Multivariate and Multiscale Data Assimilation in Terrestrial Systems: A Review

 ,
,  ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
: More and more terrestrial observational networks are being established to monitor climatic, hydrological and land-use changes in different regions of the World. In these networks, time series of states and fluxes are recorded in an automated manner, often with a high temporal resolution. These data are important for the understanding of water, energy, and/or matter fluxes, as well as their biological and physical drivers and interactions with and within the terrestrial system. Similarly, the number and accuracy of variables, which can be observed by spaceborne sensors, are increasing. Data assimilation (DA) methods utilize these observations in terrestrial models in order to increase process knowledge as well as to improve forecasts for the system being studied. The widely implemented automation in observing environmental states and fluxes makes an operational computation more and more feasible, and it opens the perspective of short-time forecasts of the state of terrestrial systems. In this paper, we review the state of the art with respect to DA focusing on the joint assimilation of observational data precedents from different spatial scales and different data types. An introduction is given to different DA methods, such as the Ensemble Kalman Filter (EnKF), Particle Filter (PF) and variational methods (3/4D-VAR). In this review, we distinguish between four major DA approaches: (1) univariate single-scale DA (UVSS), which is the approach used in the majority of published DA applications, (2) univariate multiscale DA (UVMS) referring to a methodology which acknowledges that at least some of the assimilated data are measured at a different scale than the computational grid scale, (3) multivariate single-scale DA (MVSS) dealing with the assimilation of at least two different data types, and (4) combined multivariate multiscale DA (MVMS). Finally, we conclude with a discussion on the advantages and disadvantages of the assimilation of multiple data types in a simulation model. Existing approaches can be used to simultaneously update several model states and model parameters if applicable. In other words, the basic principles for multivariate data assimilation are already available. We argue that a better understanding of the measurement errors for different observation types, improved estimates of observation bias and improved multiscale assimilation methods for data which scale nonlinearly is important to properly weight them in multiscale multivariate data assimilation. In this context, improved cross-validation of different data types, and increased ground truth verification of remote sensing products are required.1. Introduction
The basic idea behind data assimilation (DA) is to combine complementary information from measurements and models of the Earth system and thus optimally estimate geophysical fields of interest [1]. It allows model simulations to be updated with observation data, for example in the carbon cycle [2], plant phenology [3] or hydrologic remote sensing [4]. The theory of DA in the Earth sciences rests on the mathematical framework of estimation theory [1,5]. More advanced DA methods also provide a framework for incorporating model errors and for quantifying prediction uncertainties [6] or updating model parameters [7].
In the context of climate change and land-use change, more and more terrestrial observational networks are being established to monitor states and fluxes in an effort to understand water, energy, or matter fluxes, as well as their biological and physical drivers and interactions with and within the terrestrial system. Examples of these networks include the global FLUXNET [8], the US Soil Climate Analysis Network (SCAN) [9], the US Snowpack Telemetry Network (SNOTEL) [10], the European Integrated Carbon Observation System (ICOS), and the German Terrestrial Environmental Observatories (TERENO) [11]. Within these networks, a huge amount of data from different sensors is recorded on different temporal and spatial scales. Moreover, a large number of Earth observation satellites have been launched, and products are being delivered for use in terrestrial models. Examples are the leaf area index (LAI), the fraction of absorbed photosynthetic active radiation (FPAR) and the land surface temperature (LST) retrieved by the Moderate Resolution Imaging Spectroradiometer (MODIS) [12,13], the soil moisture retrieved by the Soil Moisture and Ocean Salinity (SMOS) Mission [14], and the snow water equivalent as retrieved by the Advanced Microwave Scanning Radiometer-EOS (AMSR-E) [15]. These global satellite products are generated in an operational manner, i.e., consistent time series of the variables mentioned are available.
The potential of these multiple data sets as well as their combination is often not fully exploited. DA, which is defined as the updating of modeled state variables (and possibly also other model components like parameters and forcings) using externally obtained data sets, has been applied in the Earth sciences for decades. DA techniques, such as the Ensemble Kalman Filter [16], the Particle Filter [17,18] or variational methods like 4D-VAR [19], integrate observations into terrestrial models for an enhanced description of real environmental conditions. Numerous applications of single-state assimilation have already been published, e.g., in the context of the hydrological cycle [20–30], the energy balance [31], plant physiology [32–34], the carbon cycle [35,36], nutrient cycles [37] and zoology [38]. However, the additional information contained in data from multiple-state variables compared to single-state variables may significantly improve the description of the full system by assimilation. In this context, existing DA techniques can be modified accordingly or new approaches can be developed to improve performance.
The objective of this paper is to review the state of the art of multivariate and multiscale DA techniques in terrestrial systems, to detect current limitations for the use of multivariate and multiscale DA and to provide guidance for further methodological developments and potential areas of application.
2. Data Assimilation Theory
In this section, we present a brief introduction to three prominent DA techniques, namely the Ensemble Kalman Filter (EnKF), the Particle Filter (PF) and variational methods (VAR). EnKF and PF are Bayesian-based approaches, whereas VAR uses the minimization of a cost function [in principle, EnKF can also be derived from a cost function minimization under the hypotheses of a linear model and Gaussian probability density functions (pdfs)]. The algorithms, or their derivatives, are widely used in environmental modeling. The general principle of operation will be clarified, which is important for the understanding of multivariate and multiscale DA techniques. The methods discussed here are well suited for parallel computation, since they make use of ensemble members. This is also true for VAR methods when applied in an ensemble approach [39]. Each of the ensemble members corresponds to a model run for which a separate CPU processor can be used. Figure 1 presents a schematic overview of ensemble-based DA methods. Measurements are integrated into a DA framework by an observation operator for comparison with ensemble states for state update, and in some cases for parameter update. The results are enhanced state and parameter estimates which include their uncertainties.
DA algorithms based on recursive Bayesian estimation techniques first emerged with the Kalman filter [40]. Based on this theory, the Extended Kalman Filter (EKF) was then derived for the optimization of nonlinear systems and Hoeben and Troch [41] provided an overview of this methodology. The major drawback in the application of the EKF is the need to linearize the model equations. In order to overcome this problem, the EnKF was developed [16]. The Ensemble Kalman Filter (EnKF), a Monte Carlo implementation of Bayesian updating, proposed by Evensen [16] and clarified by Burgers et al. [42], is widely used in environmental applications. It reduces the computational demand relative to the EKF by integrating an ensemble of states from which the covariances are obtained at each update. It thereby avoids the need to linearize the model equations for the propagation of the error covariance [43,44]. Similar to the Kalman filter, the EnKF relies on a Gaussian assumption of model and observation errors, which may not be valid in environmental modeling [45–47]. In addition, linear updating of model states using this method reduces its applicability for highly nonlinear systems [7]. Another albeit more CPU-intensive alternative is the use of sequential Monte Carlo methods in the form of PF [18,48]. The PF differs from classical Kalman Filtering methods as it can handle the propagation of non-Gaussian distributions through nonlinear models. Both PF and EnKF are Monte Carlo techniques which use samples (i.e., ensemble members or particles) to estimate the underlying pdf of model states and parameters. Comparative studies of both EnKF and PF can be found, e.g., in Weerts et al. [49], Han and Li [45], Jardak et al. [50], Pasetto et al. [51], Leisenring and Moradkhani [52], and DeChant and Moradkhani [53].
Variational DA (VAR) is a very successful technique for operational numerical weather prediction because it can be efficiently used in realistic, complex systems. It was introduced in a three-dimensional form (3D-VAR) by Parrish and Derber [54], and then applied in a four-dimensional form (4D-VAR) using an adjoint model to include the time dimension [55]. However, the variational method itself does not provide any estimate of predictive uncertainty. The adjoint method calculates exact gradient information of the objective function that is to be optimized. Moreover, compared with EnKF, the advantage of 3/4D-VAR is the fact that nonlinear dependencies between observations and state variables can be taken into account without any approximation.
2.1. Ensemble Kalman Filter (EnKF)
In the application of the EnKF, the system state at time step k − 1 (xk−1) is propagated to time step k as follows:
fk,k−1(.) is a nonlinear operator representing the model in state space, including the model parameters and the meteorological forcings. wk−1 is the process noise. This is a white-noise term with zero mean and covariance matrix Qk−1, and it summarizes all the uncertainties caused by the model formulation, the forcing data, and the model parameters. The system is observed as follows:
hk(.) is a nonlinear function, relating the state variables to the observations. vk is the observation noise, which is a white-noise term with zero mean and covariance matrix Rk. It should be noted that for all time steps wk and vk are independent.
Instead of propagating one single model realization, the EnKF propagates an ensemble of model realizations. The spread in the ensemble at each time step is an estimate of the uncertainty in the model results. The a priori (before the update) state variables of a single ensemble member i are stored in the vector . The superscript .− indicates an a priori estimate. This vector is obtained by propagating each ensemble member i:
The apex indicates the ensemble mean and the superscript .+ indicates an a posteriori estimate (after the update). is a realization of the model error, obtained by a perturbation of the model parameters and meteorological forcings. The background error covariance is then calculated to estimate the forecast uncertainty:
N is the number of ensemble members and the superscript .T indicates the transpose operator. The Kalman gain KK is then calculated as:
The EnKF is a sophisticated sequential DA method [57], which can be easily operationally implemented in forecast models to make use of new observations from different kinds of measurement systems. In contrast to the classical Kalman filter, the EnKF uses the sample covariance instead of the theoretical covariance matrix. Several realizations of model predictions with perturbed initial conditions, forcings and/or parameters are calculated until new observations become available. Only the states at the current time step are updated in the traditional formulation of EnKF. The updating of the states is based on the prediction with the (often nonlinear) simulation model, a measurement model and an updating scheme based on the recursive application of Bayes’ rule. The EnKF assumes that all probability density functions involved in the updating step are Gaussian. The original formulation of the EnKF by Evensen [16] was modified slightly for randomly perturbing measurements in order to take measurement error into account [42,58].
A variant of the Ensemble Kalman Filter is the Ensemble Kalman Smoother (EnKS) [59]. For EnKS, Equation (4) is modified so that the background error covariance matrix not only includes covariances among states for time step k, but also covariances between states at time step k and former time steps k − 1, k − 2, … . As a consequence, the Kalman gain [Equation (5)] is also modified, and spreads updates related to deviations between model predictions and measurements [Equation (6)] not only to the rest of the model states at time step k, but also to the model states of former time steps k − 1, k − 2, … .The EnKS is often applied to update the model states of a limited time window before time step k, and not the complete model history. Updating the complete model history demands large amounts of RAM on computers, and is less important if the correlation between a certain time step in the past and the current time step k is very weak. Both EnKF and EnKS can be extended to update both states and parameters, using for example an augmented state-vector approach. In this case, parameter values are sequentially improved profiting from correlations between states and parameters. In theory, EnKF and EnKS should give the same parameter estimates and the same state estimates for the last time step k. However, it is expected that EnKS will provide better state estimates for past time steps k − 1, k − 2, … [57].
A further variant related to EnKF and EnKS is the Ensemble Smoother (ES) [60]. In this case, all observations are assimilated simultaneously, over a given model simulation period. The deviations between the ensemble model simulations and measurements at the different time steps are used to update all past model states and parameters. In this case, the background error covariance matrix contains covariances between all model states for all time steps, and between the model states (at all time steps) and parameters. This method is in fact an inverse modeling method, and normally focuses on parameter estimation. EnKF was shown to outperform ES according to previous studies [60,61].
EnKF became popular in several fields of research for updating model states with aid of the sequential assimilation of measurements. Examples of remote sensing DA include the updating of soil moisture contents [43,62–64], snow water equivalent [65], runoff [66], groundwater storage [67] and vegetation characteristics in agroecosystems [68]. In situ measurements were assimilated in order to update, e.g., streamflow [69] or reservoir characteristics [70]. In DA with EnKF, seismic data has also been used by Skjervheim et al. [71] and synthetic electrical resistivity data were used to update groundwater states and parameters by Camporese et al. [72]. Recently, EnKF has been used to update both states and parameters [7,73–75], which is of special interest if parameters are time-dependent like riverbed hydraulic conductivities [76]. The EnKF does not ensure the consistency of the updated states or model parameters with physical constraints, e.g., the mass balance. In order to solve this problem, Wen and Chen [77,78] introduced a confirmation step to ensure consistency. This approach was extended by Gu and Oliver [79] with an iterative EnKF, where the iterations check the validity of physical constraints. The EnKS has been applied less frequently to update model states. An example is updating current and past soil moisture contents with remote sensing information [80,81]. Bateni and Entekhabi [82] also estimated model parameters with EnKS (evaporative fraction and a bulk scalar transfer coefficient), combining a land surface model and remotely sensed land surface temperature.
2.2. Particle Filter (PF)
Particle filters [18] are the sequential or online analogue of Markov Chain Monte Carlo (MCMC) batch methods. With sufficient samples, the so-called particles approach the Bayesian optimal estimate. Particle filters share the same forecast step as EnKF. The EnKF is characterized as a special case of the PF, where the Bayesian update step is approximated with a linear update step in the EnKF using only the two first moments of the predicted probability density function (pdf) [73]. A PF does not have this limitation during the update step and manages the propagation of non-Gaussian distribution more flexibly through nonlinear models [48].
The PF uses the same system description as the EnKF (Equation (1) and Equation (2)), and has been introduced in hydrology by Moradkhani et al. [48]. Plaza et al. [83] provided a detailed explanation of the algorithm. Only a short description will be provided here. In recursive Bayesian filtering, the solution to the estimation problem consists of two steps: the prediction and correction steps. These steps are formulated as follows:
In the prediction step [Equation (7)], the posterior pdf p(xk|y1:k−1) is obtained based on the fact that the transition pdf p(xk|xk−1) and the prior pdf at time step k − 1 are known, whereas in the correction step [Equation (8)], the prior pdf is corrected using the information from the likelihood pdf p(yk|xk), and the posterior pdf p(xk|y1:k) is derived. The analytical solution to Equations (7) and (8) is difficult to determine since the evaluation of the integrals might be intractable. Particle filters are a set of algorithms which approximate the posterior pdf by a group of random samples. In more detail, the integrals are mapped to discrete sums:
The selection of the proposal pdf is extremely important in the design stage of the SIS filter. The filter performance mainly depends on how well the proposal pdf approximates the posterior pdf. In Doucet et al. [84], an optimal choice for the importance density function is proposed:
This pdf is optimal in the sense that it minimizes the variance of the importance weights. However, the application of Equation (13) is complex from the implementation point of view. A common choice of the proposal is the transition prior function [18,85]:
A drawback of this approach is the lack of information regarding the model errors in the computation of the importance weights. This limitation can affect the performance of the particle filter. The choice of the transition prior to the proposal simplifies Equation (12) resulting in an expression where the importance weights depend on their past values and also on the likelihood pdf. The normalized weights are given by:
The denominator in Equation (15) normalizes the weights. After several updates, a few particles may remain with high weights and a large fraction may have a weight of zero. To avoid this degeneracy of particles, a resampling step is performed. Particles with low weights are more likely to be substituted by replicates of particles with high weights, where the probability of a selection is equal to the individual weight. After resampling, the particles are equally weighted. This method is also presented in Figure 2 modified according to van Leeuwen [86]. Finally, the best estimate of the states consists of the weighted means for these states for the particle set . The SIS filter poses the problem of particle depletion, this problem is caused by increased variance over time as stated in Kong et al. [87] and Doucet et al. [84]. Methods to overcome this problem are Sequential Resampling [18] and Residual Resampling [88].
As shown in Figure 2, the particle replicates have the same values as the particle that was duplicated, which is ineffective as it might give the same model predictions (if model forcings are deterministic). Therefore, if parameters are stochastic and are a dominant source of uncertainty, Moradkhani et al. [48] recommend a minor parameter particle perturbation after each assimilation step in order to avoid sample impoverishment.
