Rate-Distortion Region of a Gray–Wyner Model with Side Information

1
Department of Electronics Optronics and Signal Processing (DEOS), Institut Superieur de l’Aéronautique et de l’Espace Supaéro (ISAE Supaéro), 31400 Toulouse, France
2
Mathematics and Algorithmic Sciences Lab, Huawei Technologies France, 92100 Boulogne-Billancourt, France
*
Author to whom correspondence should be addressed.
†
Current address: Institut d’Électronique et d’Informatique Gaspard-Monge, Université Paris-Est, 77454 Champs-sur-Marne, France.
Entropy 2018, 20(1), 2; https://doi.org/10.3390/e20010002
Submission received: 29 November 2017
/
Revised: 13 December 2017
/
Accepted: 15 December 2017
/
Published: 22 December 2017
(This article belongs to the Special Issue Rate-Distortion Theory and Information Theory)
Abstract
:In this work, we establish a full single-letter characterization of the rate-distortion region of an instance of the Gray–Wyner model with side information at the decoders. Specifically, in this model, an encoder observes a pair of memoryless, arbitrarily correlated, sources and communicates with two receivers over an error-free rate-limited link of capacity , as well as error-free rate-limited individual links of capacities to the first receiver and to the second receiver. Both receivers reproduce the source component losslessly; and Receiver 1 also reproduces the source component lossily, to within some prescribed fidelity level . In addition, Receiver 1 and Receiver 2 are equipped, respectively, with memoryless side information sequences and . Important in this setup, the side information sequences are arbitrarily correlated among them, and with the source pair ; and are not assumed to exhibit any particular ordering. Furthermore, by specializing the main result to two Heegard–Berger models with successive refinement and scalable coding, we shed light on the roles of the common and private descriptions that the encoder should produce and the role of each of the common and private links. We develop intuitions by analyzing the developed single-letter rate-distortion regions of these models, and discuss some insightful binary examples.
1. Introduction
The Gray–Wyner source coding problem was originally formulated, and solved, by Gray and Wyner in [1]. In their original setting, a pair of arbitrarily correlated memoryless sources is to be encoded and transmitted to two receivers that are connected to the encoder each through a common error-free rate-limited link as well as a private error-free rate-limited link. Because the channels are rate-limited, the encoder produces a compressed bit string of rate that it transmits over the common link, and two compressed bit strings, of rate and of rate , that transmits over the private links each to their respective receiver. The first receiver uses the bit strings and to reproduce an estimate of the source component to within some prescribed distortion level , for some distortion measure . Similarly, the second receiver uses the bit strings and to reproduce an estimate of the source component to within some prescribed distortion level , for some different distortion measure . In [1], Gray and Wyner characterized the optimal achievable rate triples and distortion pairs .
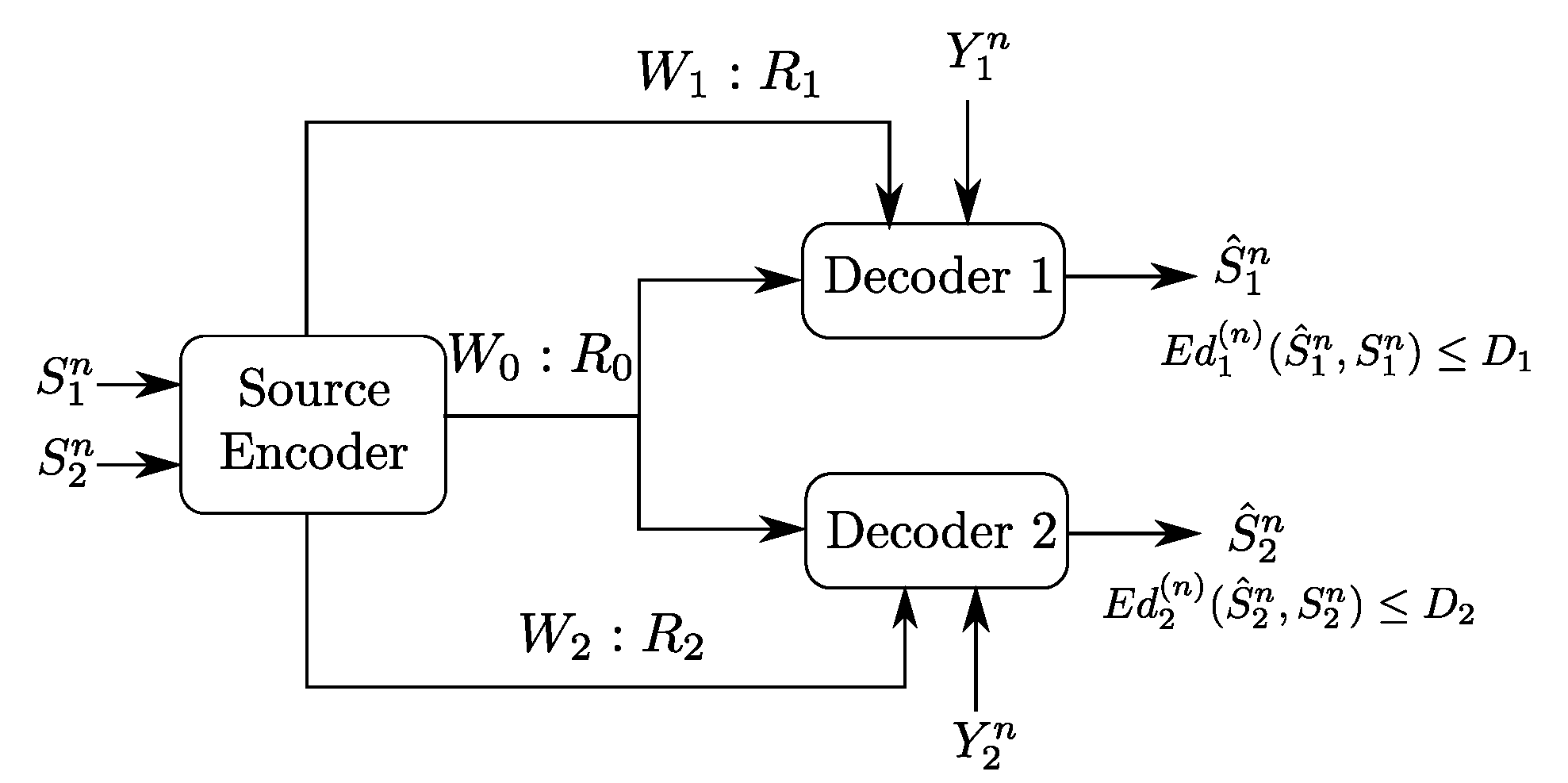
Figure 1 shows a generalization of the original Gray–Wyner model in which the receivers also observe correlated memoryless side information sequences, at Receiver 1 and at Receiver 2. Some special cases of the Gray–Wyner model with side information of Figure 1 have been solved (see the Section 1.2 below). However, in its most general form, i.e., when the side information sequences are arbitrarily correlated among them and with the sources, this problem has so-far eluded single-letter characterization of the optimal rate-distortion region. Indeed, the Gray–Wyner problem with side information subsumes the well known Heegard–Berger problem [2], obtained by setting in Figure 1, which remains, to date, an open problem.
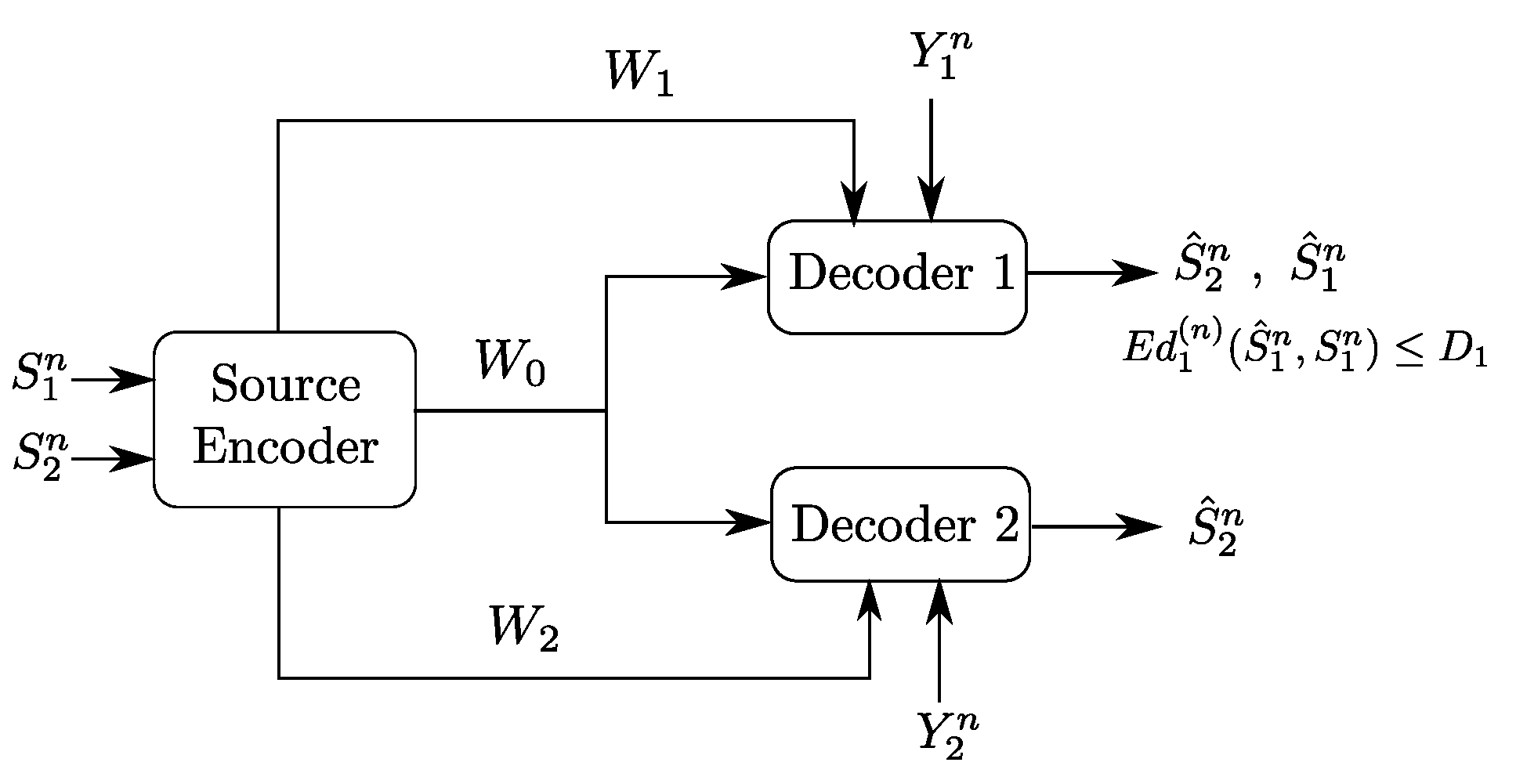
In this paper, we study an instance of the Gray–Wyner model with side information of Figure 1 in which the reconstruction sets are degraded, meaning, both receivers reproduce the source component losslessly and Receiver 1 wants also to reproduce the source component lossily, to within some prescribed distortion level . It is important to note that, while the reconstruction sets are nested, and so degraded, no specific ordering is imposed on the side information sequences, which then can be arbitrarily correlated among them and with the sources .
