Intrusion-Aware Alert Validation Algorithm for Cooperative Distributed Intrusion Detection Schemes of Wireless Sensor Networks


Abstract
:
1. Introduction
2. Taxonomy of IDS
3. Related Work
3.1. Intrusion Detection Schemes
3.2. Intrusion Prevention Schemes
4. Network Model, Assumptions and Definitions
4.1. Network Model and Assumptions
4.2. Definitions
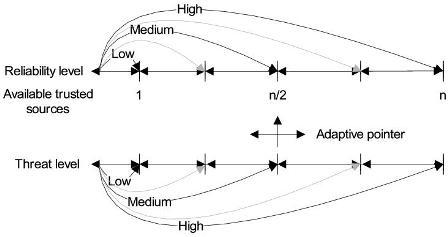
5. Intrusion-aware Alert Validation Algorithm
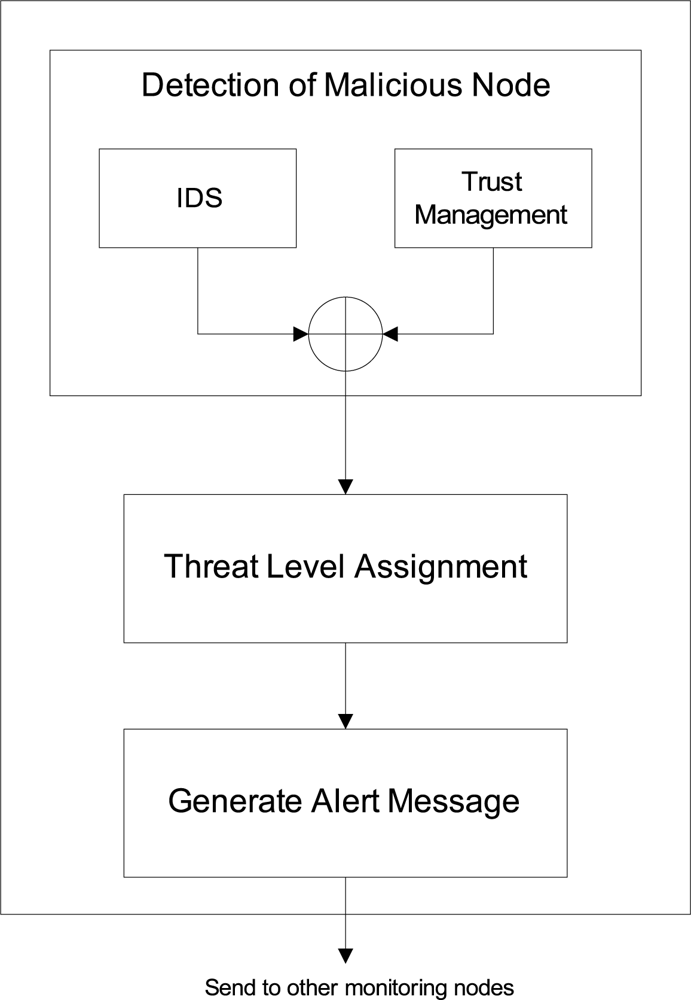
5.1. Sender Monitoring Node
Phase 1: Detection of Malicious Node
Phase 2: Threat Level Assignment
Phase 3: Generation of Alert Message
- Identity of the sender node (IDsender).
- Identity of the malicious node (IDmal).
- Threat level (Hlevel).
- Threat detail, like code etc.
