Average Throughput Performance of Myopic Policy in Energy Harvesting Wireless Sensor Networks


Department of Electrical and Electronics Engineering, Middle East Technical University (METU), 06531 Cankaya, Ankara, Turkey
*
Author to whom correspondence should be addressed.
Sensors 2017, 17(10), 2206; https://doi.org/10.3390/s17102206
Submission received: 1 August 2017
/
Revised: 16 September 2017
/
Accepted: 20 September 2017
/
Published: 26 September 2017
(This article belongs to the Special Issue Energy Harvesting Sensors for Long Term Applications in the IoT Era)
Abstract
:This paper considers a single-hop wireless sensor network where a fusion center collects data from M energy harvesting wireless sensors. The harvested energy is stored losslessly in an infinite-capacity battery at each sensor. In each time slot, the fusion center schedules K sensors for data transmission over K orthogonal channels. The fusion center does not have direct knowledge on the battery states of sensors, or the statistics of their energy harvesting processes. The fusion center only has information of the outcomes of previous transmission attempts. It is assumed that the sensors are data backlogged, there is no battery leakage and the communication is error-free. An energy harvesting sensor can transmit data to the fusion center whenever being scheduled only if it has enough energy for data transmission. We investigate average throughput of Round-Robin type myopic policy both analytically and numerically under an average reward (throughput) criterion. We show that Round-Robin type myopic policy achieves optimality for some class of energy harvesting processes although it is suboptimal for a broad class of energy harvesting processes.
1. Introduction
1.1. Motivation
The Internet of Things (IoT) is an intelligent large-scale communication infrastructure of uniquely identifiable devices capable of communicating with each other wirelessly through the Internet [1]. The devices in an IoT structure are typically equipped with wireless sensors [2]. Wireless Sensor Networks (WSNs) provide the opportunity of efficient data collection and transmission anywhere [3]. Thus, WSNs have various applications, such as agriculture [4], ambient air monitoring [5,6], frost monitoring [7], structural health monitoring [8,9,10], remote assistance for elderly people [11], home monitoring [3,11,12,13] and smart cities [14,15]. Being frugal with energy consumption is important to several WSN deployments. Energy harvesting (EH) [16] can particularly facilitate WSN applications where replacing battery is not practical. Therefore, energy harvesting is a promising approach for the emerging IoT technology [17]. Energy may be harvested from the environment in several different ways (solar, piezoelectric, wind, etc.) [17]. As energy harvesters generally depend on uncontrollable energy resources and the amount of harvested energy is generally low [17,18], WSNs need robust, self-adaptive, energy efficient policies to optimize their reliable operation lifetime [19,20].
In this paper, we consider a fusion center (FC) collecting data from M EH wireless sensors. At each time slot (TS), K sensors are scheduled for data transmission by the FC, which does not have the direct knowledge of the battery states of the sensors or the statistics of their EH processes. It is assumed that the communication is error-free and the sensors are data backlogged but limited in available energy. Each sensor has an infinite-capacity battery to store the harvested energy and battery leakage is ignored. When a sensor is scheduled in TS t, it sends data to the FC in the TS t as long as it has enough energy in that TS. Sending one packet takes up one TS. The objective of the FC is to maximize the average throughput over a time horizon.
In fact, battery states can be made available to the FC through some additional cost (i.e., feedback) and complexity in some WSNs. However, sending information about the battery state will cause extra time and energy consumption, which we avoid. Assume that the header containing only battery state is H bytes and the remaining part (payload + other headers) of the data packet is P bytes, then sending information about battery state will cause times more time and energy consumption than those consumption not sending no information about battery state. We can avoid extra time consumption by consuming significantly more energy. As it is well known in communication field, data transmission rate is a concave function of transmission power. In fact, the well known Shannon’s capacity formula [21] ( Shannon’s capacity formula is where C is the maximum capacity of the channel in bits/second otherwise called Shannon’s capacity limit for the given channel, B is the bandwidth of the channel in Hertz, S is the signal power in Watts and N is the noise power, also in Watts. The ratio is called Signal to Noise Ratio (SNR)) indicates that this concave function is a logarithmic function. Therefore, when sending info about battery state, we can avoid the extra time consumption only by consuming much more extra energy than . For example, assume that the overhead containing knowledge of battery state is one fourth of the exact data, i.e., . Then, sending both overhead and exact data instead of sending only exact data in the same time duration may cause two times more energy consumption. Thus, it can be said that although energy consumption and network lifetime are not performance metrics in the problem at hand, the problem definition (with sending no information about battery states) helps sensors decrease energy consumption per data packet transmission and thus network lifetime can be increased. Therefore, it is more relevant from a practical perspective that the FC makes scheduling decisions without any knowledge about battery states or statistics of their EH processes [22].
To set up the problem, a model about generation and usage of energy is needed. Each sensor accesses the energy state of its own battery only at the beginning of the time slots in which it is scheduled by the FC. Moreover, independent from the functional form (linear or other) and type of energy harvesting resource (solar, wind, piezoelectric, RF, etc.), the net amount of harvested energy minus used energy is stored losslessly. This assumption is consistent with typical batteries in use today for which leakage is negligibly small over several minutes because battery leakage causes the battery to self-discharge less than 10% (10% for Nickel-based batteries and 5% for Lithium-ion batteries) in 24-h from the results in [23]. Based on these mild assumptions about EH processes, an appropriate performance criterion is the average throughput (reward) criterion over a time horizon rather than expected discounted throughput (reward) for the problem at hand [24].
1.2. Related Work
Although EH processes are not limited to be Markovian in this work, under Markovian assumption, the problem could be formulated as a partially observable Markov decision process (POMDP) [25]. In this case, dynamic programming (DP) [26] may be employed for optimal solution. However, DP has exponential complexity, which limits its scalability [27].
A second approach is reinforcement learning by considering the problem as a POMDP. Q-learning [28], one of the most effective model-free reinforcement learning algorithms, would guarantee convergence to an optimal solution in this problem. However, its very slow convergence [29] deems it non-ideal for a problem with a sizeable state space, especially as the discount factor approaches 1. R-learning [30], which maximizes the average reward, may be considered; however, there is no guarantee on the convergence of R-learning. Therefore, reinforcement learning do not seem to be suitable for obtaining an efficient solution to this problem. There are other approaches that can, in the long run, guarantee convergence to optimal behavior. However, in many practical applications, a policy that achieves near optimality very quickly is preferable to the one that converges too slowly to exact optimality [29].
Another approach to this problem is to set it up as a restless multi-armed bandit (RMAB) problem. An optimal solution was proposed for RMAB problem under certain assumptions by Whittle [31]. It is shown that finding the optimal solution to a general RMAB problem is PSPACE-hard [32] (In complexity theory, PSPACE is the set of all decision problems that can be solved by a Turing machine using a polynomial amount of space). As a policy with a reasonable complexity, myopic policy (MP) has been suggested for various RMAB problems. While MP is not optimal in general since it focuses only on the present state [33], it can be proven to be optimal in certain special cases.
A very similar problem to the problem at hand is investigated in [34,35]. In fact, we pose the same problem in [34,35] with the exception that we assume infinite capacity battery without leakage at the sensors, in contrast to [34,35] where either no battery or unit capacity batteries with leakage are assumed. Both [34,35] formulate the problem as a POMDP, and, due to the myopic approach in these work, the focus is on the immediate reward instead of future rewards. In [35], a single-hop WSN consisting of EH sensors with unit capacity batteries (i.e., able to store only one transmissions’s worth of energy) and a fusion center is posed as a RMAB problem. The optimality of a round-robin (RR) based MP is proved under certain specific assumptions. Then, it is shown that this RR based MP coincides with the Whittle index policy, which is generally suboptimal for RMAB problems [36], for a specific case. In [34], the problem is formulated as a POMDP and the optimality of a MP is proven for two cases: (1) the sensors are unable to harvest and transmit simultaneously, and transition probabilities of the EH processes are affected by the scheduling decisions, and (2) the sensors have no batteries.
In [37,38,39], we investigate quite a similar problem with the problem at hand, although the problem in [38] has some differences due to its system model. In this paper, we consider more general class of energy harvesting processes than [37,39] do (as it is explained in the rest of this paper, we consider energy harvesting processes with intensities both and in this paper, whereas we consider only energy harvesting processes with intensities in [37,38,39]. Besides this, in this paper, we also consider the cases for which finding exact throughput performance of the myopic policy is not possible with using only intensities. For these cases, we find an upper bound for the throughput performance of the myopic policy).
1.3. Our Contributions
Main contributions of the paper are summarized as follows:
- We obtain an upper bound for throughput performance of the RR policies under average throughput criterion for quite general (Markov, i.i.d., nonuniform, uniform, etc.) EH processes. Furthermore, we show that all RR policies including the myopic policy achieve almost the same throughput performance under an average throughput criterion.
