Autonomous Exploration and Mapping with RFS Occupancy-Grid SLAM


1
School of Engineering, RMIT University, Melbourne VIC 3000, Australia
2
Aerospace Division, Defence Science and Technology Group, Fishermans Bend VIC 3207, Australia
*
Author to whom correspondence should be addressed.
Entropy 2018, 20(6), 456; https://doi.org/10.3390/e20060456
Submission received: 29 May 2018
/
Revised: 9 June 2018
/
Accepted: 12 June 2018
/
Published: 12 June 2018
(This article belongs to the Section Information Theory, Probability and Statistics)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:This short note addresses the problem of autonomous on-line path-panning for exploration and occupancy-grid mapping using a mobile robot. The underlying algorithm for simultaneous localisation and mapping (SLAM) is based on random-finite set (RFS) modelling of ranging sensor measurements, implemented as a Rao-Blackwellised particle filter. Path-planning in general must trade-off between exploration (which reduces the uncertainty in the map) and exploitation (which reduces the uncertainty in the robot pose). In this note we propose a reward function based on the Rényi divergence between the prior and the posterior densities, with RFS modelling of sensor measurements. This approach results in a joint map-pose uncertainty measure without a need to scale and tune their weights.
1. Introduction
The task of autonomous exploration and mapping of unknown structured environments combines the solutions to three fundamental problems in mobile robotics: (self)localisation, mapping and motion control. Localisation is the problem of determining the position of the robot within its estimated or a given map. Mapping refers to the problem of integrating robot’s ranging and/or bearing sensor measurements into a coherent representation of the environment. Motion control deals with autonomous decision making (e.g., where to move, where to “look”) for the purpose of accomplishing the mission in the most effective manner (in terms of duration and accuracy).
Algorithms for simultaneous localisation and mapping (SLAM) have been studied extensively in the last decades. While the problem is still an active research area, see [1,2], several state-of-the-art algorithms are already publicly available in the Robot Operating System (ROS) [3,4]. Integrating decision control with SLAM, thereby making the robot autonomous in modelling structured environments, proves to be a much harder problem. Heuristic approaches are reviewed and compared in [5]. More advanced approaches are based on the information gain [6,7,8,9,10].
Autonomous SLAM is a difficult problem because any SLAM algorithm can be seen as an inherently unstable process: unless the robot returns occasionally to already visited and mapped places (this act is referred to as a loop-closure), the pose (position and heading) estimate drifts away from the correct value, resulting in an inaccurate map. Decision making in autonomous SLAM therefore must balance two contradicting objectives, namely exploration and exploitation. Exploration constantly drives the robot towards unexplored areas in order to complete its task as quickly as possible. By exploitation we mean loop-closures: the robot occasionally must return to the already mapped area for the sake of correcting its error in the pose estimate.
Early approaches to robot exploration ignored the uncertainty in the pose estimate and focused on constantly driving the robot towards the nearest frontier, which is the group of cells of the occupancy-grid map on the boundary between the known and unexplored areas [11]. Current state-of-the art in autonomous SLAM is cast in the context of partially-observed Markov Decision processes. The reward function is typically the expected information (defined in the information theoretic framework) resulting from taking a particular action. Entropy reduction in joint estimation of the map and the pose was proposed in a seminal paper [6]. Assuming the uncertainty in pose and the map are independent, the joint entropy can be computed as a sum of two entropies: the entropy of the robot pose and entropy of the map. Several authors subsequently pointed out the drawback of this approach [9,10]: the scale of the numerical values of the two uncertainties is not comparable (the entropy of the map is much higher than the entropy of the pose). A weighted combination of the two entropies was proposed subsequently, with various approaches to balance the two entropies.
Most of the autonomous SLAM algorithms have been developed in the context of a Rao-Blackwellised particle filter (RBPF)-based SLAM. We will remain in this framework and develop an autonomous SLAM for the recently proposed RFS based occupancy-grid SLAM (RFS-OG-SLAM) [2], which is also implemented as a RBPF. In this short note we propose a reward function based on the Rényi divergence between the prior and the posterior joint map-pose densities, with the RFS modelling of sensor measurements. This approach results in a joint map-pose uncertainty measure without a need to scale and tune their respective weights.
2. The RFS Occupancy-Grid Based SLAM
The main feature of the RFS-OG-SLAM is that sensor measurements are modelled as a RFS. This model provides a rigorous theoretical framework for imperfect detection (occasionally resulting in false and missed detections) of a ranging sensor. The previous approaches to imperfect detection were based on ad-hoc scan-matching or a design of a likelihood function as a mixture of Gaussian, truncated exponential, and a uniform distribution [12] (Section 6.3).
