
Developing a Hierarchical Model for the Spatial Analysis of PM10 Pollution Extremes in the Mexico City Metropolitan Area

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
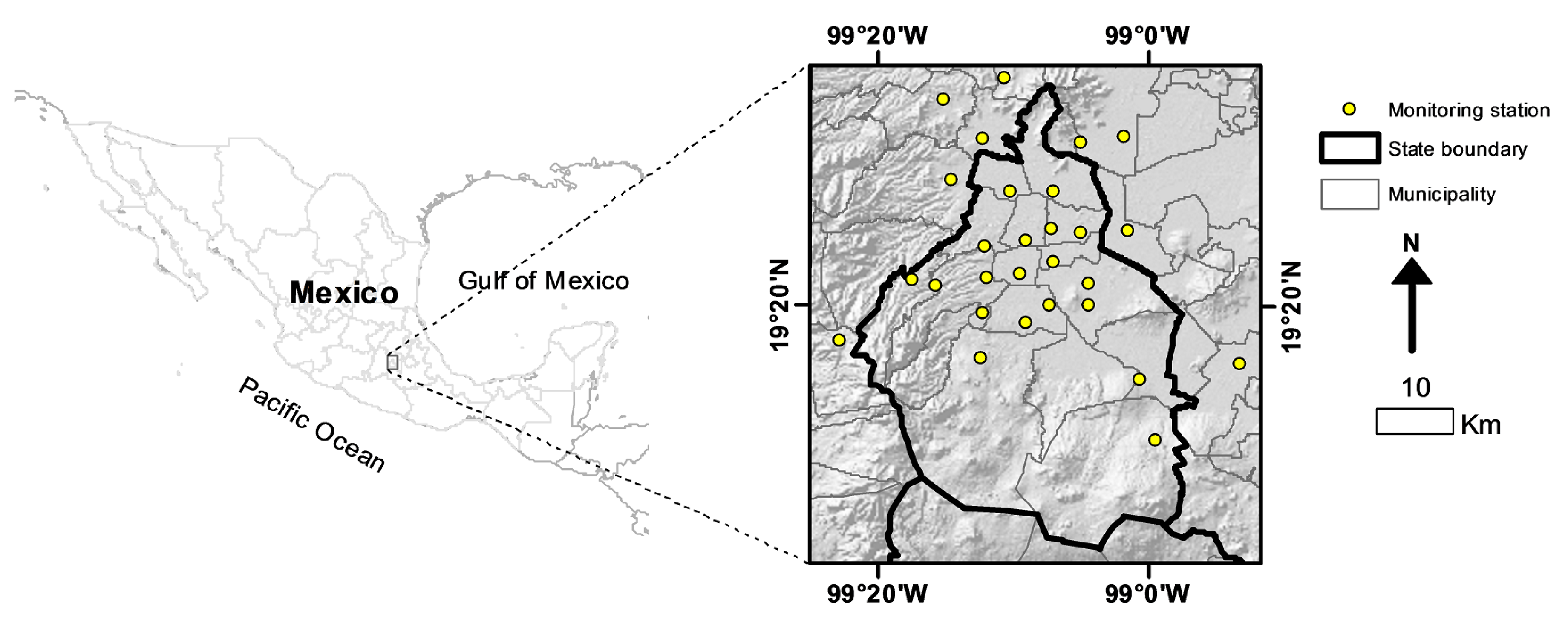
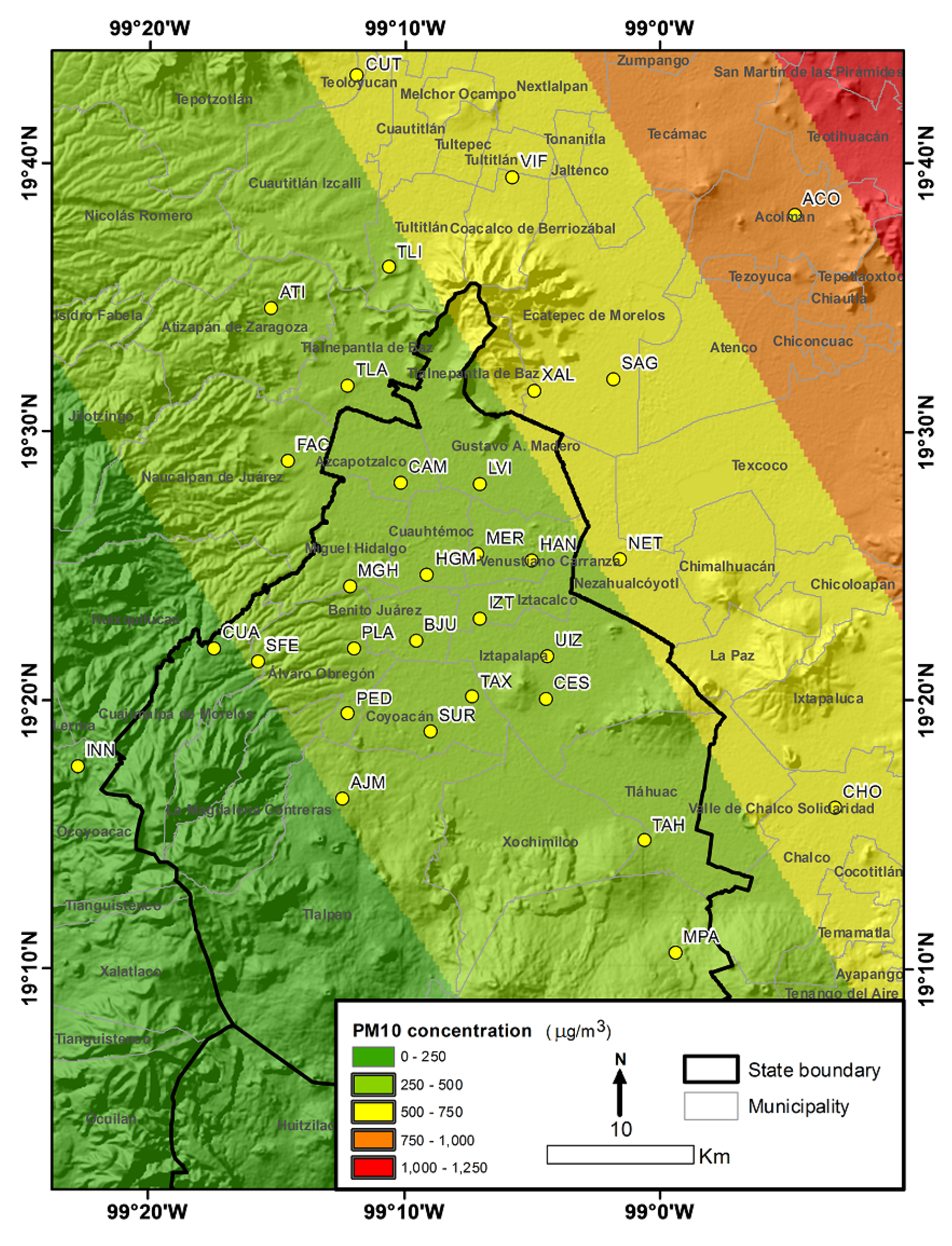
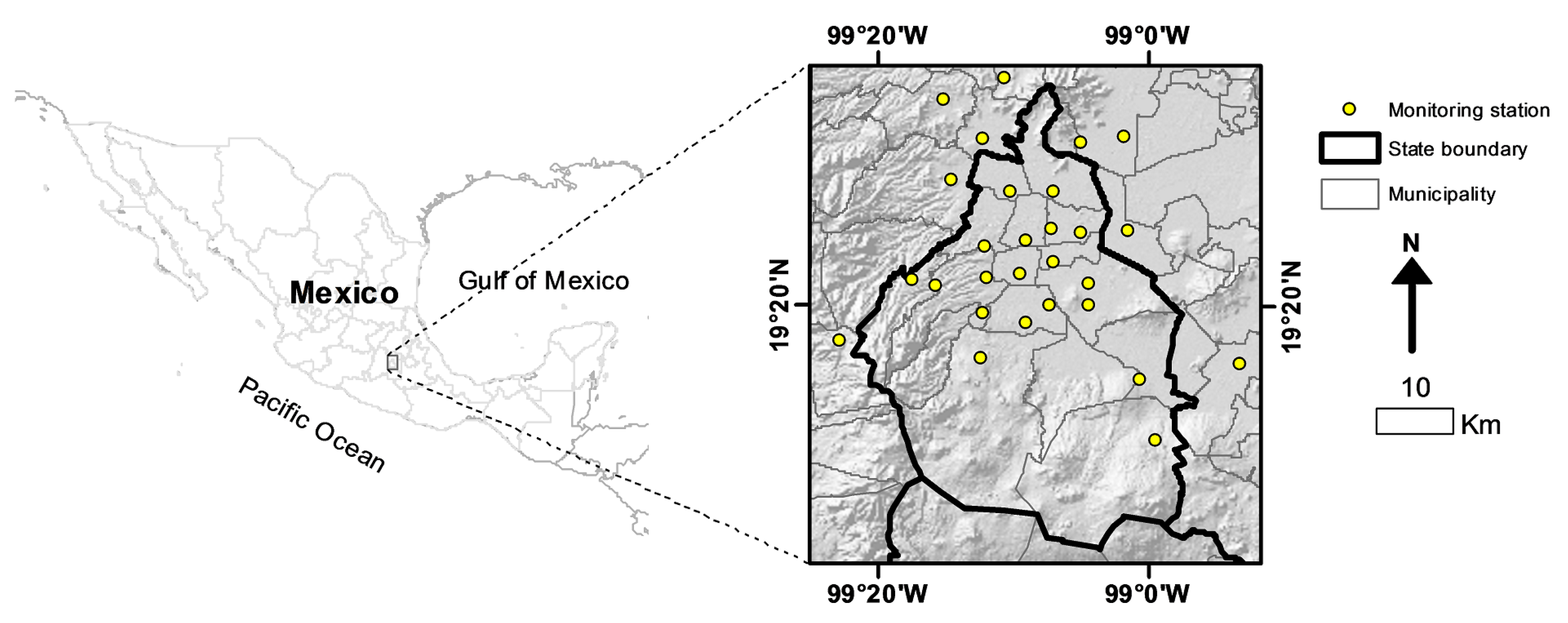
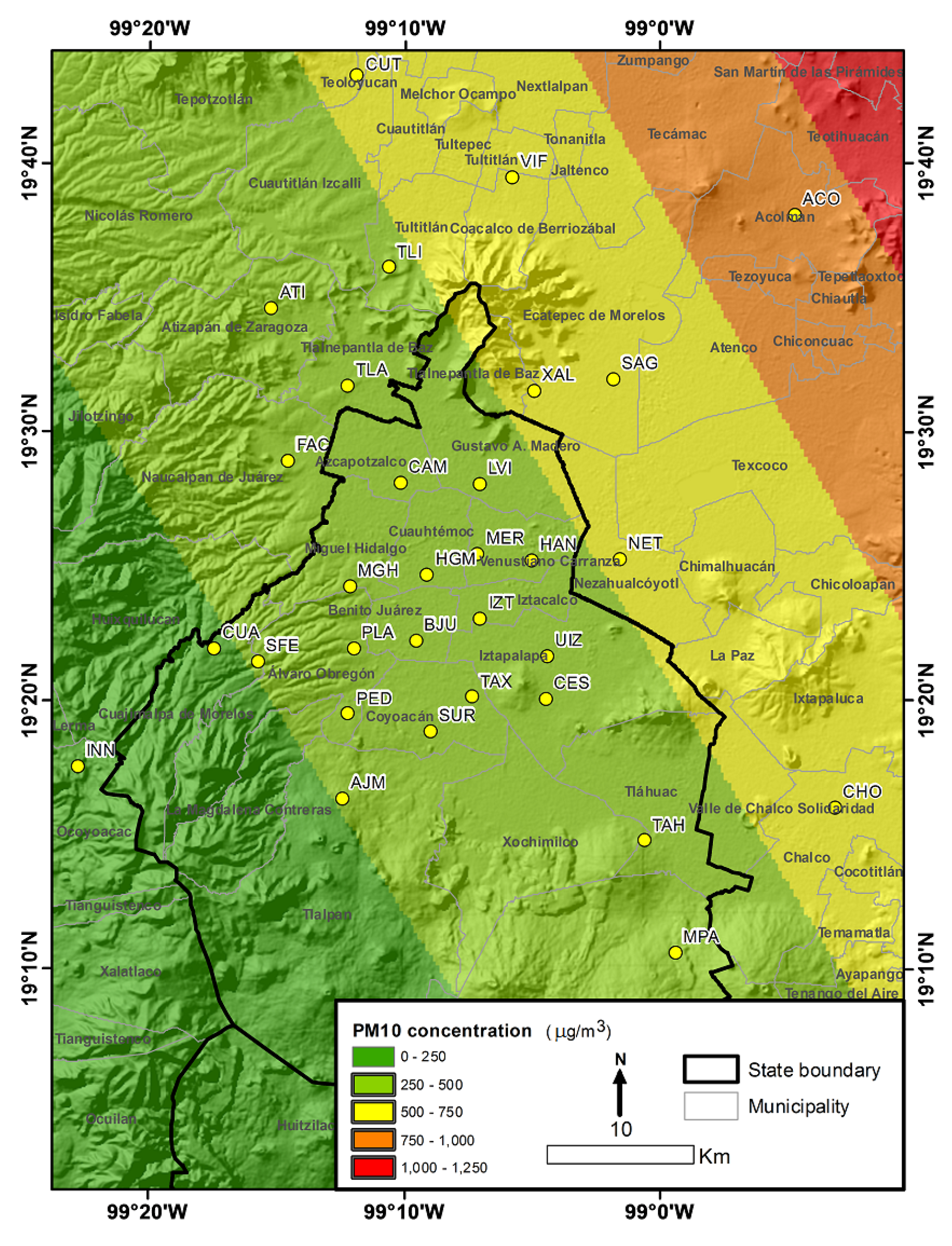
2.1. Study Area
2.2. Methodology
2.2.1. A Nonstationary GEV Model
2.2.2. Proposed Approach
2.2.3. Maximum Likelihood Estimation
2.2.4. Bayesian Implementation
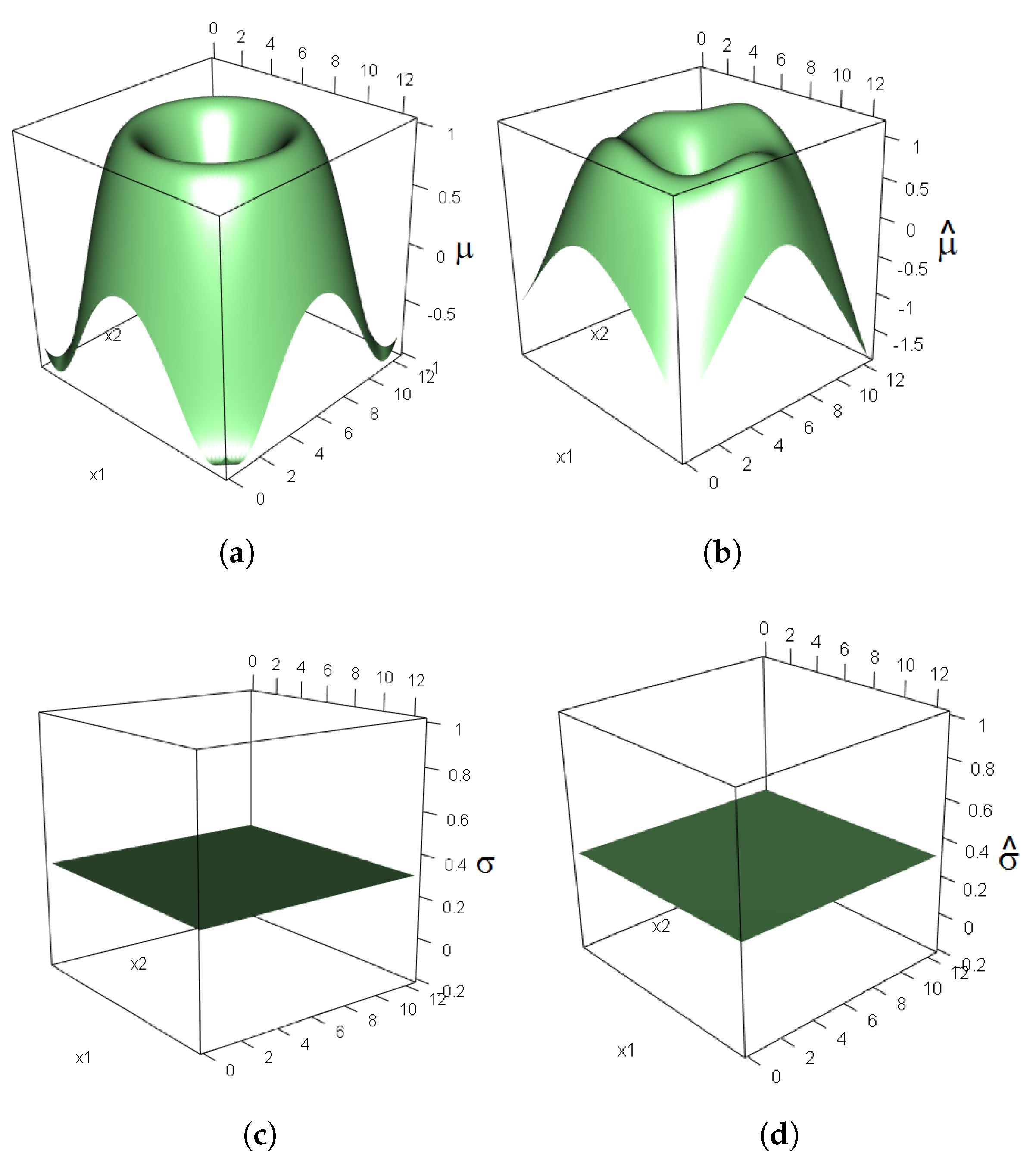
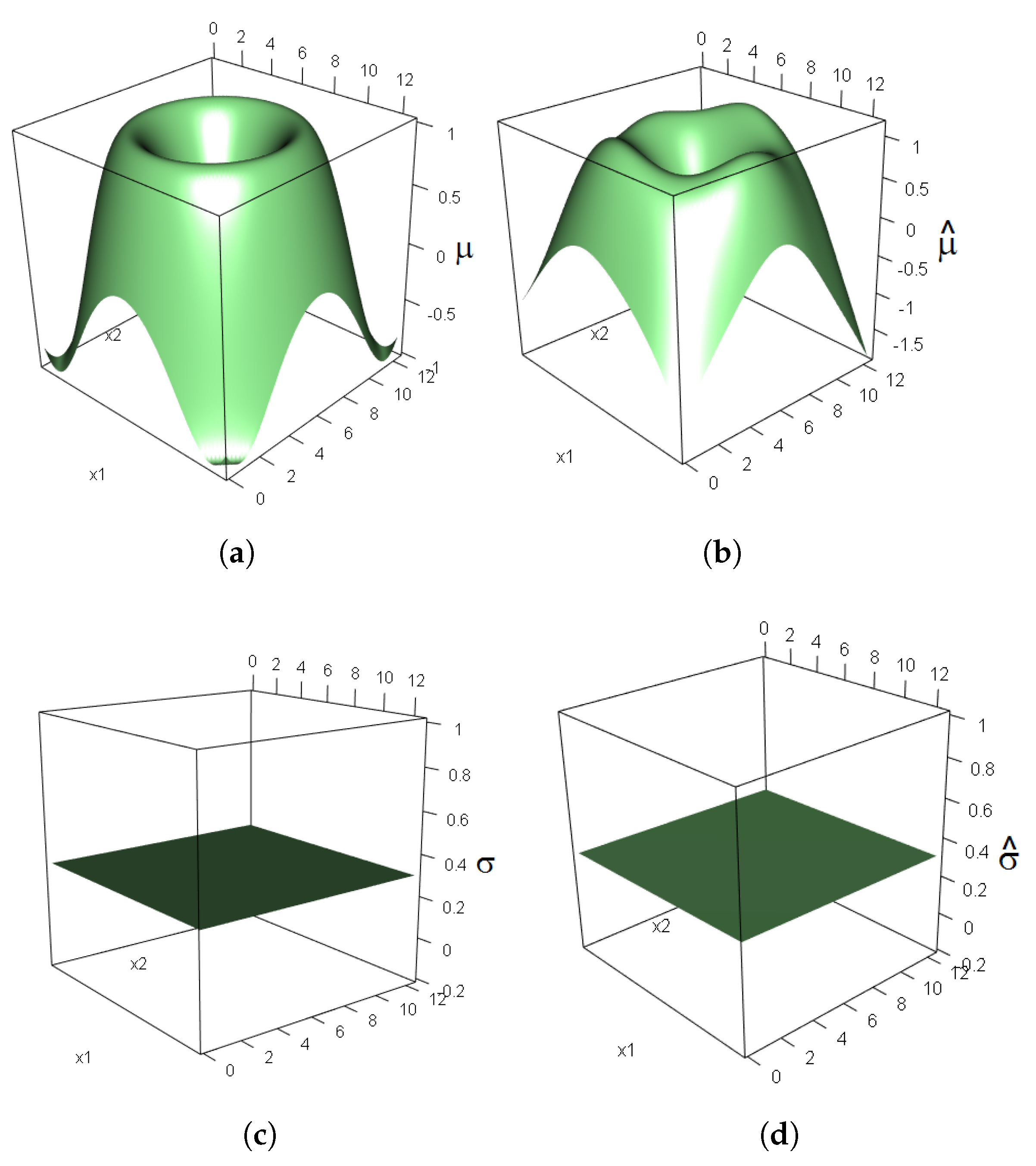
2.2.5. Simulation Study
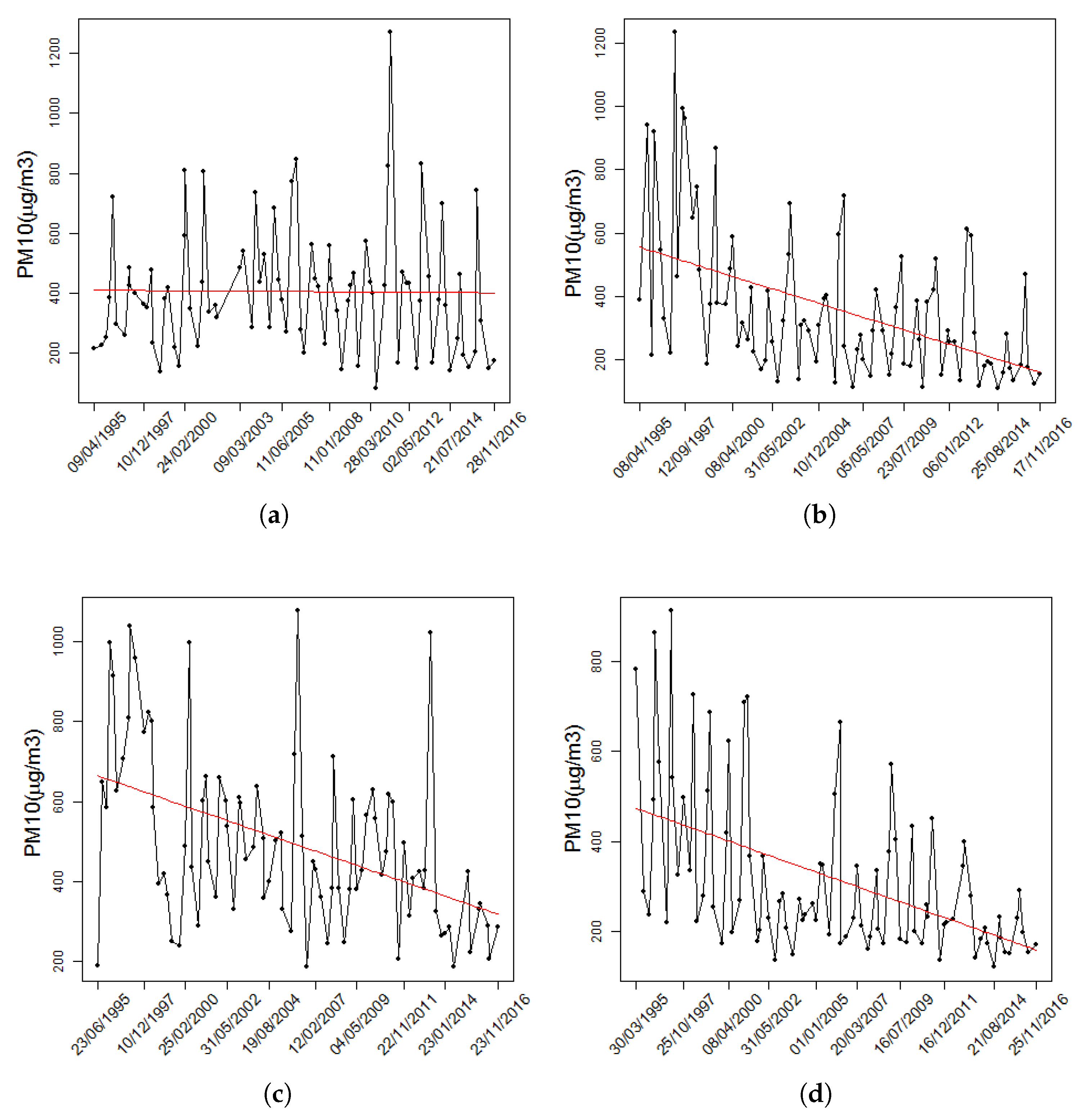
2.2.6. Maxima in Pollution Levels
Data Collection
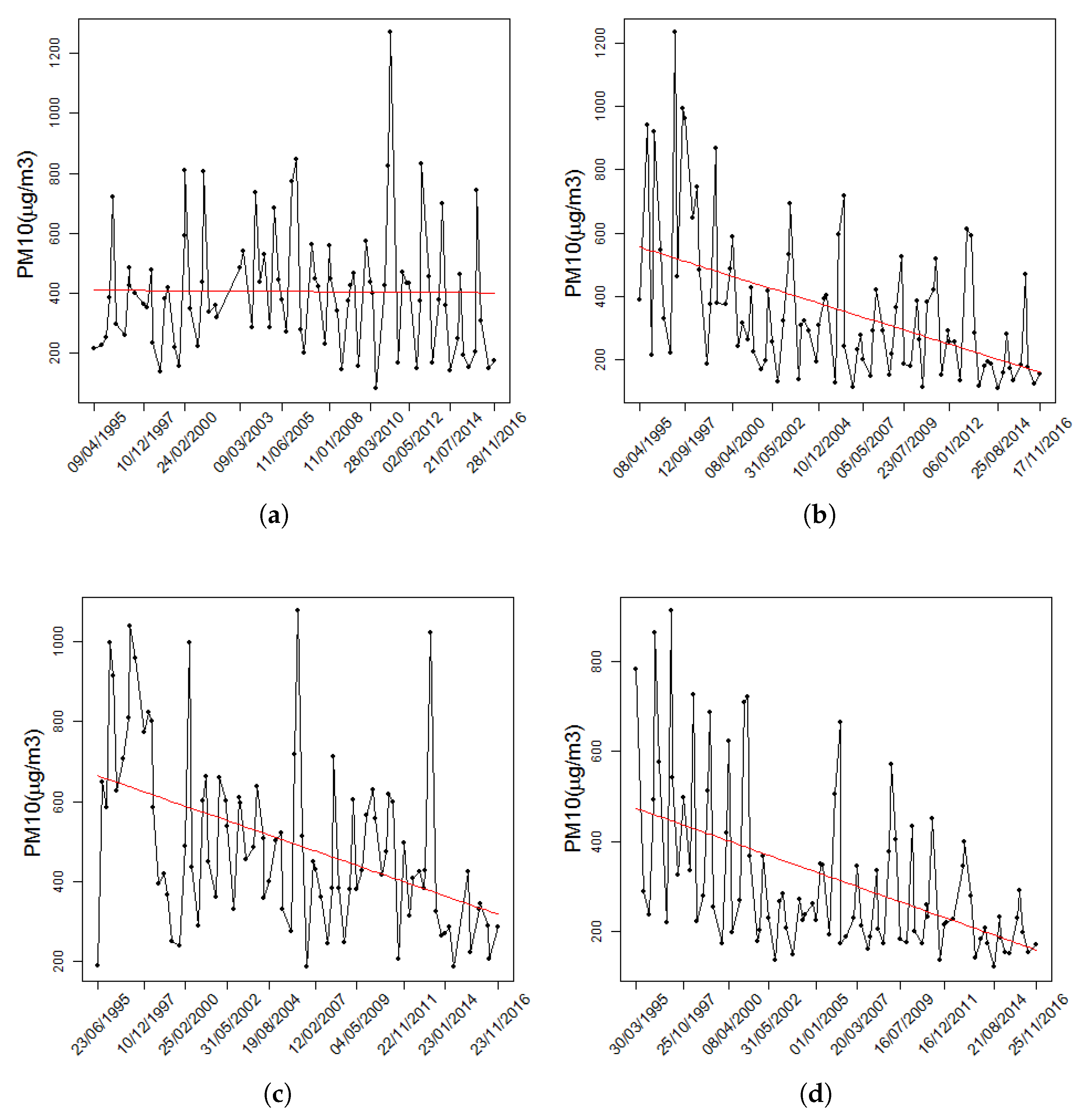
Data Analysis
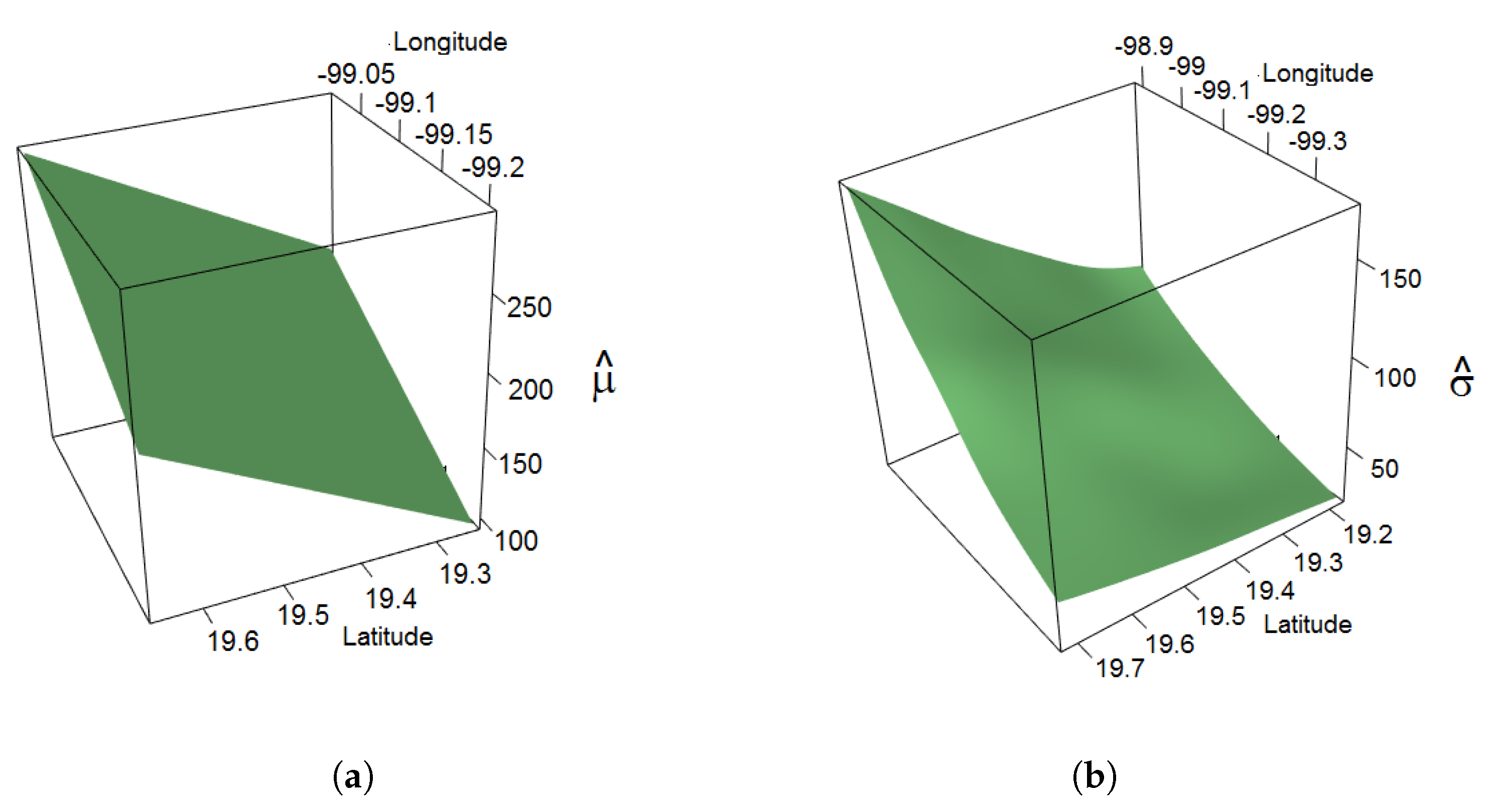
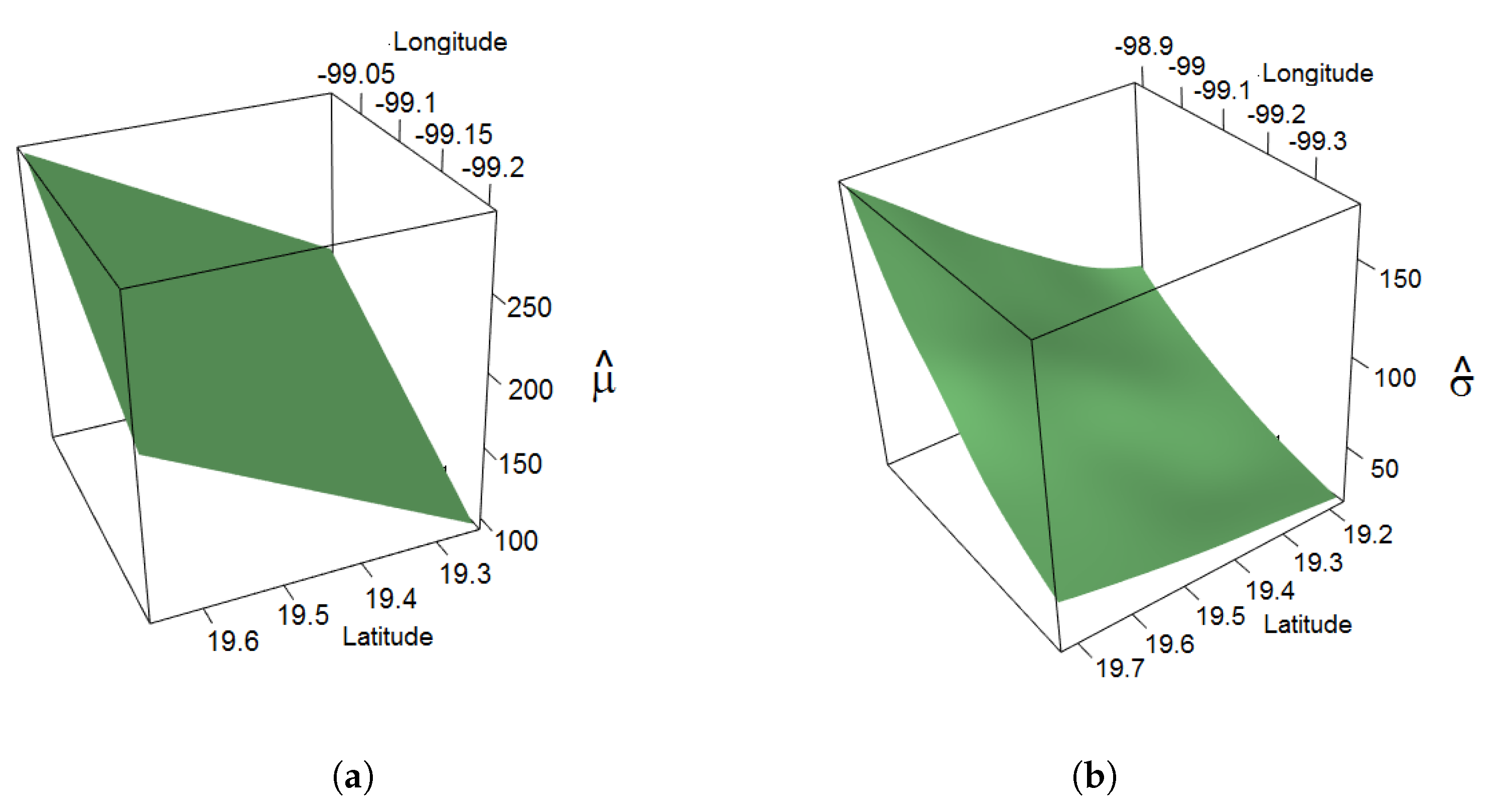
3. Results and Discussion
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Joseph, A.; Sawant, A.; Srivastava, A. PM10 and its impacts on health—A case study in Mumbai. Int. J. Environ. Health Res. 2003, 13, 207–214. [Google Scholar] [CrossRef] [PubMed]
- Kumar, P.; Jain, S.; Gurjar, B.; Sharma, P.; Khare, M.; Morawska, L.; Britter, R. New Directions: Can a “blue sky” return to Indian megacities? Atmos. Environ. 2013, 71, 198–201. [Google Scholar] [CrossRef]
- Wang, X.; Guo, Y.; Li, G.; Zhang, Y.; Westerdahl, D.; Jin, X.; Pan, X.; Chen, L. Spatiotemporal analysis for the effect of ambient particulate matter on cause-specific respiratory mortality in Beijing, China. Environ. Sci. Pollut. Res. 2016, 23, 10946–10956. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.H.; Kabir, E.; Kabir, S. A review on the human health impact of airborne particulate matter. Environ. Int. 2015, 74, 136–143. [Google Scholar] [CrossRef] [PubMed]
- Garcia, J.; Teodoro, F.; Cerdeira, R.; Coelho, L.; Kumar, P.; Carvalho, M. Developing a methodology to predict PM10 concentrations in urban areas using generalized linear models. Environ. Technol. 2016, 37, 2316–2325. [Google Scholar] [CrossRef] [PubMed]
- Edgerton, S.A.; Bian, X.; Doran, J.; Fast, J.D.; Hubbe, J.M.; Malone, E.L.; Shaw, W.J.; Whiteman, C.D.; Zhong, S.; Arriaga, J.; et al. Particulate air pollution in Mexico City: A collaborative research project. J. Air Waste Manag. Assoc. 1999, 49, 1221–1229. [Google Scholar] [CrossRef] [PubMed]
- Thishan Dharshana, K.; Coowanitwong, N. Ambient PM10 and respiratory illnesses in Colombo city, Sri Lanka. J. Environ. Sci. Health A 2008, 43, 1064–1070. [Google Scholar] [CrossRef] [PubMed]
- Elbayoumi, M.; Ramli, N.A.; Yusof, N.F.F.M.; Al Madhoun, W. Spatial and seasonal variation of particulate matter (PM10 and PM2.5) in Middle Eastern classrooms. Atmos. Environ. 2013, 80, 389–397. [Google Scholar] [CrossRef]
- Paschalidou, A.K.; Karakitsios, S.; Kleanthous, S.; Kassomenos, P.A. Forecasting hourly PM10 concentration in Cyprus through artificial neural networks and multiple regression models: Implications to local environmental management. Environ. Sci. Pollut. Res. 2011, 18, 316–327. [Google Scholar] [CrossRef] [PubMed]
