1. Introduction
A sensor is a device capable of measuring a certain physical property. Normally, in a wireless sensor network (WSN), each sensor or node can transmit and receive data wirelessly, and it has the ability of performing multiple tasks, which are usually based on simple mathematical operations such as additions and multiplications. Moreover, the sensors within a WSN are usually powered with batteries, leading to very limited energy resources.
For most tasks, it is required that each sensor computes a target value that depends on the values measured by other sensors of the WSN. Commonly, a WSN has a central entity, known as the central node, which collects the values measured by all the sensors, computes the target values, and sends each target value to the corresponding sensor. This strategy is known as centralized computation.
The main disadvantage of the centralized computation strategy is that it is extremely energy inefficient from the transmission point of view because, when a sensor is far away from the central node, it has to consume disproportionate amounts of energy, with respect to the energy provided by its battery, in order to transmit its measured value to the central node. An alternative strategy to overcome the energy inefficiency of the centralized computation is the distributed or in-network computation strategy. In distributed computation, which is a cooperative strategy, each sensor computes its target value by interchanging information with its neighbouring sensors.
In many recent signal processing applications of distributed computations (e.g., [
1,
2,
3,
4]), the average needs to be computed (i.e., each sensor seeks the arithmetic mean of the values measured by all the sensors of the WSN). The problem of obtaining that average in all the sensors of the WSN by using the distributed computation strategy is known as the distributed averaging problem, or the distributed average consensus problem. Moreover, the problem of obtaining the same value in all the sensors of the WSN by using the distributed computation strategy is known as the distributed consensus problem (see, for example, [
5] for a review on this subject).
A common approach for solving the distributed averaging problem is to use a synchronous linear iterative algorithm that is characterized by a matrix, which is called the weighting matrix. A well-known problem related to this topic is that of finding a symmetric weighting matrix that achieves consensus as fast as possible. This is the problem of finding the fastest symmetric distributed linear averaging (FSDLA) algorithm.
The FSDLA problem was solved in [
6]. Specifically, in [
6], the authors proved that solving the FSDLA problem is equivalent to solving a semidefinite program, and they used the subgradient method for efficiently solving such a problem to obtain the corresponding weighting matrix. Unfortunately, solving the FSDLA problem this way requires a central entity with full knowledge of the entire network. This central entity has to solve the FSDLA problem and then communicate the solution to each node of the network. This process has to be repeated each time the network topology changes due to, for example, a node failing, a node being added or removed (plug-and-play networks), or a node changing its location.
Moreover, WSNs may not have a central entity to compute the optimal weighting matrix. This paper proposes, for those networks without a central entity, an in-network algorithm for finding the optimal weighting matrix.
It is worth mentioning that in the literature, one can find other in-network algorithms that solve the FSDLA problem in a distributed way. In particular, in [
7], the authors present an in-network algorithm that computes the fastest symmetric weighting matrix, but only with positive weights. As will be made more explicit in the next section, this matrix is not a solution of the FSDLA problem in general, as the latter might contain negative weights.
In [
8], the FSDLA problem is solved in a centralized way when the communication among nodes is noisy. Closed-form expressions for the optimal weights for certain network topologies (paths, cycles, grids, stars, and hypercubes) are also provided. However, unless the considered network topology is one of these five, an in-network solution to the FSDLA is not provided.
Finally, in [
9], an in-network algorithm for solving the FSDLA problem is provided. However, as the authors claim, the algorithm breaks down when the second- and third-largest eigenvalues of the weighting matrix become similar or equal.
Unlike the approaches found in the literature, the in-network algorithm presented in this paper is proved to always converge to the solution of the FSDLA problem, irrespective of the considered network topology.
2. Preliminaries
2.1. The Distributed Average Consensus Problem
We consider a network composed of n nodes. The network can be viewed as an undirected graph , where is the set of nodes and is the set of edges. An edge means that nodes are connected and can therefore interchange information. Conversely, if , this means that nodes are not connected and cannot interchange information. We let K be the cardinal of , i.e., K is the number of edges in the graph G. For simplicity, we enumerate the edges in the graph G as , where for all .
