Vehicle Detection with Occlusion Handling, Tracking, and OC-SVM Classification: A High Performance Vision-Based System

 , , , , and
, , , , and
Abstract
:1. Introduction
2. Related Works
- Only reference [20] has uses greater number of Ground Truth (GT) points in the detection than us, but they used only 3326 for the classification. Therefore, our work shows the greatest number of GT for classification.
- The detection rate DR or recall of 100% reported in [37] was achieved in a restricted scenario for only nine GT vehicles in 1000 frames; so, it’s not valid.
- The most of papers don´t give information about videos, that can be downloaded and tested; or they are too short, or not show an easy replication.
- Background-foreground algorithms transform input videos or photos, with occlusion handling or not, into an output space that is used for the classification stage.
- The output space delivered by the detection stage is the set of points or vectors modelling the moving vehicles.
- It is important to keep a low dimensional output space of the detection algorithms and/or the use of low-computational complexity features to improve the performance of these real-time systems.
- In [36] the occlusion is classified into partial and full visually, and convex regions were employed, reporting an improvement of the detection. However, a metric about the occlusion has not been presented.
- In [39] the occlusion handling algorithm is based on SVM, using 11 videos for training and another three for the detection of occlusion. Although this technique is novel, it uses images as elements of the input space for the SVM classifier. Therefore, it has a greater computational complexity than other techniques that use elements of less complexity than those images.
