Relationship between Entropy and Dimension of Financial Correlation-Based Network


Department of Finance, School of Business, East China University of Science and Technology, Shanghai 200237, China
*
Author to whom correspondence should be addressed.
Entropy 2018, 20(3), 177; https://doi.org/10.3390/e20030177
Submission received: 18 January 2018
/
Revised: 25 February 2018
/
Accepted: 6 March 2018
/
Published: 7 March 2018
Abstract
:We analyze the dimension of a financial correlation-based network and apply our analysis to characterize the complexity of the network. First, we generalize the volume-based dimension and find that it is well defined by the correlation-based network. Second, we establish the relationship between the Rényi index and the volume-based dimension. Third, we analyze the meaning of the dimensions sequence, which characterizes the level of departure from the comparison benchmark based on the randomized time series. Finally, we use real stock market data from three countries for empirical analysis. In some cases, our proposed analysis method can more accurately capture the structural differences of networks than the power law index commonly used in previous studies.
1. Introduction
Many complex systems in the real world can be described using complex networks. In the last two decades, many concepts and algorithms have been proposed [1,2,3,4,5]. Since A. L. Barabási and R. Albert proposed a scale-free network model [6], the power law has become an important tool for characterizing network structures [7]. There are some dominant nodes in which the node degree is significantly larger than that of most nodes, and some researchers have discovered that there are other types of scaling laws in some networks that therefore define the dimensions of the network [8]. After the pioneering work of Song et al., other types of network dimensions were introduced [9,10,11,12,13,14,15,16,17]. For example, Daijun Wei et al. proposed the information dimension [9], and defined the Tsallis information dimension [10]. Rosenberg introduced the concept of maximal entropy minimal coverings to compute the information dimension [11]. O. Shanker defined the volume of a node in a network and introduced a new dimension based on the scaling law between the average of the volume and the distance [12,13]. The average density was defined by Guo Long et al., along with defining the dimension by the scale law of average density and distance [14].
The dimensions of weighted networks and the multifractal of networks have also been discussed by researchers [15,16,17]. In particular, researchers analyzed the multifractal of the network using the sandbox algorithm and found that there is multifractal in scale-free networks, but not in random networks [18]. A recent study shows that the heterogeneity of degree distribution is of crucial importance to the fractal properties of networks [19]. In addition to using the scaling law and information entropy to define network dimensions, some researchers also use the ergodic theory of dynamical systems to define the correlation dimension of a network [20].
In this article, we will apply the dimension proposed by O. Shanker to analyze a financial correlation-based network. We follow the terminology used by some researchers [21,22], and call the network constructed from the correlation matrix a correlation-based network.
At present, there are three usual methods for constructing correlation-based networks. One constructs the network using the minimum spanning tree (MST) algorithm [23]. The second method constructs the planar maximally filtered graph (PMFG), which can include some structures that are not in the MST, such as 4-clique and community [24]. The third approach constructs a 0–1 matrix based on a threshold and a correlation matrix, where the threshold is used to extract the structure in the correlation matrix [25,26]. For example, an element in a correlation matrix that is greater than a threshold is converted to 1, otherwise the element is converted to 0, so that a 0–1 matrix is generated as an adjacency matrix.
Since the work of Mantegna [23], many studies have explored applications of these methods, such as in stock markets [27], industrial indices [28], international indices, or foreign exchange markets [29,30]. Studies show that the degree distribution of some correlation networks satisfies the scale-free law [31,32,33,34,35,36]. Some researchers have found that the topological structure of the MST in the market changes over time, which leads to a change in the power law exponent of the degree distribution [34]. Further research has used the Rényi index to characterize the topological structural changes [36]. The Rényi Index is a standardized Rényi entropy used to characterize randomness and evenness; it has been correlated with the Lorenz curve [37,38]. Research shows that the Rényi index can effectively characterize the topological structure of MST, and this paper will analyze its relationship with the dimensions of a correlation-based network.
Many studies have applied entropy to the study of economic or financial issues [39,40]. For example, S.D. Bekiros constructed a discrete wavelet transformation based on entropy and used it to study currency returns [41]. R. Gencay and N. Gradojevic applied the maximum entropy principle to study the crash of 19 October 1987, and found the crash predictable [42]. Entropy has also been applied to the study of issues such as option pricing and asset pricing [43,44]. It can also be used to study financial hazards or predict systemic financial risks [45,46,47]. E. Maasoumi and J. Racine applied entropy metrics to study the predictability of returns in the stock market and found that the measure can detect nonlinear dependencies [48]. In particular, entropy has recently been applied to research networks and used to construct economic indicators of market fragility and systemic risk [49]. J. Yang and W. Qiu constructed a decision—making model based on entropy, and some problems that cannot be solved based on the mean—variance criterion can be dealt with [50].
In this article, we will sturdy the relationship between the dimensions of a network and the Rényi index. Our study is different from the application of entropy in finance used by most of the previous studies. This article discusses a correlation-based network, which leads us to focus on the correlation structure rather than a single financial temporal series. Recently, some researchers have applied the work of Song et al. to analyze the fractal of financial MST [51]. Based on this analytical framework, the MST of financial markets is non-fractal [51]. Here, we use the dimension proposed by O. Shanker to analyze the dimension of correlation-based networks, which is essentially a scale law defined on the basis of volume, with volume defined by the shortest distance. Then, we can directly calculate the shortest distance matrix and test whether there is a scaling law between volume and distance [12,13].
There are some differences between our calculation method and previous results [51]. First, we calculate the scaling law between volume and distance, whereas previous studies focused on the scaling law between the number of boxes and the distance. Secondly, we study the relationship between dimension and entropy, both commonly used indicators of complexity. Thirdly, to establish the relationship between these two indicators, we first generalize the definition of Shanker’s dimension and then use the data from three stock markets for empirical analysis.
The main finding of this paper is that the dimensions can be well defined on a correlation-based network and capture the details of changes in the network structure, and can therefore be used to study the dynamics of correlation-based networks.
2. Materials and Methods
2.1. Materials
We use daily closing price data from stock markets in China, the United Kingdom and the United States for empirical analysis. The Chinese data used in this paper are from the Wande database, while the data for the USA and UK markets are from Yahoo Finance.
Constituent stocks with missing data on the Chinese market for the Shanghai-Shenzhen 300 index (CSI300 index) were removed and a total of 162 stocks were selected from 4 January 2005 to 23 December 2015. Similarly, we exclude stocks with missing data in the Standard & Poor’s (S&P) 100 index between 3 January 2005 and 29 December 2014. In total, 93 stocks were selected. For comparative analysis, the daily closing price series of 80 constituent stocks of the Financial Times Stock Exchange (FTSE) 100 index were also used, excluding stocks with missing data, from 3 January 2005 to 29 December 2017.
2.2. MST and PMFG
We assume that there are n stocks , and that each stock i corresponds to a price time series . In the calculations of this paper, the stock price series needs to be preprocessed into a yield series: , where
The Pearson correlation coefficient between stocks i and j is calculated using
In this paper, MST and PMFG are, respectively, calculated based on the distance matrix and the correlation coefficient matrix . We construct the MST using the classical Prim algorithm [52]. The minimum spanning tree is a planar graph with edges and no cycles, and with the minimum possible total edge weight. More details can be found in the literature [52].
Below, we briefly describe the construction of PMFG. The PMFG is also a planar graph that includes edges, so that it contains 3-clique and 4-clique [24].
- Pearson’s correlation coefficient between any two stocks i and j is calculated and denoted as (Equation (2)).
- We extract elements of the upper triangular matrix of correlation coefficient matrix and arrange them in ascending order, denoted by .
- In order of , we add a link between the pairs of nodes of an element in when the resulting graph is a planar graph.
- The above step is repeated until a planar graph with edges is generated.
In the following, each stock i corresponds to a node, so that the corresponding node is also labeled i.
2.3. Rényi Index
In general, for a network , where matrix is the adjacency matrix, the set is the node set. The degree of node i is and the average degree is . Further, the shortest distance matrix of the network W can be calculated, where is the length of the shortest path between nodes i and j.
In this paper, we will calculate the shortest distance matrix and construct different threshold networks. First, we need to denote the Heaviside step function as:
Then, for a positive integer r, we can construct a threshold network , where the element . That is, the elements in the shortest distance matrix that are less than r are converted to 1, otherwise to 0. Here, it is assumed that . The degree of node i and the average of the threshold network are, respectively, denoted and .
The Rényi index is a standardized Rényi entropy, which can be used to characterize randomness and evenness [37]. Consider a human population consisting of n members, each of which owns wealth and thus has a wealth vector . Then, the Rényi index of the wealth vector w is defined as [37]
where is the average wealth and q is a parameter.
Further research has found that the Rényi index can be effectively applied to characterize the topological structure of financial MST [36]. In general, we can define the Rényi index of network W as
where the degree of node i is analogous to wealth.
Next, we study the relationship between the heterogeneity and dimension of correlation-based networks. Naturally, the Rényi index () of the threshold network can also be calculated as
2.4. Dimension
Since MST and PMFG are always connected networks, we can directly calculate the shortest distance between any two nodes. Based on the dimension proposed by O. Shanker [12], the calculation steps are as follows:
- We calculate MST or PMFG based on distance matrix or correlation coefficient matrix. Here, the correlation-based network is denoted as , where is a node set and is an adjacency matrix.
- The shortest distance matrix is calculated by the adjacency matrix T.
- We set the threshold set and then compute threshold network for , where the elements of .
- The number of non-zero elements in the i-th row of matrix is the volume of node i with distance . That is, the volume of node i is its degree in the threshold network . Further, the volume is calculated usingthat is, the average is calculated.
- If the scaling relationship is asthe volume dimension is defined, where C is a constant and r is the distance.
In the calculation, we need to select the appropriate set L and then estimate in the double logarithmic coordinate system by
where is a constant.
2.5. Generalized Volume-Based Dimensions
In this section, we will define the volume dimension in a generalized way based on the concept of volume. We note that the volume is the average of the volume of all nodes i (, Equation (11). In general, we define as
where . When q is a positive integer, the expression is the q-th sample moment of the volume . For any real number , the latter calculation shows that there is still a scale relationship between and distance r. As in the definition of dimension proposed by O. Shanker [12], we define the generalized dimensions as follows: if there is a scaling relationship between and distance r as
where r is the threshold, is a constant, then the index is a generalized dimension. As a special case, when , . For a set of suitable thresholds , can be fit using a least square method, as follows (C is a constant):
The generalized dimension can be used to study higher-order statistics of volume sequence and is naturally embedded in the definition of the Rényi index. Since the volume is the degree of node i () in the threshold network ,
can be obtained from Equations (10) and (14).
To further simplify Equation (17),
is introduced, where C is a constant. If , then , which means that the degree of nodes in the network is homogeneous. Based on Equation (18), the difference between the dimensions can also be expressed by the Rényi index. In particular, the original volume-based dimension () is the basic dimension, with which other dimensions are compared to characterize the Rényi index as follows:
When , Equation (18) allows the Rényi index of the original network to be expressed in terms of dimensions, as
However, r can take any value in the set of thresholds (), so the dimension also expresses the Rényi index of the threshold network . Since the degree of node i in the threshold network expresses the more neighbor information of the node, the dimension contains more information of the network structure.
3. Results
3.1. Generalized Volume-Based Dimensions
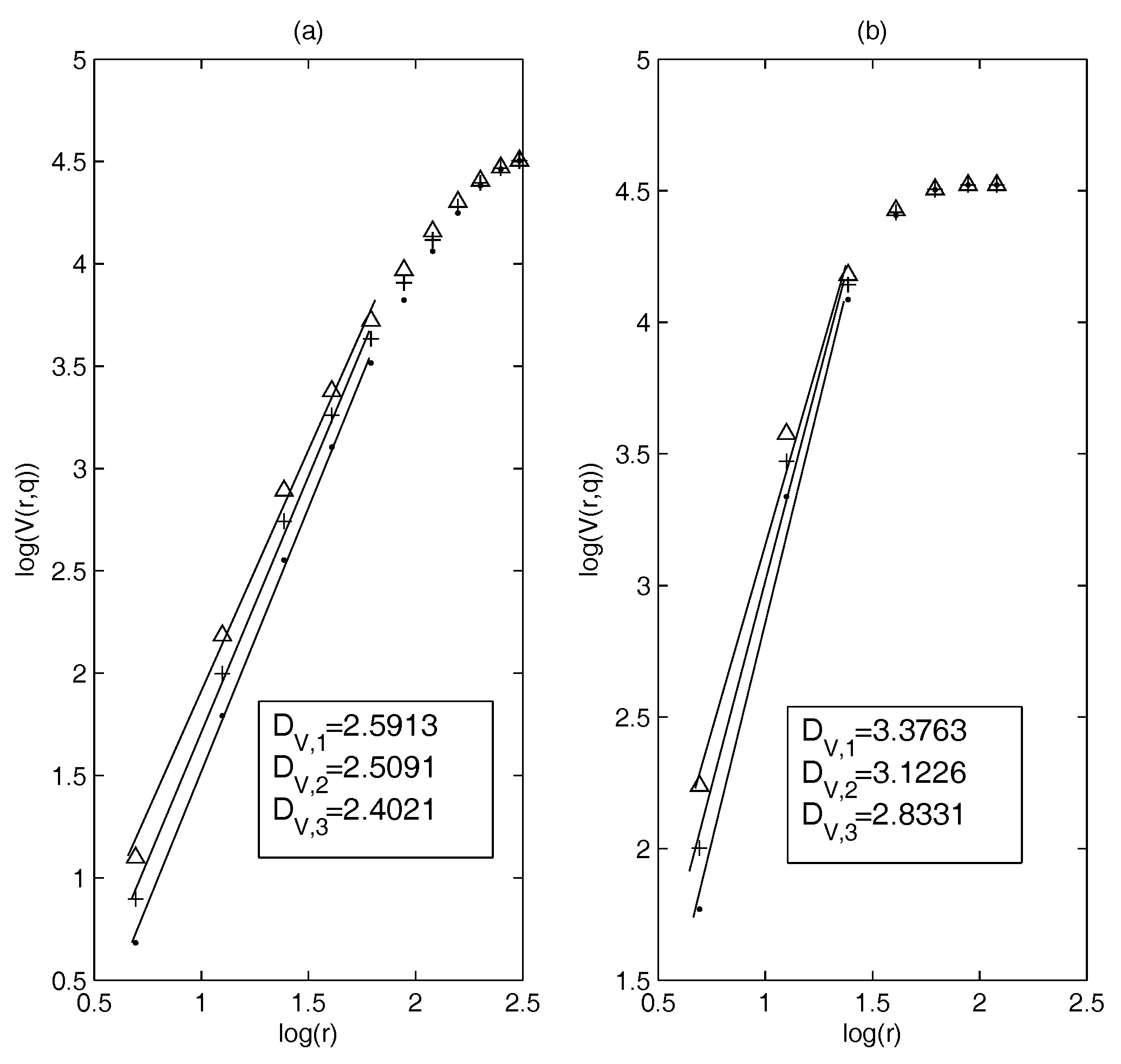
First, we calculate and based on the constituent stocks of the S&P 100 index (3 January 2005–29 December 2014) and estimate the dimensions. Figure 1a,b show the results of the dimension estimation: Figure 1a corresponds to MST and Figure 1b to the PMFG. It can be seen that in a suitable threshold interval the relationship between log() and log(r) is nearly linear. This means that in this example, the dimensions can be defined well on MST and PMFG. We choose and when estimating the dimensions of MST and PMFG, respectively. Calculations show that the generalized volume-based dimensions can be well defined on the correlation-based networks.
