Robust Biometric Authentication from an Information Theoretic Perspective †


1
Chair of Theoretical Information Technology, Technical University of Munich, Munich 80290, Germany
2
Information Theory and Applications Chair, Technische Universität Berlin, Berlin 10587, Germany
*
Author to whom correspondence should be addressed.
†
This paper is an extended version of our paper published in the 7th IEEE International Workshop on Information Forensics and Security, Rome, Italy, 16–19 November 2015.
Entropy 2017, 19(9), 480; https://doi.org/10.3390/e19090480
Submission received: 22 June 2017
/
Revised: 28 August 2017
/
Accepted: 7 September 2017
/
Published: 9 September 2017
(This article belongs to the Special Issue Information-Theoretic Security)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Robust biometric authentication is studied from an information theoretic perspective. Compound sources are used to account for uncertainty in the knowledge of the source statistics and are further used to model certain attack classes. It is shown that authentication is robust against source uncertainty and a special class of attacks under the strong secrecy condition. A single-letter characterization of the privacy secrecy capacity region is derived for the generated and chosen secret key model. Furthermore, the question is studied whether small variations of the compound source lead to large losses of the privacy secrecy capacity region. It is shown that biometric authentication is robust in the sense that its privacy secrecy capacity region depends continuously on the compound source.
1. Introduction
Biometric identifiers, such as fingerprints, iris and retina scans, are becoming increasingly attractive for the use in security systems because of their uniqueness and time invariant characteristics—for example, in authentication and identification systems. Conventional personal authentication systems usually use secret passwords or physical tokens to guarantee the legitimacy of a person. On the other hand, biometric authentication systems use the physical characteristics of a person to guarantee the legitimacy of the person to be authenticated.
Biometric authentication systems are decomposed into two phases: the enrollment and the authentication phase. A simple authentication approach is to gather biometric measurements in the enrollment phase, apply a one-way function and then store the results in a public database. In the authentication phase, new biometric measurements are gathered. The same one-way is applied and the outcome is then compared to the one stored in the database. Unfortunately, biometric measurements might be affected by noise. To deal with noisy data, error correction is needed. Therefore, helper data is generated during the enrollment phase as well based on the biometric measurements and then stored directly in the public database that will be then used in the authentication phase, which will then be used in the authentication phase to correct the noisy imperfections of the measurements.
Since the database containing the helper data is public, an eavesdropper can have access to the data if desired. How can we prevent an eavesdropper from gaining information about the biometric data from the publicly stored helper data? One is interested in encoding the biometric data into a helper data and a secret key such that the helper data does not reveal any information about the secret key. Cryptographic techniques are one approach to keeping the key secret. However, security on higher layers is usually based on the assumption of insufficient computational capabilities of eavesdroppers. Information theoretic security, on the contrary, uses the physical properties of the source to guarantee security independent from the computational capabilities of the adversary. This line of research was initiated by Shannon in [1] and has attracted considerable interest recently—cf., for example, recent textbooks [2,3,4] and references therein. In particular, Ahlswede and Csiszár in [5] and Maurer in [6] introduced a secret key sharing model. It consists of two terminals that observe the correlated sequences of a joint source. Both terminals generate a common key based on their observation and using public communication. The message transmitted over the public channel should not leak any amount of information about the common key.
Both works mentioned above use the weak secrecy condition as a measure of secrecy. Given a code of a certain blocklength, the weak secrecy condition is fulfilled if the mutual information between the key and the available information at the eavesdropper normalized by the code blocklength is arbitrarily small for large blocklengths. On the other hand, the strong secrecy condition is fulfilled if the un-normalized mutual information between the key and the available information at the eavesdropper is arbitrarily small for large blocklengths, i.e., the total amount of information leaked to the eavesdropper is negligible. The secret key sharing model satisfying the strong secrecy condition has been studied in [7].
One could model the biometric authentication similar to this secret key generation source model; however, this model does not take into account the amount of information that the public data (the helper data in the biometric scenario) leaks about the biometric measurement. The goal of biometric authentication is to perform a secret and successful authentication procedure without compromising the information about the user (privacy leakage). Compromised biometric information is unique and cannot be replaced, so once it is compromised, it is compromised forever, which might lead to an identity theft (see [8,9,10] for more information on privacy concerns). Since the helper data we use to deal with noisy data is a function of the biometric measurements, it contains information about the biometric measurement. Thus, if an attacker breaks into the data base, he could be able to extract information about the biometric measurement from where the helper data is stored. Hence, we aim to control the privacy leakage as well. An information theoretic approach of secure biometric authentication controlling the privacy leakage was studied in [11,12] under ideal conditions, i.e., with perfect source state information (SSI) and without the presence of active attackers.
In both references [11,12], the capacity results under the weak secrecy condition were derived. In [13], the capacity result for the sequential key-distillation with rate limited one-way public communication using the strong secrecy condition was shown.
For reliable authentication, SSI is needed; however, in practical systems, it is never perfectly available. Compound sources model a simple and realistic SSI scenario in which the legitimate users are not aware of the actual source realisation. Nevertheless, they know that it belongs to a known uncertainty set of sources and that it remains constant during the entire observation. This model was first introduced and studied in [14,15] in a channel coding context. Compound sources can also model the presence of an active attacker, who is able to control the state of the source. We are interested in performing an authentication process that is robust against such uncertainties and attacks. The secret key generation for source uncertainty was studied in [16,17,18,19]. In [16], the secret key generation using compound joint sources was studied and the key-capacity was established.
In [20], the achievability result of the privacy secrecy capacity region for generated secret keys for compound sources has been derived under the weak secrecy condition. In this work, we study robust biometric authentication in detail and extend this result in several directions. First, we consider a model where the legitimate users suffer from source uncertainty and/or attacks and derive achievability results under the strong secrecy conditions for both the generated and chosen secret key authentication. We then provide matching converses to obtain single-letter characterizations of the corresponding privacy secrecy capacity regions.
We further address the following question: can small changes of the compound source cause large changes in the privacy secrecy capacity region? Such a question has been first studied in [21] for arbitrarily varying quantum channels (AVQCs) showing that deterministic capacity has discontinuity points, while the randomness-assisted capacity is a continuous function of the AVQCs. This line of research is continued in [22,23], in which the classical compound wiretap channel, the arbitrarily varying wiretap channel (AVWC), and the compound broadcast channel with confidential messages (BCC) are studied. We study this for the biometric authentication problem at hand and show that the corresponding privacy secrecy capacity regions are continuous functions of the underlying uncertainty sets. Thus, small changes in the compound set lead to small changes in the capacity region only.
The rest of this paper is organized as follows. In Section 2, we introduce the biometric authentication model for perfect SSI and present the corresponding capacity results. In Section 3, we introduce the biometric authentication model for compound sources and show that secure, under the strong secrecy condition, and reliable authentication, under source uncertainty with positive rates, is possible deriving a single-letter characterization of the privacy secrecy capacity region for the chosen and generated secret key model. In Section 4, we show that the privacy secrecy capacity region for compound sources is a continuous function of the uncertainty set. Finally, the paper ends with a conclusion in Section 5.
