AlPOs Synthetic Factor Analysis Based on Maximum Weight and Minimum Redundancy Feature Selection

Abstract
:1. Introduction
2. Results and Discussions
2.1. Performance Measures
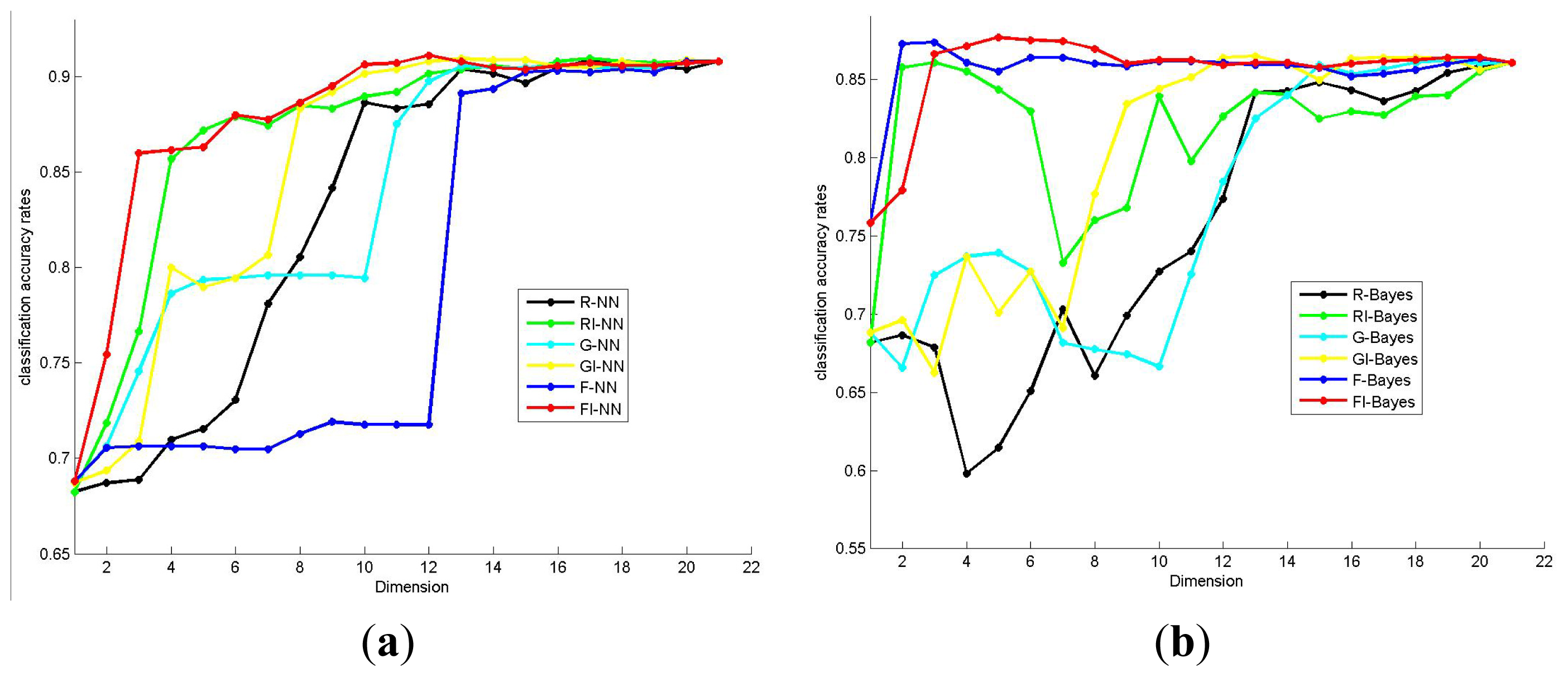
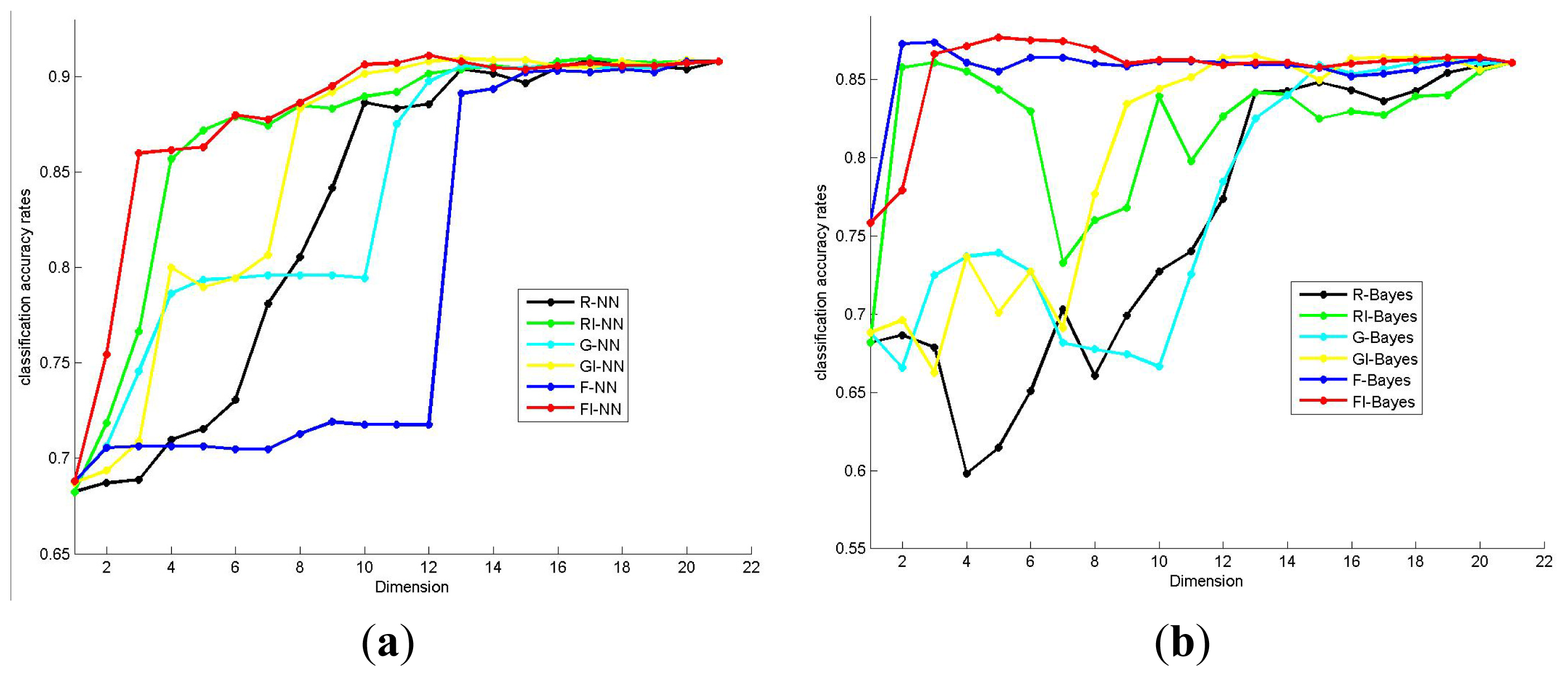
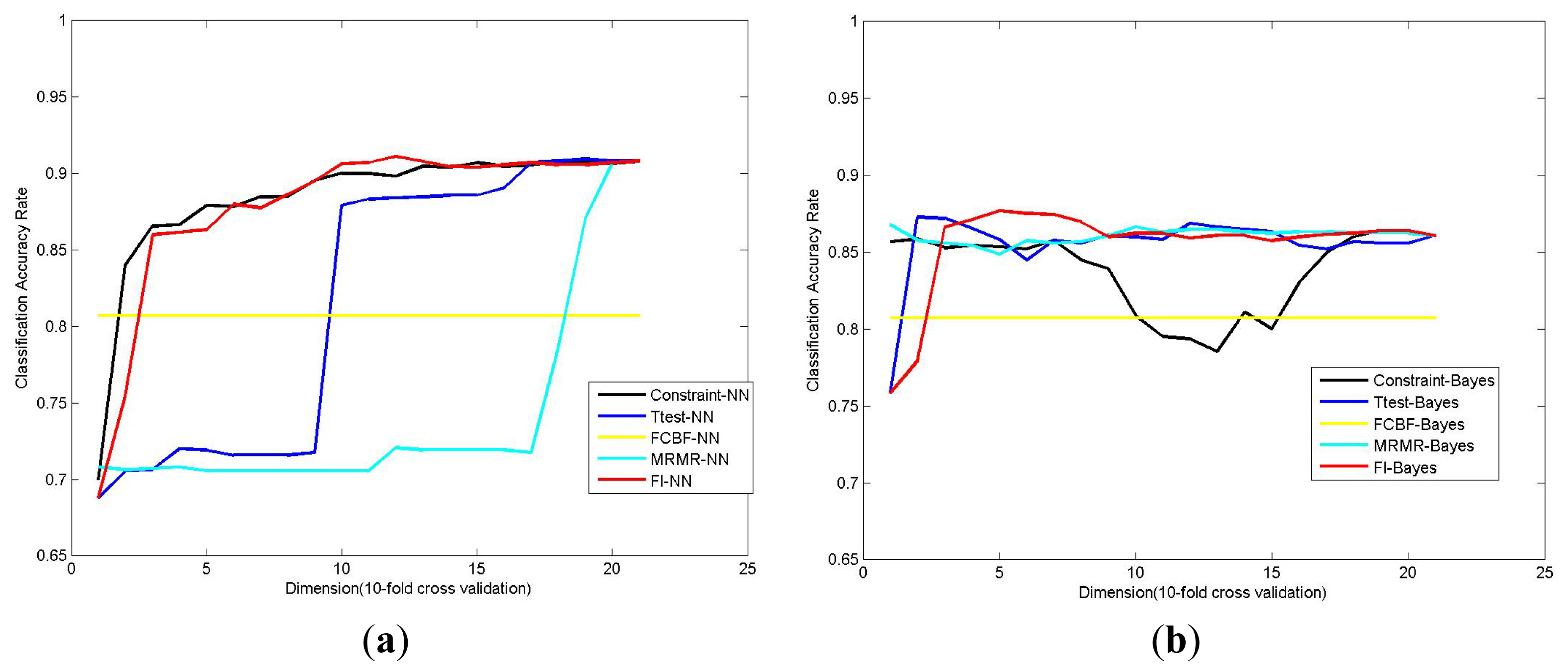
2.2. Effectiveness of the Proposed Method
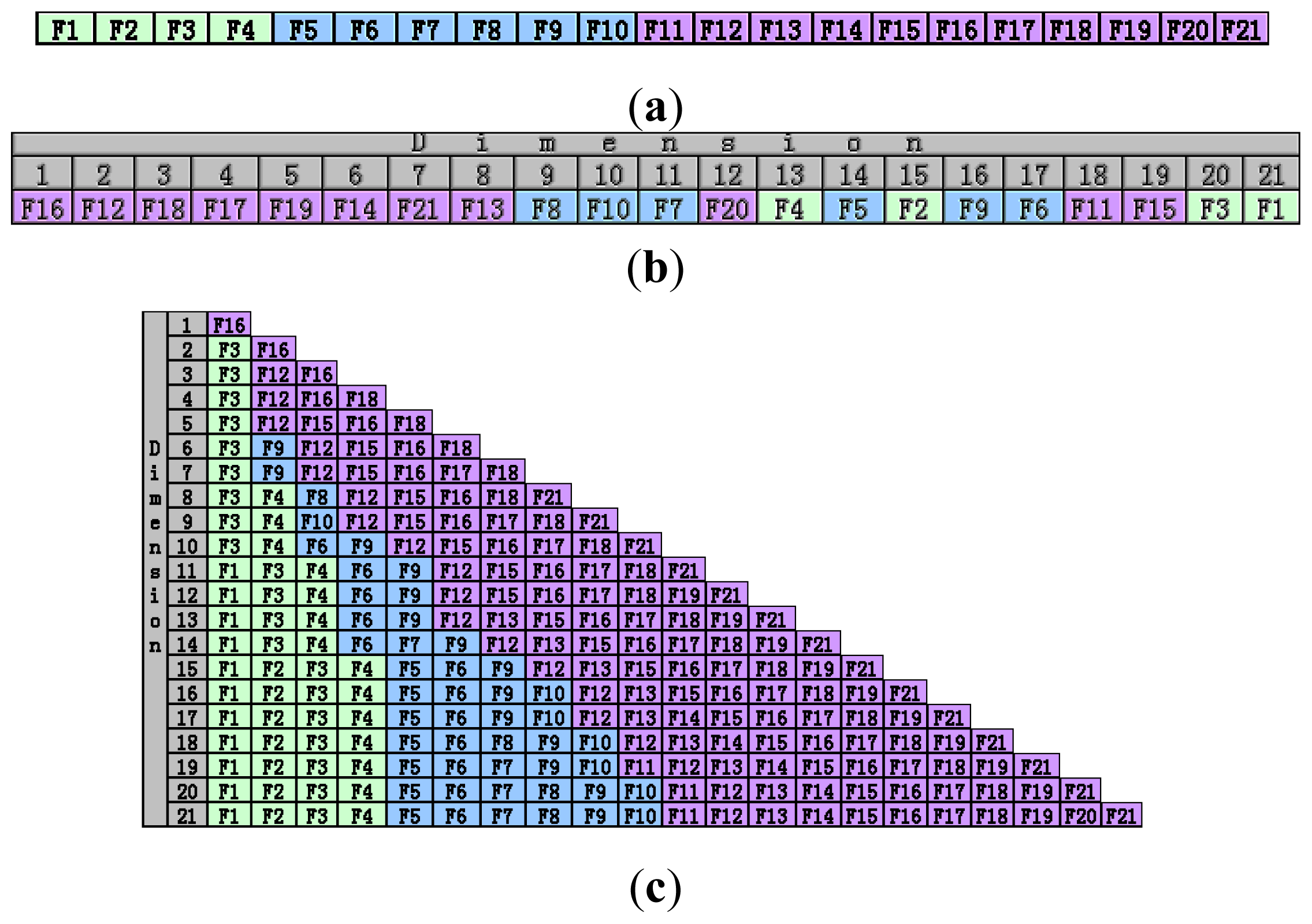
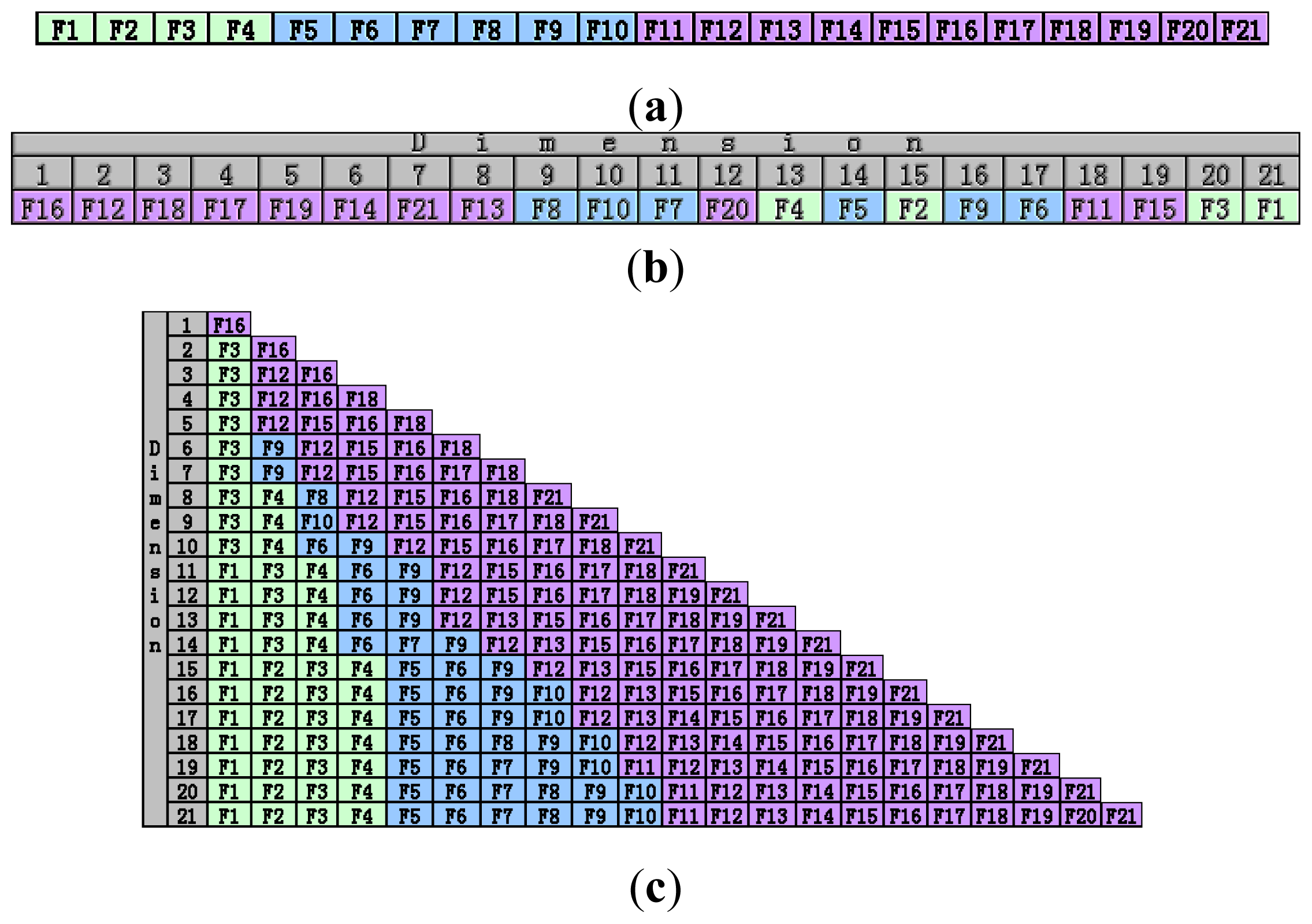
2.3. Analysis of the Feature Selection Results
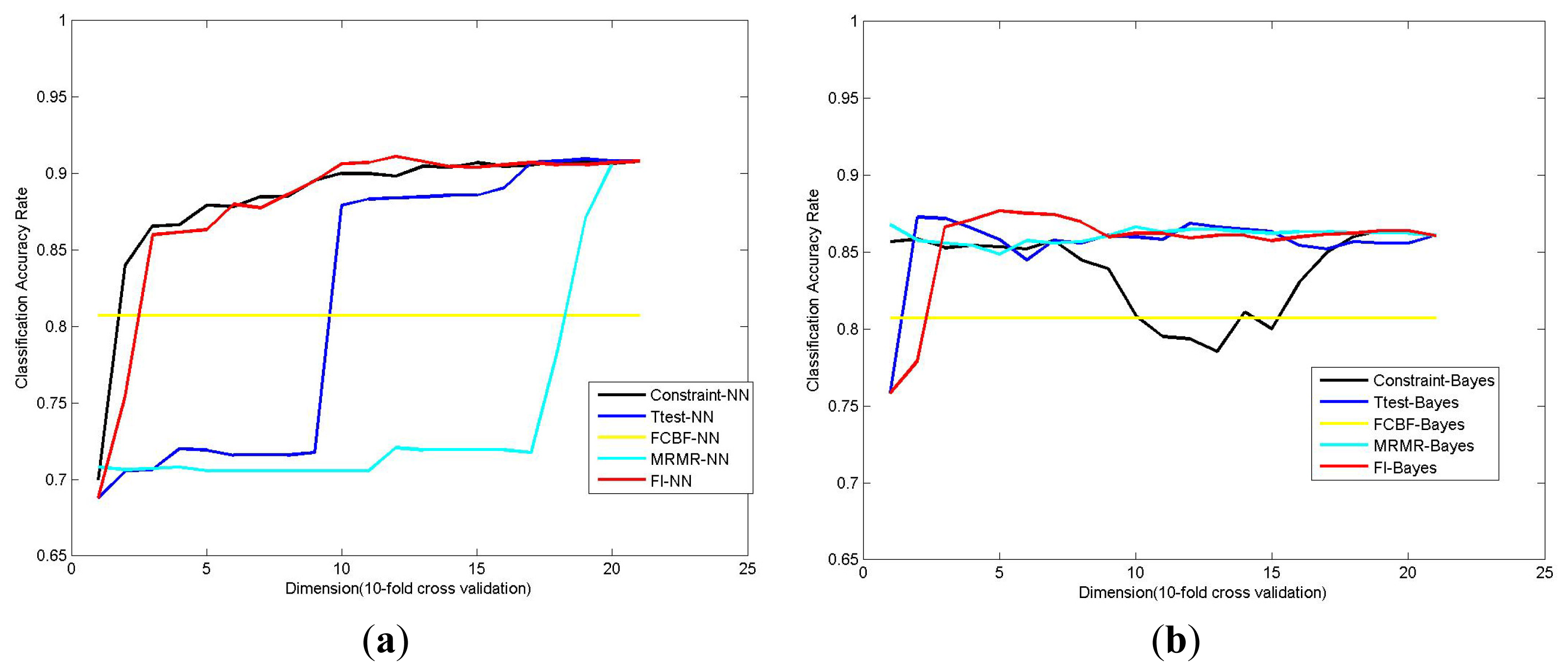
2.4. Comparisons with Other Feature Selection Methods
3. Materials and Method
3.1. Data Sets
3.2. The Proposed Algorithm
3.3. Solution
4. Conclusions

{kind=link}
{kind=link}
{kind=link}
| Hypothesis | Actual positive | Actual negative |
|---|---|---|
| Hypothesise positive | True positive (TP) | False positive (FP) |
| Hypothesise negative | False negative (FN) | True negative (TN) |
