Developing Fine-Grained Actigraphies for Rheumatoid Arthritis Patients from a Single Accelerometer Using Machine Learning

 , ,
, ,
Abstract
:1. Introduction
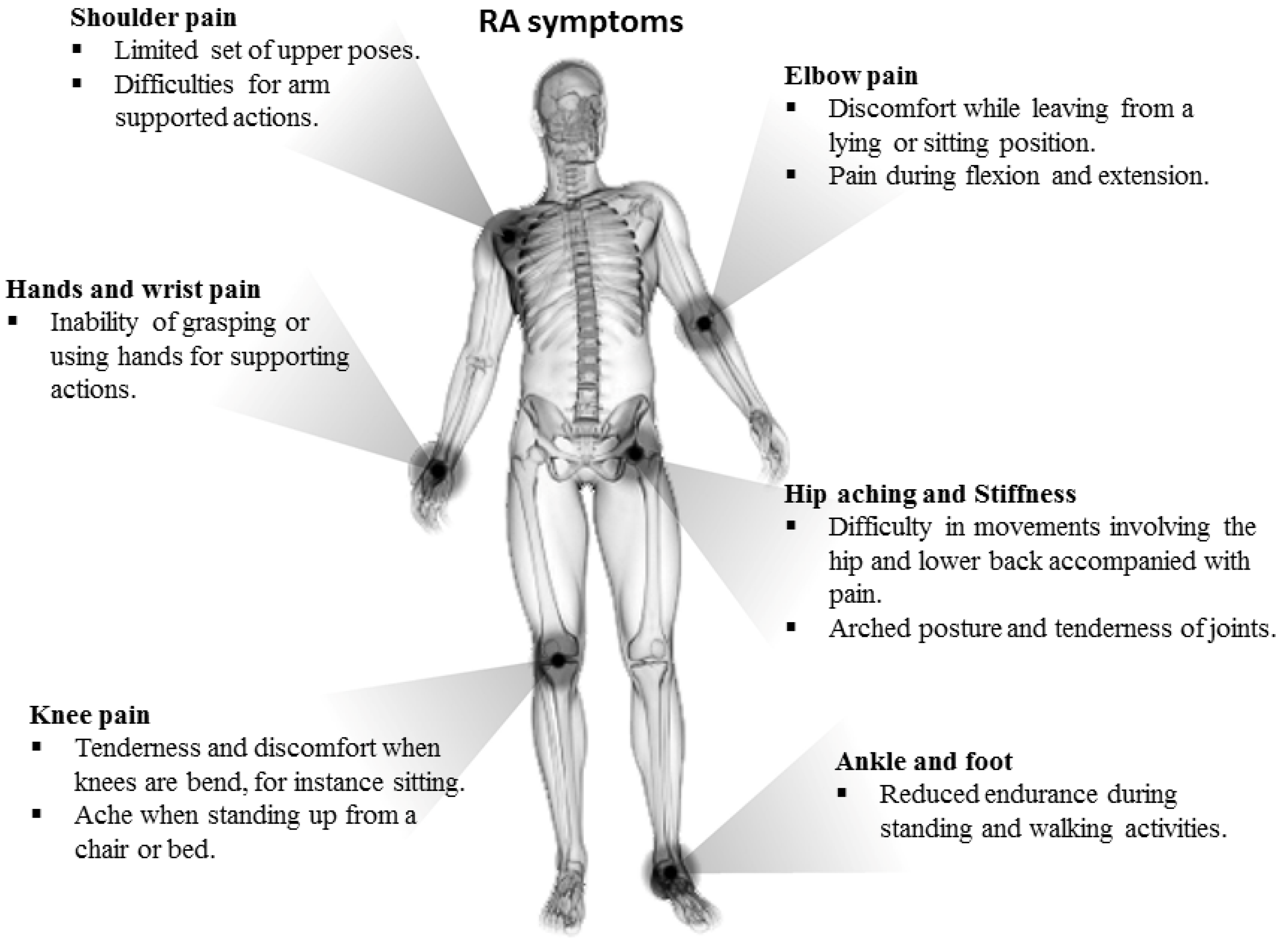
2. Background and Motivation
3. Materials and Methods
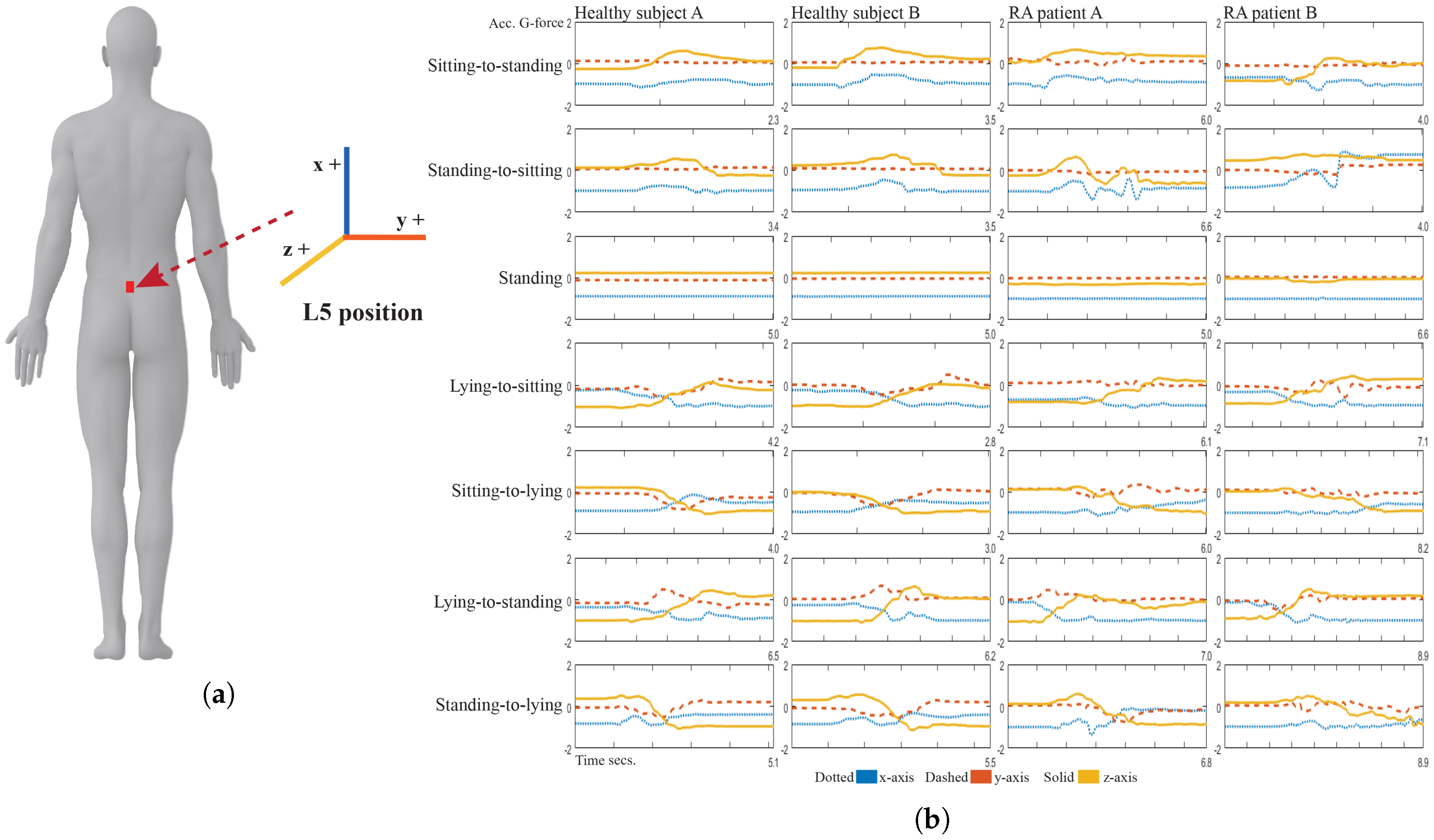
3.1. Experimental Settings
3.2. Inertial Data Pre-Processing
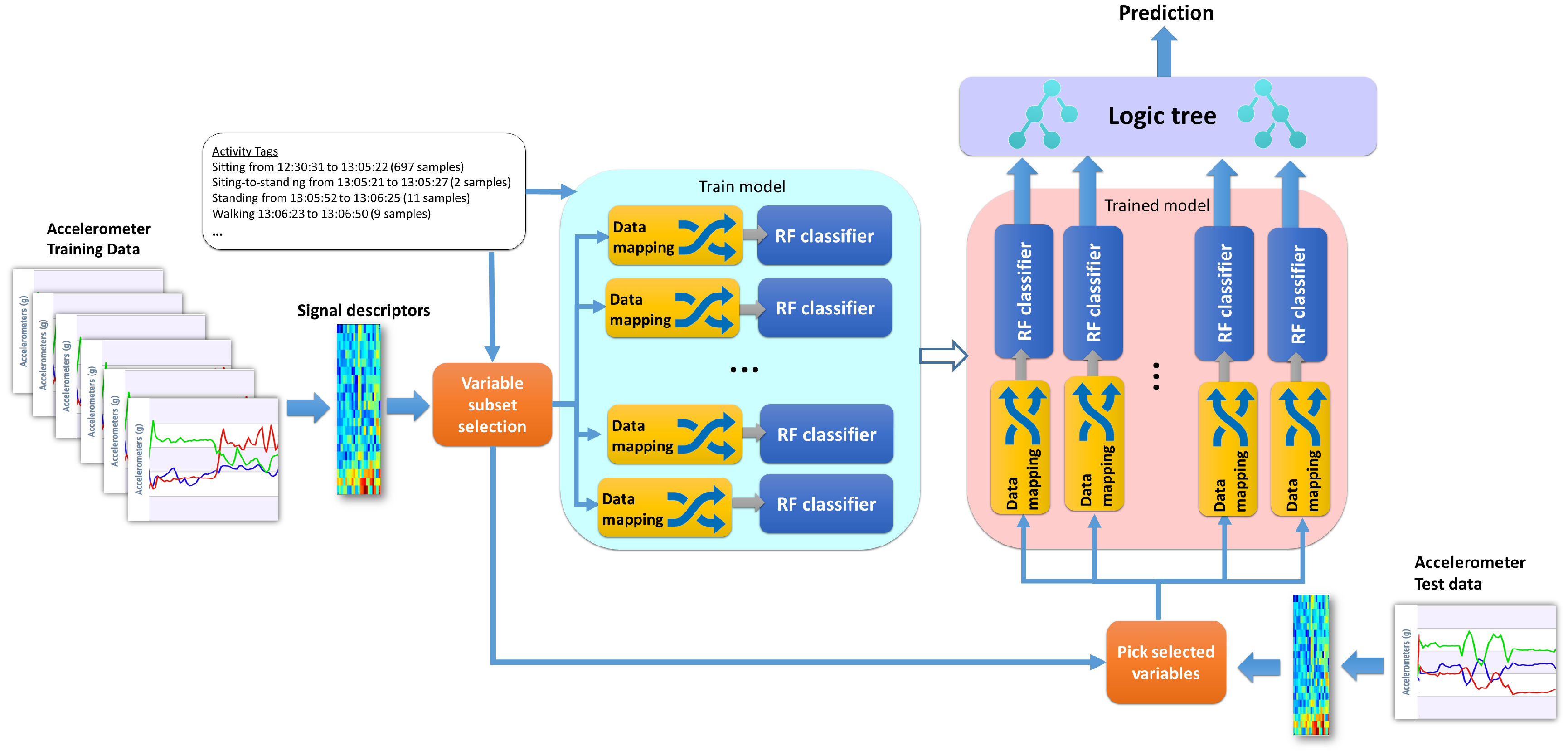
3.3. Subset Selection and Subspace Mapping
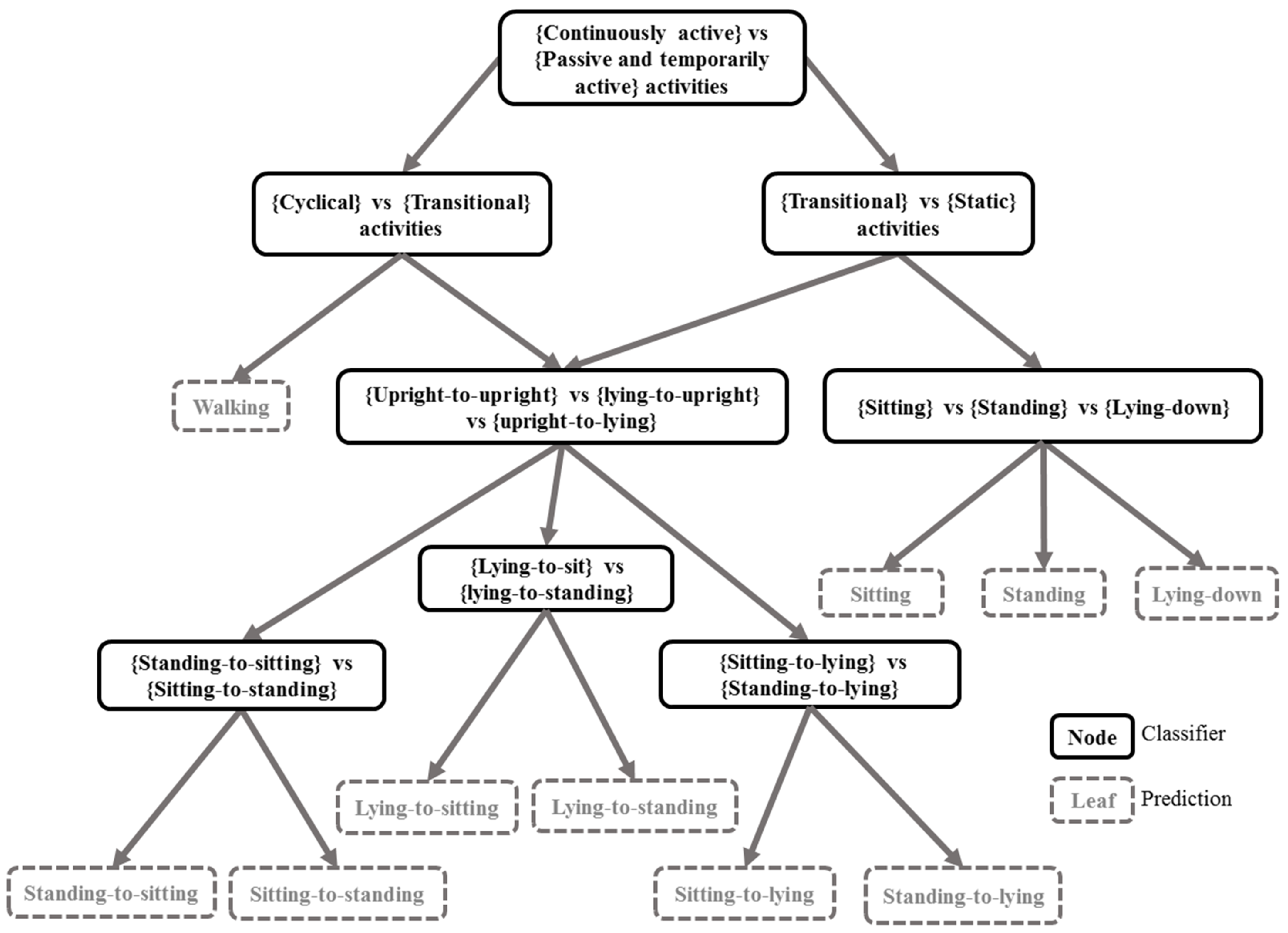
3.4. Transitional Activity Tag Classification
3.4.1. Proposed Novel Meta-Learning Method: Dichotomous Mapped Forest (DMF)
3.4.2. Machine Learning Classifiers Used for Comparison
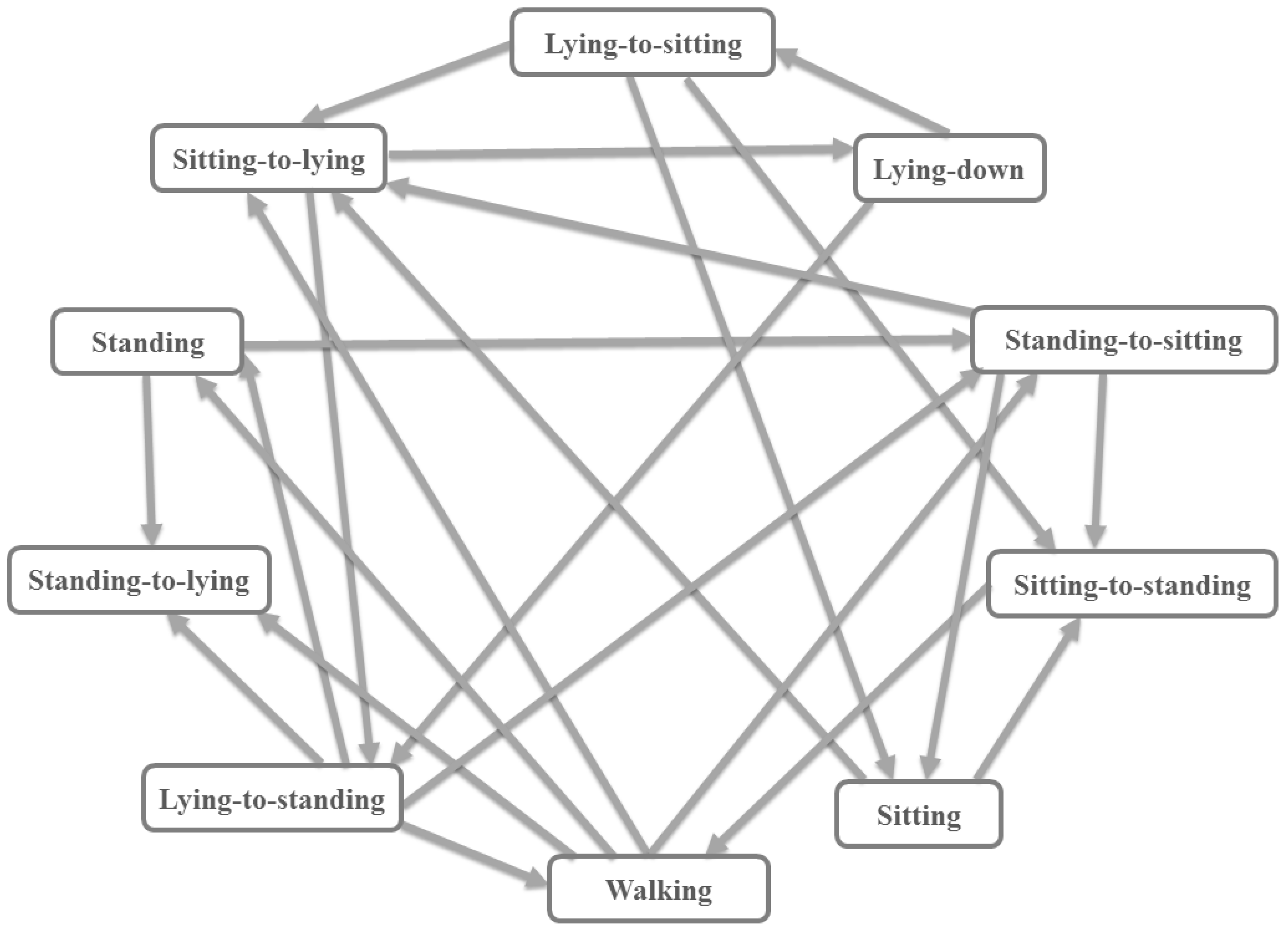
3.5. A State Machine as a Logic Filter
| Algorithm 1 Dichotomy mapped forest—Training |
| Input: X,Y Output: trained model, map &
|
| Algorithm 2 Dichotomy mapped forest—Test |
| Input: Z (test set), , , Output: |
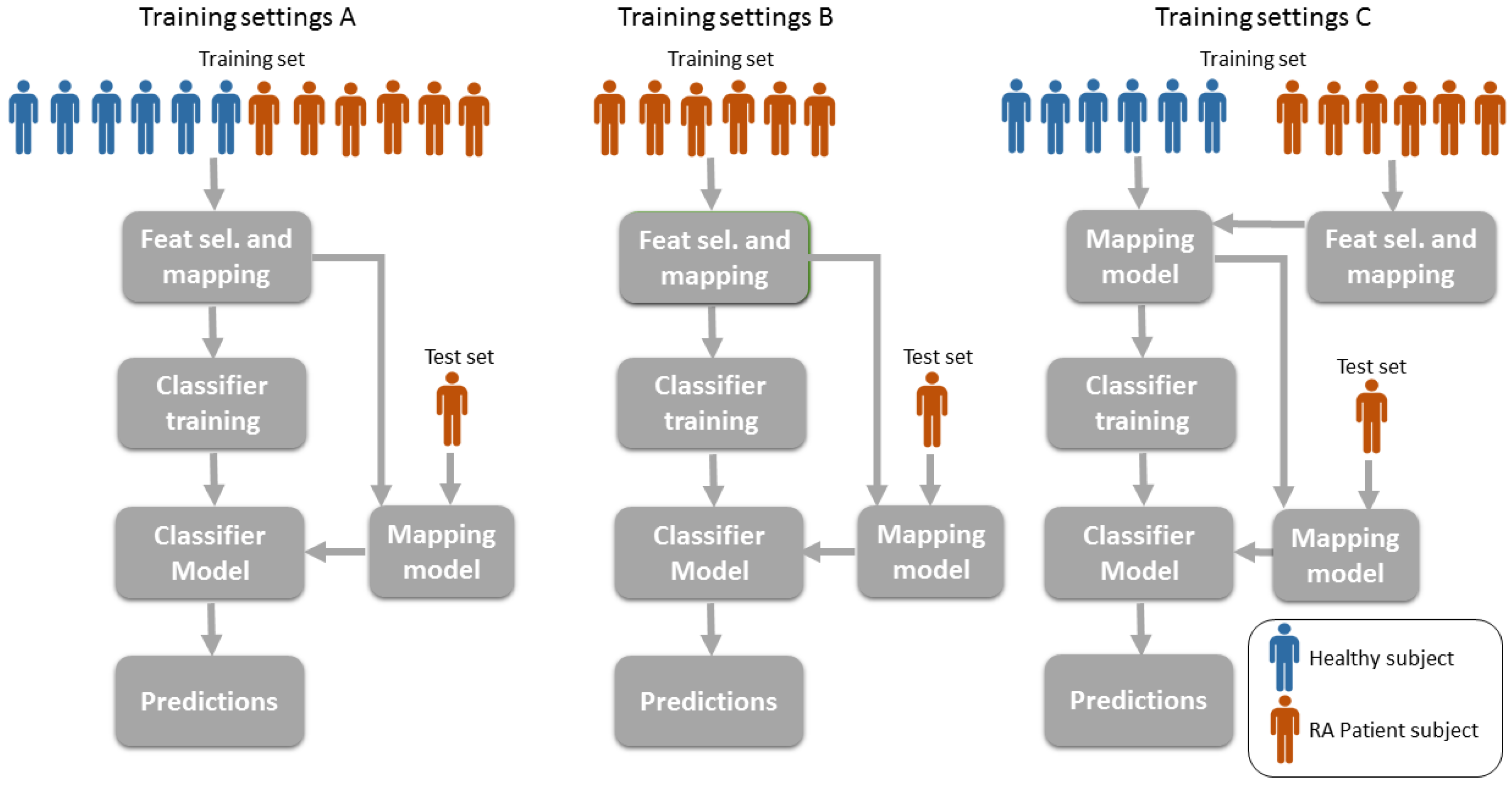
3.6. Training Settings: Mixing Patients and Healthy Volunteers
4. Results and Discussion
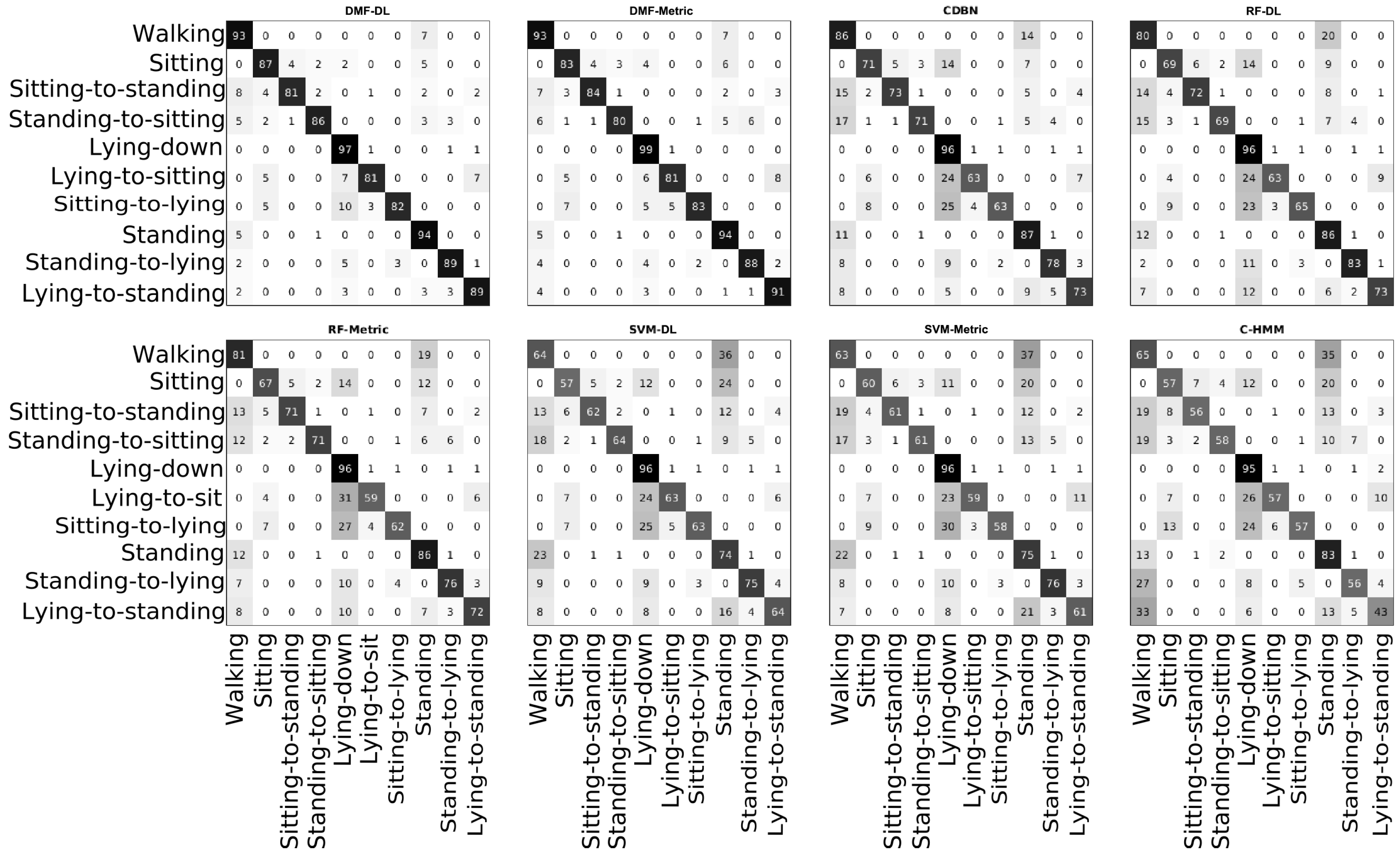
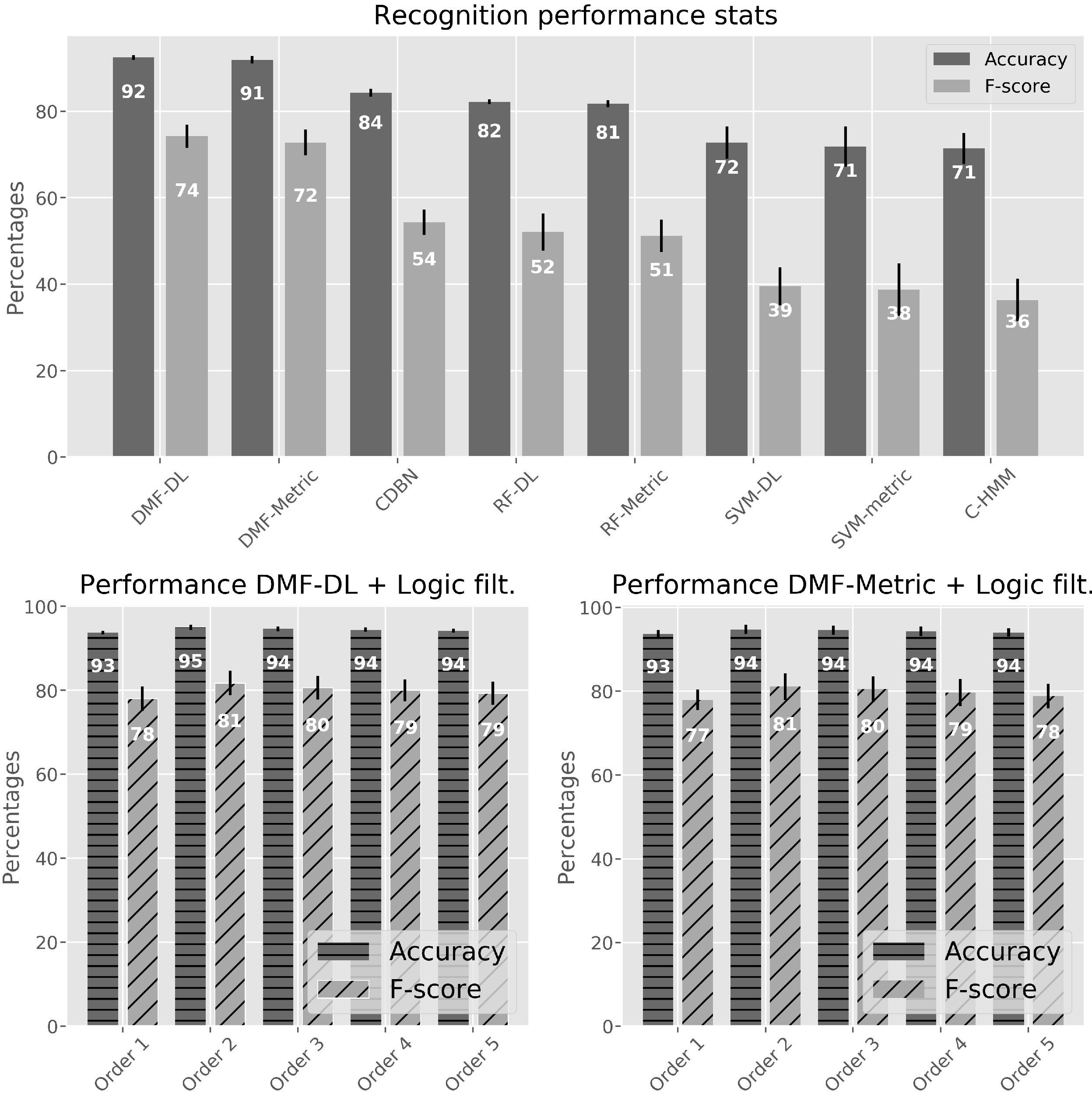
4.1. Activity Classifiers Comparison
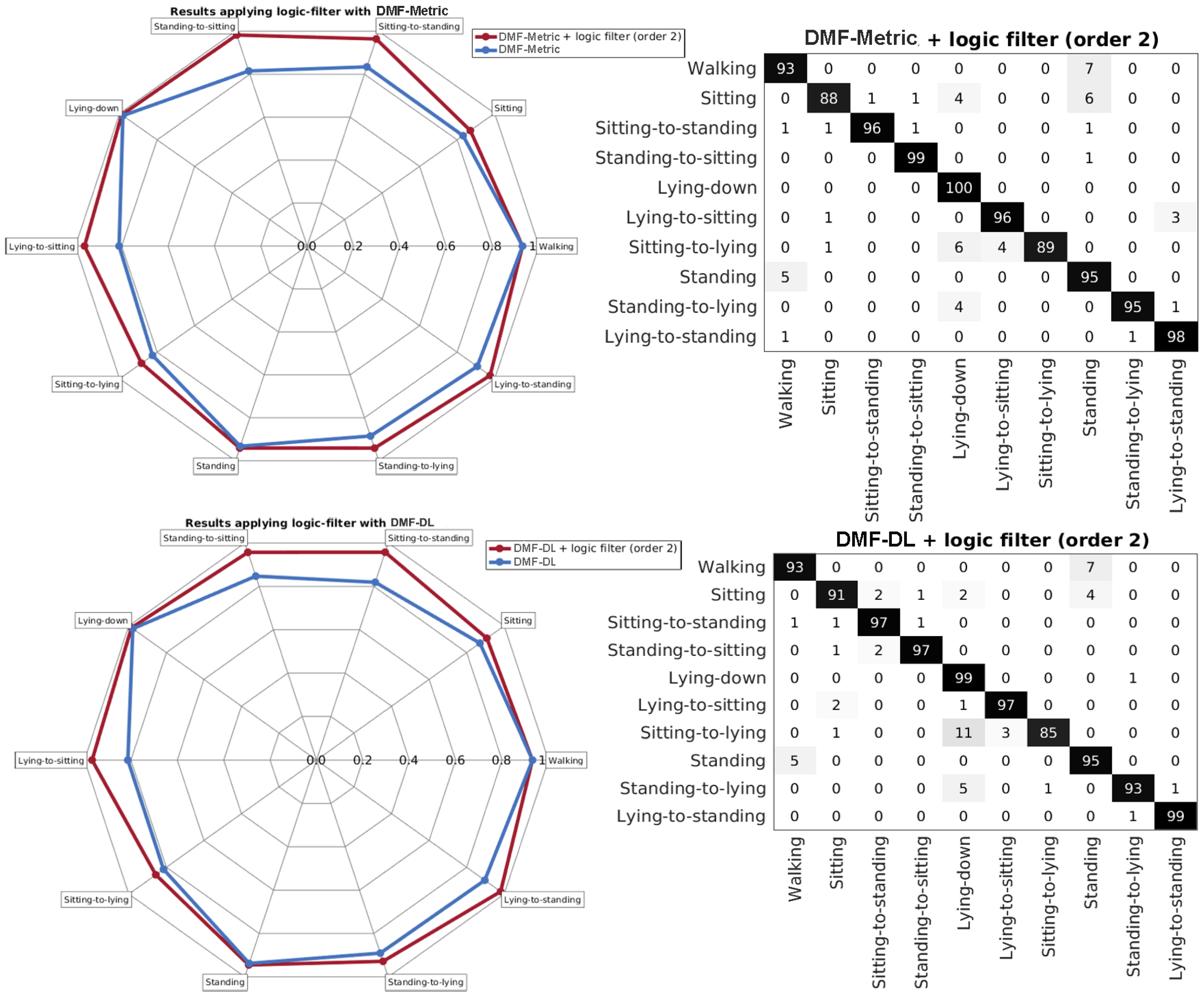
4.2. Applying the Logic Filter
4.3. Results with Different Training Settings
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| C-HMM | Continuous Hidden Markov Models |
| CDBN | Convolutional Deep Belief Networks |
| DCNN | Deep Convolutional Neural Networks |
| DL | Deep Learning |
| DMF | Dichotomous Mapped Forest |
| DMF-DL | DMF with Deep Learning mapping |
| DMF-Metric | DMF with Metric learning mapping |
