1. Introduction
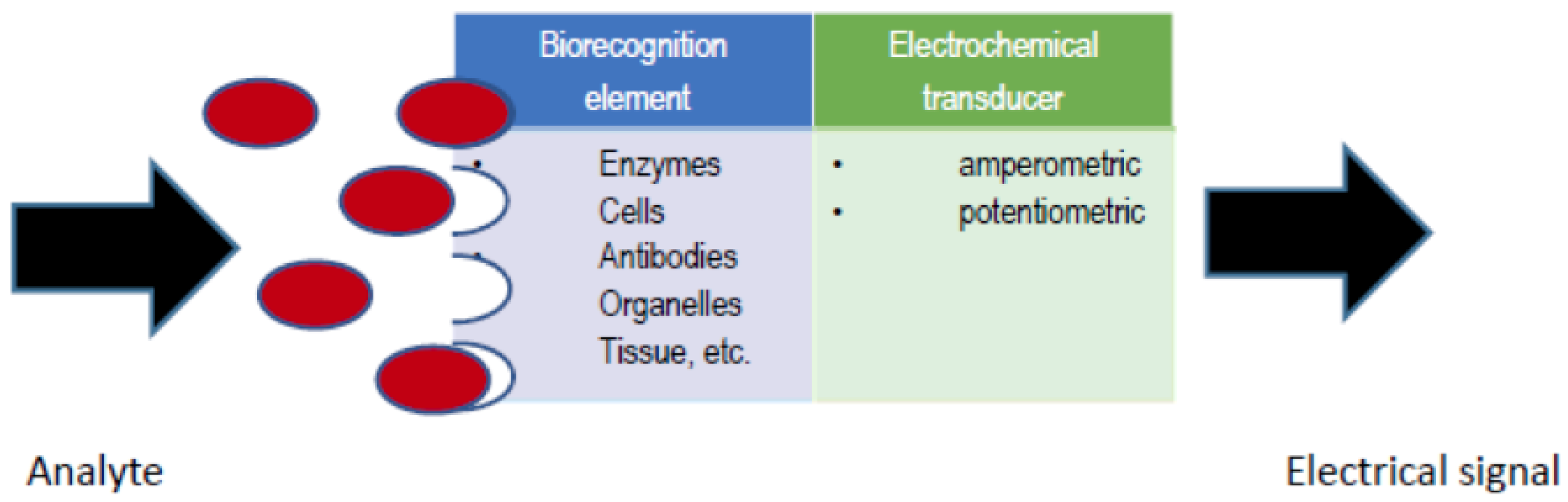
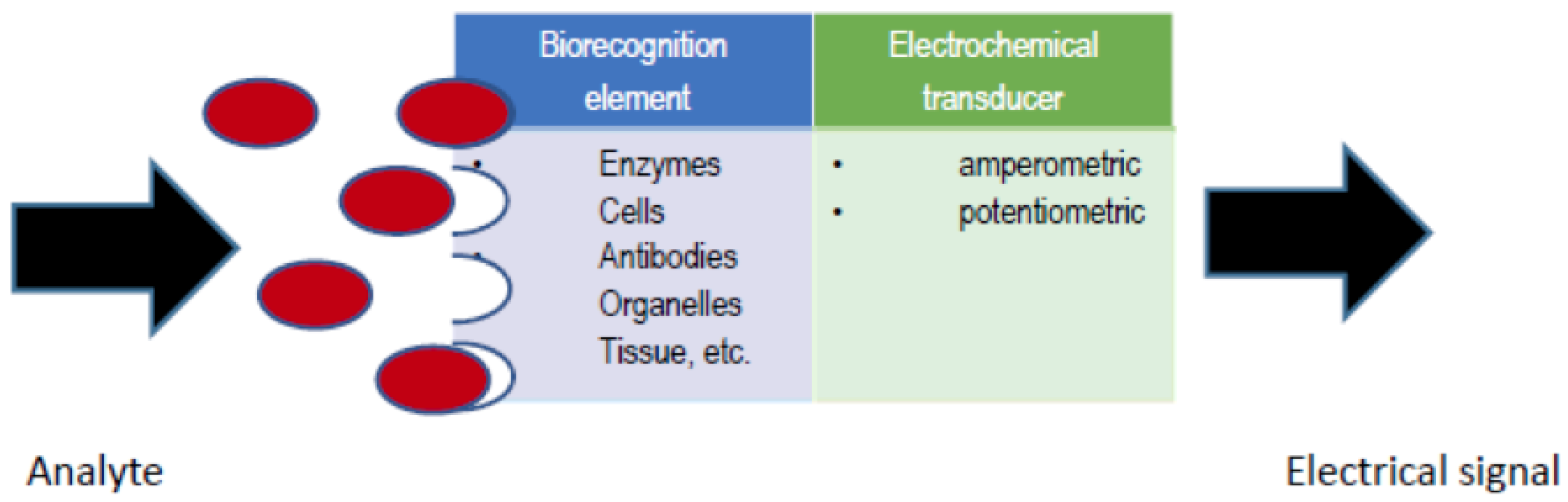
An electrochemical biosensor (see
Figure 1) is an analytical device, which contains a biological recognition element in direct spatial contact with an electrochemical transducer, to obtain a measurable analytically-useful electrical signal by coupling biochemical and electrochemical events [
1]. A number of variables affect the response of an electrochemical biosensor and therefore the biosensor analytical performance, including electrode variables (material, area and geometry), electrical variables (voltage, current, charge, impedance), electrolyte variables (bulk concentration, pH, solvent), reaction variables (kinetic and thermodynamic parameters) and external variables (temperature, pressure and time) [
2]. Taking into account that the electrochemical biosensor response results from the overall interactions among dependent variables, statistical modeling is an efficient tool to predict, describe and optimize the electrochemical biosensor response and its analytical characteristics.
Most of the mathematical approaches have aimed at modeling the sensor response as a function of the kinetic behavior of the electrochemical biosensors. For example, Blaedel et al. [
3] developed the first noteworthy model describing quantitatively the kinetic behavior of simple idealized enzyme sensors. It was applied to the treatment of the potentiometric response of urease electrodes. Using digital simulation, Mell and Maloy [
4] modeled the steady-state current response of the amperometric stationary enzyme electrodes. Nevertheless, the lack of exactly defined boundary conditions to describe the mass transport restrains its application. Taking advantage of the well-known diffusion behavior of the rotating disk electrode, Shu and Wilson [
5] demonstrated that the steady-state current response of the resultant amperometric enzyme sensor is in accordance, under mass transport limiting conditions at low substrate concentrations, with the Levich equation for the rotating disk electrodes [
6]. Under catalysis-controlled conditions, the transfer function of the biosensor complies with the Michaelis-Menten equation [
7].
Other techniques include methods to model the biosensor response by the analytical solution of partial differential equations, applicable to simple biocatalytic processes, as well as digital modeling using complex biocatalytical conversions, multi-part transducers’ geometry, and biocatalytic membrane structure; these are extensively reviewed by Baronas et al. [
8] and Bartlett et al. [
9]. More recently, Rangelova et al. [
10] and Alonso et al. [
11] demonstrated the potential of the Artificial Neural Networks (ANN) approach to electrochemical biosensor response modeling. Another promising method for analyzing overlapped signals, which cannot be calibrated and modeled by linear expressions, seems to be that of Support Vector Machines (SVM), displaying in general comparable to or better performance than ANNs and other statistical models [
12].
