
A Novel Group Decision-Making Method Based on Sensor Data and Fuzzy Information

 ,
,
Abstract
:1. Introduction
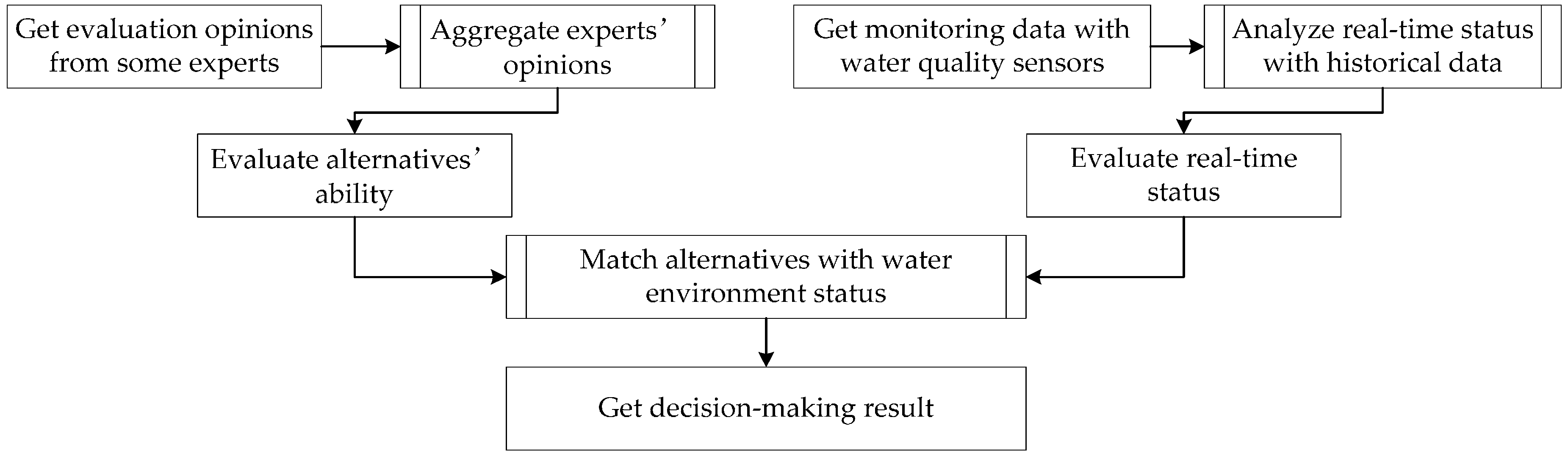
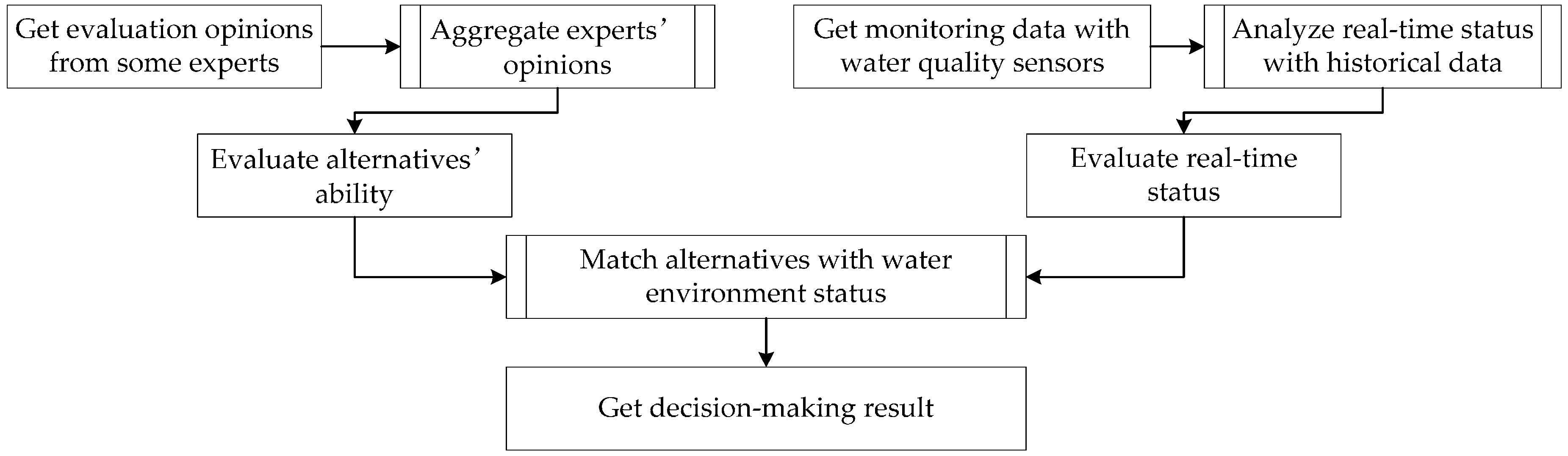
2. Group Decision-Making Method
2.1. General Solution of Group Decision-Making
2.2. Optimal Similarity Aggregation Model of Group Opinions
- Property (1) ;
- Property (2) if ;
- Property (3) .
