
Optimization of Alpha-Beta Log-Det Divergences and their Application in the Spatial Filtering of Two Class Motor Imagery Movements


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
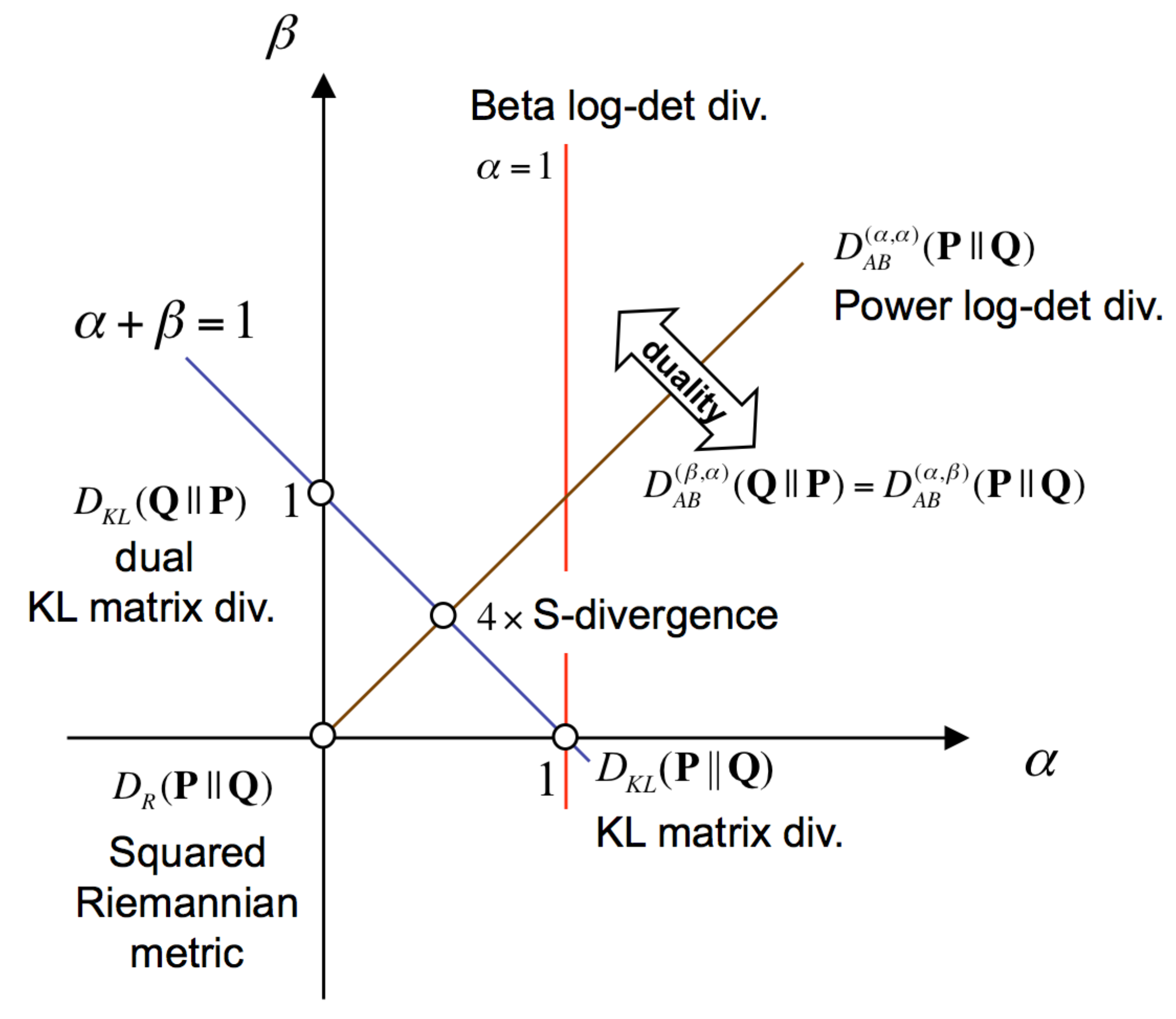
- The existing link between the CSP method and the symmetric KL divergence (see [1]), is extended to the case of the minimax optimization of the AB log-det divergences. In absence of regularization, their solutions are shown to be equivalent whenever these methods apply the same divergence-based criterion for choosing the spatial filters. Although, in general, this is not the case when the CSP method adopts the popular practical criterion of a priori fixing the number of spatial filters for each class, we show that the equivalence with the solution of the optimization of AB log-det divergences can be still preserved if a suitable scaling factor κ is used in one of the arguments of the divergence.
- The details on how to perform the optimization of the AB log-det divergence are presented. The explicit expression of the gradient of this divergence with respect to the spatial filters is obtained. Expression