Reactive Power Optimization for Distribution Network Based on Distributed Random Gradient-Free Algorithm


1
College of Energy and Electrical Engineering, Hohai University, Nanjing 211100, China
2
College of Automation, Nanjing University of Posts and Telecommunications, Nanjing 210023, China
*
Author to whom correspondence should be addressed.
Energies 2018, 11(3), 534; https://doi.org/10.3390/en11030534
Submission received: 4 February 2018
/
Revised: 22 February 2018
/
Accepted: 23 February 2018
/
Published: 1 March 2018
(This article belongs to the Section F: Electrical Engineering)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:The increasing penetration of distributed energy resources in distribution systems has brought a number of network management and operational challenges; reactive power variation has been identified as one of the dominant effects. Enormous growth in a variety of controllable devices that have complex control requirements are integrated in distribution networks. The operation modes of traditional centralized control are difficult to tackle these problems with central controller. When considering the non-linear multi-objective functions with discrete and continuous optimization variables, the proposed random gradient-free algorithm is employed to the optimal operation of controllable devices for reactive power optimization. This paper presents a distributed reactive power optimization algorithm that can obtain the global optimum solution based on random gradient-free algorithm for distribution network without requiring a central coordinator. By utilizing local measurements and local communications among capacitor banks and distributed generators (DGs), the proposed reactive power control strategy can realize the overall network voltage optimization and power loss minimization simultaneously. Simulation studies on the modified IEEE-69 bus distribution systems demonstrate the effectiveness and superiority of the proposed reactive power optimization strategy.
1. Introduction
Distribution networks (DNs), as the interface between transmission system and load-customers, is one of the key components of a power network. The generation or consumption of reactive power by compensators or Distributed Generators (DGs) is a way to reduce power loss and control voltage fluctuations. Under high demand of economic operation for DNs, the reactive power optimization (RPO) has been reported as the foremost concern for the connection of large amounts of DGs. The inversion of the power flow caused by large number of DGs may induce voltage fluctuation to which DN operators cannot effectively respond. The RPO is conducted by the regulation of reactive compensation capacitors or DGs in DN through a constrained optimization problem that aims to minimize power losses and improve voltage profiles subject to finite capacitor capacity and the upper and lower bus voltage limits. In case of meeting the constraint conditions, the main objectives of RPO are: (1) to reduce active power losses in the system; and, (2) to improve voltage profiles [1]. As such, a proper reactive power control mechanism should be devised to not only prevent voltage disturbances and conflicts, but also improve the overall system economic operation performance.
To meet the ever-increasing demand of power distribution automation, RPO is currently conducted as a multi-objective optimization problem [2]. Currently, existing centralized reactive power control strategies include traditional mathematical algorithm and artificial intelligence methods. In [3], the authors proposed a nonlinear primal-dual interior-point algorithm to overcome the local minimum of the interior-point search and the slowness of convergence rate of simple nonlinear algorithms. However, the solution is limited to the initial value determination. The DC power flow approximation linearizes the constraints and makes the problem easier to solve [4], however, accuracy is not guaranteed because this may not be a good approximation for DNs. As such, the applications of artificial intelligence methods for minimizing the DNs power loss have been developed. Authors in [5] discussed an improved genetic algorithm to find the optimization direction, which is easy to fall into local optimum. A new method based on multiple evolutionary algorithms with adaptive selection strategies was proposed in [6]. However, the solution has several drawbacks, such as parameter setting complex and slow convergence.
The optimization algorithms for reactive power optimization of DNs that are mentioned above are all centralized manners which requires a central coordinator. The volume of data that arises as a result of large-scale integration of DGs is expected to lead to a communication bottleneck in the near future because the central coordinator must collect and process all of the information for reactive power optimization. Another important issue is robustness in terms of the cyber-physical system. The central coordinator becomes a vulnerable target for both cyber and physical attacks. In the case of central coordinator, it is possible that the information transmission failure with the collapse of catastrophic accidents of the information networks. Even worse, enormous growths in a variety of controllable devices that have complex control requirements are widely distributed in distribution networks. When considering the significant challenges posed by a centralized control, a distributed reactive power optimization algorithm is preferred.
In this paper, a distributed optimization strategy is proposed. In a multi-agent optimal operation problem, each agent is basically trying to minimize its own objective function based on information communication with its neighboring agents. If each agent is able to communicate with all the other neighboring agents, then the problem can be essentially viewed as a distributed optimal operation problem. A discrete reactive power optimization method based on the generalized Benders. Decomposition has been considered to improve the efficiency of DNs [7]. A novel distributed voltage control strategy has been proposed employing a multiple agent system platform [8]. A new class of distributed weighted-consensus strategies is introduced to support distributed network calibration and localization in device-to-device networks [9].
Unfortunately, the reactive power operation problem has non-linear objective function, discrete optimization variables (for example, capacitance switching), and continuous optimization variables (for example, the output of DGs). Therefore, the RPO problem is essentially non-convex with discrete and continuous variables. The inversion of the power flow caused by DGs may produce voltage rise to which it is unable to respond effectively by distribution network operators. Furthermore, when economic efficiency and voltage quality are taken into account, the proposed RPO problem becomes a multi-objective function with a set of agents’ local non-linear sub-functions. As such, RPO is a complicated nonlinear mixed integer programming problem with discrete and continuous variables. Based on above analysis, this paper proposes a distributed random gradient-free algorithm based solution for RPO problem in distribution network. The proposed optimization algorithm can significantly guarantee voltage quality and reduce power loss by utilizing local measurements and local communications of capacitor banks and DGs. In addition, the proposed solution is flexible and robust for applications to DNs of different topologies. Simulation studies with the modified IEEE 69-bus distribution system demonstrate the effectiveness and superiority of the proposed method.
This paper is organized as follows. In Section 2, the reactive power optimization problem is discussed. Section 3 introduces the distributed random gradient-free algorithm, and the application is presented in Section 4. The simulation results in Section 5 show the solution effectiveness. Finally, the paper is summarized in Section 6.
2. Problem Formulation
2.1. Objective Function
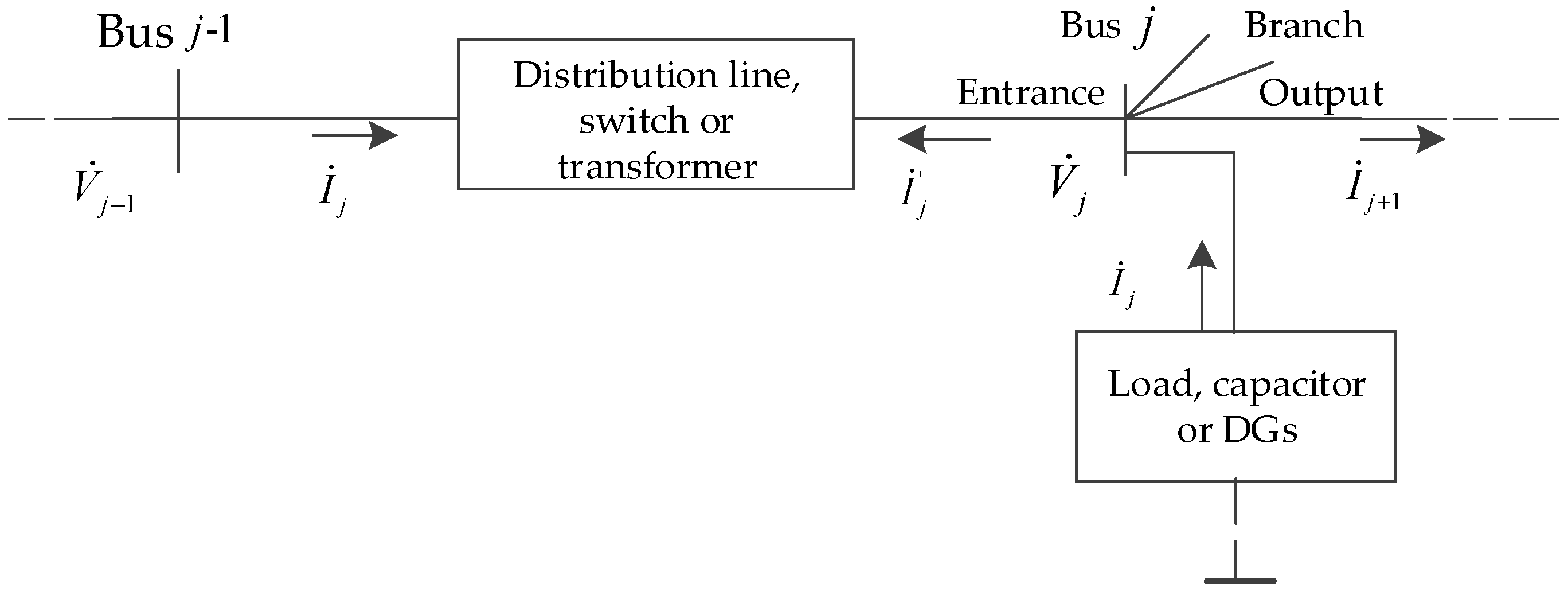
Generally, RPO focus on active power loss of DNs only. However, a voltage drop that is caused by the power flow has been reported that carries a non-negligible effect for DNs [10]. DNs have been planned to deliver power to the loads at satisfactory voltage levels [11,12]. For the basic elements in distribution network in Figure 1, a reactive power optimization scheme with minimum active power loss and improvement of voltage profile for DNs can be formulated as:
where is the active power loss, is the voltage profiles, is the number of buses, is the number of brunches, is the complex power flowing away from node to , is the voltage at node , is the impedance of the link between node and ; and denote the actual and desired bus voltage magnitudes at bus , respectively; and denote the weighting factors for and , respectively, which can be decided by the system operator.