As in the Gray–Wyner original coding scheme, the encoder produces a common description of the sources pair that is intended to be recovered by both receivers, as well as individual or private descriptions of that are destined to be recovered each by a distinct receiver. Because the side information sequences do not exhibit any specific ordering, the choice of the information that each description should carry, and, the links over which each is transmitted to its intended receiver, are challenging questions that we answer in this work.
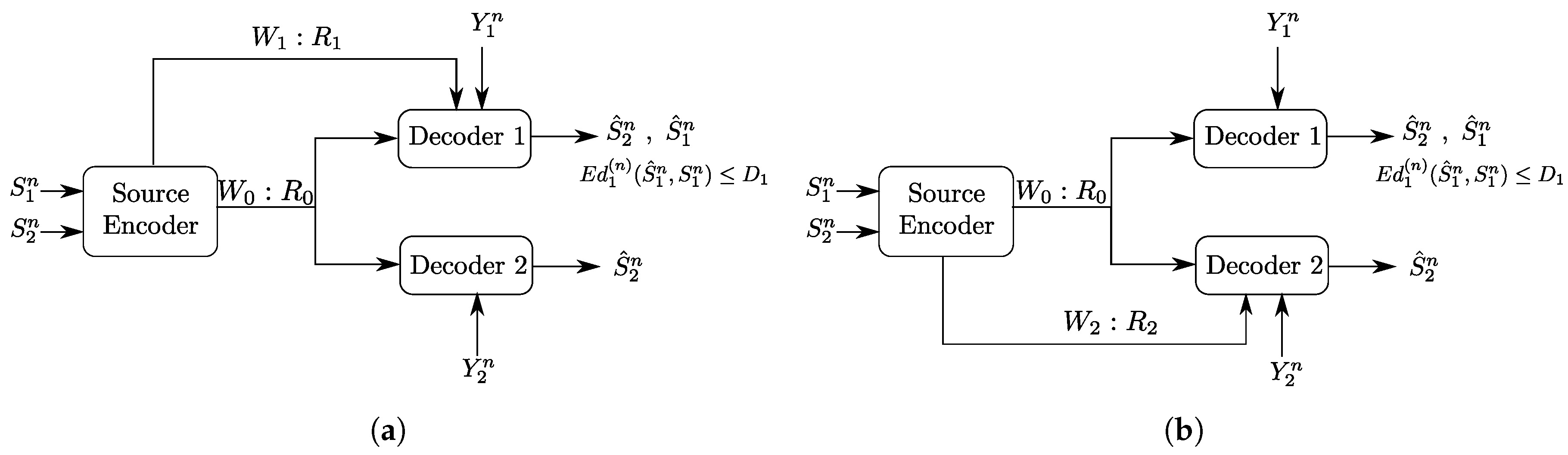
To build the understanding of the role of each of the links and of the descriptions in the optimal coding scheme for the setting of Figure 2, we will investigate as well two important underlying problems, which are Heegard–Berger type models with refinement links as shown in Figure 3. In both models, only one of the two refinement individual links has non-zero rate.
In the model of Figure 3a, the receiver that accesses the additional rate-limited link (i.e., Receiver 1) is also required to reproduce a lossy estimate of the source component , in addition to the source component which is to be reproduced losslessly by both receivers. We will refer to this model as a “Heegard–Berger problem with successive refinement”. Reminiscent of successive refinement source coding, this model may be appropriate to model applications in which descriptions of only some components (e.g., ) of the source suffices at the first use of the data; and descriptions of the remaining components (e.g., ) are needed only at a later stage.
The model of Figure 3b has the individual rate-limited link connected to the receiver that is required to reproduce only the source component . We will refer to this model as a “Heegard–Berger problem with scalable coding”, reusing a term that was introduced in [3] for a similar scenario, and in reference to that user 1 may have such a “good quality” side information that only a minimal amount of information from the encoder suffices, thus, so as not to constrain the communication by user 2 with the lower quality side information, an additional rate limited link is added to balance the decoding capabilities of both users.
1.1. Main Contributions
The main result of this paper is a single-letter characterization of the optimal rate-distortion region of the Gray–Wyner model with side information and degraded reconstruction sets of Figure 2. To this end, we derive a converse proof that is tailored specifically for the model with degraded reconstruction sets that we study here. For the proof of the direct part, we develop a coding scheme that is very similar to one developed in the context of coding for broadcast channels with feedback in [4], but with an appropriate choice of the variables which we specify here. The specification of the main result to the Heegard–Berger models with successive refinement and scalable coding of Figure 3 sheds light on the roles of the common and private descriptions and what they should carry optimally. We develop intuitions by analyzing the established single-letter optimal rate-distortion regions of these two models, and illustrate our discussion through some binary examples.
1.2. Related Works
In [4], Shayevitz and Wigger study a two-receiver discrete memoryless broadcast channel with feedback. They develop an efficient coding scheme which treats the feedback signal as a source that has to be conveyed lossily to the receivers in order to refine their messages’ estimates, through a block Markov coding scheme. In doing so, the users’ channel outputs are regarded as side information sequences; thus, the scheme clearly connects with the Gray–Wyner model with side information of Figure 1—as is also clearly explicit in [4]. The Gray–Wyner model with side information for which Shayevitz and Wigger’s develop a (source) coding scheme, as part of their study of the broadcast channel with feedback, assumes general, possibly distinct, distortion measures at the receivers (i.e., not necessarily nested) and side information sequences that are arbitrarily correlated among them and with the source. In this paper, we show that, when specialized to the model with degraded reconstruction sets of Figure 2 that we study here, Shayevitz and Wigger’s coding scheme for the Gray–Wyner model with side information of [4] yields a rate-distortion region that meets the converse result that we here establish, thus is optimal.
The Gray–Wyner model with side information generalizes another long standing open source coding problem, the famous Heegard–Berger problem [2]. Full single-letter characterization of the optimal rate-distortion function of the Heegard–Berger problem is known only in few specific cases, the most important of which are the cases of : (i) stochastically degraded side information sequences [2] (see also [5]); (ii) Sgarro’s result [6] on the corresponding lossless problem; (iii) Gaussian sources with quadratic distortion measure [3,7]; (iv) some instances of conditionally less-noisy side information sequences [8]; and (v) the recently solved HB model with general side information sequences and degraded reconstruction sets [9], i.e., the model of Figure 2 with — in the lossless case, a few other optimal results were shown, such as for the so-called complementary delivery [10]. A lower bound for general instances of the rate distortion problem with side information at multiple decoders, which is inspired by a linear-programming lower bound for index coding, has been developed recently by Unal and Wagner in [11].
Successive refinement of information was investigated by Equitz et al. in [12], wherein the description of the source is successively refined to a collection of receivers which are required to reconstruct the source with increasing quality levels. Extensions of successive refinement to cases in which the receivers observe some side information sequences was first investigated by Steinberg et al. in [13] who establish the optimal rate-distortion region under the assumption that the receiver that observes the refinement link, say receiver 1, observes also a better side information sequence than the opposite user, i.e., the Markov chain holds. Tian et al. give in [7] an equivalent formulation of the result of [13] and extend it to the N-stage successive refinement setting. In [3], Tian et al. investigate another setting, coined as “side information scalable coding”, in which it is rather the receiver that accesses the refinement link, say receiver 2, which observes the less good side information sequence, i.e., . Balancing refinement quality and side information asymmetry for such a side-information scalable source coding problem allows authors in [3] to derive the rate-distortion region in the degraded side information case. The previous results on successive refinement in the presence of side information, which were generalized by Timo et al. in [14], all assume, however, a specific structure in the side information sequences.
1.3. Outline
An outline of the remainder of this paper is as follows. Section 2 describes formally the Gray–Wyner model with side information and degraded reconstruction sets of Figure 2 that we study in this paper. Section 3 contains the main result of this paper, a full single-letter characterization of the rate-distortion region of the model of Figure 2, together with some useful discussions and connections. A formal proof of the direct and converse parts of this result appear in Section 6. In Section 4 and Section 5, we specialize the result, respectively, to the Heegard–Berger model with successive refinement of Figure 3a and the Heegard–Berger model with scalable coding of Figure 3b. These sections also contain insightful discussions illustrated by some binary examples.
Notation
Throughout the paper, we use the following notations. The term pmf stands for probability mass function. Upper case letters are used to denote random variables, e.g., X; lower case letters are used to denote realizations of random variables, e.g., x; and calligraphic letters designate alphabets, i.e., . Vectors of length n are denoted by , and is used to denote the sequence , whereas . The probability distribution of a random variable X is denoted by . Sometimes, for convenience, we write it as . We use the notation to denote the expectation of a random variable X. A probability distribution of a random variable Y given X is denoted by . The set of probability distributions defined on an alphabet is denoted by . The cardinality of a set is denoted by . For random variables X, Y and Z, the notation indicates that X, Y and Z, in this order, form a Markov Chain, i.e., . The set denotes the set of sequences strongly typical with respect to the probability distribution and the set denotes the set of sequences jointly typical with with respect to the joint pmf . Throughout this paper, we use to denote the entropy of a Bernoulli random variable, i.e., . In addition, the indicator function is denoted by . For real-valued scalars a and b, with , the notation means the set of real numbers comprised between a and b. For integers , denotes the set of integers comprised between i and j, i.e., . Finally, throughout the paper, logarithms are taken to base 2.
2. Problem Setup and Formal Definitions
Consider the Gray–Wyner source coding model with side information and degraded reconstruction sets shown in Figure 2. Let be a discrete memoryless vector source with generic variables , , and . In addition, let be a reconstruction alphabet and, a distortion measure defined as:
Definition 1.
An code for the Gray–Wyner source coding model with side information and degraded reconstruction sets of Figure 2 consists of:
- -
- Three sets of messages , , and .
- -
- Three encoding functions, , and defined, for as
- -
- Two decoding functions and , one at each user:andThe expected distortion of this code is given byThe probability of error is defined as
Definition 2.
A rate triple is said to be -achievable for the Gray–Wyner source coding model with side information and degraded reconstruction sets of Figure 2 if there exists a sequence of codes such that:
The rate-distortion region of this problem is defined as the union of all rate-distortion quadruples such that is -achievable, i.e,
As we already mentioned, we shall also study the special case Heegard–Berger type models shown in Figure 3. The formal definitions for these models are similar to the above, and we omit them here for brevity.
3. Gray–Wyner Model with Side Information and Degraded Reconstruction Sets
In the following, we establish the main result of this work, i.e., the single-letter characterization of the optimal rate-distortion region of the Gray–Wyner model with side information and degraded reconstructions sets shown in Figure 2. We then describe how the result subsumes and generalizes existing rate-distortion regions for this setting under different assumptions.
Theorem 1.
The rate-distortion region of the Gray–Wyner problem with side information and degraded reconstruction set of Figure 2 is given by the sets of all rate-distortion quadruples satisfying:
for some product pmf , such that:
- (1)
- The following Markov chain is valid:
- (2)
- There exists a function such that:
Proof.
The detailed proof of the direct part and the converse part of this theorem appear in Section 6.
The proof of converse, which is the most challenging part, uses appropriate combinations of bounding techniques for the transmitted rates based on the system model assumptions and Fano’s inequality, a series of analytic bounds based on the underlying Markov chains, and most importantly, a proper use of Csiszár–Körner sum identity in order to derive single letter bounds.
As for the proof of achievability, it combines the optimal coding scheme of the Heegard–Berger problem with degraded reconstruction sets [9] and the double-binning based scheme of Shayevitz and Wigger (Theorem 2, [4]) for the Gray–Wyner problem with side information, and is outlined in the following.