Let the robot pose be a vector which consists of its position in a planar coordinate system and its heading angle . Robot motion is modelled by a Markov process specified by a (known) transitional density, denoted by . Here the subscript refers to time instant and is the robot-control input applied during the time interval .
The occupancy-grid map is represented by a vector , where the binary variable denotes the occupancy of the nth grid-cell, , with being the number of cells in the grid.
The ranging sensor on the moving robot provides the range (and azimuth) measurements of reflections from the objects within the sensor field of view. Let the measurements provided by the sensor at time be represented by a set , where is a range-azimuth measurement vector. Both the cardinality of the set and the spatial distribution of its elements are random. For a measurement , which is a true return from an occupied grid cell n (i.e., with ), we assume the likelihood function is known. The probability of detecting an object occupying cell n, of the map, is state dependent (the probability of detection is typically less than one and may depend on the range to the obstacle, but also other factors, such as the surface characteristics of the object, turbidity of air, a temporary occlusion, etc.) and is denoted as . Finally, may include false detections modelled as follows: their spatial distribution over the measurement space is denoted by and their count in each scan is Poisson distributed, with a mean value .
The problem is to formulate the Bayes filter, which sequentially computes the joint posterior probability density function (PDF) , where denotes the sequence and likewise and .
The solution is formulated using the Rao-Blackwell dimension reduction [13] technique. Application of the chain rule decomposes the the joint posterior PDF as:
Assuming that the occupancy of one cell in the grid-map is independent of the occupancy of other cells (the standard assumption for occupancy-grid SLAM), one can approximate in (1) as a product of for . Furthermore, the update equation for the probability of occupancy of the n-th cell, i.e., , can be expressed analytically [2]:
with
The posterior PDF of the pose, in (1), is propagated using the standard prediction and update equations of the particle filter [13]. However, the likelihood function used in the update of particle weights takes the form which is equivalent to , with . Assuming the individual beams of the sensor are independent, we can approximate by a product of likelihoods for all . Finally,
where as the nearest grid cell to the point where, for a given pose , range-azimuth measurement maps to the plane.
The RBPF propagates the posterior , approximated by a weighted set of S particles . The weights are non-negative and sum up to one. Each particle consists of a pose sample and its associated probability of occupancy vector , which represents the estimate of the map.
3. Path Planning
Decision making in an autonomous SLAM algorithm includes three steps: the computation of a set of actions; the computation of the reward assigned to each action and selection of the action with the highest reward.
3.1. Computing the Set of Actions
An action is a segment of the total path the robot should follow for the sake of exploring and mapping the environment. The number of actions at a decision time (options for robot motion) typically should including both short and long displacements and all possible trajectories to the end points. Due to limited computational resources, in practice only a few actions are typically proposed. They fall into one of the following categories: exploration actions, the place re-visiting (loop-closure) actions, or a combination of the two. The exploration actions are designed to acquire information about unknown areas in order to reduce the uncertainty in the map. Exploration actions are generated by first finding the frontier cells in the map [11,14]. Figure 1 shows a partially built map by a moving robot running the RFS-OG-SLAM algorithm and the discovered frontier cells, using an image processing algorithms based on the Canny edge detector [15]. An exploration action represents a trajectory along the shortest path from the robot’s current pose to the one of the frontiers. Because the number of frontier cells can be large, they are clustered by neighbourhood. The clusters that are too small are removed, while the cells in the centre of the remaining clusters compose a set of exploratory destinations. Subsequently the A* algorithm [16] is applied to find the shortest path from the robot’s current position to each of the exploratory destinations. Because the A* algorithm assumes that the moving robot size equals the grid-cell size, its resulting path can be very close to the walls or the corners. The physical size of the robot is a priori known and therefore the empty space in the map which the robot can traverse is thinned accordingly (using the morphological image processing operations [15]). The place re-visiting actions guide the robot back to the already visited and explored areas.
3.2. Reward Function
Reward functions are typically based on a reduction of uncertainty and measured by comparing two different information states. In the Bayesian context, the two information states are the predicted density at time k and the updated density at time k (after processing the new hypothetical measurements, resulting from the action). However, no measurements are collected before the decision has been made and therefore an expectation operator must be applied with respect to the new measurements resulting from the action.
