1. Introduction
Printed text is defined by strong shape regularity. Its text lines have similar orientation and its skewness is also similar or equal, hence text orientation on same page is not variable. Descenders and ascenders from neighbor text lines are mostly disjoint and consequently, they do not interfere. Accordingly, text distances between lines are big enough to regularly split up text lines. Word in text lines are formed regularly, with similar distances and inter word spacing is decent.
Handwritten text is fully or partially cursive text. It tends to be multi-oriented and skewed. Text lines in handwritten documents are primarily curvlinear and close to each other. Descenders and ascenders from neighbor text lines are occasionally mixed up. Text distances between lines are close to each other, hence text lines run in to each other. Words in text lines are not formed regularly, so their distance is different. On the other hand, like printed text, handwritten text inter-word spacing is tolerable. Overall the appearance of skewed lines with different orientation and text lines close to each other make handwritten text less readable.
From the above, printed and handwritten text are characterized by their feature diversity. Hence, their text line segmentation as well as parameter extraction procedure can be quite dissimilar, although algorithms should fulfill these tasks for printed as well as for handwritten text.
Prior to text parameter extraction, text line segmentation should be done. It is an important step in document image processing. Although some text line detection techniques are successful in printed documents, processing of handwritten documents has remained a key problem in OCR [
1,
2]. Most text line segmentation methods are based on the assumptions that the distance between neighboring text lines is significant and that text lines are reasonably straight. However, these assumptions are not always valid for handwritten documents. Hence, text line segmentation is a leading challenge in document image analysis [
3].
Upon completion of this process, the primary goal of OCR is the extraction of text parameters from optically scanned documents, so reference text line and skew rate identification is mandatory. Their validity is of major importance for any OCR process. There are various reasons for the appearance of multi-skewed lines in text, but two of them are the most common [
1]: Firstly, some degree of misalignment of the document during the scanning process is unavoidable, but since all printed text lines in the scanned document are uniformly skewed, this way the reference text lines are almost parallel. Secondly, text lines in an original handwritten document are skewed differently due to specific individual handwriting habits, so handwriting text lines present different orientations,
i.e., they are multi-skewed. To enhance the ability of document analysis system, we need a robust algorithm for text line segmentation as well as for parameter extraction.
Many proposed algorithms have been evaluated by quite different test methods. In fact, these evaluation procedures are usually based on use of a custom text database as a test sample. Accordingly, testing result interpretation is quite dissimilar [
4]. Hence, the establishment of the test framework for the evaluation of the document image processing algorithms is of great importance. This is precisely the task of this paper, and a basic method framework for the evaluation of the text line segmentation and text parameters extraction is proposed.
The paper is organized as follows: in Section 2 the test framework is presented. It is divided into two test groups. Each of them is completely described. Section 3 contains an examination and evaluation of the test framework procedure using an example of the specific algorithm. A Gaussian isotropic kernel is used as the basic test algorithm. Results are analyzed, examined and discussed. Conclusions are given in Section 4.
2. Evaluation Test Framework
The evaluation test framework for the text parameter extraction algorithm consists of a few text experiments. They are divided into two distinct groups:
Text line segmentation experiments are related to the algorithm’s ability to achieve segmentation of the text lines. Hence, these experiments are based on various multi-line sample texts. They incorporate the following tests:
Multi-line text segmentation test,
Multi-line waved text segmentation test,
Multi-line fractured text segmentation test.
In contrast, the reference line and skew rate tests evaluate the algorithm’s competence for text line tracking. Therefore, they are based on single line sample texts as a reference. They include the following tests:
Single line skew rate test,
Single line waved text test,
Single line fractured text test.