The encoder produces a common description of that is intended to be recovered by both receivers, and an individual description that is intended to be recovered only by Receiver 1. The common description is chosen as and is thus designed to describe all of , which both receivers are required to reproduce lossessly, but also all or part of , depending on the desired distortion level . Since we make no assumptions on the side information sequences, this is meant to account for possibly unbalanced side information pairs , in a manner that is similar to [9]. The message that carries the common description is obtained at the encoder through the technique of double-binning of Tian and Diggavi in [3], used also by Shayevitz and Wigger (Theorem 2, [4]) for a Gray–Wyner model with side information. In particular, similar to the coding scheme of (Theorem 2, [4]), the double-binning is performed in two ways, one that is tailored for Receiver 1 and one that is tailored for Receiver 2.
More specifically, the codebook of the common description is composed of codewords that are drawn randomly and independently according to the product law of ; and is partitioned uniformly into superbins, indexed with . The codewords of each superbin of this codebook are partitioned in two distinct ways. In the first partition, they are assigned randomly and independently to subbins indexed with , according to a uniform pmf over . Similarly, in the second partition, they are assigned randomly and independently to subbins indexed with , according to a uniform pmf over . The codebook of the private description is composed of codewords that are drawn randomly and independently according to the product law of . This codebook is partitioned similarly uniformly into superbins indexed with , each containing subbins indexed with codewords .
Upon observing a typical pair , the encoder finds a pair of codewords that is jointly typical with . Let , and denote respectively the indices of the superbin, subbin of the first partition and subbin of the second partition of the codebook of the common description, in which lies the found . Similarly, let and denote respectively the indices of the superbin and subbin of the codebook of the individual description in which lies the found . The encoder sets the common message as and sends it over the error-free rate-limited common link of capacity . In addition, it sets the individual message as and sends it the error-free rate-limited link to Receiver 1 of capacity ; and the individual message as and sends it the error-free rate-limited link to Receiver 2 of capacity . For the decoding, Receiver 2 utilizes the second partition of the codebook of the common description; and looks in the subbin of index of the superbin of index for a unique that is jointly typical with its side information . Receiver 1 decodes similarly, utilizing the first partition of the codebook of the common description and its side information . It also utilizes the codebook of the individual description; and looks in the subbin of index of the superbin of index for a unique that is jointly typical with the pair . In the formal proof in Section IV, we argue that with an appropropriate choice of the communication rates , , , and , as well as the sizes of the subbins, this scheme achieves the rate-distortion region of Theorem 1. ☐
A few remarks that connect Theorem 1 to known results on related models are in order.
Remark 1.
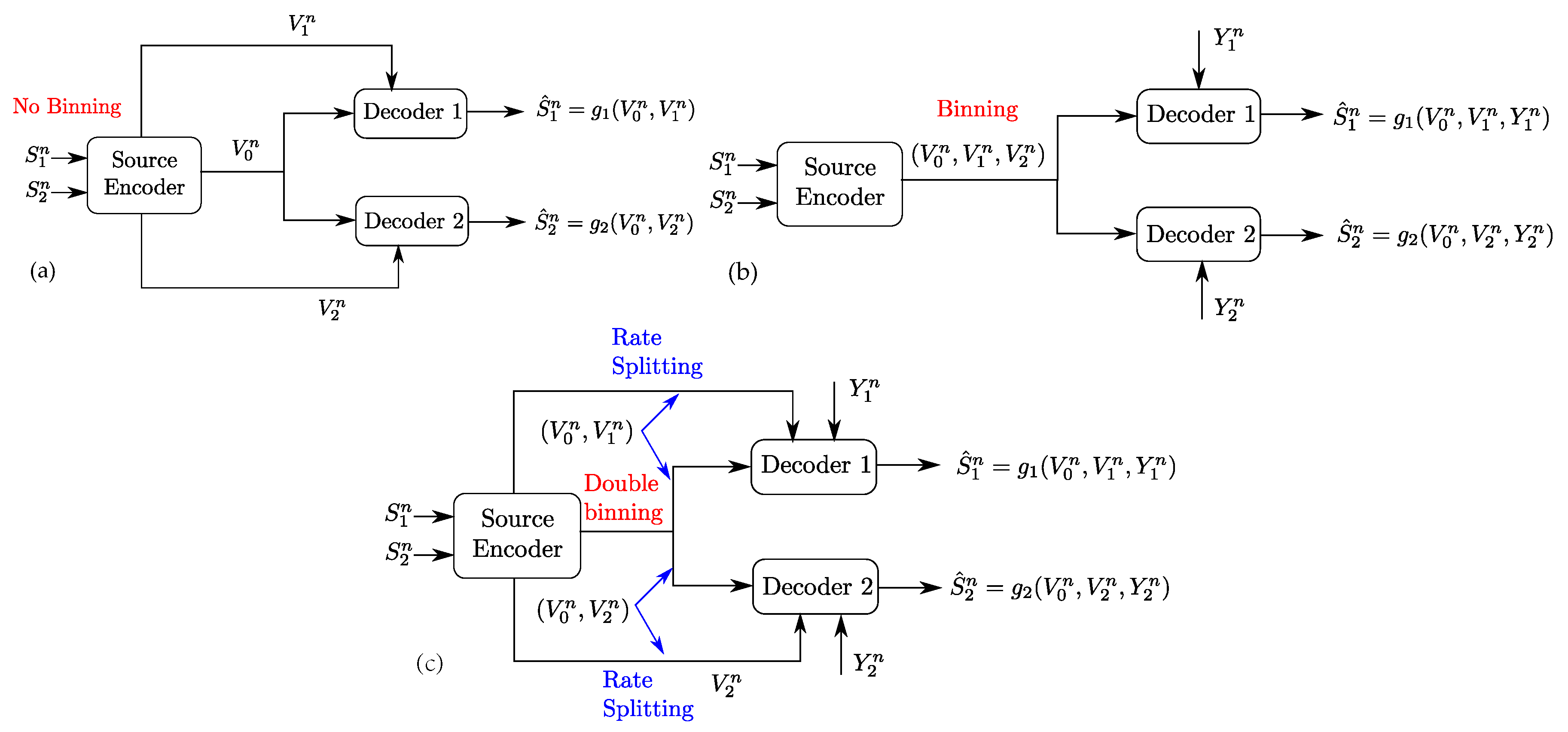
The setting of Figure 1 generalizes two important settings which are the Gray–Wyner problem, through the presence of side-information sequences and , and the Heegard–Berger problem, through the presence of private links of rates and . As such, the coding scheme for the setting of Figure 2 differs from that of the Gray–Wyner problem and that of the Heegard–Berger problem in many aspects as shown in Figure 4.
First, the presence of side information sequences imposes the use of “binning” for each of the produced descriptions and in the Gray–Wyner code construction. However, unlike the binning performed in the Heegard–Berger coding scheme, the binning of the common codeword needs to be performed with two different indices, each tailored to a side information sequence at the respective receivers, i.e., “double binning”. Another different aspect is the role of the private and common links. When in the original Gray–Wyner work, these links carried each a description, i.e., on the common link and with respect to on the private links of rates with respect to , and when in the Heegard–Berger the three descriptions and are all carried through the common link only, in the optimal coding scheme of the setting of Figure 2, the private and common links play different roles. Indeed, the common description and the private description are transmitted on both the common link and the private link of rates and , for , through rate-splitting. As such, these key differences imply an intricate interplay between the side information sequences and the role of the common and private links, which we will emphasize later on in Section 4 and Section 5.
Remark 2.
In the special case in which , the Gray–Wyner model with side information and degraded reconstruction sets of Figure 2 reduces to a Heegard–Berger problem with arbitrary side information sequences and degraded reconstruction sets, a model that was studied, and solved, recently in the authors’ own recent work [9]. Theorem 1 can then be seen as a generalization of (Theorem 1, [9]) to the case in which the encoder is connected to the receivers also through error-free rate-limited private links of capacity and respectively. The most important insight in the Heegard–Berger problem with degraded reconstruction sets is the role that the common description should play in such a setting. Authors show in (Theorem 1, [9]) that the optimal choice of this description is to contain, intuitively, the common source intended to both users, and, maybe less intuitive, an additional description , i.e., , which is used to piggyback part of the source in the common codeword though not required by both receivers, in order to balance the asymmetry of the side information sequences. In Section 4 and Section 5 we show that the utility of this description will depend on both the side information sequences and the rates of the private links.
Remark 3.
In [15], Timo et al. study the Gray–Wyner source coding model with side information of Figure 1. They establish the rate-region of this model in the specific case in which the side information sequence is a degraded version of , i.e., is a Markov chain, and both receivers reproduce the component and Receiver 1 also reproduces the component , all in a lossless manner. The result of Theorem 1 generalizes that of (Theorem 5, [15]) to the case of side information sequences that are arbitrarily correlated among them and with the source pair and lossy reconstruction of . In [15], Timo et al. also investigate, and solve, a few other special cases of the model, such as those of single source (Theorem 4, [15]) and complementary delivery (Theorem 6, [15]). The results of (Theorem 4, [15]) and (Theorem 6, [15]) can be recovered from Theorem 1 as special cases of it. Theorem 1 also generalizes (Theorem 6, [15]) to the case of lossy reproduction of the component .
4. The Heegard–Berger Problem with Successive Refinement
An important special case of the Gray–Wyner source coding model with side information and degraded reconstruction sets of Figure 2 is the case in which . The resulting model, a Heegard–Berger problem with successive refinement, is shown in Figure 3a.
In this section, we derive the optimal rate distortion region for this setting, and show how it compares to existing results in literature. Besides, we discuss the utility of the common description depending, not only on the side information sequences structures, but also on the refinement link rate . We illustrate through a binary example that the utility of , namely the optimality of the choice of a non-degenerate , is governed by the quality of the refinement link rate and the side information structure.
4.1. Rate-Distortion Region
The following theorem states the optimal rate-distortion region of the Heegard–Berger problem with successive refinement of Figure 3a.
Corollary 1.
The rate-distortion region of the Heegard–Berger problem with successive refinement of Figure 3a is given by the set of rate-distortion triples satisfying:
for some product pmf , such that:
- (1)
- The following Markov chain is valid:
- (2)
- There exists a function such that:
Proof.
The proof of Corollary 1 follows from that of Theorem 1 by setting therein. ☐
Remark 4.
Recall the coding scheme of Theorem 1. If , the second partition of the codebook of the common description, which is relevant for Receiver 2, becomes degenerate since, in this case, all the codewords of a superbin are assigned to a single subbin. Correspondingly, the common message that the encoder sends over the common link carries only the index of the superbin of the codebook of the common description in which lies the typical pair , in addition to the index of the subbin of the codebook of the individual description in which lies the recovered typical . Constraint (14a) on the common rate is in accordance with that Receiver 2 utilizes only the index in the decoding. Furthermore, note that Constraints (14b) and (14c) on the sum-rate can be combined as
which resembles the Heegard–Berger result of (Theorem 2, p. 733, [2]).
Remark 5.