The objective is to find a good balance between the demand of regulating the voltage and the requirement of minimizing the active power losses.
2.2. Operation Constraints
This paper focuses on optimal reactive power optimization through the dispatch of capacitor banks and the output of DGs, which is crucial to the economic operation of DNs. Capacitor banks and DGs dispatching means to make out a plan of the capacitor bank switching and the output of DGs setting so that the voltage is in the normal level and the network loss gets the minimum. For the distribution power flow represented by branch equality constraints [13,14], it can be represented as:
where and denote the active and reactive power generations at bus j, respectively; and denote the active and reactive power load at bus j, respectively; is the reactive power injection of the capacitor bank at bus j; and denote the real parts and the imaginary parts of the system bus matrix Y, respectively.
The security constraints are defined as:
where and denote the active and reactive power at bus , respectively; is the voltage at bus ; “” and “” denote the lower and upper bounds of the variables, respectively.
As stated before, both continuous and discrete optimization variables exist in for the above reactive power optimization problem. Moreover, the objective function is not linear but complex non-linear. Therefore, directly applying convex-programming or linearization techniques to the above non-convex problems does not have guaranteed rationality of the results [15].
3. Distributed Random Gradient-Free Algorithm
For justifying the versions of random search methods, we use a non-smooth version of the objective function
where is the original objective function, vector is always a gradient-free estimate of at ; is a non-smoothed but Lipschitz-continuous function, is a smoothing coefficient that the rules of its selection has been presented in [16], and is a random vector that is distributed uniformly over the unit sphere. Obviously, represents the Gaussian approximation of .
This paper considers the constrained multi-agent optimization problem, which has the form [17]:
where the constraints contain both equality and inequality constraints for the optimization problems. is the smoothing coefficient of the objective function, and is its smooth form, which is calculated by
We can implement the optimal iteration by constructing distributed randomized gradient-free oracles with Gaussian approximation [18]:
Write reactive power compensation into a vector form:
where is the reactive power generation. Parameter is the total number of the reactive power compensation devices.
The gradient vector of the objective functions which denoting the derivative of f with respect to Q is defined by:
The optimization problem has a unique optimal solution , without inequality constraints, the optimization results can be obtained with:
where is a column vector of ones, and is the unique optimal Lagrange multiplier. How to get in a distributed way is the critical problem for distributed RPO. According to the distributed algorithm [19], the reactive power vector can be represented as:
Noticing that each capacitor or DG that is associated with an agent optimizes effectively by eliminating global variables and global updates. As stated before, the optimization algorithm does not require finding the global information. Thus, local information acquisition and interchange can be used to develop the equations for gradient-free oracles calculation. Hence, matrix W contains all of the weight information, so the weight information is totally obtained if the self-weight at agent i and the weight associated with agent can be acquired. Following results can be obtained for Equation (13):
The above formula Equation (14) implies that if W can be determined in a distributed way, agents may utilize the local information itself or communicate with the neighboring agents to find the optimal operation of all agents available. Matrix W is calculated for DGs and capacitors as follows,
That is
The optimal point can be obtained using Equation (11):
Matrix W can be restated within the two limits:
The minimum requirement for the matrix W is that it should be symmetrical over the time. It is found that success to meet one of the factors will result in another success. According to the improved Metropolis method [19], the following results can be obtained for with different combination of i, j:
where is the number of neighboring reactive power generation devices containing capacitors or DGs of agent i in communication network topology, which can be calculated by each node from its local information as:
where is the communication line and the form of adjacency matrix A[k], connecting node i to the neighboring nodes, which can be represented as
It should be noted that each reactive power compensation device (capacitor bank or DG) under the proposed distributed optimization strategy is an independent agent trying to communicate, coordinate, and cooperate with other agents for completing a task or solving a problem. This scheme allows distributed implementation of operating or regulation by local information interaction and adjusting reactive power distribution automatically. Furthermore, distributed random gradient-free optimization algorithm converges to a global optimal solution including power loss minimization and voltage profiles improvement by the way of local communication and local computation.
4. Reactive Power Optimization Based on Distributed Random Gradient-Free Algorithm
4.1. Distributed Reactive Power Optimization
Formulate the optimization problem Equation (9) in a detailed form:
s.t. Equations (4)–(6)
where is the reactive power injection of the capacitor bank or DG at bus j.
The actual values of reactive power injected by capacitor banks and DGs of each node can be calculated from its local compensation variables as
The iteration step-size satisfies the following conditions:
A reasonable estimate of random gradient-free oracles for RPO will be [18]
4.2. Algorithm Flow
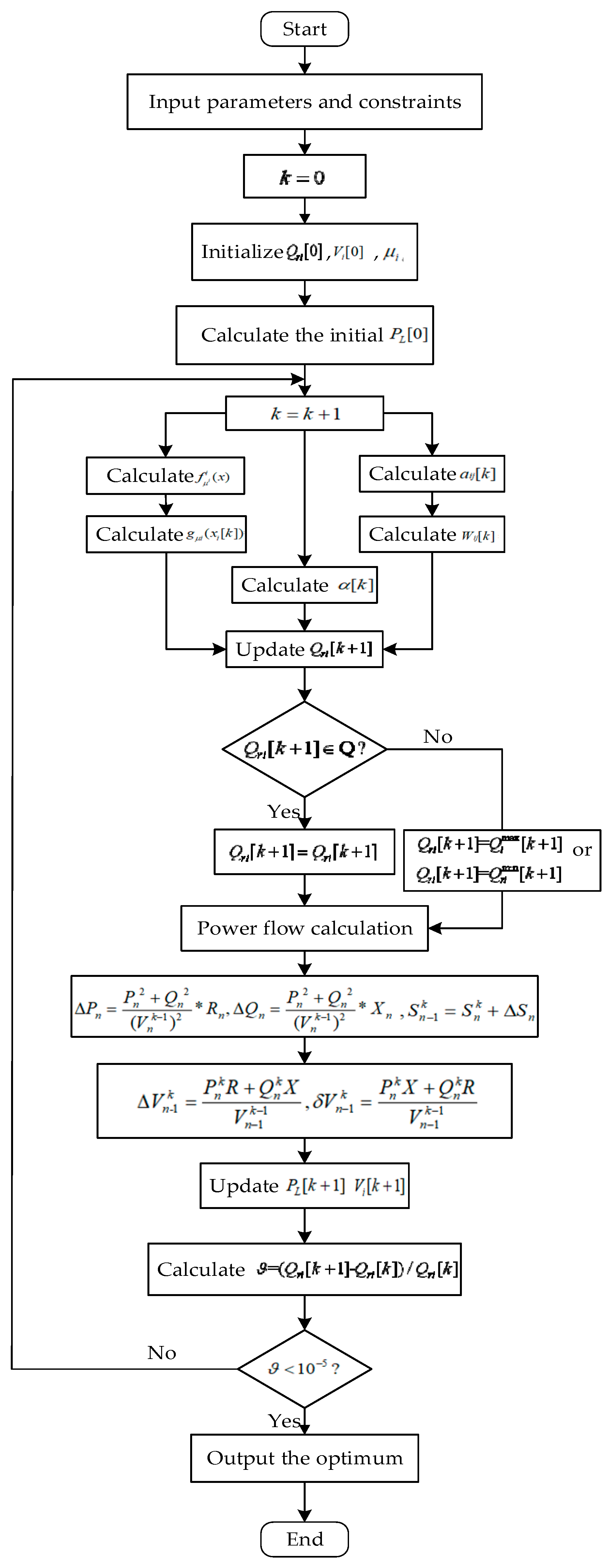
The implementation of the presented reactive power optimization via the distributed random gradient-free algorithm is shown in Figure 2, and the specific procedures are as follows:
- Input data including the coefficients of cost functions, various limits of the DNs’ power output, the total load demand, etc. The maximum available reactive power output is satisfied with Equation (5).
- The optimization variable is initialized, according to references [11]. Then, set up the smoothing coefficient of the objective function and generate the random sequence.
- According to formula Equations (2) and (3), calculate the initial power loss and voltage profiles .
- Correct the iteration step by , where the initial number of iteration steps is .