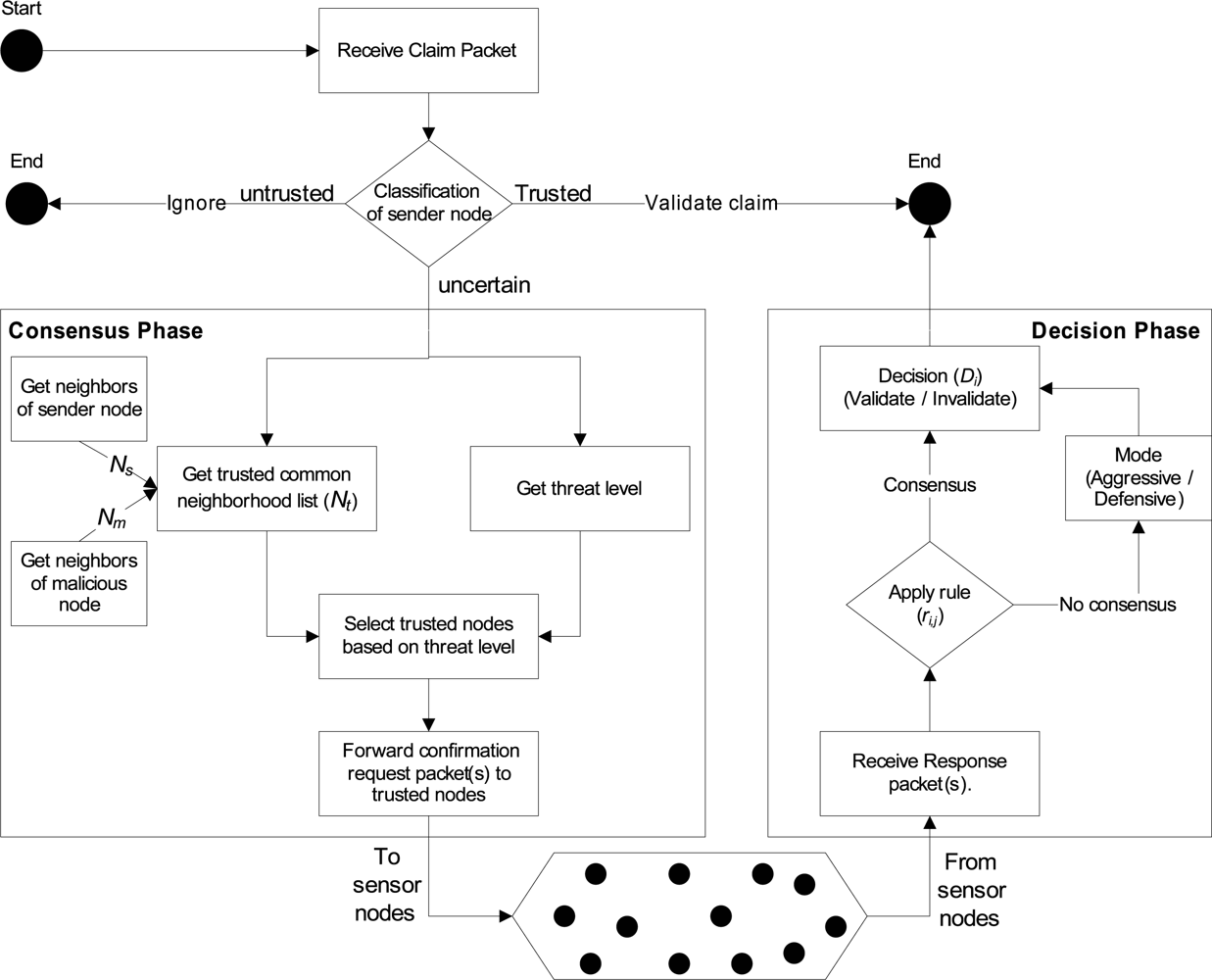
5.2. Receiver Monitoring Node
Phase 1 (Consensus Phase)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1: Received Claim Packet (IDsender, IDmal, Hlevel, detail); |
| 2: if IDsender is uncertain and IDmal is new then |
| 3: Ns = GetNeighorList(IDsender); |
| 4: Nm = GetNeighorList(IDmal); |
| 5: Nsm = Ns ∩ Nm; |
| 6: Nt = Eliminate_Known_Malicious_Nodes(Nsm); |
| 7: if Nt ≠ = ϕ then |
| 8: if ThreatLevel(T Hlevel) is Low then |
| 9: Send conf_req_pkt(rand(Nt), IDmal, Hlevel,det); |
| 10: else if ThreatLevel(T Hlevel) is Medium then |
| 11: for i = 1 to len(Nt)/2 do |
| 12: Send conf_req_pkt(rand(Nt), IDmal, Hlevel,det); |
| 13: end for |
| 14: else |
| 15: for i = 1 to len(Nt) do |
| 16: Send conf_req_pkt(IDi, IDmal,det); |
| 17: end for |
| 18: end if |
| 19: end if |
| 20: else |
| 21: Update Record; |
| 22: end if |
Phase 2 (Decision Phase)
6. Analyses and Evaluation
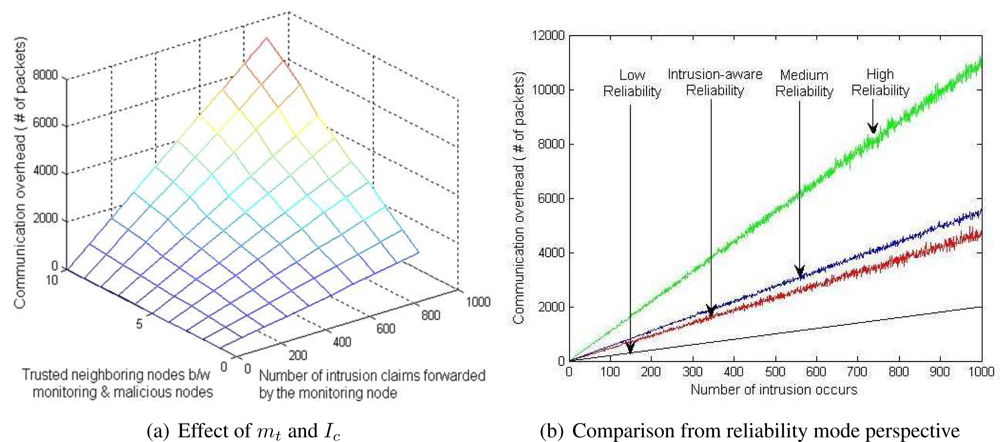
6.1. Communication Overhead Analysis
6.2. Reliability Analysis
6.3. Security Resiliency Analysis
- Event S: s sends a true claim.
- Event S̄: The complement of event S.
- Event N: All nodes in Nt send correct responses.
- Event N̄: A non-empty subset of nodes in Nt send incorrect responses.