As we already mentioned, the result of Corollary 1 holds for side information sequences that are arbitrarily correlated among them and with the sources. In the specific case in which the user who gets the refinement rate-limited link also has the “better-quality” side information, in the sense that forms a Markov chain, the rate-distortion region of Corollary 1 reduces to the set of all rate-distortion triples that satisfy
for some joint pmf for which (15) and (16) hold. This result can also be obtained from previous works on successive refinement for the Wyner–Ziv source coding problem by Steinberg and Merhav (Theorem 1, [13]) and Tian and Diggavi (Theorem 1, [7]). The results of (Theorem 1, [13]) and (Theorem 1, [7]) hold for possibly distinct, i.e., not necessarily nested, distortion measures at the receivers; but they require the aforementioned Markov chain condition which is pivotal for their proofs. Thus, for the considered degraded reconstruction sets setting, Corollary 1 can be seen as generalizing (Theorem 1, [13]) and (Theorem 1, [7]) to the case in which the side information sequences are arbitrarily correlated among them and with the sources , i.e., do not exhibit any ordering.
Remark 6.
In the case in which it is the user who gets only the common rate-limited link that has the “better-quality” side information, in the sense that forms a Markov chain, the rate distortion region of Corollary 1 reduces to the set of all rate-distortion triples that satisfy
for some joint pmf for which (15) and (16) hold. This result can also be conveyed from [3]. Specifically, in [3] Tian and Diggavi study a therein referred to as “side-information scalable” source coding setup where the side informations are degraded, and the encoder produces two descriptions such that the receiver with the better-quality side information (Receiver 2 if is a Markov chain) uses only the first description to reconstruct its source while the receiver with the low-quality side information (Receiver 1 if is a Markov chain) uses the two descriptions in order to reconstruct its source. They establish inner and outer bounds on the rate-distortion region of the model, which coincide when either one of the decoders requires a lossless reconstruction or when the distortion measures are degraded and deterministic. Similar to the previous remark, Corollary 1 can be seen as generalizing the aforementioned results of [3] to the case in which the side information sequences are arbitrarily correlated among them and with the sources .
Remark 7.
A crucial remark that is in order for the Heegard–Berger problem with successive refinement of Figure 3a, is that, depending on the rate of the refinement link , resorting to a common auxiliary variable might be unnecessary. Indeed, in the case in which needs to be recovered losslessly at the first receiver, for instance, parts of the rate-region can be achieved without resorting to the common auxiliary variable , setting , while other parts of the rate region can only be achieved through a non-trivial choice of .
As such, if , then letting yields the optimal rate region. To see this, note that the rate constraints under lossless construction of write as:
which, can be rewritten as follows
where .
Next, by noting that is achieved by , the claim follows.
However, when , the choice of might be strictly sub-optimal (as shown in the following binary example).
4.2. Binary Example
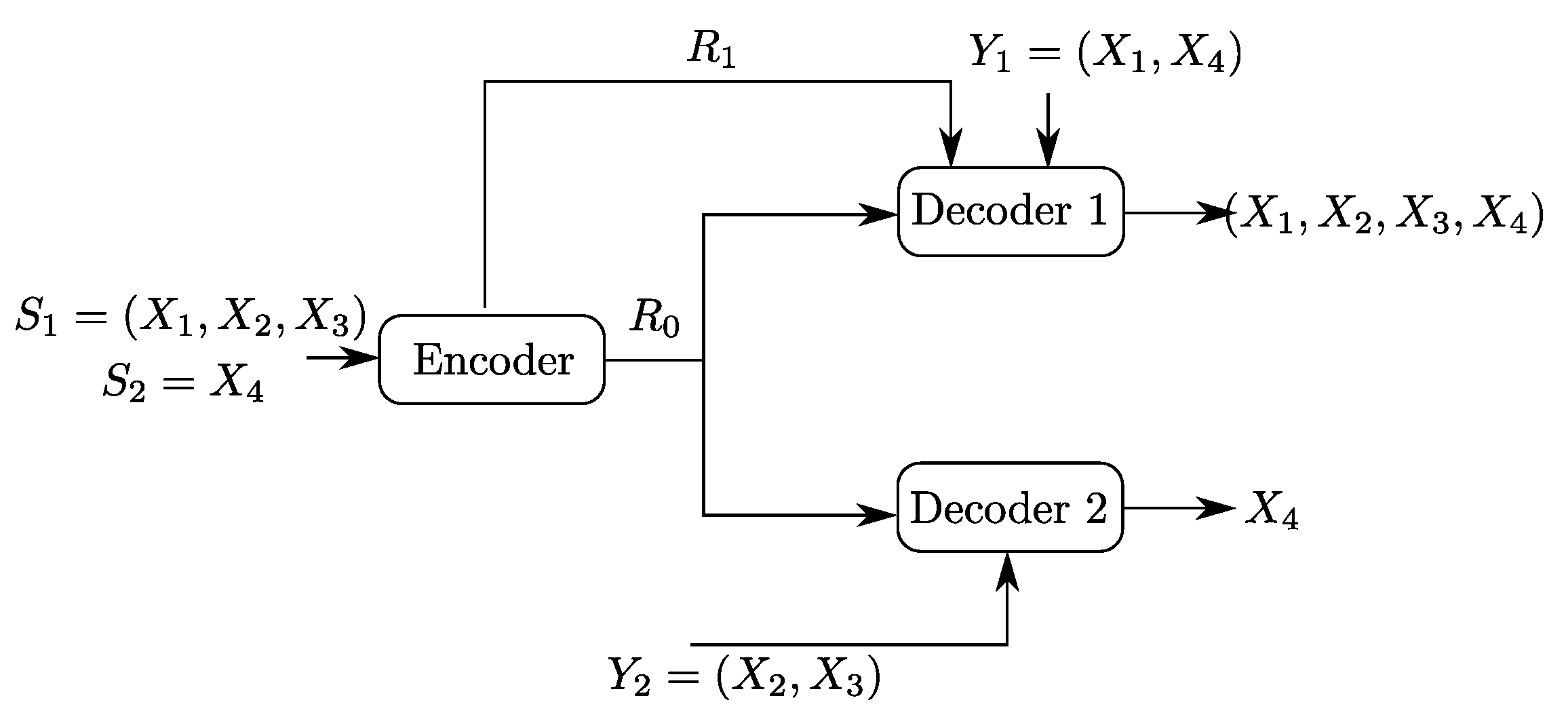
Let , , and be four independent random variables. Let the sources be and . Now, consider the Heegard–Berger model with successive refinement shown in Figure 5. The first user, which gets both the common and individual links, observes the side information and wants to reproduce the pair losslessly. The second user gets only the common link, has side information and wants to reproduce only the component , losslessly.
The side information at the decoders do not exhibit any degradedness ordering, in the sense that none of the Markov chain conditions of Remarks 5 and 6 hold. The following claim provides the rate-region of this binary example.
Claim 1.
The rate region of the binary Heegard–Berger example with successive refinement of Figure 5 is given by the set of rate pairs that satisfy
Proof.
The proof of Claim 1 follows easily by computing the rate region
in the binary setting under study.
First, we note that
which allows then to rewrite the rate region as
The proof of the claim follows by noticing that the following inequalities hold with equality for the choices or or . ☐
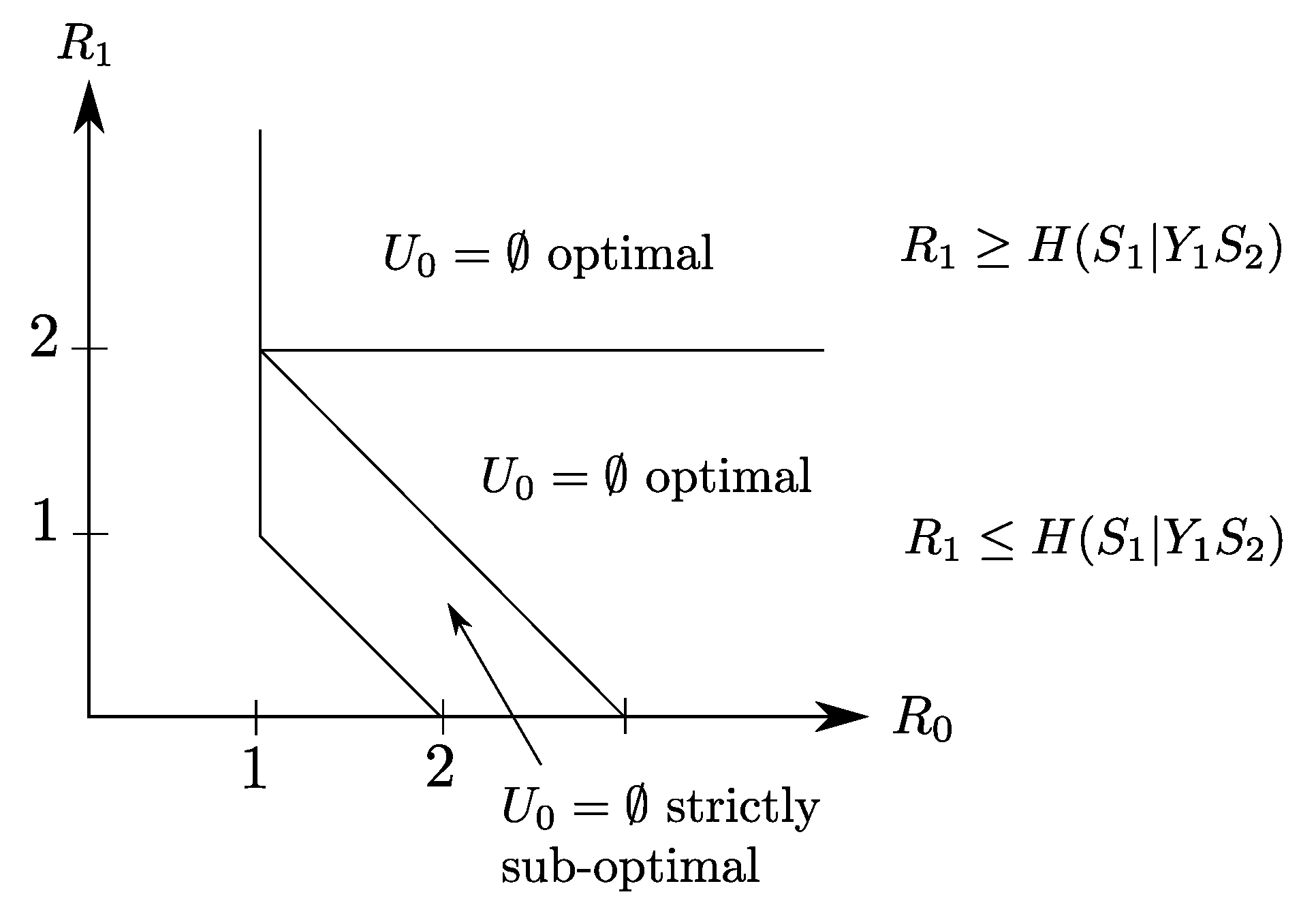
The rate region of Claim 1 is depicted in Figure 6. It is insightful to notice that although the second user is only interested in reproducing the component , the optimal coding scheme that achieves this region sets the common description that is destined to be recovered by both users as one that is composed of not only but also some part , or or , of the source component (though the latter is not required by the second user). A possible intuition is that this choice of is useful for user 1, who wants to reproduce , and its transmission to also the second user does not cost any rate loss since this user has available side information .
5. The Heegard–Berger Problem with Scalable Coding
In the following, we consider the model of Figure 3b. As we already mentioned, the reader may find it appropriate for the motivation to think about the side information as being of lower quality than , in which case, the refinement link that is given to the second user is intended to improve its decoding capability. In this section, we describe the optimal coding scheme for this setting, and show that it can be recovered, independently, from the work of Timo et al. [14] through a careful choice of the coding sets. Next, we illustrate through a binary example the interplay between the utility of the common description and the side information sequences, and the refinement rate .
