filtering is a significant issue in the field of signal processing, such as target tracking, navigation and audio signal processing. However, there is no close form solution for nonlinear filtering similar to the Kalman filter for linear and Gaussian scenarios. How to deal with the nonlinear state propagation or nonlinear measurement is crucial in the research of nonlinear filtering. Various nonlinear filtering algorithms have been proposed and widely used in the practical applications, such as Extended Kalman filter (EKF) [
1], Unscented Kalman filter (UKF) [
2], Cubature Kalman filter (CKF) [
3], and Particle filter (PF) [
4]. Among these methods, EKF, UKF and CKF can be classified into the same catalog, which also has been called as KF-type method that have the certain nonlinear approximation to utilize the common frame of traditional Kalman filter to achieve the goal. Some relations among these KF-type method are given in [
5]. The EKF utilizes the Taylor Series Expansion to exploit the analytical structure of nonlinear functions, which also be called as analytical linearization. Similarly, the UKF or CKF which exploit the statistical properties of Gaussian variables that undergo nonlinear transformations, which known as statistical linearization. While the PF is another catalog, which uses the Monte Carlo technique to approximate the PDF. It obtains a weighted sample from the posterior PDF, and provides an asymptotically exact approximation of the posterior PDF as the sample size tends to infinity [
6]. In particular, all of these methods can be unified in the framework of Bayesian filtering [
7] to induce the optimal estimation of state by means of computing the posterior PDF, i.e., the density of state conditional on the corresponding measurements.
As for the Bayesian filtering, the procedure can be split into two steps: time propagation and measurement update, which also have been called prediction and correction steps in same articles. In the nonlinear and non-Gaussian case, the state propagation step is relatively simple as it can be obtained by approximating the first two moments of the state variable that undergoes a transformation along the state transition function. But the measurement update is more difficult and challenging. Firstly, the measurement is proceeded not easily in itself, with nonlinear and/or non-Gaussian conditions. Secondly, the error which brings by the approximation of state propagation becomes more seriously under the nonlinear measurements. Thirdly, the measurement update step has associated state with measurement, and the posterior PDF of state has to be computed conditional on the measurement with noisy. Therefore, the posterior PDF is the key way to tackle this issue, and it attracted extensive attention in the research. Usually, Gaussian approximation to posterior PDF is used in the measurement update because of the analytically intractable in non-Gaussian scenario [
8]. There are two most popular estimators being utilized in the estimation for posterior PDF as the criterion. The one is the linear minimum mean square error (LMMSE) estimator, which approximates the posterior mean and covariance matrix by its estimator and its mean square error matrix, respectively. Based on the LMMSE, Zanetti [
9,
10] proposes a recursive update method for the measurement update, which overcomes some of the limitations of the EKF. In addition, the famous methods, such as EKF, UKF and CKF can be classified in this class [
11]. Another is the maximum a posteriori (MAP) estimator, which estimates the posterior mean and obtain the covariance matrix by linearizing the measurement function around the MAP estimate. As the most well-known iterated EKF (IEKF), which based on the Gauss-Newton optimization [
12] or Levenberg-Marquardt (LM) method [
13], is categorized in this class. Usually, these iterative methods for nonlinear filter have the better performance. As Lefebvre [
14] has shown that IEKF outperform the EKF, unscented Kalman filter (UKF) for implementing the measurement update of the covariance matrix. Besides, there are some other methods to analysis and approximate the posterior PDF recently, such as the Kullback-Leibler divergence (KLD) as metric to analysis the performance from the true joint posterior PDF of the state conditional on the measurement to approximation posterior PDF [
15]. This metric can be used to devise new algorithms, such as the iterated posterior linearization filter (IPLF) [
8] which can be seen as an approximate recursive KLD minimization procedure.
In particular, when we consider the posterior PDF parameterized by the estimators in itself, some natural characters may attract our attentions and provides a new viewpoints on the estimation. During the posterior PDF approximated recursively by the MAP estimator, a family of the posterior PDFs parameterized by the estimators can construct a statistical manifold, which a Riemannian manifold of probability distributions. Thus, the better approximation of the true posterior PDF can be viewed as the search for the optimum in the statistical manifold. Usually, the search along the direction of conventional gradient can obtain the optimum with the faster speed and better convergence in Euclidean space, but not for the statistical manifold. For the sake of utilizing gradient in statistical manifold, Amari [
16,
17] has proposed the natural gradient descent for the search direction traditionally motivated from the perspective of information geometry, and it has been proved that steps along the direction of natural gradient descent is the steepest descent in the Riemannian manifold [
18]. Based on the direction of steepest descent, the natural gradient descent can obtain the optimum in manifold with faster speed and better convergence. Because of these properties, it has been acted a new tool to analysis the nonlinear in the statistical problems with an optimization perspective. Further, it provides some geometric information, such as Riemannian metrics, distances, curvature and affine connections [
19], which may be improve the performance of estimation. To characterize this geometric information, there are two important elements should be considered. The one is that considering the set of PDF as a statistical manifold, and another is the Fisher Information Matrix as the metric of the statistical manifold. With the defining metric by information geometry, the natural gradient descent can be constructed as the product of inverse of Fisher Matric and the conventional steepest. After it has been proposed, natural gradient descent works well for many applications as an alternative to stochastic gradient descent, such as neural network [
20,
21], Blind Separation [
22], evolution strategy [
23,
24], and stochastic distribution control systems [
25].
Motivated by the recursively estimation for nonlinear measurement update in the Bayesian filtering, we propose a method by using the natural gradient descent method in the statistical manifold constructed by the posterior PDF for measurement update in the nonlinear filtering. After the procedure of the state propagation, the prediction state can be as a prior information in the Bayesian framework. The statistical manifold will be constructed by the posterior PDF. We consider a geometric structure of a this manifold equipped with the Fisher metric, and construct an alternate recursive process on the manifold. Given an initial point in the manifold based on the prior information, the iterated method to seek the optimum can been achieved along the natural gradient steepest descent. At each iteration, the algorithm moves from the current estimate to a new estimate along the geodesic in the direction of the natural gradient descent with a step size. Our method has the better performance compared with the update of EKF, which occur an overshooting in some nonlinear case. In addition, it has also given the theoretical justification for the nonlinear measurement update in the filtering from the information geometry insight and a mathematical interpretation of this method. There are two advantages in the estimation procedure benefitting from the natural gradient descent method. Firstly, based on the fact that the Fisher information matrix (FIM) is the inverse of Cramer-Rao Limit Bounds(CRLB) with respect to the estimation, the natural gradient descent, which has used FIM as metric in the statistical manifold, may achieve the better performance of estimation. Secondly, the natural gradient descent is asymptotically Fisher efficient and often converges faster than the conventional gradient descent shown in [
16]. With the better performance and fast convergence, the measurement update with natural gradient descent may be achieved better and faster. Furthermore, based on this measurement update stage, we can construct the different nonlinear filtering method with different state prediction method.
The paper is organized as follows. In
Section 2, we give a description for estimation in the statistical manifold and derive the iteration estimation procedure in the viewpoint of information geometry. Then the measurement update using natural gradient descent has deduced in the
Section 3. The differences between our proposed method and other existing methods have be discussed in the
Section 4. In
Section 5, the numerical experiments are presented to illustrate the performance compared with other existing methods. Finally, conclusions are made in
Section 6.
2. Information Geometry and Natural Gradient Descent
Information geometry [
17] is a new mathematical tool for the study of manifolds of probability distributions. It opens a new prospective to study the geometric structure of information theory and provides a new way to deal with existing statistical problems. It has the powerful ability to handle the non-Gaussian PDF case, such as Weibull distributions [
19,
26], gamma distributions [
27], multivariate generalized Gaussian distribution [
28], and non-Euclidean case, for example, the statistical manifold [
29], the morphogenetic system [
30]. For the optimization problems in statistical signal processing, the Natural gradient descent traditionally motivated from the perspective of information geometry and gradient descent method, has become an alternative to recursive estimation in the statistical manifold. It has a better performance and faster convergence.
