Stochastic Proximal Gradient Algorithms for Multi-Source Quantitative Photoacoustic Tomography


1
Department of Mathematics, University of Innsbruck, Technikerstraße 13, A-6020 Innsbruck, Austria
2
Institute of Basic Sciences in Engineering Science, University of Innsbruck, Technikerstraße 13, A-6020 Innsbruck, Austria
*
Author to whom correspondence should be addressed.
Entropy 2018, 20(2), 121; https://doi.org/10.3390/e20020121
Submission received: 13 December 2017
/
Revised: 22 January 2018
/
Accepted: 4 February 2018
/
Published: 11 February 2018
(This article belongs to the Special Issue Probabilistic Methods for Inverse Problems)
Abstract
:The development of accurate and efficient image reconstruction algorithms is a central aspect of quantitative photoacoustic tomography (QPAT). In this paper, we address this issues for multi-source QPAT using the radiative transfer equation (RTE) as accurate model for light transport. The tissue parameters are jointly reconstructed from the acoustical data measured for each of the applied sources. We develop stochastic proximal gradient methods for multi-source QPAT, which are more efficient than standard proximal gradient methods in which a single iterative update has complexity proportional to the number applies sources. Additionally, we introduce a completely new formulation of QPAT as multilinear (MULL) inverse problem which avoids explicitly solving the RTE. The MULL formulation of QPAT is again addressed with stochastic proximal gradient methods. Numerical results for both approaches are presented. Besides the introduction of stochastic proximal gradient algorithms to QPAT, we consider the new MULL formulation of QPAT as main contribution of this paper.
1. Introduction
Photoacoustic tomography (PAT) is an emerging imaging modality, which combines the benefits of pure ultrasound imaging (high resolution) with those of pure optical tomography (high contrast); see [1,2]. The basic principle of PAT is as follows (see Figure 1): A semitransparent sample such as a part of a human patient is illuminated with short pulses of optical radiation. A fraction of the optical energy is absorbed inside the sample, which causes thermal heating, expansion, and a subsequent acoustic pressure wave depending on the interior absorbing structure of the sample. The acoustic pressure is measured outside of the sample and used to reconstruct an image of the interior.
One important reconstruction problem in PAT is recovering the initial pressure distribution (see, for example, [3,4,5,6,7,8,9,10]). The initial pressure distribution only provides qualitative information about the tissue-relevant parameters, as it is the product of the optical absorption coefficient and the spatially varying optical intensity, which again indirectly depends on the tissue parameters. Quantitative photoacoustic tomography (QPAT) addresses this issue and aims at quantitatively estimating the tissue parameters by supplementing the inversion of the acoustic wave equation with an inverse problem for light propagation (see, for example, [11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26]).
1.1. Multi-Source QPAT
In this paper, we consider image reconstruction in QPAT using multiple sources. We allow limited view measurements, where, for each illumination, partial data are collected only from a certain angular domain. For modeling the light transport, we use the radiative transfer equation (RTE), which is commonly considered as a very accurate model for light transport in tissue (see, for example, [27,28,29,30]). In particular, opposed to the diffusion approximation, the RTE allows for modeling directed optical radiation, which is required for a reasonable QPAT forward model. Additionally, it allows for including internal voids as regions of low scattering. As proposed in [18], we work with a single-stage reconstruction procedure for QPAT, where the optical parameters are reconstructed directly from the measured acoustical data. The image reconstruction problem of multi-source QPAT using N different sources can be formulated as a system of nonlinear equations (see, for example, [18,31])
Here, is the operator that maps the unknown parameter pair consisting of the absorption coefficient and the scattering coefficient to the measured acoustic data corresponding to the i-th source distribution (see Section 2 for precise definitions). There are two main classes of methods for solving the nonlinear inverse problem (1), namely, Tikhonov type regularization on the one and iterative regularization methods on the other hand [32,33,34]. Both approaches are based on rewriting (1) as a single equation with forward operator and data . In Tikhonov regularization, one defines approximate solutions as minimizers of the penalized least squares functional . Here, is an appropriate regularization functional included to stabilize the inversion process and a regularization parameter that has to be carefully chosen depending on the data and the noise. In iterative regularization methods, stabilization is achieved via early stopping of iterative schemes. In such a situation, one usually applies iterative optimization techniques designed for minimizing the un-regularized least squares functional , and the iteration index plays the role of the regularization parameter.
Tikhonov type as well as iterative regularization methods can both be formulated as finding a solution of the optimization problem
In iterative regularization methods, one takes , the characteristic function of the domain of definition of the forward operator (taking the value 0 in and the value ∞ outside of ). In Tikhonov regularization, we take . Well established algorithms for solving Equation (2) are proximal gradient algorithms [35,36], which can be written in the form
Here, is the proximity operator and the positive step size; denotes the derivative of the i-th forward operator evaluated at with being its Hilbert space adjoint.
1.2. Stochastic Proximal Gradient Algorithms
Each iteration in the proximal gradient algorithm (3) can be numerically quite expensive, since it requires solving the forward and adjoint problems for all N equations in (1). In many cases, stochastic (proximal) gradient methods turn out to be more efficient since these methods only consider one of the equations in (1) per iteration. The stochastic proximal gradient method (see, for example, [37,38,39,40,41,42] and the references therein) for solving (2) is defined by
where corresponds to one of the equations in (1) that is selected randomly for the update in the k-th iteration. In opposition to the standard proximal gradient method, this requires solving only one forward and one adjoint problem per iteration. Therefore, one iterative step is much cheaper for the stochastic gradient method than for the full gradient method. In the case of no regularization, , the stochastic proximal gradient method reduces to the Kaczmarz method for inverse problems studied in [43,44,45].
The computationally most expensive task in the above methods is the numerical solution of the RTE. In this paper, we therefore additionally study a reformulation of the inverse problem of QPAT avoiding the computation of a solution of the RTE. For this purpose, the inverse problem is reformulated as multilinear inverse problem (35), where the RTE is added as a constraint instead of explicitly including its solution. The new formulation will be again addressed by Tikhonov regularization in combination with proximal stochastic gradient methods as discussed in Section 4.
Note that, in QPAT, it has often been assumed that the initial pressure distribution (corresponding to each illumination) is already recovered from acoustic measurements (see, for example, [13,16,23,25,26,46,47,48,49]). Research was focused on inverting the light propagation in tissues either modeled by the RTE or the diffusion approximation. In the case that acoustic measurements are only known on parts of the boundary, reconstruction of the initial pressure distribution is not possible in a stable manner. In order to obtain stable reconstruction results in [18], we propose a single-stage approach for QPAT, where the optical parameters are directly recovered from the acoustic boundary data. Throughout this paper, we will make use of this approach, which delivers stable results especially in the limited view situation. In opposition to [18], in this paper, we introduce (proximal) stochastic gradient methods, which effectively exploit the multi-illumination structure and turn out to be faster than the standard proximal gradient methods.
1.3. Outline
The remainder of this paper is organized as follows. In Section 2, we provide the mathematical model for QPAT (the forward problem) using the RTE. We allow multiple sources and partial acoustic measurements. We also recall known results for QPAT including differentiability of the forward problem. In Section 3, we address the inverse problem of QPAT using Tikhonov regularization and study the proximal stochastic gradient method for its solution. The new reformulation of the inverse problem of QPAT as a multilinear inverse problem is presented in Section 4. For the solution of the proposed formulation, we again develop proximal gradient methods. Numerical results are presented in Section 5. The paper is concluded with a summary and outlook presented in Section 6.
2. The Forward Problem in QPAT
The image reconstruction problem of QPAT can be written as the system (1) of nonlinear equations, where the forward operators map tissue relevant parameters to acoustic data sets recorded in specific regions outside the tissue. Precise formulations will be given in this section.
2.1. Mathematical Notation
We fix some mathematical notation that is used throughout this paper. We denote by a convex domain with piecewise smooth boundary modeling our domain of interest, with denoting the spatial dimension. In order to be able to impose appropriate boundary conditions for the RTE, it is convenient to split the set into inflow and outflow boundaries,
with denoting the outward pointing unit normal at and the standard inner product in . We write for the ball of radius R centered at the origin and suppose .
By and , we denote the Hilbert spaces of square integrable functions on and , respectively. By , we denote the space of all for which is finite. We further write
and define
The inner products in , , , will be denoted by , , , , respectively. The subspace of all with will be denoted by .
Elements in will be written in the form and are the parameters we aim to determine. They are actually required to be contained in the convex subset
where . Elements in will be written in the form and model the optical sources. Elements in describe the optical radiation, and elements in the measured acoustic data.
2.2. The Radiative Transfer Equation
To specify the forward operators, we require mathematical models for the light propagation, the conversion of optical into acoustic energy, and the propagation of the acoustic waves. These models will be presented in the rest of this section.
We model the optical radiation by a function , where is the density of photons at position and propagating into direction . The interaction of the photons with the background are described by absorption coefficient , the scattering coefficient , and the scattering operator , taking the form (see [27,30])
with scattering kernel . The absorption coefficient describes the ability of the background to absorb photons and the scattering coefficient describes the amount of photon scattering. The scattering kernel describes the redistribution of velocity directions due to interaction of the photons with the background. From physical considerations, it is natural to assume k to be measurable, symmetric, nonnegative, and to satisfy . In this article, we are concerned with the situation when the kernel is known a priori.
The photon density is supposed to satisfy the stationary radiative transfer equation (RTE),
with boundary conditions
Here, denotes an internal photon source and a prescribed boundary source pattern. Note that PAT uses very short light pulses (below microseconds) and that light propagation happens on time scales much shorter than the scale of acoustic wave propagation. This justifies the use of the stationary case for the RTE; see [12] for a more complete discussion.
Theorem 1 (Well-posedness of the RTE).
For every and , the stationary RTE (6) admits a unique solution . Moreover, there exists a constant C only depending on the parameters (defining the domain ), such that
Proof.
See [50]. ☐
Definition 1 (Solution operator for the RTE).
Theorem 1 guarantees that the operator , mapping to the solution of the RTE, is well defined. Note that in the actual application are prescribed sources, and are the unknown parameters to be recovered.
2.3. Heating Operator
Due to the spatially varying absorption of photons, the tissue is locally heated and emits an acoustic pressure wave. The acoustic source is proportional to the amount of absorbed photons, the light intensity and the so-called Grüneisen parameter describing the efficiency of conversion of optical to acoustical energy. We assume to be constant and after appropriate re-scaling we take ; for more details about the Grüneisen parameter, we refer to [17]. Therefore, the conversion of the optical energy into acoustic pressure wave is described by the heating operator defined as follows.
Definition 2 (Heating operator).
The heating operator is defined by
If one introduces the averaging operator defined by one may write the heating operator in the form
Because models the photon density, actually models the total light intensity. The heating operator is therefore given by the product of the absorption coefficient and the light intensity. The averaging operator is well defined and bounded and therefore the heating operator is well defined as a mapping between and .
2.4. The Wave Equation
The local heating causes an acoustic pressure wave, where the initial pressure distribution is proportional to a fraction of the absorbed energy. Assuming constant speed of sound and after rescaling, the induced acoustic pressure satisfies the free-space wave equation:
Here, the function vanishes outside , the ball of radius R, and acoustic data are collected on a subset of that we denote by . Recall that coupling of the RTE and the wave equation happens in such a way that the result of the heating operator acts as initial sound source depending on tissue parameters; see Definition 4. Standard existence and uniqueness theory for hyperbolic equations guarantees that, for any , (10) has a unique solution , which continuously depends on . Taking the trace results in loss of regularity by degree . Therefore, is continuous between and . The following Lemma implies the much stronger result that is actually an -isometry.
Lemma 1.
Let have support in and let p denote the solution of (10). Then,
Definition 3.
According to Lemma 1, the operator can be uniquely extended to a bounded linear operator defined on , denoted again by . The partial acoustic measurements made on are then modeled by .
2.5. Analysis of the Forward Problem in Multi-Source QPAT
We assume that we perform N individual experiments, where each experiment consists of separate optical sources and separate acoustic measurements. For the i-th experiment, we denote the source term by and assume the acoustic measurements are made on .
Definition 4.
For any , we denote
Here, denotes the i-th solution operator for the RTE, the i-th heating operator, the i-th partial solution operator for the wave equation, and the i-th forward operator.