| DAUT | Discriminatory Autoencoder |
| GPU | Graphical Processing Unit |
| HV | Healthy Volunteers |
| KL | Kullback-Leibler |
| L5 | L5 lumbar vertebra |
| MCM | Maximally collapsing metric |
| MEMS | Microelectromechanical systems |
| Metric | Metric Learning |
| RBF | Radial Basis Function |
| RF | Random Forest |
| ROC | Receiver Operating Characteristic |
| RBM | Restricted Boltzmann Machine |
| RA | Rheumatoid Arthristis |
| RMS | Root Mean Squared |
| SFFS | Sequential Fowards Floating Selection |
| SVM | Support Vector Machine |
References
- Yazici, Y.; Paget, S.A.; Sibley, J. Elderly-onset rheumatoid arthritis. Rheum. Dis. Clin. N. Am. 2000, 26, 517–526. [Google Scholar] [CrossRef]
- Cross, M.; Smith, E.; Hoy, D.; Carmona, L.; Wolfe, F.; Vos, T.; Williams, B.; Gabriel, S.; Lassere, M.; Johns, N. The global burden of rheumatoid arthritis: Estimates from the Global Burden of Disease 2010 study. Ann. Rheum. Dis. 2014, 73, 968–974. [Google Scholar] [CrossRef] [PubMed]
- Woolf, A.D.; Pfleger, B. Burden of major musculoskeletal conditions. Bull. World Health Organ. 2003, 81, 646–656. [Google Scholar] [PubMed]
- Gabriel, S.E.; Crowson, C.S.; O’Fallon, W.M. Mortality in rheumatoid arthritis: Have we made an impact in 4 decades? J. Rheumatol. 1999, 26, 2529–2533. [Google Scholar] [PubMed]
- Jakobsson, U.; Hallberg, I.R. Pain and quality of life among older people with rheumatoid arthritis and/or osteoarthritis: A literature review. J. Clin. Nurs. 2002, 11, 430–443. [Google Scholar] [CrossRef] [PubMed]