5.1. Rate-Distortion Region
The following theorem states the rate-distortion region of the Heegard–Berger model with scalable coding of Figure 3b.
Corollary 2.
The rate-distortion region of the Heegard–Berger model with scalable coding of Figure 3b is given by the set of all rate-distortion triples that satisfy
for some product pmf , such that:
- (1)
- The following Markov chain is valid:
- (2)
- There exists a function such that:
Proof.
The proof of Corollary 2 follows from that of Theorem 1 by seeting therein. ☐
Remark 8.
In the specific case in which Receiver 2 has a better-quality side information in the sense that forms a Markov chain, the rate distortion region of Corollary 2 reduces to one that is described by a single rate-constraint, namely
for some conditional that satisfies . This is in accordance with the observation that, in this case, the transmission to Receiver 1 becomes the bottleneck, as Receiver 2 can recover the source component losslessly as long as so does Receiver 1.
Remark 9.
Consider the case in which needs to be recovered losslessly as well at Receiver 1. Then, the rate region is can be expressed as follows
An important comment here is that the optimization problem in does not depend on the refinement link , and the optimal solution to it, i.e., the optimal choice of , meets the solution to the Heegard–Berger problem without refinement link, , rendering it optimal for all choices of , which is a main difference with the Heegard–Berger problem with refinement link of Figure 3a in which the solution to the Heegard–Berger problem (with ) might not be optimal for all values of .
Remark 10.
In (Theorem 1, [14]), Timo et al. present an achievable rate-region for the multistage successive-refinement problem with side information. Timo et al. consider distortion measures of the form , where is the source alphabet and is the reconstruction at decoder l, ; and for this reason this result is not applicable as is to the setting of Figure 3b, in the case of two decoders. However, the result of (Theorem 1, [14]) can be extended to accommodate a distortion measure at the first decoder that is vector-valued; and the direct part of Corollary 2 can then be obtained by applying this extension. Specifically, in the case of two decoders, i.e., , and with , and two distortion measures and chosen such that
and
where is the Hamming distance, letting and , a straightforward extension of (Theorem 1, [14]) to this setting yields a rate-region that is described by the following rate constraints (using the notation of (Theorem 1, [14]))
where , , , and for and such that , the function , , is defined as
where and the sets , , , , , , evaluated in this case, are given in Table 1. It is easy to see that the region described by (35) can be written more explicitly in this case as
Also, setting and in (37) one recovers the rate-region of Corollary 2. (Such a connection can also be stated for the result of Corollary 1).
5.2. Binary Example
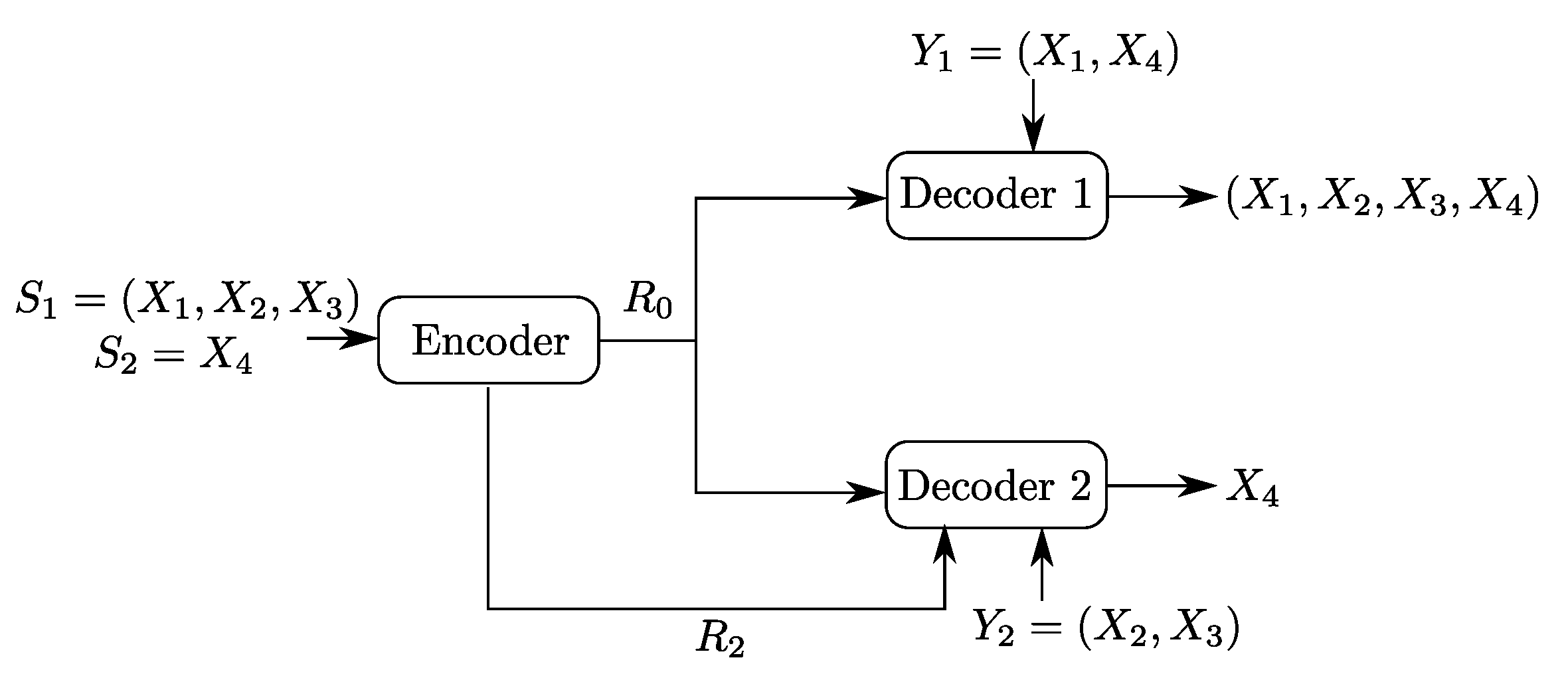
Consider the setting of Figure 7. Let , , and be four independent random variables. Let the sources be and . Now, consider the Heegard–Berger model with scalable coding shown in Figure 7. The first user, which gets both only the common link, observes the side information and wants to reproduce the pair losslessly. The second user gets both the common and private links, has side information and wants to reproduce only the component , losslessly.
Claim 2.
The rate region of the binary Heegard–Berger example with scalable coding of Figure 7 is given by the set of all rate pairs that satisfy and .
Proof.
The proof of Claim 2 follows easily by specializing, and computing, the result of Remark 9 for the example at hand. First note that
where equality in all previous inequalities is satisfied with or with or .
Note as well that the single rate constraint on writes as:
which renders the sum-rate constraint redundant and ends the proof of the claim. ☐
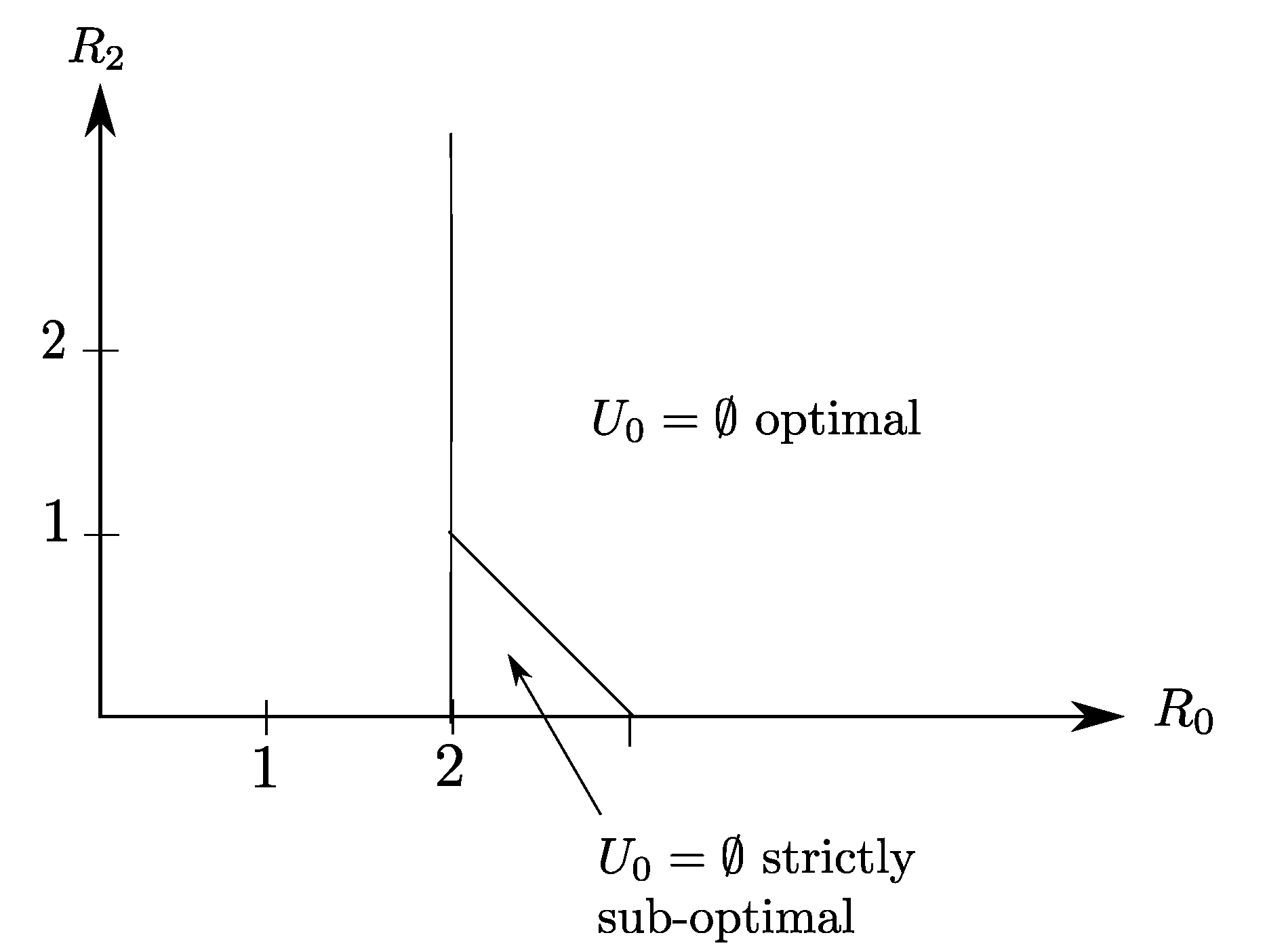
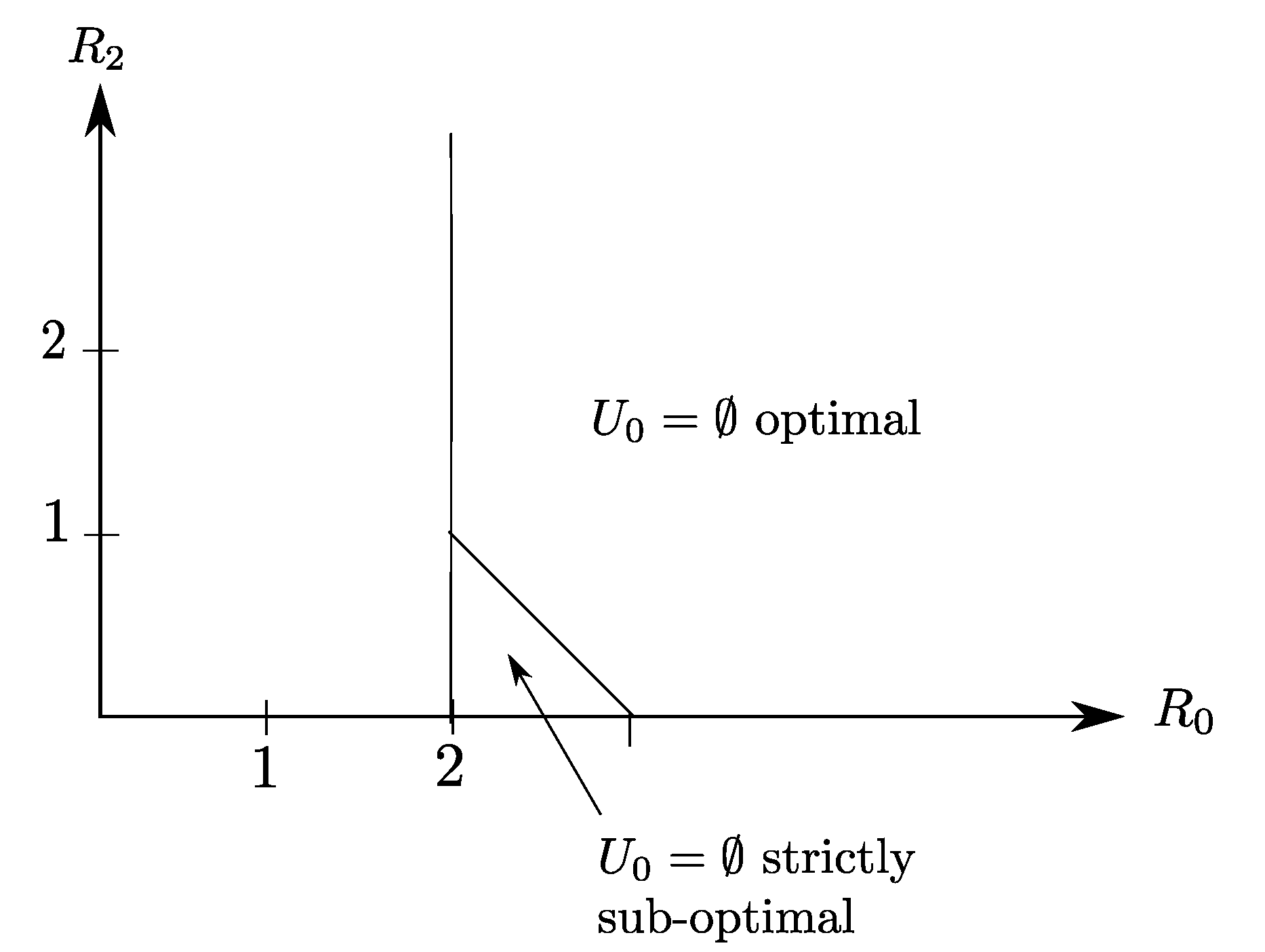
The optimal rate region of Claim 2 is depicted in Figure 8, as the region delimited by the lines and . Note that for this example, the source component , which is the only source component that is required by Receiver 2, needs to be transmitted entirely on the common link to also be recovered losslessly by Receiver 1. For this reason, the refinement link is not-constrained and appears to be useless for this example.