The principle of the operation of the first-, second- and third-generation electrochemical biosensors for glucose determination, as well as their analytical performances, advantages and drawbacks are comprehensively described in the literature; see, e.g., [
13,
14,
15,
16,
17]. The second generation amperometric GOB is well suited for blood glucose determination, since the oxygen dependence and the interference of the other components of the biological fluids are avoided. The challenges ahead rely on the development of biosensors with improved characteristics and optimized response for continuous glucose monitoring and point-of-care testing to better control and manage diabetes mellitus [
13,
14,
15,
18].
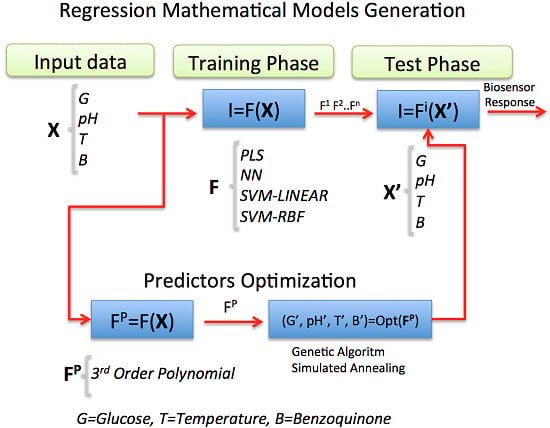
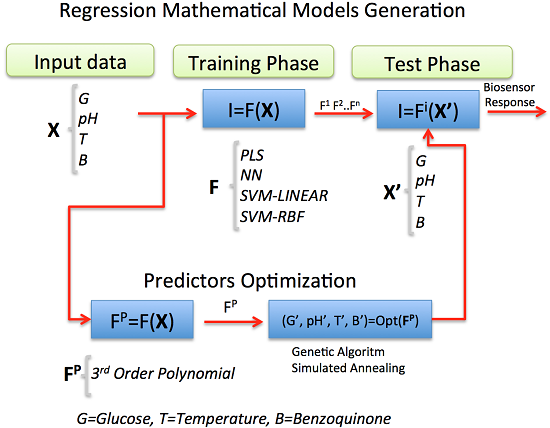
In this work, statistical Machine Learning (ML) regression models were chosen and applied as powerful techniques for estimating the current response of an amperometric second-generation glucose-oxidase biosensor (GOB), using p-benzoquinone as the electron-transfer mediator. Its function is based on the following enzymatic and electrochemical reactions:
where
and
are the reduced and oxidized forms of the enzyme glucose-oxidase and
and
are the reduced and oxidized forms of the mediator. The analytical signal is the current of
oxidation, which is proportional to the glucose concentration.
2. ML Models for Regression
Let
Y denote the response (or target) variable and
the underlying
p-variate function that represents the interaction between the predictors. The statistical Machine Learning (ML) perspective substitutes the