The resampling step is an essential part of the PF methodology and is necessary to improve the efficiency of PF. Often the Sampling Importance Resampling PF is used (SIR-PF) [18]. Alternative methods are Residual Sampling [88] and Stochastic Universal Resampling [85]. The latter have the advantage that they reduce sampling noise, and it has been shown that stochastic universal sampling has the lowest sampling noise [85]. Resampling slows down the degeneration of the weights, but it does not solve the problem. Resampling using Markov Chain Monte Carlo (MCMC) techniques is an interesting alternative, which needs to be exploited further because it could avoid the degeneration of weights. However, such resampling would require additional iterations, which are likely to cost a lot of additional CPU time [89]. More detailed discussions of the particle filter with different resampling strategies can be found, e.g., in [1,4,45,48,86].
PF has been applied for parameter estimation in rainfall-runoff modeling [48], to estimate groundwater recharge [90], to improve land surface states as well as water and energy fluxes [91], to improve surface soil moisture and model parameters [92], and to improve infiltration in a full-scale model of a dyke [29].
In the examples mentioned above, the models used had a limited number of states and only a few parameters were estimated. This is the main limitation of the PF. A very large number of particles is needed for adequate sampling of a high-dimensional state space. Resampling only partially alleviates this fundamental problem, and it is unclear whether the introduction of MCMC in the context of the PF could be CPU-efficient in the future. Neither improved estimates of the proposal distribution with Gaussian approximations nor the use of future measurement data yielded a breakthrough in this respect. Therefore, although the PF is one of the important alternatives to the EnKF, it currently needs an excessive amount of CPU time and its implementation in combination with large simulation models is not feasible. Application in high-performance computing and on parallelized architectures may help to overcome this problem. Whereas drawing samples in the state space and computing proper importance weights of each sample can be performed in parallel using a separate node for each particle, standard resampling techniques require strong interaction between nodes. However, resampling techniques specifically designed for parallel computation have recently been proposed [93].
2.3. Variational Assimilation (VAR)
In variational DA, the state vector xk−n is calculated, which minimizes a cost function. This cost function is calculated from time step k − n through k. n is the number of time steps in the assimilation window and is chosen by the user. In the cost function, all observations between time steps k − n and n are taken into account. Contrary to the Kalman filter, variational assimilation does not directly provide an estimate of the error in the state estimate. We consider the following nonlinear system:
gk+1,k is a nonlinear function relating the state at time step k to the state at time step k + 1. The system is observed as follows:
hk is a nonlinear function relating the state at time step k to the observations at time step k. Note that variational DA considers not only measurements at time step k but also those at former time steps (until k − 1). The cost function J(xk−n) over the interval of n time steps is the following:
is the background error covariance. A close inspection of the first term in the cost function shows that in effect one value indicating the error in the initial conditions is minimized. However, this formulation could be extended to include several terms, accounting for parameter calibration, or forcing terms, for example. If is equal to the identity matrix, this term is also equal to the Root Mean Square Error (RMSE) between the true state at time step k − n and the estimate of this state. If it is different to the unity matrix, the matrix can be considered as a weight factor. The second term in the cost function is again one value, indicating the mismatch between the observations and the simulations thereof. Ri is the uncertainty in the observations. If this is the identity matrix, this term is equal to the RMSE between the observations and the model simulations. If Ri is not equal to the identity matrix, it can again be considered a weight factor. The first term in the cost function is called the background error Jb, and the second term is the observation error Jo.
The objective of variational assimilation is the retrieval of the state xk − n which minimizes this cost function. This can be achieved through optimization methods such as the Newton-Rapson method or the adjoint method. In the latter, the difference between yi and hi(xi) for all time steps i between k and k − n is back-propagated in order to find the gradient in the cost function, which is then used to find the value for xk−n for which the cost function is minimal.
Both model predictions and observations provide actual and important information on environmental state variables. Similar to EnKF and PF, VAR methods combine both information sources. They do not explicitly evaluate the large error covariance matrices which are propagated by Kalman Filters, but they simultaneously process the data within a given time period and implicitly take dynamic error information into account by propagating an adjoint variable [94]. By this procedure, VAR generates state estimates which consider uncertainties in the model, initial conditions and measurements. A Bayesian performance function is minimized by adjusting these uncertain elements with the goal of maximizing the accuracy. It can be implemented in an iterative procedure, which tends to converge for well-posed problems to vanishing mismatch between observed and simulated states [95]. In practice, it is stopped when some finite converge criterion is achieved. Another option involves stochastic methods [96,97]. VAR has already been applied in meteorological [98] and oceanographic [99] simulations for long periods. In terrestrial sciences, it has been used much less, but in groundwater hydrology, the inverse problem is often solved using a formulation which is in fact a VAR approach (e.g., Carrera and Neumann [100]). The main differences with the VAR approach in atmospheric sciences are that parameters are updated instead of initial conditions, and that the method is applied in batch (and not sequential) mode focusing on reproducing a historical time series. Terrestrial VAR implementations have also been introduced in other study areas of terrestrial sciences, e.g., in hydrology [101,102], geology [103], sediment transport estimation [104], crop modeling [105] and energy balance simulations [106]. Very prominent applications are soil moisture assimilation [101,107–111], flood prediction [112] and crop production [105].
3. Data Assimilation across States and Scales
An analysis of the literature on DA showed that four major approaches exist based on the number of states that are being assimilated and their corresponding scales: (1) univariate single-scale DA (UVSS), (2) univariate multiscale DA (UVMS), (3) multivariate single-scale DA (MVSS), and (4) multivariate multiscale DA (MVMS). In the subsequent section, we will briefly present and define these approaches giving specific examples for each of them. In addition, the special case of multisource DA will be defined.
3.1. Univariate Single-Scale Data Assimilation (UVSS)
Most publications about DA applications deal with the assimilation of a single data type (“univariate”), for which it is assumed that the scale at which it is measured coincides with the computational grid scale (“single-scale”). We define these approaches as univariate single-scale DA (UVSS). It is important to realize that although the measurement scale generally does not coincide with the computational grid scale, the scale mismatch is often not very large and is therefore neglected in DA study. Typically, support scales of observed environmental states are relatively small (e.g., a few cm3 to dm3) and are often several factors smaller than the model grid scale. If these observations are assimilated into a model with a grid size of tens of meters, the difference in the spatial scale is significant. In typical UVSS DA schemes, the observations are assumed to represent the average value of the observed values of the state within the model pixel without using an appropriate data scaling technique. For example, in a small catchment, a soil moisture sensor network has been installed with several sensors in vertical and horizontal directions. Usually, the soil volume measured by a sensor is just a few cm3. These observations are then assimilated into a 3D hydrological model with a spatial grid of 1 m3 in order to update the modeled soil moisture. Here, the spatial heterogeneity within one model grid element is neglected and it is assumed that the observation at the level of a few cm−3 is valid for the whole grid element of 1 m3. As the scale discrepancy was neglected and no scaling technique was applied, this example refers to UVSS DA. UVSS DA is not further discussed in this paper. However, reviews can be found, e.g., in Evensen [61], Moradkhani [4], Han and Li [45], McLaughlin [113] and Bocquet et al. [89].
3.2. Multivariate Single-Scale Data Assimilation (MVSS)
MVSS DA refers to the simultaneous assimilation of observation data for multiple model state variables into a simulation model. In these studies, the measurement data are either of the same scale as the computational grid, or, more commonly, scale disparities are neglected. The availability of simultaneous multiobservation pairs is an important characteristic. For example, leaf area index (LAI) and surface temperature can be obtained on the same spatial scale at the same moment by the MODIS satellite. Both data types can be assimilated in a multivariate and single-scale manner. The assimilation of remotely-sensed soil moisture and soil temperature is another example of MVSS DA. However, although the same assimilation moment is not mandatory for MVSS DA, it is important that the assimilation takes place in a certain time window. Assimilating soil moisture data from a microwave satellite, which overpasses an area under investigation at 06:00, and soil temperature data from a multispectral/thermal sensor, which overpasses at 10:00, into an hourly hydrological model would still require multivariate DA. This problem is usually solved by an augmented state vector, which is an important characteristic of MVSS DA. This updates only that part of the augmented state vector for which a corresponding observation is available. In contrast, calibrating a model by soil moisture DA in the first year and updating soil temperature by DA in the second year would not necessarily be characterized as multivariate DA, as we have defined it if the basic state vector is used.
If the DA framework can update both states and parameters, time series measurements of model parameters can also be assimilated. Therefore, our definition of MVSS DA is: (i) the assimilation of measurements for at least two model state variables, or (ii) at least one state variable in combination with at least one model parameter, or (iii) at least two different model parameters, at least one of which has the form of time series. For example, in several hydrologic models, LAI is a model parameter and soil moisture is a state variable. Both are time series products made available by satellite remote sensing. In a state-parameter estimation framework, where LAI is a parameter to be estimated, multivariate DA can be performed by updating both the soil moisture state and the LAI parameter.
3.3. Univariate Multiscale Data Assimilation (UVMS)
UVMS DA refers to the assimilation of external data obtained at a significantly different resolution than the model resolution and the application of a scaling technique. In multiscale DA, a technique is required to consider statistical parameters on all scales, such as observation and model error noise variances. Examples are the assimilation of coarse-scale soil moisture contents or snow water equivalents (which are disaggregated to the fine scale) into a fine spatial scale hydrologic model. The application of a scaling technique is mandatory to distinguish between the multiscale and single-scale DA applications described above.
Multiscale definitions given in other publications, which are not in line with the UVMS DA characteristics presented in this review, should however also be taken into account. We define UVMS DA as (i) the assimilation of a certain data type measured at a scale that is different to the computational grid scale, where DA explicitly takes into account this scale mismatch, or (ii) the assimilation of a certain data type measured at two or more different spatial scales, where DA explicitly takes into account that measurements were made at different scales. In the literature, other definitions can be found. For example, Lu et al. [114] define a process that assimilates both parameters and state variables as multiscale assimilation. However, this is not necessarily multiscale DA, as parameters and states could be measured at the same spatial scale. This definition therefore does not imply that DA solves the scale mismatch [48]. Another definition is given by Montaldo and Albertson [115]. They perform a multiscale DA by updating the root zone moisture to provide a temporal trajectory of the near surface moisture that follows the trajectory of the observed surface soil moisture, whereas the hydraulic conductivity is adjusted on the basis of the time-averaged corrections applied to the root zone water content. We argue that this is not multiscale DA, but an updating procedure that is nowadays inherent to modern DA techniques. Several definitions exist which flexibly consider the multiscale issue in the temporal or spatial domain. For example, the scale denotes the temporal resolution when measurements associated with different temporal resolutions are used, as published in Lu et al. [116] and Montaldo and Albertson [115]. This is an additional interesting aspect, but not the focus of this paper. Most measurements are point measurements in time and therefore we believe that the multiscale issue in the temporal domain is not as important an issue for most hydrological DA studies as the multiscale issue in the spatial domain [117].
3.4. Multivariate Multiscale Data Assimilation (MVMS)
MVMS DA refers to the complex combination of multivariate and multiscale DA techniques as defined above.
3.5. Multisource DA
In principle, in MVSS and MVMS DA, the state variables are updated by data sets from different sensors. Moreover, in most cases the multiscale issue in UVMS and MVMS is addressed by different sensors. However, a special case is imaginable, where one state variable is updated at a single scale by two different data sets obtained from different means of observation. In such a case, we recommend introducing an explicitly multisource UVSS DA. Multisource UVSS DA involves the assimilation of equal-scale soil moisture products from specific radar on two different satellites, or two different radar types on one single satellite. The advantage of such a multisource UVSS DA application is that different observation errors can be overcome, i.e., one sensor performs better in one region, whereas the other sensor performs better in another region.
An example would be the assimilation of soil moisture products from the ERS 1 and ERS 2 satellites during their tandem phase. Two soil moisture products recorded at roughly the same time and at the same spatial resolution are provided. Such a simultaneous assimilation would not involve the DA procedures defined previously, i.e., MVSS, UVMS, MVMS. In this case, it would involve multisource UVSS DA.
4. Univariate Multiscale Data Assimilation (UVMS)
The multiscale problem has been addressed by several different approaches because a wide range of natural processes have multiscale properties in space and/or time [118,119]. In this section, we will focus on the assimilation of one state variable (or in certain cases, one parameter) obtained by (i) observation systems operating at two or more spatial scales into terrestrial models or (ii) the combination of one or more observation systems and a modeling grid at different spatial resolutions.
4.1. Methodology
Both the PF and the EnKF are excellent algorithms that assimilate data obtained at a certain spatial resolution into models that operate at a different resolution. This can be performed in two ways. The first approach is to use the observation operator [Equation (2)]. The second approach is to rescale the observations to the model scale prior to assimilation. In the following, both methods are briefly explained.
4.1.1. Use of the Observation Operator
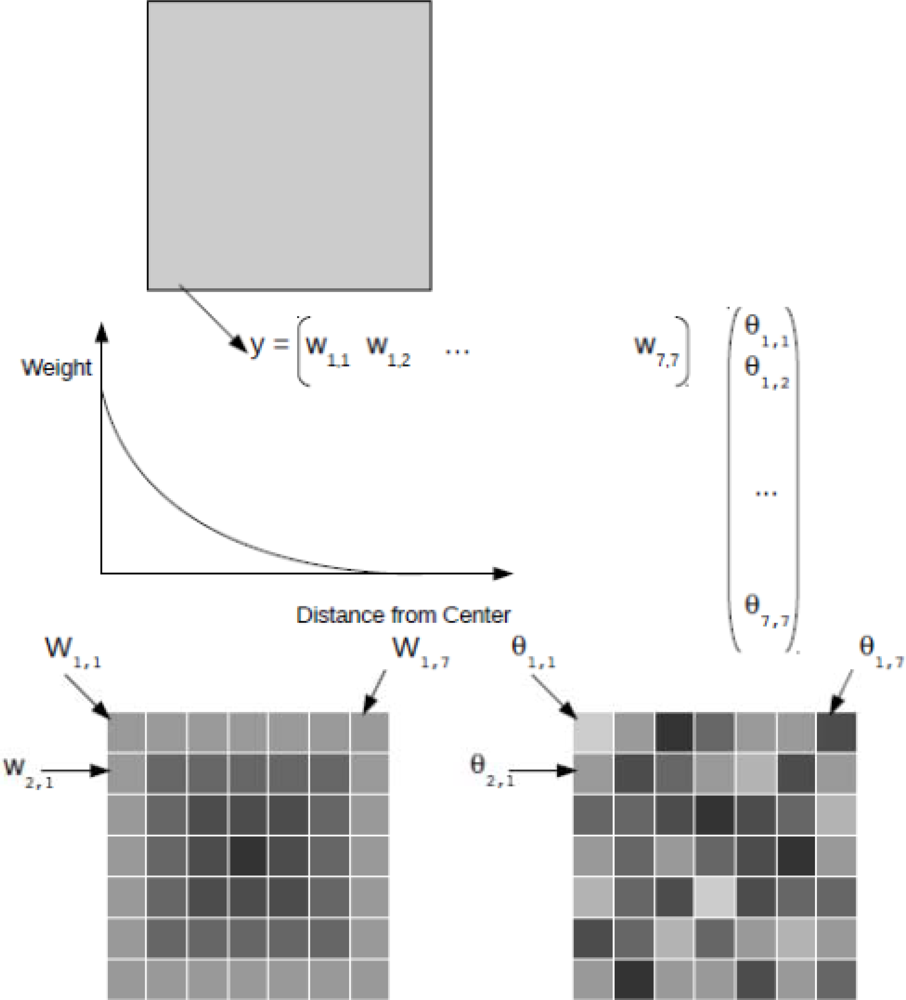
Figure 3 shows a schematic of how the observation operator can be used to assimilate coarse-scale data into a 2D fine-resolution model. In this methodology, the observation operator hk(.) [Equation (2)] uses the modeled state variables to simulate the large-scale observation. A typical example is the assimilation of coarse-scale Soil Moisture and Ocean Salinity (SMOS) data into a fine-resolution hydrologic model. It is straightforward to prove that the antenna configuration causes locations close to the center of an SMOS grid to contribute more to the observed signal than locations further away from the center [120]. In the simulation of the SMOS signal (using the fine-scale hydrologic model results), the pixels in the center of the SMOS grid should thus receive a higher weight. The simulated large-scale signal (one single value) is then used to update the soil moisture contents of all hydrologic model pixels inside the SMOS grid.