1.4. Organization of the Paper
The rest of this paper is organized as follows. The system model and problem formulation are given in Section 2. In Section 3, we show that RR based MP in [34,35] cannot achieve throughput for a broad class of EH processes under average throughput (reward) criterion. Moreover, we obtain an upper bound for throughput performance of RR policies including the myopic policy under average throughput criterion. Furthermore, we show that RR policies including the myopic policy achieve almost the same throughput as each other. In Section 4, numerical results show that the myopic policy is suboptimal for a broad class of EH processes, which supports the results found in Section 3. Section 5 concludes the paper and provides some future directions.
2. System Model and Problem Formulation
We consider a single-hop WSN where a fusion center (FC) collects data from M EH-capable sensors (please see Figure 1). The index set of all sensors is denoted by . The WSN operates in a time-slotted fashion indexed as . At the beginning of each TS, the FC schedules K sensors for data transmission by assigning each sensor to one of its K mutually orthogonal channels. As the research community working on multi-channel protocols generally either assume that channels are perfectly orthogonal (interference-free) or consider the use of only orthogonal channels [40], we assume that the channels are mutually orthogonal, i.e., there is no interference. If the sensors send data at a low data transmission rate and interference management is applied, very low-error transmission can be achieved. Therefore, we assume error-free transmission in the WSN. We assume that the sensors always have data to send as it is assumed in [34,35]. When you consider a single hop wireless sensor network in a wide lowland (flat cropland), there will be no obstacles like buildings, hills which may cause shadowing, reflection, refraction or absorption/diffractions, etc. In a single hop WSN with a central scheduler, the sensors are expected to send the same type of data such as humidity, temperature, pressure, etc. Considering the applications of WSNs in agriculture and frost monitoring [41,42,43,44,45], the sensors have nearly the same propagation conditions to send the same type of data in large croplands. Therefore, we assume that data packets have equal size and sending one packet takes up one TS. A unit energy is defined as the energy required for a sensor to send one packet in one TS.
The energy harvested by sensor i in TSs 1 through t is denoted by , and the energy harvested in TS t is denoted by ; i.e., For , we define the activation set, denoted by , as set of the sensors scheduled in TS t under a policy .
As it is assumed in [34,35], if a sensor has sufficient energy and scheduled in TS t, it sends one data packet to the FC in TS t. The number of data packets sent by sensor i in TS t under a policy can be written as where is the indicator function and is the stored energy in infinite-capacity battery of sensor i in TS t under a policy . Under the policy , is evolved as
The number of data packets sent by all sensors to the FC within the first t TSs under a policy is denoted by which is where the number of packets sent by sensor i in TSs 1 through t under a policy is denoted by .
In [34,35], the objective is to find a policy that maximizes the total throughput over the time horizon under expected discounted reward criteria, where the discount factor corresponds to battery leakage. (Ref. [34] considers the problem under discounted throughput (reward) criteria since [34] assume battery leakage with discount factor such that stored energy decreases to 90% in a time slot which is generally less than 1 ms. However, this is not realistic with recent battery technology.) On the other hand, battery leakage in typical batteries causes less than 10% decrease in the stored energy in 24 h [23]. This decrease implies that battery leakage in a 1 ms-long time slot is less than and so the discount factor is greater than , i.e., (Twenty-four hours equals to 86400000 ms. If length of a time slot is chosen as 1 ms, then which implies that ). Therefore, we neglect battery leakage in our problem formulation, which is practical in terms of engineering aspects. As the problem at hand assumes infinite data backlog and no battery leakage from [19,23], it is delay insensitive by nature. Hence, from [19,23,24], we formulate the scheduling problem as follows.
Problem 1.
Average throughput (reward) maximization over a time horizon, T
The following notions are used in the rest of the paper.
Definition 1.
For a given sequence of energy harvests, an optimal policy, , is a policy that maximizes the total throughput of all sensors upto over a time horizon, T, i.e., where G is set of feasible policies.
Definition 2.
A fully efficient policy, , is a policy under which the sensors use up all of their harvested energy at the end of the time horizon which yields (Although we use to denote the total throughput achieved in first t TSs under a policy π, the total throughput achieved in first t TSs under a policy is denoted by instead of for simplicity. Moreover, and are used instead of and , respectively. Similarly, , and are used instead of , and , respectively.), where .
For certain EH processes, an optimal policy may not be a fully efficient policy, as it is explained in Remark 1.
Definition 3.
Efficiency of a policy π, denoted by , is defined as the ratio of the throughput of a policy π over the throughput of a fully efficient policy, , over the time horizon, T. It can be expressed as
where and are the number of collected data packets (throughput) over a time horizon T under a policy π, and fully efficient policy , respectively (When K and T are in order of tens and thousands, respectively, throughput of an optimal policy is expected to be in the order of ten thousands. The term, efficiency, provides us the opportunity of dealing with small numbers less than or equal to 1 instead of large throughput numbers. Efficiency of a policy also gives us the relative throughput of that policy to the throughput of a fully efficient policy, which provide convenience in numerical results).
The efficiency term itself can also be considered as relative energy consumption of the system to total energy harvested by the system.
The number of data packets which can be sent by all sensors from TS to TS T is denoted by , i.e.,
The number of data packets which can be sent by sensor i from TS to TS T is denoted by , i.e.,
where is the set of all throughput-optimal policies (under different throughput-optimal policies, the throughput of a sensor i in first t TSs may be differed since sensor i may be scheduled by the FC different times under different throughput-optimal policies).
Notice that and .
Definition 4.
Intensity of sensor i, , is defined as the integer part of the total energy harvested by sensor i over the time horizon, T, normalized by , i.e.,
Definition 5.
Intensity , ρ, is defined as the sum of integer parts of the total energy harvested by all sensors over the time horizon, T, normalized by , i.e.,
Remark 1.
If both of the following conditions, , and , are satisfied, then an optimal policy becomes a fully efficient policy, i.e., . Otherwise, an optimal policy cannot achieve throughput of , i.e., . In the cases violating at least one of these conditions, comparing a policy with a fully efficient policy is much simpler than comparing it with an optimal policy. Therefore, we also introduce the notion of fully efficient policy.
For ease of reference, our commonly used notation is summarized in Table 1.
3. Efficiency of Myopic and Round Robin Policies
A similar problem to the problem at hand is studied in [34,35] for certain specific cases under discounted reward criterion. RR based MP is proposed in both papers in which they prove the optimality of this policy for certain specific cases. We applied this RR based myopic policy to the problem at hand. As the MP in [34,35] is an RR policy with quantum = 1 TS, we investigate only RR policies with quantum = 1 TS, denoted by , in this paper.
Definition 6.
For the network that consists of M sensors and an FC with K channels, a Round Robin (RR) policy with quantum = 1 TS is an RR policy under which the FC schedules the sensors by allocating one TS to each sensor for data transmission in a period of TSs (Quantum is defined as the number of TSs allocated to each sensor in a period (round) by an RR policy. An RR policy with quantum=n TSs is an RR policy that allocates n TSs to each sensor in a period (round) of , and so on. For applicability of RR policies with quantum = TS, must be an integer).
In this section, we show that RR policies with quantum = 1 TS are generally suboptimal by Theorem 1. Next, we study their efficiencies more precisely and obtain an upper bound for their efficiencies by Theorem 2. Then, we show that an RR policy with quantum = 1 TS achieves almost the same efficiency as another RR policy with quantum = 1 TS by Theorem 3, which implies that the MP in [34,35] is generally suboptimal and the upper bound obtained for RR policies with quantum = 1 TS is also valid for the MP in [34,35].
Theorem 1.
If there exist some sensors such that for some , all RR policies with quantum = 1 TS have efficiency lower than 100% even if fully efficient policy exists for Problem 1 (they are suboptimal).
Proof.
Under an RR policy with quantum = 1 TS, each sensor is visited by the FC either or times if is not an integer. If is an integer, then FC allocates TSs to each sensor. This means that total number of transmissions from any sensor cannot exceed . implies that sensor i need to send more than data packets in TSs through T so as to send packets, which must be sent by each sensor for full efficiency. Hence, even if a fully efficient policy exists, any RR policy with quantum = 1 TS is not fully efficient for Problem 1 (they are suboptimal). ☐
3.1. Efficiency Bounds of RR Policies with Quantum = 1 TS
In this subsection, efficiency bounds of RR policies with quantum = 1 TS are studied precisely for general EH processes.
Lemma 1.
There exists a class of EH processes with intensity , such that, for these EH processes, some sensor i transmits lower than data packets over a time horizon, T, by an RR policy with quantum = 1 TS, where is the number of TSs allocated to sensor i over the time horizon, i.e., .
Proof.
Please see Appendix A. ☐
Now, we introduce two sets, and , which are used in Theorem 2, Corollaries 1 and 2. denotes the index set of the sensors i for which TSs are allocated and . Moreover, denotes the index set of the sensors i for which TSs are allocated and . By definition, for sensors .
Theorem 2.
For general EH processes,
- (i)
- If , efficiency of an RR policy with quantum=1 TS satisfies
- (ii)
- If , efficiency of an RR policy with quantum=1 TS satisfies
Proof.
Please see Appendix B. ☐
From Theorem 2, we derive the following corollaries.
Corollary 1.
