1. Introduction
Wireless sensor networks can be broadly applied in various areas such as environmental monitoring, medical care, intelligent homes, transportation, military fields, etc. Data compression algorithms for wireless sensor networks aim to find an efficient way to compress data for reducing node energy costs and improving the synthesized ability of the whole system. Meanwhile, the accuracy must be guaranteed when data is being decoded.
Many new algorithms have been proposed recently, such as the self-based regression algorithm proposed by Deligiannakis, which first splits the recorded series into intervals of variable length [
1]. Then these intervals will be encoded based on an artificially constructed base signal, so the base signal and the extent of the piece-wise linear recorded series are critical factors of the algorithm. A multidimensional sequential pattern mining over data streams algorithm as proposed by Rassi and Plantevit in [
2] scans the temporal series record and realizes data coding based on pattern frequency. Meanwhile, multidimensional sequential patterns extracted from data can be used to compress data. Because the data need to be scanned, the memory and energy cost of nodes must be larger and the real time ability of the network will be affected. A data compression algorithm based on route choosing proposed by Pattem and Krishnamachari combines routing and data compression [
3]. The algorithm reduces data space redundancy by balancing the data relativity of adjacent nodes and the size of clusters. Then the average energy cost of node will be decreased and the longevity of system will be extended. However, the algorithm needs to set accurate positions for nodes and the distance between nodes should be same, which is hard to realize in practice. Meanwhile, the relativity of data decides the performance of the algorithm and getting relativity parameters is hard in actual applications. The Group-Independent Spanning Tree algorithm proposed by Lujun Jia and Guevara also aims to reduce the space redundancy of data [
4], by contructing a complete data transmission structure, but their discussion of algorithm parameters and eliminating redundancy within clusters is insufficient.
Zhou and Lin have proposed a distributed spatial-temporal data compression algorithm based on a ring topology wavelet transformation [
5], which supports a broad scope of wavelet transformations and is able to efficiently decrease spatial-temporal redundancy, but the algorithm may be too complex for nodes because of the wavelet transformations. Lin and Vana proposed an online information compression algorithm [
6], which first divides data obtained by nodes into different lengths of shorter data, then a dictionary can be composed according to the shorter data and updated with the increased data obtained by nodes. The algorithm can reduce the average energy cost per node and improve the accuracy of the restored data, however, the course of updating the dictionary makes the algorithm more complex than the self-based regression algorithm discussed above. The distributed structure tree depression algorithm (abbr. DSTD) proposed by Chou and Petrovic in [
7] explores the spatial-temporal relativity that exists in data and computes the relativity parameters in the sink. Then the sink restores data according to relativity parameters and part of the original data transmitted from the nodes, so the nodes’ energy cost can be reduced to some extent. However, the number of data groups transmitted from nodes to sink is not defined when estimating relativity parameters. If a node transmits too much data for estimating relativity, some redundant parameters will be imported, then the node energy will be wasted and accuracy will be affected. On the other hand, if data transmitted for estimating relativity is not enough, the accuracy of data restored in the sink will be seriously affected.
This paper proposes a cluster optimal order estimation distributed structure tree depression algorithm (abbr. COOE-DSTD). The main idea of the algorithm is injecting the theory of optimal order estimation model into the field of data compression for wireless sensor networks, which has not been tried by others before. The simulation results demonstrate that the combination of optimal order estimation and distributed coding is effective for improving the data compression algorithm of wireless sensor networks. According to optimal order estimation we define the number of groups of data transmitted by nodes for obtaining relativity parameters, so redundant parameters can be prevented. At the same time, the wireless sensor network is divided into clusters, which not only improves the efficiency of the sink to deal with data, but also strengthens the ability of the sink to locate the position of exceptions, so the monitoring ability of the whole system will be greatly improved. The second part will introduce distributed coding theory and the optimal order estimation model imported by COOE-DSTD. The basic structure and flow chart of the DSTD algorithm and the COOE-DSTD algorithm will be given in the third section. The fourth part demonstrates the performance of the COOE-DSTD algorithm through comparison with DSTD from the point of view of average energy cost per node, signal to noise ratio and the ratio of the above two factors. Meanwhile, relative simulations are shown and analyzed. Conclusions of the paper and prospects for future work are offered in the last section.
2. Distributed Coding and Optimal Order Estimation
Data obtained by nodes in wireless sensor networks includes spatial-temporal relativity, which is the basis to introduce distributed coding in the DSTD and COOE-DSTD algorithms. Meanwhile, optimal order estimation is introduced in COOE-DSTD. Now a necessary explanation of distributed coding and optimal order estimation is given.
Distributed coding is one kind of asymmetric coding. First let us take the situation of two nodes as an example, as
Figure 1 shows. Node A transmits original data or code which is coded according to data already obtained by A. So does node B. In the sink, if original data from A is obtained, the current data from A can be restored by code from A.