Recall that stands for the solution operator for the RTE (6) given in Definition 1, is the averaging operator, and the solution operator for the wave Equation (10); see Definition 3. The operator models the photon transport and its solution (via the heating operator) acts as input for the solution of the wave equation and thereby couples the optical with the acoustical part.
Next, we recall continuity and differentiability of the forward operators. For that purpose, we call a feasible direction at , if there exists some with .
Theorem 2 (Continuity and Differentiability).
- (1)
- The operators , and are sequentially continuous and Lipschitz-continuous.
- (2)
- For every , the one-sided directional derivatives , of , at μ in any feasible direction h exist, and are given by
Proof.
See [18]. ☐
Equations (13) and (14) define a bounded linear operator , which we call the derivative of at . Numerical minimization schemes actually require the adjoint of , which we compute next.
Theorem 3 (Adjoint of ).
Let and . Furthermore, set and let denote the solution of the adjoint problem
with . Then, is given by
Proof.
See [18]. ☐
Given data , most numerical schemes for QPAT use gradients of the partial data-fidelity terms for , where
By the chain rule, the gradient of is given by with , where can be computed by Theorem 3. Convergence of schemes such as the (stochastic) proximal gradient method considered in the following section require the Lipschitz continuity of , which will be shown in the following theorem.
Theorem 4 (Lipschitz continuity of ∇FI)
For any data and any subset , the map is Lipschitz-continuous.
Proof.
Without loss of generality, we assume , and write , , , , and . For any , let denote the solution of (15) with in place of v. Then, for any ,
For the second term in (18), we obtain
where and denote the Lipschitz constants of and , and is a constant. The difference in the first term in (18) is estimated in a similar manner. Furthermore, we have
Noting that , and are linear and bounded, Theorem 2 and the computations above yield the Lipschitz continuity of . ☐
3. The Stochastic Proximal Gradient Method for QPAT
3.1. Formulation of the Inverse Problem
The inverse problem of multi-source QPAT consists in finding from measured data
Here, are the unknowns to be estimated, are the unknown error vectors, and are the given noisy data. Using the notation
we can write (19) in the alternative form
Here, denotes the error vector.
There are, at least, two different strategies to address such an inverse problem: Tikhonov type regularization on the one and iterative methods on the other hand. In this section, we give an overview of such methods. In particular, we describe proximal stochastic gradient methods (for minimizing the Tikhonov functional), which seem particularly well suited for multi-source QPAT but have not been investigated yet for that purpose.
3.2. Tikhonov Regularization in QPAT
In this section, we consider a quadratic Tikhonov regularization term for solving (19). Let
be a linear, densely defined, and possibly unbounded operator between and another Hilbert space and set . In this context, any element with is called an -minimizing solution of . Tikhonov regularization with regularization term consists in computing a minimizer of the generalized Tikhonov functional , defined by
Here, denotes the regularization parameter that acts as a trade-off between the data fitting term and stability.
Theorem 5 (Well-posedness and convergence).
- (1)
- For any and any , the Tikhonov functional has at least one minimizer.
- (2)
- Let , , with . Suppose further that satisfies and as . Then:
- ■
- Every sequence with has a weakly converging subsequence.
- ■
- The limit of every weakly convergent subsequence of is an -minimizing solution of .
- ■
- If the -minimizing solution of is unique and denoted by , then .
Proof.
See [18]. ☐
3.3. The Proximal Stochastic Gradient Algorithm for QPAT
Depending on the particular choice of , the Tikhonov functional (21) may be ill-conditioned. To address this issue in [18], we proposed the proximal gradient algorithm for minimizing (21), which is a very flexible algorithm for minimizing functionals of the form , where F is smooth and G is convex (see, for example, [35,36]). Here, we extend the approach to the proximal stochastic gradient algorithm. Additionally, we propose computing the proximal step using Dykstra’s projection algorithm.
■ Proximal gradient algorithm: The proximal gradient algorithm is a splitting method that iteratively computes explicit gradient steps for F and implicit proximal steps for G. In our context, we take F as the data fidelity term and
where is the characteristic function taking the value zero inside and ∞ outside. The proximal gradient algorithm for minimizing the QPAT-Tikhonov functional (21) reads
Here, denotes the proximal mapping corresponding to the functional ,
Furthermore, is the gradient of the i-th data fidelity term computed in Theorem 3.
■ Dykstra’s projection algorithm: The constraint quadratic optimization problem (24) can efficiently be solved by a proximal variant of Dykstra’s projection algorithm [35,36,53]. For that purpose, we write with . Setting , and , Dykstra’s projection algorithm for (24) reads, for ,
Both proximal mapping in (25) and the projection in (26) can be computed explicitly. In fact, one readily verifies that
Here, is the identity operator on and the projection onto .
■ Proximal stochastic gradient algorithm: The methods described so far require in any iterative step the computation of the full gradient
The evaluation of each requires the solution of the RTE and an adjoint problem and therefore is quite time-consuming. For multi-source QPAT, where , a significant acceleration may be obtained by a Kaczmarz strategy, where in each iterative step only one of the summands is used. The resulting proximal stochastic gradient method for minimizing the Tikhonov functional (21) in QPAT reads
where is selected randomly for the update in the k-th iteration. Furthermore, is the proximal mapping of that can be computed by Dykstra algorithm (25)–(28) and is the gradient of the i-th data fidelity term that can be computed by Theorem 3.
One can also incorporate a block-iterative (or mini-batch) strategy in the stochastic gradient method, meaning that a small subset of of equations is used per iteration instead of a single one. Such a variant could be especially useful in the case of a large number of different illumination patterns. For more details about stochastic gradient methods, see [37,38,39,40,41,42] and the references therein. Note that, in general, convergence of stochastic gradient methods requires asymptotically vanishing step size [42].
3.4. Iterative Regularization Methods
An alternative class of algorithms to address nonlinear inverse problems are iterative techniques. The most basic iterative method for solving the nonlinear inverse problem is the Landweber iteration. In the case that the domain of definition is a proper subset, we have to combine the Landweber iteration with a projection step onto as presented in this subsection. The projected Landweber iteration applied to multi-source QPAT reads
where is the gradient of (see Equation (17)), and denotes the projection onto . In Tikhonov regularization, the regularity of solutions is enforced by an explicitly included penalty. In opposition to that, in iterative regularization methods, a stabilization effect is enforced by early stopping of the iteration. A common stopping rule is the discrepancy principle, where iteration is stopped at the smallest index satisfying where is an estimate for the noise and . Formally, the projected Landweber iteration (32) arises as a special case of the proximal gradient iteration (23) for minimizing the Tikhonov functional, where the regularization parameter is taken as and where the proximal mapping (24) reduces to the orthogonal projection onto .
In a similar manner, one can also use a stochastic version of the projected Landweber iteration. Using the loping strategy of [43,44,45] in order to stabilize the iterative process, the resulting projected loping Landweber–Kaczmarz iteration reads
Here, for any may be randomly selected, is an appropriately chosen positive constant, is the gradient of the i-th data fidelity term computed in Theorem 3 and denotes the projection onto . The iteration (33), (34) terminates if for all . It is worth mentioning that, for noise free data, we have for all k and, therefore, in this special situation, the iteration becomes , which formally arises from the proximal stochastic gradient method (31) with . A convergence analysis of the loping Landweber–Kaczmarz method can be found in [43,44].
4. QPAT as Multilinear Inverse Problem
Since the RTE is time-consuming to solve, we are looking for a suitable reformulation of the inverse problem in multi-source QPAT avoiding computation of a solution of the RTE in each iterative step. In this paper, we propose to write (19) as a multilinear inverse problem, where we add the RTE as a constraint instead of explicitly including its solution. The new formulation will again be addressed by Tikhonov regularization and proximal stochastic gradient methods.
4.1. Reformulation as Multilinear Inverse Problem
Recall the forward problem of QPAT governed by the RTE (6). With the abbreviation , the RTE can be written in compact form , where is the unknown parameter pair. In the case of exact data, the multi-source problem in QPAT (19) then can be reformulated as the problem of finding the tuple such that
Here, the index i indicates the i-th illumination, and , , , are the corresponding source, photon density, heating and acoustical data, respectively, and is the averaging operator. We call (35) and resulting formulations below the multilinear (MULL) formulation of QPAT.
4.2. Application of Tikhonov Regularization
In the case that the data are only known approximately, we use Tikhonov regularization for the stable solution of (35). For that purpose, we approximate (35) by the constrained optimization problem
Here, the operator is possibly unbounded, is the regularization term and the regularization parameter. Note that (36) is equivalent to (21) and therefore the well-posedness and convergence results of Theorem 5 apply to (36) as well.
The constrained optimization problem (36) proposed in this paper can be addressed by various solution methods, for example using penalty methods or augmented Lagrangian techniques [54]. In this paper, we use a penalty approach for solving (36) where the constraints are included as penalty term. To simplify notation, we introduce the unconstraint functionals
for certain parameters and . The sum of the unconstraint functionals (37) over all illuminations will actually be minimized in our numerical implementations. For that purpose, we define
Then, we have . For the approximate solution of (36), we minimize the unconstrained functional , which can be written in the forms
(Here and below, we also write , if it simplifies notation.) The formulations (38) as well as (39) can be solved by various optimization techniques. In particular, as the functionals are given as the sum of simpler terms, the stochastic (proximal) gradient method is particularly appealing.
4.3. Solution of the MULL Formulation of QPAT Using Stochastic Gradient Methods
For solving QPAT in the novel MULL formulation (35), we use stochastic gradient methods similar to previous sections. For that purpose, we require the gradients (determining the steepest descent directions) of the individual functionals with respect to , which are given as
(All other partial gradients are vanishing.) In the following, let N be the number of illuminations, write and let be a sequence of step sizes. In this paper, we propose the following instances of the stochastic proximal gradient method for QPAT based on the multilinear formulation (35).
■ MULL-projected stochastic gradient algorithm: Here, we consider the form (38). For any iteration index choose and and define the sequence of iterates by
Here, the mapping is the proximal mapping corresponding to which equals the projection in the component and equals the identity in the other components.
■ MULL-proximal stochastic gradient algorithm: Here, we consider the form (39). For any iteration index choose and and define sequence of iterates by
The second step implements the proximal mapping of with . As in the previous section, this can be computed with Dykstra’s projection algorithm (25)–(28).
For better scaling, in our actual numerical implementation, we replace the scalar step sizes by the adaptive step size rule
Note that computing such step sizes does barely increase the computational time of the stochastic gradient method, since all involved calculations are anyhow necessary for computing the gradient for the iterative update. In opposition to that, calculating a similar adaptive step size for the algorithms proposed in Section 3 would require evaluation of the forward operators and therefore would significantly increase the computation time. This might be seen as an additional advantage of the novel MULL formulation (35) and its regularized version (36).
5. Numerical Simulations
For the Tikhonov approach to multi-source QPAT, the radiative transfer equation is numerically solved by a streamline diffusion finite element method. Solving the RTE is required to evaluate the forward operator and the gradient of the data fidelity term in every iterative step. For the alternative multilinear approach, these calculations are not necessary. However, the application of the transport operator to has to be calculated for every update of . The simulations are performed on the square domain , where the absorption and the scattering coefficient are supported.
5.1. Numerical Solution of the RTE
Employing a finite element scheme, we derive the weak formulation of Equation (6) by integrating against a test function and replacing the exact solution by a linear combination in the finite element space as in [18]. Here, the basis function is the product of a basis function in space and a basis function in velocity. The spatial domain is triangulated uniformly with mesh size h and -Lagrangian element function for the spatial and velocity domain. By choosing the test function with streamline diffusion coefficient , we obtain
Equation (52) yields a system of linear equations , where evaluating the left-hand side of (52) provides the entries of , the right-hand side gives the components of vector . Note that the sparsity of matrix is low and solving the linear system for the Tikhonov approach is very time-consuming. On the other hand, the solution via the MULL formulation requires only a matrix vector multiplication, since in this case is an independent variable. Thus, only the application to has to be calculated and the transport equation does not need to be solved.
5.2. Test Scenario for Multiple Illumination
The sample is illuminated in orthogonal direction at the boundaries of . In our simulations, we use homogenous illuminations and no internal sources. The illuminations are applied separately from each side (left, right, top and bottom) with acoustic data measured on a half circle on the same side as the illumination (see Figure 2). For the scattering kernel, we use the two-dimensional Henyey–Greenstein kernel,
where the anisotropy factor is chosen as in all our experiments.