There is a sharp difference with the binary Heegard–Berger example with successive refinement of Figure 5 for which the refinement link may sometimes be instrumental to reducing the required rate on the common link. With scalable coding, the refinement link with rate does not improve the rate transmitted on the common link.
Also, it is insightful to notice that for this example, because of the side information configuration, the choice in Corollary 2 is strictly suboptimal and results in the smaller region that is described by
6. Proof of Theorem 1
In the following, we give the proof of the converse part and the direct part of Theorem 1.
The converse part is strongly dependent on the system model we investigate and consists in a series of careful bounding steps resorting to Fano’s inequality, Markov chains and Csiszár–Körner sum-identity.
The proof of achievability is two-fold, and consists in proving a general result that holds for a Gray–Wyner setting with side information, and then deriving the optimal choice of the auxiliary codewords involved for the specific setting with degraded reconstruction sets.
6.1. Proof of Converse Part
Assume that a rate triple is -achievable. Then, let , where , be the encoded indices and let be the reconstruction sequence at the first decoder such that .
Using Fano’s inequality, the lossless reconstruction of the source at both decoders implies that there exists a sequence such that:
We start by showing the following sum-rate constraint,
We have that
where in (44) stems from Fano’s inequality (42), which results from the lossless reconstruction of at receiver 2.
Let us define then:
In the following, we aim for single-letter bounds on the two quantities A and B.
Since the side information sequences and are not degraded and do not exhibit any structure, together with the sources , single-letterizing the quantity A can be obtained through some judicious bounding steps that are reported below, in which some important Markov chain are shown to hold and quantities are manipulated appropriately, together with several invocations of Csiszár–Körner sum identity .
Let us start by writing that
where (note that the lossless reconstruction of at both receivers is instrumental to the definition of which plays the role of the common auxiliary variable in the proof of converse), and where in (47) follows using the following Csiszár–Körner sum-identity
in (47) follows using the Csiszár–Körner sum-identity given by
while in (47) is the consequence of the following sequence of Markov chains
where (50a) results from that the source sequences are memoryless, while in (50) is a consequence of that is a function of the pair of sequences .
To upper-bound the term B, note the following
where in (51) is a consequence of the following sequence of Markov chains:
where (52a) results from that the source sequences are memoryless, while in (52) is a consequence of that and are each function of the pair of sequences .
Finally, letting so that the choice of satisfy the condition , we write the resulting sum-rate constraint as
Let us now prove that the following bound holds
We have
where in (55) is a consequence of Fano’s inequality in (41), which results from the lossless reconstruction of at receiver 1, and in (55) results from the upper bound on B in (51e).
As for the third rate constraint
we write
where in (57) is a consequence of Fano’s inequality in (42) and in (57) stems for the following sequence of Markov Chains.
where (58a) results from that the source sequences are memoryless, while in (58) is a consequence of that and are each function of the pair of sequences .
Let Q be an integer-valued random variable, ranging from 1 to n, uniformly distributed over [1:n] and independent of all other variables . We have
where in (59) is a consequence of that all sources are memoryless.
Let us now define and , we obtain
The two other rate constraints can be written in a similar fashion,
and this completes the proof of converse. ☐
6.2. Proof of Direct Part
We first show that the rate-distortion region of the proposition that will follow is achievable. The achievability of the rate-distortion region of Theorem 1 follows by choosing then the random variable of the proposition as .
Proposition 1.
An inner bound on the rate-distortion region of the Gray–Wyner model with side information and degraded reconstruction sets of Figure 2 is given by the set of all rate-distortion quadruples that satisfy
for some choice of the random variables such that and there exist functions , , and such that:
and
Proof of Proposition 1.
We now describe a coding scheme that achieves the rate-distortion region of Proposition 1. The scheme is very similar to one that is developed by Shayevitz and Wigger (Theorem 2, [4]) for a Gray–Wyner model with side information. In particular, similar to (Theorem 2, [4]), it uses a double-binning technique for the common codebook, one that is relevant for Receiver 1 and one that is relevant for Receiver 2. Note, however, that, formally, the result of Proposition 1 cannot be obtained by readily applying (Theorem 2, [4]) as is; and one needs to extend the result of (Theorem 2, [4]) in a manner that accounts for that the source component is to be recovered losslessly by both decoders. This can be obtained by extending the distortion measure of (Theorem 2, [4]) to one that is vector-valued, i.e., , where denotes the Hamming distance. For reasons of completeness, we provide here a proof of Proposition 1.
Our scheme has the following parameters: a conditional joint pmf that satisfies (63) and (64), and non-negative communication rates , , , , , , , , , and such that
6.2.1. Codebook Generation
- (1)
- Randomly and independently generate length-n codewords indexed with the pair of indices , where and . Each codeword has i.i.d. entries drawn according to . The codewords are partitioned into superbins whose indices will be relevant for both receivers; and each superbin is partitioned int two different ways, each into subbins whose indices will be relevant for a distinct receiver (i.e., double-binning). This is obtained by partitioning the indices as follows. We partition the indices into bins by randomly and independently assigning each index to an index according to a uniform pmf over . We refer to each subset of indices with the same index as a bin , . In addition, we make two distinct partitions of the indices , each relevant for a distinct receiver. In the first partition, which is relevant for Receiver 1, the indices are assigned randomly and independently each to an index according to a uniform pmf over . We refer to each subset of indices with the same index as a bin , . Similarly, in the second partition, which is relevant for Receiver 2, the indices are assigned randomly and independently each to an index according to a uniform pmf over ; and refer to each subset of indices with the same index as a bin , .
- (2)
- For each , randomly and independently generate length-n codewords indexed with the pair of indices , where and . Each codeword is with i.i.d. elements drawn according to . We partition the indices into bins by randomly and independently assigning each index to an index according to a uniform pmf over . We refer to each subset of indices with the same index as a bin , . Similarly, we partition the indices into bins by randomly and independently assigning each index to an index according to a uniform pmf over ; and refer to each subset of indices with the same index as a bin , .
- (3)
- Reveal all codebooks and their partitions to the encoder, the codebook of and its partitions to both receivers, and the codebook of and its partitions to only Receiver 1.
6.2.2 Encoding
Upon observing the source pair , the encoder finds an index such that the codeword is jointly typical with , i.e.,
By the covering lemma (Chapter 3, [16]), the encoding in this step is successful as long as n is large and
Next, it finds an index such that the codeword is jointly typical with the triple , i.e.,
Again, by the covering lemma (Chapter 3, [16]), the encoding in this step is successful as long as n is large and
Let , and be the bin indices such that , and . In addition, let and be the bin indices such that and . The encoder then sends the product message over the error-free rate-limited common link of capacity . In addition, it sends the product message over the error-free rate-limited individual link to Receiver 1 of capacity , and the message over the error-free rate-limited individual link to Receiver 2 of capacity .
6.2.3 Decoding
Receiver 1 gets the messages . It seeks a codeword and a codeword , with the indices and satisfying , , and , and such that
By the multivariate packing lemma (Chapter 12, [16]), the error in this decoding step at Receiver 1 vanishes exponentially as long as n is large and
Receiver 1 then sets its reproduced codewords and , respectively, as
Similary, Receiver 2 gets the message . It seeks a codeword , with satisfying and , and such that
Again, using the multivariate packing lemma (Chapter 12, [16]), the error in this decoding step at Receiver 2 vanishes exponentially as long as n is large and
Receiver 2 then sets its reconstructed codeword as
Summarizing, combining Equations (67), (69), (71) and (74), the communication rates , , , , , , , , , and satisfy the following inequalities
Choosing , , , and to also satisfy the rate relations
and, finally, using Fourier-Motzkin elimination (FME) to successively project out the nuisance variables , , , , , , and then , , , and from the set of relations formed by (65), (76) and (77), we get the region of Proposition 1.
This completes the proof of the proposition; and so that of the direct part of Theorem 1. ☐
Acknowledgments
Part of the work and the whole publication costs are supported by ISAE-Supaéro.