In the same way, current data from B can be restored according to code from B and data already restored from A. If data obtained by nodes are discrete independent identically distributed sequence, both nodes A and B can restore their original data as better as they don’t know the relativity parameters between A and B. When extending two nodes to N nodes, the sink obtains partial original data and code from nodes and computes relativity parameters. Then combined with these relativity parameters, the sink can restore all original data. Distributed coding derives from the sympatric data source coding theory which was proposed by Slepian and Wolf [
8].This theory demonstrates that if correlated random variables X, Y obey arbitrary possibility distribution
p(x,y), no matter whether the relativity between X and Y is known by the coder or not, the compression performance will be equal. When the relativity between X and Y is unknown, X can be coded with
H(x|y) bits. And
H(x|y) can be demonstrated as:
In
Equation (1),
H(x|y) stands for the uncertainty of variable X when Y is given. Now let us take an example to explain the theory in detail. Suppose variables X, Y are distributed with equal possibility in a data set whose elements consist of three bits. Variables X, Y obey
dH(X, Y) ≤ 1. That is to say, X, Y with equal possibility distribute in set {000, 101, 011, 110} and {001, 010, 100, 111} respectively. The term
dH(m,n) stands for the Hamming distance function. When Y is known by both coder and decoder, X can be coded by two bits, which stands for the uncertain information of X. However, supposing only the decoder knows Y, X still can be coded by two bits. This can be achieved by dividing the set into four cosets. They are coset1 = (000,111); coset2 = (001,110); coset3 = (010,101); coset4 = (011,100). Only two bits are needed to code four cosets. If the coset including X is known together with Y, and X will be decoded lossless. According to the above illustration, some nodes need to transmit three bits while other nodes only need to transmit two bits, so the coding mode is asymmetric and the energy cost of nodes may be different. We introduce the time period rotation method to balance the energy cost of all nodes when applying coding theory to decrease data redundancy. Besides, the way of coding described above can’t support variable compression ratios and sinks will construct a special structure tree to solve the problem, which will be illustrated in detail in the following section.
The course of getting data through nodes in wireless sensor networks is considered a stationary stochastic process in this paper. The optimal order estimation can be explained as follows: as known to all, the performance of a given autoregressive model is up to the practical process, the number of samples, the estimation algorithm and the order selection criterion. The finite sample criterion has given an empirical estimation based on the residual energy statistical average and an autoregressive estimation algorithm of predicted variance, which makes the performance of the finite sample criterion dependent on the adopted estimation method. As two important criteria, both special the finite sample information criterion (abbr. FSIC) and the combined information criterion (abbr. CIC) have considered the increasing residual energy with the increase of model order [
9], which is ignored by other criteria, so compared with FSIC and CIC, other criteria often get over fit order because they only take the expectation of the logarithm of the residual energy as the function of the order model.
Now we first illustrate FSIC and CIC in detail. For a practical stochastic process
AR(R) [
10]:
We set the model of
AR(R) as
AR(g) as follows:
In
Equation (3) εn stands for stationary stochastic process whose mean and variance are 0 and
, respectively. The last parameter
âg is called the reflection coefficient. The variance coefficient
V (
d, •) is the basic part of the finite sample criterion for the AR model. The term
d stands for model order while “•” stands for estimation method in
V (
d, •). This paper has adopted the estimation method of Burg, which is a correlation estimation method.
V (
d, •) is an approximate estimation of the empirical variance of the reflection coefficient when order
d > R. Meanwhile,
V (
d, •) is also an approximate estimation of the empirical variance of parameter
âg when fitting model
AR (g) by the least squares method. If the estimation model order is larger than the practical stochastic process, the variance of the reflection coefficient will be set as 1/
N, where
N stands for sample capacity. If we adopt the above estimation method for the
AR (g) model, we will get a
d order empirical variance estimation equation as follows [
10]:
If the d order empirical expectation of AR(d) model is negative or zero, we will get V(0,•) = 1/N. The above estimation will be accurate for practical stochastic process under the condition that d > R.
As the variance of ɛ̂
n,
is called residual variance
RES(g) when data
yn in
Equation (3) is used to estimate parameter
âd.
