Analytic Performance Prediction of Track-to-Track Association with Biased Data in Multi-Sensor Multi-Target Tracking Scenarios

Abstract
: An analytic method for predicting the performance of track-to-track association (TTTA) with biased data in multi-sensor multi-target tracking scenarios is proposed in this paper. The proposed method extends the existing results of the bias-free situation by accounting for the impact of sensor biases. Since little insight of the intrinsic relationship between scenario parameters and the performance of TTTA can be obtained by numerical simulations, the proposed analytic approach is a potential substitute for the costly Monte Carlo simulation method. Analytic expressions are developed for the global nearest neighbor (GNN) association algorithm in terms of correct association probability. The translational biases of sensors are incorporated in the expressions, which provide good insight into how the TTTA performance is affected by sensor biases, as well as other scenario parameters, including the target spatial density, the extraneous track density and the average association uncertainty error. To show the validity of the analytic predictions, we compare them with the simulation results, and the analytic predictions agree reasonably well with the simulations in a large range of normally anticipated scenario parameters.1. Introduction
In distributed multi-sensor surveillance systems, the process of associating sets of local estimates from multiple sensors is a fundamental problem, named track-to-track association (TTTA) [1,2]. It is valuable for predicting the performance of TTTA, not only in multi-sensor tracking system design, but also in subsequent situation assessment and on-line resource allocation, such as sensor tasking. Generally, performance evaluation mainly depends on Monte Carlo simulations, which are expensive and time-consuming. Furthermore, little insight can be obtained for the intrinsic relationship between the relevant scenario parameters and the performance based on numerical simulations. Therefore, analytic prediction of data association performance, which does not resort to detailed and costly simulations, is of significant practical and theoretical importance.
With respect to the analytic performance prediction of data association, Sea and Singer did pioneering work on the performance analysis of the nearest neighbor (NN) algorithm [3,4]. Saha provided a methodology for predicting the performance of a logic based ESM/radar TTTA algorithm [5]. Li et al. introduced the hybrid conditional averaging technique to predict the performance of the NN tracker [6]. Mei et al. gave the formula to calculate the theoretical probability of false association for TTTA using multiscan data [7]. Mori et al. derived an analytic expression, named the exponential law, to predict the performance of the global nearest neighbor (GNN) algorithm in terms of the probability of correct association [8,9]. On the basis of Mori's work [8], Ruan et al. developed an analytic performance prediction method for the feature-aided GNN algorithm [10]. Some oversimplified assumptions were employed in the derivations, including no false alarm, perfect detection, identical diagonal elements and all other identical elements in the feature confusion matrix, etc. Areta et al. presented procedures to calculate the probability that the measurement or the track originating from an extraneous target misassociated with a target of interest for the cases of NN and GNN association [11,12]. Mori et al. quantified the utility of additional feature/attribute information for TTTA in [13]. Although these works exhibit various degrees of success, they all do not take the impact of sensor biases on TTTA into consideration.
In performing multi-target tracking with a sensor network, the systematic errors, i.e., sensor biases, can hinder the fusion of data from multiple sensors. Specifically, TTTA is always problematic with biased data, while sensor bias registration usually requires correctly associated data. That is, association and registration actually affect each other [14,15]. To fix this problem, many approaches were proposed to formulate association and registration as a joint optimization problem. However, these joint problems are very difficult to solve, due to the combinatorial nature of the problem and the non-convexity of the objective function [14–19]. Suboptimal solutions are obtained by performing association and registration in an alternately iterative manner. To a certain degree, the prediction of TTTA performance with biased data is also helpful for designing these joint association and registration algorithms.
A number of TTTA algorithms are built upon the GNN criterion [1,2,16,20–23]. Most of them can be decomposed into two steps. The first step is to construct a matrix of association costs (or negative log-likelihood) between two sets of tracks. The second step usually consists of running a linear assignment algorithm on this cost matrix to determine the maximum likelihood association by globally minimizing the cost. The construction of the cost matrix was well discussed in [22–24]. For the second step, many optimal linear assignment algorithms, such as Munkres [25], Jonker-Volgenant [26] and Jonker-Volgenant-Canstenon [27], can be adopted to identify the optimal associations. In this paper, we pay particular attention to predicting the performance of the GNN association algorithm with biased data analytically It should be noted that Castella [28] did consider the influence of biases on the performance of the multiple site track correlation technique proposed by Singer and Kanyuck [29], but the TTTA method of Singer and Kanyuck applies a gating technique and makes the association decision based on the NN rule, rather than the GNN criterion. The goal of our study is to extend the results in [8,9], which established an effective approach for predicting the performance of the optimal assignment algorithms, in an attempt to incorporate the impact of sensor biases.
The rest of the paper is structured as follows. Section 2 describes the single-scan TTTA problem. Section 3 presents the existing analytic prediction results of the bias-free situation. Section 4 provides the analytic prediction results for the GNN association algorithm with biased data. These results are verified via simulations in Section 5. Section 6 concludes the paper.
2. Problem Statement
In this paper, we consider a two-sensor single-scan TTTA problem. Although TTTA using multi-scan data has been theoretically proven to be better than that using single-scan data in [7], the former has higher computational complexity and may, in practice, exhibit lower power. That is because using multiscan data increases the degree of freedom of the test statistics, which has a negative impact on the power of the test [30,31]. Therefore, we focus on the single-scan TTTA problem, which is a data association problem with two random point sets in an m-dimensional Euclidean space,
 m.
m.
At a given time (without the time argument, for simplicity), the track set available at sensor A is denoted by
, where yi ∈
m and
are the state estimate and error covariance matrix of the i-th target at sensor A, respectively; Na represents the number of tracks available at sensor A. Similarly to sensor A, the track set made by sensor B is
where zj ∈
m and
are the state estimate and error covariance matrix of the j-th target at sensor B, respectively; Nb represents the number of tracks available at sensor B. Let y0 and z0 represent the dummy tracks of sensor A and B, respectively. When a track in a list is not associated with any track from the other list, it will be assigned to the dummy track. Following [8,32], we can define the association between the two track sets as a one-to-one mapping, a. Its domain is Dom(a) ⊆ = {1,…, NA}, and its range is Rng(a) ⊆
 = {1, …, NB}. For i ∈ Dom(a), a(i) is the index of the track from sensor B associated with track i from sensor A. Tracks in \ Dom(a) are associated with z0, while tracks in
\ Range(a) are assigned to y0.
= {1, …, NB}. For i ∈ Dom(a), a(i) is the index of the track from sensor B associated with track i from sensor A. Tracks in \ Dom(a) are associated with z0, while tracks in
\ Range(a) are assigned to y0.
Let a* be the ground-truth association mapping. The track model is given as follows. We assume that sensors have translational biases on their local estimates of targets. The biases are modeled as additive constants. For a common target, i, we have:
The association can also be defined as an (NA + 1) ×(NB + 1) matrix h between and , with (i, j) element hij for i = 1, …, NA + 1, j = 1, …, NB + 1, such that
The relationship between a and h is: if a(i) = j, then hij = 1; if i ∈ \ Dom(a), then hi,0 = 1; if j ∈
\ Range(a), then h0,j = 1; otherwise hi,j = 0.