- El Adlouni, S.; Ouarda, T.; Zhang, X.; Roy, R.; Bobée, B. Generalized maximum likelihood estimators for the nonstationary generalized extreme value model. Water Resour. Res. 2007, 43, W03410. [Google Scholar] [CrossRef]
- Sang, H.; Gelfand, A.E. Continuous spatial process models for spatial extreme values. J. Agric. Biol. Environ. Stat. 2010, 15, 49–65. [Google Scholar] [CrossRef]
- Jenkinson, A.F. The frequency distribution of the annual maximum (or minimum) values of meteorological elements. Q. J. R. Meteorol. Soc. 1955, 81, 158–171. [Google Scholar] [CrossRef]
- Smith, R.L. Maximum likelihood estimation in a class of non-regular cases. Biometrika 1985, 72, 67–92. [Google Scholar] [CrossRef]
- Hosking, J.R.M.; Wallis, J.R.; Wood, E.F. Estimation of the generalized extreme-value distribution by the method of probability-weighted moments. Technometrics 1985, 27, 251–261. [Google Scholar] [CrossRef]
- Hosking, J.R. L-moments: Analysis and estimation of distributions using linear combinations of order statistics. J. R. Stat. Soc. Ser. B 1990, 52, 105–124. [Google Scholar]
- Madsen, H.; Rasmussen, P.F.; Rosbjerg, D. Comparison of annual maximum series and partial duration series methods for modeling extreme hydrologic events: 1. At-site modeling. Water Resour. Res. 1997, 33, 747–757. [Google Scholar] [CrossRef]
- Gaetan, C.; Grigoletto, M. A hierarchical model for the analysis of spatial rainfall extremes. J. Agric. Biol. Environ. Stat. 2007, 12, 434–449. [Google Scholar] [CrossRef]
