1. Introduction
As an important means of space-to-earth observation, spaceborne synthetic aperture radar (SAR) has the ability to collect data continuously under all weather conditions over large areas at high resolution, making it a unique instrument [
1]. SAR plays an important role in disaster emergency response, environmental monitoring, resource exploration, and geographic information access [
2,
3,
4]. Recent publications have reviewed the applications of satellite remote sensing techniques for hazards manifested by solid earth processes, including earthquakes, volcanoes, floods, landslides, and coastal inundation [
5,
6,
7].
In 1978, NASA’s SEASAT satellites demonstrated the ability of SAR to acquire high-resolution images. Since then, many countries have launched SAR satellites and conducted research on spaceborne SAR processing. For example, the Sentinel-1 mission, including both the S-1A (launched in 2014) and S-1B (launched in 2016) satellites, was specifically designed by the European Space Agency (ESA) to acquire data and information products for applications such as the observation of the marine environment, the surveillance of maritime transport zones, the mapping of land surfaces, and the offering of support during crisis situations [
8]. The TanDEM-X/TerraSAR-X (TDX/TSX) constellation is a high-resolution interferometric SAR mission of the German Aerospace Center (DLR) intended to fulfill the requirements of a global homogeneous and high-resolution coverage of all land areas, providing vital information for a variety of applications [
9]. ALOS-2 (launched in 2014) is the replacement of the Japan Aerospace Exploration Agency (JAXA) L-band SAR satellite mission to ALOS [
10]. The overall objective of ALOS-2 is to provide data continuity for cartography, regional observation, disaster monitoring, and environmental monitoring. The Korea Multi-Purpose Satellite-5 (KOMPSAT-5) was launched in 2013 by the Korea Aerospace Research Institute (KARI), and the RADARSAT Constellation Mission (RCM) is scheduled for launch in 2018 by the Canadian Space Agency (CSA). The SAR data are expected to be used mainly for maritime surveillance/national security, disaster management, and ecosystem monitoring [
11,
12].
Most of the abovementioned missions impose high demands on the real-time performance of SAR data processing. On-board processing is an efficient solution which allows higher-precision SAR data to be processed, leading to better image quality and enabling an optional image compression. This technique improves the downlink bandwidth utilization and provides rapid feedback to the radar controller. With these processed data products, decision makers can quickly plan and respond. As early as 2000, the MIT Lincoln Laboratory began a study of the implementation of real-time signal processors for SAR front-end signal processing [
13]. The processors were designed, based on their own VLSI bit-level systolic array technology, to have high computational throughput and low power implementations. S. Langemeyer et al. of the University of Hannover, Germany, proposed a multi-DSP system for real-time SAR processing using the highly parallel digital signal processor (HiPAR-DSP) technique in 2003 [
14]. The small volume and low power consumption of their processor make it suitable for on-board usage in compact air- or spaceborne systems. The Jet Propulsion Laboratory (JPL) has also worked to develop on-board processing. An experimental SAR processing system based on VLSI/SOC hardware was proposed [
15]. A fault-tolerant FPGA (Xilinx Virtex-II Pro)-based architecture was proposed and tested using the SIR-C data [
16,
17]. The University of Florida developed a high-performance space computing framework based on a hardware/software interface in 2006 [