For sufficiently large T, we have . By the definition, so . Hence, upper bound of efficiency of an RR policy with quantum=1 TS can approximately be written as .
Corollary 2.
For sufficiently large T, . If in part (i) of Theorem 2 is neglected and
- (i)
- If , then .
- (ii)
- If , and , , then where .
3.2. Throughput Difference of RR Policies with Quantum = 1 TS
We will prove that the throughput difference between any two RR policies with quantum = 1 TS cannot be greater than in a time horizon. Recall that, for all RR policies with quantum = 1 TS, the scheduling is periodic with a period of TSs. The only difference between any two RR policies with quantum = 1 TS is their initial scheduling time, ; therefore, an RR policy with quantum = 1 TS that starts to send first packet in TS can be labeled as , where .
Lemma 2.
The number of transmissions of sensor i can be varied at most one under two different RR policies with quantum = 1 TS over the time horizon T, i.e.,
Proof.
Please see Appendix C. ☐
The following example is given to illustrate Lemma 2.
Example 1.
Assume that , and . There are three RR policies with quantum=1 TS which schedule the same sensor node i in different TSs as follows.
: Sensor i is scheduled in TSs
: Sensor i is scheduled in TSs
: Sensor i is scheduled in TSs
Notice that sensor i have the chance of transmission five times under and while it has a chance of transmission only four times under . Denote the transmission times of sensor i under different RR policies by where are the indices (initial scheduling times) of RR policies and or 5 are transmission times of sensor i under the applied RR policy in this example. for and for and for ; therefore, . On the other hand, for ; therefore, . The difference between the most and the least efficient RR policies with quantum = 1 TS are
Hence, it is observed that throughput of a sensor i can be varied at most 1 under any RR policies with quantum = 1 TS.
The following theorem is based on the extension of Lemma 2 for the whole network.
Theorem 3.
An RR policy with quantum = 1 TS achieves at most more throughput than another RR policy with quantum = 1 TS over the time horizon T, i.e.,
where is the set of all RR policies with quantum = 1 TS.
Proof.
In this proof, we first consider the case of transmitting messages of sensors over a single channel under an RR policy with quantum = 1 TS. Then, we extend the result of Lemma 2 to the case of multiple (K) channels. Notice that
is the best choice regardless of the sensor i and this most efficient RR policy must be applied to one of the sensors over a single channel. When K channels of the FC are considered, this most efficient RR policy must be applied to K of M sensors. By considering this fact and Lemma 2, an RR policy with quantum = 1 TS transmits at most more data packets than another RR policy with quantum = 1 TS. ☐
Remark 2.
From Theorem 3 and Definition 2,
where is the set of all RR policies with quantum = 1 TS.
