3.1. Experimental Database and Experimental Setups
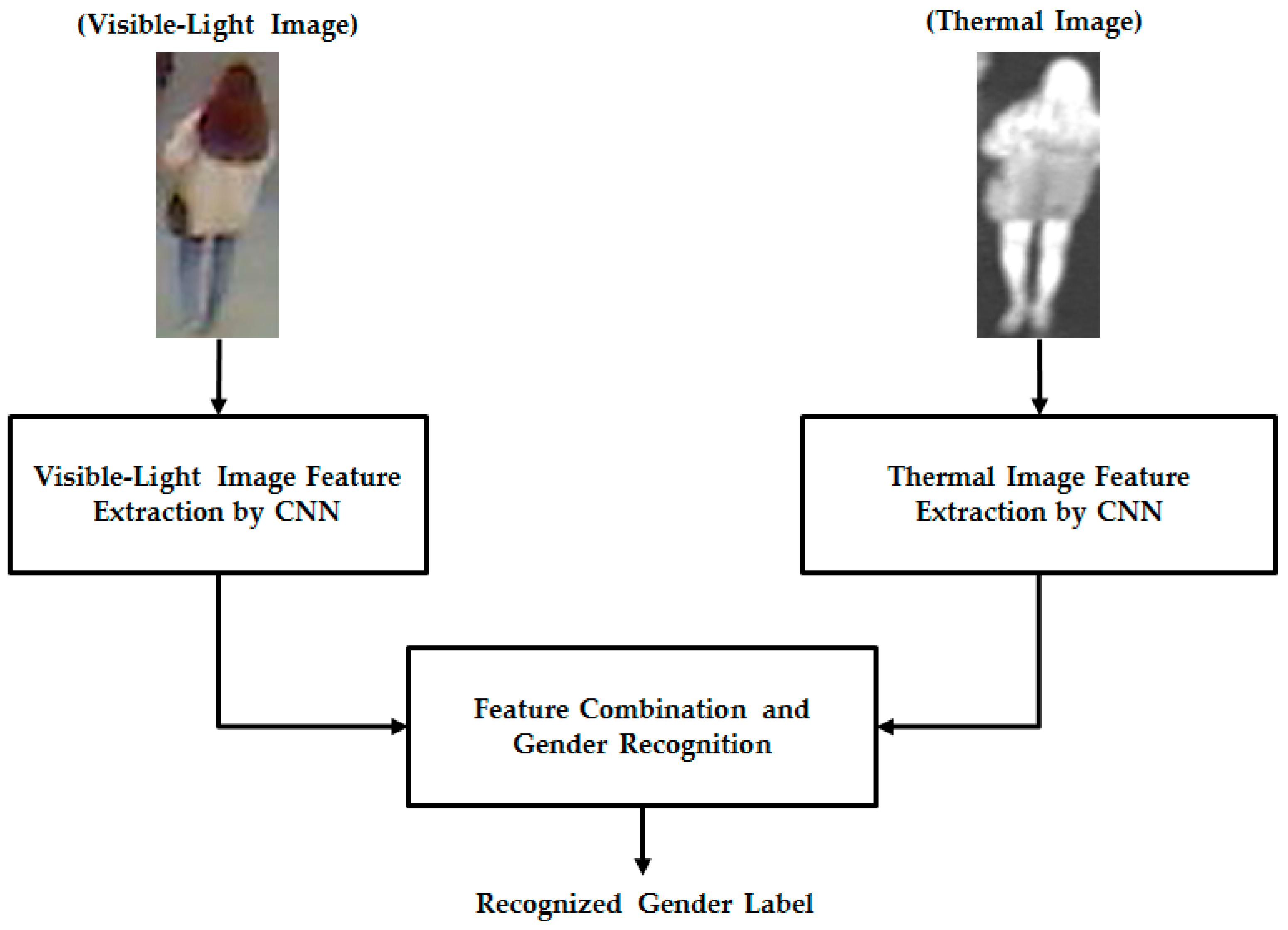
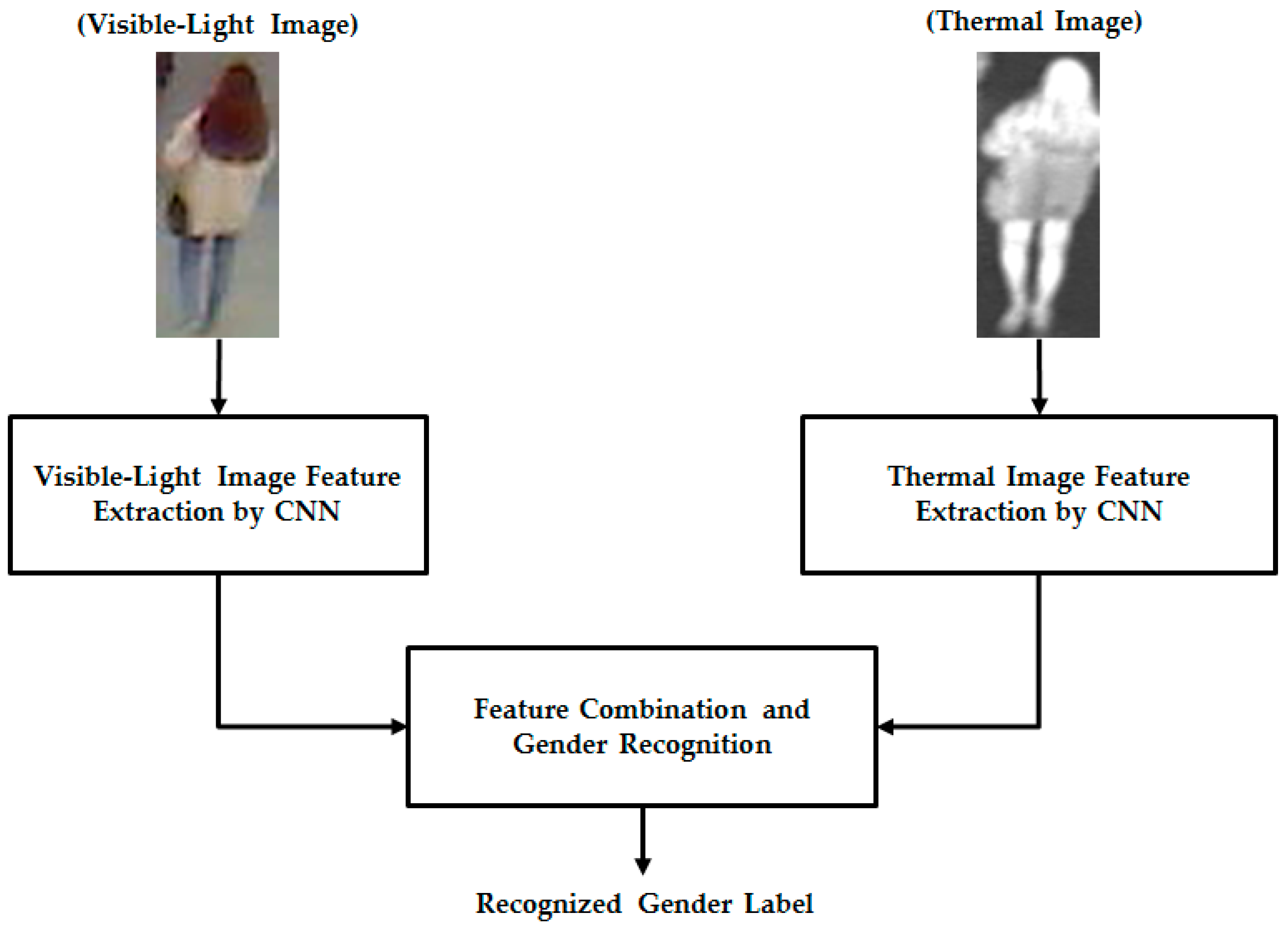
Given that our proposed method uses two different types of human body images for gender recognition, i.e., visible-light and thermal images, as shown in
Figure 1, it is necessary to obtain a pair of visible-thermal images simultaneously to recognize the gender of the observed human in our proposed method for gender recognition. Although there are several open databases of the human body images, such as a visible-light database [
36,
37,
38,
39,
40] or thermal database [
41], these databases cannot be used by our proposed method because they contain only single type of human body image (only visible-light or only thermal images). To the best of our knowledge, a public dataset does exist that contains visible-light and thermal images of pedestrians simultaneously that is dedicated to the pedestrian detection problem [
42]. However, this dataset was captured at a very far distance between the people and the camera. In addition, the number of persons is too small to be used for gender recognition problem (approximately 40 persons). Therefore, to measure the recognition accuracy of our proposed method, we used our self-established database [
12]. A detailed description of our database is given in
Table 3. The database contains images from 412 male and female people comprising 254 males and 158 females. For each person, we captured 10 visible-light images and 10 corresponding thermal images. Consequently, we captured 8240 images (4120 visible-light images and 4120 thermal images). All images were captured using our lab-made dual visible-light and thermal cameras that were placed at a height of approximately 6 m above the observation scene to simulate the actual operation of surveillance systems [
12]. To the best of our knowledge, there is little previous research on body-based gender recognition using both visible-light and thermal images. As a result, there is no public database for evaluating the performance of such gender recognition systems. Therefore, we make this database available for other researchers to use in their work, from which development and comparison can be performed [
43]. Some sample human-body-region images in our database (human body region images) are shown in
Figure 5. As shown in this figure, our database contains male and female images with a large variation of texture and body poses.