For the simulated data, we choose a spatial mesh size , in order to discretize the velocity direction the unit circle is divided in 64 subintervals. In order to avoid inverse crime, for the reconstruction, we use a different spatial mesh size and use velocity directions. Calculating the simulated data corresponds to evaluating the forward operators with perpendicular boundary illumination constant along one side of the boundary square, , where is an approximation of the Dirac delta function and the indicator function of side i of . In this way, we simulate data
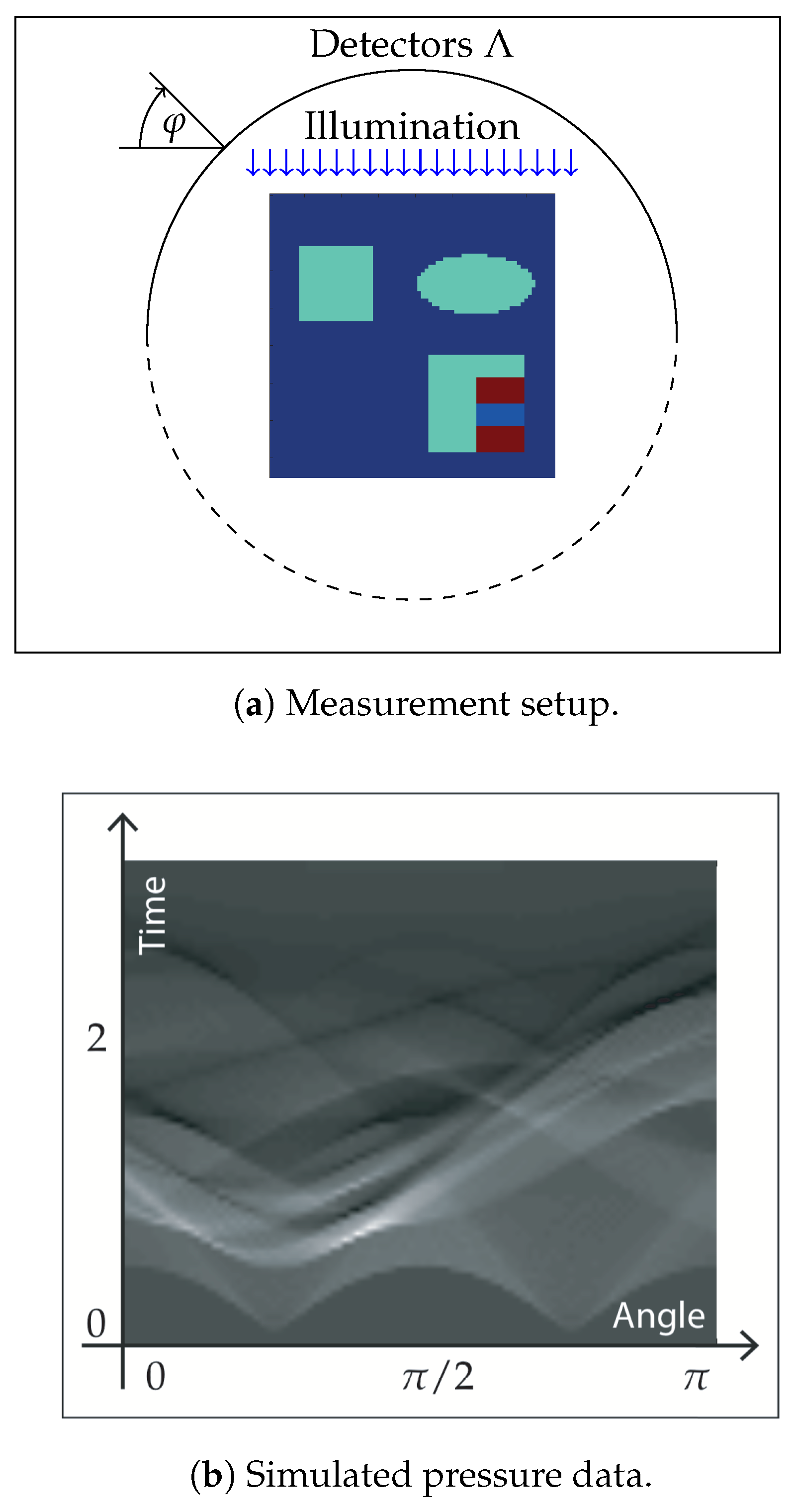
Thereby, the heating operator is computed numerically by solving the RTE as described in Section 5.1. The wave operator is evaluated by straightforward discretization of the well-known explicit formulas for (10) that can be found, for example, in [55,56]. In the following, we present results for exact data (where ) as well as for noisy data. For the noisy data case, we add random noise to the simulated data, i.e., we take the maximum value of the simulated pressure and add white noise with a standard deviation of of that maximal value. The phantom, the setup and the simulated data for one of the four illuminations (top) are shown in Figure 2 and Figure 3.
5.3. Numerical Results
For regularizing the absorption and scattering coefficient, we make use of Laplace regularization and choose and , respectively. We assume that the coefficient is known at the boundary of and is therefore used as the starting value of our iterative schemes. Furthermore, we use the boundary value of for regularization; that is, we implement it in the Dykstra projection procedure (26) by iteratively projecting on the known boundary value. In the following, we discuss the methods that we have outlined in the previous section.
■ Standard formulation of QPAT (19): We assume that the scattering coefficient is known and we restrict ourself to reconstructing the absorption coefficient. Then, the proximal gradient and proximal stochastic gradient algorithm, respectively, read
In contrast, to the full proximal gradient algorithm, the proximal stochastic gradient algorithm avoids evaluating the full gradient , but selects randomly an illumination number for each iterative step. Because of formula (16), each iteration of the above procedures requires the calculation of the solution of the radiative transfer equation as well of its adjoint .
The top row in Figure 4 shows reconstruction result for the absorption coefficient using the original formulation with the proximal gradient method with and 10 iterative steps. The left picture shows the relative error . Note that, in this case, solutions of the RTE and its adjoint have to be computed for four illuminations per iterative step. The reconstruction results in the bottom row in Figure 4 are obtained by the proximal stochastic gradient method with . The regularization parameters have been selected empirically as a trade-off between stability and accuracy. The total number of iterations is taken as 30. In each iteration, a illumination pattern is chosen randomly and the computation of RTE and its adjoint is executed only for this single illumination. Therefore, the computational effort for the proximal stochastic gradient method is approximately 3/4 of the proximal gradient algorithm using full gradients. For the algorithms based on the standard formulation (19), calculating adaptive step sizes similar to (51) is time-consuming as this requires another evaluation of the forward operator and therefore another solution of the RTE. Therefore, we simply use a constant step size rule; in our numerical experiments, it turned out that is a suitable choice.
■ Novel MULL formulation of QPAT (35): The multilinear approach overcomes the problem of solving the RTE by minimizing (38) or (39). In both cases, one selects an arbitrary functional and performs a steepest descent step, resulting in an iterative scheme for the variables , , and H. Recall that none of the partial gradients (40)–(48) requires solving the RTE (which is the most time-consuming part for the standard formulation of QPAT). In each iterative step, we take a random illumination number and a random functional number . The gradient step then consists of the update rule
Dykstra’s algorithm for smoothing the component is applied after each iterative step when . Iteration (55) contains a gradient step for the RTE. Since one gradient step is not enough to obtain an appropriate approximation to the solution of the transport equation, we apply iteration (55) 40 times whenever is chosen. In this situation, we apply the Dykstra iteration in the component after these 40 iteration steps, whereas the positivity projection is done in every step. Flowcharts of the stochastic gradient algorithms (standard and MULL formulations) are shown in Figure 5. For the projected stochastic gradient method, regularization of is done by incorporating the regularization functional in the random choice of functionals; see (38). The positivity restriction is realized with the cut projection applied after every iterative step.
Figure 6 shows reconstructions with the stochastic gradient methods for the novel MULL formulation of QPAT (35). The results in the top row are for the MULL-proximal stochastic gradient algorithm with and in the the bottom row results for the MULL-projected stochastic gradient method with are shown. In both cases, we used 1000 iterations.
Remark 1.
Note that in the stochastic gradient methods for the novel MULL formulation of QPAT calculating the matrix vector product is the most costly part. In contrast, the standard formulation (19) requires the solution of the system . Since the matrix is sparse only in its spatial domain, this is very time-consuming. On the other hand, the matrix (which is a discretization of ) has a simple dependence on the variables . We therefore can compute the velocity entries of at the beginning of the iterative process to save computation time.
The reconstruction times for the final reconstructions using all methods described above are shown in Table 1. For the standard formulation of QPAT, the reconstruction times seem to be in accordance with reported results using gradient or Newton-type methods for QPAT (see, for example, [48].) The methods based on the new MULL formulation (35) (after 1000 iterations) are faster than the methods based on the standard formulation (19) of QPAT (after 10, respectively, 40 iterations). From the relative reconstruction errors shown in Figure 4 and Figure 6, one notices that, opposed to the methods based on (19), the methods using the MULL formulation could even be stopped much earlier while still obtaining a comparable reconstruction quality. We roughly estimate a speedup of a factor 10 using the novel MULL formulation instead of the standard formulation of QPAT.
In Figure 7, we show results for noisy data using the proximal gradient method based on the standard formulation (19) (top) and the proximal stochastic gradient method using the MULL formulation for QPAT (bottom). The regularization parameter is chosen as in the exact data case. Finally, in Figure 8, we show reconstruction results using only two consecutive illuminations applied from the top and from the left with noisy data. We use 10 iterations for the proximal gradient algorithm based on (19) (shown in left image in Figure 8) and 500 iterations for the stochastic gradient algorithms based on the MULL formulation (35) (shown in the right image in Figure 8).
6. Conclusions
In this paper, we developed efficient proximal stochastic gradient methods for image reconstruction in multi-source QPAT. We used the RTE as an accurate model for light transport and employed the single stage approach for QPAT introduced in [18]. One class of the proximal stochastic gradient methods has been developed based on the standard formulation for QPAT given in (19). Additionally, we developed another class using proximal stochastic gradient methods for the new MULL formulations (35) and (36) for QPAT. Besides proposing proximal stochastic gradient methods for QPAT, we also consider the formulations (35) and (36) as the main contributions of the present article. These new formulations avoid the time-consuming evaluation of the RTE at each iteration and allow for treating the QPAT problem as a constrained optimization problem, which enables the use of a variety of numerical algorithms. Here, we used a penalty approach in combination with stochastic gradient methods for the solution. Future work will be done in the direction of developing new algorithms based on (35) and (36). Additionally, we will investigate the use of different regularization terms in (36). Finally, the theoretical convergence analysis of proximal gradient algorithms and other iterative algorithms for solving (35) will be the subject of future research.
Acknowledgments
Markus Haltmeier acknowledges support of the Austrian Science Fund (FWF), project P 30747. Simon Rabanser is a recipient of a DOC Fellowship of the Austrian Academy of Sciences (OEAW) and acknowledges support of the OEAW for his PhD project. We thank the referees for helpful comments that increased the readability of the this manuscript, as well as pointing out some interesting references to us.