- Reich, B.; Shaby, B.; Cooley, D. A Hierarchical model for serially-dependent Extremes: A study of heat waves in the Western US. J. Agric. Biol. Environ. Stat. 2014, 19, 119–135. [Google Scholar] [CrossRef]
- Cooley, D.; Sain, S.R. Spatial hierarchical modeling of precipitation extremes from a regional climate model. J. Agric. Biol. Environ. Stat. 2010, 15, 381–402. [Google Scholar] [CrossRef]
- Leadbetter, M.R.; Lindgren, G.; Rootzen, H. Extremes and Related Properties of Random Sequences and Processes; Springer: New York, NY, USA, 1983; p. 336. [Google Scholar]
- Wang, X.L.; Zwiers, F.W.; Swail, V. North Atlantic Ocean wave climate scenarios for the 21st century. J. Clim. 2004, 17, 2368–2383. [Google Scholar] [CrossRef]
- Kharin, V.V.; Zwiers, F.W. Estimating extremes in transient climate change simulations. J. Clim. 2005, 18, 1156–1173. [Google Scholar] [CrossRef]
- Weissman, I. Estimation of parameters and large quantiles based on the k largest observations. J. Am. Stat. Assoc. 1978, 73, 812–815. [Google Scholar]
- Tawn, J. Bivariate extreme value theory: Models and estimation. Biometrika 1988, 75, 397–415. [Google Scholar] [CrossRef]
- Scarf, P.A. Estimation for a four parameter generalized extreme value distribution. Commun. Stat. Theory M 1992, 21, 2185–2201. [Google Scholar] [CrossRef]
- Rosen, O.; Cohen, A. Extreme percentile regression. In Statistical Theory and Computational Aspects of Smoothing; Springer: New York, NY, USA, 1996; pp. 200–214. [Google Scholar]
- Pauli, F.; Coles, S. Penalized likelihood inference in extreme value analyses. J. Appl. Stat. 2001, 28, 547–560. [Google Scholar] [CrossRef]