18]. An FPGA serves as the co-processor/accelerator of the CPU. A near-real-time SAR processor (NRTP) was developed by the Indian Space Research Organization (IRSO) based on the Analog Devices TigerSHARC TS101S/TS201S DSP multiprocessor. On-board or on-ground quick-look real-time SAR signal processing was found to be achievable for ISRO’s RISAT-1 [
19]. With the rapid development of the storage capacity and computing capacity of the commercial-off-the-shelf (COTS) FPGA, the state-of-art Xilinx Virtex-6 FPGA was adopted for the entire real-time SAR imaging system in 2013 [
20]. In recent years, the graphics processing unit (GPU), with its large computing power, has also been used for real-time SAR processing [
21].
As indicated by the development of on-board SAR real-time processing, building a high-performance SAR real-time processing platform for space deployment is hampered by the hostile environmental conditions and power constraints in space. The FPGA, ASIC, DSP, CPU, and GPU are, to some extent, superior with respect to real-time processing. Although the GPU has a high processing power, its large power consumption makes it unsuitable for the harsh conditions of spaceborne on-board processing. The CPU and DSP take advantage of their design flexibility; however, they cannot provide enough FLOPS per watt, which leads to a bottleneck in their potential applications. Benefiting from its customized design, the ASIC can provide sufficient processing power and high computation ability; however, in implementing an ASIC for SAR imaging, the large-scale, complicated logic design requires a longer development period. The FPGA has made great progress in terms of on-chip storage resources, arithmetic logic resources, and hardware-software co-design. The FPGA can adapt to a large throughput rate and strict real-time signal processing requirements. Moreover, the structural characteristics of the FPGA make it suitable for homogeneous extension.
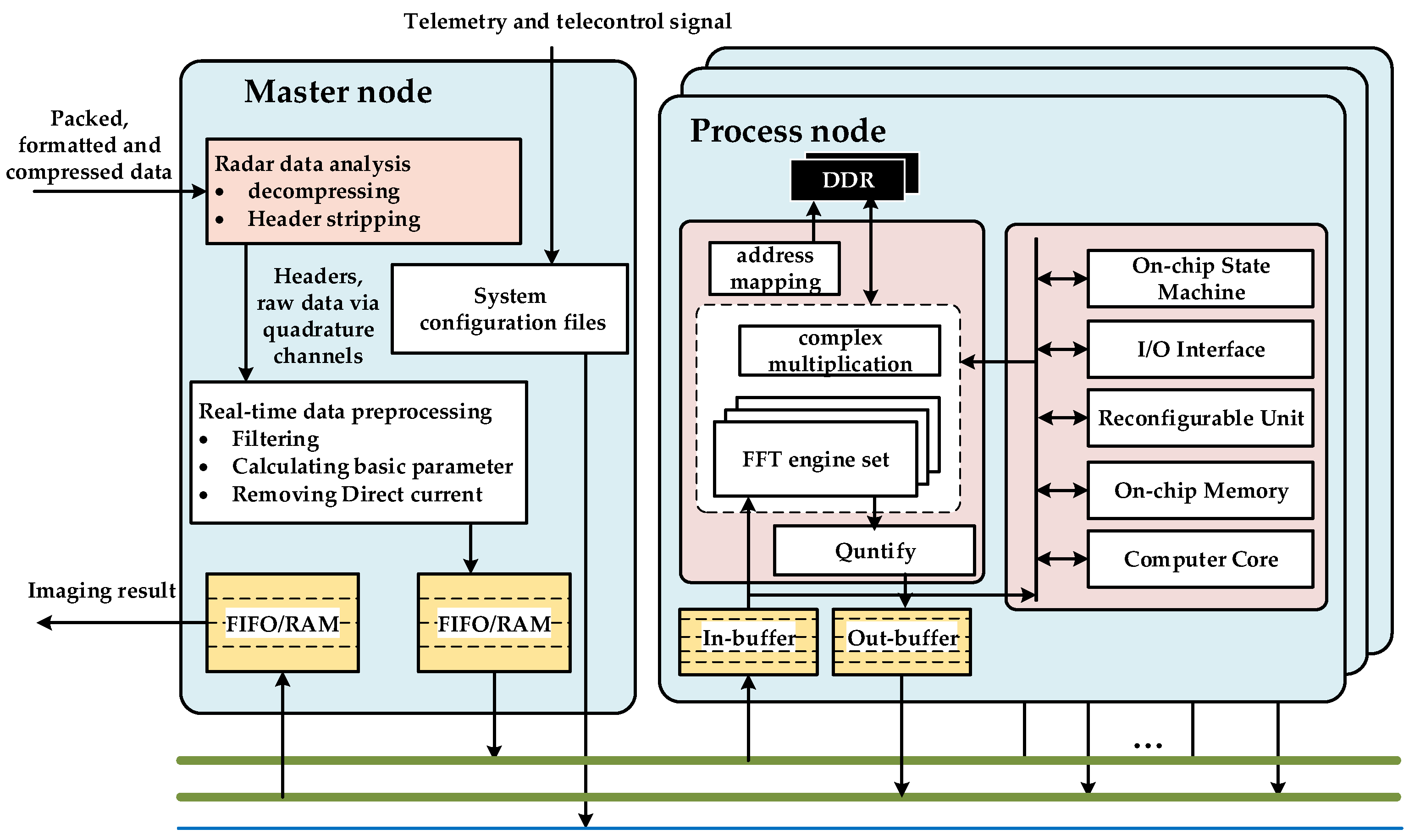
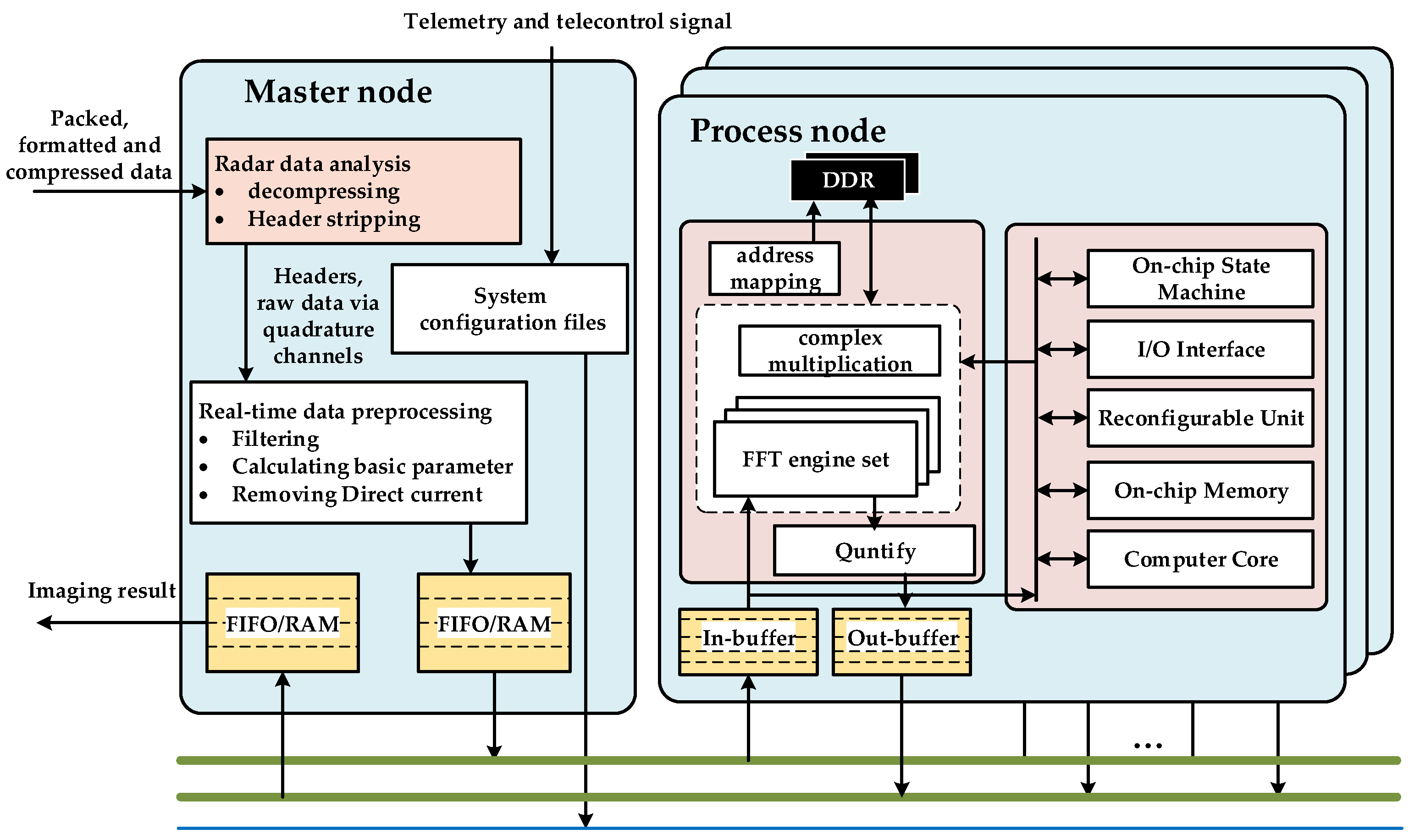
In this paper, we propose a multi-node parallel accelerating system to realize an on-board real-time SAR processing system. The mainstream spaceborne SAR imaging algorithm, chirp scaling (CS), is implemented in this system. Previous researchers have imported CS algorithms to special FPGA processors. However, further optimizations are required for the existing methods to accelerate SAR imaging processing. For example, four times all-pixel FFTs are the most computation-hungry operations of CS implementation, and the efficiency burden mainly occurs in the data access after corner turning (matrix transposition) [
22]. In a previous study [
23], the window access mode was used to accelerate the matrix transposition, while in another study [
24], ping pong buffers were used for Dual data rate (DDR) SDRAM to solve this problem. However, these approaches have various limitations of universality, e.g., two-dimensional rate mismatch and the method of complicated phase function generation, which can reduce the hardware resource utilization and meets the level of real-time imaging. We provide the following contributions to the existing research:
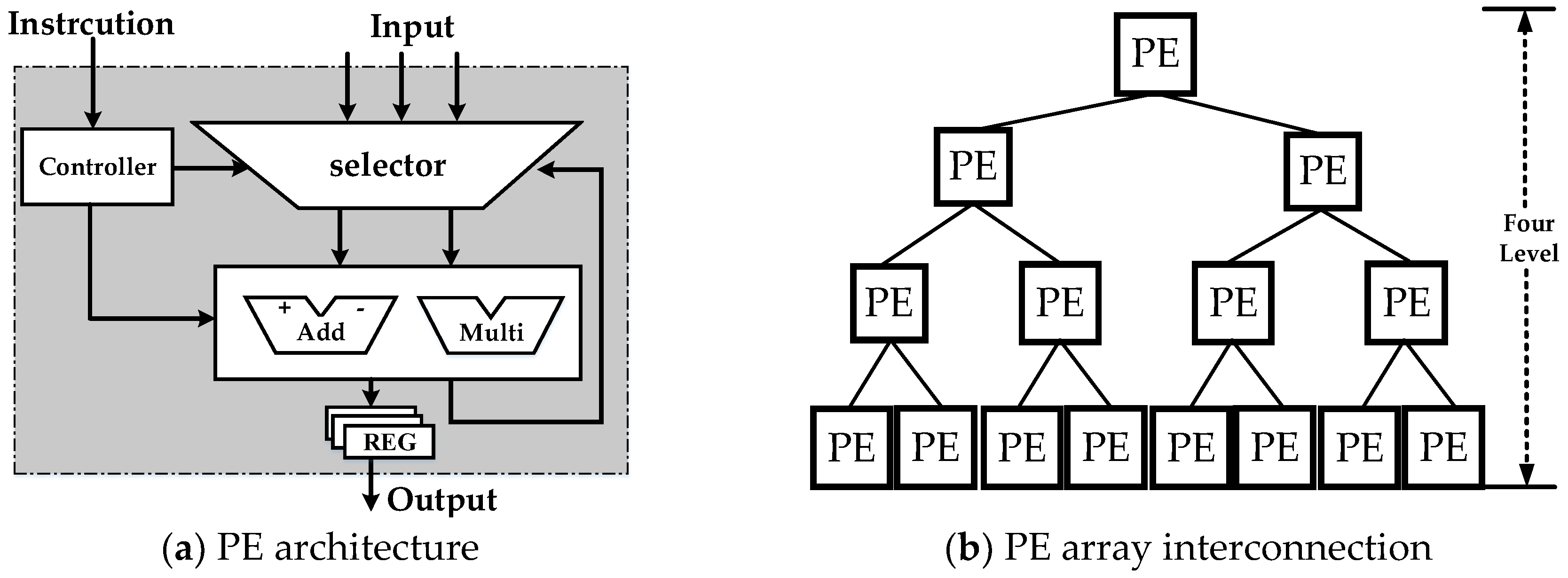
Optimized mapping methodology for single-chip integration. The CS algorithm can be decomposed in to two parts. For the nonlinear part, nonlinear–operation linearization method, logic-memory optimum allocation, and hierarchical reconfiguration structure are proposed to reduce the complexity and time consumption. Two-dimensional bandwidth dynamic balance technology is introduced to achieve a good real-time performance between the linear part and transpose operations.