Usually in the Euclidean space, the recursive method for estimation can be along the direction of steepest descent in which is relatively straightforward, but it is not the straightforward direction in the Riemannian geometry because of the curved coordinate system. In this case, the curvature of the manifold should be considered, and the steepest gradient descent should follow the curvature of the manifold. This is the important factor for estimation in the manifold, which has been considered in the natural gradient descent method.
In the view of information geometry, the initial point and the target point in the Riemannian manifold are corresponding with the initial and final estimation in the parameters space, respectively. Thus the estimation of parameters can be converted to the recursive procedure seeking optimum in the manifold. With the direction provided by the natural gradient descent, the recursive in the Riemannian manifold can obtain the optimization estimation of parameters.
In a Riemannian manifold, the Riemannian metric is used at every point p, which describes the relationship between the tangent space and its neighborhood tangent space. If the tangent vectors at point p base on the basis , then the Riemannian metric can be obtained as , where denotes an inner product defined on the tangent space as the same as in the Euclidean space. With these definitions, the inner product of tangent space at point p can be induced as , where and . Given the description of tangent basis and , their inner product will be .
Consider a family of probability distributions
on
parameterized by
n real-valued variables
as
where
is a random variable and Θ is a open subset of
. The mapping
defined by
can be viewed as a coordinate system of
. With the Fisher information matrix (FIM)
as the Riemannian metric
in the view of information geometry, which also termed Fisher metric, the
can be considered as a Riemannian manifold. Thus the
can be called an
n-dimensional statistical manifold on
, which the parameter
θ plays the role of the coordinate system for
. The element of the Riemannian metric
can be written as the follow formation
where
denotes the expectation with respect to
y. The Fisher metric is the only invariant metric to be given to the statistical manifold [
31]. Because of the fact that
the FIM can also be expressed in terms of the expectation of Hessian matrix of log-likelihood through algebraic manipulations, which may be easier to compute for certain problems.
Consider the smooth mapping
, then a set of basis of tangent space of
can be given as
. For example, when the usual log-likelihood functions
as the mapping, the set of basis of tangent space of
is
. This definition has established the local coordinate systems of statistical manifold
. Let
P and
Q be two close points on statistical manifold
corresponding to the coordinates
and
. Assume that the vector
has a fixed length, namely
where
ε is a sufficiently small positive constant, and a neighborhood ball can be defined according to the constant
ε. Then one can obtain the relationship in the tangent space as
where
. This relationship can be considered as a tangent vector of
at the point
P in the view of geometry. For normalizing the tangent vector, the tangent vector satisfies the constraint
. In the statistical manifold, the tangent vector is with respect to the random variable
y. As the description
is denoted and the expectation is used in the constraint, we can get the relationship
where
is the Fisher metric of the statistical manifold
.
Considering two points
P and
Q in
, which have been mapped into the Euclidean space as
and
, we can obtain the approximation formation as
where
For simplifying the description, the tangent vector
can be rewritten as
In the tangent space of the manifold
S at the point
P, the two points satisfy the relationship
Combining the Equations (
7), (
9) and (
12), we can get the relationship between the parameter space and the tangent space of manifold
To obtain the parameter
in the tangent space under the constraint (
8), we use the Lagrange function method
where
λ is the Lagrange multiplier. Then we have
Solving this equation, one obtains
Substituting the Equation (
16) into (
8), we obtain the conclusion in equation
Since
is positive, the value of multiplier
λ can be computed as
Then, the relationship between point
P and
Q in the tangent space of manifold
can be obtained.
Simultaneously, the correspondence relationship in the parameter space
is
where the
is the inverse of the Fisher metric
. In particular, the representation
is called natural gradient of the mapping
ℓ in the Riemannian manifold. Compared with the steepest direction
in the Euclidean space, the natural gradient introduces the inverse of Fisher metric