- Slatkowsky-Christensen, B.; Mowinckel, P.; Loge, J.H.; Kvien, T.K. Health-related quality of life in women with symptomatic hand osteoarthritis: A comparison with rheumatoid arthritis patients, healthy controls, and normative data. Arthritis Rheum. 2007, 57, 1404–1409. [Google Scholar] [CrossRef] [PubMed]
- Dickens, C.; McGowan, L.; Clark-Carter, D.; Creed, F. Depression in rheumatoid arthritis: A systematic review of the literature with meta-analysis. Psychosom. Med. 2002, 64, 52–60. [Google Scholar] [CrossRef] [PubMed]
- Söderlin, M.K.; Hakala, M.; Nieminen, P. Anxiety and depression in a community-based rheumatoid arthritis population. Scand. J. Rheumatol. 2000, 29, 177–183. [Google Scholar] [PubMed]
- Iyengar, S.; Bonda, F.T.; Gravina, R.; Guerrieri, A.; Fortino, G.; Sangiovanni-Vincentelli, A. A framework for creating healthcare monitoring applications using wireless body sensor networks. In Proceedings of the ICST 3rd International Conference on Body Area Networks, Tempe, AZ, USA, 13–17 March 2008; pp. 8–9. [Google Scholar]
- Fortino, G.; Giannantonio, R.; Gravina, R.; Kuryloski, P.; Jafari, R. Enabling Effective Programming and Flexible Management of Efficient Body Sensor Network Applications. IEEE Trans. Hum. Mach. Syst. 2013, 43, 115–133. [Google Scholar] [CrossRef]
- Galzarano, S.; Giannantonio, R.; Liotta, A.; Fortino, G. A Task-Oriented Framework for Networked Wearable Computing. IEEE Trans. Autom. Sci. Eng. 2016, 13, 621–638. [Google Scholar] [CrossRef]
- Gravina, R.; Alinia, P.; Ghasemzadeh, H.; Fortino, G. Multi-sensor fusion in body sensor networks: State-of-the-art and research challenges. Inf. Fusion 2017, 35, 68–80. [Google Scholar] [CrossRef]