| Nearest Neighbor | Naive Bayes | |||
|---|---|---|---|---|
| Method | Highest Acc_Rate | Dimension | Highest Acc_Rate | Dimension |
| F | 0.9080 | 20 | 0.8736 | 3 |
| FI | 0.9112 | 12 | 0.8767 | 5 |
| R | 0.9088 | 17 | 0.8608 | 21 |
| RI | 0.9096 | 17 | 0.8608 | 3 |
| G | 0.9080 | 21 | 0.8624 | 19 |
| GI | 0.9096 | 13 | 0.8648 | 13 |
| Method | Highest F-measure (Nearest Neighbor) | Highest F-measure (Naive Bayes) |
|---|---|---|
| F | 0.8144 | 0.7817 |
| FI | 0.8586 | 0.8071 |
| R | 0.8585 | 0.7851 |
| RI | 0.8599 | 0.7851 |
| G | 0.8518 | 0.7640 |
| GI | 0.8579 | 0.8003 |
| Nearest Neighbor | Naive Bayes | |||
|---|---|---|---|---|
| Method | Highest Acc_Rate | Dimension | Highest Acc_Rate | Dimension |
| Constraint Score | 0.908 | 21 | 0.8639 | 19 |
| Ttest | 0.9096 | 19 | 0.8728 | 2 |
| FCBF | 0.8072 | / | 0.8584 | / |
| MRMR | 0.908 | 21 | 0.868 | 1 |
| Our algorithm (FI) | 0.9112 | 12 | 0.8767 | 5 |