Notation: Discrete random variables are denoted by capital letters and their realizations and ranges by lower case and script letters. denotes the set of all probability distributions on ; denotes the expectation of a random variable; , and indicate the probability, the entropy of a random variable, and mutual information between two random variables; is the information divergence; is the total variation distance between p and q on defined as . The set denotes the set of typical sequences of length n with respect to the distribution p; the set denotes the set of conditional typical sequences with respect to the conditional distribution and sequence ; denotes the empirical distribution of the sequence .
2. Information Theoretic Model for Biometric Authentication
Let and be two finite alphabets. Let be a pair of biometric sequences of length ; then, the discrete memoryless joint-source is given by the joint probability distribution . This models perfect SSI, i.e., all possible measurements are generated by the discrete memoryless joint-source source Q, which is perfectly known at both the enrollment and the authentication terminal.
2.1. Generated Secret Key Model
The information theoretic authentication model consists of a discrete memoryless joint-source Q, which represents the biometric measurement source, and two terminals: the enrollment terminal and the authentication terminal as shown in Figure 1. At the enrollment terminal, the enrollment sequence is observed and the secret key K and helper data are generated. At the authentication terminal, the authentication sequence is observed. An estimate of the secret key is made based on the authentication sequence and the helper data . Since the helper data is stored in a public database, this should not reveal anything about the secret key K and also as little as possible about the enrollment measurement . The distribution of the key must be close to uniform.
We consider a block-processing of arbitrary but fixed length n. Let be the helper data set and the secret key set.
Definition 1.
An -code for generated secret key authentication for joint-source consists of an encoder f at the enrollment terminal with
and a decoder ϕ at the authentication terminal
Remark 1.
Note that the function f means that every is mapped into a , which implies that .
Definition 2.
A privacy secrecy rate pair is called achievable for the generated secret key authentication for a joint-source Q, if, for any there exist an and a sequence of -codes such that, for all we have
Remark 2.
Remark 3.
Definition 3.
The set of all achievable privacy secrecy rate pairs for generated key authentication is called privacy secrecy capacity region and is denoted by .
We next present the privacy secrecy capacity region for the generated key authentication for the joint-source Q, which was first established in [11,12].
To do so, for some U with alphabet and , we define the region as the set of all satisfying
with .
2.2. Chosen Secret Key Model
In this section, we study the authentication model for systems for which the secret key is chosen beforehand. At the enrollment terminal, a secret key K is chosen uniformly and independent of the biometric measurements. The secret key K is bound to the biometric measurements and, based on this, the helper data is generated as shown in Figure 2. At the authentication terminal, the authentication measurement is observed. An estimate of the secret key is made based on the authentication sequence and the helper data . Since the helper data is stored in a public database, this should not reveal anything about the secret key and minimize the information leakage about the enrollment sequence . However, we should be able to reconstruct K. To achieve this, a masking layer based on the one-time pad principles is used.
The masking layer, which is another uniformly distributed chosen secret key K, is added to the top of the generated secret key authentication. At the enrollment terminal, a secret key and a helper data M are generated. The generated secret key is added modulo- to the masking layer K and sent together with the helper data as additional helper data, i.e., . At the authentication terminal, an estimation of the generated secret key is made based on and M and the estimation of masking layer is made .
We consider a block-processing of arbitrary but fixed length n. Let be the helper data set and the secret key set.
Definition 4.
An -code for chosen secret key authentication for joint-source consists of an encoder f at the enrollment terminal with
and a decoder ϕ at the authentication terminal
Definition 5.
A privacy secrecy rate pair for chosen secret key authentication is called achievable for a joint-source Q, if, for any there exist an and a sequence of -codes, such that, for all we have
Remark 4.
The difference between Definition 5 and 2 is that, in here, the uniformity of the key is already guaranteed.
Definition 6.
The privacy secrecy capacity region for chosen secret key authentication for the joint-source is called privacy secrecy capacity region and is denoted as .
We next present the privacy secrecy capacity region for chosen secret key authentication for the joint-source Q as showed in [11].
Theorem 2
3. Authentication for Compound Sources
Let and be two finite sets and a finite state set. Let be a sequence pair of length . For every the discrete memoryless joint-source is given by the joint probability distribution with a marginal distribution on and a stochastic matrix.
Definition 7.
The discrete memoryless compound joint-source is given by the family of joint probabilities distributions on as
We define the finite set of marginal distributions over the alphabet from the compound joint-source as
We define as the index set of . Note that .
For every , we define the subset of the compound joint-source with the same marginal distribution as
For every , we define the index set of as
Remark 5.
Note that, for every with , it holds that , , and .
3.1. Compound Generated Secret Key Model
In this section, we study the generated secret key authentication for finite compound joint-sources, which is a special class of sources that model a limited SSI, as shown in Figure 3.
We consider a block-processing of arbitrary but fixed length n. Let be the helper data set and the secret key set.
Definition 8.
An -code for generated secret key authentication for the compound joint-source consists of an encoder f at the enrollment terminal with
and a decoder ϕ at the authentication terminal
Definition 9.
A privacy secrecy rate pair is called achievable for generated secret key authentication for the compound joint-source , if, for any there exist an and a sequence of -codes, such that for all and for every we have
Consider the compound joint-source . For a fixed , and for every , we define the region as the set of all that satisfy
with .
Theorem 3.
The privacy secrecy capacity region for generated secret key authentication for the compound joint-source is given by
Proof.
The proof of Theorem 3 consists of two parts: achievability and converse. The achievability scheme uses the following protocol:
- Estimate the marginal distribution from the observed sequence at the enrollment terminal via hypothesis testing.
- Compute the key K and a helper data M based on , a common shared sequence by the enrollment and authentication terminal and using an extractor function with whose input are the shared sequence T and a sequence of d uniformly distributed bits . The helper data M is equivalent to the helper data for the case with perfect SSI. The extended helper data in this case contains also the state of the marginal distribution and the uniformly distributed bits sequence, i.e., .
- Store the extended helper data in the public database.
- Estimate the key at the authentication terminal, based on the observations and , which can be seen as the outcome of one of the channels in .
A detailed proof can be found in Appendix A. □
Remark 6.
Remark 7.
As we already mentioned, we aim for strong secrecy, i.e., in contrast to the weak secrecy constraint in (1c), we now require the un-normalized mutual information between the key and the helper data to be negligibly small. It would be Ideal to show perfect secrecy and a perfectly uniformed key, i.e., and . It would be interesting to see how this constraint affects the achievable rate region. We suspect that the achievable rate region under perfect secrecy and perfectly uniformed key remains the same as in Theorem 3.
Remark 8.