- According to formula Equation (19), calculate the weighted mean values, according to formula Equation (8) calculate the Gauss approximation.
- According to formula Equation (25) calculate distributed randomized gradient-free oracles; according to formula Equation (16) calculate the current iteration step by .
- According to formula Equation (23), implement the optimal iteration of the reactive power output variables.
- Determine whether the current variables are within the available space. If they satisfy, proceed to the next step; otherwise, the variables take the upper () or lower () limits of the constraints.
- Calculate the power flow via the back/forward sweep method [19]. Calculate the power loss by , , then calculate the power flow ; based on known power injection, calculate the voltage drop , , then the terminal voltage is .
- Calculate the iteration error .
- Determine whether the iteration error satisfies the allowable value. If it satisfies, then proceed to the next step; otherwise, return to step Equation (4) for the next iteration.
- Output the optimal solution vector.
5. Numerical Example
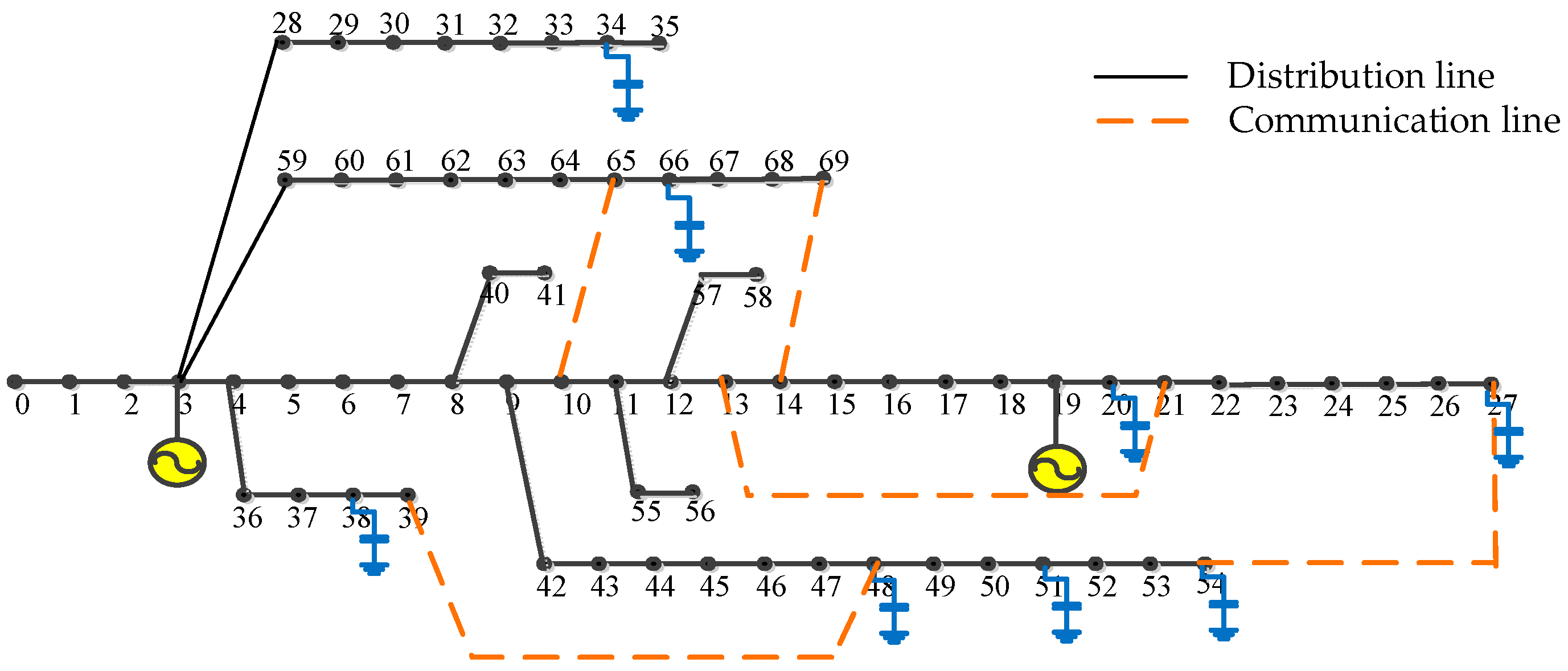
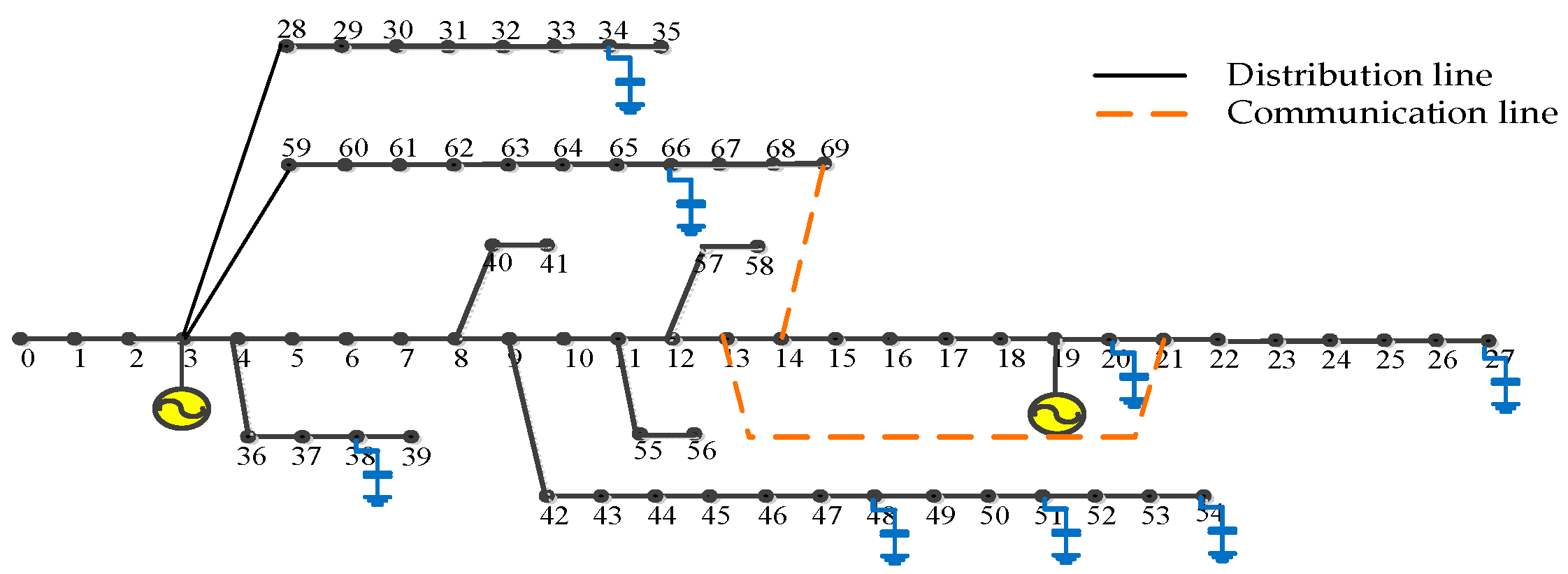
In this section, a modified IEEE-69 standard distribution system shown in Figure 3 is used to evaluate the presented solution [11]. The distribution lines and communication lines are overlapped over the overall network. The voltage regulation of each agent is in the range of [0.80 p.u., 1.05 p.u.]. The distribution network has sixty-nine buses with eight reactive compensation capacitor banks and two DGs. The modified diagram has been associated with eight shunt capacitor banks. Each capacitance is 500 kvar and each bank consists of 50 kvar capacitors simultaneously, while the maximum limited power of the two DGs is 800 kvar. The power base is 10 MVA in this test system.
To compare the performance of centralized and distributed optimization solutions, we consider the active power loss and voltage profiles of the system simultaneously. The authors in [9] examined the solutions of weighting factors and . To evaluate the optimality of the obtained solutions, the centralized algorithm (PSO, Particle Swarm Optimization) is considered to find the global optimal [20]. This section implements three simulation scenarios on the revised IEEE 69-bus test system as follows. Scenario A: the performance of our distributed optimization algorithm. Scenario B: the adaptability of the distributed reactive power optimization algorithm under different communication topology. Scenario C: the performance of the presented reactive power distributed optimization algorithm with flexible plug-and-play of DGs.