| Method | F-measure (Nearest Neighbor) | F-measure (Naive Bayes) |
|---|---|---|
| Constraint Score | 0.8388 | 0.7588 |
| Ttest | 0.8046 | 0.7825 |
| FCBF | 0.5416 | 0.7730 |
| MRMR | 0.7723 | 0.7721 |
| Our algorithm (FI) | 0.8586 | 0.8071 |
| Category | ID | Description |
|---|---|---|
| Gel composition | F1 | The molar amount of Al2O3 in the gel composition |
| F2 | The molar amount of P2O5 in the gel composition | |
| F3 | The molar amount of solvent in the gel composition | |
| F4 | The molar amount of template in the gel composition | |
| Solvent | F5 | The density |
| F6 | The melting point | |
| F7 | The boiling point | |
| F8 | The dielectric constant | |
| F9 | The dipole moment | |
| F10 | The polarity | |
| Organic template | F11 | The longest distance of organic template |
| F12 | The second longest distance of organic template | |
| F13 | The shortest distance of organic template | |
| F14 | The Van der Waals volume | |
| F15 | The dipole moment | |
| F16 | The ratio of C/N | |
| F17 | The ratio of N/(C + N) | |
| F18 | The ratio of N/Van der Waals volume | |
| F19 | The Sanderson electronegativity | |
| F20 | The number of free rotated single bond | |
| F21 | The maximal number of protonated H atoms | |
| Input: The original data sample D. Output: The indicator vector f. 1. Compute scores of features S and correlation matrix C. 2. Initialize f; 3. Do 4. Select Pi ε U1 ∪ U2 which has the largest reward ri(f); 5. Select Pj ε U2 ∪U3 which has the smallest reward rj(f); 6. if ri(f) > rj(f) Compute α using Equation (11), and then update fi and fj according to Equation (8); 7. else if ri(f) = rj(f) 8. if 2Cij − Cii − Cjj > 0 Compute α using Equation (11), and then update fi and fj according to Equation (8); 9. else if 2Cij − Cii − Cjj = 0 Check whether there exist a P0 ε U1 ∪ U2 and a Px