GACEM: Genetic Algorithm Based Classifier Ensemble in a Multi-sensor System

Abstract
:
1. Introduction
2. Problem Formulation and Analysis
2.1 Problem formulation
2.2 Definition of Meta-feature and Trans-function
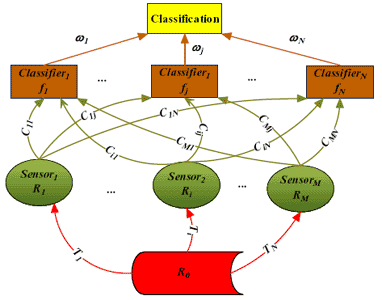
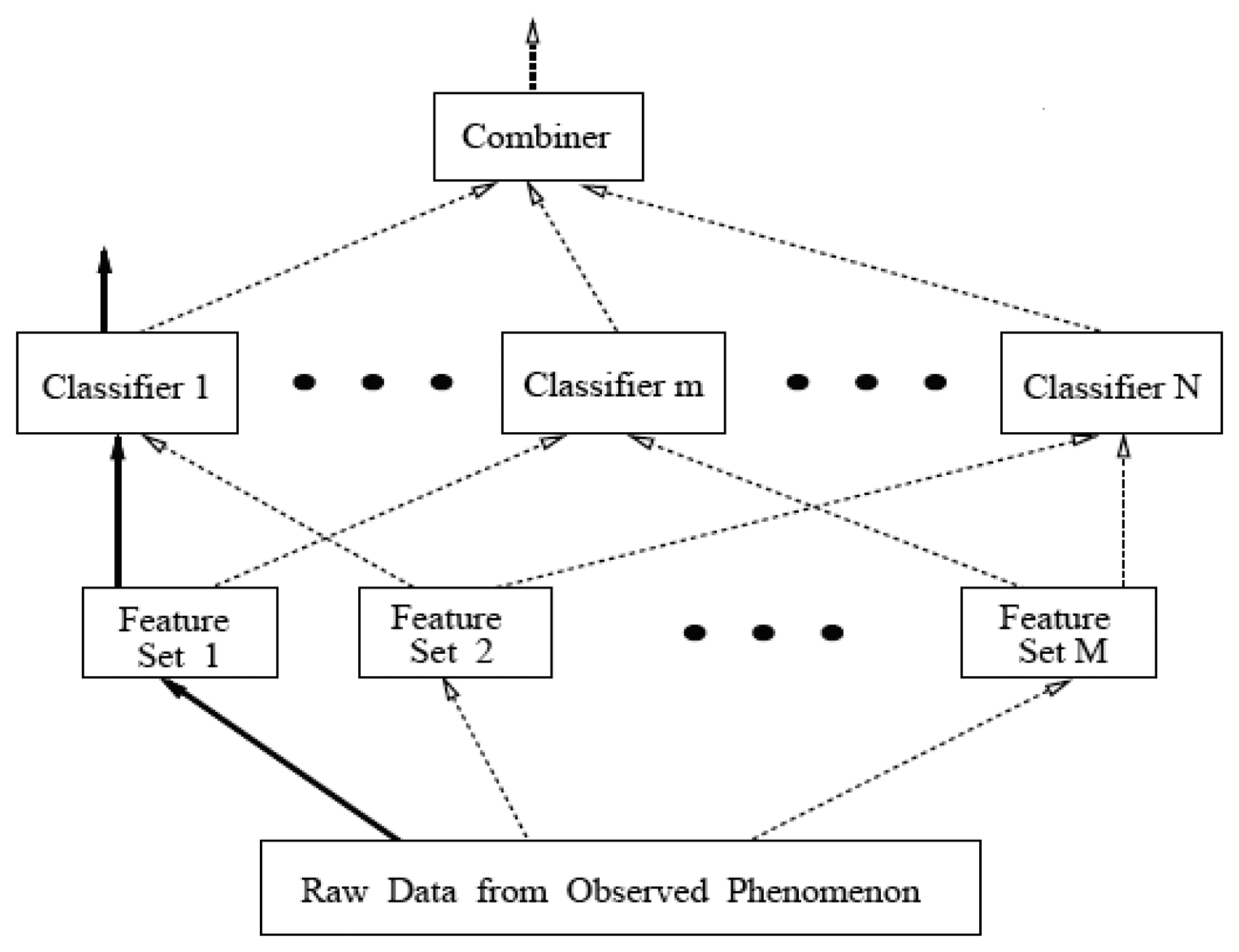
2.3 Classifier ensembles in multi-sensor systems
3. GACEM: Genetic Algorithm based Classifier Ensemble in a Multi-sensor System
3.1 A brief introduction of GA
- Step 1.
