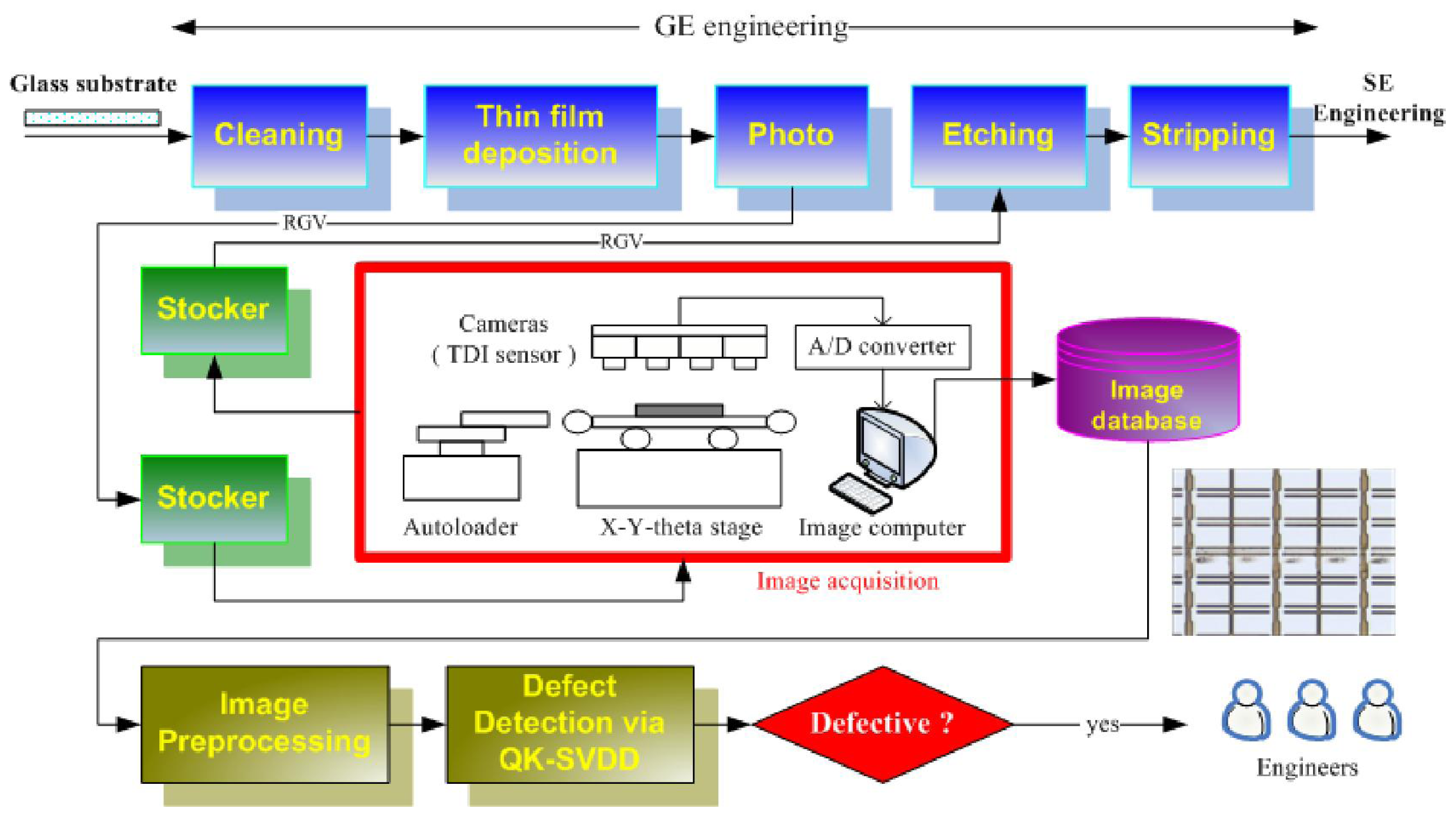
2.1. Basic Idea
According to real LCD manufacturing conditions, the number of normal LCD panels exceeds greatly the number of defective LCD panels. Therefore, the normal PRs greatly outnumber the defective PRs. As a result, the collected data set for training would be imbalanced if a two-class classification approach is adopted, the SVM by Vapnik [
4] for example, the class imbalance problem occurs.
