
Online Classification of Contaminants Based on Multi-Classification Support Vector Machine Using Conventional Water Quality Sensors


Abstract
:1. Introduction
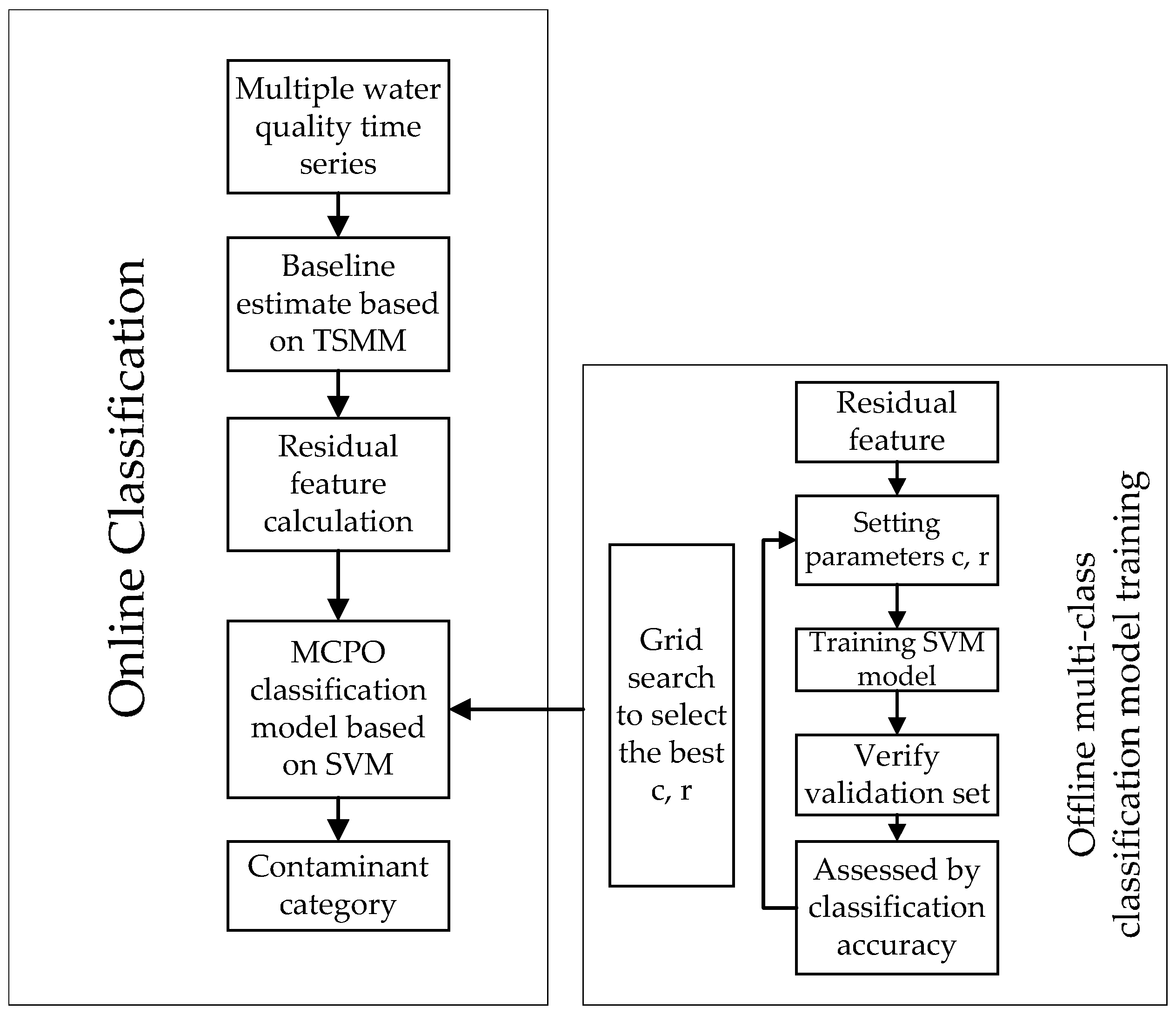
2. Methodology
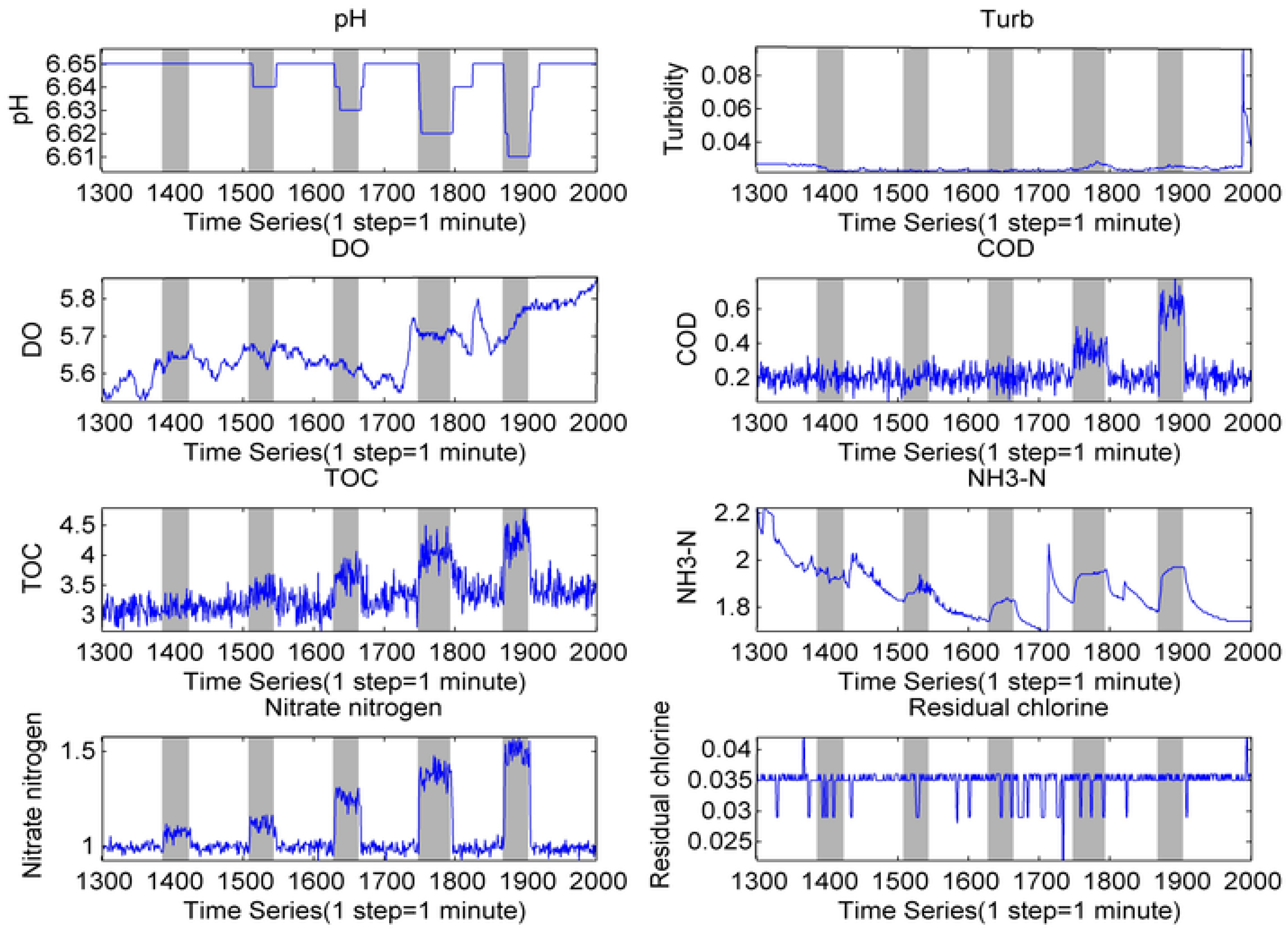
2.1. Baseline Estimate Based on Time Series Movement Mean (TSMM)
2.2. MCPO Classification Model Based on SVM
2.2.1. Fundamentals of SVM
- Linear kernel function: ;
- Polynomial kernel function: ;
- Radial basic function: ; and
- Sigmoid function: .
2.2.2. Multi-Classification Probability Based on SVM
- Utilize Equation (11) to update
- Normalize the parameter .
- Verify whether satisfies Equation (9); if satisfied, then stop the iteration, and obtain the multiple classification probabilities .