We assume that each node
has an initial value
, where
denotes the set of (finite) real numbers. Accordingly, in this paper,
denotes the set of
real matrices. We consider that all the nodes are interested in obtaining the arithmetic mean (average)
of the initial values of the nodes, that is,
using a distributed algorithm. This problem is commonly known as the distributed averaging problem, or the distributed average consensus problem.
The approach that will be considered here for solving the distributed averaging problem is to use a linear iterative algorithm of the form
where time
t is assumed to be discrete (namely,
) and
are the weights that need to be set so that
for all
and for all
. From the point of view of communication protocols, there exist efficient ways of implementing synchronous consensus algorithms of the form of Equation (
1) (e.g., [
10]).
We observe that Equation (
1) can be written in matrix form as
where
, and
is called the
weighting matrix, which is such that its entry at the
ith row and
jth column,
, is given by
Therefore, Equation (
2) can be rewritten as
where
, and
is the
matrix of ones.
We only consider algorithms of the form of Equation (
3), for which the weighting matrix
is symmetric. If
is symmetric, it is shown in [
6] (Theorem 1) that Equation (
5) holds if and only if
and
, where
denotes the spectral norm. For the reader’s convenience, we here recall that if
is symmetric, then
, where
,
, denote the eigenvalues of
, which, in this paper, are arranged such that
(e.g., [
11] (pp. 350, 603)).
We observe that Equation (
10) can be computed in a distributed way if each node
is able to know
. The following result provides a means of computing such a unit eigenvector
of
in a distributed way.
2.2. Considered Minimization Problem: FSDLA Problem
We denote with
the set of all the
real symmetric matrices that satisfy Equation (
4) and
simultaneously, that is,
In [
6], the convergence time of an algorithm of the form of Equation (
3) with symmetric weighting matrix
is defined as
This convergence time is a mathematical measure of the convergence speed of the algorithm.
According to the previous, we call the FSDLA problem to find a weighting matrix
such that
We observe that in this definition the meaning of fastest is in terms of convergence time.
It is shown in [
6] that the FSDLA problem of Equation (
7) is a constrained convex minimization problem that can be efficiently solved. In fact, in [
6], it is shown that the FSDLA problem of Equation (
7) can be expressed as a semidefinite program, and semidefinite programs can be efficiently solved [
12]. However, to the best of our knowledge, there are yet no approaches for solving this FSDLA problem in a distributed (in-network) way. The contribution of this paper is to solve the FSDLA problem of Equation (
7) in a distributed way. To do so, we develop a distributed subgradient method.
Finally, it should be mentioned that in [
7], the authors solved, in a distributed way, a related problem: they find the fastest mixing Markov chain (FMMC). The FMMC problem is devoted to finding a matrix
such that
for all
. We observe that
, i.e., the solution of the FSDLA problem is faster than, or is at least as fast as, the solution of the FMMC problem.
2.3. FSDLA as an Unconstrained Convex Minimization Problem
In order to use a distributed subgradient method (the classical reference on subgradient methods is [
13]), we first need to convert the FSDLA problem into an unconstrained convex minimization problem. We observe that if
, it is clear that
depends on
for all
. We notice that
is well defined because
is symmetric. In fact, as it was stated in [
6], given the vector
, there exists a unique
such that
for all
, namely
where
is the
identity matrix and
is defined as
In other words, the function
defined in Equation (
8) is a bijection. We define the function
as
. We observe that the FSDLA problem of Equation (
7) can now be expressed as an unconstrained minimization of the function
f.
In the sequel, we denote with
a solution of the FSDLA problem, that is,
It is easy to show that f has a bounded set of minimum points . In the sequel, we will refer to the function f as the cost function of the FSDLA problem. We finish the section with Lemma 1 which will be useful in the derivation of the algorithm.
Proof. Observe that as
is symmetric and
, there exists an eigenvalue decomposition of
,
, where
is a real
orthogonal matrix such that
for all
and
. As
, we have
☐
3. Algorithm for the In-Network Solution of the FSDLA Problem
We here derive the algorithm that solves the FSDLA problem in a distributed way (Algorithm 1). To this end, we assume that
n is known by all the nodes of the network. The task of counting nodes can be performed in a distributed way (see [
14]). The algorithm is a distributed implementation of a subgradient method. More specifically, each pair of nodes
will update their weight
according to the following iterative formula:
where
is the vector of weights at the
pth step,
is the stepsize, and
is a subgradient of
f at
. We recall here that a vector
is a subgradient of
at
if
for all
.
