3.2. Generation Reliability Based on DEG Algorithm
The DEGA uses PIS to simulate evolution. Under the survival rule, it calculates the fitness for each of the individual populations, which is randomly created. In DEGA, the individual inside the random population is called a chromosome. Each chromosome is represented by binary numbers {0, 1}, which also represent the generation unit. During the simulation of the generating system reliability, it is assumed that there are two states, up and down, and the chromosome length “
L” refers to the total number of components or generators system. Identical components or generators are split into groups, with each particular group representing a part of a chromosome. Thus, each chromosome will consist of “
n” parts. Additionally, each chromosome represents the system states capacities.
Figure 4 shows that, each chromosome is represented by a number of components.
In the process of evaluating the adequacy of power generation, the applied elementary model consists of a conventional generating unit model and a chronological load model. These two models are incorporated or superposed to produce the risk model. This study only considers any available generating capacity to represent the risk model in comparison with the expected load of the system.
Hence, by employing the DEGA, each chromosome represents a state in the system. In the space state of the system, the chromosome with a capacity that is higher than the total load represents a success state, while the chromosome with a capacity that is lower than the total load represents a failure state. In order to construct the system state array to estimate the generating system adequacy, this study considers chromosomes in the failure state during a search in the state space pruning of the system.
State array chromosomes are responsible for the highest contribution to the loss states in a load, which, therefore, consists of the binary data of the chromosomes after performing the evaluation process when selecting from random initial populations to be a store. The state array consists of fields that represent the information evaluated from the chromosomes. Such information is stored in these states array groupings. The first field has an array with several columns similar to the number of chromosome parts. The column includes several generators in the upstate mean (take bit one) in a similar part. In the remaining fields of state array area range, each of this state “
i” contains generation capacity (
Capi), probability (
PGi), the total number of equivalent permutations (
Copyi) and frequency (
FGi).
Figure 5 depicts the construct of the state array which displays the chromosome stored in these fields.
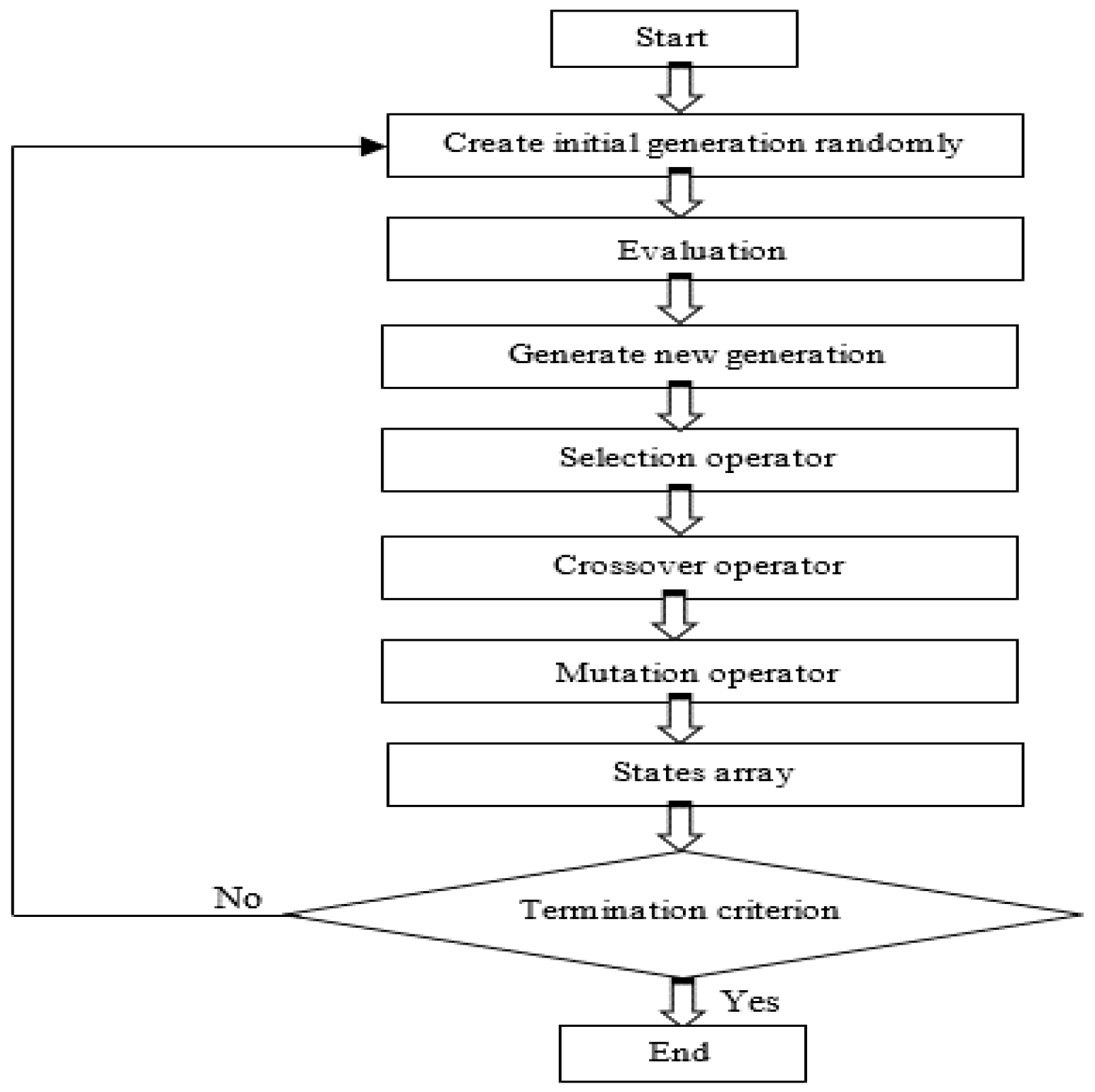
To evaluate the adequacy of the generating system, the initial procedure is in construct the array of failure-states with regards to the total load demand using DEGA. The next step is the indices for reliability, which is calculated through the convolution of the effective available capacity, where the chronological load is based on the state array previously achieved. The constructions of the state array are summarized as follows:
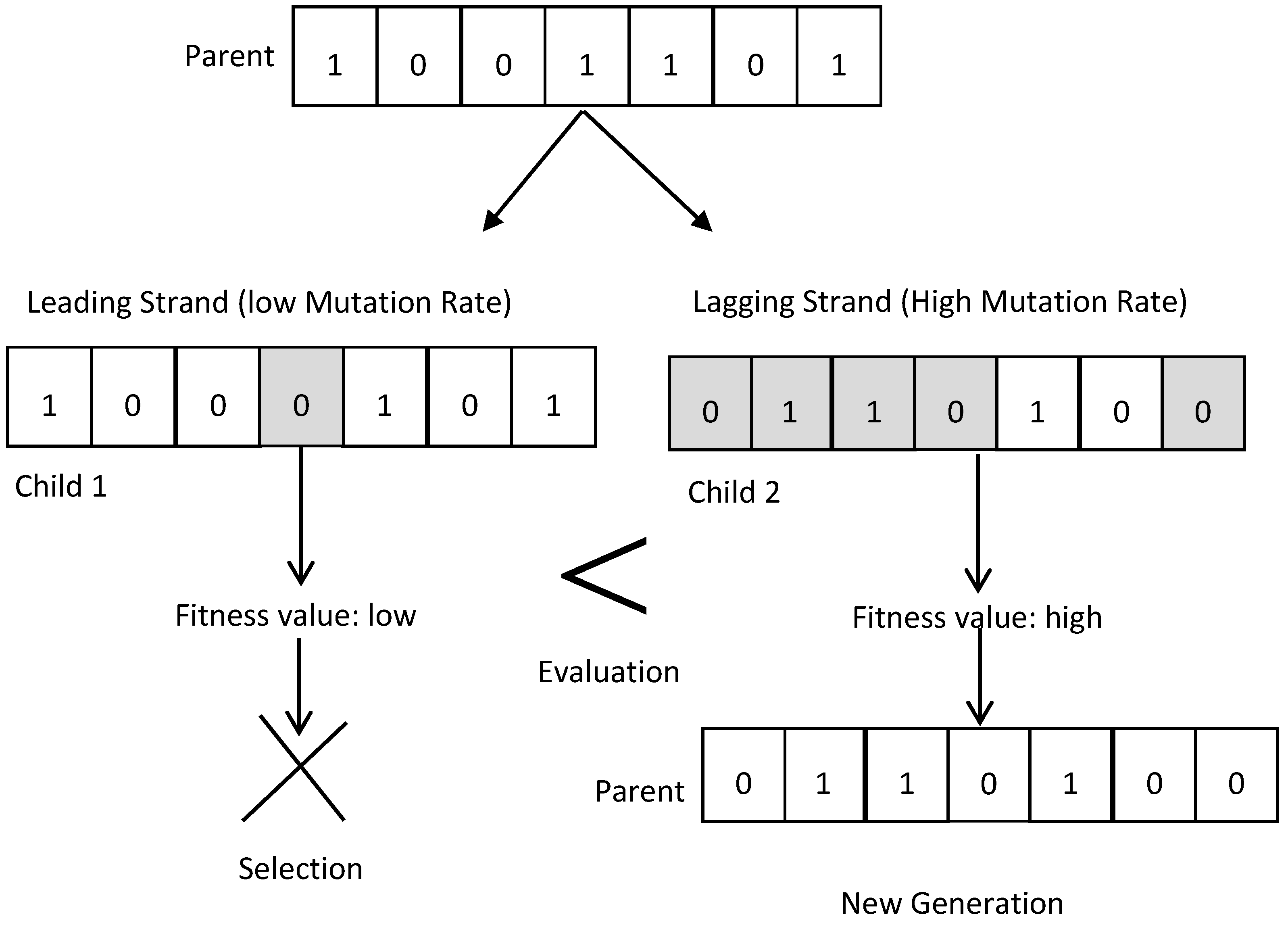
Step 1: The values of the control parameters of the DEGA is set, which include pop_size, Pc, and Pm, which has a double structure. Then, values are set, which include the probability of the leading strand (Ple), and of the lagging strand (Pla), and the reliability parameters (FOR, µ, λ) for the generation unit and threshold probability (tp).