To measure the accuracy of the recognition system, we performed a five-fold cross-validation method. For this purpose, we iterate a division procedure that divides the entire database in
Table 3 into learning and testing sub-databases five times. In each division, we use images of approximately 80% of the number of males and females to form the learning sub-database, and the other images of the remaining number of males and females are assigned to the testing sub-database. As a result, we obtain five learning sub-databases and five testing sub-databases. Each learning sub-database contains images of 204 males and 127 females, whereas each testing sub-database contains images of 50 males and 31 females.
As discussed in
Section 2.2, to reduce the over-fitting problem, we manually made the augmentation database from the original database to enlarge the size of the database [
21]. In addition, given that the number of males is larger than the number of females in our database (254 males versus 158 females in
Table 3), we intend to make the number of augmented images for males smaller than the number of augmented images for females to make the number of images of males and females similar. For this purpose, we made 18 images from each male image and 30 images from each female image by removing two or four pixels from the left, right, top, and bottom sides of the original image. Consequently, we obtained an augmented database for each learning and testing sub-database as shown in
Table 4, where a detailed description of each learning and testing sub-database is shown.
Similar to previous studies on body-based gender recognition [
5,
12], we used the equal error rate (EER) to evaluate the performance of the gender recognition system. The EER is a principal error measurement that has been widely used in recognition systems, such as finger-vein recognition [
44,
45], iris recognition [
46,
47], and face recognition [
48]. By definition, the EER is the error when the false acceptance rate (FAR) is equal to the false rejection rate (FRR). In our case of gender recognition, we have two classes, male and female. Therefore, we have two possible error cases of “a ground-truth male image that is falsely recognized as female image” and “a ground-truth female image that is falsely recognized as a male image”. In this study, we call the first case of error, where a ground-truth male image is falsely recognized as a female image, as the FAR; and the other error is the FRR. In biometrics studies, we normally use