From the protocol, note that once we have estimated the marginal distribution we deal with a compound channel model without channel state information (CSI) at the transmitter (see [24]).
Remark 9.
The order of the set operations of the capacity region displays the fact that the marginal distribution is first estimated. This can be seen as partial state information, where the marginal distribution over is known.
3.2. Compound Chosen Secret Key Model
In this section, we study chosen secret key authentication for finite compound joint-sources (see Figure 4).
We consider a -code of arbitrary but fixed length n.
Definition 10.
A privacy secrecy rate pair is called achievable for chosen secret key authentication for the compound joint-source , if for any there exist an and a sequence of -codes, such that, for all and for every we have
Consider the compound joint-source . For a fixed , and for every , we define the region as the set of all that satisfy
with .
Theorem 4.
The privacy secrecy capacity region for chosen secret key authentication for the compound joint-source is given by
Proof.
The proof can be found in Appendix B. □
Remark 10.
Note that, as for generated secret key authentication for compound sources, chosen secret key authentication for compound sources is a generalization of the models studied by [11]. Furthermore, for perfect SSI, one can see that the capacity region under the strong secrecy condition equals the capacity region under the weak secrecy condition showed by [11].
Remark 11.
Note that the privacy secrecy capacity region for the generated key model equals the privacy secrecy capacity region for chosen secret key authentication, i.e., .
4. Continuity of the Privacy Secrecy Capacity Region for Compound Sources
We are interested in studying how small variations in the compound source affect the privacy secrecy capacity region. The question of whether the capacity or capacity region is a continuous function of a source or channel is not always clear, especially if the source or channel are complicated. In [22], one can find an example of AVWCs, whose uncertainty set consists of only two channels, which already shows discontinuity points in its unassisted secrecy capacity. For a detailed discussion, see [25]. In this section, we study the continuity of the privacy secrecy capacity region for compound sources. For this purpose, we introduce the distance between two compound sources and capacity regions, respectively.
4.1. Distance between Compound Sources
Definition 11.
Let and be two compound sources. We define
The Hausdorff distance between and is defined as
Definition 12.
Let and be two non-empty subsets of the metric space with for all . We define the distance between two sets as
4.2. Continuity of the Privacy Secrecy Capacity Region
Theorem 5.
Let and . Let and be two compound sources. If
then it holds
with where and .
Remark 12.
Note that since the privacy secrecy capacity region for the chosen secret key equals the privacy secrecy capacity region for the chosen secret key, the continuity behaviour holds also for the chosen secret key privacy capacity region.
Remark 13.
This theorem shows that the privacy secrecy capacity region is a continuous function of the uncertainty set. In other words, small variations of the uncertainty set lead to small variations in the capacity region.
Proof.
A detailed proof can be found in Appendix C. □
Remark 14.
A complete characterisation of the discontinuity behaviour of the AVC capacity under list decoding can be found in [26]. Note that this behaviour, based on Theorem 5, can not occur.
5. Conclusions
In this paper, we considered a biometric authentication model in the presence of source uncertainty. In particular, we studied a model where the actual source realization is not known, however it belongs to a known source set: this is the finite compound source model. We have shown that biometric authentication is robust against source uncertainty and certain classes of attacks. In other words, reliable and secure authentication is possible at positive key rates. We further characterize the minimum privacy leakage rate under source uncertainty. For future work, perfect secrecy for the biometric authentication model and a compound source with infinite sources is of great interest.
Acknowledgments
The authors would like to thank their Sebastian Baur for insightful discussions. This work was supported by the Gottfried Wilhelm Leibniz Programme of the German Research Foundation (DFG) under Grant BO 1734/20-1, Grant BO 1734/24-1 and Grant BO 1734/25-1.
Author Contributions
Andrea Grigorescu, Holger Boche and Rafael Schaefer conceived this study and derived the results. Andrea Grigorescu and wrote the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 3
Appendix A.1. Achievability of Theorem 3
Appendix A.1.1. State Estimation
We first show that we can estimate the marginal distribution correctly with probability approaching one. Then, for every we use the random coding argument to show that all rate pairs are achievable.
To estimate the actual source realization, we perform hypothesis testing. The set of hypotheses is the set of finite marginal distributions . For every we define
We choose and consider the test set (typical sequences set) . Note that, for every with we have that . We show this by arbitrarily choosing a sequence of type and show that for . By the triangle inequality, we have
Hence,
proving the disjointness of the sets.
The test function is the indicator function , i.e., after observing the test looks for the hypothesis for which .
Appendix A.1.2. Code Construction
For each we consider the auxiliary random variable U and the channel V and construct a code for which we analyze the decoding error, secrecy and privacy condition.
Generate codewords with and by choosing each symbol in the codebook independently at random according to , computed from . We denote the codebook as .
For every and every we define the following channels and that satisfy:
for every .
Appendix A.1.3. Encoding Sets
For every we define the encoding sets as follows:
with .
Remark 15.
Appendix A.1.4. Decoding Sets
For every we define the decoding sets as follows:
with .
Remark 16.
One could consider sending some bits of the sequences through the public channel, such that the user at the authentication terminal can be able to estimate the actual source realization and so avoid the complicated decoding strategy. However, this approach would violate the strong secrecy condition.
Appendix A.1.5. Encoder–Decoder Pair Sets
For every , we define the encoder–decoder pair set as follows:
with .
Appendix A.1.6. Error Analysis
For every assume that the marginal distribution was estimated correctly, i.e., . We analyze the probability of each error event separately. We denote the error at the enrollment terminal given the codebook as . An error occurs at the enrollment terminal if, for every the observed sequence does not belong to , i.e.,
Averaging over all codebooks, from the independence of the random variables involved and from Lemma 2.13 in [27], we have
The inequality (A2) follows from , which holds for every .
Letting and choosing
the right-hand side of (A2) goes doubly exponentially fast to zero. An error at the authentication terminal occurs, when was encoded at the enrollment terminal, but was decoded at the authentication terminal. The set of joint observations describing this event is given by
We denote the error probability of this event given the codebook for each correlated source with as .
Averaging over all codebooks and applying Lemma 2.12 in [27], we have
with and .
For and applying from Lemma 3.3 in [28], we can bound the second term of the last inequality by
with , since with probability one. For any we have
For every and every , we have
There is an such that for all for which we have
for all . By choosing
and letting , the right-hand side of (A4) tends to zero. Considering (A5) and (A3), the helper data rate is lower bounded by
Appendix A.1.7. Key Distribution
Besides reliability, a privacy secrecy rate pair has to fulfill three other conditions. One of them is that the secret key distribution must be close to the uniform distribution. Here, we show that this is indeed satisfied using the proof of [13]. For completeness, we introduce a sketch of the proof shown in [13] for a sequential key distillation, which consists of two phases: reconciliation and privacy amplification. The reconciliation step is equivalent to the reliability proved above. The privacy amplification step consists on the construction of the key K from a common shared sequence using an extractor function with whose inputs are the shared sequence T and a sequence of d uniformly distributed bits and gives as output a k nearly uniformly distributed sequence.