Author Contributions
Authors had equal contributions in the paper. All authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gray, R.; Wyner, A. Source coding for a simple network. Bell Syst. Tech. J. 1974, 53, 1681–1721. [Google Scholar] [CrossRef]
- Heegard, C.; Berger, T. Rate distortion when side information may be absent. IEEE Trans. Inf. Theory 1985, 31, 727–734. [Google Scholar] [CrossRef]
- Tian, C.; Diggavi, S.N. Side-information scalable source coding. Inf. Theory IEEE Trans. 2008, 54, 5591–5608. [Google Scholar] [CrossRef]
- Shayevitz, O.; Wigger, M. On the capacity of the discrete memoryless broadcast channel with feedback. IEEE Trans. Inf. Theory 2013, 59, 1329–1345. [Google Scholar] [CrossRef]
- Kaspi, A.H. Rate distortion function when side information may be present at the decoder. IEEE Trans. Inf. Theory 1994, 40, 2031–2034. [Google Scholar] [CrossRef]
- Sgarro, A. Source coding with side information at several decoders. Inf. Theory IEEE Trans. 1977, 23, 179–182. [Google Scholar] [CrossRef]
- Tian, C.; Diggavi, S.N. On multistage successive refinement for Wyner–Ziv source coding with degraded side informations. Inf. Theory IEEE Trans. 2007, 53, 2946–2960. [Google Scholar] [CrossRef]
- Timo, R.; Oechtering, T.; Wigger, M. Source Coding Problems With Conditionally Less Noisy Side Information. Inf. Theory IEEE Trans. 2014, 60, 5516–5532. [Google Scholar] [CrossRef]
- Benammar, M.; Zaidi, A. Rate-distortion function for a heegard-berger problem with two sources and degraded reconstruction sets. IEEE Trans. Inf. Theory 2016, 62, 5080–5092. [Google Scholar] [CrossRef]
- Timo, R.; Grant, A.; Kramer, G. Rate-distortion functions for source coding with complementary side information. In Proceedings of the 2011 IEEE International Symposium on Information Theory (ISIT), St. Petersburg, Russia, 31 July–5 August 2011; pp. 2934–2938. [Google Scholar]
- Unal, S.; Wagner, A. An LP bound for rate distortion with variable side information. In Proceedings of the Data Compression Conference (DCC), Snowbird, UT, USA, 4–7 April 2017. [Google Scholar]
- Equitz, W.H.; Cover, T.M. Successive refinement of information. IEEE Trans. Inf. Theory 1991, 37, 269–275. [Google Scholar] [CrossRef]
- Steinberg, Y.; Merhav, N. On successive refinement for the Wyner-Ziv problem. IEEE Trans. Inf. Theory 2004, 50, 1636–1654. [Google Scholar] [CrossRef]
- Timo, R.; Chan, T.; Grant, A. Rate distortion with side-information at many decoders. Inf. Theory IEEE Trans. 2011, 57, 5240–5257. [Google Scholar] [CrossRef]
- Timo, R.; Grant, A.; Chan, T.; Kramer, G. Source coding for a simple network with receiver side information. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Toronto, ON, Canada, 6–11 July 2008; pp. 2307–2311. [Google Scholar]
- Gamal, A.E.; Kim, Y.H. Network Information Theory; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
Figure 1.
Gray–Wyner network with side information at the receivers.
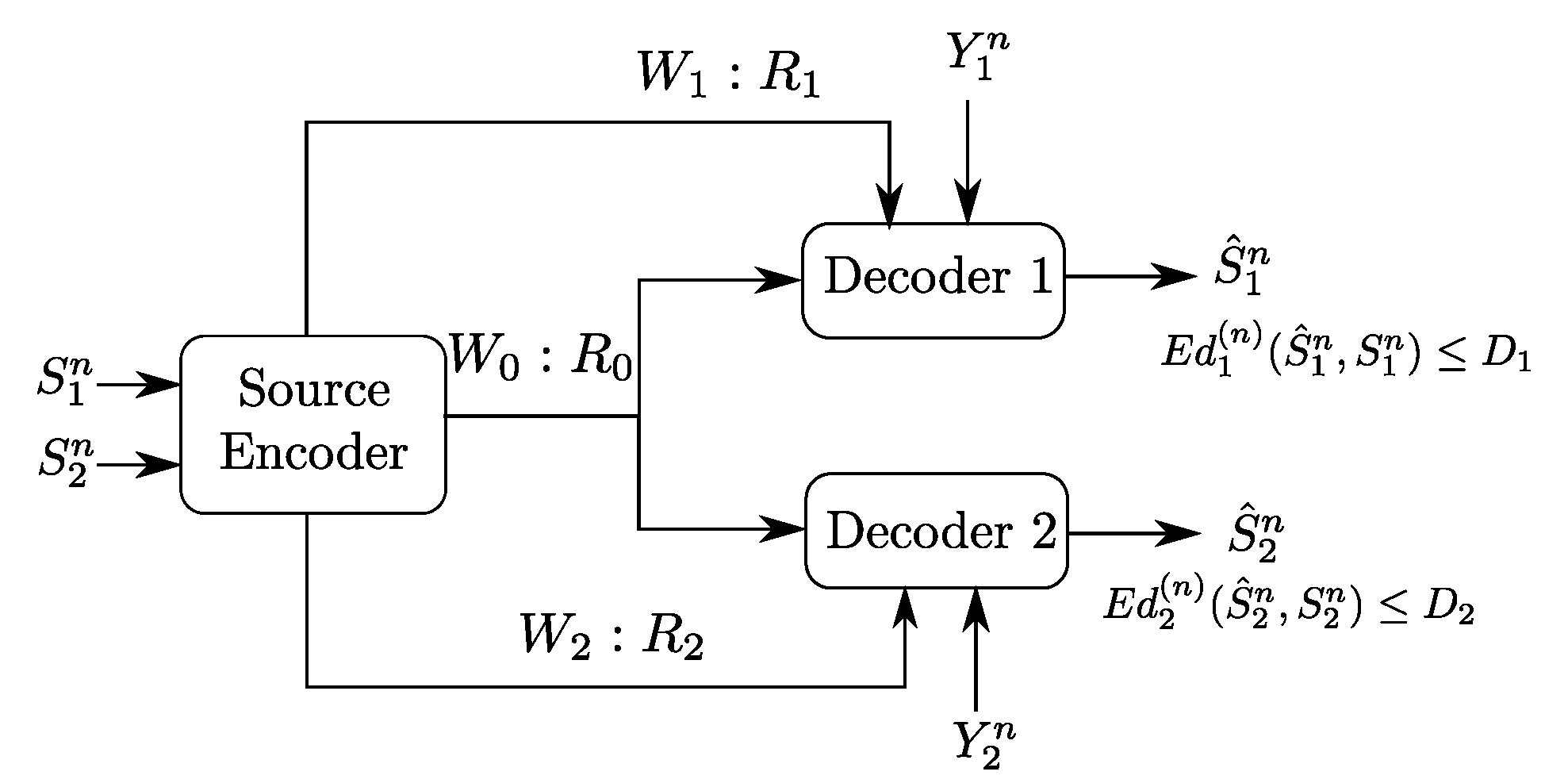
Figure 2.
Gray–Wyner model with side information at both receivers and degraded reconstruction sets.
Figure 2.
Gray–Wyner model with side information at both receivers and degraded reconstruction sets.
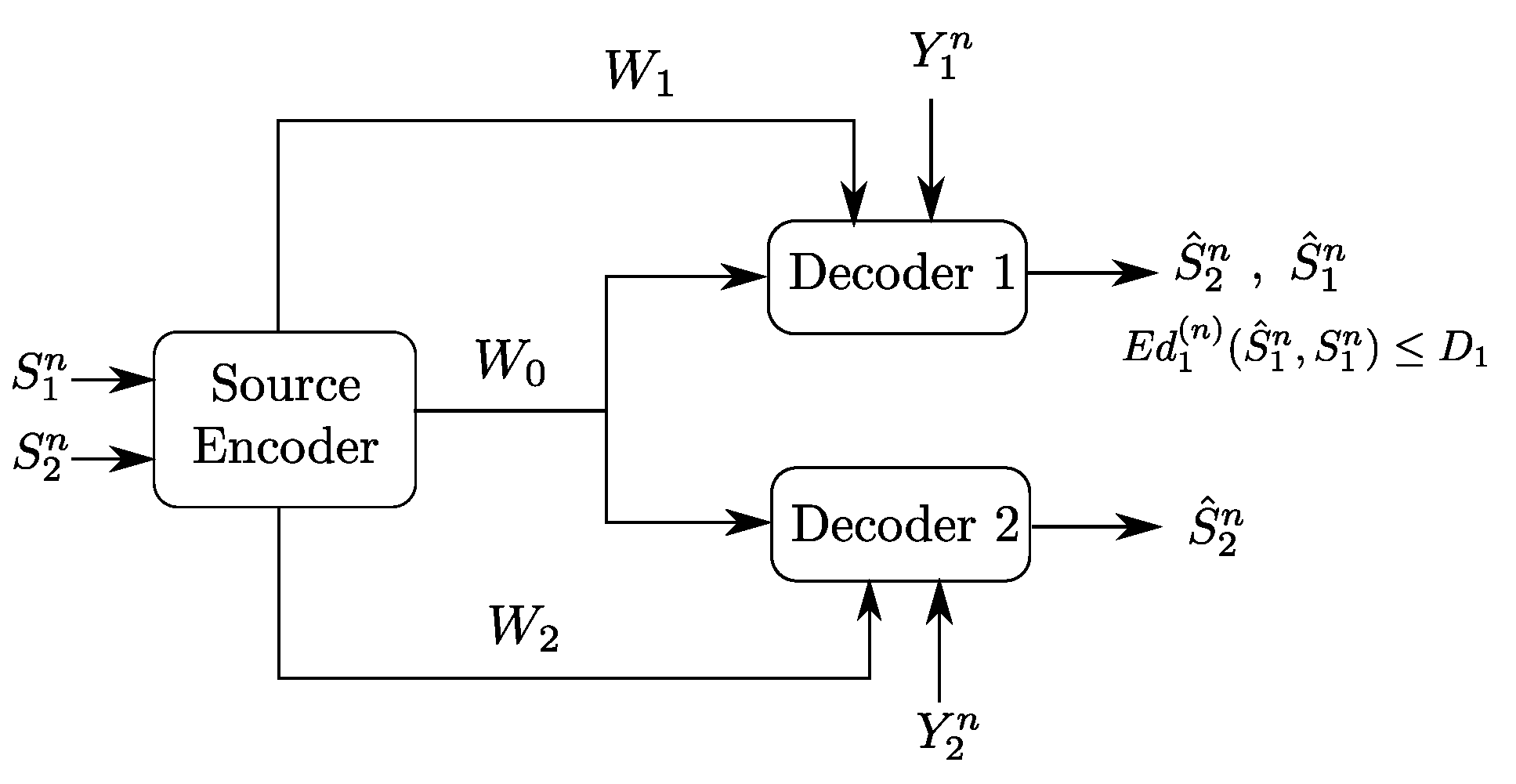
Figure 3.
Two classes of Heegard–Berger models (HB models): (a) HB model with successive refinement; and (b) HB model with scalable coding.
Figure 3.
Two classes of Heegard–Berger models (HB models): (a) HB model with successive refinement; and (b) HB model with scalable coding.