- Fortino, G.; Galzarano, S.; Gravina, R.; Li, W. A framework for collaborative computing and multi-sensor data fusion in body sensor networks. Inf. Fusion 2015, 22, 50–70. [Google Scholar] [CrossRef]
- Bussmann, J.B.J.; Martens, W.L.J.; Tulen, J.H.M.; Schasfoort, F.C.; van den Berg-Emons, H.J.G.; Stam, H.J. Measuring daily behavior using ambulatory accelerometry: The Activity Monitor. Behav. Res. Methods Instrum. Comput. 2001, 33, 349–356. [Google Scholar] [CrossRef] [PubMed]
- Doherty, A.; Jackson, D.; Hammerla, N.; Plötz, T.; Olivier, P.; Granat, M.H.; White, T.; van Hees, V.T.; Trenell, M.I.; Owen, C.G. Large Scale Population Assessment of Physical Activity Using Wrist Worn Accelerometers: The UK Biobank Study. PLoS ONE 2017, 12, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Stone, A.A.; Broderick, J.E.; Porter, L.S.; Kaell, A.T. The experience of rheumatoid arthritis pain and fatigue: Examining momentary reports and correlates over one week. Arthritis Care Res. 1997, 10, 185–193. [Google Scholar] [CrossRef] [PubMed]
- Cutolo, M.; Villaggio, B.; Otsa, K.; Aakre, O.; Sulli, A.; Seriolo, B. Altered circadian rhythms in rheumatoid arthritis patients play a role in the disease’s symptoms. Autoimmun. Rev. 2005, 4, 497–502. [Google Scholar] [CrossRef] [PubMed]
- Katz, P.P. The impact of rheumatoid arthritis on life activities. Arthritis Care Res. 1995, 8, 272–278. [Google Scholar] [CrossRef] [PubMed]
- Luyster, F.S.; Chasens, E.R.; Wasko, M.C.M.; Dunbar-Jacob, J. Sleep quality and functional disability in patients with rheumatoid arthritis. J. Clin. Sleep Med. 2011, 7, 49–55. [Google Scholar] [PubMed]