The class imbalance problem has attracted growing attention in the machine learning community. In a two-class classification problem, the class imbalance typically occurs when there are more instances of one (majority) class than the other (minority). This problem also occurs in a multi-class classification application if imbalances exist between the various classes. Most standard classification algorithms assume or expect balanced class distributions or equal misclassification costs. Consequently, those algorithms would tend to provide severely imbalanced degree of testing accuracy if the training set is severely imbalanced.
Previously, several workshops/special issues have been held/published to discuss and address this problem [
12–
15]. Various approaches for imbalanced learning have also been proposed, such as sampling (e.g., [
16–
18]), integration of sampling with ensemble learning (e.g., [
19,
20]), cost-sensitive learning (e.g., [
21–
23]), and SVM-based approach (e.g., [
24–
28]). These discrimination-based (two-class) approaches have shown to be useful in dealing with class imbalance problems. In addition, several works have also suggested that a one-class learning approach can provide a viable alternative to the discrimination-based approaches [
29–
33]. Interested readers can refer to [
34] for a broad overview on the state-of-the-art methods in the field of imbalanced learning.
In practice, in addition to the class imbalance problem, the LCD defect detection also suffers from another critical problem resulting from the absence of negative information. To facilitate the following problem description, the normal PR class and the defective PR class are defined as the positive class and negative class, respectively.
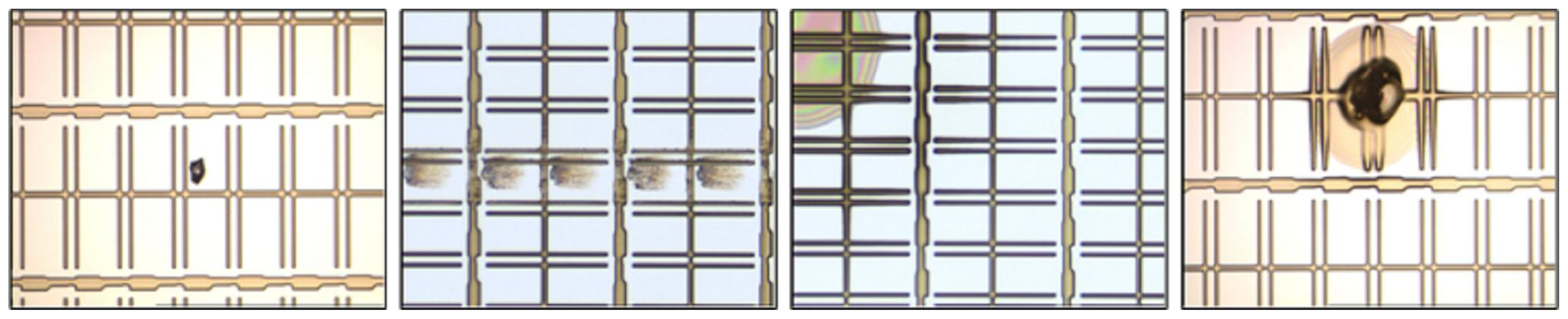
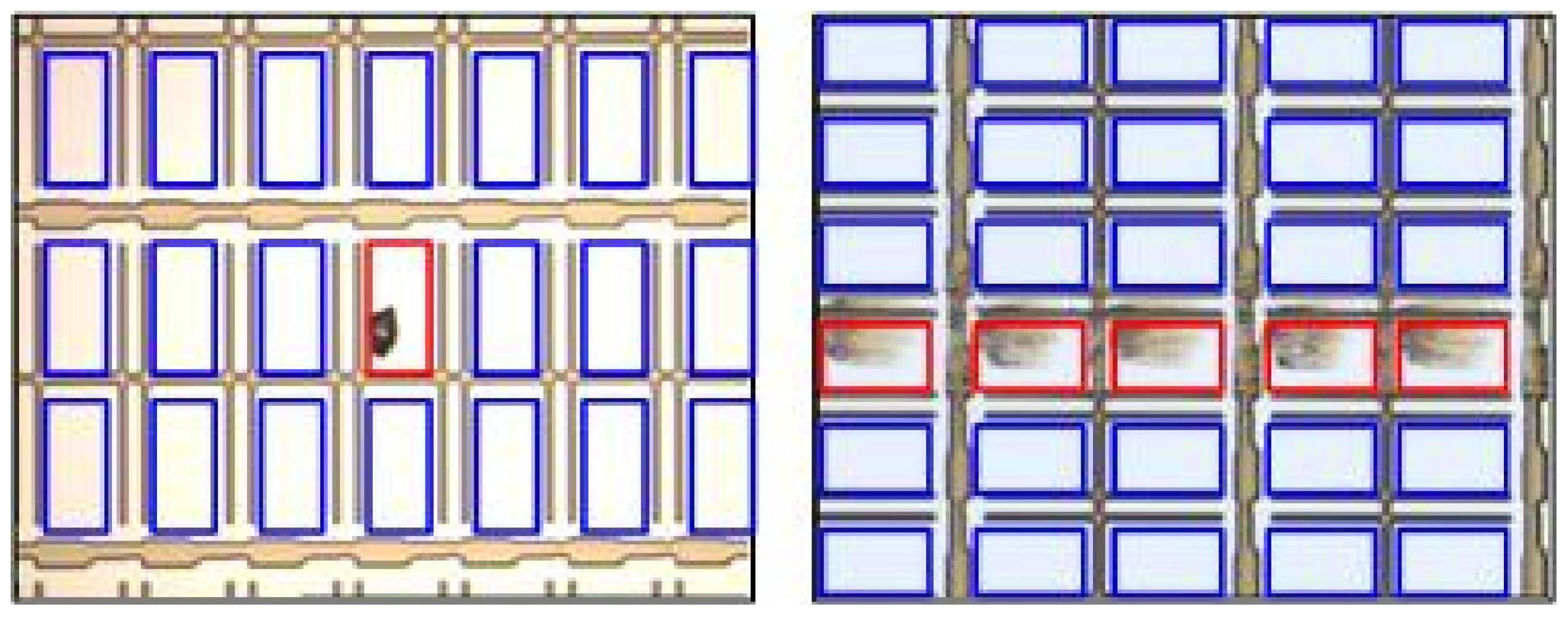
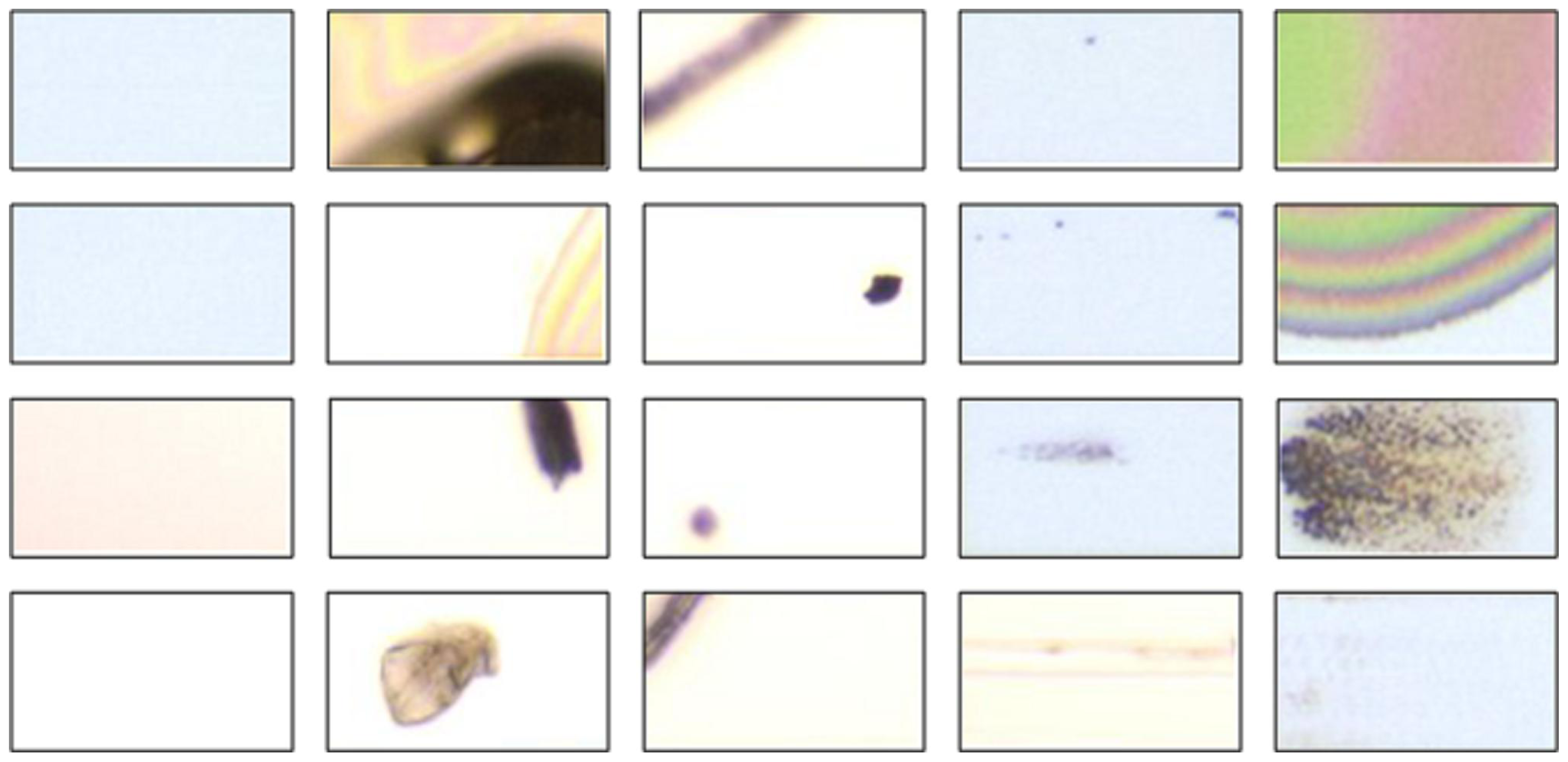
The main difference between a normal PR and a defective PR is that their appearances are apparently different, as can be observed from
Figure 4. The color (or gray level) of a normal PR is nearly uniform, implying that the variation of the gray-level distribution of normal PRs is very small. On the contrary, the surfaces of defective PR not only contain various kinds of textures, but also vary greatly in color, implying that the variation of the true distribution for negative class in the data space is very large. Collecting a set of positive training data that can represent the true distribution of positive class is easy, because: (1) the variation of positive-class distribution is very small; and (2) most of the LCD panels are normal (the number of normal PRs is considerably large). Therefore, the positive class can be well-sampled during the data collection stage in real practice. However, representative defective PRs are difficult to obtain in practice for several reasons. For example, there are numerous types of defects in array process, more than 10 types at least. However, not all the defects would occur frequently. Some of the defects seldom appear, for example the defect caused by abnormal photo-resist coating (APRC). The defect “APRC” seldom occurs, because equipment/process engineers maintain the coating machines periodically. Even so, the coating machines might still break down occasionally. As a result, the number of available images containing the APRC defects is quite limited. But, the APRC defect has a large variation in color and texture. Unfortunately, limited APRC examples cannot stand for all kinds of APRC defects. Therefore, the collected negative training data are most likely under-sampled. Here, the “under-sampled” means that the collected negative training set cannot represent the true negative-class distribution in the data space, which is the problem of absence of negative information. Due to this problem, numerous false positive (
i.e., missing defects) will be produced if a two-class classification approach (e.g., a binary SVM) is applied to the LCD defect detection, which has been evidenced by the results reported in [
7]. Compared with two-class classification approach, novelty detection approach is a better choice.