- Randomly generate initial population of chromosomes.
- Step 2.
- Evaluate fitness (objective function) of each chromosome.
- Step 3.
- Are the termination criteria met? If YES, go to step 7. If NO, go to step 4.
- Step 4.
- Generate new population by selecting pairs for mating, recombination using crossover and mutation.
- Step 5.
- Evaluate fitness (objective function) of each new chromosome.
- Step 6.
- Identify the fittest individual in the population. Go to step 3.
- Step 7.
- End.
3.2 Detail of GACEM
3.2.1 Chromosome coding strategy
3.2.2 Fitness function
3.2.3 Selection operators
3.2.4 Crossover operator
3.2.5 Mutation operator
3.2.6 Stopping criteria
3.3 Flowchart
| M | Number of sensors |
| N | Number of classifiers |
| ClassifierBas | Basic classifier |
| Fdc | Decision combination function |
| λ | Threshold for classifier selection |
| Strain | Training set |
| Sval | Validation set |
| nPop | Population size |
| Imax | Terminal number of generations |
| Lfit | Value of fitness limit |
| Pc | Crossover probability |
| Pm | Mutation probability |
| Step 1. | Generate initial population of chromosomes. |
| Step 2. | Evaluate fitness (classification accuracy on Sval) of each new chromosome: |
| for i = 1 : nPop | |
| { | |
| Decoding the i -th chromosome and building N classifiers based on Strain; | |
| Choosing those classifiers whose weight is bigger than λ to construct the classifier ensemble; | |
| Calculating the classification accuracy (i.e., fitness of the i -th chromosome) of Sval using the generated classifier ensemble; | |
| Find the chromosome with highest fitness among the population; | |
| } | |
| Step 3. | Are the optimization criteria met? If YES, go to step 9. If NO, go to step 4. |
| Step 4. | Generate new population using the selection operator. |
| Step 5. | Perform the crossover operator according to the crossover probability Pc. |
| Step 6. | Perform the mutation operator according to the mutation probability Pm. |
| Step 7. | Evaluate fitness of each new chromosome: |
| for i = 1 : nPop | |
| { | |
| Decoding the i -th chromosome and building N classifiers based on Strain; | |
| Choosing those classifiers whose weight is bigger than λ to construct the classifier ensemble; | |
| Calculating the classification accuracy (i.e., fitness of the i -th chromosome) of Sval using the generated classifier ensemble; | |
| Find the chromosome with highest fitness Chmb and the worst one Chmw; | |
| } | |
| Step 8. | Find the best chromosome during the evolution history and guarantee its survival to the next generation, i.e., comparing Chmb and, if the fitness of is greater than Chmb, then replace Chmw with; otherwise replace with Chmb. Go to step 3. |
| Step 9. | End. |
4. Experimental Section
4.1. Experiment description
4.1.1 Experiment environment
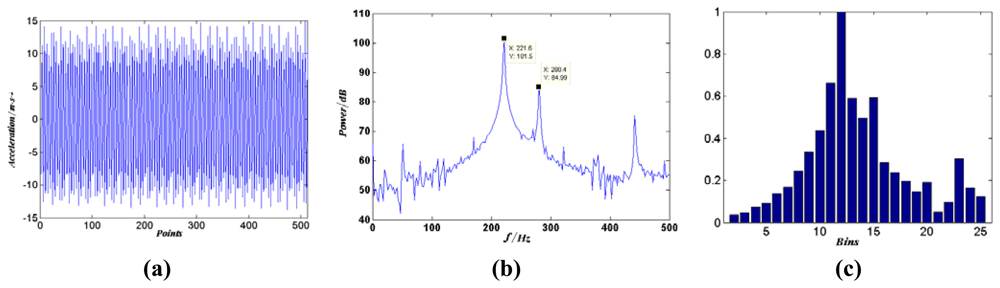
4.1.2 Feature generation
4.1.3 Experimental methodology
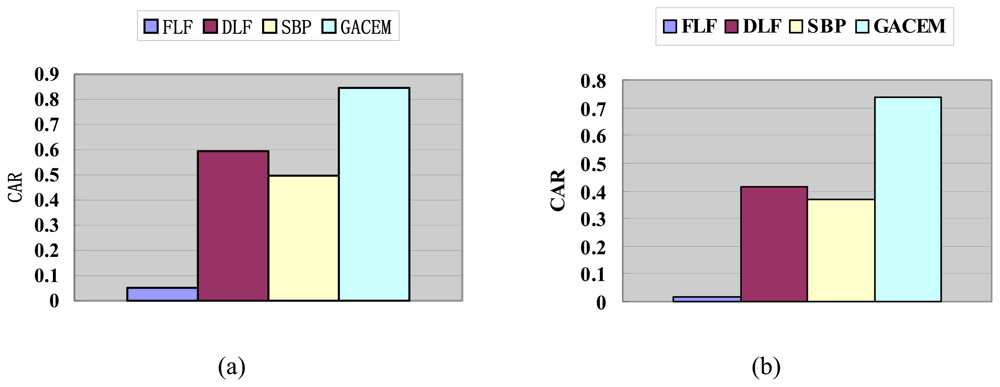
4.2. Results and discussion
4.2.1 Performance with N = M and λ = 0.05
4.2.2 Performance with N = 3M and λ = 1/ N
4.2.3 Performance comparison among different combination functions
5. Conclusions
Acknowledgments
References and Notes
- Rajagopal, R.; Sankaranarayanan, B.; Rao P, R. Target Classification in A Passive Sonar - An Expert System Approach. International Conference on Acoustics, Speech, and Signal Processing 1990, 2911–2914. [Google Scholar]