The reward function can be formulated as the gain defined by an information-theoretic measure, such as the Fisher information, the entropy, the Kullback–Leibler (KL) divergence, etc [17]. We adopt the reward function based on the Rényi divergence between the current and the future information state. The Rényi divergence between two densities, and , is defined as [17]:
where is a parameter which determines how much we emphasize the tails of two distributions in the metric. In the special cases of and , the Rényi divergence becomes the Kullback–Leibler divergence and the Hellinger affinity, respectively [17].
Using the particle filter approximation of the joint posterior at time , that is , the expected reward function for an action can be expressed as [18] (Equation 18):
where
with and being a draw from . Computation of has been explained at the end of Section 2. Drawing from can be done by ray-casting assuming action resulted in pose and using the current estimate of the map. In doing so, the probability of a cast ray hitting an object at an occupancy grid cell is made proportional to its probability of occupancy.
An action in the context of active SLAM is a path which can be translated into a sequence of control vectors . Computation of the reward for this case is still given by (6) and (7), but one would have to replace and with and , respectively. This is computationally very demanding and so we approximate that reward as a sum of single step rewards.
The last step of an active SLAM is to select the action with the highest reward and to subsequently execute it. Autonomous SLAM also needs to decide when to terminate its mission. The termination criterion we use is based on the number of frontier cells.
4. Numerical Results
Figure 2 shows the map of the area used in simulations for testing and evaluation of the proposed path planning algorithm. The true initial robot pose (distance is measured in arbitrary units, a.u.) is . The SLAM algorithm is initialised with particles of equal weights, zero pose vectors and the probability of occupancy for all cells set to . The simulated ranging sensor is characterised with a coverage of 360°, angular resolution 0.8°, and if the distance between the robot and n-th cell is less than a.u. False detections are modeled with and as a uniform distribution over