Theorem 1. If such that , and is such that and for some , then a subgradient of f at is We observe that Equation (
10) can be computed in a distributed way if each node
is able to know
. The following result provides a means of computing such a unit eigenvector
of
in a distributed way.
The rest of the section is devoted to proving that Equation (
9) can be computed in a distributed way (Theorems 1–3), and to proving that Equation (
9) actually converges to
(Theorem 4).
In order to compute Equation (
9) in a distributed way, we need to compute a subgradient of
f in a distributed way. With this in mind, we review a result given in [
6].
Theorem 2. If is such that ,
then for all ,
where and for all .
Furthermore, given ,
for almost every ,
the following assertions are equivalent:
- (a)
, where is the zero matrix.
- (b)
is an eigenvalue of .
| Algorithm 1 In-network solution of the FSDLA problem. |
- 1:
- 2:
for all pair of nodes do - 3:
- 4:
end for - 5:
- 6:
for all nodes do - 7:
▹ An arbitrary value - 8:
- 9:
- 10:
- 11:
if then - 12:
- 13:
end if - 14:
- 15:
- 16:
- 17:
if then - 18:
- 19:
- 20:
else - 21:
- 22:
- 23:
- 24:
end if - 25:
end for - 26:
for all pair of nodes do - 27:
- 28:
- 29:
end for - 30:
if go to 5
|
Proof. Let be as in the proof of Lemma 1, with . Observe that , as .
If is an eigenvalue of for some , then we denote by its algebraic multiplicity. Otherwise we set . From Lemma 1, and consequently and cannot be simultaneously zero. Moreover, without loss of generality we can assume that .
Then, we have that
where
for all
,
and
On the one hand, from Equation (
13), we obtain
for all
. On the other hand, as
for all
, we have that
Combining Equations (
14) and (
15), we obtain Equation (
11).
From Equation (
11), (a) implies (b) for all
.
As
, from Lemma 1 and Equation (
15), we have
if and only if
. Consequently, if (b) holds, the set of
such that
is a vector space whose dimension is less than
n; thus it has Lebesgue measure 0. Therefore, (a) and (b) are equivalent for almost every
. ☐
Theorem 2 implies that
and
cannot be zero simultaneously. Therefore, either
or
is the unit eigenvector required for computing Equation (
10). We notice that the norm of a vector can be computed in a distributed way because it is the square root of
n times the average of the squares of its entries. Consequently, we only need to know how to compute Equation (
12) in a distributed way, or equivalently, how to compute the cost function
f in a distributed way:
Theorem 3. If such that ,
thenfor almost every ,
where for all .
Proof. Let
be as in the proof of Lemma 1, with
. Then,
for all
, where
for all
. Consider
such that
. Observe that
, as
. Consequently, from the pythagorean theorem,
for all
. Assume that
, which holds for almost every
. As
for all
, we conclude that
☐
We observe that Equation (
16) can be computed in a distributed way because a norm can be computed in a distributed way. Moreover, we observe that the condition
holds if and only if
(this is possible only if every pair of nodes of the network is connected, i.e., it is a fully-connected network; in this case,
and consequently the FSDLA problem makes no sense). Therefore, for any non-fully-connected network,
.
At this point, we have shown that the iterative Equation (
9) can be computed in a distributed way. It only remains to be shown that Equation (
9) actually converges to
:
Theorem 4. Consider such that .
Let be a sequence of real numbers satisfying and .
We also assume that where is defined in Equation (
9).
Then,
.
Consequently, as
f has a bounded set of minimum points, the result now follows from [
13] (Theorem 2.4). ☐
We observe that the initial point
in Theorem 4 can be taken, for instance, as that given by the Metropolis-Hastings algorithm (e.g., [
8]). That is, if
is that given by the Metropolis-Hastings algorithm, then
for all
, where
is the degree of node
(i.e., the number of nodes to which node
i is connected). Therefore,
can be computed in a distributed way.
Table 1 relates Algorithm 1 with the theoretical aspects shown in this section.
