Boosting-Based On-Road Obstacle Sensing Using Discriminative Weak Classifiers


Abstract
: This paper proposes an extension of the weak classifiers derived from the Haar-like features for their use in the Viola-Jones object detection system. These weak classifiers differ from the traditional single threshold ones, in that no specific threshold is needed and these classifiers give a more general solution to the non-trivial task of finding thresholds for the Haar-like features. The proposed quadratic discriminant analysis based extension prominently improves the ability of the weak classifiers to discriminate objects and non-objects. The proposed weak classifiers were evaluated by boosting a single stage classifier to detect rear of car. The experiments demonstrate that the object detector based on the proposed weak classifiers yields higher classification performance with less number of weak classifiers than the detector built with traditional single threshold weak classifiers.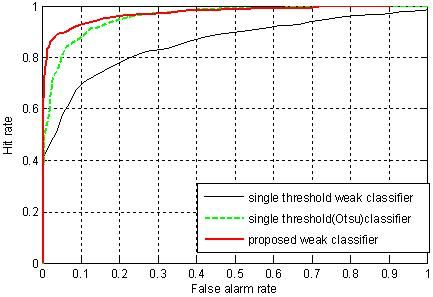
1. Introduction
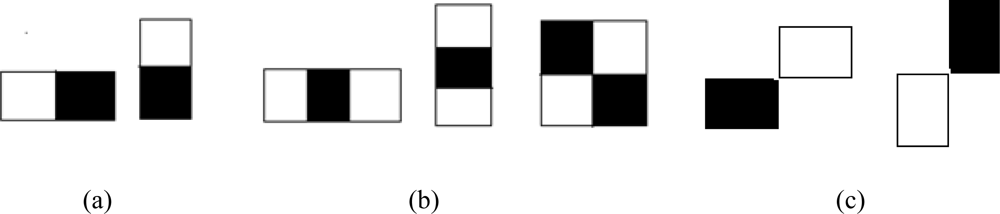
In pattern recognition, object detection generally is a two-class classification problem with two essential issues of feature selection and classifier design based on the selected features. Classifiers based on Haar-like features [1] have been successfully used for object detection. Viola and Jones [2] proposed an object detection framework where these Haar-like features are selected and classifier is trained using AdaBoost [3]. This approach has become a popular framework for object detection and several extensions of this framework have been proposed. One of the extensions is the improvement in the boosting algorithm. Modified versions of AdaBoost such as Real AdaBoost [4], FloatBoost [5] and KLBoosting [6] are available. Real AdaBoost is used for multi-view face detection [7]. In addition to face detection [5] Float Boost is also applied to hand shape detection [8]. The other extension of the original framework is to use an extended set of Haar-like features so that different image patterns can be evaluated. In addition to the basic feature set of Figure 1(a), an extended set of Haar-like features as shown in Figure 1(b,c) are introduced in [9,10], and [11]. Mita et al. [12] have selected multiple co-occurring linear weak classifiers to form a more efficient classifier. Boosting in a hierarchical feature space where the local Haar-like features are replaced by global features derived from PCA in later stages of boosting is introduced in [13]. An extension of Haar-like features in which different weights, determined by techniques like Brute force search, Genetic algorithms and Fischer’s linear discriminant analysis, are assigned to the rectangles of Haar-like features is proposed in [14]. Hybrid features composed of gradient features, Edgelet features and Haar-like features are used in [15] for pedestrian detection.
The selection of threshold for the Haar-like features is not a trivial task and has not been explained in detail in [2]. The weak classifiers based on single threshold Haar-like features are sub-optimal and not efficient for discriminating object and non-object. At later stages of the cascade these single threshold Haar-like features become too weak for discrimination and make boosting ineffective [13]. In this paper, we propose a different set of weak classifiers for boosting that achieves higher classification accuracy with less number of weak classifiers. Unlike in [2], the proposed weak classifiers do not require explicit thresholds be calculated for the Haar-like features and present a more general solution to the threshold selection problem. The proposed weak classifiers are equally efficient for discrimination at later stages of boosting also.
The rest of the paper is organized as follows: Section 2 describes the AdaBoost learning of the Haar-like features. Section 3 presents the proposed method for realizing efficient weak classifiers. Experimental setup and results are presented in Section 4, followed by concluding remarks in Section 5.
2. Boosting of Weak Classifiers
This section describes the conventional weak classifiers and AdaBoost learning algorithm for constructing a strong classifier by selecting the weak classifiers.
2.1. Boosting of Weak Classifiers
The Haar-like features have scalar values that represent the difference in the sum of intensities between the adjacent rectangular regions. To capture the ad hoc knowledge about the domain, these features are evaluated at different positions and with different sizes exhaustively according to the base resolution of the classifier. For example, when the classifier resolution is 24 × 18 pixels, 91,620 features are generated from the five features in Figure 1(a,b). Each feature is evaluated on all the training samples and the probability density for each of the object and non-object class is calculated as shown in Figure 2. In [2], a single threshold that separates these two distributions is selected for each feature. These features along with their respective thresholds and polarity form the weak classifiers for the learning algorithm.
A weak classifier can be mathematically described as:
2.2. AdaBoost
AdaBoost is a machine learning boosting algorithm that constructs a strong classifier by combining a set of weak classifiers. A small number of discriminative weak classifiers are selected by updating the sample distribution. The prediction of the strong classifier is produced through a weighted majority voting of the weak classifiers. Pseudo code of a variant of AdaBoost used in the implementation is given in Algorithm 1.