7. Conclusion and Future Work
Acknowledgments
References and Notes
- Bhuse, V.; Gupta, A. Anomaly Intrusion Detection in Wireless Sensor Networks. J. High Speed Netw 2006, 15, 33–51. [Google Scholar]
- Du, W.; Fang, L.; Ning, P. LAD: Localization Anomaly Detection for Wireless Sensor Networks. J. Parallel Distrib. Comput 2006, 66, 874–886. [Google Scholar]
- Loo, C.E.; Ng, M.Y.; Leckie, C.; Palaniswami, M. Intrusion Detection for Routing Attacks in Sensor Networks. Inter. J. Distrib. Sensor Netw 2006, 2, 313–332. [Google Scholar]
- Chatzigiannakis, V.; Papavassiliou, S. Diagnosing Anomalies and Identifying Faulty Nodes in Sensor Networks. IEEE Sens. J 2007, 7, 637–645. [Google Scholar]
- da Silva, A.P.R.; Martins, M.H.T.; Rocha, B.P.S.; Loureiro, A.A.F.; Ruiz, L.B.; Wong, H.C. Decentralized Intrusion Detection in Wireless Sensor Networks. Proceedings of the 1st ACM international workshop on Quality of service & security in wireless and mobile networks (Q2SWinet’05), 2005; ACM: New York, NY, USA; pp. 16–23.
- Liu, F.; Cheng, X.; Chen, D. Insider Attacker Detection in Wireless Sensor Networks. Proceedings of 26th Annual IEEE Conference on Computer Communications (INFOCOM07), Anchorage, Alaska, USA, 2007; pp. 1937–1945.