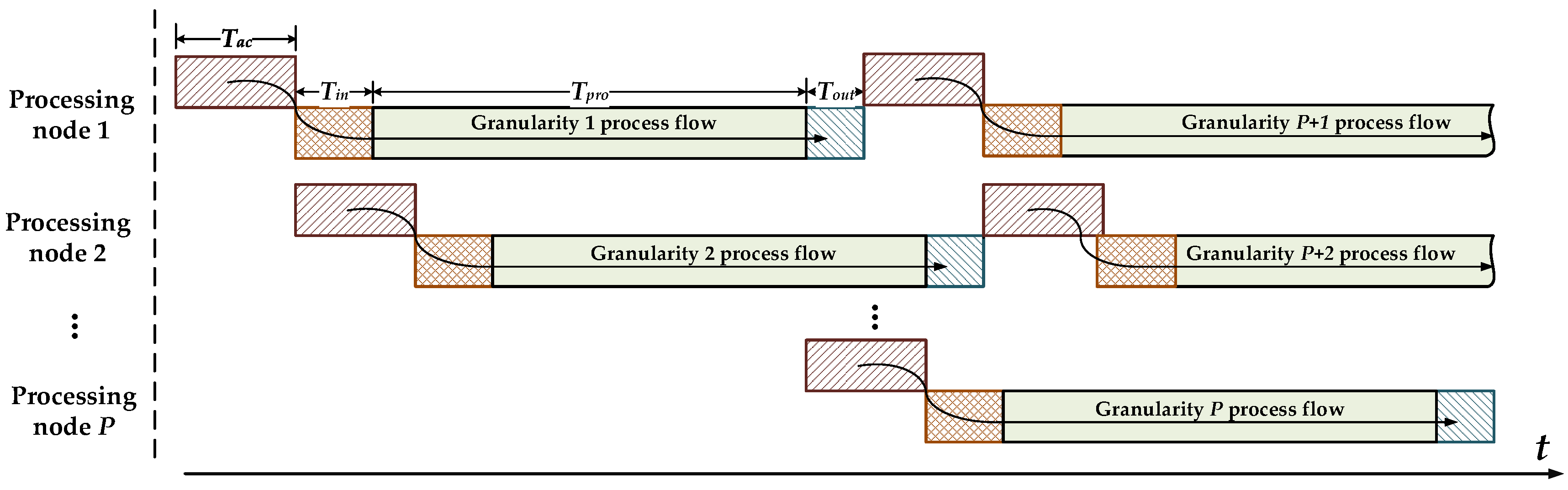
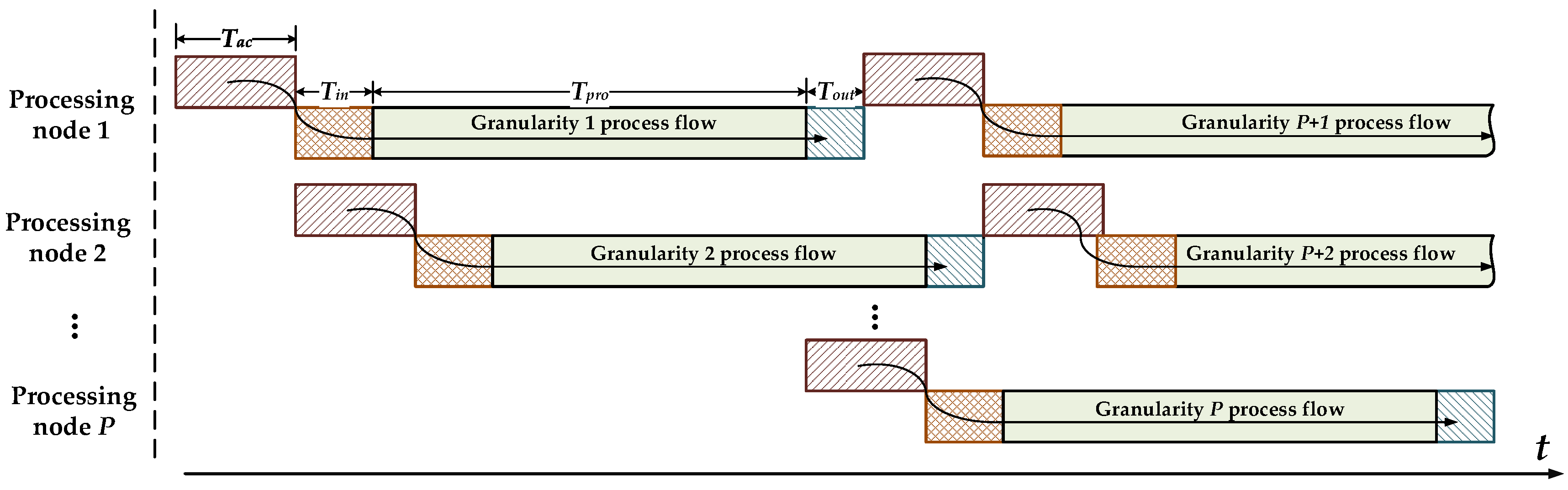
Multi-node parallel accelerating technique for strong real-time requirements. By analyzing the spaceborne SAR real-time imaging processing conditions, this paper presents a parallel accelerating architecture consisting of a master node and multiple independent processing nodes with high processing performance, high real-time performance, and linear scalability features.