As the MP in [34,35] is also an RR policy with quantum = 1 TS, from Remark 2, it has almost same efficiency as another RR policy with quantum=1 TS for sufficiently large time horizon T, i.e., if . For sufficiently large time horizons, these results can be extended for RR policies with quantum = TSs.
4. Numerical Results
In this section, efficiency of the myopic policy (MP) is evaluated for the cases of infinite battery and finite battery with ( implies that the battery of a sensor can store energy enough to send 50 data packets since we assume that each data packet transmission requires one unit of energy) at the time horizons varying from 0 to 2000 TSs via simulations (as efficiency of a policy are defined only for the time horizon, T, we obtain efficiency vs. time horizon figures in this section. Notice that efficiency of the MP at is taken as 0 for these simulations).
For each node i, the Markovian EH process is modelled by a state space and a transition matrix . The harvested energy for sensor i in TS t is where EH state of sensor i in TS t is denoted by .
Notice that efficiency of the MP in [34,35] is almost the same as efficiency of an RR policy with quantum=1 TS since for sufficiently large T from Theorem 3 and Remark 2. We observe efficiency of the MP under nonuniform EH processes (it is obvious that the MP achieve efficiencies close to efficiency of an optimal policy for uniform EH processes. As this case is trivial, we did not show the results for this case).
The simulations are made by taking and under Markovian and i.i.d EH processes with various intensities which are adjusted by choosing intensities of some sensors as and choosing others as as explained in Table 2 (In WSNs, it is highly possible that some EH sensors can harvest energy much efficiently than others due to their energy harvesting resource (solar, piezoelectric, RF, wind, etc.) and environmental conditions. For example, solar energy harvesting is generally more efficient than the others. Therefore, we choose intensities of some sensors much larger than the others (3.0 for some sensors and 0.3 for the remaining ones) in order to represent the difference between the amount of energy harvested by sensors).
4.1. Infinite Capacity Battery
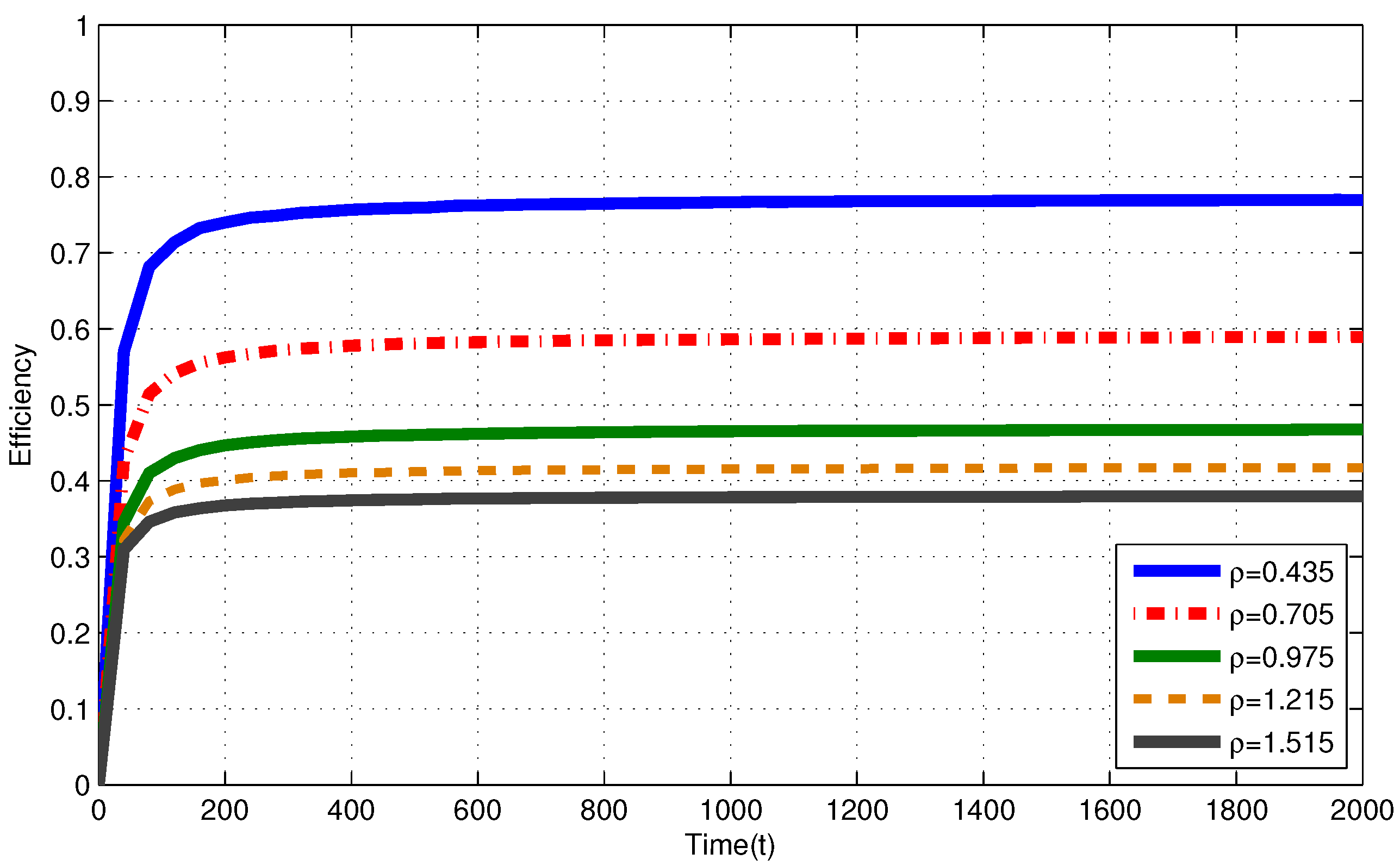
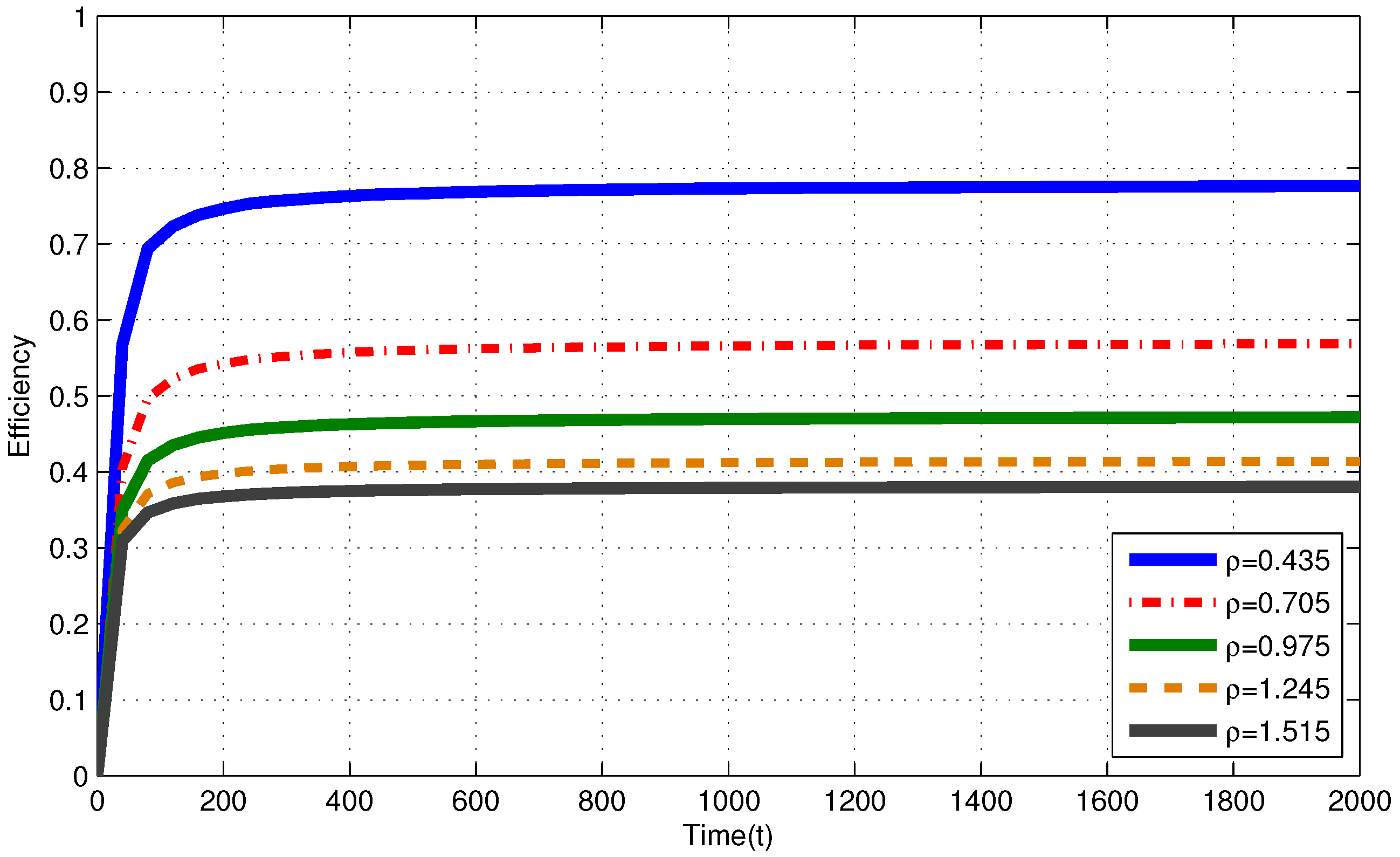
In Figure 2, for i.i.d. EH process with , efficiencies of the MP at are , and for , and , respectively. In Figure 3, for Markov EH process with , at , the MP achieves efficiency of , and for , and , respectively. The dramatic difference between efficiencies of the MP in these three intensities is expected since Theorem 2 and Corollary 1 state that, as the number of nodes with intensity increases, the efficiency of RR policies with quantum = 1 TS decrease. Notice that, from Theorem 2 and Corollary 1, efficiencies of an RR policy with quantum = 1 TS at are expected to be , and for , and , respectively. When EH processes have memory (Markov processes), we observe similar results to the results in memoriless (i.i.d.) EH processes with same intensity.