- Darwish, A.; Hassanien, A.E. Wearable and Implantable Wireless Sensor Network Solutions for Healthcare Monitoring. Sensors 2011, 11, 5561–5595. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Semanik, P.; Song, J.; Chang, R.W.; Manheim, L.; Ainsworth, B.; Dunlop, D. Assessing physical activity in persons with rheumatoid arthritis using accelerometry. Med. Sci. Sports Exerc. 2010, 42, 1493–1501. [Google Scholar] [CrossRef] [PubMed]
- Khoja, S.S.; Almeida, G.J.; Chester Wasko, M.; Terhorst, L.; Piva, S.R. Association of Light-Intensity Physical Activity With Lower Cardiovascular Disease Risk Burden in Rheumatoid Arthritis. Arthritis Care Res. 2016, 68, 424–431. [Google Scholar] [CrossRef] [PubMed]
- Häkkinen, A.; Kautiainen, H.; Hannonen, P.; Ylinen, J.; Mäkinen, H.; Sokka, T. Muscle strength, pain, and disease activity explain individual subdimensions of the Health Assessment Questionnaire disability index, especially in women with rheumatoid arthritis. Ann. Rheum. Dis. 2006, 65, 30–34. [Google Scholar] [CrossRef] [PubMed]
- Munro, B.J.; Steele, J.R.; Bashford, G.M.; Ryan, M.; Britten, N.; Alexander, N.; Schultz, A.; Warwick, D.; Andrews, M.; Arborelius, U.; et al. A kinematic and kinetic analysis of the sit-to-stand transfer using an ejector chair. J. Biomech. 1997, 31, 263–271. [Google Scholar] [CrossRef]
- Cieza, A.; Stucki, G. New approaches to understanding the impact of musculoskeletal conditions. Best Pract. Res. Clin. Rheumatol. 2004, 18, 141–154. [Google Scholar] [CrossRef] [PubMed]