Algorithm 1. Pseudo code of Discrete AdaBoost
-Given example images (x1, y1),..., (xn, yn) where yi = −1,1 for negative and positive examples.
-Initialize weights , where l and m are the number of positives and negatives respectively
-For t = 1,...,T:
Normalize the weights,
Select the best weak classifier with respect to the weighted error:
Define ht(x) = h(x, ft, pt, θt) where ft, pt and θt are minimizers of ɛt
Update the weights: where,
– The final strong classifier is:
3. Proposed Weak Classifiers
This section describes the proposed weak classifiers which eliminate the need of explicit threshold for the Haar-like features. First we formulate the definition of the new weak classifiers based on Bayesian decision theory and quadratic discriminant analysis [16]. Later we discuss the motivation to use and the relative advantage of the proposed weak classifiers over the traditional single threshold weak classifiers.
3.1. Bayesian Decision Rule
Given a set of features, the Bayesian decision theory for classification requires decision boundaries that minimize the error rate on the training data. Let us consider a two class problem with ω1 and ω2 as the state of nature. If x is the observed feature value, the decision boundary that minimizes the classification error is given in terms of the posterior probabilities as P(ω1|x) = P(ω2|x). The corresponding decision rule is: decide ω1 if P(ω1|x) > P(ω2|x); else decide ω2.
3.2. Discriminant Function for Normal Density
One of the most useful ways to represent pattern classifiers is in terms of a set of discriminant functions gi(x); i = 1, 2,…, c, where c is the number of categories to discriminate. The classifier is said to assign a feature x to class ωi if:
The effect of the decision rule is to divide the feature space into c decision regions. The regions are separated by decision boundaries, surfaces in the feature space where ties occur among the largest discriminant functions [16]. Assuming the distribution of the univariate Haar-like features to be normal, i.e., p(x|ωi) ∼ N(μi, Σi), the minimum error rate classification can be achieved by the use of discriminant function of the form given in Equation (3) [16]:
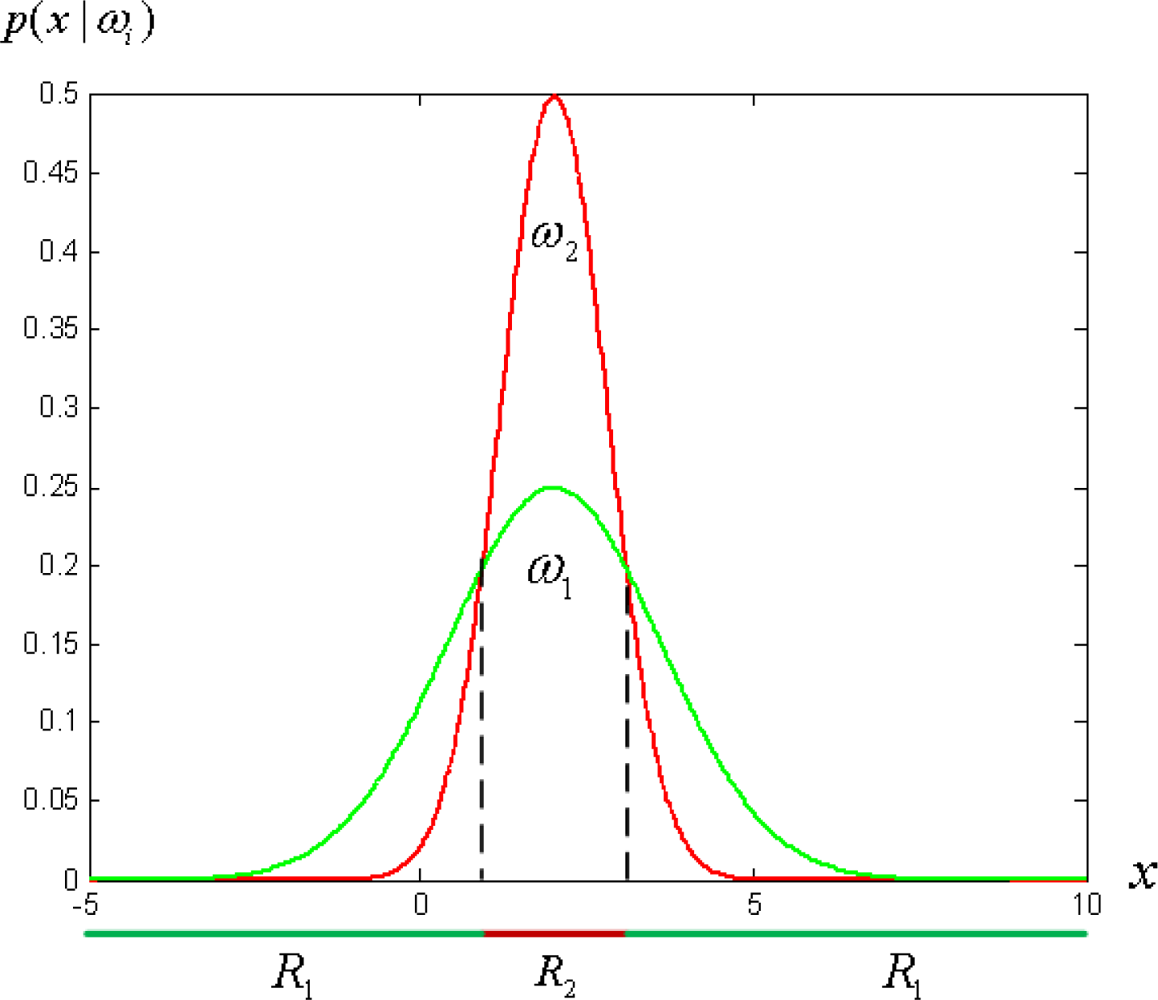
The discriminant functions of Equation (4) are inherently quadratic. The decision surfaces are hyperquadrics and in one dimensional case the decision regions needn’t be simply connected as shown in Figure 3. This observation motivates us to formulate new kind of weak classifiers without explicitly specifying the threshold for each weak classifier.