to describe the curvature of Riemannian manifold, and it is invariant under the choice of coordinate system.
As the simplification form of Amari suggested in the article [
16], the Equation (
20) can be written as
where the parameter satisfies
and it controls the convergence speed.
The geometric interpretation of this method is that the process path has moved from point
P to point
Q in the manifold
along the steepest direction, while the parameter has moved from
to
in parameter space. As the process path has been moving in the manifold
, the parameter has been estimated recursively. The recursive formation as follow
where
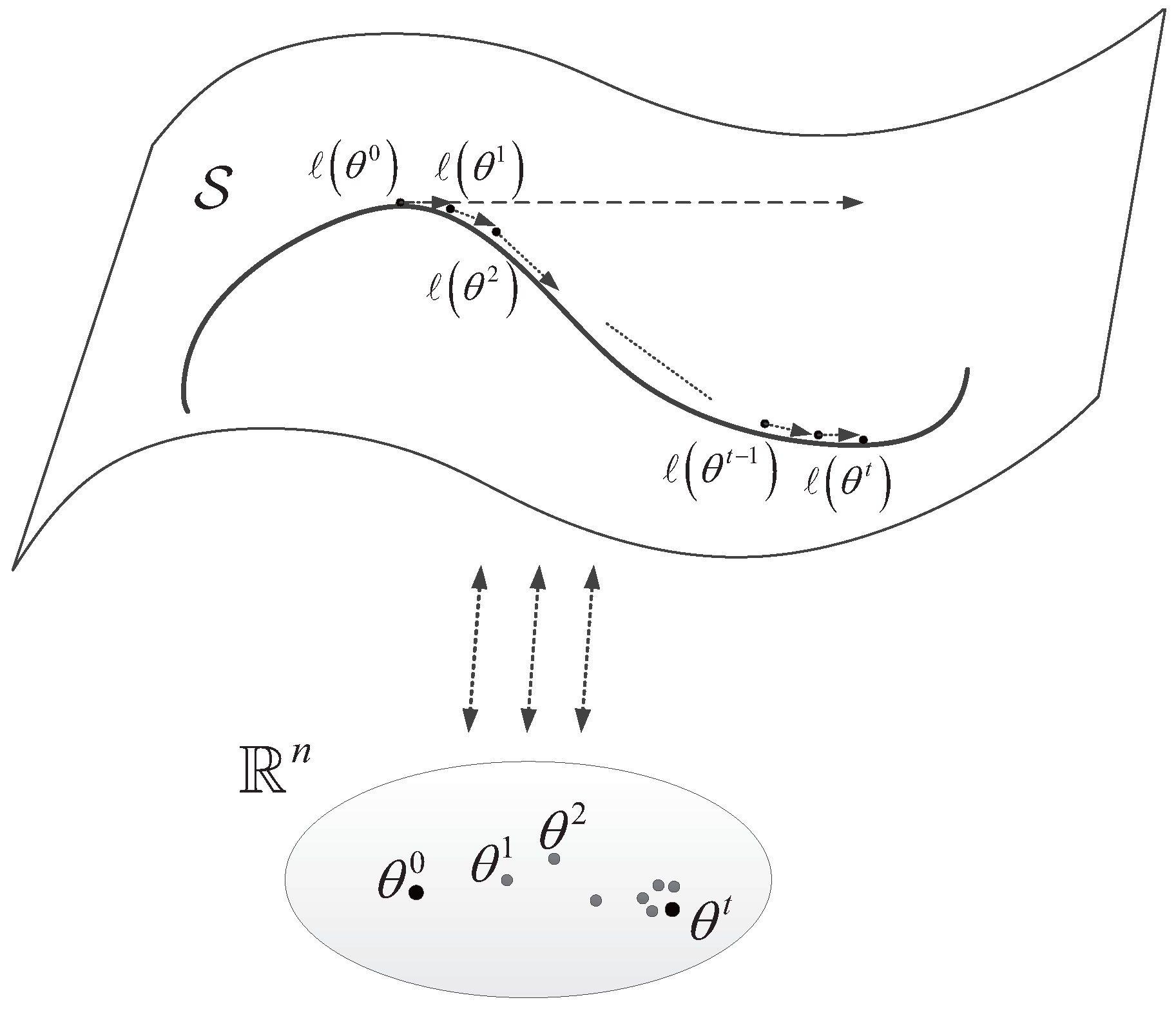
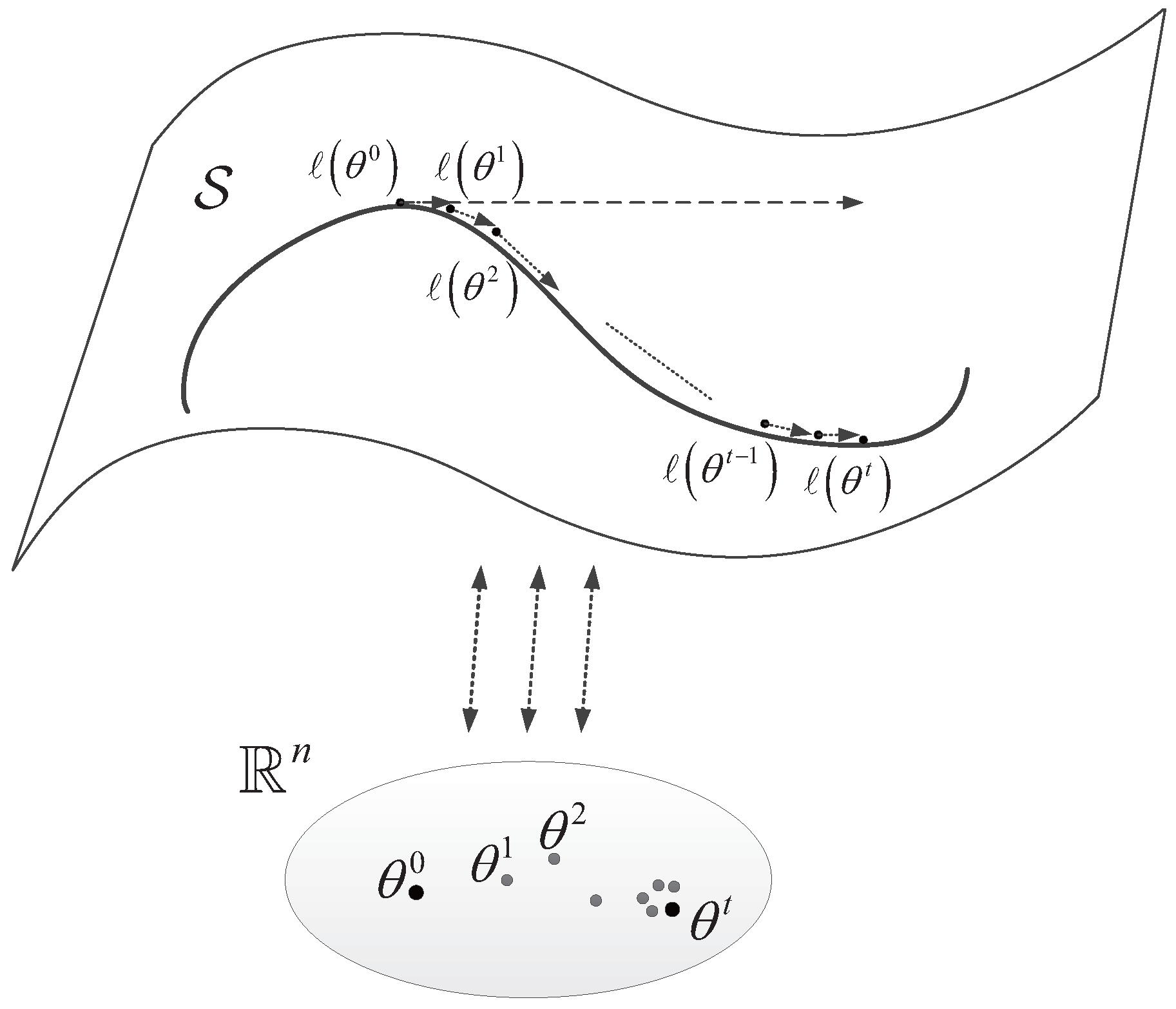
t denotes the times of iterative procedure in which correspond with the iterated points in the statistical manifold. This iteration procedure has been illustrated in
Figure 1.
For the recursive process, we can use KLD, which is often used to show the discrepancy between two probability distributions, as the stopping criterion. It is defended by
where
and
as the specification with respect to two parameters
and
, respectively. When the two probability distributions are infinitesimally close, corresponding with
, the KLD between two nearby distributions can be expanded as
Motivated by the relationship between the statistical manifold and the parameter space, the estimation of state conditional on the measurement in state parameter space can be converted to the iteration procedure on the manifold in which constructed by the posterior PDF. This method provides a new alternative for the measurement update in nonlinear filtering based on the Bayesian framework.
3. Filtering Based on Information Geometry
In this section, we present the ideas of measurement update based on the natural gradient descent. In Bayesian framework, the predicted state acts as the prior information with respect to the state to deduce the posterior distribution under the condition of measurements. Then the natural gradient descent method has been used to estimation the final state recursively. Here, we consider the usual scenario which discrete-time state space as follow
where
and
denote the system discrete-time state and measurement at the instant
k respectively,
f and
h denote the state transition and measurement functions.
and
are the noise correspondence with state and measurement respectively. Generally the additive white Gaussian noise (AWGN) has been studied for simplicity.
In Bayesian filtering, the time propagation can be processed according to the state transition function, and the prediction of state can be achieved in this step. Based on the Bayesian principle, the prediction of state is considered as the prior information about the state.
where
. The relationship
means that the current state only depends on current measurement and is conditionally independent from all past measurements. The PDF
and
denote the state transition PDF and posterior PDF of state for last time, respectively. To aim at obtaining the posterior PDF of current time under the condition of current measurement, we can use the Bayesian principle for deducing. The procedure of the measurement update in the form of Bayesian filtering as
since the likelihood
, i.e., the measurement
is conditionally independent of all past measurements. The denominator of the posterior PDF is the normalizing constant independent of the state. Thus the posterior PDF can be rewrite as
where ∝ means “is proportional to”.
and
are the prior and the likelihood respectively. In this paper, we assume that they are all Gaussian distribution for simplicity, which the Gaussian approximation has been used for non-Gaussian distribution and beyond our paper. Based on the procedure of state propagation, the prior distribution can be described as
Usually, the likelihood with respect to the measurement is chosen as
where
is the determinant,
n and
m are the number of dimension of state and measurement, respectively.
In the stage of measurement update, the goal is to obtain the optimal estimation of state under the conditions of the corresponding measurement and the prior information of state. From the Bayesian perspective, it is the maximum a posterior PDF of the prior and the likelihood. This MAP method has been used in the estimation for statistical signal processing extensively. With the optimization view, the solution that maximizes
is equivalent to minimizing its negative log likelihood function. The negative log operation of posterior distribution is
where
C is a constant which not effect the estimation of state
. Defining the negative log likelihood function
thus the object function can be convert into
Based on the posterior PDF, the statistical manifold
can be defined as
Meanwhile, the negative log function as the mapping from to , i.e., has constructed the coordinate system.