- All occlusion management algorithms should be tested with long-duration, high-frame-rate videos, 135-s videos and frame rates of 8 are relatively low.
- Vehicle ROI extraction based on GMM to reduce computational complexity is achieved in some works like [43].
- In our work assumptions such as (1) processing in the pixel domain, (2) tracking and decision at frame-level, (3) the use of low-computational complexity features and (4) processing of pixels in certain regions with high variability, are kept to reduce the computational complexity because these assumptions are crucial for a necessary future parallelization of these algorithms.
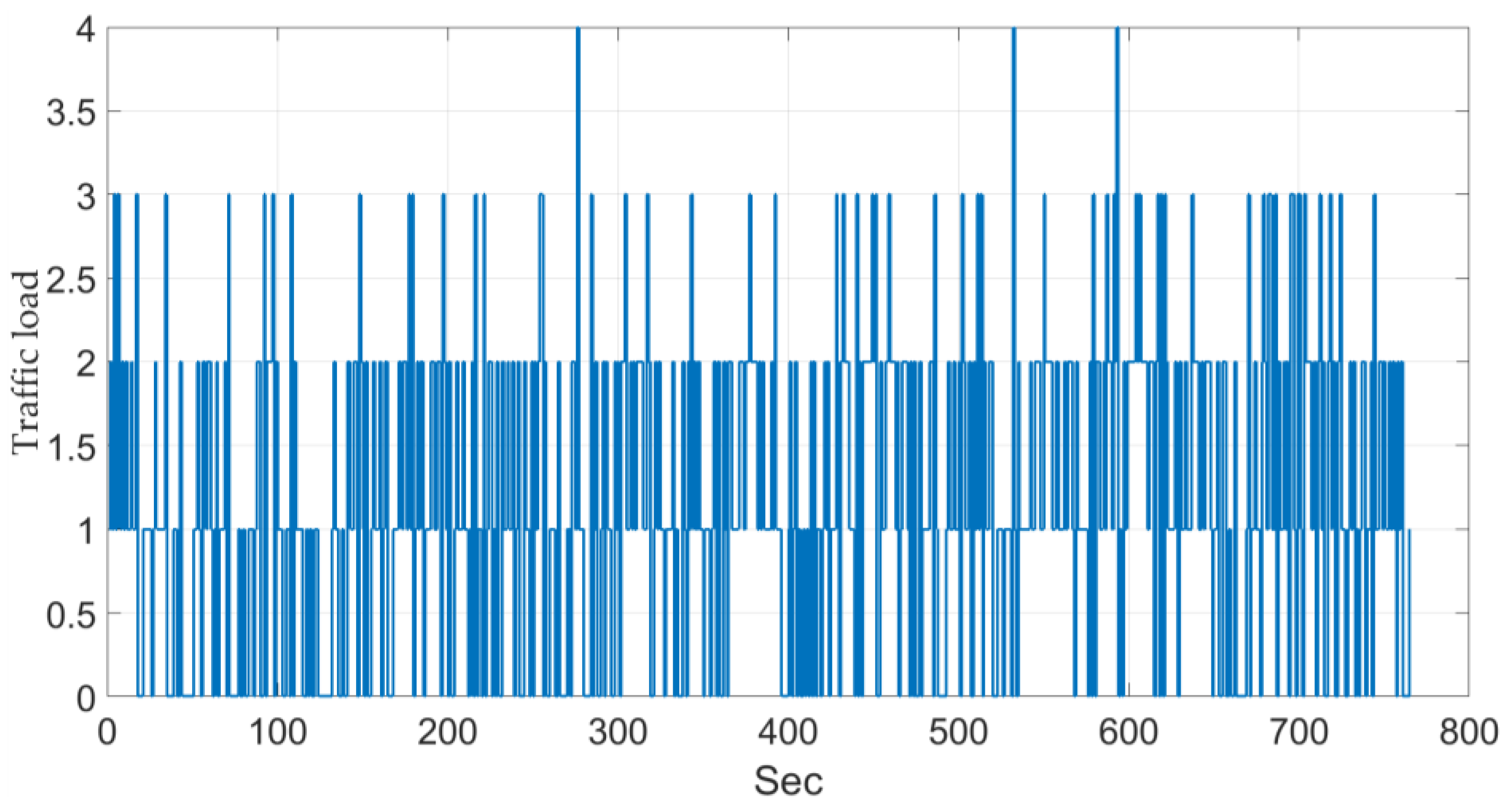
- Our work has the largest number of different scenarios for detection and the largest number of frames. In addition, traffic load and other metrics are given.
- Several systems used in addition to the video camera, other sensors, then different input spaces were created. Consequently, the use of a single static camera helps to maintain a low cost hardware system, and we have demonstrated that it is possible to have a high performance system.
- The test scenarios used in this work are richer than those presented in related papers.
- For traffic monitoring in Smart City IoT with a static camera located on the road-side, our system showed the highest performance and we calculated more performance metrics.
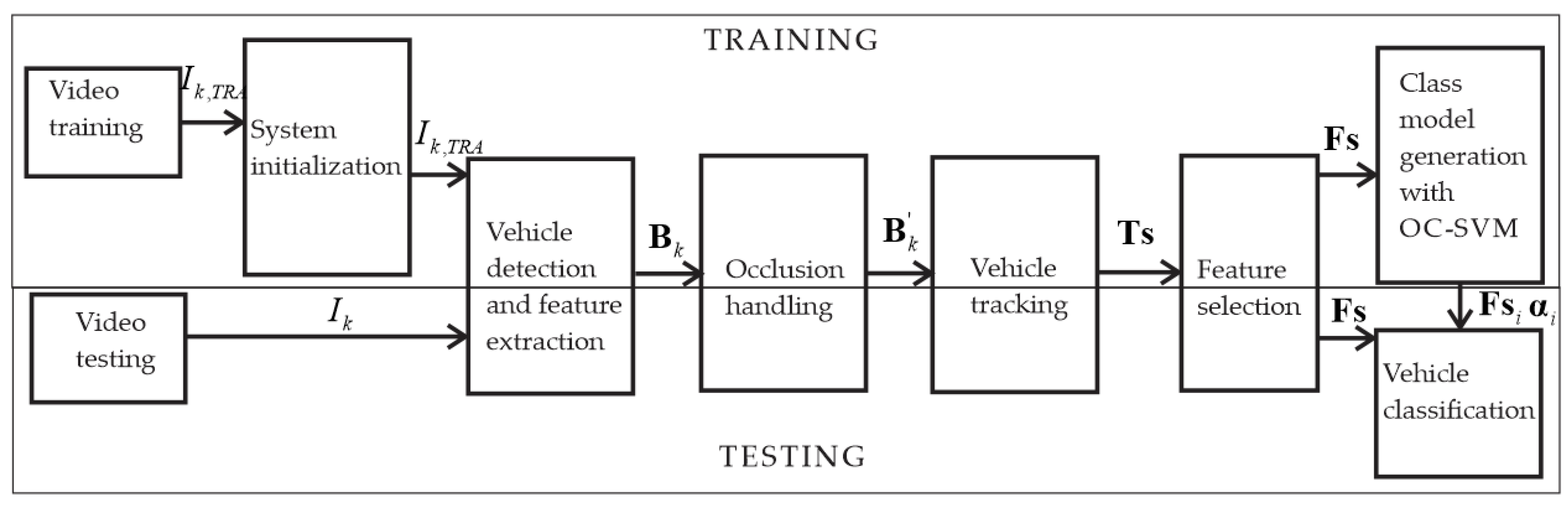
3. The Proposed System
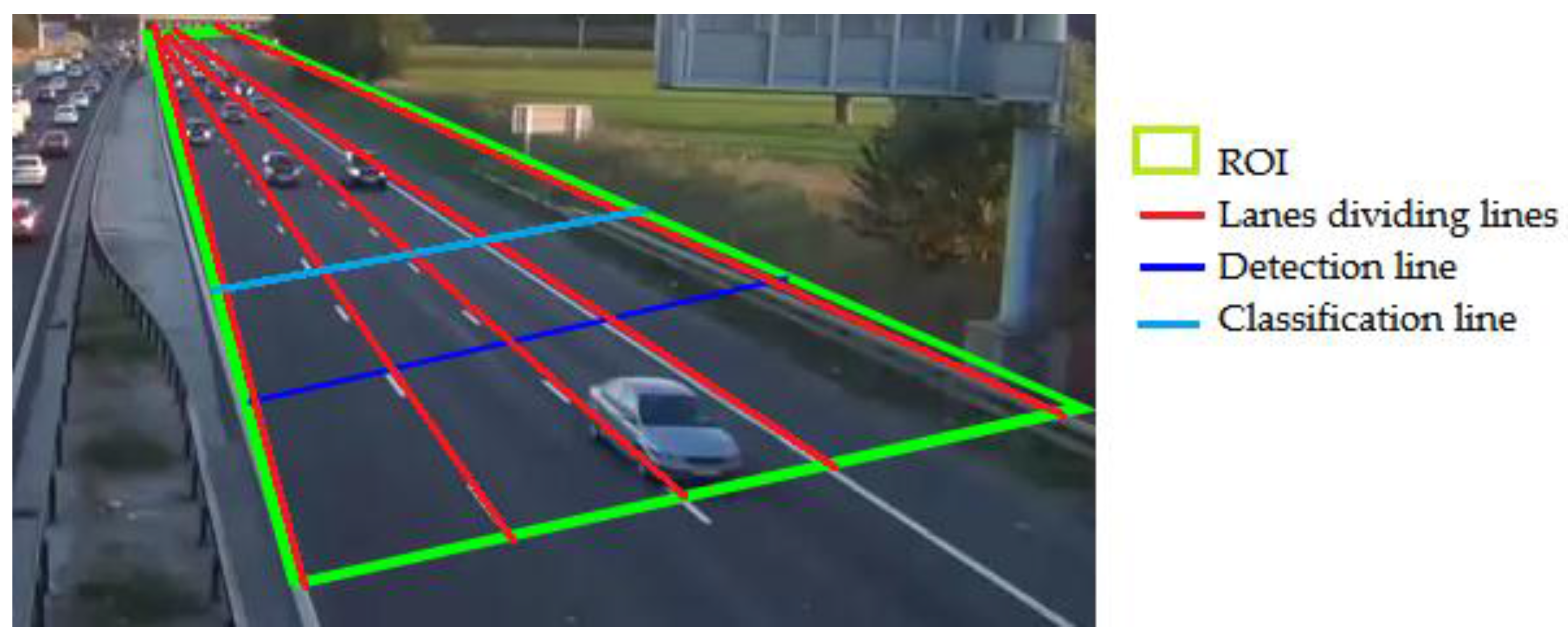
3.1. System Initialization
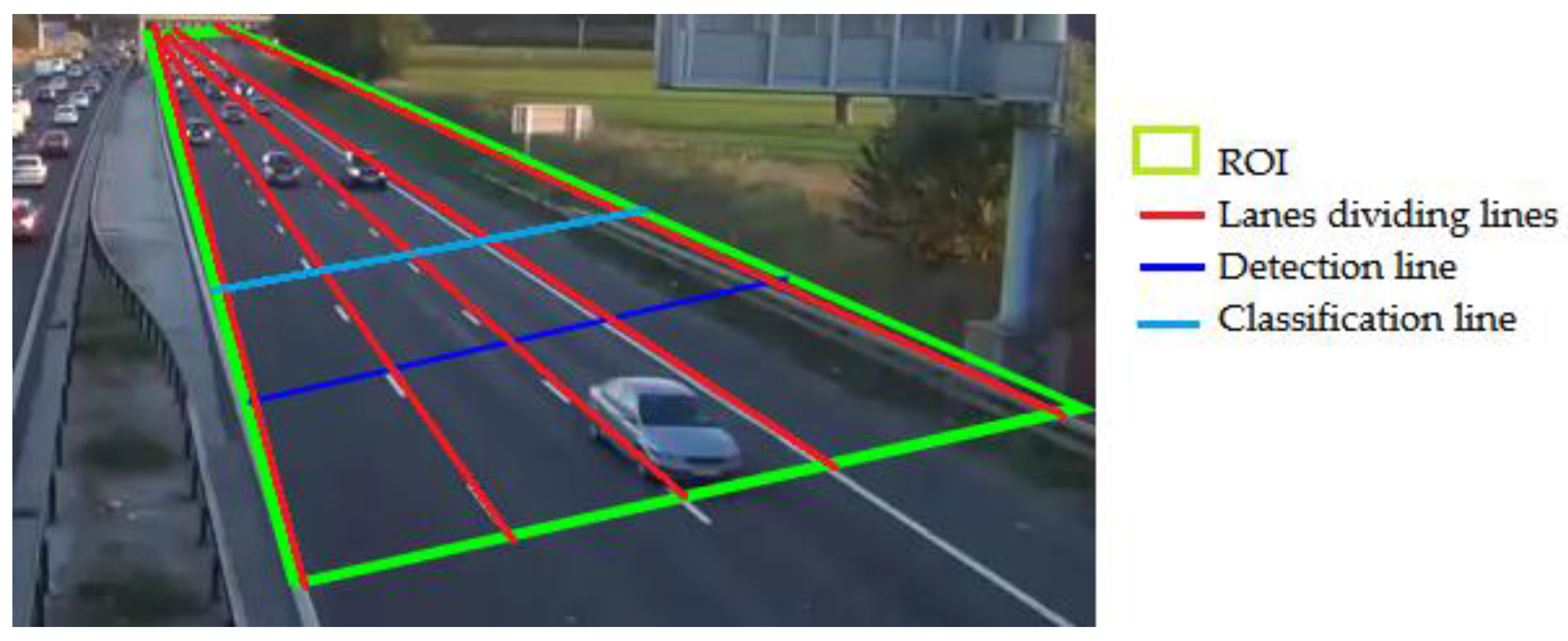
- Manual selection of the Region of Interest (ROI), which is the set of all pixels where moving objects or vehicles can be detected, tracked and classified. This concept helps to reduce the whole processing time.
- Manual setting of the lane-dividing lines, detection line, and classification line.