3.3. Proposed Weak Classifiers
The proposed weak classifiers are based on the quadratic discriminant functions described above. Each Haar-like feature from the pool of 91,620 features is evaluated on the training samples and one-dimensional probability densities for object and non-object classes are calculated. Assuming the density of each feature to be normal, the distributions of feature on the object and non-object classes are parameterized by their maximum likelihood estimators, i.e., mean μ and variance Σ. The distribution for the object (positive) class is p(x|ωp) ∼ N(μp, Σp), and for non-object (negative) class is p(x|ωn) ∼ N(μn, Σn). The decision regions for the two distributions are given from Equation (2), i.e., assign the observed feature value x to class ωp if:
This decision rule divides the feature space into decision regions which needn’t be simply connected for the same class. The proposed weak classifiers for the Haar-like features are defined as:
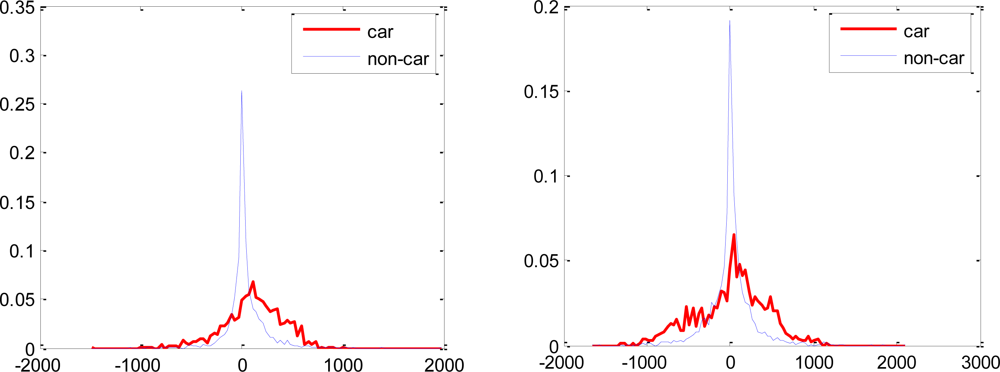
For the weak classifiers of Equation (1), each feature produces a single scalar value and the decision boundary corresponds to a scalar threshold. But the choice of this threshold is not stated clearly in [2] and determination of an optimal threshold is a nontrivial task. The proposed weak classifiers of Equation (6) are more general and do not require any explicit representation of the threshold. In fact, the weak classifiers of Equation (1) are a special case of the proposed weak classifiers when Σp and Σn are identical. The weak classifiers based on single threshold commonly employ “average of means” of the two distributions, i.e., (μp + μn)/2, as decision threshold. Under this hypothesis, it is statistically observed that most of the Haar-like features are non-discriminative and inefficient for boosting.
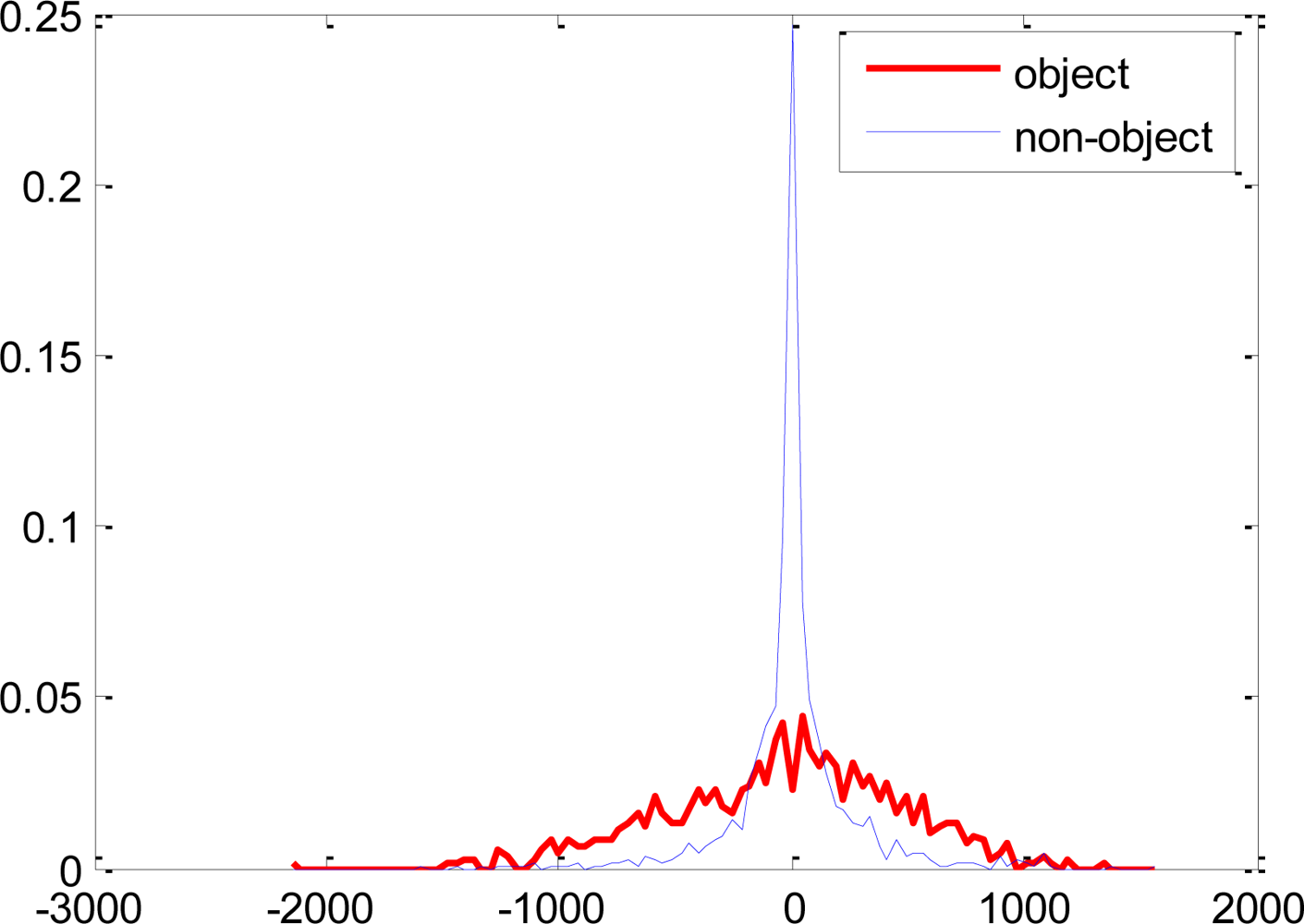
The error rates of these single threshold weak classifiers selected at later stages of the boosting process become large as the sample distribution consists of samples which are difficult to discriminate as shown in Figure 4. The single threshold weak classifiers are not efficient in discriminating such distributions. The proposed weak classifiers are expected to efficiently discriminate the underlying distribution of Figure 4, as disjoint decision regions are also supported as shown in Figure 3.