Let
and
stand for the first and second part of the Equation (
33),
and
for the error of measurement and the state estimation respectively. Computing the first derivative of
and
about the
and
respectively
where
denotes the Jacobian of
about
. The covariance matrix
and
are symmetry. Thus the gradient of the negative log likelihood is
Then the Fisher metric
of manifold
can be obtained
where
and
denotes the expectation with respect to the measurement
. In the above deducing procedure, the follow principle has been used
With the computed gradient and Fisher metric, the natural gradient of manifold is
Meanwhile, considering the denominator of Equation (
20), it can be computed as
For simplicity, we use the expectation value to substitute the value which computed in each iterative procedure. Thus
where
and
are independent, and
is the
n-dimension square matrix which correspondence to the
n-dimension state. Based on the natural gradient descent, we can construct the recursive procedure to get the optimal estimation in the measurement update step
where
n is the dimension of the state. Replacing the parameter as
, the natural gradient descent method becomes the simplification form suggested by Amari. Given the above, the iterative procedure for estimating the state can be constructed
where
, and
is the covariance matrix after the
iterative procedure.
For the iterative procedure, a stopping criterion should be set for final estimation. In the statistical manifold, the KLD is a better criterion for measurement the distance between two PDF. Because of the estimated state corresponding with the posterior PDF, the convergence in statistical manifold also means the better estimation in parameter space. Besides, Morelande [
15] has shown that the lower KLD value to select the optimum parameter for the approximation posterior PDF has better performance. Thus, we choose the KLD as the stopping criterion in the iteration procedure of measurement update following the statistical manifold.
Also, we can choose a stopping criterion as the follow form from the view of parameter space in which has been used in the IEKF or other iterated estimation problems
Based on this measurement update method, we can construct nonlinear filtering by combining the existing method for state propagation. Here, we use the Ensemble Kalman filter (EnKF) for state propagation, which uses the Monte Carlo technique for integral operation in the Bayesian filtering. For the last procedure ensemble has
elements as
We can get the prediction ensemble as
where
is generated according the state process noise. Then, the mean and the covariance matrix can be computed
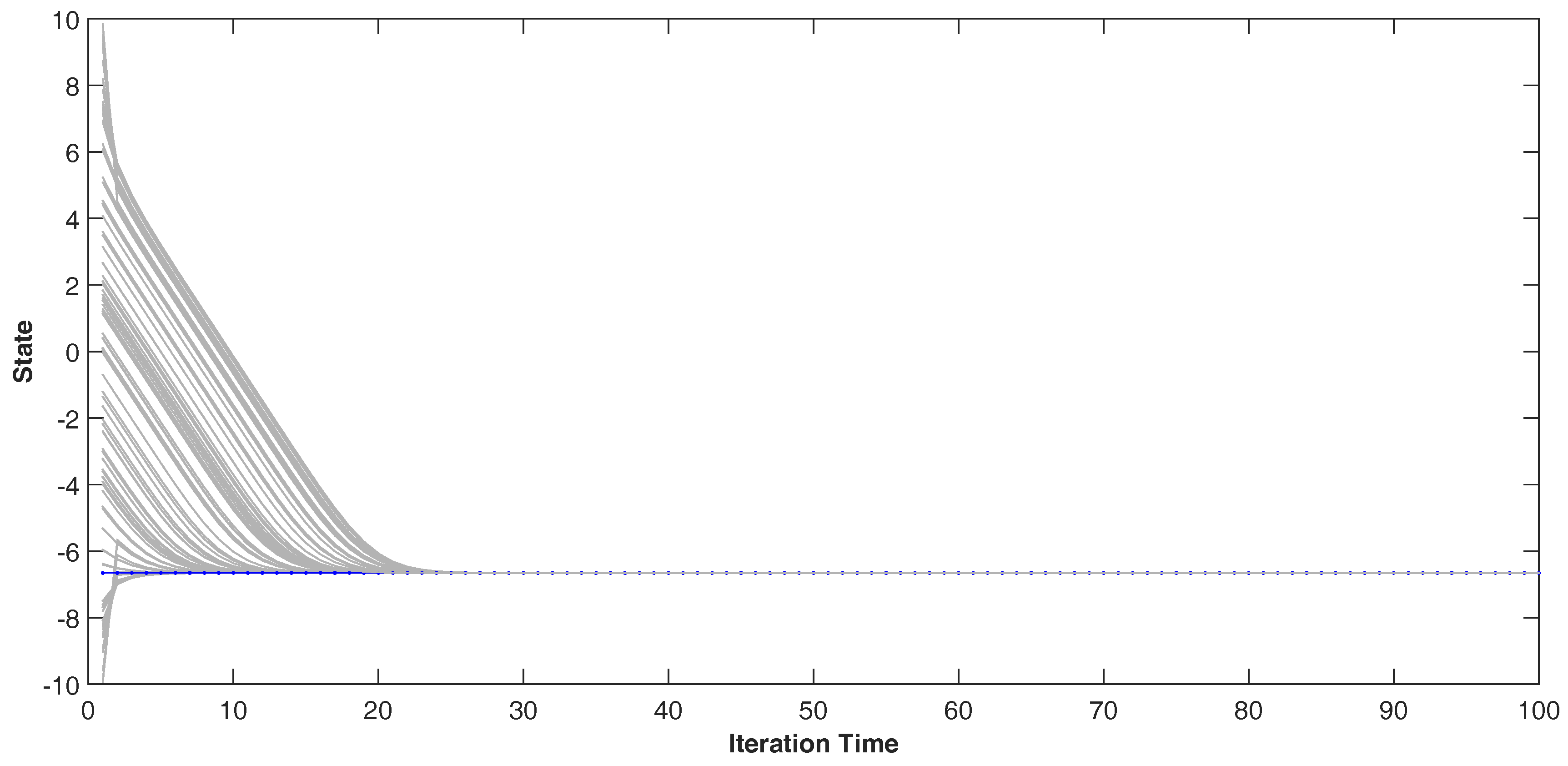
In the Bayesian framework, these prediction means and covariance will be incorporated in the procedure as prior information of state to propel the measurement update by the natural gradient method. With the stopping criterion of iterative procedure, we can get the final estimation of state. Meanwhile, the iterative estimation will converge to its final value because of the convergence of the natural gradient descent, and the iterative procedure can process some iterative estimation value of state. Here, we consider these values as the ensemble of measurement update for next period of nonlinear filter in the EnKF.
Thus, the complete nonlinear filter method has proposed based on state propagation by EnKF and measurement update by natural gradient descent method, and has been shown in Algorithm 1.
| Algorithm 1 Natural Gradient Descent Method for Measurement Update in EnKF |
| Input: Measurement , ensemble , parameter . |
| Initialize: , , , ensemble . |
| For |
| % compute prediction ensemble |
| ; |
| % compute mean and covariance of prediction ensemble |
| ; |
| ; |
| % natural gradient descent for measurement update |
| , , ; |
| For |
| ; |
| ; |
| ; |
| ; |
| ; |
| ; |
| End for |
| % Select final estimation |
| For |
| If and |
| ; |
| ; |
| End if |
| End for |
| ; |
| End for |
| Output: State |
4. Comparing with the Existing Methods
As the natural gradient descent method for measurement update, we can get some conclusions comparing with the existing methods. When we choose the parameter as
with a single iteration, the iterative procedure (
47) will be simplified as
Thus, the update has deduced to the traditional Kalman filter and the EKF. When the measurement function is linear, i.e.,
, the Jacobian of
can be obtained easily as
,
. As for the nonlinear measurement function, the first-order Taylor expansion has been used as the same as the linear case. The procedure becomes
where the matrix inversion lemma
has been used in the simplification. In comparison, this is the same as the measurement update in traditional Kalman filter and EKF.
Besides, there are two iteration methods existing before. The one is IEKF [
12,
32], which also has been derived based on the MAP method. Its update step has the form as
where
.