The GNN algorithm determines the best association decision from all possibilities by minimizing the overall cost [1,2]:
Constraints (5) and (6) guarantee that each track from a list is assigned to one and at most one track from the other list or to the dummy track. In problem (4), Dij (i, j ≠ 0) is the cost between yi and zj, defined by their normalized distance as:
In the GNN algorithm, the probability of correct association, PC, of target i is defined as:
3. Previous Results with Bias-Free Data
Mori et al. [8,9] derived the analytic expression for the correct association probability, PC, of the GNN algorithm with bias-free data (i.e., bA = 0 in Equation (1), bB = 0 in Equation (2)), which obeys an exponential law:
The relevant parameters and assumptions used in Equations (10) and (11) (also effective in the subsequent analysis) are given as follows.
Cm is a constant defined by:
where:and Bm is the volume of the unit m-dimensional ball:βT denotes the spatial density of targets defined as the expected number of targets in a unit volume of the measurement space,
![Sensors 13 12244i1]() m:
m:
Targets are assumed to be independently identically distributed with a common distribution, which is uniform on a m-dimensional ball, with a large enough radius, r. The target number, NT, is a Poisson random variable with a mean, λT, that is:
Dm is a constant given by:
where:βF denotes the spatial density of extraneous objects:
The states of the extraneous objects share the same distribution with targets. The number of false objects, NF, is another Poisson random variable with mean λF, that is:
σ̄ is the average innovation standard deviation.
Actually, the results of Equations (10) and (11) are specified for measurement-to-track association in single-sensor multi-target tracking problems. The novelty of this paper is to extend these results to the TTTA problem with biased data in multi-sensor multi-target tracking applications.
4. Analytic Performance Prediction of the GNN Algorithm with Biased Data
In this section, we consider the impact of sensor biases and propose the analytic prediction results for the GNN algorithm.
4.1. Association without Extraneous Tracks
First, we start with the two-target case, target i and j (i ≠ j). An optimal association, â, is correct, i.e., â(i) = a*(i) and a(j) = a*(j), if and only if the cost of the correct association is less than that of the incorrect association, that is:
Considering track model (1) and (2), we have:
Then, Equation (23) is equivalent to:
Thus, based on the detailed derivations in Appendix A, the probability of correct association with two targets is:
It is very difficult to extend Equation (30) to the multi-target case, because the incorrect associations may have more complicated errors besides the two-object transposition, such as the multi-object transposition. To overcome this difficulty, let the event, EC{â(i) = a*(i)} (target i is correctly associated), be approximated by the event that there is no two-object transposition of ΔJij > 0 involving target i. With Equation (16) and a further assumption that the event {Δ Jij > 0} is independent for each j, i.e., each “potential” transposition is independent, we have:
Generally, r ≫ σ̄. Hence:
To maintain consistency with [8–10], Equation (42) is used in the following discussions. Since the bias terms are canceled out in Equations (24) and (25), Equation (42) is the same as (10), which does not account for sensor biases. Then, we can see that without extraneous and missed tracks, the translational biases do not affect the performance of the GNN association algorithm.
4.2. Extraneous Tracks Only Existing in One Track Set
In Section 4.1, we assumed that the cardinalities of the two given random point sets are identical. In reality, false tracks may disturb the situation. In this section, we discuss the effects of false tracks on the TTTA performance with biased data, in which there are false tracks only in the track set of sensor B. The event, EC{â(i) = a*(i)}, can be written as
We can use the result of Equation (42) for P(ECT). The focus now is to analyze P(ECF) in the situation where sensors have translational biases.
Given an extraneous track, ze, and the target track, za*(i), from sensor B, let Pie be the probability that ze is not associated with yi, that is:
Without loss of generality, let yi = 0. Then, Equation (45) is equivalent with:
According to the track model (1), we can get the real state of target i, for the form only, as:
Consequently, together with Equations (2) and (47), we have:
 (Δb, S). Thus,
is distributed according to the noncentral chi-squared distribution with the degree of freedom, m, and the noncentrality parameter, δ, i.e.,
[36]. The noncentrality parameter, δ, is:
(Δb, S). Thus,
is distributed according to the noncentral chi-squared distribution with the degree of freedom, m, and the noncentrality parameter, δ, i.e.,
[36]. The noncentrality parameter, δ, is:
Assuming that the extraneous track, ze, is uniformly distributed on the m-dimensional ball with radius r, the distribution of can be expressed as:
Let ; then, its probability density function is
Let and the probability density function of X be denoted by fX (x; m, δ). Considering that the extraneous track, ze, and the target track, za*(i), are independent, the joint probability density function of random variables, X and Y, can be calculated as:
Then, we have:
If m = 2k and k is a positive integer, Equation (63) becomes
When there are NF false tracks in the track set of sensor B, with the independence assumption, the probability that no extraneous track is associated with yi is
Under the assumption of the false track number in Equation (20), we have:
By substituting Equations (42) and (71) into Equation (44), we have:
When there are no extraneous tracks, i.e., βF = 0, Equation (76) is the same with Equation (42). The effect of sensor biases is coupled with false tracks by the multiplying factor, . With m = 2, we have Cm = π, ; then:
In addition, if sensors do not have biases (or have the same translational biases), i.e., Δb = 0, then δ = 0, , and
4.3. Extraneous Tracks Existing in Both Track Sets
When false tracks exist in both track sets, with a simple generalization of Equation (43), we have:
Comparing Equation (82) with (76), it seems that the situation with false tracks in both track sets has the same difficulty with that in only one sensor. However, this is not true. As shown in Section 5.3, the relative quantities of false tracks between sensors have a large impact on the PC; so, the simple sum of βFA+ βFB in Equation (82) is not sufficient to reflect the intrinsic impact of false tracks on the correct association probability. Other risks in analytic performance prediction using Equation (82) will be examined through simulations in Section 5.3. Here, we just give the main conclusion that in a large range of normally anticipated operating conditions, Equation (82) can be used as an upper bound for the performance of the GNN association algorithm in terms of the correct association probability.
5. Simulation
To show the validity of our theoretical analysis, we test the above analytic results by comparing them to the simulation results. We consider the single-scan TTTA problem and make use of the Munkres algorithm to solve the GNN assignment problem [25]. The scenario consists of two sensors tracking multiple targets. The targets are distributed uniformly in a two-dimensional ball space (m = 2) with target extent radius r. The number of targets is a Poisson variable with mean λT = 20, and the target spatial density is varied by changing r. The random error covariance matrices of the target state estimates are presumed to satisfy PA = PB. The correlation among tracks from different sensors due to the common process noise is neglected in the following simulations, and the detailed analysis and simulations for the correlated tracks can be found in [33,34]. Sensors may report extraneous tracks, which are assumed to have the same spatial distribution with the target state. The track detection probability of each sensor is presumed to be one. Since the translational biases are in Cartesian coordinates, only the difference of them is observable. Therefore, the relative biases between sensors, instead of the absolute biases of each sensor, are considered in simulation. Let Δbx, Δby represent the relative translational biases in the x,y coordinate, respectively. All of the simulation results are based upon 500 Monte Carlo runs.