In Figure 2, for i.i.d. EH process with , efficiencies of the MP at are and for and , respectively. In Figure 3, for Markov EH process with , at , the MP achieves efficiency of and for and , respectively. From Corollary 1, efficiencies of an RR policy with quantum = 1 TS at are expected to be and for and , respectively. For EH processes with , from Definitions 1–3, efficiency of an optimal policy is Hence, at , and for and , respectively. Markov EH processes have similar results to the results for i.i.d. EH processes with same intensity.
4.2. Finite Capacity Battery
In this subsection, the simulations are made by considering a finite battery capacity with under Markovian and i.i.d EH processes with the intensities in Table 2.
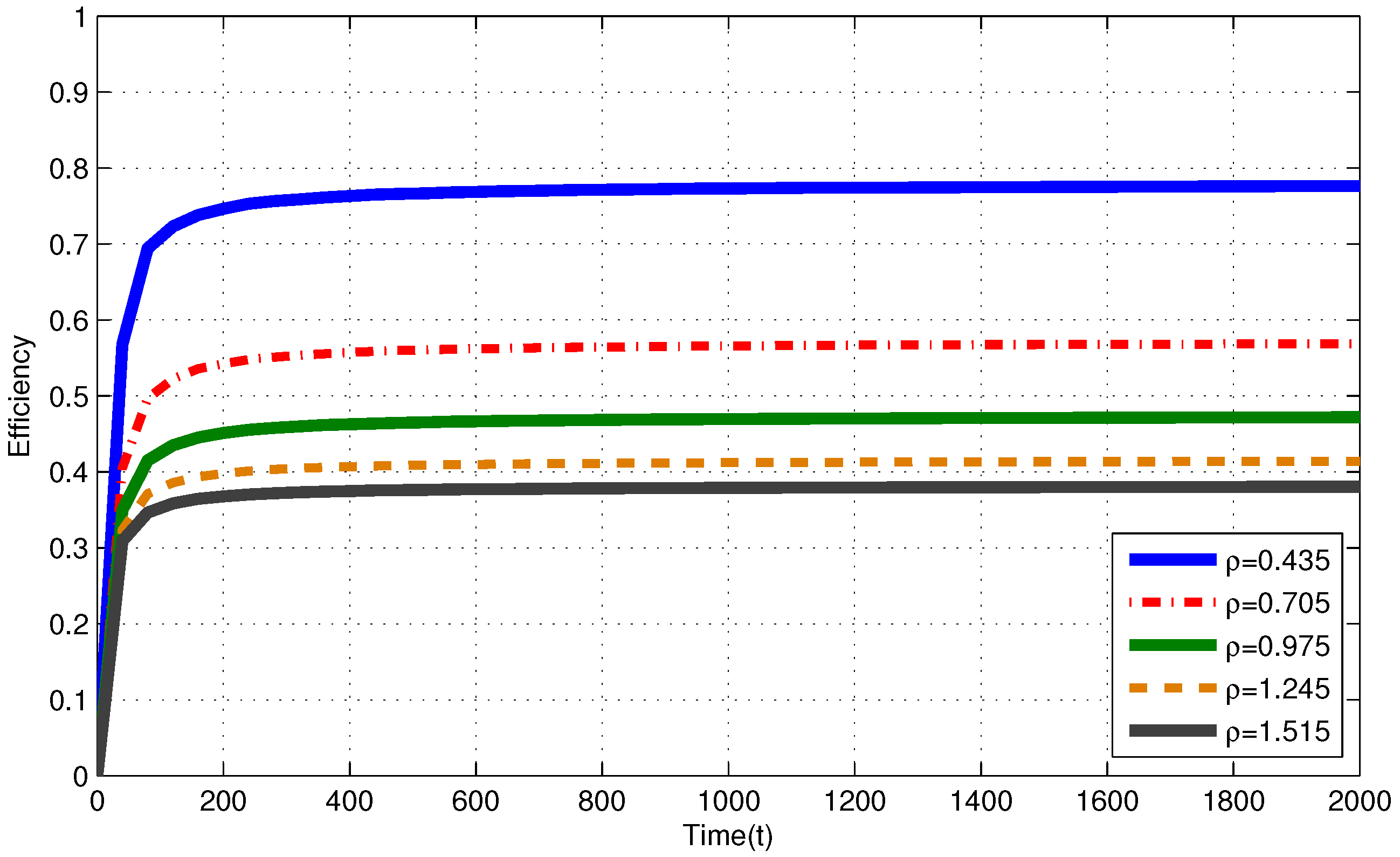
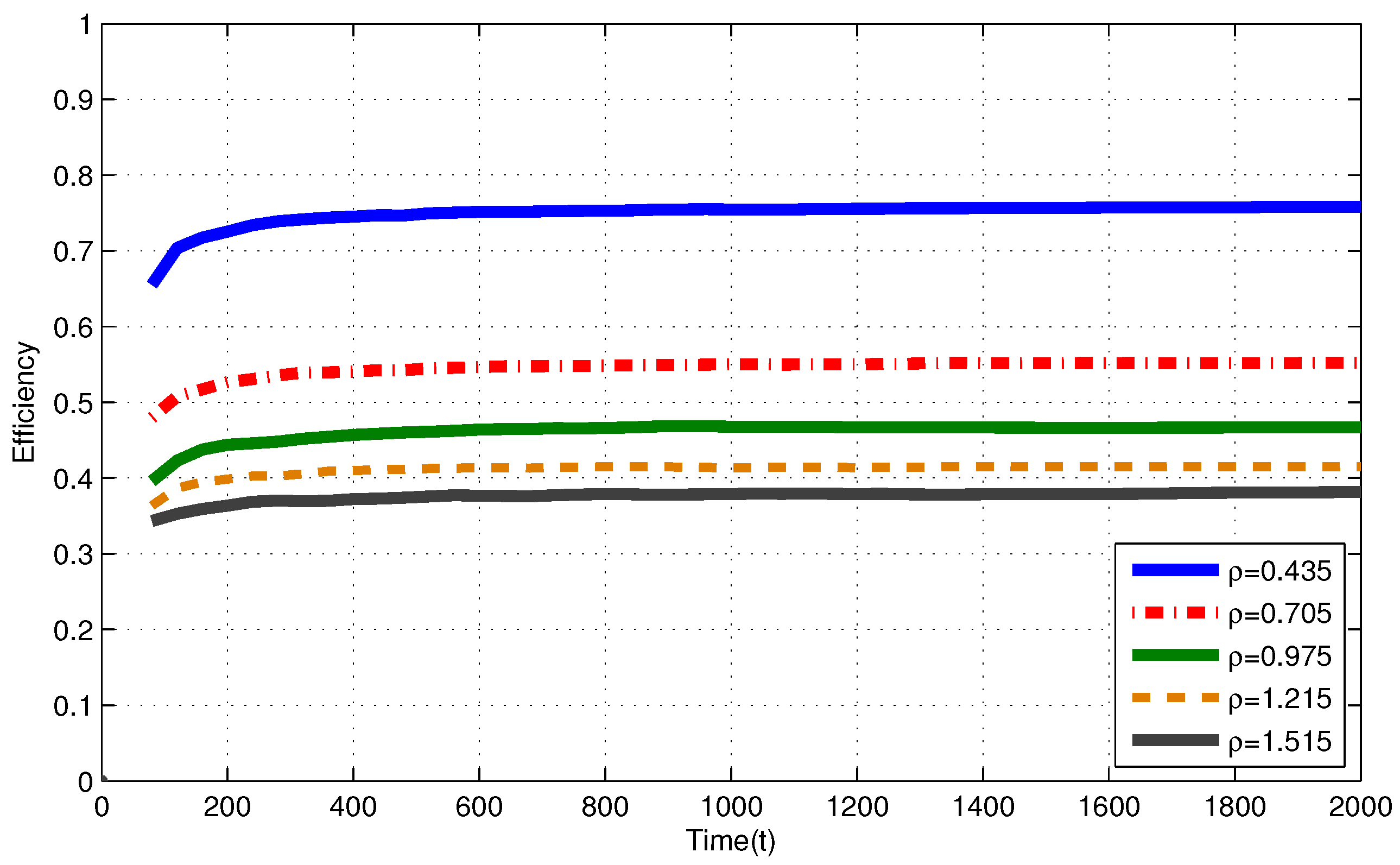
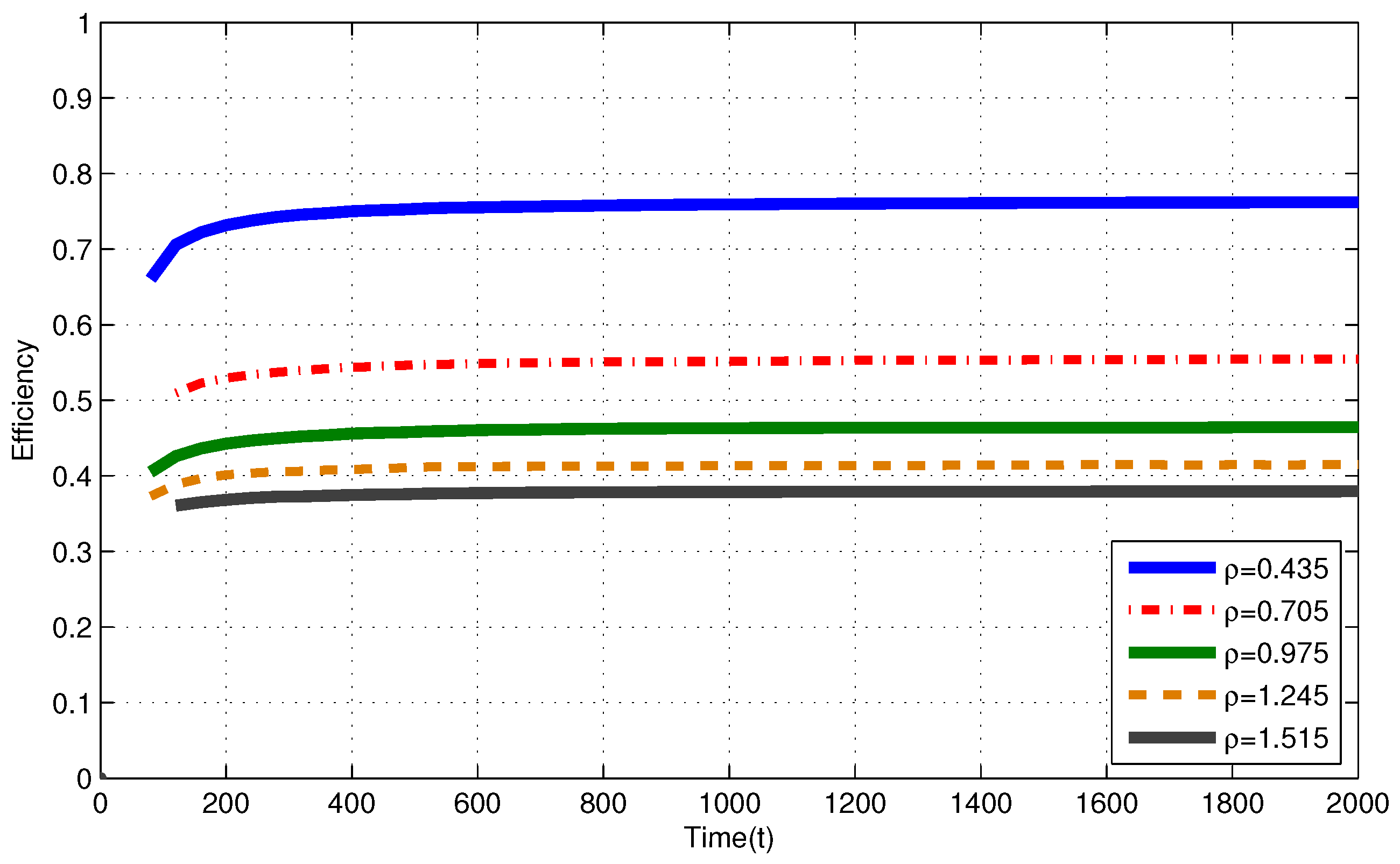
In Figure 4 (i.i.d. EH process), efficiencies of the MP at are , , , and for , , , and , respectively. In Figure 5 (Markov EH process), at , the MP achieves efficiency of , , , and for , , , and , respectively. From Corollary 1, efficiencies of an RR policy with quantum = 1 TS at are expected to be , , and for , , , and , respectively.
Markov EH processes have similar results to the results for i.i.d. EH processes with the same intensity.
4.3. Discussion
In this subsection, the efficiencies of the myopic policy in both infinite and finite capacity battery cases are compared with each other based on the numerical results in Table 3. Besides this, these numerical results are compared with the expected upper bounds for efficiency of myopic policy. Finally, the complexity of the Round-Robin based myopic policy is investigated.
From Table 3, it can observed that the maximum efficiency difference () occurs between () and () for i.i.d. EH processes with intensity . For this intensity, the efficiency in finite battery case is less than the efficiency in infinite battery case. Besides this, the minimum difference (0.000) occurs between () and () for i.i.d. EH processes with . Therefore, the efficiency of MP for is only less than that for at most. Hence, we can conclude that the MP can achieve almost the same throughput performance with a reasonable finite capacity () battery as that with infinite capacity battery.
Moreover, from Table 3, it can observed that the maximum deviation (difference) occurs between the upper bound () and efficiency of MP for i.i.d. EH processes () with intensity . For this intensity, the efficiency is less than the upper bound. Besides this, the minimum deviation occurs between the upper bound () and efficiency of MP for i.i.d. EH processes () with . For this intensity, the efficiency is only less than the upper bound. Based on these results, we can say that the upper bounds for efficiency of the MP are generally tight.
In addition, the Round Robin based myopic policy is a simple policy for this problem. There is an initial ordering and the order is kept during the time interval when Round Robin based scheduling is performed. Sorting algorithms that are required for initial ordering has a worst case complexity of and Round Robin algorithm has a complexity of . Therefore, the myopic policy is a low-complexity solution for the problem at hand.