The rest of the paper is organized as follows:
Section 2 reviews the CS algorithm and analyses the characteristic of each part of the CS algorithm.
Section 3 presents a single-FPGA integration design for optimizing the CS algorithm implementation with optimized mapping strategy. In
Section 4, the design methodology of the multi-node parallel accelerating system under the real-time principle is described. In
Section 5, the corresponding hardware realization details and results are discussed. A comparison with related works is conducted to show the validity of our system.
Section 6 concludes the paper.
2. Chirp Scaling (CS) Algorithm Review
The CS algorithm is one of the most fundamental and popular algorithms for spaceborne SAR data processing. Compared to other algorithms, the superiority of the CS algorithm lies primarily in its use of the “chirp scaling” principle, in which phase multiplies are used instead of a time-domain interpolator to implement range-variant range cell migration correction (RCMC) shift [
25]. As a kernel algorithm, the CS algorithm can process various modes with certain pre- or post-steps, such as the stripmap, scan SAR, spotlight, Tops, and Mosaic modes. This algorithm can also solve the problem of the dependence of the secondary range compression (SRC) on the azimuthal frequency because of the requirement for data processing in the two-dimensional frequency domain.
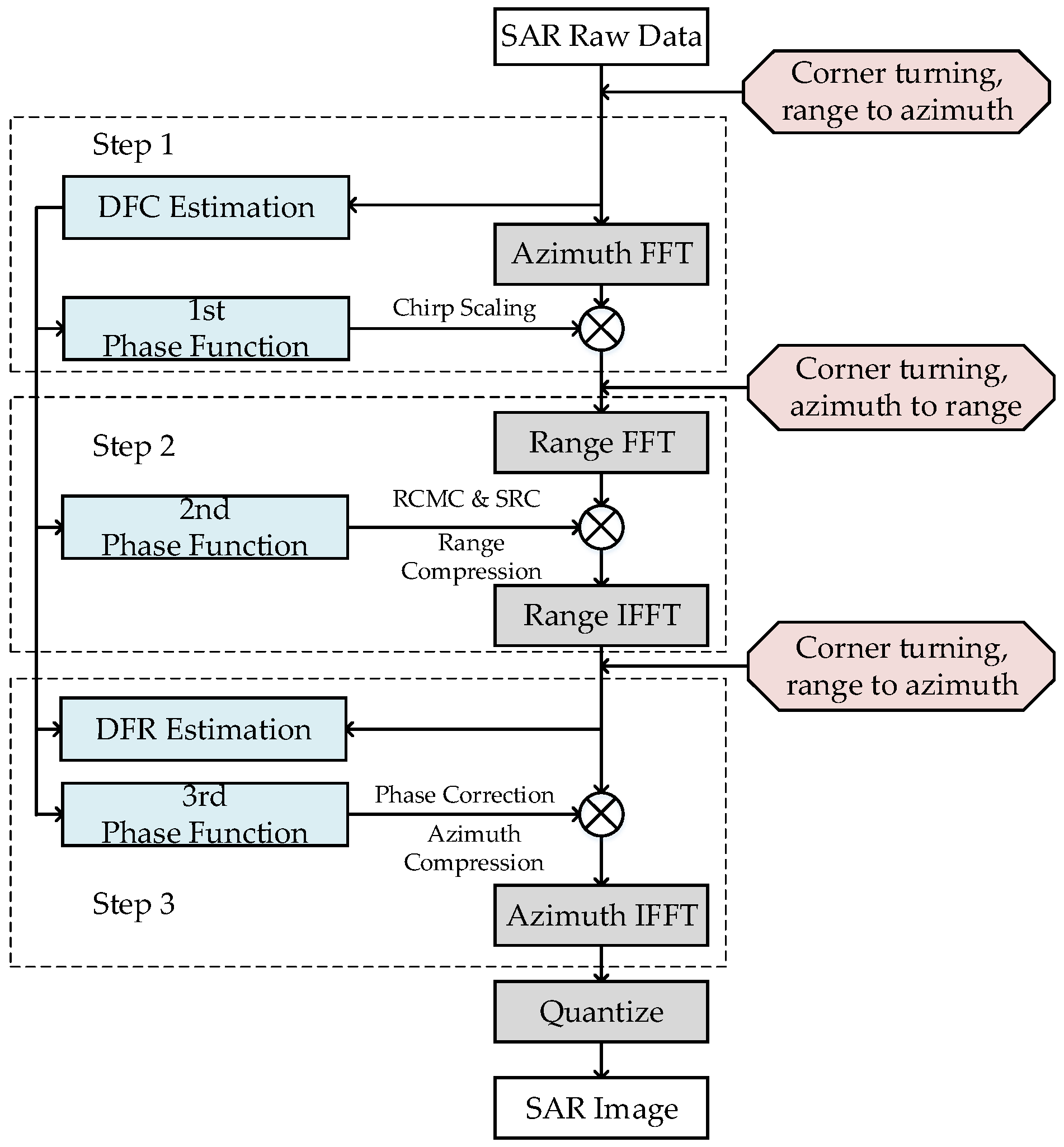
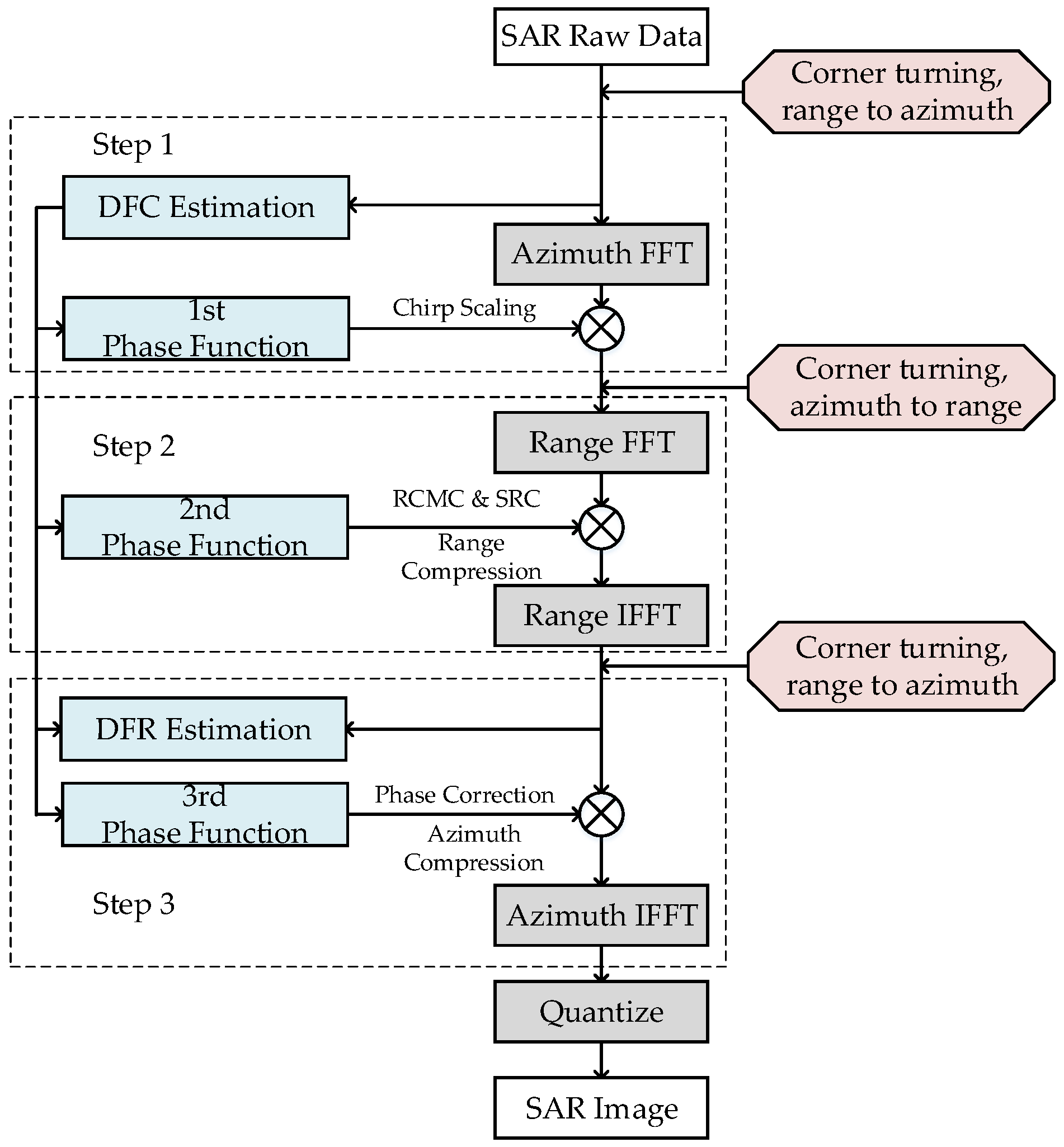
The high-level block diagram of the CS algorithm based on the squint equivalent range model is illustrated in
Figure 1. The algorithm mainly includes operations of four FFTs, three phase functions, and two Doppler parameters (Doppler frequency center (DFC) and Doppler frequency rate (DFR)) estimation. Note that the proposed flow introduces the raw-data-based method to ensure the precision of Doppler parameters. The steps in the CS algorithm are as follows:
First, the SAR raw data are divided into two parallel branches: one branch is transferred to the Range-Doppler domain via an FFT in the azimuthal direction, and the other branch is used to estimate DFC. DFC can be treated as a basic parameter for subsequent phase functions and DFR calculation. Second, the data are multiplied by the 1st phase function to achieve the chirp scaling, which makes all the range migration curves the same. The 1st phase function can be described as follows:
where
is the range time,
is the azimuthal frequency,
is the reference distance,
is the modulating frequency in the phase center of the range direction, and
is the curvature factor, expressed as follows:
where
is the wave length,
b is the modulation frequency of the transmitted signal,
and
represent equivalent squint angle and equivalent squint velocity, respectively. These variables can be described as follows:
where
represents DFC and
represents DFR. Because step 1 and step 2 consider the range dimension, the initial values obtained by the ephemeris parameter can be adopted to simplify calculation.
Third, the data are transferred to the two-dimensional frequency domain via an FFT in the range direction. Next, the data are multiplied by the 2nd phase function to complete the range compression, the SRC, and the remaining RCMC. The 2nd phase function can be described as follows:
where
is the range frequency.
Next, the data are transferred to the Range-Doppler domain via an inverse FFT in the range direction. The data can be multiplied by the 3rd phase function to complete the azimuth compression and the phase correction. The DFR based on the raw data is used to refine the equivalent velocity
v to ensure the precision of the 3rd phase function and is described as follows:
Finally, the inverse FFT operation in the azimuthal direction is executed to complete the CS algorithm. A visualized grayscale image can be obtained after performing the 8-bit quantization operation.
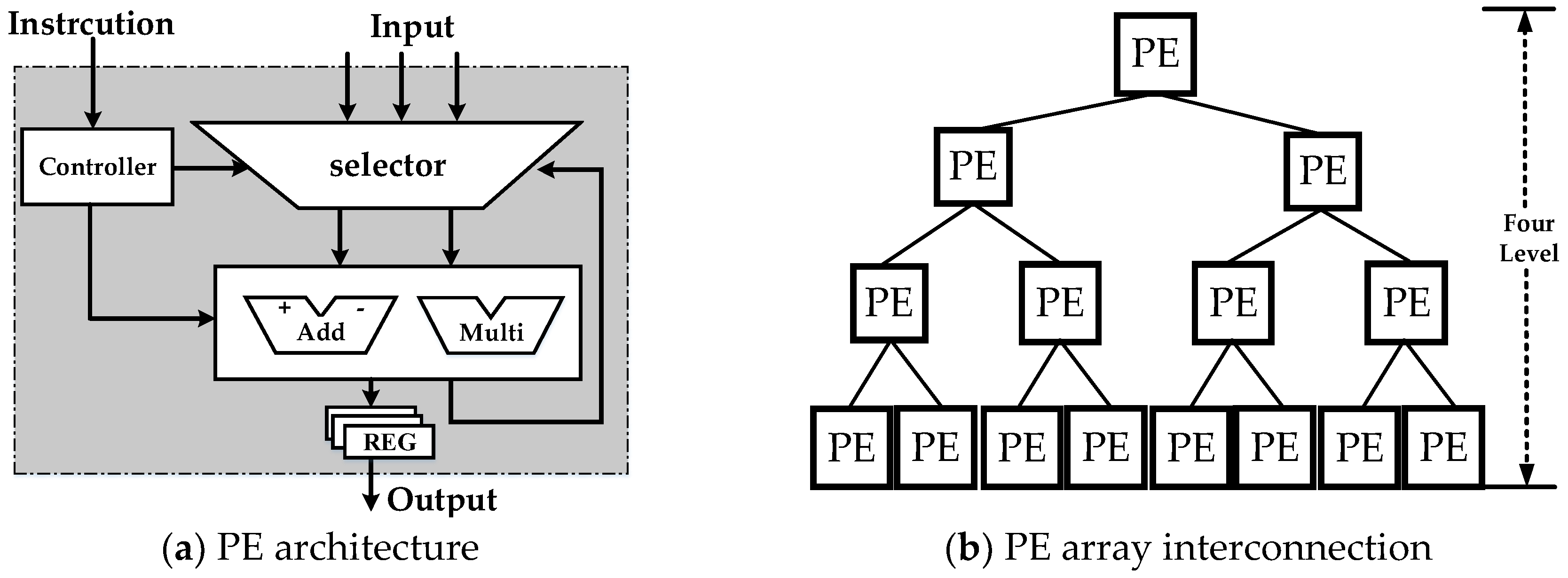
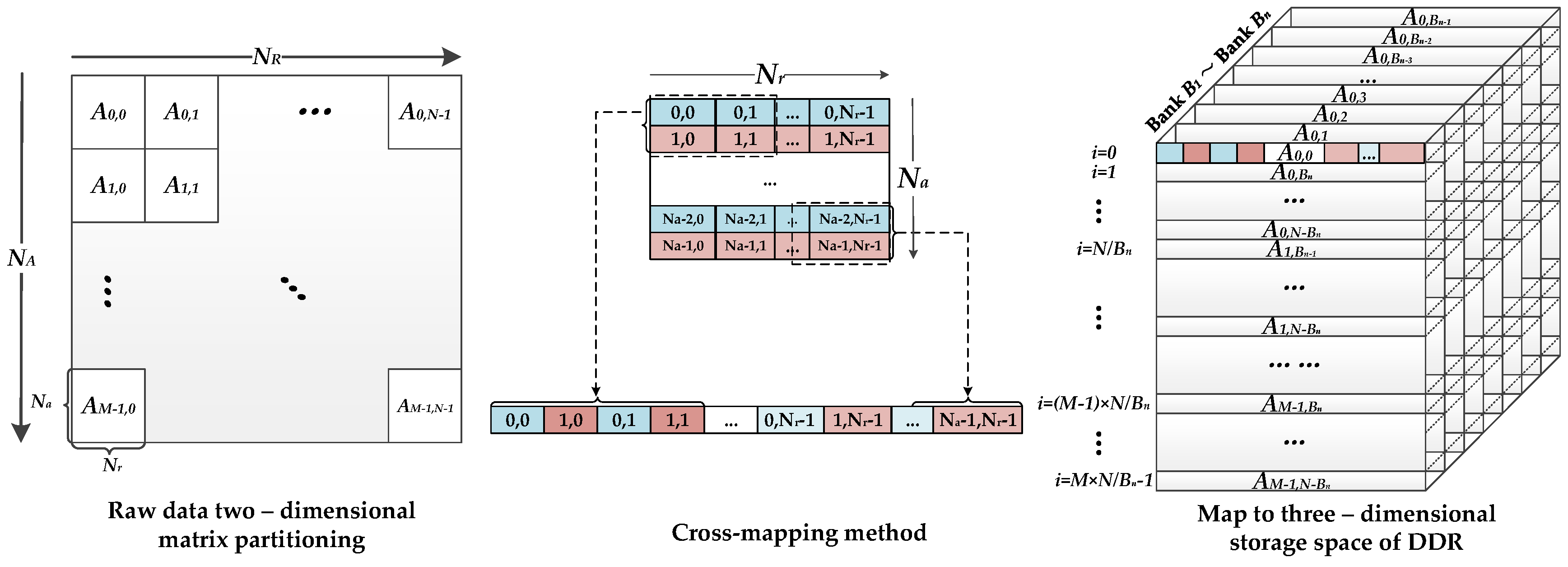
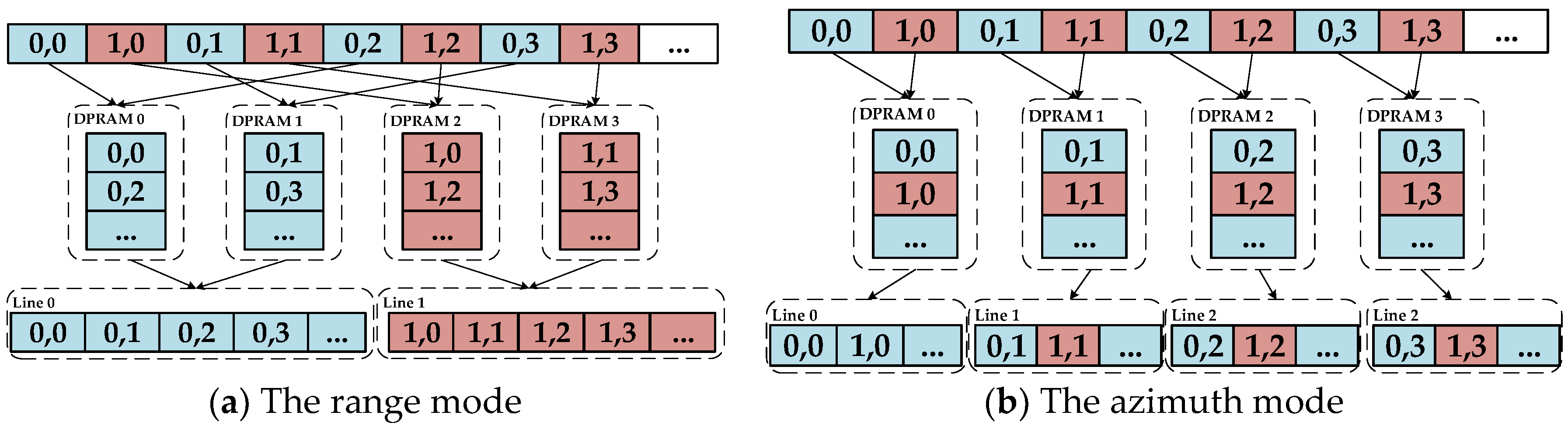
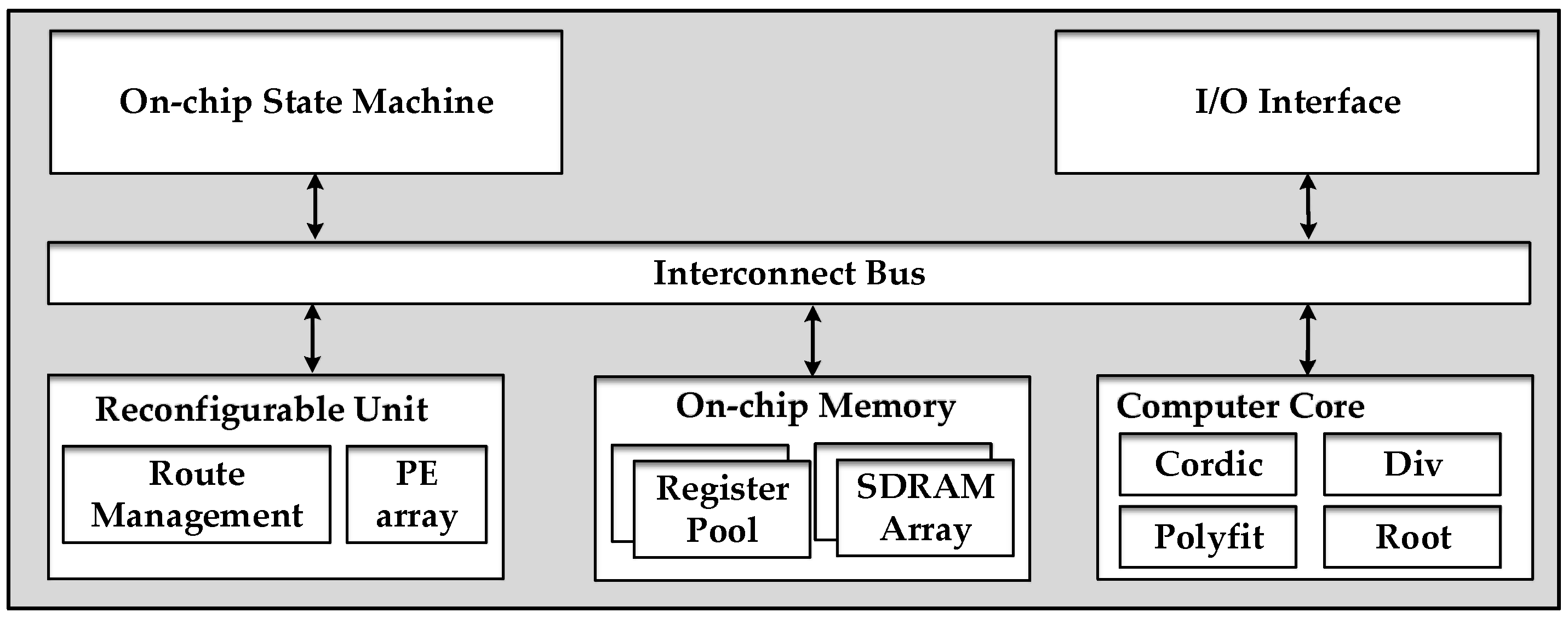
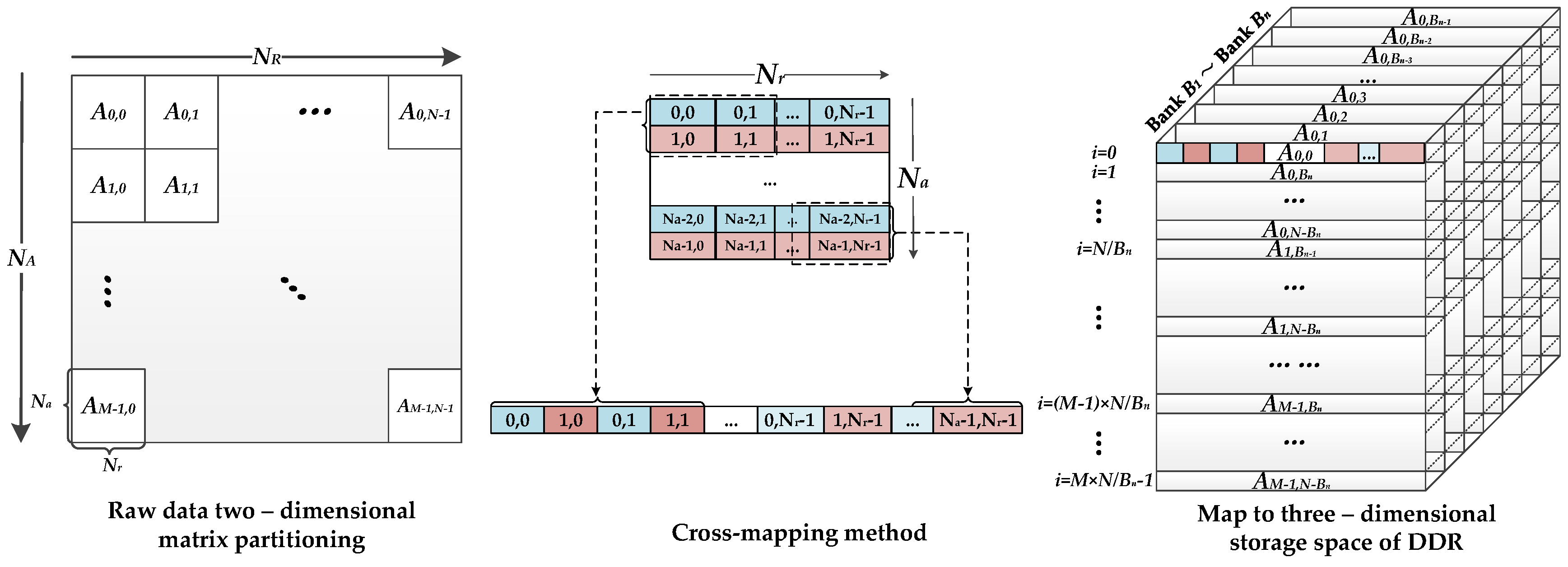
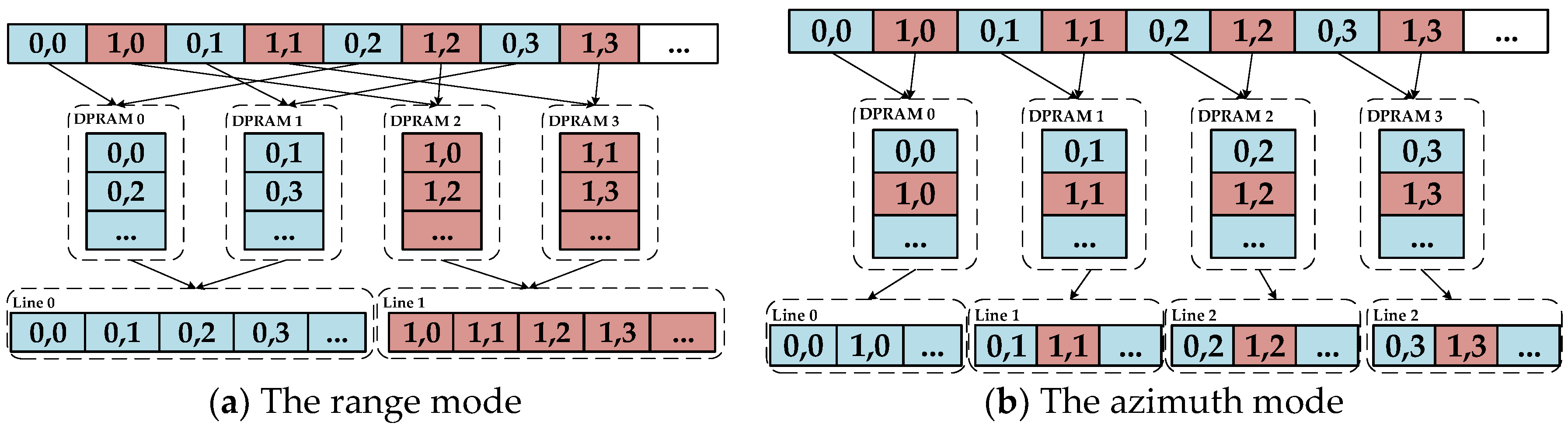
The processing element selected for this system design is the FPGA. DDR SDRAMs are introduced into the system to act as the external storage medium for the SAR raw data. The corner turning represented in the red boxes in
Figure 1 is required before each step to fit the step’s data operation dimension. For the convenience of hardware processing, the high-robustness and low-overhead algorithms called time-domain-autocorrelation (TDA) [
26] and shift-and-correlate (SAC) [
27] are chosen for DFC and DFR estimation, respectively. Otherwise, the SAC method would require one additional FFT operation. Thus, different mapping and implementation strategies must be designed for different operation parts.