5.1. No Extraneous Tracks
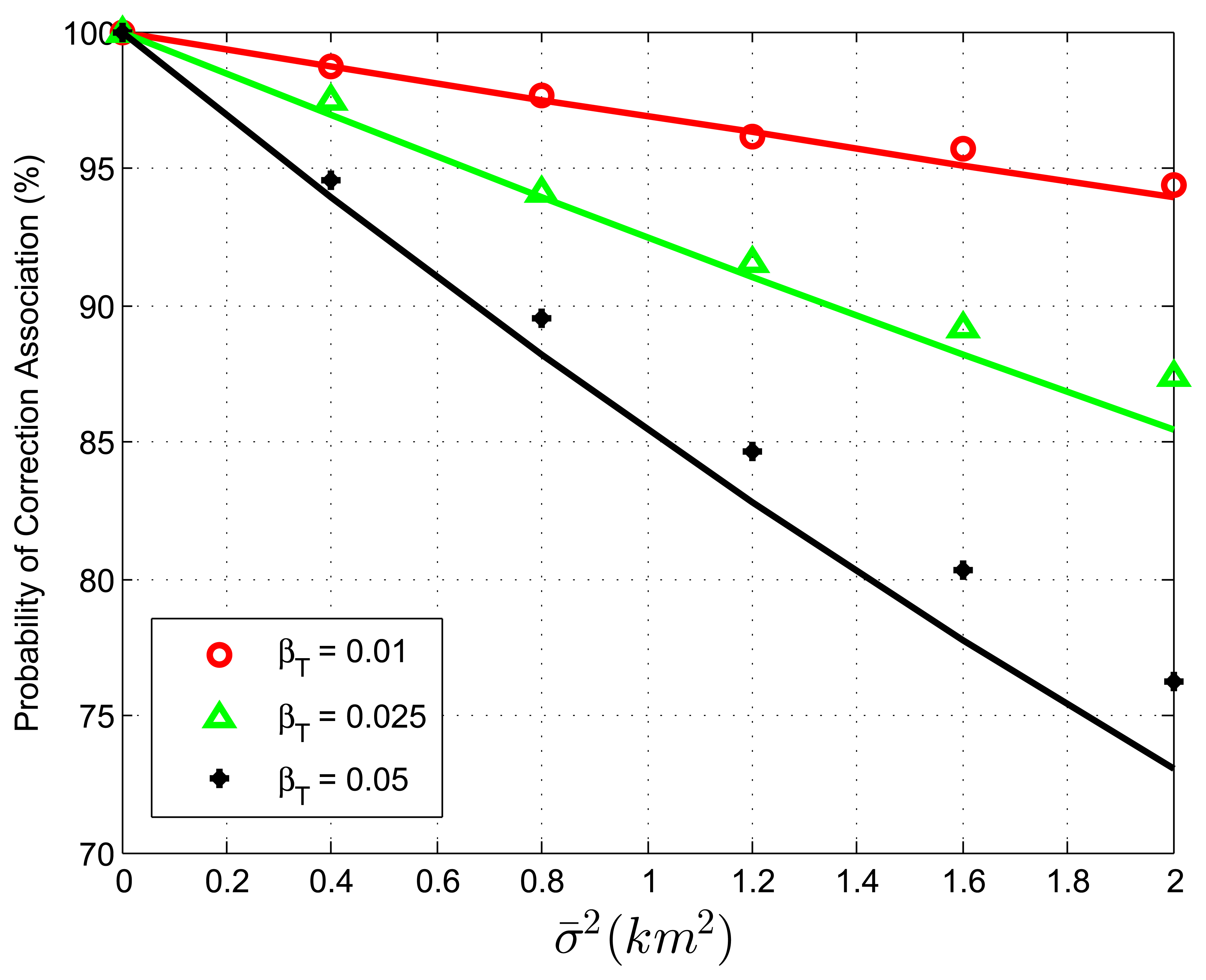
When we study the validity of Equation (42) with biased data and no extraneous tracks, two simulation experiments are designed. The target spatial density, βT, is set to be 0.01, 0.025, 0.05 reports/km2, with the target extent radius r being 25.23, 15.95, 11.28 km, respectively. In the first experiment, the average association uncertainty covariance matrix is fixed to be S = diag[1, 1] km2, while Δbx, Δby vary from −3 km to 3 km in increments of 1 km. Tables 1, 2 and 3 show that the correct association probability, PC, obtained by simulations remains approximately unchanged and matches the analytic prediction well, even if the sensor biases vary in a big range. That is because, when no extraneous tracks exist, the PC of the GNN association algorithm is not associated with translational biases in Equation (42). From the comparison between Tables 1, 2 and 3, the theoretical PC value given by Equation (42) is less accurate as the track density increases. An explanation of this phenomenon is that, although the assumption of a large enough r is necessary in the derivation of Equation (42), the target extent radius, r, is not large enough under a high target density. Another possible reason might originate from the more complicated association errors, i.e., multi-object transpositions, which we did not model. However, the statistics concerning such “high-order” transpositions are not clear at the moment. In the second experiment, sensor biases are fixed to be Δbx = Δby = 1 km, while the average association variance, σ̄2, varies from 0 km2 to 2 km2 in increments of 0.4 km2. Figure 1 plots the correct association probability, PC, as a function of σ̄2, and each point is compared with the prediction (solid line) by Equation (42). The analytic prediction results match the simulation results very well, with a few exceptions: when the targets are dense and the average association variance is large. In view of the approximations we have employed, including some quite “bold” ones, such as the independent transposition assumption, this consistency between the simulation results and the theoretical prediction is rather remarkable.
