On the Reliability Function of Variable-Rate Slepian-Wolf Coding †

1
College of Electronic Information and Automation, Tianjin University of Science and Technology, Tianjin 300222, China
2
Department of Electrical and Computer Engineering, McMaster University, Hamilton, ON L8S 4K1, Canada
3
Google, Mountain View, CA 94043, USA
4
IBM Thomas J. Watson Research Center, Yorktown Heights, NY 10598, USA
*
Author to whom correspondence should be addressed.
†
This paper is an extended version of our paper published in the 45th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 26–28 September 2007.
Entropy 2017, 19(8), 389; https://doi.org/10.3390/e19080389
Submission received: 13 June 2017
/
Revised: 14 July 2017
/
Accepted: 27 July 2017
/
Published: 28 July 2017
(This article belongs to the Special Issue Multiuser Information Theory)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:The reliability function of variable-rate Slepian-Wolf coding is linked to the reliability function of channel coding with constant composition codes, through which computable lower and upper bounds are derived. The bounds coincide at rates close to the Slepian-Wolf limit, yielding a complete characterization of the reliability function in that rate region. It is shown that variable-rate Slepian-Wolf codes can significantly outperform fixed-rate Slepian-Wolf codes in terms of rate-error tradeoff. Variable-rate Slepian-Wolf coding with rate below the Slepian-Wolf limit is also analyzed. In sharp contrast with fixed-rate Slepian-Wolf codes for which the correct decoding probability decays to zero exponentially fast if the rate is below the Slepian-Wolf limit, the correct decoding probability of variable-rate Slepian-Wolf codes can be bounded away from zero.
1. Introduction
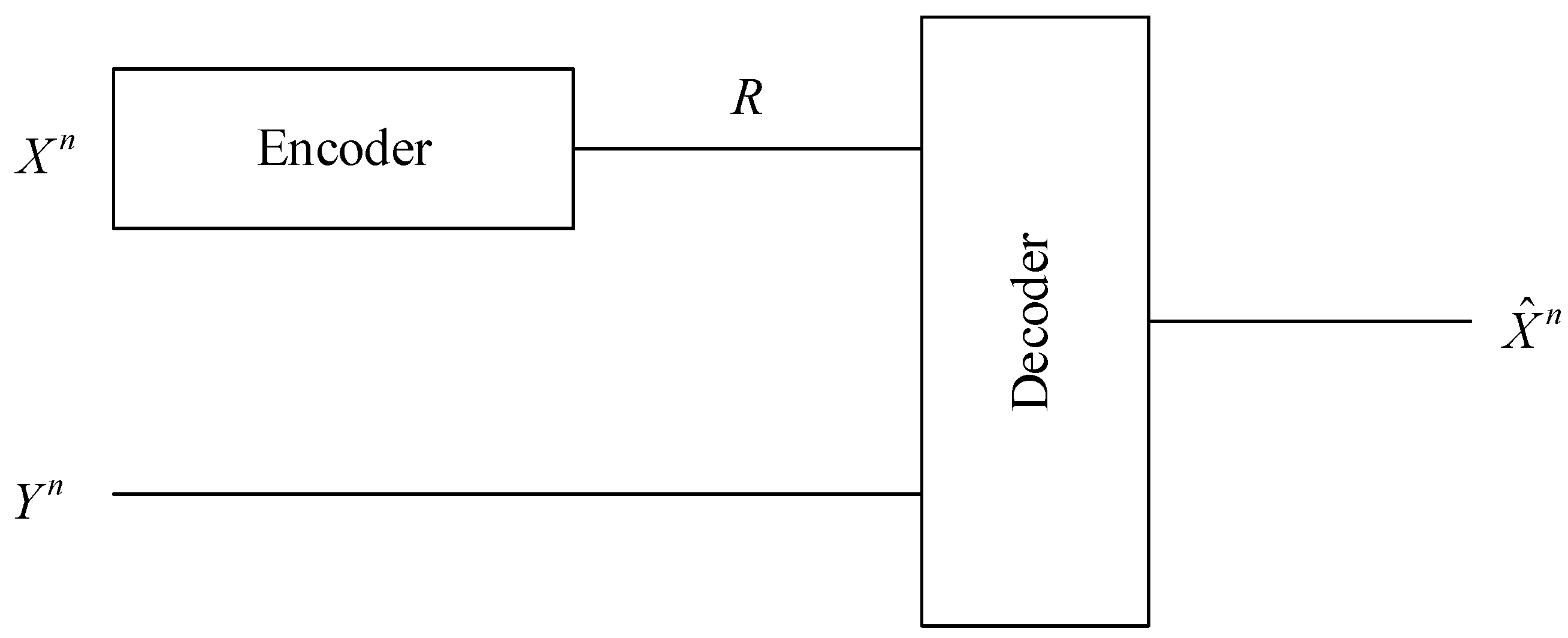
Consider the problem (see Figure 1) of compressing with side information available only at the decoder. Here is a joint memoryless source with zero-order joint probability distribution on finite alphabet . Let and be the marginal probability distributions of X and Y induced by the joint probability distribution . Without loss of generality, we shall assume for all . This problem was first studied by Slepian and Wolf in their landmark paper [1]. They proved a surprising result that the minimum rate for reconstructing at the decoder with asymptotically zero error probability (as block length n goes to infinity) is , which is the same as the case where the side information is also available at the encoder. The fundamental limit is often referred to as the Slepian-Wolf limit. We shall assume throughout this paper.
Different from conventional lossless source coding, where most effort has been devoted to variable-rate coding schemes, research on Slepian-Wolf coding has almost exclusively focused on fixed-rate codes (see, e.g., [2,3,4,5] and the references therein). This phenomenon can be partly explained by the influence of channel coding. It is well known that there is an intimate connection between channel coding and Slepian-Wolf coding. Intuitively, one may view as the channel output generated by channel input through discrete memoryless channel , where is the probability transition matrix from to induced by the joint probability probability distribution . Since is not available at the encoder, Slepian-Wolf coding is, in a certain sense, similar to channel coding without feedback. In a channel coding system, there is little incentive to use variable-rate coding schemes if no feedback link exists from the receiver to the transmitter. Therefore, it seems justifiable to focus on fixed-rate codes in Slepian-Wolf coding.
This viewpoint turns out to be misleading. We shall show that variable-rate Slepian-Wolf codes can significantly outperform fixed-rate codes in terms of rate-error tradeoff. Specifically, it is revealed that variable-rate Slepian-Wolf codes can beat the sphere-packing bound for fixed-rate Slepian-Wolf codes at rates close to the Slepian-Wolf limit. It is known [6] that the correct decoding probability of fixed-rate Slepian-Wolf codes decays to zero exponentially fast if the rate is below the Slepian-Wolf limit. Somewhat surprisingly, the decoding error probability of variable-rate Slepian-Wolf codes can be bounded away from one even when they are operated below the Slepian-Wolf limit, and the performance degrades gracefully as the rate goes to zero. Therefore, variable-rate Slepian-Wolf coding is considerably more robust.