which generalizes and extends the gradient of several more established well-known divergences, for instance, the gradient of the Alpha–Gamma divergence and the gradient of the Kullback–Leibler divergence between SPD matrices.
- The robustness property of the AB log-det divergence with respect to outliers has been analyzed. The study reveals that the hyperparameters of the divergence can be chosen to underweight or overweight, at convenience, the influence of the larger and smaller generalized eigenvalues in the estimating equations.
- Motivated by the success of criteria based on the Beta divergence [1] in the robust spatial filtering of the motor imagery movements, in this work, we consider the use of a criterion based on AB log-det divergences for the same purpose. A subspace optimization algorithm based on regularized AB log-det divergences is proposed for obtaining the relevant subset of spatial filters. Some exemplary simulations illustrate its robustness over synthetic and real datasets.
2. Notation and Model of the Measurements
3. The Common Spatial Patterns Algorithm
4. The Divergence Optimization Interpretation of CSP
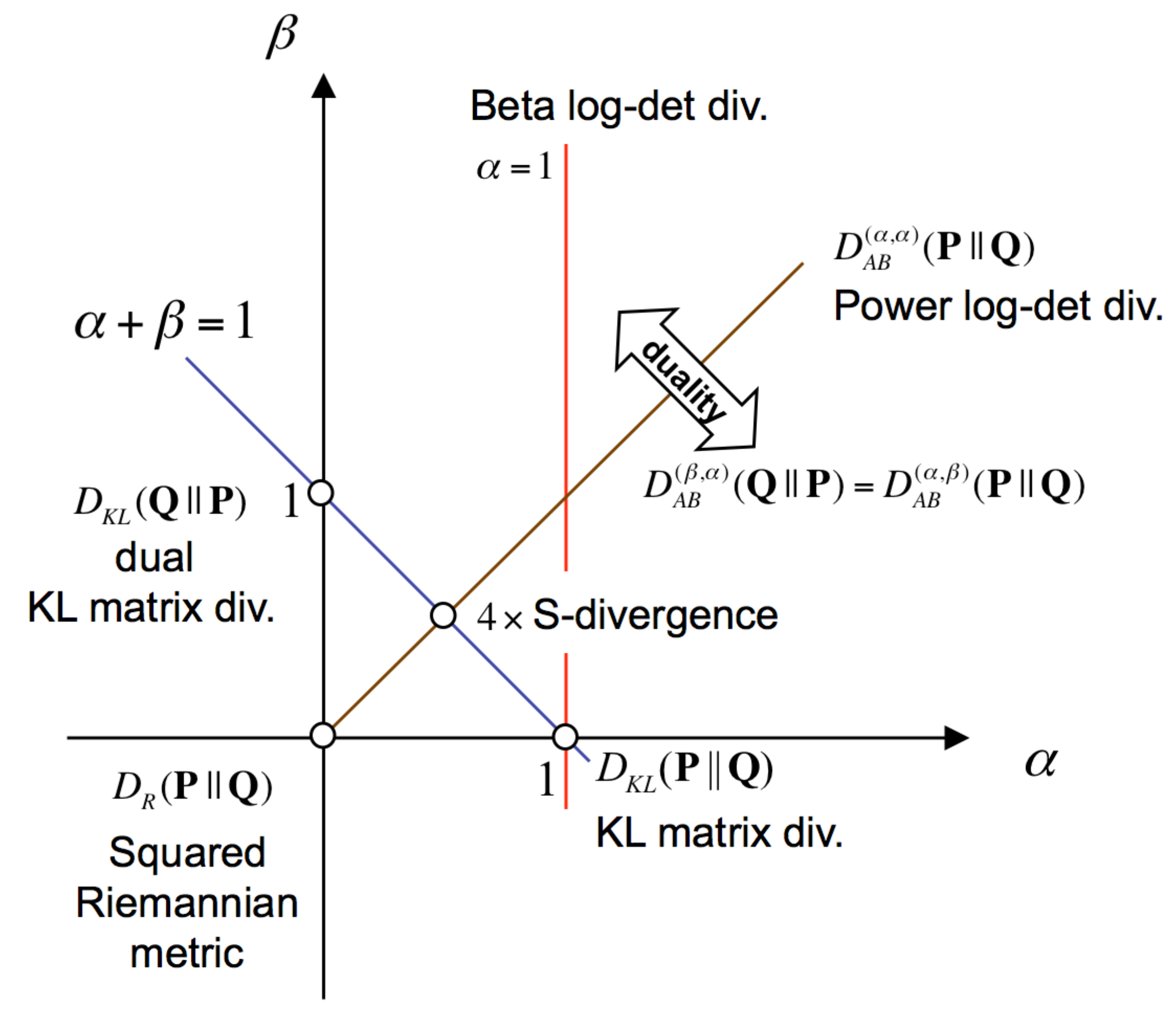
5. The Definition of the AB Log-Det Divergence
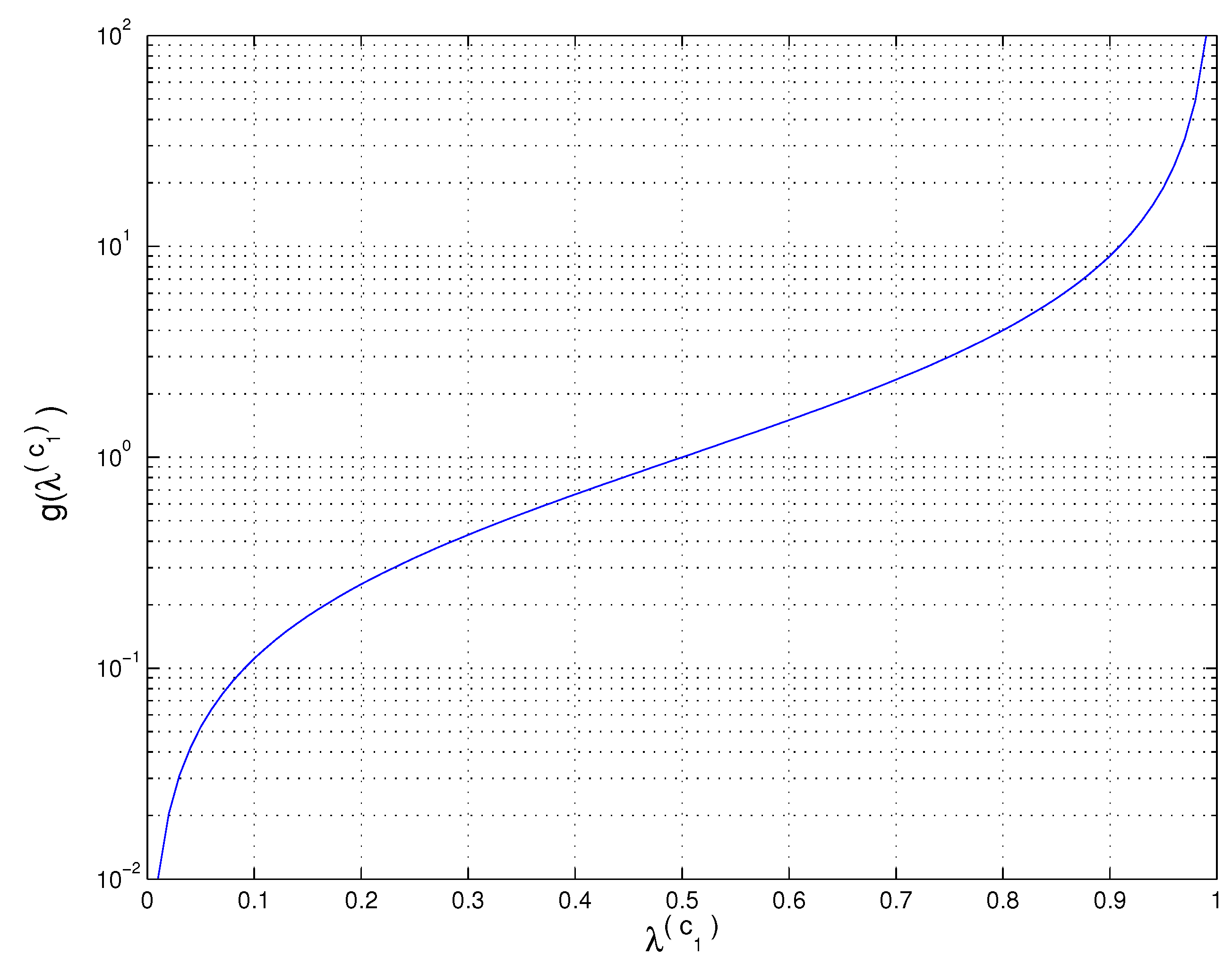
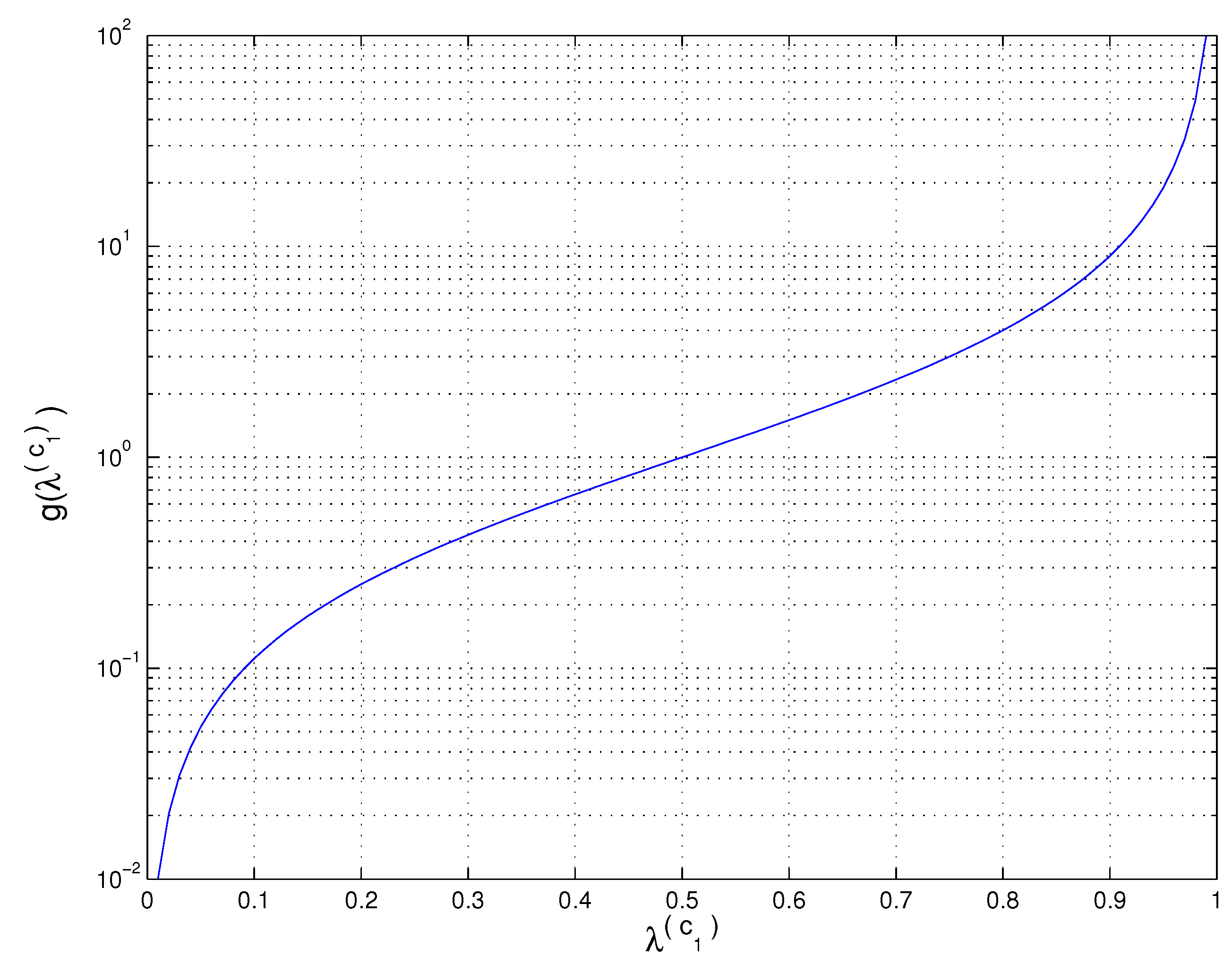
5.1. A Tight Upper-Bound for the AB Log-Det Divergences
5.2. Relationship between the Generalized Eigenvalues and Eigenvectors of the Matrix Pencils and
5.3. Linking the Optimization of the Divergence and the CSP Solution
6. The Gradient of the AB Log-Det Divergence
6.1. Validation of Equation (95) with the Gradient of the KL Divergence
6.2. Validation of Equation (95) with the Gradient of the AG Divergence
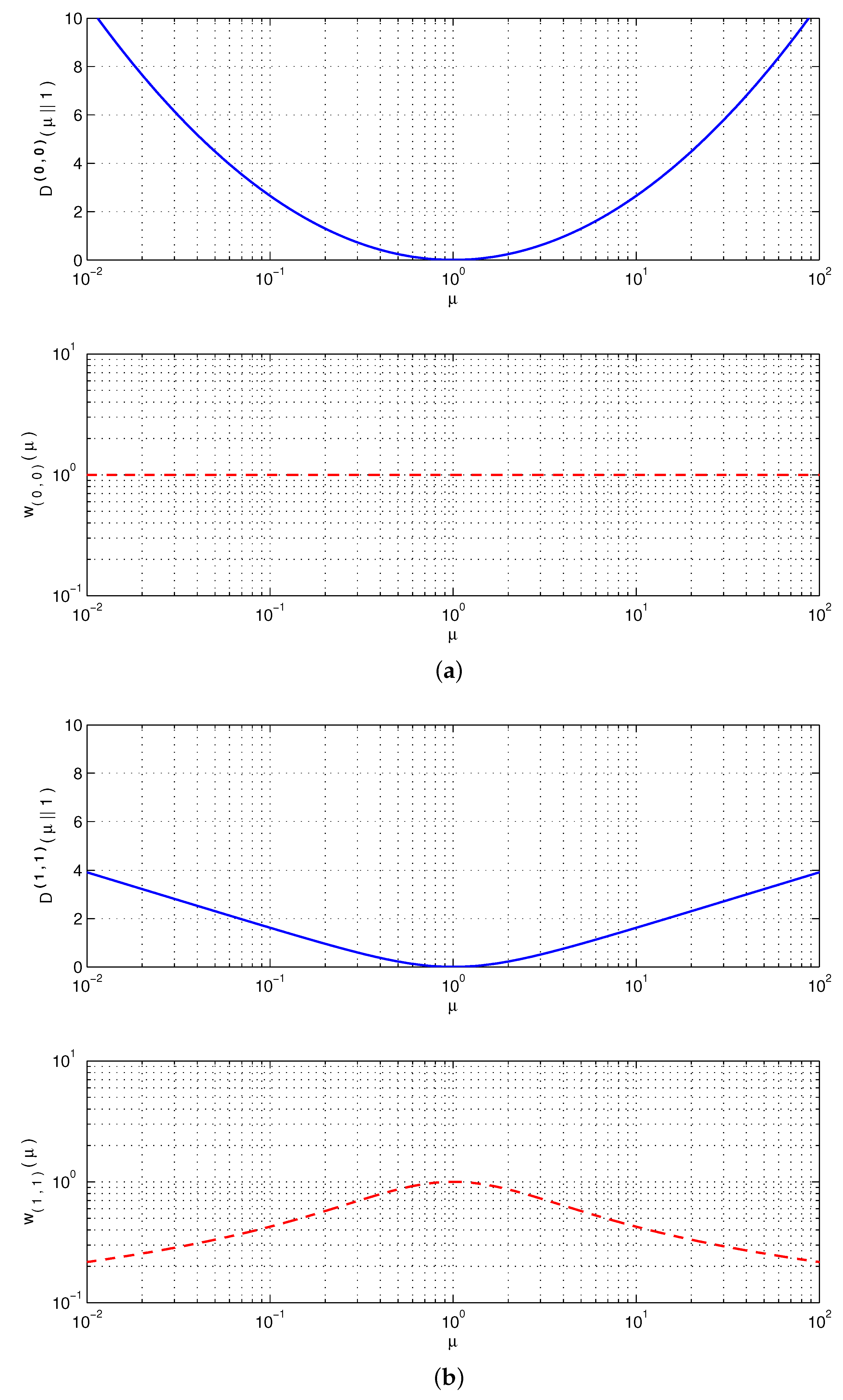
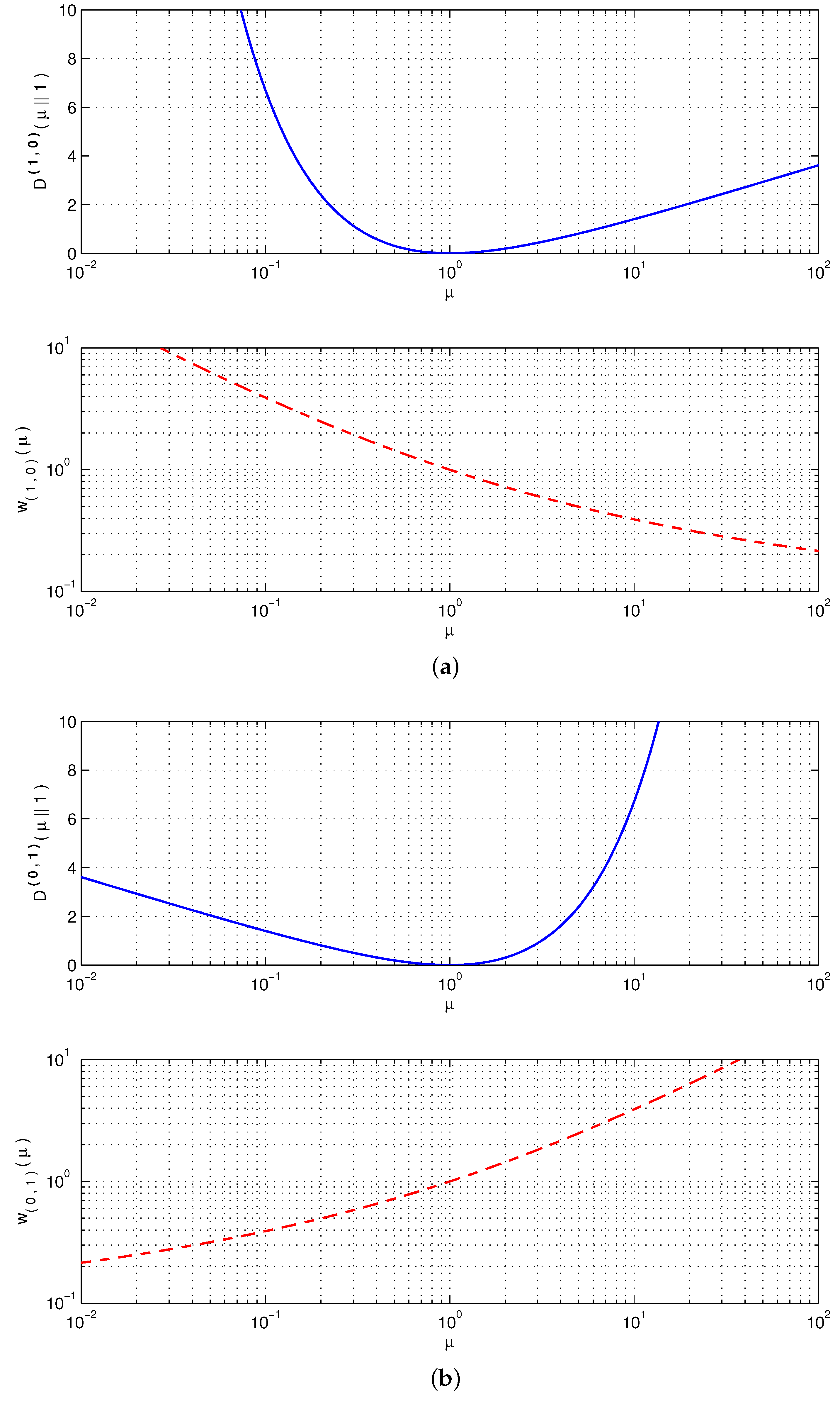
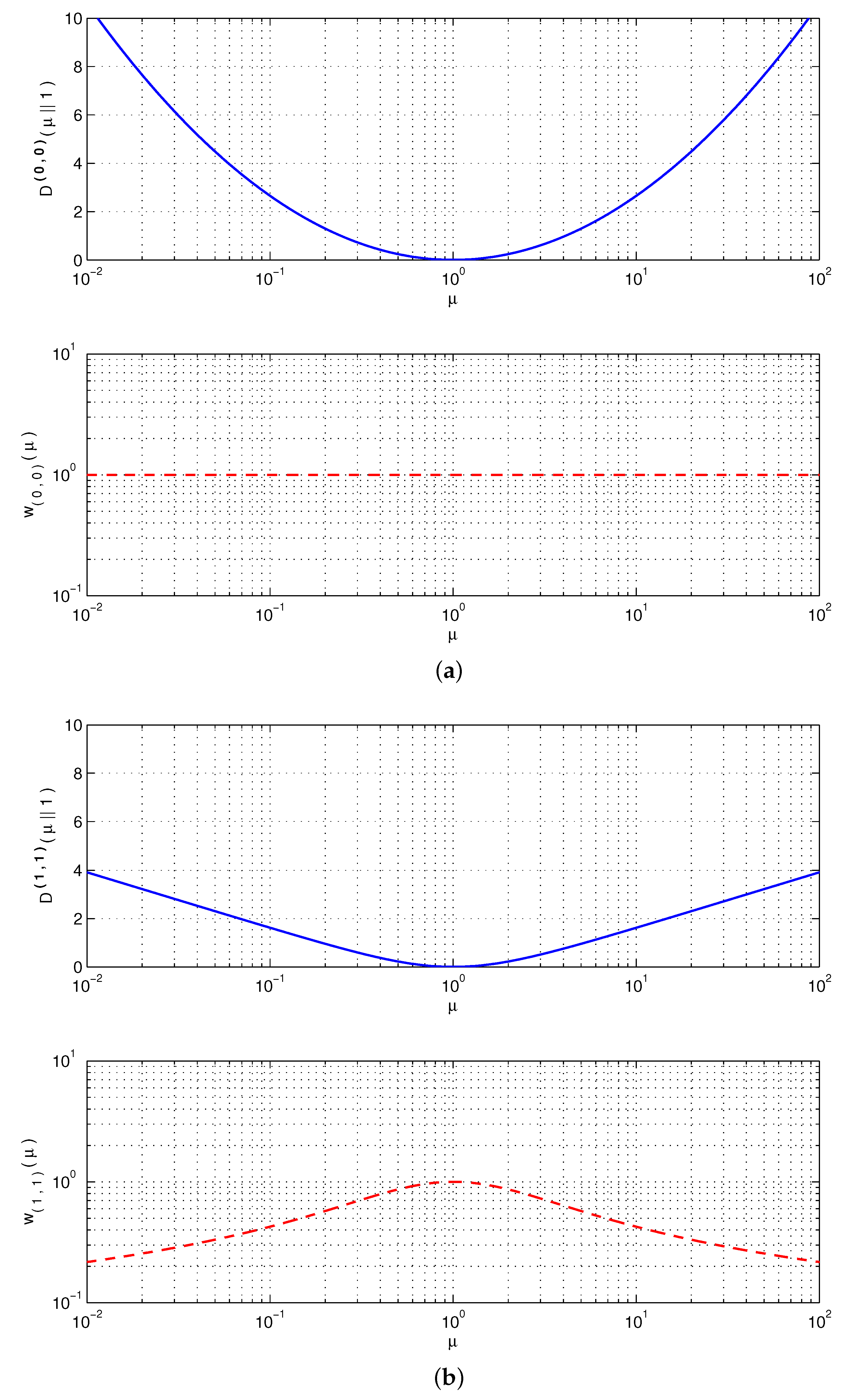
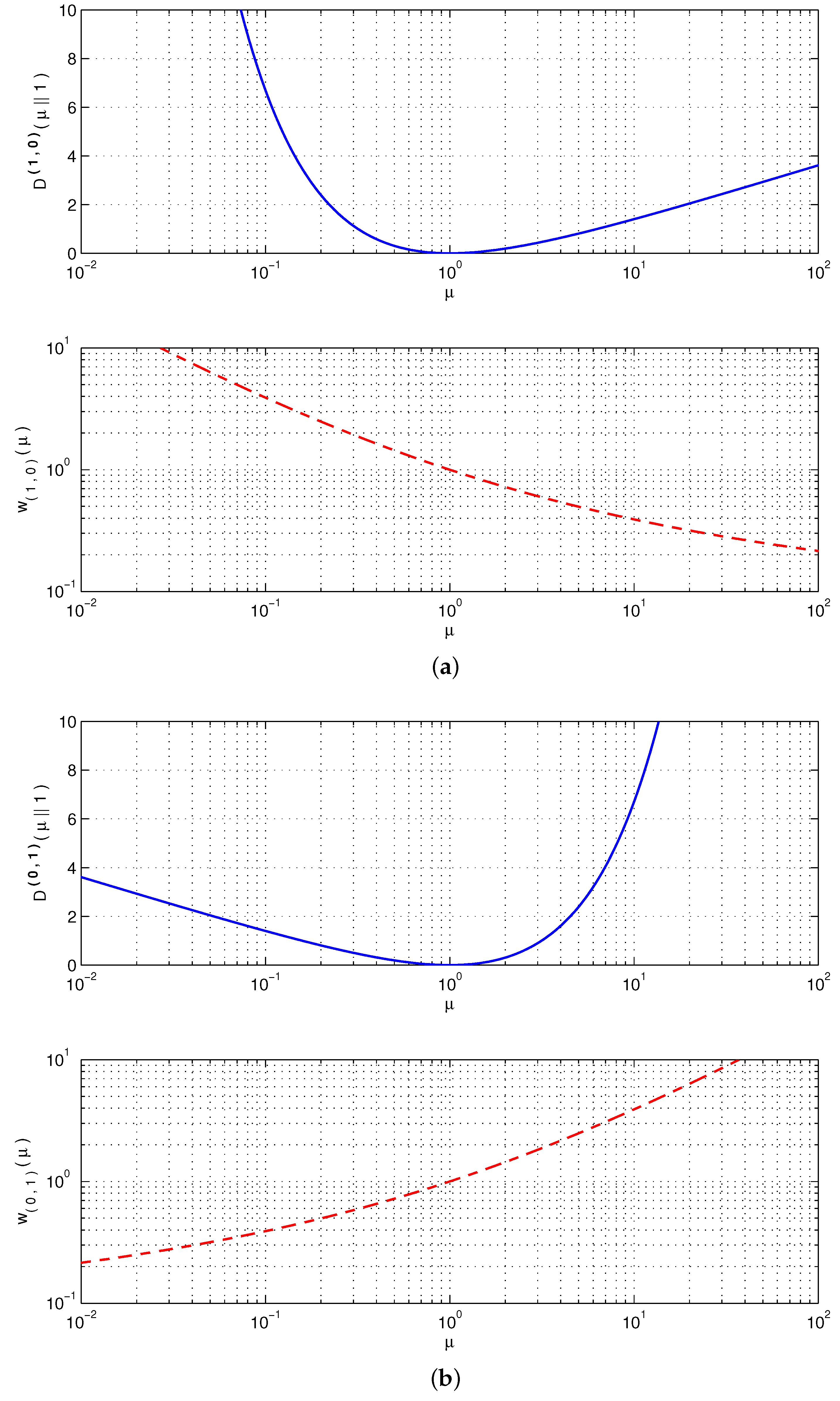
7. Robustness of the AB Log-Det Divergence in Terms of and
8. Review of Some Related Techniques for the Spatial Filtering of Motor Imagery Movements
9. Proposed Criterion and Algorithm for Spatial Filtering
The Subspace Optimization Algorithm (Sub-ABLD)
| Algorithm 1 Sub-ABLD algorithm |
|
10. Experimental Study
10.1. Simulations Data and Preprocessing
10.2. EEG Dataset and Preprocessing