4. Experimental Results
4.1. Data Preparation
The experiments were carried out for detection of rear of cars. The experiments were done using 1,500 positive and 3,500 negative samples. The positive samples consisted of instances of rear of cars cropped from a video taken from a camera mounted at the front of a host car while driving in an urban environment. Each instance was resized to a base size of 24 × 18 pixels. The negative samples consisted of images cropped from random high resolution images that did not contain any instance of rear of car. Each negative sample was also resized to base size of 24 × 18 pixels. 1,000 positives and 3,000 negative samples were used for training the classifiers while the remaining 500 positive and 500 negative samples were used for validation. Figure 5 shows some of the positive and negative samples used for the experiment.
4.2. Performance Comparison between Proposed Weak Classifiers and Single Threshold Weak Classifiers
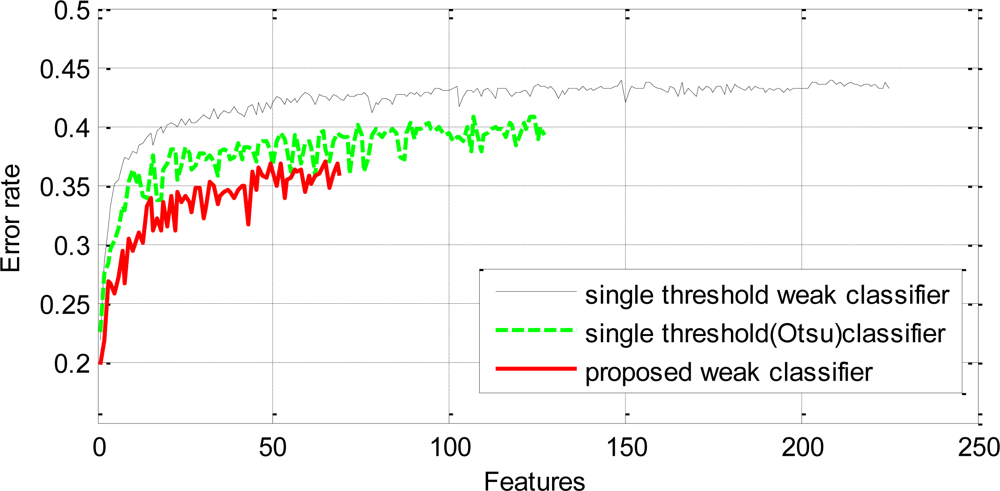
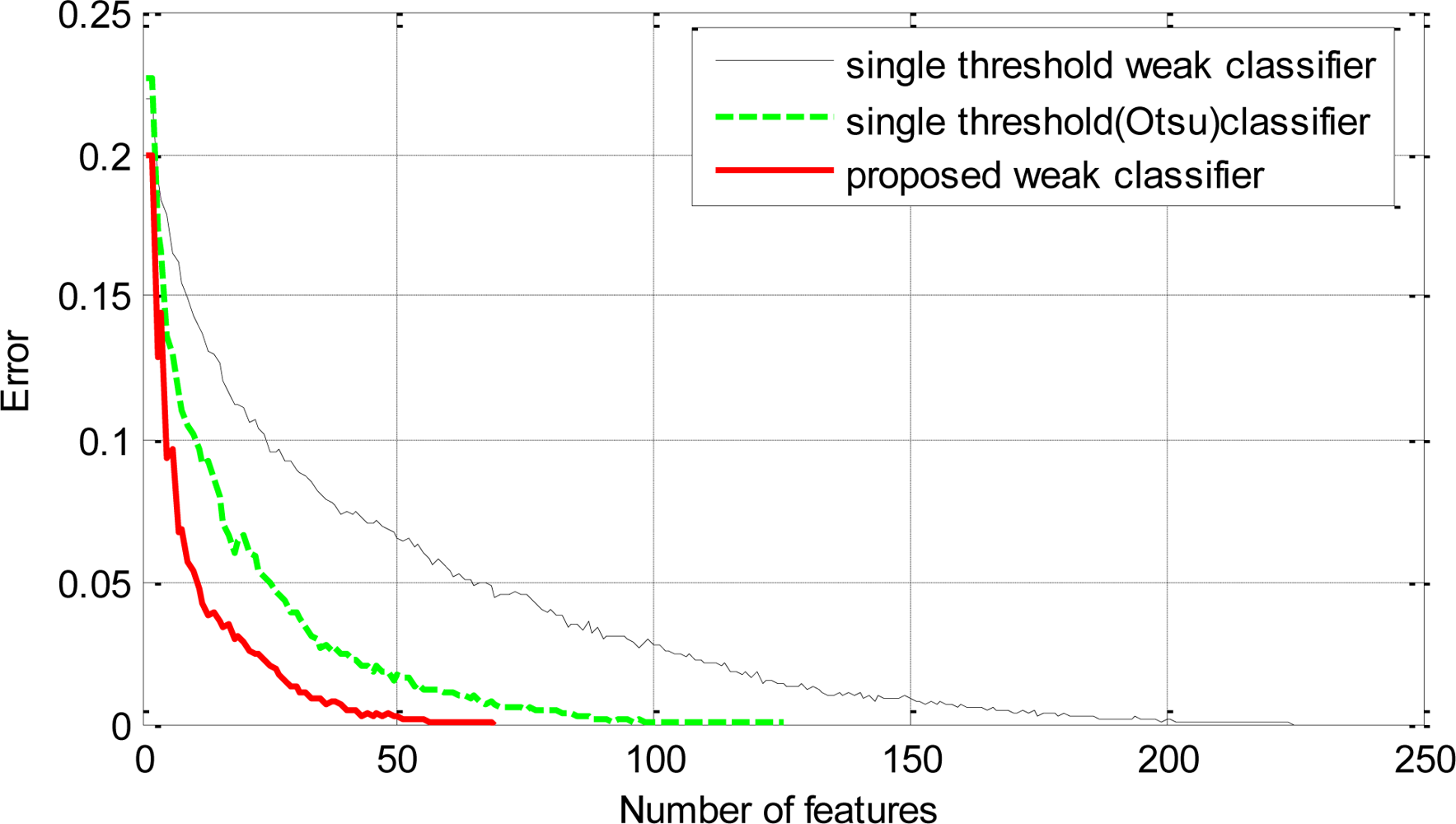
A single stage classifier was trained by AdaBoost on the training data using the proposed weak classifiers to achieve 100% hit rate on the positive samples and zero false positive on the negative samples. The final strong classifier achieved the required performance on the training data with a total of 69 proposed weak classifiers. The first weak classifier selected by AdaBoost yielded an error rate of 0.2. The subsequent selected weak classifiers yielded comparatively higher error rates. The worst error rate among the selected classifiers was 0.37 for the 66th classifier. The error rates of subsequent selected classifiers can be seen in Figure 6. Another strong classifier was trained on the same training data using the conventional single threshold based weak classifiers. These classifiers employed the average of means as the threshold. The final strong classifier required 225 weak classifiers to achieve similar performance on the training data. The error