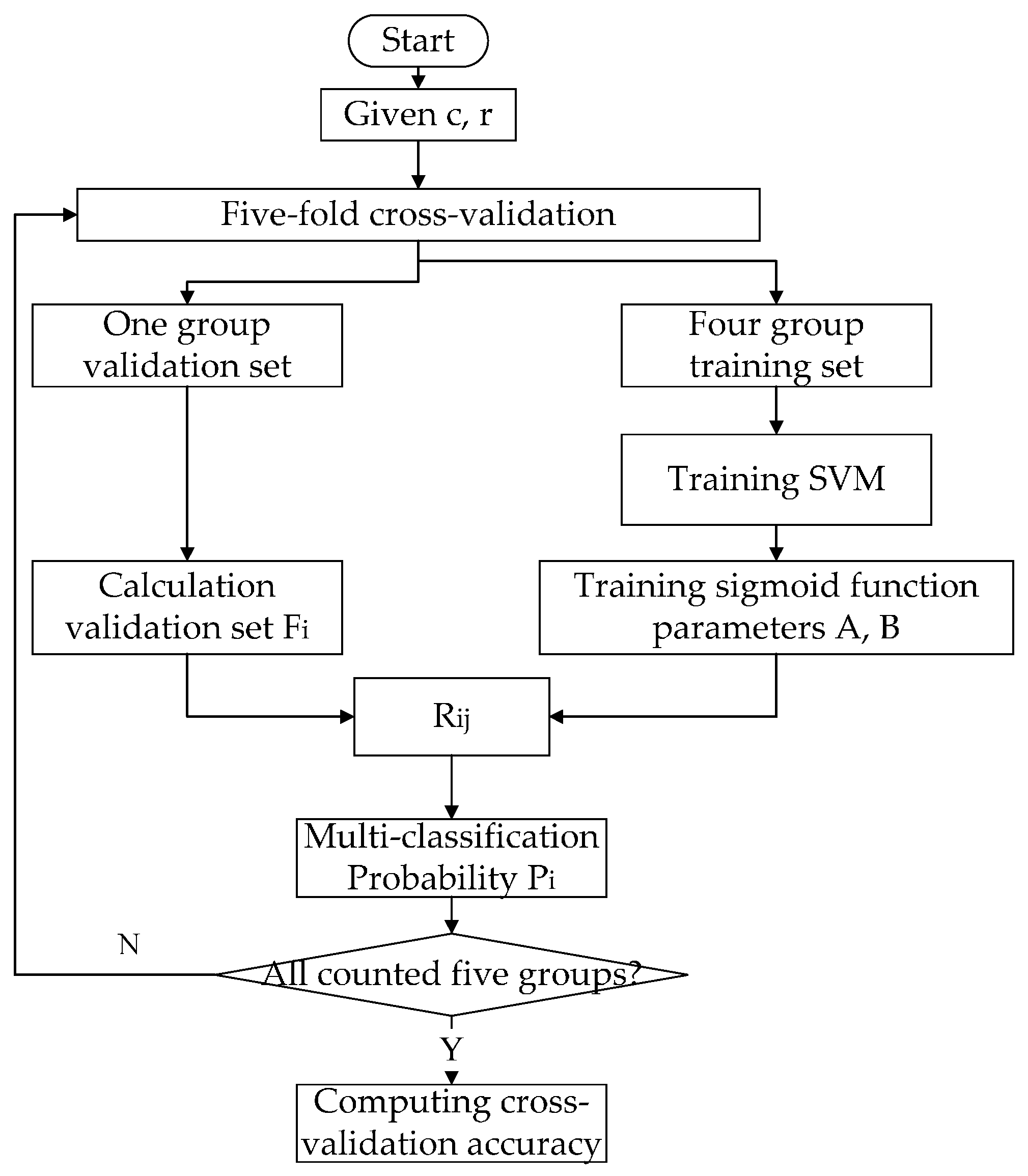
2.3. Parameter Selection of SVM Model
2.4. Evaluation of Classification Performance
2.4.1. Confusion Matrix
2.4.2. Classification Accuracy
3. Experimental and Results
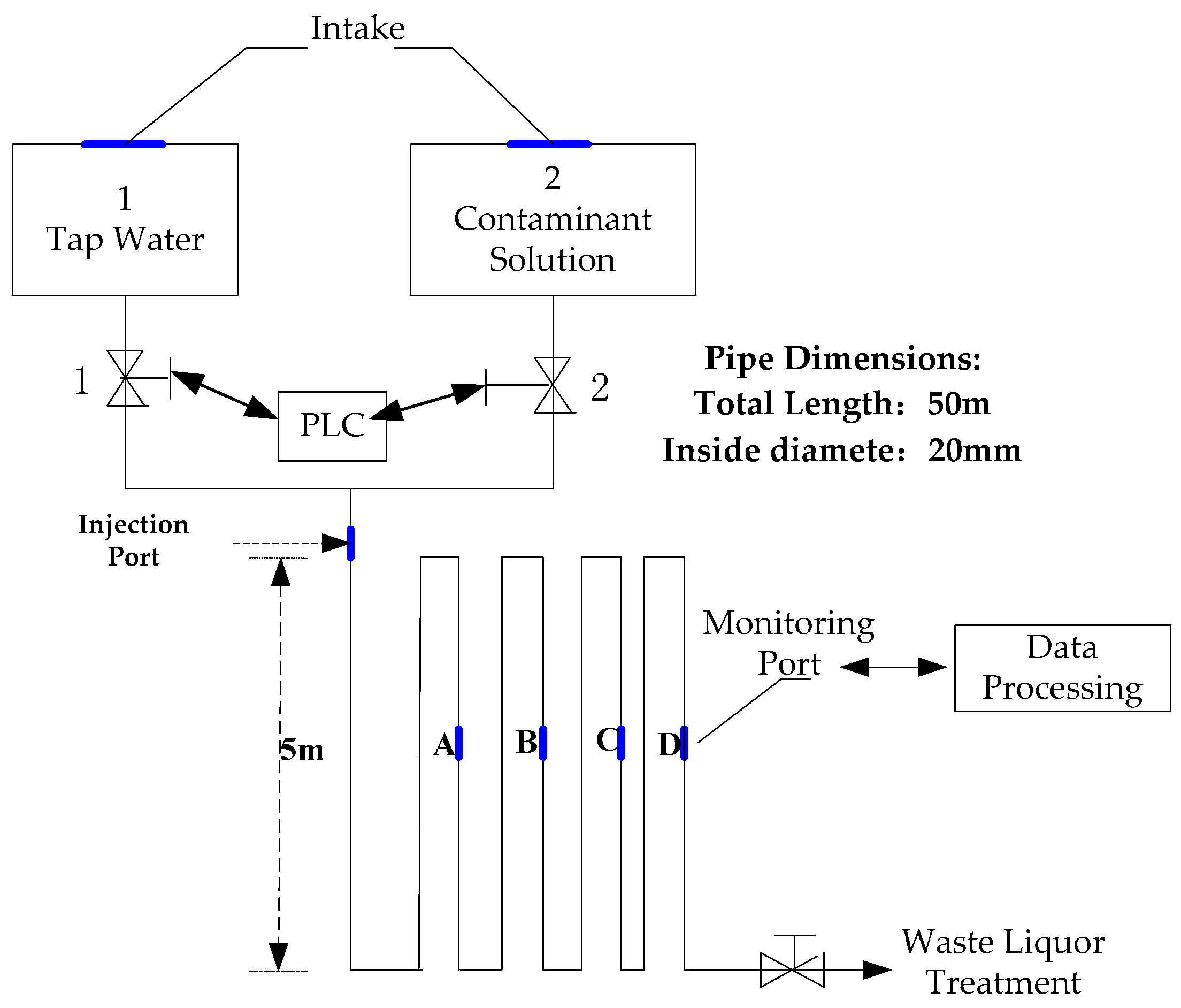
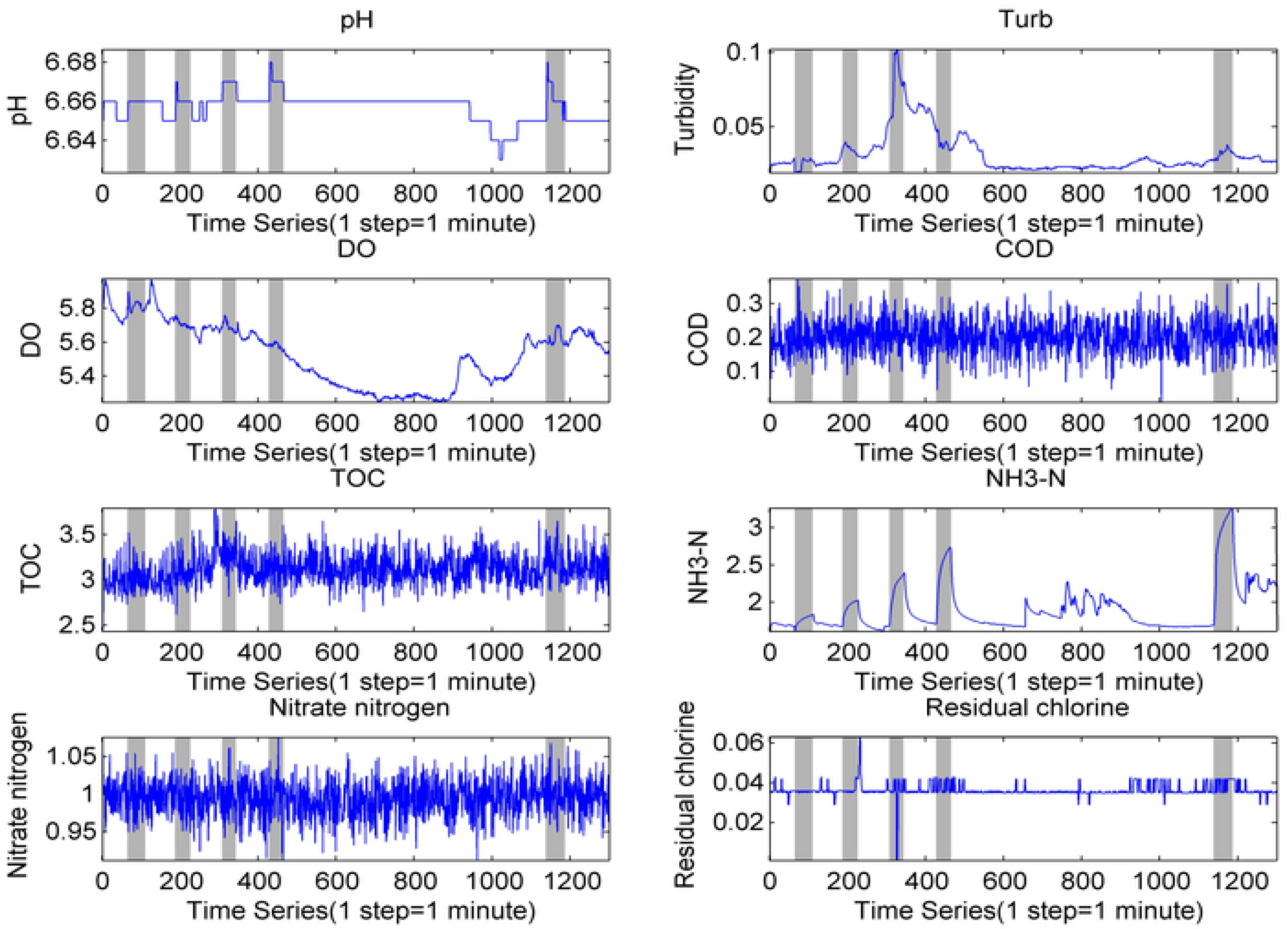
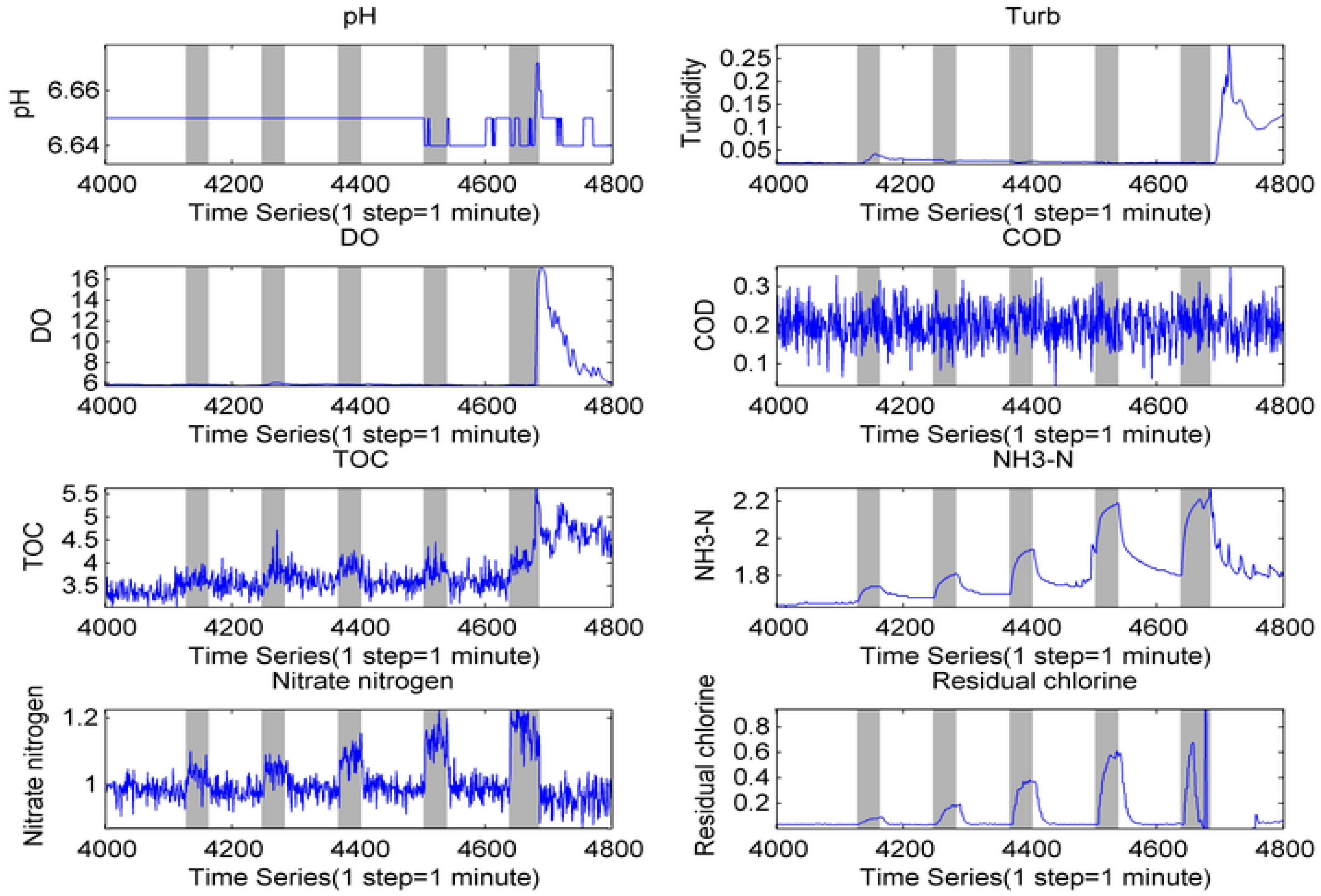
3.1. Experimental Data Acquisition
3.1.1. Experimental Design
3.1.2. Investigated Contaminants
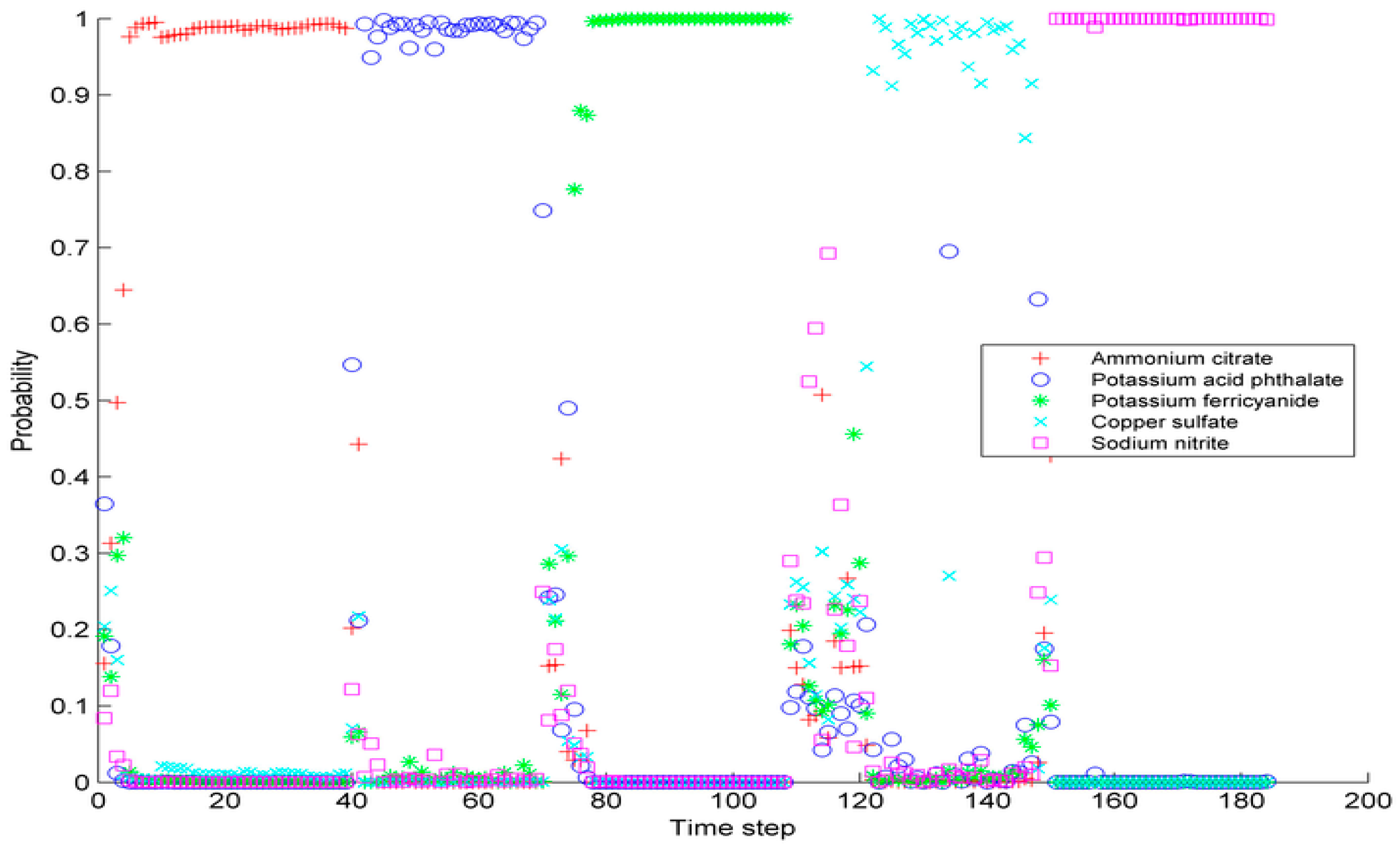
3.2. Classification Results of the MCPO Model
3.2.1. Concentration of the Test Pollutant within the Range of Pollutant Library
3.2.2. Concentration of the Test Pollutant outside the Range of Pollutant Library
4. Discussion
4.1. MCPO Model for Alleviating the Influence of Concentration When Constructing the Pollutants Library