Novelty detection is one-class classification [
10,
35], which is to solve the conventional two-class classification problems where one of the two classes is under-sampled, or only the data of one single class can be available for training [
5,
6,
9–
11,
35–
40]. As analyzed above, for the LCD defect detection application, the normal PRs can be well-sampled, while the defective PRs are in general undersampled. Therefore, the LCD defect detection can be treated as a typical novelty detection problem. Accordingly, one-class classification is a better solution.
To summarize, it can be seen that the LCD defect detection suffers from two problems simultaneously: one is the class imbalance problem, and the other is the problem of the absence of negative information. For the first problem, there have been many sophisticated solutions, including sampling, cost-sensitive learning, SVM-based, and one-class learning approaches. However, the only solution to the second problem is the novelty detection approach (i.e., one-class classification approach). Therefore, one-class classification would be a more appropriate approach to the LCD defect detection application.
One-class classifiers (also called novelty detectors) are to find a compact description for a class (usually being referred to target class). So, a one-class classifier is trained on the target class alone. In a testing stage, any points that do not belong to this description are considered as outliers. In this paper the normal PRs are treated as target data, while defective PRs are treated as outliers.
There are several approaches for one-class classification, such as density approach (e.g., Gaussian mixture model [
5]), boundary approach (e.g., SVDD [
9] and one-class SVM [
40]), neural network approach [
6,
36], and reconstruction-based approach (e.g., the kernel principal component analysis for novelty detection [
35]). It has been proven in [
9] that when a Gaussian kernel is used, the SVDD proposed by Tax and Duin [
9] is identical to the one-class SVM proposed by Schölkopf
et al. [
40]. This paper focuses on the SVDD since it has been applied to the same application in the works of [
7] and [
10], and has shown to be effective in detecting defective PRs. However, as discussed in Section 1, generalization performance of SVDD is limited. Therefore, the intent of this paper is on proposing a method to improve generalization performance of SVDD, and applying the improved SVDD to the LCD defect detection treated as a novelty detection problem. The improved SVDD is called quasiconformal kernel SVDD (QK-SVDD). Note that the QK-SVDD and SVDD are not two independent classifiers. To obtain QK-SVDD, one has to train an SVDD first, which will be introduced in Section 2.4. In the following part of the paper, we first introduce the defect detection scheme, and then derive the proposed method in details.
2.3. SVDD
In order to facilitate the following introduction, a normal PR datum is simply called a target datum, and a defective PR datum is called an outlier hereafter.
Given a target training set T = {xi ε Rd }i=1 N, where xi are target training data and d is the dimension of the space (d = 900), SVDD first maps the training data into a higher-dimensional feature space F from the input space S = Rd by a nonlinear mapping φ, and then finds a minimum-volume sphere in F such that all or most of the mapped target data are tightly enclosed by the sphere, which can be formulated as the constrained optimization problem:
where
C ε[1/
N,1] is the penalty weight;
aF and
R are the center and the radius of the sphere in
F, respectively; and
ξi are slack variables representing training errors. The dual of (
1) is
where αi are Lagrange multipliers; and K is the kernel function defined by K(x, y) =φ (x)T φ (y). We consider only the Gaussian kernel K (x, y) = exp(− ||x − y||2 /2σ 2 ) in this paper, where σ is the width of Gaussian and a user-defined kernel parameter. The training data for which 0 <αi ≤ C are called support vectors (SVs). The center aF of the sphere is spanned by the mapped training data:
and the radius R of the sphere can be obtained by taking any xk ε UBSVs, to calculate the distance between its image φ (xk ) and aF:
For a test datum x, its output can be computed by the decision function:
If
f (
x) ≥ 0,
x is accepted as a target (a normal PR); otherwise it is rejected as an outlier (a defective PR). We can see from
equation (5) that the decision function is nonlinearly related to the input data. Therefore, although the decision boundary
f (
x) = 0 is the sphere boundary in the feature space
F, it is actually flexible (non-spherical) in the original space
S, and thus being able to fit any irregular-shaped target sets.