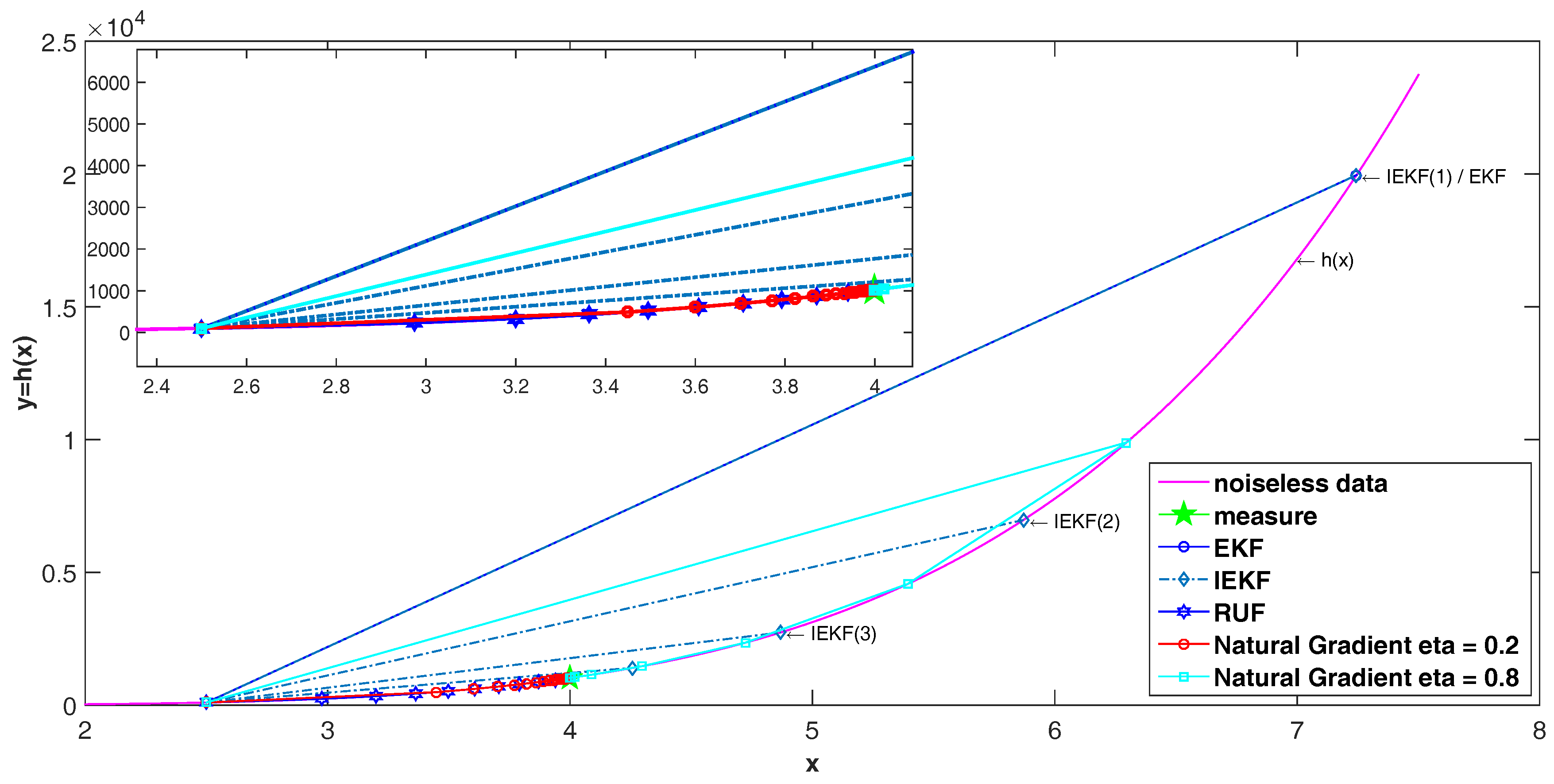
Comparing with IEKF and our proposed method, there are some differences. Firstly, the initial estimation value in each iteration is the same as the prior estimation in the IEKF, while our proposed method bases on the last iterated estimation. Secondly, the parameter η of the natural gradient descent controls the update step of state, but the IEKF has no parameters to control the update step. Thirdly, the innovations are used in the natural gradient descent method, while the IEKF adds the prediction error of current estimation state and the prior estimation state. Further from the formulation of the IEKF update, the first step of IEKF is identified to the EKF, and later steps are from the direction of overestimation convergence to the true state.
Another iteration method is RUF [
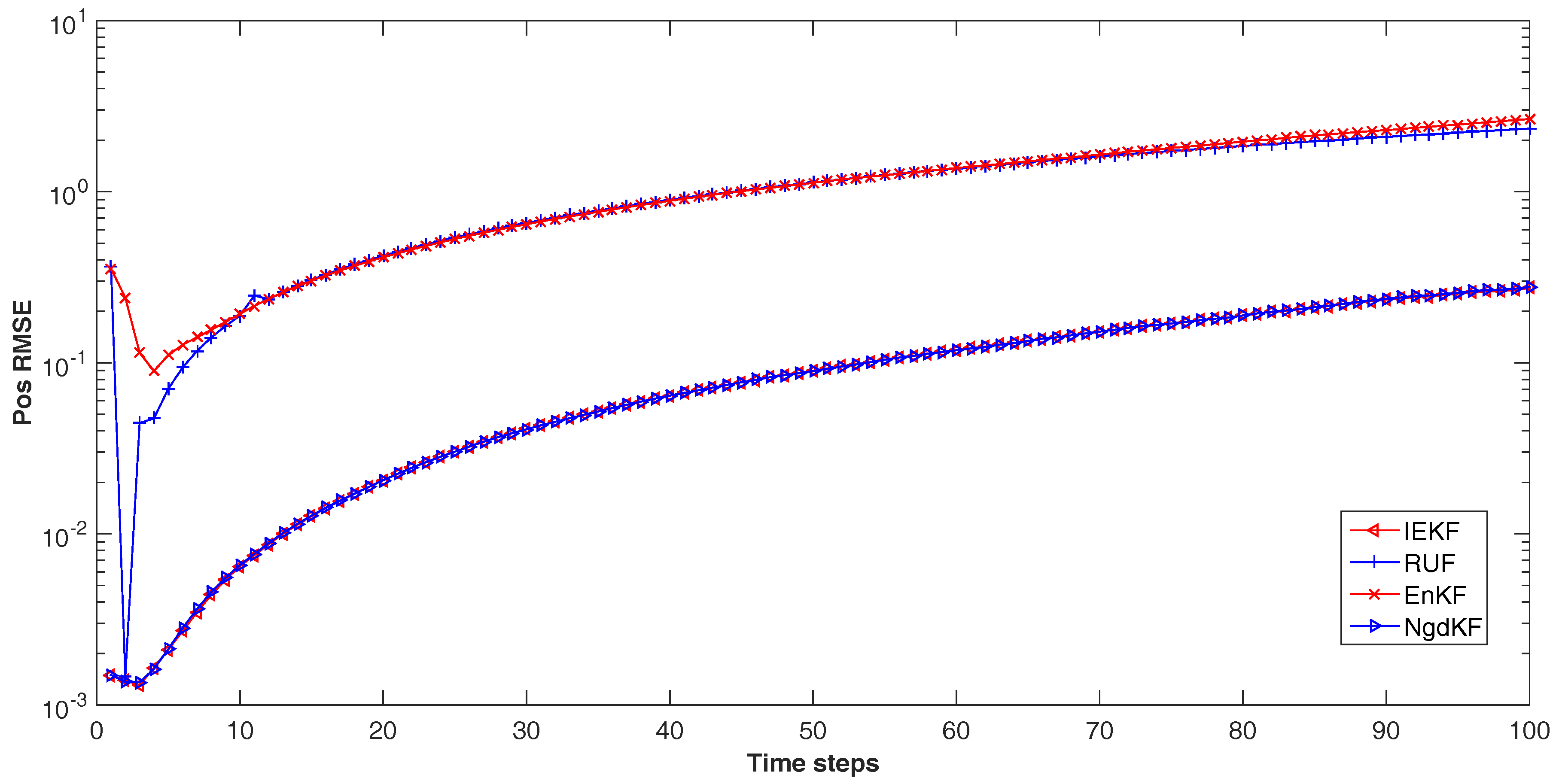