- Smith, D.; Singh, S. Approaches to Multisensor Data Fusion in Target Tracking: A Survey. IEEE Transactions on Knowledge and Data Engineering 2006, 18, 1696–1710. [Google Scholar]
- Kittler, J.; Matas, J.; Jonsson, K.; Ramos Sanchez, M. U. Combining Evidence in Personal Identity Verification Systems. Pattern Recognition Letters 1997, 18, 845–852. [Google Scholar]
- Kacalenga, R.; Erickson, D.; Palmer, D. Voting Fusion for Landmine Detection. IEEE Aerospace and Electronic Systems Magazine 2003, 18, 13–19. [Google Scholar]
- Costa, A. D.; Sayeed, A.M. Data versus Decision Fusion in Wireless Sensor Networks. International Conference on Acoustics, Speech, and Signal Processing 2003, 832–835. [Google Scholar]
- Brooks, R.R.; Ramanathan, P.; Sayeed, A.M. Distributed Target Classification and Tracking in Sensor Networks. Proceedings of the IEEE 2003, 91, 1163–1171. [Google Scholar]
- Luo, R.C.; Yih, C.-C.; Su, K. L. Multisensor Fusion and Integration: Approaches, Applications, and Future Research Directions. IEEE Sensors Journal 2002, 2, 107–119. [Google Scholar]
- Hall, D.L.; Llinas, J. An Introduction to Multisensor Data Fusion. Proceedings of the IEEE 1997, 85, 6–23. [Google Scholar]
- Clouqueur, T.; Ramanathan, P.; Saluja, K. K.; Wang, K.-C. Value-Fusion versus Decision-Fusion for Fault-Tolerance in Collaborative Target Detection in Sensor Networks. Proc. 4th Ann. Conf. on Information Fusion 2001. TuC2/25-TuC22/30. [Google Scholar]
- Roli, F.; Giacinto, G.; Vernazza, G. Methods for Designing Multiple Classifier Systems. Proceedings of the Second International Workshop on Multiple Classifier Systems 2001, 78–87. [Google Scholar]
- Kittler, J.; Hatef, M.; Duin, R.P.W.; Matas, J. On Combining Classifiers. IEEE Transactions on Pattern Analysis and Machine Intelligence 1998, 20, 226–239. [Google Scholar]
- Kuncheva, L.I.; Whitaker, C.J. Measures of Diversity in Classifier Ensembles and Their Relationship with the Ensemble Accuracy. Machine Learning 2003, 51, 181–207. [Google Scholar]
- Hansen, L.K.; Salamon, P. Neural Network Ensembles. IEEE Transactions on Pattern Analysis and Machine Intelligence 1990, 12, 993–1101. [Google Scholar]
- Ueda, N. Optimal Linear Combination of Neural Networks for Improving Classification Performance. IEEE Transactions on Pattern Analysis and Machine Intelligence 2000, 22, 207–215. [Google Scholar]
- Kittler, J. Multi-Sensor Integration and Decision Level Fusion. Proc. DERA/IEE Workshop Intelligent Sensor Processing 2001, 1–6. [Google Scholar]
- Polikar, R.; Parikh, D.; Shreekanth, Mandayam. Multiple Classifier Systems for Multisensor Data Fusion. SAS 2006 - IEEE Sensors Applications Symposium 2006, 180–184. [Google Scholar]
- Schapire, R. E. A Brief Introduction to Boosting. Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence 1999, 1401–1406. [Google Scholar]
- Dietterich, T.G. Machine learning research: Four current directions. AI Magazine 1997, 18, 97–136. [Google Scholar]
- Breiman, L. Bagging Predictors. Machine Learning 1996, 24, 123–140. [Google Scholar]
- Xu, R.; He, L.; Zhang, L.; Ben, K. Identification of Mechanical Noise Source on Sparse Data. Chinese Journal of Mechanical Engineering 2008, 44, 151–160. [Google Scholar]
- Roli, F.; Giacinto, G.; Serpico, S.B. Classifier Fusion for Multisensor Image Recognition. Proceedings of SPIE - Image and Signal Processing for Remote Sensing 2001, 103–110. [Google Scholar]
- Kuncheva, L.I.; Jain, L. C. Designing Classifier Fusion Systems by Genetic Algorithms. IEEE Transactions on Evolutionary Computation 2000, 4, 327–336. [Google Scholar]