ε U2 ∪ U3 such that 2Cox − Coo − Cxx > 0 and ro(f) = rx(f). If the pair (Po, Px) can be found, Compute α using Equation (11), and then update fo and fx according to Equation (8); Otherwise, f is a solution of Equation (4); 10. end if 11. end if 12. until f is a solution of Equation (4). |
Acknowledgments
Conflicts of Interest
References
- Hyunjoo, L.; Zones, S.I.; Davis, M.E. A combustion-free methodology for synthesizing zeolites and zeolite-like materials. Nature 2003, 425, 385–388. [Google Scholar]
- Yu, J.H.; Xu, R.R. Insight into the construction of open-framework aluminophosphates. Chem. Soc. Rev 2006, 25, 593–604. [Google Scholar]
- Li, Y.; Yu, J.H.; Liu, D.H.; Yan, W.F.; Xu, R.R.; Xu, Y. Design of zeolite frameworks with defined pore geometry through constrained assembly of atoms. Chem. Mater 2003, 15, 2780–2785. [Google Scholar]
- Li, Y.; Yu, J.H.; Wang, Z.P.; Zhang, J.N.; Guo, M.; Xu, R.R. Design of chiral zeolite frameworks with specified channels through constrained assembly of atoms. Chem. Mater 2005, 17, 4399–4405. [Google Scholar]
- Li, Y.; Yu, J.H.; Xu, R.R.; Baerlocher, C.; McCusker, L.B. Combining structure modeling and electron microscopy to determine complex zeolite framework structures. Angew Chem 2008, 120, 4473–4477. [Google Scholar]
- Li, Y.; Yu, J.H.; Jiang, J.X.; Wang, Z.P.; Zhang, J.N.; Xu, R.R. Prediction of open-framework aluminophosphate structures using the automated assembly of secondary building units method with Lowenstein’s constraints. Chem. Mater 2005, 17, 6086–6093. [Google Scholar]
- Ren, X.Y.; Li, Y.; Pan, Q.H.; Yu, J.H.; Xu, R.R.; Xu, Y. A crystalline germanate with mesoporous 30-ring channels. J. Am. Chem. Soc 2009, 131, 14128–14129. [Google Scholar]