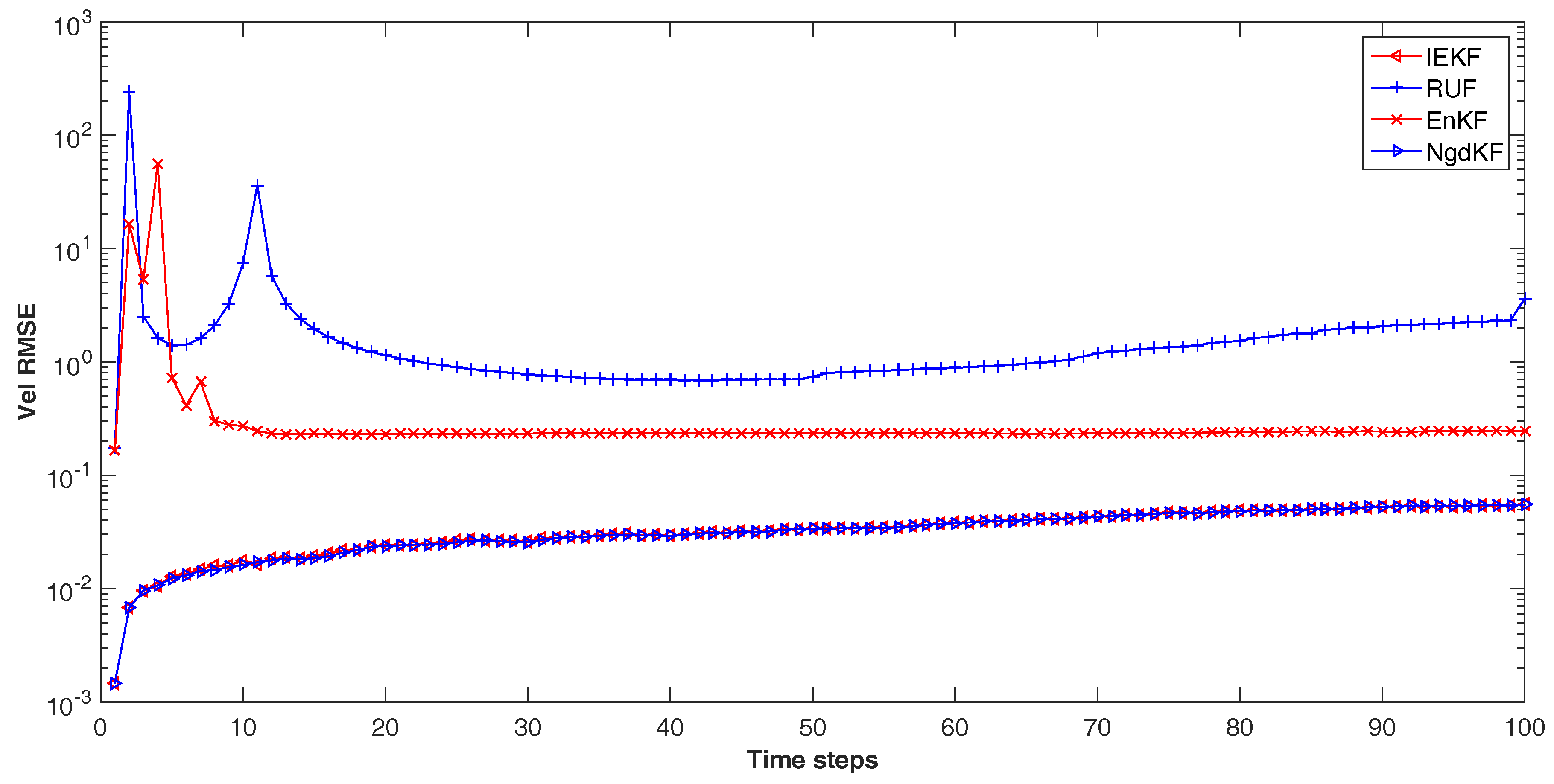
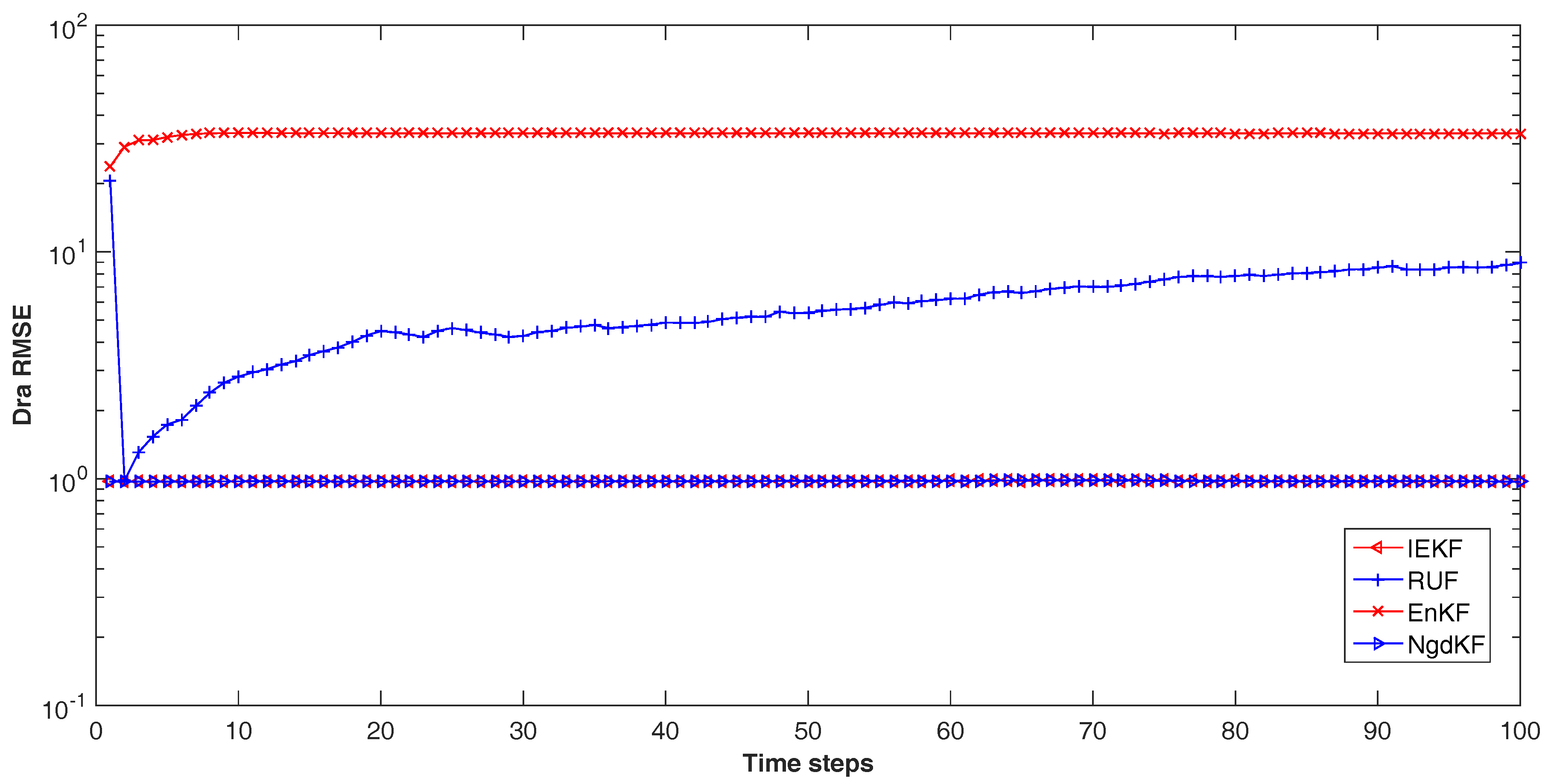
9], which derived based on the LMMSE method. It defines the cross-covariance between the measurement noise and the estimation error for each steps. Then the LMMSE method has been used to deduce the update step. Also, it has considered the fraction of update, which selected as the reciprocal of the number of iteration steps. In comparison with our proposed method, the RUF uses the manual setting number of iteration steps, which also influences the update step, and has no criterion for evaluation the estimation performance. In some case, the other criterions may provide guarantee for convergence and performance in the procedure. Moreover the detailed differences among these methods will be discussed in the numerical examples in the next section.