3.2. Vehicle Detection
3.3. Feature Extraction
3.4. Occlusion Handling
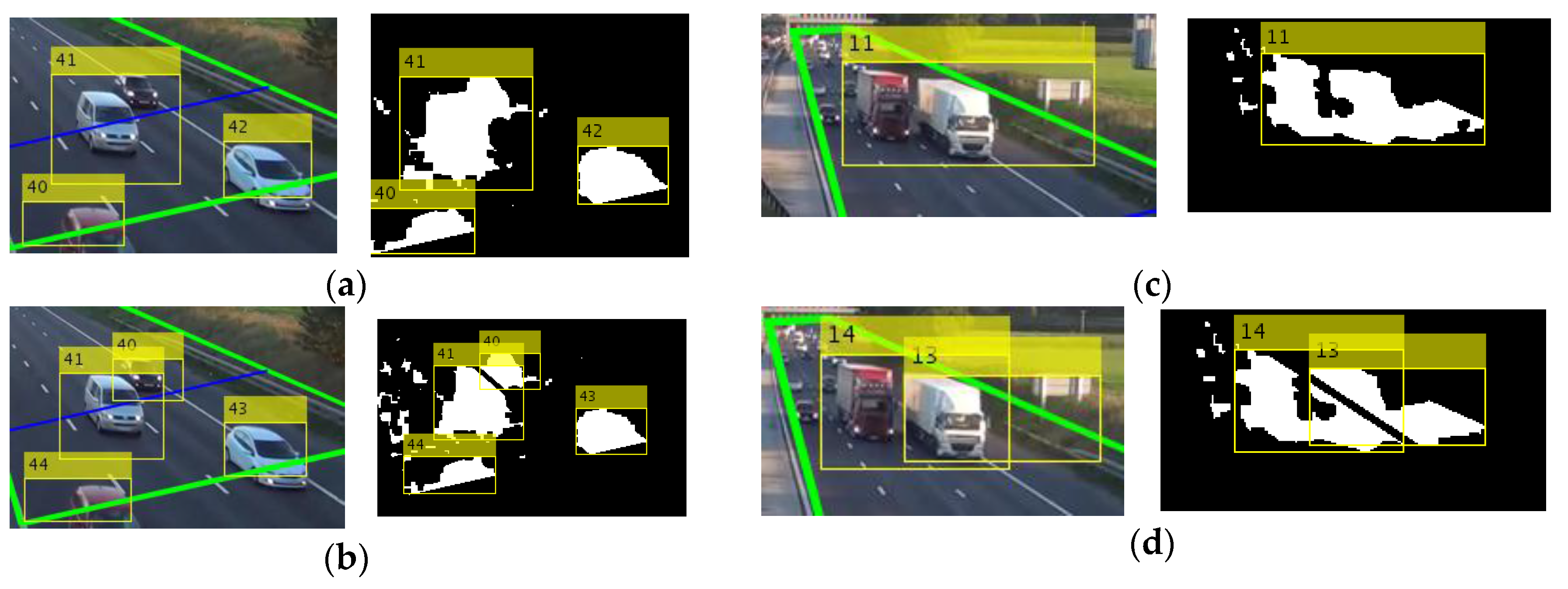
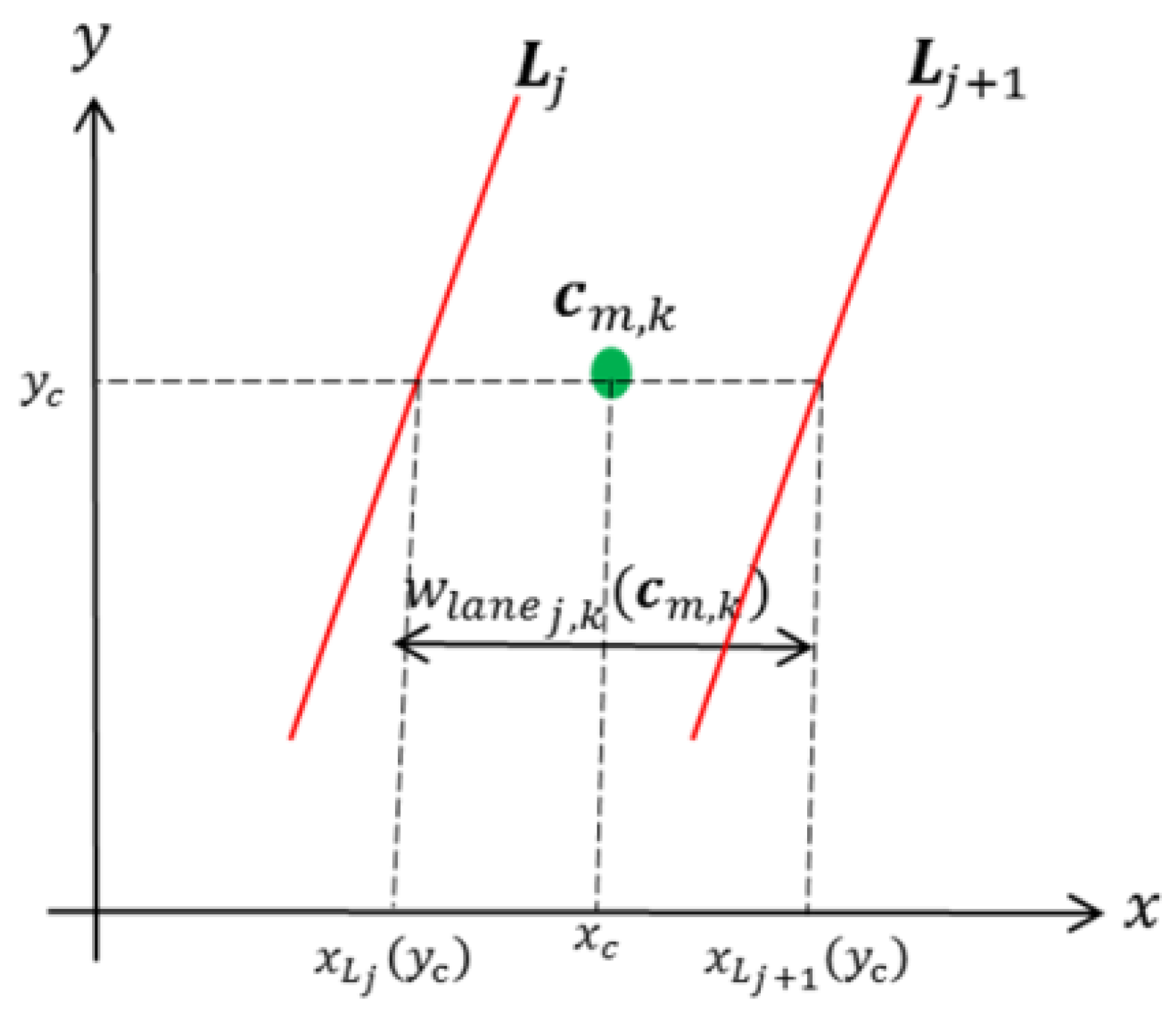
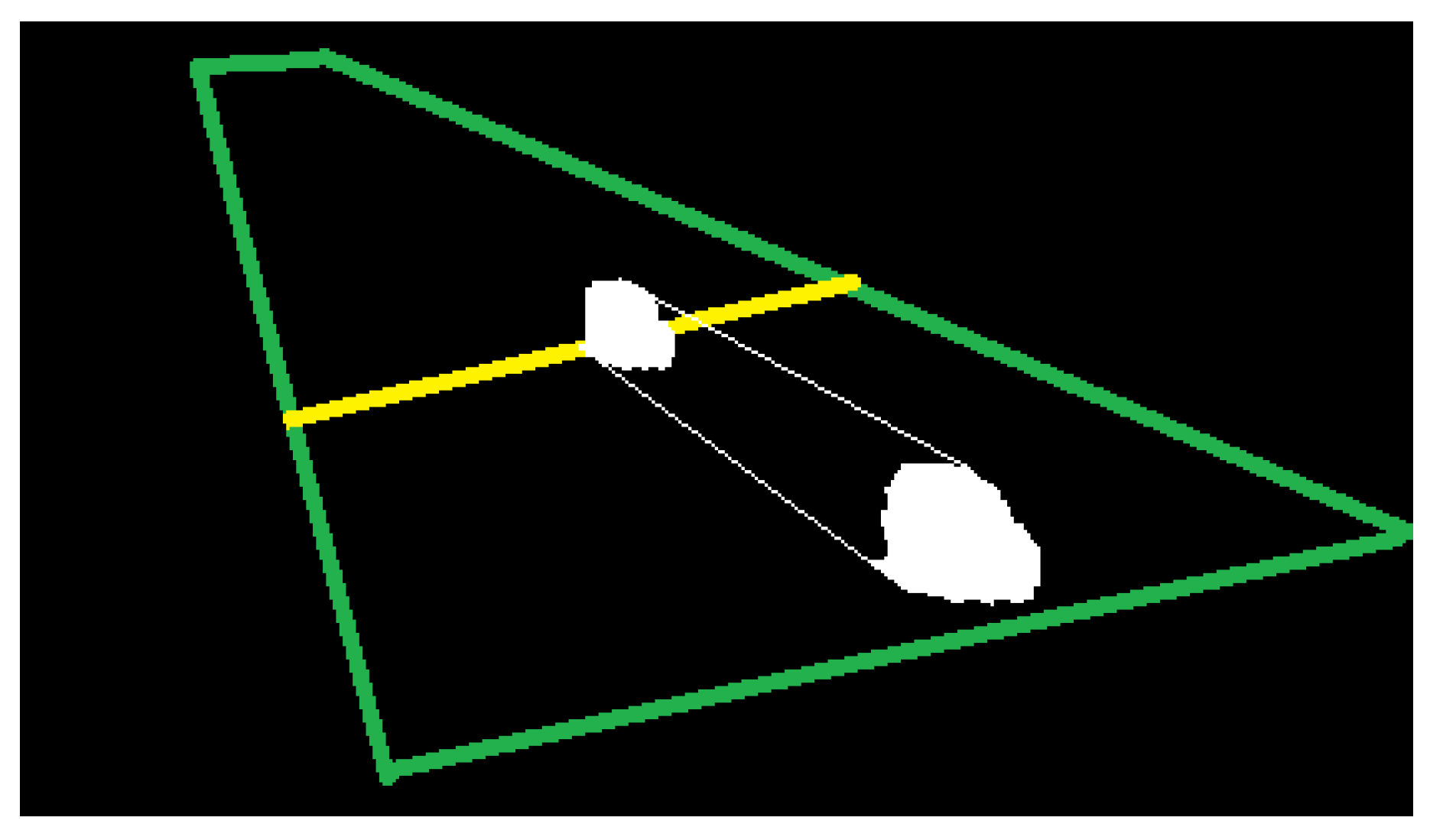
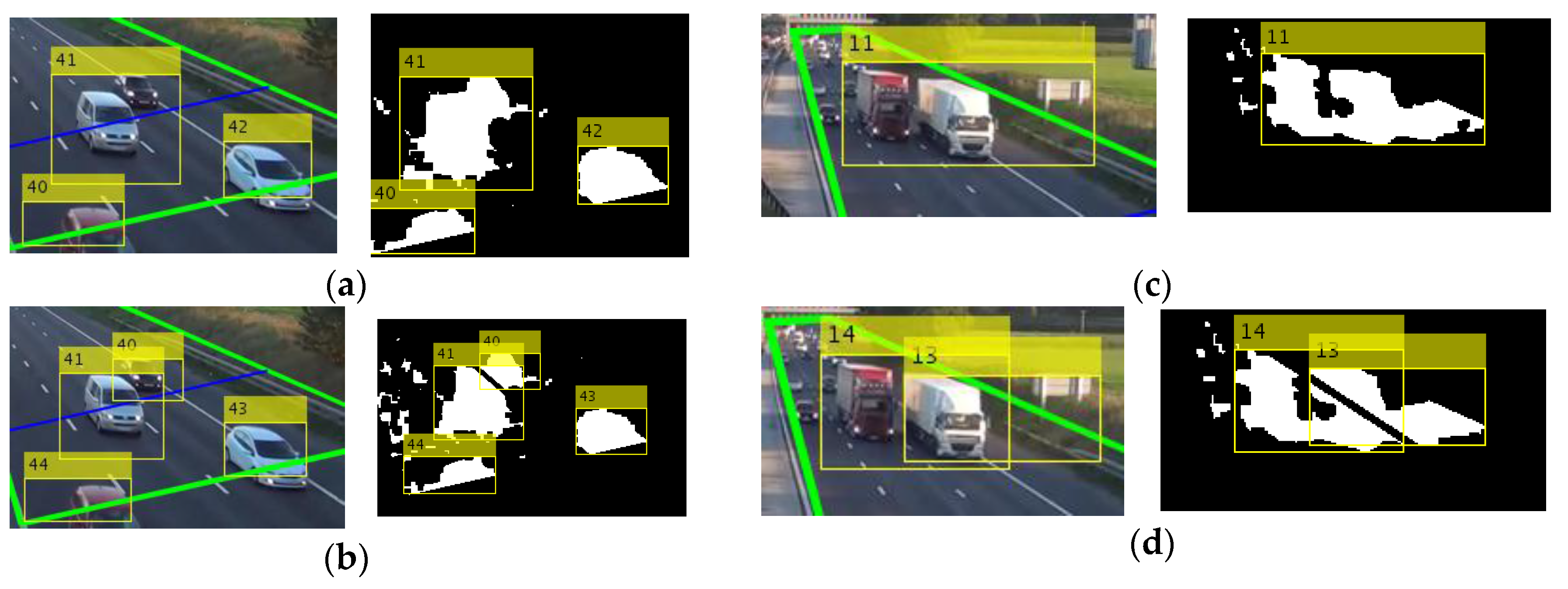
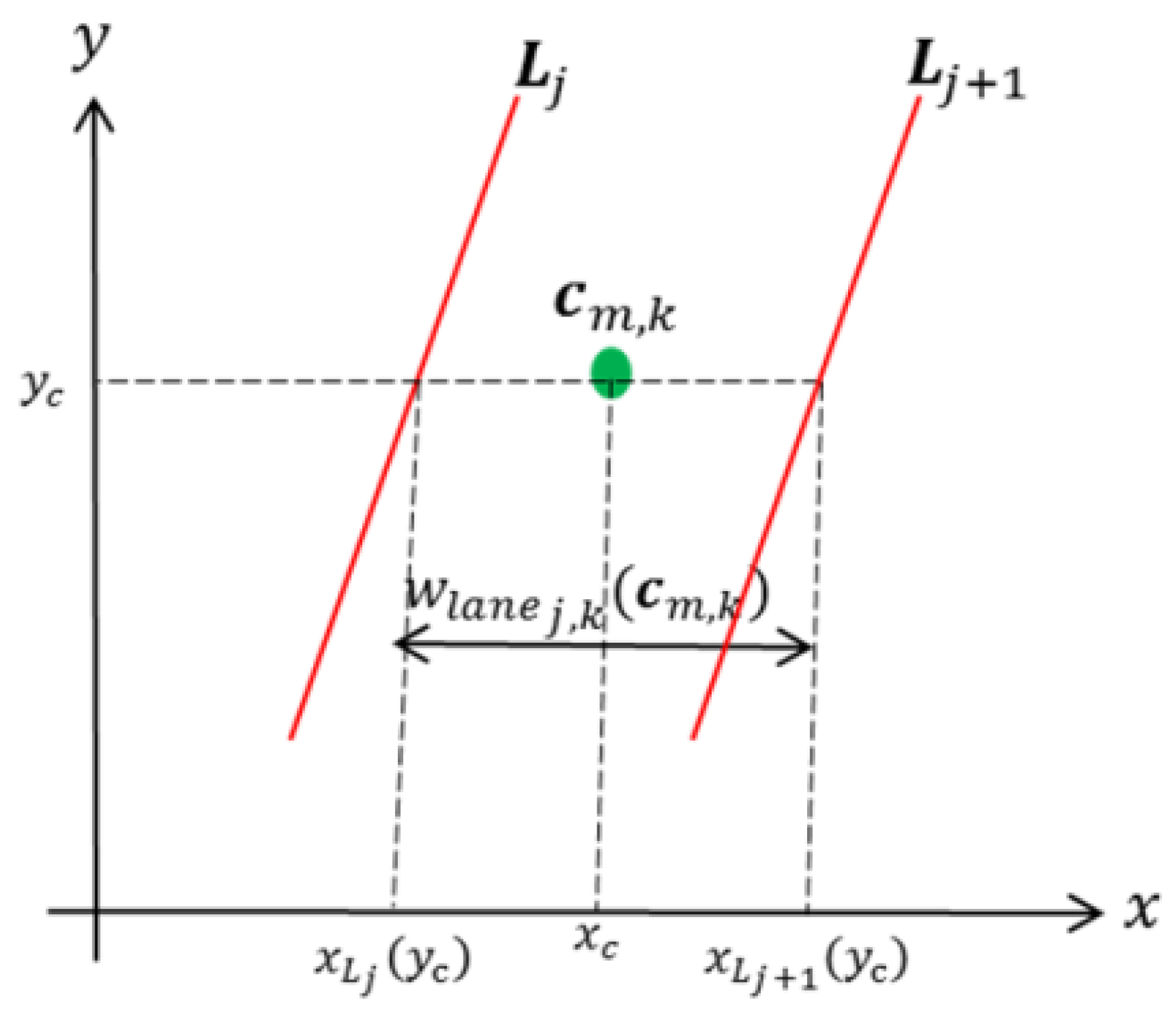
- The width of a vehicle cannot be greater than the width of one lane, except when it is a large vehicle that is completely inside the ROI (due to perspective effects), i.e.,:
- The width of a vehicle that is before the detection line cannot be greater than the width of two lanes, even if it is a large vehicle, i.e.,:where is the vehicle width (bounding box width), is the lane width, is the normalized area, is the detection line, and and are the thresholds with values 1.22, 2.27, and 0.12, respectively. The values of thresholds were selected using a training video with occluded vehicles; the values that increase the detection rate were selected. If at least one case is fulfilled (Figure 4a,c), then we use the lane-dividing lines to separate vehicles traveling side by side, which are detected as a single object.
3.4.1. Algorithm for Occlusion Handling Based on Lane Division
3.4.2. Vehicle Occlusion Index
3.5. Vehicle Tracking
- (1)
- Process equationwhere is the state vector, is the transition matrix, and is the process noise; the subscript denotes discrete time instant. The process noise is assumed to be additive, white, and Gaussian, with zero mean and the covariance matrix defined by:where the superscript denotes matrix transposition.
- (2)
- Measurement equationwhere is the measurement vector, is the measurement matrix, and is the measurement noise, which is assumed to be additive, white, and Gaussian, with zero mean and the covariance matrix defined by:
3.6. Feature Selection and Environment for Classification
- Instead of 1D geometric feature space, the use of a 3-D geometric feature space, . Then, for the detected vehicles or are used the input points .