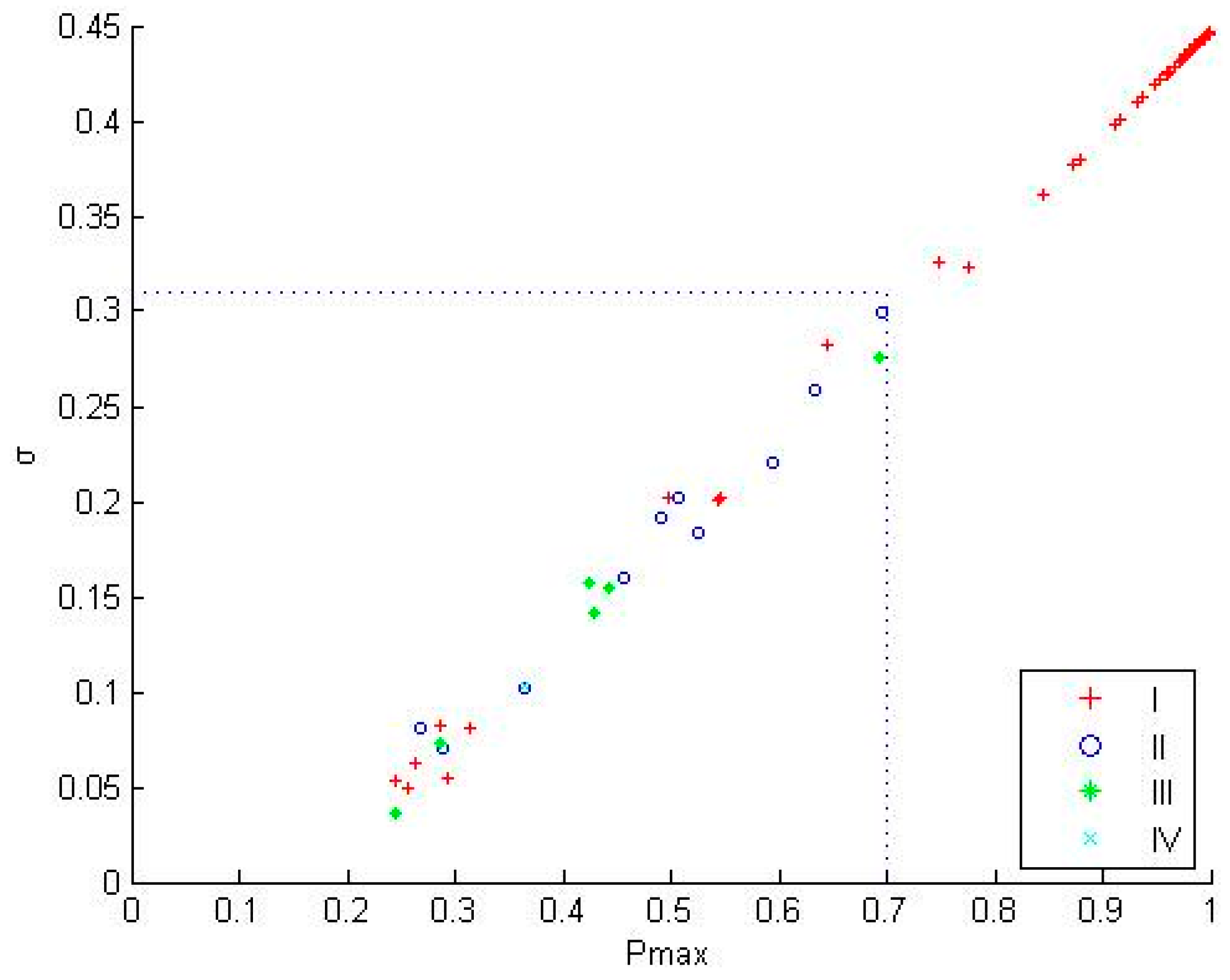
4.2. Analysis on Misclassifying the Contaminant Introductionin in the Initial Phase
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A




References
- Toolbox, R.P. Planning for and Responding to Drinking Water Contamination Threats and Incidents; USEPA: Washington, DC, USA, 2003.
- USEPA. Water sentinel System Architecture Draft Version 1.0; Environmental Protection Agency: Washington, DC, USA, 2005; pp. 41–60.
- Hoogh, C.J.D.; Wagenvoort, A.J.; Jonker, F.; Leerdam, J.A.V.; Hogenboom, A.C. HPLC-DAD and Q-TOF MS techniques identify cause of Daphnia biomonitor alarms in the River Meuse. Environ. Sci. Technol. 2006, 8, 2678–2685. [Google Scholar] [CrossRef]