{kind=link}
{kind=link}
{kind=link}
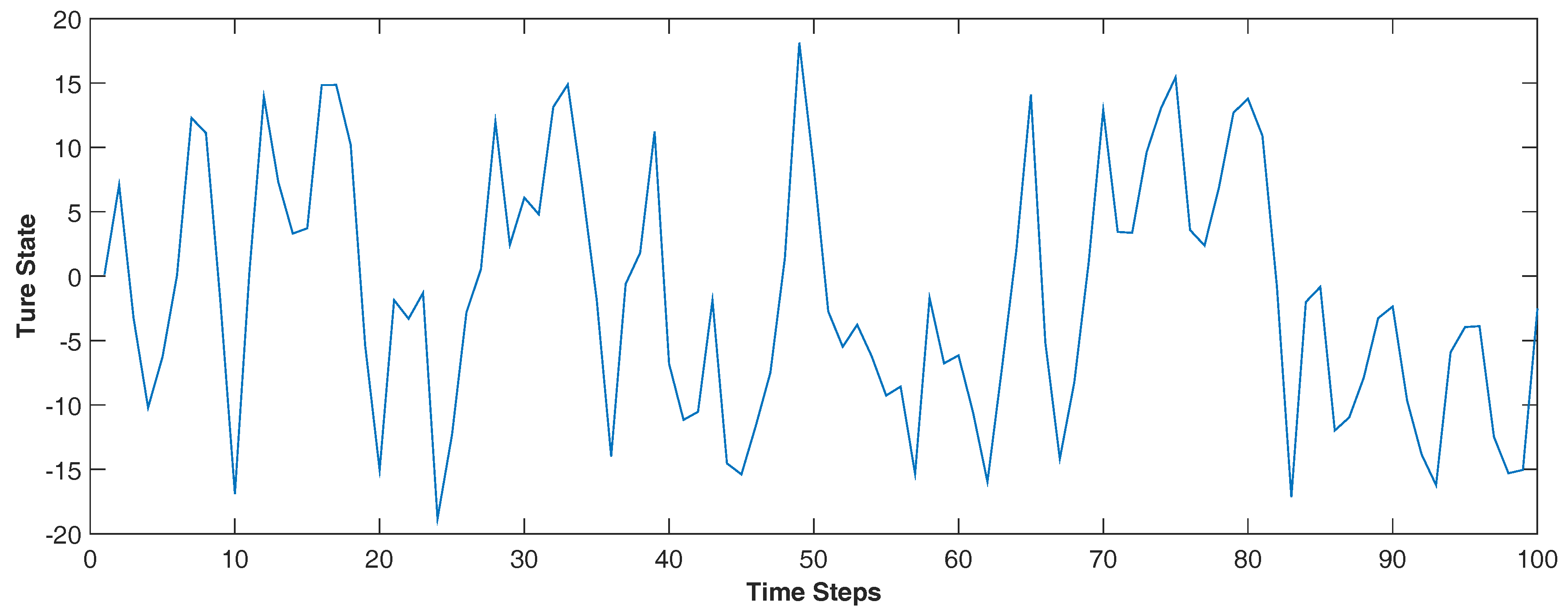{kind=link}
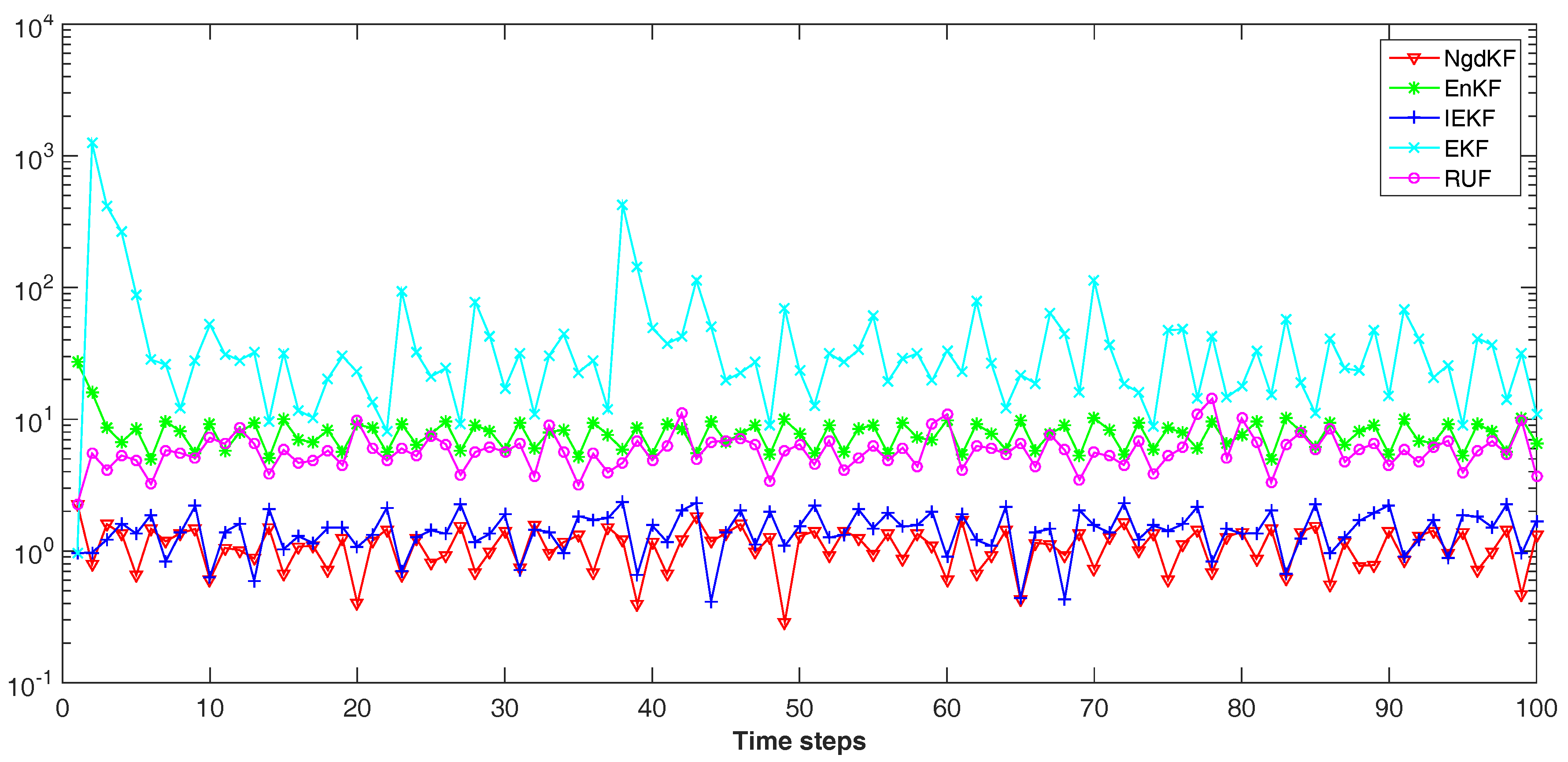{kind=link}