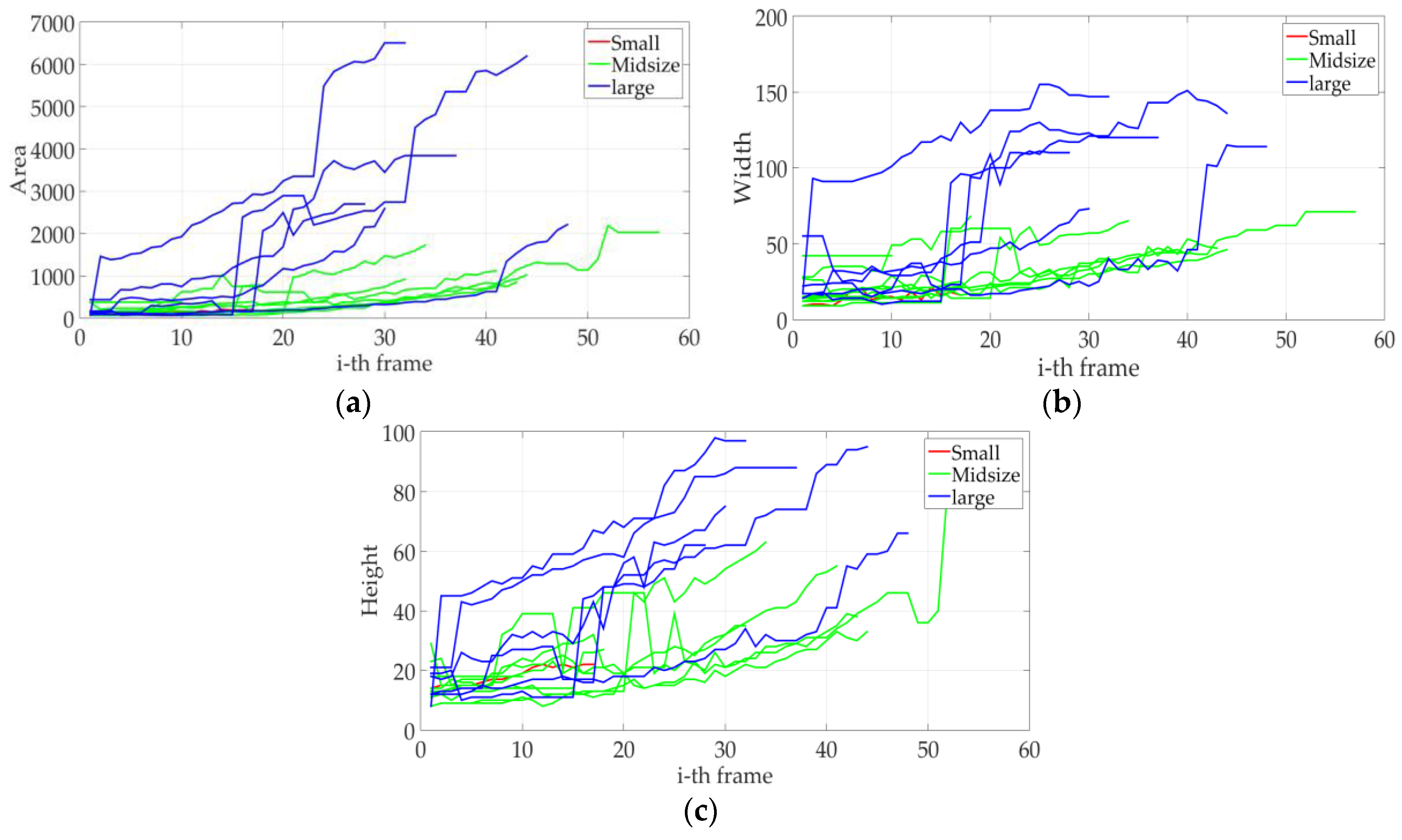
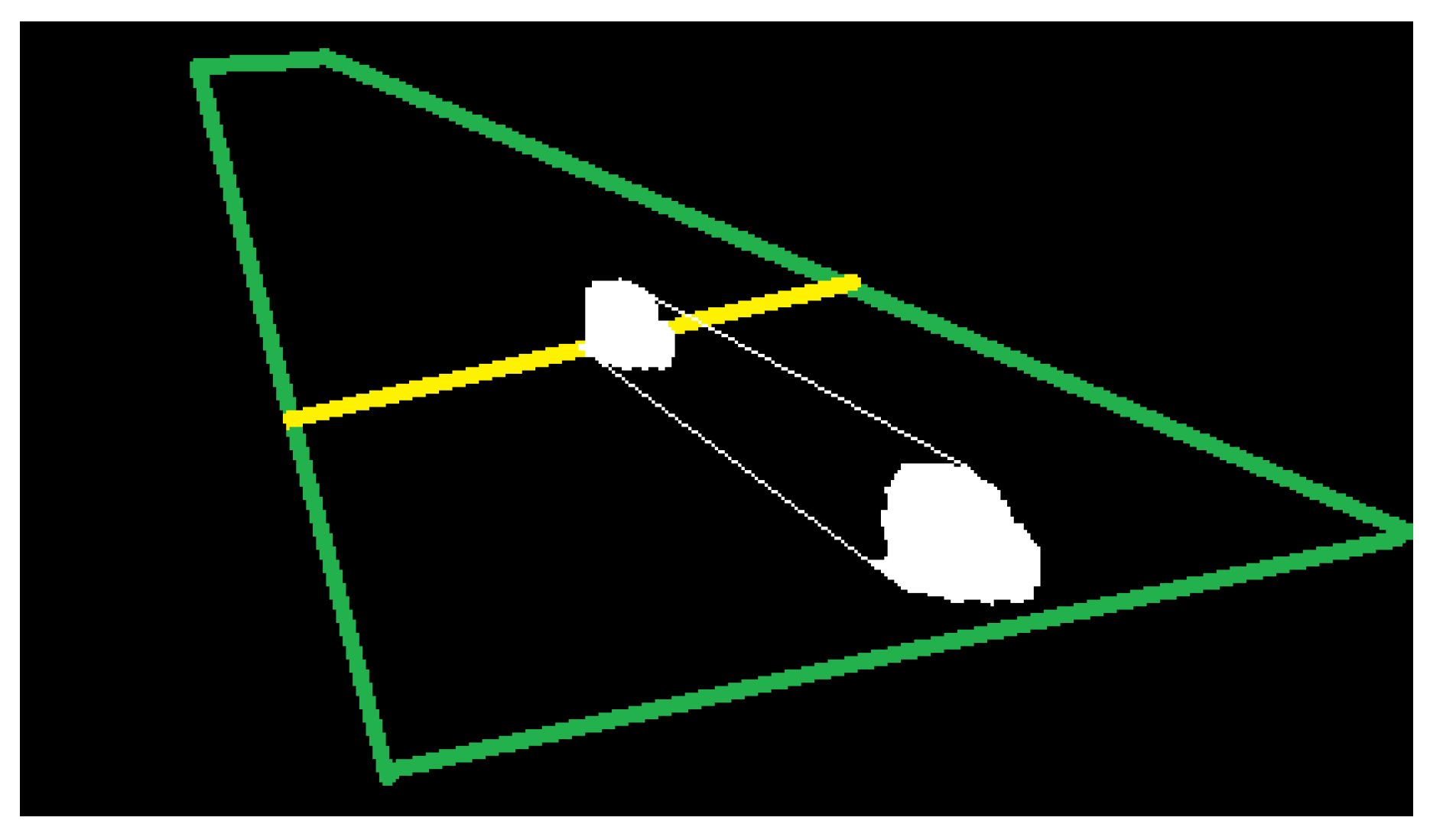
- Classification is performed in a specific line of the ROI, called here classification line, to reduce intra-class differences of the space of tracking sequences Ts(x) (see Figure 7).
- Reduction in the variation of the feature values of any input point by using the average of feature values of the last three instances—detected at k-th frame after the classification line—and projecting them to the classification line, i.e., Proj(x).
3.7. Vehicle Classification
- 1D feature input space and thresholds.
- 3D feature input space and K-means.
- 3D feature input space and SVM.
- 3D feature input space and OC-SVM.
4. Experimental Results
4.1. Video Processing: Test Environment
- GT in the video is the ground truth or input space,
- TP is the number of vehicles successfully detected,
- FP is the number of false vehicles detected as vehicles,
- FN is the number of vehicles not detected,
- GT’ is the output space or the set of all points detected as moving vehicle, then GT’ is greater than GT.
- is now the new input space for classification,
- is the number of vehicles classified into the correct class ,
- is the number of vehicles classified into class that belong to another class
- is the number of vehicles of class i classified into another class
4.2. Vehicle Detection Results
4.3. Vehicle Classification Results
5. Discussion
5.1. Test Environment
5.2. Occlusion Handling Algorithm and VOI-Index
5.3. Clustering Analysis
5.4. SVM and OC-SVM
5.5. 3-D Geometric Feature Space
5.6. Real Time Processing
- For the GMM based detection stage, the system does not require sample training and camera calibration.
- Except for ROI, lane-dividing lines, the detection line, and the classification line, it requires no other initialization.
- A proposed simple algorithm reduces occlusions, particularly in those cases where vehicles move side by side.
- The use of OC-SVM and a 3D geometric feature space for the classification stage.
6. Conclusions
- Develop algorithms for the formation of background with different color spaces and updating is crucial for the different stages of traffic surveillance.
- Develop algorithms for automatic detection of the ROI and the lane-dividing lines.
- Improve algorithms for occlusion caused by high traffic loads, particularly for large vehicles, to increase the detection rate and, consequently, decrease variance of the values of points belonging to the input space for tracking and classification, and to characterize the occlusion by metrics.
- Due to the number of features associated with this problem and the variance of intra-class and interclass feature values, the determination of the optimal number of classes for classification remains an open issue.