In our study, we find that the threshold sets and are suitable for estimating the dimensions of MST and PMFG, respectively. Therefore, the later threshold set in the calculation is consistent with this example.
Next, to establish a benchmark for comparative analysis, we randomize the yield series and calculate the correlation-based network, then estimate the dimensions and compare them with the dimensions based on the real data. We still choose the data used in Figure 1.
Now, the series of yield for each stock is randomly reordered. Note that this step does not change the distribution of yield. Then the correlation coefficient matrix and distance matrix between the yield series are calculated. Finally, we calculate MST and PMFG and estimate their dimensions.
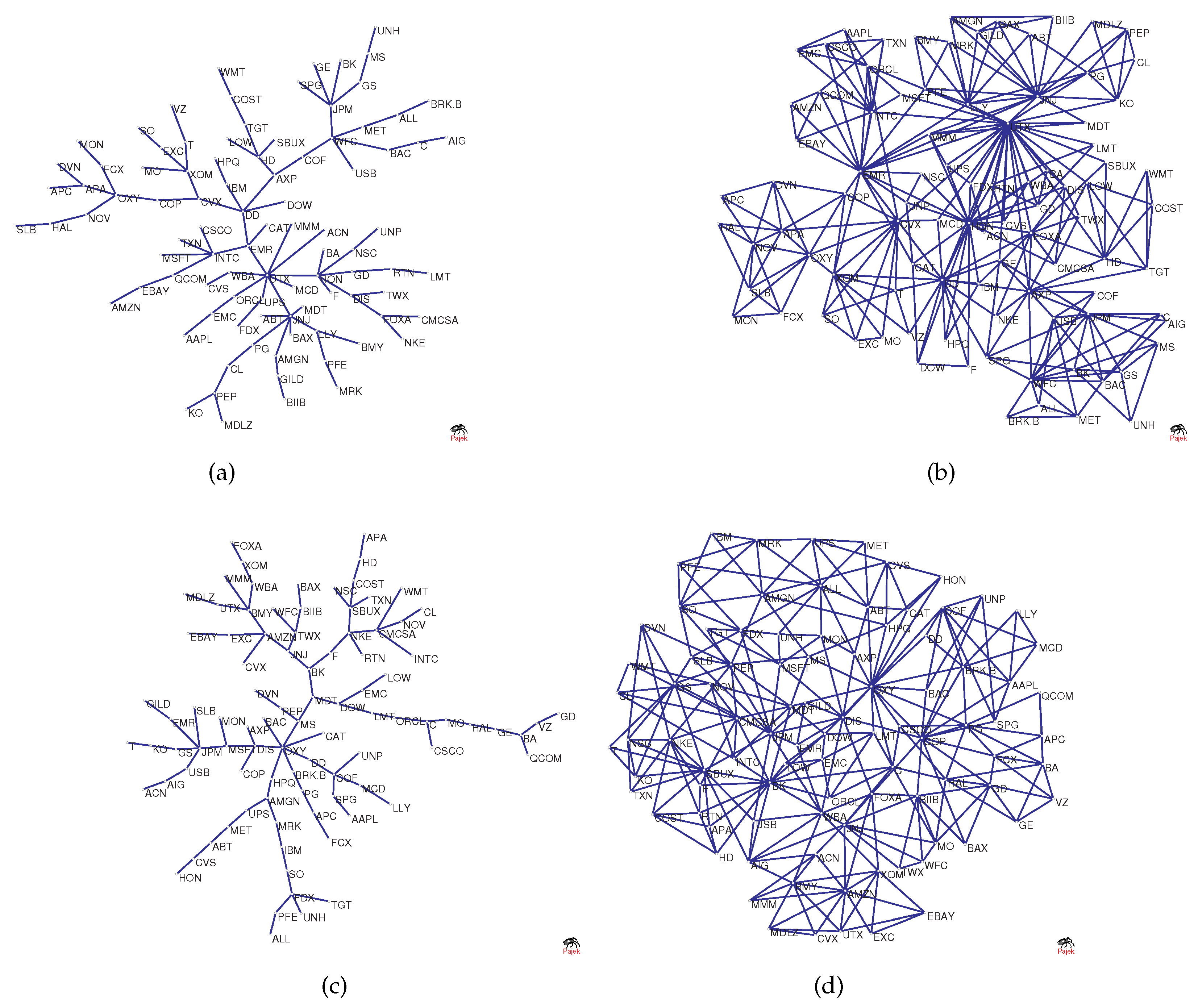
To visualize the structural changes in the network, Figure 2a–d shows the original network versus the network as a benchmark. The figure shows MST and PMFG based on real data, where the maximum degree () in Figure 2a is 9, and the maximum degree () in Figure 2b is 30. However, the degree of node in Figure 2c is 2 and in Figure 2d it is 5. This is because randomized series eliminate the original correlation structure, causing hub nodes to lose their core positions.
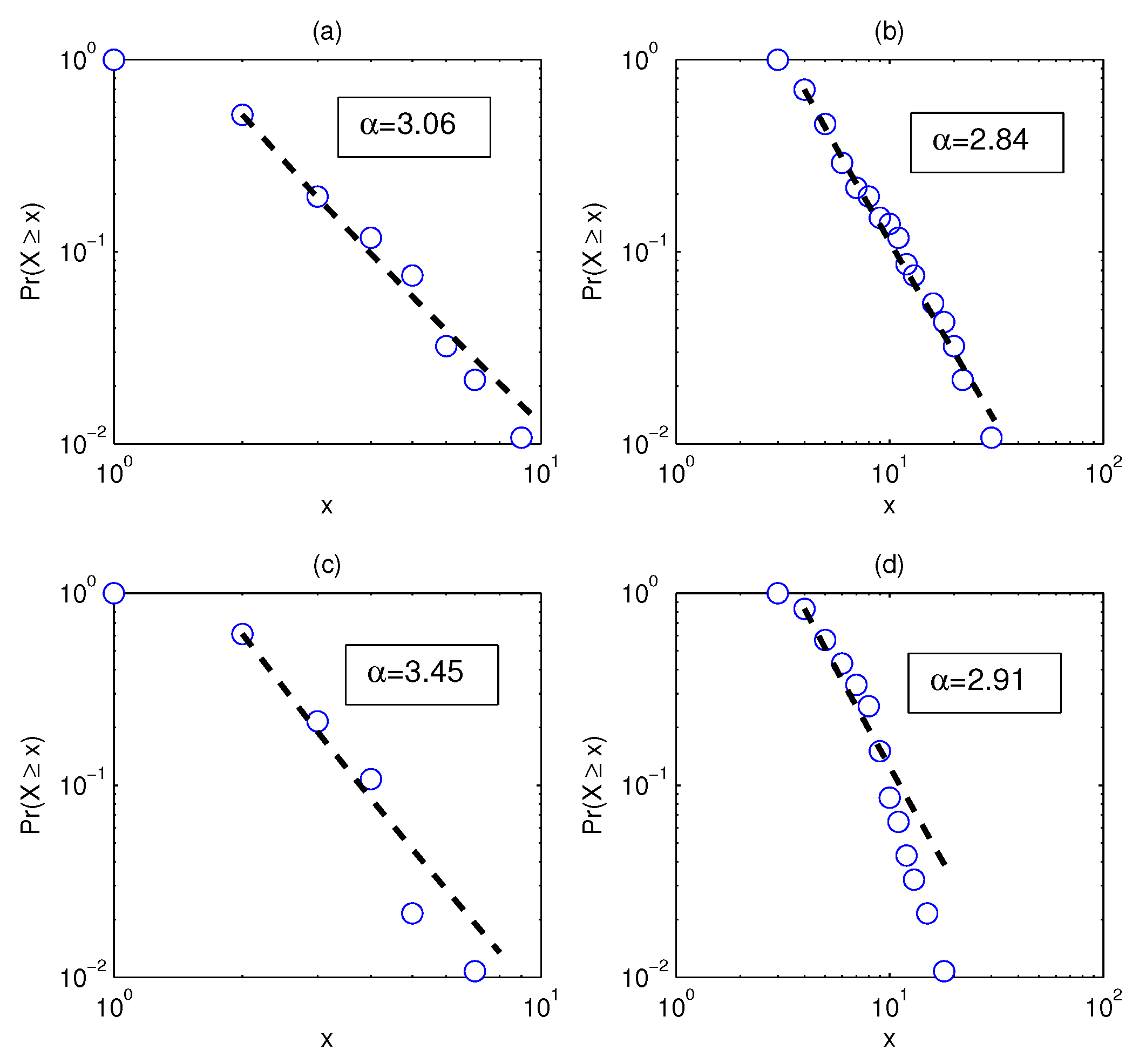
The structural changes directly lead to the changes in the degree distribution. Figure 3a–d shows the degree distributions of the four networks in Figure 2. It is assumed here that the degree distribution satisfies the power law . We compare Figure 3a,c and find that the power law exponent of the latter is larger, which implies that the degree distribution is less heterogeneous.
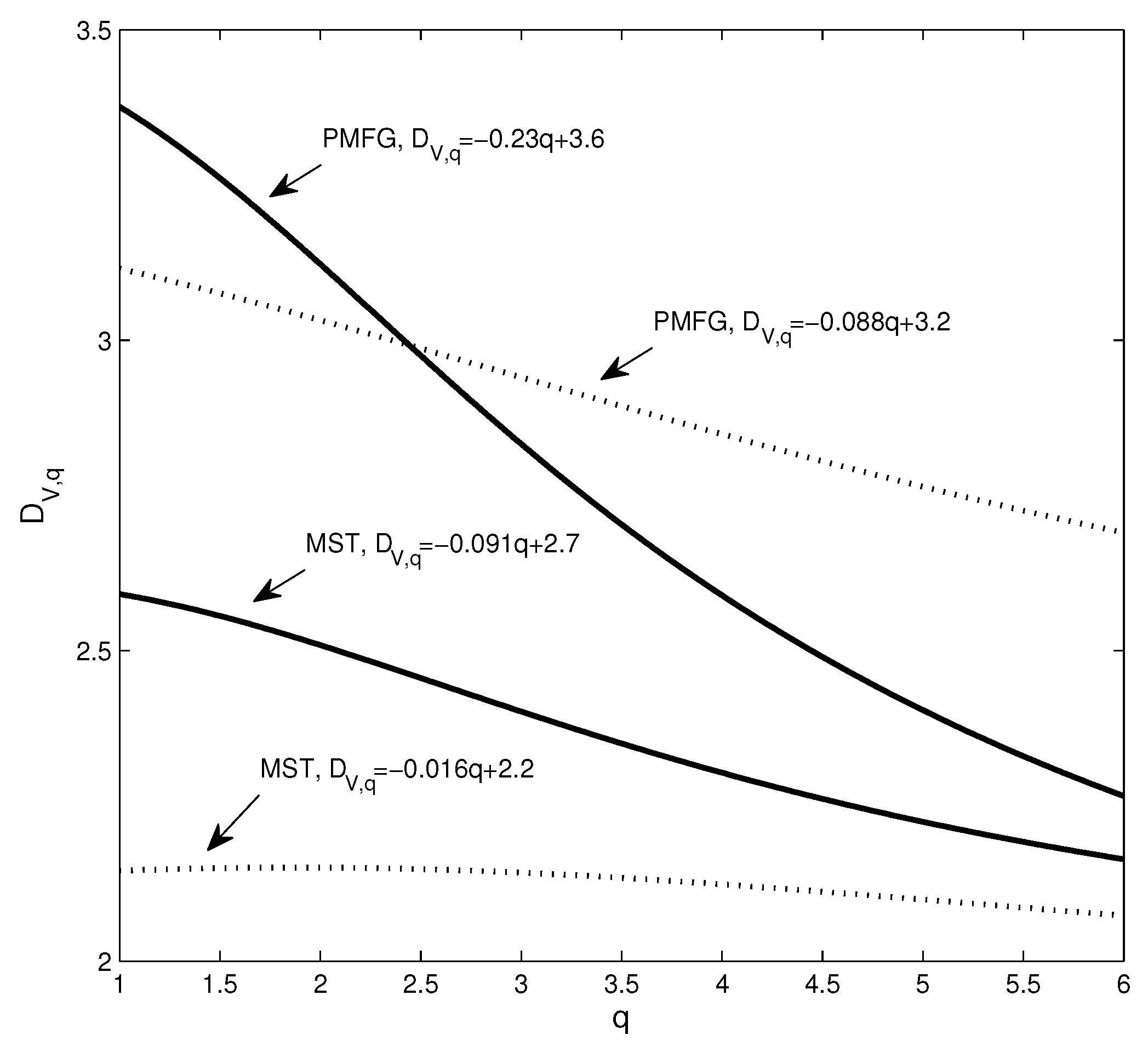
Next, we use the dimension and Rényi index to analyze the changes in the structure of the network. Figure 4 shows the estimation of the dimensions when taking different q values, where the solid line corresponds to the network based on real data and the dotted line corresponds to the network based on the randomized series. Intuitively, it can be found that the change of the dotted line is smoother. In addition, we calculate the Rényi index index for each network. Corresponding to the four subgraphs in Figure 3a–d, the Rényi indices are 0.3476 (Figure 2a), 0.3715 (Figure 2b), 0.2352 (Figure 2c), and 0.1885 (Figure 2d).
To show the changes of the four dimension sequences in Figure 4 more clearly, the four data sets are approximated by straight lines. It can be seen that the absolute value of the coefficient of q corresponding to the solid line is significantly larger than the coefficient of the benchmark-based q. For example, the absolute value of the coefficient of q corresponding to the PMFG of the real data is 0.23, which is more than 2.6 times 0.088. In particular, the differences in the structure of some networks cannot be accurately captured by the power law exponent. The power law exponent of the networks shown in Figure 2b,d is 2.84 and 2.91, respectively. The difference between the two power law exponents is small, yet Figure 4 shows that there is a significant difference between the two networks. We find that the Rényi index and the dimensions can clearly and quantitatively show the structural changes.
Below, we analyze the results based on a factor model. In modern finance theory, multi-factor models are often used to model stock returns [53]. For example, the three-factor model is one of the most commonly used multifactor models [54]. More recently, some researchers have also used factor models to study networks, such as constructing factor models to analyze network structures [55], or applying a three-factor model to studying network-based portfolios [56]. In the factor model, in general, a normalized series of returns can be expressed as a linear combination of m factors, as shown in [57]
In Equation (21), the are the linear exposure of the variable to the factor () at time t and the is the idiosyncratic part of ().
Furthermore, Equation (21) can be re-expressed as a matrix form, as shown in
where , , , and [57]. Here, t represents the transpose of the matrix. Thus, we can express the covariance matrix of a set of yield series as shown in
where is the covariance matrix of the factors and is the covariance matrix of the residuals [57].