5.1. Scenario A: The Performance of the Distributed Optimization Algorithm
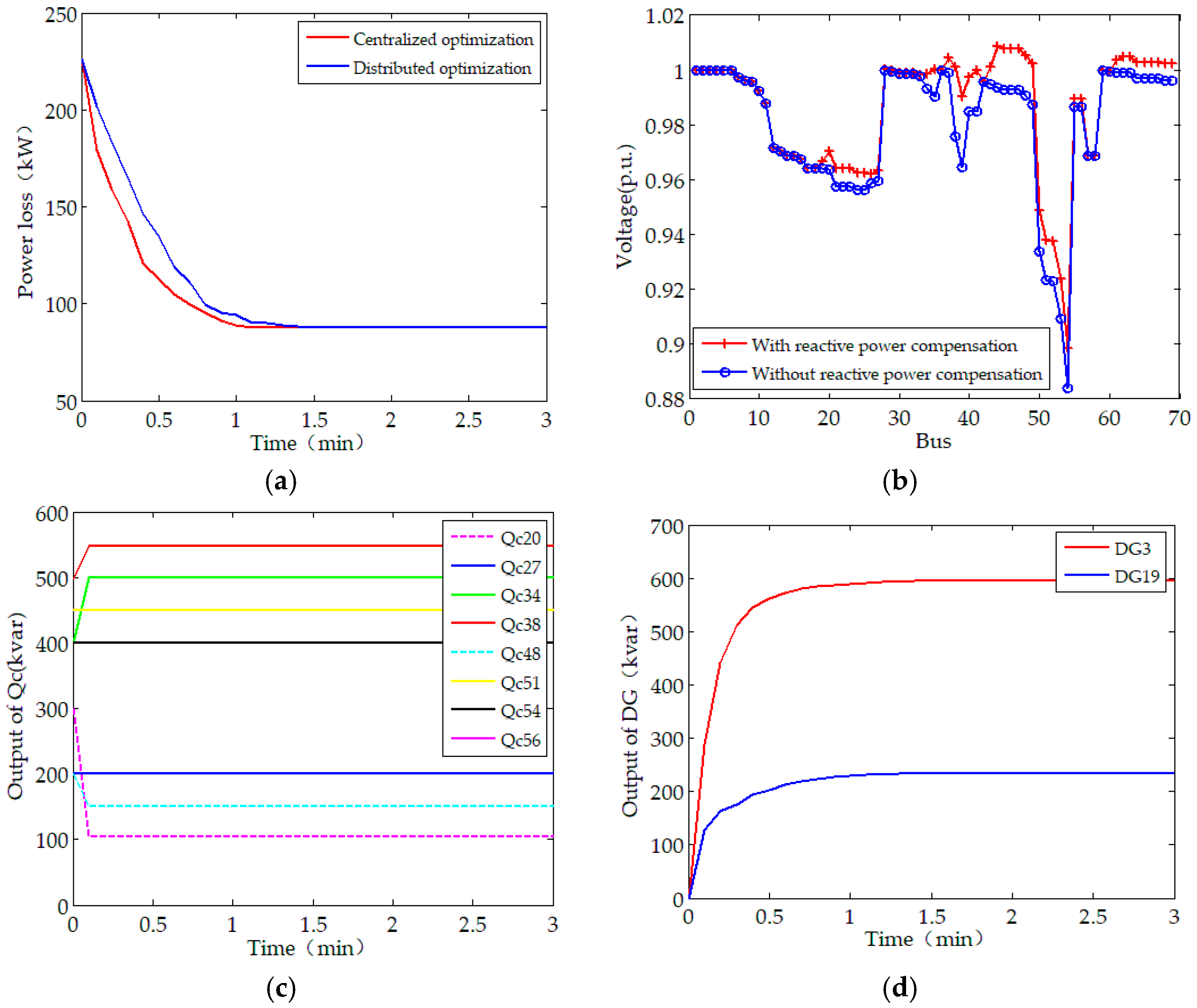
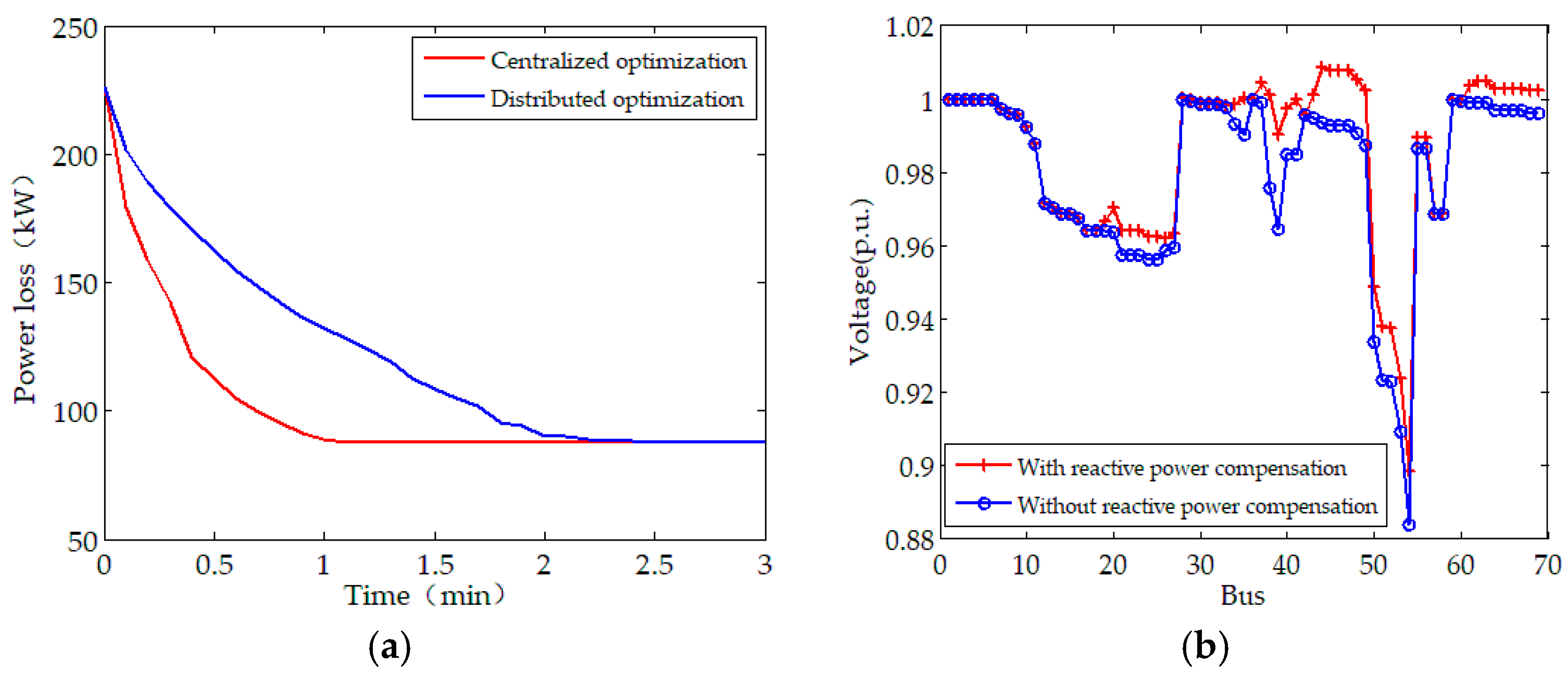
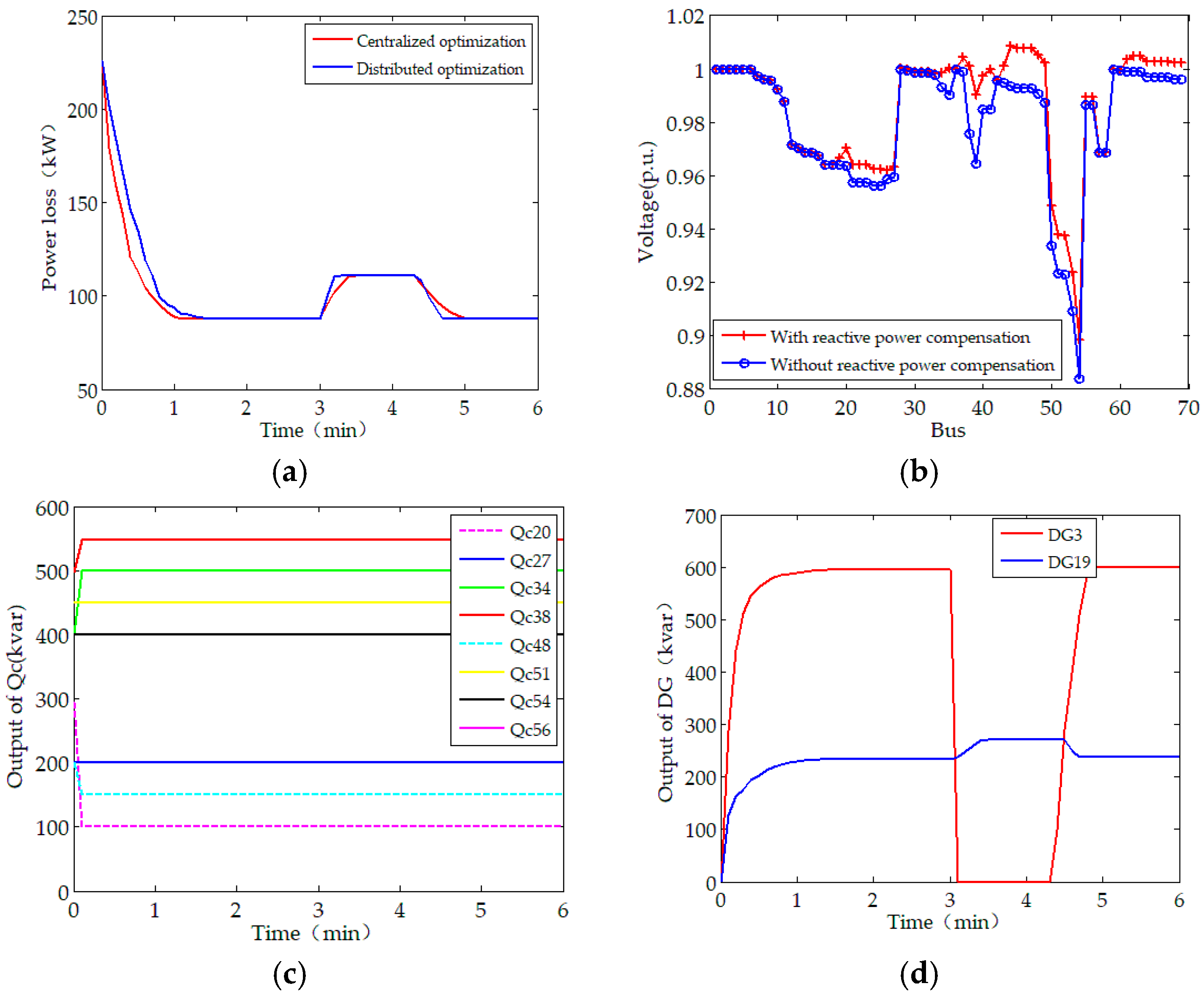
Figure 4 and Figure 5 provide the optimal scheduling under this scenario. As shown in Figure 4, the converged values of the objective function with the distributed and centralized solutions are the same and both are superior to the case without optimization. For the PSO that perhaps will run into local optima, the distributed approach finds the optimal reactive power operation without centralized controller for communication and data processing. When considering the communication cost, the distributed algorithm will be more economical.