If the EnKF is used, the impact of the different weights can be assessed by examining the update equations. Let us assume that the hydrologic model is column-based, which means that the model results of all modeled pixels are independent of each other. This is a common feature of many hydrologic models, such as the widely used Community Land Model [121]. Let us also assume that the uncertainties are identical in the model results for the different pixels.
Under these conditions is the identity matrix multiplied by the variance in the modeled results calculated over the ensemble. In this case hk(.) is a linear function (a linearly weighted average is obtained in order to simulate the large-scale observation), and can be written as the Hk vector (the vector containing all the weights). The denominator in the Kalman gain equation is a single variable. Since is a uniform diagonal matrix, the magnitude of the Kalman gain for each state variable will be determined by the value of its entry in Hk, the weight matrix. In other words, pixels with a higher weight will receive a larger update than pixels with a lower weight. A limiting case may occur when the weight of a certain pixel is zero, which implies that its value does not contribute to the large-scale signal. In this case, the requirement of observability of the system is violated and the pixel should be left out of the analysis.
The impact of the averaging weight is fundamentally different when a PF is applied. The large-scale observation is simulated in exactly the same way as for the EnKF. However, in this case, one single particle contains the states (and possibly parameters) at all the modeled pixels, and is one of the ensemble members of the model realizations. Each particle possesses its own weight. The adaption of the weight depends on the deviation of the simulation of the large-scale observation from the actual observation. The particles could then be resampled. However, in this case, the modeled state variables for a certain particle are simply duplicated. In other words, there is no differential update in contrast to the EnKF.
VAR deals with this problem in another way. An initial state vector is eventually retrieved that minimizes the cost function. Since the pixels located near the center of the large-scale grid have the highest weight, their state estimate will match the truth better than the pixels further away from the center. The difference compared to the EnKF is that these results are not obtained through an update, but through a minimization of a cost function. The same reasoning can be applied when an entire profile needs to be updated instead of one single layer. The difference is that the matrix Hk will contain zeros for all state variables that are not in the uppermost layer of the profile.
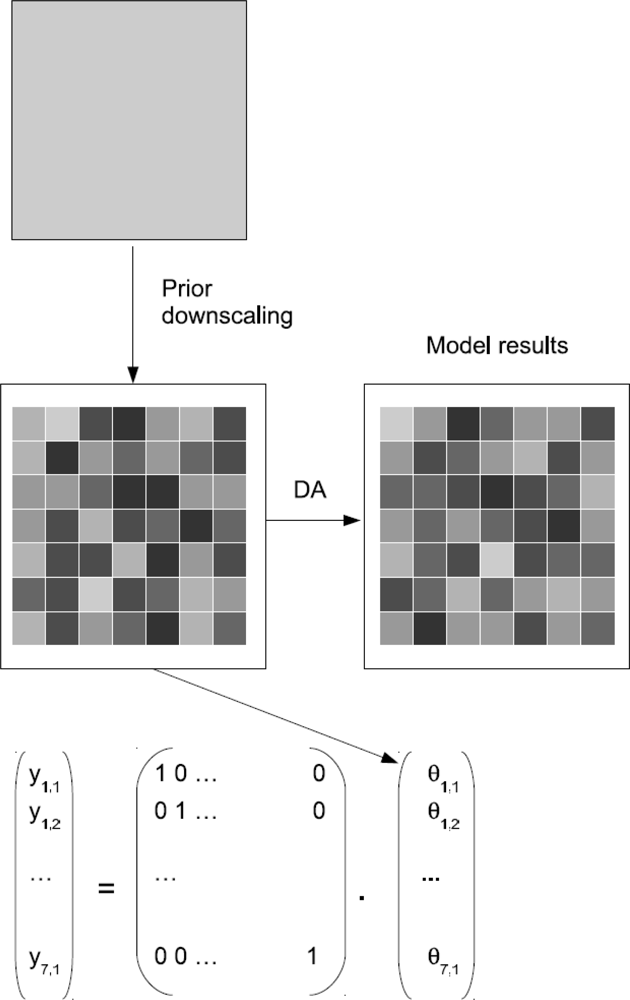
4.1.2. Prior Downscaling
A different approach involves downscaling the observations to the spatial resolution of the model before the observations are assimilated. Figure 4 shows a schematic of this approach for a model with one model layer. In this case, the dimension of the observation vector yk is the same as the number of pixels inside the large-scale grid. Hk is the identity matrix. The downscaled model results can then directly be assimilated into the fine-scale model. In some applications, only one layer might be observed (e.g., from remote sensing), but multilayer systems need to be updated. In such cases, Hk again contains zero values for all model variables that are not located in the uppermost layer.
A drawback of this methodology is the need for a downscaling algorithm and the quantification of the measurement uncertainty on the fine scale. On the other hand, the advantage is the straightforward application of the DA algorithms, especially when multiple data sets at different spatial resolutions need to be assimilated.
This is also true for the assimilation of one state variable obtained on two or more spatial scales into terrestrial models. An example would be the assimilation of fused top-soil-moisture products obtained by active (relatively higher spatial resolution) and passive (relatively lower spatial resolution) microwave methods. In addition to the prior individual downscaling of both data sets to the model resolution, prior data fusion could also be feasible. A huge range of methods have been published in relation to satellite image fusion [122,123]. However, if the physical information of the data set is to be conserved, well-established techniques, such as Intensity-Hue-Saturation (IHS) transformation [124], Brovey Fusion [125], and Principal Component Fusion (PCA) [126], cannot be used for DA. Here, the coarse-scale data set is transferred into a new data system (e.g., IHS or PCA) with several components, one component is substituted by the fine resolution data set, and the transfer procedure is inverted. This results in a combined fine-resolution data set, but the absolute values are heavily altered. In contrast, the wavelet theory provides several options for an application in multiscale terrestrial DA [127–129]. In principle, the method published by Das et al. [130] for the multiscale fusion of active and passive microwave data obtained by the SMAP mission [131] is a wavelet-based approach.
4.2. Applications
4.2.1. Univariate Dual-Scale Data Assimilation
Several studies have been published assimilating one state variable at a specific spatial resolution to a model on another spatial resolution. As a simple method of transfering the spatial differences in soil moisture observations from ASCAT (∼25 km) and AMSR-E (∼38 km) to the model grid of 25 km, Draper et al. [132] used a simple nearest neighbor interpolation. Here, the scale difference is not large which could justify the approximation made. McLaughlin [133] addressed the interpolation problem in hydrological DA using a multiplicative cascade model for statistical downscaling prior to assimilation. Reichle et al. [101] used 4D-VAR to constrain a physically based soil-vegetation-atmosphere (SVAT) model with surface soil moisture and L-band brightness temperature measurements. One goal was to derive soil moisture estimates on a finer scale based on coarse-scale satellite observations. The downscaling procedure made use of a simple arithmetic average to reflect the transfer of information from observation pixels (at larger scales) to nested estimation pixels (at smaller scales). Li et al. [134] coupled the EnKF with a statistical upscaling in order to introduce fine-scale hydraulic conductivity data into a coarse-scale groundwater flow and mass transport model. Merlin et al. [135] assimilated simulated SMOS observations to a distributed SVAT model with the EnKF. In principle, two data sets are used for the assimilation of one state variable. Prior downscaling was performed with fine-scale soil skin temperature observations from thermal/optical sensors describing the spatial variability of surface soil moisture within the simulated SMOS pixel. The disaggregated soil moisture is calculated by inserting the fine-scale skin temperature residuals into the coarse-scale SMOS soil moisture product. Using this observation operator, the observation and the model have similar spatial scales.
Parada and Liang [136] used the multiscale Kalman filtering (MKF) technique based on the data fusion method by Chou et al. [137] for the assimilation of near-surface soil moisture fields derived from an electronically scanned thinned array radiometer (ESTAR) into the three-layer variable infiltration capacity (VIC-3L) land surface model [138]. VIC-3L was calculated at a resolution of 1/32° (approx. 3.2 km), whereas the ESTAR retrievals were recorded at a resolution of 800 m. To fully describe the spatial dependence of near-surface soil moisture with the MKF-based DA approach, both the land surface model predictions for near-surface soil moisture and the remotely sensed imagery are treated as observation sources with individual observation noise terms. This accounts for the fact that the degree of uncertainty in the predictions from both land surface models and observations vary over time. The MKF captures the persistent spatial dependence of soil moisture over large distances and it further and better constrains the optimal state estimates. Future studies may exploit this concept by integrating additional multiscale data sources of the same state variable into the system. Moreover, the ability to account for the presence of bias in the model as well as the observations may support the use of this method for the multiscale assimilation of soil moisture. An Expectation Maximization Algorithm [139] can be used to obtain time-varying statistical parameters to describe how the uncertainty in the observed and the modeled soil moisture may change over time. As radiometer-based soil moisture estimates refer to the top few centimeters of soil only [14,140], model predictions and no observations exist for the deeper soil layers. Without additional observations, however, we can say that the soil layers 2 and 3 of VIC-3L are single-scale hidden states. In order to additionally update these single-scale states, a conditioning function can be specified based on the underlying physics describing soil moisture dynamics in the VIC-3L land surface model. An important aspect of this approach is the ability to retain mass conservation at all scales, so that the mean near-surface and deeper layer soil moisture content is preserved from scale to scale.
Frakt and Willsky [141] introduced the multiscale autoregressive (MAR) framework. The advantage of MAR is the replacement of a high-dimensional filtering problem with low-dimensional localized filtering problems defined across scales. The method was later established by Zhou et al. [142] in an ensemble form, i.e., the ensemble multiscale filter (EnMSF). Pan et al. [118] introduced the EnMSF to hydrological land surface-driven applications, accounting for the horizontal coupling in surface hydrology, and the subsequent horizontal error correlations in measurements and state variables. Horizontal coupling allows the filter to update one pixel based on measurements of other pixels. More research on UVMS DA is needed to adequately address the horizontal coupling issue and to extend it to spatial error correlations. Pan and Wood [143] further analyzed the impacts of accuracy, spatial availability and assimilation frequency (i.e., satellite re-visit time) on this assimilation framework. A multiscale tree topology of states is generated by dividing a root node into different clusters of child nodes, which are again divided into different clusters. Once a coarse observation is available, it is recursively clustered to the finer computing grid using the tree topology. With a synthetic experiment, Burke et al. [144] presented an approach to assimilate coarse-scale brightness temperature to a coupled soil-water-evaporation and transpiration (SWEAT) and microwave emission (MICRO) model on a finer scale. They calculated the brightness temperature using Mesonet data and generated coarse-scale simulated observations by area averaging. They then reduced the precipitation by 40% and re-calculated the brightness temperature on a finer resolution. The latter was updated by the simulated observations by comparing the area average. This technique does not alter the relative differences between the model grid squares of the finer scale, but the result is de-biased. Here, brightness temperature observations from satellites without any bias are mandatory. So far, this is not the case for SMOS for specific regions [145–147].
Another synthetic experiment was performed by Hill et al. [148]. They used the Monte Carlo Metropolis-Hastings Sequential Particle Filter as proposed by Dowd [149] to assimilate Normalized Difference Vegetation Index (NDVI) using a model operator translated to LAI. The net ecosystem exchange of carbon was calculated from respiration and gross primary production estimates. The coarse resolution observations were combined with an estimate of their subpixel probability distribution function and fine-resolution model states. The resulting fine-resolution disaggregated observations were then assimilated with standard procedures.
4.2.2. Univariate Multiscale Data Assimilation with Prior Fusion or Downscaling
In order to meet the problem of assimilating two or more observation data sets at dissimilar spatial scales, these observations are often fused prior to the assimilation. For example, in a synthetic study in the Arkansas-Red River Basin, Dunne et al. [80] generated “true” soil moisture states at a resolution of 1 km with the topographically based land-atmosphere transfer scheme (TOPLATS) model [150]. Simulated active and passive microwave observations were generated using the Microwave Emission and Backscatter Model. These synthetic observations were aggregated to meet the mission concept of the Soil Moisture Active and Passive (SMAP) Mission [131], i.e., 36 km for brightness temperatures and 3 km for backscatter data. The Noah Land Surface Model was used for assimilation at a spatial resolution of 6 km. Hence, three spatial scales are present in the DA system (3 km, 6 km, and 36 km). A transformation matrix is created to relate the predicted measurements on the Noah model scale to the observations of brightness temperature and backscatter at their respective resolutions. The brightness temperatures predicted at 6 km were linearly averaged within each 36 km radiometer grid cell for comparison with the observed brightness temperatures. Each 6 km predicted backscatter measurement was transformed into four collocated 3 km predicted backscatter values for comparison with the radar observations [80]. This information was then assimilated into the Noah model by an Ensemble Kalman Smoother (EnKS).
Wang et al. [117] further developed the multiscale Kalman Smoother-based framework by Parada and Liang [136] in order to fuse precipitation data from different data sets. The intention was to consider the individual noise characteristics and biases of each data set. The study focused on combining data sets with different spatial resolutions. It combined precipitation as recorded by in situ rain gauges, ground-based US Next-Generation Radar (NEXRAD) network and the PERSIANN system, which already combines the Tropical Rainfall Measuring Mission (TRMM), the Microwave Imager (TMI) and the Geosynchronous Satellite Longwave Infrared Imagery (GOES-IR). The multiscale Kalman Smoother (MKS) algorithm can be used flexibly in a time or space domain. In order to achieve the same estimated mean of the fused precipitation at all scales, a bias compensator was introduced. This bias compensator minimizes the impacts of inconsistencies (e.g., biases) between measurements at different scales on the fused precipitation. The method makes use of an upward sweep followed by a downward sweep, where information in multiscale measurements collectively propagate to all the nodes of the multiscale tree, as expressed by the root on the coarse scale and the leaves on the fine scale. Via the upward sweep, the finer-resolution data add their influences to the estimates of the hidden states at coarser resolutions. Via the downward sweep, the coarser-resolution data add their influences to the estimates of the hidden states at finer resolutions. During this downward sweep, the estimates of the hidden states are further refined using a scale-recursive Kalman smoothing step.
5. Multivariate Single-Scale Data Assimilation (MVSS)
5.1. Methodology
The EnKF, and variants of it, were used more often than PF and variational methods for multivariate DA in hydrology. For EnKF, the different observation types are all grouped together in the vector yk. Therefore, compared to the univariate case, the vector yk is “extended” to include different types of measurements. The state vector xk also includes different types of state variables, and possibly parameters as well. These different variables and parameters are included in the state vector in the form of blocks: a first block for the first state variable, then additional blocks for additional state variables, and finally blocks for the different parameters. The covariance matrix is therefore also extended and includes cross-covariances between different state variables, or cross-covariances between a state variable and a parameter. The update equation for EnKF, which is valid both for univariate and multivariate DA, is:
We will now look at the example of two state variables, which were modeled and observed. Moreover, two distributed parameter fields were calibrated, and observations were available for one of the parameters. The augmented state vector, observation vector and covariance matrix are now composed of the following blocks:
Variational methods have also been used in several cases for multivariate DA in hydrology. Multivariate DA with variational methods is performed by evaluating the second term on the right-hand side of Equation (18) for all observations. However, a key role is played by matrix Ri in this expression. This matrix contains the estimated measurement error variances for each of the observations. The different types of observations are associated with different uncertainties and the diagonal elements of Ri will therefore have different values. The matrix Ri weights the influence of the different observations to update the simulated model values with the observations. The correcting influence of the observations also depends on the values in Rk compared to the covariance matrix for the background errors, Pk. The inclusion of additional observations, and the comparison of the measured values with the simulated ones, according to Equation (18), makes the calculation of the gradient of the objective function more cumbersome. For example, if observations for additional state variables are included, the gradient of the objective function with respect to those state variables should also be calculated.
The PF has not yet been used frequently for multivariate DA in hydrology. Different data sources can be relatively easily included as conditioning information in the particle filter, which can be understood by inspecting the likelihood function. The likelihood for the multivariate case is obtained by comparing the different measurement data with their simulated equivalents, and weighting each of the residuals with the measurement variance. For the univariate case, the probability of the observations in the modeled state was given by Moradkhani et al. [48] as:
For the definition of Rk and Hk, see Section 2.1 on EnKF. In these expressions, it was assumed that all observations have the same measurement error variance. For the multivariate case, the expression for the likelihood of the observation modifies to:
We see in this expression that the measurement error variances are in matrix notation, which acknowledges that different measurement types will be associated with different uncertainties. Measurement errors for different observations can also be correlated in space, as could be the case for remote sensing data. The uncertainty of the different (types of) observations affects the weighting of the particles.