- Li, J.Y.; Li, L.; Liang, J.; Chen, P.; Yu, J.H.; Xu, Y.; Xu, R.R. Template-designed syntheses of open-framework zinc phosphites with extra-large 24-ring channels. Cryst. Growth Des 2008, 8, 2318–2323. [Google Scholar]
- Li, J.Y.; Yu, J.H.; Yan, W.F.; Xu, Y.H.; Xu, W.G.; Qiu, S.L.; Xu, R.R. Structures and templating effect in the formation of 2D layered aluminophosphates with Al3P4O163− stoichiometry. Chem. Mater 1999, 11, 2600–2606. [Google Scholar]
- Yu, J.H.; Li, J.Y.; Wang, K.X.; Xu, R.R.; Sugiyama, K.; Terasaki, O. Rational synthesis of microporous aluminophosphates with an inorganic open framework analogous to Al4P5O20HC6H18N2. Chem. Mater 2000, 12, 3783–3787. [Google Scholar]
- Xu, R.R.; Pang, W.Q.; Yu, J.H.; Huo, Q.S.; Chen, J.S. Chemistry of Zeolites and Related Porous Materials: Synthesis and Structure; John Wiley and Sons: Singapore, 2007. [Google Scholar]
- Li, J.Y.; Yu, J.H.; Xu, R.R. Database of AlPO Syntheses. Available online: http://zeobank.jlu.edu.cn (accessed on 26 October 2011).