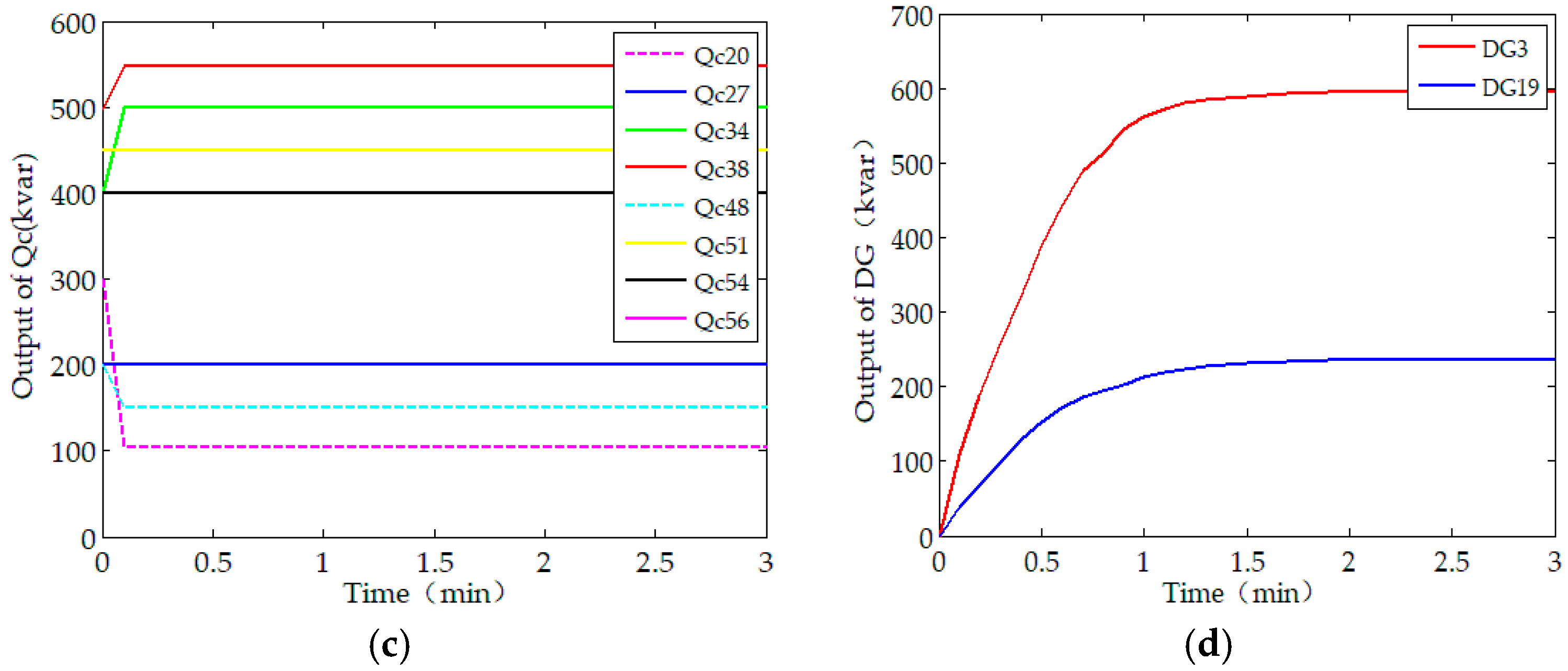
As shown in Figure 4b, the minimum bus voltage without RPO is 0.883 p.u. (at bus #54), however, it increases to 0.898 p.u. after the proposed solution is employed. With reactive power optimization, the voltage profiles are improved to some extent after the reactive power control devices are employed. The convergence of optimal reactive outputs of capacitor banks and DGs are shown in Figure 4c,d. Note that the capacitor banks are discrete optimization variables, the state of capacitor banks presents a step-type-change, or keep constant. While DGs regulate the reactive power continuously and converge to optimal solution steadily. With the dispatch of capacitor banks and DGs, the overall economics of the test system is improved.
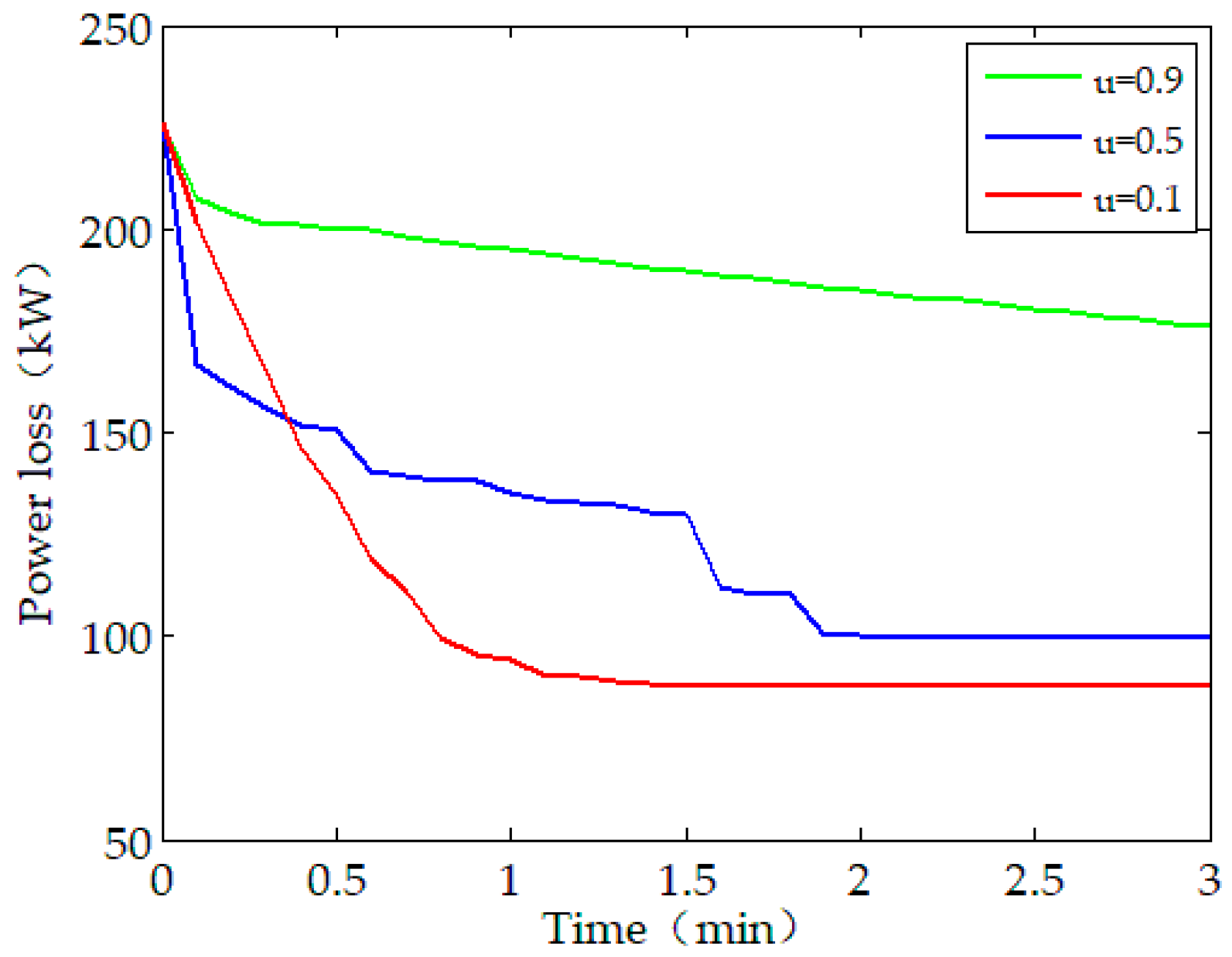
The convergence of the proposed distributed method is further influenced by the choice of the parameter . As illustrated in Figure 5, the convergence rate is sensitive to the choice of . We use , as we found, via empirical experimentation, which has the best convergence properties for the test system algorithm, for implementing the simulations.