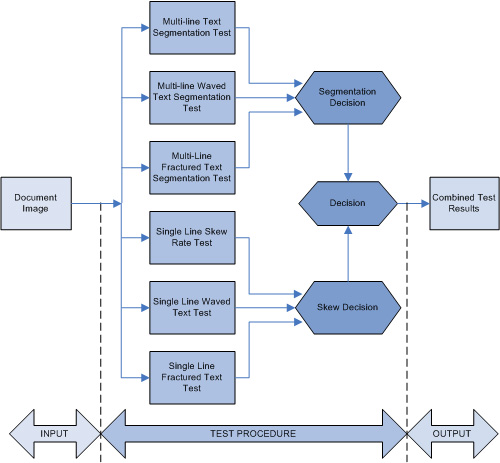
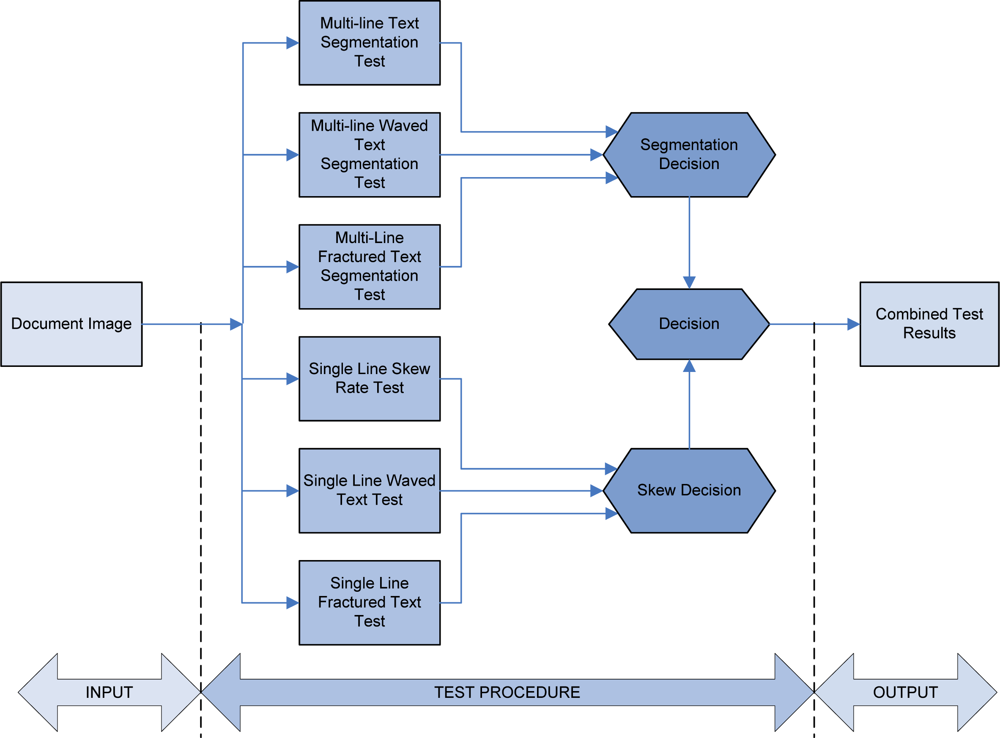
A schematic diagram of the integral framework test procedure is shown in
Figure 1. According to everything presented above, decision making is required at the end of the test procedure. Firstly, decision making is mandatory for the multi-line text segmentation experiments process. As a result of this decision, the sub-set values of the algorithm parameters are obtained. These parameter values are used as an optimization starting point. Further, results from single line text experiments are evaluated. These results narrow the algorithm optimization choice by creating its own parameters value sub-set. Although the test experiments are quite diverse, their results are inter-related. Hence, the last decision includes a new parameter sub-set values taking into account the all previously obtained parameter sub-set values. This final result represents the optimized parameter values.
2.1. Document text image
At the beginning of the test process, an original image is used. Assume that original image is continual function
f (
x,
y). A document text image is obtained as a product of the original image scanning. Hence, the values of the coordinates (
x,
y) become discrete quantities. Now, the document text image is a digital text image represented by a matrix
D with
M rows,
N columns, and intensity with
L discrete levels of gray.
L is the integer number from the set {0,…,255}. Hence, the intensity of matrix
D is represented as [
5]:
where the origin of the function
f (
x,
y) is point (
x,
y) = (0, 0), while the origin of the matrix
D is (
r,
c) = (1, 1). Hence, row
r ∈ {1,…,
M} replaces
x ∈ {0,…,
M–1} and column
c ∈ {1,…,
N} replaces
y ∈ {0,…,
N–1}.
After applying intensity segmentation with binarization, the intensity function is converted into a binary intensity function given by:
where
Dth is given by the Otsu algorithm [
6]. It represents a threshold sensitivity decision value.
