Expanding Window Compressed Sensing for Non-Uniform Compressible Signals

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
: Many practical compressible signals like image signals or the networked data in wireless sensor networks have non-uniform support distribution in their sparse representation domain. Utilizing this prior information, a novel compressed sensing (CS) scheme with unequal protection capability is proposed in this paper by introducing a windowing strategy called expanding window compressed sensing (EW-CS). According to the importance of different parts of the signal, the signal is divided into several nested subsets, i.e., the expanding windows. Each window generates its own measurements using a random sensing matrix. The more significant elements are contained by more windows, so they are captured by more measurements. This design makes the EW-CS scheme have more convenient implementation and better overall recovery quality for non-uniform compressible signals than ordinary CS schemes. These advantages are theoretically analyzed and experimentally confirmed. Moreover, the EW-CS scheme is applied to the compressed acquisition of image signals and networked data where it also has superior performance than ordinary CS and the existing unequal protection CS schemes.1. Introduction
Compressed sensing (CS) [1,2] is an emerging technology that promises low-complexity signal acquisition which is especially important for energy-constrained devices or large data sets, e.g., in high-resolution image signal processing, MRI imaging, etc. In the CS methodology, the signal which is sparse or compressible on a certain orthonormal basis can be successfully recovered from a highly incomplete set of samples, called measurements. Moreover, the measurements can be obtained by multiplying the signal by a randomly generated sensing matrix that is incoherent with most of the orthonormal basis. Thus, CS greatly improves the efficiency and decreases the complexity of signal compression.
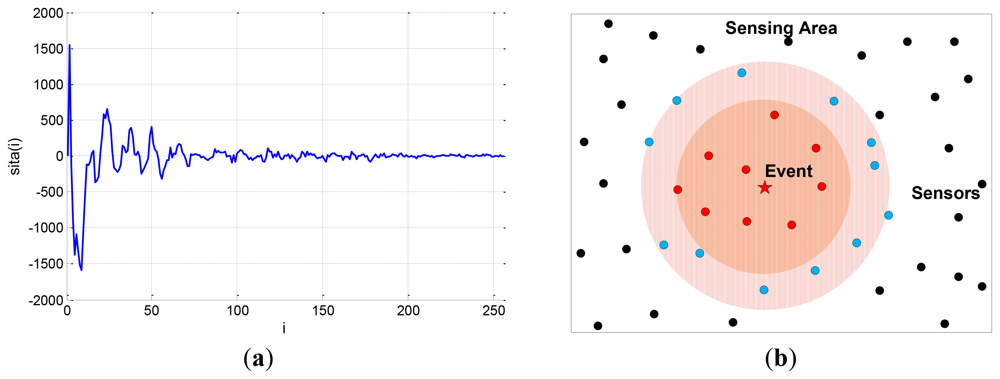
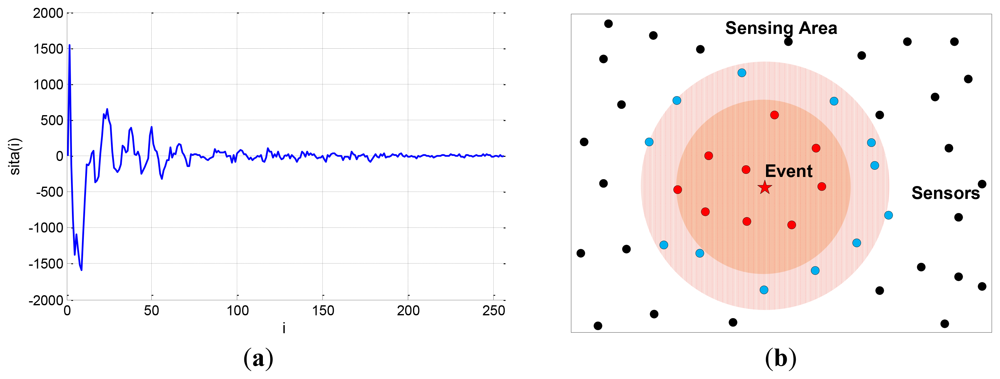
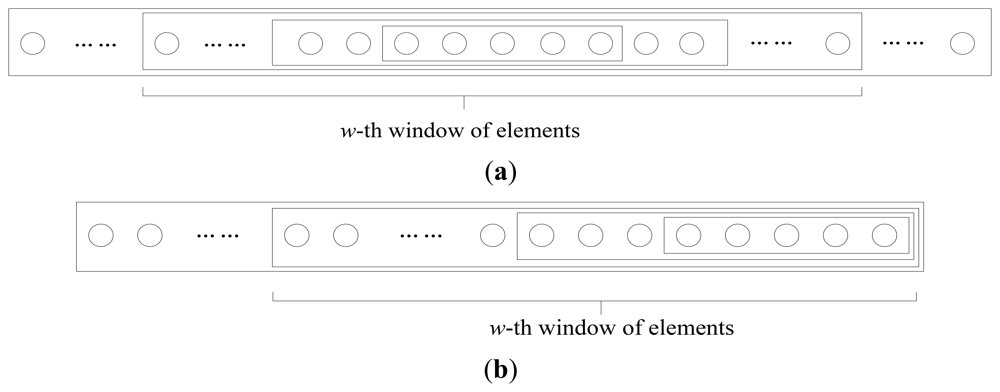
The compressible signal can be indicated by the index of the sparse non-zero components and the value of the non-zero components, where the index of the sparse non-zero components is called sparse support. The ordinary CS algorithms are designed without any constraint on the distribution of the support of the sparse signal. Actually, many natural signals do have special support structures. For example, the image signal is compressible in the discrete cosine transform (DCT) basis or discrete wavelet transform (DWT) basis. The transform coefficients constitute a non-uniform compressible signal where the significant coefficients mostly appear at lower frequency, as shown in Figure 1(a). Another example is the CS of networked data [3] in wireless sensor networks, also called compressive wireless sensing (CWS) [4]. A large number of sensors are distributed in the sensing area, as shown in Figure 1(b), whose data are regarded as elements of a signal, called networked data. When an event occurs, the sensors around it will collect more significant data, so this networked data is also a kind of non-uniform compressible signal whose significant elements are placed within a certain part of the signal.
Considering these largely existing non-uniform compressible signals, if we can utilize the prior-knowledge of the support distribution to provide unequal protection for different parts of the signal, we can instinctively achieve better performance. In this paper, such a CS algorithm is proposed to improve the sensing and recovery efficiency for the non-uniform compressible signals, called the expanding window compressed sensing (EW-CS). The windowing method is inspired by the expanding window fountain codes [5,6], where the concept of expanding window is used in the binary field. We explore how to utilize the support window in a real field. With the prior knowledge that some parts of the signal are more important than others, the signal is divided into several nested subsets called windows. The more important the part is, and there will be more windows containing this part. Each window generates their own measurements with CS's random sensing matrix, so the more important part's elements are sampled in more measurements to guarantee higher protection level. This design makes the EW-CS scheme have more convenient implementation.
The proposed EW-CS scheme treats the different parts of the compressible signal discriminately to pursue the improved overall performance. The more attention on the more important parts is at the expense of the less important parts. Nevertheless, it is worthwhile to do this, because most of the energy or the useful information is contained in the more important parts. The overall performance improvement also has its prerequisite that is the prior knowledge of the rough non-uniform distribution of the significant elements. This prior information is not difficult to get in most cases. For image signals, the significant transform coefficients mostly appear at lower frequency. For networked data, the significant data is surrounding the emerging event. The above statements about the EW-CS are presented and proved from theoretical and numerical perspectives in our paper. Moreover, the EW-CS is applied to image signals and networked data, and shown to provide better performance than the ordinary CS and the existing unequal protection CS schemes.
The rest of this paper is organized as follows: in Section 2, the key issues of CS are briefly reviewed, and the related existing CS algorithms considering non-uniform compressible signals are presented and compared with our EW-CS algorithm. The details of the EW-CS scheme are introduced in Section 3. Section 4 is devoted to analyze the recovery error upper bounds of the proposed EW-CS to compare with the ordinary CS. In Section 5, the variation of basic EW-CS algorithm is discussed. The experimental results are shown and analyzed in Section 6. Section 7 concludes this paper and gives some directions for future work.
2. Related Work
2.1. Basics of Compressed Sensing
A signal X ∈ ℝN is said to be sparse, if the transform coefficient vector Θ = { θi, i = 1,2, …, N}, of X in an orthogonal basis ΨN×N are mostly zero. The sparse support of Θ (or X) is defined as S = {i: θi ≠ 0, i = 1,2,…, N}, and the length of S is the sparsity K = |S|, K ≪ N, so signal X is called as K-sparse signal. We consider a linear sparse case that K = αN, 0 < α ≪ 1 is a constant. If the most coefficients are not exactly zero but with small magnitude, signal X is called compressible signal. The elements with larger absolute value are regarded as significant. CS theory [1,2] states that M measurements of compressible signal X is enough for exact recovery where M < N. The sensing matrix ФM×N should be incoherent with the representation basis ΨN×N to guarantee the successful recovery. Fortunately, random matrices are largely incoherent with any fixed basis ΨN×N. Thus, the measurements usually are called random projections when a random matrix is used in CS encoding. The CS encoding is quite simple that:
Although (l0) can give the unique solution with only M > 2K measurements, it is a NP hard problem. A relaxation of (l0) is the linear programming problem, also known as basis pursuit [7]:
The restricted isometriy property (RIP) [8] is a sufficient condition for guarantee the equivalence of the (l0) and (l1) solutions with overwhelming probability. Let δk be a smallest positive number such that:
2.2. Compressed Sensing with Non-Uniform Compressible Signals
The investigation of utilizing compressible signals' statistic characteristics has already attracted a lot of interest. The most influential one is the Bayesian compressive sensing (BCS) [13] which recovers the signal by estimating its posterior density function. With different signal models, there are several BCS schemes. The sparse Bayesian learning algorithm in [13] invokes a hierarchical prior to simplify the Laplace prior of compressible signal. The authors in [14] also use Laplace priors. The BCS via belief propagation is proposed in [15] by assuming that the compressible signal obeys the mixture Gaussian model. In [16] the authors combine the belief propagation and Bayesian learning algorithms together to provide a more universal and low-complexity BCS scheme.