The rest of this paper is organized as follows. In Section 2, we review the existing bounds on the reliability function of fixed-rate Slepian-Wolf coding, and point out the intimate connections with their counterparts in channel coding. In Section 3, we characterize the reliability function of variable-rate Slepian-Wolf coding by leveraging the reliability function of channel coding with constant composition codes. Computable lower and upper bounds are derived. The bounds coincide at rates close to the Slepian-Wolf limit. The correct decoding probability of variable-rate Slepian-Wolf coding with rate below the Slepian-Wolf limit is studied in Section 4. An illustrative example is given in Section 5. We conclude the paper in Section 6. Throughout this paper, we assume the logarithm function is to base e unless specified otherwise.
2. Fixed-Rate Slepian-Wolf Coding and Channel Coding
To facilitate the comparisons between the performances of fixed-rate Slepian-Wolf coding and variable-rate coding, we shall briefly review the existing bounds on the reliability function of fixed-rate Slepian-Wolf coding. It turns out that a most instructive way is to first consider their counterparts in channel coding. The reason is two-fold. First, it provides the setup to introduce several important definitions. Second and more important, it will be clear that the reliability function of fixed-rate Slepian-Wolf coding is closely related to that of channel coding; indeed, such a connection will be further explored in the context of variable-rate Slepian-Wolf coding.
For any probability distributions on and probability transition matrices , we use , , , and to denote the standard entropy, mutual information, divergence, and conditional divergence functions; specifically, we have
The main technical tool we need is the method of types. First, we shall quote a few basic definitions from [7]. Let denote the set of all probability distributions on . The type of a sequence , denoted as , is the empirical probability distribution of . Let denote the set consisting of the possible types of sequences . For any , the type class is the set of sequences in of type P. We will make frequent use of the following elementary results:
A block code is an ordered collection of sequences in . We allow to contain identical sequences. Moreover, for any set , we say that if for all . Note that does not imply . The rate of is defined as
Given a channel , a block code , and channel output , the output of the optimal maximum likelihood (ML) decoder is
where the ties are broken in an arbitrary manner. The average decoding error probability of block code over channel is defined as
The maximum decoding error probability of block code over channel is defined as
The average correct decoding probability of block code over channel is defined as
Definition 1.
Given a channel , we say that an error exponent is achievable with block codes at rate R if for any , there exists a sequence of block codes such that
The largest achievable error exponent at rate R is denoted by . The function is referred to as the reliability function of channel .
Similarly, we say that a correct decoding exponent is achievable with block channel codes at rate R if for any , there exists a sequence of block codes such that
The smallest achievable correct decoding exponent at rate R is denoted by . It will be seen that is positive if and only if , where is the capacity of channel . Therefore, we shall refer to the function as the reliability function of channel above the capacity.
Remark 1.
Given any block code of average decoding error probability , we can expurgate the worst half of the codewords so that the maximum decoding error probability of the resulting code is bounded above by . Therefore, the reliability function is unaffected if we replace by in (4).
Definition 2.
Given a probability distribution and a channel , we say that an error exponent is achievable at rate R with constant composition codes of type approximately if for any , there exists a sequence of block codes with for some such that
where is the norm.
The largest achievable error exponent at rate R for constant composition codes of type approximately is denoted by . The function is referred to as the reliability function of channel for constant composition codes of type approximately .
Similarly, we say that a correct decoding exponent is achievable at rate R with constant composition codes of type approximately if for any , there exists a sequence of block codes with for some such that
The smallest achievable correct decoding exponent at rate R for constant composition codes of type approximately is denoted by .
Remark 2.
The reliability function is unaffected if we replace by in (5).
Let and . Define
where in (6), and are respectively the marginal probability distribution of and the joint probability distribution of X and induced by and .
Let be the smallest with . We have
It is known ([7], Exercise 5.18) that is a decreasing convex function of R for ; moreover, the minimum in (9) is achieved at if and only if
where the probability distribution Q and the constant c are uniquely determined by the condition .
It is shown in ([8], Lemma 3) that, for some , we have
It is also known ([7], Corollary 5.4) that
where is the smallest R at which the convex curve meets its supporting line of slope −1. It is obvious that .
Proposition 1.
if and only if the value of
does not depend on y for all such that .
Proof.
See Appendix A ☐
Define . It is known ([7], Exercise 5.3) that
where the minimum is taken over those ’s for which whenever ; in particular, if and only if for every there exists an with and .
Proposition 2.
The minimum in (12) is achieved at if and only if the value of
does not depend on y for all such that .
Proof.
The proof is similar to that of Proposition 1. The details are omitted. ☐
One can readily prove the following result by combining Propositions 1 and 2.
Proposition 3.
The following statements are equivalent:
- ;
- ;
- the value ofdoes not depend on y for all such that .
Proposition 4.
- ;
- with the possible exception of at which point the inequality not necessarily holds;
- .
Remark 3.
, , and are respectively the expurgated exponent, the random coding exponent, and the sphere packing exponent of channel for constant composition codes of type approximately . The results in Proposition 4 are well known [7,9]. However, bounding the decoding error probability of constant composition codes often serves as an intermediate step in characterizing the reliability function for general block codes; as a consequence, the reliability function for constant composition codes is rarely explicitly defined. Moreover, , , and are commonly used to bound the decoding error probability of constant composition codes for a fixed block length n; therefore, it is implicitly assumed that is taken from (see, e.g., [7]). In contrast, we consider a sequence of constant composition codes with block length increasing to infinity and type converging to for some (see Definition 2). A continuity argument is required for passing from to . For completeness, we supply the proof in Appendix B. Note that different from , the function has been completely characterized.
Proposition 5.
- ,
- .
Remark 4.
In view of the fact that is a continuous function of defined on a compact set, we can replace “inf" with “min" in the above equation, i.e.,
Proof.
It is obvious that ; the other direction follows from the fact that every block code contains a constant composition code with and . Similarly, it is clear that ; the other direction follows from the fact that given any block code , one can construct a constant composition code with and [9]. ☐
The expurgated exponent, random coding exponent, and sphere packing exponent of channel for general block codes are defined as follows:
- expurgated exponent
- random coding exponent
- sphere packing exponent
Let be the smallest R to the right of which is finite. It is known ([7], Exercise 5.3) and [10] that
By Propositions 4 and 5, we recover the following well-known result [7,10]:
with the possible exception of at which point the second inequality in (17) not necessarily holds.