2.3. Evaluation of Approaches Based on Vague Value
2.3.1. Approach-Index Matrix
2.3.2. Evaluation of Approaches Based on Aggregated Opinion
- (1)
- For l approach-index matrices, the index is fixed as cj, and l experts’ evaluation opinions are transferred to the expert-approach matrix:in which each row means the evaluation opinions of m alternatives from an expert.
- (2)
- For the matrix in Formula (22), the initial consistent weight is , , and . The similarity of every two experts is given with Formula (2).
- (3)
- and are calculated with Formulas (17) and (18), in which t is the iteration step, . The iteration is finished if . Otherwise this step is repeated with .
- (4)
- Setting , the experts’ aggregation coefficient Hk is calculated with Formula (19).
- (5)
- The experts’ aggregated opinion in the j-th index is calculated with Formula (20):in which Rj is the aggregated opinion in the j-th index which is a row vector. Opinions in all indexes are aggregated with the process above. n row vectors are combined and transposed to obtain a composite approach-index matrix:
2.4. Selection of Approaches Based on Sensors’ Monitoring Data
- (1)
- To operate with the follow-up index value in real number, the Vague elements in matrix AC are transferred to real number with the superiority function:
- (2)
- The real-time index is standardized with groups of historical data to eliminate the influence of different indexes’ dimensions. The standardization can also reflect the comparison between the real-time and routine indexes.in which is the mean value of the sample, , and is the standard deviation of the sample, .
- (3)
- The standardized index is denoted as . We plan to compare the alternatives’ ability with the real-time index point to point. Then the approach closest to the real-time index trend is selected from the alternatives using the method of the grey relational degree:in which is the resolution coefficient, and . Set to reduce the data distortion caused by the large absolute difference. Then, the grey relational degree is synthesized by row:in which li is the relational degree between the i-th approach and the real-time index. The higher the relational degree, the more suitable the approach.