Now, extracted text lines are represented as a digitized document image by matrix
X featuring
M rows by
N columns. Currently, the document text image is represented as a black and white image. It consists of the only black and white pixels. Each character or word consists of the only black pixels. Each pixel
Xi,j,
i.e.,
X(
i, j) is represented by the number of coordinate pairs such as:
where
i = 1,…,
M,
j = 1,…,
N of matrix
X [
5]. In addition, value 0 represents black pixels, while value 1 from (2) converted in number 255 represents white pixels. This circumstance is shown by the document text image fragment in
Figure 2.
2.2. Test procedure
2.2.1. Multi-line text segmentation experiment
Algorithm quality examination consists of few text experiments representing the test procedure. In the first group of the experiments, text line segmentation quality is examined. These tests are significant because they are a prerequisite for obtaining the other text parameters. If segmentation experiment fails, then the examination of other features will be meaningless. Hence, its importance is critical. For this purpose, as the first experiment, a multi line text is used. Sample multi-line text with its skew angle parameter
α is shown in
Figure 3.
A number of existing text objects in a multi-line text image relate to the success of text segmentation. Hence, the less objects the better segmentation process, except the number may not be less than the number of text lines. As a quality measure, the root mean square error
RMSEseg has been used. It is calculated as [
7–
9]:
where
k = 1,…,
P is the number of examined text samples,
Ok,ref is the number of referent objects in text,
i.e., number of text lines, and
Ok,est is the number of objects obtained in the text by the applied algorithm.
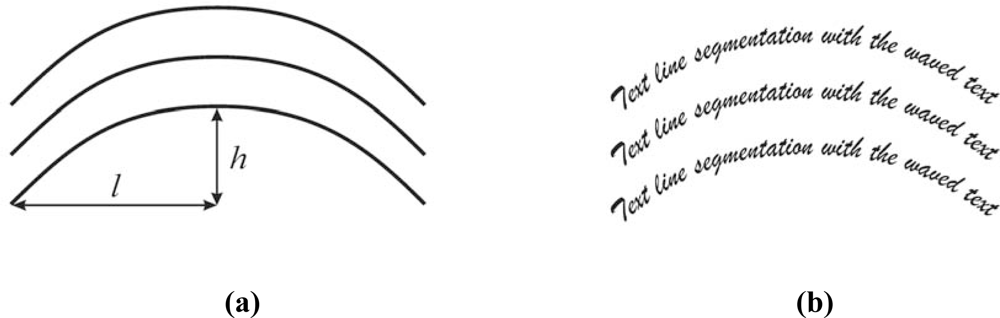
2.2.2. Multi-line waved text segmentation experiment
The second text line segmentation experiment is a multi-line curved text one. Sample text is formed as a group of text lines using a curved reference line for its basis. The reference line is defined by the parameter
ɛ =
h/l. Typically,
ɛ is used from the set {1/8, 1/6, 1/4, 1/3, …}. A sample multi-line curved text for the experiment is shown in
Figure 4.
Like in the previous segmentation test, the number of existing text objects after the algorithm is applied relates to the text segmentation quality. Again, as a quality measure, the root mean square error
RMSEseg,wav has been used. It is calculated as [
7–
9]:
where
l = 1,…,
R is the number of examined text samples,
Ol,ref is the number of referent objects in text,
i.e., number of text lines, and
Ol,est is the number of objects obtained in the text by the applied algorithm.
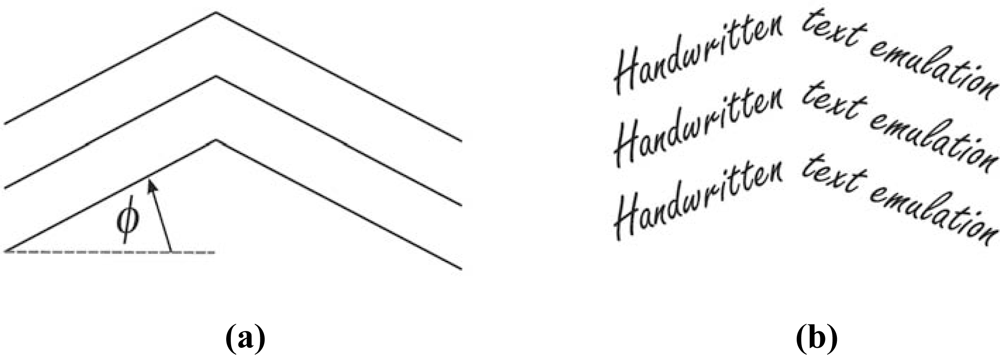
2.2.3. Multi-line fractured text segmentation experiment
The last experiment in the first test group is a multi-line fractured text segmentation experiment. The sample text for this experiment is formed by using a reference fractured line as a basis. This fractured text reference line is defined by the slope angle
ϕ, as a parameter. Typically,
ϕ is used from the set {5°, 10°, 15°, 20°}. A sample multi-line fractured text for the last segmentation experiment is shown in
Figure 5.