Now we proceed to review the results on the reliability function of fixed-rate Slepian-Wolf coding. A fixed-rate Slepian-Wolf code is a mapping from to a set . The rate of is defined as
Given and , the output of the optimal maximum a posteriori (MAP) decoder is
where the ties are broken in an arbitrary manner. The decoding error probability of Slepian-Wolf code is defined as
The correct decoding probability of Slepian-Wolf code is defined as
Definition 3.
Given a joint probability distribution , we say that an error exponent is achievable with fixed-rate Slepian-Wolf codes at rate R if for any , there exists a sequence of fixed-rate Slepian-Wolf codes such that
The largest achievable error exponent at rate R is denoted by . The function is referred to as the reliability function of fixed-rate Slepian-Wolf coding.
Similarly, we say that a correct decoding exponent is achievable with fixed-rate Slepian-Wolf codes at rate R if for any , there exists a sequence of fixed-rate Slepian-Wolf codes such that
The smallest achievable correct decoding exponent at rate R is denoted by . It will be seen that is positive if and only if . Therefore, we shall refer to the function as the reliability function of fixed-rate Slepian-Wolf coding below the Slepian-Wolf limit.
The expurgated exponent, random coding scheme, and sphere packing exponent of fixed-rate Slepian-Wolf coding are defined as follows:
- expurgated exponent
- random coding exponent
- sphere packing exponent
Equivalently, the random coding exponent and sphere packing exponent of fixed-rate Slepian-Wolf coding can be written as [11]:
To see the connection between the random coding exponent and the sphere packing exponent, we shall write them in the following parametric forms [11]:
and
where the joint distribution of is , which is specified by
Define the critical rate
Note that and coincide when . Let . It is shown in [12] that
It is well known [8,11,13] that the reliability function is upper-bounded by and lower-bounded by and , i.e.,
with the possible exception of at which point the second inequality in (23) not necessarily holds. Note that is completely characterized for .
Comparing (14) with (18), (15) with (19), (16) with (20), and (13) with (24), one can easily see that there exists an intimate connection between fixed-rate Slepian-Wolf coding for source distribution and channel coding for channel . This connection can be roughly interpreted as the manifestation of the following facts [15].
- Given, for each type , a constant composition code with and , one can use to partition type class into approximately disjoint subsets such that each subset is a constant composition code of type with the maximum decoding error probability over channel approximately equal to or less than that of . Note that these partitions, one for each type class, yield a fixed-rate Slepian-Wolf code of rate approximately R with . Since (cf. (2) and (3)), it follows that . The overall decoding error probability of the resulting Slepian-Wolf code can be upper-bounded, on the exponential scale, by , where . In contrast, one has the freedom to choose in channel coding, which explains why maximization (instead of minimization) is used in (14)–(16).
- Given a fixed-rate Slepian-Wolf code with and , one can, for each type , lift out a constant composition code with and .
- The correct decoding exponents for channel coding and fixed-rate Slepian-Wolf coding can be interpreted in a similar way. Note that in channel coding, to maximize the correct decoding probability one has to minimize the correct decoding exponent; this is why in (13) minimization (instead of maximization) is used.
Therefore, it should be clear that to characterize the reliability functions for channel coding and fixed-rate Slepian-Wolf coding, it suffices to focus on constant composition codes. It will be shown in the next section that a similar reduction holds for variable-rate Slepian-Wolf coding. Indeed, the reliability function for constant component codes plays a predominant role in determining the fundamental rate-error tradeoff in variable-rate Slepian-Wolf coding.
3. Variable-Rate Slepian-Wolf Coding: Above the Slepian-Wolf Limit
A variable-rate Slepian-Wolf code is a mapping from to a binary prefix code . Let denote the length of binary string . The rate of variable-rate Slepian-Wolf code is defined as
It is worth noting that depends on only through .
Given and , the output of the optimal maximum a posteriori (MAP) decoder is
where the ties are broken in an arbitrary manner. The decoding error probability of variable-rate Slepian-Wolf code is defined as
The correct decoding probability of Slepian-Wolf code is defined as
Definition 4.
Given a joint probability distribution , we say that an error exponent is achievable with variable-rate Slepian-Wolf codes at rate R if for any , there exists a sequence of variable-rate Slepian-Wolf codes such that
The largest achievable error exponent at rate R is denoted by . The function is referred to as the reliability function of variable-rate Slepian-Wolf coding.
The power of variable-rate Slepian-Wolf coding results from its flexibility in rate allocation. Since there are only polynomial number of types for any given n (cf. (1)), the encoder can convey the type information to the decoder using negligible amount of rate when n is large enough. Therefore, without loss of much generality, we can assume that the type of is known to the decoder. Under this assumption, an optimal fixed-rate Slepian-Wolf encoder of rate R should partition into disjoint subsets for each . It can be seen that the rate allocated to is always R if . In general, the type that dominates the error probability of fixed-rate Slepian-Wolf coding is different from . In contrast, for variable-rate Slepian-Wolf coding, we can losslessly compress the sequences of types that are bounded away by allocating enough rate to those type classes (but its contribution to the overall rate is still negligible since the probability of those type classes are extremely small), and therefore, effectively eliminate the dominant error event in fixed-rate Slepian-Wolf coding. As a consequence, the types that can cause decoding error in variable-rate Slepian-Wolf coding must be very close to . This is the main intuition underlying the proof of the following theorem. A similar argument has been used in the context of variable-rate Slepian-Wolf coding under mismatched decoding [16].
Theorem 1.
.
Proof.
The proof is divided into two parts. Firstly, we shall show that . The main idea is that one can use a constant composition code of type approximately and rate approximately to construct a variable-rate Slepian-Wolf code with , , and .
By Definition 2, for any , there exists a sequence of constant composition codes with for some such that
Since for all , we have
for all sufficiently n, where
Let . When n is large enough, we can, for each , construct a constant composition code of length and type P by appending a fixed sequence in to each codeword in . It is easy to see that
for all . One can readily show by invoking the covering lemma in [17] that for each , there exist permutations of the integers such that
where
In view of (25), we can rewrite as
Note that
Given , we can partition into disjoint subsets:
It is clear that
Now construct a sequence of variable-rate Slepian-Wolf codes as follows.
- The encoder sends the type of to the decoder, where each type is uniquely represented by a binary sequence of length .
- If for some , the encoder sends losslessly to the decoder, where each is uniquely represented by a binary sequence of length .
- If for some , the encoder finds the set that contains and sends the index to the decoder, where each index in is uniquely represented by a binary sequence of length .
Specifically, we choose
Note that
where
Therefore, we have
Now we proceed to show that . The main idea is that one can extract a constant composition code of type approximately and rate approximately or greater from a given variable-rate Slepian-Wolf code of rate approximately R such that the average decoding error probability of this constant composition code over channel is bounded from above by , where is a constant that does not depend on n.