- Bhuse, V.S. Lightweight Intrusion Detection: A Second Line of Defense for Unguarded Wireless Sensor Networks. PhD thesis,. Western Michigan University, Kalamazoo, MI, USA, 2007. [Google Scholar]
- Su, W.-T.; Chang, K.-M.; Kuo, Y.-H. eHIP: An Energy-Efficient Hybrid Intrusion Prohibition System for Cluster-Based Wireless Sensor Networks. Comput. Netw 2007, 51, 1151–1168. [Google Scholar]
- Zhang, Q.; Yu, T.; Ning, P. A Framework for Identifying Compromised Nodes in Wireless Sensor Networks. ACM Trans. Infor. Syst. Secur 2008, 11, 1–37. [Google Scholar]
- Barborak, M.; Dahbura, A.; Malek, M. The Consensus Problem in Fault-Tolerant Computing. ACM Comput. Surv 1993, 25, 171–220. [Google Scholar]
- Pfleeger, S.L. Security in Computing; Prentice Hall: Upper Saddle River, New Jersey, USA, 2003. [Google Scholar]
- Newman, D.P.; Manalo, K.M.; Tittel, E. CSIDS Exam Cram 2 (Exam Cram 623-531); Que Publishing: Upper Saddle River, NJ, USA, 2004. [Google Scholar]
- Perrig, A.; Canetti, R.; Tygar, J.D.; Song, D. Efficient Authentication and Signing of Multicast Streams Over Lossy Channels. Proceedings of IEEE Symposium on Research in Security and Privacy, Oakland, Canada, 2000; pp. 56–73.
- Younis, O.; Krunz, M.; Ramasubramanian, S. Node Clustering in Wireless Sensor Networks: Recent Developments and Deployment Challenges. IEEE Netw 2006, 20, 20–25. [Google Scholar]
- Heinzelman, W.B.; Chandrakasan, A.P.; Balakrishnan, H. An Application-Specific Protocol Architecture for Wireless Microsensor Networks. IEEE Trans. Wirel Comm 2002, 1, 660–670. [Google Scholar]
- Jin, Y.; Wang, L.; Kim, Y.; Yang, X.-Z. Energy Efficient Non-uniform Clustering Division Scheme in Wireless Sensor Networks. Wirel. Pers. Comm 2008, 45, 31–43. [Google Scholar]
- Hac, A. Wireless Sensor network Designs; John Wiley & Sons, Ltd: New Jersey, USA, 2003. [Google Scholar]
- Shaikh, R.A.; Lee, S.; Khan, M.A.U.; Song, Y.J. LSec: Lightweight Security Protocol for Distributed Wireless Sensor Network. Lect. Not. Comput. Sci 2006, 4217, 367–377. [Google Scholar]
- Shaikh, R.A.; Jameel, H.; Lee, S.; Song, Y.J.; Rajput, S. Trust Management Problem in Distributed Wireless Sensor Networks. Proceedings of 12th IEEE International Conference on Embedded Real Time Computing Systems and its Applications (RTCSA 2006); IEEE Computer Society: Sydney, Australia, 2006; pp. 411–415. [Google Scholar]
- Jiang, P. A New Method for Node Fault Detection in Wireless Sensor Networks. Sensors 2009, 9, 1282–1294. [Google Scholar]
- Shaikh, R.A.; Jameel, H.; d’Auriol, B.J.; Lee, H.; Lee, S.; Song, Y.J. Group-based Trust Management Scheme for Clustered Wireless Sensor Networks. IEEE Trans. Parall Distrib. Sys. (in press)..
- Buchegger, S.; Le Boudec, J.-Y. A Robust Reputation System for Peer-To-Peer and Mobile Ad-Hoc Networks. Proceedings of P2PEcon, Harvard University, MA, USA; 2004. [Google Scholar]
- Gupta, S. Automatic Detection of DOS Routing Attacks in Wireless Sensor Networks, MS thesis,. University of Houston, Houston, USA, 2006.