Again, the number of existing text objects relate to the text segmentation quality. The root mean square error
RMSEseg,frac has been used. It is calculated as [
7–
9]:
where
m = 1,…,
Q is the number of examined text samples,
Om,ref is the number of referent objects in text,
i.e., number of text lines, and
Om,est is the number of objects obtained in the text by the applied algorithm.
2.2.4. Skew rate text experiment
Further experiments belong in the second test group. The first of them, a skew rate test experiment, is mainly concerned with skew rate identification. It evaluates the algorithm’s performance in the skew tracking domain. Although, this experiment is primarily based on printed text, it is good prerequisite for testing handwritten text as well. In this test, a sample printed text rotated from 0° to 90° in 5° steps around the
x-axis is used. This is presented in
Figure 6.
The reference line of the test sample text is represented by:
After applying any algorithm to the sample text, reference text line estimation implies calculation of the average positions of only black pixels in every column of the document text image. It is calculated by [
1,
7,
10]:
where
xi is the point position of calculated reference text line,
i is the number of column position of the calculated reference text,
yj is the position of black pixel in column
j and
L is the sum of black pixel number in a specified column
j of an image.
After calculation, an image matrix with only one black pixel per column is obtained. It defines the calculated i.e. estimated reference text line as well as text line skewness. This reference text line forms a continuous or discontinuous line partly or completely “representing” the reference text line. To achieve a continuous linear reference text line, the least squares method is used. The function is approximated by a first-degree polynomial is given by:
Further,
ndp represents the number of data points. It is used in the relation for calculating the slope
a’, and the
y-intercept
b’ as follows [
8]:
and:
For algorithm approximation and evaluation, a quantity called relative error [
9] is important. The reference line hit rate
i.e.,
RLHR incorporates this quantity. It is defined as [
7,
10]:
where
βref is the arc tangent from the origin (7)
i.e.,
a and
βest is the arc tangent from estimate (9),
i.e.,
a’. Obviously,
RLHR is equal to 1– the relative error [
9]. Now, the root mean square error
RMSEskew is calculated by [
7–
10]:
where
n = 1,…,
S is the number of examined text rotating angles up to 90°,
xn,ref is
RLHR for
βest equal to
βref, due to normalization equal to 1, and
xn,est is
RLHR.
2.2.5. Handwritten curved text experiment
The second experiment in this test group is primarily linked with handwritten text. Particularly, in this experiment a hypothetical reference text line is represented by a wavy line. This test examines the algorithm’s capability to follow a wavy reference text line. This wavy text sample as well as its definition is given in
Figure 7.
Different types of wavy text can be examined. As can be seen, it is completely defined by the ratio
η =
h/w (see
Figure 7a), where
h represents height of the waved line, while
w represents the half length of the wavy line. This experiment used the parameter set
η = {1/8, 1/4, 1/2, 1}. Algorithm criteria quality and handwritten referent text line is measured and evaluated by the root mean square error
RMSEwav calculated as [
7–
9]:
where
o = 1,…,
T is the number of examined text pixels,
i.e., columns of interest,
xo,ref is pixel position of original referent text line in
o-th column, and
xo,est is pixel position of calculated,
i.e., estimated referent text line in
o-th column.