By Definition 4, for any , there exists a sequence of variable-rate Slepian-Wolf codes such that
Suppose induces a partition of , , into disjoint subsets . Here the partition is defined as follows: if for some i, and if for . Let
It follows from the source coding theorem that
Define
where
Moreover, we have
since otherwise
which is absurd.
Define
It follows from the weak law of large numbers that
We have
where (40) is due to (37)–(39), and (41) is due to (34). Therefore, is non-empty for all sufficiently large n. Pick an arbitrary from for each sufficiently large n. We can construct a constant composition code of length and type for some by concatenating a fixed sequence in to each sequence in such that
Note that
The following result is an immediate consequence of Theorem 1 and Proposition 4.
Corollary 1.
Define
We have
- ;
- with the possible exception of at which point the inequality not necessarily holds.
Remark 5.
- We have for , and for . Therefore, and are respectively the upper bound and the lower bound on the zero-error rate of variable-rate Slepian-Wolf coding.
- In view of (11), we havefor . Note thatwhere the first inequality is strict unless the minimum in (20) is achieved at , (i.e., , where is the marginal distribution of induced by and in (21) and (22)). Therefore, variable-rate Slepian-Wolf coding can outperform fixed-rate Slepian-Wolf coding in terms of rate-error tradeoff.
For , it is possible to obtain upper bounds on that are tighter than . Let and be respectively the expurgated exponent and the sphere packing exponent of channel . The straight-line exponent of channel [10] is the smallest linear function of R which touches the curve and also satisfies
where is assumed to be finite. Let be the point at which and coincide. It is well known [10] that for . Since , it follows from Theorem 1 that
for .
Note that the straight-line exponent holds for arbitrary block codes; one can obtain further improvement at high rates by leveraging bounds tailored to constant composition codes. Let be the concave upper envelope of considered as a function of . In view of ([7], Exercise 5.21), we have
for any and . Now it follows from Theorem 1 that
for .
The following theorem provides the second order expansion of at the Slepian-Wolf limit.
Theorem 2.
Assuming (see Proposition 1 for the necessary and sufficient condition), we have
where .
Remark 6.
If , then we have for , which implies
It is also worth noting that the second order expansion of at the Slepian-Wolf limit yields the redundancy-error tradeoff constant of variable-rate Slepian-Wolf coding derived in [18].
Proof.
Since , it follows that when r is sufficiently close to zero. In this case, we have
where the last equality follows from the fact that is a strictly decreasing convex function of R for .
Let for , . Let for . By the Taylor expansion,
and
Here means .
As , we have , for all . Therefore, by ignoring the high order terms which do not affect the limit, we get
where the minimization is over () subject to the constraints
- for all ,
- .
Introduce the Lagrange multipliers and for these constraints, and define
The Karush-Kuhn-Tucker conditions yield
Therefore, we have
Therefore, we have
Constraint 2 and (47) together yield
4. Variable-Rate Slepian-Wolf Coding: Below the Slepian-Wolf Limit
Definition 5.
Given a joint probability distribution , we say that a correct decoding exponent is achievable with variable-rate Slepian-Wolf codes at rate R if for any , there exists a sequence of variable-rate Slepian-Wolf codes such that
The smallest achievable correct decoding exponent at rate R is denoted by .
In view of Theorem 1, it is tempting to conjecture that . It turns out this is not true. We shall show that for all R. Actually we have a stronger result—the correct decoding probability of variable-rate Slepian-Wolf coding can be bounded away from zero even when . This is in sharp contrast with fixed-rate Slepian-Wolf coding for which the correct decoding probability decays to zero exponentially fast if the rate is below the Slepian-Wolf limit. To make the statement more precise, we need the following definition.
Definition 6.
Given a joint probability distribution , we say that a correct decoding probability is achievable with variable-rate Slepian-Wolf codes at rate R if for any , there exists a sequence of variable-rate Slepian-Wolf codes such that
The largest achievable correct decoding probability at rate R is denoted by .
Theorem 3.
for .
Remark 7.
It is obvious that for . Moreover, since is a monotonically increasing function of R, it follows that .
Proof.
The intuition underlying the proof is as follows. Assume the rate is below the Slepian-Wolf limit, i.e., . For each type P in the neighborhood of , the rate allocated to the type class should be no less than in order to correctly decode the sequences in . However, since almost all the probability are captured by the type classes whose types are in the neighborhood of , there is no enough rate to protect all of them. Note that if the rate is evenly allocated among these type classes, none of them can get enough rate; consequently, the correct decoding probability goes to zero. A good way is to protect only a portion of them to accumulate enough rate. Specifically, we can protect fraction of these type classes so that the rate allocated to each of them is about and leave the remaining type classes unprotected. It turns out this strategy achieves the maximum correct decoding probability as the block length n goes to infinity. Somewhat interestingly, although , the function does play a fundamental role in establishing the correct result.
The proof is divided into two parts. Firstly, we shall show that . For any , define
Since for all , we can choose small enough so that
Using Stirling’s approximation
we have, for any ,
which implies that converges uniformly to zero as for all . Moreover, it follows from the weak law of large numbers that
Therefore, for any , , and sufficiently large n, we can find a set such that
Now consider a sequence of variable-rate Slepian-Wolf codes specified as follows.
- The encoder sends of type of to the decoder, where each type is uniquely represented by a binary sequence of length .
- For each , the encoder partitions the type class into subsets . If for some , the encoder finds the subset that contains and sends the index to the decoder, where each index in is uniquely represented by a binary sequence of length .
- The remaining type classes are left uncoded.
Specifically, we let
It follows from ([8], Theorem 2) that for each , it is possible to partition the type class into disjoint subsets so that
uniformly for all when n is sufficiently large. In view of the fact that and that as a function of the pair is uniformly equicontinuous, we have
for sufficiently small .
For this sequence of constructed variable-rate Slepian-wolf codes , it can be readily verified that
and
Since is arbitrary, it follows from Definition 6 that .
Now we proceed to prove the other direction. It follows from Definition 6 that for any , there exists a sequence of variable-rate Slepian-Wolf codes with
Recall the definition of as well as in the proof of Theorem 1. For , define
Each can be viewed as a constant composition code of type P and we have
Note that for and ,
Therefore, it follows from ([9], Lemma 5) that
uniformly for all and when n is sufficiently large. In view of the fact that and that as a function of the pair is uniformly equicontinuous, we have
for sufficiently small .