However, these compressible signal probability density functions are still based on the assumption that the significant elements are uniformly distributed. Considering the image signals with non-uniform distribution, the wavelet tree model is introduced in BCS in [17]. Besides BCS, the prior information of compressible signal is also used in other ways. In [18], a new weighted rule for the iterative reweighted l1-norm minimization algorithm is integrated by explore the hidden Markov tree model of the wavelet coefficients. In [19], a weighted sampling scheme is proposed according to the statistics of image signals, where the weight matrix is determined by parameters of the direct-current and alternating-current components' distributions. The authors of [20] and [21] design unequal protection of the wavelet sub-bands in different scales by sampling with different random Gaussian matrices, and their difference is the measurement allocation strategy.
Compared with the unequal protection methods like the hidden Markov tree model in [18]. which uses an extra training process to estimate the exact statistics feature of the signal, the proposed EW-CS scheme firstly only need a coarse sparse support distribution trend as the prior knowledge, e.g., the well-known fact that the significant DCT or DWT coefficients appear at the low frequency. This makes the EW-CS scheme be widely used and easily implemented. From this point, the EW-CS is similar to the schemes presented in [20] and [21]. Nevertheless, the unequal protection mechanism of our scheme is quite different from theirs. They treat each sub-band (or parts with different importance) separately, but we provide nested windows to exploit the combined effect of different parts. With this design, the protection of the significant elements is further enhanced such that the overall performance of the EW-CS outperforms that of [21].
3. Proposed EW-CS Scheme
The proposed EW-CS scheme is detailed in this section. First, the non-uniform compressible signal is formularized. Then, the general EW-CS encoding and decoding algorithms are presented. Finally, we simplify the EW-CS to a two-window case which is quite important for applications and analysis.
3.1. Non-Uniform Compressible Signal
In the proposed EW-CS scheme, for clearer explanation, we assume that the signal X = {xi | i = 1,2,…N}T is compressible in the canonical basis, i.e., the orthogonal basis ΨN×N = I. The scheme can be directly applied to other basis. A more tractable definition of the compressible signal X is using the power law that the k-th largest entry of the signal obeys |x(k)| ≤ Cp·k−1/p, where Cp > 0 and 0 <p <1. Cp represents the energy of the signal which is a constant depending on p, and p is the speed of decay. The sparsity is defined as K when there are K significant elements containing the most energy of the compressible signal, i.e., the first K largest elements |x(k)|, k = 1,…K.
The non-uniform compressible signal means that the distribution of the significant elements in the sparse support is non-uniform, that is, the support distribution has some structured characteristics. We use importance classes to describe this distribution. From the sparsity perspective, the importance of a class is corresponding to how many significant elements it contains. The compressible signal X is divided into W non-overlapped importance classes. The size of the w-th class is defined by sw so that w = 1, 2, …, W, 0 ≤ sw ≤ N. We further assume that the importance of a class decreases with the class's index, i.e., the w-th class is more important than the (w + 1)-th class. The division can be described using a generating polynomial (GP) , where the parameter Πk = (sk/N) ϵ [0,1] is the ratio of the elements in the importance class w to all the N elements. The sparsity distribution is given as where 0 ≤ Λw ≤ 1 is the proportional factor representing the number of significant elements placed in the w-th class.
3.2. General EW-CS
3.2.1. Encoding
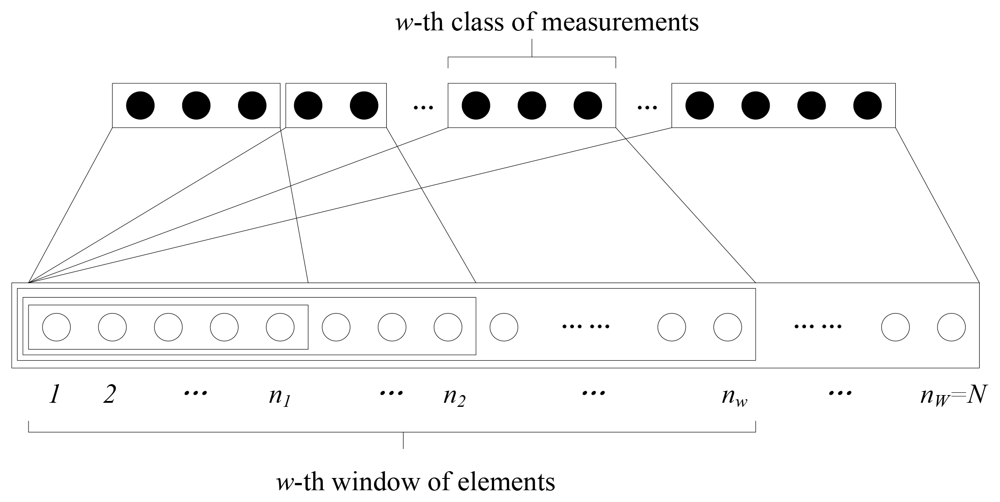
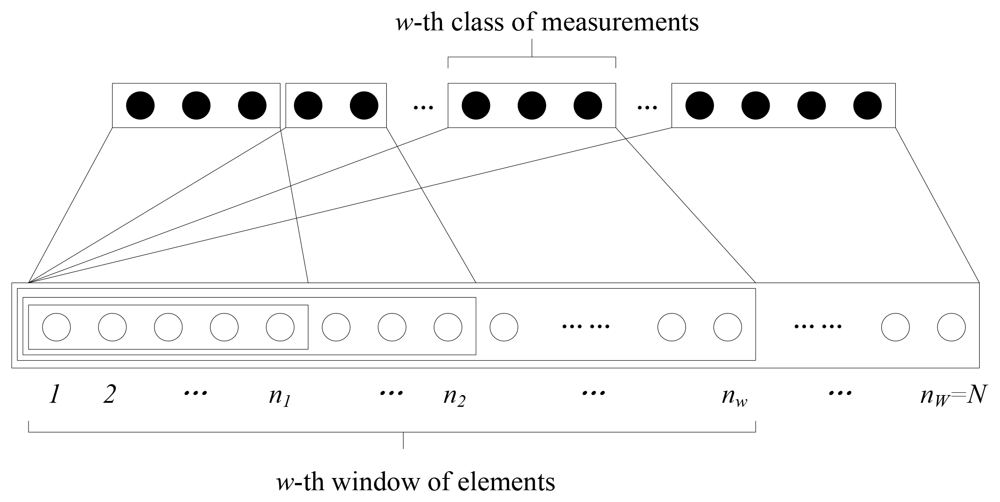
The importance class determines a sequence of strictly increasing subsets of the signal's elements, which we call windows. The w-th window consists of all the first w classes, so the size of the window is, w = 1, 2, …, W; thus, the last window contains all the signal's elements with nw = N. The structure of the EW-CS is shown in Figure 2.
In the classical CS algorithm, one method to generate the random sensing matrix is by picking the entries from Gaussian distribution N (0,1). Given the overall sensing rate R, the number of the random projections is M = RN. The measurements allocated for each window can also be given by a measuring polynomial (MP) where 0 ≤ Ωw ≤ 1 denotes the ratio of measurements assigned for the w-th window to all the measurements. It means that we generate mw = ΩwM random projections (the w-th class of measurements as shown in Figure 2) for the nw elements of the w-th window, and . So the sensing matrix Фw is a mw × nw random Gaussian matrix. The measurement vector of w-th window is calculated as where X(w) is the vector of the elements in w-th window, and X(w) = X.
It can be noticed from Figure 2 that the w-th importance class belongs to the w-th window and all its subsequent windows, so the elements of w-th importance class are sampled by the w-th and all the subsequent classes of measurements. For example, the first importance class (also the first window) is sampled in all M measurements, and the last importance class is sampled only in ΩwM measurements. Therefore, the elements in importance class with smaller index corresponding to more measurements obtain more protection.
Although the classes of measurements are described to be generated sequentially in Figure 2, we can use a random selection strategy to introduce diversity. Each measurement is randomly assigned to a window according to a designed window selection distribution where Γw is the probability that the w-th window is chosen. Encoding with the window selection distribution may bring uncertain sensing rate, but it can be roughly regarded that mw = ΓwM. As in a CS system each measurement is actually the inner product of the corresponding row of the sensing matrix and the signal vector, it can be calculated separately. For instance, if one measurement k = 1, 2, …, mw, j = 1, 2, …, M is the k-th measurement assigned to the w-th window, we get where is a random Gaussian vector with length nk and can be regarded as the k-th row of the sensing matrix . This random window selection design may bring the robustness to the degradation caused by burst loss of measurements.
