2.2. Some Robust Estimations
Estimation methods based on LSE are sensitive to the deviations from the normal distribution of observation errors; therefore, LSE is not distributionally robust. We cannot determine that a unique robust method is better than other methods since there is no unique criterion related to the robustness. The most commonly used estimators in the literature are M-, L-, and R-Estimators [
8-
9]. M-Estimators stand out as the most flexible estimators and considered by many as the most favorable estimator group [
8]. M-Estimation is the most convenient technique for debugging observations that include gross errors. It can be applied for heavy tailed normal distribution. It is assumed that the geodetic data follow a normal distribution.
LSE is a special case of M-Estimation, whose score function is
. The computational algorithm may follow an iteratively reweighted scheme as mentioned in [
10-
11] although there are other approaches in the literature.
While
ρ(
v) is a continuous and convex function,
ψ(
v) =
∂ρ(
v)/
∂v is the influence function and
w(
v) =
ψ(
v)/
v is the robust weight factor which decreases when the absolute of the residual increases. The estimation procedure is as follows:
where
P̅ is the equivalent weight matrix,
P is the first weight matrix,
w is the robust weight factor,
A is the design matrix,
v is the vector of residuals,
x is the vector of the unknown parameters,
ℓ is the vector of reduced observations,
i is the iteration number. In the first iteration,
w is taken as the unit matrix.
where
n is the number of observations. The iterations are executed until the difference between the parameters
xi+1 and
xi are negligible. At the end of the sequence of iterations, it is observed that the equivalent weights of the outliers become smaller, even reduced to zero. The weights of the normal observations either do not change during the iterations or show little change.
As shown above, the equivalent weight matrix is used to give a decision about whether observations are normal or outlying. In obtaining the equivalent weight matrix, a robust weight factor is used. The robust weight factors are obtained by comparing the residuals with critical values derived from calculations or given constant values. In order to calculate the critical value, a procedure can be applied as follows:
Here
c represents the critical value,
s0 is the a priori standard deviation,
Qvv is the cofactor matrix of the residuals,
P is the weight matrix of the observations,
f is the degree of freedom,
α0 is the significance level, and
t represents the Student distribution.
The associate critical value is calculated by averaging the critical values calculated for each observation as:
In this study, some of the critical values of the estimations have been calculated and others taken as constant values. The weight functions of the M-Estimations used are listed in
Table 2.
s0 in
Table 2 is the a priori standard deviation of the unit weight, and
,
ṽi is the normalized residual which is equal to
vi/
svi.
2.3. Fuzzy Logic Method
In the fuzzy logic approach, the fuzzy set and the statistical test theory are used together. There are two important properties of the fuzzy sets used to identify outliers. These are the complementation and the intersection properties. At the beginning, a statistical test is applied to the residuals and the residuals are classified as ‘normal’ and ‘abnormal’ residuals according to their test statistic [
12]. From now on, a test will be called “the first test” when the results are presented:
Here
ti shows the test statistic and
q is the critical value. The membership functions are used to clarify the vagueness concerning the residuals having test statistic very close to the critical value.
Here
μF (
vi) is the membership function related to the subset
F, d is the standardization component that shows the meaningful deviation magnitude of the test statistic from the critical value [
7]. It is impossible to state a definite value for
d. Therefore, several values have been assigned to this component.
After the definition of the membership values of the residuals, the fuzzy membership relations between the observation errors are determined. The membership values of the residuals and the redundancy matrix are used to realize this goal. The relation between the residuals and the errors is given as follows:
Here, the multiplication
Qvv P is equal to the redundancy matrix
R, and the equation represents the transformation between the residuals and observation errors. In order to obtain the effects of all observation errors on a residual, the relative redundancy matrix
R̃ is used. The elements of this matrix are obtained as follows:
where
n is the number of observations,
rij are the elements of the redundancy matrix, and subscript
j in the lower position is the column number of the element with maximum value of the
ith row. The rows of the relative redundancy matrix indicate the relative contributions of all observation errors to an individual residual, and the columns indicate the relative contribution of an individual error to all residuals.
The set of the gross errors
H is defined as the intersection of the set of the errors having the greatest effect on the residuals that are most likely abnormal
A and the set of the errors having the least effect on the residuals that are most likely normal
B. The membership value of an observation error in the set
H is defined as follows:
In order to obtain the membership values of the observation errors in the set
A and
B, the maximum relative contribution of the
ith observation error to the residuals that have membership values equal or greater than 0.5 in the subset
F and
P is searched, respectively. Then, this relative value and its complementary value are multiplied by the membership value of the corresponding residual as follows:
The membership values of the observation errors in the intersection set
H are compared with a critical value. This value can be calculated using an arithmetic or weighted mean [
7].