- Axivity Ltd. Axivity AX3; Axivity Ltd: York, UK. Available online: http://axivity.com/product/ax3 (accessed on 24 August 2017).
- Frosio, I.; Pedersini, F.; Borghese, N. Autocalibration of MEMS Accelerometers. IEEE Trans. Instrum. Meas. 2009, 58, 2034–2041. [Google Scholar] [CrossRef]
- Pedley, M. Tilt Sensing Using a Three-Axis Accelerometer; Freescale Semiconductor Application Note; Document Number: AN3461; Freescale Semiconductor, Inc.: Austin, TX, USA, 2013; pp. 2012–2013. [Google Scholar]
- Yang, G.Z.; Andreu-Perez, J.; Hu, X.; Thiemjarus, S. Multi-sensor Fusion. In Body Sensor Networks; Springer: London, UK, 2014; pp. 301–354. [Google Scholar]
- Globerson, A.; Roweis, S. Metric Learning by Collapsing Classes. In Proceedings of the Neural Information Processing Systems, NIPS 2005, Vancouver, BC, Canada, 5–8 December 2005. [Google Scholar]
- Engl, H.W.; Grever, W. Using the L–curve for determining optimal regularization parameters. Numer. Math. 1994, 69, 25–31. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Canu, S.; Grandvalet, Y.; Guigue, V.; Rakotomamonjy, A. SVM and Kernel Methods Matlab Toolbox. Perception Systmes et Information, INSA de Rouen: Rouen, France, 2005. Available online: http://asi.insarouen.fr/enseignants/~arakoto/toolbox/index.html (accessed on 24 August 2017).
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. Adv. Neural Inf. Process. Syst. 2012, 25, 2951–2959. [Google Scholar]
- Cawley, G.C.; Talbot, N.L.C. On Over-fitting in Model Selection and Subsequent Selection Bias in Performance Evaluation. J. Mach. Learn. Res. 2010, 11, 2079–2107. [Google Scholar]