3.2.2. Decoding
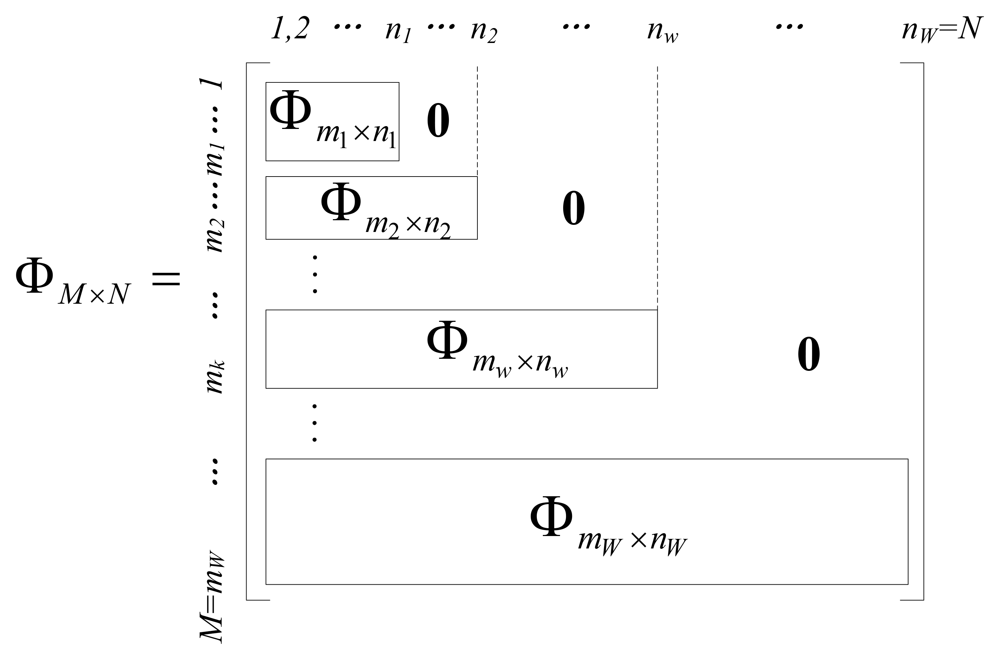
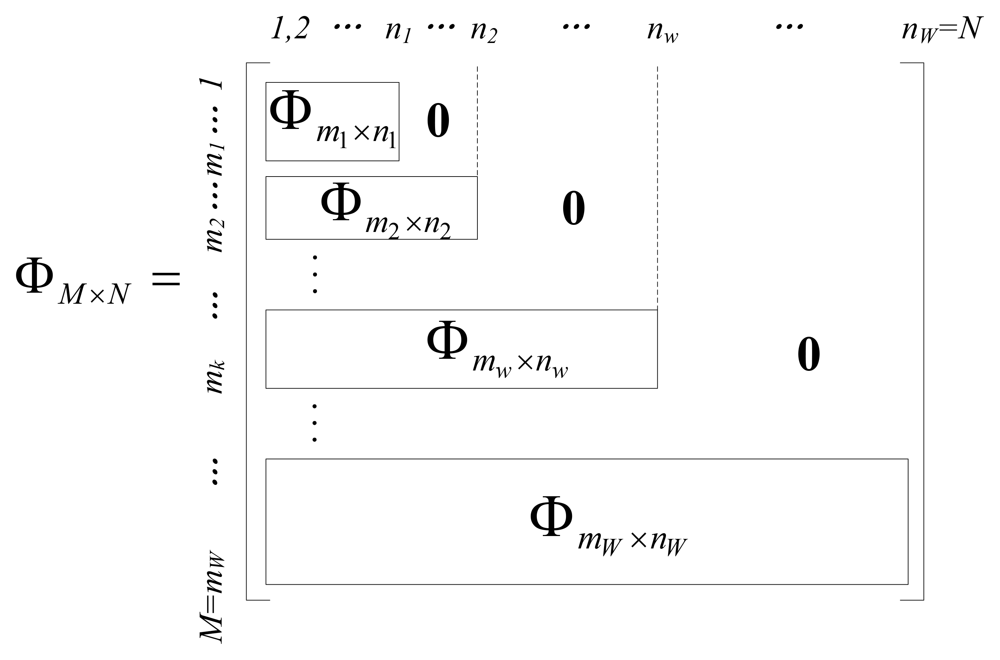
The encoding strategy of the EW-CS is presented class by class. This is sometimes necessary for constrained encoder or distributed coding scenarios, but it is usually more efficient to use joint decoder, which combines the measurements together, and recovers the original X simultaneously through CS reconstruction method. If we use the sequential generation method, the joint sensing matrix ФM×N can be written as a combination of all the window sensing matrix Фw, as shown in Figure 3. The blank blocks are all zeros. Comparing with the ordinary CS sensing matrix, the constructed sensing matrix in Figure 3 is sparser so that the encoding computational complexity of our scheme is lower than that of ordinary CS. If we use the random window selection method, the sensing matrix is written as .
Thus, the joint decoding can be implemented using this joint sensing matrix. At the decoder side, all the received random projections compose a measurement vector which is generated by the sensing matrix ФM×N, i.e., Y = ФM×NX. Thus, the signal X can be recovered using ordinary CS recovery algorithms mentioned in Section 2.
3.3. EW-CS with Two Windows
In the previous subsection, we described the proposed EW-CS scheme in general format. Nevertheless, the most common situation is that the significant elements of a natural compressible signal are concentrated at a certain part of the signal. Therefore, two importance classes are enough for the usual non-uniform compressible signal. The first importance class consists of more large elements than the second importance class. The first importance class is also the first window, and the entire signal is the second window. The two-window EW-CS has wider application prospects; thus, this special case of the EW-CS is discussed in detail below.
In the two-window EW-CS, the GP is Π(x) = Π1x + (1 − Π1)x2 which is determined by only one coefficient Π1 ∈ [0,1]. Similarly, the sparsity distribution can be written as Λ(x) = Λ1x + (1 − Λ1) x2. If the first class really has more significant elements, 0.5 < Λ1 ≤ 1; otherwise 0 < Λ1 ≤ 0.5. For clarification, we adopt the sequential generation as shown in Figure 2, so the MP is Ω(x) = Ω1x + (1−Ω1)x2. By increasing Ω1, we progressively increase the protection of the first importance class. The extreme cases of Π1 = M1 = 0 and Π1 = M1 = 0 are the ordinary CS problems.
Based on above definitions, the joint sensing matrix is given as:
It must be noted that X1 and X2 denote the signal elements of the two importance classes not the two windows, which are defined as different from X(1) and X(2). The joint coding format is necessary for facilitating the performance analysis of the EW-CS and contrast with the ordinary CS in the next section.
4. Recovery Error Upper Bounds Analysis of the EW-CS
In this section, the reconstruction error upper bounds of the EW-CS is analyzed and contrasted with the ordinary CS scheme (using CS for short). The simple two-window EW-CS is firstly discussed, and then the results are further extended to the general EW-CS.
4.1. EW-CS with Two Windows
The l2-norm recovery error defined as ‖X − X̂‖l2 is adopted to judge the recovery performance. The performance analysis is presented by contrasting between the CS and the EW-CS. According to the joint coding format of the EW-CS in Subsection 3.3, the CS problem is also formulated by correspondingly divided the signal vector X, the measurement vector Y and the sensing matrix Ф into different parts. It is given as:
The most direct relationship between the CS and the EW-CS can be obtained by replacing the sub-matrix Ф1,2 with all zero matrix of the same size, and then the CS problem becomes the EW-CS as shown in Equation (8). In CS, the measurement vectors of two windows are calculated as:
It can be found that the only difference between the CS and the EW-CS is the different generation of the first class of measurements, i.e., Y1CS and Y1EW. However, the joint recovery algorithms for the CS and the EW-CS use both of the two classes of measurements, so we need a joint coding representation to reveal the difference shown in Equations (10) and (11). Firstly, the compressible signal X can be written as . The N dimensional vector is identical to the vector X for the first n1 elements, and the remaining (n2 − n1) elements of are set to zero. Similarly, the vector is identical to X for the last (n2 − n1) elements, and the remaining elements of are set to zero. Then, the encoding of CS is given as:
For analyzing the discriminational protection of different importance classes, we should consider X1 and X2 separately. This is equal to considering and . If the joint recovery is regarded for recovering only, the Equations (12) and (13) are further rewritten as:
The first terms on the right hand of Equations (14) and (15) are the same according to Equations (8) and (9), so the difference between the CS and the EW-CS is the noise on the 's measurements. It is obvious that the energy of the noise in the CS scheme is larger than that in the EW-CS scheme. Intuitively, the recovery quality of in the EW-CS is better than in the CS.
This result can also be proved with the aid of mathematical formulae. From the Theorem 2 in [22], the l2-norm recovery error from inaccurate measurements have the upper bound as:
For the , all the measurements contribute to the recovery, so we can assume that the measurements are enough. Based on the result in Equation (16), the error upper bounds for the CS and the EW-CS respectively are given as:
Note that the second terms on the right side of Equations (17) and (18) are the same for the same . The only difference of the recovery performance of between the CS and the EW-CS is on the noise error. According to Equations (14) and (15), the noise energy of the CS and the EW-CS has the relation as below:
Comparing with Equations (14) and (15), the information term and the noise term are exchanged, so in this case it is found that the noise for the CS and the EW-CS is the same, while the measurements of are different. It can be predicted from Equation (16) that the recovery error upper bounds for of the CS and the EW-CS vary on the approximation error term. However, the approximation error term in Equation (16) is based on the assumption that the measurements are enough for best recovery. The measurements for constitute only (1 − Ω1) percentage of all the measurements, so they may not guarantee the best recovery. Oher looser bounds for approximation error are introduced here for analyzing . Of cause, the looser bounds can also be substituted into Equations (17) and (18) for analyzing , and results are also the same as we've already given.
For compressible signals obeying the power law, there is an earlier result in [1] and [2] which states that the estimation from accurate measurements with minimal l1-norm obeys the following result with overwhelming probability:
This is a looser one than Equation (16), for there is a probability of failure although it is quite trivial. If we assume that the component signal is still a compressible signal obeying the power law, the recovery error upper bounds of for the CS and the EW-CS then can be given as:
Now, the comparison between the CS and the EW-CS for the entire signal X is discussed. The square error of signal X is given as:
Thus, the overall recovery error upper bounds for X using the CS and the EW-CS can be derived by substituting Equations (17), (18), (24) and (25) into Equation (26) such that:
We assume that . From the analysis above, we've known that the first term in right hand side of Equation (28) is smaller than Equation (27) but the second term is larger, so the comparison between Equation (27) and Equation (28) is undetermined. With the same settings, the difference between the upper bounds of the CS and the EW-CS is a function depending only on ε1 and M2 which are determined by sparsity distribution and MP, i.e., the parameters Λ1 and Ω1. However, if there are really more significant elements placed in , i.e., 0.5 < Λ1 ≤ 1, the first term will dominate the overall error upper bounds; otherwise, the second term will do so. Thus, the EW-CS is superior to the CS for a non-uniform compressible signal with proper importance classes assignment.
4.2. General EW-CS
Based on the ana1ysis of the two-window EW-CS, the results are easily extended to W ≥ 3 windows case. The encoding of the W-window EW-CS is written as:
Note that the EW-CS's sensing matrix ΦEW is a lower triangular matrix. We only consider one importance class at a time, and assume that it is compressible obeying the power law; thus, the looser bound in Equation (23) is used. So the recovery error upper bound of the elements in this class is:
Comparing with the conventional CS, only for the first importance class vector , the second terms on the right hand sides of Equations (30) and (31) are the same, so the first class is always better protected in the EW-CS than in the CS. For the last importance class vector , the first terms are the same, and the second term of the EW-CS has high probability to be larger than the CS; thus, the last importance class is usually sacrificed. For other importance classes, the two terms on the right hand side are both different from the CS, so it is hard to judge the protection level comparing with the CS. However, it can be instinctively known that the smaller w is, the w-th importance class has better recovery quality. Finally, the overall error upper bound for the EW-CS is given as:
5. Variations of the EW-CS
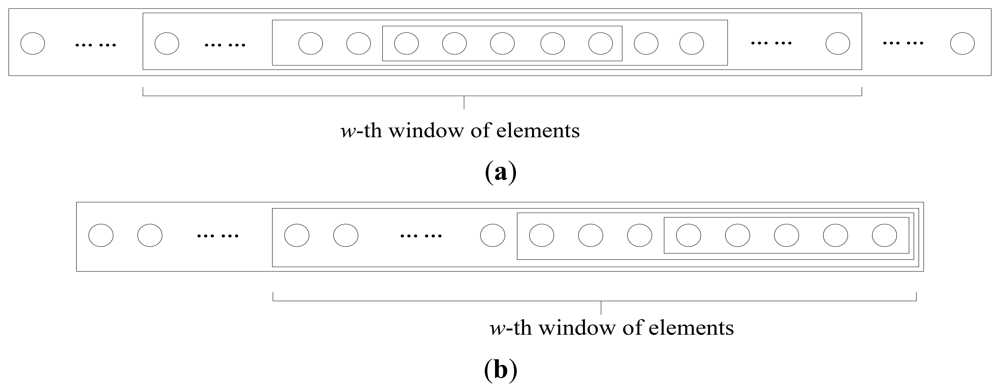
During the introduction of the EW-CS scheme in Section 3, there may be a question that what happens if the importance of classes doesn't decrease with the class index as we assumed. From the analysis in last section, we know that the performance of the EW-CS degraded badly when the more important class doesn't contain more significant elements, i.e., 0.5 < Λ1 ≤ 1 in the two-window case. Thus, the extension of the EW-CS is necessary for this case. The two basic variations are shown in Figure 4 that the window design can changed according to the location of the important class. If the significant elements concentrate in several parts of the signal, the same class of window can also be divided into several parts to match. Nevertheless, the benefit of using the EW-CS in this case will be not worth the complexity it causes; thus, it may be better to use other methods or the CS.