the field of view with the radius . Standard deviation is set to a.u. for range measurements and 0.3° for angular measurements. The occupancy-grid cell size is adopted as a.u. The number of particles . The parameter of the Rényi divergence is set to . The mission is terminated when none of the clusters of frontier cells has more than 14 members.
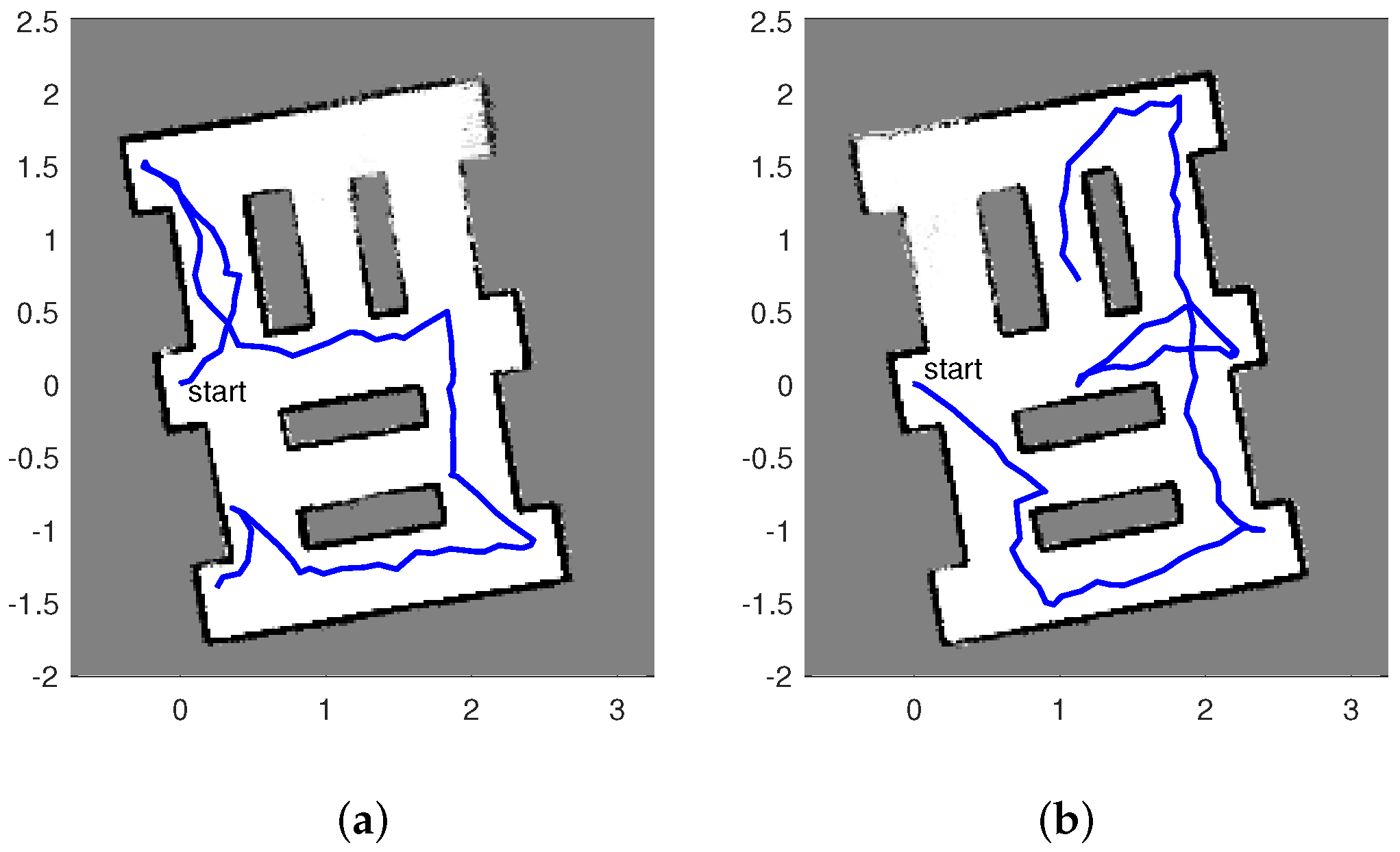
Figure 3 displays two estimated maps created by the described autonomous RFS-OG-SLAM for the scenario shown in Figure 2. An estimated map at time k is reconstructed from the probability of occupancy vector , computed as the average of particles , . The maps are tilted because the initial pose of the SLAM algorithm is set to a zero vector. Figure 3 also shows the estimated paths created by the autonomous RFS-OG-SLAM (the blue lines). An estimated path is constructed from the two first components of the mean of the pose particles , . Duration of exploration and mapping is expressed in the number of discrete-time steps required; the maps in Figure 3a,b required 85 and 98 time steps, respectively. The quality of an estimated map at time k is expressed by the entropy of vector , defined as:
Initially, at time , map entropy is . The entropy of the maps in Figure 3a,b are and , respectively. An avi movie of a single run of the algorithm can be found in Supplementary Material.
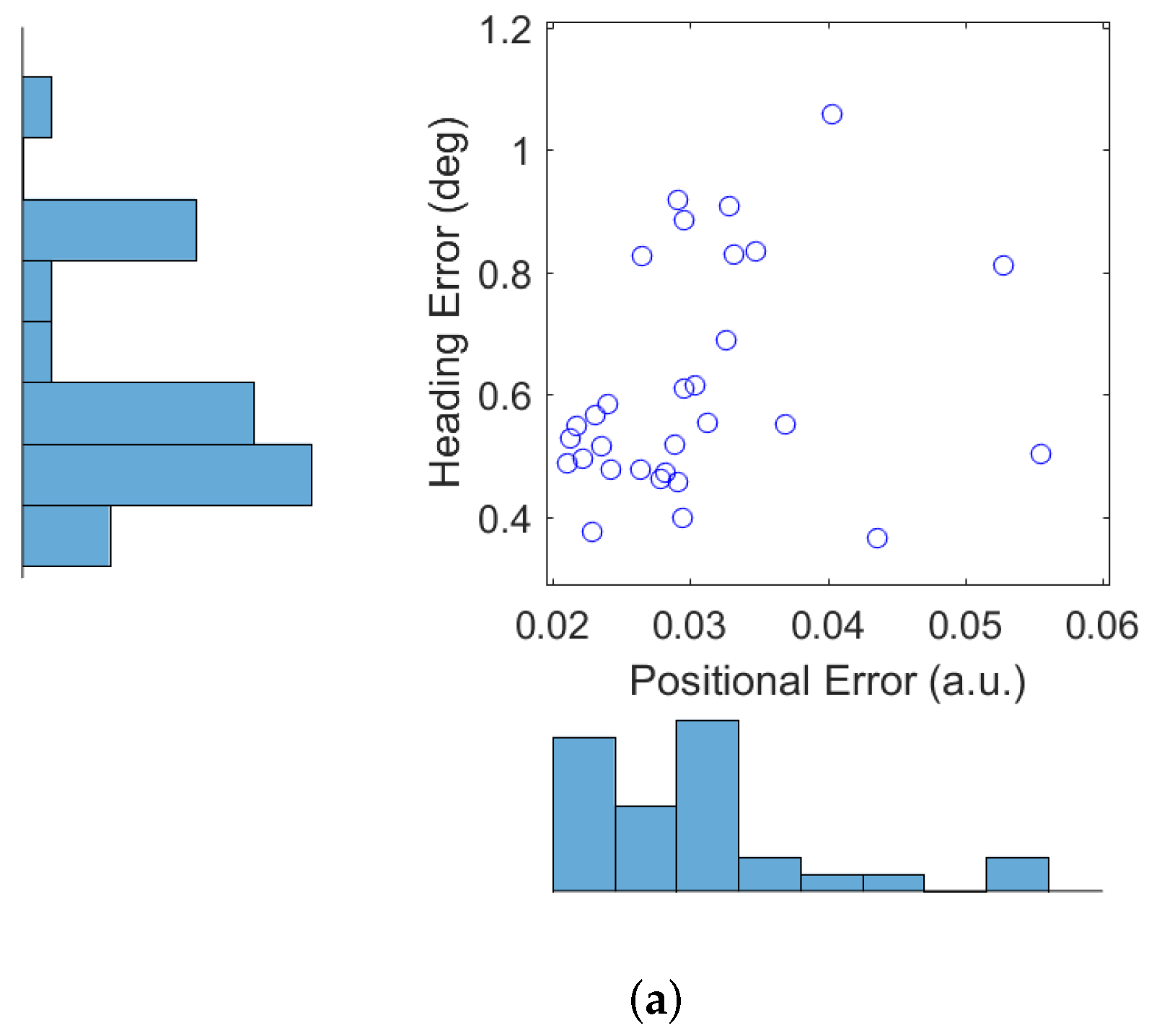
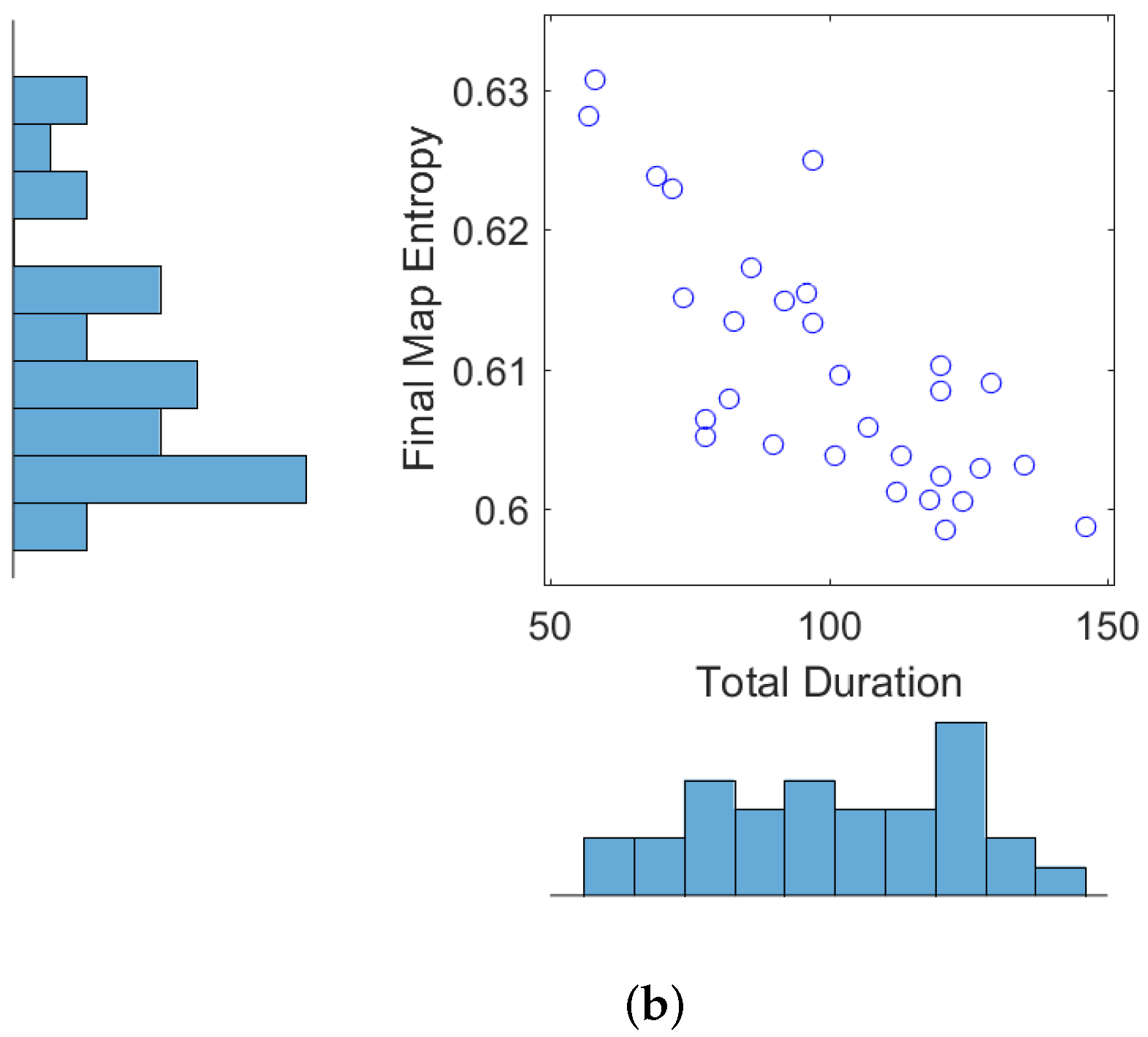
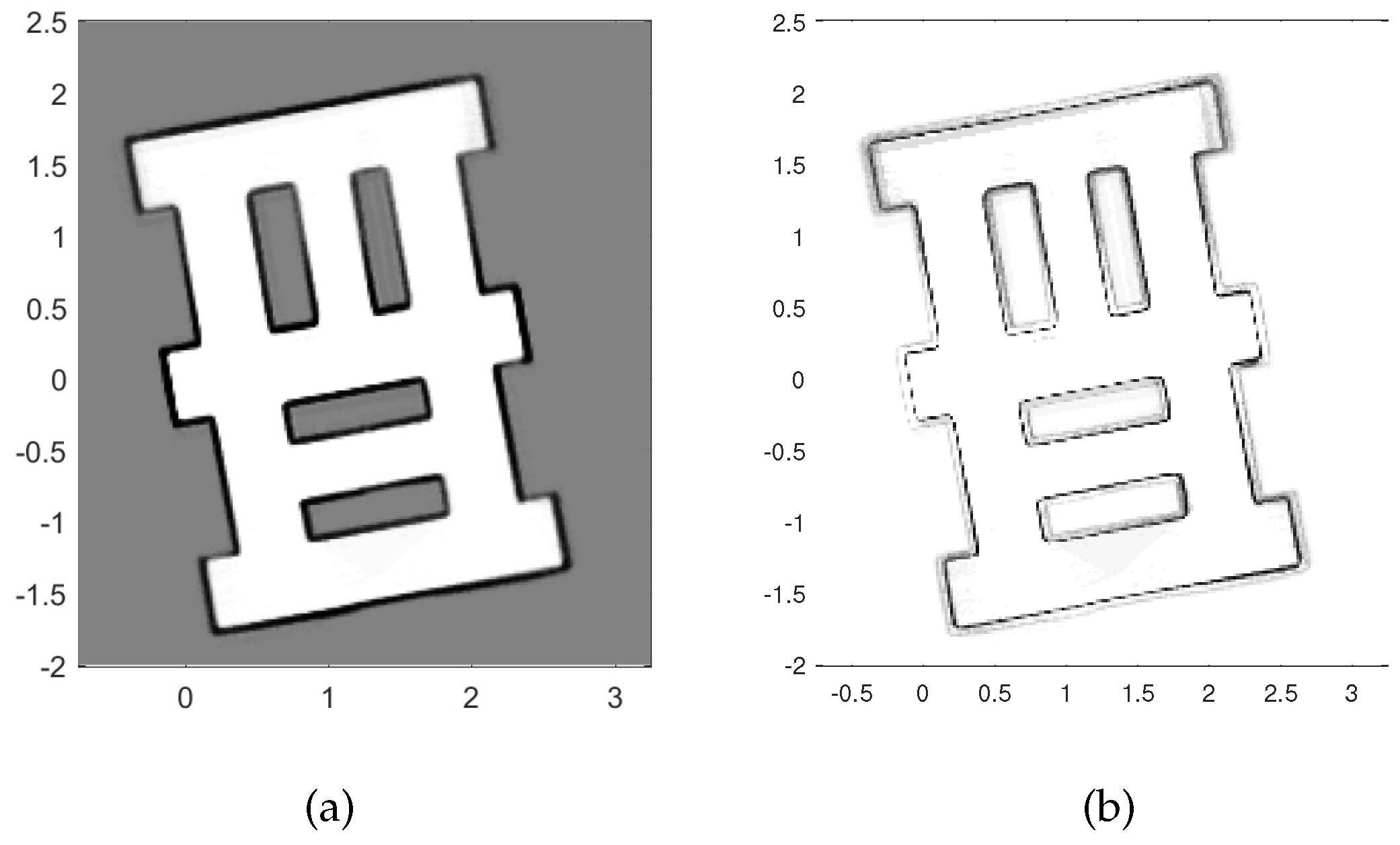
Next we show the results obtained from 30 Monte Carlo runs of the autonomous RFS-OG-SLAM, using the simulation setup described above. Figure 4a shows the error of the robot estimated position (in a.u.) and the error of the robot estimated heading (in degrees), averaged over time and over all 30 trajectories. Figure 4b displays the final map entropy versus the duration of the exploration and mapping mission. The average estimated map over 30 Monte Carlo runs is shown in Figure 5a, while the variance is displayed in Figure 5b. Variability in the performance of the autonomous RFS-OG-SLAM is due to many causes, such as the inherent randomness of particle filtering, clustering and reward computation. Overall, however, the proposed autonomous RFS-OG-SLAM performs robustly and produces quality maps without a need for human intervention.