- Rifkin, R.; Klautau, A. In Defense of One-Vs-All Classification. J. Mach. Learn. Res. 2004, 5, 101–141. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Dietterich, T.G. An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting, and Randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Lee, H.; Grosse, R.; Ranganath, R.; Ng, A.Y. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; ACM Press: New York, NY, USA, 2009; pp. 1–8. [Google Scholar]
- Lee, H.; Ekanadham, C.; Ng, A.Y. Sparse deep belief net model for visual area V2. In Advances in Neural Information Processing Systems 20 (NIPS 2007); Platt, J.C., Koller, D., Singer, Y., Roweis, S.T., Eds.; Curran Associates, Inc.: New York, NY, USA, 2008; pp. 873–880. [Google Scholar]
- Ravi, D.; Wong, C.; Lo, B.; Yang, G.Z. Deep learning for human activity recognition: A resource efficient implementation on low-power devices. In Proceedings of the 2016 IEEE 13th International Conference on Wearable and Implantable Body Sensor Networks (BSN), San Francisco, CA, USA, 14–17 June 2016; pp. 71–76. [Google Scholar]
- Attal, F.; Mohammed, S.; Dedabrishvili, M.; Chamroukhi, F.; Oukhellou, L.; Amirat, Y. Physical Human Activity Recognition Using Wearable Sensors. Sensors 2015, 15, 31314–31338. [Google Scholar] [CrossRef] [PubMed]
- Mannini, A.; Sabatini, A.M. Machine Learning Methods for Classifying Human Physical Activity from On-Body Accelerometers. Sensors 2010, 10, 1154–1175. [Google Scholar] [CrossRef] [PubMed]
- Collins, M. The Forward-Backward Algorithm. Available online: http://www.cs.columbia.edu/~mcollins/fb.pdf (accessed on 24 August 2017).