5. Conclusions
This paper investigates a problem occurring in a single-hop WSN where an FC schedules a set of EH sensors to collect data from them. The FC does not know the instantaneous battery states or the statistics of EH processes at sensors that are data backlogged and the communication is error-free. There is no leakage from the infinite-capacity batteries. The problem at hand is set up as an average throughput (reward) maximization problem. The myopic policy in [34,35] that has an RR structure is applied to this problem as a solution. It is shown that RR policies with quantum = 1 TS are suboptimal for a broad class of EH processes. Next, an upper bound is obtained for efficiencies of RR policies with quantum = 1 TS. Then, it is shown that the myopic policy have almost equal efficiency as another RR policy with quantum = 1 TS. Furthermore, numerical results show that the myopic policy is suboptimal for a broad class of EH processes although it achieves optimality for certain specific cases.
As a future work, we search for a simple, optimal solution to this problem for quite general EH processes. As another future work, we look for extending the single hop problem to multi hop case. Moreover, we plan to investigate the same problem under finite capacity battery case and make the throughput performance analysis of the myopic policy under finite capacity battery case. In addition, we will work to extend the problem in our future works such that we can consider the network lifetime as a performance metric. We believe that novel approaches and concepts in this paper will give insight to the researchers who study similar scheduling problems.
Author Contributions
Omer Melih Gul conceived and designed the system model; Omer Melih Gul and Mubeccel Demirekler analyzed the throughput performance of the Round Robin based myopic policy proposed to the problem; Omer Melih Gul performed the simulations of the model; Omer Melih Gul and Mubeccel Demirekler wrote the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| IoT | Internet of Things |
| WSN | Wireless sensor network |
| EH | Energy harvesting |
| FC | Fusion center |
| TS | time slot |
| SNR | Signal to Noise Ratio |
| RF | Radio frequency |
| POMDP | Partially Observable Markov Decision Processes |
| DP | Dynamic Programming |
| RMAB | Restless Multi Armed Bandit |
| PSPACE | Polynomial Space |
| MP | Myopic policy |
| RR | Round-Robin |
| IID | independent and identically distributed |
Appendix A. Proof of Lemma 1
Define a new function, , for a sensor i as
where is the set of all RR policies with quantum = 1 TS.
Assume for some sensor i and t. From Label (A1),
where .
In the interval, , sensor i can send at most data packets under an RR policy with quantum = 1 TS. Therefore, Label (A2) implies that packets cannot be sent by sensor i over a time horizon, T, where . If the EH process at sensor i were a constant EH process with intensity (for these EH processes, for all ), then sensor i would send packets over a time horizon, T, from Definition 5 and Remark 1. Hence, efficiencies of RR policies with quantum=1 TS under such an EH process that for some sensor i and t become lower than they do under a constant EH process with intensity . This implies that there exists a class of EH processes for which some sensor i cannot achieve the throughput of packets over time horizon, T.
Appendix B. Proof of Theorem 2
Define
where q and m are integers and . Recall for applicability of RR policies with quantum = 1 TS.
Case i: Assume and the RR policy with quantum = 1 TS starts to scheduling with sensor 1 without loss of generality. Notice that if . If the order is followed by the RR policy with quantum=1 TS for the scheduling, sensors are scheduled times and sensors are scheduled q times over a time horizon, T. From Lemma 1, for some EH processes,
otherwise, Label (A4) becomes equality for other EH processes. Hence,
Let where and are the index sets of sensors that have enough energy to send more than and q data packets, respectively. With this specification, the total throughput is
From Label (A6) and Definition 3,
If the numerator and denominator of the second term of the right-hand side in Label (A7) are normalized by ,
From Definition 4, . Labels (A3) and (A8) yields
where
Hence, efficiencies of RR policies with quantum = 1 TS satisfy
Case ii: If , then since in Label (A3) in this case. Let where is index set of sensors that have enough energy to send more than q data packets. (Notice that and if .) By following similar steps in part (i), we obtain
From Label (A10) and Definition 3, efficiency of RR policies with quantum = 1 TS can be expressed as
From Label (A3), Definitions 4 and 5, we obtain
Appendix C. Proof of Lemma 2
Recall that for applicability of RR policies with quantum = 1 TS. There are RR policies with quantum=1 TS which start to schedule a sensor i in different TSs. Recall that where is initial time for policy to schedule the sensor i. The proof is divided into two cases:
Case i: Assume that . Then, where q and r are integers such that and . Some of the RR policies with quantum=1 TS schedules a sensor i times, whereas the other RR policies schedules the sensor iq times. The set of initial times of the RR policies which scheduled sensor i times is denoted by whereas the set of others is denoted by . denotes the transmission time of sensor i under an RR policy, , which starts to schedule sensor i in TS n, where or are transmission times of sensor i under the applied RR policy, . By definition,
which yields
Notice that (in fact, ). Therefore,
which yields
Similarly, . Therefore,
which yields
From Labels (A12)–(A14),
Furthermore,
which yields
From Label (A16),
From Labels (A15) and (A17),
Hence, the lemma is proved for the first case, .
Case ii: If , each of RR policies with quantum=1 TS schedules a sensor i times. The set of initial times of RR policies with quantum=1 TS is denoted by . denotes transmission time of sensor i under an RR policy, , where are transmission times of sensor i under the applied RR policy, , in this case
which yields
Moreover,
which yields
From Labels (A19) and (A20),
Hence, the lemma is proved for the second case, .
References
- Sheng, Z.; Yang, S.; Yu, Y.; Vasilakos, A.; Mccann, J.; Leung, K. Survey on the IETF Protocol Suite for the Internet of Things: Standards, Challenges, and Opportunities. IEEE Wirel. Commun. 2013, 20, 91–98. [Google Scholar] [CrossRef]
- Kamalinejad, P.; Mahapatra, C.; Sheng, Z.; Mirabbasi, S.; Leung, V.C.M.; Guan, Y.L. Wireless Energy Harvesting for the Internet of Things. IEEE Commun. Mag. 2015, 53, 102–108. [Google Scholar] [CrossRef]
- Tsai, C.W.; Hong, T.P.; Shiu, G.N. Metaheuristics for the lifetime of WSN: A review. IEEE Sens. J. 2016, 16, 2812–2831. [Google Scholar] [CrossRef]
- Wark, T.; Corke, P.; Sikka, P.; Klingbeil, L.; Guo, Y.; Crossman, C.; Valencia, P.; Swain, D.; Bishop-Hurley, G. Transforming Agriculture through Pervasive Wireless Sensor Networks. IEEE Pervasive Comput. 2007, 6. [Google Scholar] [CrossRef] [Green Version]
- Chaiwatpongsakorn, C.; Lu, M.; Keener, T.C.; Khang, S.-J. The deployment of carbon monoxide wireless sensor network (CO-WSN) for ambient air monitoring. Int. J. Environ. Res. Public Health 2014, 11, 6246–6264. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.-Y.; Zhu, Y.; Kong, L.; Liu, C.; Gu, Y.; Vasilakos, A.V.; Wu, M.-Y. CDC: Compressive data collection for wireless sensor networks. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 2188–2197. [Google Scholar] [CrossRef]
- Valente, J.; Sanz, D.; Barrientos, A.; del Cerro, J.; Ribeiro, A.; Rossi, C. An Air-Ground Wireless Sensor Network for Crop Monitoring. Sensors 2011, 11, 6088–6108. [Google Scholar] [CrossRef]
- Fu, T.; Ghosh, A.; Johnson, E.A.; Krishnamachari, B. Energy-Efficient Deployment Strategies in Structural Health Monitoring using Wireless Sensor Networks. J. Struct. Control Health Monit. 2012, 20, 971–986. [Google Scholar] [CrossRef]
- Aderohunmu, F.; Balsamo, D.; Paci, G.; Brunelli, D. Long Term WSN Monitoring for Energy Efficiency in EU Cultural Heritage Buildings. Lect. Notes Electr. Eng. 2013, 281, 253–261. [Google Scholar]
- Balsamo, D.; Paci, G.; Benini, L.; Davide, B. Long Term, Low Cost, Passive Environmental Monitoring of Heritage Buildings for Energy Efficiency Retrofitting. In Proceedings of the 2013 IEEE Workshop on Environmental Energy and Structural Monitoring Systems (EESMS), Trento, Italy, 11–12 September 2013; pp. 1–6. [Google Scholar]
- Suryadevara, N.K.; Mukhopadhyay, S.C. Wireless sensor network based home monitoring system for wellness determination of elderly. IEEE Sens. J. 2012, 12, 1965–1972. [Google Scholar] [CrossRef]
- Yetgin, H.; Cheung, K.T.K.; El-Hajjar, M.; Hanzo, L. Network lifetime maximization of wireless sensor networks. IEEE Access 2015, 3, 2191–2226. [Google Scholar] [CrossRef]
- Zhou, F.; Chen, Z.; Guo, S.; Li, J. Maximizing Lifetime of Data-Gathering Trees With Different Aggregation Modes in WSNs. IEEE Sens. J. 2016, 16, 8167–8177. [Google Scholar] [CrossRef]
- Hancke, G.P.; de Carvalho e Silva, B.; Hancke, G.P., Jr. The role of advanced sensing in smart cities. Sensors 2013, 13, 393–425. [Google Scholar] [CrossRef] [PubMed]
- Gomez, C.; Paradells, J. Urban Automation Networks: Current and Emerging Solutions for Sensed Data Collection and Actuation in Smart Cities. Sensors 2015, 15, 22874–22898. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paradiso, J.A.; Starner, T. Energy scavenging for mobile and wireless electronics. IEEE Pervasive Comput. 2005, 4, 18–27. [Google Scholar] [CrossRef]
- Sudevalayam, S.; Kulkarni, P. Energy Harvesting Sensor Nodes: Survey and Implications. IEEE Commun. Surv. Tutor. 2011, 13, 443–461. [Google Scholar] [CrossRef]
- Akyildiz, I.F.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. A survey on sensor networks. IEEE Commun. Mag. 2002, 40, 102–114. [Google Scholar] [CrossRef]
- Kansal, A.; Hsu, J.; Zahedi, S.; Srivastava, M.B. Power management in energy harvesting sensor networks. ACM Trans. Embed. Comput. Syst. 2007, 6, 32. [Google Scholar] [CrossRef]
- Garcia-Hernandez, C.F.; Ibargengoytia-Gonzalez, P.H.; Garcia-Hernandez, J.; Perez-Diaz, J.A. Wireless Sensor Networks and Applications: A Survey. IJCSNS Int. J. Comput. Sci. Netw. Secur. 2007, 7, 264–273. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Technol. J. 1948, 27, 379–426. [Google Scholar] [CrossRef]
- Alsheikh, M.A.; Hoang, D.T.; Niyato, D.; Tan, H.; Lin, S. Markov Decision Processes With Applications in Wireless Sensor Networks: A Survey. IEEE Commun. Surv. Tutor. 2015, 17, 1239–1267. [Google Scholar] [CrossRef]
- Battery University (Cadex Electronics). BU-802b: What Does Elevated Self-discharge Do? Available online: http://batteryuniversity.com/learn/article/elevatingselfdischarge (accessed on 4 April 2017).