Now it is easy to see that
which implies
Therefore, we have
Since is arbitrary, this completes the proof. ☐
5. Example
Consider the joint distribution over with and . We assume , . It is easy to compute that
For this joint distribution, we have , where is the binary entropy function (i.e., ). Given , let q be the unique number satisfying and . It can be verified that
Note that
which is a concave function of . Therefore,
Moreover, we have
It is easy to show that
where the minimizer is given by
Define
We have
6. Concluding Remarks
We have studied the reliability function of variable-rate Slepian-Wolf coding. An intimate connection between variable-rate Slepian-Wolf codes and constant composition codes has been revealed. It is shown that variable-rate Slepian-Wolf coding can outperform fixed-rate Slepian-Wolf coding in terms of rate-error tradeoff. Finally, we would like to mention that Theorem 1 has been generalized by Weinberger and Merhav in their recent paper on the optimal tradeoff between the error exponent and the excess-rate exponent of variable-rate Slepian-Wolf coding [19].
Acknowledgments
Jun Chen was supported in part by the Natural Sciences and Engineering Research Council of Canada through a Discovery Grant.
Author Contributions
All the authors contributed to the problem formulation and the proof of Theorem 2; Jun Chen established the remaining results and wrote the paper. All authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Proposition 1
In view of (7) and (11), we have if and only if the minimum of the convex optimization problem
is achieved at . Let be a minimizer to the above optimization problem. Note that for such that , there is no loss of generality in setting . Let and for . We can rewrite (A1) in the following equivalent form:
subject to
Define
where () and (). The Karush-Kuhn-Tucker conditions yield
By the complementary slackness conditions (i.e., ), we have if and only if for all , ,
i.e., the value of
does not depend on y for all such that .
Appendix B. Proof of Proposition 4
- It is known ([7], Exercise 5.17) that for every , , and there exists a constant composition code such thatwhenever . Let be a sequence of types with andDefinewhere the minimization is over subject to the constraintsNote that must contain a converging subsequence . DefineIt is easy to verify thatTherefore, we have
- By Definition 2, for every , there exists a sequence of block channel codes with for some such thatWithout loss of generality, we can set for all . It is easy to see that there exists an such thatfor all with . Therefore, for all sufficiently large n,Combining (A2)–(A4), we getIn view of the fact that is arbitrary and that for fixed P and , is a decreasing continuous convex function of R in the interval where it is finite ([7], Lemma 5.4), the proof is complete.
- It is known ([9], Lemma 5) that every constant composition code of common type P for some and rate (with and ) haswhenever . Moreover, it is also known ([9], Lemma 2) ([7], Exercise 5.16) that for every , , and there exists a constant composition code such thatwhenever . In view of the fact that + as a function of the pair is uniformly equicontinuous, it can be readily shown thatThe proof is complete.
References
- Slepian, D.; Wolf, J.K. Noiseless coding of correlated information sources. IEEE Trans. Inf. Theory 1973, 19, 471–480. [Google Scholar] [CrossRef]
- Csiszár, I. Linear codes for sources and source networks: Error exponents, universal coding. IEEE Trans. Inf. Theory 1982, 28, 585–592. [Google Scholar] [CrossRef]
- Pradhan, S.S.; Ramchandran, K. Distributed source coding using syndromes (DISCUS): Design and construction. IEEE Trans. Inf. Theory 2003, 49, 626–643. [Google Scholar] [CrossRef]
- Chen, J.; He, D.-K.; Jagmohan, A. The equivalence between Slepian-Wolf coding and channel coding under density evolution. IEEE Trans. Commun. 2009, 57, 2534–2540. [Google Scholar] [CrossRef]
- Sun, Z.; Tian, C.; Chen, J.; Wong, K.M. LDPC code design for asynchronous Slepian-Wolf coding. IEEE Trans. Commun. 2010, 58, 511–520. [Google Scholar] [CrossRef]
- Oohama, Y.; Han, T.S. Universal coding for the Slepian-Wolf data compression system and the strong converse theorem. IEEE Trans. Inf. Theory 1994, 40, 1908–1919. [Google Scholar] [CrossRef]
- Csiszár, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Academic: New York, NY, USA, 1981. [Google Scholar]
- Csiszár, I.; Körner, J. Graph decomposition: A new key to coding theorems. IEEE Trans. Inf. Theory 1981, 27, 5–12. [Google Scholar] [CrossRef]
- Dueck, G.; Körner, J. Reliability function of a discrete memoryless channel at rates above capacity. IEEE Trans. Inf. Theory 1979, 25, 82–85. [Google Scholar] [CrossRef]
- Gallager, R.G. Information Theory and Reliable Communication; Wiley: New York, NY, USA, 1968. [Google Scholar]
- Gallager, R.G. Source Coding with Side Information and Universal Coding, MIT LIDS Technical Report (LIDS-P-937). Unpublished work. 1976.
- Chen, J.; He, D.-K.; Jagmohan, A.; Lastras-Montaño, L. On the redundancy-error tradeoff in Slepian-Wolf coding and channel coding. In Proceedings of the 2007 IEEE International Symposium on Information Theory, Nice, France, 24–29 Junuary 2007; pp. 1326–1330. [Google Scholar]
- Csiszár, I.; Körner, J. Towards a general theory of source networks. IEEE Trans. Inf. Theory 1980, 26, 155–165. [Google Scholar] [CrossRef]
- Chen, J.; He, D.-K.; Jagmohan, A.; Lastras-Montaño, L.A.; Yang, E.-H. On the linear codebook-level duality between Slepian-Wolf coding and channel coding. IEEE Trans. Inf. Theory 2009, 55, 5575–5590. [Google Scholar] [CrossRef]
- Ahlswede, R.; Dueck, G. Good codes can be produced by a few permutations. IEEE Trans. Inf. Theory 1982, 28, 430–443. [Google Scholar] [CrossRef]
- Chen, J.; He, D.-K.; Jagmohan, A. On the duality between Slepian-Wolf coding and channel coding under mismatched decoding. IEEE Trans. Inf. Theory 2009, 55, 4006–4018. [Google Scholar] [CrossRef]
- Ahlswede, R. Coloring hypergraphs: A new approach to multi-user source coding—II. J. Comb. Inf. Syst. Sci. 1980, 5, 220–268. [Google Scholar]
- He, D.-K.; Lastras-Montaño, L.; Yang, E.-H.; Jagmohan, A.; Chen, J. On the redundancy of Slepian-Wolf coding. IEEE Trans. Inf. Theory 2009, 55, 5607–5627. [Google Scholar] [CrossRef]
- Weinberger, N.; Merhav, N. Optimum tradeoffs between the error exponent and the excess-rate exponent of variable-rate Slepian-Wolf coding. IEEE Trans. Inf. Theory 2015, 61, 2165–2190. [Google Scholar] [CrossRef]
Figure 1.
Slepian-Wolf coding.