10.3. Feature Extraction and Feature Classification
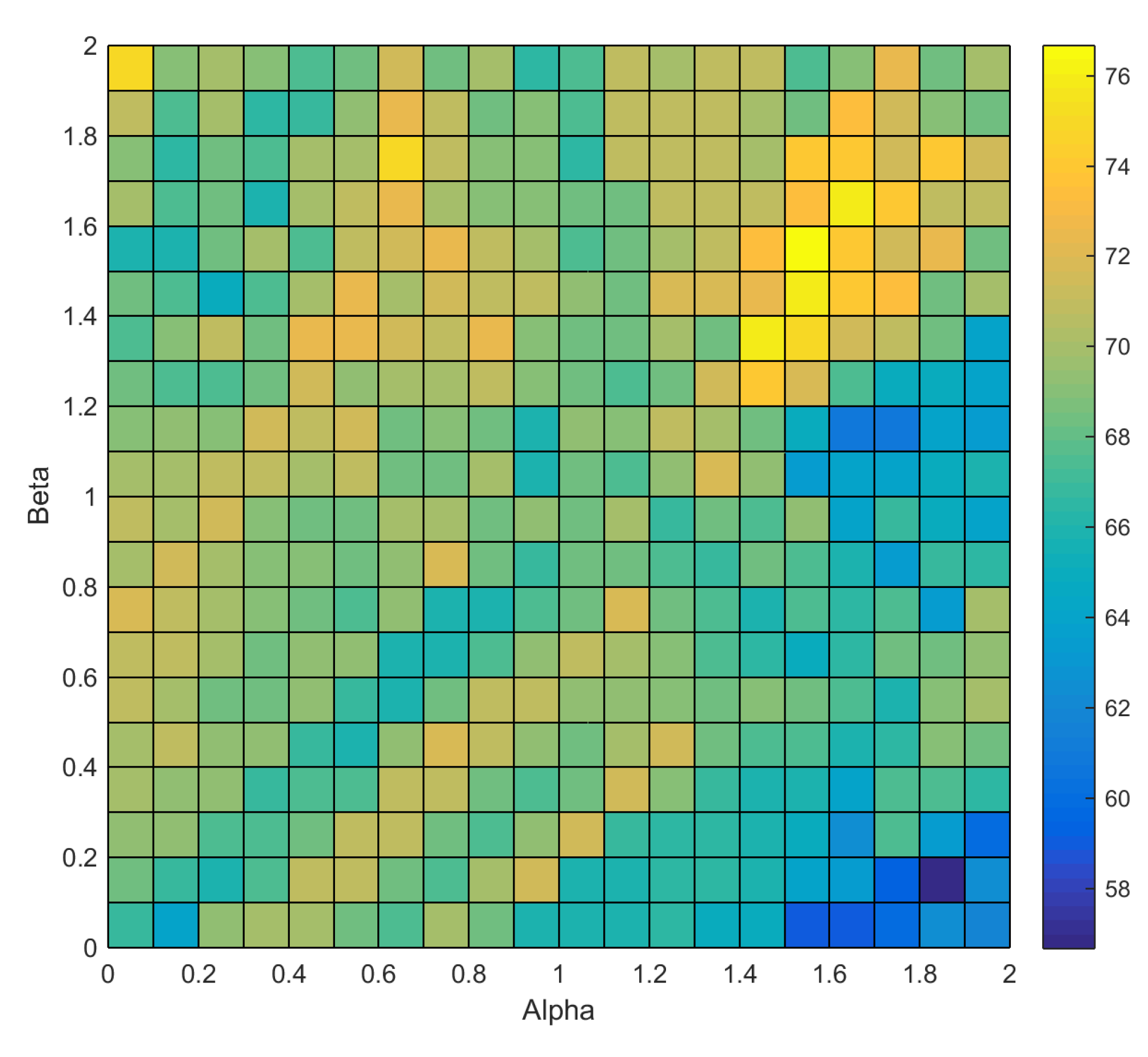
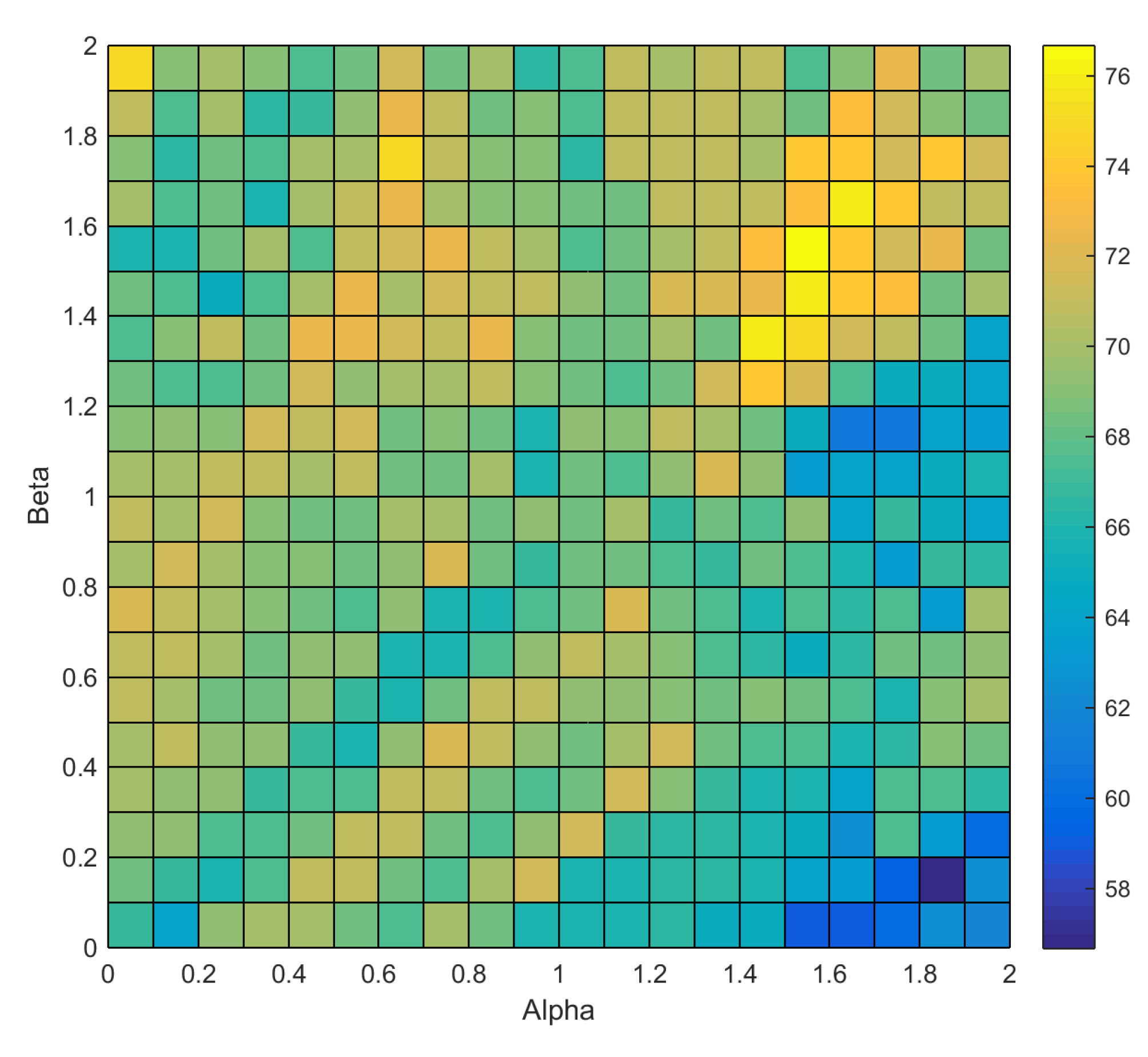
10.4. Selection of α, β and η Values
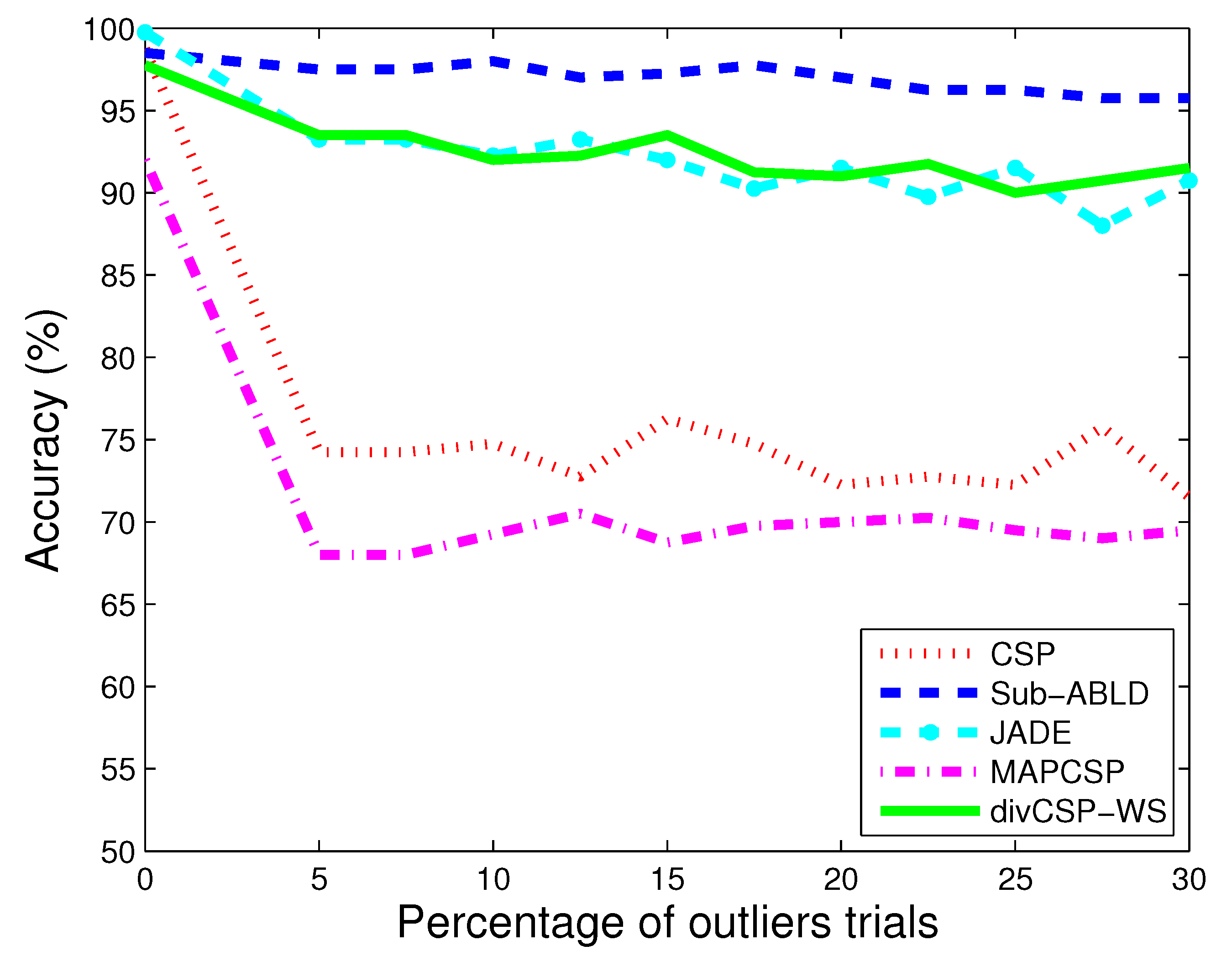
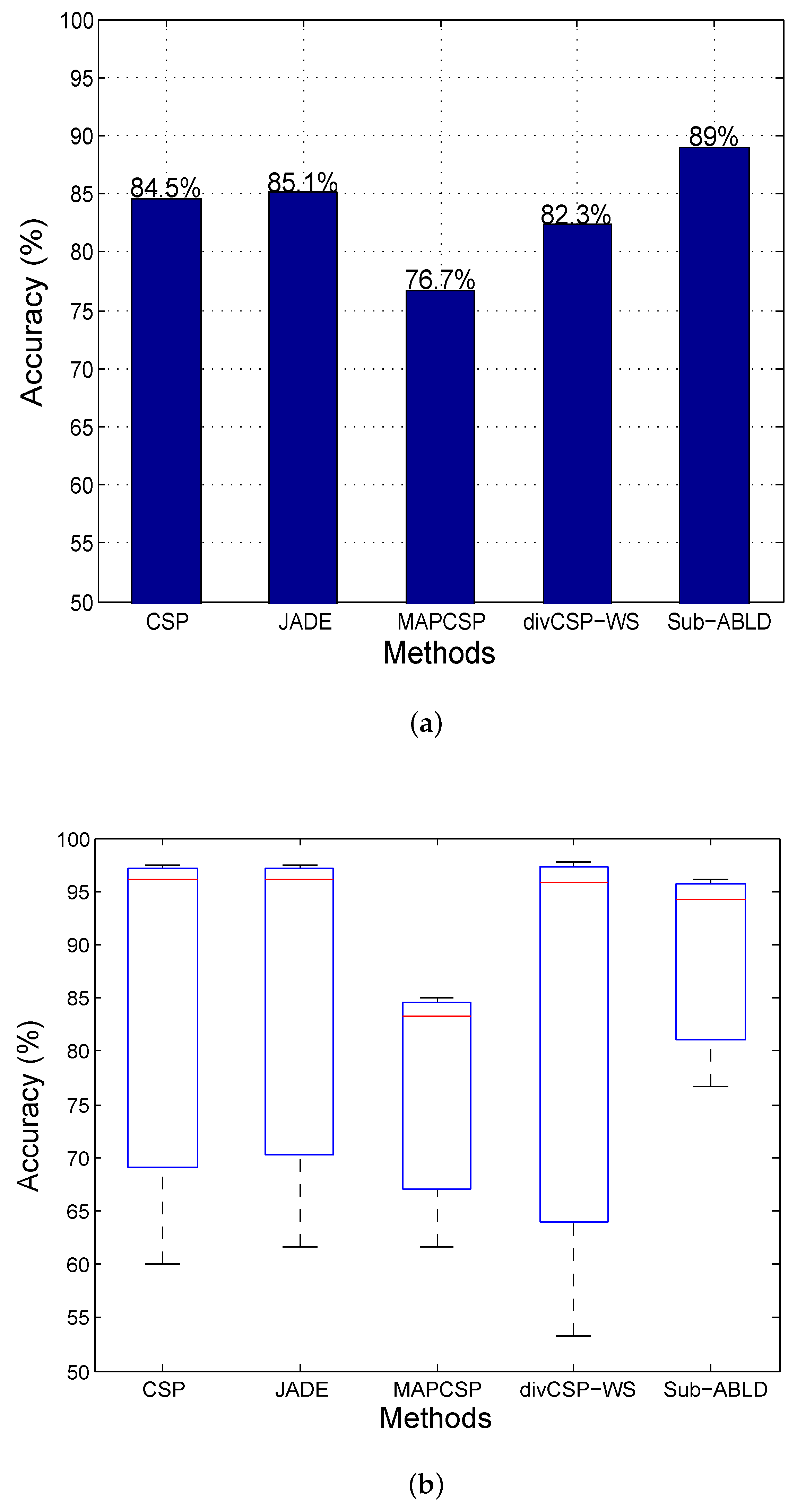
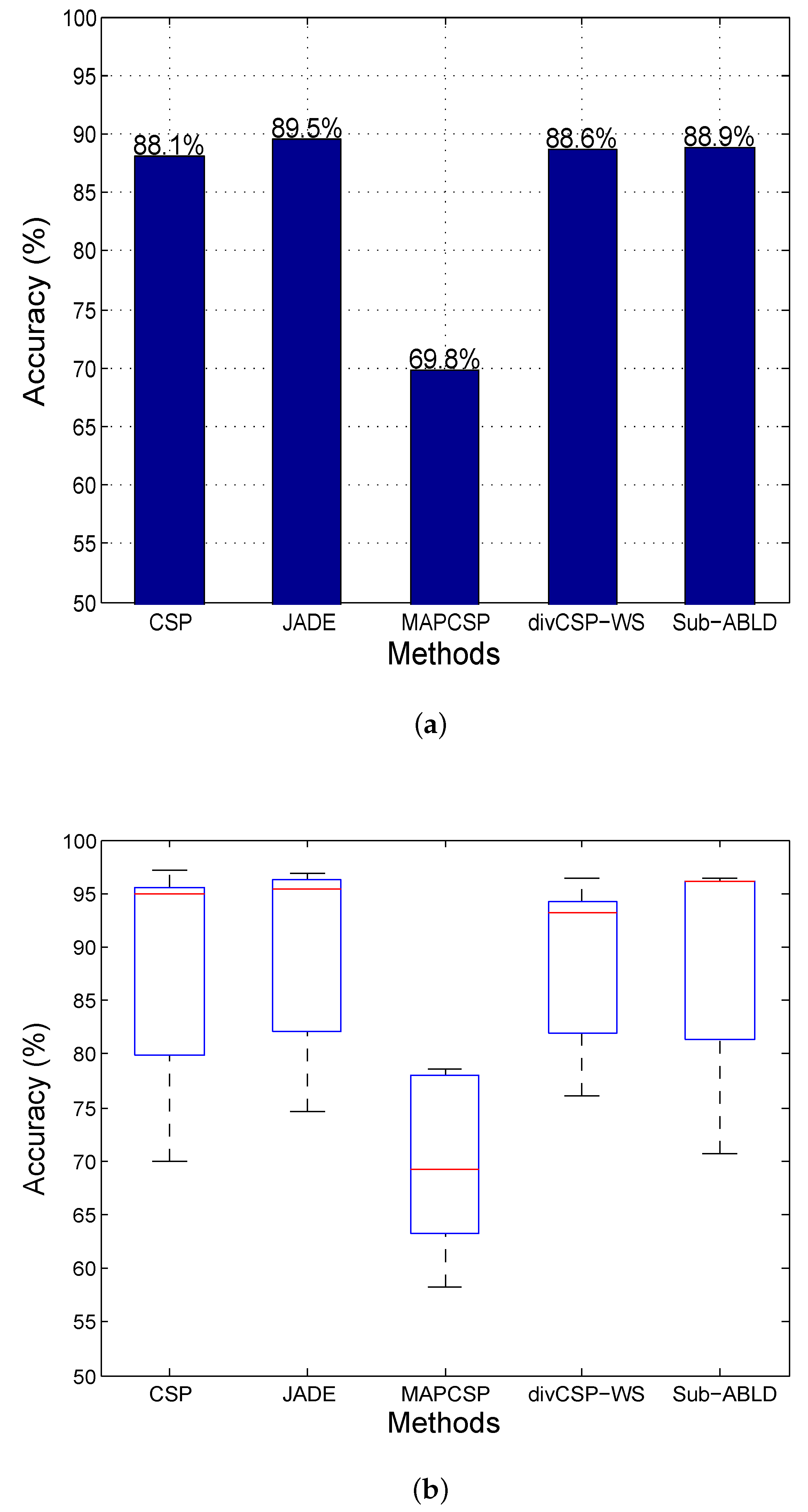
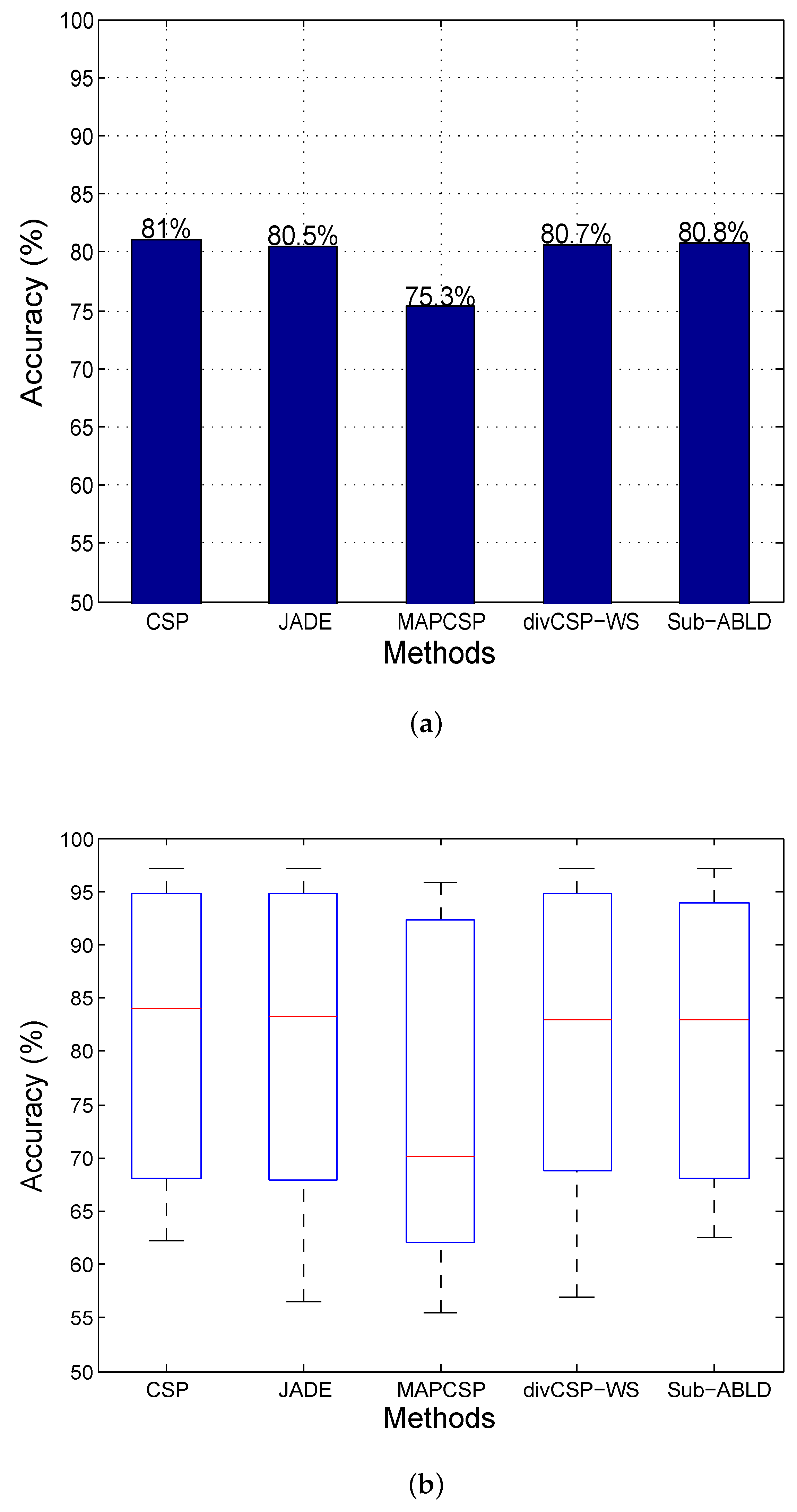
11. Results and Discussion
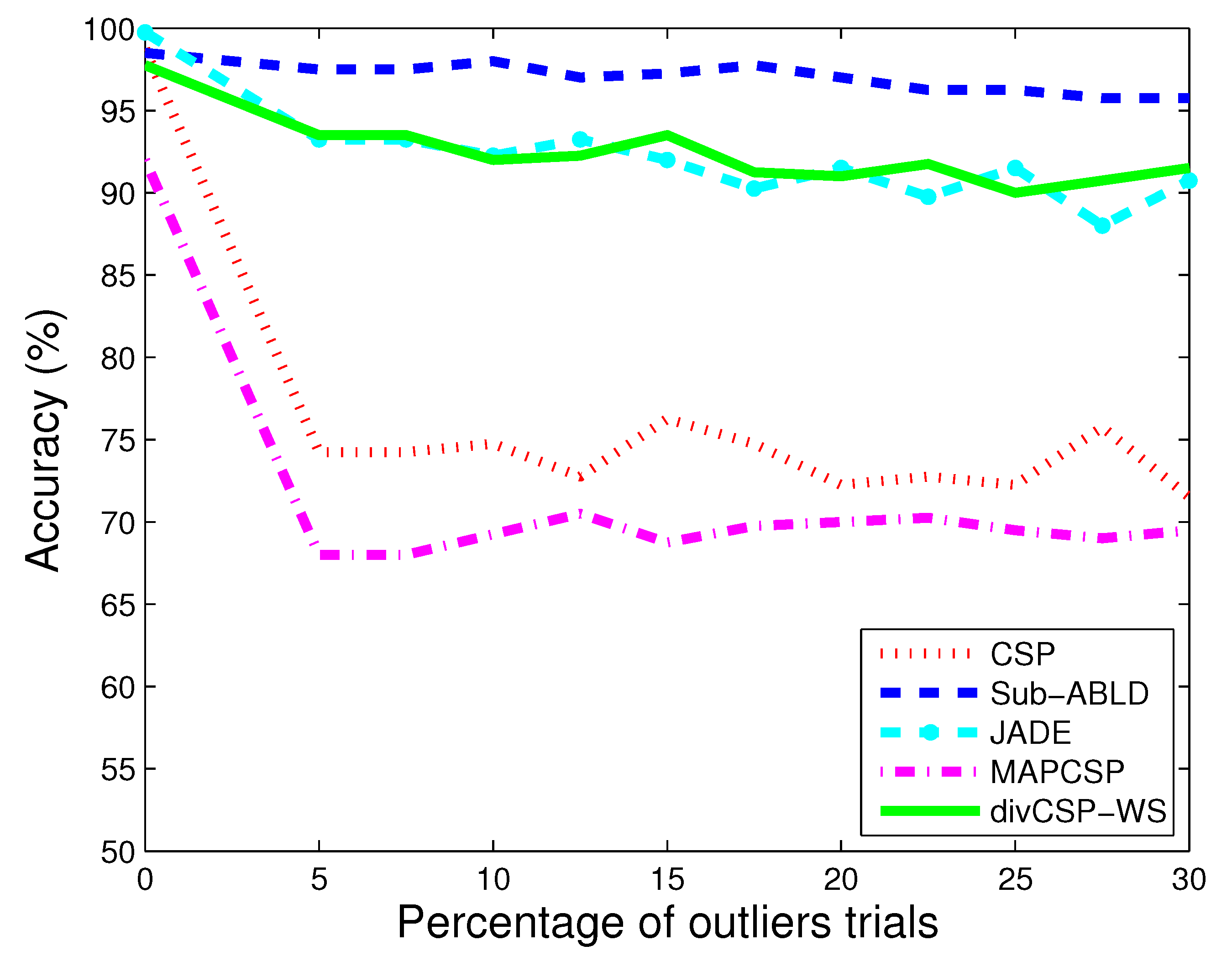
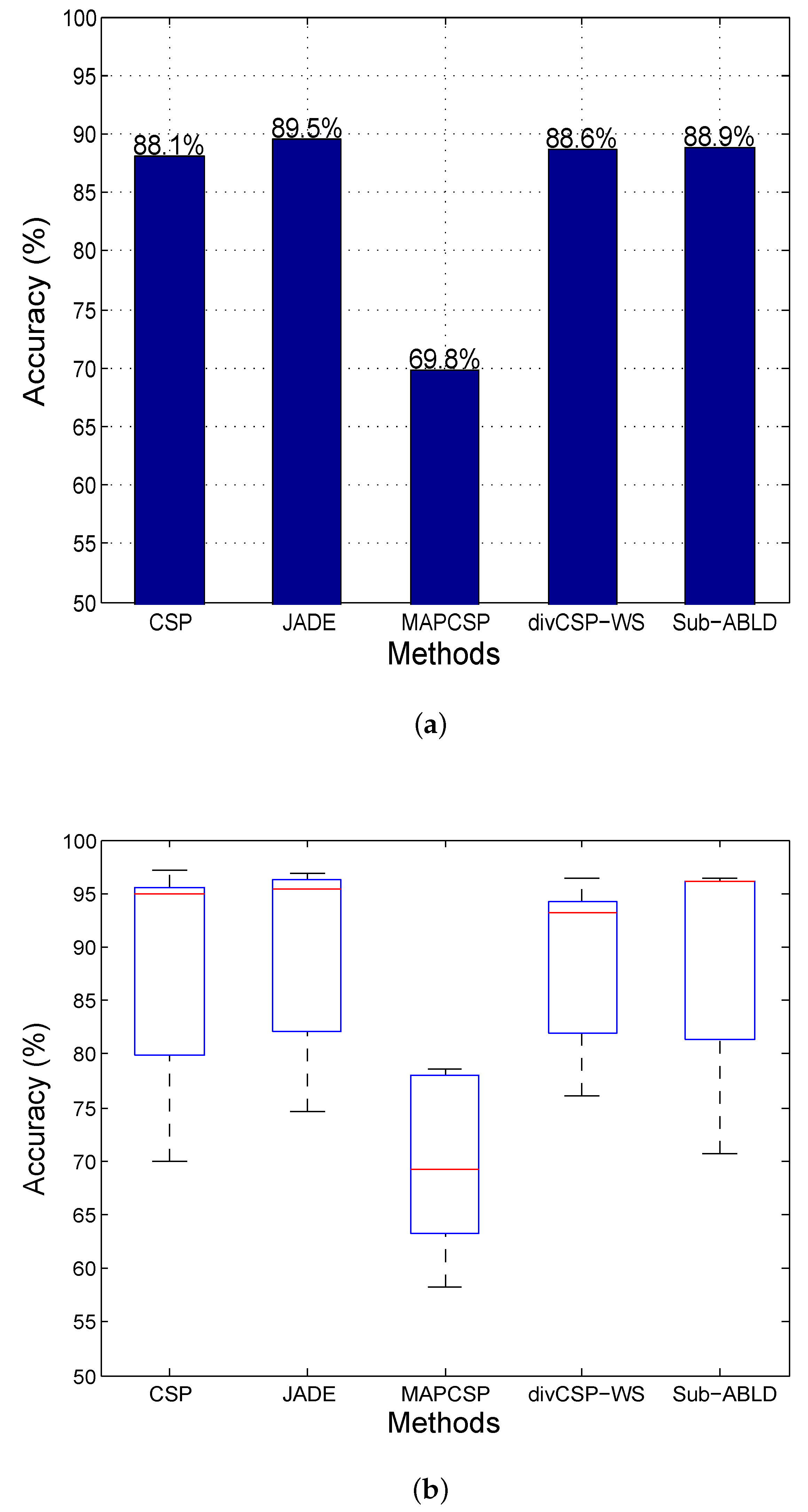
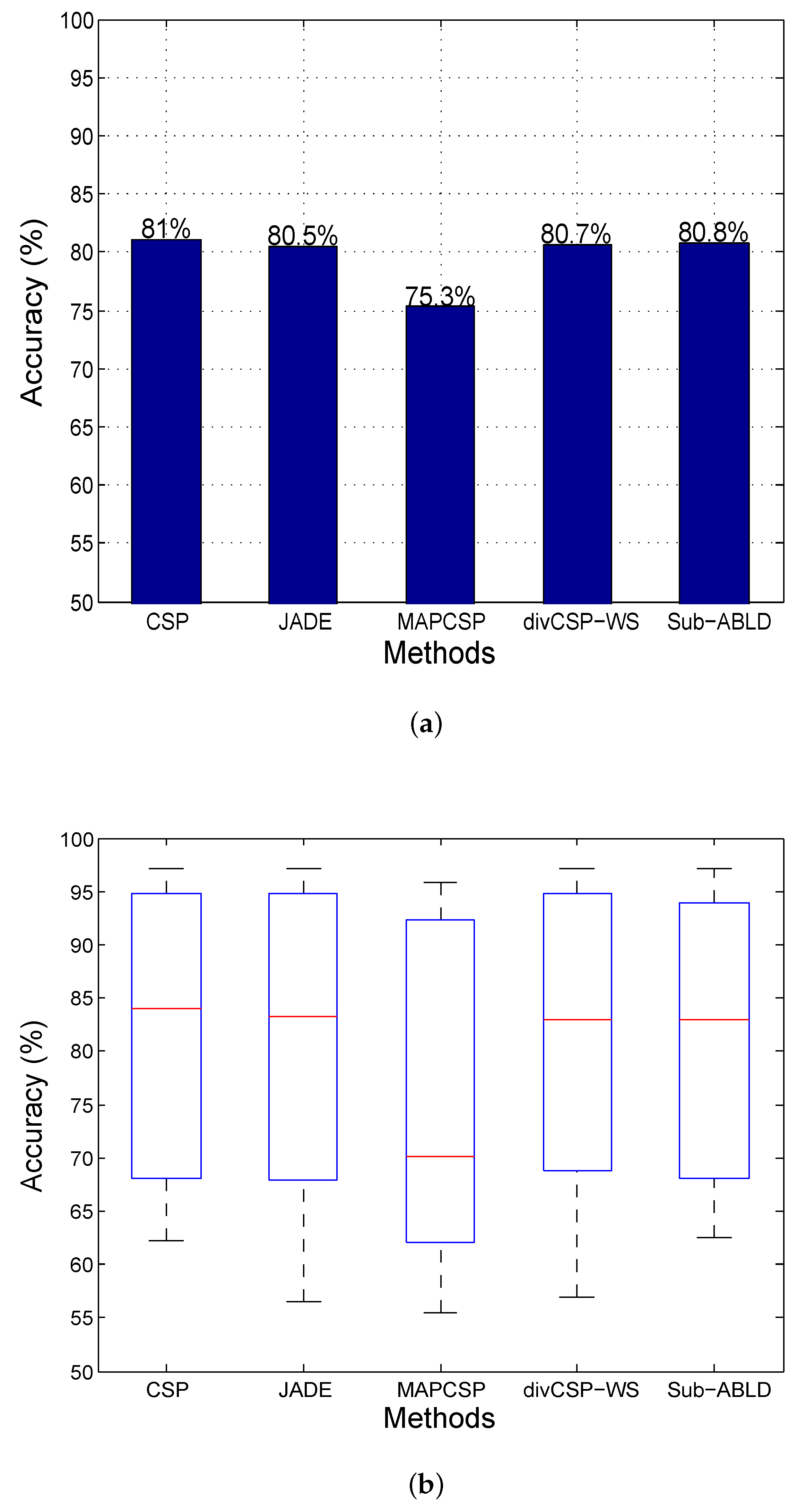
11.1. Observations for Simulated Data
11.2. Observations for BCI Competition Datasets
12. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
Appendix A.1 Obtaining the Upper-Bound of the AB Log-Det Divergence
Appendix A.2 Proof of the Link between the Optimization of the Divergence and the CSP Solution
Appendix A.3 Differential of the Inverse Square Root of a SPD Matrix
Appendix A.4 The Gradient of the KL Divergence between Gaussian Densities
References
- Samek, W.; Kawanabe, M.; Müller, K.R. Divergence-based framework for common spatial patterns algorithms. IEEE Rev. Biomed. Eng. 2014, 7, 50–72. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Wang, R.; Shan, S.; Li, X.; Chen, X. Log-Euclidean Metric Learning on Symmetric Positive Definite Manifold with Application to Image Set Classification. In Proceedings of the 32nd International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015.
- Salzmann, M.; Hartley, R. Dimensionality Reduction on SPD Manifolds: The Emergence of Geometry-Aware Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2016. [Google Scholar] [CrossRef]
- Sra, S.; Hosseini, R. Geometric Optimization in Machine Learning Algorithmic Advances in Riemannian Geometry and Applications: For Machine Learning, Computer Vision, Statistics, and Optimization; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Horev, I.; Yger, F.; Sugiyama, M. Geometry-aware principal component analysis for symmetric positive definite matrices. In Proceedings of the 7th Asian Conference on Machine Learning, Hong Kong, China, 20–22 November 2015; pp. 1–16.
- Cichocki, A.; Cruces, S.; Amari, S.i. Log-Determinant Divergences Revisited: Alpha-Beta and Gamma Log-Det Divergences. Entropy 2015, 17, 2988–3034. [Google Scholar] [CrossRef]
- Minh, H.Q. Infinite-dimensional Log-Determinant divergences II: Alpha-Beta divergences. arXiv 2017. [Google Scholar]
- Dornhege, G. Toward Brain-Computer Interfacing; MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Wolpaw, J.; Wolpaw, E.W. Brain-computer Interfaces: Principles and Practice; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Pfurtscheller, G.; Da Silva, F.L. Event-related EEG/MEG synchronization and desynchronization: Basic principles. Clin. Neurophysiol. 1999, 110, 1842–1857. [Google Scholar] [CrossRef]
- Fukunaga, K.; Koontz, W.L.G. Application of the Karhunen-Loeve Expansion to Feature Selection and Ordering. IEEE Trans. Comput. 1970, C-19, 440–447. [Google Scholar] [CrossRef]
- Koles, Z.J. The quantitative extraction and topographic mapping of the abnormal components in the clinical EEG. Electroencephalogr. Clin. Neurophysiol. 1991, 79, 440–447. [Google Scholar] [CrossRef]
- Ramoser, H.; Müller-Gerking, J.; Pfurtscheller, G. Optimal spatial filtering of single trial EEG during imagined hand movement. IEEE Trans. Rehabil. Eng. 2000, 8, 441–446. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Chen, Z.; Gao, X.; Li, Y.; Brown, E.N.; Gao, S. Probabilistic common spatial patterns for multichannel EEG analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 639–653. [Google Scholar] [CrossRef] [PubMed]
- Bhatia, R. Matrix Analysis; Graduate Texts in Mathematics; Springer: Berlin/Heidelberg, Germany, 1997. [Google Scholar]
- Wang, H. Harmonic mean of Kullback–Leibler divergences for optimizing multi-class EEG spatio-temporal filters. Neural Process. Lett. 2012, 36, 161–171. [Google Scholar] [CrossRef]
- Samek, W.; Blythe, D.; Müller, K.R.; Kawanabe, M. Robust spatial filtering with beta divergence. In Proceedings of the Advances in Neural Information Processing Systems, Stateline, NV, USA, 5–10 December 2013; pp. 1007–1015.
- Cichocki, A.; Amari, S. Families of Alpha- Beta- and Gamma- Divergences: Flexible and Robust Measures of Similarities. Entropy 2010, 12, 1532–1568. [Google Scholar] [CrossRef]
- Brandl, S.; Müller, K.R.; Samek, W. Robust common spatial patterns based on Bhattacharyya distance and Gamma divergence. In Proceedings of the 2015 3rd International Winter Conference on Brain-Computer Interface (BCI), Jeongsun-Kun, Korea, 12–14 January 2015; pp. 1–4.