{kind=link}
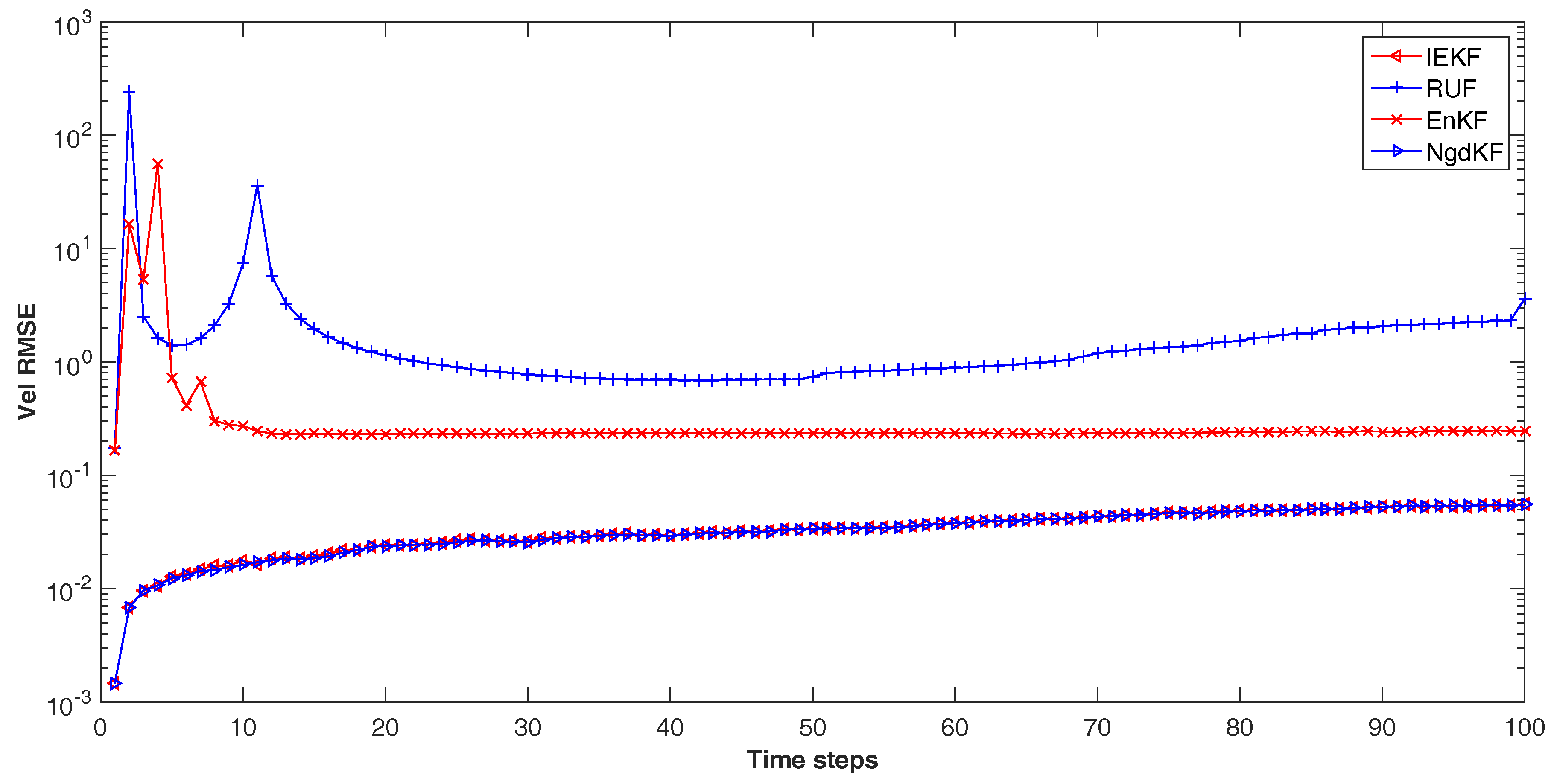{kind=link}
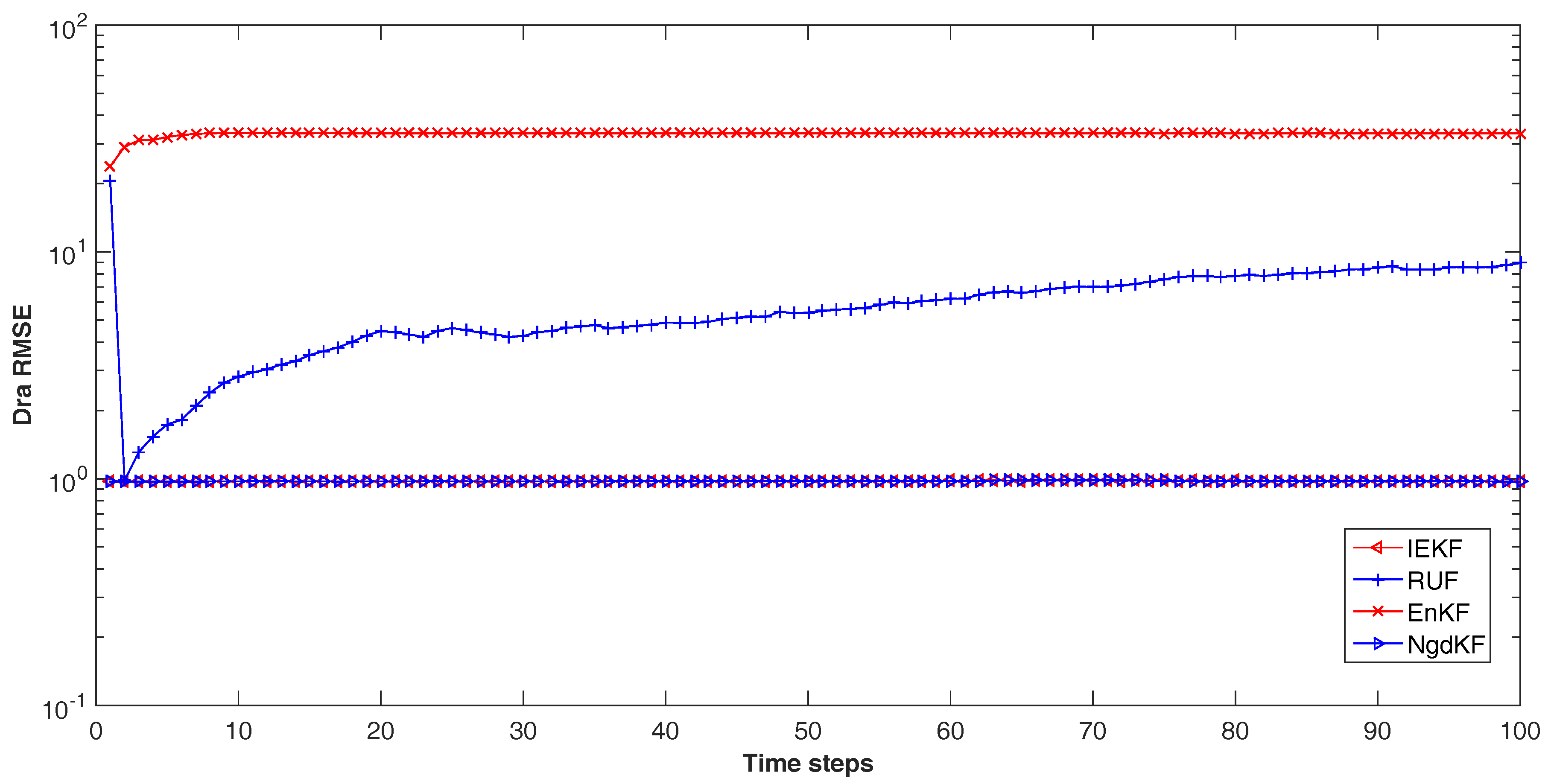{kind=link}