Remark 1. As f is continuous, from every initial sequence of real numbers with and (e.g. ), a subsequence of stepsizes satisfying Equation (
17)
can be constructed. We finish the section by describing Algorithm 1. For ease of notation, we define
which is the
tth iteration of Equation (
1) and can clearly be computed in a distributed way. As for Algorithm 1, we fix
to be the number of iterations of Equation (
1) required for a desired precision. We observe that because the worst possible network topology is a path, if we set
, then
(see [
15]), and therefore
can also be obtained in a distributed way.
4. Numerical Results
We here present the numerical results obtained using Algorithm 1 for two networks with
nodes. The chosen starting point
was that given by the Metropolis-Hastings algorithm [
8], and the chosen initial sequence of stepsizes was
for all
. Moreover, we took
.
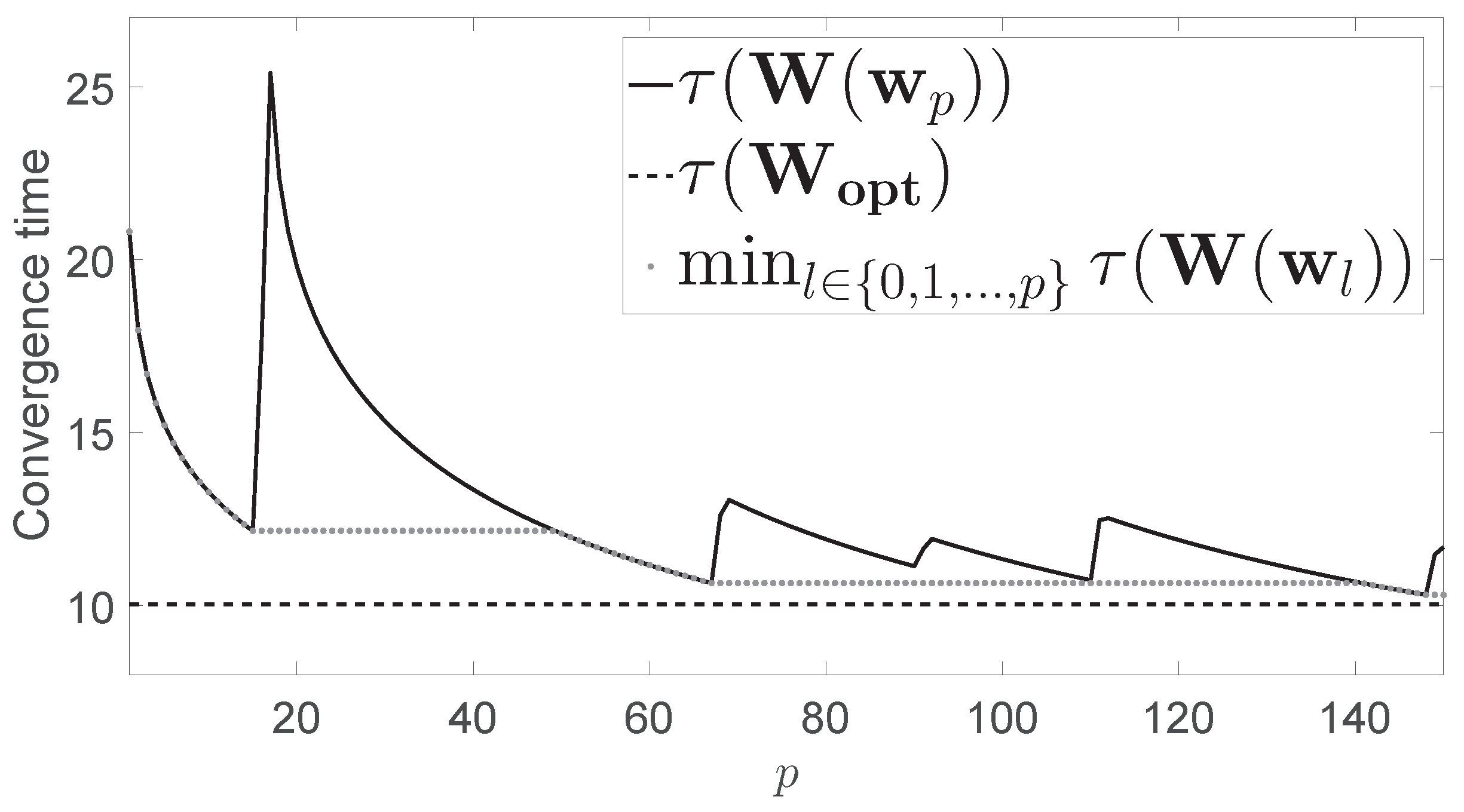
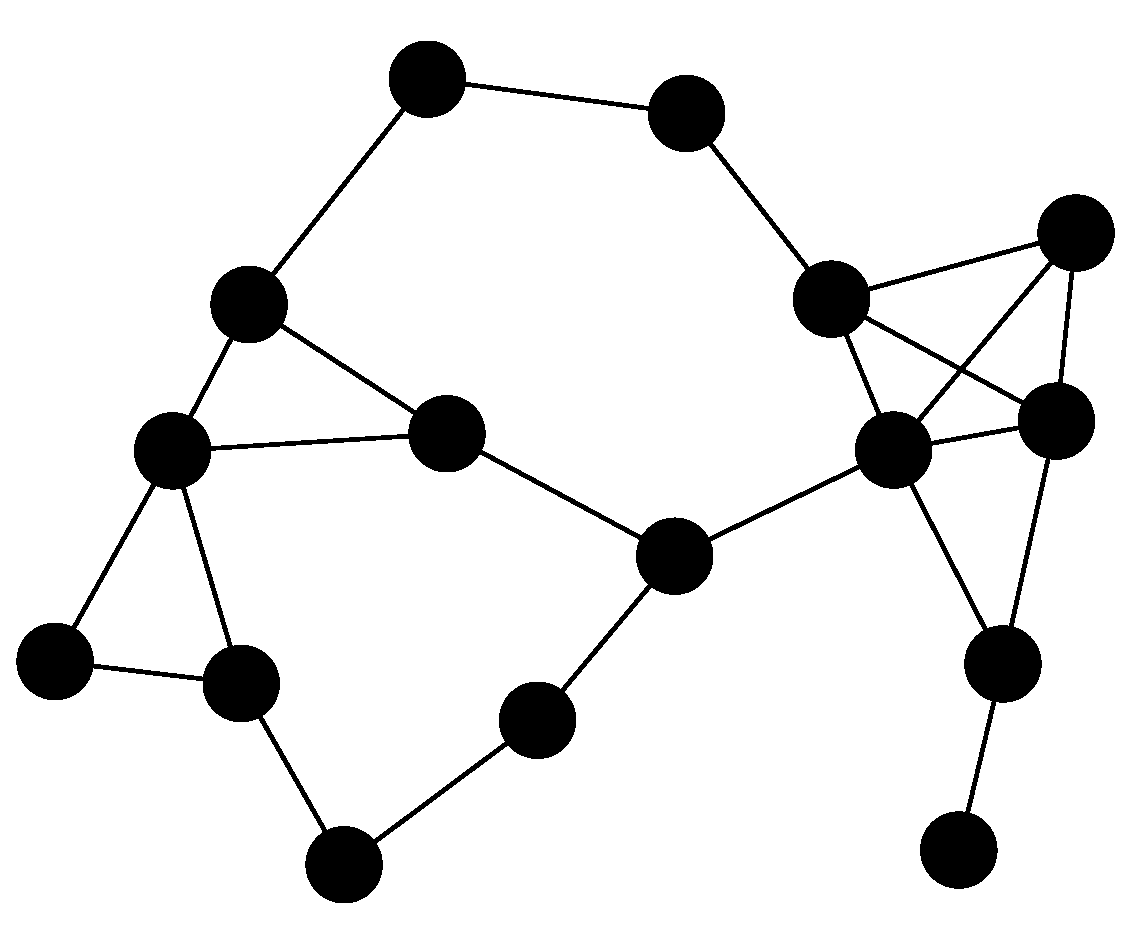
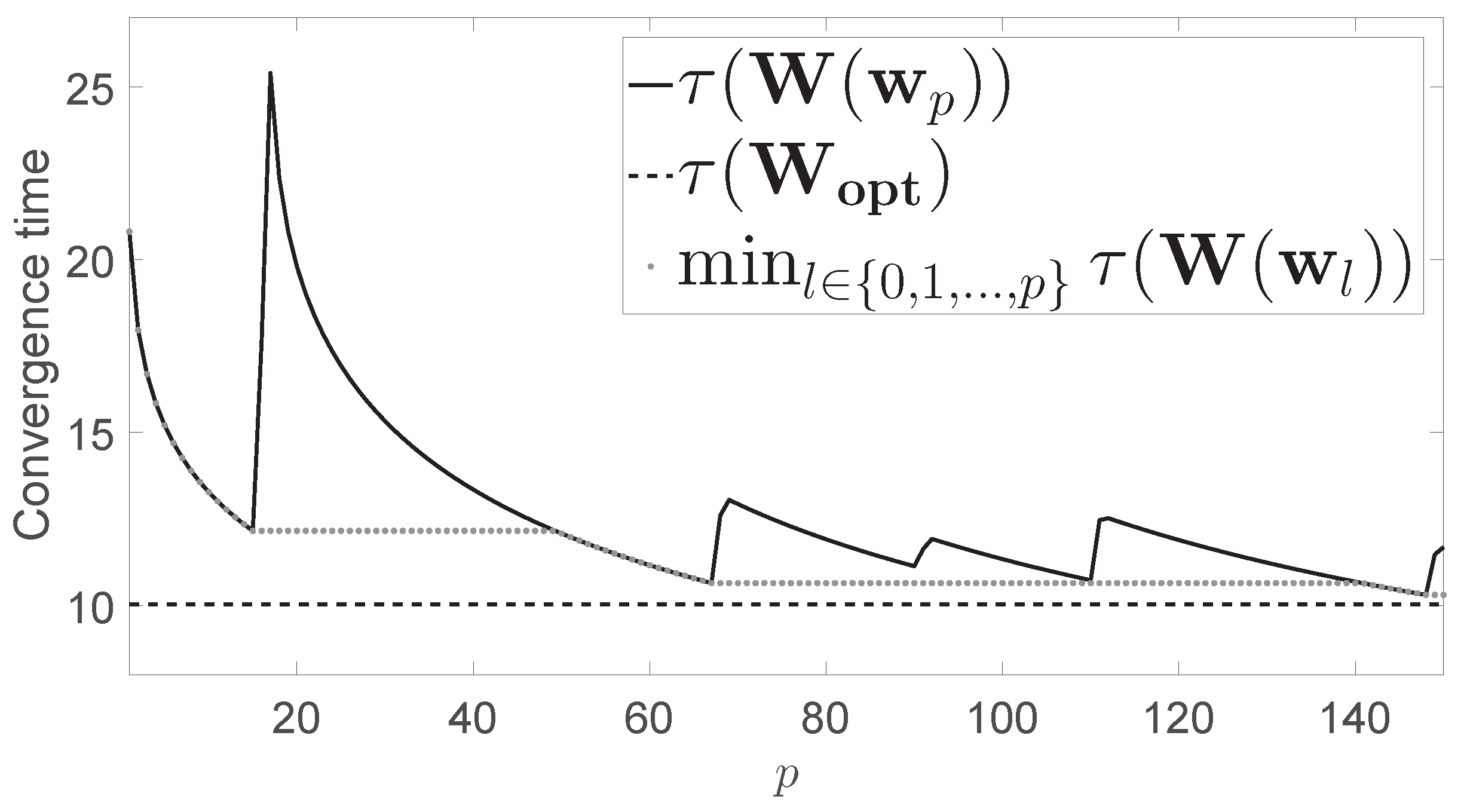
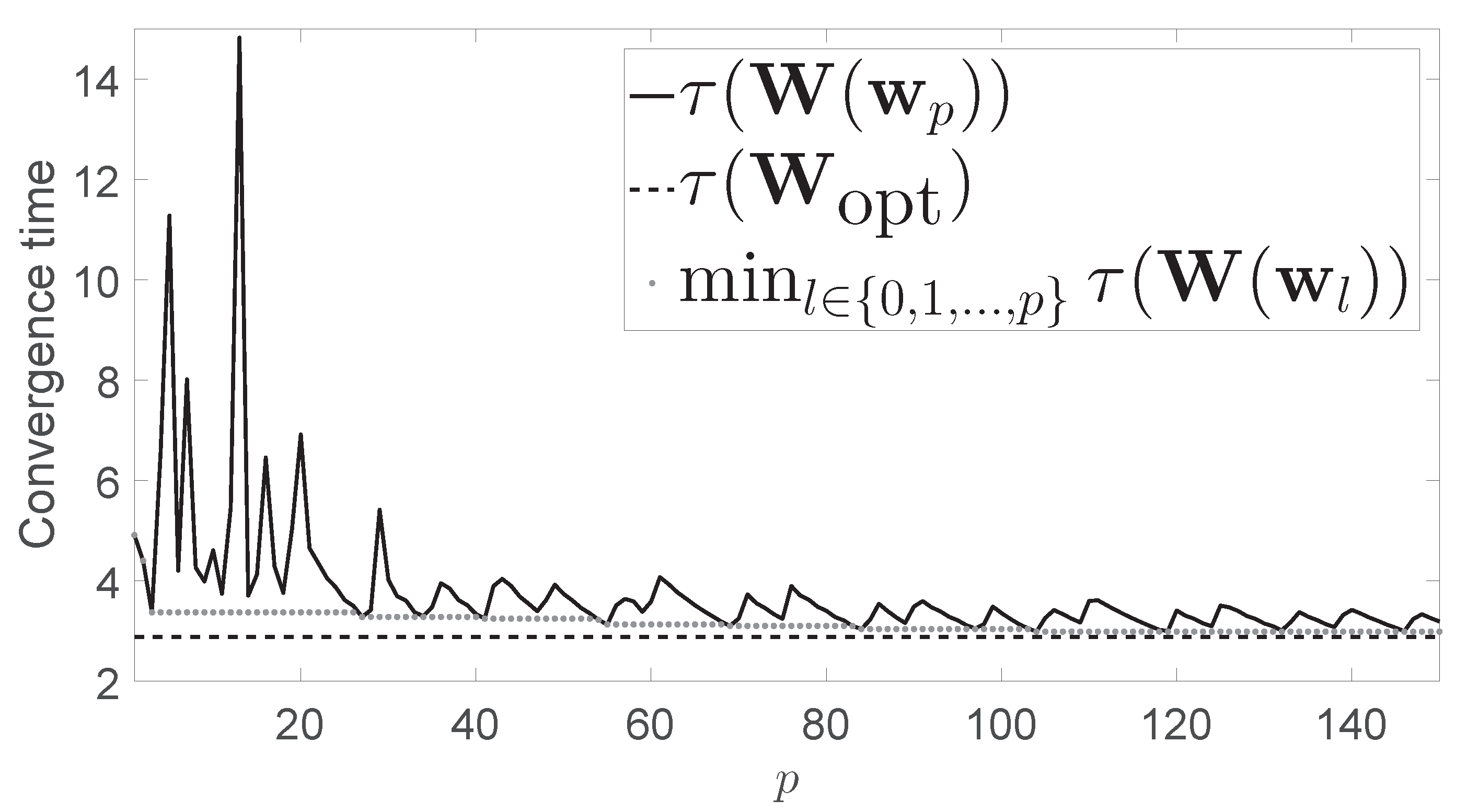
Figure 1 shows the convergence time
for the network presented in
Figure 2 (solid line).
Figure 1 also shows
, which was obtained by using CVX, a package for specifying and solving convex programs in a centralized way [
16,
17] (dashed line). Finally,
Figure 1 also shows the minimum value of
obtained up to step
p (dotted line). For comparison purposes, we observe that the convergence time yielded by the Metropolis-Hastings algorithm was
, while the minimum convergence time obtained after 150 iterations of our algorithm was
.