The covariance matrix of the normalized series is the correlation coefficient matrix of the yield series. Equation (23) means that the matrix of correlation coefficients can be linearly represented by some factors. In our study, when the yield series are randomized, the yield series are no longer factor driven. As a result, the hub node is converted to a non-hub node, as shown in Figure 2. Structural changes can be captured by the Rényi index and the dimension sequence, as shown in Figure 4. In general, when the structural changes of the network, such as from the star to the chain, the Rényi index also changes, based on Equation (19), the dimension sequence changes.
In summary, we can characterize the differences between the networks and their benchmarks by analyzing the curvature of dimension sequences. Since a network for the comparison benchmark is generated based on a randomized time series, it can be considered as having no notable structure. Thus, the more dramatic changes in the dimension sequence, the higher the deviation from the benchmark. Therefore, the sequence of dimensions characterizes the complexity of the network. In addition, we construct the relationship between the Rényi index and the dimensions, as shown in Equations (18) and (19). This means that the dimension sequence also contains information about the structure of the threshold network, whereas the original network can be considered as a special threshold network (). In the next section, we will study the relationship between the dimension and the Rényi index of the threshold network.
3.2. Relationship between the Dimension and the Rényi Index of the Threshold Network
In the previous section, Equation (18) implied that the dimension not only contains the information of the structure of the original network but also the information in the threshold network . We select the network in Figure 2a as an example to generate the threshold networks and , as shown, respectively, in Figure 5a,b. Intuitively, we can see that there is a significant difference between and , and network includes even more edges. Network includes second-order information of a node, that is, other nodes at a distance of 2 from the node are regarded as neighbors, and network includes third-order information.
We will next show that the dimension contains information about the structure of networks and . Based on Equation (18), and are estimated using the dimensions and estimated in Figure 1a, respectively. In addition, The Rényi index of the threshold network can be calculated directly using Equation (10), denoted as . The comparison results are shown in Table 1. In Table 1, the Rényi index calculated based on dimensions is denoted as . Calculations show that the Rényi index value of is less than the Rényi index value of , which means its degree distribution is more homogeneous. It can also be seen that the difference between and is small.
In summary, our analysis shows that the dimension sequence includes information on the structure of the threshold network.
3.3. Empirical Analysis Based on Different Countries
In this section, we use data from three stock markets for analysis. We choose a special case to show the relationship between the dimension and the Rényi index. We set and to calculate the dimension series, and to calculate the Rényi index series. For convenience, we define
in the following subsections.
During the period considered, the number of trading days in the UK and China markets were approximately 253 and 242, respectively. In this section, we only set the length of the calculation window to 126 days, which is about half the number of trading days in the USA market. In the following, the dimension series , and Rényi series are calculated simultaneously, where the calculation window is 126 days and the sliding window is 1 day. Then, the difference between and is calculated for each time period.
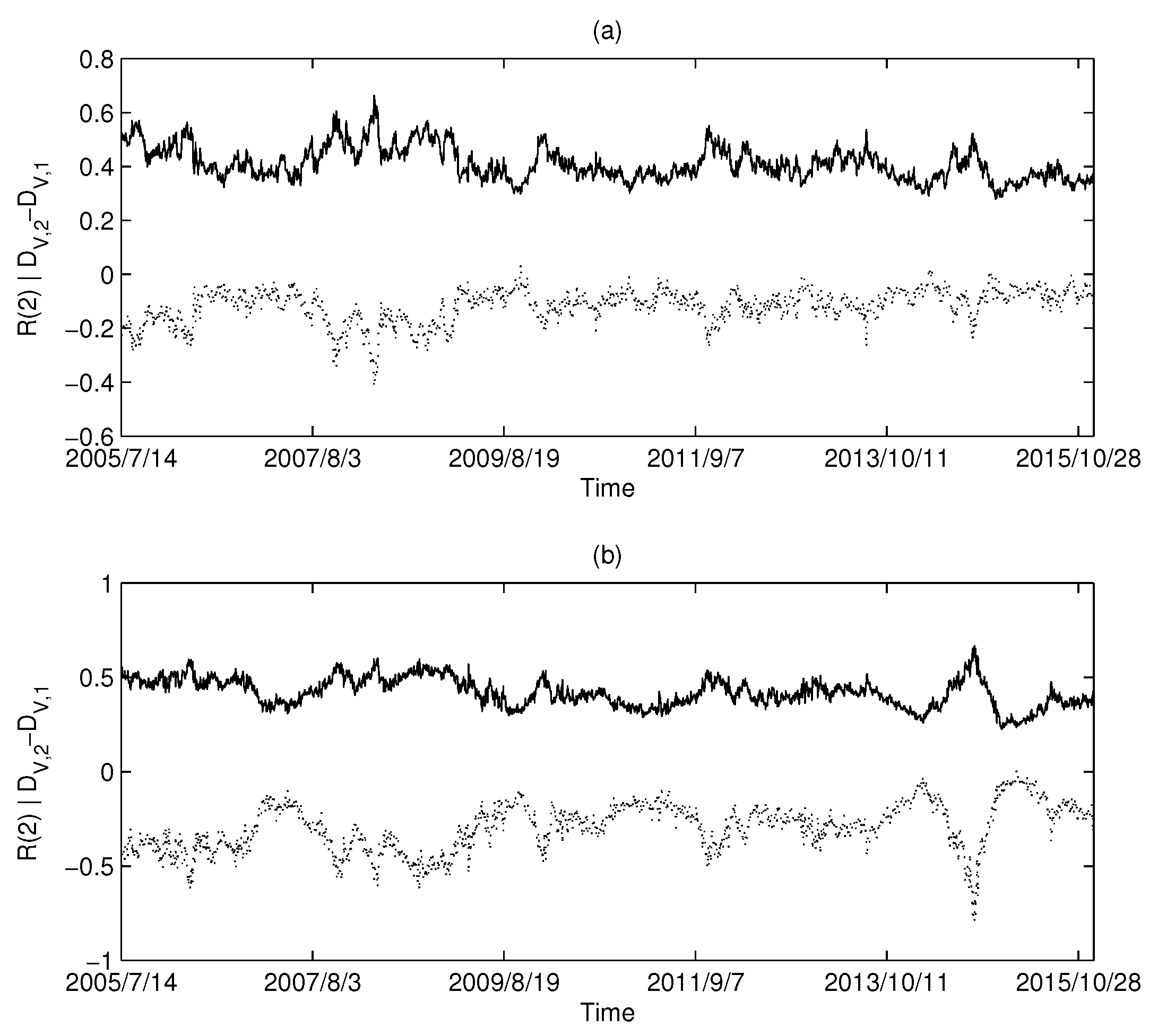
The calculation results of the USA market are shown in Figure 6a,b: Figure 6a corresponds to MST and Figure 6b corresponds to PMFG. Intuitively, we can find that there is a highly negative correlation between the and Rényi series in the USA market.
Similarly, the calculated results using UK market data and China market data are shown in Figure 7 and Figure 8, respectively. Both the UK and China markets showed similar results to the USA market. Intuitively, we find that there is a synchronization between the series and the Rényi index series. We calculated the Pearson correlation between each pair of series and the Rényi series and are listed in Table 2. The high level of correlation shown in the calculations is consistent with the results predicted by Equations (18) and (19).
3.4. Robust Analysis of Calculation Window
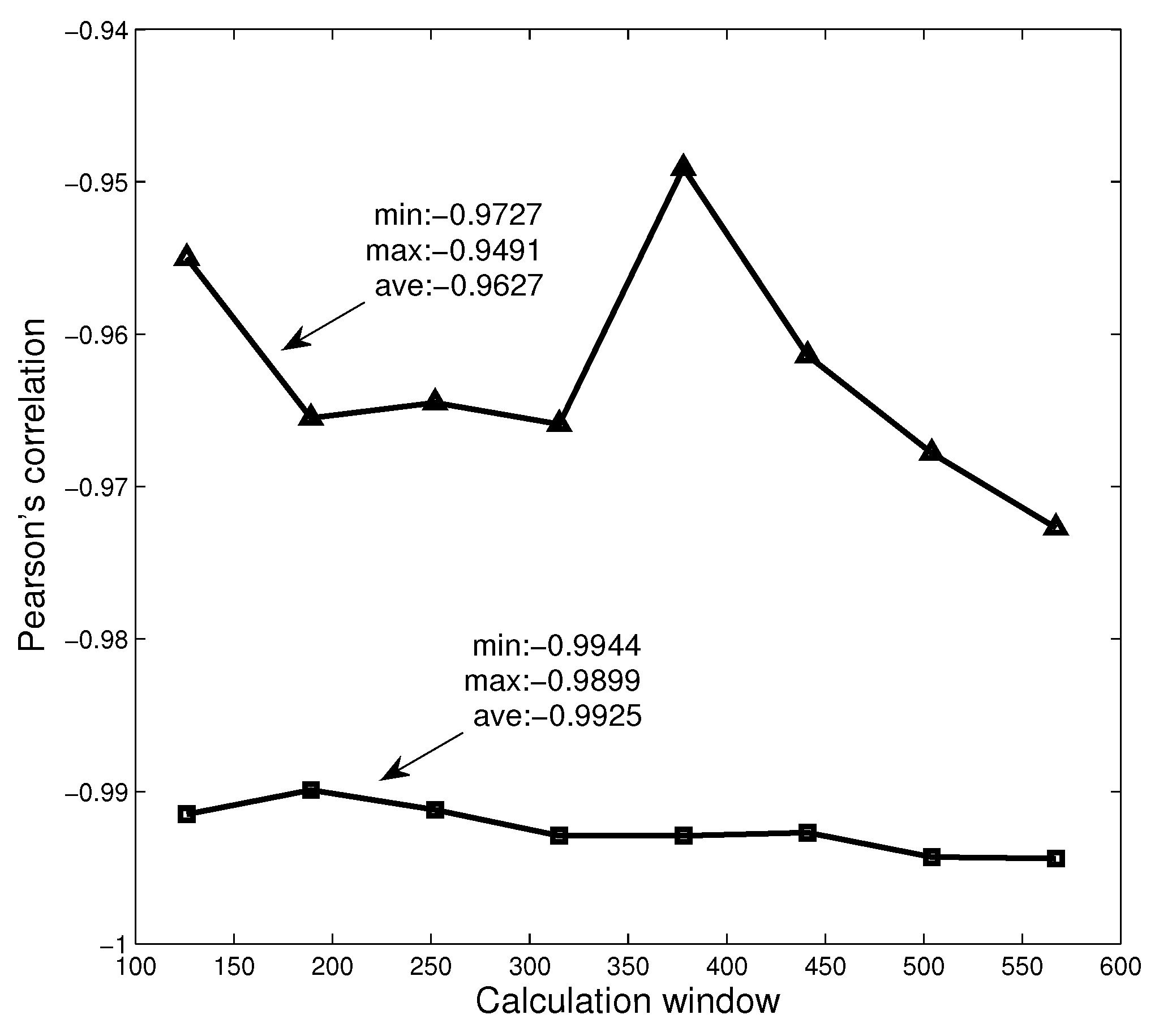
In the previous section, we have analyzed the relationship between the Rényi index series and the dimension series of networks in three different markets. In the analysis, we set the calculation time window to be 126 days. To further study the robustness of the calculation window, we set different time windows and study the relationship between Rényi index and dimension. Here, we choose the data of American market and set eight windows ( days, ), respectively, to calculate Rényi index series and series. The calculation results are shown in Figure 9, where the triangles and squares correspond to MST and PMFG, respectively. It can be found that the Pearson correlation coefficients corresponding to all time windows are less than −0.94, and the average values corresponding to MST and PMFG are all less than −0.96. The calculation results show that the time window does not change the conclusion that there is a high correlation between Rényi index and series.