5.2. Extraneous Tracks Only in One Track Set
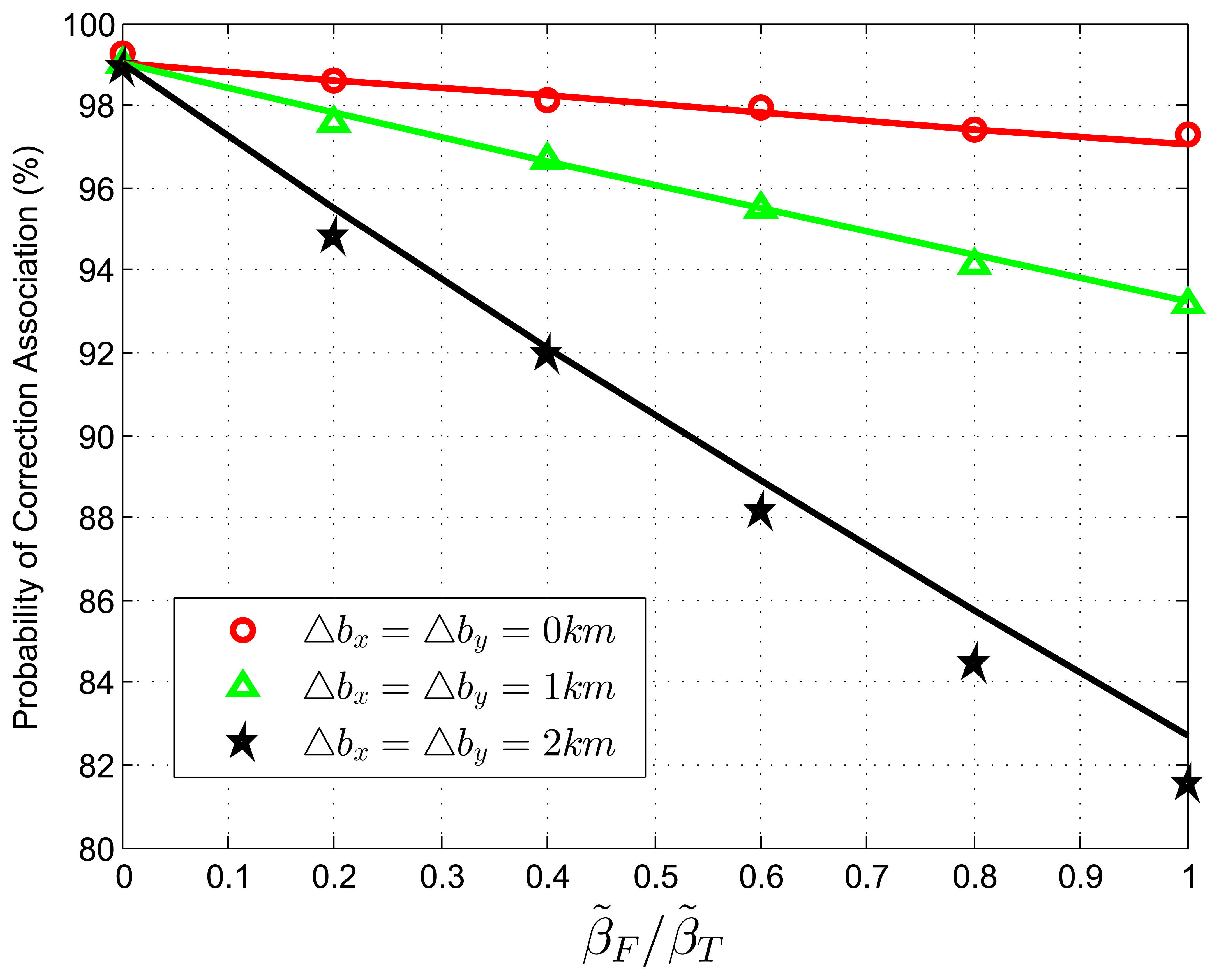
When we test Equation (76) with extraneous tracks in the track set of sensor B, the normalized target density, β˜T, is fixed to be 0.05 reports, with the average association uncertainty covariance matrix, S = diag[0.5, 0.5] km2, and the target extent radius, r = 14.14 km. The relative translational biases are set as Δbx = Δby = 0, 1, 2 km. The ratio, β˜F/β˜T, is changed from zero to one in increments of 0.2. In each Monte Carlo run, false tracks are added according to given densities. Figure 2 shows the correct association probability as a function of the ratio, β˜F/β˜F, which determines the relative density of extraneous tracks to target tracks. The analytic prediction results (solid lines) match the simulation results (points) very well, and they perform better matching when small sensor biases occur.
5.3. Extraneous Tracks in Both Track Sets
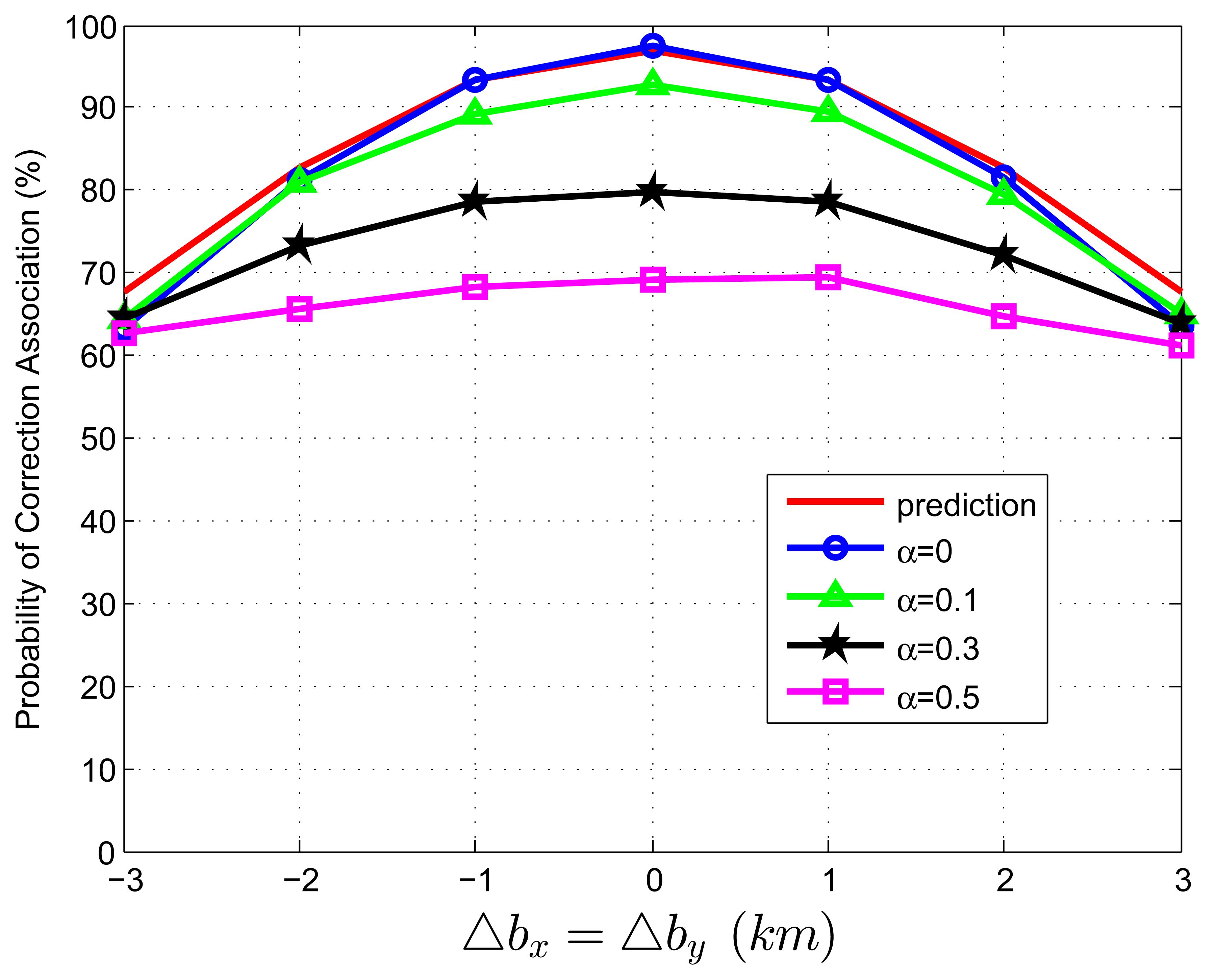
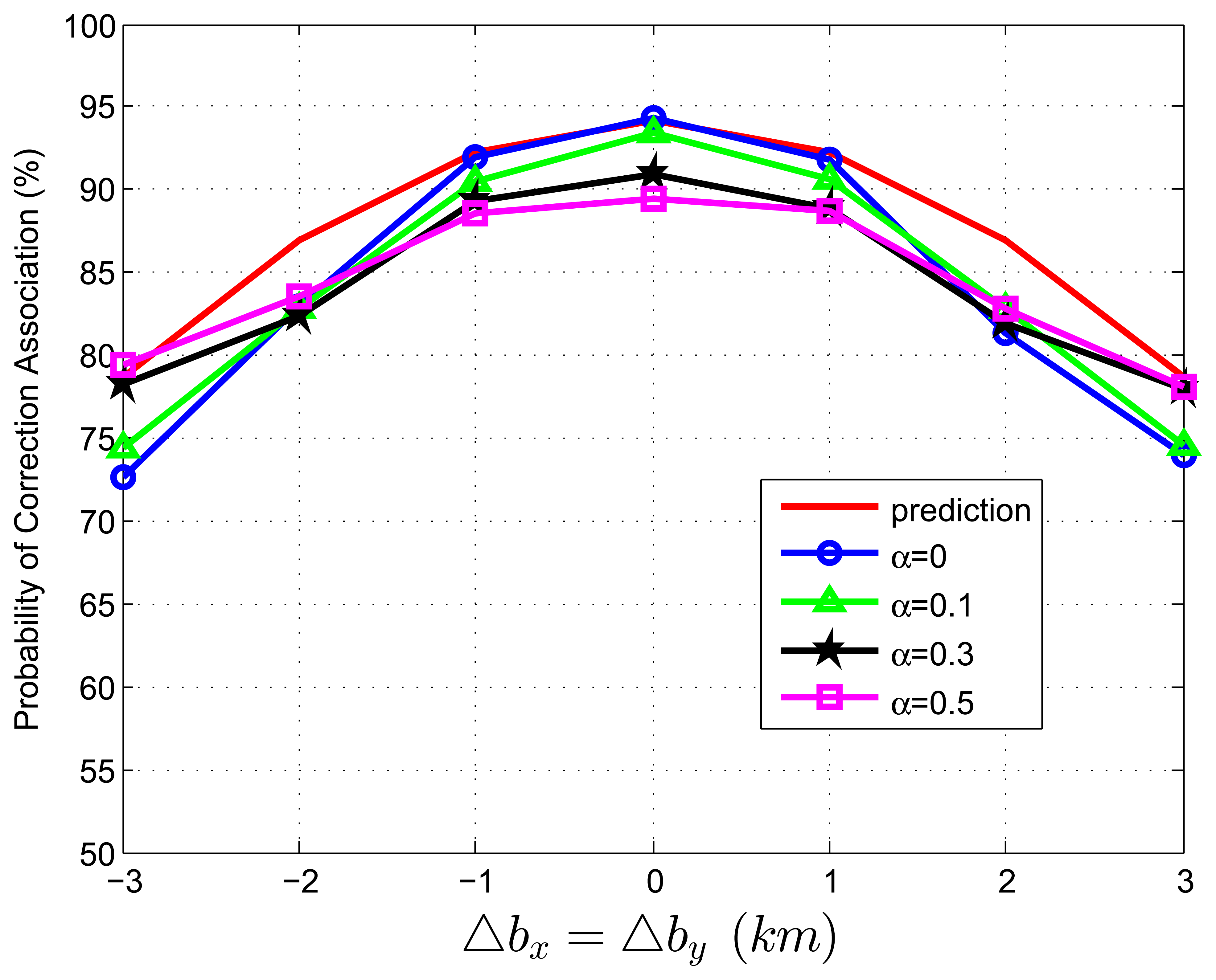
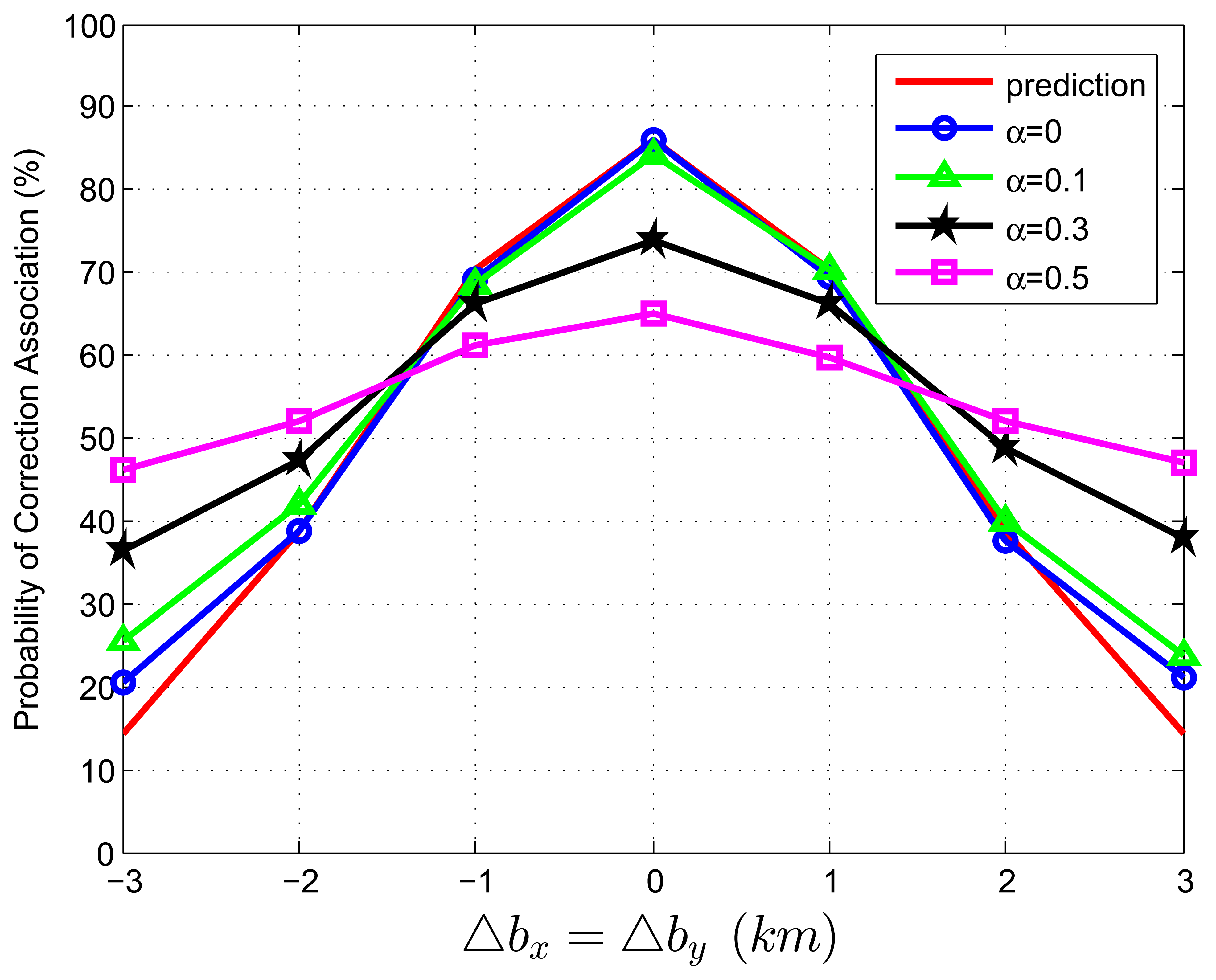
When we test Equation (82) with extraneous tracks in both track sets, the average association covariance matrix is set to be S = diag[0.5, 0.5] km2, and Δbx is assumed to be equal with Δby varying from -3 km to 3 km in increments of 1 km. Let β˜F be the total normalized density of extraneous tracks, and β˜F = β˜FA + β˜FB. Let α be the ratio of false tracks from sensor A, and α = β˜FA/β˜F. Given the total density of false tracks, the parameter, α, reflects the allocation (or the relative quantity) of the extraneous tracks between sensor A and B. Four cases of α (α = 0, 0.1, 0.3, 0.5) are considered in the simulations. To better understand the prediction performance of Equation (82), two groups of simulation experiments are performed. In the first group, the normalized target spatial density, β˜T, is fixed to be 0.01 reports (accordingly, r is set as 31.62 km). Figures 3 and 4 plot the correct association probability as a function of sensor biases, with β˜F = 0.1β˜T and β˜F = β˜T, respectively. In the second group, β˜T is fixed to be 0.05 reports (accordingly, r is 14.14 km). Figures 5 and 6 plot the correct association probability as a function of sensor biases, with β˜F = 0.1β˜T and β˜F = β˜T, respectively.