the genuine acceptance rate (GAR) instead of the FRR value for EER calculation. The GAR is defined as (100 − FRR) (%). With the recognition system, we always hope that the error is as small as possible. Therefore, a smaller value of EER indicates a better recognition system. In our experiments, the final recognition accuracy (EER) of the recognition system is measured by averaging the EERs of five testing databases. In addition, the FAR-GAR pair-value is shown in bold type at the corresponding EER point in our experimental results in
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9.
3.2. Gender Recognition Accuracy Assessment
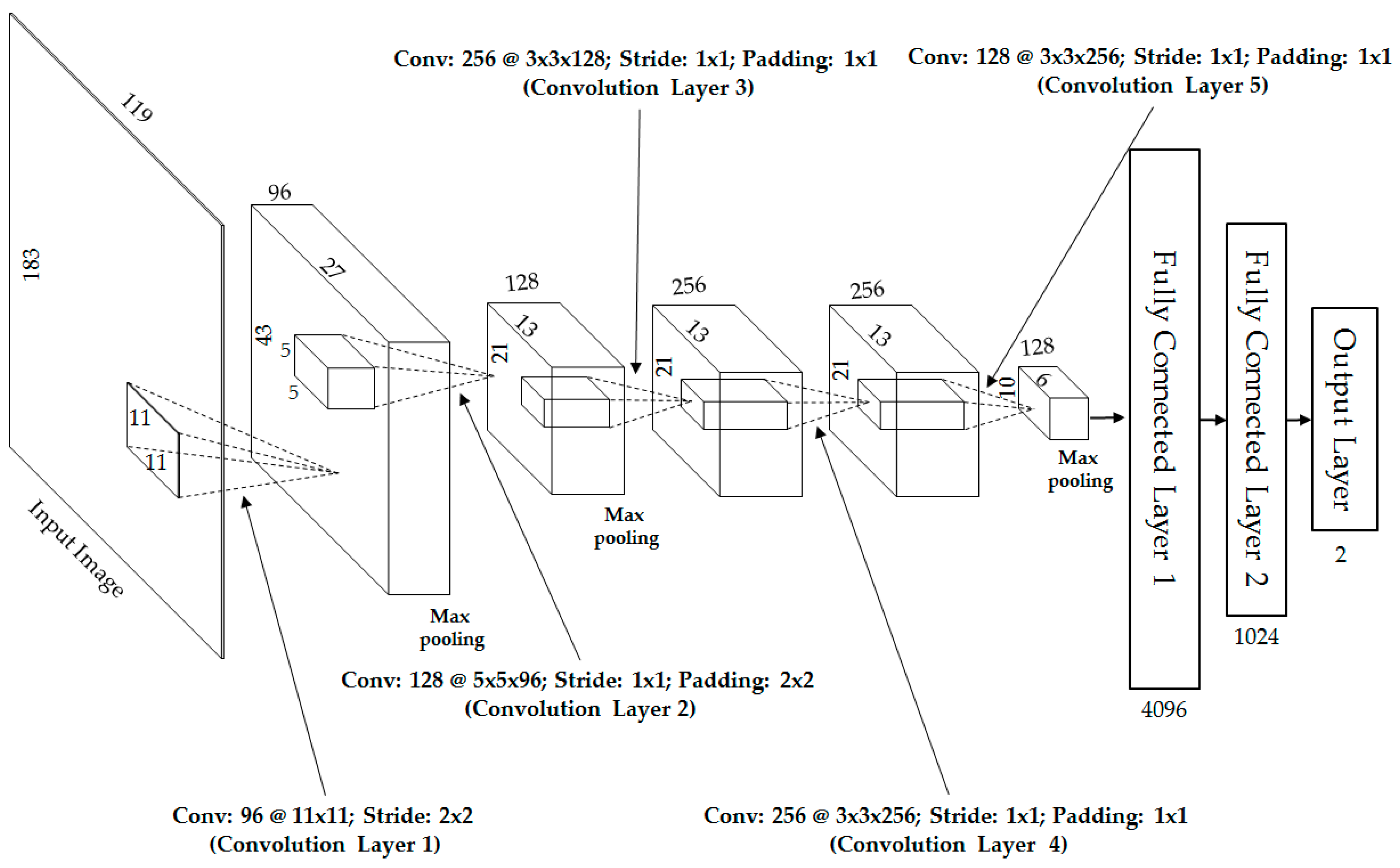
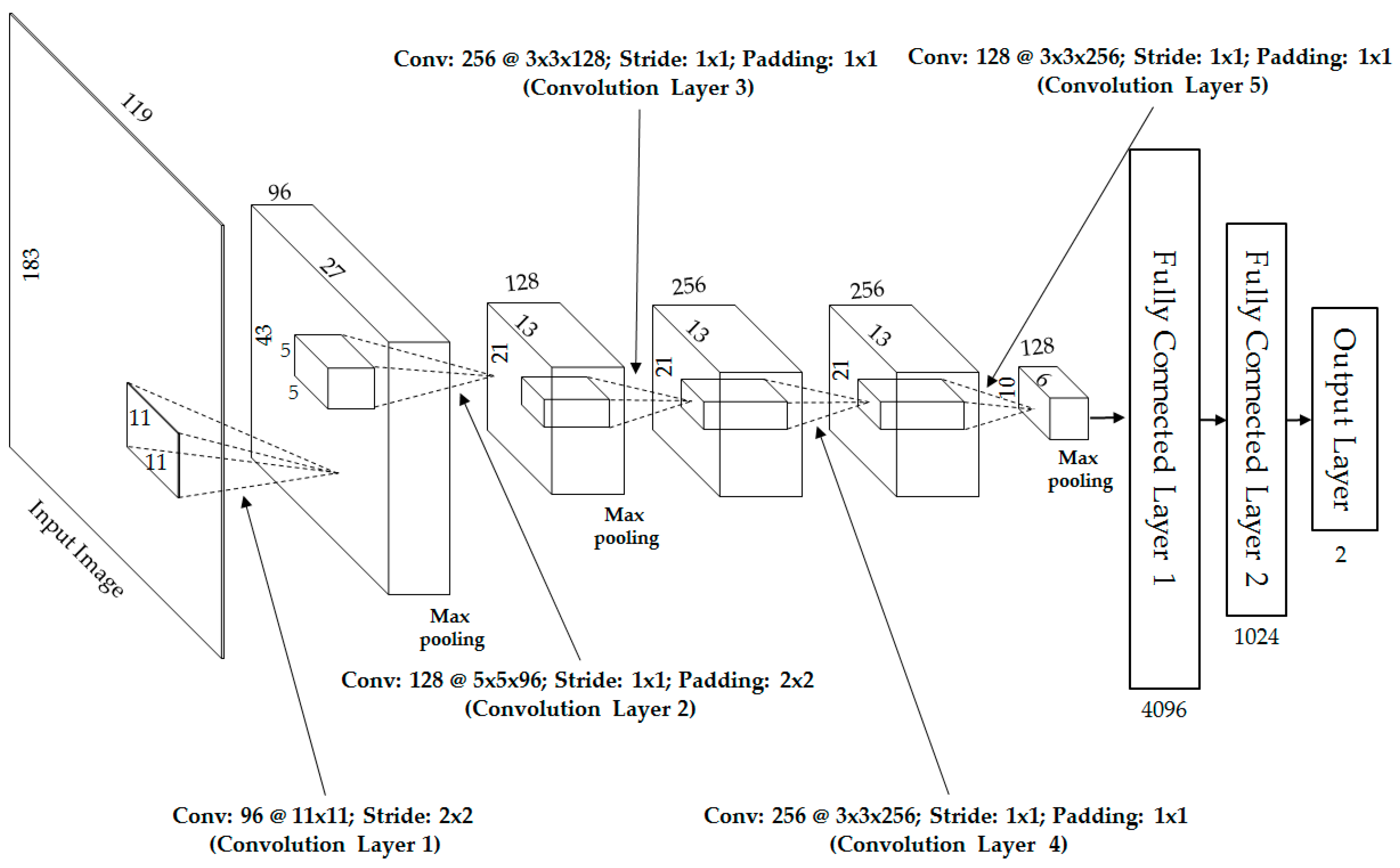
In our first experiment, we performed the training/testing procedures to train the CNN-based feature extractor model for visible-light images and thermal images, respectively, using the CNN structure (in
Figure 2) and only single visible-light and only single thermal images. In
Table 4, we describe the training and testing databases, which contain both visible-light and thermal images. Therefore, in this experiment, we used 74,820 images (36,720 male images (204 × 10 × 18) and 38,100 female images (127 × 10 × 30)) as training data and 18,300 images (9000 male images (50 × 10 × 18) and 9300 female images (31 × 10 × 30)) as testing data for recognition systems that use only visible-light images and thermal images for gender recognition, respectively. For training the CNN model, we used the MATLAB implementation [
31]. In addition, we set the number of epochs to 60. The initial learning rate is 0.01 with a learn-rate-drop factor of 0.1 after every 20 epochs. The detailed experimental results are shown in
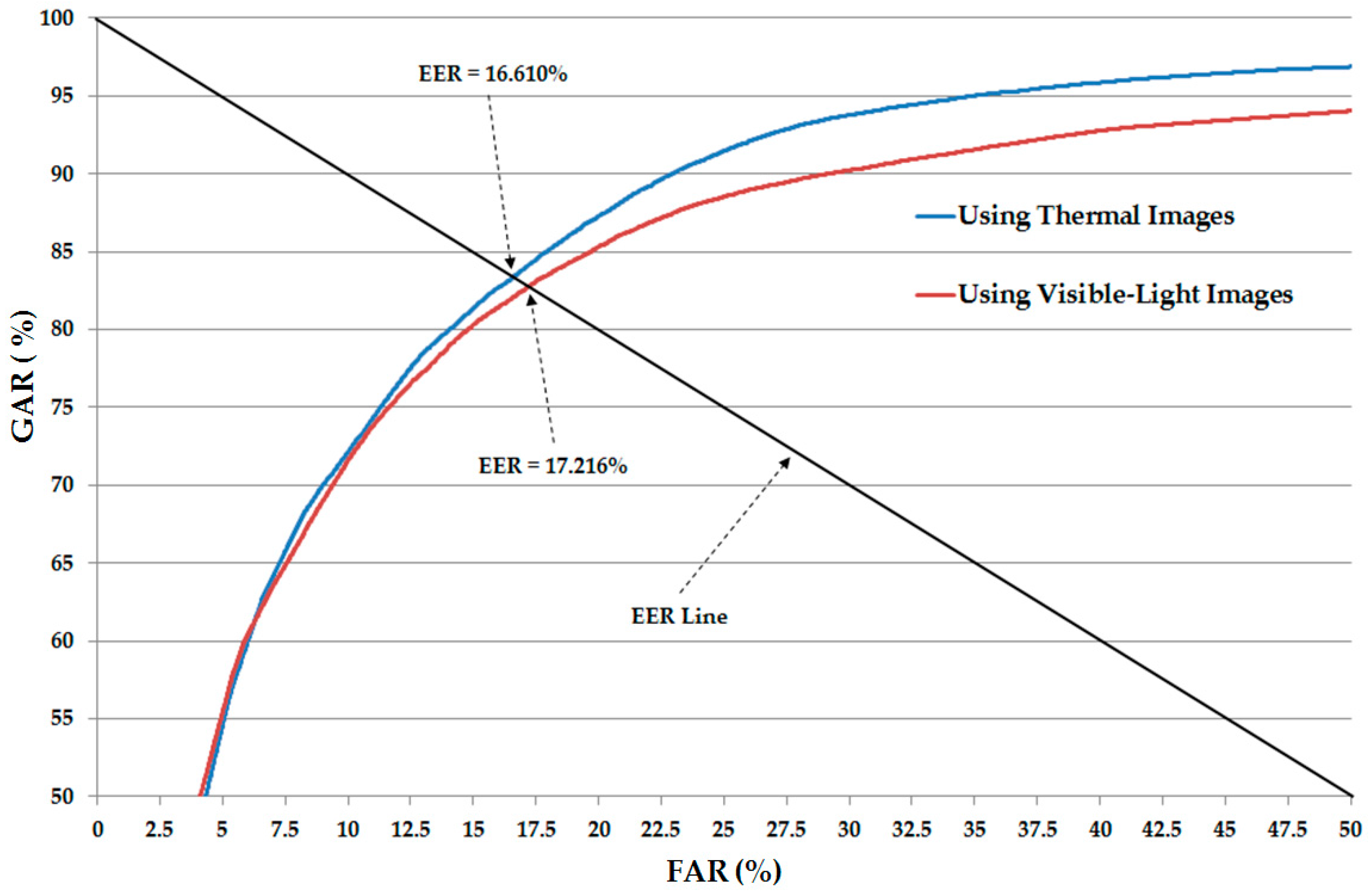
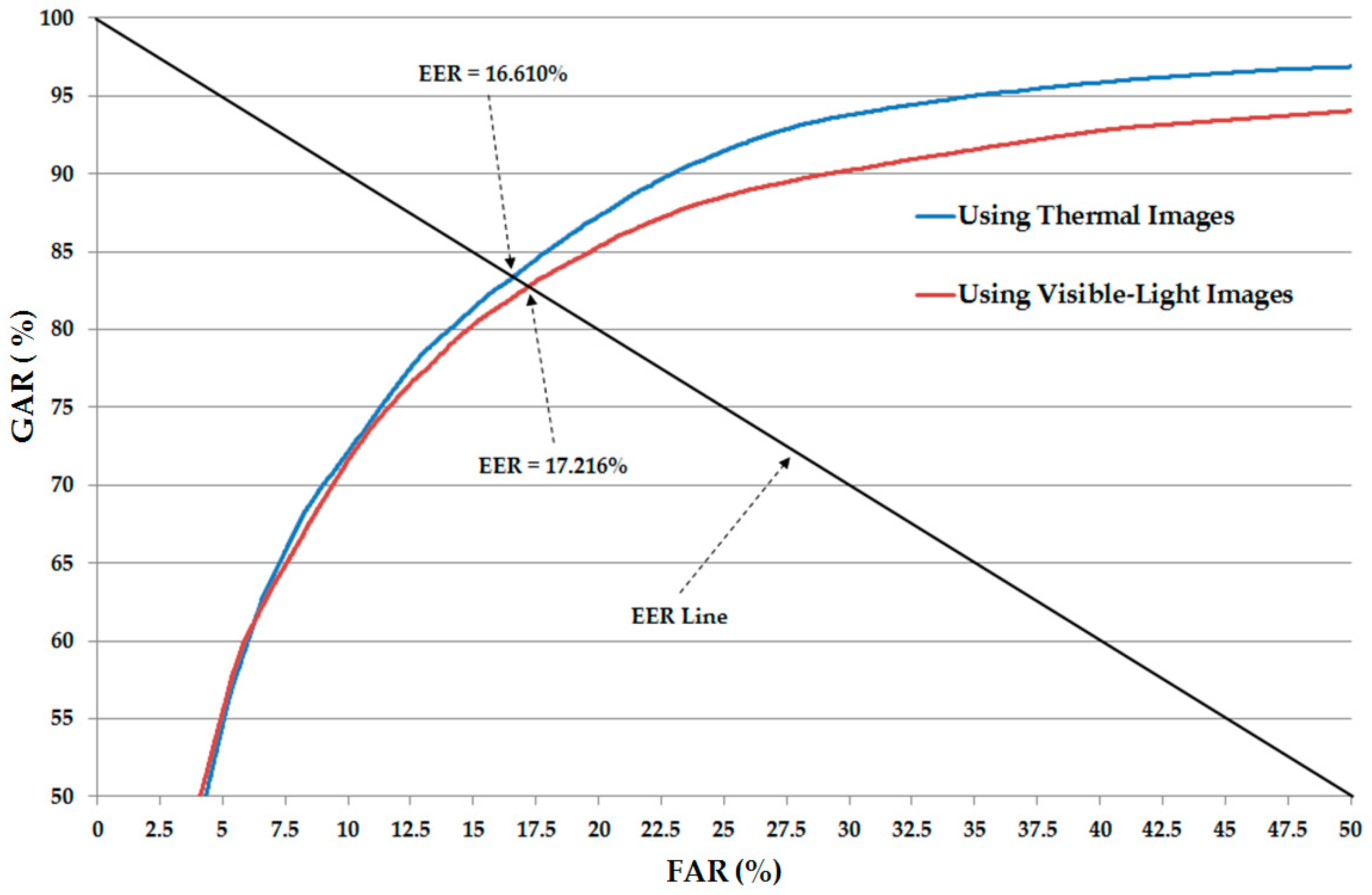
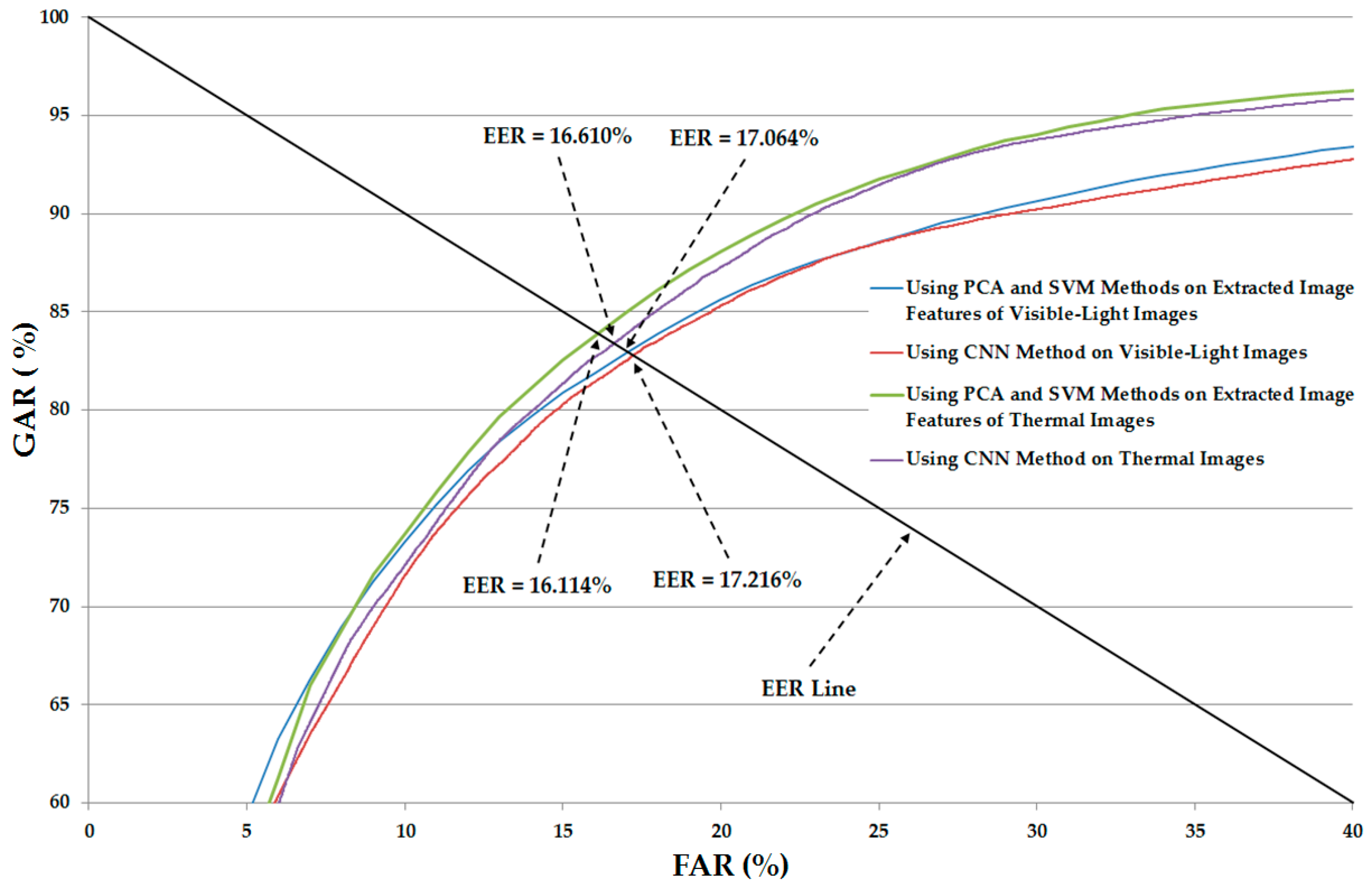
Table 5. In addition, we show the receiver-operating curve (ROC) of the CNN-based recognition system using only single visible-light and only thermal images in
Figure 6. As shown in
Table 5 and
Figure 6, the average EER of the CNN-based recognition system using only visible-light images is approximately 17.216%, and the average EER of the CNN-based recognition system using only thermal images is approximately 16.610%. As shown in
Table 10, these recognition results are comparable to the recognition results of recognition systems that use only visible-light or only thermal images for the gender recognition problem, as shown in previous studies [
5,
10,
11,