Step 2: Each chromosome is arranged in “n” parts; each part includes adjacent binary number representation for the conventional generating units, with the same reliability parameters and MW capacity.
Step 3: The length of the chromosome, when part number
i is represented as
Li:
Step 4: Therefore, each chromosome represents the system state capacity.
Step 5: The initial population is randomly generated, with each bit having a random binary number [0, 1]; this procedure is repeated for all initial populations of the chromosomes.
Step 6: The state array that must be saved is constructed.
Step 7: The effective generating capacity of system state
i; is calculated:
where
bj represents the state of the generating unit
j;
mg refers to the number of generating units;
gj refers to the MW capacity of each unit. If the capacity
Capi >
Lmxa, it represents the chromosome state of success, therefore, the fitness of its corresponding chromosome is allocated a very small value so as to reduce its chance to influence the next generation population.
Step 8: The failure state of the system state “
i” is calculated; if
Capi <
Lmxa, then the state is in the failure state. Therefore, the chromosome failure probability is calculated as follows:
where
mg is the number of generating unit
j;
Pj is the probability value, which can take one of these two values: if
bj = 1, then
Pj = 1 −
FORj, and if
bj = 0, then
Pj =
FORj.
The number of all the possible permutations for the evaluated state
i is identified as follows:
where
Oj refers to the number of “noes” in group
j of length
Ln.
Equation (7) is used to calculate the fitness of the system state:
The objective function is applied in this algorithm and maximized by the DEGA based optimizer search.
The frequency is determined according to the method described by [
16]. In this study, the system state is determined by:
where
bj refers to the generating unit state; while
µj, and,
λj indicate the respective rates for repair and failure of the generating unit
j.
Step 9: The information on eligible chromosome state is saved.
The above process is repeated for all the chromosomes until all the remaining states are evaluated. All chromosomes are checked before being evaluated to ensure that they are not previously saved from another evaluation step. If the state has been saved previously, a very small number of the fitness is assigned so that the probability of this state could be multiplied to reduce the chance of it appearing in the next generation. This state is disregarded and is not added to the state array.
Step 10: The number of iterations is increased by one.
Step 11: Each stopping criterion is checked to determine whether it is met, so that the algorithm could be paused, and the output of the state array can be derived. If the stopping criterion is not met, step 12 will be conducted.