It doesn't mean that the EW-CS can only be used in the simple cases where the significant elements concentrate in the front, in the middle or at the back of the signal. It has an even more complicated variation in a certain case. Recall that we have designed a window selection distribution such that each measurement can select the window it belongs to. Similarly, the signal element can also choose the window that it belongs to. It looks a little abnormal in our usual practice, for the signal element may not know its own importance or even do the selection. However, it can be realized in certain case, the wireless sensor network scenarios.
Let us consider the CWS [4] problem. The N sensors' data is regarded as a compressible signal X = {xi | i = 1, 2, …, N}, where xi is the data of the i-th sensor. Using ordinary CS, each sensor send yij = φjixi to the sink node, and then the sink can collect all the received data to generate one measurement . Repeat this process for several times until the sink get enough measurements to recover the compressible signal X. This mechanism assumes that all the sensors' data are equal importance, but it is a common situation in wireless sensor networks that a warning line is set a priori for the temperature, pressure or gas strength detection systems. In this case, the EW-CS scheme can be used to simplify this collection process. Each sensor can decide its sensed data is important or not according to the warning line, and then choose the window it belongs to. With one warning line, the two-window EW-CS is applied. If the sensor's data is beyond the warning line, it is in the first window and sends its yji for M times. If its data is within the security region, it is in the second window and sends its yji for only m2 < M times. This leads to the better recovery quality for the warning sensor's data, and resaves the transmission energy for the safe sensors.
6. Experimental Results
6.1. Simulation Results for Synthetical Signals
In our simulation, the l2-norm of the recovery error, i.e., ∥ X − X̂ ∥ℓ2, is used to evaluate the performance of the proposed EW-CS algorithm. A compressible signal X ∈ ℝN is generated obeying the power law with the parameters Cp = 10 and p = 1 The length of the signal is N = 512, and the sparsity is set as K = 50. The two-window EW-CS is used to compare with the ordinary CS. For constructing the signal in a non-uniform format, the randomly selected Λ1K elements from the first K K largest elements are placed in the first importance class, and the rest (1−Λ1)K elements are placed in the second importance class. Other (N−K) smaller elements are distributed randomly. The parameters defining the size of the first importance class and its corresponding number of measurements are fixed as Π1 = 0.3 and Ω1 = 0.5.
The overall sensing rate is R, and the total number of measurements is M. The sensing matrix ФEW is constructed by first creating a M × N matrix, i.e., the sensing matrix ФCS, with i.i.d. draws of a Gaussian distribution N(0,1), then the right upper Ω1M × (1−Π1)N sub-matrix is replaced by all zero matrix with the same size. The recovery algorithm we used is the l1 based method which is implemented by using a package for specifying and solving convex programs [23,24].
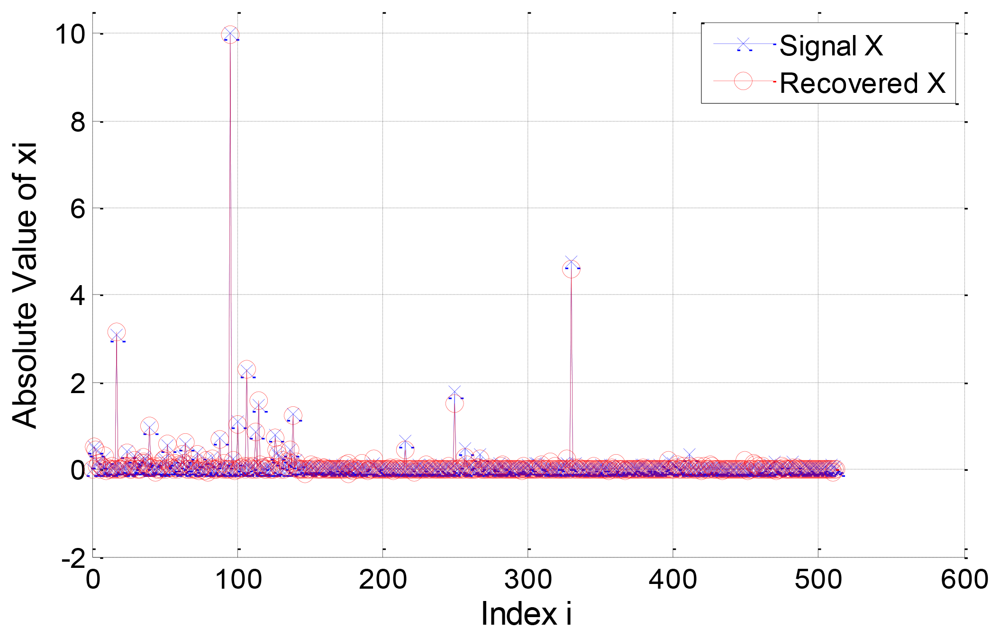
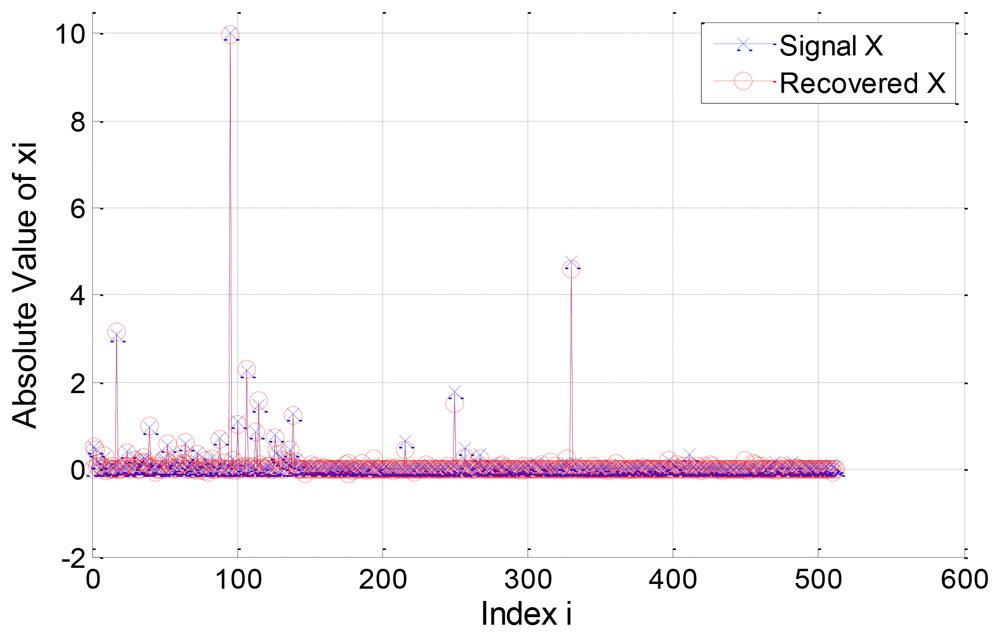
In the first example, we consider a compressible signal with Λ1 = 0.8 and R = 0.4. The original signal and its recovered version are plotted in Figure 5. The l2-norm error for the component signals and are 4.9488 and 11.2609 respectively, and the l2-norm error for the signal X is 1.1808. Note that the significant elements of the signal are almost well recovered and the elements in the first importance class have better recovery quality than that in the second class.
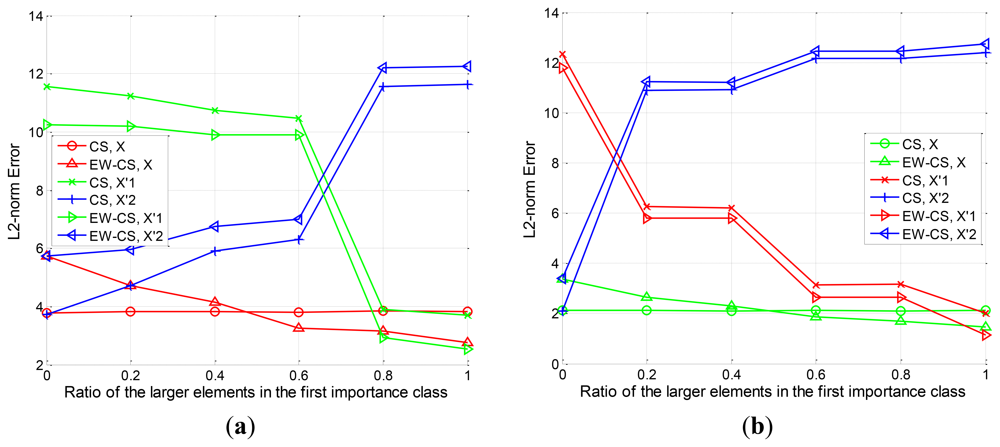
For various choices of Λ1, the l2-norm error of the signal X and the component signals and using the proposed EW-CS and ordinary CS is shown in Figure 6. We ran each value 100 times, and simulations are presented for overall sensing rates R = 0.2 and R = 0.4. The results indicate that the performance of the EW-CS varies with the ratio Λ1, while the ordinary CS is not impacted by Λ1. With the increase of Λ1, the recovery error of the EW-CS decreases. Roughly speaking, when 0 ≤ Λ1 ≤ 0.5, the CS outperforms the EW-CS. This because that the first importance class is not the really most important one. It means that using the EW-CS with wrong matched window settings will introduce more errors.
Nevertheless, when 0.5 ≤ Λ1 ≤ 1, the EW-CS begins to outperform the CS. In this case, the window settings match the signal's features, so the superiority of the EW-CS is demonstrated. It can also be noticed that the performance for the component signal in the EW-CS is always superior to that in the CS. It verifies the theoretical result proved in Subsection 4.1 that the elements in the first class are better protected. However, the performance for the component signal in the EW-CS is worse than that in the CS. This also agrees with our analysis.