- Alsheikh, M.A.; Selim, A.; Niyato, D.; Doyle, L.; Lin, S.; Tan, H.P. Deep Activity Recognition Models with Triaxial Accelerometers. In Proceedings of the Workshops of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Guenterberg, E.; Ghasemzadeh, H.; Loseu, V.; Jafari, R. Distributed Continuous Action Recognition Using a Hidden Markov Model in Body Sensor Networks. In Distributed Computing in Sensor Systems. DCOSS 2009, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; pp. 145–158. [Google Scholar]
- Millor, N.; Lecumberri, P.; Gomez, M.; Martinez-Ramirez, A.; Izquierdo, M. Kinematic Parameters to Evaluate Functional Performance of Sit-to-Stand and Stand-to-Sit Transitions Using Motion Sensor Devices: A Systematic Review. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 926–936. [Google Scholar] [CrossRef] [PubMed]
- Del Din, S.; Godfrey, A.; Rochester, L. Validation of an Accelerometer to Quantify a Comprehensive Battery of Gait Characteristics in Healthy Older Adults and Parkinson’s Disease: Toward Clinical and at Home Use. IEEE J. Biomed. Heal. Inform. 2016, 20, 838–847. [Google Scholar] [CrossRef] [PubMed]
- Marschollek, M.; Rehwald, A.; Wolf, K.H.; Gietzelt, M.; Nemitz, G.; Meyer zu Schwabedissen, H.; Haux, R. Sensor-based Fall Risk Assessment—An Expert ‘to go’. Methods Inf. Med. 2011, 50, 420–426. [Google Scholar] [CrossRef] [PubMed]
- Stack, E.; King, R.; Janko, B.; Burnett, M.; Hammersley, N.; Agarwal, V.; Hannuna, S.; Burrows, A.; Ashburn, A. Could In-Home Sensors Surpass Human Observation of People with Parkinson’s at High Risk of Falling? An Ethnographic Study. Biomed Res. Int. 2016, 2016, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Inan, O.T.; Whittingslow, D.C.; Teague, C.N.; Hersek, S.; Baran Pouyan, M.; Millard-Stafford, M.; Kogler, G.F.; Sawka, M.N. Wearable Knee Health System Employing Novel Physiological Biomarkers. J. Appl. Physiol. 2017. [Google Scholar] [CrossRef] [PubMed]
- D’Lima, D.D.; Fregly, B.J.; Colwell, C.W.J. Implantable sensor technology: Measuring bone and joint biomechanics of daily life in vivo. Arthritis Res. Ther. 2013, 15, 203–211. [Google Scholar] [CrossRef] [PubMed]
- Andreu-Perez, J.; Leff, D.R.; Ip, H.M.D.; Yang, G.Z. From Wearable Sensors to Smart Implants–Toward Pervasive and Personalized Healthcare. IEEE Trans. Biomed. Eng. 2015, 62, 2750–2762. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics | DMF-DL | DMF-Metric | CDBN | RF-DL | RF-Metric | SVM-DL | SVM-Metric | C-HMM |
|---|---|---|---|---|---|---|---|---|
| Accuracy | 92.44 ± 0.54 | 91.95 ± 0.82 | 84.30 ± 0.98 | 82.25 ± 0.55 | 81.76 ± 0.86 | 72.75 ± 3.73 | 71.84 ± 4.67 | 71.40 ± 3.6 |
| Sensitivity | 92.20 ± 1.98 | 90.82 ± 1.98 | 78.88 ± 1.14 | 81.42 ± 1.66 | 80.87 ± 0.62 | 74.37 ± 2.06 | 73.78 ± 0.88 | 68.12 ± 2.61 |
| F-score | 74.22 ± 2.63 | 72.76 ± 2.96 | 54.33 ± 2.94 | 52.02 ± 4.29 | 51.21 ± 3.75 | 39.48 ± 4.42 | 38.70 ± 6.10 | 36.32 ± 4.94 |
| Specificity | 92.46 ± 0.55 | 92.13 ± 0.96 | 85.04 ± 1.05 | 82.35 ± 0.67 | 81.88 ± 0.97 | 72.49 ± 4.15 | 71.64 ± 5.31 | 71.85 ± 4.92 |
| Algorithm | Statistics | Order 1 | Order 2 | Order 3 | Order 4 | Order 5 |
|---|---|---|---|---|---|---|
| DMF-DL | Accuracy | 93.78 ± 0.45 | 95.00 ± 0.65 | 94.64 ± 0.55 | 94.43 ± 0.50 | 94.21 ± 0.43 |
| F-score | 78.05 ± 2.93 | 81.77 ± 2.90 | 80.63 ± 2.82 | 79.97 ± 2.67 | 79.30 ± 2.65 | |
| DMF-Metric | Accuracy | 93.75 ± 0.88 | 94.76 ± 1.15 | 94.56 ± 1.10 | 94.31 ± 1.11 | 94.06 ± 1.01 |
| F-score | 77.92 ± 2.50 | 81.12 ± 3.20 | 80.44 ± 3.13 | 79.67 ± 3.23 | 78.87 ± 2.97 |
| Algorithm | Without Logic Filter | With Logic Filter | ||
|---|---|---|---|---|
| Accuracy | F-score | Accuracy | F-score | |
| DMF-DL patient data only (setting B) | 78.01 ± 0.96 | 43.78 ± 3.72 | 84.11 ± 1.12 | 53.69 ± 3.22 |
| DMF-DL patient mapping (setting C) | 83.12 ± 1.42 | 52.31 ± 3.7 | 88.84 ± 4.55 | 63.88 ± 4.55 |
| DMF-Metric patient data only (setting B) | 81.45 ± 1.28 | 50.39 ± 3.86 | 87.63 ± 1.65 | 60.98 ± 4.63 |
| DMF-Metric patient mapping (setting C) | 85.06 ± 0.95 | 55.75 ± 4.16 | 90.37 ± 1.15 | 61.79 ± 4.46 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Andreu-Perez, J.; Garcia-Gancedo, L.; McKinnell, J.; Van der Drift, A.; Powell, A.; Hamy, V.; Keller, T.; Yang, G.-Z. Developing Fine-Grained Actigraphies for Rheumatoid Arthritis Patients from a Single Accelerometer Using Machine Learning. Sensors 2017, 17, 2113. https://doi.org/10.3390/s17092113
Andreu-Perez J, Garcia-Gancedo L, McKinnell J, Van der Drift A, Powell A, Hamy V, Keller T, Yang G-Z. Developing Fine-Grained Actigraphies for Rheumatoid Arthritis Patients from a Single Accelerometer Using Machine Learning. Sensors. 2017; 17(9):2113. https://doi.org/10.3390/s17092113
Chicago/Turabian StyleAndreu-Perez, Javier, Luis Garcia-Gancedo, Jonathan McKinnell, Anniek Van der Drift, Adam Powell, Valentin Hamy, Thomas Keller, and Guang-Zhong Yang. 2017. "Developing Fine-Grained Actigraphies for Rheumatoid Arthritis Patients from a Single Accelerometer Using Machine Learning" Sensors 17, no. 9: 2113. https://doi.org/10.3390/s17092113