Author Contributions
Markus Haltmeier, Lukas Neumann and Simon Rabanser developed the reconstruction algorithms and the numerical implementation; Simon Rabanser performed the numerical experiments; Markus Haltmeier, Lukas Neumann and Simon Rabanser wrote the paper; Markus Haltmeier and Lukas Neumann supervised the project.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Beard, P. Biomedical photoacoustic imaging. Interface Focus 2011, 1, 602–631. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.V. Multiscale photoacoustic microscopy and computed tomography. Nat. Photonics 2009, 3, 503–509. [Google Scholar] [CrossRef] [PubMed]
- Agranovsky, M.; Kuchment, P.; Kunyansky, L. On reconstruction formulas and algorithms for the thermoacoustic tomography. In Photoacoustic Imaging and Spectroscopy; Wang, L.V., Ed.; CRC Press: Boca Raton, FL, USA, 2009; pp. 89–101. [Google Scholar]
- Burgholzer, P.; Bauer-Marschallinger, J.; Grün, H.; Haltmeier, M.; Paltauf, G. Temporal back-projection algorithms for photoacoustic tomography with integrating line detectors. Inverse Probl. 2007, 23, S65–S80. [Google Scholar] [CrossRef]
- Haltmeier, M. Universal inversion formulas for recovering a function from spherical means. SIAM J. Math. Anal. 2014, 46, 214–232. [Google Scholar] [CrossRef]
- Haltmeier, M.; Nguyen, L.V. Analysis of iterative methods in photoacoustic tomography with variable sound speed. SIAM J. Imaging Sci. 2017, 10, 751–781. [Google Scholar] [CrossRef]
- Haltmeier, M.; Schuster, T.; Scherzer, O. Filtered backprojection for thermoacoustic computed tomography in spherical geometry. Math. Methods Appl. Sci. 2005, 28, 1919–1937. [Google Scholar] [CrossRef]
- Huang, C.; Wang, K.; Nie, L.; Wang, L.V.; Anastasio, M.A. Full-wave iterative image reconstruction in photoacoustic tomography with acoustically inhomogeneous media. IEEE Trans. Med. Imaging 2013, 32, 1097–1110. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, L.V.; Kunyansky, L.A. A Dissipative Time Reversal Technique for Photoacoustic Tomography in a Cavity. SIAM J. Imaging Sci. 2016, 9, 748–769. [Google Scholar] [CrossRef]
- Rosenthal, A.; Ntziachristos, V.; Razansky, D. Acoustic Inversion in Optoacoustic Tomography: A Review. Curr. Med. Imaging Rev. 2013, 9, 318–336. [Google Scholar] [CrossRef] [PubMed]
- Ammari, H.; Bossy, E.; Jugnon, V.; Kang, H. Reconstruction of the Optical Absorption Coefficient of a Small Absorber from the Absorbed Energy Density. SIAM J. Appl. Math. 2011, 71, 676–693. [Google Scholar] [CrossRef]
- Bal, G.; Jollivet, A.; Jugnon, V. Inverse transport theory of photoacoustics. Inverse Probl. 2010, 26, 025011. [Google Scholar] [CrossRef]
- Bal, G.; Ren, K. Multi-source quantitative photoacoustic tomography in a diffusive regime. Inverse Probl. 2011, 27, 075003. [Google Scholar] [CrossRef]
- Chen, J.; Yang, Y. Quantitative photo-acoustic tomography with partial data. Inverse Probl. 2012, 28, 115014. [Google Scholar] [CrossRef]
- Cox, B.T.; Arridge, S.A.; Beard, P.C. Gradient-Based Quantitative Photoacoustic Image Reconstruction for Molecular Imaging. Proc. SPIE 2007, 6437, 64371T. [Google Scholar]
- Cox, B.T.; Arridge, S.R.; Köstli, P.; Beard, P.C. Two-dimensional quantitative photoacoustic image reconstruction of absorption distributions in scattering media by use of a simple iterative method. Appl. Opt. 2006, 45, 1866–1875. [Google Scholar] [CrossRef] [PubMed]
- Cox, B.T.; Laufer, J.G.; Arridge, S.R.; Beard, P.C. Quantitative spectroscopic photoacoustic imaging: A review. J. Biomed. Opt. 2012, 17, 0612021. [Google Scholar] [CrossRef] [PubMed]
- Haltmeier, M.; Neumann, L.; Rabanser, S. Single-stage reconstruction algorithm for quantitative photoacoustic tomography. Inverse Probl. 2015, 31, 065005. [Google Scholar] [CrossRef]
- Haltmeier, M.; Neumann, L.; Nguyen, L.V.; Rabanser, S. Analysis of the Linearized Problem of Quantitative Photoacoustic Tomography. arXiv, 2017; arXiv:1702.04560. [Google Scholar]
- Kruger, R.A.; Lui, P.; Fang, Y.R.; Appledorn, R.C. Photoacoustic Ultrasound (PAUS)–Reconstruction Tomography. Med. Phys. 1995, 22, 1605–1609. [Google Scholar] [CrossRef] [PubMed]
- Mamonov, A.V.; Ren, K. Quantitative photoacoustic imaging in radiative transport regime. Commun. Math. Sci. 2014, 12, 201–234. [Google Scholar] [CrossRef]
- Naetar, W.; Scherzer, O. Quantitative Photoacoustic Tomography with Piecewise Constant Material Parameters. SIAM J. Imaging Sci. 2014, 7, 1755–1774. [Google Scholar] [CrossRef]
- Ren, K.; Gao, H.; Zhao, H. A hybrid reconstruction method for quantitative PAT. SIAM J. Imaging Sci. 2013, 6, 32–55. [Google Scholar] [CrossRef]
- Rosenthal, A.; Razansky, D.; Ntziachristos, V. Fast Semi-Analytical Model-Based Acoustic Inversion for Quantitative Optoacoustic Tomography. IEEE Trans. Med. Imaging 2010, 29, 1275–1285. [Google Scholar] [CrossRef] [PubMed]
- Tarvainen, T.; Cox, B.T.; Kaipio, J.P.; Arridge, S.A. Reconstructing absorption and scattering distributions in quantitative photoacoustic tomography. Inverse Probl. 2012, 28, 084009. [Google Scholar] [CrossRef]
- Yao, L.; Sun, Y.; Jiang, H. Transport-based quantitative photoacoustic tomography: Simulations and experiments. Phys. Med. Biol. 2010, 55, 1917–1934. [Google Scholar] [CrossRef] [PubMed]
- Arridge, S.R. Optical tomography in medical imaging. Inverse Probl. 1999, 15, R41–R93. [Google Scholar] [CrossRef]
- Dautray, R.; Lions, J. Mathematical Analysis and Numerical Methods for Science and Technology; Springer: Berlin, Germany, 1993. [Google Scholar]
- Egger, H.; Schlottbom, M. Numerical methods for parameter identification in stationary radiative transfer. Comput. Optim. Appl. 2015, 62, 67–83. [Google Scholar] [CrossRef]
- Kanschat, G. Solution of radiative transfer problems with finite elements. In Numerical Methods in Multidimensional Radiative Transfer; Springer: Berlin, Germany, 2009; pp. 49–98. [Google Scholar]
- Gao, H.; Feng, J.; Song, L. Limited-view multi-source quantitative photoacoustic tomography. Inverse Probl. 2015, 31, 065004. [Google Scholar] [CrossRef]
- Engl, H.W.; Hanke, M.; Neubauer, A. Regularization of Inverse Problems; Springer Science & Business Media: Berlin, Germany, 1996. [Google Scholar]
- Kaltenbacher, B.; Neubauer, A.; Scherzer, O. Iterative Regularization Methods for Nonlinear Ill-Posed Problems; Walter de Gruyter: Berlin, Geramny, 2008. [Google Scholar]
- Scherzer, O.; Grasmair, M.; Grossauer, H.; Haltmeier, M.; Lenzen, F. Variational Methods in Imaging; Applied Mathematical Sciences; Springer: New York, NY, USA, 2009. [Google Scholar]
- Combettes, P.L.; Wajs, V.R. Signal recovery by proximal forward-backward splitting. Multiscale Model. Simul. 2005, 4, 1168–1200. [Google Scholar] [CrossRef]
- Bauschke, H.H.; Combettes, P.L. Convex Analysis and Monotone Operator Theory in Hilbert Spaces; Springer: Berlin, Germany, 2011. [Google Scholar]
- Bertsekas, D.P. Incremental gradient, subgradient, and proximal methods for convex optimization: A survey. In Optimization for Machine Learing; Sra, S., Nowozin, S., Wright, S.J., Eds.; The MIT Press: London, UK, 2012. [Google Scholar]
- Bertsekas, D.P. Incremental proximal methods for large scale convex optimization. Math. Program. 2011, 129, 163–195. [Google Scholar] [CrossRef] [Green Version]
- Xiao, L.; Zhang, T. A proximal stochastic gradient method with progressive variance reduction. SIAM J. Optim. 2014, 24, 2057–2075. [Google Scholar] [CrossRef]
- Duchi, J.; Singer, Y. Efficient online and batch learning using forward backward splitting. J. Mach. Learn. Res. 2009, 10, 2899–2934. [Google Scholar]
- Li, H.; Haltmeier, M. The Averaged Kaczmarz Iteration for Solving Inverse Problems. arXiv, 2017; arXiv:1709.00742. [Google Scholar]
- Pereyra, M.; Schniter, P.; Chouzenoux, E.; Pesquet, J.-C.; Tourneret, J.Y.; Hero, A.O.; McLaughlin, S. A survey of stochastic simulation and optimization methods in signal processing. IEEE J. Sel. Top. Signal Process. 2016, 10, 224–241. [Google Scholar] [CrossRef]
- De Cezaro, A.; Haltmeier, M.; Leitão, A.; Scherzer, O. On steepest-descent-Kaczmarz methods for regularizing systems of nonlinear ill-posed equations. Appl. Math. Comput. 2008, 202, 596–607. [Google Scholar] [CrossRef]
- Haltmeier, M.; Leitao, A.; Scherzer, O. Kaczmarz methods for regularizing nonlinear ill-posed equations I: convergence analysis. Inverse Probl. Imaging 2007, 1, 289–298. [Google Scholar]
- Haltmeier, M.; Kowar, R.; Leitao, A.; Scherzer, O. Kaczmarz methods for regularizing nonlinear ill-posed equations II: Applications. Inverse Probl. Imaging 2007, 1, 507–523. [Google Scholar]
- Alberti, G.; Ammari, H. Disjoint sparsity for signal separation and applications to hybrid inverse problems in medical imaging. Appl. Comput. Harmon. Anal. 2017, 42, 319–349. [Google Scholar] [CrossRef]
- Ammari, H.; Garnier, J.; Kang, H.; Nguyen, L.; Seppecher, L. Multi-Wave Medical Imaging, Mathematical Modelling & Imaging Reconstruction; World Scientific Publishing: London, UK, 2017. [Google Scholar]
- Saratoon, T.; Tarvainen, T.; Cox, B.T.; Arridge, S.R. A gradient-based method for quantitative photoacoustic tomography using the radiative transfer equation. Inverse Probl. 2013, 29, 075006. [Google Scholar] [CrossRef]
- Wang, C.; Zhou, T. On iterative algorithms for quantitative photoacoustic tomography in the radiative transport regime. Inverse Probl. 2017, 33, 115006. [Google Scholar] [CrossRef]
- Egger, H.; Schlottbom, M. Stationary radiative transfer with vanishing absorption. Math. Models Methods Appl. Sci. 2014, 24, 973–990. [Google Scholar] [CrossRef]
- Finch, D.; Patch, S.K.; Rakesh. Determining a function from its mean values over a family of spheres. SIAM J. Math. Anal. 2004, 35, 1213–1240. [Google Scholar] [CrossRef]
- Finch, D.; Haltmeier, M.; Rakesh. Inversion of spherical means and the wave equation in even dimensions. SIAM J. Appl. Math. 2007, 68, 392–412. [Google Scholar] [CrossRef]
- Combettes, P.L.; Pesquet, J.C. Proximal splitting methods in signal processing. In Fixed-Point Algorithms for Inverse Problems in Science and Engineering; Springer: New York, NY, USA, 2011; pp. 185–212. [Google Scholar]
- Ito, K.; Kunisch, K. Lagrange Multiplier Approach to Variational Problems and Applications; Society for Industrial and Applied Mathematics (SIAM): Philadelphia, PA, USA, 2008. [Google Scholar]
- John, F. Partial Differential Equations, 4th ed.; Applied Mathematical Sciences; Springer: New York, NY, USA, 1982. [Google Scholar]
- Evans, L.C. Partial Differential Equations; Graduate Studies in Mathematics; American Mathematical Society: Providence, RI, USA, 1998. [Google Scholar]
Figure 1.
Basic principles of PAT. Left: the investigated object is illuminated with a short optical pulse; Middle: due to the thermoelastic effect, the absorbed light distribution induces an acoustic pressure wave depending on internal tissue properties; Right: the acoustic pressure wave is measured outside the object and used to reconstruct an image of the interior.
Figure 1.
Basic principles of PAT. Left: the investigated object is illuminated with a short optical pulse; Middle: due to the thermoelastic effect, the absorbed light distribution induces an acoustic pressure wave depending on internal tissue properties; Right: the acoustic pressure wave is measured outside the object and used to reconstruct an image of the interior.

Figure 2.
(a) The phantom is defined on the square and the acoustic pressure is measured on a semi-circle on the side of the illumination; (b) the simulated pressure correspond to the phantom and the illumination in (a) and are represented as gray scale density.