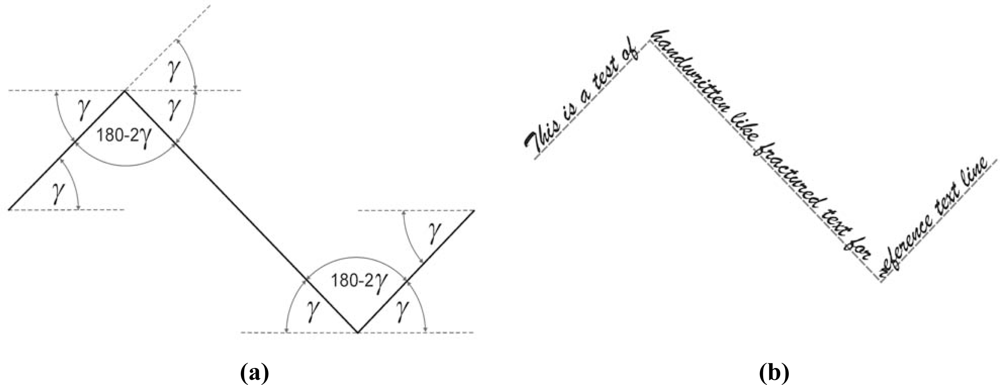
2.2.6. Handwritten fractured text experiment
The next and the last experiment is also linked with handwritten text. A hypothetical reference text line is represented by a fractured line. This test examines the algorithm’s ability to follow a fractured text line which represents abrupt changes in direction. The fractured text sample is given in
Figure 8. In the figure,
γ is the slope angle of the first, second and third part of the fractured text line. It can be observed that the second and third part of text line is rotated by an angle of 2
γ from previous part of reference text line at once. Hence, this test example is a rather extreme one.
This experiment is typically performed for
γ from 5° to 25° in 5° steps around the horizontal
x-axis. Again, the evaluated reference text line is evaluated by root mean square error (
RMSE) method. Further,
RMSEfrac is calculated as [
7–
9]:
where
p = 1,…,
U is number of examined text pixels,
i.e., columns of interest,
xp,ref is pixel position of original referent text line in
p-th column, and
xp,est is pixel position of calculated,
i.e., estimated referent text line in
p-th column.
2.2.7. Decision Making
Results obtained from different experiments during test procedure are inter-related. It should be noted that if the algorithm was examined and evaluated for text line segmentation as well as for text parameter extraction, then text line segmentation should be primary goal. Therefore, it is prerequisite for text parameters extraction such as reference text line and skew rate. This will be followed by the experiments for text parameter extraction and identification. Although, they are of second-rate importance compared to text line segmentation, their importance is evident at the next level of algorithm quality evaluation.
2.3. Combined test results
Combined test results represent merged results. Although, it is very similar to decision making, it is quite diverse from it. In fact, for the investigation of the algorithm under different parameters and restrictions, such merging of results leads to optimized parameter(s) value extraction. This way, an optimized subset of parameter(s) values is obtained. This process is invaluable for the algorithm evaluation as well as for obtaining any conclusions from it.
3. Test Example and Discussion
For the illustration, above test framework procedure will be examined using as an example the Gaussian isotropic kernel algorithm [
7]. This algorithm will be just briefly explained. Its main task is expanding black pixel areas of text by scattering every black pixel in its neighborhood. This way, distinct areas that mutually separate text lines are established. Its primary purpose is joining only text elements from the same text line into the same distinct continuous areas. Gaussian probability function is taken as template that gives the probability of the random function. Consequently, it represents probability of the hypothetical expansion around every black pixel that represents a text element. Hence, around every black pixel, new pixels are non-uniformly dispersed. These new pixels have lower black intensity. Because the level of probability expansion relates to distance from black pixel, their intensity depends completely on their position
i.e., the distance from the original black pixel. Hence, these newly formed pixels are grayscale. Currently, document text image is represented by a grayscale image matrix. Thus, intensity pertains in level region {0,…,255}. Hence, after applying Gaussian isotropic kernel, equal to 2
K + 1 in
x-direction as well as in
y-direction, text is scattered forming an enlarged area around it. Now, inside the kernel a “probability” sub area is formed using the radius 3
σ, where
σ represents standard deviation defining curve spread parameter. Converting all these pixels into black pixels as well as inverting image, forms the new black pixel expanded areas [
7]. These areas are named boundary-growing areas.