Lemma 1
([7]). Let be the random variable that represents the common sequence shared by both terminals and let E be the random variable that represents the total knowledge about T available to the eavesdropper. Let e be a particular realization of E. If both terminals know the conditional min-entropy for some , then there exists an extractor
with
with and if is a random variable with uniform distribution on and both terminals choose as their secret key, then
Sequential key distillation protocol: For every source realization we have an such that . For every we perform the following protocol:
- Repeat times the reconciliation protocol creating i shared sequences of length n.
- Perform the privacy amplification phase based on an extractor with output size k, i.e., with . has to be transmitted through the public channel together with the public message .
- The total information available to the eavesdropper is , with being a binary random variable introduced for calculation purposes informing if .
Appendix A.1.8. Privacy Leakage
Another condition that has to be fulfilled by an achievable privacy secrecy rate pair is that the information rate provided by the helper data about the sequence is bounded. We show here that this condition is fulfilled.
For every source realization we have an such that . For every we have
We analyze the second term of the right-hand side of (A14):
Appendix A.1.9. Secrecy Leakage
The last condition that has to be fulfilled by an achievable privacy secrecy rate pair is that the information rate provided by the helper data about the secret key is negligibly small. For every source realization we have an such that . For every we have
We first consider the first term of (A18). Using (A8) and (A12), we get that
We consider the second term of (A18). Using (A13), we get
Hence,
Note that the right-hand side of the inequality goes to zero for large enough N, showing that for every source realization , the secret key information rate leaked by the helper is negligibly small.
Note that we showed that the rate pair can be achieved for large , i.e., not for all . To show the achievability for all blocklengths we define the sequence with with . We showed that for the sequence of blocklengths with , there exists a blocklength such that for all blocklengths , we can find a code sequence that fulfills the achievability conditions. For every one can rewrite with . We use only the first symbols to generate the key and discard the rest . One can easily see that there is a such that, for all conditions are fulfilled. This completes the proof of achievability.
Appendix A.2. Converse of Theorem 3
For the converse, we consider a genie-aided enrollment and authentication terminal, i.e., the user at the enrollment and authentication terminal has partial knowledge of the source, i.e., he knows the actual state of the marginal distribution but not the complete source state. The converse follows from the corresponding result for a joint-source with perfect SSI shown in [11]. For a fixed , and we define the region as the set of all that satisfy
We start analyzing the secret key rate. For a fixed and we have
where is a deterministic function of and , i.e.,
where (A21) holds for and follows from Fano’s Inequality and (A22) from forming a Markov chain. This comes from
We define . The Equality (A23) is obtained using a time-sharing variable T uniformly distributed over and independent of all other variables. Setting , and for we obtain
Dividing by n, we get
where the last inequality holds with for (see [11]).
Assuming the rate pair is achievable, we have that and obtain
We continue with the privacy leakage. For a fixed we have
Dividing by n, we get
Assuming is achievable, we have that and obtain
We have shown that . This means that if holds, then we have that . Equivalently, if , then .
Assume . This implies that there exists a such that, for all auxiliary channels V, we have that , which implies that . This completes the converse and therewith proves the desired result.
It remains to derive the bound on the cardinality of the auxiliary random variables U. Let be arbitrarily but fixed and U be a random variable fulfilling for all . We show that there is a random variable with range
for all . We consider the following real valued continuous functions on
for all . We have that having -measure . Then, it holds that
for all . According to (Lemma 15.4, [27]), there exists a random variable fulfilling the Markov condition with values in and (A26) holds (see also Lemma 15.5 in [27]). □
Appendix B. Proof of Theorem 4
Appendix B.1. Achievability of Theorem 4
The achievability proof of Theorem 4 is very similar to the achievability proof of Theorem 3, where first the index of marginal distribution ℓ over is estimated. The difference is that, in this model, we use a generated secret key in a one-pad system to conceal the uniformly distributed chosen key K over the set ; as in [11], it is additionally sent together with the generated helper message and the index of the estimated marginal distribution over the public message, i.e., the helper data is . The error analysis is similar to the error analysis for Theorem 3 and the key is already uniformly distributed; however, we should take a deeper look into the privacy leakage and the secrecy leakage. We perform the privacy amplification step as in Appendix A to show that the strong secrecy is fulfilled.
Appendix B.1.1. Privacy Leakage
Another condition that has to be fulfilled by an achievable privacy secrecy rate pair is that the information rate provided by the helper data about the sequence is bounded. We show here that this condition is fulfilled.
Appendix B.1.2. Secrecy Leakage
For every source realization , we have an such that . Following similar steps as for the privacy leakage, it can be shown that the secrecy leakage is upper-bounded by
Appendix B.2. Converse of Theorem 4
The converse of Theorem 4 can be shown using the same lines of arguments as for the converse of Theorem 3. □
Appendix C. Proof Lemma 1
For every channel , for every and we have the following effective sources:
Let then there exists a and such that . Then, we have that
and
For every channel , for every and there is an and the region with is rectangular. Therefore, to calculate the Hausdorff distance between regions, we are only interested in the corner points:
Let V be arbitrary but fixed. Then, for every and we have
For , and there is a and . Using [27], Lemma 2.12 and Using Lemma 1 in [22], we get
Following the same line of arguments as for (A34), we get
Hence, for every channel , and we have
with where and .