6.2. Simulation Results for Natural Images
For testing the practical performance of the proposed EW-CS, instead of using artificially generated signals, we used real-world non-uniform compressible signals. The image signals' DCT or DWT coefficients constitute non-uniform compressible signals. With this prior knowledge, the random sensing with the EW-CS can be accomplished. The 512 × 512 test gray images with different features, i.e., “Lena”, “Boat”, “Peppers” and “Aerial”, are used for simulation. The images are divided into 32 × 32 blocks for computational facility.
The M-CS scheme in [21] is simulated here for comparison. M-CS needs to do 2-D DWT at the encoder for exploiting the frequency bands feature of wavelet coefficients. Then they used the l1 based method to recover the wavelet coefficients, and did the inverse wavelet transform to recover the original image. In our simulation, the three level DWT is used in M-CS with the measurement allocation rule in [21]. The level-3 (the lowest band) is assigned 60 measurements, and the number of measurements of level-1 is approximately four times of level-2.
Although the importance class design in the EW-CS can also directly use the sub-bands of 2-D DWT coefficients, the additional transform process is not willing to do. Thus, we choose 1-D DCT as the sparse representation basis which will be used only at the decoder so that the low-complexity encoder is guaranteed. The ordinary CS is also simulated with the 1-D DCT.
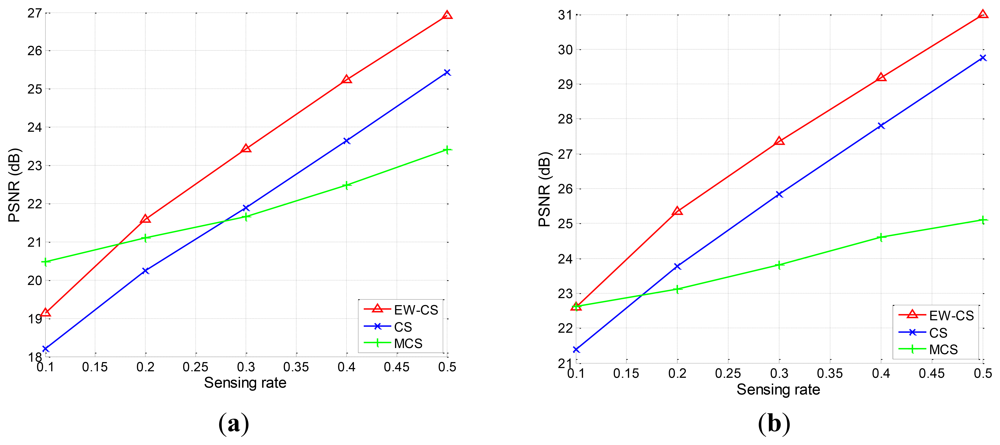
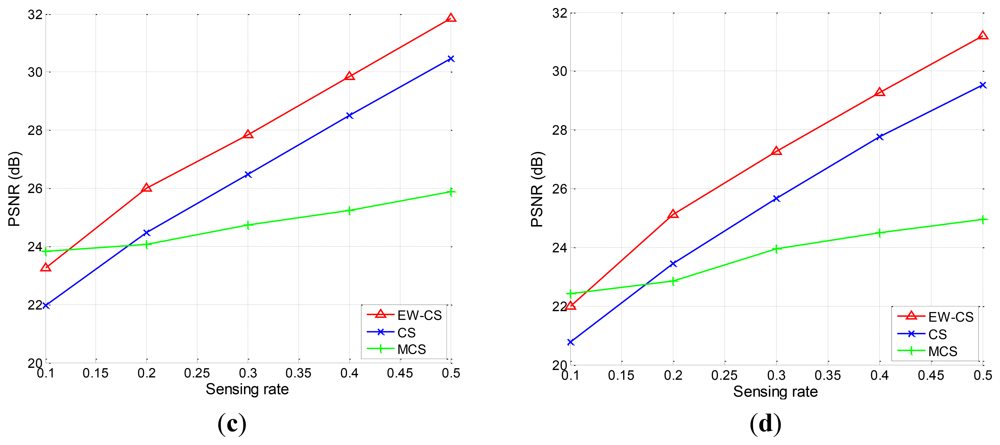
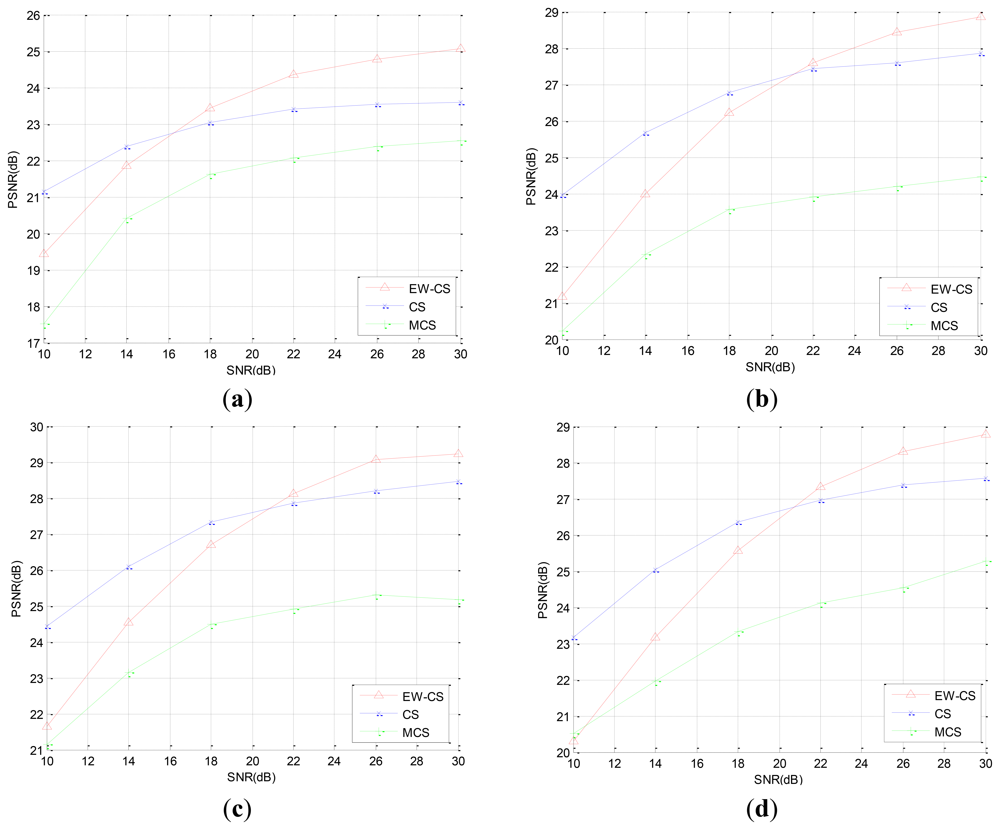
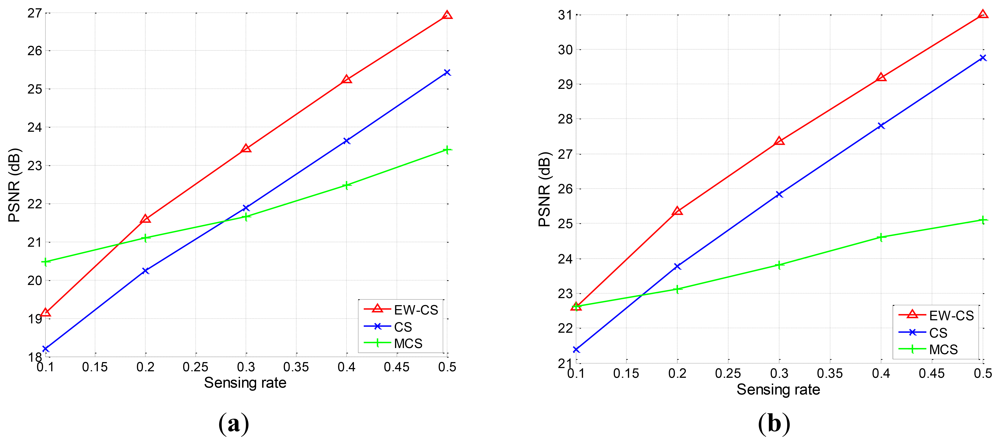
Firstly, we use the two-window EW-CS with the parameters Π1 = 0.3 and Ω1 = 0.5. The visual quality comparison for “Lena” is given in Figure 7 and the PSNR performances with different sensing rates of the four images are further shown in Figure 8. It is obvious that the proposed EW-CS scheme outperforms the other methods expect for a small number of low sensing rates. The significant coefficients of image signal really appear in the first window of the EW-CS such that they are well recovered. Thus, the EW-CS achieves better overall performance than the ordinary CS.
In M-CS, the significant coefficients are only sampled by the measurements allocated to the sub-band they belong, not all the measurements, so its performance is worse than the EW-CS at most sensing rates. At low sensing rate, the number of measurements for the most significant coefficients in the M-CS is fixed to guarantee successful recovery, and these measurements are noiseless. However, the EW-CS cannot recover the elements in the first importance class from the noisy measurements even though they are more. When the sensing rate increases, this problem will not exist.