Since a series of assumptions are made in the derivation of Equation (82), the prediction accuracy degrades in the scenario where false tracks exist in both sensors. When the number of extraneous objects is far less than the number of targets (β˜F = 0.1β˜T), the prediction results are an upper bound for the simulation results, and the prediction deviation is below 7%, as shown in Figures 3 and 5. While there are a lot of false tracks (β˜F = β˜T) in Figures 4 and 6, Figure 4 shows that, in the sparse-target scenario (β˜T = 0.01 reports), even with lots of false tracks, Equation (82) can also be used as an upper bound for the simulation results. Comparing Figure 6 with Figures 3, 4 and 5, we can see that this prediction upper bound becomes invalid only in the scenario with a high target density (β˜T = 0.05 reports), a high false track density (β˜F = β˜T) and large sensor biases (| Δbx| > 1.3km). Meanwhile, the prediction departure becomes larger as α increases. The fundamental reason for the prediction departure is not clear at this point. Two possible explanations are given as follows. First, in this complicated scenario, especially with a large α (≤ 0.5), false tracks of different sensors may associate with each other. This leads to a “reduction” of the false track density. In this sense, βFA + βFB in Equation (82) overestimates the density of false tracks. In addition, this false track “reduction” effect can be amplified under large sensor biases, since the multiplying factor, , in Equation (82) is a quadratic function of sensor biases. Second, when both track sets have false tracks, the multi-object transpositions we did not model are apt to occur. Yet, for all that, under large sensor biases and a large α (in Figure 6), the extreme pessimistic tendency of the prediction does not matter very much, because it appears only when PC is quite small (below 50%).
To sum up, in a large range of normally anticipated operating conditions, Equation (82) can be used as an upper bound for the simulation results. Further investigations are needed to provide a more accurate prediction of TTTA in the cases where false tracks exist in both sensors.
6. Conclusion
In this paper, we proposed an analytic performance prediction method for the GNN association algorithm with biased data in multi-sensor multi-target tracking applications. The probability of correct association is adopted as the performance criteria. The novelty of the method lies in that it accounts for the sensor biases in the TTTA problem, and analytic approaches are developed to reveal the intrinsic relationship between a set of key scenario parameters and the performance of the optimal TTTA algorithm. To verify the validity of the predictions, we compared them with the results of Monte-Carlo simulations. These shows that the analytic predictions agree reasonably well with the simulation results. In a word, the main results of the paper are as follows:
- (1)
When both track sets are free from extraneous tracks, the correct association probability of the GNN association algorithm in Equation (42) has nothing to do with the translational biases of sensors. It is only related with target spatial density and the average association errors.
- (2)
When one track set suffers from extraneous tracks, an exponential law was given in Equation (76), which uncovers the relationship between the correct association probability and the scenario parameters, including the average association errors, sensor biases, the target spatial density, as well as the false track density. The impact of sensor biases is embodied by an amplification coefficient of the false track density.
- (3)
When both track sets contain extraneous tracks, an analytic upper bound of the correct association probability for the GNN association algorithm was proposed in Equation (82), which is effective in a large range of scenario parameters.
A series of assumptions were made to get concise and explicit mathematical results, including no missed detection, the translational bias model, identical association uncertainty covariance on all tracks, etc. The results derived based on these assumptions are not intended to be used directly in practice. The major contribution of the paper is to help designers understand the intrinsic relationship between a set of key scenario parameters and the performance of TTTA and to demonstrate the possibility that analytic performance prediction can be a potential substitute for the costly Monte Carlo simulation method.
To make the proposed analytic method more practical, a lot of work is needed in the following directions:
- (1)
Further investigations are needed to improve the prediction accuracy of our method in the scenario where false tracks exist in both sensors. The statistics concerning the more complicated association error,s such as multi-object transpositions, can be addressed in the future.
- (2)
For simplicity, we assumed that the track detection probabilities of both sensors are one. However, missed detections and false tracks do happen in real environments. To complicate matters, when missed detections occur at one sensor, the corresponding tracks that are supposed to associate with these missed tracks in the track set of the other sensor are equivalent to extraneous tracks for the remaining tracks of the former sensor. When sensors suffer from both missed detections and extraneous tracks, accounting for the missed detections in the formula of the correct association probability needs to be investigated in the future.