12]. However, the recognition result using visible-light images is slightly worse than that of the system using the weighted HOG feature extraction method. The reason is that the weighted HOG method estimates the effects of background regions that could have strong effects on the extracted image features using visible-light images. As shown in
Figure 5, the background regions of thermal images are much darker than the foreground regions (human body regions). Therefore, the recognition result of a system that uses the CNN-based method and thermal images is better than that of systems using HOG or weighted HOG in previous studies [
5,
12].
Using the CNN-based method, we can perform gender recognition using either only single visible-light images or only thermal images. Therefore, to combine the visible-light images and thermal images for gender recognition problem, our proposed method uses the CNN-based model for image feature extraction and the SVM for classification. In the next experiment, we performed gender recognition using only visible-light images or only thermal images on the basis of feature extraction by the CNN-based method and classification using SVM. For this purpose, the pre-trained CNN-based models obtained from the first experiment were saved and used to extract the image features of all images in our database shown in
Table 4. With the extracted image features, we performed the gender recognition on the basis of SVM [
5,
12]. As discussed in
Section 2.3, our proposed method intends to use PCA for noise and feature dimension reduction. To demonstrate the efficiency of the PCA method on the recognition system, we measured the recognition accuracies in both cases of with and without PCA for comparison purposes. In addition, two types of SVM kernels viz. linear and RBF kernels are used to classify the gender using SVM. The detailed experimental results of this experiment are shown in
Table 6 and
Table 7. In
Table 6, we show the recognition accuracies of the recognition system that uses only visible-light images or only thermal images without applying PCA on the extracted image features. As shown in this table, the recognition accuracies (EER) using the linear kernel are 17.379% and 16.560% using visible and thermal images, respectively. Using the RBF kernel, the recognition accuracies are 17.379% and 16.510%. These experimental results are quite similar to those of
Table 5. Therefore, we find that the recognition performance produced by the SVM method is similar to that of the CNN-based method.