5.2. Applications
Although multivariate DA seems like a relatively straightforward extension of univariate DA, most studies in terrestrial systems assimilate only one data type. The complication of MVSS DA is not so much of an algorithmic nature, but is related to the specification of the measurement uncertainty for all data types involved. If different data types are assimilated, the correct weighting of the different pieces of information becomes very important for the efficiency of the procedure. The following discussion of the papers that deal with MVSS DA is organized according to the application area, focusing on developments during the last decade and on EnKF, PF and VAR.
5.2.1. Groundwater
In groundwater hydrology, sequential DA focused from the outset on jointly updating states and parameters by assimilating piezometric head data using an augmented state vector approach. The work of Chen and Zhang was among the first in this area [74]. Initial work on multivariate DA considered the joint assimilation of time series of piezometric heads and conditioning to hydraulic conductivity data. In such publications, information on hydraulic conductivity was assimilated in the first step and later preserved in the DA [151–153]. The joint assimilation of measurements for more than one state variable is less frequently reported in the literature. Liu et al. [154] and Nowak [151] assimilated both piezometric head and concentration data, but they provided few details about the assimilation of the concentration data and the (expected) non-Gaussian concentration distribution. Li et al. [155] provided a more detailed analysis of the value of additional concentration data, and found that the joint assimilation of head and concentration data gave much better results than the assimilation of head data only. They used the classic EnKF and a very large ensemble size (1,000 realizations). In addition to head and concentration data, Li et al. [155] also assimilated hydraulic conductivity and porosity data, which are both model parameters. Schöniger et al. [156] pointed out that when concentration data is assimilated, EnKF is expected to perform suboptimally because local pdfs of concentration tend to be non-Gaussian, and simple univariate normal score transformations cannot be expected to render bivariate pdfs Gaussian.
5.2.2. Integrated Surface-Subsurface Hydrology
There has been a recent increase in papers concerned with DA for partial differential equation-based coupled surface-subsurface models. Crow and van Loon [47] suggested that the joint assimilation of soil moisture and stream discharge data is one strategy of detecting erroneous assumptions about the magnitude of model errors. Camporese et al. [157] assimilated pressured head and streamflow data in CATHY [158–161] using EnKF. They concluded from the synthetic experiment that pressure head data are helpful for improving both the characterization of subsurface states and river discharge, whereas river discharge data do not improve the characterization of subsurface states. Pasetto et al. [51] further studied the joint assimilation of discharge and pressure head data in the CATHY model, this time using PF, but (again) without updating model parameters. They proposed a modification of SIR-PF for more efficient assimilation, and otherwise their conclusions were similar to those from Camporese et al. [157]; discharge data contributed little to improving the characterization of subsurface states. Bailey and Baù [162] had a slightly different focus and updated not only model states, but also hydraulic conductivities. They assimilated piezometric head measurements, groundwater return flow volume data and hydraulic conductivity data to estimate the spatially variable hydraulic conductivity field and they showed that the best results are obtained when all data are jointly assimilated. In their synthetic experiment, they used an Ensemble Smoother for assimilation, which considers current and past time steps together in the conditioning approach. In a later publication, Bailey and Baù [163] used the ensemble smoother in combination with CATHY to assimilate pressure head and water level data. They found that water level data are much more helpful for conditioning than streamflow discharge data. In their study, information on surface flow also contributed to an improved characterization of subsurface hydraulic conductivities. An additional feature of their synthetic study was that geostatistical parameters of the subsurface were also made uncertain.
5.2.3. Rainfall Runoff
Some authors used more conceptual hydrological models for assimilation focusing on the reproduction of river discharge. In an early publication, Seo et al. [164] used the Sacramento model [165,166] and VAR to assimilate discharge data, precipitation and potential ET. However, precipitation and potential ET were not assimilated in the classical sense, but were incorporated as observed model forcings. Lee et al. [167] used SACRAMENTO to assimilate discharge and soil moisture data with VAR. Their conclusions were very similar to the ones drawn by Camporese et al. [157] and Pasetto et al. [51], but they found that river discharge data also improved the characterization of subsurface states in the synthetic case to some degree. Interestingly, this was not the case for the real-world case study of the Eldon catchment (Oklahoma and Arkansas, USA). The authors assumed perfectly known forcings and no measurement errors in both the synthetic and real-world cases, which is unrealistic for the real-world case. Xie and Zhang [168] used SWAT [169–171] to assimilate runoff, soil moisture and evapotranspiration data with EnKF and they updated various model parameters. This was also a synthetic study, and it was assumed that soil moisture and evapotranspiration was known for complete sub-catchments. In this very optimistic setting, best results were again obtained when all data were jointly used for assimilation, but evapotranspiration data contributed less than the other types of measurements.
5.2.4. Vadose Zone
The applications of DA in vadose zone hydrology are traditionally concerned with the assimilation of remote sensing data. In these applications, normally only states are updated, while for soil hydraulic parameter calibration, inverse methods are used. DA for vadose zone hydrology has a strong link with land surface hydrology and we distinguish here between assimilation experiments for single soil columns (vadose zone hydrology) and studies for larger areas with distributed land surface models (land surface hydrology). Although Walker et al. [172] already carried out synthetic experiments for the assimilation of soil moisture and surface temperature data from satellite into vadose zone models, the joint assimilation of these data was not considered in this publication or in the years that followed. Visser et al. [173] assimilated both measured groundwater level and soil moisture data (De Bilt, The Netherlands) in a model for flow in the unsaturated zone and drainage. They used a simplified form of Newtonian nudging in their experiments. In Newtonian nudging, deviations between model prediction and measurements are included as additional sink and source terms in the equation. They showed that DA can reduce the errors for soil moisture prediction, and that best results were obtained when soil hydraulic parameters were also calibrated. They found that the model error had the greatest influence on the prediction error.
5.2.5. Large-Scale Land Surface
One option for improving the prediction quality of larger-scale land surface models is the joint assimilation of soil moisture and surface temperature data. Barrett and Renzullo [174] developed nonlinear measurement operators for the assimilation of satellite-measured brightness temperature and land surface temperature. They then investigated the conditions under which the joint assimilation of these data could be useful. Brightness temperature always puts a strong constraint on soil moisture content, but surface temperature data can only put additional constraints on soil moisture content estimates if: (i) the measurement error is not too big (around 1 K), (ii) the background error on soil moisture contents is relatively large (e.g., 5 vol%), and (iii) the sensitivity of surface temperature with respect to soil moisture is increased (which is the case for larger LAI). Han et al. [175] tested the joint assimilation of brightness temperature and surface temperature in a synthetic study and their conclusions agree well with those of Barrett and Renzullo [174]. The joint assimilation only improved the results marginally compared to the assimilation of one data type only. Another way of improving the prediction quality of larger-scale land surface models is the joint assimilation of soil moisture data and LAI. Pauwels et al. [176] used the land surface model TOPLATS [177] coupled with the crop growth module of WOFOST [178] to assimilate these data with EnKF. They found in a synthetic study that soil moisture data help to improve the estimates of LAI during the growth season, whereas LAI hardly improved soil moisture characterization. The best results were again obtained when both observation types were jointly assimilated, and for LAI it was important that data were assimilated in a biweekly interval. Sabater et al. [179] reached similar conclusions when applying a land surface model simulating crop growth to data from a field site close to Toulouse in France. They used a 1D VAR approach to jointly assimilate LAI and soil moisture data. Albergel et al. [180] studied the joint assimilation of soil moisture and LAI at the same site in the ISBA land surface model [181–184] using the EKF. The joint assimilation resulted in improved estimates of water, energy and carbon fluxes. Draper et al. [185] analyzed the assimilation of remotely sensed soil moisture from AMSR-E as well as temperature and relative humidity measured at 2 m in the land surface model ISBA using the EKF. Both data products resulted in very different updates of soil moisture and the joint assimilation was not very different from the assimilation of temperature and relative humidity alone. It was concluded that AMSR-E could not constrain the soil moisture estimates very much.
DA might violate the mass balance because at each assimilation time step, mass might be removed or injected into the system. Pan and Wood [186] proposed the Constrained Ensemble Kalman Filter (CEnKF) to put additional constraints on the mass balance and to avoid large mass imbalances. This method is especially interesting in combination with different kinds of observations that allow the mass balance to be constrained. Pan and Wood [186] assimilated soil moisture data, latent heat estimates and stream flow into the VIC land surface model [138,187,188]. The authors also demonstrated that soil moisture data can be used to constrain precipitation measurements with this methodology. Although this involved a multivariate DA, Pan and Wood [186] did not focus on the value of the different pieces of information in this paper.
5.2.6. Snow Hydrology
In the area of snow hydrology, multivariate DA has also been explored as a method of improving the characterization of snow pack and runoff estimates during snow melt. Durand and Margulis [189] investigated the potential of remotely sensed snow observations and combined the Special Sensor Microwave Imager (SSM/I), 12 channels of the Advanced Microwave Scanning Radiometer-Earth Observing System (AMSR-E) and broadband albedo observations to improve the estimation of snow water equivalent (SWE) using EnKF as a DA technique. They found a strong improvement in the characterization of SWE, with a RMSE as low as 3 cm (for a total maximum SWE of 80 cm). Pullianen [15] also assimilated SWE from AMSR-E and SSM/I in combination with in situ snow depth measurements and used a Bayesian approach. The approach was tested for areas in Finland, Russia and Canada. It was found that a combination of different data sources gave the best results. Pullianen [15] introduced a forward modeling approach for the brightness temperature. Kolberg et al. [190] assimilated a remotely sensed snow-covered area (from Landsat 7 ETM+ images) and related this via a simple model to SWE. The combined assimilation of remotely sensed snow-covered area and river discharge gave the best results. The time of assimilating the Landsat 7 ETM+ images had an important impact on the results, and the best results were generated when the assimilation was performed shortly before the main flood peak.
6. Multivariate Multiscale Data Assimilation (MVMS)
Studies presenting a complex combination of multiscale (Section 4) and multivariate (Section 5) DA techniques are discussed in the following. Most of the MVMS DA studies deal with the assimilation of snow data and the assimilation of soil moisture and surface temperature. Durand et al. [191] assimilated synthetic 25 km snow water equivalent (SWE) and 1 km snow grain size data to a land surface model with a resolution of 1 km using adaptive EnKF. They examined the impacts of different uncertainties on the efficiency of the snowpack characterization in DA. The results showed that the SWE and grain size estimation efficiency were both influenced by the snow grain size and precipitation accuracy and were related to the coefficient of variation and correlation length for both the precipitation and grain size. De Lannoy et al. [192] used the snow water equivalent (SWE) from 25 km resolution AMSR-E products and a snow cover fraction (SCF) from 500 m resolution MODIS products to improve the snow water equivalent estimation in the Noah model (resolution 0.01 degree) with a multiscale EnKF framework. The coarse SWE data were assimilated with the aggregated model simulation, and the high-resolution SCF data were aggregated to the model resolution and were transformed to SWE using the snow depletion curve as the observation operator. A rule-based update of SWE was used for SCF. The results showed that the joint assimilation of SWE and SCF improved the model estimation significantly for areas with shallow snow packs. For the deep snow areas, the results were not improved significantly because of the bias in the coarse SWE products and the assimilation of SCF only had a marginal impact. Su et al. [193] studied the impact of assimilating the GRACE terrestrial water storage (TWS) and MODIS snow cover fraction (SCF) data into the Community Land Model. The ensemble Kalman filter and smoother were used and the joint assimilation yielded better estimates of SWE and snow depth than the MODIS-only approach.
Balsamo et al. [194] used an observation system simulation experiment (OSSE) to study the impacts of microwave L-band and C-band, infrared surface temperature, screen-level temperature and relative humidity MVMS DA on the daily soil moisture and temperature analysis in a land DA system with a simplified VAR. In general, OSSE is designed to enable the modeler to examine the performance of data assimilation procedures and even to obtain the sensitivity of the procedure to different models with different parameterizations, observation operators and physical representations. The spatial coverage, temporal availability, and nominal or expected errors were considered using the present satellite observation information. The results showed that the observable with the largest dynamical response to perturbations of the model states contributed significantly to the analysis. Barbu et al. [195] studied the joint assimilation of the soil wetness index (SWI) and LAI through a simplified extend Kalman filter in the ISBA-A-gs land surface model. The results showed that the assimilation of surface-measured SWI could improve the root zone soil moisture significantly, and that LAI could correct a number of deficiencies in the model. The root mean square errors of CO2 fluxes were also reduced by about 5% with this joint scheme.
7. Advantages and Disadvantages of Multivariate and Multiscale Data Assimilation
Compared to UVSS DA techniques, multivariate and multiscale assimilation (MVSS, UVMS, MVMS) allow additional data containing information about the states to be updated and quantities of interest (e.g., fluxes) to be modeled. Advantages have been outlined in several studies [30,143]. However, multivariate and multiscale assimilation raises questions about the information content of these data.
7.1. Univariate Multiscale Data Assimilation (UVMS)
UVMS DA allows observations with different “support” scales to be integrated into mathematical models. However, this necessitates the availability of upscaling and downscaling approaches. One problem associated with UVMS DA is the assimilation of data measured at a certain scale into a model with a different grid resolution. It has been shown that assimilation is straightforward. For methods like EnKF, it can be handled by the observation operator, while PF can assimilate directly. Simulated values can be compared with measured values in a relatively straightforward manner: if for example the measurement comprises multiple computation grid cells, the observation operator can handle an equal weighting of all the measurement grid cells, while also taking account of an unequal weighting of the grid cells (as was the case in the SMOS example in Section 4.1). However, the problem is more complicated if a property scales nonlinearly. This is the case for example for brightness temperature measured by microwave sensors, which is nonlinearly related to soil moisture. When the relation between brightness temperature and soil moisture is applied to the larger-scale grid, we expect the soil moisture value to be different to the value we would receive if the brightness temperature was available for all smaller computational grid cells and if the conversion from brightness temperature to soil moisture was calculated for each of these grid cells. For properties that scale linearly, we expect the direct application of the observation operator (in the case of EnKF) to give the best results. For properties that scale nonlinearly, alternative strategies such as prior downscaling are promising. A systematic comparison of methods solving assimilation problems for properties that scale nonlinearly is still lacking. Here, more insight is needed, which could be obtained using synthetic studies mimicking real-world conditions as closely as possible or using real-world studies with sound verification. A second multiscale DA problem is when measurements are available at multiple scales. More experience is required with the assimilation of measurements at different scales. In theory, this is easy for problems that scale linearly, but in practice the data could conflict. Studies should not focus solely on the optimal fusion of data, as the bias correction of the observation data is also important [145]. It is also important that the different measurement data be weighted correctly. Expected measurement errors are therefore needed. These are often not well known and require increased ground truth verification. However, the measurement errors of the scaled data sets must be derived from the measurement errors at the original observation scale considering the applied scaling method. If data on two or more spatial scales are to be assimilated, a hierarchical approach constrained by the mass balance or further conditions may outperform a prior fusion. Here, assimilation results may be sensitive to the relative weights attributed to these different data sets, especially when they are observed at different spatial resolutions.
The relative weights are not relevant, if an observation operator is used. Its scaling performance depends on the complexity of the observation operator. Let us take the example outlined in Section 4.1.1, where the antenna weighting of SMOS was used to calculate the magnitude of the update for different pixels. This approach considers additional information about the measurement system. Compared to a statistical scaling, such as calculating the average state of fine-scale data on the coarse scale, it is a more sophisticated approach. A more complex scaling observation operator with respect to the example given is the method published by Merlin et al. [196]. In short, SMOS soil moisture on the coarse scale (∼40 km) is downscaled using MODIS soil skin temperature and MODIS NDVI (both fixed to 10 km) amongst others. The MODIS data contain completely new information that is not related to the SMOS soil moisture measurement itself. The method makes use of the finding, that soil evaporative efficiency (estimated based on soil temperature) is directly related to soil moisture.