3. Example and Results
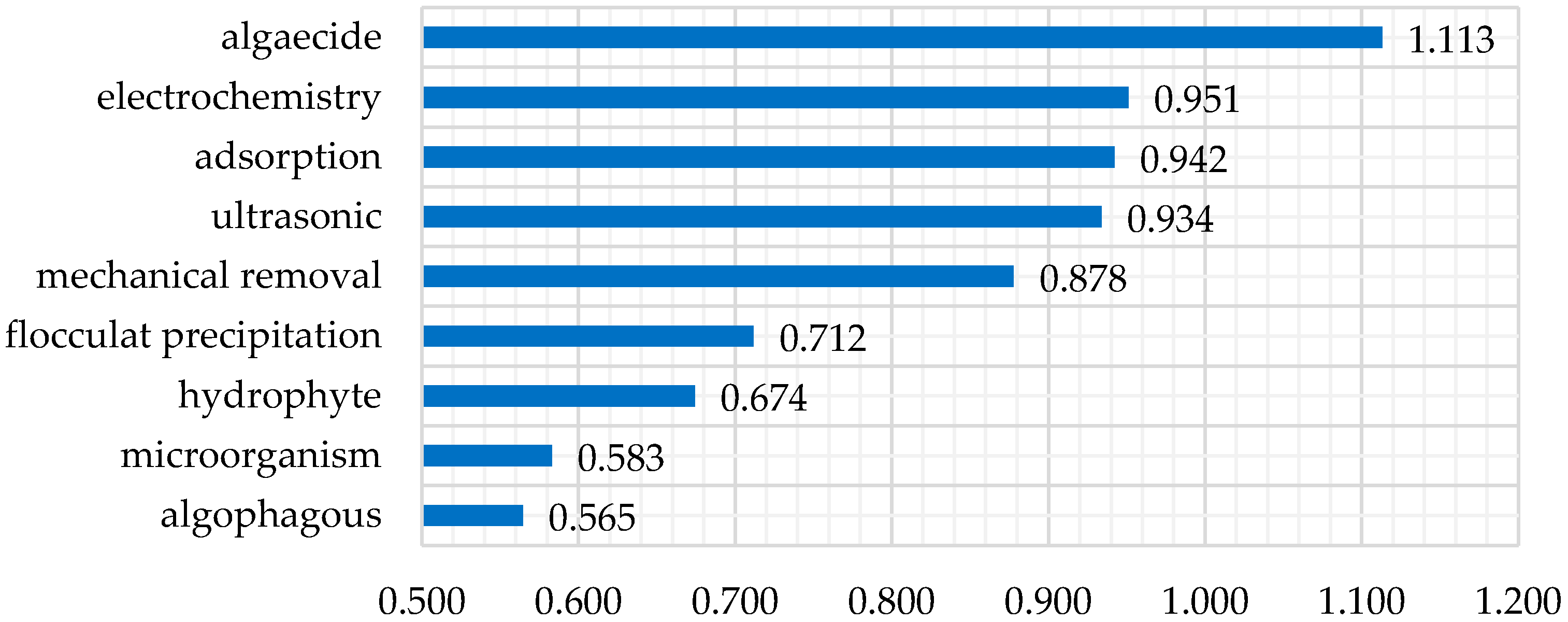
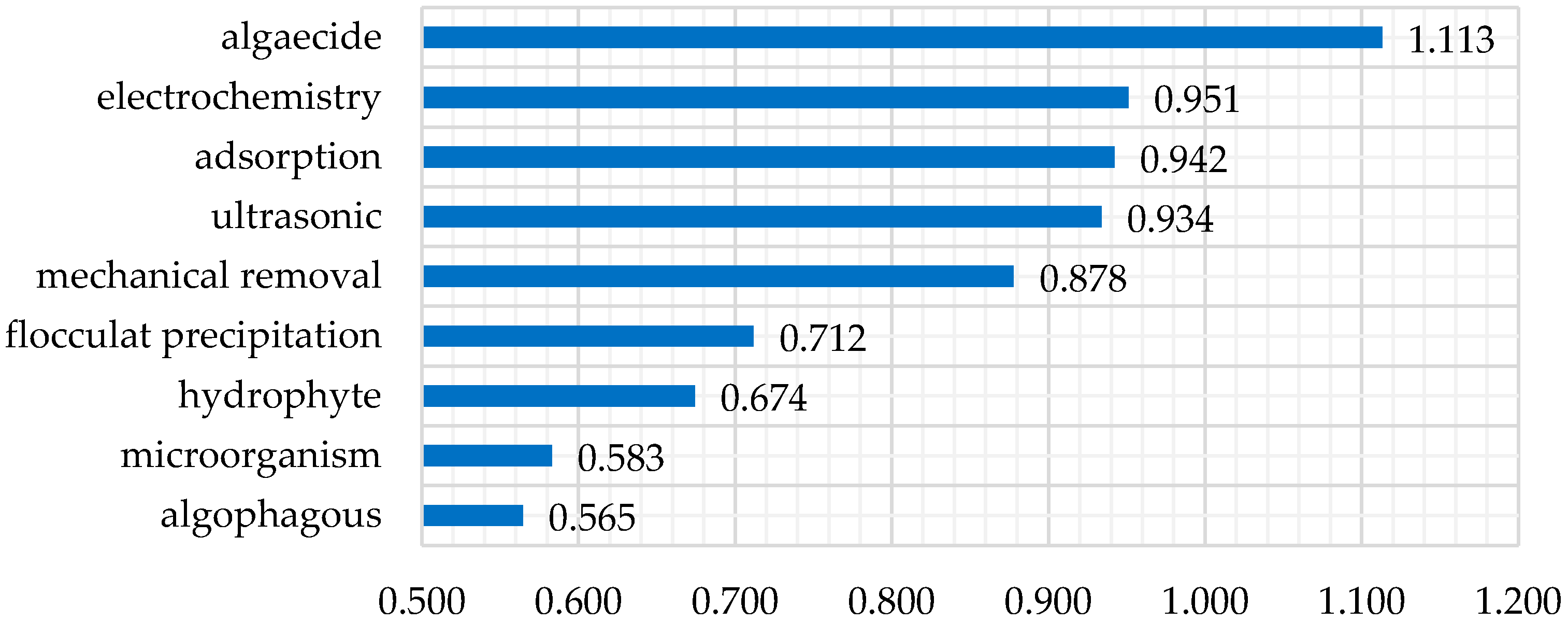
3.1. Remediation Approaches and Indexes of Algal Bloom
3.2. Aggregation of Group Experts’ Opinions
| EA1= | [0.2, 0.3] | [0.1, 0.15] | [0.1, 0.15] | [0.4, 0.6] | [0.3, 0.45] | [0.5, 0.5] | [0.6, 0.8] | [0.6, 0.8] | [0.5, 0.5] |
| [0.3, 0.45] | [0.2, 0.3] | [0.2, 0.3] | [0.5, 0.5] | [0.2, 0.3] | [0.6, 0.8] | [0.7, 0.85] | [0.5, 0.5] | [0.4, 0.6] | |
| [0.3, 0.45] | [0.2, 0.3] | [0.2, 0.3] | [0.5, 0.5] | [0.4, 0.6] | [0.6, 0.8] | [0.7, 0.85] | [0.7, 0.85] | [0.6, 0.8] | |
| [0.3, 0.45] | [0, 0] | [0.3, 0.45] | [0.5, 0.5] | [0.5, 0.5] | [0.4, 0.6] | [0.5, 0.5] | [0.5, 0.5] | [0.4, 0.6] |
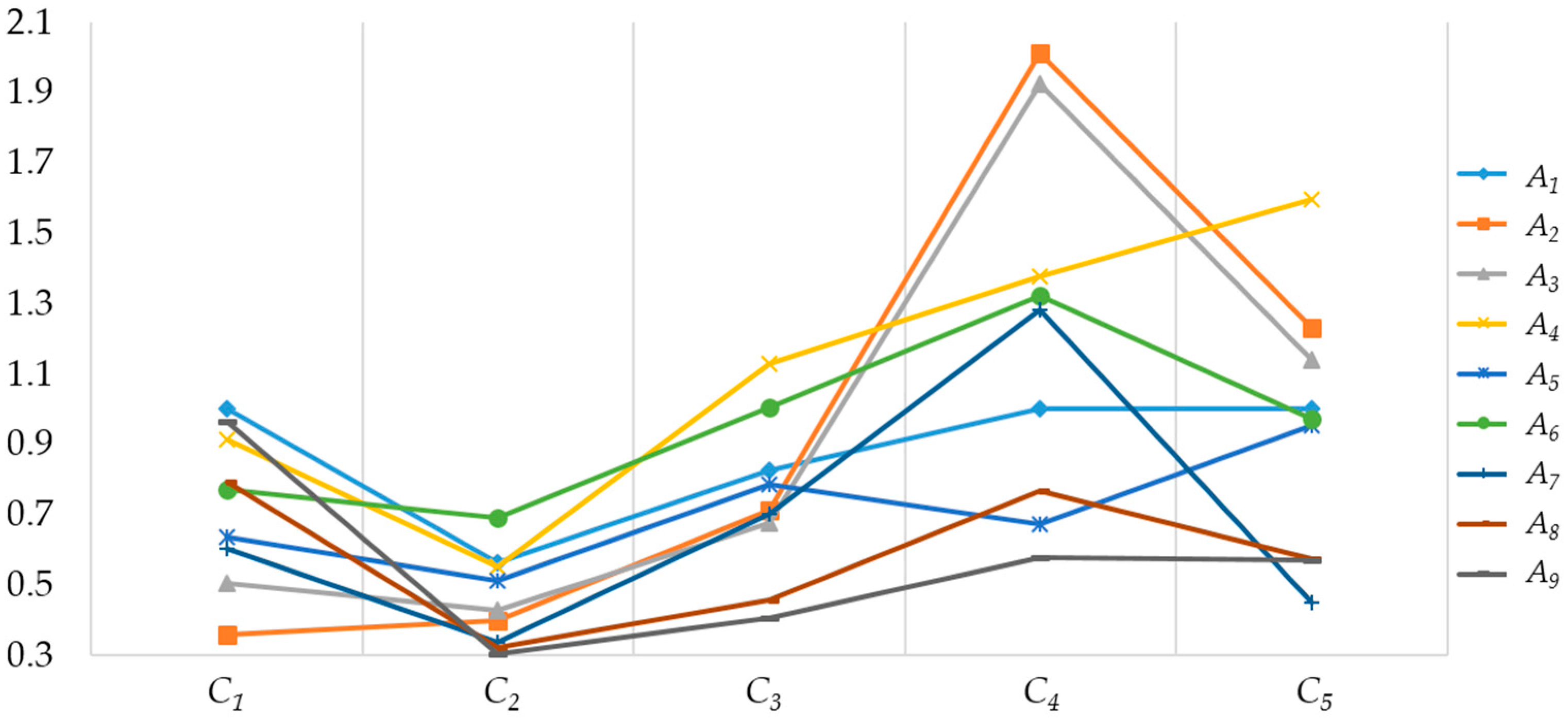
3.3. Processing of Real-Time Data and Selection of Remediation Approach
4. Discussion and Conclusions
- (1)
- The novel decision-making method combines the sensors’ monitoring data with the fuzzy evaluation information. It quantifies the qualitative information, and then realizes the fusion of different types of data.