Figure 2.
(a) The phantom is defined on the square and the acoustic pressure is measured on a semi-circle on the side of the illumination; (b) the simulated pressure correspond to the phantom and the illumination in (a) and are represented as gray scale density.
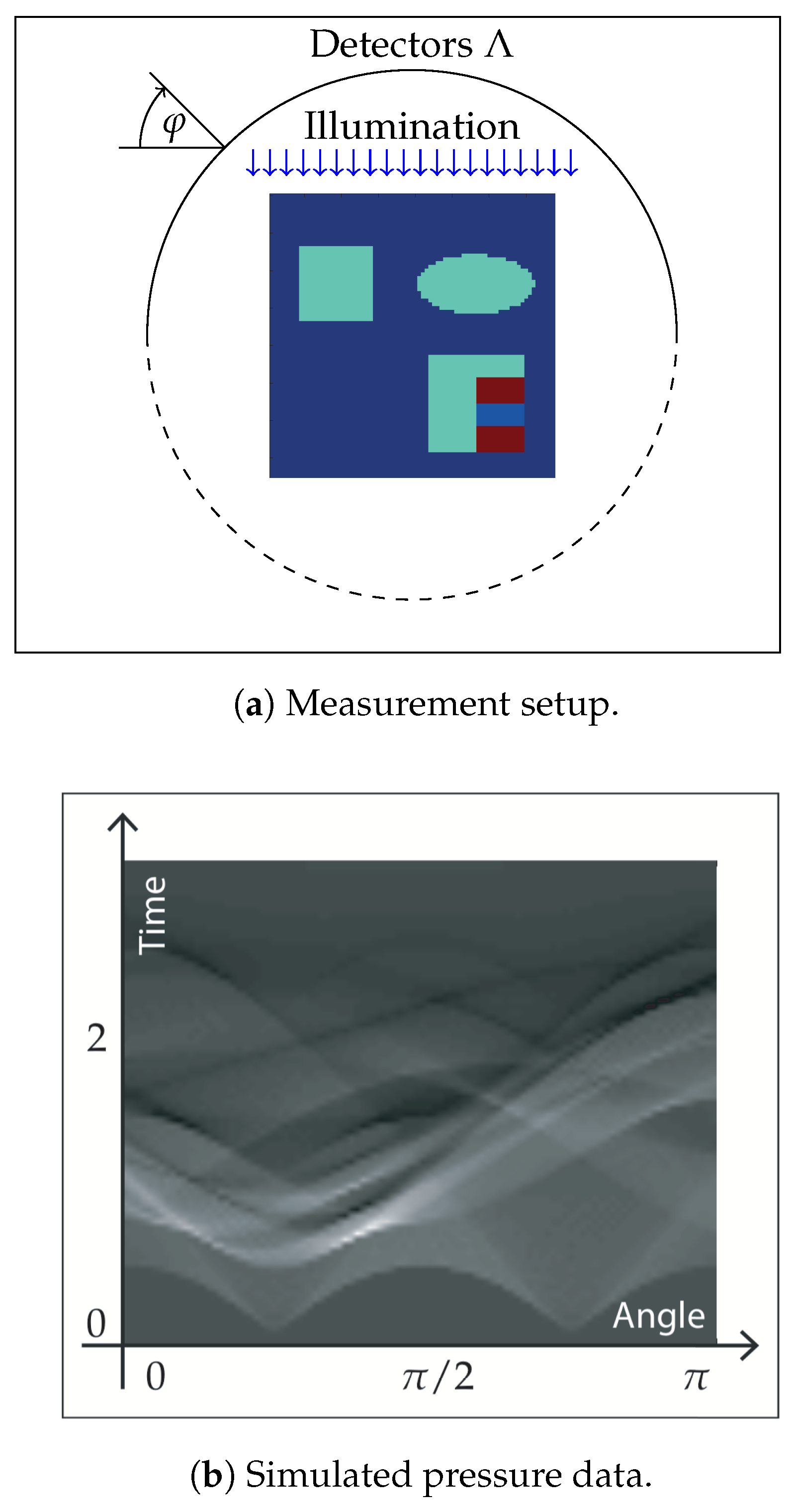
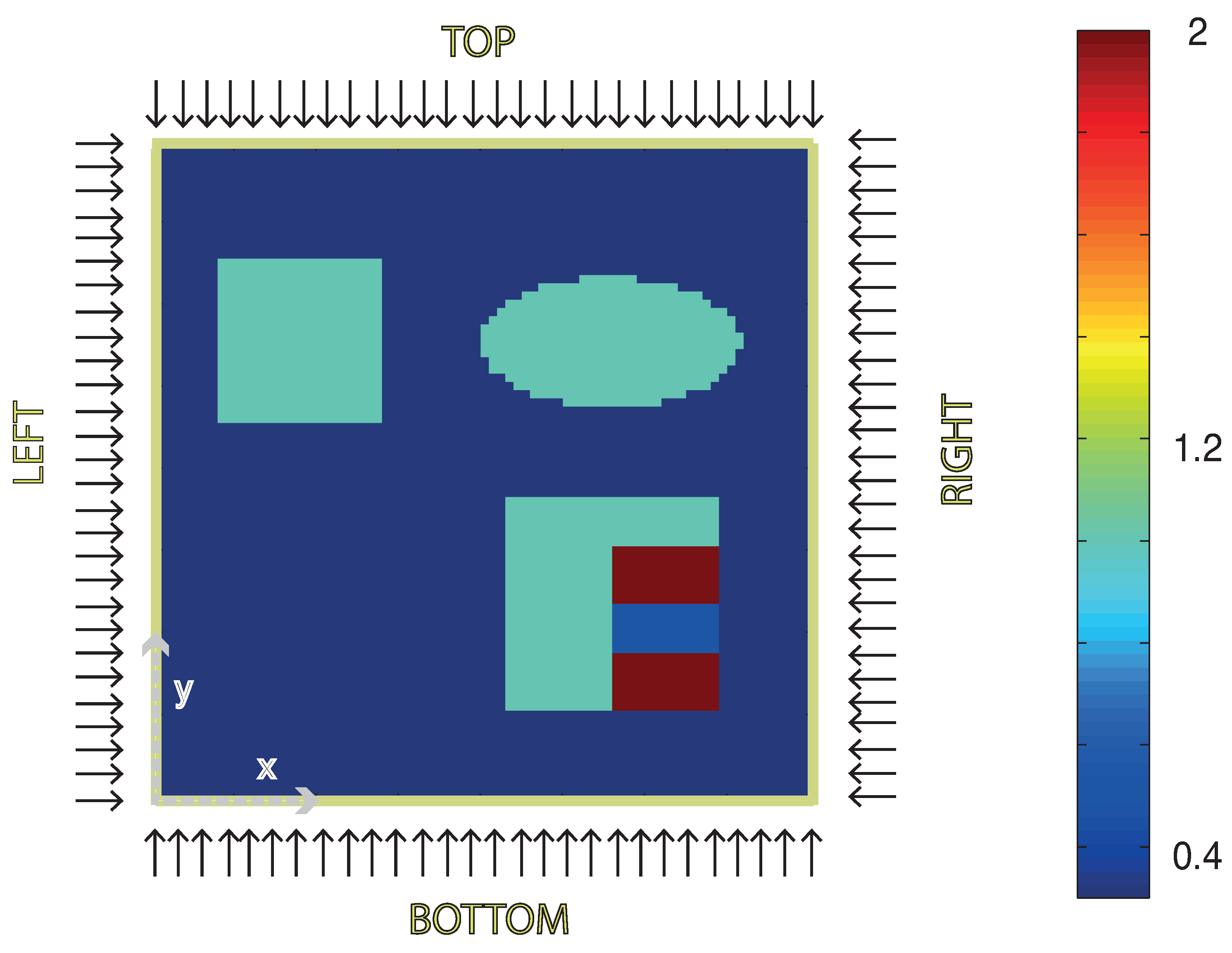
Figure 3.
Absorption coefficient distribution of the tissue sample used for the numerical examples. Background absorption of the tissue is taken as , the blue obstacles have and the red stripes . The area between the red stripes has absorption coefficient . The scattering coefficient is constant in the whole sample and chosen to be . Illuminations are applied consecutively from top, right, bottom and left. The corresponding boundary sources are given by . The x- and y-axis cover .