- Hawkins, P.R.; Novic, S.; Cox, P.; Neilan, B.A.; Burns, B.P.; Shaw, G.; Wickramasinghe, W.; Peerapornpisal, Y.; Ruangyuttikarn, W.; Itayama, T. A review of analytical methods for assessing the public health risk from microcystin in the aquatic environment. J. Water Supply Res. Technol.-Aqua 2005, 8, 509–518. [Google Scholar]
- Kroll, D.J. Securing Our Water Supply: Protecting a Vulnerable Resource; PennWell Books: Tulsa, OK, USA, 2006. [Google Scholar]
- Jeffrey, Y.Y.; Haught, R.C.; Goodrich, J.A. Real-time contaminant detection and classification in a drinking water pipe using conventional water quality sensors: Techniques and experimental results. J. Environ. Manag. 2009, 8, 2494–2506. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Han, C.; Smith, K.; Tian, C. A real time method of contaminant classification using conventional water quality sensors. J. Environ. Manag. 2015, 154, 13–21. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Che, H.; Smith, K.; Chang, T. Contaminant classification using cosine distances based on multiple conventional sensors. Environ. Sci. Process. Impacts 2015, 2, 343–350. [Google Scholar] [CrossRef] [PubMed]
- Bi, J.; Lu, M.; Guo, C.; Wang, Y.; Liu, X. A transformer fault diagnosing method based on multi-classified probability output. Autom. Electr. Power Syst. 2015, 39, 88–93, 100. [Google Scholar]
- Jack, L.B.; Nandi, A.K. Fault Detection Using Support Vector Machines and Artificial Neural Networks, Augmented by Genetic Algorithms. Mech. Syst. Signal Process. 2002, 2, 373–390. [Google Scholar] [CrossRef]
- Shi, W. Support Vector Machines Based Approach for Fault Diagnosis of Valves in Reciprocating Pumps. J. Mech. Strength 2002, 3, 1622–1627. [Google Scholar]
- Meng, W.U. Application of Support Vector Machines in Financial Time Series Forecasting. Neurocomputing 2002, 1, 847–861. [Google Scholar]
- Zhang, H.R.; Han, Z.Z.; Chang-Gang, L.I. Support Vector Machine Based Nonlinear Systems Identification. Acta Simulata Syst. Sinica 2003, 1, 034. [Google Scholar] [CrossRef]
- Yan, W.; Shao, H. Application of support vector machine nonlinear classifier to fault diagnoses. In Proceedings of the World Congress on Intelligent Control and Automation, Shanghai, China, 10–14 June 2002; pp. 2697–2700.