- Arapostathis, A.; Borkar, V.S.; Fernández-gaucherand, E.; Ghosh, M.K.; Marcus, S.I. Discrete-time controlled Markov processes with average cost criterion: A survey. SIAM J. Control Optim. 1993, 31, 282–334. [Google Scholar] [CrossRef]
- Monahan, G.E. State of the art-A survey of partially observable Markov decision processes: Theory, models, and algorithms. Manag. Sci. 1982, 28, 1–16. [Google Scholar] [CrossRef]
- Bellman, R.E. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Littman, M.L.; Dean, T.L.; Kaelbling, L.P. In the complexity of solving Markov decision problems. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–20 August 1995; pp. 394–402. [Google Scholar]
- Watkins, C.J. Learning from Delayed Rewards. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 1989. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar]
- Mahadevan, S. Average reward reinforcement learning: Foundations, algorithms, and empirical results. Mach. Learn. Spec. Issue Reinf. Learn. 1996, 22, 159–196. [Google Scholar]
- Whittle, P. Restless bandits: Activity allocation in a changing world. J. Appl. Probab. 1988, 25, 287–298. [Google Scholar] [CrossRef]
- Papadimitriou, C.H.; Tsitsiklis, J.N. The complexity of optimal queueing network control. Math. Oper. Res. 1999, 24, 293–305. [Google Scholar] [CrossRef]
- Hero, A.; Castanon, D.; Cochran, D.; Kastella, K. Foundations and Applications of Sensor Management; Springer: New York, NY, USA, 2007. [Google Scholar]
- Blasco, P.; Gunduz, D.; Dohler, M. Low-Complexity Scheduling Policies for Energy Harvesting Communication Networks. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Istanbul, Turkey, 7–12 July 2013; pp. 1601–1605. [Google Scholar]
- Iannello, F.; Simeone, O.; Spagnolini, U. Optimality of myopic scheduling and whittle indexability for energy harvesting sensors. In Proceedings of the 46th Annual Conference on Information Sciences and Systems(CISS), Princeton, NJ, USA, 21–23 March 2012; pp. 1–6. [Google Scholar]
- Gittins, J.; Glazerbrook, K.; Weber, R. Multi-Armed Bandit Allocation Indices; Wiley: West Sussex, UK, 2011. [Google Scholar]
- Gul, O.M.; Uysal-Biyikoglu, E. A randomized scheduling algorithm for energy harvesting wireless sensor networks achieving nearly 100% throughput. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Istanbul, Turkey, 6–9 April 2014; pp. 2456–2461. [Google Scholar]
- Gul, O.M.; Uysal-Biyikoglu, E. Achieving nearly 100% throughput without feedback in energy harvesting wireless networks. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Honolulu, HI, USA, 29 June–4 July 2014; pp. 1171–1175. [Google Scholar]
- Gul, O.M.; Uysal-Biyikoglu, E. UROP: A Simple, Near-Optimal Scheduling Policy for Energy Harvesting Sensors. arXiv, 2014; arXiv:1401.0437. [Google Scholar]
- Durmaz Incel, O. A survey on multi-channel communication in wireless sensor networks. Comput. Netw. 2011, 55, 3081–3099. [Google Scholar] [CrossRef]
- Beckwith, R.; Teibel, D.; Bowen, P. Unwired Wine: Sensor Networks in Vineyards. In Proceedings of the 2014 IEEE Sensors, Vienna, Austria, 24–27 October 2004; pp. 1–4. [Google Scholar]
- Chaudhary, D.D.; Nayse, S.P.; Waghmare, L.M. Application of Wireless Sensor Networks for Greenhouse Parameter Control in Precision Agriculture. Int. J. Wirel. Mob. Netw. IJWMN 2011, 3, 140–149. [Google Scholar]
- Srbinovska, M.; Gavrovski, C.; Dimcev, V.; Krkoleva, A.; Borozan, V. Environmental parameters monitoring in precision agriculture using wireless sensor networks. J. Clean. Prod. 2015, 88, 297–307. [Google Scholar] [CrossRef]
- Project RHEA. Robot Fleets For Highly Effective Agriculture And Forestry Management. From 2010-08-01 to 2014-07-31, Closed Project. Available online: http://cordis.europa.eu/project/rcn/95055en.html (accessed on 29 May 2017).
- Project CROPS. Intelligent Sensing and Manipulation for Sustainable Production and Harvesting of High Value Crops, Clever Robots for Crops. From 2010-10-01 to 2014-09-30, Closed Project. Available online: http://cordis.europa.eu/project/rcn/96216_en.html (accessed on 25 May 2017).
Figure 1.
An example single hop WSN where an FC collects data from 10 EH sensors.
Figure 2.
Efficiency of the myopic policy (MP) for i.i.d. EH processes under infinite capacity battery assumption.
Figure 2.
Efficiency of the myopic policy (MP) for i.i.d. EH processes under infinite capacity battery assumption.
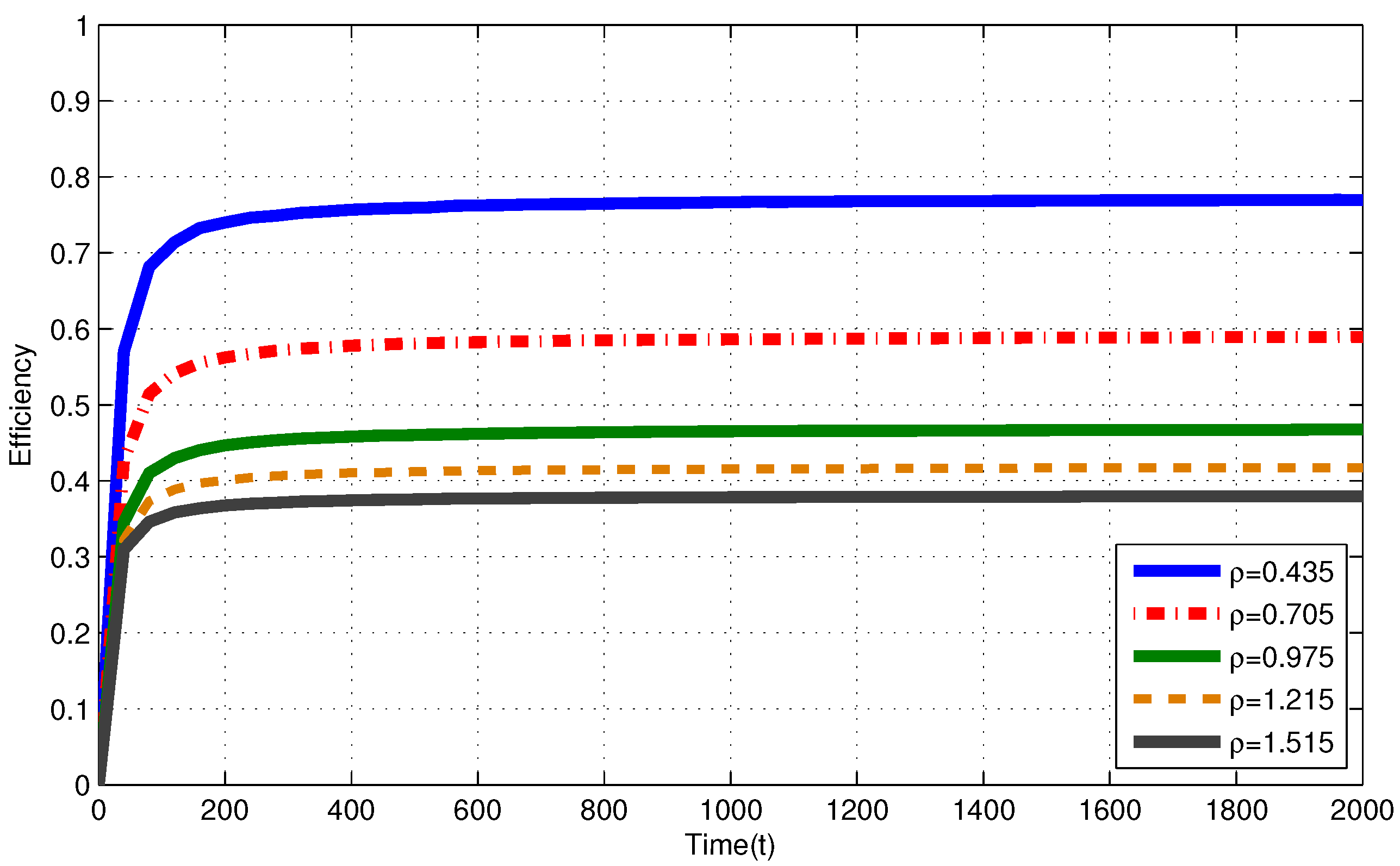
Figure 3.