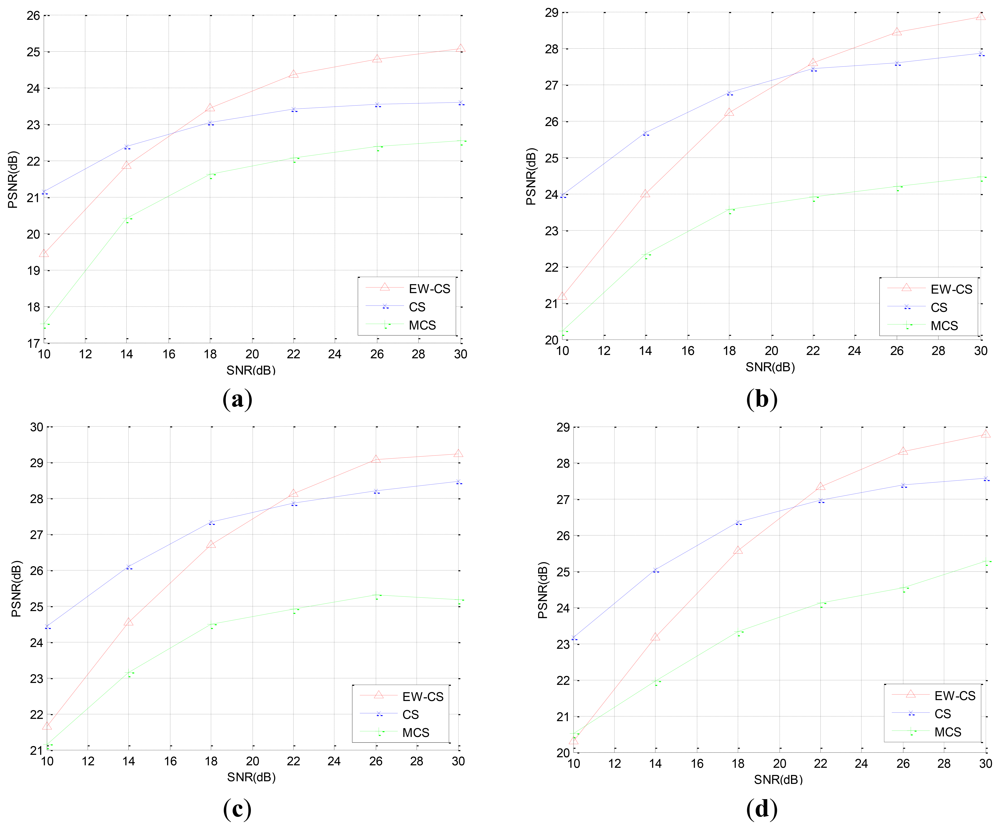
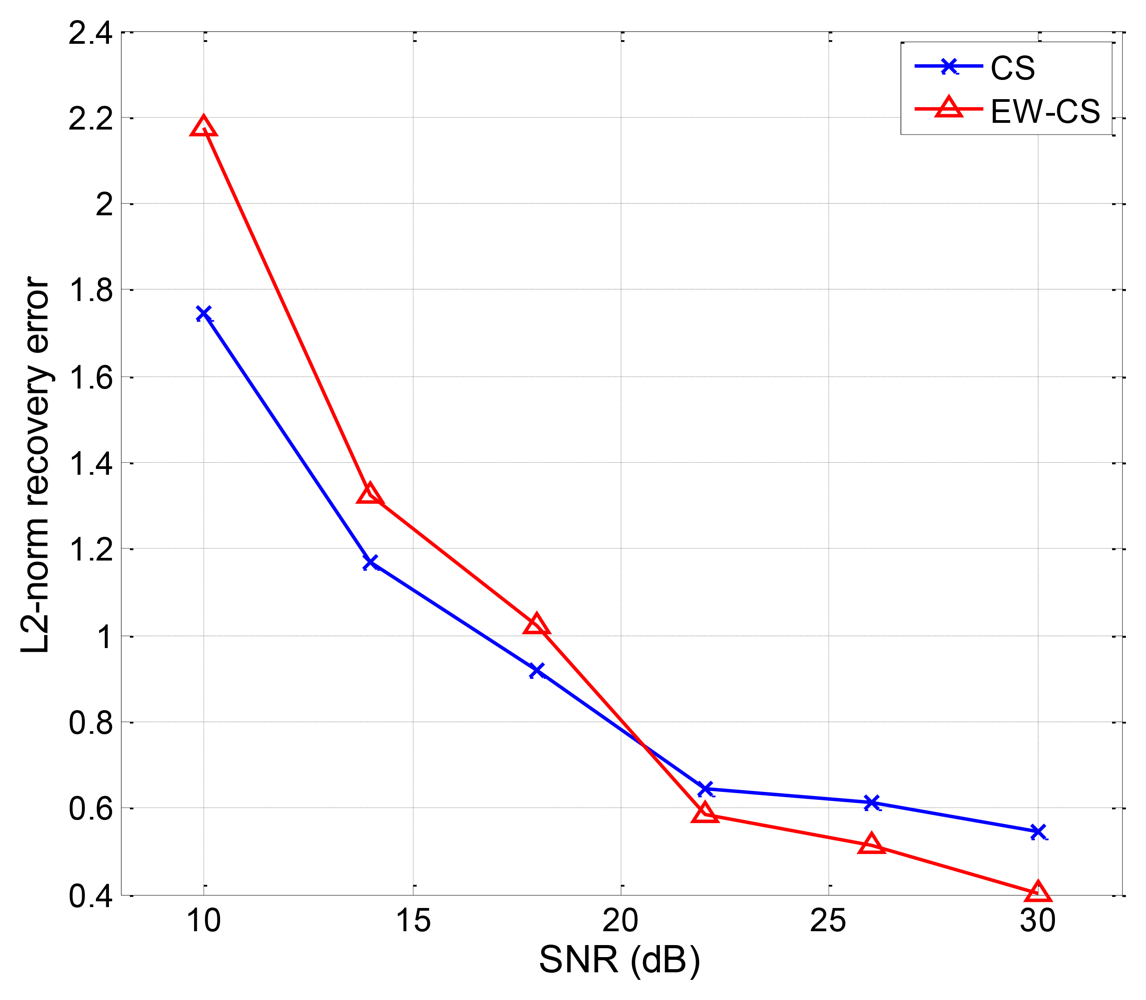
In the second simulation, we reconstruct the images from the noisy measurements which are transmitted through an AWGN channel. The sensing rate is fixed as R = 0.4. In order to compare the PSNR performance of the original CS method and the EW-CS method, we fix the signal power, and compensate the power of the all zero matrix Φ1,2 to the Φ1,1 to enlarge the signal power of the most significant class. The PSNR performances with different signal-to-noise ratio (SNR) for the four images are shown in Figure 9.
We can observe that the EW-CS is worse than the CS at lower SNR, but outperforms the CS when the SNR increases. The M-CS's PSNR is lowest at the same SNR, but its decay speed is similar to the CS and is slower than the EW-CS. When the channel noise energy gets greater, the advantage of recovery the first importance class of the EW-CS is weaken, and the recovery quality of the second importance class degrades further. Thus, the EW-CS algorithm is more applicable to the mild transmission environments.
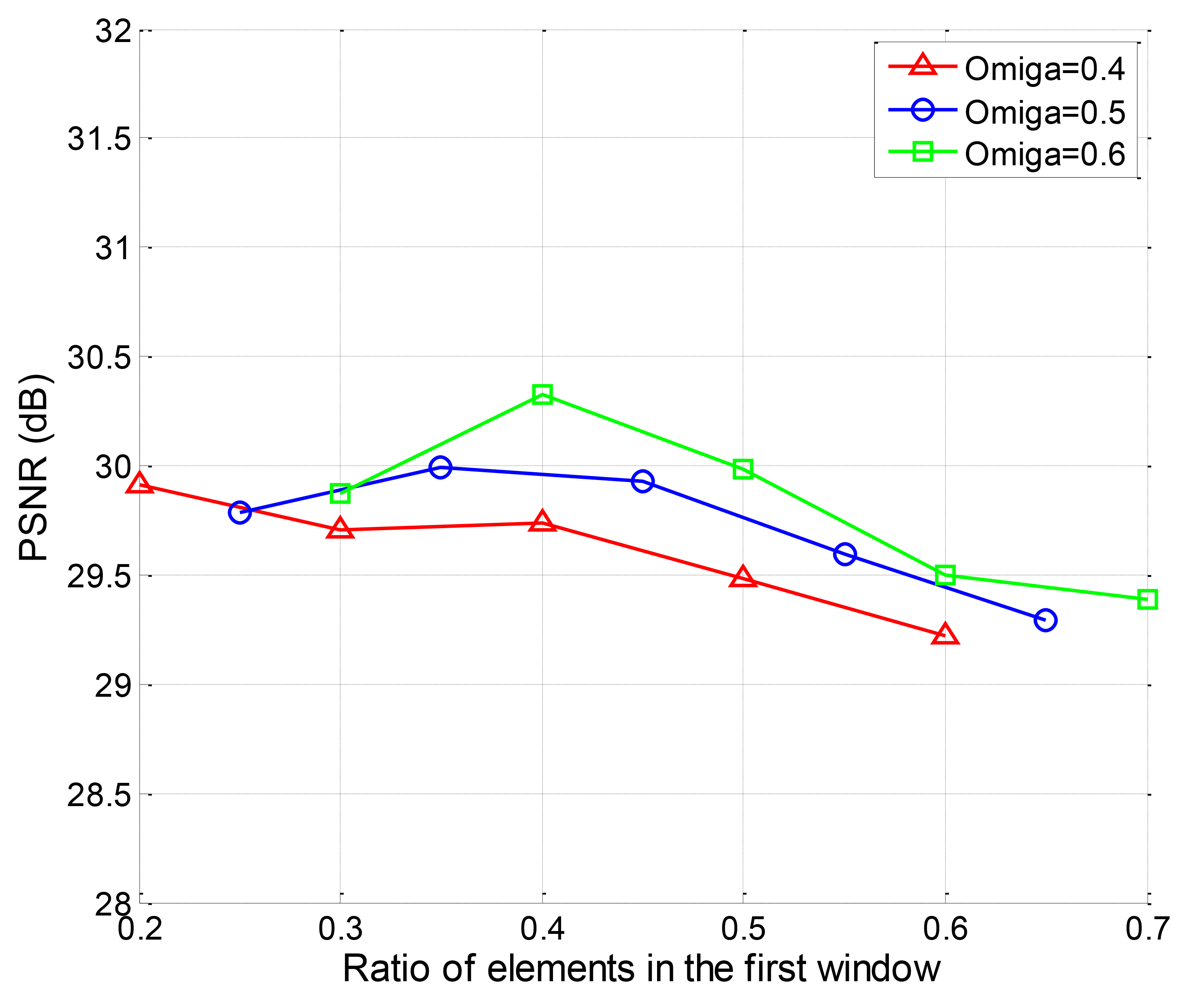
Then, we investigate the impact of changing window size on the recovery quality of the two-window EW-CS. The PSNR performance of “Lena” with different Π1 is given in Figure 10. The window design must follow a basic rule that the rank of the joint sensing matrix of the EW-CS must be larger than the total number of measurements, or the convex programming problem is an unsolved one. So the ranges of Π1 for different measurement allocation parameters Ω1 will be different. That's why the x axis for each curve in Figure 10 is different. For a fixed Ω1, there is a optimal first window size, but the general trend is the first window should not be too large.