- Du, X.; Guizani, M.; Xiao, Y.; Chen, H.H. Two Tier Secure Routing Protocol for Heterogeneous Sensor Networks. IEEE Trans. Wirel. Commun 2007, 6, 3395–3401. [Google Scholar]
- Karlof, C.; Wagner, D. Secure Routing in Wireless Sensor Networks: Attacks and Countermeasures. Proceedings of the First IEEE International Workshop on Sensor Network Protocols and Applications (WSNA’03); IEEE Computer Society: Anchorage, Alaska, USA, 2003; pp. 113–127. [Google Scholar]
- Srinivasan, A.; Teitelbaum, J.; Liang, H.; Wu, J.; Cardei, M. Reputation and Trust-based Systems for Ad Hoc and Sensor Networks. In Algorithms and Protocols for Wireless Ad Hoc and Sensor Networks; Boukerche, A., Ed.; Wiley & Sons: New Jersey, USA, 2006. [Google Scholar]
- Yacoub, S.; Lin, X.; Burns, J. Analysis of the Reliability and Behavior of Majority and Plurality Voting Systems. Hewlett-Packard Development Company, L.P.: Palo Alto, CA, USA, 2002. [Google Scholar]







| [1] | [2] | [3] | [4] | [5] | [6] | ||
|---|---|---|---|---|---|---|---|
| Classification | Technique | Signature-based | Statistical-based | Statistical-based | Statistical-based | Statistical-based | Statistical-based |
| Architecture | Distributed & cooperative | Distributed & cooperative | Distributed & uncooperative | Hybrid | Distributed & uncooperative | Distributed & cooperative | |
| Specifications | Installation of IDS | Each sensor node | Each sensor node | Each sensor node | Each primary node of a group | Special monitor nodes in network | Each sensor node |
| IDS Scope | Multilayer (Appl., Net., MAC & Phy.) | Application layer | Network layer | Application layer | Multilayer (Appl., Net., MAC & Phy.) | Network layer | |
| Attacks detects | Masquerade attack, and forged packets attacks | Localization anomalies | Routing attacks e.g., Periodic error route attack, active & passive sinkhole attack | Correlated anomalies / attacks (invalid data insertion) | Worm hole, data alteration, selective forwarding, black hole, & jamming | Routing attacks e.g., packet dropping etc. | |
| Network | Sensor node | Static / Mobile | Static | Static / Mobile | Static / Mobile | Static | Static |
| Topology | Any | Any | Any | Cluster-based | Tree-based | Any | |
| Cost | |
|---|---|
| Low | 2Ic |
| Medium | mtIc |
| High | 2mtIc |
| Intrusion-aware | 2Il + (Im + 2Ih)mt |
© 2009 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Shaikh, R.A.; Jameel, H.; D’Auriol, B.J.; Lee, H.; Lee, S.; Song, Y.-J. Intrusion-Aware Alert Validation Algorithm for Cooperative Distributed Intrusion Detection Schemes of Wireless Sensor Networks. Sensors 2009, 9, 5989-6007. https://doi.org/10.3390/s90805989
Shaikh RA, Jameel H, D’Auriol BJ, Lee H, Lee S, Song Y-J. Intrusion-Aware Alert Validation Algorithm for Cooperative Distributed Intrusion Detection Schemes of Wireless Sensor Networks. Sensors. 2009; 9(8):5989-6007. https://doi.org/10.3390/s90805989
Chicago/Turabian StyleShaikh, Riaz Ahmed, Hassan Jameel, Brian J. D’Auriol, Heejo Lee, Sungyoung Lee, and Young-Jae Song. 2009. "Intrusion-Aware Alert Validation Algorithm for Cooperative Distributed Intrusion Detection Schemes of Wireless Sensor Networks" Sensors 9, no. 8: 5989-6007. https://doi.org/10.3390/s90805989