3.5. The Dynamics of the Rényi Index
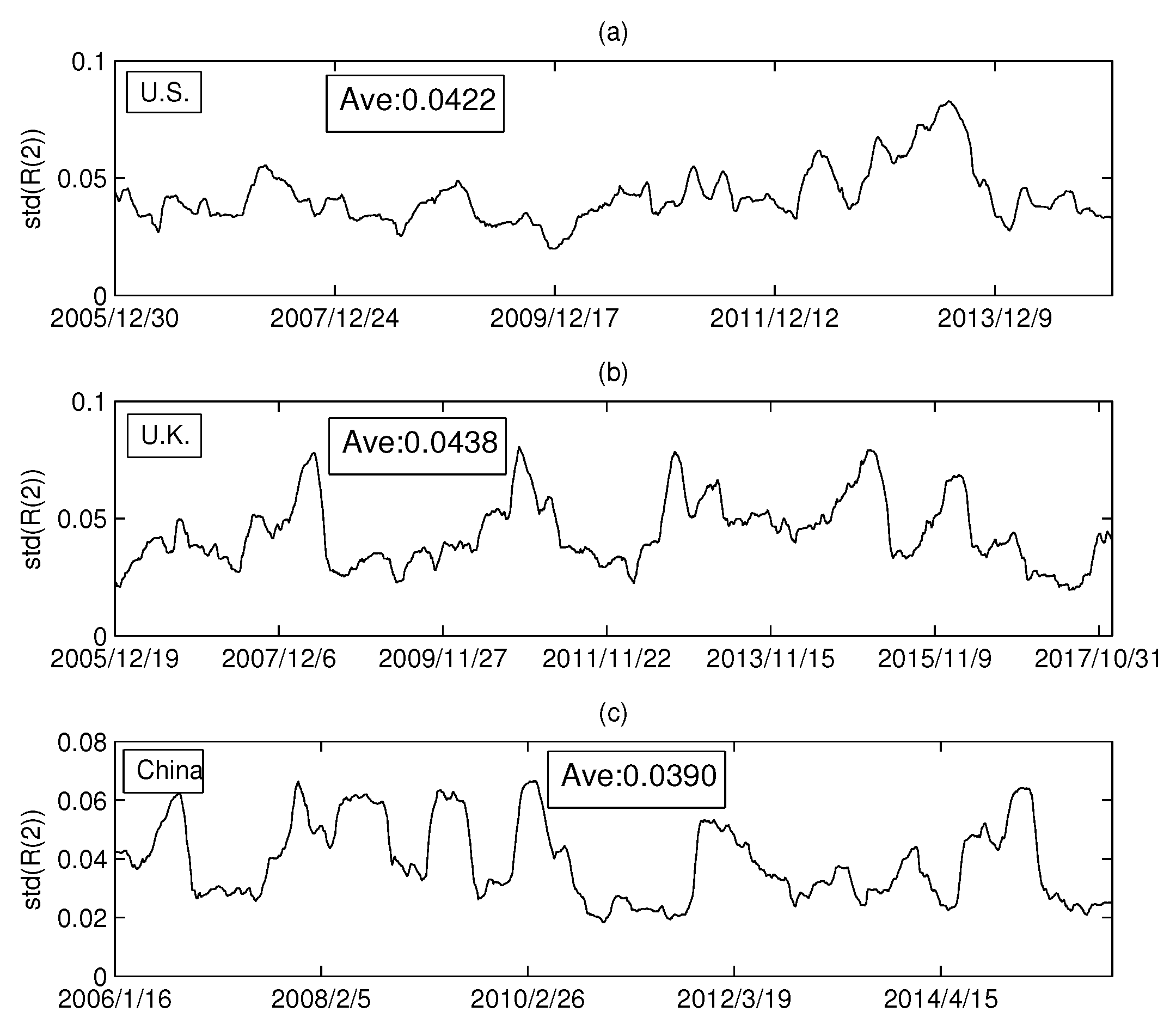
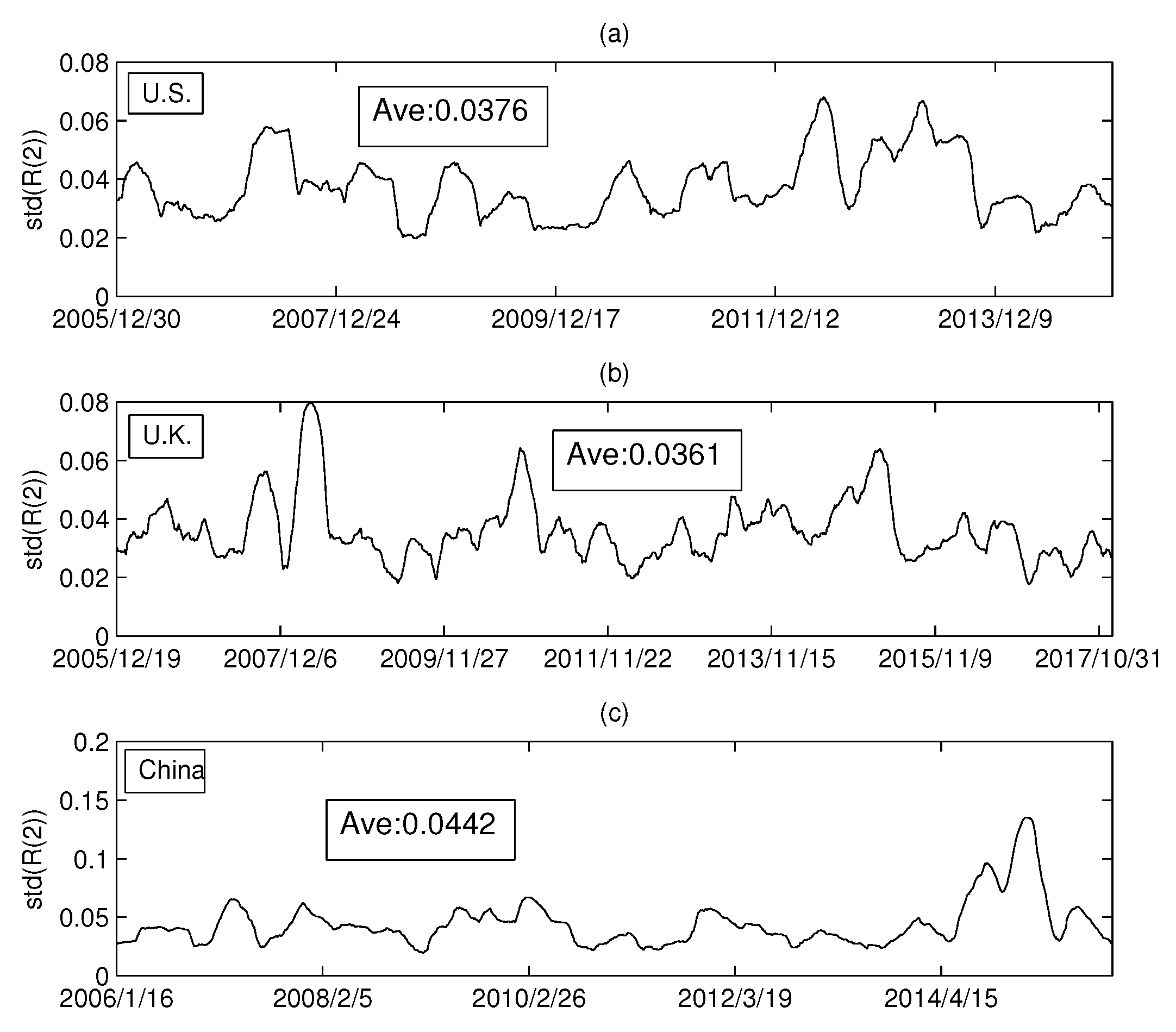
In the previous section, we empirically analyzed the relationship between the Rényi index and the volume dimension. Intuitively, the Rényi index was found to vary drastically over time. To analyze the dynamics of the Rényi index in more detail, this section will calculate the standard deviation of the Rényi series for the three markets. We set the calculation time window at 126 days, and the sliding window at one day. In this way, a standard deviation series of Rényi series is calculated. Figure 10a–c shows the standard deviations of the MST Rényi index for the U.S. market, the U.K. market, and the China market, respectively. Similarly, Figure 11a–c shows the standard deviation series of the Rényi index for PMFG.
We calculated the average of each series in Figure 10 and found that the difference between the three markets was small. However, Figure 11 shows that the Rényi index of PMFG in China fluctuates significantly more than that of the other two markets. The dramatic change in the index over a period of time can lead to an increase in the standard deviation. Comparing the Chinese market with the other two markets, we find that the Rényi index in the Chinese market changed drastically from 2014 to 2015, as shown in Figure 11c. A more detailed analysis shows that the mean of the data up to 30 June 2014 is 0.0392. The difference between 0.0392 and the average of the other two markets (0.0376 and 0.0361) is not significant. Therefore, the difference between the Chinese market and the other two markets is mainly due to the data changes from July 2014 to June 2015. During this period, a huge bubble was generated in the Chinese market and was broken in June 2015. Taking the CSI 300 Index as an example, the index on 1 July 2014 was 2164.559 and reached the peak of 5353.751 on 8 June 2015. After that, the bubble broke down and the index dropped drastically to 4253.021 on 1 July 2005. In addition, the maximum (0.1351) in Figure 11c reached on 2 March 2015, and then rapidly decreased to 0.0299 (on 12 June 2015).
We have found in Section 2.1 that there is no hub node in the network based on the randomized sequence, resulting in a decrease of the Rényi index. Similarly, in previous studies, researchers found changes in the network structure, such as the central company changes as the marginal company, leading to power law exponent changes [34]. Our research also shows that the drastic change in the number of central firms that correspond to the core nodes leads to a change in the Rényi index, as shown in Figure 2 and Figure 3. The drastic change in the Rényi index also suggests that the relationship between companies changes significantly over time, leading to more unstable structures. Therefore, the results shown in Figure 11 show that the changes in PMFG in the Chinese market may be related to this structural change. Furthermore, since the time series can be explained by a multifactor model, as shown in Section 2.1, we speculate that the underlying causes of this change are due in part to changes in economic factors in the Chinese market. The market index has fluctuated dramatically during the period when the bubble was generated and broken. The economic factors that drive the price changes of stocks during this period may have changed, leading to differences between the Chinese market and the other two markets.
3.6. Example of Volume-Based Dimension Analysis
The calculations in the previous section show that the structure of the network varies drastically over time. In this section, we will examine a concrete example using the analytic framework of dimension-entropy.
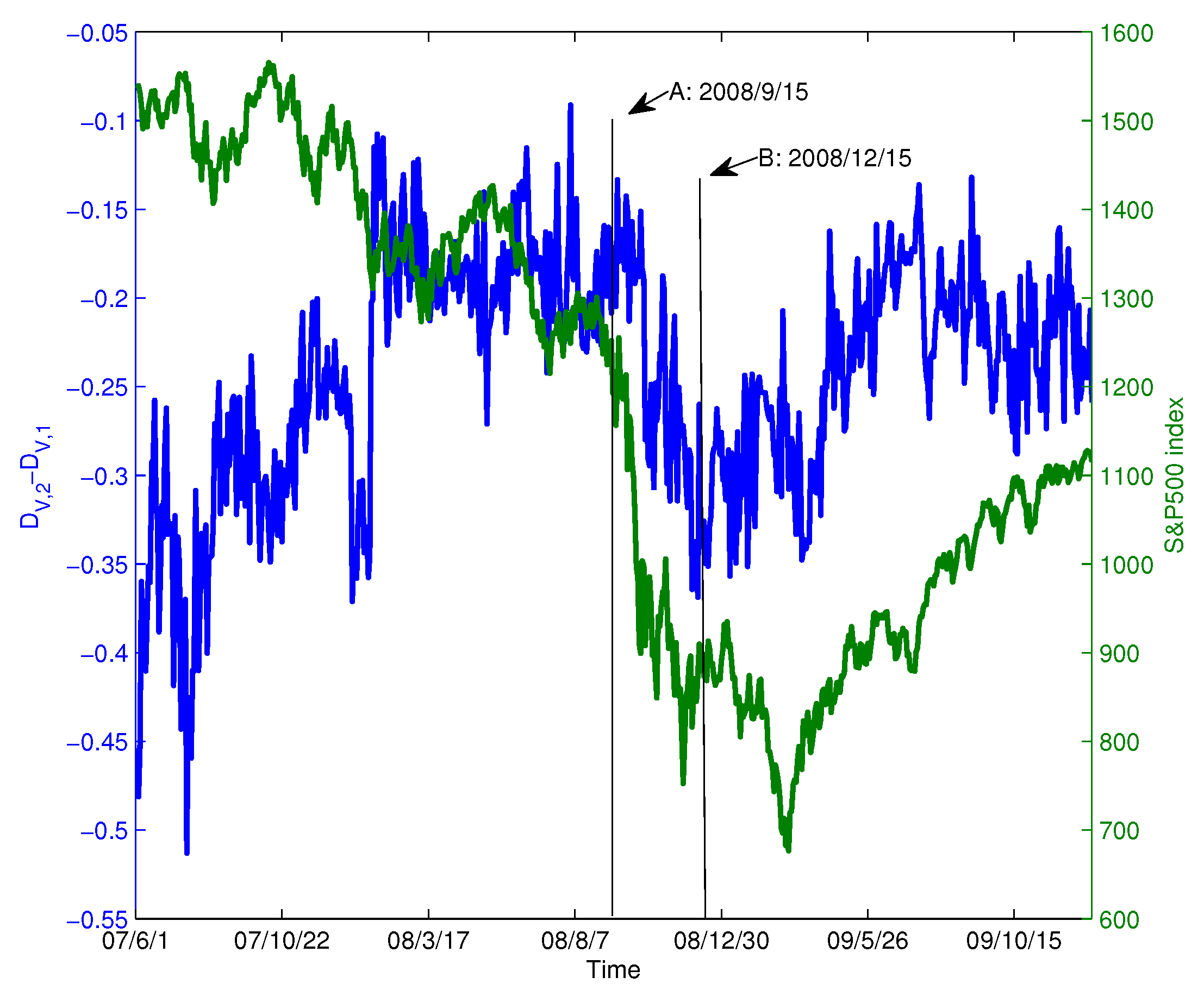
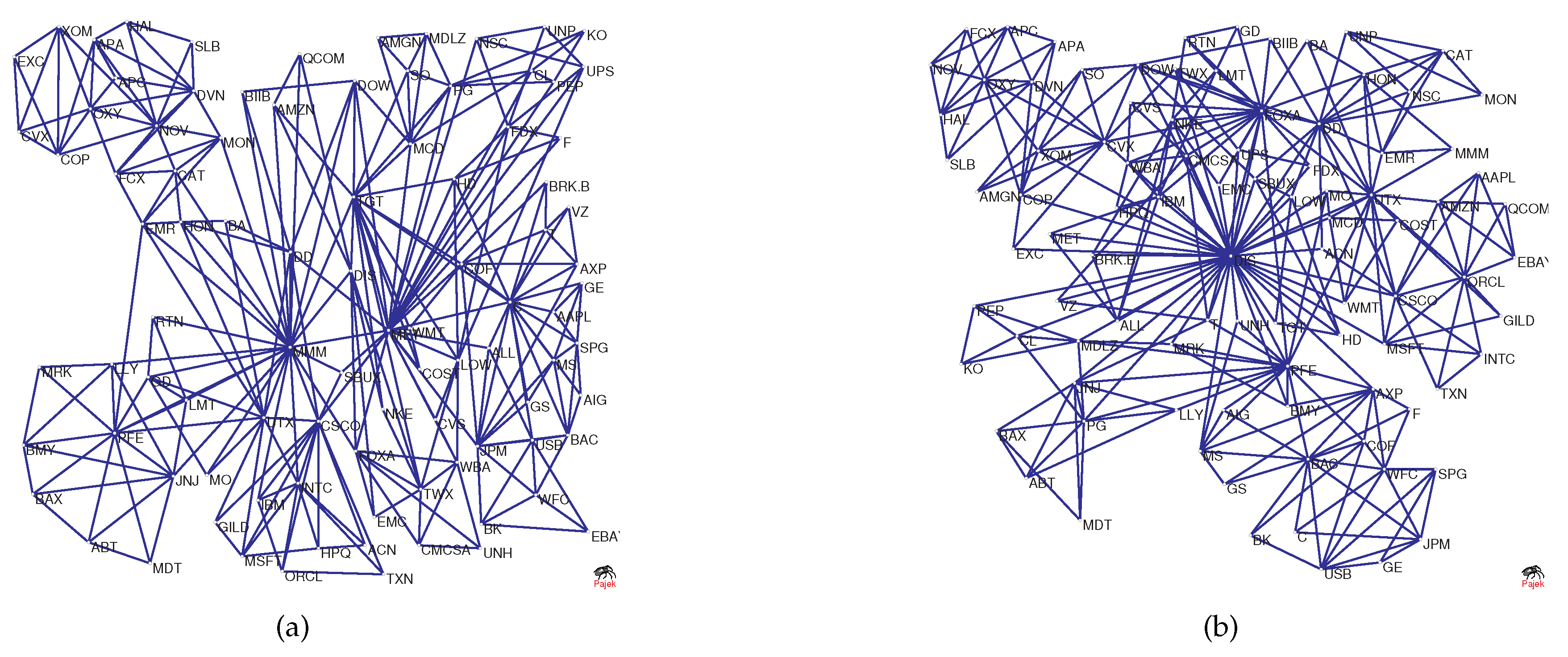
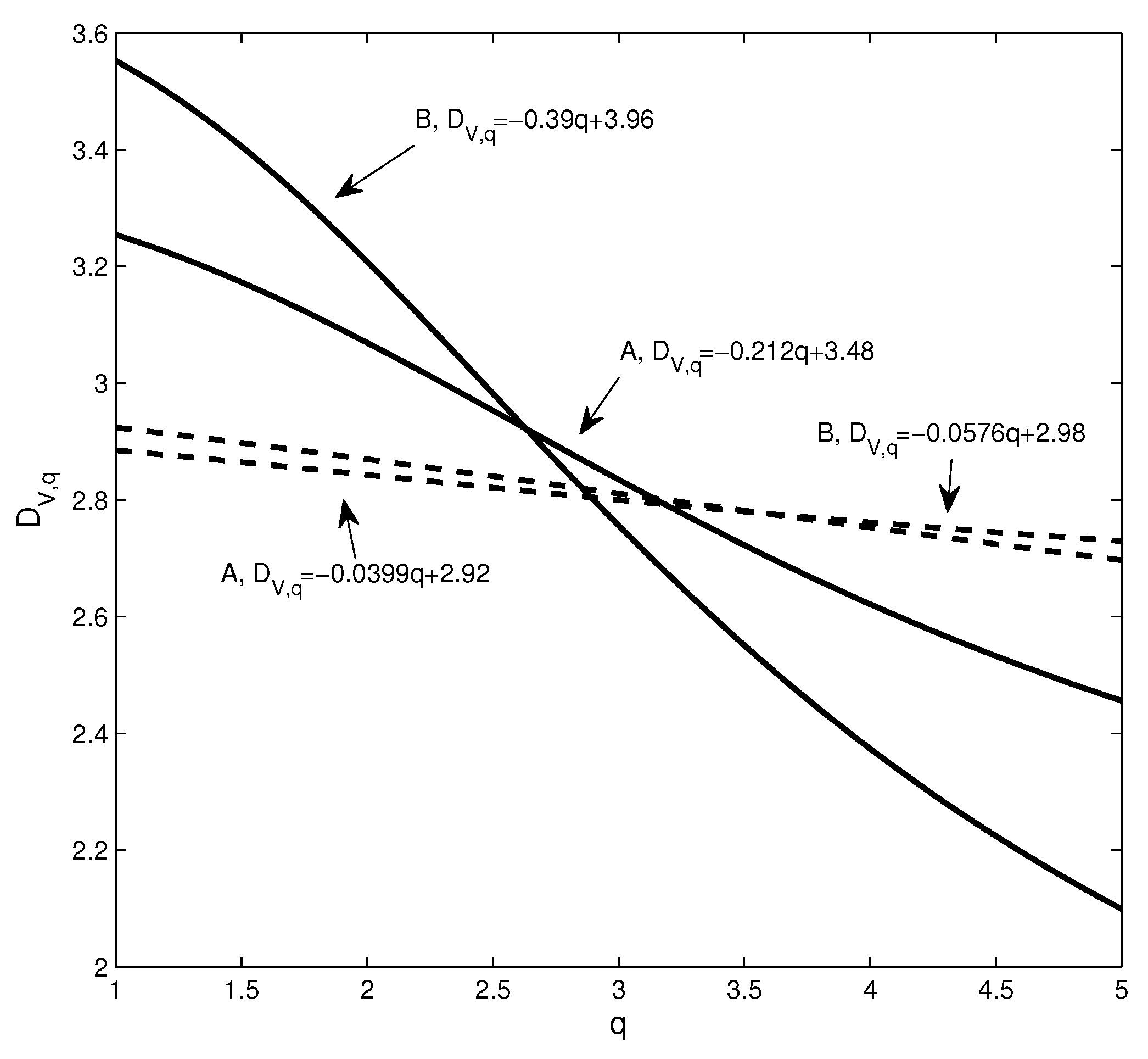
During the financial crisis of 2008, the collapse of Lehman Brothers was an important event. We chose the data of constituent stocks in the S&P100 index from 1 June 2007–31 December 2009 for analysis. We extract the data for this period from Figure 6b and show it in Figure 12 (blue line). For comparison, the S&P 500 index is also shown in Figure 12 (green line). In the figure, Point A corresponds to the collapse of Lehman Brothers on 15 September 2008. Overall, we find that as the index decreases drastically, also changes drastically and declines from 15 September–15 December 2008. At Point A, the value of is −0.1850; however, after that, the value of varies dramatically and reaches −0.3445 after three months. This implies that the structure of the PMFG varies significantly. To visualize this change, Figure 13a,b shows the PMFGs for Points A and B.