- Zhou, Z.-H.; Wu, J.; Tang, W. Ensembling Neural Networks: Many Could Be Better Than All. Artificial Intelligence 2002, 137, 239–263. [Google Scholar]
- Tumer, K.; Ghosh, J. Linear and Order Statistics Combiners for Pattern Classification. In Combining Artificial Neural Nets: Ensemble and Modular Multi-Net Systems; Sharkey, A., Ed.; Springer Verlag: London, 1999; pp. 127–162. [Google Scholar]
- Lam, L.; Suen, C.Y. Application of majority voting to pattern recognition: An analysis of the behavior and performance. IEEE Transactions on Systems, Man, and Cybernetics 1997, 27, 553–567. [Google Scholar]
- Lin, X.; Yacoub, S.; Burns, J.; Simske, S. Performance analysis of pattern classifier combination by plurality voting. Pattern Recognition Letters 2003, 24, 1959–1969. [Google Scholar]
- Perrone, M. P. Improving Regression Estimation: Averaging Methods for Variance Reduction with Extensions to General Convex Measure Optimization; Brown University: Providence, RI, 1993. [Google Scholar]
- Maslov, I.V.; Gertner, I. Multi-sensor fusion: an Evolutionary algorithm approach. Information Fusion 2006, 7, 304–330. [Google Scholar]
- Buczak, A.L.; Uhrig, R.E. Hybrid Fuzzy-Genetic Technique for Multisensor Fusion. Information Sciences 1996, 93, 265–281. [Google Scholar]
- Ruta, D.; Gabrys, B. Classifier Selection for Majority Voting. Information Fusion 2005, 6, 63–81. [Google Scholar]
- Narasimhamurthy, A. Theoretical Bounds of Majority Voting Performance for a Binary Classification Problem. IEEE Transactions on Pattern Analysis and Machine Intelligence 2005, 27, 1988–1995. [Google Scholar]
- Seto, M. L.; Hutt, D. Ship Signatures Management System – Towards increased warship survivability. Underwater Defence Technology 2004, 1–10. [Google Scholar]
- Friedman, J.H. Regularized Discriminant Analysis. Journal of the American Statistical Association 1989, 84, 165–175. [Google Scholar]
- Cover, T.; Hart, P. Nearest Neighbor Pattern Classification. EEE Transactions on Information Theory 1967, 13, 21–27. [Google Scholar]
- Lawrence, R.L.; Wright, A. Rule-based Classification Systems Using Classification And Regression Tree (CART). Analysis Photogrammetric Engineering & Remote Sensing 2001, 67, 1137–1142. [Google Scholar]
- Gardner, J.W.; Boilot, P.; Hines, E.L. Enhancing Electronic Nose Performance by Sensor Selection Using a New Integer-based Genetic Algorithm Approach. Sensors and Actuators B 2005, 106, 114–121. [Google Scholar]
- Worden, K.; Burrows, A.P. Optimal Sensor Placement for Fault Detection. Engineering Structures 2001, 23, 885–901. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sound source ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| fA(Hz) | 0 | 0 | 0 | 0 | 0 | 20 | 20 | 20 | 20 | 20 |
| fB(Hz) | 20 | 110 | 220 | 280 | 320 | 0 | 20 | 110 | 220 | 280 |
| Sound source ID | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| fA(Hz) | 20 | 110 | 110 | 110 | 110 | 110 | 110 | 220 | 220 | 220 |
| fB(Hz) | 320 | 0 | 20 | 110 | 220 | 280 | 320 | 0 | 20 | 110 |
| Sound source ID | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| fA(Hz) | 220 | 220 | 220 | 280 | 280 | 280 | 280 | 280 | 280 | 320 |
| fB(Hz) | 220 | 280 | 320 | 0 | 20 | 110 | 220 | 280 | 320 | 0 |
| Sound source ID | 31 | 32 | 33 | 34 | 35 | |||||
| fA(Hz) | 320 | 320 | 320 | 320 | 320 | |||||
| fB(Hz) | 20 | 110 | 220 | 280 | 320 | |||||
- ●
- There are 35 kinds of different sound sources in all.