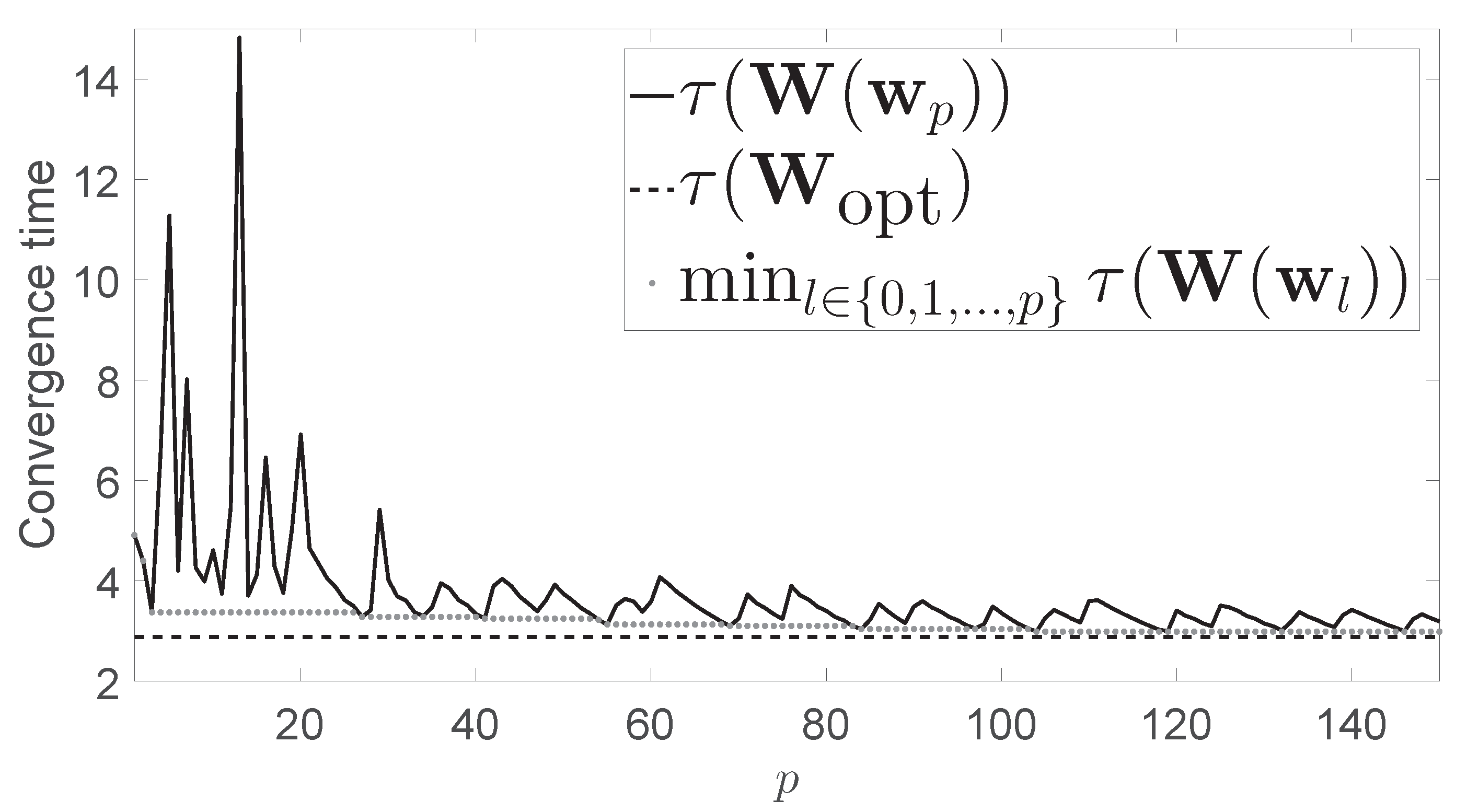
Figure 3 is of the same type as
Figure 1, but in this case, the considered network was a
grid. In this case, if the problem is optimally solved in a centralized way it yields
. The convergence time yielded by the Metropolis-Hastings algorithm was
, while the minimum convergence time obtained after 150 iterations of our algorithm was
.
We finish the section with a note on the number of exchanged messages (number of transmissions). For every iteration p of Algorithm 1, the number of exchanged messages per node was at most , divided as follows: message exchanges were required for lines 8 and 9, another message exchanges were needed in line 10 (lines 14 and 15 did not require new message exchanges), and line 16 required another message exchanges. Finally, depending on the if-clause, another message exchanges were required in line 21. Therefore, the overall number of required transmissions per node was between and .



{kind=link}
{kind=link}
{kind=link}