References
- Shannon, C.E. Communication theory of secrecy systems. Bell Syst. Tech. J. 1949, 28, 656–715. [Google Scholar] [CrossRef]
- Liang, Y.; Poor, H.V.; Shamai, S. Information theoretic security. Found. Trends Commun. Inf. Theor. 2009, 5, 355–580. [Google Scholar] [CrossRef]
- Bloch, M.; Barros, J. Physical-Layer Security; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Schaefer, R.F.; Boche, H.; Khisti, A.; Poor, H.V. Information Theoretic Security and Privacy of Information Systems; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Ahlswede, R.; Csiszàr, I. Common randomness in information theory and cryptography—Part I: Secret sharing. IEEE Trans. Inf. Theor. 1993, 39, 1121–1132. [Google Scholar] [CrossRef]
- Maurer, U.M. Secret key agreement by public discussion from common information. IEEE Trans. Inf. Theor. 1993, 39, 733–742. [Google Scholar] [CrossRef]
- Maurer, U.; Wolf, S. Information-theoretic key agreement: From weak to strong secrecy for free. Adv. Crypt. EUROCRYPT 2000, 1807, 351–368. [Google Scholar]
- Schneier, B. Inside risks: The uses and abuses of biometrics. Commun. ACM 1999, 42, 136. [Google Scholar] [CrossRef]
- Ratha, N.K.; Connell, J.H.; Bolle, R.M. Enhancing security and privacy in biometrics-based authentication systems. IBM Syst. J. 2001, 40, 614–634. [Google Scholar] [CrossRef]
- Prabhakar, S.; Pankanti, S.; Jain, A.K. Biometric recognition: Security and privacy concerns. IEEE Secur. Priv. 2003, 1, 33–42. [Google Scholar] [CrossRef]
- Ignatenko, T.; Willems, F.M. Biometric systems: Privacy and secrecy aspects. IEEE Trans. Inf. Forensics Secur. 2009, 4, 956–973. [Google Scholar] [CrossRef]
- Lai, L.; Ho, S.W.; Poor, H.V. Privacy–security trade-offs in biometric security systems—Part I: Single use case. IEEE Trans. Inf. Forensics Secur. 2011, 6, 122–139. [Google Scholar] [CrossRef]
- Chou, R.A.; Bloch, M.R. One-way rate-limited sequential key-distillation. In Proceedings of the IEEE International Symposium Information Theory, Cambridge, MA, USA, 1–6 July 2012; pp. 1777–1781. [Google Scholar]
- Wolfowitz, J. Simultaneous channels. Arch. Ration. Mech. Anal. 1959, 4, 371–386. [Google Scholar] [CrossRef]
- Blackwell, D.; Breiman, L.; Thomasian, A. The capacity of a class of channels. Ann. Math. Stat. 1959, 30, 1229–1241. [Google Scholar] [CrossRef]
- Boche, H.; Wyrembelski, R.F. Secret key generation using compound sources-optimal key-rates and communication costs. In Proceedings of the 9th International ITG Conference on Systems, Communication and Coding, München, Germany, 21–24 January 2013; pp. 1–6. [Google Scholar]
- Bloch, M. Channel intrinsic randomness. In Proceedings of the IEEE International Symposium on Information Theory, Austin, TX, USA, 13–18 June 2010; pp. 2607–2611. [Google Scholar]
- Chou, R.; Bloch, M.R. Secret-key generation with arbitrarily varying eavesdropper’s channel. In Proceedings of the IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 277–280. [Google Scholar]
- Tavangaran, N.; Boche, H.; Schaefer, R.F. Secret-key generation using compound sources and one-way public communication. IEEE Trans. Inf. Forensics Secur. 2017, 12, 227–241. [Google Scholar] [CrossRef]
- Grigorescu, A.; Boche, H.; Schaefer, R.F. Robust PUF based authentication. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Rome, Italy, 16–19 November 2015; pp. 1–6. [Google Scholar]
- Boche, H.; Nötzel, J. Positivity, discontinuity, finite resources, and nonzero error for arbitrarily varying quantum channels. J. Math. Phys. 2014, 55, 122201. [Google Scholar] [CrossRef]
- Boche, H.; Schaefer, R.F.; Poor, H.V. On the continuity of the secrecy capacity of compound and arbitrarily varying wiretap channels. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2531–2546. [Google Scholar] [CrossRef]
- Grigorescu, A.; Boche, H.; Schaefer, R.F.; Poor, H.V. Capacity region continuity of the compound broadcast channel with confidential messages. In Proceedings of the IEEE Information Theory Workshop, Jerusalem, Israel, 24 April–1 May 2015; pp. 1–6. [Google Scholar]
- Wolfowitz, J. Coding Theorems of Information Theory; Springer: New York, NY, USA, 1978. [Google Scholar]
- Schaefer, R.F.; Boche, H.; Poor, H.V. Super-activation as a unique feature of secure communication in malicious environments. Information 2016, 7, 24. [Google Scholar] [CrossRef]
- Boche, H.; Schaefer, R.F.; Poor, H.V. Characterization of Super-Additivity and Discontinuity Behavior of the Capacity of Arbitrarily Varying Channels Under List Decoding. Available online: http://ieeexplore.ieee.org/abstract/document/8007044/ (accessed on 7 September 2017).
- Csiszàr, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Bjelaković, I.; Boche, H.; Sommerfeld, J. Secrecy results for compound wiretap channels. Probl. Inf. Transm. 2013, 49, 73–98. [Google Scholar] [CrossRef]
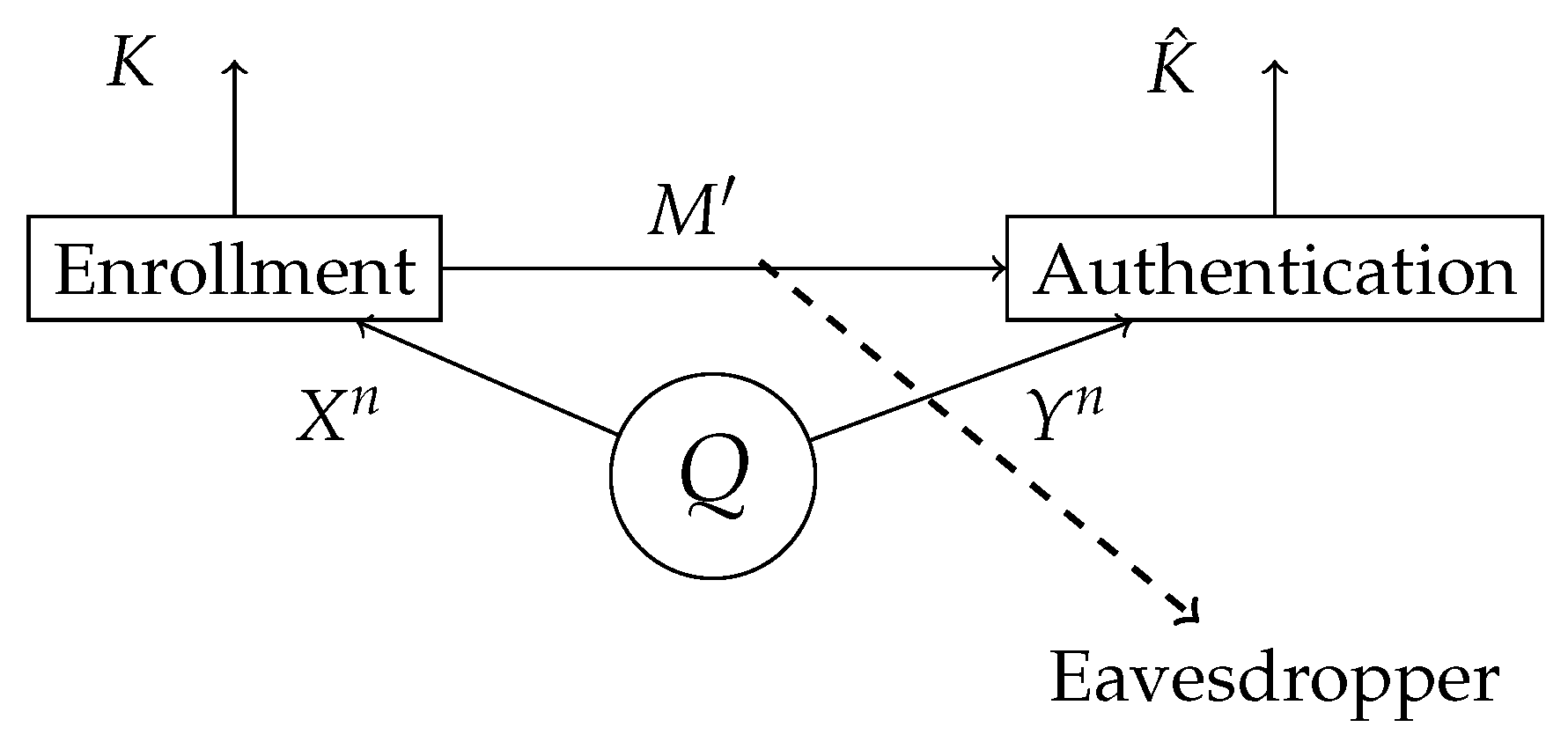
Figure 1.