- Bocci, C.; Caporali, E.; Petrucci, A. Geoadditive modeling for extreme rainfall data. ASTA Adv. Stat. Anal. 2013, 97, 181–193. [Google Scholar] [CrossRef]
- Yee, T.W.; Stephenson, A.G. Vector generalized linear and additive extreme value models. Extremes 2007, 10, 1–19. [Google Scholar] [CrossRef]
- Rodriguez, S.; Reyes, H.; Perez, P.; Vaquera, H. Selection of a subset of meteorological variables for ozone analysis: Case study of pedregal station in Mexico City. Environ. Sci. Eng. A 2012, 1, 11–20. [Google Scholar]
- Cannon, A.J. A flexible nonlinear modelling framework for nonstationary generalized extreme value analysis in hydroclimatology. Hydrol. Process. 2010, 24, 673–685. [Google Scholar] [CrossRef]
- Jauregui, E. Local wind and air pollution interaction in the Mexico basin. Atmósfera 1988, 1, 131–140. [Google Scholar]
- Fisher, R.A.; Tippett, L.H.C. Limiting forms of the frequency distribution of the largest or smallest member of a sample. Proc. Camb. Philos. Soc. 1928, 24, 180–190. [Google Scholar] [CrossRef]
- Coles, S. An Introduction to Statistical Modeling of Extreme Values; Springer: London, UK, 2001. [Google Scholar]
- Figueiredo, M.A. On Gaussian radial basis function approximations: Interpretation, extensions, and learning strategies. In Proceedings of the 15th International Conference on Pattern Recognition (ICPR-2000), Barcelona, Spain, 3–7 September 2000; Volume 2, pp. 618–621. [Google Scholar]