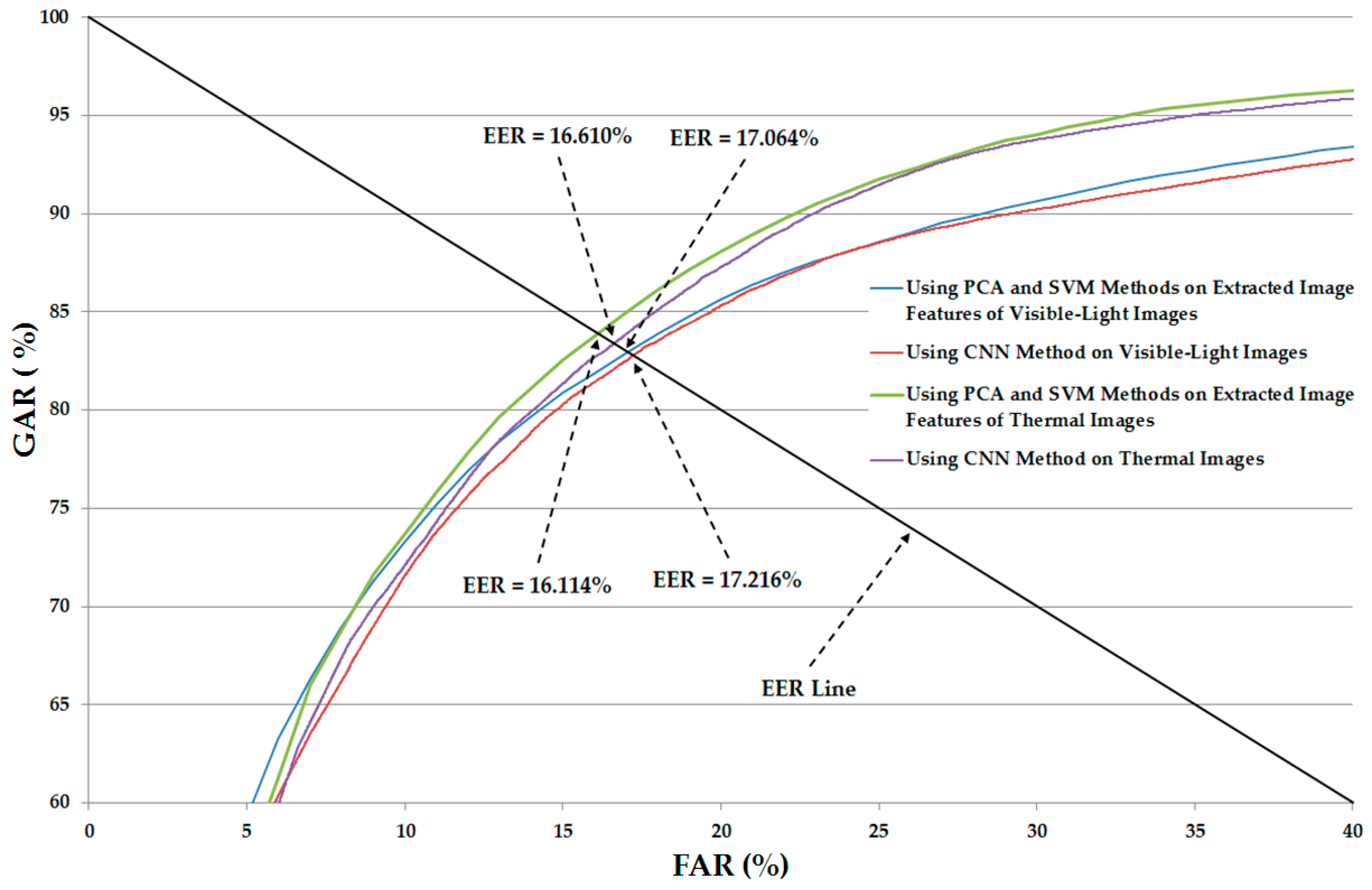
Table 7 shows the recognition accuracies of the recognition system, and is similar to
Table 6 except for the case of applying the PCA on the extracted image features for noise and feature dimension reduction. As shown in this table, the linear kernel outperforms the RBF kernel for gender recognition. In detail, using only visible-light images, we obtained an EER of 17.064%, which is lower than the EER of 17.489% produced by RBF kernel. This recognition accuracy is also lower than that of the recognition system that uses the CNN-based method (EER of 17.216% in
Table 5) and the system that uses SVM without PCA (EER of 17.379% in
Table 6). Using only thermal images, we obtained an EER of 16.144%. This EER result is also lower than the EER of 16.610% of the system that uses the CNN-based method (
Table 5) and 16.510% of the system that uses the SVM without PCA (
Table 6). From the experimental results in
Table 5,
Table 6 and
Table 7, we conclude that gender recognition based on the SVM method is comparable with that of the CNN-based method when using a single type of human body image for gender recognition. In addition, the PCA method is sufficient for enhancing the recognition accuracy. In