rate of the first selected weak classifier was 0.21 but it increased rapidly for the subsequent classifiers and the worst was 0.44 for the 208th classifier. A third strong classifier was trained on the same training data using single threshold based weak classifiers which employed Otsu’s method [17] for optimal threshold selection. The final classifier consisted of 125 weak classifiers. The error rate of the first weak classifier was 0.22 and the highest error rate was 0.41 for the 124th classifier. Figure 6 shows that the error rates of the proposed weak classifiers are consistently lower than the single threshold based counterparts.
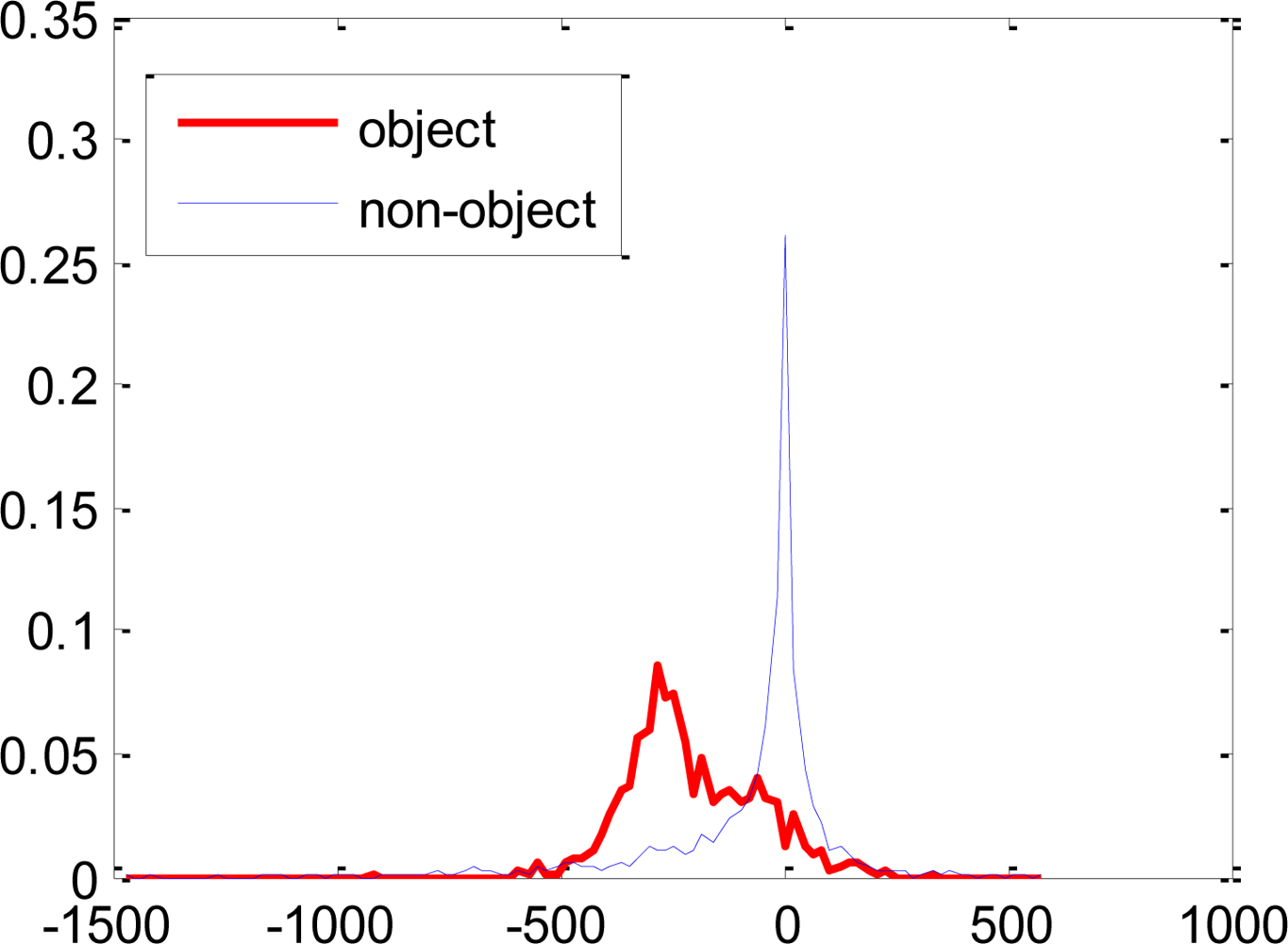
Most of the features selected using the proposed weak classifiers have overlapping distributions of the object and non-object classes. Though these features have lower error rates and are boostable under the proposed hypothesis, they would have been rendered useless for boosting under the single threshold hypothesis. Some of the feature distributions are shown in Figure 7.
The selection of efficient classifiers at each round of boosting helps the learning algorithm to converge faster (in terms of the number of weak classifiers) on the training data as can be seen in Figure 8. Similar performance (in terms of hit rate and false positive rate) on the training data can be achieved with a significant reduction in the total number of weak classifiers by using the proposed weak classifiers over the conventional single threshold weak classifiers.
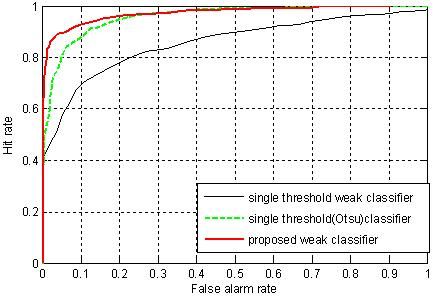
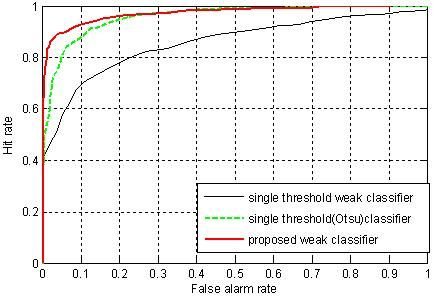
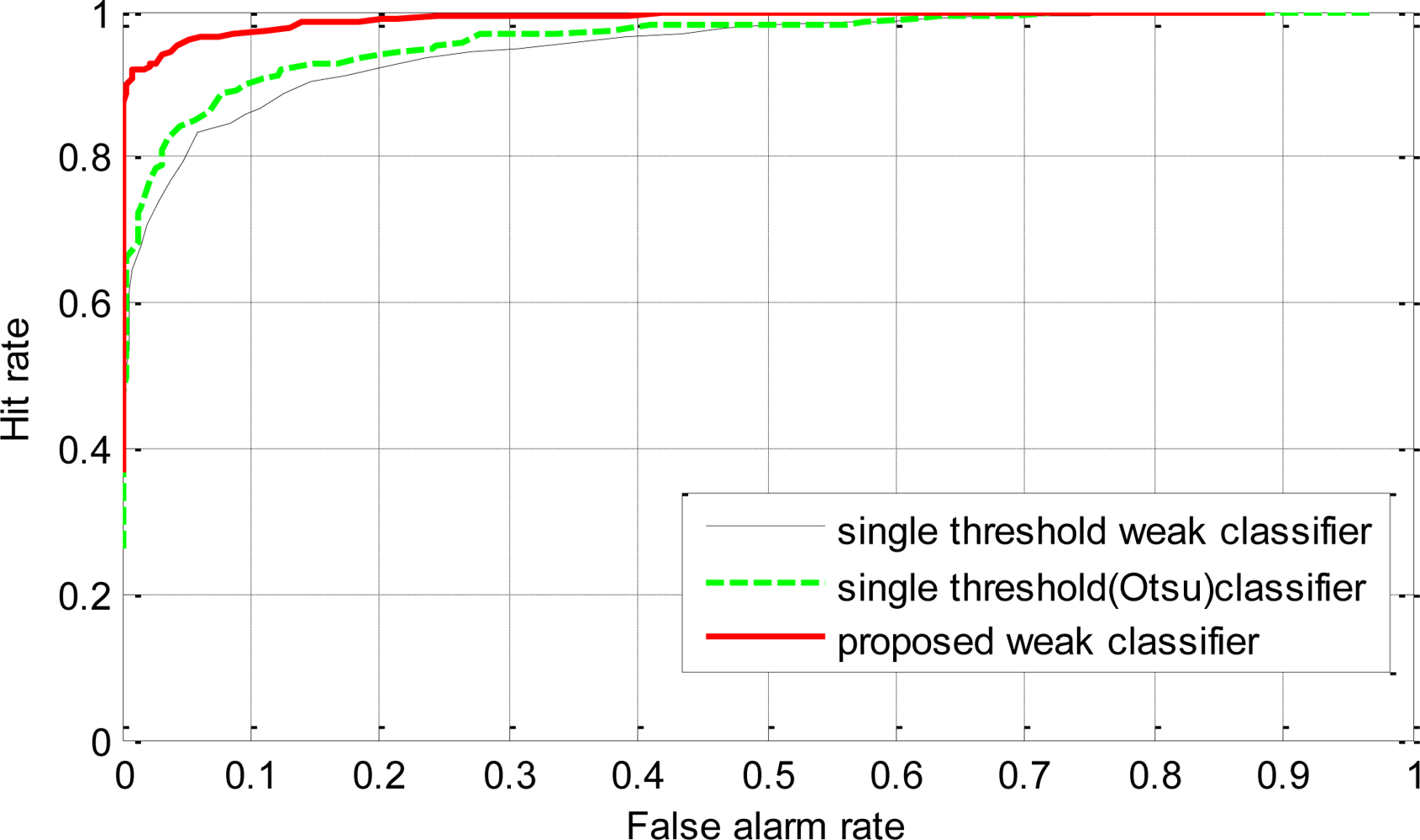
To investigate the generalization performance of the proposed weak classifiers, the strong classifiers were tested on a validation dataset. The validation data set consisted of 500 positive and 500 negative sample images that were not used for training. ROC curves were generated using the validation dataset. The points in the ROC curves were obtained by evaluating each of the strong classifiers against the validation dataset by sliding the stage threshold from −10 to +10 at step of 0.25. The thresholds for the stage were chosen because