Efficiency of the myopic policy (MP) for Markov EH processes under infinite capacity battery assumption.
Figure 3.
Efficiency of the myopic policy (MP) for Markov EH processes under infinite capacity battery assumption.

Figure 4.
Efficiency of the myopic policy (MP) for Markov EH processes under finite capacity () battery assumption.
Figure 4.
Efficiency of the myopic policy (MP) for Markov EH processes under finite capacity () battery assumption.
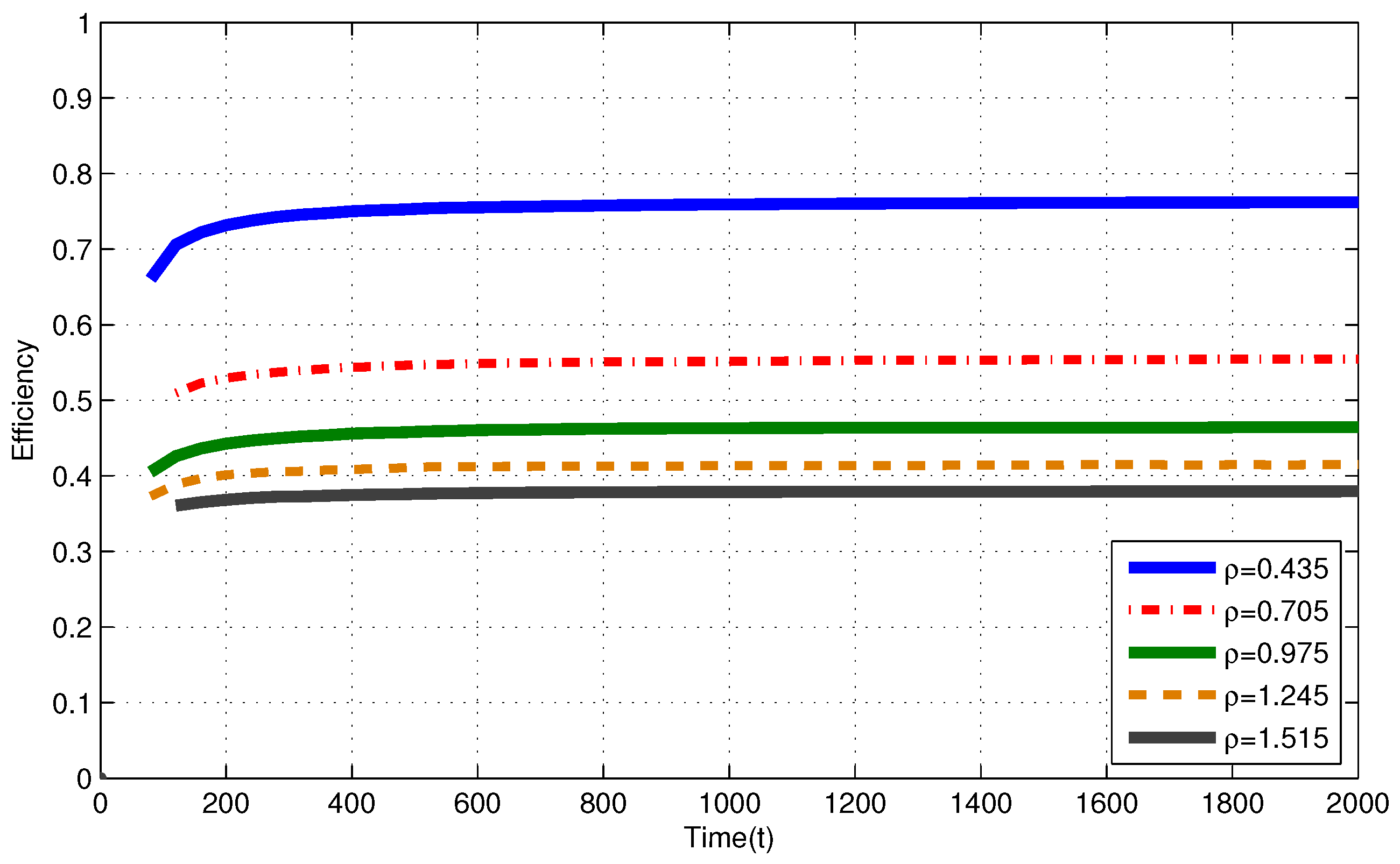
Figure 5.
Efficiency of the myopic policy (MP) for i.i.d. EH processes finite capacity () battery assumption.
Figure 5.
Efficiency of the myopic policy (MP) for i.i.d. EH processes finite capacity () battery assumption.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Summary of commonly used symbols and notation.
| Symbol | Definition |
|---|---|
| M | The number of energy harvesting nodes |
| K | The number of mutually orthogonal channels of FC |
| S | The index set of all nodes |
| T | The time horizon |
| Throughput of all nodes in TSs 1 through t under a policy | |
| Throughput of node i in TSs 1 through t under a policy | |
| Efficiency of a policy | |
| The number of packets which can be sent by node i in | |
| Intensity of node i | |
| Intensity |
Table 2.
W and L denote the numbers of sensors with and , respectively. denotes the resultant intensity.
Table 2.
W and L denote the numbers of sensors with and , respectively. denotes the resultant intensity.
| W | 95 | 85 | 75 | 65 | 55 |
| L | 5 | 15 | 25 | 35 | 45 |
Table 3.
Efficiency of MP for IID and Markov EH processes under both infinite and finite capacity battery assumptions and stands for infinite and finite capacity batteries, respectively. denotes the intensity. Max. efficiency difference between and represents the efficiency difference between and cases for the same intensity. Max. efficiency difference (%) btw. and represents the percentage of efficiency difference between and cases over the efficiency in case for the same intensity. Max. deviation between the bound and efficiency of MP represents the difference between the upper bound of efficiency of MP and minimum efficiency result of MP for the same intensity.
Table 3.
Efficiency of MP for IID and Markov EH processes under both infinite and finite capacity battery assumptions and stands for infinite and finite capacity batteries, respectively. denotes the intensity. Max. efficiency difference between and represents the efficiency difference between and cases for the same intensity. Max. efficiency difference (%) btw. and represents the percentage of efficiency difference between and cases over the efficiency in case for the same intensity. Max. deviation between the bound and efficiency of MP represents the difference between the upper bound of efficiency of MP and minimum efficiency result of MP for the same intensity.
| Efficiency of MP for Markov EH process, | |||||
| Efficiency of MP for Markov EH process, | |||||
| Efficiency of MP for IID EH process, | |||||
| Efficiency of MP for IID EH process, | |||||
| Max. efficiency difference between and | |||||
| Max. efficiency difference (%) btw. and | |||||
| Upper bound for efficiency of MP | |||||
| Max. deviation between the bound and efficiency of MP |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Gul, O.M.; Demirekler, M. Average Throughput Performance of Myopic Policy in Energy Harvesting Wireless Sensor Networks. Sensors 2017, 17, 2206. https://doi.org/10.3390/s17102206
AMA Style
Gul OM, Demirekler M. Average Throughput Performance of Myopic Policy in Energy Harvesting Wireless Sensor Networks. Sensors. 2017; 17(10):2206. https://doi.org/10.3390/s17102206
Chicago/Turabian StyleGul, Omer Melih, and Mubeccel Demirekler. 2017. "Average Throughput Performance of Myopic Policy in Energy Harvesting Wireless Sensor Networks" Sensors 17, no. 10: 2206. https://doi.org/10.3390/s17102206
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.