- Oliker, N.; Ostfeld, A. A coupled classification–Evolutionary optimization model for contamination event detection in water distribution systems. Water Res. 2014, 51, 234–245. [Google Scholar] [PubMed]
- He, H.M.; Hou, D.B.; Zhao, H.F.; Huang, P.J.; Zhang, G.X. Multi-parameters fusion algorithm for detecting anomalous water quality. J. Zhejiang Univ. 2013, 4, 735–740. [Google Scholar]
- Hou, D.B.; Yue, C.; Zhao, H.F.; Huang, P.J.; Zhang, G.X. Water quality anomaly detection method based on RBF neural network and wavelet analysis. Transducer Microsyst. Technol. 2013, 2, 138–141. [Google Scholar]
- McKenna, S.A.; Hart, D.B.; Klise, K.A.; Cruz, V.A.; Wilson, M.P. Event detection from water quality time series. In Proceedings of the World Environmental and Water Resources Congress 2007: Restoring Our Natural Habitat, Tampa, FL, USA, 15–19 May 2007.
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 2013. [Google Scholar]
- Vapnik, V.N. Statistical Learning Theory. Encycl. Sci. Learn. 2010, 4, 3185. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 3, 389–396. [Google Scholar] [CrossRef]
- Platt, J.C. Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods. Adv. Large Margin Classif. 2000, 10, 61–74. [Google Scholar]
- Wu, T.; Lin, C.; Weng, R.C. Probability estimates for multi-class classification by pairwise coupling. J. Mach. Learn. Res. 2004, 5, 975–1005. [Google Scholar]
- Hastie, T.; Tibshirani, R. Classification by pairwise coupling. Ann. Stat. 1998, 2, 451–471. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predict Class | Ammonium Citrate | Potassium Acid Phthalate | Potassium Ferricyanide | Copper Sulfate | Sodium Nitrite | |
|---|---|---|---|---|---|---|
| Real Class | ||||||
| Ammonium citrate | 38 | 0 | 0 | 1 | 0 | |
| Potassium acid phthalate | 0 | 29 | 0 | 1 | 1 | |
| potassium ferricyanide | 1 | 0 | 29 | 8 | 0 | |
| copper sulfate | 3 | 4 | 1 | 19 | 12 | |
| sodium nitrite | 1 | 5 | 0 | 0 | 31 | |
| Predict Class | Ammonium Citrate | Potassium Acid Phthalate | Potassium Ferricyanide | Copper Sulfate | Sodium Nitrite | |
|---|---|---|---|---|---|---|
| Real Class | ||||||
| Ammonium citrate | 37 | 0 | 0 | 2 | 0 | |
| Potassium acid phthalate | 0 | 27 | 0 | 1 | 3 | |
| potassium ferricyanide | 0 | 1 | 34 | 3 | 0 | |
| copper sulfate | 0 | 2 | 0 | 32 | 5 | |
| sodium nitrite | 0 | 1 | 0 | 2 | 34 | |
| Classification Method | Euclidean Distance | Mahalanobis Distance | Cosine Distance | MCPO | |
|---|---|---|---|---|---|
| Test Pollutants | |||||
| Ammonium citrate | 0.89 | 0.87 | 0.97 | 0.95 | |
| Potassium acid phthalate | 0.77 | 0.45 | 0.93 | 0.88 | |
| Potassium ferricyanide | 0.73 | 0.65 | 0.76 | 0.90 | |
| Copper sulfate | 0.28 | 0.23 | 0.48 | 0.82 | |
| Sodium nitrite | 0.86 | 0.81 | 0.83 | 0.92 | |
| Average | 0.69 | 0.61 | 0.80 | 0.90 | |
| Predict Class | Ammonium Citrate | Potassium Acid Phthalate | Potassium Ferricyanide | Copper Sulfate | Sodium Nitrite | |
|---|---|---|---|---|---|---|
| Real Class | ||||||
| Ammonium citrate | 26 | 0 | 0 | 11 | 0 | |
| Potassium acid phthalate | 0 | 22 | 0 | 4 | 3 | |
| potassium ferricyanide | 2 | 0 | 24 | 10 | 0 | |
| copper sulfate | 3 | 4 | 3 | 15 | 12 | |
| sodium nitrite | 3 | 6 | 0 | 0 | 27 | |
| Predict Class | Ammonium Citrate | Potassium Acid Phthalate | Potassium Ferricyanide | Copper Sulfate | Sodium Nitrite | |
|---|---|---|---|---|---|---|
| Real Class | ||||||
| Ammonium citrate | 33 | 0 | 0 | 4 | 0 | |
| Potassium acid phthalate | 0 | 25 | 0 | 1 | 3 | |
| potassium ferricyanide | 0 | 2 | 30 | 4 | 0 | |