f function by predefined algorithms with configurable parameters, leaving aside the task to establish complex mathematical relationships. The field offers a wide spectrum of regression models, which can be cast in some specific areas:
In the following sections, the chosen statistical regression models, intended to model the biosensor response in terms of some input variables, will be explained.
2.1. Partial Least Squares
Partial Least Squares (PLS) is considered a dimension reduction method, which identifies a new set of features
that are linear combinations of the original, then fits a linear model through least squares by using the
m new features [
19]. Let
X be the inputs or predictors and
the prediction;
X and
are decomposed into the following matrices:
where
T is the score matrix;
are the loadings (or weights) of
, respectively; and
B is a diagonal matrix. These new latent variables are sorted according to the amount of variance of
that they explain, very much as in principal component analysis. Rewriting now
as a regression model:
with
where
is the Moore-Penrose pseudoinverse of
.
2.2. Artificial Neural Networks
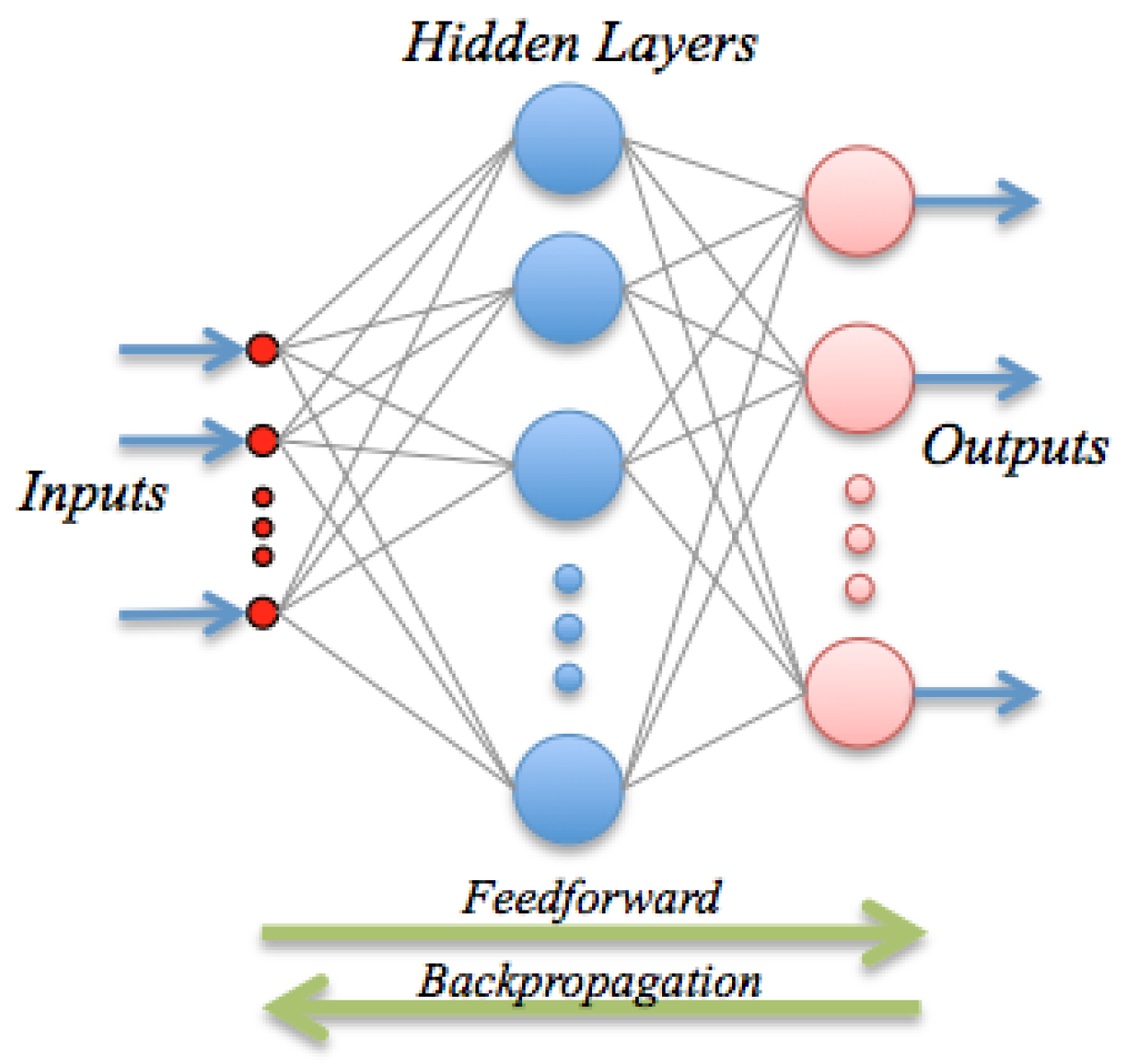
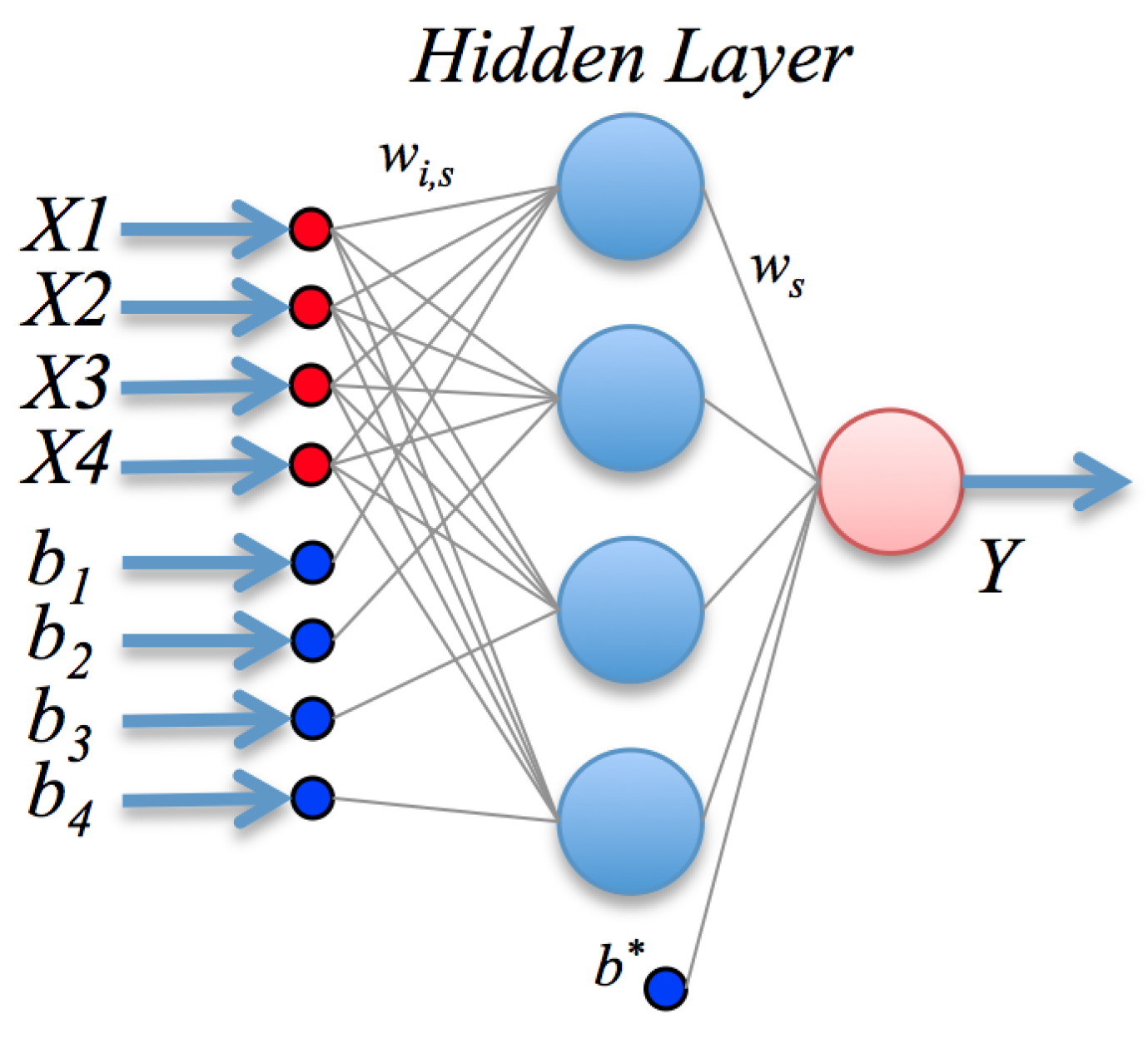
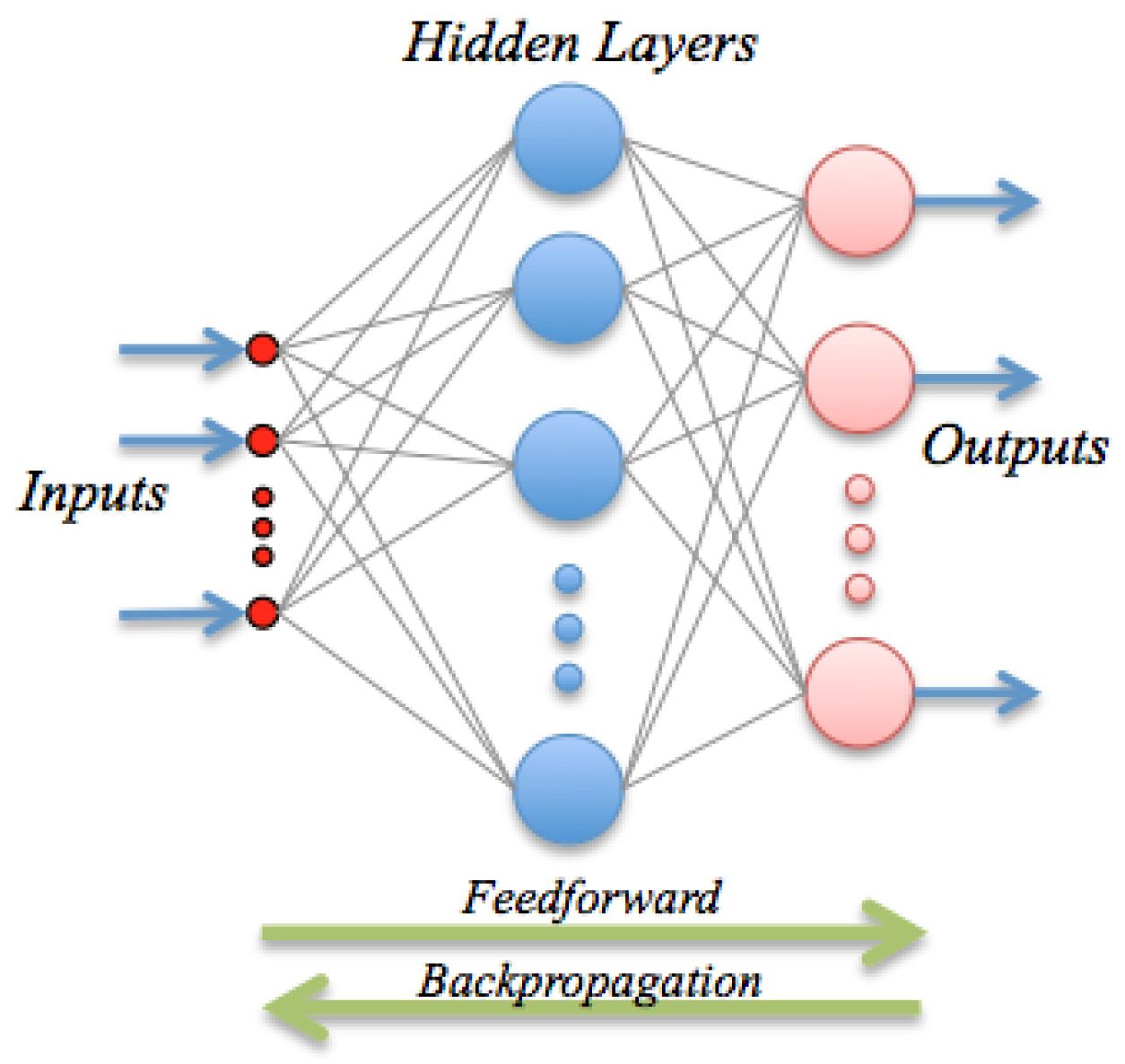
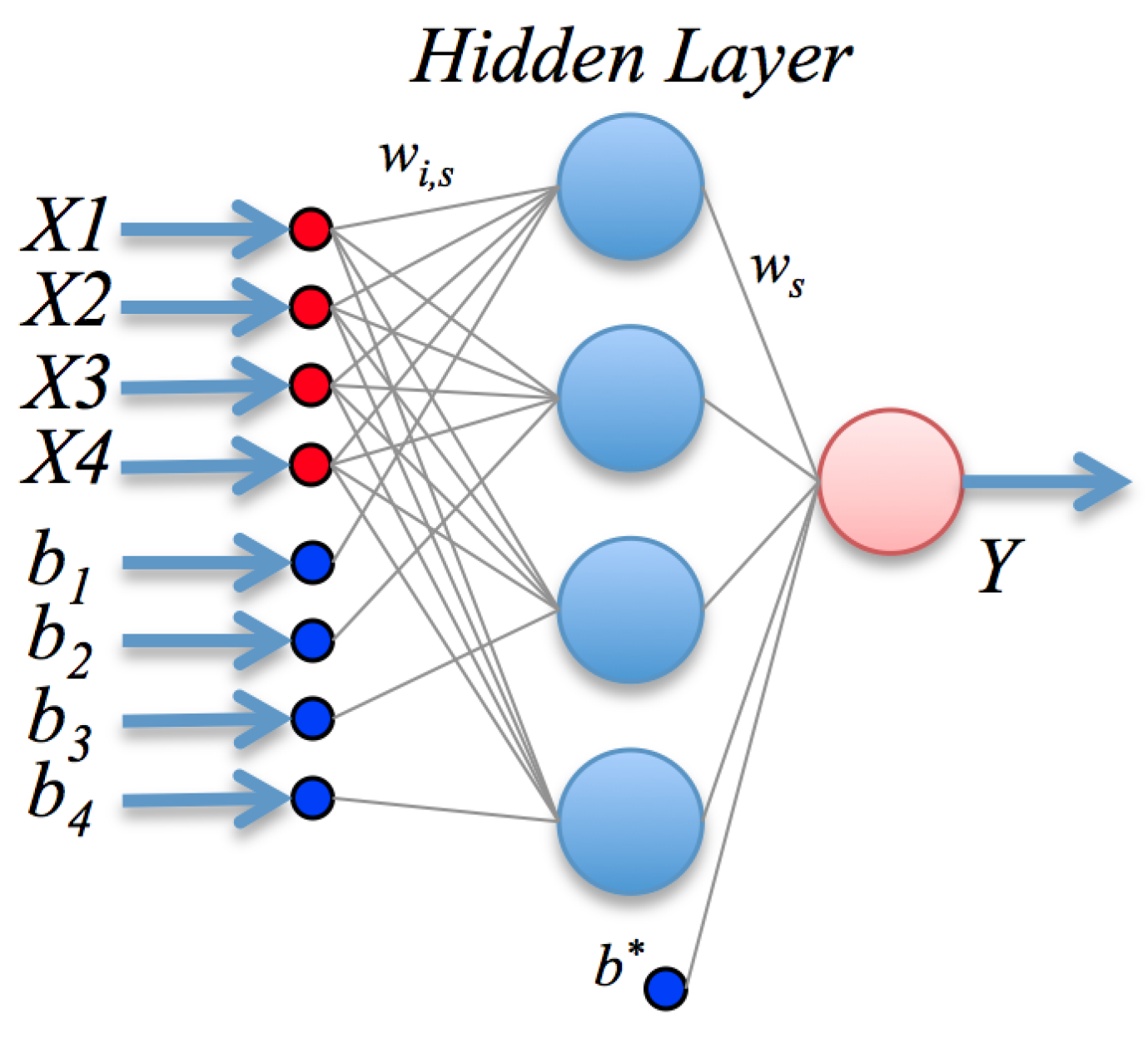
ANN are inspired by the biological mechanism of brain and constitute an inspiration to develop mathematical representations of the information processing by neurons. They consist of processing units (nodes) interconnected through a certain topology; see
Figure 2. The most widespread architecture is the feed-forward configuration, which assembles a linear combination of
m fixed non-linear basis functions with parameters