2.4. QK-SVDD
Looking back at
equation (1), we can see that SVDD does not consider the factor of class separation in its formulation, but consider simply the volume of the sphere in
F and the number of target training errors. Thus, the decision boundary
f (
x) = 0 would be too close to the target set to give satisfactory generalization performance. In this paper, we propose a method to improve generalization performance of SVDD, which is based on the kernel geometry in the kernel-induced feature space
F.
When a Gaussian kernel is used, the associated mapping
φ embeds the input space
S into an infinite-dimensional feature space
F as a Riemannian manifold, and the kernel induces a Riemannian metric in the input space
S [
41,
42]:
where xi stands for the ith element of the vector x, and gij (x) is the Riemannian metric induced by a kernel at x. The Riemannian distance ds in F caused by a small vector dx in S is given by
Thus, the volume form in a Riemannian space can be defined as
where
is a magnification factor, and
G (
x) is the matrix with elements
gij (
x).
Equation (8) shows how a local volume in
S is magnified or contracted in
F under the mapping of
φ. Furthermore, a quasiconformal transformation of the Riemannian metric is given by
where Ω (x) is a scalar function of x. To realize this transformation, it is necessary to find a new mapping φ̃. In practice, it is difficult to achieve this because the mappings are usually unknown in kernel methods. However, if φ̃ is defined as
where D (x) is a positive real-valued quasiconformal function, then we obtain a quasiconformal transformation of the original kernel K by using a simple kernel trick:
where
K̃ is called quasiconformal kernel. Finally, substituting (
11) into (
6) yields the new metric
g̃ij (
x) associated with
K̃:
Suppose that the goal is to magnify the local volume around the image of a particular data point
x ε
S, the first step is to choose a function
D (
x) in a way that it is the largest at the position of
φ (
x) and decays with the distance from
φ (
x). By doing so, new Riemannian metric
g̃ij (
x) becomes larger around
x and smaller elsewhere, as can be seen from
equation (12). As a result, the local volume around
φ (
x) is magnified, and magnifying the volume around
φ (
x) is equivalent to enlarging the spatial resolution in the vicinity of
φ (
x) in
F.
Recently, the technique of the quasiconformal transformation of a kernel has been applied to improve generalization performance of existing methods, including SVM [
43], nearest neighbor classifier [
44], and kernel Fisher discriminant analysis (KFDA) [
45]. In this paper we present a way of introducing this technique into SVDD. The idea is as follows.
If we hope to improve generalization performance of SVDD, we need to increase the separability of classes (target and outlier), which can be achieved by enlarging the spatial resolution around the boundary of the minimum-enclosing sphere in F. According to the technique of quasiconformal kernel mentioned above, the function D (x) should be chosen in a way that it is the largest at the sphere boundary and decays with the distance from the sphere boundary in F. However, the difficulty is that we do not know where the sphere boundary is located, because the feature space F is actually implicit. Nevertheless, there is an indirect way. According to the Kuhn-Tucker (KT) conditions
the SVs can be divided into two categories: 1) the images of the SVs with 0 < αi < C are on the sphere boundary, and 2) the images of the SVs with αi = C fall outside the sphere boundary. The SVs in the first category called unbounded SVs (UBSVs), and the ones in the second category are called bounded SVs (BSVs). Since the mapped UBSVs lie exactly on the SVDD sphere boundary in F, increasing the Riemannian metric around the UBSVs in S is therefore equivalent to enlarging the spatial resolution in the vicinity of the sphere boundary in F. As a result, the separability of classes is increased, and generalization performance of SVDD is improved.