If the additional data is also a state variable of the main model, they can be assimilated into the model (i.e., multivariate DA) and used in the scaling algorithm as well. As discussed in Section 4.2.1, Merlin et al. [135] assimilated this disaggregated soil moisture into a SVAT model. Here, the additional MODIS soil skin temperature can also be predicted by the SVAT model. Therefore, one integrated approach may use the MODIS temperature product to update the simulated soil skin temperature, which can then be used for the observation operator. This may be performed in two steps, first by assimilating coarse-scale soil moisture and fine-scale soil temperature, and then by assimilating downscaled soil moisture in a second step. Another approach may directly insert the fine-scale soil temperature into the disaggregation and assimilate both the fine-scale soil moisture and soil temperature into the SVAT model. The extension of this framework mentioned above refers to MVMS DA, as discussed in Section 6.
7.2. Multivariate Single-Scale Data Assimilation (MVSS)
Although many different data types are available to constrain hydrological model parameterization and prediction, relatively few DA papers deal with MVSS DA. In groundwater hydrology, vadose zone hydrology and rainfall-runoff modeling sequential DA is a relatively novel approach with an increasing number of papers only in the last five years. Very few papers are therefore concerned with MVSS DA. The situation is different for land surface hydrology, where sequential DA was first used more than a decade ago. This is also the area with a larger number of papers on multivariate DA. However, it also lacks papers dealing with the assimilation of many different data types. In land surface hydrology, the main topic has been the assimilation of soil moisture data from satellites. This involves serious complications: biased data (e.g., vegetation, interferences), limited vertical penetration depth, nonlinear observation operators and scale mismatch. In addition, land surface hydrological models often use strongly simplified concepts of vegetation and the hydrological cycle, where the assimilation of LAI or FPAR data is not possible (they are a parameter in such models) and the assimilation of river discharge data or groundwater data is difficult because of strong model simplifications.
On the other hand, synthetic experiments have shown that multivariate DA is generally superior to univariate DA. Considering the evolution in the last years, we expect that an increasing number of applications will further investigate the benefits of multivariate DA. We also expect that it will be more successful in real-world applications in the area of land surface hydrology if it is combined with better models (e.g., models that allow lateral flows in the subsurface) and coupled models (e.g., in combination with a crop growth model to assimilate vegetation data). Improving our understanding of remotely sensed data, such as indirect estimates of soil moisture is also essential for increasing the use of MVSS DA (especially in land surface models). In Section 5.1, we showed that a key element in MVSS DA is the relative weighting of the different data types. Therefore, the uncertainty of the measured data must be better understood, and increased ground truth verification is required under different conditions. The equations in Section 5.1 also showed that the impact of the data is greater if measurement errors are smaller. Again, especially for remotely sensed data, a better understanding of the relation between what is measured (e.g., brightness temperature) and what we want to know (i.e., soil moisture) is essential. To conclude, the implementation of MVSS DA schemes and more synthetic test studies are not enough to improve the predictive capacities of terrestrial models. MVSS DA should be combined with improved model structures, an increased understanding of what is being measured and the specification of the relative uncertainty of different measurement data under different environmental conditions.
7.3. Multivariate Multiscale Data Assimilation (MVMS)
Multivariate multiscale DA is the most complicated form of DA. For this type of assimilation, both aspects mentioned for multiscale DA (UVMS) and multivariate DA (MVSS) also hold here. Uncertainty assessment and bias correction of measurement data and appropriate multiscale methods to handle nonlinear scaling states and/or parameters are all important aspects. Although the combination of complications makes MVMS DA more problematic, we do not believe that it involves additional theoretical complications compared to MVSS or UVMS DA alone.
To date, only simple aggregation or disaggregation methods have been used to match the spatial resolution between observations and model states. More advanced downscaling methods, such as the downscaling of coarse passive soil moisture products with high-resolution remote sensing data [197,198], have not yet been used in MVMS DA. These methods would be expected to improve the DA performance further. Several publications were concerned with snow DA. The remote sensing products of soil moisture and surface temperature are also diverse in scale and source, and more work is necessary to study the impacts of MVMS assimilation of soil moisture and surface temperature at different spatial resolutions.
7.4. Other Aspects
A complication of multivariate and/or multiscale DA where parameters are also updated is that the parameter estimates cannot be directly verified in the field. Therefore, only indirect verification of calibrated parameter values is possible. This can be done by comparing uncalibrated and calibrated parameter values in independent model prediction experiments. If errors are significantly smaller for runs with calibrated parameter values (compared to uncalibrated values), then this would indicate that parameter estimation helped to improve model parameterization. Nevertheless, it is also possible that improved predictions with calibrated parameters are related to the fact that the updated parameter values compensate for another model structural error.
Running high-resolution models with many unknown states (and parameters) in an ensemble mode is very CPU-intensive and large amounts of stored data need to be managed. Small ensemble sizes give suboptimal results and therefore a certain minimum ensemble size is needed. High-performance computing is therefore an essential part of the DA methodology, and this is even more so the case for MVMS DA. For some very CPU-intensive applications, such as land surface modeling, this may have prohibited to some extent a more widespread use of these techniques until now.
8. Conclusions
In the context of climate change, several activities have been established for the long-term monitoring of environmental conditions. In general, in situ sensors used work in an automated way, and the data is collected in databases, which are often available to the general public with online access. Additionally, the initiation of various national and international space and science programs has ensured a further operationalization of the space infrastructure to provide information on important environmental variables. Available time series of environmental data (also in near-real time) are not fully utilized in terrestrial models. DA is the ideal technique to combine model simulations with observations because it considers the individual uncertainties. Several examples have already been published, e.g., for model calibration, model enhancement, and parameter estimation. The rising complexity of models, observation operators, and measurement systems favors the assimilation of data on different spatial scales as well as different state variables.
In this paper, we reviewed the state of the art of DA utilizing observational data from different spatial scales and different sources. We summarized three prominent DA methods: the ensemble Kalman filter (EnKF), the particle filter (PF) and variational methods (VAR). We identified four major classes of assimilation studies:
Univariate single-scale DA (UVSS, not discussed here as review papers exist in the various fields of research).
Univariate multiscale DA (UVMS). This refers to the assimilation of external data obtained at a different resolution than the model resolution. Examples are the assimilation of coarse-scale soil moisture contents or snow water equivalents into a hydrologic model, which is applied at a fine spatial scale.
Multivariate single-scale DA (MVSS). This refers to the assimilation of data for multiple variables (for example, surface temperature and soil moisture contents) into a simulation model.
Multivariate multiscale DA (MVMS). This refers to a complex combination of UVMS and MVSS.
We discussed several studies aiming to assimilate observations into models at dissimilar spatial scales. Some applications used the observation operator to align the spatial reference, others used prior downscaling before assimilation. If more than one observation of the same variable was used with a different spatial resolution, the majority of studies fused these data first. In a second step, one combined data set was usually assimilated. This approach may lead to underrepresentation of the variability as well as the accuracy of the state variable.
MVSS DA can be handled by EnKF, PF, VAR and other DA techniques. A crucial role is played by the appropriate determination of the measurement error variances for the different information. MVSS DA has been applied in several studies, but there are still few applications using real-world data or several (more than two) types of data. Most studies concluded that the results obtained when different types of data are assimilated are better than UVSS DA. Examples of this include the joint assimilation of soil moisture and LAI, the joint assimilation of river discharge and soil moisture, or the joint assimilation of surface temperature and brightness temperature. We argued that model deficiencies and an incomplete understanding of the relation between the measurement and the variable of interest has hampered a more extensive use of multivariate DA in the past. In order to ensure the successful application of multivariate DA in the future, these points and an increased understanding of the magnitude of measurement errors under different environmental conditions are important.
In conclusion, methods already exist for the simultaneous assimilation of various data types on different spatial scales. In atmospheric science, multivariate and multiscale DA is well established. In terrestrial systems, they are not yet generally established, and published studies are often synthetic. Further activities are needed to fully exploit the availability of environmental data, which could improve our knowledge of terrestrial processes as well as their interdependencies and teleconnections with the climate system.
Acknowledgments
This study was supported by the German Research Foundation DFG (Transregional Collaborative Research Centre 32—Patterns in Soil-Vegetation-Atmosphere Systems: Monitoring, modeling and data assimilation). It was also supported by the Helmholtz Alliance on “Remote Sensing and Earth System Dynamics”.
References
- Reichle, R.H. Data assimilation methods in the earth sciences. Adv. Water Resour 2008, 31, 1411–1418. [Google Scholar]
- Rayner, P.J. The current state of carbon-cycle data assimilation. Curr. Opin. Env. Sustain 2010, 2, 289–296. [Google Scholar]
- Oleson, K.W.; Niu, G.Y.; Yang, Z.L.; Lawrence, D.M.; Thornton, P.E.; Lawrence, P.J.; Stöckli, R.; Dickinson, R.E.; Bonan, G.B.; Levis, S.; et al. Improvements to the community land model and their impact on the hydrological cycle. J. Geophys. Res 2008, 113, G01021. [Google Scholar]
- Moradkhani, H. Hydrologic remote sensing and land surface data assimilation. Sensors 2008, 8, 2986–3004. [Google Scholar]
- Cohn, S.E. An introduction to estimation theory. J. Meteorol. Soc. Jpn 1997, 75, 257–288. [Google Scholar]
- Camporese, M.; Paniconi, C.; Putti, M.; Orlandini, S. Surface-subsurface flow modeling with path-based runoff routing, boundary condition-based coupling, and assimilation of multisource observation data. Water Resour. Res. 2010, 46. [Google Scholar] [CrossRef]
- Moradkhani, H.; Sorooshian, S.; Gupta, H.V.; Houser, P.R. Dual state-parameter estimation of hydrological models using ensemble kalman filter. Adv. Water Resour 2005, 28, 135–147. [Google Scholar]
- Baldocchi, D.; Falge, E.; Gu, L.H.; Olson, R.; Hollinger, D.; Running, S.; Anthoni, P.; Bernhofer, C.; Davis, K.; Evans, R.; et al. Fluxnet: A new tool to study the temporal and spatial variability of ecosystem-scale carbon dioxide, water vapor, and energy flux densities. Bull. Am. Meteorol. Soc 2001, 82, 2415–2434. [Google Scholar]
- Schaefer, G.L.; Cosh, M.H.; Jackson, T.J. The usda natural resources conservation service soil climate analysis network (scan). J. Atmos. Ocean. Technol 2007, 24, 2073–2077. [Google Scholar]
- Serreze, M.C.; Clark, M.P.; Armstrong, R.L.; McGinnis, D.A.; Pulwarty, R.S. Characteristics of the western united states snowpack from snowpack telemetry (snotel) data. Water Resour. Res 1999, 35, 2145–2160. [Google Scholar]
- Zacharias, S.; Bogena, H.; Samaniego, L.; Mauder, M.; Fuss, R.; Putz, T.; Frenzel, M.; Schwank, M.; Baessler, C.; Butterbach-Bahl, K.; et al. A network of terrestrial environmental observatories in germany. Vadose Zone J 2011, 10, 955–973. [Google Scholar]
- Myneni, R.B.; Hoffman, S.; Knyazikhin, Y.; Privette, J.L.; Glassy, J.; Tian, Y.; Wang, Y.; Song, X.; Zhang, Y.; Smith, G.R.; et al. Global products of vegetation leaf area and fraction absorbed par from year one of modis data. Remote Sens. Environ 2002, 83, 214–231. [Google Scholar]
- Sobrino, J.A.; Kharraz, J.E.; Li, Z.L. Surface temperature and water vapour retrieval from modis data. Int. J. Remote Sens 2003, 24, 5161–5182. [Google Scholar]
- Kerr, Y.H.; Waldteufel, P.; Wigneron, J.P.; Martinuzzi, J.M.; Font, J.; Berger, M. Soil moisture retrieval from space: The soil moisture and ocean salinity (smos) mission. IEEE Trans. Geosci. Remote Sens 2001, 39, 1729–1735. [Google Scholar]
- Pulliainen, J. Mapping of snow water equivalent and snow depth in boreal and sub-arctic zones by assimilating space-borne microwave radiometer data and ground-based observations. Remote Sens. Environ 2006, 101, 257–269. [Google Scholar]
- Evensen, G. Sequential data assimilation with a nonlinear quasi-geostrophic model using monte-carlo methods to forecast error statistics. J. Geophys. Res. Oceans 1994, 99, 10143–10162. [Google Scholar]
- Arulampalam, M.S.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-gaussian bayesian tracking. IEEE Trans. Signal Process 2002, 50, 174–188. [Google Scholar]
- Gordon, N.J.; Salmond, D.J.; Smith, A.F.M. Novel-approach to nonlinear non-gaussian bayesian state estimation. IEE Proc. F Radar Signal Process 1993, 140, 107–113. [Google Scholar]
- Courtier, P.; Thepaut, J.N.; Hollingsworth, A. A strategy for operational implementation of 4d-var, using an incremental approach. Q. J. R. Meteorol. Soc 1994, 120, 1367–1387. [Google Scholar]
- Walker, J.P.; Willgoose, G.R.; Kalma, J.D. Three-dimensional soil moisture profile retrieval by assimilation of near-surface measurements: Simplified kalman filter covariance forecasting and field application. Water Resour. Res 2002, 38, 1301. [Google Scholar]
- Montzka, C.; Moradkhani, H.; Weihermuller, L.; Franssen, H.J.H.; Canty, M.; Vereecken, H. Hydraulic parameter estimation by remotely-sensed top soil moisture observations with the particle filter. J. Hydrol 2011, 399, 410–421. [Google Scholar]
- Pauwels, V.R.N.; Hoeben, R.; Verhoest, N.E.C.; de Troch, F.P. The importance of the spatial patterns of remotely sensed soil moisture in the improvement of discharge predictions for small-scale basins through data assimilation. J. Hydrol 2001, 251, 88–102. [Google Scholar]
- Moradkhani, H.; Sorooshian, S. General review of rainfall-runoff modeling: Model calibration, data assimilation, and uncertainty analysis. In Hydrological Modelling and the Water Cycle—Coupling the Atmospheric and Hydrological Models; Sorooshian, S., Hsu, K.-L., Coppola, E., Tomassetti, B., Verdecchia, M., Visconti, G., Eds.; Springer: Berlin, Germany, 2008. [Google Scholar]
- Seo, D.J.; Cajina, L.; Corby, R.; Howieson, T. Automatic state updating for operational streamflow forecasting via variational data assimilation. J. Hydrol 2009, 367, 255–275. [Google Scholar]
- Vrugt, J.A.; Gupta, H.V.; Nuallain, B.O. Real-time data assimilation for operational ensemble streamflow forecasting. J. Hydrometeorol 2006, 7, 548–565. [Google Scholar]
- Viterbo, P.; Beljaars, A.; Mahfouf, J.F.; Teixeira, J. The representation of soil moisture freezing and its impact on the stable boundary layer. Q. J. R. Meteorol. Soc 1999, 125, 2401–2426. [Google Scholar]
- DeChant, C.; Moradkhani, H. Radiance data assimilation for operational snow and streamflow forecasting. Adv. Water Resour 2011, 34, 351–364. [Google Scholar]
- Franssen, H.J.H.; Kinzelbach, W. Real-time groundwater flow modeling with the ensemble kalman filter: Joint estimation of states and parameters and the filter inbreeding problem. Water Resour. Res 2008, 44. [Google Scholar] [CrossRef]
- Rings, J.; Huisman, J.A.; Vereecken, H. Coupled hydrogeophysical parameter estimation using a sequential bayesian approach. Hydrol. Earth Syst. Sci 2010, 14, 545–556. [Google Scholar]
- Camporese, M.; Paniconi, C.; Putti, M.; Salandin, P. Comparison of data assimilation techniques for a coupled model of surface and subsurface flow. Vadose Zone J 2009, 8, 837–845. [Google Scholar]
- Huang, C.L.; Li, X.; Lu, L. Retrieving soil temperature profile by assimilating modis lst products with ensemble kalman filter. Remote Sens. Environ 2008, 112, 1320–1336. [Google Scholar]
- Guerif, M.; Duke, C. Calibration of the sucros emergence and early growth module for sugar beet using optical remote sensing data assimilation. Eur. J. Agron 1998, 9, 127–136. [Google Scholar]
- Jarlan, L.; Mangiarotti, S.; Mougin, E.; Mazzega, P.; Hiernaux, P.; Le Dantec, V. Assimilation of spot/vegetation ndvi data into a sahelian vegetation dynamics model. Remote Sens. Environ 2008, 112, 1381–1394. [Google Scholar]
- Appel, F.; Bach, H.; Ohl, N.; Mauser, W. Provision of snow water equivalent from satellite data and the hydrological model promet using data assimilation techniques. Proceedings of IGARSS: IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007; pp. 4209–4212.