- ●
- fA represents the working frequency of exciter A and fB represents the working frequency of exciter B.
- ●
- 0 Hz means the exciter is unused.
| Sensor NO. | Sensor Type (ID) | Position |
|---|---|---|
| 1 | Hydrophone (H1) | Far field |
| 2 | Hydrophone (H2) | Near field |
| 3 | Accelerometer (A1) | Outer shell |
| 4 | Accelerometer (A2) | Outer shell |
| 5 | Accelerometer (A3) | Outer shell |
| 6 | Accelerometer (A4) | Inner shell |
| 7 | Accelerometer (A5) | Inner shell |
| Sound source ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Training set | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Validation set | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| Test set | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 |
| Sound source ID | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Training set | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Validation set | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| Test set | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 |
| Sound source ID | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| Training set | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Validation set | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| Test set | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 |
| Sound source ID | 31 | 32 | 33 | 34 | 35 | Total | ||||
| Training set | 4 | 4 | 4 | 4 | 4 | 140 | ||||
| Validation set | 5 | 5 | 5 | 5 | 5 | 175 | ||||
| Test set | 10 | 10 | 10 | 10 | 10 | 350 | ||||
| H1 | H2 | A1 | A2 | A3 | A4 | A5 | Weight | H1 | H2 | A1 | A2 | A3 | A4 | A5 | Weight | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| f1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0.2075 | f1 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0.2068 | |
| f2 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0.0521 | f2 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0.2214 | |
| f3 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0.1354 | f3 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0.1713 | |
| f4 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0.1781 | f4 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0.086 | |
| f5 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0.0688 | f5 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0.096 | |
| f6 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0.1634 | f6 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0.1436 | |
| f7 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0.1948 | f7 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0.0749 | |
| (a) | (b) | |||||||||||||||||
| H1 | H2 | A1 | A2 | A3 | A4 | A5 | Weight | H1 | H2 | A1 | A2 | A3 | A4 | A5 | Weight | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| f1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0.1367 | f1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0.2213 | |
| f2 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0.0578 | f2 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0.1335 | |
| f3 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0.2177 | f3 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0.1374 | |
| f4 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0.1225 | f4 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0.1258 | |
| f5 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0.1507 | f5 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0.1976 | |
| f6 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0.1777 | f6 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0.0821 | |
| f7 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0.1369 | f7 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0.1024 | |
| (c) | (d) | |||||||||||||||||
| H1 | H2 | A1 | A2 | A3 | A4 | A5 | Weight | |
|---|---|---|---|---|---|---|---|---|
| f1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0.0280 |
| f2 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0.0109 |
| f3 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0.0095 |
| f4 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0.0110 |
| f5 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0.0261 |
| f6 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0.0068 |
| f7 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0.0082 |
| f8 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0.0083 |
| f9 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0.0125 |
| f10 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0.0091 |
| f11 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0.0277 |
| f12 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0.0184 |
| f13 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0.0049 |
| f14 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0.0113 |
| f15 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0.1960 |
| f16 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0.4410 |
| f17 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0.0132 |
| f18 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0.0053 |
| f19 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0.0964 |
| f20 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0.0186 |
| f21 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0.0359 |
© 2008 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Xu, R.; He, L. GACEM: Genetic Algorithm Based Classifier Ensemble in a Multi-sensor System. Sensors 2008, 8, 6203-6224. https://doi.org/10.3390/s8106203
Xu R, He L. GACEM: Genetic Algorithm Based Classifier Ensemble in a Multi-sensor System. Sensors. 2008; 8(10):6203-6224. https://doi.org/10.3390/s8106203
Chicago/Turabian StyleXu, Rongwu, and Lin He. 2008. "GACEM: Genetic Algorithm Based Classifier Ensemble in a Multi-sensor System" Sensors 8, no. 10: 6203-6224. https://doi.org/10.3390/s8106203