- (3)
We only examined the impact of translational biases on the performance of TTTA. Since the impact of translational biases on the tracks is uncoupled with the states of targets, the translational biases can be named state-independent biases. However, in some applications, sensors can have biases on their range and azimuth measurements. The impact of these biases on the position estimates of targets is dependent on the real states of targets. Therefore, we name the range and azimuth biases the state-dependent biases. Under the scenario with state-dependent biases, the bias terms cannot be canceled out in Equations (24) and (25). Thus, the state-dependent biases affect the performance of the GNN association algorithm, even if there are no false tracks and missed detections. How to deal with the more complicated state-dependent biases in analytic performance prediction is left for the future.
Acknowledgments
The authors would like to thank the anonymous reviewers for their careful review and detailed comments, which have greatly improved the readability and contents of this paper.
In this appendix, we give the derivation of Equation (30). Most of the results in this appendix are taken from [8].
Consider the case where target i is located at the origin, while target j is at a random position according to the uniform distribution within the m-ball with radius r. Then, we have:
 (r) with
m, assuming that r is large enough. By using a kind of spherical integral shown in Appendix B, we have:
(r) with
m, assuming that r is large enough. By using a kind of spherical integral shown in Appendix B, we have:
Then, based on Equations (88) and (91), we have:
In this appendix, a kind of spherical integral, used in the derivation of Equation (30), is given by [38]. Let m be a positive integer and f be a real valued measurable function defined on [0, ∞), such that f(a) ≥ 0 for all a. Then, we have:
m, and Bm is the volume of the unit ball in
m.Conflicts of Interest
The authors declare no conflicts of interest.
References
- Blackman, S.S.; Popoli, R. Design and Analysis of Modern Tracking Systems; Artech House: Norwood, MA, USA, 1999. [Google Scholar]
- Bar-Shalom, Y.; Willett, P.K.; Tian, X. Tracking and Data Fusion; YBS publishing: Storrs, CT, USA, 2011. [Google Scholar]
- Sea, R.G. An Efficient Suboptimal DecisionProcedure for Associating Sensor Data with Stored Tracks in Real-Time Surveillance Systems. Proceeding of 1971 IEEE Conference on Decision and Control, Miami Beach, FL, USA, December 1971; pp. 33–37.
- Singer, R.; Sea, R.G. New results in optimizing surveillance system tracking and data correlation performance in dense multitarget environments. IEEE Trans. Autom. Control 1973, 18, 571–582. [Google Scholar]
- Saha, R.K. Analytical Evaluationof an Esm/Radar Track Association Algorithm. Proceeding of Signal and Data Processing of Small Targets, Orlando, FL, USA, April 1992; pp. 338–347.
- Li, X.R.; Bar-Shalom, Y. Tracking in clutter with nearest neighbor filters: Analysis and performance. IEEE Trans. Aerosp. Electron. Sys. 1996, 32, 995–1010. [Google Scholar]
- Mei, W.; Shan, G. Performance of a multiscan track-to-track association technique. Signal Process. 2005, 85, 1493–1500. [Google Scholar]
- Mori, S.; Chang, K.C.; Chong, C.Y. Performance analysis of optimal data association with applications to multiple target tracking. Multitarg. Multisens. Track. Appl. Adv. 1992, 2, 183–235. [Google Scholar]
- Mori, S.; Chang, K. C.; Chong, C.Y.; Dunn, K.P. Prediction of track purity and track accuracy in dense target environments. IEEE Trans. Autom. Control 1995, 40, 953–959. [Google Scholar]
- Ruan, Y.; Hong, L.; Wicker, D. Analytic performance prediction of feature-aided global nearest neighbour algorithm in dense target scenarios. IET Radar Sonar Navig. 2007, 1, 369–376. [Google Scholar]
- Areta, J.A.; Bar-Shalom, Y.; Rothrock, R. Misassociation probability in M2TA and T2TA. J. Adv. Inf. Fusion 2007, 2, 113–127. [Google Scholar]
- Areta, J.A.; Bar-Shalom, Y.; Rothrock, R. The Probability of Misassociation Between Neighboring Targets. Proceedings of Signal and Data Processing of Small Targets, Orlando, FL, USA, 16 March 2008; pp. 69691B:1–69691B:11.
- Mori, S.; Chong, C.Y.; Chang, K.C. Performance Prediction of Feature Aided Track-to-Track Association. Proceedings of the 14th International Conference on Information Fusion (FUSION 2011), Chicago, IL, USA, 5–8 July 2011; pp. 1–8.
- Chen, S.; Leung, H.; Bosse, E. A Maximum Likelihood Approach to Joint Registration, Association and Fusion for Multi-Sensor Multi-Target Tracking. Proceeding of 12th International Conference on Information Fusion (FUSION 2009), Seattle, WA, USA, 6–9 July 2009; pp. 686–693.
- Li, Z.; Chen, S.; Leung, H.; Bosse, E. Joint data association, registration, and fusion using em-kf. IEEE Trans. Aerosp. Electron. Sys. 2010, 46, 496–507. [Google Scholar]
- Moy, G.; Blaty, D.; Farber, M.; Nealy, C. Fusion of Radar and Satellite Target Measurements. Proceeding of Sensors and Systems for Space Applications IV, Orlando, FL, USA, 16 May 2011; pp. 804405–804405.
- Papageorgiou, D.J.; Sergi, J.D. Simultaneous Track-to-Track Association and Bias Removal Using Multistart Local Search. Proceeding of IEEE Aerospace Conference, Big Sky, MT, USA, 1–8 March 2008; pp. 1–14.
- Danford, S.; Kragel, B.; Poore, A. Joint Map Bias Estimation and Data Association: Algorithms. Proceeding of Signal and Data Processing of Small Targets, San Diego, CA, USA, 26 August 2007; pp. 66991E:1–66991E:18.
- Levedahl, M. Explicit Pattern Matching Assignment Algorithm. Proceedings of Signal and Data Processing of Small Targets, Orlando, FL, USA, 1 April 2002; pp. 461–469.
- Deb, S.; Yeddanapudi, M.; Pattipati, K.; Bar-Shalom, Y. A generalized sd assignment algorithm for multisensor-multitarget state estimation. IEEE Trans. Aeros. Electron. Sys. 1997, 33, 523–538. [Google Scholar]
- Pattipati, K.R.; Kirubarajan, T.; Popp, R.L. Survey of assignment techniques for multitarget tracking. Multitarg. Multisens. Track. Appl. Adv. 2000, 3, 77–159. [Google Scholar]
- Hurley, M.B. Track Association with Bayesian Probability Theory; Technical Report 1085; Massachusetts Institute of Technology Lincoln Laboratory: Cambridge, MA, USA; October; 2003. [Google Scholar]
- Kaplan, L.; Bar-Shalom, Y.; Blair, W. Assignment costs for multiple sensor track-to-track association. IEEE Trans. Aeros. Electron. Syst. 2008, 44, 655–677. [Google Scholar]
- Blair, W.D.; Kaplan, L.M. Assignment Costs for Multiple Sensor Track-to-Track Association. Proceeding of Seventh International Conference on Information Fusion (Fusion 2004), Stockholm, Sweden, 28 June–1 July 2004.