- Moore, D.J.P.; Hu, J.; Sacks, W.J.; Schimel, D.S.; Monson, R.K. Estimating transpiration and the sensitivity of carbon uptake to water availability in a subalpine forest using a simple ecosystem process model informed by measured net co2 and h2o fluxes. Agric. For. Meteorol 2008, 148, 1467–1477. [Google Scholar]
- Faugeras, B.; Bernard, O.; Sciandra, A.; Levy, M. A mechanistic modelling and data assimilation approach to estimate the carbon/chlorophyll and carbon/nitrogen ratios in a coupled hydrodynamical-biological model. Nonlinear Process. Geophys 2004, 11, 515–533. [Google Scholar]
- Zhao, L.; Wei, H.; Xu, Y.F.; Feng, S.Z. An adjoint data assimilation approach for estimating parameters in a three-dimensional ecosystem model. Ecol. Model 2005, 186, 234–249. [Google Scholar]
- Lawson, L.M.; Spitz, Y.H.; Hofmann, E.E.; Long, R.B. A data assimilation technique applied to a predator-prey model. Bull. Math. Biol 1995, 57, 593–617. [Google Scholar]
- Bishop, C.H.; Hodyss, D. Adaptive ensemble covariance localization in ensemble 4d-var state estimation. Mon. Weather Rev 2011, 139, 1241–1255. [Google Scholar]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng 1960, 82, 35–45. [Google Scholar]
- Hoeben, R.; Troch, P.A. Assimilation of active microwave measurements for soil moisture profile retrieval under laboratory conditions. Proceedings of IGARSS: IEEE 2000 International Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 24–28 July 2000; pp. 1271–1273.
- Burgers, G.; van Leeuwen, P.J.; Evensen, G. Analysis scheme in the ensemble kalman filter. Mon. Weather Rev 1998, 126, 1719–1724. [Google Scholar]
- Reichle, R.H.; Walker, J.P.; Koster, R.D.; Houser, P.R. Extended versus ensemble kalman filtering for land data assimilation. J. Hydrometeorol 2002, 3, 728–740. [Google Scholar]
- Moran, M.S.; Peters-Lidard, C.D.; Watts, J.M.; McElroy, S. Estimating soil moisture at the watershed scale with satellite-based radar and land surface models. Can. J. Remote Sens 2004, 30, 805–826. [Google Scholar]
- Han, X.; Li, X. An evaluation of the nonlinear/non-gaussian filters for the sequential data assimilation. Remote Sens. Environ 2008, 112, 1434–1449. [Google Scholar]
- Teuling, A.J.; Uijlenhoet, R.; Hupet, F.; van Loon, E.E.; Troch, P.A. Estimating spatial mean root-zone soil moisture from point-scale observations. Hydrol. Earth Syst. Sci 2006, 10, 755–767. [Google Scholar]
- Crow, W.T.; van Loon, E. Impact of incorrect model error assumptions on the sequential assimilation of remotely sensed surface soil moisture. J. Hydrometeorol 2006, 7, 421–432. [Google Scholar]
- Moradkhani, H.; Hsu, K.L.; Gupta, H.; Sorooshian, S. Uncertainty assessment of hydrologic model states and parameters: Sequential data assimilation using the particle filter. Water Resour. Res. 2005, 41. [Google Scholar] [CrossRef]
- Weerts, A.H.; El Serafy, G.Y.H. Particle filtering and ensemble kalman filtering for state updating with hydrological conceptual rainfall-runoff models. Water Resour. Res. 2006, 42. [Google Scholar] [CrossRef]
- Jardak, M.; Navon, I.M.; Zupanski, M. Comparison of sequential data assimilation methods for the kuramoto-sivashinsky equation. Int. J. Numer. Method Fluids 2010, 62, 374–402. [Google Scholar]
- Pasetto, D.; Camporese, M.; Putti, M. Ensemble kalman filter versus particle filter for a physically-based coupled surface-subsurface model. Adv. Water Resour 2012, 47, 1–13. [Google Scholar]
- Leisenring, M.; Moradkhani, H. Snow water equivalent prediction using bayesian data assimilation methods. Stoch. Environ. Res. Risk Assess 2011, 25, 253–270. [Google Scholar]
- DeChant, C.M.; Moradkhani, H. Examining the effectiveness and robustness of sequential data assimilation methods for quantification of uncertainty in hydrologic forecasting. Water Resour. Res 2012. in press.. [Google Scholar]
- Parrish, D.F.; Derber, J.C. The national-meteorological-centers spectral statistical-interpolation analysis system. Mon. Weather Rev 1992, 120, 1747–1763. [Google Scholar]
- Lorenc, A.C. Modelling of error covariances by 4d-var data assimilation. Q. J. R. Meteorol. Soc 2003, 129, 3167–3182. [Google Scholar]
- Pauwels, V.R.N.; de Lannoy, G.J.M. Ensemble-based assimilation of discharge into rainfall-runoff models: A comparison of approaches to mapping observational information to state space. Water Resour. Res 2009, 45. [Google Scholar] [CrossRef]
- Evensen, G. Data Assimilation: The Ensemble Kalman Filter; Springer: New York, NY, USA, 2007. [Google Scholar]
- Whitaker, J.S.; Hamill, T.M. Ensemble data assimilation without perturbed observations. Mon. Weather Rev 2002, 130, 1913–1924. [Google Scholar]
- Evensen, G.; van Leeuwen, P.J. An ensemble kalman smoother for nonlinear dynamics. Mon. Weather Rev 2000, 128, 1852–1867. [Google Scholar]
- Van Leeuwen, P.J.; Evensen, G. Data assimilation and inverse methods in terms of a probabilistic formulation. Mon. Weather Rev 1996, 124, 2898–2913. [Google Scholar]
- Evensen, G. Advanced data assimilation for strongly nonlinear dynamics. Mon. Weather Rev 1997, 125, 1342–1354. [Google Scholar]
- Reichle, R.H.; McLaughlin, D.B.; Entekhabi, D. Hydrologic data assimilation with the ensemble kalman filter. Mon. Weather Rev 2002, 130, 103–114. [Google Scholar]
- Crow, W.T.; Wood, E.F. The assimilation of remotely sensed soil brightness temperature imagery into a land surface model using ensemble kalman filtering: A case study based on estar measurements during sgp97. Adv. Water Resour 2003, 26, 137–149. [Google Scholar]
- Margulis, S.A.; McLaughlin, D.; Entekhabi, D.; Dunne, S. Land data assimilation and estimation of soil moisture using measurements from the southern great plains 1997 field experiment. Water Resour. Res 2002, 38. [Google Scholar] [CrossRef]
- Andreadis, K.M.; Lettenmaier, D.P. Assimilating remotely sensed snow observations into a macroscale hydrology model. Adv. Water Resour 2006, 29, 872–886. [Google Scholar]
- Crow, W.T.; Ryu, D. A new data assimilation approach for improving runoff prediction using remotely-sensed soil moisture retrievals. Hydrol. Earth Syst. Sci 2009, 13, 1–16. [Google Scholar]
- Zaitchik, B.F.; Rodell, M.; Reichle, R.H. Assimilation of grace terrestrial water storage data into a land surface model: Results for the mississippi river basin. J. Hydrometeorol 2008, 9, 535–548. [Google Scholar]
- Dorigo, W.A.; Zurita-Milla, R.; de Wit, A.J.W.; Brazile, J.; Singh, R.; Schaepman, M.E. A review on reflective remote sensing and data assimilation techniques for enhanced agroecosystem modeling. Int. J. Appl. Earth Obs. Geoinformation 2007, 9, 165–193. [Google Scholar]
- Clark, M.P.; Rupp, D.E.; Woods, R.A.; Zheng, X.; Ibbitt, R.P.; Slater, A.G.; Schmidt, J.; Uddstrom, M.J. Hydrological data assimilation with the ensemble kalman filter: Use of streamflow observations to update states in a distributed hydrological model. Adv. Water Res 2008, 31, 1309–1324. [Google Scholar]
- Aanonsen, S.I.; Naevdal, G.; Oliver, D.S.; Reynolds, A.C.; Valles, B. The ensemble kalman filter in reservoir engineering-a review. SPE J 2009, 14, 393–412. [Google Scholar]
- Skjervheim, J.A.; Evensen, G.; Aanonsen, S.I.; Ruud, B.O.; Johansen, T.A. Incorporating 4d seismic data in reservoir simulation models using ensemble kalman filter. SPE J 2007, 12, 282–292. [Google Scholar]
- Camporese, M.; Cassiani, G.; Deiana, R.; Salandin, P. Assessment of local hydraulic properties from electrical resistivity tomography monitoring of a three-dimensional synthetic tracer test experiment. Water Resour. Res 2011, 47, W12508. [Google Scholar]
- Evensen, G. The ensemble kalman filter for combined state and parameter estimation monte carlo techniques for data assimilation in large systems. IEEE Control Syst. Mag 2009, 29, 83–104. [Google Scholar]
- Chen, Y.; Zhang, D.X. Data assimilation for transient flow in geologic formations via ensemble kalman filter. Adv. Water Resour 2006, 29, 1107–1122. [Google Scholar]
- Vrugt, J.A.; Diks, C.G.H.; Gupta, H.V.; Bouten, W.; Verstraten, J.M. Improved treatment of uncertainty in hydrologic modeling: Combining the strengths of global optimization and data assimilation. Water Resour. Res. 2005, 41. [Google Scholar] [CrossRef]
- Kurtz, W.; Franssen, H.J.H.; Vereecken, H. Identification of time-variant river bed properties with the ensemble kalman filter. Water Resour. Res 2012, 48, W10534. [Google Scholar] [CrossRef]
- Wen, X.H.; Chen, W.H. Some practical issues on real-time reservoir model updating using ensemble kalman filter. SPE J 2007, 12, 156–166. [Google Scholar]
- Wen, X.H.; Chen, W.H. Real-time reservoir model updating using ensemble kalman filter with confirming option. SPE J 2006, 11, 431–442. [Google Scholar]
- Gu, Y.; Oliver, D.S. An iterative ensemble kalman filter for multiphase fluid flow data assimilation. SPE J 2007, 12, 438–446. [Google Scholar]
- Dunne, S.C.; Entekhabi, D.; Njoku, E.G. Impact of multiresolution active and passive microwave measurements on soil moisture estimation using the ensemble kalman smoother. IEEE Trans. Geosci. Remote Sens 2007, 45, 1016–1028. [Google Scholar]
- Dunne, S.; Entekhabi, D. Land surface state and flux estimation using the ensemble kalman smoother during the southern great plains 1997 field experiment. Water Resour. Res 2006, 42, W01407. [Google Scholar]
- Bateni, S.M.; Entekhabi, D. Surface heat flux estimation with the ensemble kalman smoother: Joint estimation of state and parameters. Water Resour. Res 2012, 48, W08521. [Google Scholar]
- Plaza, D.A.; de Keyser, R.; de Lannoy, G.J.M.; Giustarini, L.; Matgen, P.; Pauwels, V.R.N. The importance of parameter resampling for soil moisture data assimilation into hydrologic models using the particle filter. Hydrol. Earth Syst. Sci 2012, 16, 375–390. [Google Scholar]
- Doucet, A.; Gordon, N.J.; Krishnamurthy, V. Particle filters for state estimation of jump markov linear systems. IEEE Trans. Signal Process 2001, 49, 613–624. [Google Scholar]
- Kitagawa, T.; Tsunekawa, T.; Iwayama, K. Monte carlo simulations on adsorptions of benzene and xylenes in sodium-y zeolites. Microporous Mater 1996, 7, 227–233. [Google Scholar]
- Van Leeuwen, P.J. Particle filtering in geophysical systems. Mon. Weather Rev 2009, 137, 4089–4114. [Google Scholar]
- Kong, A.; Liu, J.S.; Wong, W.H. Sequential imputations and bayesian missing data problems. J. Am. Stat. Assoc 1994, 89, 278–288. [Google Scholar]
- Liu, J.S.; Chen, R. Sequential monte carlo methods for dynamic systems. J. Am. Stat Assoc 1998, 93, 1032–1044. [Google Scholar]
- Bocquet, M.; Pires, C.A.; Wu, L. Beyond gaussian statistical modeling in geophysical data assimilation. Mon. Weather Rev 2010, 138, 2997–3023. [Google Scholar]
- Ng, G.H.C.; McLaughlin, D.; Entekhabi, D.; Scanlon, B. Using data assimilation to identify diffuse recharge mechanisms from chemical and physical data in the unsaturated zone. Water Resour. Res 2009, 45. [Google Scholar] [CrossRef]
- Pan, M.; Wood, E.F.; Wojcik, R.; McCabe, M.F. Estimation of regional terrestrial water cycle using multi-sensor remote sensing observations and data assimilation. Remote Sens. Environ 2008, 112, 1282–1294. [Google Scholar]
- Qin, J.; Liang, S.L.; Yang, K.; Kaihotsu, I.; Liu, R.G.; Koike, T. Simultaneous estimation of both soil moisture and model parameters using particle filtering method through the assimilation of microwave signal. J. Geophys. Res. Atmos 2009, 114. [Google Scholar] [CrossRef]
- Miguez, J. Analysis of parallelizable resampling algorithms for particle filtering. Signal Process 2007, 87, 3155–3174. [Google Scholar]
- Errico, R.M. What is an adjoint model? Bull. Am. Meteorol. Soc 1997, 78, 2577–2591. [Google Scholar]