- Kütchenhoff, H.; Thamerus, M. Extreme value analysis of Munich air pollution data. Environ. Ecol. Stat. 1996, 3, 127–141. [Google Scholar] [CrossRef]
- Lin, C.Y.; Chiang, M.L.; Lin, C.Y. Empirical model for evaluating PM10 concentration caused by river dust episodes. Int. J. Environ. Res. Public Health 2016, 13, 553. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
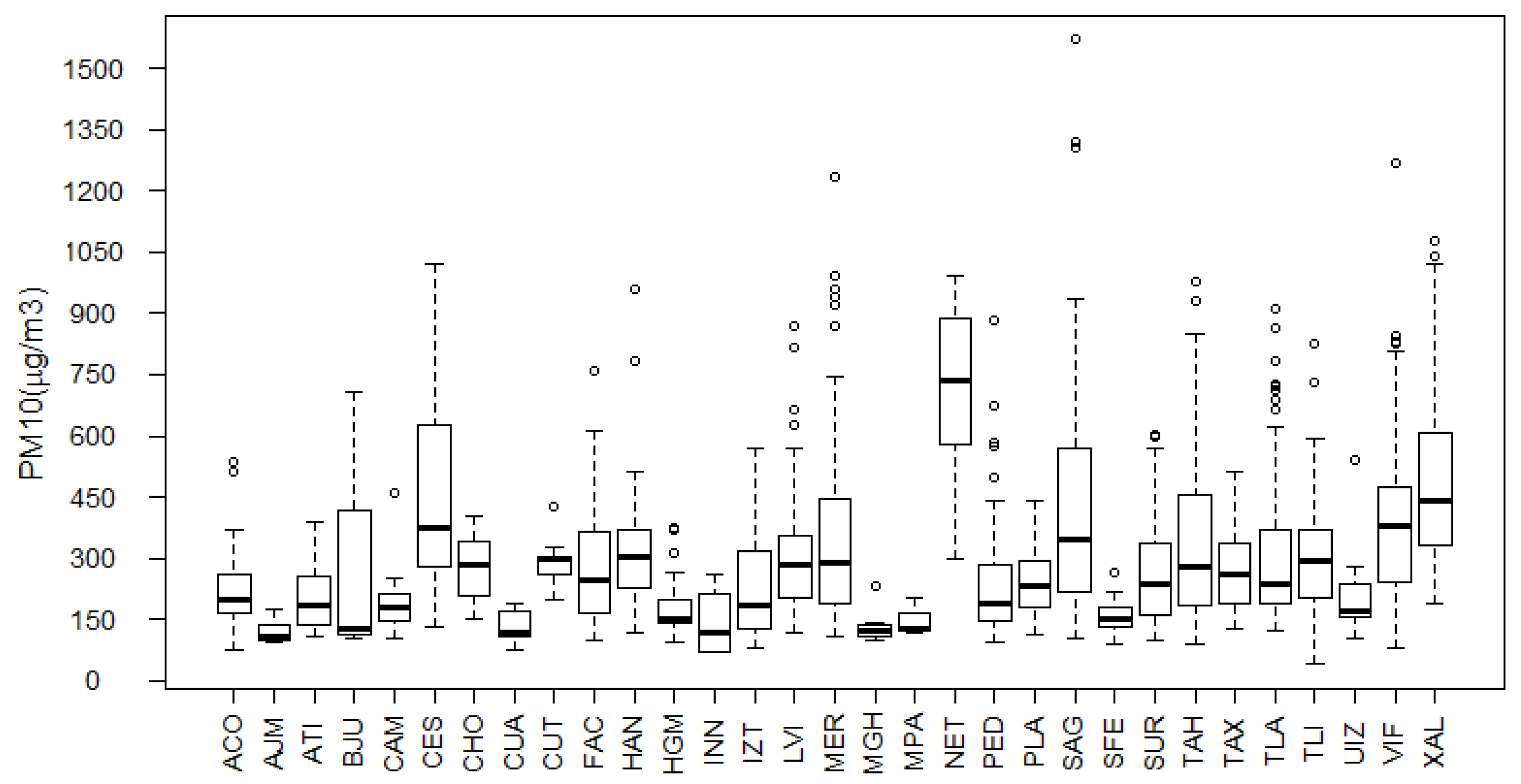
| Name | Symbol | Long | Lat | Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. |
|---|---|---|---|---|---|---|---|---|---|
| Acolman | ACO | 9907 03.89 | 192804.4 | 76 | 166.2 | 197.5 | 230.5 | 252.5 | 535 |
| Ajusco Medio | AJM | 991216.54 | 193144.67 | 92 | 99 | 109 | 121.1 | 137 | 175 |
| Atizapan | ATI | 990456.64 | 193133.58 | 108 | 137 | 185 | 203.9 | 256 | 387 |
| Benito Juárez | BJU | 990710.53 | 192528.59 | 102 | 118.5 | 127 | 265.8 | 274.2 | 707 |
| Camarones | CAM | 991214.88 | 191930.52 | 102 | 150 | 181.5 | 189.8 | 213.2 | 462 |
| Cerro de la Estrella | CES | 990428.84 | 192005.03 | 130 | 279 | 373 | 444 | 617.5 | 1023 |
| Chalco | CHO | 990134.02 | 192516.14 | 150 | 207.5 | 283 | 272.3 | 341 | 401 |
| Cuajimalpa | CUA | 991037.82 | 193609.15 | 75 | 108 | 119 | 131.7 | 168 | 191 |
| Cuautitlán | CUT | 990547.72 | 193929.60 | 198 | 267.2 | 297 | 289.5 | 305 | 427 |
| FES Acatlán | FAC | 990038.03 | 191447.25 | 98 | 167.5 | 248 | 272.3 | 364 | 758 |
| Hangares | HAN | 990859.97 | 191852.12 | 117 | 228 | 302 | 333.8 | 369 | 959 |
| Hospital General de México | HGM | 991436.68 | 192856.90 | 96 | 143.8 | 153 | 190 | 193.2 | 376 |