Figure 7, we show the ROC curves of various recognition system configurations that use only visible-light or only thermal images for gender recognition. This figure again confirms that the recognition system that uses the SVM and PCA methods (SVM-based method) for gender recognition outperforms the recognition system that uses the CNN-based method.
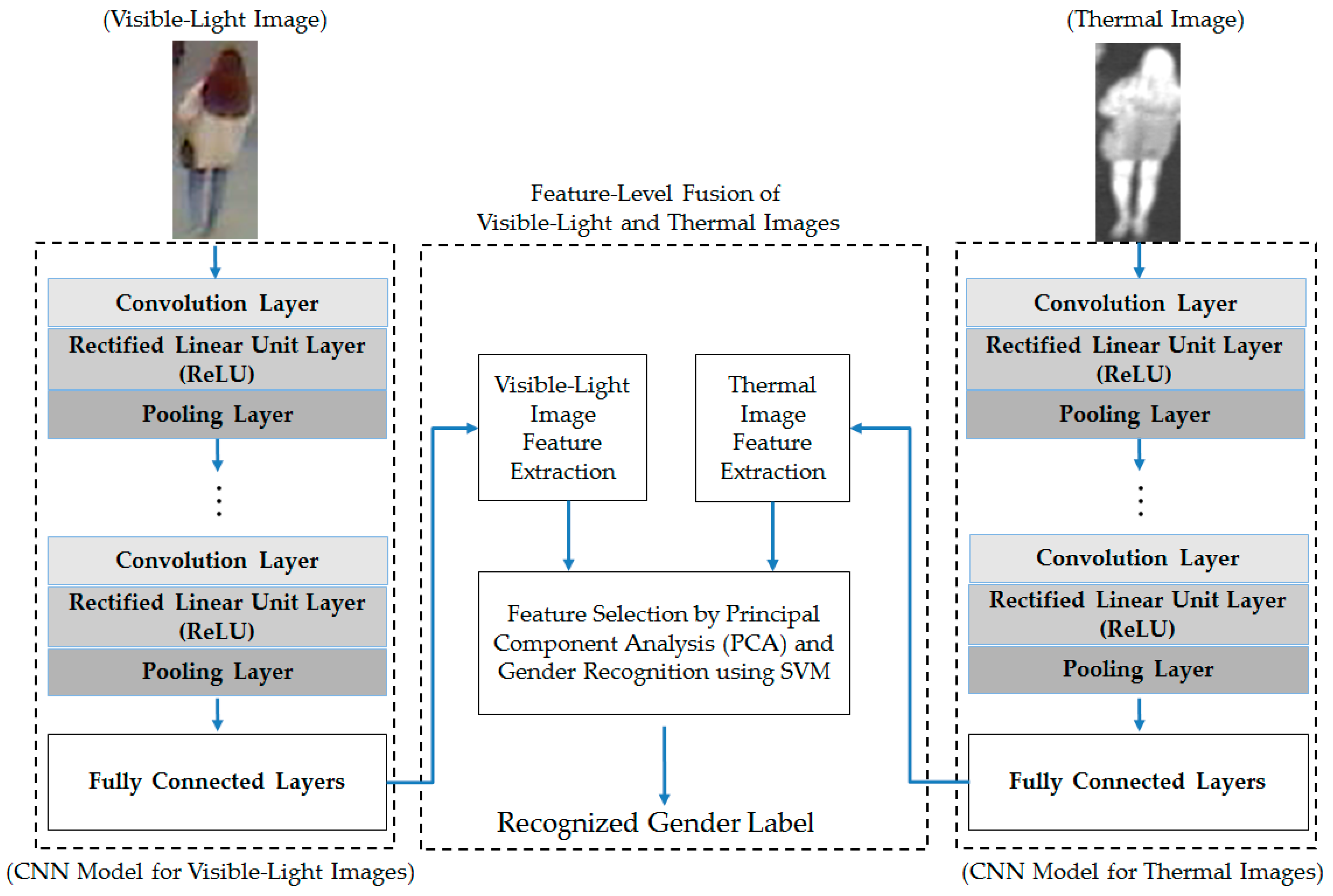
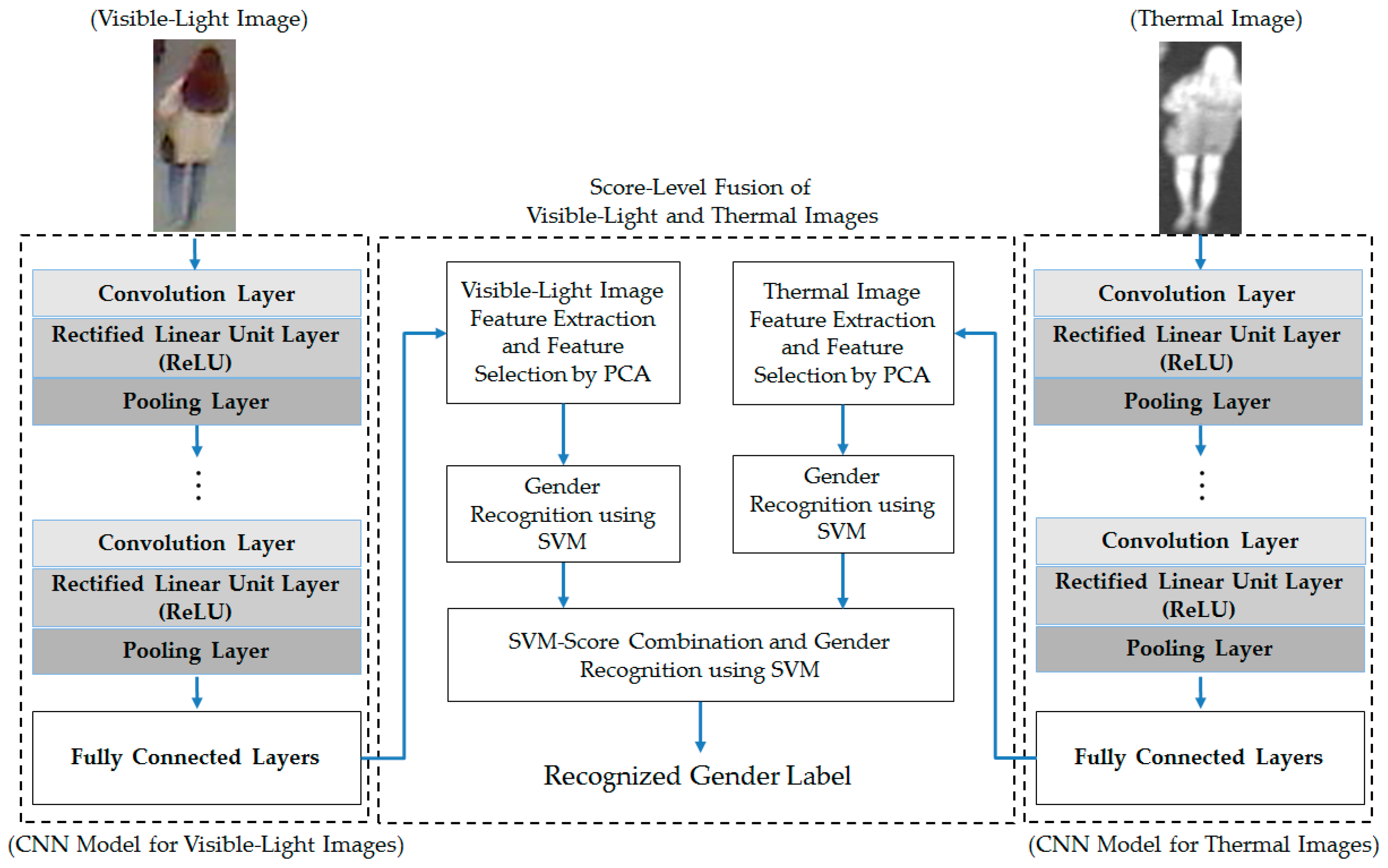
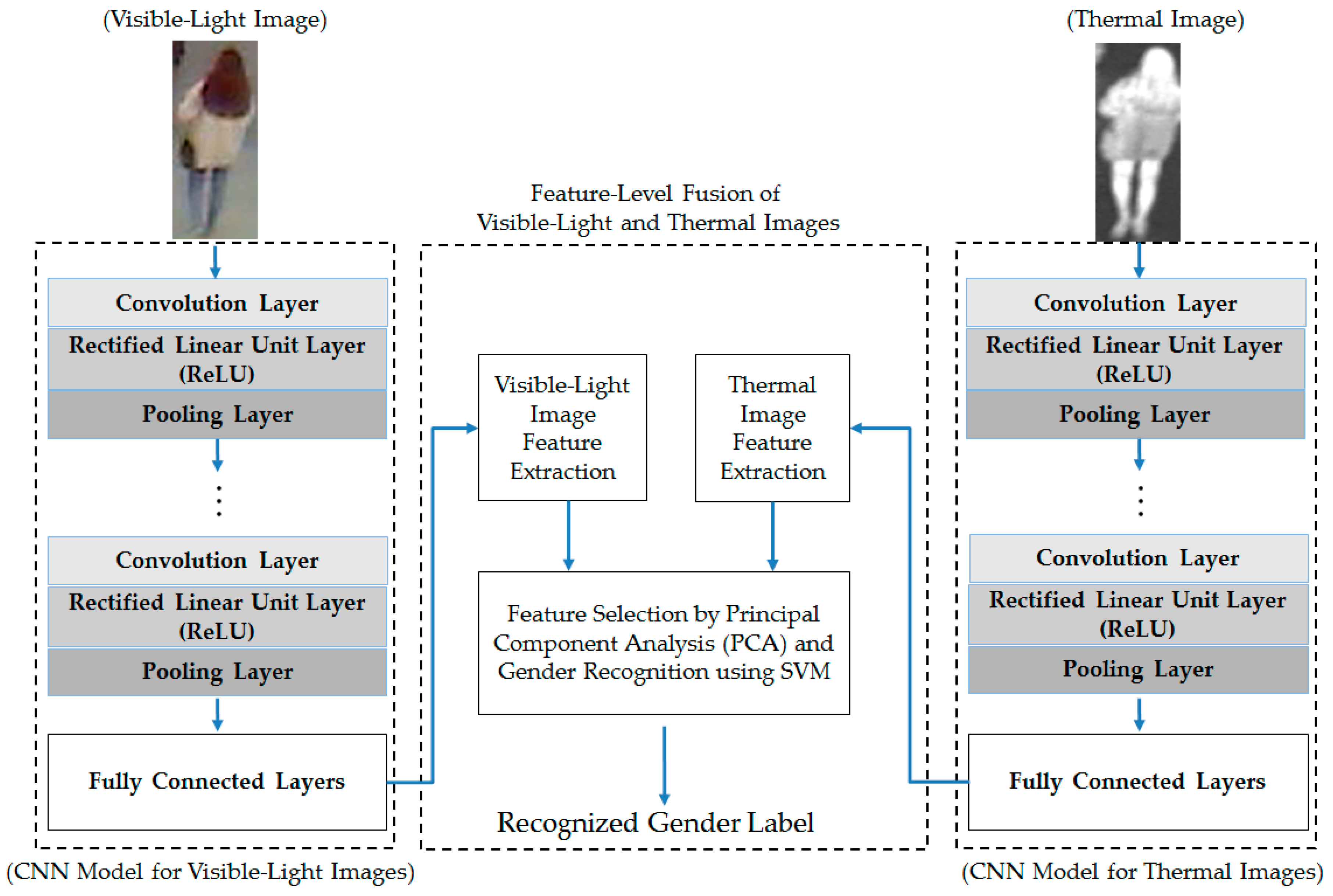
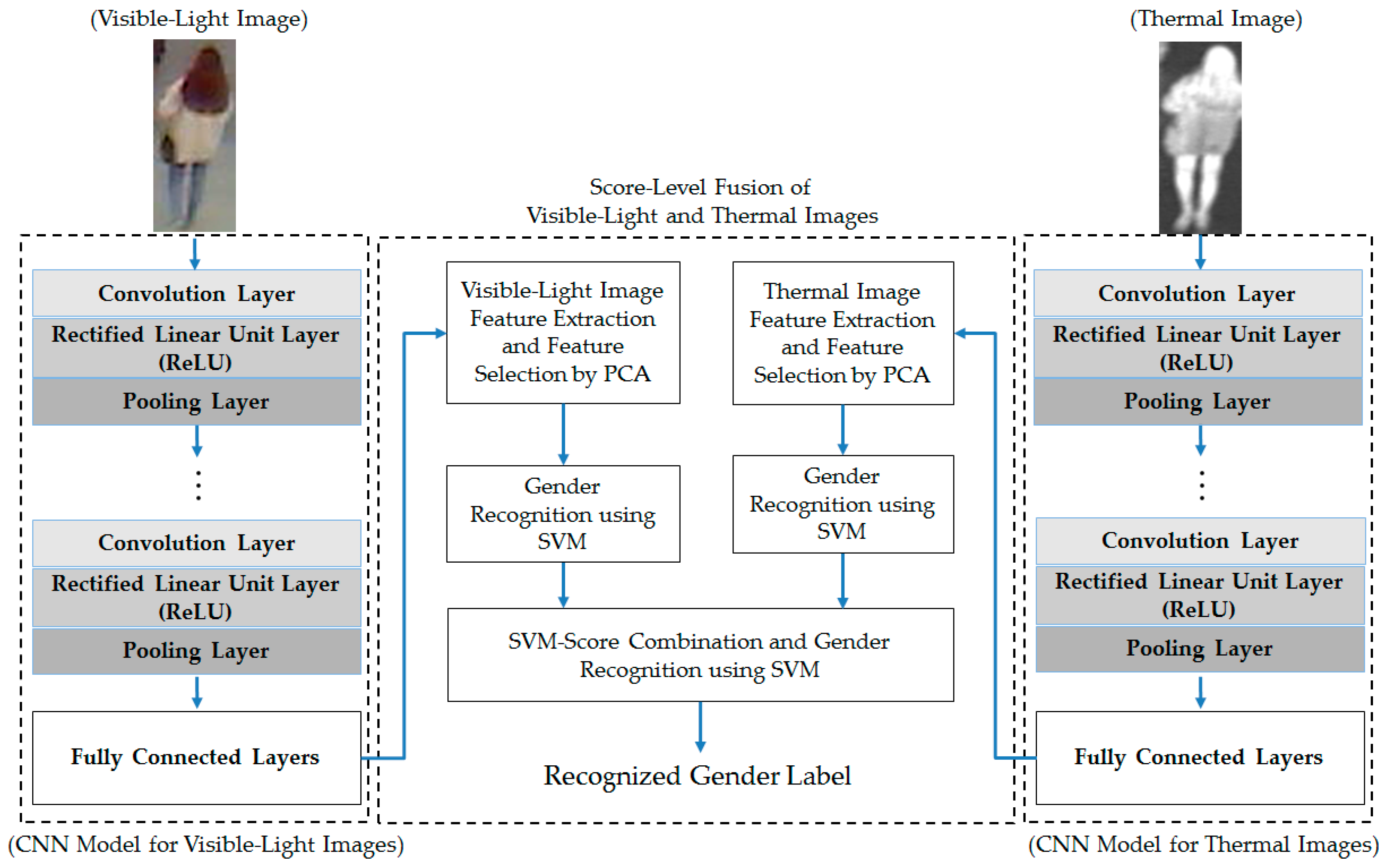
From these experimental results, we performed our next experiment to combine the visible-light and thermal images of the human body for the gender recognition problem. As discussed in
Section 2.3, we used two approaches for combining the visible and thermal images, including feature-level fusion (as detailed in
Section 2.3 and
Figure 3) and score-level fusion (as detailed in
Section 2.3 and
Figure 4). In addition, we again performed the experiment for two cases, with and without applying PCA for noise and feature dimension reduction, to confirm the efficiency of the PCA method for the gender recognition problem. The experimental results are shown in