Accordingly, we can choose the function
D (
x) to have larger values at the positions of the mapped UBSVs and smaller elsewhere. Following the suggestion from [
28], the quasiconformal function
D (
x) here is chosen as a set of Gaussian functions:
where the parameter τi is given by
The parameter
τi 2 computes the mean squared distance from
φ (
xi ) to its
M nearest neighbors
φ (
xn ), where
xn ε
UBSVs. We set
M = 3 in this study. As can be seen from (
14), the function
D (
x) decreases exponentially with the distance to the images of the UBSVs.
In summary, the QK-SVDD consists of three training steps:
First, an SVDD is initially trained on a target training set by a primary kernel, thereby producing a set of UBSVs and BSVs. The primary kernel is the Gaussian kernel.
Second, the primary kernel is replaced by the quasiconformal kernel defined in
equation (11).
Then, retrain the SVDD with the quasiconformal kernel using the same target training set.
After training the QK-SVDD, a set of new Lagrange multipliers, α̃1,···,α̃N, will be obtained. A new enclosing sphere with center
and radius R̃ will also be obtained. Finally, we arrive at the decision function of QK-SVDD:
Note that for the Gaussian kernel, K(x, x) = 1, ∀x ε Rd. For a test data point x, it is classified as a target if f̃ (x) ≥0 ; an outlier otherwise. Also note that the last term is a constant. Therefore, the testing time complexity of QK-SVDD, similar to SVDD, is also linear in the number of training data.
2.5. Comparison between Our Method and the Kernel Boundary Alignment (KBA) Algorithm
Here we compare our method with the KBA algorithm proposed by Wu and Chang [
28], since the KBA algorithm is also based on the quasiconformal transformation of a kernel.
Recall that when a binary SVM is trained on an imbalanced data set, the learned optimal separating hyperplane (OSH), denoted as
f (
x) = 0, would be skewed toward the minority class in a kernel-induced feature space. The KBA was designed to deal with the class-boundary-skew problem due to imbalanced training data sets. The KBA algorithm consists of two steps. In the first step, the KBA algorithm estimates an “ideal” separating hyperplane within the margin of separation by an interpolation procedure. The ideal hyperplane and the OSH are parallel to each other, but may be different in location. If the training data set is balanced, the estimated ideal hyperplane and the OSH will be the same; otherwise, compared with the OSH, the estimated (or interpolated) ideal hyperplane should be closer to the majority support-instance hyperplane, defined as
f (
x) = −1 in [
28], such that the class-boundary-skew problem due to the imbalanced training data set can be solved. Assuming that the distance between the ideal hyperplane and the OSH is
η, the objective of this step is to find the optimal value of
η subject to the constraint: 0 ≤
η ≤ 1. Therefore, the interpolation procedure is formulated as constrained optimization problem (see [
28] for details). Then, in the second step, the KBA algorithm chooses a feasible conformal function to enlarge the spatial resolution around the estimated ideal hyperplane in the feature space.
The advantages of the KBA-based SVM over the regular binary SVM is two-fold: not only the class-boundary-skew problem due to imbalanced training data sets can be solved, but also the generalization performance can be improved simultaneously.
The design of KBA is based on information of separation margin in the interpolation procedure. Without this information, this procedure cannot be formulated as a constrained optimization problem, and as a result, the location of the ideal hyperplane cannot be estimated. Therefore, the KBA algorithm cannot be applied to SVDD, since SVDD is trained on a single target class alone: there is no such margin of separation. The decision boundary learned from SVDD is simply a sphere boundary in the feature space.
The main difference between the KBA and our method is that the KBA is designed for binary classifier SVM while our method is designed for one-class classifier SVDD. The common is that both KBA and our method are based on the technique of quasiconformal transformation of a kernel. Although our method is much simpler, it works, as demonstrated in the next section.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}