varying the thresholds in this range proved to be sufficient to generate the whole range in the ROC curves. The plot of the hit rate versus the false alarm rate for all the methods is given in Figure 9. From the ROC curves in Figure 9, we can see that the classifier trained using the proposed weak classifiers perform consistently better than the classifier trained using single threshold weak classifiers. The detection rate of the classifier based on the proposed weak classifiers is always higher than the classifier based on single threshold weak classifiers. And for a given detection rate, the classifier using the proposed weak classifier always has less false alarm rate than the classifiers using single threshold weak classifiers. The higher performance of the proposed method reflects the benefit of the usage of discriminant function based weak classifiers, which are more effective at discriminating car and non-car examples.
4.3. Performance Comparison on Relatively Difficult Samples
In this experiment, the classifiers were trained on relatively difficult samples than those of Section 4.2. The positive samples contained 500 positive images from the original training set. The negative samples contained 2,000 negative images. The negative samples were the false positives generated when a 10 stage cascade was evaluated on random high resolution images. The 10 stage cascade was trained on the original training set using the single threshold weak classifiers. In this sense, the negative samples are relatively difficult for the single threshold weak classifiers to discriminate. Three different classifiers were trained using the three types of weak classifiers on this data to achieve 100% hit rate and zero false positives. The classifier using the proposed weak classifiers required only 36 features whereas the classifier using single threshold weak classifier employing average of means required 236 features and the classifier employing Otsu’s thresholding method required 90 features to achieve same performance on the training data. This shows that the proposed weak classifiers are equally efficient in discriminating difficult samples than the single threshold counterparts. The