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test | Video | GT | TP | FP | FN | Detection Rate | Precision | F-Measure |
|---|---|---|---|---|---|---|---|---|
| Without occlusion handling | V6 | 797 | 653 | 6 | 144 | 81.932 | 99.089 | 89.697 |
| V7 | 725 | 624 | 12 | 101 | 86.069 | 98.113 | 91.697 | |
| V8 | 903 | 755 | 16 | 148 | 83.610 | 97.924 | 90.203 | |
| Total | 2425 | 2032 | 34 | 393 | 83.793 | 98.354 | 90.492 | |
| With occlusion handling | V6 | 797 | 761 | 53 | 36 | 95.483 | 93.488 | 94.475 |
| V7 | 725 | 686 | 43 | 39 | 94.620 | 94.101 | 94.360 | |
| V8 | 903 | 862 | 82 | 41 | 95.459 | 91.313 | 93.340 | |
| Total | 2425 | 2309 | 178 | 116 | 95.216 | 92.842 | 94.014 |
| Threshold | K-Means | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| S | M | L | T | S | M | L | T | ||
| S | 9 | 1 | 0 | 10 | S | 10 | 0 | 0 | 10 |
| M | 434 | 1875 | 27 | 2336 | M | 246 | 2079 | 11 | 2336 |
| L | 40 | 62 | 39 | 141 | L | 1 | 23 | 117 | 141 |
| T | 2487 | T | 2487 | ||||||
| (a) | (b) | ||||||||
| SVM | OC-SVM | ||||||||
| S | M | L | T | S | M | L | T | ||
| S | 16 | 0 | 0 | 16 | S | 7 | 3 | 0 | 10 |
| M | 99 | 2214 | 20 | 2333 | M | 13 | 2298 | 25 | 2336 |
| L | 1 | 4 | 133 | 138 | L | 1 | 3 | 137 | 141 |
| T | 2487 | T | 2487 | ||||||
| (c) | (d) | ||||||||
References
- Sivaraman, S.; Trivedi, M.M. Looking at vehicles on the road: A survey of vision-based vehicle detection, tracking, and behavior analysis. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1773–1795. [Google Scholar] [CrossRef]
- Liu, X.; Dai, B.; He, H. Real-time on-road vehicle detection combining specific shadow segmentation and SVM classification. In Proceedings of the 2011 Second International Conference on Digital Manufacturing and Automation (ICDMA), Zhangjiajie, China, 5–7 August 2011; pp. 885–888. [Google Scholar] [CrossRef]
- Fang, S.; Liao, H.; Fei, Y.; Chen, K.; Huang, J.; Lu, Y.; Tsao, Y. Transportation modes classification using sensors on smartphones. Sensors 2016, 16, 1324. [Google Scholar] [CrossRef] [PubMed]
- Oh, S.; Kang, H. Object detection and classification by decision-level fusion for intelligent vehicle systems. Sensors 2017, 17, 207. [Google Scholar] [CrossRef] [PubMed]
- Llorca, D.; Sánchez, S.; Ocaña, M.; Sotelo, M. Vision-based traffic data collection sensor for automotive applications. Sensors 2010, 10, 860–875. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Yu, G.; Wang, Y.; Wu, X.; Ma, Y. A hybrid vehicle detection method based on viola-jones and HOG + SVM from UAV images. Sensors 2016, 16, 1325. [Google Scholar] [CrossRef] [PubMed]
- Cao, X.; Wu, C.; Yan, P.; Li, X. Linear SVM classification using boosting HOG features for vehicle detection in low-altitude airborne videos. In Proceedings of the 2011 18th IEEE International Conference on Image Processing (ICIP), Brussels, Belgium, 11–14 September 2011; pp. 2421–2424. [Google Scholar] [CrossRef]
- Lamas-Seco, J.; Castro, P.; Dapena, A.; Vazquez-Araujo, F. Vehicle classification using the discrete fourier transform with traffic inductive sensors. Sensors 2015, 15, 27201–27214. [Google Scholar] [CrossRef] [PubMed]
- Zhou, F.; Wang, M. A new SVM algorithm and AMR sensor based vehicle classification. In Proceedings of the Second International Conference On Intelligent Computation Technology and Automation, Changsha, China, 10–11 October 2009; pp. 421–425. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, Y. The research of vehicle classification using SVM and KNN in a ramp. In Proceedings of the International Forum on Computer Science-Technology and Applications, Chongqing, China, 25–27 December 2009; pp. 391–394. [Google Scholar] [CrossRef]
- Lipton, A.J.; Fujiyoshi, H.; Patil, R.S. Moving target classification and tracking from real-time video. In Proceedings of the Fourth IEEE Workshop on Applications of Computer Vision, Princeton, NJ, USA, 19–21 October 1998; pp. 8–14. [Google Scholar] [CrossRef]
- Cucchiara, R.; Piccardi, M.; Mello, P. Image analysis and rule-based reasoning for a traffic monitoring system. Intell. Transp. Syst. 2000, 1, 119–130. [Google Scholar] [CrossRef]
- Zhang, G.; Avery, R.; Wang, Y. Video-based vehicle detection and classification system for real-time traffic data collection using uncalibrated video cameras. Transp. Res. Board 2007, 1993, 138–147. [Google Scholar] [CrossRef]
- Gupte, S.; Masoud, O.; Martin, R.F.; Papanikolopoulos, N.P. Detection and classification of vehicles. Intell. Transp. Syst. IEEE Trans. 2002, 3, 37–47. [Google Scholar] [CrossRef]
- Nagai, A.; Kuno, Y.; Shirai, Y. Surveillance system based on spatio-temporal information. In Proceedings of the IEEE International Conference on Image Processing, Lausanne, Switzerland, 19 September 1996; pp. 593–596. [Google Scholar] [CrossRef]
- Xu, T.; Liu, H.; Qian, Y.; Zhang, H. A novel method for people and vehicle classification based on Hough line feature. In Proceedings of the International Conference on Information Science and Technology (ICIST), Nanjing, China, 26–28 March 2011; pp. 240–245. [Google Scholar] [CrossRef]
- Kafai, M.; Bhanu, B. Dynamic bayesian networks for vehicle classification in video. IEEE Trans. Ind. Inform. 2012, 8, 100–109. [Google Scholar] [CrossRef]
- Hu, W.; Tan, T.; Wang, L.; Maybank, S. A survey on visual surveillance of object motion and behaviors. IEEE Trans. Syst. Man Cybern. Part C 2004, 34, 334–352. [Google Scholar] [CrossRef]
- Bottino, A.; Garbo, A.; Loiacono, C.; Quer, S. Street viewer: An autonomous vision based traffic tracking system. Sensors 2016, 16, 813. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, J.-W.; Yu, S.-H.; Chen, Y.-S.; Hu, W.-F. Automatic traffic surveillance system for vehicle tracking and classification. IEEE Trans. Intell. Transp. Syst. 2006, 7, 175–187. [Google Scholar] [CrossRef]
- Pham, H.V.; Lee, B.-R. Front-view car detection and counting with occlusion in dense traffic flow. Int. J. Control Autom. Syst. 2015, 13, 1150–1160. [Google Scholar] [CrossRef]
- Li, X.; Wang, K.; Wang, W.; Li, Y. A multiple object tracking method using Kalman filter. In Proceedings of the 2010 IEEE International Conference on Information and Automation, Harbin, China, 20–23 June 2010; pp. 1862–1866. [Google Scholar] [CrossRef]
- Weng, S.-K.; Kuo, C.-M.; Tu, S.-K. Video object tracking using adaptive Kalman filter. J. Vis. Commun. Image Represent. 2006, 17, 1190–1208. [Google Scholar] [CrossRef]
- Li, N.; Liu, L.; Xu, D. Corner feature based object tracking using adaptive Kalman filter. In Proceedings of the 9th International Conference on Signal Processing ICSP, Beijing, China, 26–29 October 2008; pp. 1432–1435. [Google Scholar] [CrossRef]
- De Oliveira, A.B.; Scharcanski, J. Vehicle counting and trajectory detection based on particle filtering. In Proceedings of the 23rd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Gramado, Brazil, 30 August–3 September 2010; pp. 376–383. [Google Scholar]
- Ranga, H.T.P.; Kiran, M.R.; Shekar, S.R.; Kumar, S.K.N. Vehicle detection and classification based on morphological technique. In Proceedings of the International Conference on Signal and Image Processing (ICSIP), Chennai, India, 15–17 December 2010; pp. 45–48. [Google Scholar] [CrossRef]