of the form:
where
g is a suitable non-linear activation function (e.g., a sigmoid), or the identity in the case of regression, and
w is the vector of linear weights; the
are the non-linear weight vectors, and
is the bias or offset. The basis functions typically have the form:
Besides its formal definition, a neural network involves also the optimization procedure: once the output has been computed, the error, i.e., the difference between the predicted value and the observed value, is back-propagated. These error signals are then used to adjust the weights by a number of strategies; in this paper, we use a Levenberg-Marquardt method.
2.3. Support Vector Machines
The Support Vector Machine for Regression (SVMR) has become a popular tool for the modeling of non-linear regression tasks [
20]. The SVMR is a nonlinear kernel-based method, which attempts to estimate a regression hyperplane
with a small risk in a high-dimensional feature space. Unlike the classical least-squares solution for linear fitting, SVMR tries to minimize the
ε-insensitive loss function. This imposes a linear penalty when the value of the estimate
with respect to the corresponding observed
y is off-target by
ε or more, as
, usually leading to sparser representations, entailing both algorithmic and representational advantages [
21].
Let be a real RKHS (Reproducing Kernel Hilbert Space) with kernel κ. The input data are transformed with a feature map , to obtain the new dataset , where is the input space. In an SVMR, the aim is to find a function , for some and , which is as flat as possible and deviates a maximum of ε from the given target values , for all .