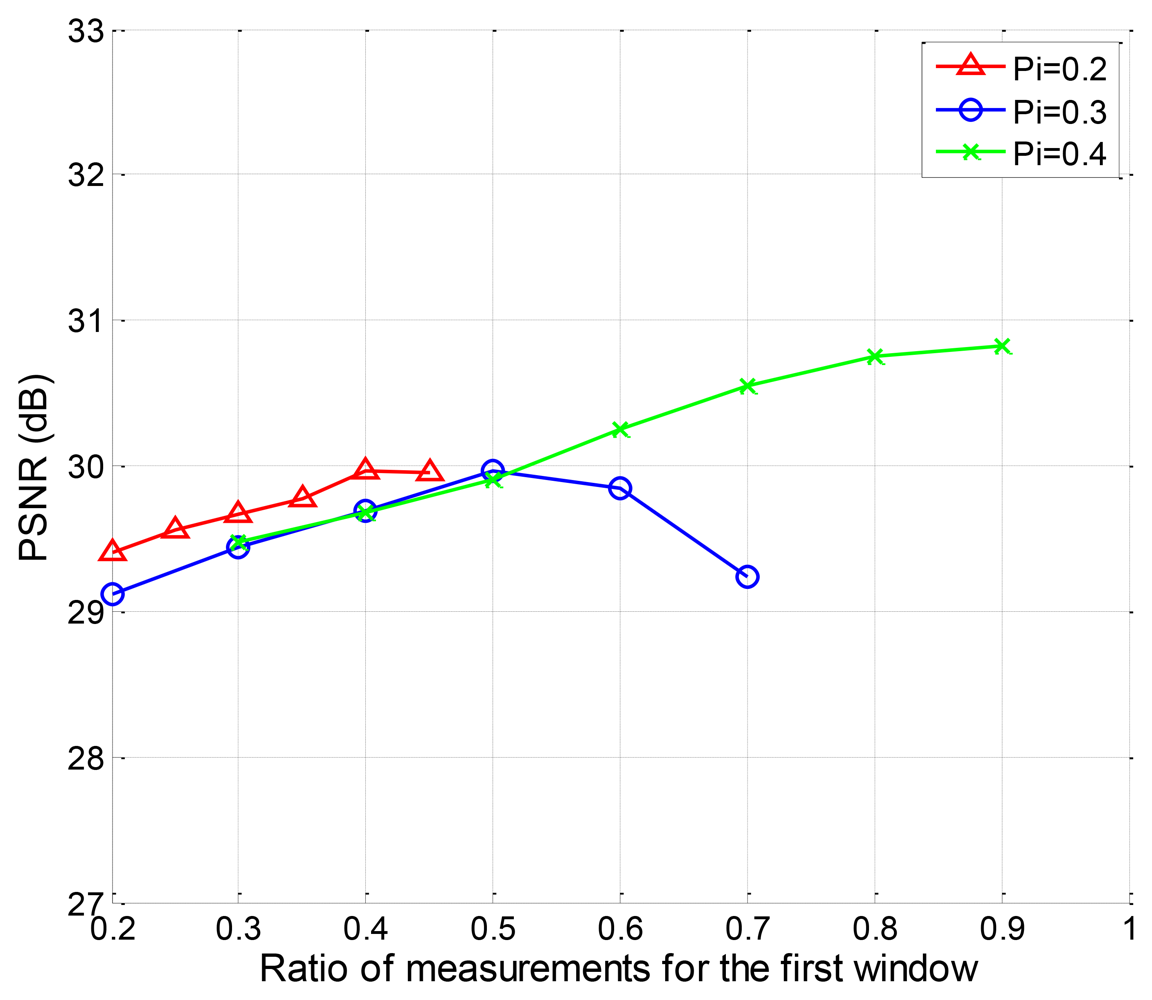
We also evaluate the PSNR performance of the EW-CS with different Ω1 when Π1 = 0.2, Π1 = 0.3 and Π1 = 0.4. The available ranges of Ω1 for different Π1 are different according to the design rule of the joint sensing matrix. The simulation results are plotted in Figure 11. It can be found that for the fixed first window size with Π1 = 0.2 and Π1 = 0.3, there is an optimal number of measurements that should be assigned to it. For Π1 = 0.4, however, the more measurements, the better.
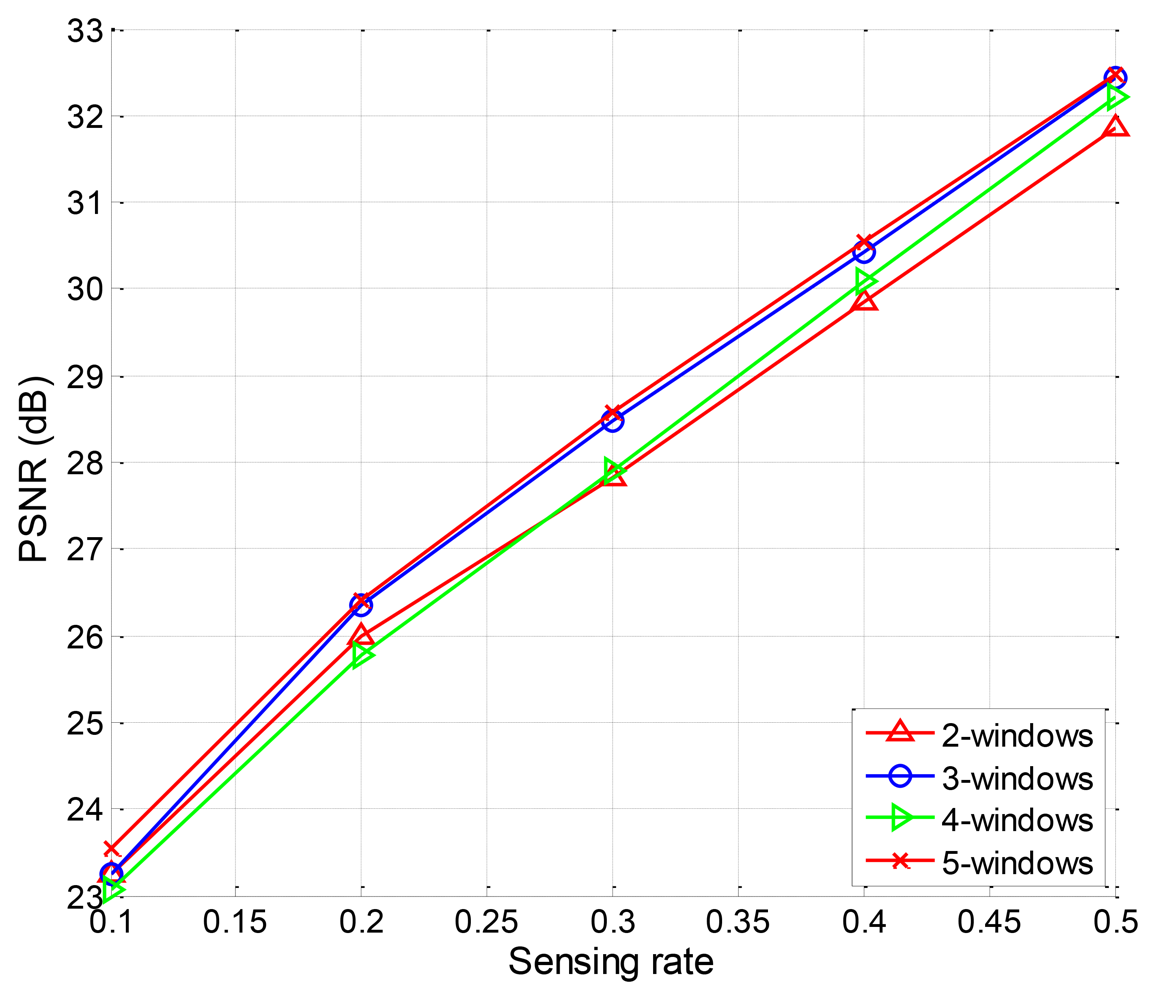
Finally, we design the EW-CS with more than two windows. The rank law should also be obeyed. So the three-window EW-CS is designed with the GP Π(x) = 0.3x + 0.2x2 + 0.5x3 and MP Ω(x) = 0.5x + 0.2x2 + 0.3x. The four-window EW-CS is designed withΠ(x) = 0.1x + 0.2x2 + 0.3x3 + 0.4x4 and Ω(x) = 0.1x + 0.2x2 + 0.3x3 + 0.4x4. The five-window EW-CS is designed with Π(x) = 0.1x + 0.1x2 + 0.1x3 + 0.2x4 + 0.5x5 and Ω(x) = 0.1x + 0.1x2 + 0.3x3 + 0.2x4 + 0.3x5. The PSNR performance for different window designs for image “Lena” is shown in Figure 12. The differences among the four different window designs are trivial. It means that the simple EW-CS with two windows is competent in most image signal compression applications.
6.3. Simulation Results for Networked Data
The variation of the EW-CS applied in wireless sensor networks is implemented here. We define a 500 m × 500 m sensing area. N = 256 sensors are randomly distributed within this area to monitor the events of interest. When E events happen, the sensor's data is affected by all the events, and the relationship between them is assumed to be a distance decaying model, which is determined by the distance di,j from the sensor i to the event j, where i = 1, 2, …, N and j = 1, 2, …, E, and the attenuation factor. If the j-th event's magnitude is Cj, the i-th sensor's data is calculated as , where α is the propagation loss factor. Here we assume that E = 3, and all Cj are equal to 100, α = 3.8.