5. Conclusions
The note presented a path planning method for autonomous exploration and mapping by a recently proposed RFS occupancy-grid SLAM. The reward function is defined as the Rényi divergence between the prior and the posterior densities, with RFS modelling of sensor measurements. This approach resulted in a joint map-pose uncertainty measure without a need to tune the weighting of the map versus the pose uncertainty. Numerical results indicate reliable performance, combining short exploration with a good quality of estimated maps.
Supplementary Materials
The supplementary materials are available online at https://www.mdpi.com/1099-4300/20/6/456/s1.
Author Contributions
Conceptualization, B.R. and J.L.P.; Methodology, B.R.; Software, B.R.; Validation, B.R.; Resources, J.L.P.; Original Draft Preparation, B.R.; Review & Editing, J.L.P.; Project Administration, J.L.P.
Funding
This research was funded in part by the Defence Science and Technology group through its Strategic Research Initiative on Trusted Autonomous Systems.
Acknowledgments
The authors acknowledge Daniel Angley for technical support in relation to A* algorithm.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Adams, M.; Vo, B.N.; Mahler, R.; Mullane, J. SLAM gets a PHD: New concepts in map estimation. IEEE Robot. Autom. Mag. 2014, 21, 26–37. [Google Scholar] [CrossRef]
- Ristic, B.; Angley, D.; Selvaratnam, D.; Moran, B.; Palmer, J.L. A Random Finite Set Approach to Occupancy-Grid SLAM. In Proceedings of the 19th International Conference on Information Fusion, Heidelberg, Germany, 5–8 July 2016. [Google Scholar]
- Santos, J.M.; Portugal, D.; Rocha, R.P. An evaluation of 2D SLAM techniques available in robot operating system. In Proceedings of the 2013 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Linkoping, Sweden, 21–26 October 2013; pp. 1–6. [Google Scholar]
- Fang, L.; Fisher, A.; Kiss, S.; Kennedy, J.; Nagahawatte, C.; Clothier, R.; Palmer, J. Comparative Evaluation of Time-of-Flight Depth-Imaging Sensors for Mapping and SLAM Applications. In Proceedings of the Australian Robotics and Automation Association, Brisbane, Australia, 5–7 December 2016; pp. 1–7. [Google Scholar]
- Juliá, M.; Gil, A.; Reinoso, O. A comparison of path planning strategies for autonomous exploration and mapping of unknown environments. Auton. Robots 2012, 33, 427–444. [Google Scholar] [CrossRef]
- Stachniss, C.; Grisetti, G.; Burgard, W. Information Gain-based Exploration Using Rao—Blackwellized Particle Filters. Robot. Sci. Syst. 2005, 2, 65–72. [Google Scholar]
- Stachniss, C.; Hähnel, D.; Burgard, W.; Grisetti, G. On actively closing loops in grid-based FastSLAM. Adv. Robot. 2005, 19, 1059–1079. [Google Scholar] [CrossRef] [Green Version]
- Blanco, L.L.; Fernandez-Madrigal, J.A.; González, J. A novel measure of uncertainty for mobile robot SLAM with Rao-Blackwellized particle filters. Int. J. Robot. Res. 2008, 27, 73–89. [Google Scholar] [CrossRef]
- Carlone, L.; Du, J.; Ng, M.K.; Bona, B.; Indri, M. Active SLAM and exploration with particle filters using Kullback–Leibler divergence. J. Intel. Robot. Syst. 2014, 75, 291–311. [Google Scholar] [CrossRef]
- Carrillo, H.; Dames, P.; Kumar, V.; Castellanos, J.A. Autonomous robotic exploration using occupancy grid maps and graph SLAM based on Shannon and Rényi entropy. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 487–494. [Google Scholar]
- Yamauchi, B. Frontier-based exploration using multiple robots. In Proceedings of the 2nd International Conference on Autonomous Agents, Minneapolis, MN, USA, 10–13 May 1998; pp. 47–53. [Google Scholar]