The usual formulation of the optimization problem is as the dual of the convex quadratic program:
for
. To solve Equation (
8), one considers the dual problem derived by the Lagrangian:
Exploiting the saddle point conditions, it can be proven that
; given that
, the solution becomes:
4. Results and Discussion
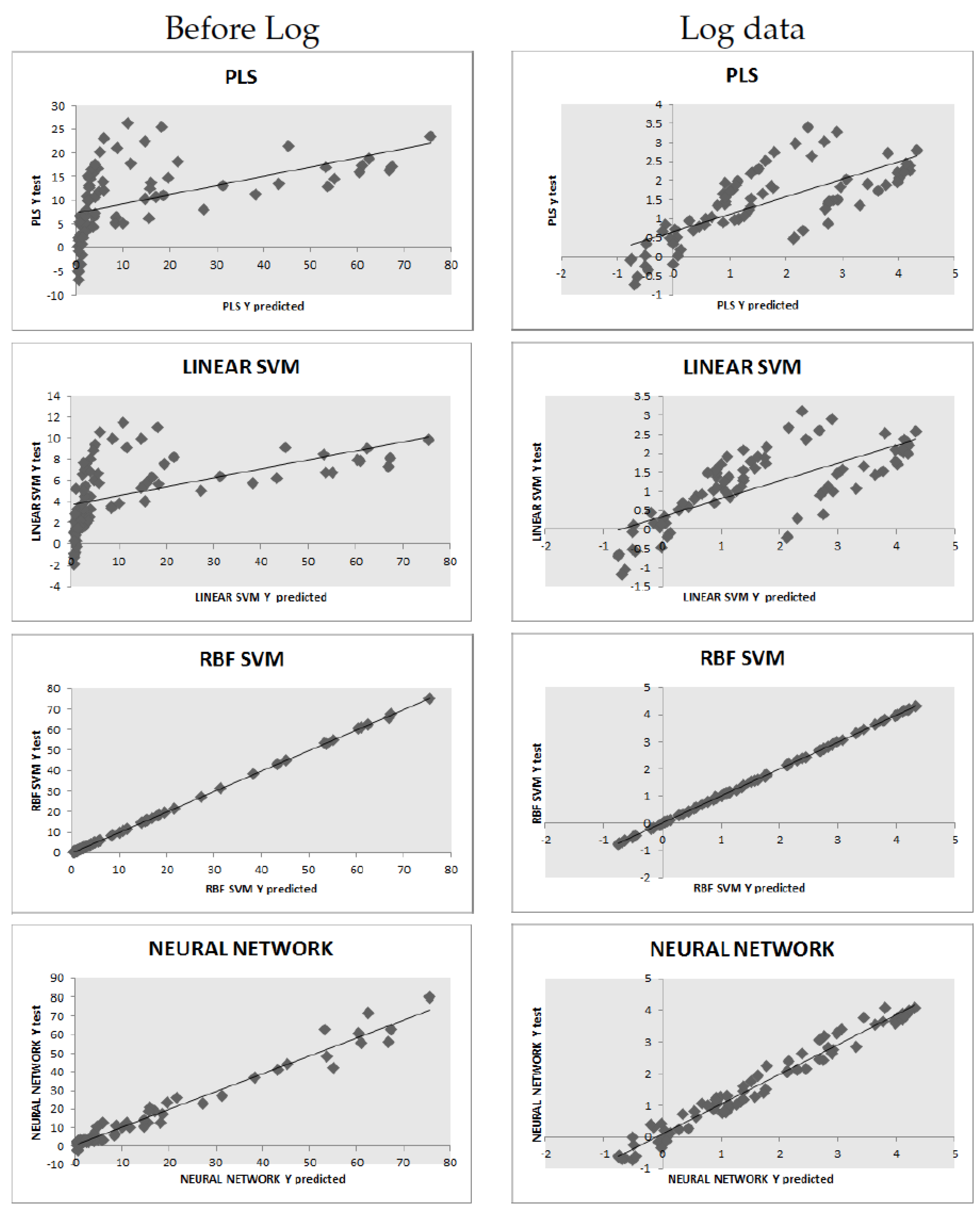
Two groups of experiments were performed, by training and testing the learning algorithms with and without applying the natural log to the target variable.
Table 2 shows the cross-validation NRMSE for each learner, before log and log data, resp. It is clearly seen that the linear models, PLS and the linear SVM, are outperformed by the non-linear models, the ANN and the SVMR-RBF, the latter being the best model overall, although the difference of two models is not statistically significant: a Wilcoxon signed-rank test comparing the results, in the log data, shows that the null hypothesis that the difference between the cross-validation NRMSE medians is zero cannot be rejected at the 95% level (
p-value
). The test
regression coefficients are also shown. For completeness, we also display the full test prediction plots for all models; see
Figure 3.
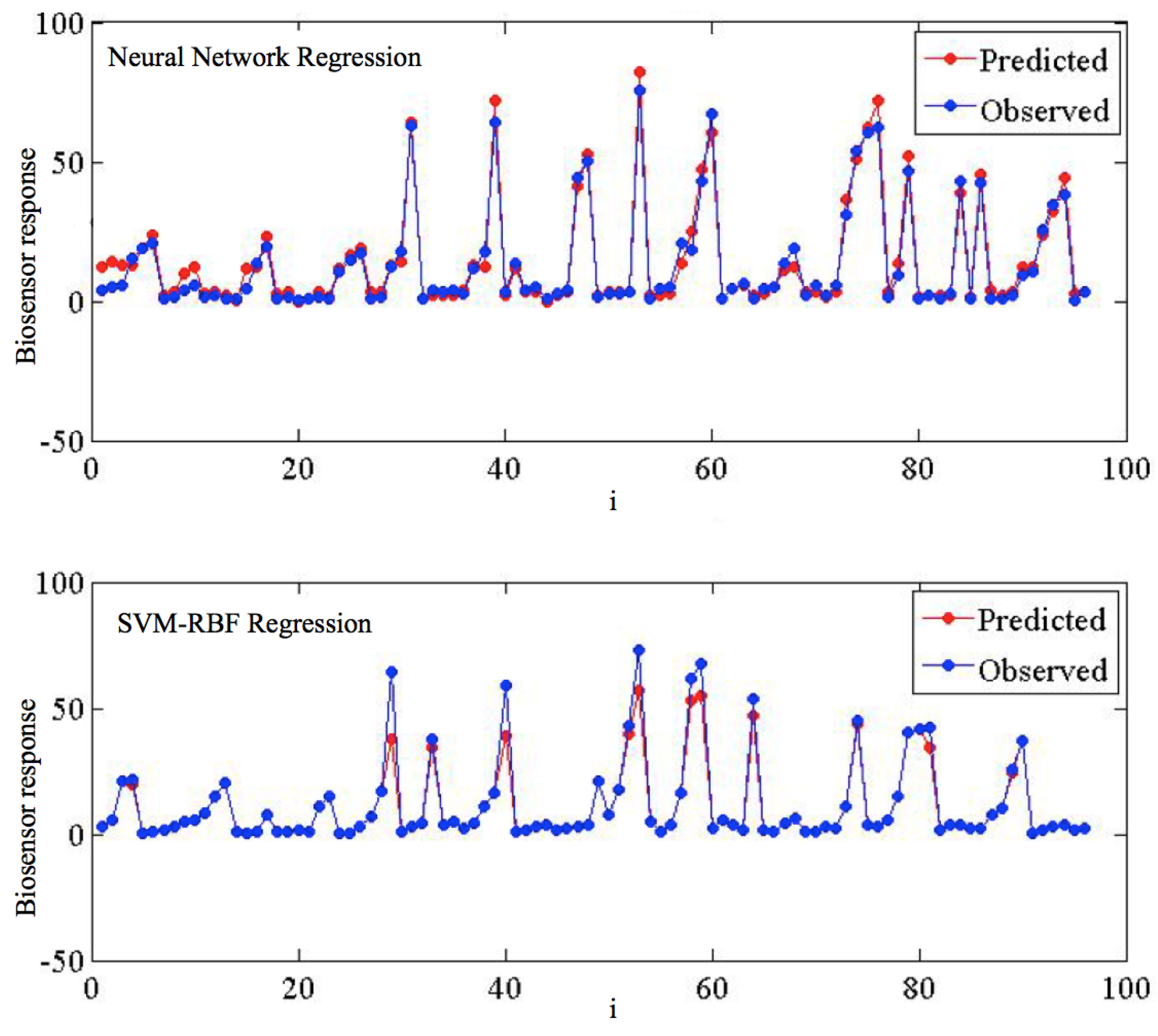
Figure 4 details the predicted vs. observed target values for the SVMR-RBF and the ANN. Despite most of the signal being very satisfactorily predicted, some of the points present divergences w.r.t. the observed target values; specifically, very high peaks are in general underestimated.