| copper sulfate | 0 | 2 | 0 | 30 | 5 | |
| sodium nitrite | 0 | 2 | 0 | 2 | 31 | |
| Classification Method | Euclidean Distance | Mahalanobis Distance | Cosine Distance | MCPO | |
|---|---|---|---|---|---|
| Test Pollutants | |||||
| Ammonium citrate | 0.62 | 0.68 | 0.70 | 0.89 | |
| Potassium acid phthalate | 0.63 | 0.52 | 0.75 | 0.86 | |
| Potassium ferricyanide | 0.66 | 0.62 | 0.67 | 0.83 | |
| Copper sulfate | 0.25 | 0.21 | 0.40 | 0.81 | |
| Sodium nitrite | 0.82 | 0.72 | 0.75 | 0.89 | |
| Average | 0.60 | 0.55 | 0.65 | 0.86 | |
| Contaminant Category | Sample Number | Support Vector Number | |
|---|---|---|---|
| Ammonium citrate | 1 mg/L | 47 | 38 |
| 2 mg/L | 40 | 10 | |
| 4 mg/L | 37 | 3 | |
| 8 mg/L | 50 | 6 | |
| Total | 174 | 57 | |
| Potassium acid phthalate | 1 mg/L | 39 | 29 |
| 2 mg/L | 37 | 29 | |
| 4 mg/L | 37 | 18 | |
| 8 mg/L | 37 | 6 | |
| Total | 150 | 82 | |
| Sodium nitrite | 1 mg/L | 38 | 29 |
| 2 mg/L | 38 | 14 | |
| 4 mg/L | 38 | 6 | |
| 8 mg/L | 37 | 3 | |
| Total | 154 | 52 | |
| Potassium ferricyanide | 1 mg/L | 37 | 35 |
| 2 mg/L | 38 | 23 | |
| 6 mg/L | 38 | 5 | |
| 8 mg/L | 21 | 7 | |
| Total | 134 | 70 | |
| Copper sulfate | 1 mg/L | 40 | 29 |
| 2 mg/L | 38 | 14 | |
| 6 mg/L | 38 | 6 | |
| 8 mg/L | 46 | 3 | |
| Total | 162 | 52 | |
| Total | 774 | 313 | |
| Sample No. | Contaminant Classification Result | Real Contaminant | SVM Predicted Class | |||||
|---|---|---|---|---|---|---|---|---|
| A | B | C | D | E | Type | |||
| 1 | 0.16 | 0.36 | 0.19 | 0.20 | 0.08 | IV | A | B |
| 2 | 0.98 | 0.00 | 0.01 | 0.01 | 0.00 | I | A | A |
| 3 | 0.99 | 0.00 | 0.01 | 0.01 | 0.00 | I | A | A |
| 4 | 0.44 | 0.21 | 0.07 | 0.22 | 0.06 | III | B | A |
| 5 | 0.00 | 0.95 | 0.00 | 0.00 | 0.05 | I | B | B |
| 6 | 0.15 | 0.25 | 0.21 | 0.21 | 0.17 | III | C | B |
| 7 | 0.42 | 0.07 | 0.11 | 0.31 | 0.09 | III | C | A |
| 8 | 0.04 | 0.49 | 0.30 | 0.05 | 0.12 | II | C | B |
| 9 | 0.07 | 0.01 | 0.87 | 0.03 | 0.02 | I | C | C |
| 10 | 0.20 | 0.10 | 0.18 | 0.23 | 0.29 | II | D | E |
| 11 | 0.51 | 0.04 | 0.09 | 0.30 | 0.06 | II | D | A |
| 12 | 0.06 | 0.07 | 0.10 | 0.08 | 0.69 | III | D | E |
| 13 | 0.27 | 0.07 | 0.23 | 0.26 | 0.18 | II | D | A |
| 14 | 0.15 | 0.11 | 0.46 | 0.24 | 0.05 | II | D | C |
| 15 | 0.00 | 0.04 | 0.01 | 0.93 | 0.01 | I | D | D |
| 16 | 0.00 | 0.70 | 0.01 | 0.27 | 0.02 | II | D | B |
| 17 | 0.03 | 0.63 | 0.07 | 0.02 | 0.25 | II | E | B |
| 18 | 0.43 | 0.08 | 0.10 | 0.24 | 0.15 | III | E | A |
| 19 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | I | E | E |
| Type | Quantity | Pmax Average/% | σ Average |
|---|---|---|---|
| I | 167 | 0.9488 | 0.42 |
| II | 10 | 0.482 | 0.1767 |
| III | 6 | 0.4199 | 0.1398 |
| IV | 1 | 0.3648 | 0.1033 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, P.; Jin, Y.; Hou, D.; Yu, J.; Tu, D.; Cao, Y.; Zhang, G. Online Classification of Contaminants Based on Multi-Classification Support Vector Machine Using Conventional Water Quality Sensors. Sensors 2017, 17, 581. https://doi.org/10.3390/s17030581
Huang P, Jin Y, Hou D, Yu J, Tu D, Cao Y, Zhang G. Online Classification of Contaminants Based on Multi-Classification Support Vector Machine Using Conventional Water Quality Sensors. Sensors. 2017; 17(3):581. https://doi.org/10.3390/s17030581
Chicago/Turabian StyleHuang, Pingjie, Yu Jin, Dibo Hou, Jie Yu, Dezhan Tu, Yitong Cao, and Guangxin Zhang. 2017. "Online Classification of Contaminants Based on Multi-Classification Support Vector Machine Using Conventional Water Quality Sensors" Sensors 17, no. 3: 581. https://doi.org/10.3390/s17030581