- Gupte, S.; Masoud, O.; Papanikolopoulos, P. Vision-based vehicle classification. In Proceedings of the IEEE Intelligent Transportation Systems, Dearborn, MI, USA, 1–3 October 2000; pp. 46–51. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, K. Vehicle classification system based on dynamic Bayesian network. In Proceedings of the IEEE International Conference on Service Operations and Logistics, and Informatics (SOLI), Qingdao, China, 8–10 October 2014; pp. 22–26. [Google Scholar] [CrossRef]
- Xiong, N.; He, J.; Park, J.H.; Cooley, D.H.; Li, Y. A Neural network based vehicle classification system for pervasive smart road security. J. UCS 2009, 15, 1119–1142. [Google Scholar]
- Goyal, A.; Verma, B. A neural network based approach for the vehicle classification. In Proceedings of the IEEE Symposium on Computational Intelligence in Image and Signal Processing, Honolulu, HI, USA, 1–5 April 2007; pp. 226–231. [Google Scholar] [CrossRef]
- Ozkurt, C.; Camci, F. Automatic traffic density estimation and vehicle classification for traffic surveillance systems using neural networks. Math. Comput. Appl. 2009, 14, 187–196. [Google Scholar] [CrossRef]
- Lee, S.H.; Bang, M.; Jung, K.H.; Yi, K. An efficient selection of HOG features for SVM classification of vehicle. In Proceedings of the 2015 IEEE International Symposium on Consumer Electronics (ISCE), Madrid, Spain, 24–26 June 2015; pp. 1–2. [Google Scholar] [CrossRef]
- Arróspide, J.; Salgado, L.; Nieto, M. Video analysis-based vehicle detection and tracking using an MCMC sampling framework. EURASIP J. Adv. Signal Process. 2012, 2012, 2. [Google Scholar] [CrossRef] [Green Version]
- Huang, S.C. An advanced motion detection algorithm with video quality analysis for video surveillance systems. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 1–14. [Google Scholar] [CrossRef]
- Hu, Z.; Wang, C.; Uchimura, K. 3D vehicle extraction and tracking from multiple viewpoints for traffic monitoring by using probability fusion map. In Proceedings of the 2007 IEEE Intelligent Transportation Systems Conference, Seattle, WA, USA, 30 September–3 October 2007; pp. 30–35. [Google Scholar] [CrossRef]
- Zhang, W.; Wu, Q.M.J.; Yang, X.; Fang, X. Multilevel framework to detect and handle vehicle occlusion. IEEE Trans. Intell. Transp. Syst. 2008, 9. [Google Scholar] [CrossRef]
- Fang, W.; Zhao, Y.; Yuan, Y.; Liu, K. Real-time multiple vehicles tracking with occlusion handling. In Proceedings of the 2011 Sixth International Conference on Image and Graphics (ICIG), Hefei, Anhui, 12–15 August 2011; pp. 667–672. [Google Scholar]
- Saunier, N.; Sayed, T. A feature-based tracking algorithm for vehicles in intersections. In Proceedings of the 3rd Canadian Conference on Computer and Robot Vision, Quebec City, QC, Canada, 7–9 June 2006. [Google Scholar]
- Shirazi, M.S.; Morris, B. Vision-Based Vehicle Counting with High Accuracy for Highways with Perspective View; Springer: Cham, Switzerland, 2015; pp. 809–818. [Google Scholar]
- Stauffer, C.; Grimson, W.E.L. Adaptive background mixture models for real-time tracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Fort Collins, CO, USA, 23–25 June 1999; Volume 2. [Google Scholar] [CrossRef]
- Mandellos, N.A.; Keramitsoglou, I.; Kiranoudis, C.T. A background subtraction algorithm for detecting and tracking vehicles. Expert Syst. Appl. 2011, 38, 1619–1631. [Google Scholar] [CrossRef]
- Cheng, F.C.; Chen, B.H.; Huang, S.C. A hybrid background subtraction method with background and foreground candidates detection. ACM Trans. Intell. Syst. Technol. 2015, 7, 7. [Google Scholar] [CrossRef]
- Huang, Z.; Qin, H.; Liu, Q. Vehicle ROI extraction based on area estimation gaussian mixture model. In Proceedings of the 2017 3rd IEEE International Conference on Cybernetics (CYBCONF), Exeter, UK, 21–23 June 2017; pp. 1–7. [Google Scholar]
- Kamkar, S.; Safabakhsh, R. Vehicle detection, counting and classification in various conditions. IET Intell. Transp. Syst. 2016, 10, 406–413. [Google Scholar] [CrossRef]
- Liang, M.; Huang, X.; Chen, C.H.; Chen, X.; Tokuta, A. Counting and classification of highway vehicles by regression analysis. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2878–2888. [Google Scholar] [CrossRef]
- Moussa, G.S. Vehicle type classification with geometric and appearance attributes. Int. J. Civ. Arch. Sci. Eng. 2014, 8, 273–278. [Google Scholar]
- Sun, Z.; Bebis, G.; Miller, R. Monocular Precrash vehicle detection: Features and classifiers. IEEE Trans. Image Process. 2006, 15, 2019–2034. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Pears, N.; Freeman, M.; Austin, J. A Gaussian mixture model and support vector machine approach to vehicle type and Colour classification. IET Intell. Transp. Syst. 2014, 8, 135–144. [Google Scholar] [CrossRef]
- TelecomCinvesGdl—Youtube. Available online: https://www.youtube.com/channel/UCGcLe9kzQvJGkeR_AO1cBwg (accessed on 3 June 2017).
- Power, P.W.; Schoonees, J.A. Understanding background mixture models for foreground segmentation. In Proceedings of the Proceedings Image and Vision Computing, Auckland, New Zealand, 26–28 November 2002; pp. 10–11. [Google Scholar]
- Grewal, M.S.; Andrews, A.P. Kalman Filtering: Theory and Practice with MATLAB; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.C.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Schölkopf, B.; Burges, C.J.C.; Smola, A.J. Advances in Kernel Methods: Support Vector Learning; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Guerrero-Gomez-Olmedo, R.; Lopez-Sastre, R.J.; Maldonado-Bascon, S.; Fernandez-Caballero, A. Vehicle Tracking by Simultaneous Detection and Viewpoint Estimation; IWINAC 2013, Part II, LNCS 7931; Springer: Berlin, Germany, 2013; pp. 306–316. [Google Scholar]
- GRAM Road-Traffic Monitoring. Available online: http://agamenon.tsc.uah.es/Personales/rlopez/data/rtm/ (accessed on 3 June 2017).
- M6 Motorway Traffic—Youtube. Available online: https://www.youtube.com/watch?v=PNCJQkvALVc (accessed on 3 June 2017).
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2. [Google Scholar] [CrossRef]





| Reference | GT | Frames | Scenarios | Traffic Load | DR or Recall | Precision | F-Measure |
|---|---|---|---|---|---|---|---|
| Saunier, N.; Sayed, T. [38] (2006) | 302 | 8360 | 3 | - | 88.4 | - | - |
| Hsieh, J.-W.; Yu, S.-H.; Chen, Y.-S.; Hu, W.-F. [20] (2006) | 20,443 | 16,400 | 3 | - | 82.16 | - | - |
| Hu, Z.; Wang, C.; Uchimura, K. [35] (2007) | 1074 | Not indicated | - | - | 99.3 | - | - |
| Zhang, W.; Wu, Q. M. J.; Yang, X.; Fang, X. [36] (2008) | 427 | Not indicated | - | - | 93.87–84.43, 100–83.8 | - | - |
| Fang, W.; Zhao, Y.; Yuan, Y.; Liu, K [37] (2011) | 226 | 3500 | 2 | - | 86.8, 100 | - | - |
| Arróspide, J.; Salgado, L.; Nieto, M. [35] (2012) | 4000 | NA | - | - | 96.14, 89.92, 94.14 | - | - |
| Pham, H.V.; Lee, B.-R. [21] (2015) | 672 | 18,000 | 1 | - | 97.17 | - | - |
| Shirazi, M.S.; Morris, B. [39] (2015) | Not indicated | 1080 at 8 fps | 3 | - | 94 | - | - |
| Our System (2017) | 4111 | 92,160 at 25 fps | 5 | 1.34 | 82.42–99.24 | 68.7–99.5 | 74.6–98.3 |
| Reference | Sensors | Scenarios | Input Space | Result | Reported Metrics |
|---|---|---|---|---|---|
| Hsieh, J.-W.; Yu, S.-H.; Chen, Y.-S.; Hu, W.-F. [20] (2006) | Camera only | Static side-road camera | Size and the “linearity” of a vehicle | Global TPR of up to 94.8% for cars, minivans, trucks, and van-trucks | TPR |
| Feng, Z.; Mingzhe, W. [9] (2009) | Anisotropic magnetoresistive (AMR) sensor | Vehicle passes through the sensor | Features of wave length, mean, variance, peak, valley, and acreage | 86%, 80%, 81%, and 89% TPR for big truck, bus, van, and car | TPR |