is defined as the predicted error
PE(g) when parameters
âd and
yn are mutually independent. If model order g is larger than or equal to the practical random order
R and the Burg estimation method is adopted to estimate
AR(g), we will get approximate expressions of the residual variance
RES(g) and predicted variance
PE(g) as follows [
10]:
Replacing
V (
d, •) in
(5),
(6) with the definite value of
V (
d, •) in
(4) we can get an approximate expectation of
RES (g) and
PE (g). So, both
(5) and
(6) can be fitted by the least squares method and relative proof can be found in [
9]. The expectation of the ratio of
PE (g) and
RES (g) is introduced in the finite sample information criterion. We can get
Equation (7) for order estimation [
10]:
Compared with other criteria which just modify
ln {RES (g)}, FSIC can reflect the main fluctuation of g/
N under the condition of g/
N > 0.1. That is to say, FSIC can obtain an optimal order better than other criteria under the situation of g/
N > 0.1. However, if the optimal model order is small, it will be hard for FISC to give a good estimation. CIC can solve the above problem very well. Because the punishment factors and merits of FISC are adopted by CIC at the same time. Punishment factor is suitable for a low order optimal estimation while FISC is appropriate for a low order optimal estimation. No matter whether the optimal order of the model is high or low, CIC can obtain suitable order estimation. The definition of CIC is as follows [
10]:
If the optimal order of model is low, the CIC can avoid optimal order being estimated too low through a punishment factor
. The CIC can switch to the form of FSIC automatically to avoid the optimal order being estimated too high when the optimal order of model is high, so the combined information criterion is used to estimate the optimal order in the following algorithm proposed in this paper.
3. Descriptions and Flow Chart of the Algorithm
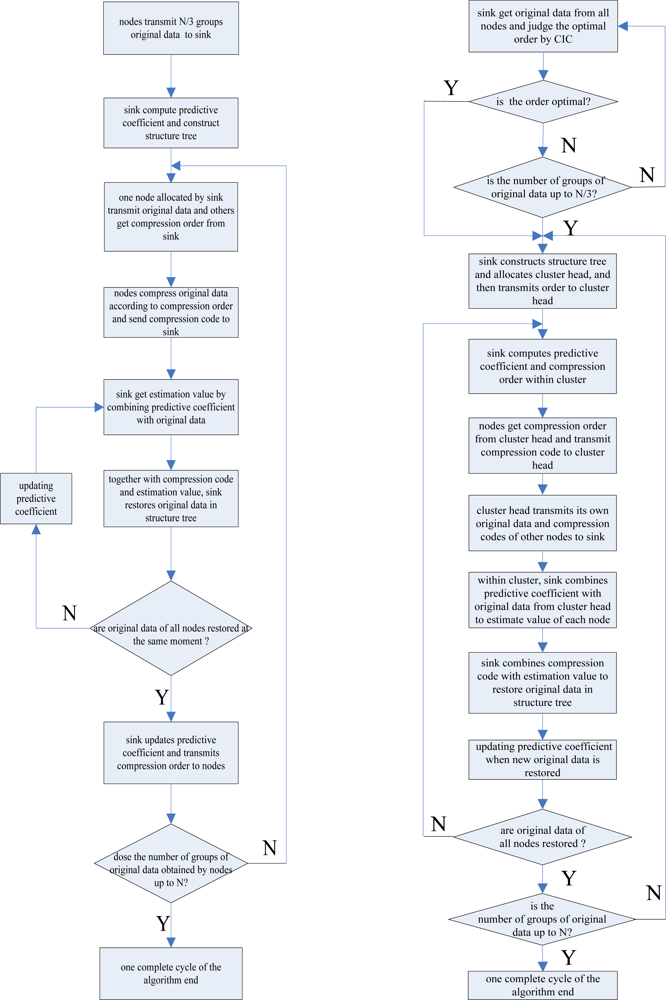
A simple description of the basic theory referred in the proposed algorithm is given above. Now we will illustrate the algorithm in detail. Based on distributed coding theory, DSTD first let nodes transmit N/3 groups’ original data to the sink, then the sink constructs the structure tree and computes prediction relativity parameters and number i based on original data. N stands for the number of data groups sensed by nodes in a complete cycle of the algorithm and i stands for the number of bits which is needed for nodes to compress the original data. By contrast, in the COOE-DSTD algorithm proposed in this paper all nodes transmit the obtained data to the sink and then the sink will judge whether it is getting the optimal order or not through the combined information criteria once the one time data transmission is finished by every node. If the order is not optimal and the number of transmission times is smaller than N/3, nodes will continue to transmit original data, or the sink will compute the initial predictive coefficients and construct the structure tree. The distributed coding method is also used in the COOE-DSTD algorithm, so the sink needs to appoint a node to transmit its original data. The node which transmits the original data expends more energy than those transmitting compressed code, therefore the sink will allocate a node in turn to transmit its original data to balance the energy consumption of all nodes. When a node receives the compression instruction i, a modulo operation of the original data (analog to digital conversed) by 2i will be made in the node, then the original data is compressed into i bits code, which will be received by the sink. The code will map a little data sequence in the structure tree built in the sink. With original data sensed by the allocated node and the predicted parameters computed above, we can restore different original data mapped by different i bits code. If all nodes’ original data of the same cycle are restored, combining with new original data, the sink will update the predicted parameters and compute the value of i for next cycle. The cycle continues and new data will be restored cycle by cycle.