Table 8 and
Table 9 for the cases with and without PCA, respectively.
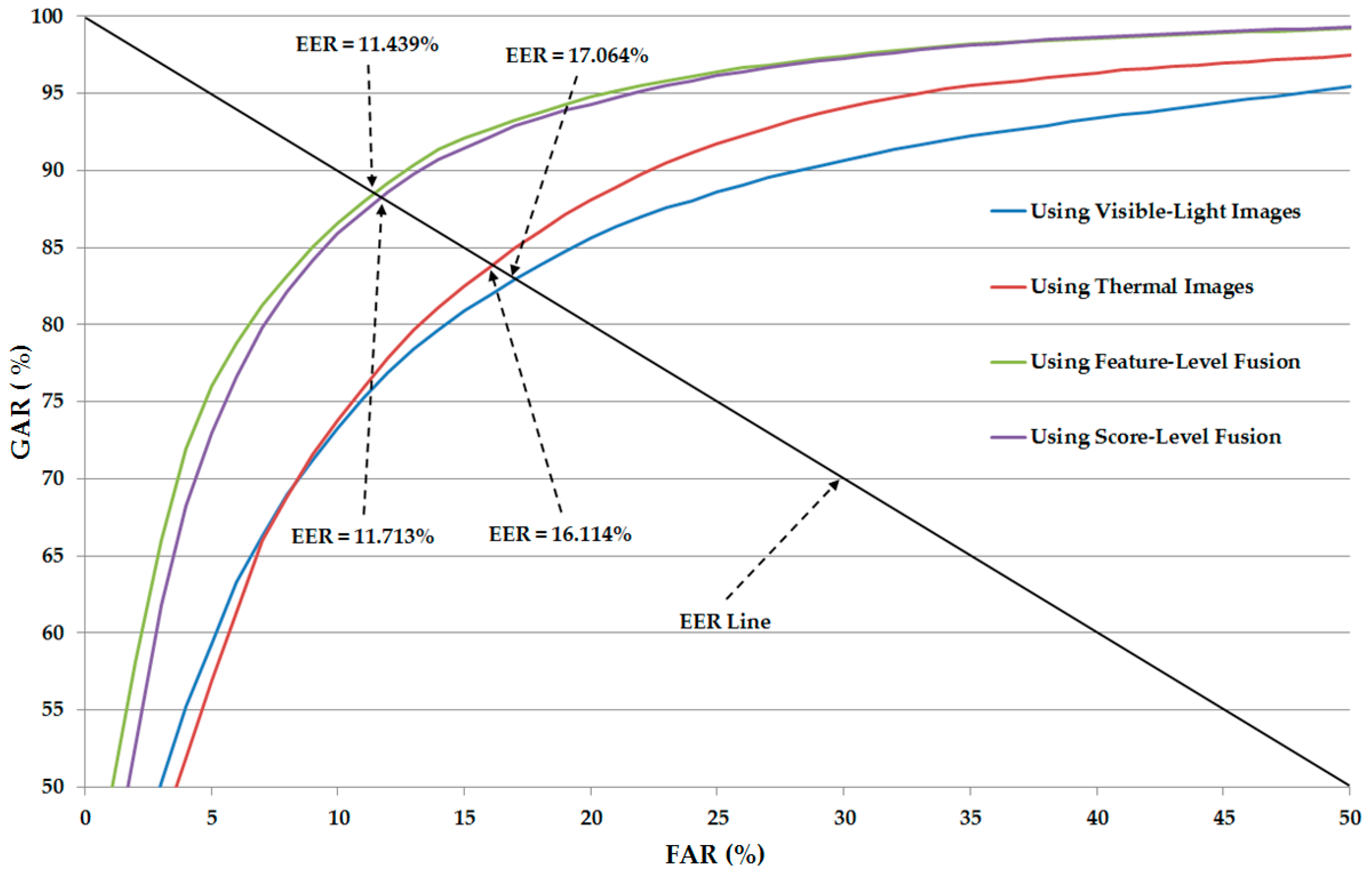
In
Table 8, we show the recognition accuracies of the recognition system that uses the combination of visible-light and thermal images without applying the PCA method. As shown in
Table 8, the best recognition accuracy using feature-level fusion was obtained with an EER of 11.684% using the RBF kernel. Using score-level fusion, the best EER is 11.850% using the RBF kernel in the first SVM layer and the linear kernel in the second SVM layer. Compared to the recognition accuracies produced by systems that use only visible or only thermal images for recognition in
Table 5 and
Table 7 (EER of 17.064% using visible images and 16.114% using thermal images), we can conclude that the combination of visible and thermal images is much more efficient for enhancing the gender recognition problem. As shown in
Table 10, this recognition accuracy is also much better than those using the HOG, entropy-weighted histograms of oriented gradients (EWHOG), or weighted HOG methods in previous studies [
5,
12].