| Changjun, Z.; Yuzong, C. [10] (2009) | Acoustic signals | Vehicles on the road ramp | Set of frequency feature vectors | 95.12% accuracy for car, bus, truck, and container truck | Accuracy |
| Chen, Z.; Pears, N.; Freeman, M.; Austin, J. [48] (2014) | Stationary roadside (CCTV) camera | Static side-road camera | Size and width of the blob | 88.35%, 69.07%, and 73.47% TPR for car, van, and heavy goods vehicles | TPR, TNR, FPR |
| Moussa, G.S. [46] (2014) | Laser sensor | Top-down laser over road (different scenarios from those presented here.) | Geometric-based features | 99.5%, 93.0%, and 97.5% TPR for small, midsize, and large | TPR |
| Liang, M.; Huang, X.; Chen, C.H.; Chen, X.; Tokuta, A. [45] (2015) | Camera only | Static side-road camera | Low level features | 79.9%, 63.4%, and 92.7%, TPR for small, midsize, and large | TPR |
| Lamas-Seco, J.; Castro, P.; Dapena, A.; Vazquez-Araujo, F. [8] (2015) | Inductive Loop detectors | Vehicle passes through the sensor | Fourier Transform of inductive signatures | Global TPR of up to 95.82% for small, midsize, and large | TPR |
| Kamkar, S.; Safabakhsh, R. [44] (2016) | Camera only | Static side-road camera | Vehicle length and Grey-Level Co-occurrence matrix features | 71.9% Global TPR for small, midsize, and large | TPR |
| Our System (2017) | Camera only | Static side-road camera | 3-D geometric-based features | Global TPR of up to 98.190% for small, midsize, and large | Recall or TPR, F-measure, Precision, and VOI-Index |
| Video | Frames | Vehicles per Second | Occlusion Index | Recording Place | Vehicle Direction | Weather |
|---|---|---|---|---|---|---|
| V1 | 16,925 | 1.24 | 0.312 | Ringroad, Guadalajara, Mexico | Front | Sunny |
| V2 | 5400 | 1.05 | 0.189 | Ringroad, Guadalajara, Mexico | Front | Sunny |
| V3 | 3875 | 0.75 | 0.124 | Ringroad, Guadalajara, Mexico | Front | 0 to 20 s Sunny, 21 to 140 s Cloudy |
| V4 | 7520 | 0.88 | 0.000 | M-30, Madrid, Spain | Rear | Sunny |
| V5 | 9390 | 0.63 | 0.000 | M-30, Madrid, Spain | Rear | Cloudy |
| V6 | 15,050 | 1.32 | 0.249 | M6 motorway, England | Front | Cloudy |
| V7 | 14,875 | 1.21 | 0.203 | M6 motorway, England | Front | Cloudy |
| V8 | 19,125 | 1.18 | 0.202 | M6 motorway, England | Front | Cloudy |
| Video | GT | TP | FP | FN | Detection Rate | Precision | F-Measure |
|---|---|---|---|---|---|---|---|
| V1 | 842 | 694 | 324 | 148 | 82.422 | 68.172 | 74.623 |
| V2 | 228 | 202 | 104 | 26 | 88.596 | 66.013 | 75.655 |
| V3 | 116 | 103 | 30 | 13 | 88.793 | 77.44 | 82.730 |
| V4 | 264 | 262 | 7 | 2 | 99.242 | 97.397 | 98.311 |
| V5 | 236 | 228 | 1 | 8 | 96.610 | 99.563 | 98.064 |
| V6 | 797 | 761 | 53 | 36 | 95.483 | 93.488 | 94.475 |
| V7 | 725 | 686 | 43 | 39 | 94.620 | 94.101 | 94.360 |
| V8 | 903 | 862 | 82 | 41 | 95.459 | 91.313 | 93.340 |
| Video | Class | Input Space | TP | FP | FN | Recall | Precision | F-Measure |
|---|---|---|---|---|---|---|---|---|
| V1 | S | 179 | 179 | 132 | 0 | 100.000 | 57.556 | 73.061 |
| M | 789 | 669 | 20 | 120 | 84.790 | 97.097 | 90.527 | |
| L | 50 | 16 | 2 | 34 | 32.000 | 88.888 | 47.058 | |
| T | 1018 | 864 | 154 | 154 | 84.872 | 84.872 | 84.872 | |
| V2 | S | 35 | 34 | 26 | 1 | 97.142 | 56.666 | 71.578 |
| M | 210 | 177 | 5 | 33 | 84.285 | 97.252 | 90.306 | |
| L | 61 | 55 | 9 | 6 | 90.163 | 85.937 | 88.000 | |
| T | 306 | 266 | 40 | 40 | 86.928 | 86.928 | 86.928 | |
| V3 | S | 11 | 10 | 1 | 1 | 90.909 | 90.909 | 90.909- |
| M | 97 | 95 | 8 | 2 | 97.938 | 92.233 | 95.000 | |
| L | 25 | 18 | 1 | 7 | 72.000 | 94.736 | 81.818 | |
| T | 133 | 123 | 10 | 10 | 92.481 | 92.481 | 92.481 | |
| V4 | S | 16 | 15 | 12 | 1 | 93.750 | 55.555 | 69.767 |
| M | 233 | 222 | 4 | 11 | 95.279 | 98.230 | 96.732 | |
| L | 20 | 14 | 2 | 6 | 70.000 | 87.500 | 77.777 | |
| T | 269 | 251 | 18 | 18 | 93.308 | 93.308 | 93.308 | |
| V5 | S | 3 | 3 | 6 | 0 | 100.00 | 33.333 | 50.000 |
| M | 220 | 211 | 0 | 9 | 95.909 | 100.000 | 97.911 | |
| L | 6 | 4 | 5 | 2 | 66.666 | 44.444 | 53.333 | |
| T | 229 | 218 | 11 | 11 | 95.196 | 95.196 | 95.196 | |
| V6 | S | 3 | 2 | 2 | 1 | 66.667 | 50.000 | 57.142 |
| M | 766 | 755 | 1 | 11 | 98.564 | 99.867 | 99.211 | |
| L | 45 | 45 | 9 | 0 | 100.000 | 83.333 | 90.909 | |
| T | 814 | 802 | 12 | 12 | 98.525 | 98.525 | 98.525 | |
| V7 | S | 2 | 1 | 3 | 1 | 50.000 | 25.000 | 33.333 |
| M | 688 | 676 | 2 | 12 | 98.255 | 99.705 | 98.975 | |
| L | 39 | 37 | 10 | 2 | 94.871 | 78.723 | 86.046 | |
| T | 729 | 714 | 15 | 15 | 97.942 | 97.942 | 97.942 | |
| V8 | S | 5 | 4 | 9 | 1 | 80.000 | 30.769 | 44.444 |
| M | 882 | 867 | 3 | 15 | 98.299 | 99.655 | 98.972 | |
| L | 57 | 55 | 6 | 2 | 96.491 | 90.163 | 93.220 | |
| T | 944 | 926 | 18 | 18 | 98.093 | 98.093 | 98.093 |
| Classification with the Thresholds and 1D Feature Input Space | ||||||||
| Test | Class | Input Space | TP | FP | FN | Recall | Precision | F-Measure |
| With occlusion handling | S | 10 | 9 | 474 | 1 | 90.000 | 1.863 | 3.651 |
| M | 2336 | 1875 | 63 | 461 | 80.265 | 96.749 | 87.739 | |
| L | 141 | 39 | 27 | 102 | 27.659 | 59.090 | 37.681 | |
| Total | 2487 | 1923 | 564 | 564 | 77.322 | 77.322 | 77.322 | |
| Classification with K-Means and 3D Feature Input Space | ||||||||
| Test | Class | Input Space | TP | FP | FN | Recall | Precision | F-Measure |
| With occlusion handling | S | 10 | 10 | 247 | 0 | 100.00 | 3.891 | 7.490 |
| M | 2336 | 2079 | 23 | 257 | 88.998 | 98.905 | 93.690 | |
| L | 141 | 117 | 11 | 24 | 82.978 | 91.406 | 86.988 | |
| Total | 2487 | 2206 | 281 | 281 | 88.701 | 88.701 | 88.701 | |
| Classification with SVM and 3D Feature Input Space | ||||||||
| Test | Class | Input Space | TP | FP | FN | Recall | Precision | F-Measure |
| With occlusion handling | S | 16 | 16 | 100 | 0 | 100.000 | 13.793 | 24.242 |
| M | 2333 | 2214 | 4 | 119 | 94.899 | 99.819 | 97.736 | |
| L | 138 | 133 | 20 | 5 | 96.376 | 86.928 | 91.408 | |
| Total | 2487 | 2363 | 124 | 124 | 95.014 | 95.014 | 95.014 | |
| Classification with OC-SVM and 3D Feature Input Space | ||||||||
| Test | Class | Input Space | TP | FP | FN | Recall | Precision | F-Measure |
| With occlusion handling | S | 10 | 7 | 14 | 3 | 70.000 | 33.333 | 45.161 |
| M | 2336 | 2298 | 6 | 38 | 98.373 | 99.739 | 99.051 | |
| L | 141 | 137 | 25 | 4 | 97.163 | 84.567 | 90.429 | |
| Total | 2487 | 2442 | 45 | 45 | 98.190 | 98.190 | 98.190 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Velazquez-Pupo, R.; Sierra-Romero, A.; Torres-Roman, D.; Shkvarko, Y.V.; Santiago-Paz, J.; Gómez-Gutiérrez, D.; Robles-Valdez, D.; Hermosillo-Reynoso, F.; Romero-Delgado, M. Vehicle Detection with Occlusion Handling, Tracking, and OC-SVM Classification: A High Performance Vision-Based System. Sensors 2018, 18, 374. https://doi.org/10.3390/s18020374
Velazquez-Pupo R, Sierra-Romero A, Torres-Roman D, Shkvarko YV, Santiago-Paz J, Gómez-Gutiérrez D, Robles-Valdez D, Hermosillo-Reynoso F, Romero-Delgado M. Vehicle Detection with Occlusion Handling, Tracking, and OC-SVM Classification: A High Performance Vision-Based System. Sensors. 2018; 18(2):374. https://doi.org/10.3390/s18020374
Chicago/Turabian StyleVelazquez-Pupo, Roxana, Alberto Sierra-Romero, Deni Torres-Roman, Yuriy V. Shkvarko, Jayro Santiago-Paz, David Gómez-Gutiérrez, Daniel Robles-Valdez, Fernando Hermosillo-Reynoso, and Misael Romero-Delgado. 2018. "Vehicle Detection with Occlusion Handling, Tracking, and OC-SVM Classification: A High Performance Vision-Based System" Sensors 18, no. 2: 374. https://doi.org/10.3390/s18020374