generalization performance of the trained classifiers was tested on the validation set as in Section 4.2. The ROC curves in Figure 10, generated against the validation dataset show significant performance improvement of the classifier trained using the proposed weak classifiers over the classifier using single threshold weak classifiers.
4.4. Comparison of the Speed of the Object Detector
The speed of a cascaded object detector is directly proportional to the number of features evaluated per scanned sub-window in the image. To compare the speed of the detector, we trained three 15 stage cascade using the single threshold classifiers and the proposed weak classifiers on the UIUC Image database for car detection. The cascades were evaluated on the UIUC car test image set at different scales. For the classifier with single threshold employing average of means, an average of 14.5 features out of the total 248 features and for the one employing Otsu’s optimal threshold an average of 13 features out of the total of 230 were evaluated per sub-window, whereas for the proposed classifiers only an average of 8 features out of the total 131 features were evaluated per sub-window. Table 1 shows the total number of sub-windows scanned and the total features evaluated for seven images randomly sampled from the UIUC car test images at different scales. The feature value calculation time for the proposed classifier is the same as that for the single threshold Haar-like features. But from Equation (3) we see that the proposed weak classifier requires additional multiplication and addition operation to make the class decision. This makes them relatively more expensive to compute than the single threshold classifiers. The experiments conducted show that the proposed weak classifier requires around 1.6 times more computation time than the single threshold classifier to make a class decision. However as seen from Table 1, the single threshold classifiers need to evaluate on average around 1.6 times more features per sub-window than the proposed weak classifiers. This makes the speed of the proposed detector comparable to that of the conventional single threshold based detector.