Comparing Figure 13a with Figure 13b, we find that there is a super hub node in Figure 13b, which has a degree of 43, whereas, in Figure 13a, the maximum degree is 25.
This structural change can be well captured using the dimension sequence, as shown in Figure 14. The changes in the dimension sequences corresponding to the two networks are significantly different. For comparison, we randomize the yield series for the time period and construct the PMFG according to the method of generating the benchmark shown in Section 2.1.
We find three differences between the dimension sequences at Points A and B. First, the corresponding dimension () of Point B is greater than Point A, which means that as the distance increases, the volume changes more rapidly. Second, the solid line corresponding to Point A changes more smoothly, which means that the PMFG at Point B deviates farther from the benchmark. Third, to show the difference between different dimension sequences, we use a line to fit the data to get the relationship between dimension and q as shown in the figure. It can be seen that the PMFGs at Points A and B are all significantly different from the benchmark, and the difference at Point B is greater.
In summary, we find that the market’s correlation structure changed drastically and deviated significantly from the benchmark. This also suggests that the complexity of the correlation structure in the market changes over time, especially during a financial crisis.
4. Discussion and Conclusions
4.1. Discussion
In our study, both the dimension and the Rényi index are defined on an undirected network, which are used to extract the structure in the Pearson correlation matrix. At present, some research focuses on the networks constructed by other methods, for instance constructing partial networks by using partial correlation coefficients or constructing causal networks [58,59,60]. One area of further possible study is to discuss the dimension and Rényi index on these directed networks.
In this article, we use the method of rolling time windows to construct the network. Recently, researchers have estimated the dynamic correlation between time series and constructed networks that can avoid rolling time windows; however, it is difficult to estimate and construct larger networks [61,62]. Therefore, further research should focus on networks based on dynamic correlation.
Here, the dynamics of dimension and Rényi index have been studied, but its mechanism needs further study. First, in Section 2.1, we use a multifactor model to explain the change in the correlation structure caused by the randomized time series, and this change is captured by the Rényi index and the dimension sequence. Second, in Section 2.3 and Section 2.5, calculations show that the dimension series and the Rényi index change over time in different markets, whereas the Rényi index of the PMFG in the Chinese market changes more drastically. On the one hand, the yield series can be directly expressed as a linear combination of factors. On the other hand, the change of network structure can be affected by the change of factors, as shown in Section 2.1. Therefore, it is necessary to further study the mechanism explanation of network structure changes based on economic factors. Further research may need to focus on the influence of the factors on the network structure, as well as on the dynamics of Rényi index and dimension.
4.2. Conclusions
In studying the relationship between the dimensions of the correlation network and the Rényi Index, using the data of three markets for empirical analysis, we find that volume-based dimension is well defined on a correlation-based network. Our studies have shown that there is also a scaling relationship between the higher moment of the volume and the distance. Based on this empirical fact, we constructed a general volume-based dimension. We also find that the volume-based dimensions are intrinsically linked to the network’s Rényi index.
Our analysis results show that the dimensions can reveal the topological structure of the network well and include the neighbor information of the nodes. Volume-based dimension sequences characterize the level of deviation from the benchmark based on randomized series, thus describing the complexity of correlation-based networks. In addition, our analytical framework may also be applied to complex systems, such as those in financial markets, where each element can be characterized by time series, and the relationships among the different elements can be constructed based on the correlation.
Acknowledgments
This research was partially supported by the National Natural Science Foundation of China (Fund Number: 71371073) and Shanghai Pujiang Program of China (Fund Number: 13PJC025).
Author Contributions
Chun-Xiao Nie and Fu-Tie Song designed the steps of empirical analysis. Chun-Xiao Nie analyzed the data and plotted the graphs. Chun-Xiao Nie and Fu-Tie Song wrote the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Boccaletti, S.; Latora, V.; Moreno, Y.; Chavez, M.; Hwang, D.-U. Complex networks: Structure and dynamics. Phys. Rep. 2006, 424, 175–308. [Google Scholar] [CrossRef]
- Newman, M.E.J. The structure and function of complex networks. SIAM Rev. 2006, 45, 167–256. [Google Scholar] [CrossRef]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef]
- Malliaros, F.D.; Vazirgiannis, M. Clustering and community detection in directed networks: A survey. Phys. Rep. 2013, 533, 95–142. [Google Scholar] [CrossRef]
- Zanin, M.; Papo, D.; Sousa, P.A.; Menasalvas, E.; Nicchi, A.; Kubik, E.; Boccaletti, S. Combining complex networks and data mining: Why and how. Phys. Rep. 2016, 635, 1–44. [Google Scholar] [CrossRef]
- Barabási, A.L.; Albert, R. Emergence of Scaling in Random Networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed]
- Clauset, A.; Shalizi, C.R.; Newman, M.E. Power-law distributions in empirical data. SIAM Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef]
- Song, C.; Havlin, S.; Makse, H.A. Self-similarity of complex networks. Nature 2005, 433, 392–395. [Google Scholar] [CrossRef] [PubMed]
- Wei, D.; Wei, B.; Hu, Y.; Zhang, H.; Deng, Y. A new information dimension of complex networks. Phys. Lett. A 2014, 378, 1091–1094. [Google Scholar] [CrossRef]
- Zhang, Q.; Luo, C.; Li, M.; Deng, Y.; Mahadevan, S. Tsallis information dimension of complex networks. Physica A 2015, 419, 707–717. [Google Scholar] [CrossRef]
- Rosenberg, E. Maximal entropy coverings and the information dimension of a complex network. Phys. Lett. A 2017, 381, 574–580. [Google Scholar] [CrossRef]
- Shanker, O. Defining dimension of a complex network. Modern Phys. Lett. B 2007, 21, 321–326. [Google Scholar] [CrossRef]
- Shanker, O. Graph zeta function and dimension of complex network. Mod. Phys. Lett. B 2007, 21, 639–644. [Google Scholar] [CrossRef]
- Long, G.U.O.; Cai, X.U. The Fractal Dimensions of Complex Networks. Chin. Phys. Lett. 2009, 26, 088901. [Google Scholar] [CrossRef]
- Wei, D.J.; Liu, Q.; Zhang, H.X.; Hu, Y.; Deng, Y.; Mahadevan, S. Box-covering algorithm for fractal dimension of weighted networks. Sci. Rep. 2013, 3, 3049. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.-L.; Yu, Z.-G.; Anh, V. Multifractal analysis of complex networks. Chin. Phys. B 2012, 21, 080504. [Google Scholar] [CrossRef]
- Furuya, S.; Yakubo, K. Multifractality of complex networks. Phys. Rev. E 2011, 84, 036118. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.-L.; Yu, Z.-G.; Anh, V. Determination of multifractal dimensions of complex networks by means of the sandbox algorithm. Chaos 2015, 25, 023103. [Google Scholar] [CrossRef] [PubMed]
- Jalan, S.; Yadav, A.; Sarkar, C.; Boccaletti, S. Unveiling the multi-fractal structure of complex networks. Chaos Solitons Fractals 2017, 97, 11–14. [Google Scholar] [CrossRef]
- Lacasa, L.; Gámez-Gardenes, J. Correlation Dimension of Complex Networks. Phys. Rev. Lett. 2013, 110, 168703. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.; Li, W.; Cai, X. Structure and dynamics of stock market in times of crisis. Phys. Lett. A 2016, 380, 654–666. [Google Scholar] [CrossRef]
- Birch, J.; Pantelous, A.A.; Soramäki, K. Analysis of correlation based networks representing DAX 30 stock price returns. Comput. Econ. 2016, 47, 501–525. [Google Scholar] [CrossRef]
- Mantegna, R.N. Hierarchical structure in financial markets. Eur. Phys. J. B Condens. Matter Complex Syst. 1999, 11, 193–197. [Google Scholar] [CrossRef]
- Tumminello, M.; Aste, T.; Di Matteo, T.; Mantegna, R.N. A tool for filtering information in complex systems. Proc. Natl. Acad. Sci. USA 2005, 102, 10421–10426. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Yang, H. Complex network-based time series analysis. Physica A 2008, 387, 1381–1386. [Google Scholar] [CrossRef]
- Chi, K.T.; Liu, J.; Lau, F.C. A network perspective of the stock market. J. Empir. Financ. 2010, 17, 659–667. [Google Scholar] [CrossRef]
- Tumminello, M.; Di Matteo, T.; Aste, T.; Mantegna, R.N. Correlation based networks of equity returns sampled at different time horizons. Eur. Phys. J. B 2007, 55, 209–217. [Google Scholar] [CrossRef]
- Buccheri, G.; Marmi, S.; Mantegna, R.N. Evolution of correlation structure of industrial indices of US equity markets. Phys. Rev. E 2007, 88, 012806. [Google Scholar] [CrossRef] [PubMed]
- Matesanz, D.; Ortega, G.J. Network analysis of exchange data: Interdependence drives crisis contagion. Qual. Quant. 2014, 48, 1835–1851. [Google Scholar] [CrossRef] [Green Version]
- Vodenska, I.; Becker, A.P.; Zhou, D.; Kenett, D.Y.; Stanley, H.E.; Havlin, S. Community analysis of global financial markets. Risks 2016, 4, 13. [Google Scholar] [CrossRef]
- Naylor, M.J.; Rose, L.C.; Moyle, B.J. Topology of foreign exchange markets using hierarchical structure methods. Physica A 2007, 382, 199–208. [Google Scholar] [CrossRef]
- Garas, A.; Argyrakis, P. Correlation study of the athens stock exchange. Physica A 2007, 380, 199–208. [Google Scholar] [CrossRef]
- Onnela, J.P.; Chakraborti, A.; Kaski, K.; Kertesz, J.; Kanto, A. Dynamics of market correlations: Taxonomy and portfolio analysis. Phys. Rev. E 2003, 68, 056110. [Google Scholar] [CrossRef] [PubMed]
- Wiliński, M.; Sienkiewicz, A.; Gubiec, T.; Kutner, R.; Struzik, Z.R. Structural and topological phase transitions on the German Stock Exchange. Physica A 2013, 392, 5963–5973. [Google Scholar] [CrossRef]
- Górski, A.Z.; Drożdż, S.; Kwapień, J. Scale free effects in world currency exchange network. Eur. Phys. J. B 2008, 66, 91–96. [Google Scholar] [CrossRef]
- Nie, C.X.; Song, F.T.; Li, S.P. Rényi indices of financial minimum spanning trees. Physica A 2016, 444, 883–889. [Google Scholar] [CrossRef]
- Eliazar, I. Randomness, evenness, and Rényi’s index. Physica A 2011, 390, 1982–1990. [Google Scholar] [CrossRef]
- Eliazar, I.I.; Sokolov, I.M. Measuring statistical evenness: A panoramic overview. Physica A 2012, 391, 1323–1353. [Google Scholar] [CrossRef]
- Maasoumi, E. A compendium to information theory in economics and econometrics. Econ. Rev. 1993, 12, 137–181. [Google Scholar] [CrossRef]
- Zhou, R.; Cai, R.; Tong, G. Applications of entropy in finance: A review. Entropy 2013, 15, 4909–4931. [Google Scholar] [CrossRef]
- Bekiros, S.D. Timescale analysis with an entropy-based shift-invariant discrete wavelet transform. Comput. Econ. 2014, 44, 231–251. [Google Scholar] [CrossRef]
- Gençay, R.; Gradojevic, N. Crash of ’87—Was it expected? Aggregate market fears and long-range dependence. J. Empir. Financ. 2011, 17, 270–282. [Google Scholar] [CrossRef]
- Stutzer, M.J. Simple entropic derivation of a generalized Black-Scholes option pricing model. Entropy 2000, 2, 70–77. [Google Scholar] [CrossRef]
- Kitamura, Y.; Stutzer, M. Connections between entropic and linear projections in asset pricing estimation. J. Econ. 2002, 107, 159–174. [Google Scholar] [CrossRef]
- Bowden, R.J. Directional entropy and tail uncertainty, with applications to financial hazard. Quant. Financ. 2011, 11, 437–446. [Google Scholar] [CrossRef]
- Gradojevic, N.; Caric, M. Predicting systemic risk with entropic indicators. J. Forecast. 2017, 36, 16–25. [Google Scholar] [CrossRef]
- Billio, M.; Casarin, R.; Costola, M.; Pasqualini, A. An entropy-based early warning indicator for systemic risk. J. Int. Financ. Markets Inst. Money 2016, 45, 42–59. [Google Scholar] [CrossRef]
- Maasoumi, E.; Racine, J. Entropy and predictability of stock market returns. J. Econ. 2002, 107, 291–312. [Google Scholar] [CrossRef]
- Sandhu, R.S.; Georgiou, T.T.; Tannenbaum, A.R. Ricci curvature: An economic indicator for market fragility and systemic risk. Sci. Adv. 2016, 2, e1501495. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Qiu, W. A measure of risk and a decision-making model based on expected utility and entropy. J. Oper. Res. 2005, 164, 792–799. [Google Scholar] [CrossRef]
- Zeng, Z.J.; Xie, C.; Yan, X.G.; Hu, J.; Mao, Z. Are stock market networks non-fractal? Evidence from New York Stock Exchange. Financ. Res. Lett. 2016, 17, 97–102. [Google Scholar] [CrossRef]
- Prim, R.C. Shortest connection networks and some generalizations. Bell Syst. Tech. J. 1957, 36, 1389–1401. [Google Scholar] [CrossRef]
- Campbell, J.Y.; Lo, A.W.C.; MacKinlay, A.C. (Eds.) Multifactor Pricing Models. In The Econometrics of Financial Markets; Princeton University Press: Princeton, NJ, USA, 1997; pp. 219–251. [Google Scholar]
- Fama, E.F.; French, K.R. Common risk factors in the returns on stocks and bonds. J. Financ. Econ. 1993, 33, 3–56. [Google Scholar] [CrossRef]
- Tumminello, M.; Lillo, F.; Mantegna, R.N. Hierarchically nested factor model from multivariate data. Europhys. Lett. 2007, 78, 30006. [Google Scholar] [CrossRef]
- Ma, J.; Yang, J.; Zhang, X.; Huang, Y. Analysis of Chinese stock market from a complex network perspective: Better to invest in the central. In Proceedings of the 2015 34th Chinese Control Conference (CCC), Hangzhou, China, 28–30 July 2015; Volume 34, pp. 8606–8611. [Google Scholar]
- Bun, J.; Bouchaud, J.P.; Potters, M. Cleaning large correlation matrices: Tools from random matrix theory. Phys. Rep. 2017, 666, 1–109. [Google Scholar] [CrossRef]
- Kenett, D.Y.; Tumminello, M.; Madi, A.; Gur-Gershgoren, G.; Mantegna, R.N.; Ben-Jacob, E. Dominating clasp of the financial sector revealed by partial correlation analysis of the stock market. PLoS ONE 2010, 5, e15032. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Billio, M.; Getmansky, M.; Lo, A.W.; Pelizzon, L. Econometric measures of connectedness and systemic risk in the finance and insurance sectors. J. Financ. Econ. 2012, 104, 535–559. [Google Scholar] [CrossRef]
- Papana, A.; Kyrtsou, C.; Kugiumtzis, D.; Diks, C. Financial networks based on Granger causality: A case study. Physica A 2017, 482, 65–73. [Google Scholar] [CrossRef]
- Isogai, T. Dynamic correlation network analysis of financial asset returns with network clustering. Appl. Netw. Sci. 2017, 2, 8. [Google Scholar] [CrossRef]
- Yin, K.; Liu, Z.; Liu, P. Trend analysis of global stock market linkage based on a dynamic conditional correlation network. J. Bus. Econ. Manag. 2017, 18, 779–800. [Google Scholar] [CrossRef]
Figure 1.