5.2. Scenario B: The Adaptability of the Distributed Algorithm under Different Communication Topology
Due to the uncertainty of communication, the network topology perhaps changes and communication links occasionally interrupted. When compared with Scenario A, Scenario B has three communication lines out of service, as shown in Figure 6. Note that scenario B still has communication connectivity. As shown in Figure 7, although the optimal operation of the system has time-delays, the algorithm finds the global optimum ultimately at t = 2.4 min, while the system under Scenario A converges to final optimum at t = 1.4 min, which shows the adaptability of the presented distributed algorithm under different communication topology.
5.3. Scenario C: The Performance of the Distributed Reactive Power Optimization with Flexible Plug-and-Play of DGs
The distributed generation, especially the renewable energy sources, including photovoltaic generation and wind power generation, has the properties of intermittent and volatility. Based on network topology of scenario A, the operation states of DGs are shown in Figure 8, with the assumption that one of DGs (DG19) disconnection from power network at min and re-connected to the test system at min. It can be seen that reactive power is redistributed via the distributed random gradient-free algorithm when DG19 plug-off from the test system. Therefore, the distributed scheduling method that is proposed in this paper can accommodate to the plug-and-play events of the DG units friendly, and therefore improve the robustness of the system.
6. Conclusions
The problem of reactive power optimization in distribution network has non-linear objective function with continuous and discrete optimization variables. The proposed distributed optimization strategy can guarantee voltage quality and reduce power loss by utilizing local measurements and local communications of capacitor banks and DGs via random gradient-free algorithm. Based on the distributed optimization algorithm, the RPO problem converges to a global optimal solution effectively. Simulation studies with the revised IEEE 69-bus test distribution system under different communication topology demonstrate the effectiveness and the robustness of the proposed optimization solution.
In comparison with centralized schemes, the proposed distributed solution does not require a centralized processor, and is computational efficient that is based on the information exchange among neighboring agents. In addition, the solution is capable for online application with strong robustness. The next task will be to incorporate wind power and solar power DGs to the proposed reactive power optimization model and algorithm in distribution network.
Acknowledgments
This study is supported in part by the National Science Foundation of China under Grant No. 51207074 and the State Grid Corporation of China project “Study on Key Technologies for Power and Frequency Control of System with ‘Source-Grid-Load’ Interactions” under Grant No. 2016YFB0901100.
Author Contributions
All the authors contributed to this work. Jun Xie designed the study, developed the mathematical model, performed the analysis and checked the overall logic of this work. Chunxiang Liang developed the reactive power optimization model, set the simulation environment and performed the simulations. Yichen Xiao contributed to the distributed random gradient-free algorithm and provided important comments on the modeling and analysis.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhou, X.Y.; Tian, J.; Chen, L.J. Local Voltage Control in Distribution Networks: A Game-Theoretic Perspective. In Proceedings of the North American Power Symposium (NAPS), Denver, CO, USA, 18–20 September 2016. [Google Scholar]
- Yang, W.; Peng, Z.; Li, W.Y. Online overvoltage prevention control of photovoltaic generators in microgrids. IEEE Trans. Smart Grid 2012, 3, 2071–2078. [Google Scholar]
- Deshmukh, S.; Natarajan, B.; Pahwa, A. Voltage/Var control in distribution networks via reactive power injection through distributed generators. IEEE Trans. Smart Grid 2012, 3, 1226–1234. [Google Scholar] [CrossRef]
- Tinney, W.F.; Bright, J.M.; Demaree, K.D. Some deficiencies in optimal power flow. IEEE Trans. Power Syst. 1988, 3, 676–683. [Google Scholar] [CrossRef]
- Niknam, T. A novel approach based on ant colony optimization for daily volt/var control in distribution networks considering distributed generators. Energy Convers. Manag. 2008, 49, 3417–3424. [Google Scholar] [CrossRef]
- Kim, Y.J.; Ahn, S.J.; Hwang, P.I.; Pyo, G.C.; Moon, S.I. Coordinated control of a DG and voltage control devices using a dynamic programming algorithm. IEEE Trans. Power Syst. 2013, 28, 42–51. [Google Scholar] [CrossRef]
- Lin, C.H.; Wu, W.C.; Zhang, B.M.; Wang, B.; Zheng, W.; Li, Z. Decentralized reactive power optimization method for transmission and distribution networks accommodating large-scale DG integration. IEEE Trans. Sustain. Energy 2017, 8, 363–373. [Google Scholar] [CrossRef]
- Kashem, M.A.; Ledwich, G. Multiple distributed generators for distribution feeder voltage support. IEEE Trans. Energy Convers. 2005, 20, 676–684. [Google Scholar] [CrossRef]
- Win, T.S.; Hisada, Y.; Tanaka, T.; Hiraki, E.; Okamoto, M.; Lee, S.R. Novel simple reactive power control strategy with DC capacitor voltage control for active load balancer in three-phase four-wire distribution systems. IIEEE Trans. Ind. Appl. 2015, 51, 4091–4099. [Google Scholar] [CrossRef]
- Maknouninejad, A.; Qu, Z.H. Realizing unified microgrid voltage profile and loss minimization: A cooperative distributed optimization and control approach. IEEE Trans. Smart Grid 2014, 5, 1621–1630. [Google Scholar] [CrossRef]
- Zheng, W.; Wu, W.; Zhang, B.; Sun, H.; Liu, Y. A fully distributed reactive power optimization and control method for active distribution networks. IEEE Trans. Smart Grid 2016, 7, 1021–1033. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, W.X.; Wang, X. Distributed multiple agent system based online optimal reactive power control for smart grids. IEEE Trans. Smart Grid 2014, 5, 2421–2431. [Google Scholar] [CrossRef]
- Vaisakh, K.; Rao, P.K. Optimal reactive power allocation using PSO-DV hybrid algorithm. In Proceedings of the Annual IEEE India Conference, INDICON 2008, Kanpur, India, 11–13 December 2008; pp. 246–251. [Google Scholar]
- Baran, M.; Wu, F. Optimal capacitor placement on radial distribution systems. IEEE Trans. Power Deliv. 1989, 4, 725–734. [Google Scholar] [CrossRef]
- Qian, L.P.; Zhang, Y.J. S-MAPEL: Monotonic optimization for non-convex joint power control and scheduling problems. IEEE Trans. Wirel. Commun. 2010, 9, 1708–1719. [Google Scholar] [CrossRef]
- Olfati-Saber, R.; Fax, J.A.; Murry, R.M. Consensus and cooperation in networked multi-agent systems. Proc. IEEE 2010, 98, 1353–1354. [Google Scholar] [CrossRef]
- Yuan, D.M.; Ho, W.C. Randomized gradient-free method for multiagent optimization over time-varying networks. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 1342–1347. [Google Scholar] [CrossRef] [PubMed]
- Eduardo, R.L.; Sonia, M. Gradient-free distributed resource allocation via simultaneous perturbation. In Proceedings of the 2016 54th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 27–30 September 2016; pp. 590–595. [Google Scholar]
- Zhang, W.; Liu, W.; Wang, X.; Liu, L.; Ferrese, F. Online optimal generation control based on constrained distributed gradient algorithm. IEEE Trans. Power Syst. 2015, 30, 35–45. [Google Scholar] [CrossRef]
- Chen, S.H.; Hu, W.H.; Su, C.; Zhang, X.; Chen, Z. Optimal reactive power and voltage control in distribution networks with distributed generators by fuzzy adaptive hybrid particle swarm optimization method. IET Gener. Transm. Distrib. 2015, 9, 1096–1103. [Google Scholar] [CrossRef]
Figure 1.
Basic elements in distribution network.