5. Conclusions
In this paper, we have proposed a new set of weak classifiers for efficient boosting. The proposed weak classifiers do not require an explicit decision threshold to be calculated as is required for the single threshold weak classifiers and present a general solution for the optimal threshold finding problem. The proposed quadratic discriminant analysis based solution significantly improves the ability of the weak classifiers to discriminate object and non-object classes. The experimental results demonstrate that the proposed weak classifiers have far less classification error rate than the single threshold weak classifiers. An object detector trained using the proposed weak classifiers using AdaBoost facilitated efficient boosting and the final classifier yielded higher classification performance with less number of weak classifiers than a detector built with traditional single threshold weak classifiers.
References
- Papageorgiou, CP; Oren, M; Poggio, T. A general framework for object detection. Proceedings of the International Conference on Computer Vision, Bombay, India, 4–7 January 1998; pp. 555–562.
- Viola, P; Jones, M. Rapid object detection using a boosted cascade of simple features. Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001.
- Freund, Y; Schapire, R. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci 1997, 55, 119–139. [Google Scholar]
- Schapire, RE; Singer, Y. Improved boosting algorithms using confidence-rated predictions. Mach. Learn 1999, 37, 297–336. [Google Scholar]
- Liu, C; Shum, HY. Kullback-leibler boosting. Proceedings of Computer Vision and Pattern Recognition, Madison, WI, USA, 16–22 June 2003; pp. 587–594.
- Li, SZ; Zhang, ZQ. Floatboost learning and statistical face detection. IEEE Trans. Pattern Anal. Mach. Intell 2004, 26, 1112–1123. [Google Scholar]
- Wu, B; Ai, H; Huang, C; Lao, S. Fast rotation invariant multi-view face detection based on real adaboost. Proceedings of the 6th International Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 17–19 May 2004; pp. 79–84.
- Ong, EJ; Bowden, R. A boosted classifier tree for hand shape detection. Proceedings of IEEE Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 17–19 May 2004; pp. 889–894.
- Lienhart, R; Maydt, J. An extended set of Haar-like features for rapid object detection. Proc. IEEE Int. Conf. Image Process 2003, 1, 900–903. [Google Scholar]
- Wu, B; Ai, H; Huang, C; Lao, S. Fast rotation invariant multi-view face detection based on real AdaBoost. Proceedings of IEEE Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 17–19 May 2004; pp. 79–84.
- Kolsch, M; Turk, M. Robust hand detection. Proceedings of IEEE Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 17–19 May 2004; pp. 614–619.
- Mita, T; Kaneko, T; Stenger, B; Hori, H. Discriminative feature co-occurrence selection for object detection. IEEE Trans. Pattern Anal. Mach. Intell 2008, 30, 1257–1269. [Google Scholar]
- Zhang, D; Li, SZ; Perez, DG. Real-time face detection using boosting in hierarchical feature Spaces. Proceedings of International Conference on Pattern Recognition, Cambridge, UK, August 2004; pp. 411–414.
- Pavani, SK; Delgado-Gomez, D; Frangi, AF. Haar-like features with optimally weighted rectangles for rapid object detection. Pattern Recog 2010, 43, 160–172. [Google Scholar]
- Hu, B; Wang, S; Ding, X. Multi features combination for pedestrian detection. J. Multimed 2010, 5, 79–84. [Google Scholar]
- Duda, R; Hart, P; Stork, D. Pattern Classification; Wiley-Interscience: Malden, MA, USA, 2000. [Google Scholar]
- Otsu, NA. Threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern 1972, 9, 62–66. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S.No. | Total sub-windows scanned | Proposed Method | Single Threshold Method | ||||
|---|---|---|---|---|---|---|---|
| Average of Means | Otsu’s Threshold | ||||||
| Total features evaluated | Average feature/sub-window | Total features evaluated | Average feature/sub-window | Total features evaluated | Average feature/sub-window | ||
| 1 | 63,313 | 521,545 | 8.23 | 868,037 | 13.7 | 790,047 | 12.4 |
| 2 | 63,618 | 541,644 | 8.51 | 929,962 | 14.61 | 859,328 | 13.5 |
| 3 | 85,106 | 692,548 | 8.13 | 1,173,507 | 14.9 | 1,032,627 | 12.13 |
| 4 | 87,378 | 763,826 | 8.74 | 1,302,362 | 14.9 | 1,122,984 | 12.85 |
| 5 | 40,810 | 366,326 | 8.97 | 653,903 | 16.3 | 620,030 | 15.19 |
| 6 | 82,354 | 688,846 | 8.36 | 1,078,020 | 13.1 | 1,052,336 | 12.77 |
| 7 | 58,590 | 492,783 | 8.41 | 842,548 | 14.38 | 753,639 | 12.86 |
© 2011 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Adhikari, S.P.; Yoo, H.-J.; Kim, H. Boosting-Based On-Road Obstacle Sensing Using Discriminative Weak Classifiers. Sensors 2011, 11, 4372-4384. https://doi.org/10.3390/s110404372
Adhikari SP, Yoo H-J, Kim H. Boosting-Based On-Road Obstacle Sensing Using Discriminative Weak Classifiers. Sensors. 2011; 11(4):4372-4384. https://doi.org/10.3390/s110404372
Chicago/Turabian StyleAdhikari, Shyam Prasad, Hyeon-Joong Yoo, and Hyongsuk Kim. 2011. "Boosting-Based On-Road Obstacle Sensing Using Discriminative Weak Classifiers" Sensors 11, no. 4: 4372-4384. https://doi.org/10.3390/s110404372