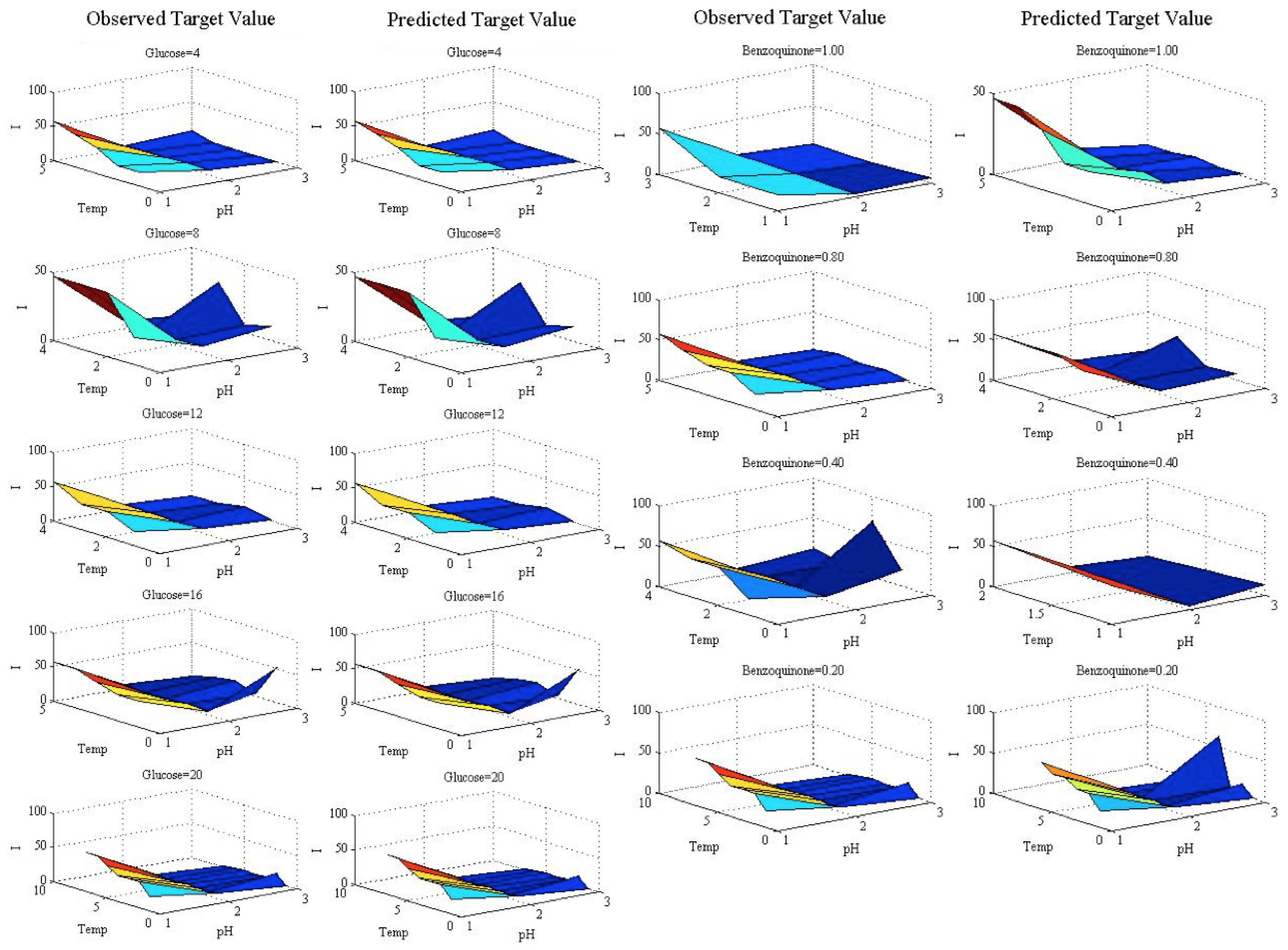
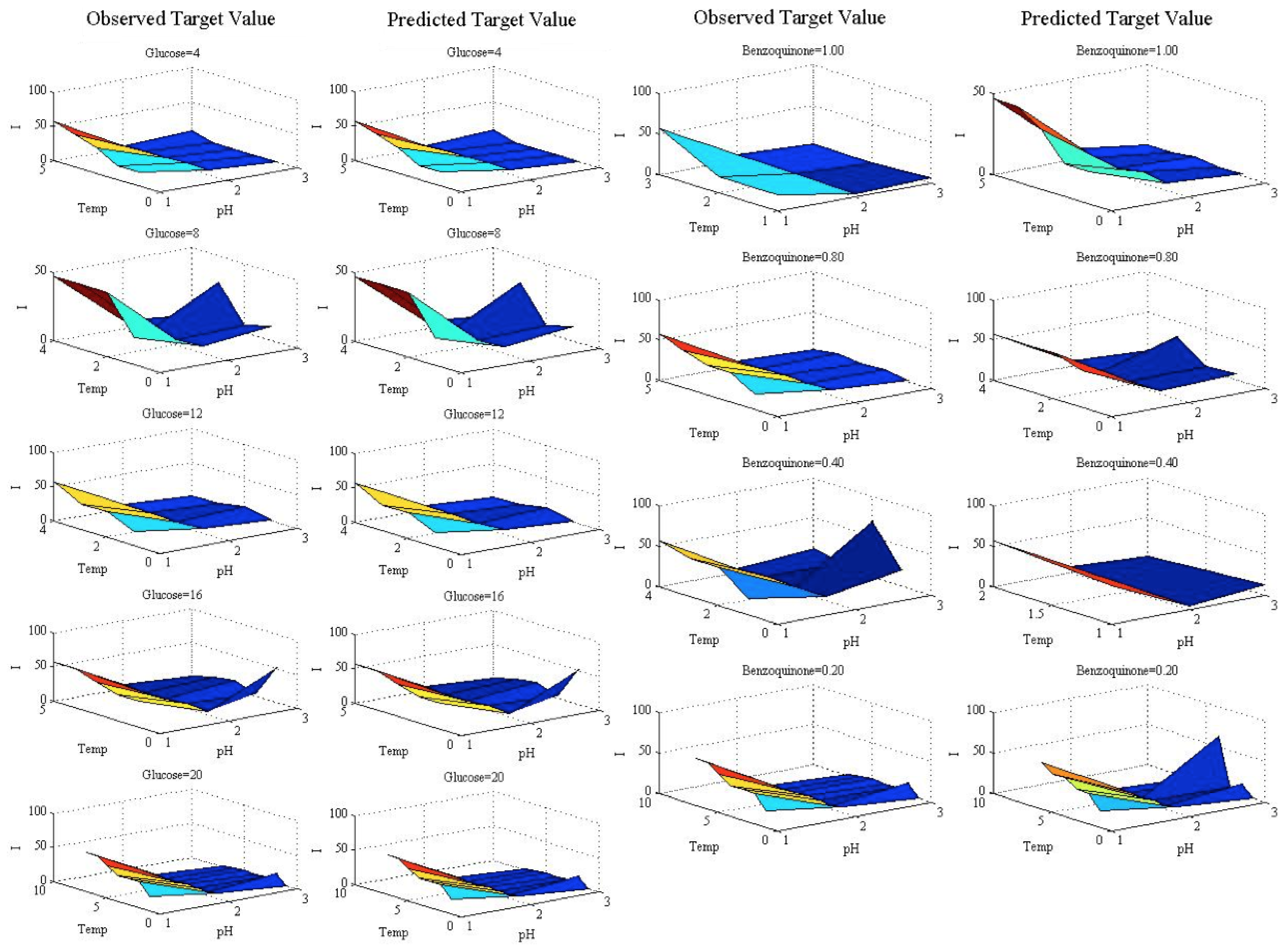
To explore this phenomenon,
Figure 5 shows particular sections of the target value by displaying the observed and predicted values in the test set. The charts are formed by fixing the value of the benzoquinone to 0.2 for different glucose values, and by fixing the value of the glucose to four for different benzoquinone values. The
X-
Y axes are the temperature and pH variables, and the vertical axis shows the target value (biosensor response). The slight differences pointed out (for high-valued outputs) can be seen in Columns 3–4 of
Figure 5.