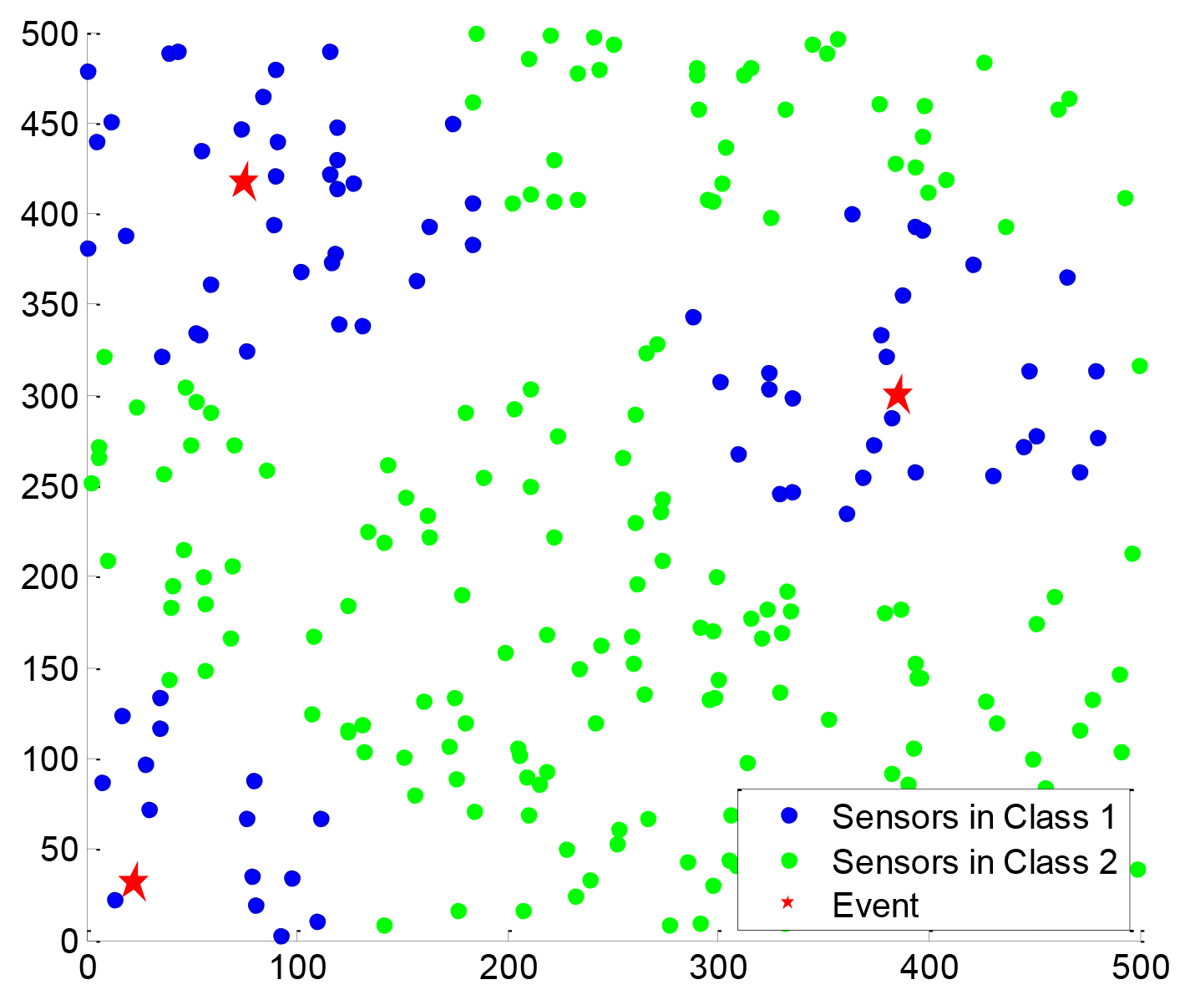
For the two-window EW-CS, Figure 13 shows a scenario under our settings with the first window ratio Π1 = 0.3. The first window size is determined by the threshold given to each sensor from the collection centre (not shown in Figure 13). All the sensors transmit their data to the centre using one hop. As the EW-CS using less number of transmissions than the ordinary CS with the same sensing rate, we define the transmission rate (the ratio between the total number of transmissions and the number of sensors) as the criterion. The networked data in Figure 13 and its recovered version with the transmission rate 0.4 are shown in Figure 14, where Ω1 = 0.5. The l2-norm recovery error of this example is 0.2401. More simulation results with different transmission rates are plotted in Figure 15. The performance of the EW-CS is quite superior to the ordinary CS. Considering the transmission noise through the AWGN channel, the l2-norm recovery error with different SNR is given in Figure 16, where the transmission rate is fixed as 0.4. In the noisy case, the EW-CS performs similar as in image compression that it holds its advantage only at high SNR.
Finally, the performance of the EW-CS with changing first window size is shown in Figure 17, where Ω1 = 0.5 and the transmission channel is noiseless. The EW-CS in CWS case has the feature that the Π1N elements in the first window are expected to be the first Π1N largest ones. With the same ratio Ω1, the smaller the first window is, the more measurements are assigned to the most largest or significant elements, so the overall performance is inversely proportional to the size of the first window as shown in Figure 17. When the first window size approaches the entire network data, the EW-CS's performance gets closer to the ordinary CS.
7. Conclusions
A novel compressed sensing scheme called expanding window compressed sensing is proposed in this paper to provide unequal protection for non-uniform compressible signals. The efficiency of the proposed scheme is analyzed from the recovery error upper bounds perspective by comparing with ordinary compressed sensing. Different from weighted methods, the windowing technology is adopted to make the scheme more flexible and efficient. Comparing with the blocked sensing method, the nested window design gets more benefit from the joint recovery algorithm for the nested window. The scheme is further applied to practical non-uniform compressible signals, i.e., image signals and networked data, to verify its superior performance. However, its noise-resilient performance is not very good, which is the problem we decided to solve in future work. The adaptive version of the proposed scheme that can optimize the parameters of designed windows is also an interesting direction to be investigated.
Acknowledgments
This work is partially supported by National Science Foundation of China (No. 61201149), the 111 Project (No. B08004), and the Fundamental Research Funds for the Central Universities. This work is also supported (in part) by Korea Evaluation Institute of Industrial Technology (KEIT), under the R&D support program of Ministry of Knowledge Economy, Korea.
References
- Candès, E.; Tao, T. Near-optimal signal recovery from random projections and universal encoding strategies. IEEE Trans. Inf. Theor. 2006, 52, 5406–5245. [Google Scholar]
- Donoho, D. Compressed sensing. IEEE Trans. Inf. Theor. 2006, 52, 1289–1306. [Google Scholar]
- Haupt, J.; Bajwa, W.; Rabbat, M.; Nowak, R. Compressed sensing for networked data. IEEE Signal. Process. Mag. 2008, 25, 92–101. [Google Scholar]
- Bajwa, W.; Haupt, J.; Sayeed, A.; Nowak, R. Compressive Wireless Sensing. Proceedings of the 5th International Conference on Information Processing in Sensor Networks, Nashville, TN, USA, 19–21 April 2006.
- Sejdinovic, D.; Vukobratovic, D.; Doufexi, A.; Senk, V.; Piechocki, R.J. Expanding Window Fountain Codes for Unequal Error Protection. Proceedings of the 41st Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 4–7 November 2007.
- Sejdinovic, D.; Vukobratovic, D.; Doufexi, A.; Senk, V.; Piechocki, R.J. Expanding window fountain codes for unequal error protection. IEEE Trans. Commun. 2009, 57, 2510–2516. [Google Scholar]
- Chen, S.S.; Donoho, D.L.; Wakin, M.; Saunders, M.A. Atomic decomposition by basis pursuit. SIAM J. Sci. Comput. 1998, 20, 33–61. [Google Scholar]
- Candès, E.; Tao, T. Decoding by linear programming. IEEE Trans. Inf. Theor. 2005, 51, 4203–4215. [Google Scholar]
- Baraniuk, R.; Davenport, M.; DeVore, R.; Wakin, M. A simple proof of the restricted isometry property for random matrices. Constr. Approx. 2008, 28, 253–263. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. Roy. Stat. Soc. B 1994, 58, 267–288. [Google Scholar]
- Figueiredo, M.A.T.; Nowak, R.D.; Wright, S.J. Gradient projection for sparse reconstruction: Application to compressed sensing and other inverse problems. IEEE J. Signal Process. 2007, 1, 586–597. [Google Scholar]
- Tropp, J.A.; Gilbert, A.C. Signal recovery from random measurements via orthogonal matching pursuit. IEEE Trans. Inf. Theor. 2007, 53, 4655–4666. [Google Scholar]
- Ji, S.; Xue, Y.; Carin, L. Bayesian compressive sensing. IEEE Trans. Signal Process. 2008, 56, 2346–2356. [Google Scholar]
- Babacan, S.; Molina, R.; Katsaggelos, A.K. Bayesian compressive sensing using Laplace priors. IEEE Trans. Image Process. 2010, 19, 53–64. [Google Scholar]
- Baron, D.; Sarvotham, S.; Baraniuk, R.G. Bayesian compressive sensing via belief propagation. IEEE Trans. Signal Process. 2010, 58, 269–280. [Google Scholar]
- Tan, X.; Li, J. Computationally efficient sparse Bayesian learning via belief propagation. IEEE Trans. Signal Process. 2010, 58, 2010–2021. [Google Scholar]
- He, L.; Carin, L. Exploiting structure in wavelet-based bayesian compressive sensing. IEEE Trans. Signal Process. 2009, 57, 3488–3497. [Google Scholar]
- Duarte, M.F.; Wakin, M.B.; Baraniuk, R.B. Wavelet-Domain Compressive Signal Reconstruction Using a Hidden Markov Tree Model. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 30 March–4 April 2008.
- Yang, Y.; Au, O.C.; Fang, L.; Wen, X.; Tang, W. Reweighted Compressive Sampling for Image Compression. Proceedings of the Picture Coding Symposium, Chicago, IL, USA, 6–8 May 2009.
- Tsaig, Y.; Donoho, D.L. Extensions of compressed sensing. Signal Process. 2006, 86, 533–548. [Google Scholar]
- Deng, C.; Lin, W.; Lee, B.; Lau, C.T. Robust Image Compression Based on Compressive Sensing. Proceedings of the IEEE International Conference on Multimedia and Expo, Singapore, 19–23 July 2010.
- Candès, E.J.; Romberg, J.; Tao, T. Stable signal recovery from incomplete and inaccurate measurements. Comm. Pure Appl. Math. 2006, 59, 1207–1223. [Google Scholar]
- Grant, M.; Boyd, S. CVX: Matlab Software for Disciplined Convex Programming, Version 1.21. Available online: http://cvxr.com/cvx (accessed on 7 June 2012).
- Grant, M.; Boyd, S. Graph Implementations for Nonsmooth Convex Programs, Recent Advances in Learning and Control (a Tribute to M. Vidyasagar); Blondel, V., Boyd, S., Kimura, H., Eds.; Springer: New York, NY, USA, 2008; pp. 95–110. [Google Scholar]






© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Liu, Y.; Zhu, X.; Zhang, L.; Cho, S.H. Expanding Window Compressed Sensing for Non-Uniform Compressible Signals. Sensors 2012, 12, 13034-13057. https://doi.org/10.3390/s121013034
Liu Y, Zhu X, Zhang L, Cho SH. Expanding Window Compressed Sensing for Non-Uniform Compressible Signals. Sensors. 2012; 12(10):13034-13057. https://doi.org/10.3390/s121013034
Chicago/Turabian StyleLiu, Yu, Xuqi Zhu, Lin Zhang, and Sung Ho Cho. 2012. "Expanding Window Compressed Sensing for Non-Uniform Compressible Signals" Sensors 12, no. 10: 13034-13057. https://doi.org/10.3390/s121013034