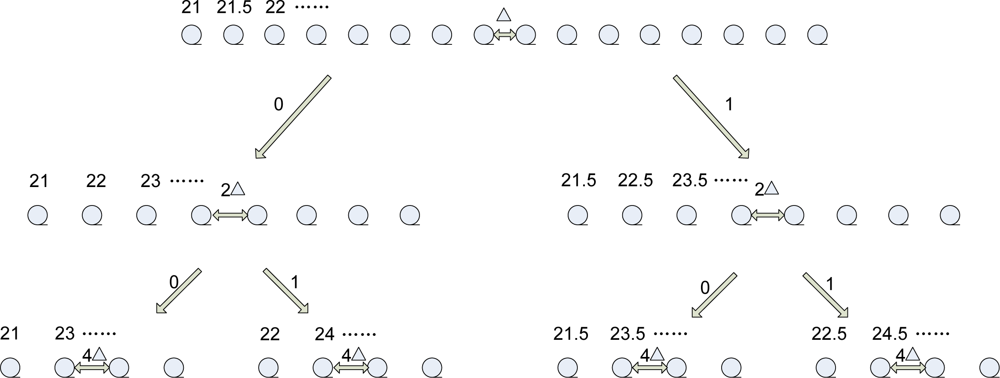
Both the DSTD algorithm and COOE-DSTD algorithm adopt the same theory to get predicted correlation coefficients and the same way to establish the structure tree for getting the coding instruction i. Now it is necessary to give some explanation about the structure tree, predicted correlation coefficients and the coding instruction i referred above. In the DSTD algorithm we start with the average value of N/3 groups of original data for building the structure tree and extend the average original data from both sides by the interrupt of Δ, which can affect the accuracy of the algorithm. The range of extension is up to the practical application. Correspondingly, in the COOE-DSTD algorithm the establishment of the structure tree begins from the average value of the first group of original data. If we split the sequence into odd and even, then we will get two sub-sequences, which are interrupted by 2Δ. The sub-sequences can be split in the same way. After i times splitting, we can get some sub-sequences. Every sub-sequence maps to a code, which includes i bits. Let us use an example to explain the above process. Suppose all nodes monitor temperature and the average of the first N/3 groups data is 25 cent degrees. We set Δ = 0.5 and the range of extension is from 21 cent degrees to 28.5 cent degrees. If the range is exceeded, we will get an exception signal, which will be transmitted to the sink immediately. According to the above description, we can construct a structure tree as follows:
The
i bits code mapped to the last row sub-sequence in
Figure 2 is 00,01,10,11. If the sink gets an
i bits code, it will map a sub-sequence. Combining with an estimation value based on prediction parameters, the sink can ascertain a value nearest to the corresponding original data in the sub-sequence. Then we can estimate original data.
Because of the existence of spatial-temporal relativity in the original data, we can construct a predictive model in the sink. That is to say, we can estimate the original data for the next moment based on the obtained data. It is necessary to declare that the node clustering operation is used after getting the optimal order of the estimation model in the COOE-DSTD algorithm. Both spatial relativity and temporal relativity of the original data obtained from nodes are relative to the optimal order, so the sink can divide all nodes into some clusters based on the value of the optimal order in the COOE-DSTD algorithm. For the first step, every node broadcasts its residual energy to nearby nodes. Secondly, every node compares its own residual energy with the received energy messages from nearby nodes. Thirdly, if one node detects that its energy is larger than that of a certain number of nodes (the number is determined by the value of optimal order), it will broadcast to those nearby nodes (those nodes’ remain energy are lower than that of the broadcaster) that it is their cluster head node. Many border nodes may be found after clustering, and these nodes can join a nearby cluster randomly. In this way, those nodes that have spatial relativity can be clustered together naturally. Then the Compression instruction will be computed by the sink for every node within a cluster. By contrast, in the DSTD algorithm the sink will compute predicted correlation coefficients and compression instructions within the whole sensor network, which will be more complex and more time and energy will be spent.