- (2)
- Group opinions of decision-making experts were aggregated in the thought of optimal similarity aggregation. The inconsistency between the aggregated opinion and the original opinions was minimized using the optimal model, making the aggregated opinion more comprehensive.
- (3)
- On the premise of the Vague set, problems of traditional methods applied in the interval number environment were solved by the proposed method. It enhances the expansibility of the classical methods in real numbers while also preserving the advantage of Vague set theory.
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| No. | pH | TP (mg/L) | TN (mg/L) | Chl_a (ug/L) | DO (mg/L) | No. | pH | TP (mg/L) | TN (mg/L) | Chl_a (ug/L) | DO (mg/L) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 8.40 | 0.09 | 2.26 | 3.00 | 8.38 | 26 | 7.90 | 0.01 | 1.60 | 32.27 | 16.01 |
| 2 | 8.70 | 0.09 | 2.26 | 5.90 | 9.52 | 27 | 7.30 | 0.01 | 1.60 | 35.00 | 15.48 |
| 3 | 8.10 | 0.09 | 2.26 | 8.80 | 9.69 | 28 | 7.09 | 0.01 | 1.60 | 34.35 | 13.54 |
| 4 | 8.30 | 0.06 | 2.26 | 8.80 | 12.45 | 29 | 7.10 | 0.02 | 1.60 | 37.67 | 13.13 |
| 5 | 8.70 | 0.05 | 2.26 | 9.90 | 14.38 | 30 | 7.30 | 0.03 | 1.45 | 42.00 | 13.24 |
| 6 | 8.80 | 0.05 | 2.50 | 13.50 | 15.32 | 31 | 7.20 | 0.02 | 1.45 | 43.56 | 13.57 |
| 7 | 8.80 | 0.05 | 2.50 | 15.30 | 16.45 | 32 | 7.10 | 0.02 | 1.45 | 45.12 | 13.78 |
| 8 | 8.70 | 0.04 | 2.25 | 15.78 | 16.58 | 33 | 7.00 | 0.02 | 1.45 | 41.23 | 13.29 |
| 9 | 8.90 | 0.03 | 2.50 | 20.56 | 17.23 | 34 | 7.00 | 0.02 | 1.30 | 41.12 | 13.89 |
| 10 | 8.50 | 0.03 | 2.25 | 25.78 | 17.42 | 35 | 7.00 | 0.01 | 1.30 | 40.23 | 14.56 |
| 11 | 8.40 | 0.03 | 2.26 | 26.78 | 16.89 | 36 | 7.05 | 0.01 | 1.30 | 35.00 | 14.96 |
| 12 | 8.50 | 0.03 | 2.26 | 27.23 | 16.93 | 37 | 7.10 | 0.02 | 1.20 | 34.78 | 14.92 |
| 13 | 8.80 | 0.02 | 2.26 | 28.46 | 16.24 | 38 | 7.20 | 0.02 | 0.80 | 31.26 | 14.87 |
| 14 | 9.30 | 0.02 | 2.26 | 29.34 | 15.99 | 39 | 7.90 | 0.02 | 0.80 | 42.36 | 15.78 |
| 15 | 9.10 | 0.02 | 2.10 | 30.35 | 15.78 | 40 | 7.50 | 0.02 | 0.80 | 43.67 | 15.34 |
| 16 | 8.60 | 0.01 | 2.10 | 32.14 | 15.34 | 41 | 7.04 | 0.02 | 0.80 | 45.78 | 15.24 |