The dimension estimation of: (a) minimum spanning tree (MST); and (b) planar maximally filtered graph (PMFG) (point: , +: , triangle: ).
Figure 1.
The dimension estimation of: (a) minimum spanning tree (MST); and (b) planar maximally filtered graph (PMFG) (point: , +: , triangle: ).
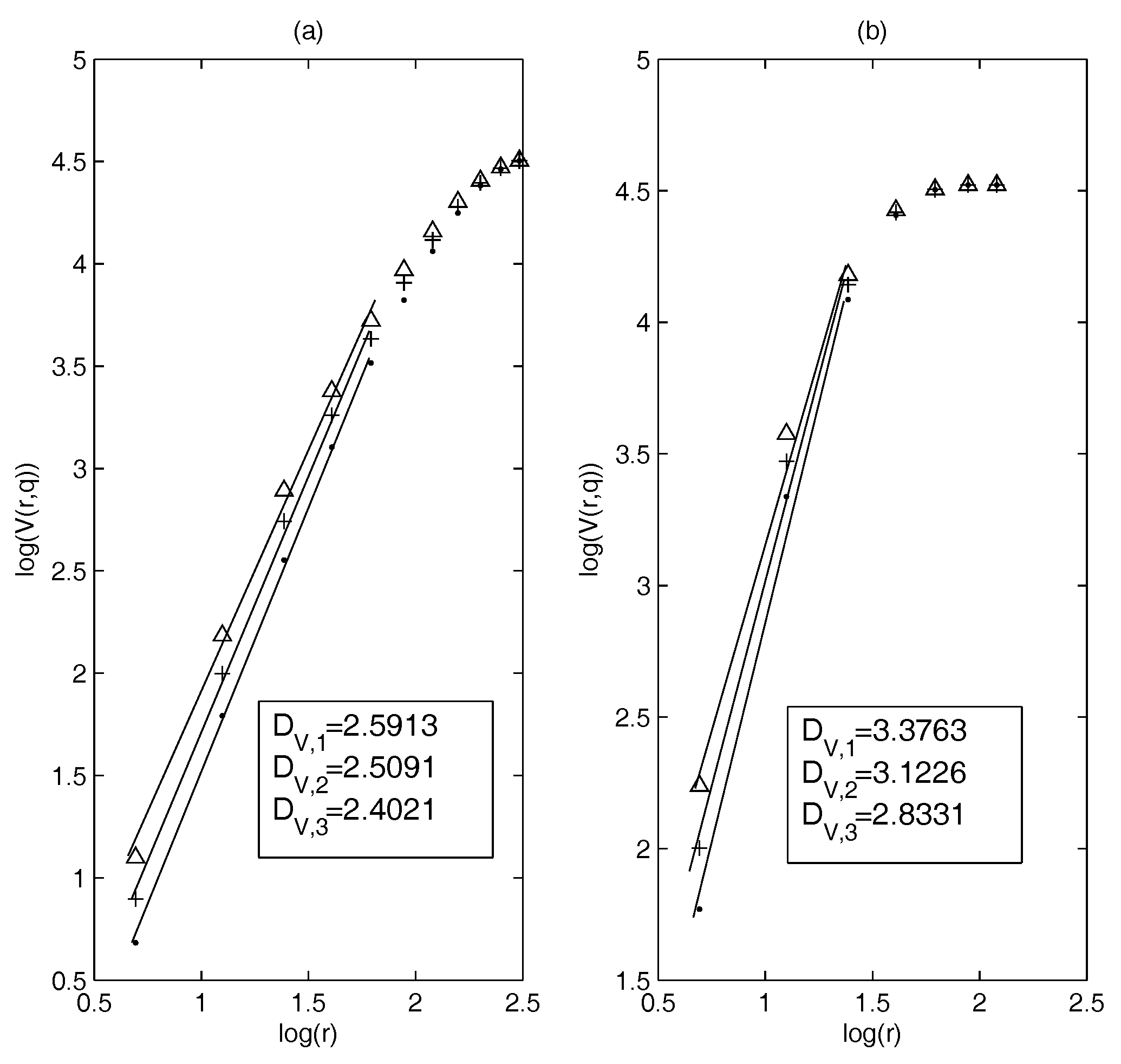
Figure 2.
(a,b) The original networks; and (c,d) the benchmark networks used for comparison.
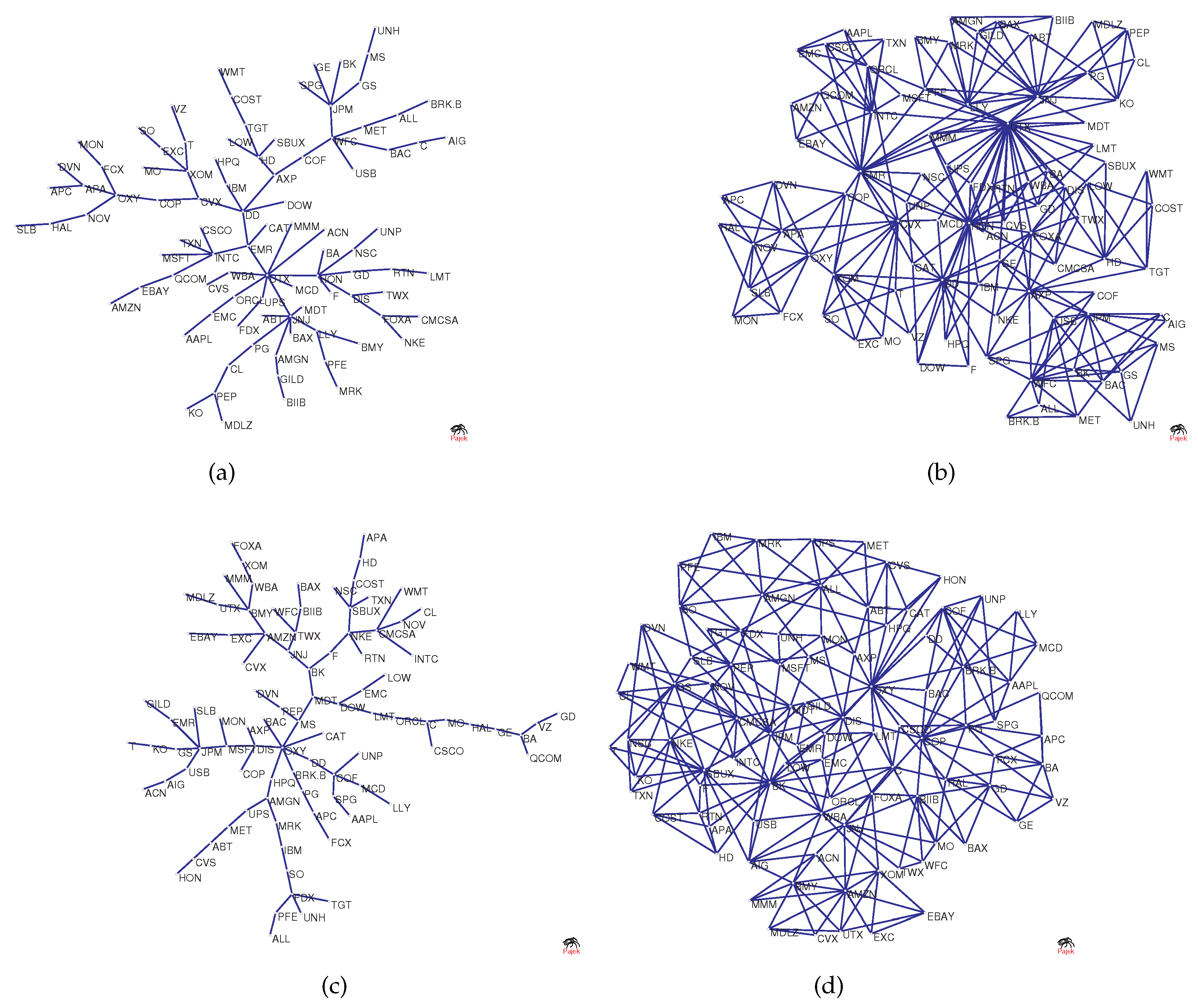
Figure 3.
The degree distribution of the network in Figure 2, in which the labels of the four subgraphs correspond to the labels in Figure 2 one by one, for example, Figure 3a corresponds to Figure 2a and so on. (a) ; (b) ; (c) ; (d) .

Figure 4.
The dimension sequences of the different networks, where the solid line corresponds to the real data and the dotted line corresponds to the randomized data.
Figure 4.
The dimension sequences of the different networks, where the solid line corresponds to the real data and the dotted line corresponds to the randomized data.
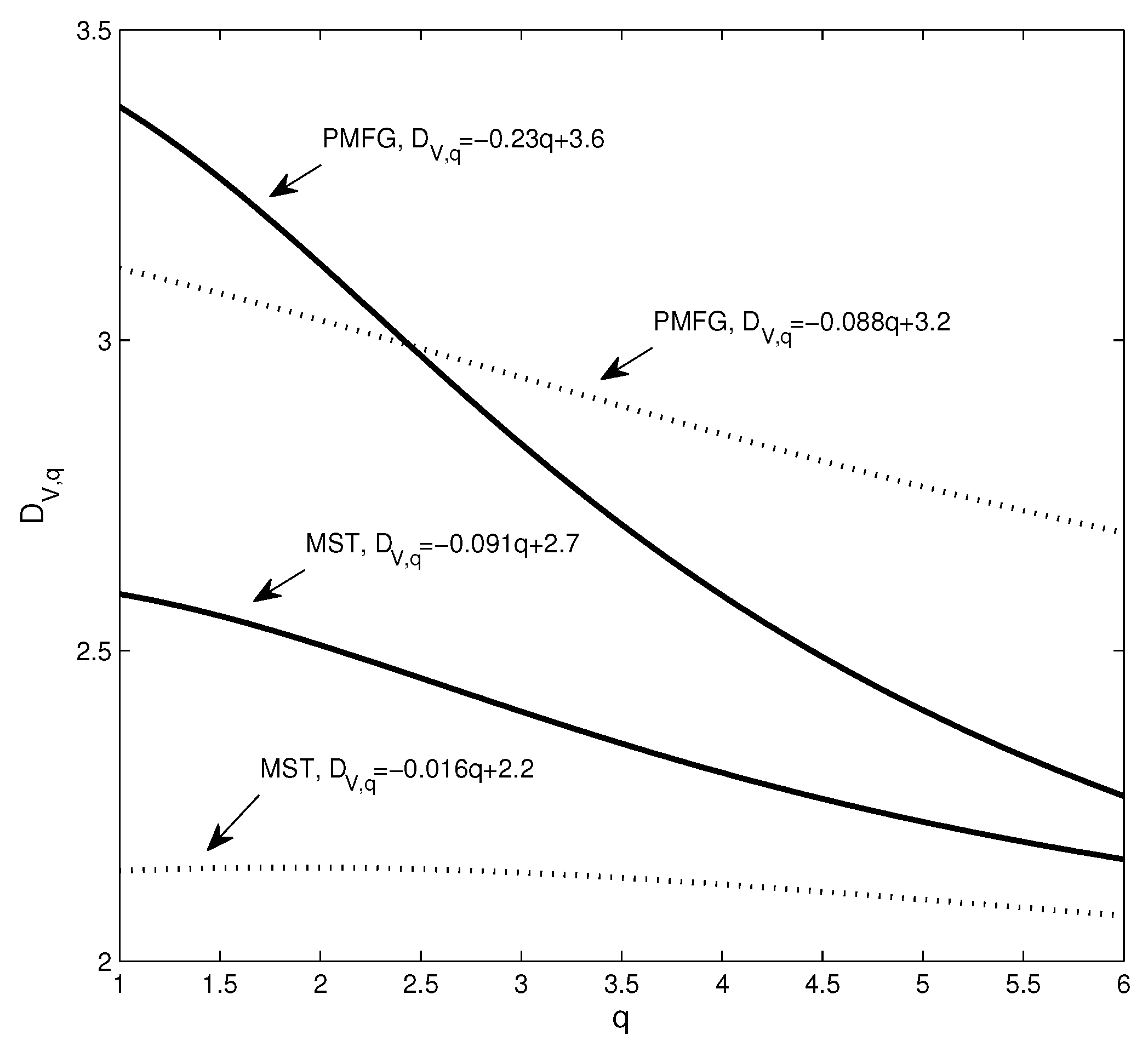
Figure 5.