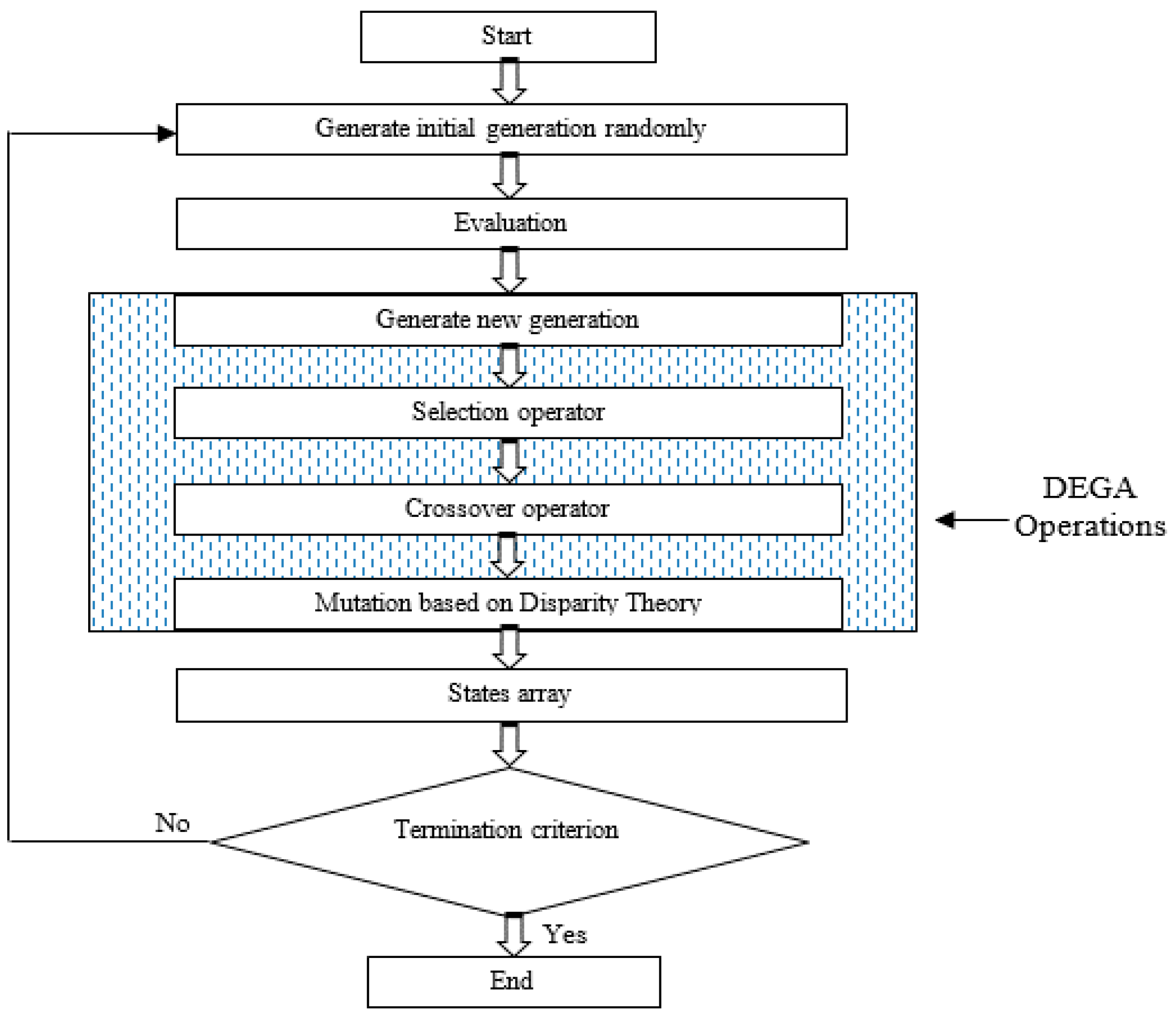
Step 12: Different DEGA operators are adopted to produce the next generation, then, Steps 6 to 9 are repeated until all stopping criteria are met.
Step 13: The reliability indices were calculated based on the previously achieved state arrays.
3.3. Calculating Reliability Indices
Any of the stopping criteria mentioned in [
16] could be used to stop the DEGA. The reliability indices for LOLE, LOEE, and LOLF are calculated based on the achieved state arrays and the convolution of the hourly load values. This study considers the
Li, to represent the discrete values for the load levels at the hour (
t). The loss of load probability (LOLP) load value is evaluated as shown:
where sa represents the total number of state arrays, while, the status of the system state is
Sj. The status value will be equal zero if it is a success state, i.e.,
Capj ≥
LHi, while the status value is equal to one if it is a failure state, i.e.,
Capj <
LHi. After the LOLP is done for all load levels, the LOLE per year in an hour is measured using Equation (10):
The expected power not supplied (
PNS) in each load level per hour (in megawatts) is calculated using the following Equation (11):
The calculation for LOLF involves two main components; frequency due to load fluctuation
FL, and frequency of generating system capacity
FG [
11]. Each component is calculated independently, as follows:
The Vj equals “zero” when negative value represents the value between the brackets and is equal to “one” otherwise. Meanwhile, the indices for annual LOLF occurrences can be calculated using Equation (3).
This algorithm has several advantages, such as in the construct of the probability outage capacity table of the generating system. It can also determine how much the combinations of the generating unit contribute to the failure state of the system. This is useful in increasing these units’ reliability or when there is an attempt to add more units into the system.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}