The biometric measurements and are observed in the enrollment and authentication terminal, respectively. In the enrollment terminal, the key K and the helper data are generated. The helper data is public, hence the eavesdropper also has access to it. In the authentication terminal, an estimation of a key is made based on the observed biometric measurements and the helper data .
Figure 1.
The biometric measurements and are observed in the enrollment and authentication terminal, respectively. In the enrollment terminal, the key K and the helper data are generated. The helper data is public, hence the eavesdropper also has access to it. In the authentication terminal, an estimation of a key is made based on the observed biometric measurements and the helper data .

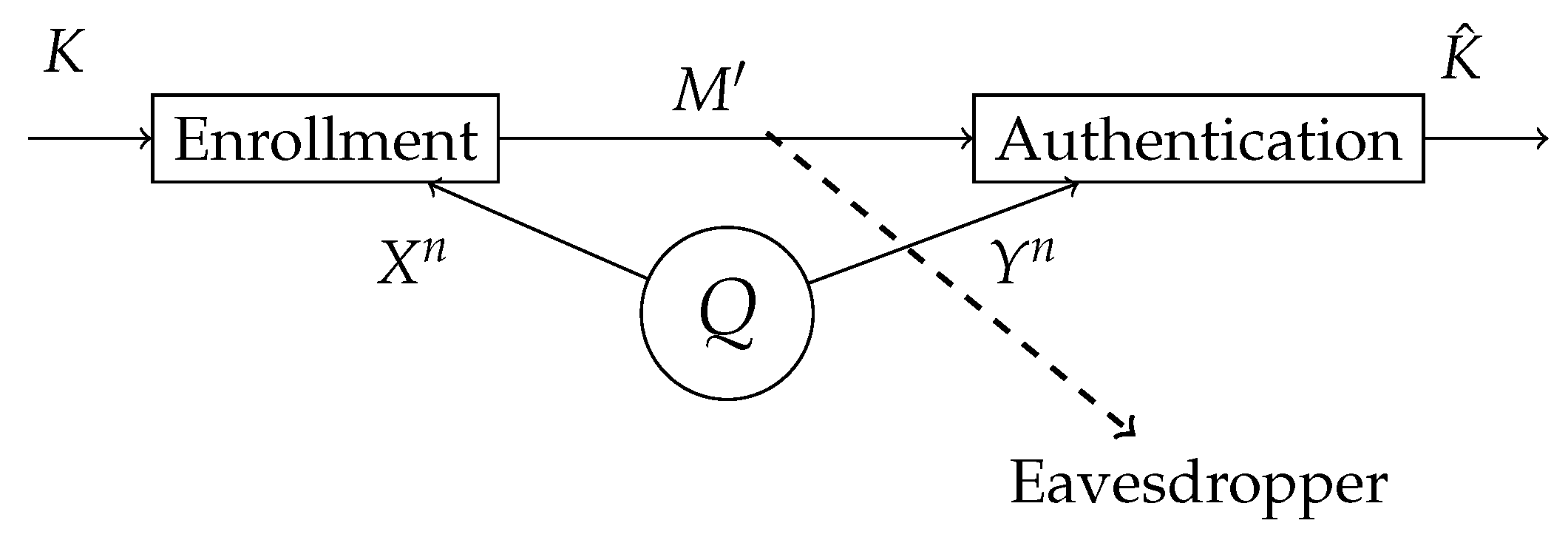
Figure 2.
The biometric sequences and are observed at the enrollment and authentication terminal, respectively. In the enrollment terminal, the helper data is generated for a given secret key K. The helper data is public, hence the eavesdropper also has access to it. In the authentication terminal, an estimation of a key is made based on the observed biometric authentication sequence and the helper data .
Figure 2.
The biometric sequences and are observed at the enrollment and authentication terminal, respectively. In the enrollment terminal, the helper data is generated for a given secret key K. The helper data is public, hence the eavesdropper also has access to it. In the authentication terminal, an estimation of a key is made based on the observed biometric authentication sequence and the helper data .