- Thrun, S.; Burgard, W.; Fox, D. Probabilistic Robotics; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Doucet, A.; De Freitas, N.; Murphy, K.; Russell, S. Rao-Blackwellised particle filtering for dynamic Bayesian networks. In Proceedings of the Proceedings of the Sixteenth Conference on Uncertainty in Artificial Intelligence, UAI’00, Stanford, CA, USA, 30 June–3 July 2000; pp. 176–183. [Google Scholar]
- Quin, P.D.; Alempijevic, A.; Paul, G.; Liu, D. Expanding Wavefront Frontier Detection: An Approach for Efficiently Detecting Frontier Cells. In Proceedings of the Australasian Conference on Robotics and Automation, Melbourne, Australia, 2–4 December 2014. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E.; Eddins, S.L. Digital Image Processing Using MATLAB; McGraw Hill: New York, NY, USA, 2004. [Google Scholar]
- Zeng, W.; Church, R.L. Finding shortest paths on real road networks: The case for A*. Int. J. Geogr. Inf. Sci. 2009, 23, 531–543. [Google Scholar] [CrossRef]
- Hero, A.O.; Kreucher, C.M.; Blatt, D. Information theoretic approaches to sensor management. In Foundations and Applications of Sensor Management; Hero, A.O., Castanòn, D., Cochran, D., Kastella, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; Chapter 3; pp. 33–57. [Google Scholar]
- Ristic, B.; Vo, B.N. Sensor control for multi-object state-space estimation using random finite sets. Automatica 2010, 46, 1812–1818. [Google Scholar] [CrossRef]
Figure 1.
Frontiers and path planing: the image shows a partial map created by the simultaneous localisation and mapping (SLAM) algorithm, using the gray scale to indicate the probability of occupancy (black for probability equal to 1); magenta coloured dots are discovered frontier cells; the robot current position shown as a green circle; a proposed path plotted in blue.
Figure 1.
Frontiers and path planing: the image shows a partial map created by the simultaneous localisation and mapping (SLAM) algorithm, using the gray scale to indicate the probability of occupancy (black for probability equal to 1); magenta coloured dots are discovered frontier cells; the robot current position shown as a green circle; a proposed path plotted in blue.

Figure 2.
Scenario used in simulations.

Figure 3.
Two maps estimated by the autonomous RFS based occupancy-grid SLAM (RFS-OG-SLAM); blue lines indicate robot trajectories.
Figure 3.
Two maps estimated by the autonomous RFS based occupancy-grid SLAM (RFS-OG-SLAM); blue lines indicate robot trajectories.

Figure 4.
Performance of autonomous RFS-OG-SLAM (from 30 Monte Carlo runs): (a) robot position and heading errors; (b) final map entropy versus duration of the mission.
Figure 4.
Performance of autonomous RFS-OG-SLAM (from 30 Monte Carlo runs): (a) robot position and heading errors; (b) final map entropy versus duration of the mission.


Figure 5.
Map statistics from 30 Monte Carlo runs: (a) the average estimated map; (b) the variance of the estimated map.
Figure 5.
Map statistics from 30 Monte Carlo runs: (a) the average estimated map; (b) the variance of the estimated map.

© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ristic, B.; Palmer, J.L. Autonomous Exploration and Mapping with RFS Occupancy-Grid SLAM. Entropy 2018, 20, 456. https://doi.org/10.3390/e20060456
AMA Style
Ristic B, Palmer JL. Autonomous Exploration and Mapping with RFS Occupancy-Grid SLAM. Entropy. 2018; 20(6):456. https://doi.org/10.3390/e20060456
Chicago/Turabian StyleRistic, Branko, and Jennifer L. Palmer. 2018. "Autonomous Exploration and Mapping with RFS Occupancy-Grid SLAM" Entropy 20, no. 6: 456. https://doi.org/10.3390/e20060456
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.