- Wigneron, J.P.; Olioso, A.; Calvet, J.C.; Bertuzzi, P. Estimating root zone soil moisture from surface soil moisture data and soil-vegetation-atmosphere transfer modeling. Water Resour. Res 1999, 35, 3735–3745. [Google Scholar]
- Demarty, J.; Ottle, C.; Braud, I.; Olioso, A.; Frangi, J.P.; Bastidas, L.A.; Gupta, H.V. Using a multiobjective approach to retrieve information on surface properties used in a svat model. J. Hydrol 2004, 287, 214–236. [Google Scholar]
- Demarty, J.; Ottle, C.; Braud, I.; Olioso, A.; Frangi, J.P.; Gupta, H.V.; Bastidas, L.A. Constraining a physically based soil-vegetation-atmosphere transfer model with surface water content and thermal infrared brightness temperature measurements using a multiobjective approach. Water Resour. Res 2005, 41. [Google Scholar] [CrossRef]
- Tsuyuki, T.; Miyoshi, T. Recent progress of data assimilation methods in meteorology. J. Meteorol. Soc. Jpn 2007, 85B, 331–361. [Google Scholar]
- Nodet, M. Variational assimilation of lagrangian data in oceanography. Inverse Probl 2006, 22, 245–263. [Google Scholar]
- Carrera, J.; Neuman, S.P. Estimation of aquifer parameters under transient and steady-state conditions .1. Maximum-likelihood method incorporating prior information. Water Resour. Res 1986, 22, 199–210. [Google Scholar]
- Reichle, R.H.; McLaughlin, D.B.; Entekhabi, D. Variational data assimilation of microwave radiobrightness observations for land surface hydrology applications. IEEE Trans. Geosci. Remote Sens 2001, 39, 1708–1718. [Google Scholar]
- Atanov, G.A.; Evseeva, E.G.; Meselhe, E.A. Estimation of roughness profile in trapezoidal open channels. J. Hydraul. Eng 1999, 125, 309–312. [Google Scholar]
- Bunge, H.P.; Hagelberg, C.R.; Travis, B.J. Mantle circulation models with variational data assimilation: Inferring past mantle flow and structure from plate motion histories and seismic tomography. Geophys. J. Int 2003, 152, 280–301. [Google Scholar]
- Yang, Z.Q.; Hamrick, J.M. Variational inverse parameter estimation in a cohesive sediment transport model: An adjoint approach. J. Geophys. Res. Oceans 2003, 108. [Google Scholar] [CrossRef]
- Olioso, A.; Inoue, Y.; Ortega-Farias, S.; Demarty, J.; Wigneron, J.-P.; Braud, I.; Jacob, F.; Lecharpentier, P.; Ottie, C.; Calvet, J.-C.; Brisson, N. Future directions for advanced evapotranspiration modeling: Assimilation of remote sensing data into crop simulation models and svat models. Irrigation Drainage Syst 2005, 19, 377–412. [Google Scholar]
- Caparrini, F.; Castelli, F.; Entekhabi, D. Estimation of surface turbulent fluxes through assimilation of radiometric surface temperature sequences. J. Hydrometeorol 2004, 5, 145–159. [Google Scholar]
- Jones, A.S.; Vukicevic, T.; Vonder Haar, T.H. A microwave satellite observational operator for variational data assimilation of soil moisture. J. Hydrometeorol 2004, 5, 213–229. [Google Scholar]
- Pathmathevan, M.; Koike, T.; Li, X.; Fujii, H. A simplified land data assimilation scheme and its application to soil moisture experiments in 2002 (smex02). Water Resour. Res 2003, 39. [Google Scholar] [CrossRef]
- Yang, K.; Watanabe, T.; Koike, T.; Li, X.; Fuji, H.; Tamagawa, K.; Ma, Y.M.; Ishikawa, H. Auto-calibration system developed to assimilate amsr-e data into a land surface model for estimating soil moisture and the surface energy budget. J. Meteorol. Soc. Jpn 2007, 85A, 229–242. [Google Scholar]
- Sabater, J.M.; Jarlan, L.; Calvet, J.C.; Bouyssel, F.; de Rosnay, P. From near-surface to root-zone soil moisture using different assimilation techniques. J. Hydrometeorol 2007, 8, 194–206. [Google Scholar]
- Calvet, J.C.; Noilhan, J. From near-surface to root-zone soil moisture using year-round data. J. Hydrometeorol 2000, 1, 393–411. [Google Scholar]
- Castaings, W.; Dartus, D.; Honnorat, M.; Dimet, F.-X.L.; Loukili, Y.; Monnier, J. Automatic differentiation: A tool for variational data assimilation and adjoint sensitivity analysis for flood modeling. Lect. Notes Comput. Sci. Eng 2006, 50, 249–262. [Google Scholar]
- McLaughlin, D. Environmental data assimilation: Methods and challenges. Dev. Water Sci 2004, 55, 1331–1343. [Google Scholar]
- Lu, H.S.; Yu, Z.B.; Zhu, Y.H.; Drake, S.; Hao, Z.C.; Sudicky, E.A. Dual state-parameter estimation of root zone soil moisture by optimal parameter estimation and extended kalman filter data assimilation. Adv. Water Resour 2011, 34, 395–406. [Google Scholar]
- Montaldo, N.; Albertson, J.D. Multi-scale assimilation of surface soil moisture data for robust root zone moisture predictions. Adv. Water Resour 2003, 26, 33–44. [Google Scholar]
- Lu, H.S.; Yu, Z.B.; Horton, R.; Zhu, Y.H.; Wang, Z.L.; Hao, Z.C.; Xiang, L. Multi-scale assimilation of root zone soil water predictions. Hydrol. Process 2011, 25, 3158–3172. [Google Scholar]
- Wang, S.G.; Liang, X.; Nan, Z.T. How much improvement can precipitation data fusion achieve with a multiscale kalman smoother-based framework? Water Resour. Res 2011, 47. [Google Scholar] [CrossRef]
- Pan, M.; Wood, E.F.; McLaughlin, D.B.; Entekhabi, D.; Luo, L.F. A multiscale ensemble filtering system for hydrologic data assimilation. Part I: Implementation and synthetic experiment. J. Hydrometeorol 2009, 10, 794–806. [Google Scholar]
- Vereecken, H.; Kasteel, R.; Vanderborght, J.; Harter, T. Upscaling hydraulic properties and soil water flow processes in heterogeneous soils: A review. Vadose Zone J 2007, 6, 1–28. [Google Scholar]
- Reul, N.; Tenerelli, J.E.; Floury, N.; Chapron, B. Earth-viewing l-band radiometer sensing of sea surface scattered celestial sky radiation—Part ii: Application to smos. IEEE Trans. Geosci. Remote Sens 2008, 46, 675–688. [Google Scholar]
- Dai, Y.J.; Zeng, X.B.; Dickinson, R.E.; Baker, I.; Bonan, G.B.; Bosilovich, M.G.; Denning, A.S.; Dirmeyer, P.A.; Houser, P.R.; Niu, G.Y.; et al. The common land model. Bull. Am. Meteorol. Soc 2003, 84, 1013–1023. [Google Scholar]
- Aanaes, H.; Sveinsson, J.R.; Nielsen, A.A.; Bovith, T.; Benediktsson, J.A. Model-based satellite image fusion. IEEE Trans. Geosci. Remote Sens 2008, 46, 1336–1346. [Google Scholar]
- Canty, M.J. Image Analysis, Classification, and Change Detection in Remote Sensing; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Carper, W.J.; Lillesand, T.M.; Kiefer, R.W. The use of intensity-hue-saturation transformations for merging spot panchromatic and multispectral image data. Photogramm. Eng. Remote Sensing 1990, 56, 459–467. [Google Scholar]
- Vrabel, J. Multispectral imagery band sharpening study. Photogramm. Eng. Remote Sensing 1996, 62, 1075–1083. [Google Scholar]
- Welch, R.; Ehlers, M. Merging multiresolution spot hrv and landsat tm data. Photogramm. Eng. Remote Sensing 1987, 53, 301–303. [Google Scholar]
- Daubechies, I.; Mallat, S.; Willsky, A.S. Special issue on wavelet transforms and multiresolution signal analysis—Introduction. IEEE Trans. Inf. Theory 1992, 38, 529–531. [Google Scholar]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A. Context-driven fusion of high spatial and spectral resolution images based on oversampled multiresolution analysis. IEEE Trans. Geosci. Remote Sens 2002, 40, 2300–2312. [Google Scholar]
- Ranchin, T.; Wald, L. Fusion of high spatial and spectral resolution images: The arsis concept and its implementation. Photogramm. Eng. Remote Sensing 2000, 66, 49–61. [Google Scholar]
- Das, N.N.; Entekhabi, D.; Njoku, E.G. An algorithm for merging smap radiometer and radar data for high-resolution soil-moisture retrieval. IEEE Trans. Geosci. Remote Sens 2011, 49, 1504–1512. [Google Scholar]
- Entekhabi, D.; Njoku, E.G.; O'Neill, P.E.; Kellogg, K.H.; Crow, W.T.; Edelstein, W.N.; Entin, J.K.; Goodman, S.D.; Jackson, T.J.; Johnson, J.; et al. The soil moisture active passive (smap) mission. Proc. IEEE 2010, 98, 704–716. [Google Scholar]
- Draper, C.S.; Reichle, R.H.; de Lannoy, G.J.M.; Liu, Q. Assimilation of passive and active microwave soil moisture retrievals. Geophys. Res. Lett 2012, 39. [Google Scholar] [CrossRef]
- McLaughlin, D. An integrated approach to hydrologic data assimilation: Interpolation, smoothing, and filtering. Adv. Water Resour 2002, 25, 1275–1286. [Google Scholar]
- Li, L.P.; Zhou, H.Y.; Franssen, H.J.H.; Gomez-Hernandez, J.J. Modeling transient groundwater flow by coupling ensemble kalman filtering and upscaling. Water Resour. Res 2012, 48. [Google Scholar] [CrossRef]
- Merlin, O.; Chehbouni, A.; Boulet, G.; Kerr, Y. Assimilation of disaggregated microwave soil moisture into a hydrologic model using coarse-scale meteorological data. J. Hydrometeorol 2006, 7, 1308–1322. [Google Scholar]
- Parada, L.M.; Liang, X. Optimal multiscale kalman filter for assimilation of near-surface soil moisture into land surface models. J. Geophys. Res. Atmos 2004, 109. [Google Scholar] [CrossRef]
- Chou, K.C.; Willsky, A.S.; Benveniste, A. Multiscale recursive estimation, data fusion, and regularization. IEEE Trans. Autom. Control 1994, 39, 464–478. [Google Scholar]
- Liang, X.; Lettenmaier, D.P.; Wood, E.F.; Burges, S.J. A simple hydrologically based model of land surface water and energy fluxes for general circulation models. J. Geophys. Res 1994, 99, 14415–14428. [Google Scholar]
- Digalakis, V.; Rohlicek, J.R.; Ostendorf, M. Ml estimation of a stochastic linear system with the em algorithm and its application to speech recognition. IEEE Trans. Speech Audio Proc 1993, 1, 431–442. [Google Scholar]
- Nedeltchev, N.M. Thermal microwave emission depth and soil moisture remote sensing. Int. J. Remote Sens 1999, 20, 2183–2194. [Google Scholar]
- Frakt, A.B.; Willsky, A.S. Computationally efficient stochastic realization for internal multiscale autoregressive models. Multidimens. Syst. Signal Proc 2001, 12, 109–142. [Google Scholar]
- Zhou, Y.H.; McLaughlin, D.; Entekhabi, D.; Ng, G.H.C. An ensemble multiscale filter for large nonlinear data assimilation problems. Mon. Weather Rev 2008, 136, 678–698. [Google Scholar]
- Pan, M.; Wood, E.F. Impact of accuracy, spatial availability, and revisit time of satellite-derived surface soil moisture in a multiscale ensemble data assimilation system. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens 2010, 3, 49–56. [Google Scholar]
- Burke, E.J.; Shuttleworth, W.J.; Lee, K.H.; Bastidas, L.A. Using area-average remotely sensed surface soil moisture in multipatch land data assimilation systems. IEEE Trans. Geosci. Remote Sens 2001, 39, 2091–2100. [Google Scholar]
- Montzka, C.; Grant, J.; Moradkhani, H.; Franssen, H.-J.H.; Weihermüller, L.; Drusch, M.; Vereecken, H. Estimation of radiative transfer parameters from l-band passive microwave brightness temperatures using advanced data assimilation. Vadose Zone J 2012. submitted for publication.. [Google Scholar]
- Bircher, S.; Balling, J.E.; Skou, N.; Kerr, Y.H. Validation of smos brightness temperatures during the hobe airborne campaign, western denmark. IEEE Trans. Geosci. Remote Sens 2012, 50, 1468–1482. [Google Scholar]
- Montzka, C.; Bogena, H.R.; Weihermüller, L.; Jonard, F.; Bouzinac, C.; Kainulainen, J.; Balling, J.E.; Loew, A.; Dall’Amico, J.T.; Rouhe, E.; et al. Brightness temperature and soil moisture validation at different scales during the smos validation campaign in the rur and erft catchments, germany. IEEE Trans. Geosci. Remote Sens 2012, 99, 1–16. [Google Scholar]
- Hill, T.C.; Quaife, T.; Williams, M. A data assimilation method for using low-resolution earth observation data in heterogeneous ecosystems. J. Geophys. Res. Atmos 2011, 116. [Google Scholar] [CrossRef]
- Dowd, M. Bayesian statistical data assimilation for ecosystem models using markov chain monte carlo. J. Mar. Syst 2007, 68, 439–456. [Google Scholar]