| 17 | 8.70 | 0.01 | 2.10 | 33.45 | 14.89 | 42 | 7.05 | 0.02 | 0.80 | 46.78 | 15.79 |
| 18 | 8.70 | 0.02 | 1.80 | 35.12 | 14.32 | 43 | 7.10 | 0.02 | 0.80 | 45.12 | 14.45 |
| 19 | 8.80 | 0.02 | 1.80 | 36.34 | 14.56 | 44 | 7.09 | 0.02 | 0.60 | 45.87 | 14.38 |
| 20 | 8.90 | 0.02 | 1.80 | 37.45 | 14.94 | 45 | 7.10 | 0.03 | 0.60 | 45.60 | 14.40 |
| 21 | 8.90 | 0.02 | 1.80 | 36.56 | 15.53 | 46 | 7.09 | 0.09 | 0.60 | 51.60 | 15.77 |
| 22 | 8.70 | 0.02 | 1.80 | 35.00 | 15.23 | 47 | 7.10 | 0.09 | 0.60 | 46.80 | 16.94 |
| 23 | 7.90 | 0.02 | 1.80 | 35.45 | 15.45 | 48 | 7.10 | 0.09 | 0.45 | 45.34 | 17.56 |
| 24 | 7.80 | 0.02 | 1.80 | 34.56 | 15.67 | 49 | 7.09 | 0.09 | 0.45 | 46.70 | 18.31 |
| 25 | 7.70 | 0.01 | 1.60 | 34.00 | 15.80 | 50 | 7.05 | 0.09 | 0.45 | 53.80 | 17.89 |
| x* | 1.08 | 2.11 | 1.75 | 1.65 | 1.51 |
References
- Zhao, W.; Wang, H. Strategic decision-making learning from label distributions: an approach for facial age estimation. Sensors 2016, 16, 994–1013. [Google Scholar] [CrossRef] [PubMed]
- Qiao, L.Y.; Xu, L.X.; Gao, M. Infrared image sequence complexity analysis based on multi-attribute decision making. Acta Photonica Sinica 2015, 44. [Google Scholar] [CrossRef]
- Gong, Y.C.; Ren, Z.Y.; Ding, F.; Lan, S.S. Grey relation-projection pursuit dynamic cluster method for multi-attribute decision making assessment with trapezoidal intuitionistic fuzzy numbers. Control Decis. 2015, 7, 1333–1339. [Google Scholar]
- Xu, Z.; Wang, H. Managing multi-granularity linguistic information in qualitative group decision making: An overview. Granular Comput. 2016, 1, 21–35. [Google Scholar] [CrossRef]
- Huang, J. A new model of regional water environment protection in the era of big data technology. Chem. Eng. Equip. 2015, 8, 280–281. [Google Scholar] [CrossRef]
- Li, Y.L. Research on Decision Theory and Method from the Perspective of Network Analysis. Ph.D. Thesis, Harbin Institute of Technology, Harbin, China, December 2014. [Google Scholar]
- China Environment Bulletin Released. Available online: http://jcs.mep.gov.cn/hjzl/zkgb/2014zkgb/201506/t20150605_303011.shtml (accessed on 5 June 2015).