Let the number of the elements belonging to set
H with membership values different from zero be
k. Now, the critical value
CμH can be calculated with an arithmetic mean as:
In the weighted mean method, weights are given to the membership values taking into consideration the relative effect of the observation errors in their own set as follows:
After obtaining the observation errors that have membership values greater than the critical value
CμH, the a priori knowledge about the location of these errors is also obtained. In order to verify this determination, a procedure is proposed by [
12] as follows:
where
Hn×m is the location matrix of the gross errors,
Pssm×m is the weight matrix of the gross errors,
Pn×n is the weight matrix of the observations,
An×u is the design matrix,
vnx1 is the vector of the residuals, ∇
smx1 is the vector of the gross errors. Here, the indices
n and
m are the number of all observations and the number of the observations that exceed the critical value
CμH, respectively. In the
H matrix, the column element that corresponds to the observation with gross error is taken as 1. Consequently, the significance of the estimated gross errors is tested using one of the statistical tests. When presenting the results, this will be the last test.



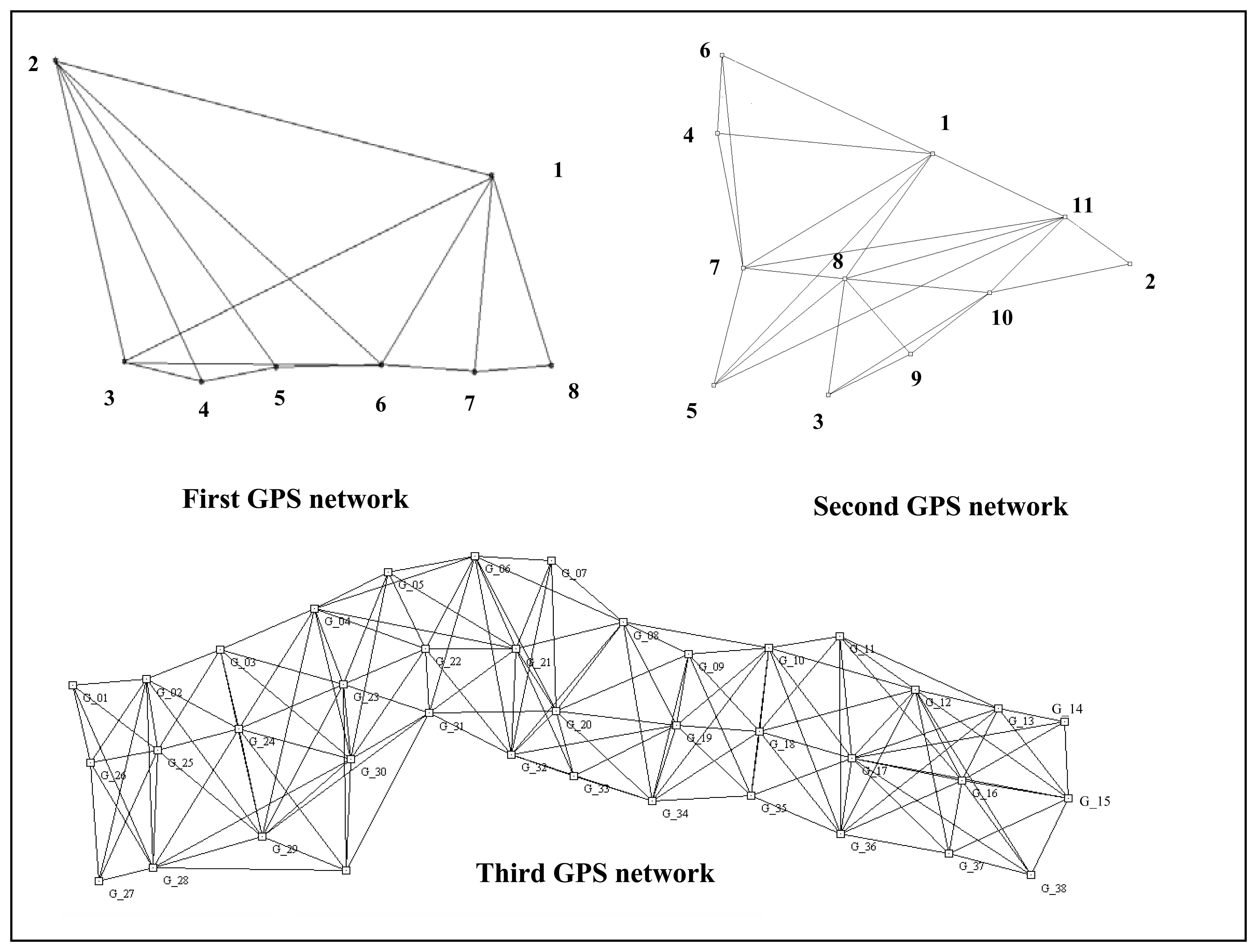{kind=link}