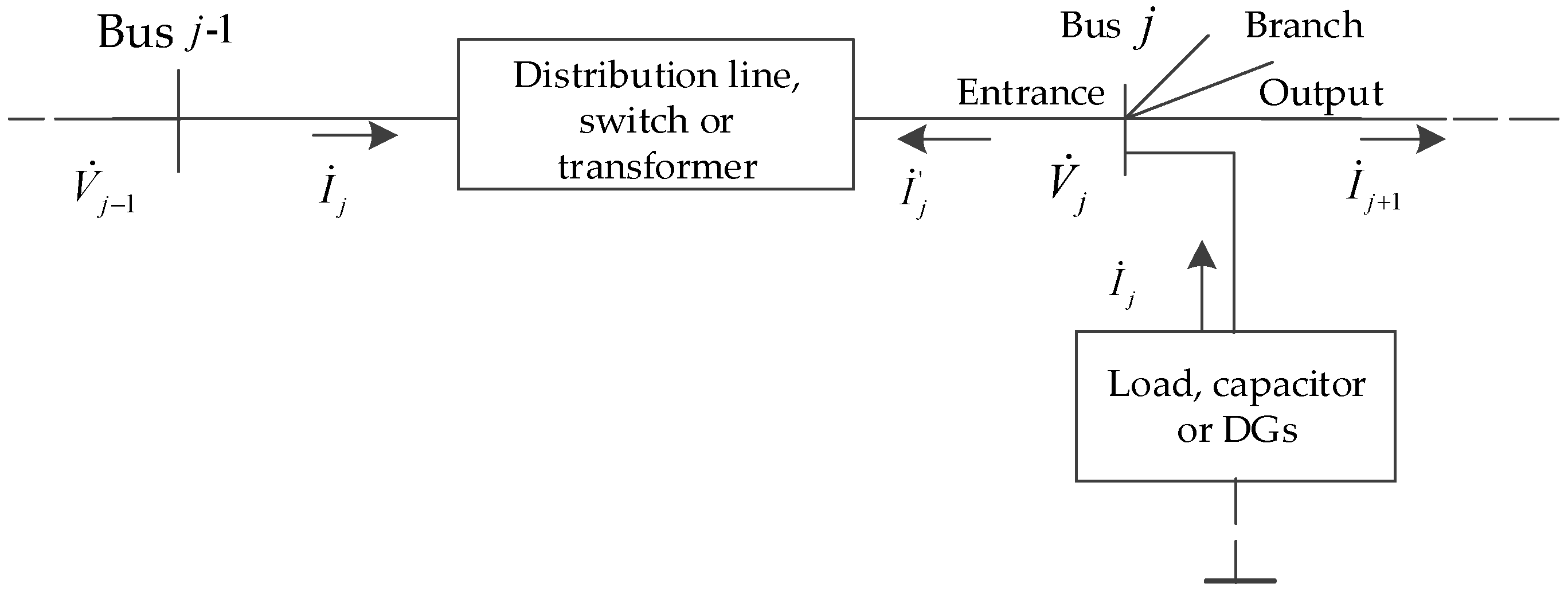
Figure 2.
The flowchart for reactive power optimization for distribution network via the distributed random gradient free algorithm.
Figure 2.
The flowchart for reactive power optimization for distribution network via the distributed random gradient free algorithm.
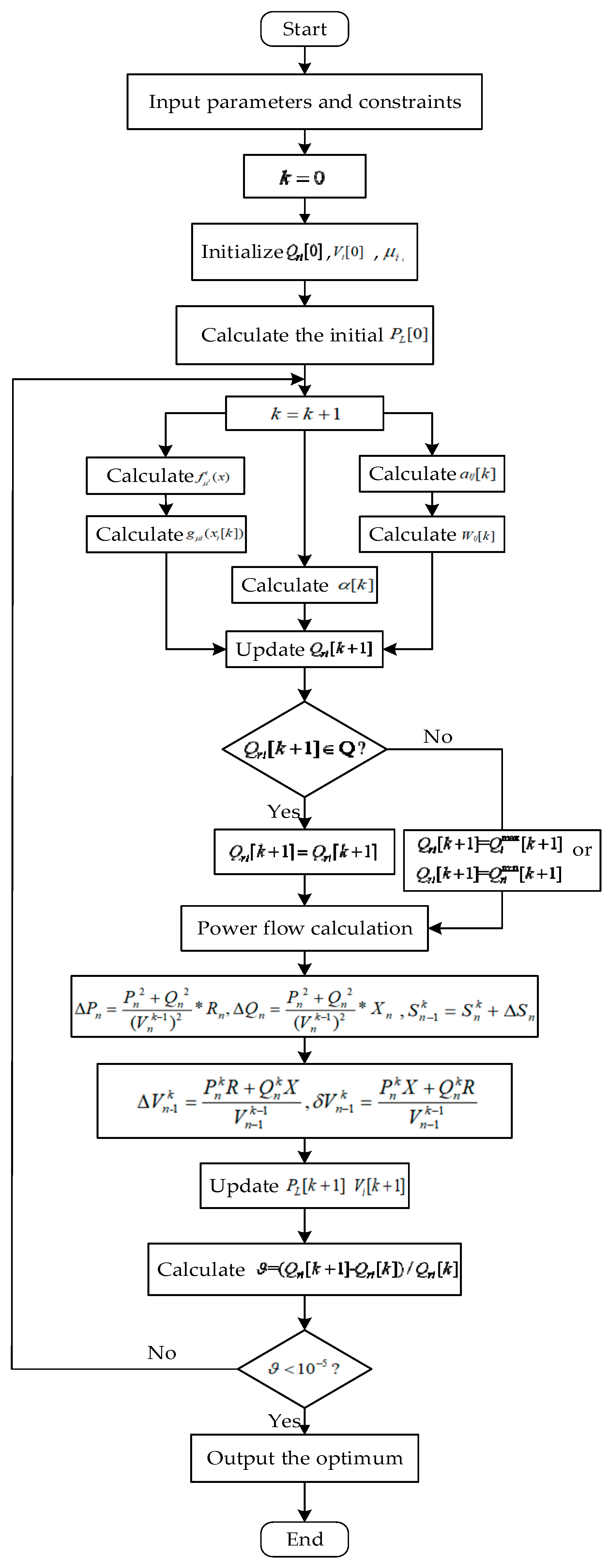
Figure 3.
The diagram for the modified IEEE 69-bus test system.
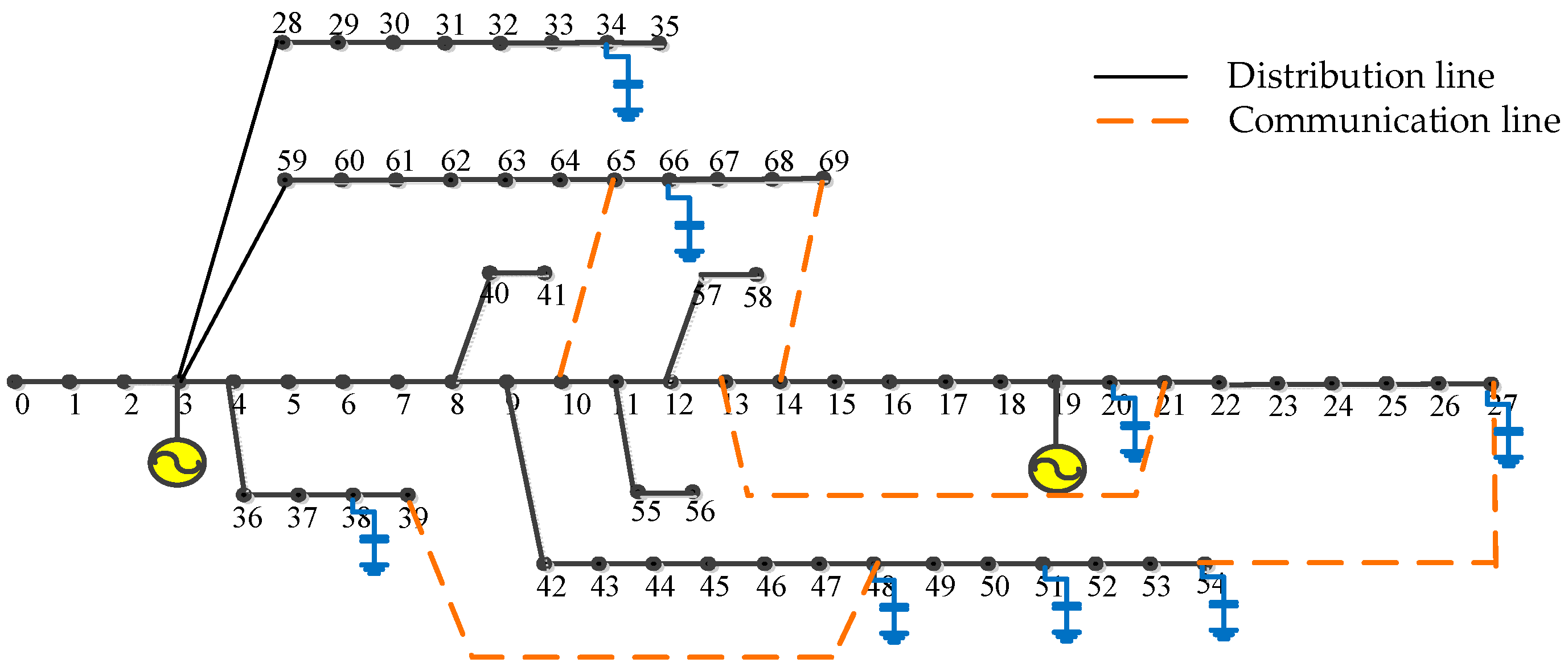
Figure 4.