Figure 3.
Absorption coefficient distribution of the tissue sample used for the numerical examples. Background absorption of the tissue is taken as , the blue obstacles have and the red stripes . The area between the red stripes has absorption coefficient . The scattering coefficient is constant in the whole sample and chosen to be . Illuminations are applied consecutively from top, right, bottom and left. The corresponding boundary sources are given by . The x- and y-axis cover .
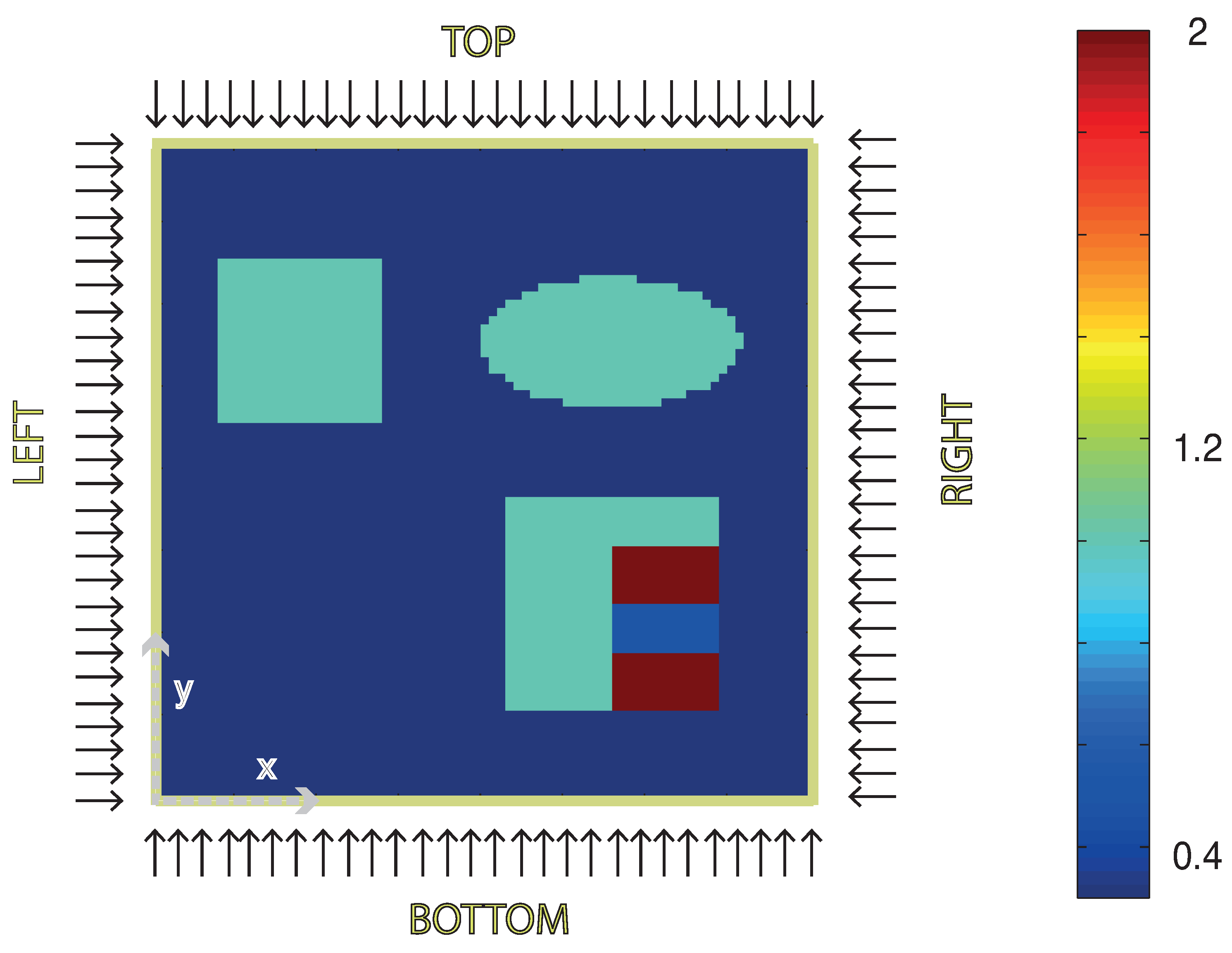
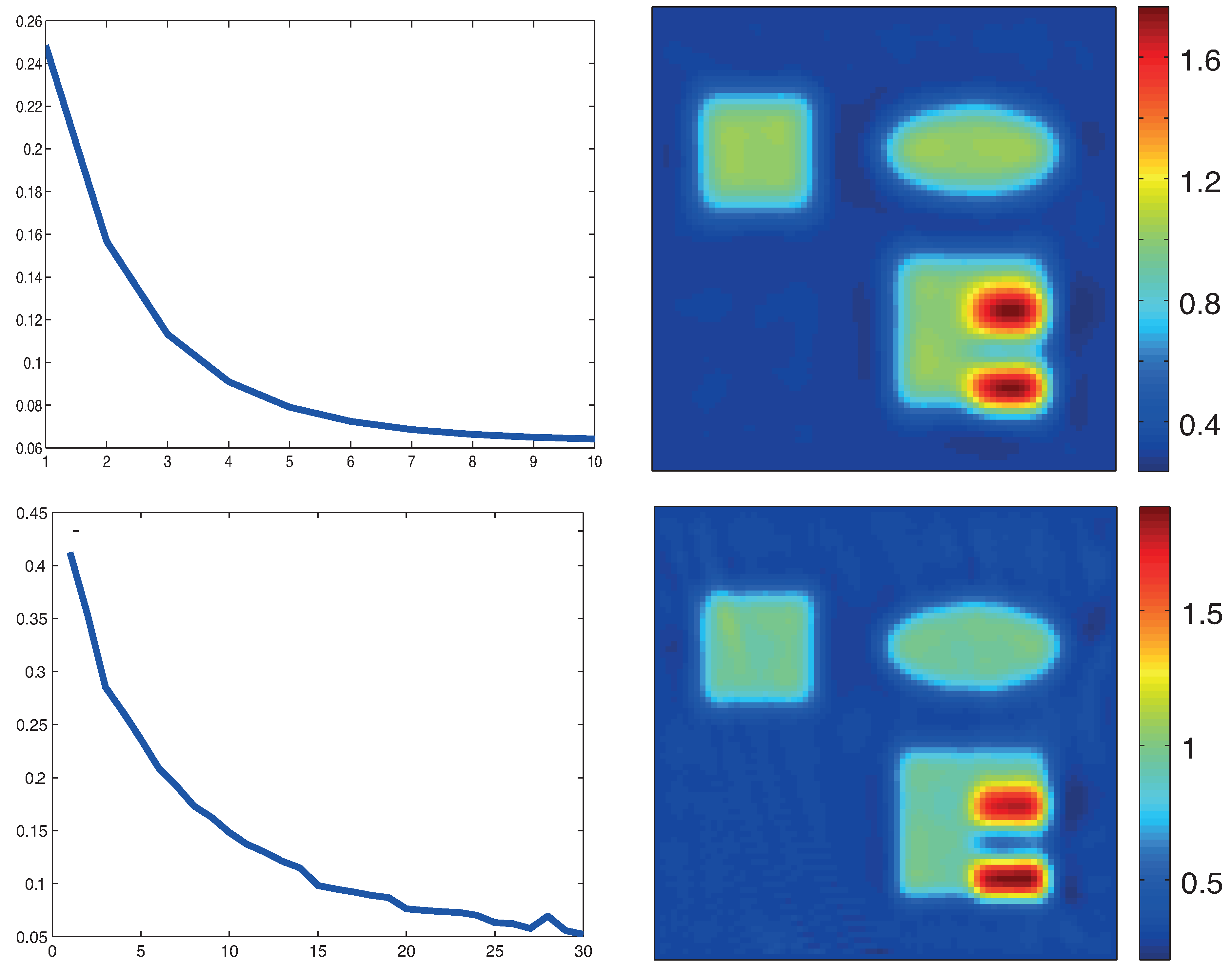
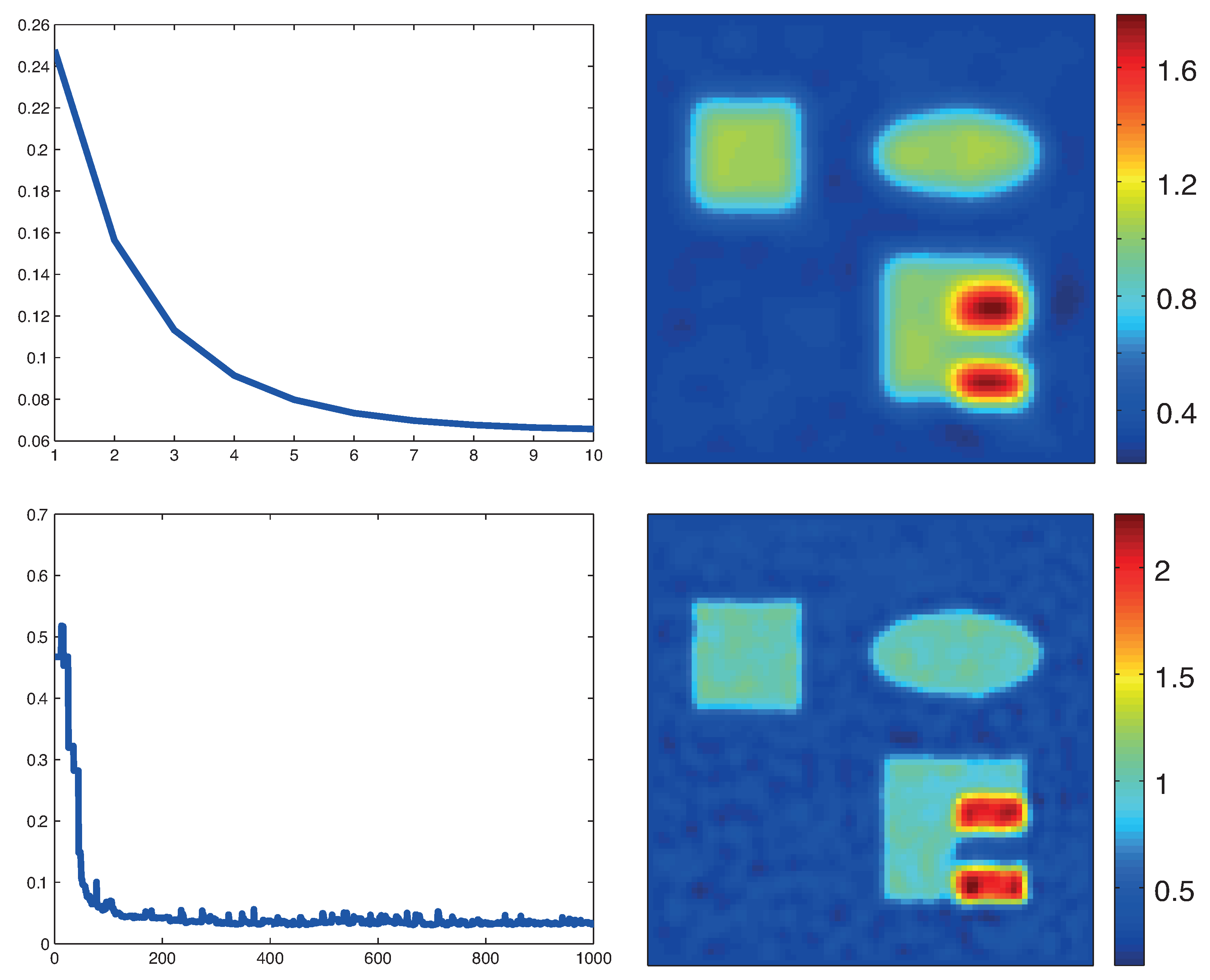
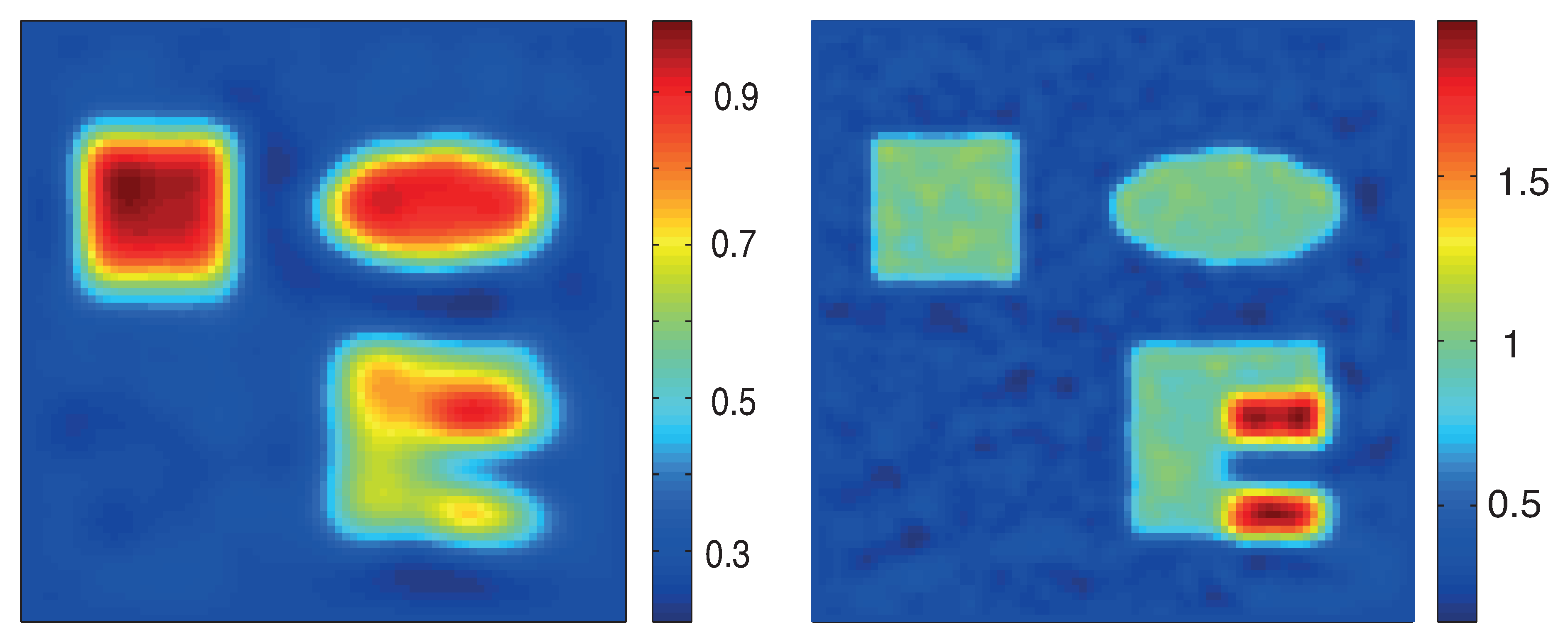
Figure 4.