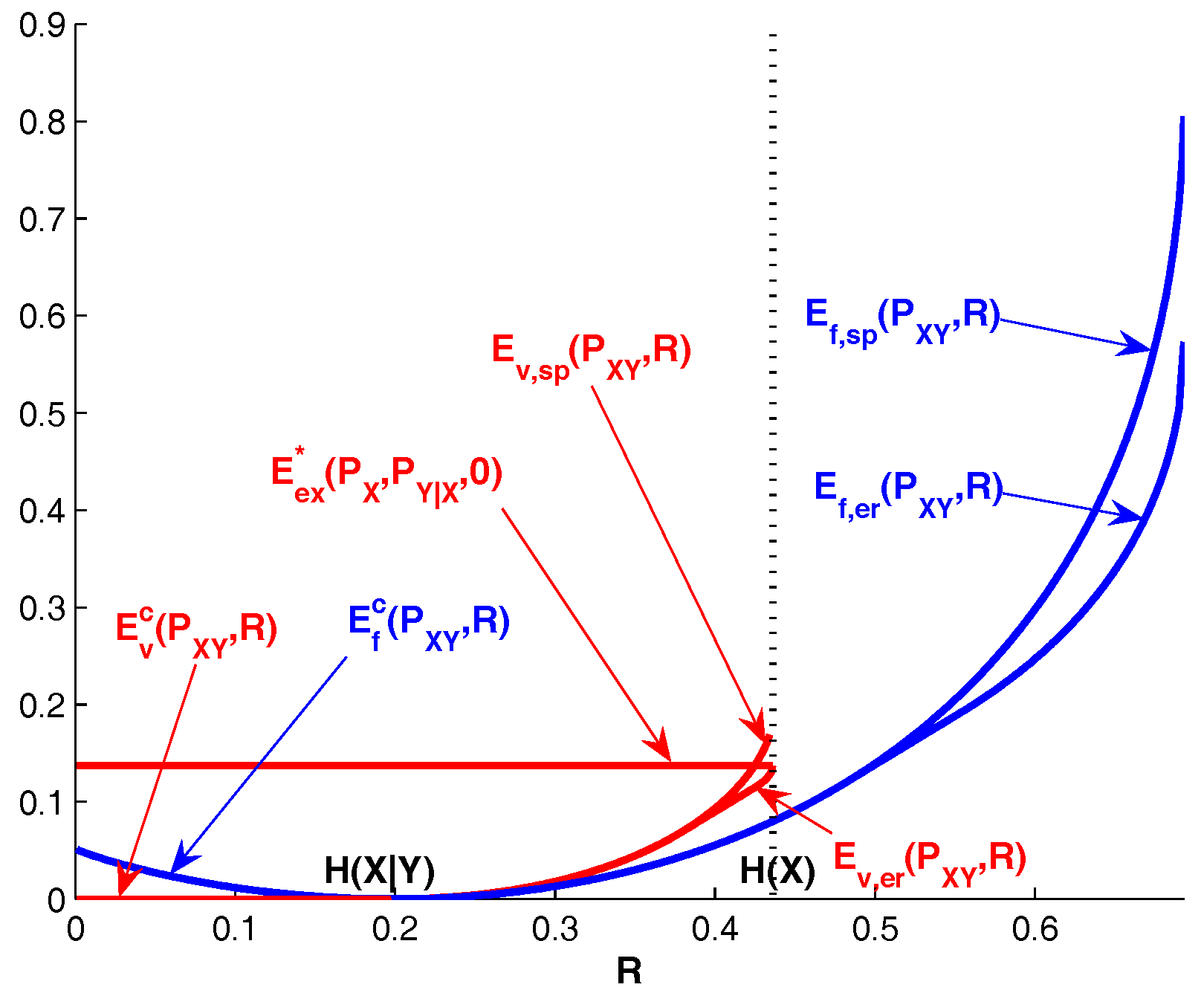
Figure 2.
, .
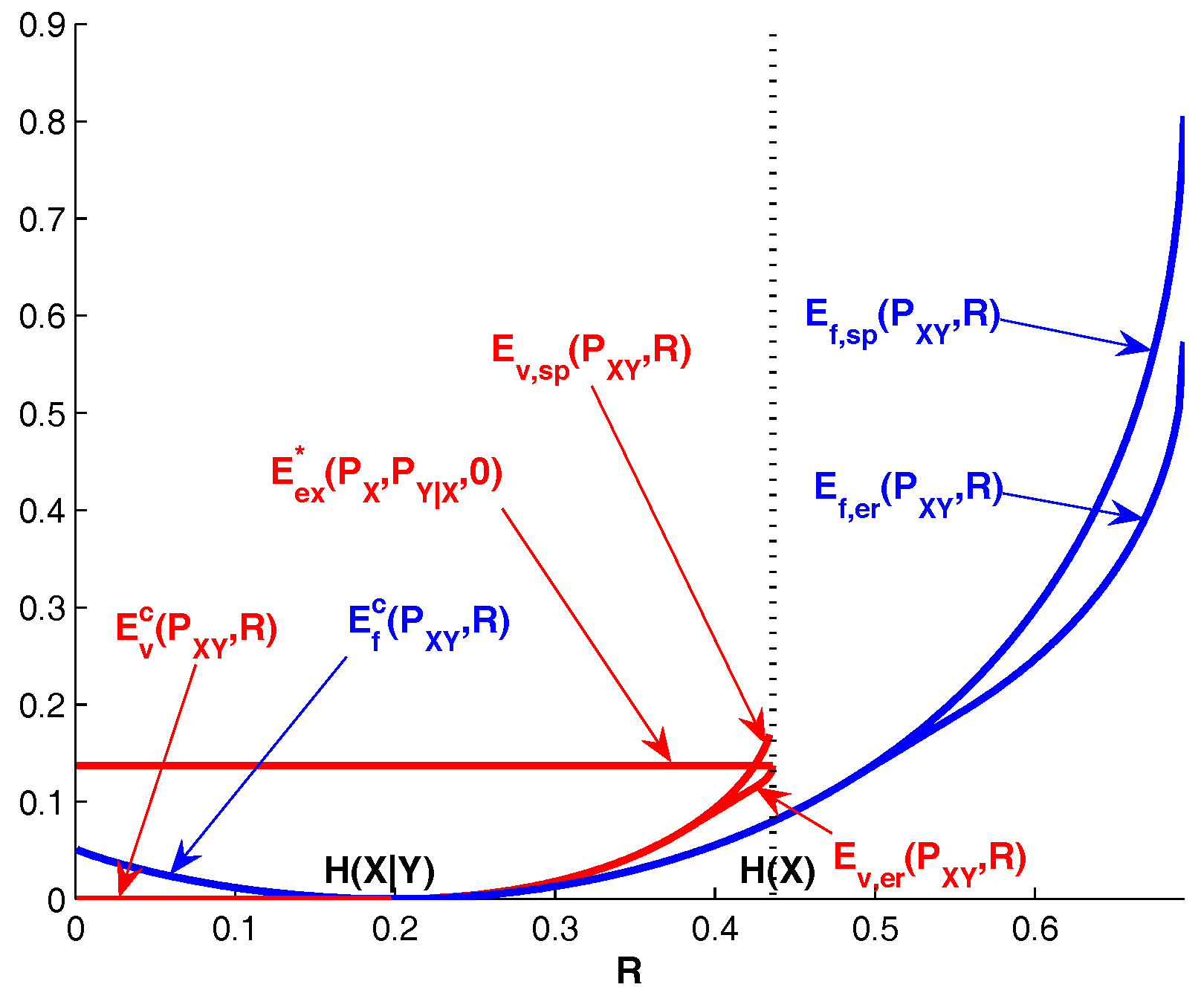