- Bourgeoism, F.; Lassalle, J.C. An extension of the munkres algorithm for the assignment problem to rectangular matrices. Commun. ACM 1971, 14, 802–804. [Google Scholar]
- Jonker, R.; Volgenant, A. A shortest augmenting path algorithm for dense and sparse linear assignment problems. Computing 1987, 38, 325–340. [Google Scholar]
- Castañón, D.A. New assignment algorithms for data association. Proceedings of Signal and Data Processing of Small Targets, Orlando, FL, USA, 20 April 1992; pp. 313–323.
- Castella, F.R. Theoretical Performance of a Multisensor Track-to-Track Correlation Technique. Proceeding of IEE Radar Sonar Navigation, December 1995; pp. 281–285.
- Singer, R.A.; Kanyuck, A.J. Computer control of multiple site track correlation. Automatica 1971, 7, 455–463. [Google Scholar]
- Tian, X.; Bar-Shalom, Y. Sliding Window Test vs. Single Time Test for Track-to-Track Association. Proceeding of 11th International Conference on Information Fusion (Fusion 2008), Cologne, Spain, 30 June–3 July 2008; pp. 1–8.
- Tian, X.; Bar-Shalom, Y. Track-to-track fusion configurations and association in a sliding window. J. Adv. Inf. Fusion 2009, 4, 146–164. [Google Scholar]
- Mori, S.; Chong, C.Y. Effects of Unpaired Objects and Sensor Biases on Track-to-Track Association: Problems and Solutions. Proceedings of MSS National Symposium on Sensor and Data Fusion, San Antonio, TX, USA, 20–22 June 2000; pp. 137–151.
- Bar-Shalom, Y.; Li, X.R. Multitarget-Multisensor Tracking: Principles and Techniques; University of Connecticut: Storrs, CT, USA, 1995. [Google Scholar]
- Bar-Shalom, Y.; Chen, H. Multisensor track-to-track association for tracks with dependent errors. J. Adv. Inf. Fusion 2006, 1, 2674–2679. [Google Scholar]
- Soule, P.W. Performance of Two-way Association of Complete Data Sets.; No. TOR0074(4085)-15; Aerospace Corp.: El Segundo, CA, USA; January; 1974. [Google Scholar]
- Kay, S.M. Fundamentals of Statistical Signal Processing, Volume 2: Detection Theory; Prentice Hall PTR: London, UK, 1998. [Google Scholar]
- Harvey, J.R. Fractional Moments of a Quadratic Form in Noncentral Normal Random Variables. PhD. Thesis, North Carolina State University, April 1965. [Google Scholar]
- Fortmann, T.E.; Bar-Shalom, Y.; Scheffe, M.; Gelfand, S. Detection Thresholds for Multi-Target Tracking in Clutter; No. 5495; BBN Laboratory. Inc.: Cambridge, MA, USA; December; 1983. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PC (%) | Δbx | |||||||
|---|---|---|---|---|---|---|---|---|
| −3km | −2km | −1km | 0km | 1km | 2km | 3km | ||
| Δby | -3 km | 96.87 | 97.16 | 96.63 | 97.23 | 97.48 | 97.55 | 97.09 |
| -2 km | 96.85 | 96.86 | 97.03 | 97.23 | 97.26 | 97.10 | 97.06 | |
| -1 km | 97.21 | 96.80 | 96.37 | 96.91 | 96.62 | 96.95 | 97.00 | |
| 0 km | 97.43 | 97.37 | 96.79 | 97.24 | 97.26 | 97.43 | 96.95 | |
| 1 km | 97.19 | 97.04 | 97.67 | 97.52 | 97.11 | 97.16 | 97.17 | |
| 2 km | 97.07 | 97.20 | 97.17 | 96.90 | 97.62 | 97.67 | 97.32 | |
| 3 km | 97.26 | 97.08 | 97.28 | 96.88 | 97.19 | 97.17 | 97.11 | |
| PC (%) | Δbx | |||||||
|---|---|---|---|---|---|---|---|---|
| −3km | −2km | −1km | 0km | 1km | 2km | 3km | ||
| Δby | -3 km | 92.98 | 93.14 | 93.07 | 93.36 | 93.47 | 92.96 | 92.5 |
| -2 km | 93.54 | 92.98 | 93.55 | 93.03 | 93.25 | 93.18 | 93.27 | |
| -1 km | 92.87 | 94.02 | 92.83 | 93.15 | 93.35 | 92.98 | 92.21 | |
| 0 km | 93.03 | 92.41 | 93.30 | 93.21 | 93.00 | 93.02 | 92.89 | |
| 1 km | 92.14 | 93.67 | 92.87 | 92.95 | 93.44 | 93.44 | 93.92 | |
| 2 km | 93.17 | 92.80 | 92.40 | 93.11 | 93.24 | 92.76 | 93.15 | |
| 3 km | 92.87 | 92.91 | 93.58 | 92.83 | 93.14 | 93.17 | 92.77 | |
| PC (%) | Δbx | |||||||
|---|---|---|---|---|---|---|---|---|
| −3km | −2km | −1km | 0km | 1km | 2km | 3km | ||
| Δby | -3 km | 87.81 | 86.85 | 87.20 | 87.79 | 86.73 | 87.03 | 86.62 |
| -2 km | 87.51 | 86.83 | 86.48 | 87.34 | 86.31 | 86.29 | 87.63 | |
| -1 km | 86.88 | 87.78 | 86.66 | 86.63 | 86.61 | 87.28 | 86.25 | |
| 0 km | 87.24 | 87.07 | 86.39 | 88.13 | 87.64 | 86.46 | 86.98 | |
| 1 km | 87.17 | 87.01 | 87.10 | 86.63 | 87.02 | 86.95 | 88.18 | |
| 2 km | 86.73 | 86.68 | 86.74 | 87.27 | 86.42 | 87.10 | 86.86 | |
| 3 km | 86.48 | 86.49 | 87.28 | 86.85 | 86.57 | 87.34 | 86.71 | |
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Tian, W.; Wang, Y.; Shan, X.; Yang, J. Analytic Performance Prediction of Track-to-Track Association with Biased Data in Multi-Sensor Multi-Target Tracking Scenarios. Sensors 2013, 13, 12244-12265. https://doi.org/10.3390/s130912244
Tian W, Wang Y, Shan X, Yang J. Analytic Performance Prediction of Track-to-Track Association with Biased Data in Multi-Sensor Multi-Target Tracking Scenarios. Sensors. 2013; 13(9):12244-12265. https://doi.org/10.3390/s130912244
Chicago/Turabian StyleTian, Wei, Yue Wang, Xiuming Shan, and Jian Yang. 2013. "Analytic Performance Prediction of Track-to-Track Association with Biased Data in Multi-Sensor Multi-Target Tracking Scenarios" Sensors 13, no. 9: 12244-12265. https://doi.org/10.3390/s130912244