Similar to
Table 8,
Table 9 shows the recognition results except for the case of using PCA for noise and feature dimension reduction. By applying the PCA method on the CNN-based features, we reduce the recognition error (EER) from 11.684% (in
Table 8) to 11.439% using the feature-level fusion approach and linear kernel. Using the score-level fusion approach, we reduce the recognition error from 11.850% to 11.713% using the RBF kernel in the first SVM layer and a linear kernel in the second SVM layer. This result again confirms that the PCA method is sufficient for enhancing the recognition performance. This result also shows that the linear kernel is more sufficient than the RBF kernel for gender recognition using CNN-based feature extraction method.
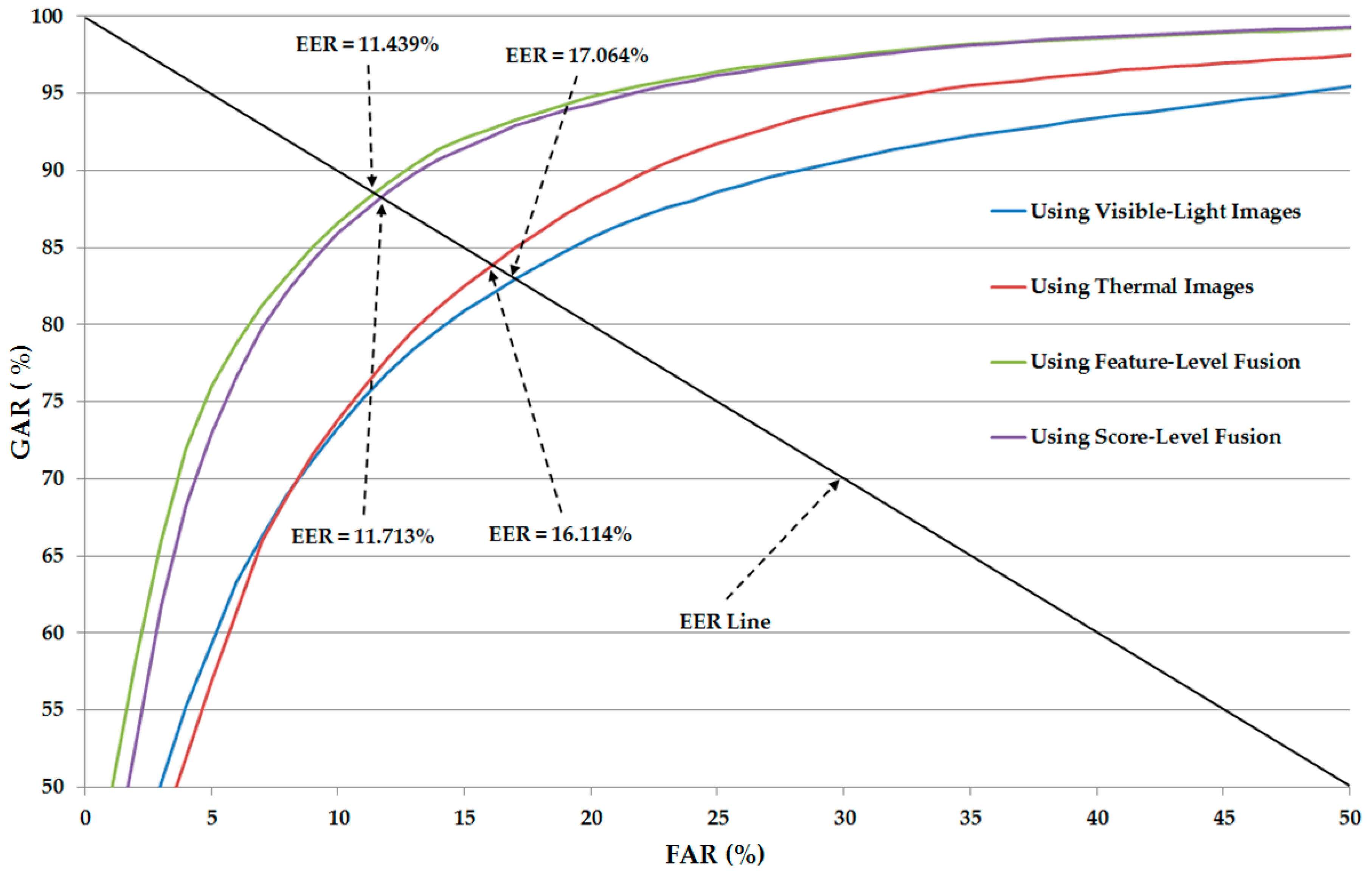
Figure 8 shows the average ROC curves of various system configurations, including the systems using only visible-light or only thermal images for gender recognition and the systems using the combination of visible-light and thermal images (feature-level fusion and score-level fusion methods) for gender recognition. As shown in this figure, the systems using the combination of visible-light and thermal images produced the higher recognition accuracies compared to the systems using a single type of human body images (only visible-light or only thermal images) for the recognition problem. This figure again confirms that the combination of two types of human body images can help to enhance the recognition accuracy.
In
Table 10, we summarize the recognition accuracies of our proposed method using single visible-light images, using single thermal images, and the combination of the two types of images in comparison with previous studies. As shown in this table, the best recognition accuracy (EER of 11.439%) was obtained using our proposed method with feature-level fusion. This result is much better than the other recognition results using previous methods in [
5,
12] and the use of only a single type of images (only visible-light or only thermal images). From this result, we find that our proposed method outperforms the previous studies for the human-body-based gender recognition problem.
For demonstration purposes, we show some sample recognition results by our proposed method in
Figure 9 and
Figure 10. As shown in
Figure 9, our proposed method successfully recognized the gender of people in images regardless of front or back view. However,
Figure 10 shows some recognition error cases produced by our proposed method.
Figure 10a–c shows error cases when the ground-truth male images were incorrectly recognized as female images.
Figure 10d,f shows error cases when the ground-truth female images were incorrectly recognized as male images. From this figure, the appearance of the human body in these images is ambiguous. The images in
Figure 10a,b were captured from the back view when the people wore winter clothes. As a result, it is difficult to recognize their gender (male) even by human perception. In
Figure 10c, the recognition failed because of the complex background regions. A similar situation also occurred in
Figure 10d–f. In
Figure 10d, the images of a female person were captured from the back view. In addition, the persons in both cases (
Figure 10d,f) wore winter clothes. The female person in
Figure 10e wore a military uniform. As we can see from this figure, wearing winter and/or uniform clothes can reduce the distinction between male and female. It is difficult for us to recognize the gender in these sample images despite using human perception. In addition, the surveillance system captures images at a distance from the camera (approximately 10 m). Therefore, the quality of the captured images is normally not good. These negative effects cause the consequent errors of the recognition system.
As shown in our experimental results (
Figure 8 and
Table 8 and
Table 9), the linear kernel outperformed the RBF kernel by producing a lower error (EER) value. In addition, the recognition accuracy of systems with PCA is better than those of systems without PCA (
Table 8 and
Table 9). These results are slightly different from those of the previous studies [
5,
12]. The reason is that the feature extraction methods used in these studies are different. In previous studies, the HOG or weighted HOG image feature extraction methods were used. In contrast, we used an up-to-date feature extraction method based on CNN. Given the difference of feature extraction, the linear kernel is more suitable for gender recognition than the RBF kernel using CNN-based features. As shown in the previous method by Guo et al. [
11], which used the BIFs feature extraction method for image feature extraction, the linear kernel is also the best kernel compared to other types of SVM kernels. This result is attributed to the similarity of the BIFs feature extraction method to the CNN-based method. The difference between the two methods is that the BIFs method uses predesigned Gabor kernels as filters for the convolution layers, whereas the CNN-based method trains the filters according to input data and the corresponding ground-truth labels. Consequently, the performance of the CNN-based feature is better than the BIFs features. In addition, although the image features are extracted by a trained CNN-based model, the redundant information can be associated with these features because of the noise in the input images, the characteristics of the training data, and the large variation in the human body images (such as the difference in clothes, hair styles, accessories, and other factors). Consequently, the use of PCA can enhance the recognition accuracy of the system.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}