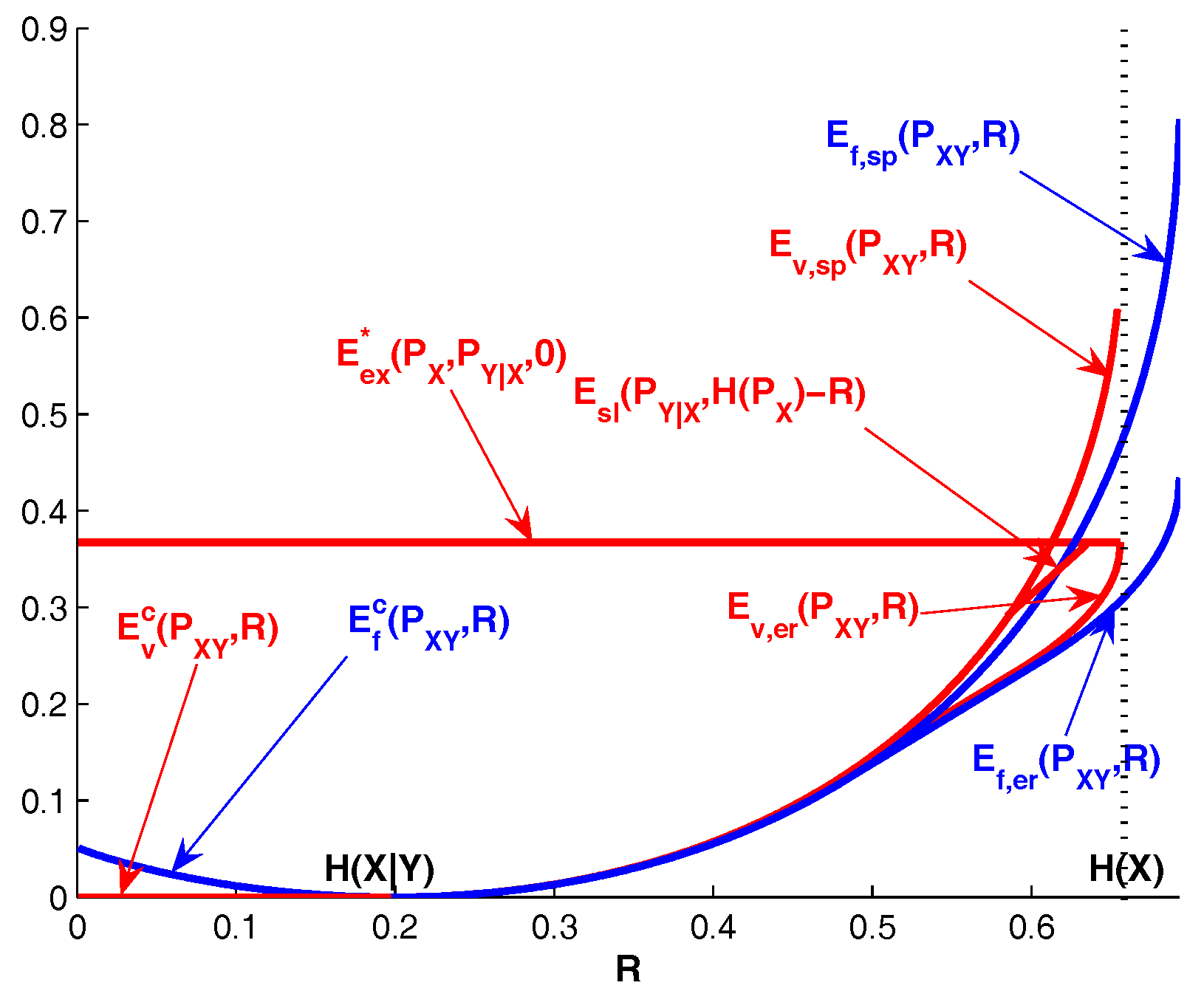
Figure 3.
, .