- Pichler, M.A.; Perone, S.P. Computerized pattern recognition applications to chemical analysis: Development of interactive feature selection methods for the K-nearest neighbor technique. Anal. Chem 1974, 46, 1790–1798. [Google Scholar]
- Liu, Y. A comparative study on feature selection methods for drug discovery. J. Chem. Inf. Comput. Sci 2004, 44, 1823–1828. [Google Scholar]
- Teramoto, R.; Fukunishi, H. Supervised consensus scoring for docking and virtual screening. J. Chem. Inf. Model 2007, 47, 526–534. [Google Scholar]
- Venkatraman, V.; Dalby, A.R.; Yang, Z.R. Evaluation of mutual information and genetic programming for feature selection in QSAR. J. Chem. Inf. Comput. Sci 2004, 44, 1686–1692. [Google Scholar]
- Rodgers, S.; Glen, R.C.; Bender, A. Characterizing bitterness: Identification of key structural features and development of a classification model. J. Chem. Inf. Model 2006, 46, 569–576. [Google Scholar]
- Li, J.Y.; Qi, M.; Kong, J.; Wang, J.Z.; Yan, Y.; Huo, W.F.; Yu, J.H.; Xu, R.R.; Xu, Y. Computational prediction of the formation of microporous aluminophosphates with desired structural features. Microporous Mesoporous Mater 2010, 129, 251–255. [Google Scholar]
- Huo, W.F.; Gao, N.; Yan, Y.; Li, J.Y.; Yu, J.H.; Xu, R.R. Decision trees combined with feature selection for the rationalsynthesis of aluminophosphate AlPO4–5. Acta Phys. Chim. Sin 2011, 27, 2111–2117. [Google Scholar]
- Chen, Y.W.; Lin, C.-J. Combining SVMs with various feature selection strategies. Feature Extraction 2006, 207, 315–324. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection for Discrete and Numeric Class Machine Learning. In Machine Learning: Proceedings of the International Conference; Morgan Kaufmann: San Francisco, CA, USA, 2000; pp. 359–366. [Google Scholar]
- Zhang, D.Q.; Chen, S.C.; Zhou, Z.-H. Constraint score: A new filter method for feature selection with pairwise constraints. Pattern Recogn 2008, 41, 1440–1451. [Google Scholar]
- Ding, C.; Peng, H.C. Minimum redundancy feature selection from microarray gene expression data. J. Bioinf. Comput. Biol 2005, 3, 185–205. [Google Scholar]
- Peng, H.C.; Long, F.H.; Ding, C. Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell 2005, 27, 1226–1238. [Google Scholar]
- Yu, L.; Liu, H. Feature Selection for High-Dimensional Data: A Fast Correlation-Based Filter Solution. Proceedings of the Twentieth International Conference on Machine Learning (ICML-2003), Washington, DC, USA, 21–24 August 2003.
- Soda, P. A multi-objective optimization approach for class imbalance learning. Pattern Recogn 2011, 44, 801–1810. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Kononenko, I. Estimating Features: Analysis and Extension of RELIEF. Proceedings of the 6th European Conference on Machine Learning, Catania, Italy, 6–8 April 1994; pp. 171–182.
- Breiman, L.; Friedman, J.H.; Olshen, R.A. Classification and Regression Trees; Wadsworth International Group: Belmont, CA, USA, 1984. [Google Scholar]
- Saeys, Y.; Inza, I.; Larranaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar]
- Yan, Y.; Li, J.Y.; Qi, M.; Zhang, X.; Yu, J.H.; Xu, R.R. Database of open-framework aluminophosphate syntheses: Introduction and application (I). Sci. China Ser. B 2009, 52, 1734–1738. [Google Scholar]
- Liu, H.R.; Yang, X.W.; Latecki, L.J.; Yan, S.C. Dense neighborhoods on affinity graph. Int. J. Comput. Vis 2012, 98, 65–82. [Google Scholar]
- Kuhn, W.; Tucker, A. Nonlinear Programming. Proceedings of the Second Berkeley Symposium, Berkeley, CA, USA, 31 July–12 August 1950; pp. 481–492.
© 2013 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Guo, Y.; Wang, J.; Gao, N.; Qi, M.; Zhang, M.; Kong, J.; Lv, Y. AlPOs Synthetic Factor Analysis Based on Maximum Weight and Minimum Redundancy Feature Selection. Int. J. Mol. Sci. 2013, 14, 22132-22148. https://doi.org/10.3390/ijms141122132
Guo Y, Wang J, Gao N, Qi M, Zhang M, Kong J, Lv Y. AlPOs Synthetic Factor Analysis Based on Maximum Weight and Minimum Redundancy Feature Selection. International Journal of Molecular Sciences. 2013; 14(11):22132-22148. https://doi.org/10.3390/ijms141122132
Chicago/Turabian StyleGuo, Yuting, Jianzhong Wang, Na Gao, Miao Qi, Ming Zhang, Jun Kong, and Yinghua Lv. 2013. "AlPOs Synthetic Factor Analysis Based on Maximum Weight and Minimum Redundancy Feature Selection" International Journal of Molecular Sciences 14, no. 11: 22132-22148. https://doi.org/10.3390/ijms141122132