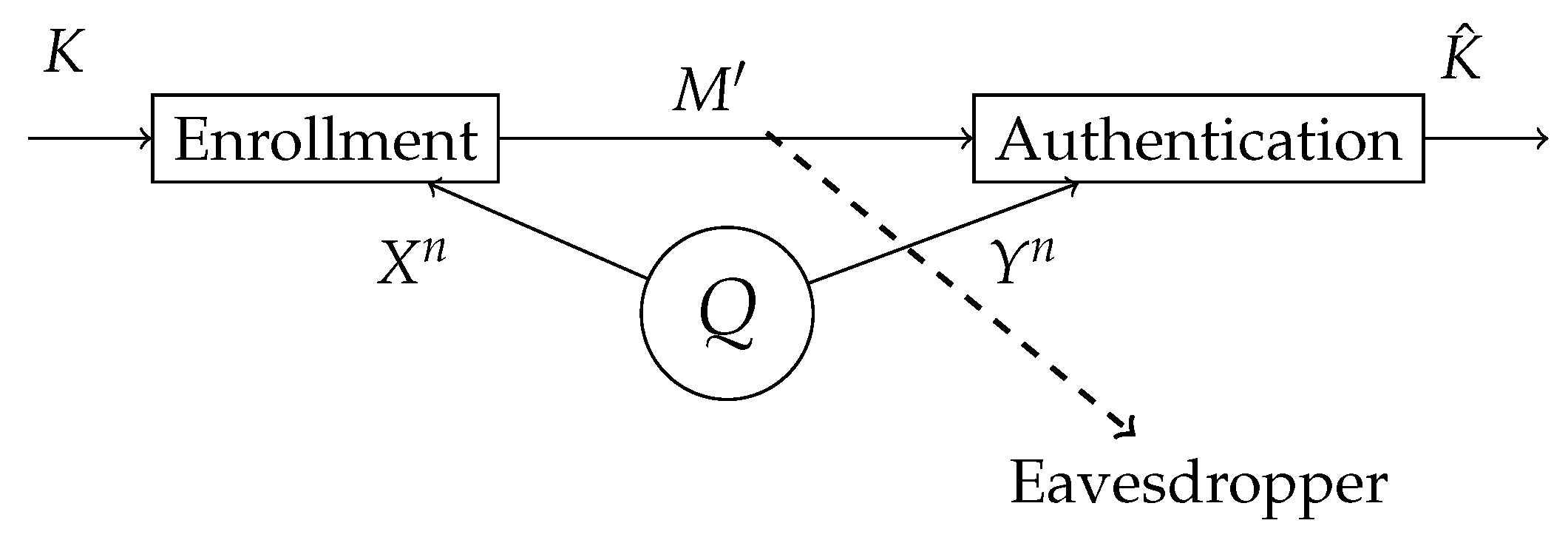
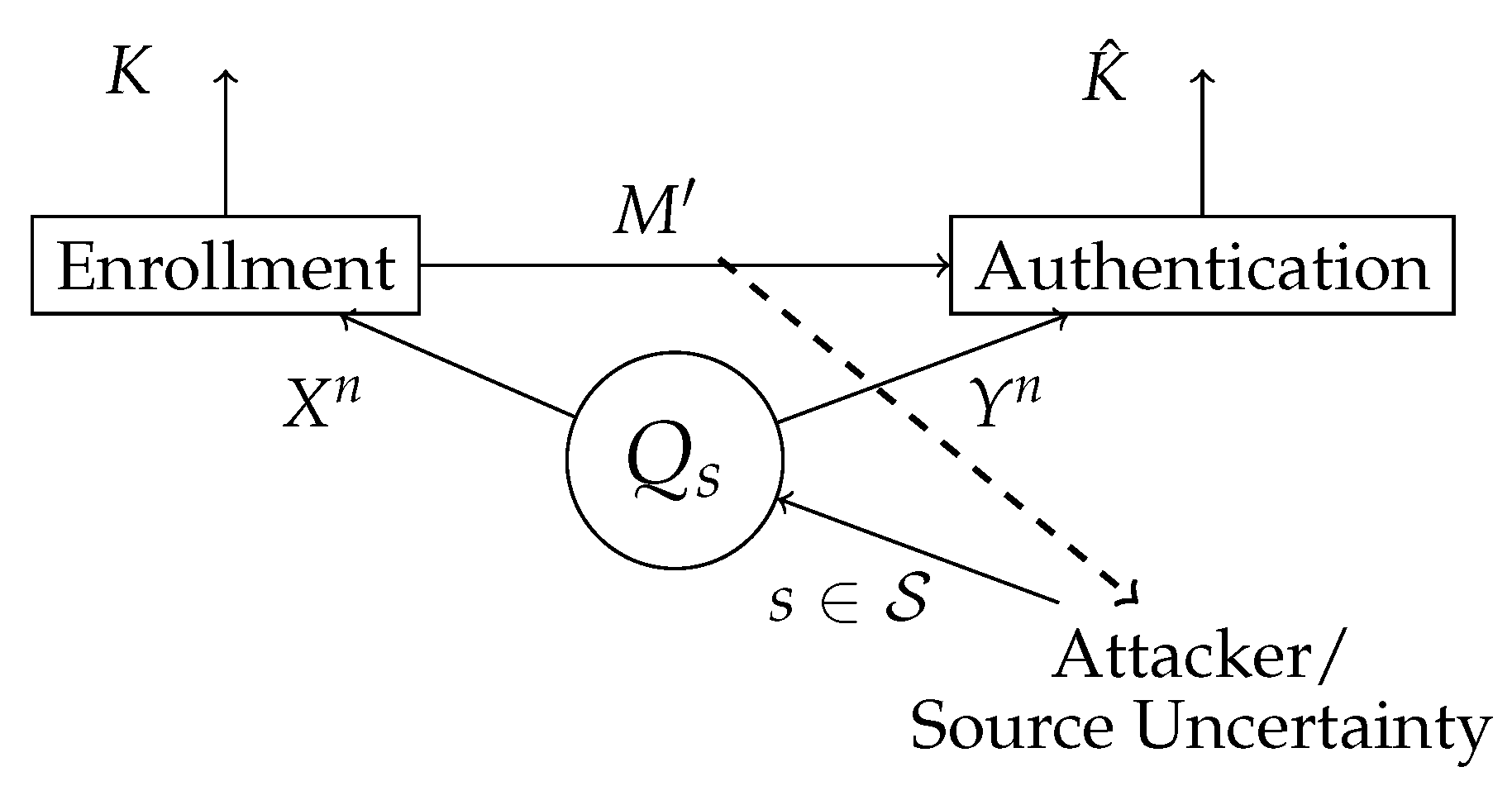
Figure 3.
The attacker controls the state of the source . The biometric sequences and are observed at the enrollment and authentication, terminal respectively. In the enrollment terminal, the key K and the helper data are generated. The helper data is public, hence the attacker also has access to it. In the authentication terminal, an estimation of a key is made based on the observed authentication sequence and the helper data .
Figure 3.
The attacker controls the state of the source . The biometric sequences and are observed at the enrollment and authentication, terminal respectively. In the enrollment terminal, the key K and the helper data are generated. The helper data is public, hence the attacker also has access to it. In the authentication terminal, an estimation of a key is made based on the observed authentication sequence and the helper data .