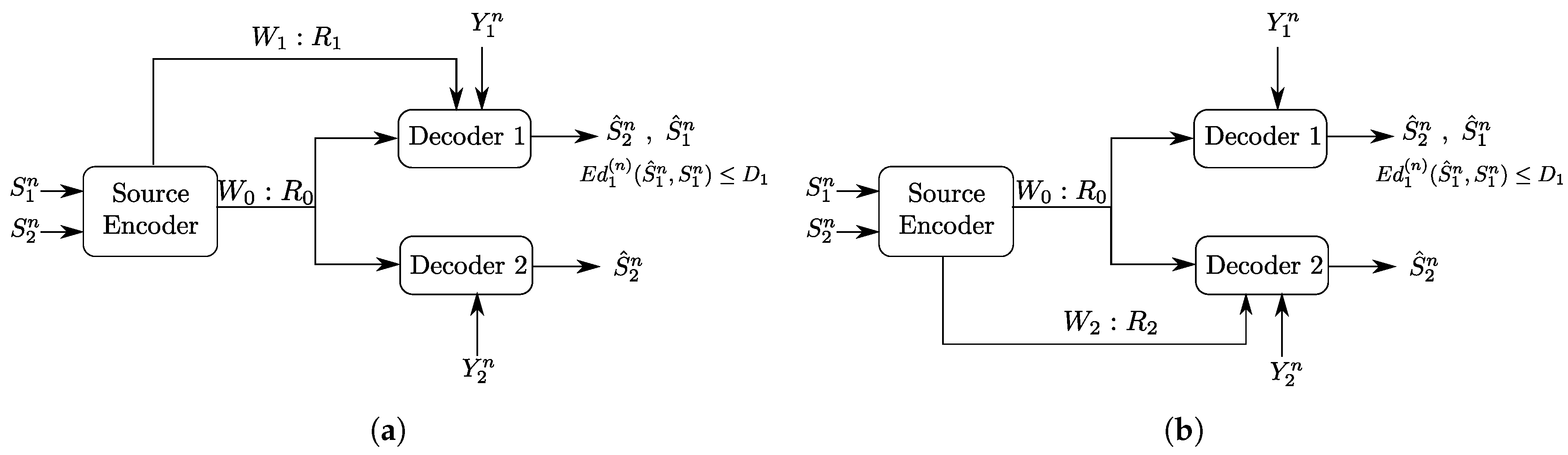
Figure 4.
Comparison of coding schemes for the Gray–Wyner network with side information, Gray–Wyner network and the Heegard–Berger problem: (a) coding scheme for the Gray–Wyner network; (b) coding scheme for the Heegard–Berger problem; and (c) coding scheme for the Gray–Wyner network with side information.
Figure 4.
Comparison of coding schemes for the Gray–Wyner network with side information, Gray–Wyner network and the Heegard–Berger problem: (a) coding scheme for the Gray–Wyner network; (b) coding scheme for the Heegard–Berger problem; and (c) coding scheme for the Gray–Wyner network with side information.
Figure 5.
Binary Heegard–Berger example with successive refinement.
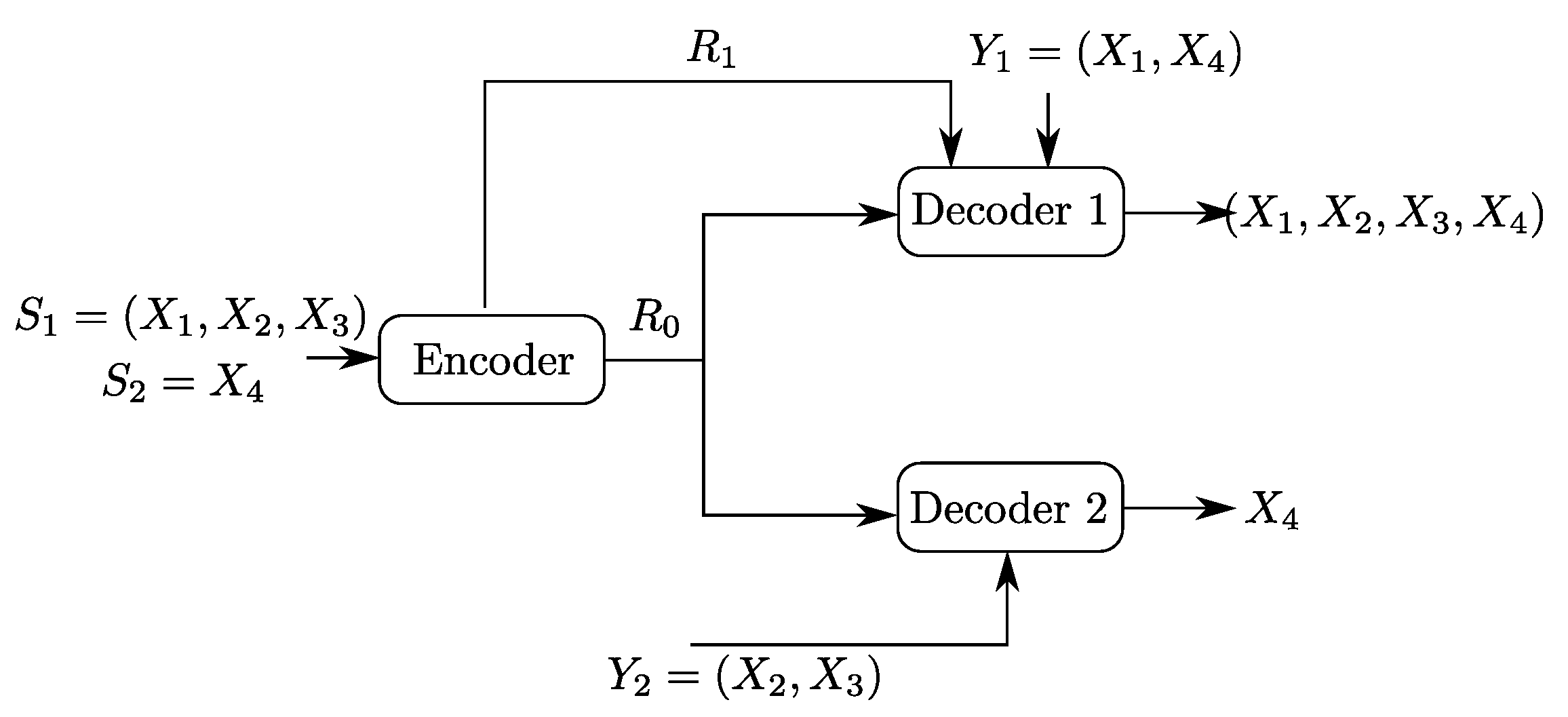
Figure 6.
Rate region of the binary example of Figure 5. The choices or or are optimal irrespective of the value of , while the degenerate choice is optimal only in some slices of the region.
Figure 6.
Rate region of the binary example of Figure 5. The choices or or are optimal irrespective of the value of , while the degenerate choice is optimal only in some slices of the region.
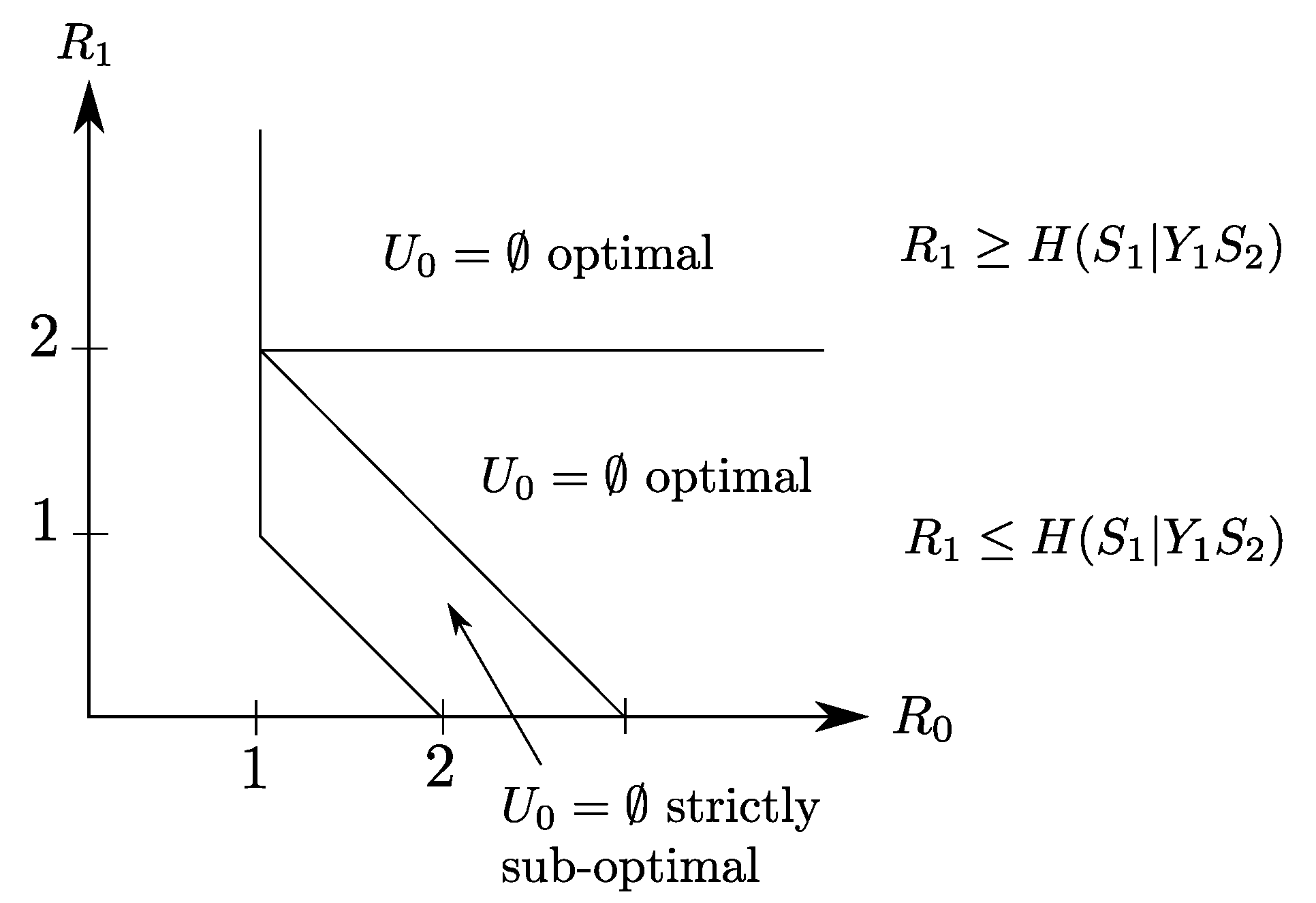
Figure 7.
Binary Heegard–Berger example with scalable coding.
Figure 8.
The optimal rate region for the setting of Figure 7 given by (). The choice of is optimal only in a slice of the region.
Figure 8.
The optimal rate region for the setting of Figure 7 given by (). The choice of is optimal only in a slice of the region.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Auxiliary random variables associated with the subsets that appear in (36).
| ∅ | ∅ | ||
| ∅ | |||
| ∅ | ∅ | ||
| ∅ | ∅ | ∅ | |
| ∅ | ∅ | ∅ | |
| ∅ | ∅ | ∅ |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Benammar, M.; Zaidi, A. Rate-Distortion Region of a Gray–Wyner Model with Side Information. Entropy 2018, 20, 2. https://doi.org/10.3390/e20010002
AMA Style
Benammar M, Zaidi A. Rate-Distortion Region of a Gray–Wyner Model with Side Information. Entropy. 2018; 20(1):2. https://doi.org/10.3390/e20010002
Chicago/Turabian StyleBenammar, Meryem, and Abdellatif Zaidi. 2018. "Rate-Distortion Region of a Gray–Wyner Model with Side Information" Entropy 20, no. 1: 2. https://doi.org/10.3390/e20010002
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.