4.1. Artificial Neural Network Model
Letting
represent the glucose, p-benzoquinone, temperature and pH and
Y the biosensor response, the mathematical model found by the ANN, seen graphically in
Figure 6, is assembled as (refer to the description in
Section 2.2):
where
and the basis functions use the hyperbolic tangent sigmoid function as
g; the vector
w of linear weights and bias
are given by:
The non-linear weight vectors
and biases
for each neuron
j in the hidden layer are conveniently expressed in matrix form as:
4.2. Support Vector Machine RBF Model
The SVMR-RBF parameters that offer the best performance (lowest cross-validation NRMSE) are found to be as follows:
The
C and
ε parameters are used in solving the optimization problem as described in
Section 2.3;
γ is used in the computation of the kernel function
, in our case the RBF kernel, defined as:
5. Optimization of Experimental Conditions
The experimental results show very low prediction errors for GOB modeling through statistical learning methods from a regression perspective. Such models would be effective in case there is an interest in embedding them as a sub-system of other analytical processes.
These models are black boxes, in that they can be viewed solely in terms of their inputs and output, without any knowledge of the internal workings. However, a more in-depth theoretical modeling of the biosensor response would enable a better understanding about the importance of the factors affecting its analytical performance in terms of dynamic linear concentration range, sensitivity and the limit of detection, among others. Moreover, it would facilitate its optimization in a given matrix. Some current efforts are directed toward sensitivity improvement and lowering of the limit of detection by maximization of the biosensor response.
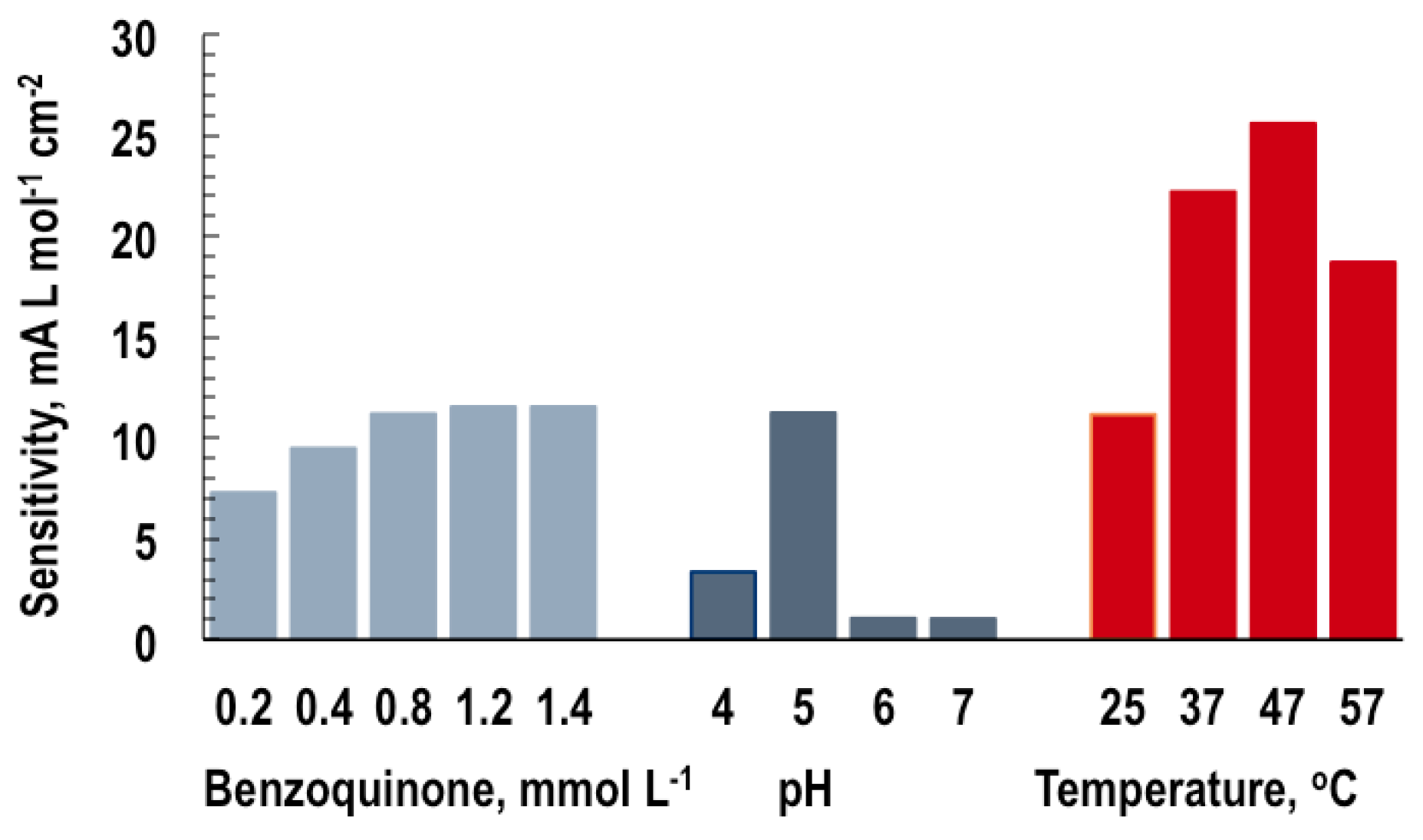
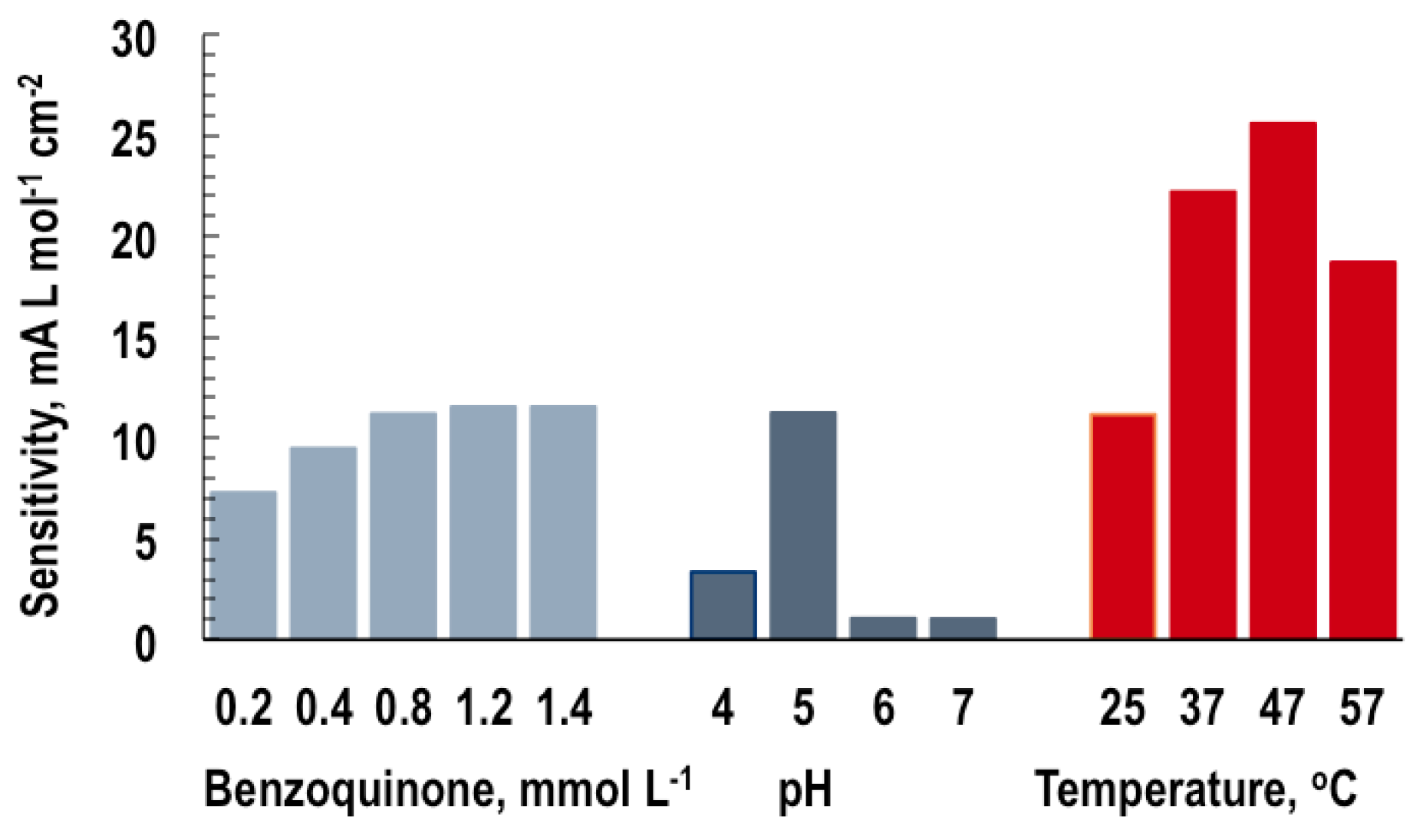
The sensitivity and linear concentration range of steady-state calibration curves are determined by plotting the steady-state responses (in our case, the GOB response), possibly corrected for a blank signal, vs. the analyte concentration (the glucose). The sensitivity is the slope of the calibration curve and is used for the evaluation of biosensor capabilities: a more sensitive device responds to smaller amounts or weaker signals. Thus, there is a need for analytical procedures for sensitivity maximization, i.e., the finding of input values that yield a maximum biosensor response. Since this is seen to strongly depend on the input variables, p-benzoquinone concentration, pH and temperature (see
Figure 7), the aim of the analyses in this section was to determine the impact and optimum values of these individual input variables plus the glucose on the GOB response.
In this vein, the two developed regression models—the ANN and the SVMR-RBF—are excellent predictive models (aimed at generalization), but are not amendable to be optimized, in the sense of assessing the best input values to get the maximum output. Instead, polynomial optimization (of limited degree) is a more feasible task: once the coefficients are found, the polynomial can be optimized by a number of methods. The idea can be summarized in the following procedure:
Approximate a third-degree polynomial model by Ordinary Least Squares (OLS) estimation.
Maximize the polynomial as a function of the input variables.
Use these values to find the best output or biosensor response.
As in
Section 4, letting
represent the glucose, p-benzoquinone, temperature and pH and
Y the biosensor response, a third order polynomial was assembled as follows:
In order to maximize