| Investigaciones Nucleares | INN | 990501.04 | 192513.86 | 69 | 71.25 | 120 | 142 | 190.8 | 259 |
| Iztacalco | IZT | 991200.39 | 192157.12 | 78 | 128.5 | 186 | 230.8 | 317 | 569 |
| La Villa | LVI | 990149.16 | 193158.68 | 118 | 203.8 | 286 | 309 | 355.5 | 871 |
| Merced | MER | 990723.53 | 192008.48 | 109 | 187.5 | 290.5 | 357.8 | 437 | 1233 |
| Miguel Hidalgo | MGH | 990703.50 | 192303.88 | 100 | 109 | 121 | 134.7 | 137 | 230 |
| Milpa Alta | MPA | 985443.21 | 193807.8 | 119 | 123.5 | 128 | 150.3 | 166 | 204 |
| Netzahualcoyotl | NET | 991011.25 | 192806.25 | 298 | 580.5 | 737 | 722.4 | 887 | 991 |
| Pedregal | PED | 990425.96 | 192138.85 | 94 | 146 | 189 | 233 | 284 | 884 |
| Plateros | PLA | 990907.94 | 192441.82 | 112 | 178 | 233 | 241.2 | 294 | 440 |
| San Agustín | SAG | 991546.31 | 192126.48 | 104 | 216.5 | 346 | 430.9 | 571 | 1570 |
| Santa Fe | SFE | 991154.96 | 194319.86 | 91 | 131 | 149 | 159.2 | 182 | 267 |
| Santa Ursula | SUR | 985309.91 | 191601.01 | 100 | 164 | 237 | 265.8 | 335 | 603 |
| Tlahuac | TAH | 991514.87 | 193437.06 | 91 | 183 | 281 | 336.9 | 463.2 | 977 |
| Taxqueña | TAX | 991730.13 | 192155.12 | 128 | 188.5 | 262 | 280.6 | 334.5 | 513 |
| Tlalnepantla | TLA | 991209.57 | 192414.58 | 121 | 190 | 236 | 317.3 | 374 | 912 |
| Tultitlán | TLI | 991227.87 | 191619.77 | 41 | 203.2 | 293 | 303 | 368.5 | 828 |
| UAM Iztapalapa | UIZ | 990934.54 | 192213.67 | 105 | 158 | 172 | 201.8 | 238 | 539 |
| Villa de las Flores | VIF | 992249.87 | 191731.08 | 82 | 243.8 | 380.5 | 405.8 | 470.8 | 1269 |