The main purpose of the testing is optimization of the algorithm parameters. In our example, parameter of interest is
K that defines kernel size. Further, the algorithm will be examined and evaluated. Firstly, the algorithm is examined by a multi-line text segmentation test. The multi-line text sample is skewed by an angle
α (see
Figure 3). Gaussian kernel size is defined by
K value (in pixels), which is used as parameter. Because of the size of the letters,
K is used from the set {5, 10, 15, 20, 25}. Obtained results are presented in
Figures 9 and
10.
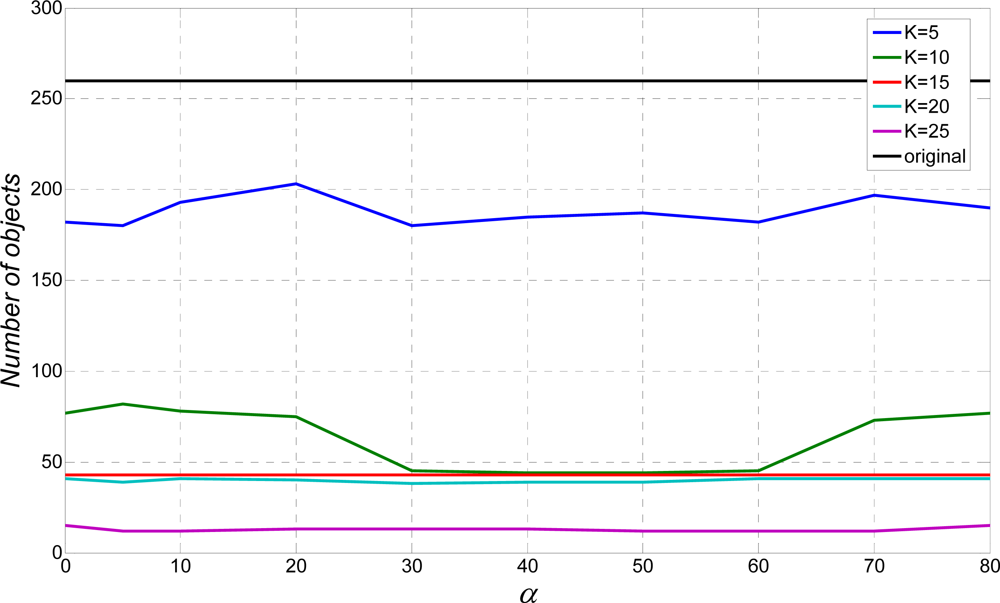
Although it is not part of the “relevant” measurement test, but just for the illustration purposes, the number of segmentation objects for different
K is shown in
Figure 9. Parameter
K = 0 represents situation without an applied algorithm. Obviously, a bigger
K value leads to better segmentation results due to stretching of the original text. Still, too big a
K will join different text lines.
Similarly, the results presented in
Figure 10 confirm that a big
K, especially bigger than 15 leads to satisfactory segmentation results, while a small
K, less than 10 are completely unacceptable. Hence, as a starting point, a
K bigger than 15 is a good choice. Further, the algorithm is evaluated by a single line skew rate test. The obtained results are represented by the
RLHR value from (12). They are shown in
Figure 11.
This time, a bigger
K is not an advantage. Hence, a medium size
K like {15, 20} is the optimal value [
7]. Scattering results from the previous test is represented by the
RMSE method in
Figure 12.
Bigger
K leads to slightly bigger
RMSEskew. This is obvious because skewed reference line is more stretched by a bigger kernel which leads to slightly bigger scattering results. Finally, the algorithm is examined with a single line wavy text as well as a fractured text test. Algorithm criteria quality is measured by the
RMSE method. Results for the wavy text test are shown in
Figure 13.
From
Figure 7a, the ratio
η =
h/w is the severe element. Response to the sample wavy text is optimal for a
K value chosen from the set {15, 20, 25} that confirms their candidacy for the optimal values. Finally, results for the fractured text test are shown in
Figure 14. The most promising
RMSEfrac value for this test is for
K = 15. Hence, from all the above results, after intersection decision making, the optimal values for
K are 15 or 20.
From the obtained and presented measurement results, it is obvious that the results of above tests are quite sufficient for the evaluation of the algorithm quality in the domain of the text segmentation and feature extraction. Hence, they can represent a basic test framework for the evaluation of the text line segmentation and text parameters extraction.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}