p, two well-known optimization algorithms were used: a genetic algorithm and simulated annealing, briefly described next. A Genetic Algorithm (GA) is a method for solving optimization problems based on natural selection, mimicking biological evolution by borrowing ideas from the dynamics of natural populations. It works under the assumption that the strongest individuals will prevail through time and, hence, their best features. Given a population, the algorithm iteratively selects individuals that represent the best characteristics of the population, as measured by a certain fitness function. These individuals are taken as a seed to produce the next generation by the use of genetic operators (crossover and mutation). At each step, the current population seeks to enhance the fitness function, eventually evolving to an optimal solution [
23].
Simulated Annealing (SA) is a stochastic technique inspired by statistical mechanics for finding near globally optimum solutions to large (combinatorial) optimization problems. The algorithm works by assuming that some part of the current solution, i.e., the input variables assigned with some real value within their respective range, belongs to a potentially better one, and thus, this part should be retained by exploring neighbors of the current solution; SA has the ability to jump from valley to valley and to escape or simply avoid sub-optimal solutions [
24].
Table 3 shows the results of this optimization process; it also shows the ANN and SVMR-RBF response when evaluated in the same solution, as a reference. Both the GA and SA show very similar values for the polynomial model, the small difference being attributable to rounding, which are achieved at the same readings for the inputs, a possible indication that a true maximum has been reached. Upon evaluation of the ANN and SVMR-RBF on these values, the results are again remarkably similar, a fact suggesting that the predictive models are essentially correct.
6. Conclusions and Future Work
Several statistical machine learning methods have been used to model the amperometric response of a GOB. The reported experimental results show a promising very low prediction error of the biosensor output by using artificial neural networks and support vector machines for regression. It has also been shown that the relationship between the available predictors (temperature, benzoquinone, pH and glucose concentration) and the response corresponds to a non-linear behavior. In biosensor response analysis, there is sometimes a need to find the optimum predictor values, namely those that yield a maximum response. It has been shown that a particular combination of the available predictors is able to deliver a maximized value for the predictive models. We thus recommend the learned SVMR-RBF model (with parameters , and ) as a solid predictor of the amperometric response.
Glucose monitoring by means of a GOB can constitute a valuable ally to diabetic patients. GOBs are solid candidates for fast, reliable and inexpensive monitoring, in order to avoid serious collateral chronic complications; however, their design is still under development, in order to improve both their predictive accuracy and stability upon changing conditions. In a biosensor design scenario, mathematical modeling is a highly promising tool, given that it facilitates computational simulations, avoiding destructive testing, as long as time and resources permit. In this sense, the experimental proposal and conditions offered in this paper could be applied for other scenarios in the wide spectrum of bio-sensing technology.
Future work will include the fine-tuning of the small divergences found in the prediction of peaks. One possible direction could be to model the signal as a wave, where it could be natural to use nonparametric or local regression models, such as splines or wavelets [
25].


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}