- Hu, C.; Barnes, B.B.; Qi, L. A harmful algal bloom of Karenia brevis in the northeastern Gulf of Mexico as revealed by MODIS and VIIRS: A comparison. Sensors 2014, 15, 2873–2887. [Google Scholar] [CrossRef] [PubMed]
- Yao, J.; Xiao, P.; Zhang, Y. A mathematical model of algal blooms based on the characteristics of complex networks theory. Ecol. Modell. 2011, 222, 3727–3733. [Google Scholar] [CrossRef]
- Li, D.G. Bloom Research on Algal Bloom Forecast and Emergency Decision-Making Intelligence Method. Master’s Thesis, Beijing Technology and Business University, Beijing, China, June 2011. [Google Scholar]
- Wang, X.Y.; Chen, C.; Liu, Z.W.; Xu, J.P. Research on the Emergency Control Decision on Water Bloom in Lake and Reservoir Based on Fuzzy Bayes under Comprehensive Restrictions. Intell. Syst. Des. Eng. Appl. 2012, 894–898. [Google Scholar] [CrossRef]
- Liu, Z.W.; Li, L.; Wang, X.Y. Researches of water bloom emergency management decision making method and system based on fuzzy multiple attribute decision making. Int. J. Comput. Sci. Issues 2012, 9, 48–53. [Google Scholar]
- Bai, Y.T.; Wang, L.; Wang, X.Y.; Xu, J.P. Method of multi-level decision-making on governance of water bloom based on entropy and gray correlation degree. Comput. Simul. 2014, 31, 251–255. [Google Scholar]
- Bai, Y.T.; Wang, X.Y.; Wang, L.; Xu, J.P. The research of decision-making method for multi-objective in water bloom emergency governance based on vague set theory. J. Comput. Inf. Syst. 2014, 10, 2099–2106. [Google Scholar]
- Mishra, J.; Ghosh, S. Uncertain query processing using vague set or fuzzy set: which one is better? Int. J. Comput. Commun. Control 2014, 9. [Google Scholar] [CrossRef]
- Chen, S.M. Measures of similarity between vague sets. Fuzzy Sets Syst. 1995, 74, 217–223. [Google Scholar] [CrossRef]
- Hong, D.H.; Chul, K. A note on similarity measures between vague sets and between elements. Inf. Sci. 1999, 115, 83–96. [Google Scholar] [CrossRef]
- Li, F.; Xu, Y.Z. Measures of similarity between vague sets. J. Software 2001, 12, 922–927. [Google Scholar]
- Zhou, X.G.; Zhang, Q. Comparision and improvement on similarity measures between vague sets and between elements. J. Syst. Eng. 2005, 20, 613–619. [Google Scholar]
- Li, D.F.; Cheng, C.T. New similarity measures of intuitionistic fuzzy sets and application to pattern recognitions. Pattern Recognit. Lett. 2002, 23, 221–225. [Google Scholar]
- Chen, S.J.; Chen, S.M. Fuzzy risk analysis based on similarity measures of generalized fuzzy numbers. IEEE Trans. Fuzzy Syst. 2003, 11, 45–46. [Google Scholar] [CrossRef]
- Pedrycz, W.; Chen, S.M. Granular Computing and Decision-Making: Interactive and Iterative Approaches; Springer: Heidelberg, Germany, 2015. [Google Scholar]
- Mendel, J.M. A comparison of three approaches for estimating (synthesizing) an interval type-2 fuzzy set model of a linguistic term for computing with words. Granular Comput. 2016, 1, 59–69. [Google Scholar] [CrossRef]

| No. | Grade | Classical Vague Value | No. | Grade | Classical Vague Value |
|---|---|---|---|---|---|
| 1 | absolutely high (AH) | [1, 1] | 7 | medium low (ML) | [0.4, 0.6] |
| 2 | very high (VH) | [0.9, 0.95] | 8 | fairy low (FL) | [0.3, 0.45] |
| 3 | high (H) | [0.8, 0.9] | 9 | low (L) | [0.2, 0.3] |
| 4 | fairly high (FH) | [0.7, 0.85] | 10 | very low (VL) | [0.1, 0.15] |