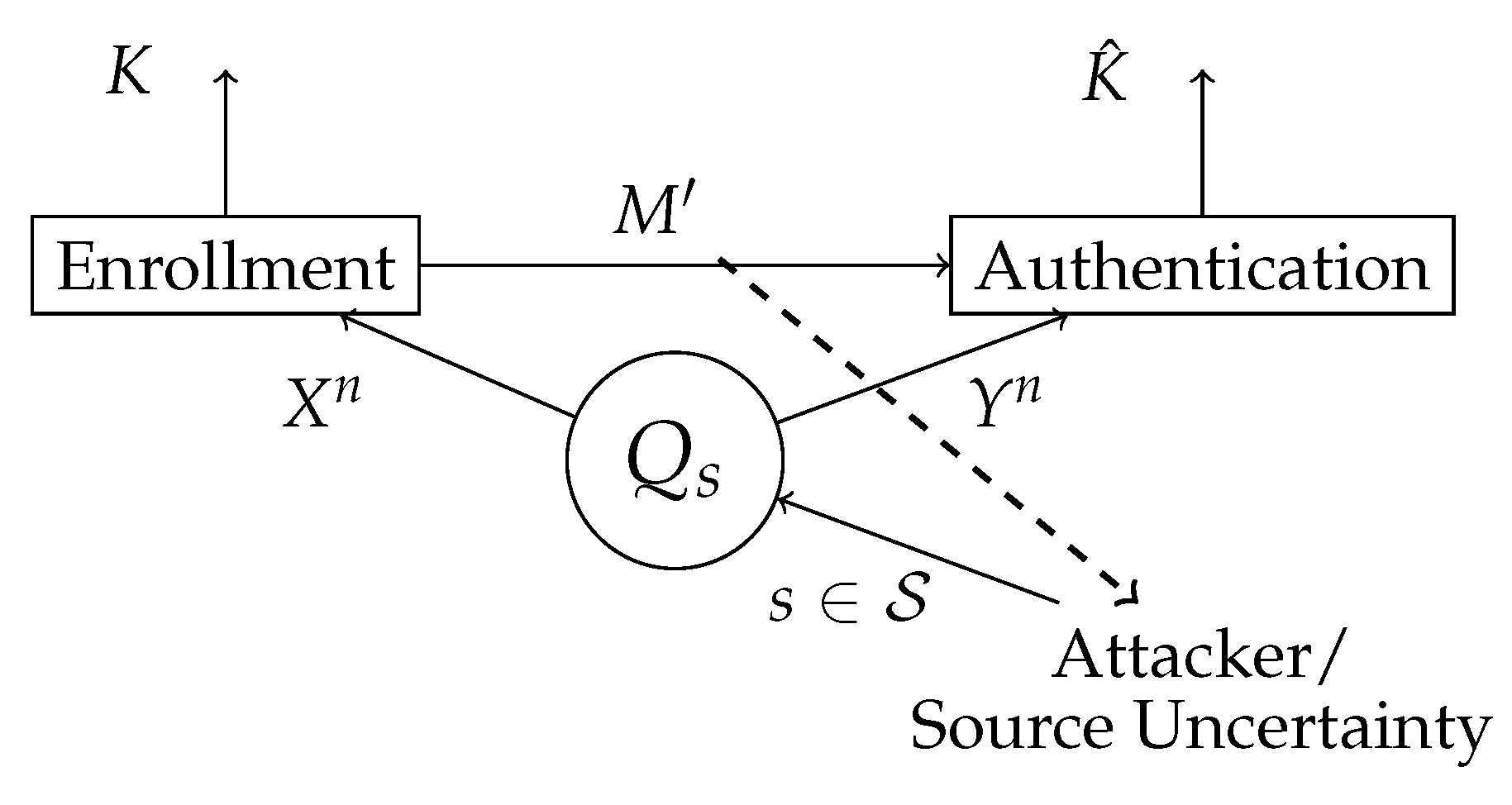
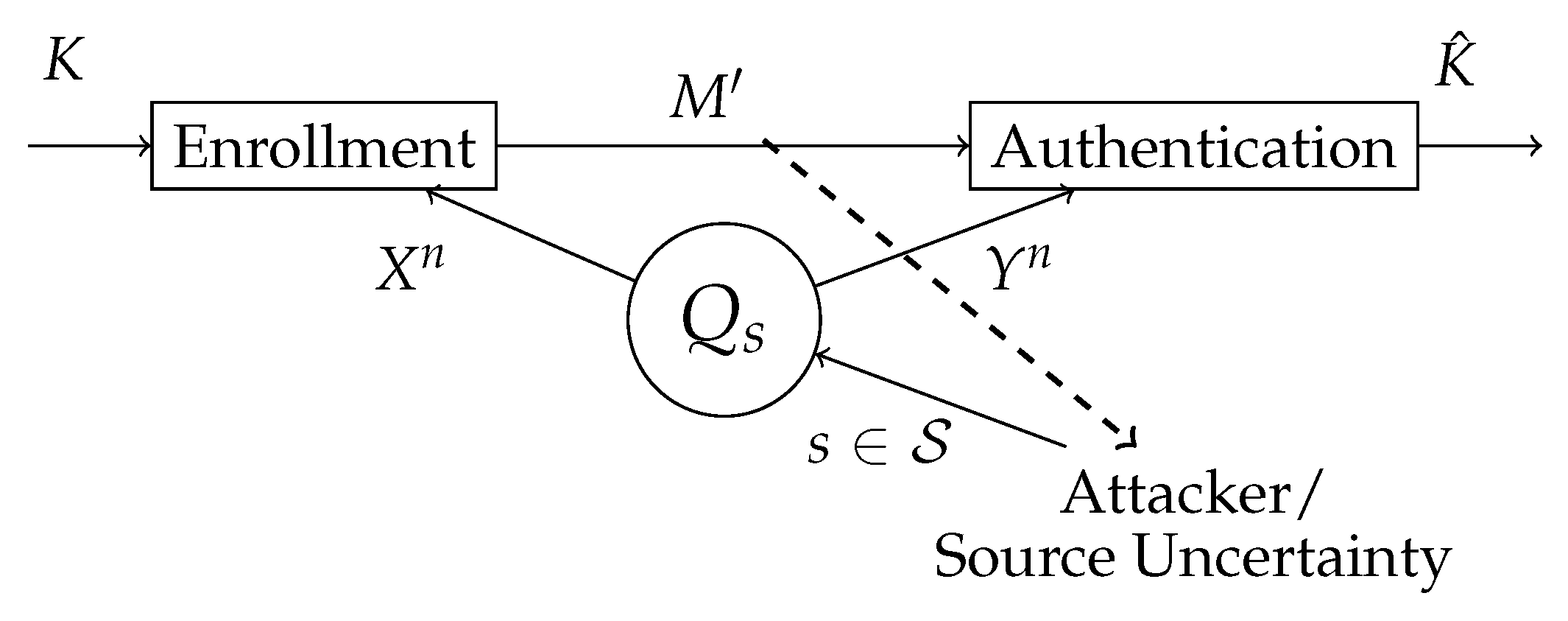
Figure 4.
The attacker controls the state of the source . The biometric sequences and are observed in the enrollment and authentication terminal, respectively. In the enrollment terminal, the key K is predefined and the helper data is generated. The helper data is public, hence the attacker also has access to it. In the authentication terminal, an estimation of a key is made based on the observed authentication sequences and the helper data .
Figure 4.
The attacker controls the state of the source . The biometric sequences and are observed in the enrollment and authentication terminal, respectively. In the enrollment terminal, the key K is predefined and the helper data is generated. The helper data is public, hence the attacker also has access to it. In the authentication terminal, an estimation of a key is made based on the observed authentication sequences and the helper data .
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Grigorescu, A.; Boche, H.; Schaefer, R.F. Robust Biometric Authentication from an Information Theoretic Perspective. Entropy 2017, 19, 480. https://doi.org/10.3390/e19090480
AMA Style
Grigorescu A, Boche H, Schaefer RF. Robust Biometric Authentication from an Information Theoretic Perspective. Entropy. 2017; 19(9):480. https://doi.org/10.3390/e19090480
Chicago/Turabian StyleGrigorescu, Andrea, Holger Boche, and Rafael F. Schaefer. 2017. "Robust Biometric Authentication from an Information Theoretic Perspective" Entropy 19, no. 9: 480. https://doi.org/10.3390/e19090480
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.