- Tao, T. Topics in Random Matrix Theory; American Mathematical Society: Providence, RI, USA, 2012; Volume 132. [Google Scholar]
- Blankertz, B.; Kawanabe, M.; Tomioka, R.; Hohlefeld, F.; Müller, K.R.; Nikulin, V.V. Invariant common spatial patterns: Alleviating nonstationarities in brain-computer interfacing. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 113–120.
- Lotte, F.; Guan, C. Spatially regularized common spatial patterns for EEG classification. In Proceedings of the 2010 20th International Conference on Pattern Recognition (ICPR), Istanbul, Turkey, 23–26 August 2010; pp. 3712–3715.
- Kang, H.; Nam, Y.; Choi, S. Composite common spatial pattern for subject-to-subject transfer. IEEE Signal Process. Lett. 2009, 16, 683–686. [Google Scholar] [CrossRef]
- Lotte, F.; Guan, C. Learning from other subjects helps reducing brain-computer interface calibration time. In Proceedings of the 2010 IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 614–617.
- Lu, H.; Plataniotis, K.N.; Venetsanopoulos, A.N. Regularized common spatial patterns with generic learning for EEG signal classification. In Proceedings of the 2009 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 3–6 September 2009; pp. 6599–6602.
- Xinyi Yong, R.K.W.; Birch, G.E. Robust Common Spatial Patterns for EEG Signal Preprocessing. In Proceedings of the IEEE EMBS 30th Annual International Conference, Vancouver, BC, Canada, 20–25 August 2008; pp. 2087–2090.
- Kawanabe, M.; Vidaurre, C. Improving BCI performance by modified common spatial patterns with robustly averaged covariance matrices. In Proceedings of the World Congress on Medical Physics and Biomedical Engineering, Munich, Germany, 7–12 September 2009.
- Samek, W.; Binder, A.; Müller, K.R. Multiple kernel learning for brain-computer interfacing. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 7048–7051.
- Lotte, F.; Guan, C. Regularizing common spatial patterns to improve BCI designs: unified theory and new algorithms. IEEE Trans. Biomed. Eng. 2011, 58, 355–362. [Google Scholar] [CrossRef] [PubMed]
- Arvaneh, M.; Guan, C.; Ang, K.K.; Quek, H.C. Spatially sparsed common spatial pattern to improve BCI performance. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 2412–2415.
- Farquhar, J.; Hill, N.; Lal, T.N.; Schölkopf, B. Regularised CSP for sensor selection in BCI. In Proceedings of the 3rd International BCI workshop, Graz, Austria, 21–24 September 2006; pp. 1–2.
- Yong, X.; Ward, R.K.; Birch, G.E. Sparse spatial filter optimization for EEG channel reduction in brain-computer interface. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2008), Las Vegas, NV, USA, 31 March–4 April 2008; pp. 417–420.
- Kawanabe, M.; Vidaurre, C.; Scholler, S.; Müller, K.R. Robust common spatial filters with a maxmin approach. In Proceedings of the 2009 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 3–6 September 2009; pp. 2470–2473.
- Kawanabe, M.; Samek, W.; Müller, K.R.; Vidaurre, C. Robust common spatial filters with a maxmin approach. Neural Comput. 2014, 26, 349–376. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Tang, Q.; Zheng, W. L1-norm-based common spatial patterns. IEEE Trans. Biomed. Eng. 2012, 59, 653–662. [Google Scholar] [CrossRef] [PubMed]
- Park, J.; Chung, W. Common spatial patterns based on generalized norms. In Proceedings of the 2013 International Winter Workshop on Brain-Computer Interface (BCI), Jeongsun-kun, Korea, 18–20 February 2013; pp. 39–42.
- Von Bünau, P.; Meinecke, F.C.; Király, F.C.; Müller, K.R. Finding stationary subspaces in multivariate time series. Phys. Rev. Lett. 2009, 103, 214101. [Google Scholar] [CrossRef] [PubMed]
- Samek, W.; Kawanabe, M.; Vidaurre, C. Group-wise stationary subspace analysis–A novel method for studying non-stationarities. In Proceedings of the International Brain–Computer Interfacing Conference, Graz, Austria, 22–24 September 2011; pp. 16–20.
- Samek, W.; Müller, K.R.; Kawanabe, M.; Vidaurre, C. Brain-computer interfacing in discriminative and stationary subspaces. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), San Diego, CA, USA, 28 August–1 September 2012; pp. 2873–2876.
- Von Bünau, P.; Meinecke, F.C.; Scholler, S.; Müller, K.R. Finding stationary brain sources in EEG data. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Buenos Aires, Argentina, 31 August–4 September 2010; pp. 2810–2813.
- Arvaneh, M.; Guan, C.; Ang, K.K.; Quek, C. Optimizing spatial filters by minimizing within-class dissimilarities in electroencephalogram-based brain–computer interface. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 610–619. [Google Scholar] [CrossRef] [PubMed]
- Müller-Gerking, J.; Pfurtscheller, G.; Flyvbjerg, H. Designing optimal spatial filters for single-trial EEG classification in a movement task. Clin. Neurophysiol. 1999, 110, 787–798. [Google Scholar] [CrossRef]
- Allwein, E.L.; Schapire, R.E.; Singer, Y. Reducing multiclass to binary: A unifying approach for margin classifiers. J. Mach. Learn. Res. 2001, 1, 113–141. [Google Scholar]
- Dornhege, G.; Blankertz, B.; Curio, G.; Müller, K.R. Boosting bit rates in noninvasive EEG single-trial classifications by feature combination and multiclass paradigms. IEEE Trans. Biomed. Eng. 2004, 51, 993–1002. [Google Scholar] [CrossRef] [PubMed]
- Grosse-Wentrup, M.; Buss, M. Multiclass common spatial patterns and information theoretic feature extraction. IEEE Trans. Biomed. Eng. 2008, 55, 1991–2000. [Google Scholar] [CrossRef] [PubMed]
- Naeem, M.; Brunner, C.; Leeb, R.; Graimann, B.; Pfurtscheller, G. Separability of four-class motor imagery data using independent components analysis. J. Neural Eng. 2006, 3, 208–216. [Google Scholar] [CrossRef] [PubMed]
- Barachant, A.; Bonnet, S.; Congedo, M.; Jutten, C. Multiclass brain–Computer interface classification by Riemannian geometry. IEEE Trans. Biomed. Eng. 2012, 59, 920–928. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Yang, H.; Guan, C. Bayesian learning for spatial filtering in an EEG-based brain–computer interface. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1049–1060. [Google Scholar] [CrossRef] [PubMed]
- Barber, D. Bayesian Reasoning and Machine Learning; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Edelman, A.; Arias, T.A.; Smith, S.T. The geometry of algorithms with orthogonality constraints. SIAM J. Matrix Anal. Appl. 1998, 20, 303–353. [Google Scholar] [CrossRef]
- Amari, S.I. Natural gradient works efficiently in learning. Neural Comput. 1998, 10, 251–276. [Google Scholar] [CrossRef]
- Cruces, S.; Cichocki, A.; Amari, S. From Blind Signal Extraction to Blind Instantaneous Signal Separation. IEEE Trans. Neural Netw. 2004, 15, 859–873. [Google Scholar] [CrossRef] [PubMed]
- Nishimori, Y. Learning algorithm for ICA by geodesic flows on orthogonal group. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Washington, DC, USA, 10–16 July 1999; pp. 933–938.
- BCI Competition III. Available online: http://www.bbci.de/competition/iii/ (accessed on 26 August 2014).
- BCI Competition IV. Available online: http://www.bbci.de/competition/iv/ (accessed on 26 August 2014).
- Schlögl, A.; Lee, F.; Bischof, H.; Pfurtscheller, G. Characterization of four-class motor imagery EEG data for the BCI-competition 2005. J. Neural Eng. 2005, 2, L14. [Google Scholar] [CrossRef] [PubMed]
- Blankertz, B.; Müller, K.R.; Krusienski, D.J.; Schalk, G.; Wolpaw, J.R.; Schlögl, A.; Pfurtscheller, G.; Millan, J.R.; Schröder, M.; Birbaumer, N. The BCI competition III: Validating alternative approaches to actual BCI problems. IEEE Trans. Neural Syst. Rehabil. Eng. 2006, 14, 153–159. [Google Scholar] [CrossRef] [PubMed]
- Tangermann, M.; Müller, K.R.; Aertsen, A.; Birbaumer, N.; Braun, C.; Brunner, C.; Leeb, R.; Mehring, C.; Miller, K.J.; Mueller-Putz, G.; et al. Review of the BCI competition IV. Front. Neurosci. 2012, 6, 55. [Google Scholar]
- Duda, R.O.; Hart, P.E. Pattern Classification and Scene Analysis; Wiley: New York, NY, USA, 1973; Volume 3. [Google Scholar]
- The Divergence Methods Web Site. Available online: http://www.divergence-methods.org (accessed on 4 April 2016).
- Machine Learning in Neural Engineering. Available online: http://brain-computer-interfaces.net/ (accessed on 29 January 2015).
- Li, R. Rayleigh Quotient Based Optimization Methods For Eigenvalue Problems. In Summary of Lectures Delivered at Gene Golub SIAM Summer School 2013; Fudan University: Shanghai, China, 2013; pp. 1–27. [Google Scholar]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thiyam, D.B.; Cruces, S.; Olias, J.; Cichocki, A. Optimization of Alpha-Beta Log-Det Divergences and their Application in the Spatial Filtering of Two Class Motor Imagery Movements. Entropy 2017, 19, 89. https://doi.org/10.3390/e19030089
Thiyam DB, Cruces S, Olias J, Cichocki A. Optimization of Alpha-Beta Log-Det Divergences and their Application in the Spatial Filtering of Two Class Motor Imagery Movements. Entropy. 2017; 19(3):89. https://doi.org/10.3390/e19030089
Chicago/Turabian StyleThiyam, Deepa Beeta, Sergio Cruces, Javier Olias, and Andrzej Cichocki. 2017. "Optimization of Alpha-Beta Log-Det Divergences and their Application in the Spatial Filtering of Two Class Motor Imagery Movements" Entropy 19, no. 3: 89. https://doi.org/10.3390/e19030089