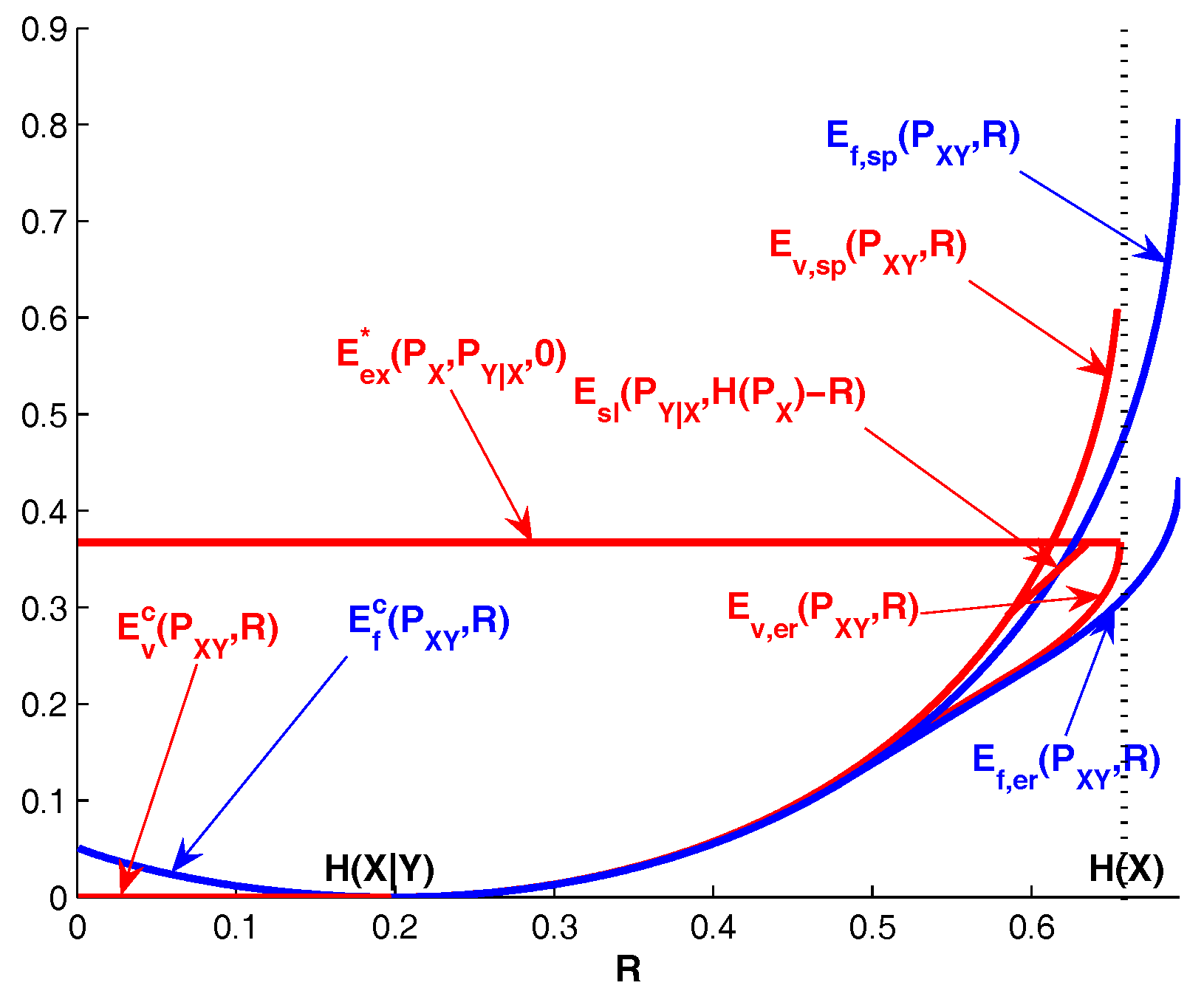
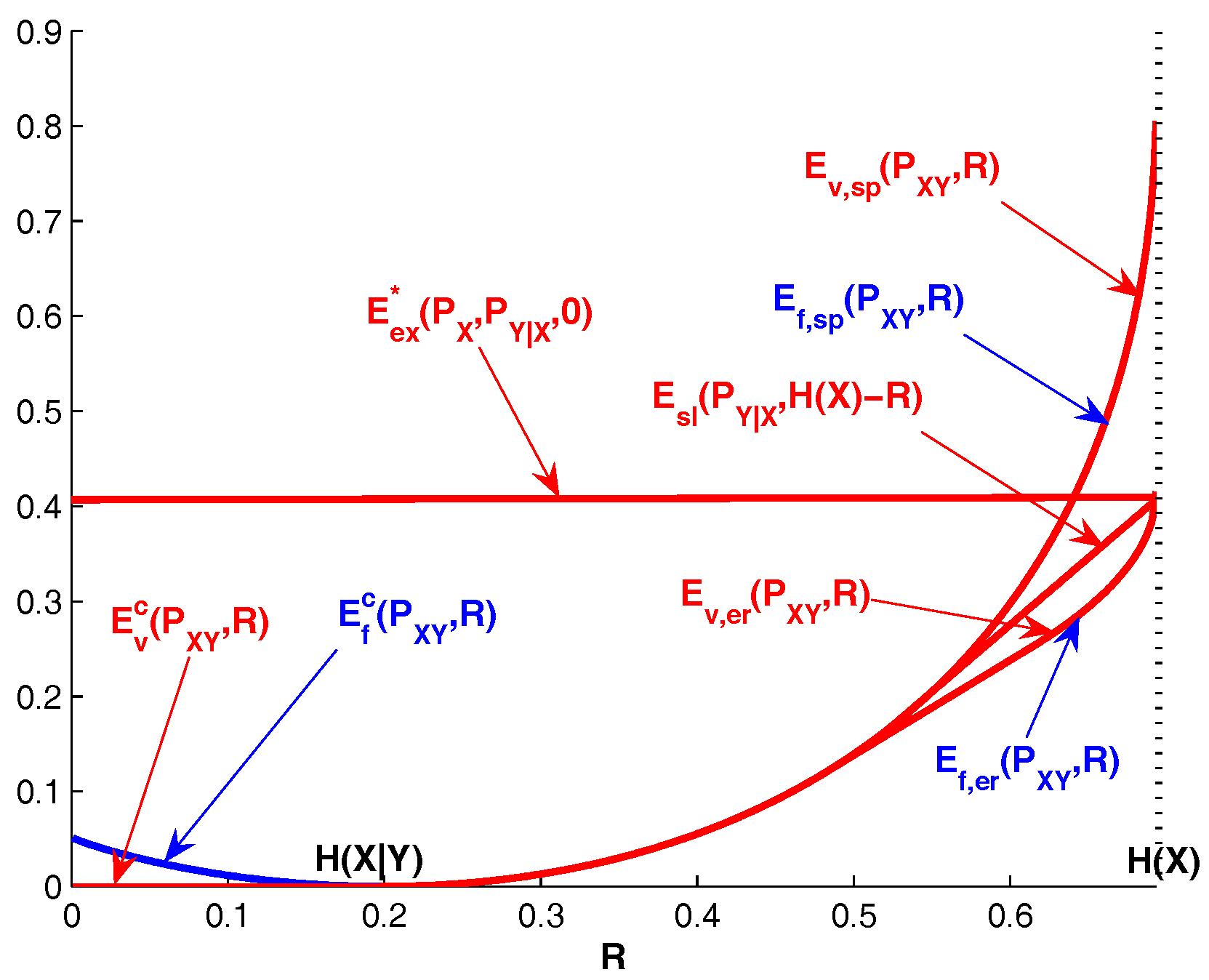
Figure 4.
, .
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Chen, J.; He, D.-k.; Jagmohan, A.; Lastras-Montaño, L.A. On the Reliability Function of Variable-Rate Slepian-Wolf Coding. Entropy 2017, 19, 389. https://doi.org/10.3390/e19080389
AMA Style
Chen J, He D-k, Jagmohan A, Lastras-Montaño LA. On the Reliability Function of Variable-Rate Slepian-Wolf Coding. Entropy. 2017; 19(8):389. https://doi.org/10.3390/e19080389
Chicago/Turabian StyleChen, Jun, Da-ke He, Ashish Jagmohan, and Luis A. Lastras-Montaño. 2017. "On the Reliability Function of Variable-Rate Slepian-Wolf Coding" Entropy 19, no. 8: 389. https://doi.org/10.3390/e19080389
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.