The figure shows two threshold networks based on Figure 2a: (a) ; and (b) .
Figure 5.
The figure shows two threshold networks based on Figure 2a: (a) ; and (b) .

Figure 6.
The dimension and Rényi index series of the correlation-based networks in the USA market: (a) MST; and (b) PMFG. The solid line corresponds to the Rényi index, and the dotted line corresponds to .
Figure 6.
The dimension and Rényi index series of the correlation-based networks in the USA market: (a) MST; and (b) PMFG. The solid line corresponds to the Rényi index, and the dotted line corresponds to .
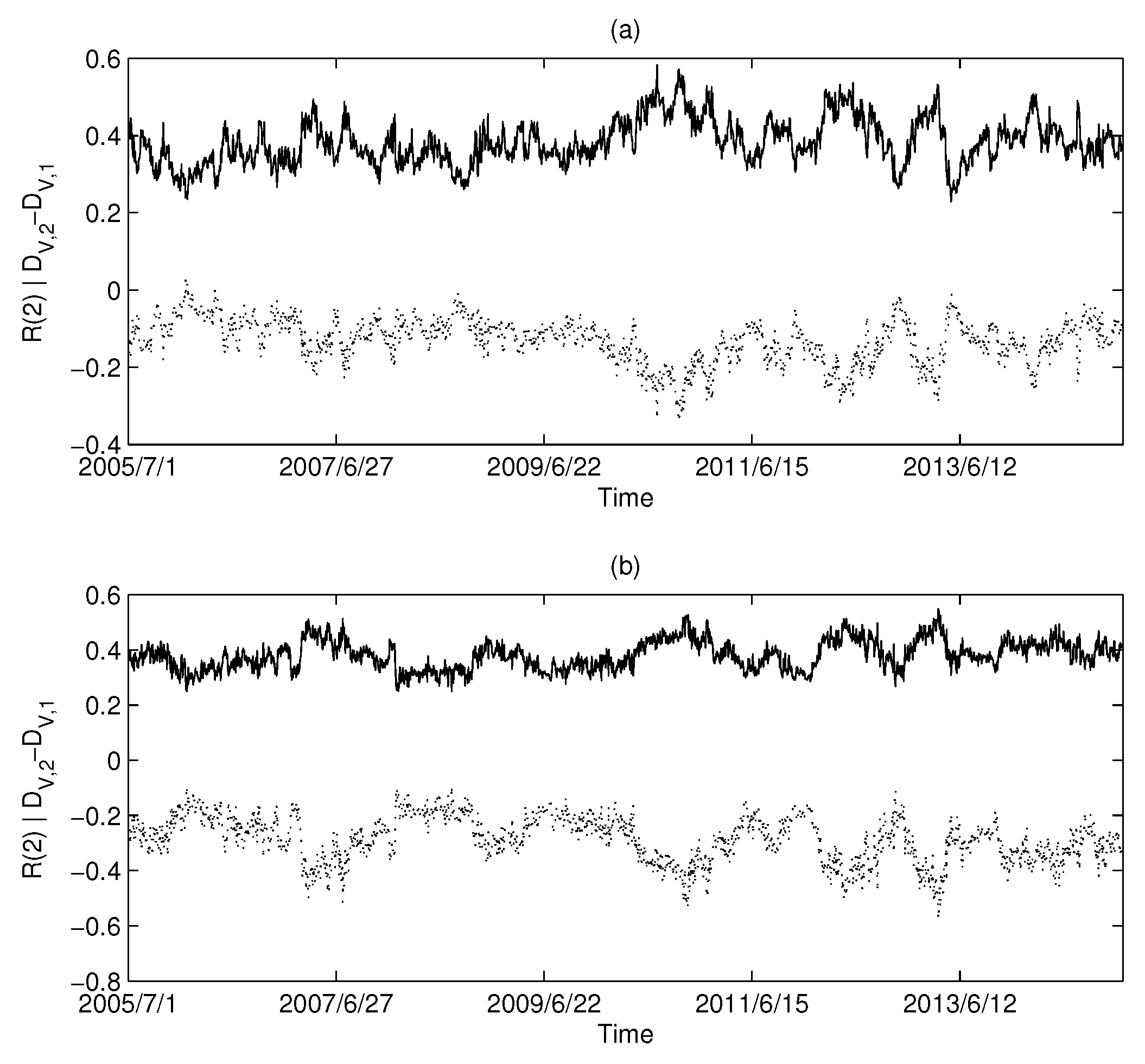
Figure 7.
The dimension and Rényi index series of the correlation-based networks in the British market: (a) MST; and (b) PMFG. The solid line corresponds to the Rényi index, and the dotted line corresponds to .
Figure 7.
The dimension and Rényi index series of the correlation-based networks in the British market: (a) MST; and (b) PMFG. The solid line corresponds to the Rényi index, and the dotted line corresponds to .
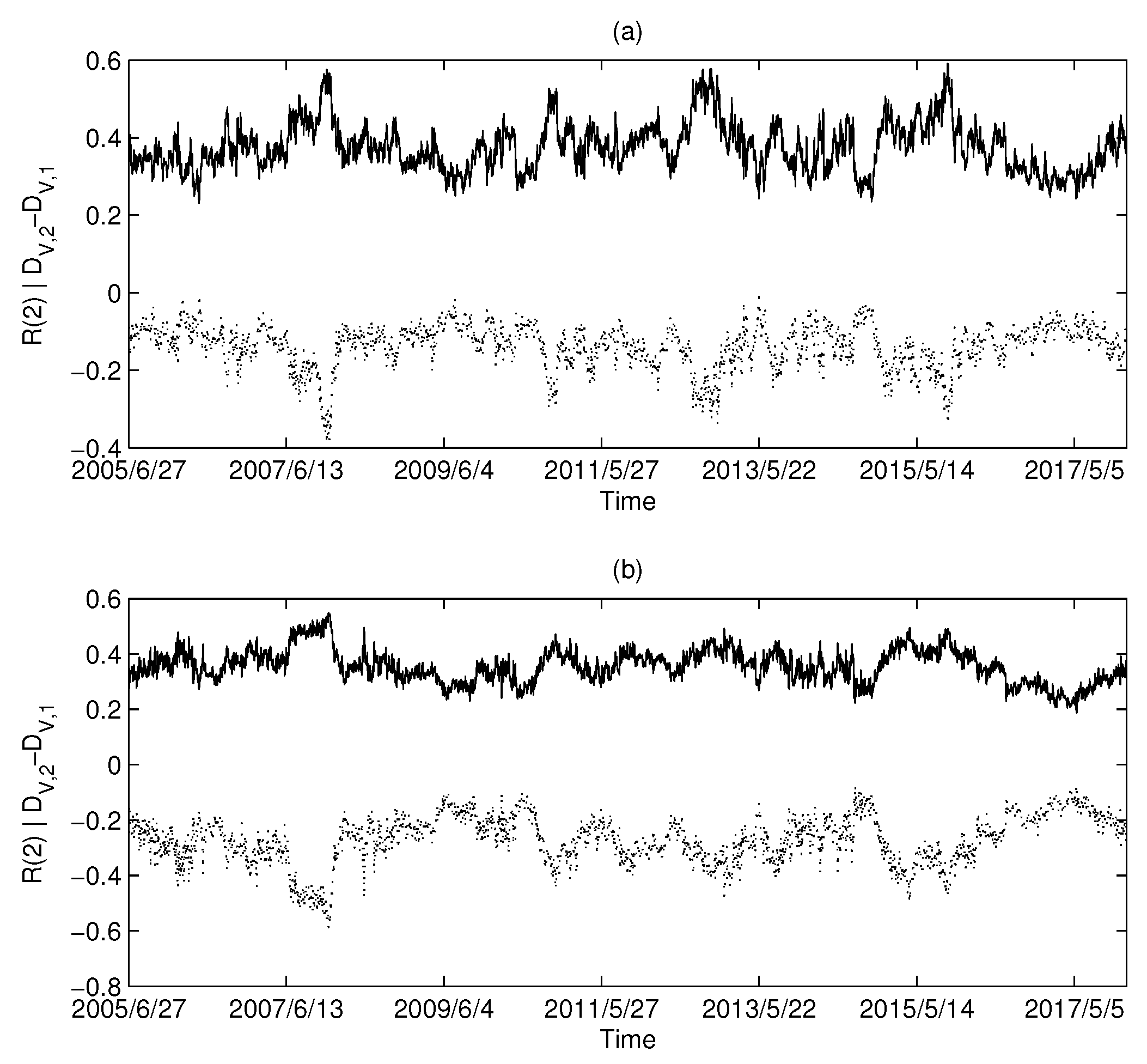
Figure 8.
The dimensionality and Rényi index series of the correlation-based networks in the Chinese market: (a) MST; and (b) PMFG. The solid line corresponds to the Rényi index, and the dotted line corresponds to .
Figure 8.
The dimensionality and Rényi index series of the correlation-based networks in the Chinese market: (a) MST; and (b) PMFG. The solid line corresponds to the Rényi index, and the dotted line corresponds to .
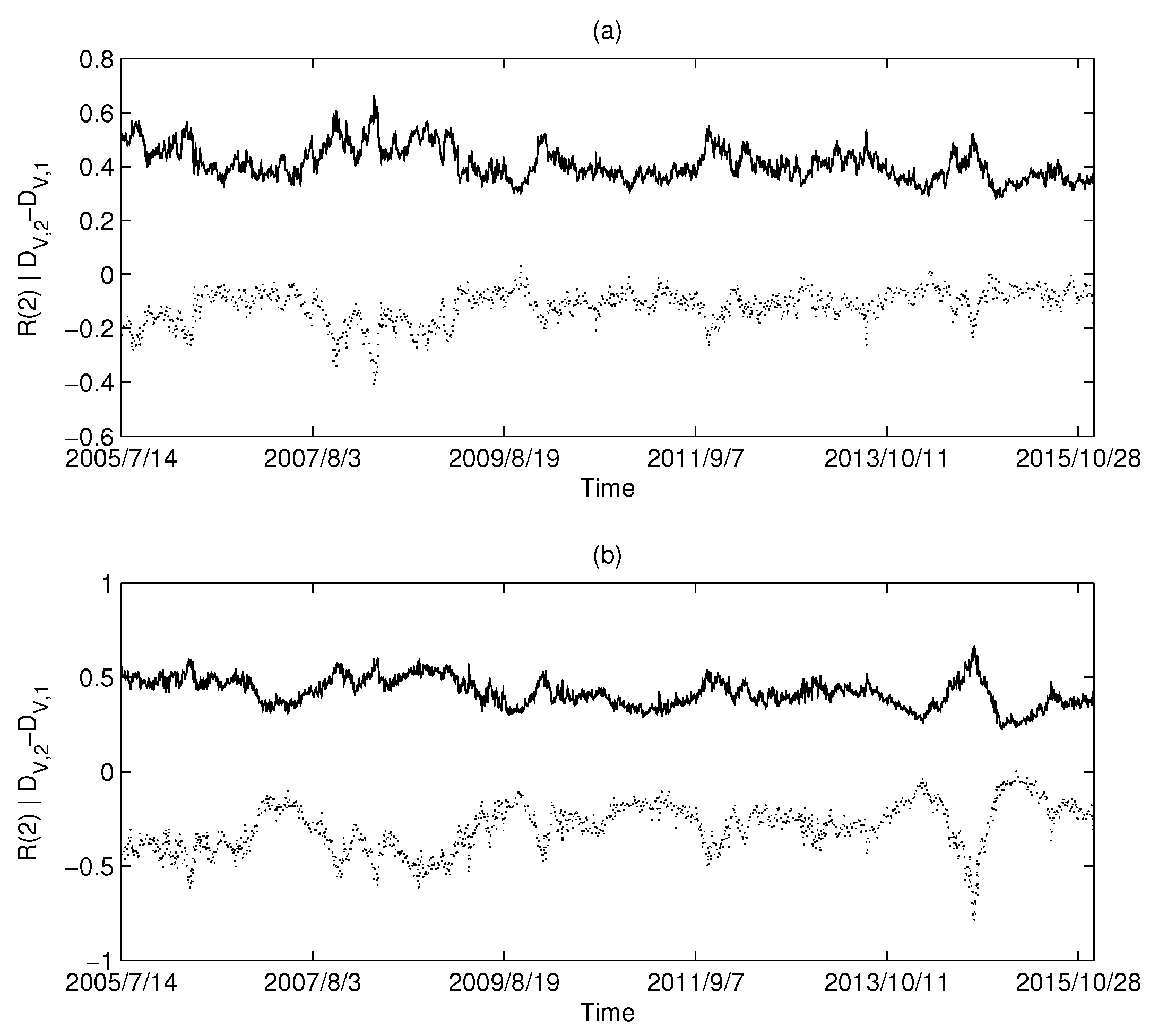
Figure 9.
The figure shows the relationship between the Pearson correlation coefficient and the calculation window.
Figure 9.
The figure shows the relationship between the Pearson correlation coefficient and the calculation window.