Supposing node j obtains some original data
at moment T. We can get
through linearly fitting
as follows [
7]:
In
Equation (9),
stands for W continuous original data obtained by node
j before moment T and
stands for S original data obtained by different nodes nearby node
j at the moment T. W, S stand for the number of values obtained by the same node in different moments and different nodes in the same moment, respectively. So how to obtain proper predictive parameters
αk (
k = 1,2 ⋯
W) and
βt (
t = 1,2 ⋯
S) is the critical problem for obtaining
with certain accuracy in order to make
approach
as much as possible. Here we take E[(N
j)
2] as the difference of
and
. Then we can obtain
Equation (10) as follows [
7]:
Suppose discrete data
and
(h, t = 1,2 ⋯
S) obtained by different nodes at the same time are paired jointly wide sense stationary and set [
7]:
In order to get predictive coefficients
Φj when minimizing E[(N
j)
2], we can differentiate E[(N
j)
2] with respect to
Φj, and thus get
Equation (19):
According to the above analysis, if we get certain groups of original data (for example N/3 discussed in DSTD), we can get predictive coefficients
Φj through
Equation (20). Then we can predict the original data obtained by the node at the next moment in the sink. However, data obtained by nodes are time-variant and we must regulate
Φj in time. Here we let
Φj move along the opposite direction of the gradient function of E[(N
j)
2] to realize the adjustment of
Φj in time [
7], as follows:
We can obtain
through
Equation (19),
n stands for certain moment and
μ stands for the parameter of the opposite direction of the gradient. Because the objective function is convex, we can obtain the minimum value. When we choose
μ appropriately, we can get the optimal value through
Equation (21). The deduction for updating
Φj goes as follows [
7]:
Combining with the following two equations [
7]:
So the updating formula of
Φj can be expressed as follows [
7]:
Up to now, we can estimate
by updating coefficient
Φj. In order to get original data in structure tree, we need the compression code transmitted from the nodes. Now let’s explain how the sink can compute the value of
i, which is needed by the nodes to compress original data. We can estimate
through
under the condition that the distance of neighbor nodes in sub-sequence 2
i−1 Δ is larger than
Nn,j. The mean and variance of
Nn,j are 0 and
respectively. If 2
i−1 Δ is larger than
Nn,j under the probability
P, according to the Chebyshev inequality, we can get the value of
i through the following formula:
For a given probability
P, the sink can compute the value of
i according to
equation (33) and
can be initialized by
Equation (34) [
7]:
According to the above analysis, we can describe the DSTD algorithm as follows:
The sink obtains N/3 groups of original data transmitted from all nodes and then computes the initial predicted coefficient Φj and constructs the structure tree based on the obtained original data (N represents the number of original data groups sensed by node in a complete algorithm cycle)
The sink allocates a node in turn to transmit original data and computes the value of i for other nodes.
The node allocated in (2) transmits original data to the sink. Other nodes get compression order i from the sink and compute the compression code through the modulo operator. Then compression codes are transmitted to the sink from the nodes.
Combining the predictive coefficient Φj in Step (2) with the original data transmitted in Step (3), the sink can get
(corresponding to the estimated value of the original data obtained by node j at the moment n). Meanwhile, the compression code obtained from the node can locate a sub-sequence. Together with
, the sink can get
in the sub-sequence as the optimal estimation of the original data. Then
becomes an already known condition for the next node to estimate original data at the same moment. That is to say, the new estimated data should be considered when regulating Φj.
If original data of all nodes are estimated, the sink will compute and transmit compression order to nodes for the next moment. If the number of groups of original data obtained by nodes is up to N, the algorithm will turn to Step (1) or turn to Step (2).
The flow chart of the DSTD algorithm is shown in
Figure 3a. According to the theory introduced above, this paper has proposed the COOE-DSTD algorithm, which is illustrated as follows (the flow chart of the COOE-DSTD algorithm is shown in
Figure 3b):
All nodes transmit original data to the sink and then the sink will judge whether the order is optimal or not by CIC when every cycle transmission is finished. If the order is not optimal and the number of rounds is smaller than N/3, nodes will continue to transmit original data, or the sink will compute the initial predictive coefficient Φm and construct the structure tree.
The value of the optimal order is related with the predicted estimation coefficients which are associated with the space relativity of the original data obtained from nodes, so the sink divides all nodes into some clusters based on the value of the optimal order. Then the sink allocates a cluster head for every cluster and computes the compression instruction for every node in the cluster.
Nodes within a cluster apply the mod operation to the original data based on the compression order for getting the compression code. Then the cluster transmits all compression codes and its own original data to the sink.
Within a cluster, the sink combines the predictive coefficient Φm in Step (2) with the original data transmitted by the cluster head, and the sink can get
(corresponding to the estimated value of the original data obtained by node m at the moment r). The compression code obtained from the node can locate a sub-sequence. Together with
, the sink can ascertain the value
in the sub-sequence as the optimal estimation of the original data. Then
becomes an available condition for the next node to estimate original data at the same moment. Namely, new estimated data should be considered when regulating Φm.
If the original data of all nodes are estimated, the ink will compute and transmit the compression order to clusters for the next moment. If the number of groups of original data obtained by the nodes is up to N, the algorithm will turn to Step (1), or, turn to Step (2).