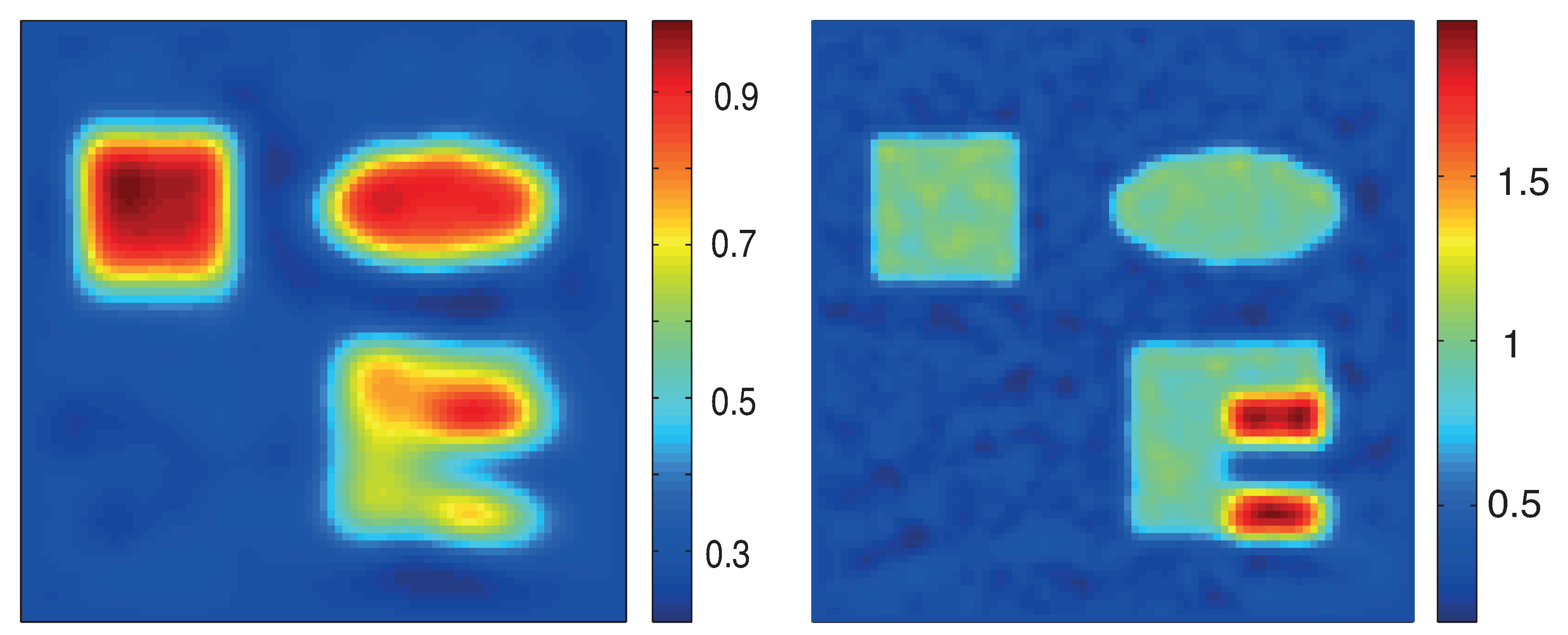
Reconstruction results based on standard formulation (19). Top: proximal gradient method; Bottom: proximal stochastic gradient method. The left images show the relative reconstruction errors of the reconstructed absorption coefficient as a function of the number of iterations, whereas the right pictures show the result after the final iteration. (The phantom is as described in Figure 3.)
Figure 4.
Reconstruction results based on standard formulation (19). Top: proximal gradient method; Bottom: proximal stochastic gradient method. The left images show the relative reconstruction errors of the reconstructed absorption coefficient as a function of the number of iterations, whereas the right pictures show the result after the final iteration. (The phantom is as described in Figure 3.)
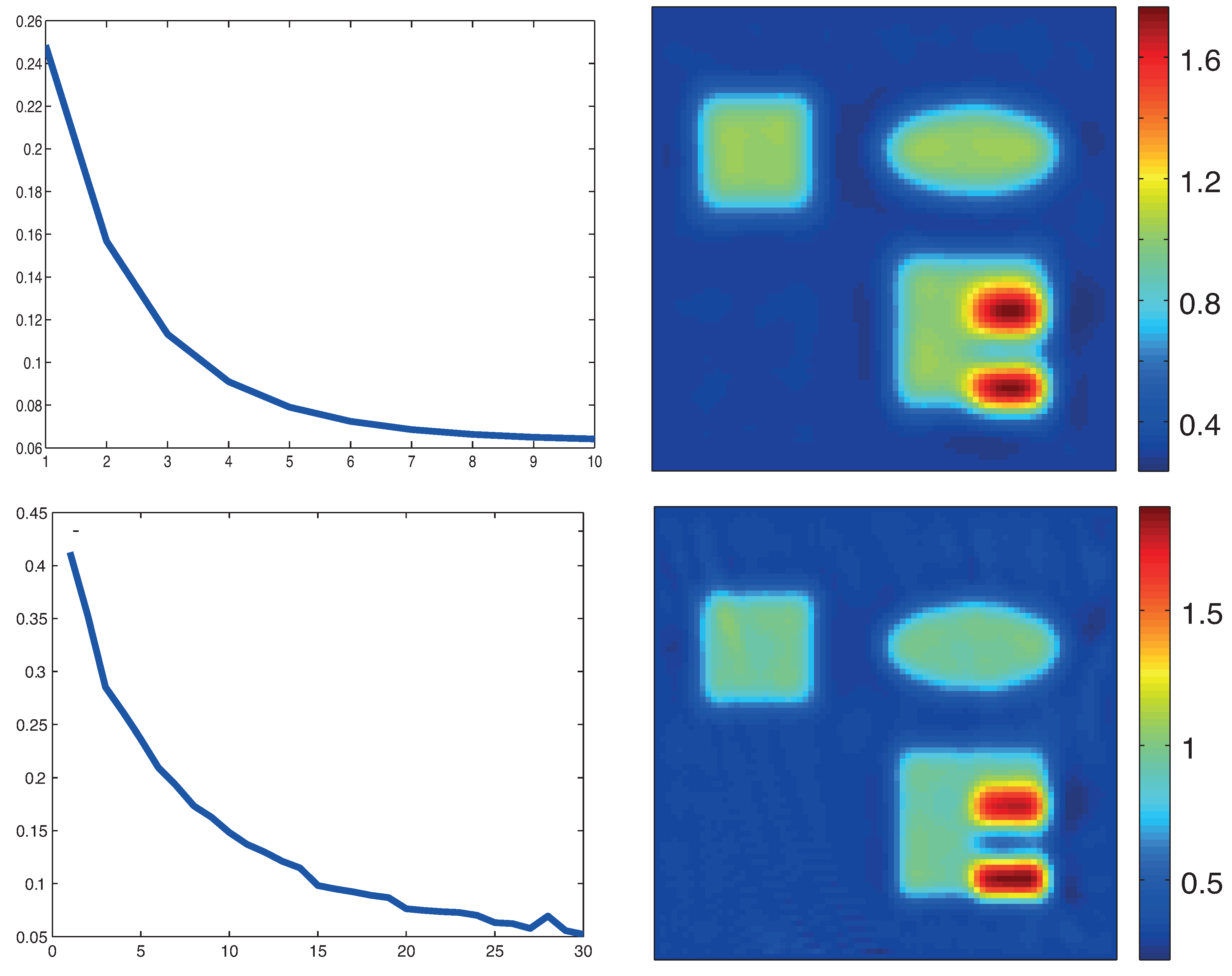
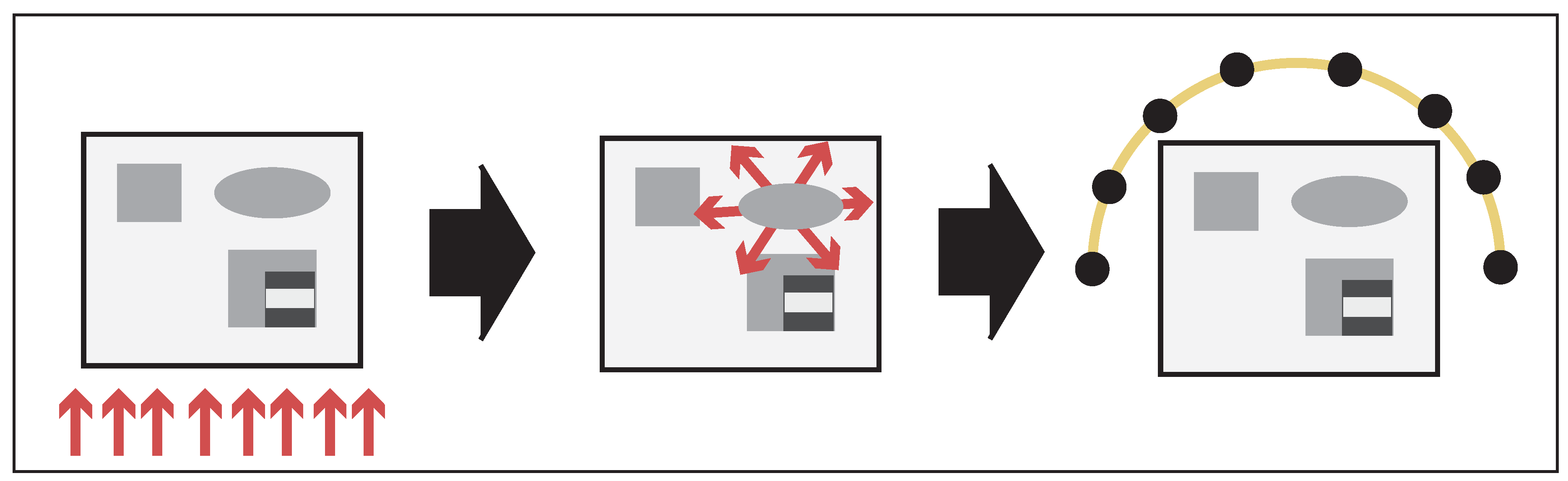
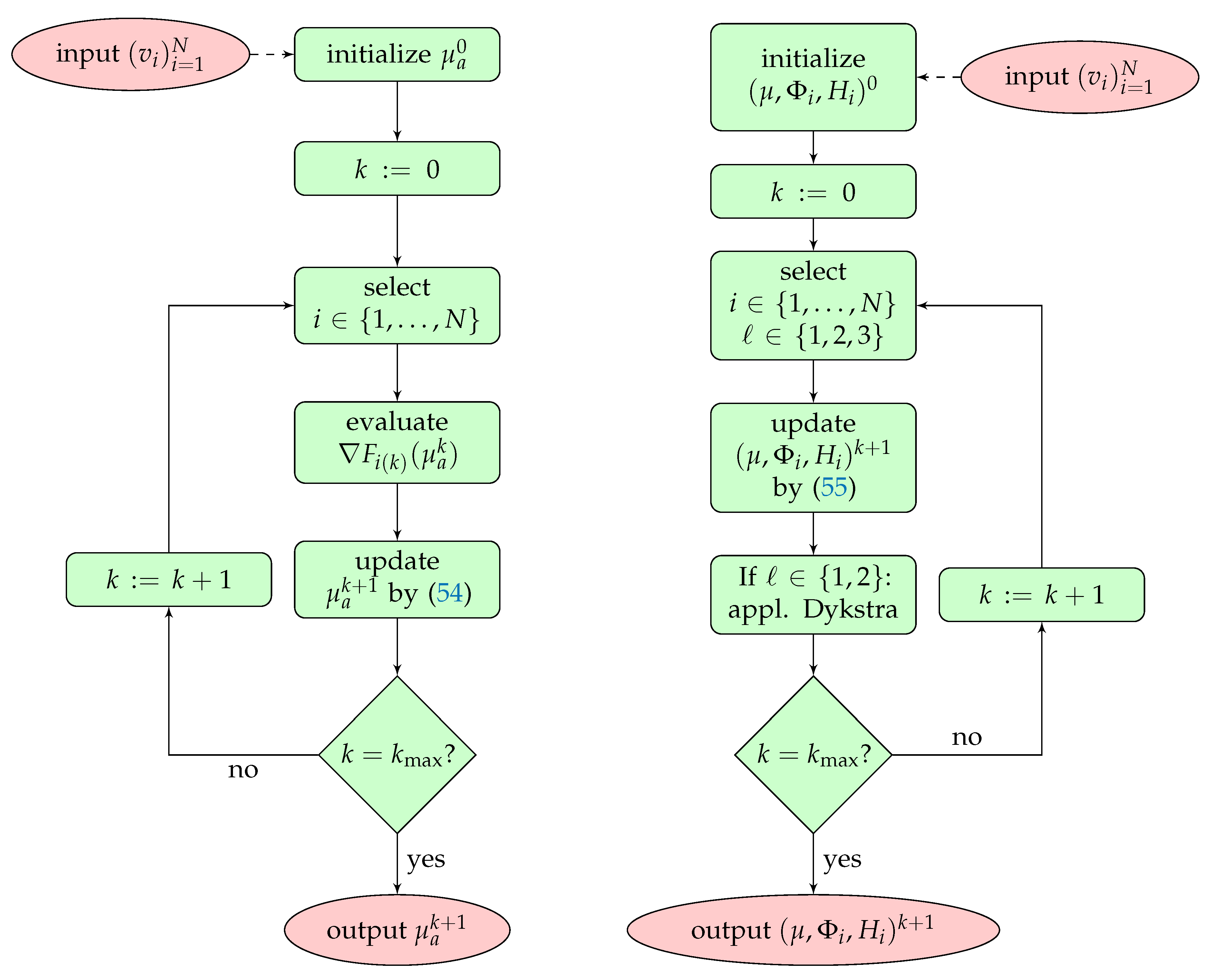
Figure 5.