| 5 | medium high (MH) | [0.6, 0.8] | 11 | absolutely low (AL) | [0, 0] |
| 6 | medium ( M) | [0.5, 0.5] |
| Expert 4 | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | C1 | C2 | C3 | C4 | C5 | C1 | C2 | C3 | C4 | C5 | C1 | C2 | C3 | C4 | C5 | |
| A1 | L | M | M | VH | H | FL | ML | ML | H | FH | FL | MH | MH | AH | VH | FL | FL | MH | AH | H |
| A2 | VL | ML | ML | H | VH | L | L | FL | FH | H | L | M | M | VH | AH | AL | L | M | H | VH |
| A3 | VL | ML | ML | FH | M | L | FL | FL | MH | ML | L | M | M | H | MH | FL | L | FL | FH | M |
| A4 | ML | FH | FH | FH | FH | M | MH | MH | MH | MH | M | H | H | H | H | M | M | FH | FH | MH |
| A5 | FL | MH | MH | M | MH | L | M | M | ML | M | ML | FH | FH | MH | FH | M | FH | MH | ML | M |
| A6 | M | H | FH | FH | H | MH | FH | MH | H | FH | MH | VH | H | H | VH | ML | VH | H | FH | FH |
| A7 | MH | M | MH | H | FL | FH | ML | M | FH | L | FH | ML | FH | VH | ML | M | ML | FH | FH | L |
| A8 | MH | ML | ML | MH | ML | M | FL | FL | M | FL | FH | M | M | FH | M | M | FL | M | MH | M |
| A9 | M | FL | FL | M | ML | ML | L | L | ML | FL | MH | ML | ML | MH | M | ML | ML | ML | ML | ML |
| Expert 1 | Expert 2 | Expert 3 | Expert 4 | |
|---|---|---|---|---|
| d | 0.156 | 0.357 | 0.130 | 0.357 |
| H | 0.203 | 0.304 | 0.190 | 0.304 |
| C1 | C2 | C3 | C4 | C5 | |
|---|---|---|---|---|---|
| A1 | [0.279, 0.419] | [0.447, 0.584] | [0.513, 0.660] | [0.918, 0.959] | [0.787, 0.893] |
| A2 | [0.118, 0.178] | [0.317, 0.422] | [0.413, 0.511] | [0.788, 0.894] | [0.887, 0.943] |
| A3 | [0.210, 0.315] | [0.347, 0.467] | [0.369, 0.500] | [0.688, 0.844] | [0.487, 0.585] |
| A4 | [0.479, 0.520] | [0.647, 0.769] | [0.691, 0.845] | [0.688, 0.844] | [0.662, 0.831] |
| A5 | [0.349, 0.448] | [0.613, 0.730] | [0.591, 0.720] | [0.458, 0.617] | [0.562, 0.640] |
| A6 | [0.518, 0.678] | [0.813, 0.906] | [0.713, 0.856] | [0.749, 0.874] | [0.762, 0.881] |
| A7 | [0.618, 0.733] | [0.426, 0.573] | [0.613, 0.730] | [0.758, 0.879] | [0.262, 0.393] |
| A8 | [0.558, 0.627] | [0.369, 0.500] | [0.413, 0.511] | [0.588, 0.718] | [0.413, 0.510] |
| A9 | [0.458, 0.617] | [0.313, 0.469] | [0.313, 0.469] | [0.458, 0.617] | [0.387, 0.535] |
| C1 | C2 | C3 | C4 | C5 | |
|---|---|---|---|---|---|
| A1 | 0.699 | 1.033 | 1.174 | 1.878 | 1.681 |
| A2 | 0.297 | 0.740 | 0.924 | 1.683 | 1.831 |
| A3 | 0.525 | 0.815 | 0.870 | 1.533 | 1.073 |
| A4 | 1.000 | 1.417 | 1.537 | 1.533 | 1.493 |
| A5 | 0.797 | 1.344 | 1.312 | 1.076 | 1.203 |
| A6 | 1.197 | 1.720 | 1.570 | 1.624 | 1.643 |
| A7 | 1.353 | 1.000 | 1.344 | 1.637 | 0.655 |
| A8 | 1.186 | 0.870 | 0.924 | 1.307 | 0.923 |
| A9 | 1.076 | 0.783 | 0.783 | 1.076 | 0.923 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, Y.-T.; Zhang, B.-H.; Wang, X.-Y.; Jin, X.-B.; Xu, J.-P.; Su, T.-L.; Wang, Z.-Y. A Novel Group Decision-Making Method Based on Sensor Data and Fuzzy Information. Sensors 2016, 16, 1799. https://doi.org/10.3390/s16111799
Bai Y-T, Zhang B-H, Wang X-Y, Jin X-B, Xu J-P, Su T-L, Wang Z-Y. A Novel Group Decision-Making Method Based on Sensor Data and Fuzzy Information. Sensors. 2016; 16(11):1799. https://doi.org/10.3390/s16111799
Chicago/Turabian StyleBai, Yu-Ting, Bai-Hai Zhang, Xiao-Yi Wang, Xue-Bo Jin, Ji-Ping Xu, Ting-Li Su, and Zhao-Yang Wang. 2016. "A Novel Group Decision-Making Method Based on Sensor Data and Fuzzy Information" Sensors 16, no. 11: 1799. https://doi.org/10.3390/s16111799