6. Conclusions
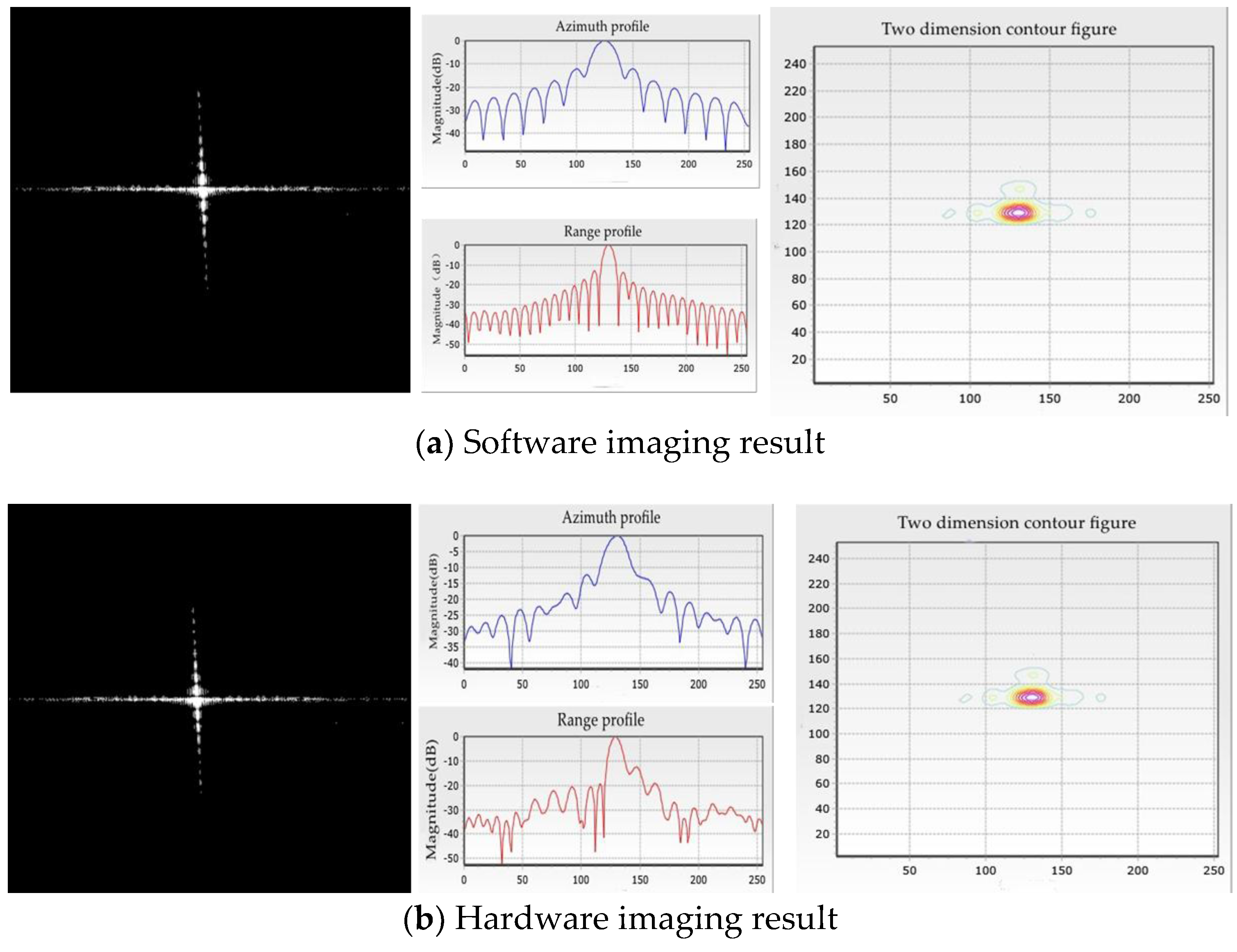
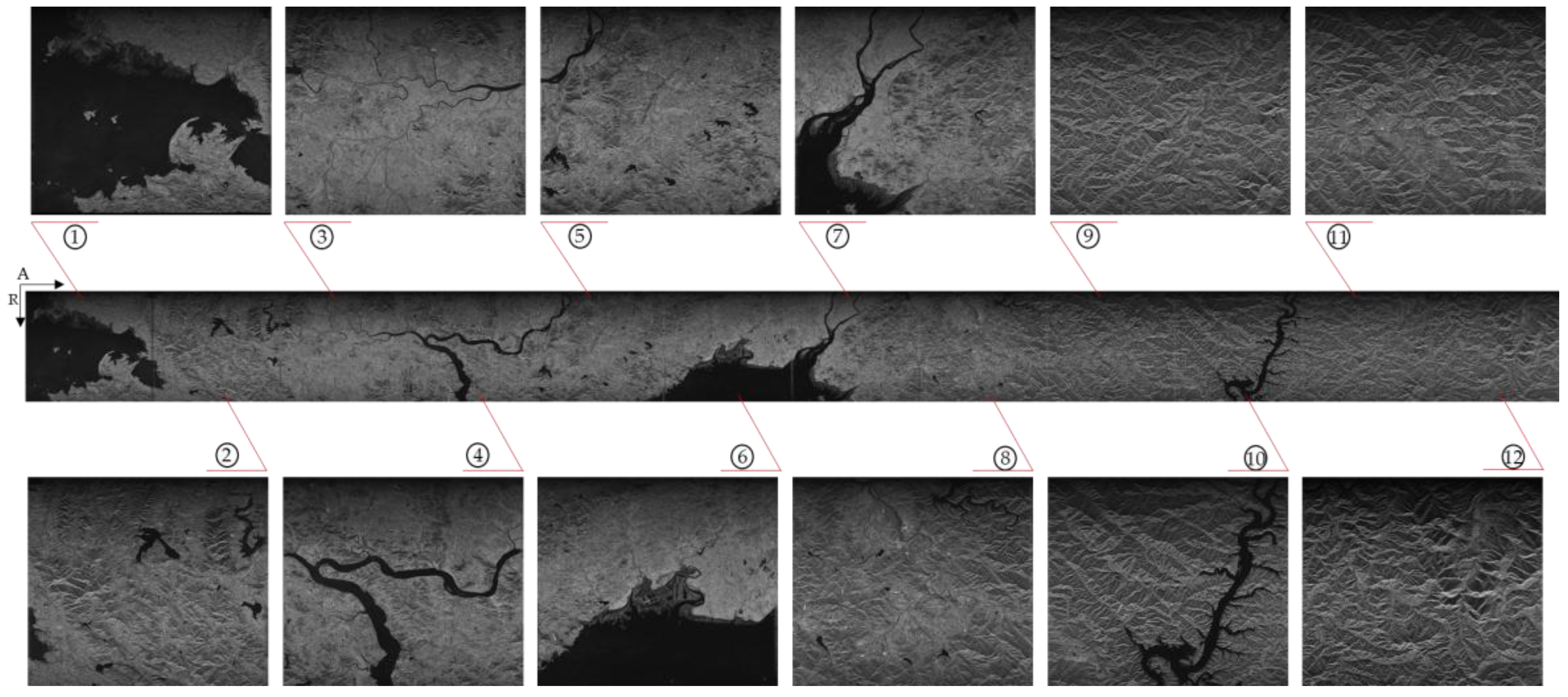
In this paper, to complete the on-board real-time SAR imaging processing task, a float-point imaging system using multi-node parallel acceleration technology is proposed. With an efficient mapping methodology, the whole SAR imaging procedure can be integrated in a single FPGA. To satisfy the requirement of real-time performance, we designed a prototype system with one master node and several processing nodes, and verified the performance via both a point target and an actual scene imaging quality evaluation. The efficient architecture achieves high real-time performance with low power consumption. A single-processing board requires 10.6 s and consumes 17 W to focus 25-km width, 5-m resolution stripmap SAR raw data with a granularity of 16,384 × 16,384, and the prototype single machine is suitable for continuous imaging processing.
The indicators of the single machine, such as weight, volume, and power, can satisfy the needs of spaceborne SAR imaging processing. With the development of anti-radiation reinforcement technology and system fault-tolerant technology, the proposed framework is expandable and feasible for potential spaceborne real-time SAR imaging processing.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}