- Peters-Lidard, C.D.; Zion, M.S.; Wood, E.F. A soil-vegetation-atmosphere transfer scheme for modeling spatially variable water and energy balance processes. J. Geophys. Res 1997, 102, 4303–4324. [Google Scholar]
- Nowak, W. Best unbiased ensemble linearization and the quasi-linear kalman ensemble generator. Water Resour. Res 2009, 45. [Google Scholar] [CrossRef]
- Nan, T.C.; Wu, J.C. Groundwater parameter estimation using the ensemble kalman filter with localization. Hydrogeol. J 2011, 19, 547–561. [Google Scholar]
- Zhou, H.Y.; Gomez-Hernandez, J.J.; Franssen, H.J.H.; Li, L.P. An approach to handling non-gaussianity of parameters and state variables in ensemble kalman filtering. Adv. Water Resour 2011, 34, 844–864. [Google Scholar]
- Liu, G.S.; Chen, Y.; Zhang, D.X. Investigation of flow and transport processes at the made site using ensemble kalman filter. Adv. Water Resour 2008, 31, 975–986. [Google Scholar]
- Li, L.P.; Zhou, H.Y.; Gomez-Hernandez, J.J.; Franssen, H.J.H. Jointly mapping hydraulic conductivity and porosity by assimilating concentration data via ensemble kalman filter. J. Hydrol 2012, 428, 152–169. [Google Scholar]
- Schöniger, A.; Nowak, W.; Franssen, H.J.H. Parameter estimation by ensemble kalman filters with transformed data: Approach and application to hydraulic tomography. Water Resour. Res 2012, 48. [Google Scholar] [CrossRef]
- Camporese, M.; Paniconi, C.; Putti, M.; Salandin, P. Ensemble kalman filter data assimilation for a process-based catchment scale model of surface and subsurface flow. Water Resour. Res 2009, 45. [Google Scholar] [CrossRef]
- Paniconi, C.; Putti, M. A comparison of picard and newton iteration in the numerical-solution of multidimensional variably saturated flow problems. Water Resour. Res 1994, 30, 3357–3374. [Google Scholar]
- Paniconi, C.; Wood, E.F. A detailed model for simulation of catchment scale subsurface hydrologic processes. Water Resour. Res 1993, 29, 1601–1620. [Google Scholar]
- Orlandini, S.; Rosso, R. Diffusion wave modeling of distributed catchment dynamics. J. Hydrol. Eng 1996, 1, 103–113. [Google Scholar]
- Orlandini, S.; Rosso, R. Parameterization of stream channel geometry in the distributed modeling of catchment dynamics. Water Resour. Res 1998, 34, 1971–1985. [Google Scholar]
- Bailey, R.; Baù, D. Ensemble smoother assimilation of hydraulic head and return flow data to estimate hydraulic conductivity distribution. Water Resour. Res 2010, 46. [Google Scholar] [CrossRef]
- Bailey, R.; Baù, D. Estimating geostatistically parameters and spatially variable hydraulic conductivity within a catchment system using an ensemble smoother. Hydrol. Earth Syst. Sci 2012, 16, 287–304. [Google Scholar]
- Seo, D.J.; Koren, V.; Cajina, N. Real-time variational assimilation of hydrologic and hydrometeorological data into operational hydrologic forecasting. J. Hydrometeorol 2003, 4, 627–641. [Google Scholar]
- Burnash, R.J.C.; Ferral, R.L.; McGuire, R.A. A Generalized Streamflow Simulation System—Conceptual Modeling for Digital Computers; National Weather Service, NOAA, and the State of California Depart of Water Resources Tech. Rep.,; Joint Federal-State River Forecast Center: Sacramento, CA, USA, 1973. [Google Scholar]
- Koren, V.; Reed, S.; Smith, M.; Zhang, Z.; Seo, D.J. Hydrology laboratory research modeling system (hl-rms) of the us national weather service. J. Hydrol 2004, 291, 297–318. [Google Scholar]
- Lee, H.; Seo, D.J.; Koren, V. Assimilation of streamflow and in situ soil moisture data into operational distributed hydrologic models: Effects of uncertainties in the data and initial model soil moisture states. Adv. Water Resour 2011, 34, 1597–1615. [Google Scholar]
- Xie, X.H.; Zhang, D.X. Data assimilation for distributed hydrological catchment modeling via ensemble kalman filter. Adv. Water Resour 2010, 33, 678–690. [Google Scholar]
- Gassman, P.W.; Reyes, M.R.; Green, C.H.; Arnold, J.G. The soil and water assessment tool: Historical development, applications, and future research directions. Trans. ASABE 2007, 50, 1211–1250. [Google Scholar]
- Luzio, M.D.; Srinivasan, R.; Arnold, J.G.; Neitsch, S.L. Arcview Interface for Swat2000: User’s Guide; Blackland Research Center, Texas Agricultural Experiment Station: Temple, TX, USA, 2002. [Google Scholar]
- Neitsch, S.L.; Arnold, J.G.; Kiniry, J.R.; Williams, J.R. Soil and Water Assessment Tool, Theoretical Documentation: Version 2000; Temple: Blackland Research Center, Texas Agricultural Experiment Station: Temple, TX, USA, 2001. [Google Scholar]
- Walker, J.P.; Willgoose, G.R.; Kalma, J.D. One-dimensional soil moisture profile retrieval by assimilation of near-surface measurements: A comparison of retrieval algorithms. Adv. Water Resour 2002, 24, 631–650. [Google Scholar]
- Visser, A.; Stuurman, R.; Bierkens, M.F.P. Real-time forecasting of water table depth and soil moisture profiles. Adv. Water Resour 2006, 29, 692–706. [Google Scholar]
- Barrett, D.J.; Renzullo, L.J. On the efficacy of combining thermal and microwave satellite data as observational constraints for root-zone soil moisture estimation. J. Hydrometeorol 2009, 10, 1109–1127. [Google Scholar]
- Han, X.; Hendricks Franssen, H.J.; Li, X.; Zhang, Y.; Montzka, C.; Vereecken, H. Joint assimilation of surface temperature and l-band microwave brightness temperature in land data assimilation. Vadose Zone J. 2012. accepted for publication.. [Google Scholar]
- Pauwels, V.R.N.; Verhoest, N.E.C.; de Lannoy, G.J.M.; Guissard, V.; Lucau, C.; Defourny, P. Optimization of a coupled hydrology-crop growth model through the assimilation of observed soil moisture and leaf area index values using an ensemble kalman filter. Water Resour. Res 2007, 43. [Google Scholar] [CrossRef]
- Famiglietti, J.S.; Wood, E.F. Multiscale modeling of spatially-variable water and energy-balance processes. Water Resour. Res 1994, 30, 3061–3078. [Google Scholar]
- Vandiepen, C.A.; Wolf, J.; Vankeulen, H.; Rappoldt, C. Wofost—A simulation-model of crop production. Soil Use Manage 1989, 5, 16–24. [Google Scholar]
- Sabater, J.M.; Rudiger, C.; Calvet, J.C.; Fritz, N.; Jarlan, L.; Kerr, Y. Joint assimilation of surface soil moisture and lai observations into a land surface model. Agric. For. Meteorol 2008, 148, 1362–1373. [Google Scholar]
- Albergel, C.; Calvet, J.C.; Mahfouf, J.F.; Rudiger, C.; Barbu, A.L.; Lafont, S.; Roujean, J.L.; Walker, J.P.; Crapeau, M.; Wigneron, J.P. Monitoring of water and carbon fluxes using a land data assimilation system: A case study for southwestern france. Hydrol. Earth Syst. Sci 2010, 14, 1109–1124. [Google Scholar]
- Calvet, J.C.; Noilhan, J.; Roujean, J.L.; Bessemoulin, P.; Cabelguenne, M.; Olioso, A.; Wigneron, J.P. An interactive vegetation svat model tested against data from six contrasting sites. Agric. For. Meteorol 1998, 92, 73–95. [Google Scholar]
- Calvet, J.C.; Rivalland, V.; Picon-Cochard, C.; Guehl, J.M. Modelling forest transpiration and co2 fluxes—Response to soil moisture stress. Agric. For. Meteorol 2004, 124, 143–156. [Google Scholar]
- Calvet, J.C.; Gibelin, A.L.; Roujean, J.L.; Martin, E.; Le Moigne, P.; Douville, H.; Noilhan, J. Past and future scenarios of the effect of carbon dioxide on plant growth and transpiration for three vegetation types of southwestern france. Atmos. Chem. Phys 2008, 8, 397–406. [Google Scholar]
- Gibelin, A.L.; Calvet, J.C.; Roujean, J.L.; Jarlan, L.; Los, S.O. Ability of the land surface model isba-a-gs to simulate leaf area index at the global scale: Comparison with satellites products. J. Geophys. Res. Atmos 2006, 111, D18102. [Google Scholar]
- Draper, C.S.; Mahfouf, J.F.; Walker, J.P. Root zone soil moisture from the assimilation of screen-level variables and remotely sensed soil moisture. J. Geophys. Res. Atmos 2011, 116. [Google Scholar] [CrossRef]
- Pan, M.; Wood, E.F. Data assimilation for estimating the terrestrial water budget using a constrained ensemble kalman filter. J. Hydrometeorol 2006, 7, 534–547. [Google Scholar]
- Liang, X.; Lettenmaier, D.P.; Wood, E.F. One-dimensional statistical dynamic representation of subgrid spatial variability of precipitation in the two-layer variable infiltration capacity model. J. Geophys. Res. Atmos 1996, 101, 21403–21422. [Google Scholar]
- Liang, X.; Wood, E.F.; Lettenmaier, D.P. Modeling ground heat flux in land surface parameterization schemes. J. Geophys. Res. Atmos 1999, 104, 9581–9600. [Google Scholar]
- Durand, M.; Margulis, S.A. Feasibility test of multifrequency radiometric data assimilation to estimate snow water equivalents. J. Hydrometeorol 2006, 7, 443–457. [Google Scholar]
- Kolberg, S.; Rue, H.; Gottschalk, L. A bayesian spatial assimilation scheme for snow coverage observations in a gridded snow model. Hydrol. Earth Syst. Sci 2006, 10, 369–381. [Google Scholar]
- Durand, M.; Margulis, S.A. Effects of uncertainty magnitude and accuracy on assimilation of multiscale measurements for snowpack characterization. J. Geophys. Res. Atmos 2008, 113, D02105. [Google Scholar]
- De Lannoy, G.J.M.; Reichle, R.H.; Arsenault, K.R.; Houser, P.R.; Kumar, S.; Verhoest, N.E.C.; Pauwels, V.R.N. Multiscale assimilation of advanced microwave scanning radiometer-eos snow water equivalent and moderate resolution imaging spectroradiometer snow cover fraction observations in northern colorado. Water Resour. Res 2012, 48. [Google Scholar] [CrossRef]
- Su, H.; Yang, Z.L.; Dickinson, R.E.; Wilson, C.R.; Niu, G.Y. Multisensor snow data assimilation at the continental scale: The value of gravity recovery and climate experiment terrestrial water storage information. J. Geophys. Res. Atmos 2010, 115. [Google Scholar] [CrossRef]
- Balsamo, G.; Mahfouf, J.F.; Belair, S.; Deblonde, G. A land data assimilation system for soil moisture and temperature: An information content study. J. Hydrometeorol 2007, 8, 1225–1242. [Google Scholar]
- Barbu, A.L.; Calvet, J.C.; Mahfouf, J.F.; Albergel, C.; Lafont, S. Assimilation of soil wetness index and leaf area index into the isba-a-gs land surface model: Grassland case study. Biogeosciences 2011, 8, 1971–1986. [Google Scholar]
- Merlin, O.; Walker, J.P.; Chehbouni, A.; Kerr, Y. Towards deterministic downscaling of smos soil moisture using modis derived soil evaporative efficiency. Remote Sens. Environ 2008, 112, 3935–3946. [Google Scholar]
- Merlin, O.; Al Bitar, A.; Walker, J.P.; Kerr, Y. An improved algorithm for disaggregating microwave-derived soil moisture based on red, near-infrared and thermal-infrared data. Remote Sens. Environ 2010, 114, 2305–2316. [Google Scholar]
- Kim, J.; Hogue, T.S. Improving spatial soil moisture representation through integration of amsr-e and modis products. IEEE Trans. Geosci. Remote Sens 2012, 50, 446–460. [Google Scholar]
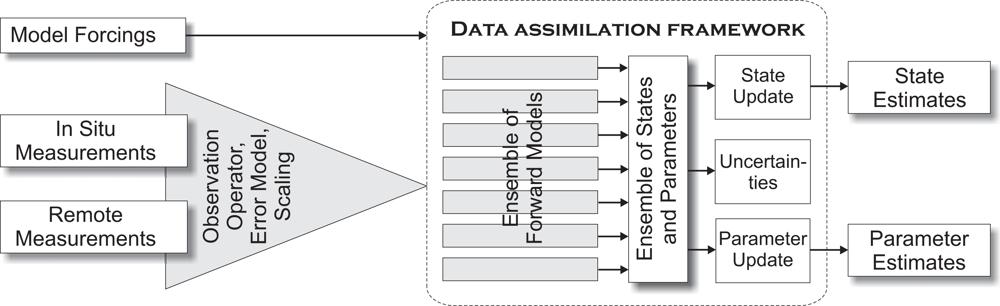
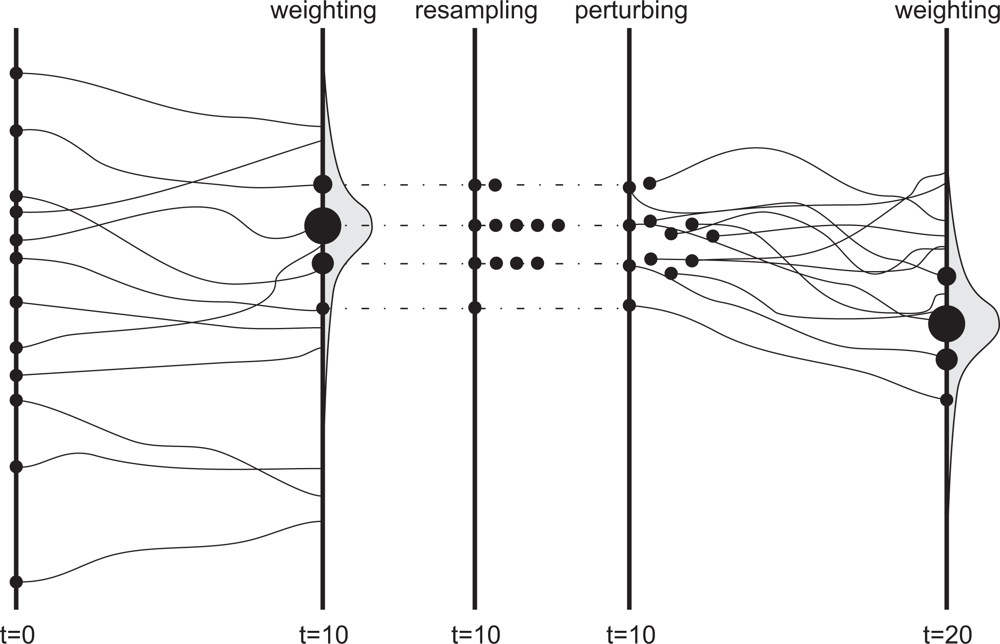
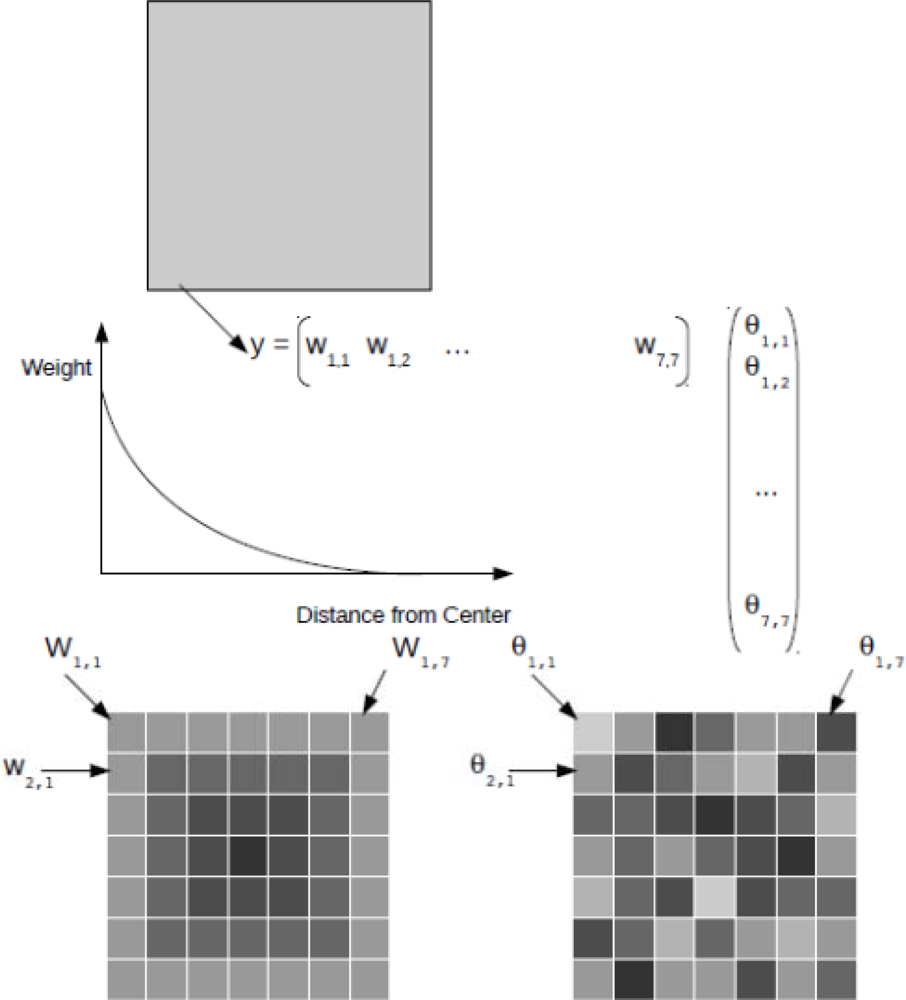
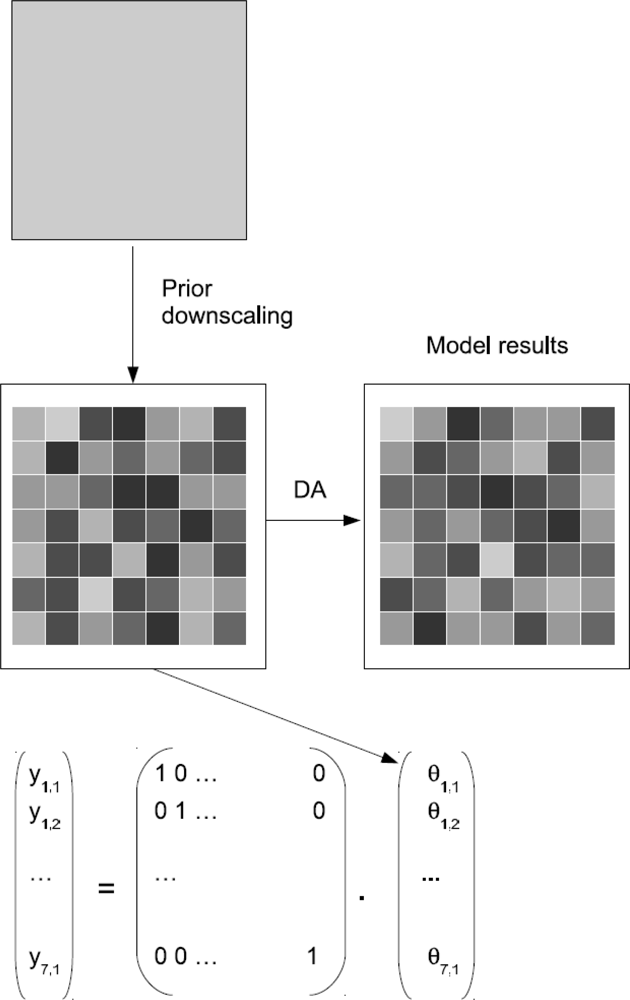
© 2012 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Montzka, C.; Pauwels, V.R.N.; Franssen, H.-J.H.; Han, X.; Vereecken, H. Multivariate and Multiscale Data Assimilation in Terrestrial Systems: A Review. Sensors 2012, 12, 16291-16333. https://doi.org/10.3390/s121216291
Montzka C, Pauwels VRN, Franssen H-JH, Han X, Vereecken H. Multivariate and Multiscale Data Assimilation in Terrestrial Systems: A Review. Sensors. 2012; 12(12):16291-16333. https://doi.org/10.3390/s121216291
Chicago/Turabian StyleMontzka, Carsten, Valentijn R. N. Pauwels, Harrie-Jan Hendricks Franssen, Xujun Han, and Harry Vereecken. 2012. "Multivariate and Multiscale Data Assimilation in Terrestrial Systems: A Review" Sensors 12, no. 12: 16291-16333. https://doi.org/10.3390/s121216291