| Xalostoc | XAL | 985924.68 | 191036.83 | 187 | 330 | 443 | 497 | 609 | 1076 |
| % Method | Model | Deviance | p-value | ||
|---|---|---|---|---|---|
| ML | GEV0 | 32 | 0.12 | ||
| GEV1 | |||||
| Penalized ML | GEV0 | 26.6 | 0.33 | ||
| GEV1 |
| % Parameter | Mean | 95% CI |
|---|---|---|
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aguirre-Salado, A.I.; Vaquera-Huerta, H.; Aguirre-Salado, C.A.; Reyes-Mora, S.; Olvera-Cervantes, A.D.; Lancho-Romero, G.A.; Soubervielle-Montalvo, C. Developing a Hierarchical Model for the Spatial Analysis of PM10 Pollution Extremes in the Mexico City Metropolitan Area. Int. J. Environ. Res. Public Health 2017, 14, 734. https://doi.org/10.3390/ijerph14070734
Aguirre-Salado AI, Vaquera-Huerta H, Aguirre-Salado CA, Reyes-Mora S, Olvera-Cervantes AD, Lancho-Romero GA, Soubervielle-Montalvo C. Developing a Hierarchical Model for the Spatial Analysis of PM10 Pollution Extremes in the Mexico City Metropolitan Area. International Journal of Environmental Research and Public Health. 2017; 14(7):734. https://doi.org/10.3390/ijerph14070734
Chicago/Turabian StyleAguirre-Salado, Alejandro Ivan, Humberto Vaquera-Huerta, Carlos Arturo Aguirre-Salado, Silvia Reyes-Mora, Ana Delia Olvera-Cervantes, Guillermo Arturo Lancho-Romero, and Carlos Soubervielle-Montalvo. 2017. "Developing a Hierarchical Model for the Spatial Analysis of PM10 Pollution Extremes in the Mexico City Metropolitan Area" International Journal of Environmental Research and Public Health 14, no. 7: 734. https://doi.org/10.3390/ijerph14070734