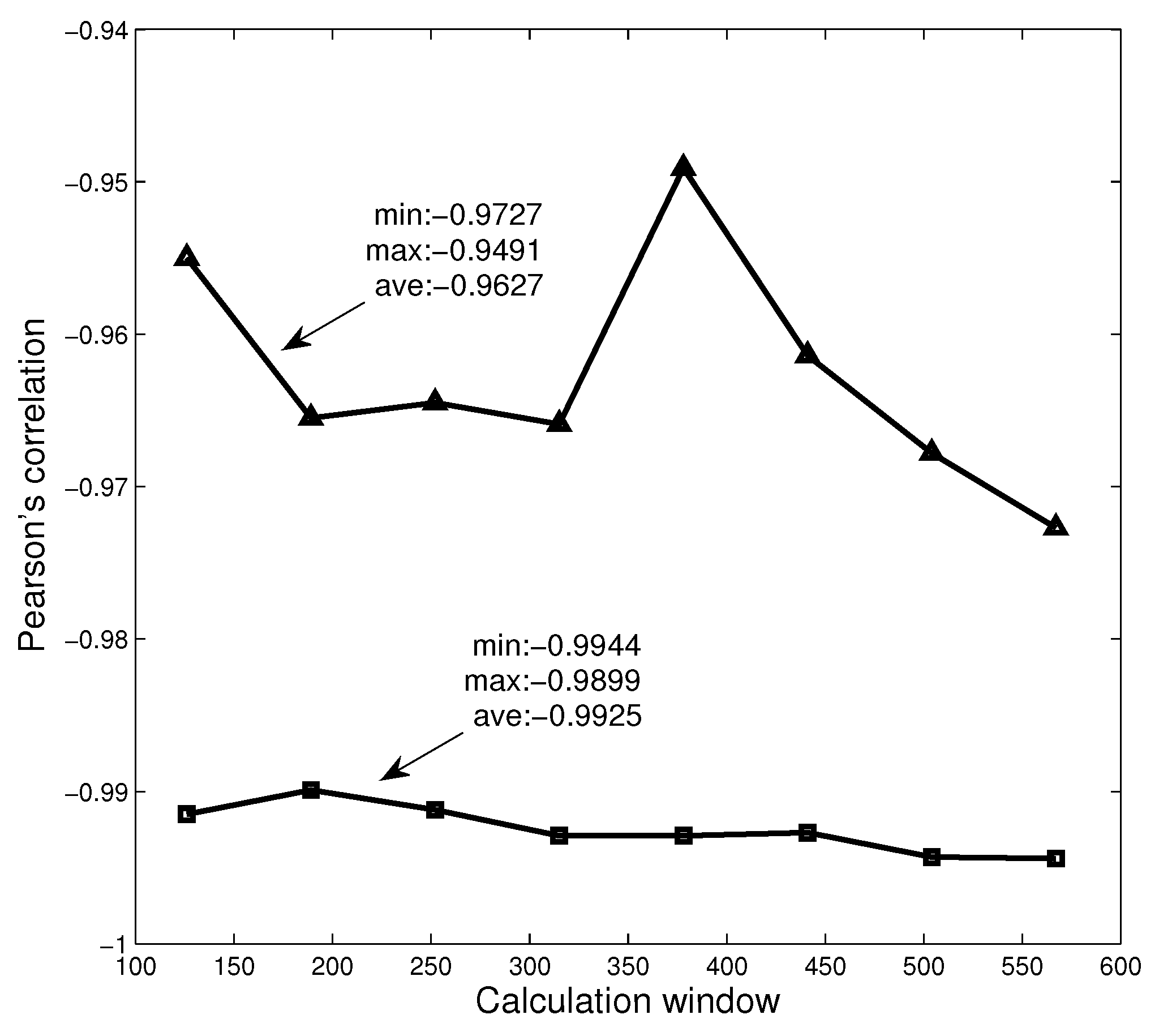
Figure 10.
The series of standard deviations (): (a) the USA market; (b) the UK market; and (c) the China market.
Figure 10.
The series of standard deviations (): (a) the USA market; (b) the UK market; and (c) the China market.
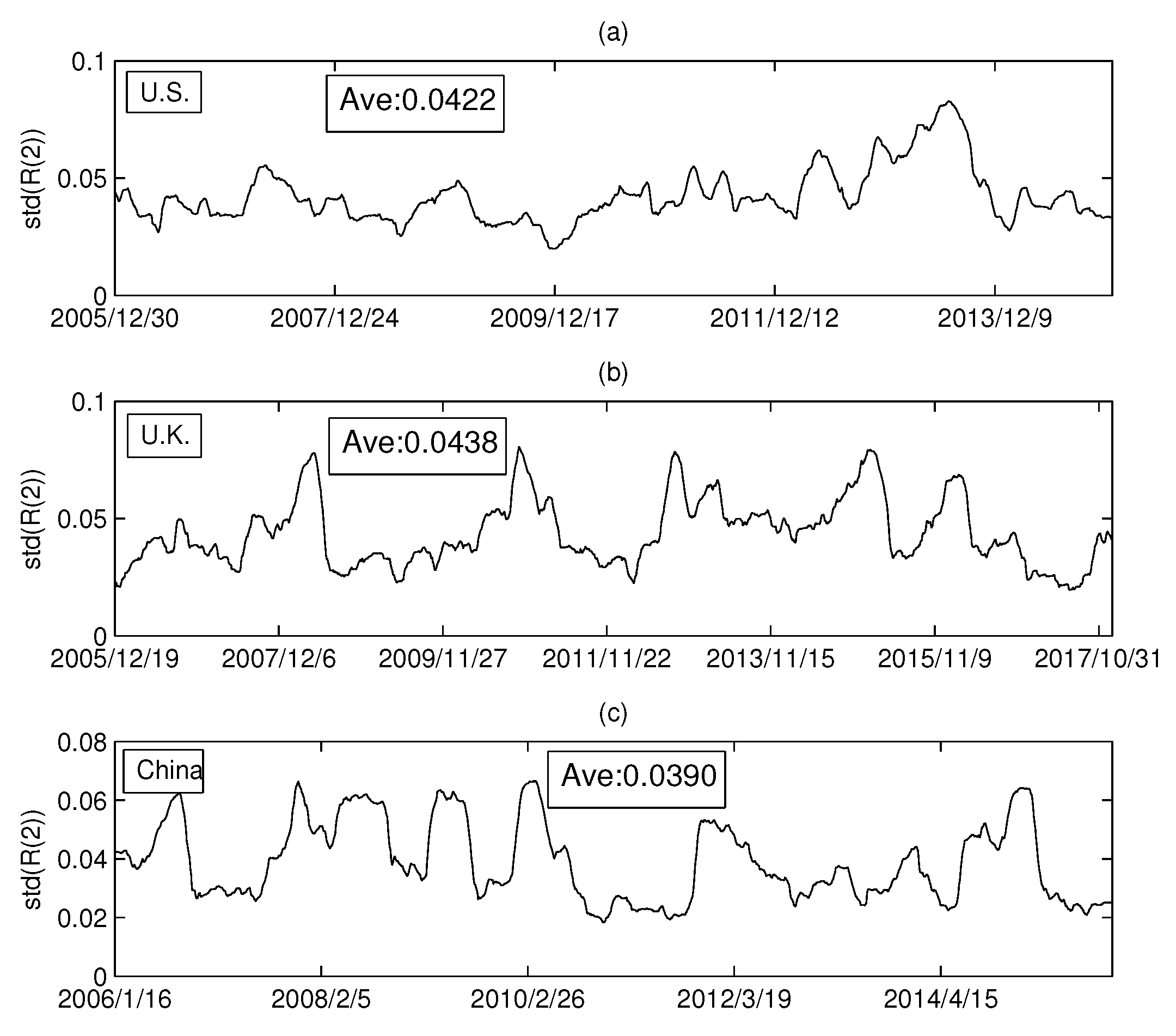
Figure 11.
The series of standard deviations (): (a) the USA market; (b) the UK market; and (c) the China market.
Figure 11.
The series of standard deviations (): (a) the USA market; (b) the UK market; and (c) the China market.

Figure 12.
The series and the S&P 500 index, where Point A corresponds to the collapse of Lehman Brothers, while Point B corresponds to 15 December 2008.
Figure 12.
The series and the S&P 500 index, where Point A corresponds to the collapse of Lehman Brothers, while Point B corresponds to 15 December 2008.
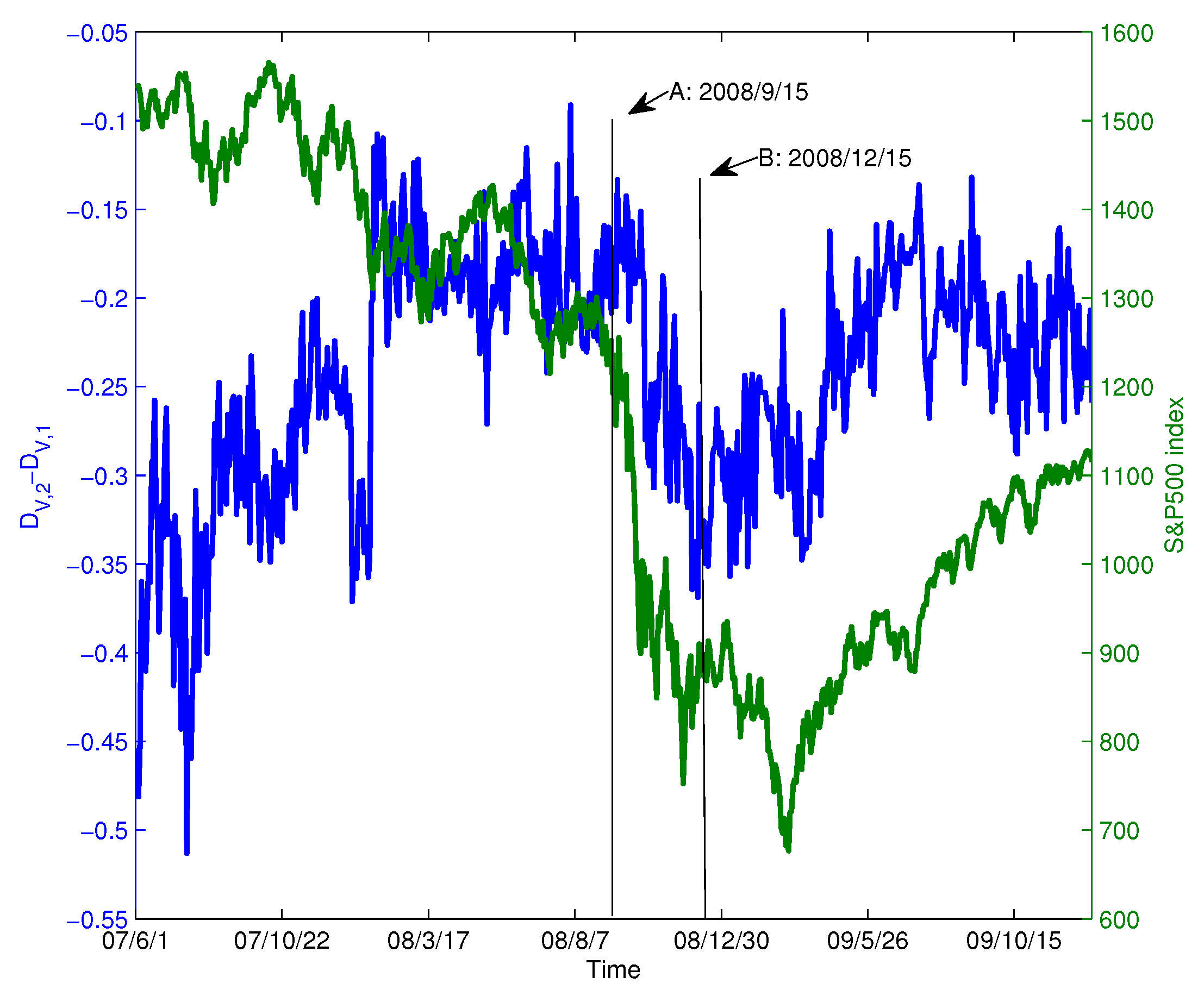
Figure 13.
The PMFG corresponding to Points A and B: (a) the collapse of Lehman Brothers; and (b) 15 December 2008.
Figure 13.
The PMFG corresponding to Points A and B: (a) the collapse of Lehman Brothers; and (b) 15 December 2008.
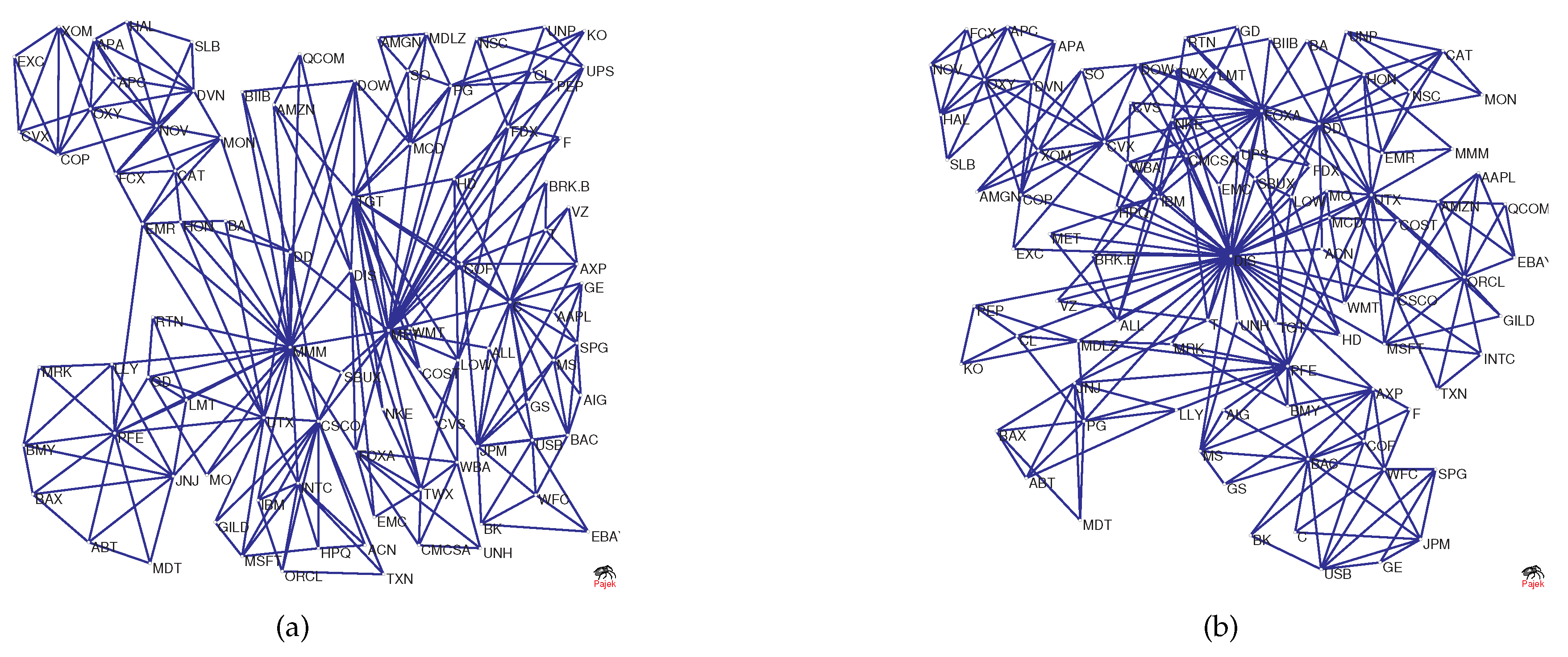
Figure 14.
The dimension sequence corresponding to the two points in Figure 11; the solid and dotted lines correspond to the real data and the benchmark, respectively.
Figure 14.
The dimension sequence corresponding to the two points in Figure 11; the solid and dotted lines correspond to the real data and the benchmark, respectively.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Nie, C.-x.; Song, F.-t. Relationship between Entropy and Dimension of Financial Correlation-Based Network. Entropy 2018, 20, 177. https://doi.org/10.3390/e20030177
AMA Style
Nie C-x, Song F-t. Relationship between Entropy and Dimension of Financial Correlation-Based Network. Entropy. 2018; 20(3):177. https://doi.org/10.3390/e20030177
Chicago/Turabian StyleNie, Chun-xiao, and Fu-tie Song. 2018. "Relationship between Entropy and Dimension of Financial Correlation-Based Network" Entropy 20, no. 3: 177. https://doi.org/10.3390/e20030177
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.