Flowcharts of stochastic gradient algorithms for QPAT proposed in this paper. Left: algorithm based on the standard formulation (19). Right: algorithm based on the novel MULL formulation (35). The update (54) using the standard formulation requires solving the forward RTE and the adjoint RTE, which is not required by (55) with the MULL formulation. Simulations are performed with .
Figure 5.
Flowcharts of stochastic gradient algorithms for QPAT proposed in this paper. Left: algorithm based on the standard formulation (19). Right: algorithm based on the novel MULL formulation (35). The update (54) using the standard formulation requires solving the forward RTE and the adjoint RTE, which is not required by (55) with the MULL formulation. Simulations are performed with .

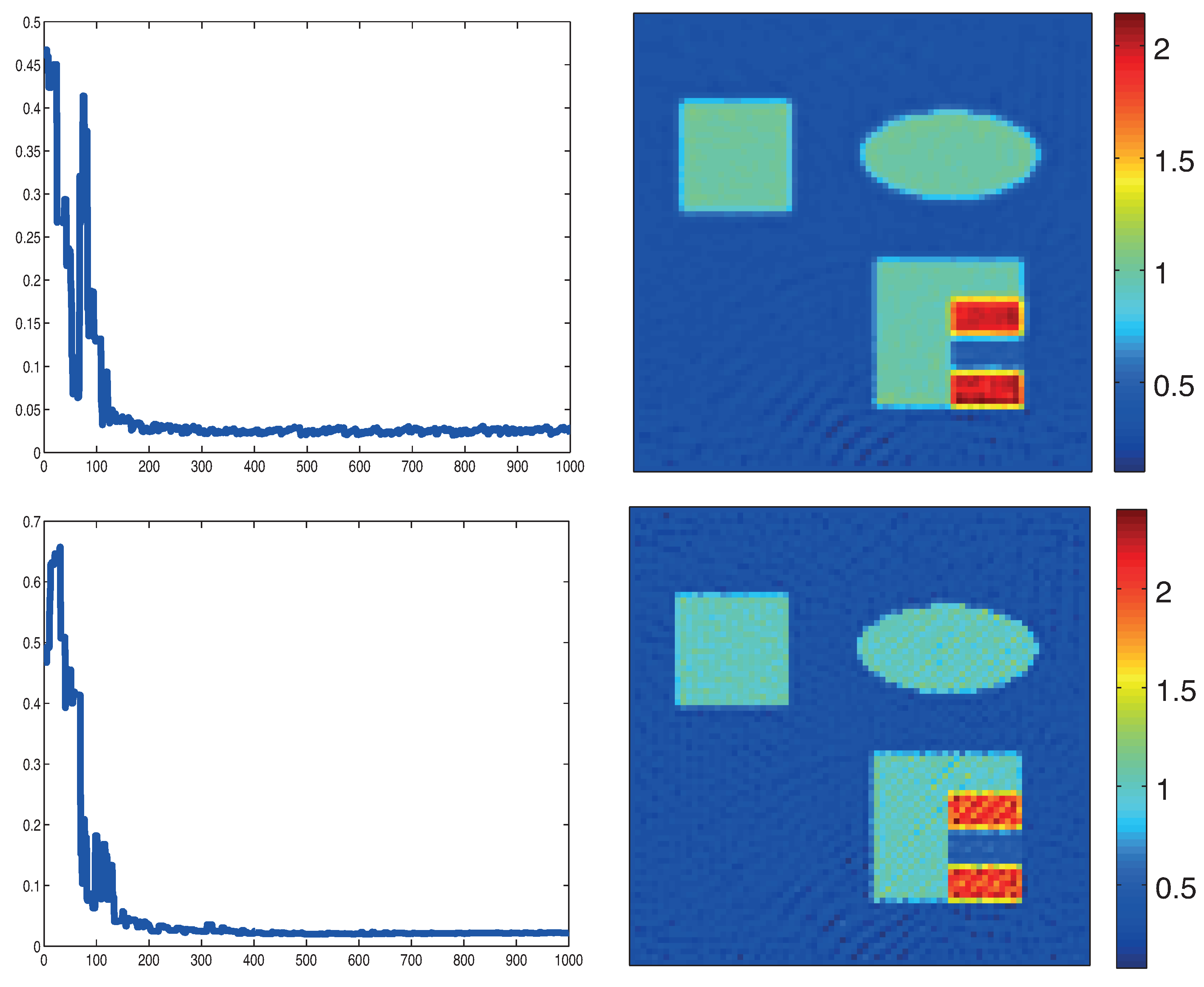
Figure 6.
Reconstruction results based on the novel MULL formulation (35). Top: MULL-proximal stochastic gradient method based on the decomposition (38). Bottom: MULL-projected stochastic gradient method based on the decomposition (39). The left images show the relative reconstruction errors of the reconstructed absorption coefficient as a function of the number of iterations, whereas the right pictures show the results after the last iterations. (The phantom is as described in Figure 3.)
Figure 6.
Reconstruction results based on the novel MULL formulation (35). Top: MULL-proximal stochastic gradient method based on the decomposition (38). Bottom: MULL-projected stochastic gradient method based on the decomposition (39). The left images show the relative reconstruction errors of the reconstructed absorption coefficient as a function of the number of iterations, whereas the right pictures show the results after the last iterations. (The phantom is as described in Figure 3.)

Figure 7.
Reconstruction results from noisy data. Top: Proximal gradient method based on (19). Bottom: MULL-proximal stochastic gradient method. The left images show the relative reconstruction errors of the reconstructed absorption coefficient as a function of the number of iterations, whereas the right pictures show the results after the last iterations. (The phantom is as described in Figure 3.)
Figure 7.
Reconstruction results from noisy data. Top: Proximal gradient method based on (19). Bottom: MULL-proximal stochastic gradient method. The left images show the relative reconstruction errors of the reconstructed absorption coefficient as a function of the number of iterations, whereas the right pictures show the results after the last iterations. (The phantom is as described in Figure 3.)
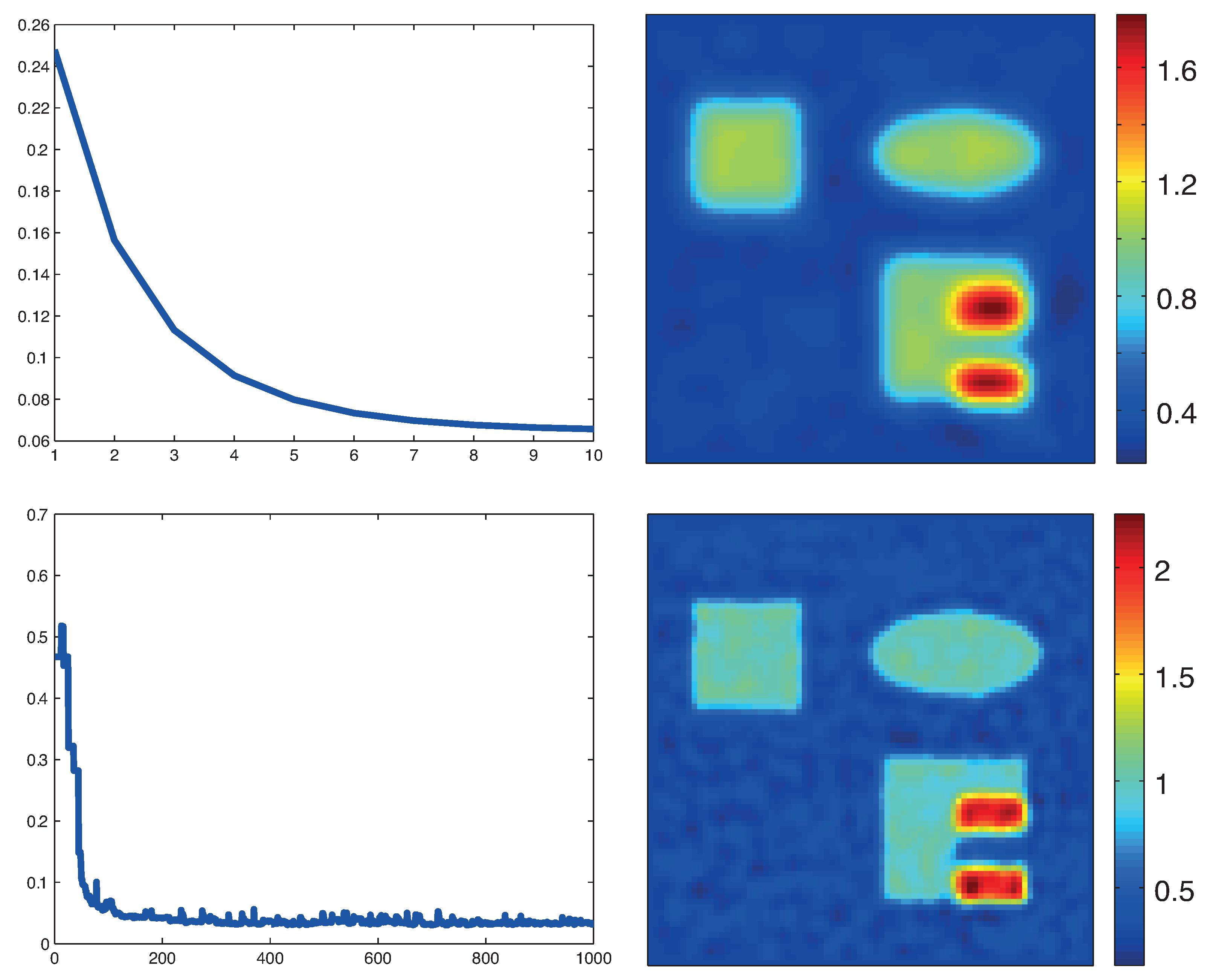
Figure 8.
Reconstruction results from noisy data for two illuminations. Left: proximal gradient method based on (19) using 10 iterations. Right: MULL-proximal stochastic gradient method using only 500 iterations. The phantom is as described in Figure 3 and, for the reconstruction methods, we use two consecutive illuminations (from the top and from the left). The reconstruction time has been about 14 h for the method based on the standard formulation (19) and 3 h for the proposed MULL-proximal stochastic gradient method.
Figure 8.
Reconstruction results from noisy data for two illuminations. Left: proximal gradient method based on (19) using 10 iterations. Right: MULL-proximal stochastic gradient method using only 500 iterations. The phantom is as described in Figure 3 and, for the reconstruction methods, we use two consecutive illuminations (from the top and from the left). The reconstruction time has been about 14 h for the method based on the standard formulation (19) and 3 h for the proposed MULL-proximal stochastic gradient method.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Reconstruction times for all methods. Recall that one iteration of the proximal stochastic gradient method is approximately four times cheaper than one iteration of the full proximal gradient method (both based on (19)). Further recall that one step in the methods based on the MULL formulation (35) is much less time consuming than for the methods based on (19); see Remark 1.
Table 1.
Reconstruction times for all methods. Recall that one iteration of the proximal stochastic gradient method is approximately four times cheaper than one iteration of the full proximal gradient method (both based on (19)). Further recall that one step in the methods based on the MULL formulation (35) is much less time consuming than for the methods based on (19); see Remark 1.
| Algorithm | Model | Update | No. Iterations | Reconstruction Time |
|---|---|---|---|---|
| Proximal gradient | (19) | (23) | 10 | h |
| Proximal stochastic gradient | (19) | (31) | 30 | h |
| MULL-proximal stochastic gradient | (35) | (49) | 1000 | h |
| MULL-projected stochastic gradient | (35) | (50) | 1000 | h |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Rabanser, S.; Neumann, L.; Haltmeier, M. Stochastic Proximal Gradient Algorithms for Multi-Source Quantitative Photoacoustic Tomography. Entropy 2018, 20, 121. https://doi.org/10.3390/e20020121
AMA Style
Rabanser S, Neumann L, Haltmeier M. Stochastic Proximal Gradient Algorithms for Multi-Source Quantitative Photoacoustic Tomography. Entropy. 2018; 20(2):121. https://doi.org/10.3390/e20020121
Chicago/Turabian StyleRabanser, Simon, Lukas Neumann, and Markus Haltmeier. 2018. "Stochastic Proximal Gradient Algorithms for Multi-Source Quantitative Photoacoustic Tomography" Entropy 20, no. 2: 121. https://doi.org/10.3390/e20020121
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.