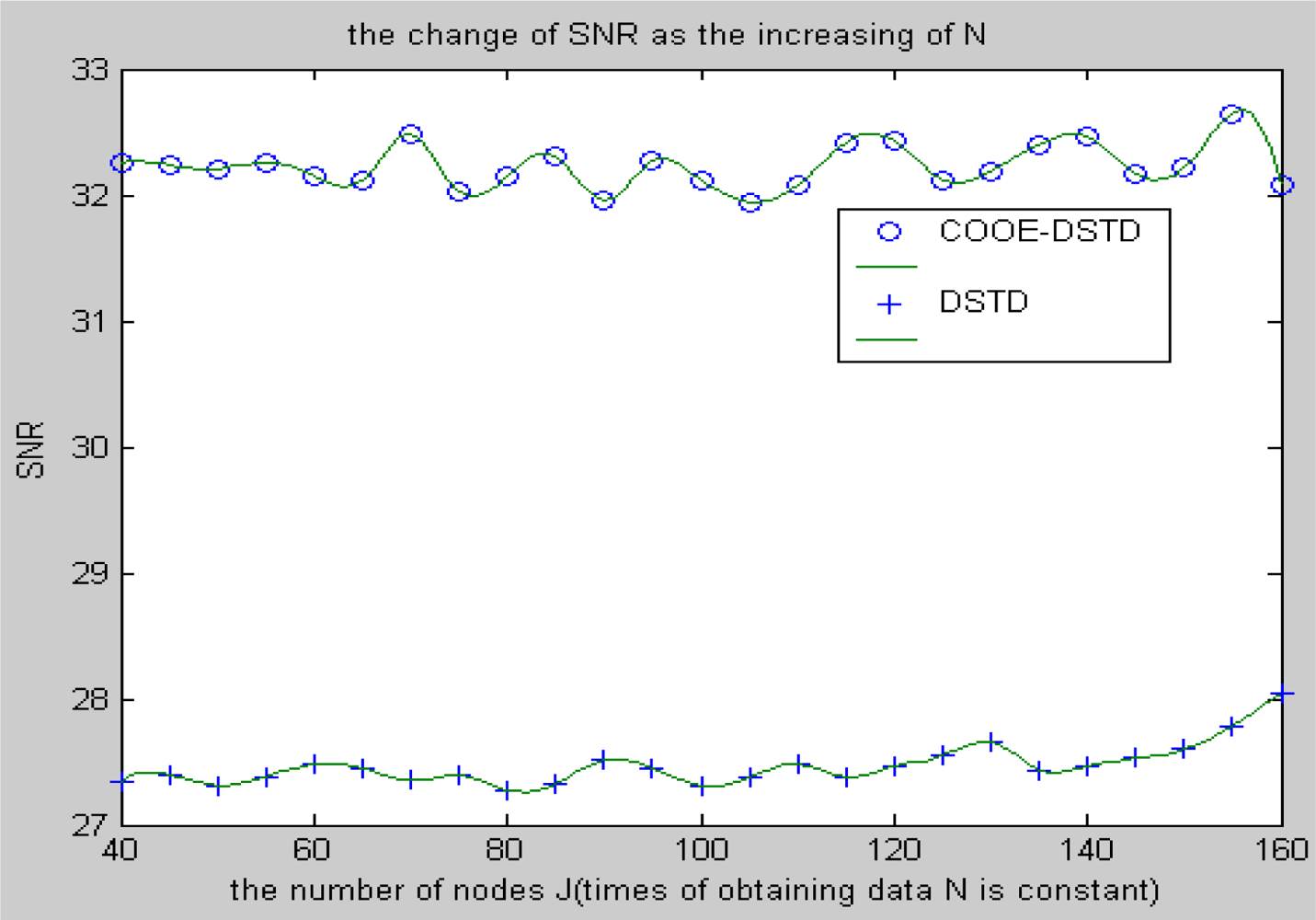
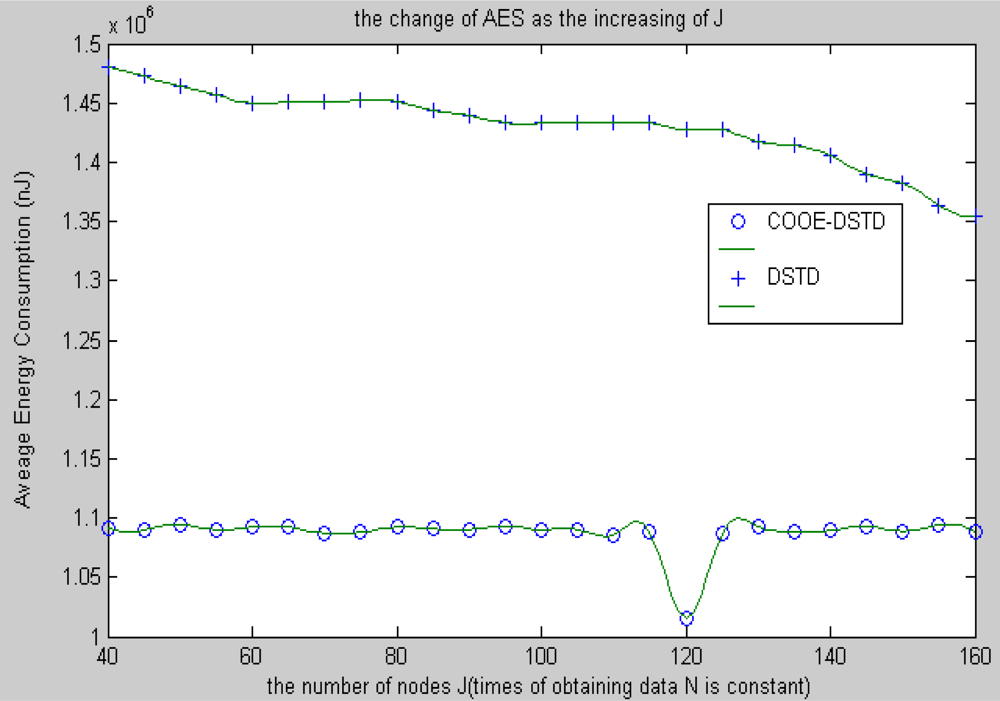
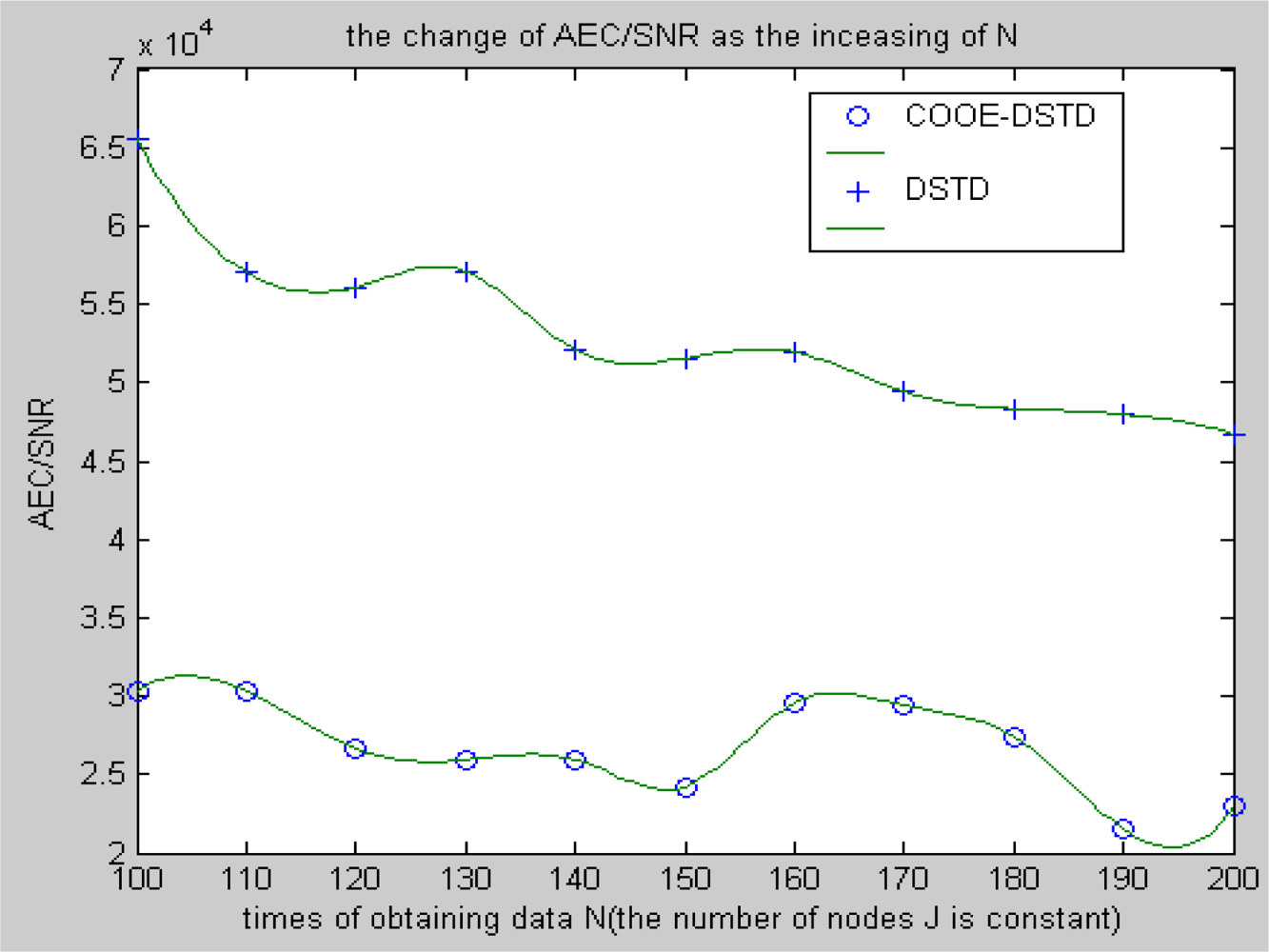
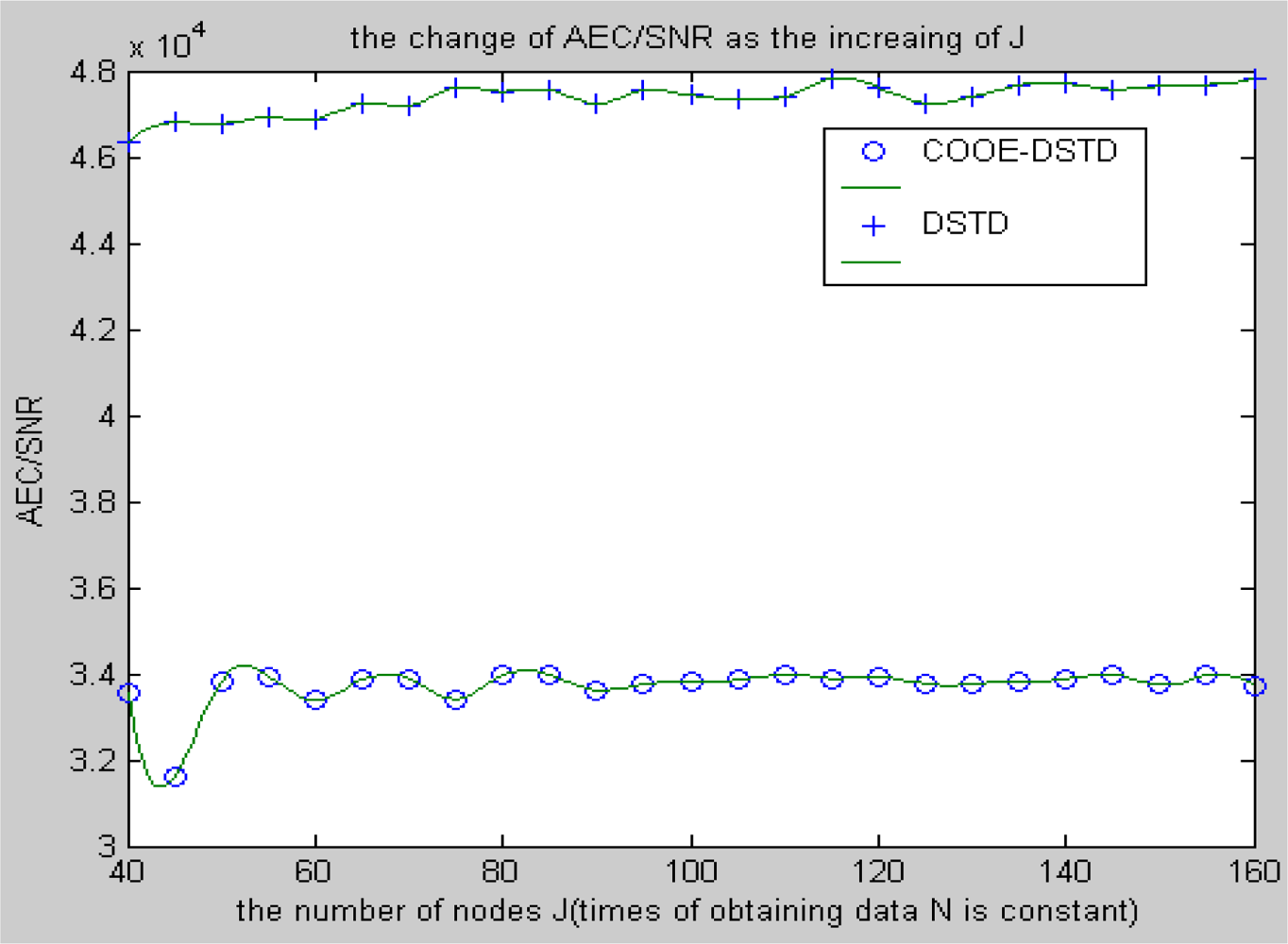
Compared with the DSTD algorithm, optimal order estimation and the operation of clustering are introduced in the COOE-DSTD algorithm, which can decrease the dimension of the data disposed in the sink. The reason is that DSTD algorithm takes all nodes as relative nodes of the node waiting for estimating. If the size of the wireless sensor networks is big enough, some remote nodes which have little relativity with the node waiting for estimating will be considered impertinently, which not only increases the complexity of computation, but also decreases the accuracy of the algorithm.
Contrarily, the COOE-DSTD algorithm only considers those nodes which have spatial-temporal relativity with the node waiting for estimating through the judgment of optimal order estimation, which not only decreases the complexity of computation and the time delay, but also increases the accuracy of the restored data. Meanwhile, the average energy of node can be reduced because the actual data transmitted from nodes to sink is deceased. The method of dividing nodes into clusters is introduced in the COOE-DSTD algorithm, so the sink can locate the place where exceptions have taken place through the cluster structure. Because the predicted coefficients are constructed based on clusters and the data obtained by nodes in the same cluster naturally have spatial-temporal relativity, so the real-time ability and expandability of the whole monitoring system are obviously improved when the COOE-DSTD algorithm is used.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