The optimal dispatch scheme under Scenario A: (a) Evolution of the objective function; (b) Voltage profiles with and without the distributed optimization solution; (c) Capacitor bank control sequences; (d) Output of Distributed Generators (DGs).
Figure 4.
The optimal dispatch scheme under Scenario A: (a) Evolution of the objective function; (b) Voltage profiles with and without the distributed optimization solution; (c) Capacitor bank control sequences; (d) Output of Distributed Generators (DGs).
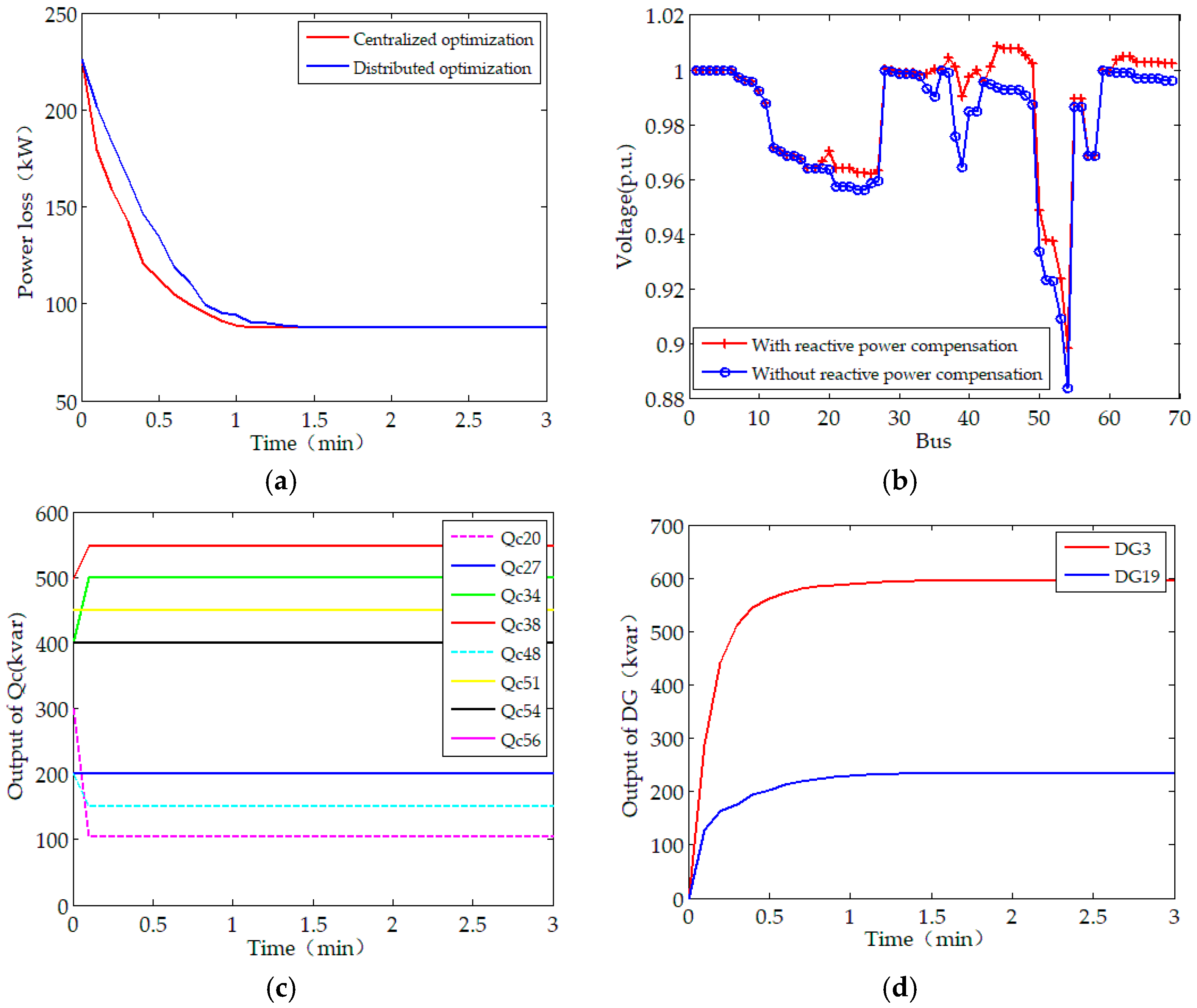
Figure 5.
Sensitivity of smoothing coefficient under Scenario A.
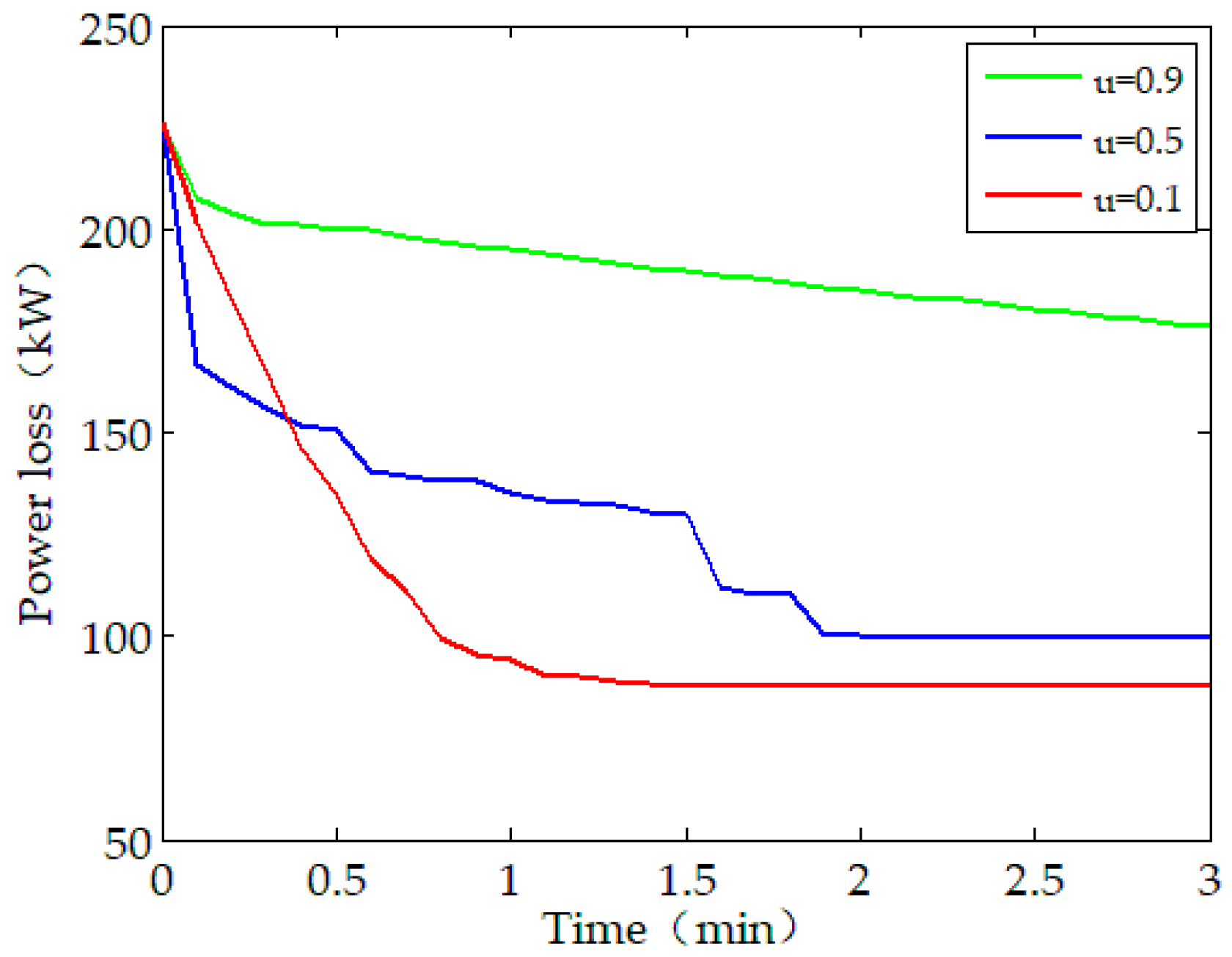
Figure 6.
Modified communication topology for the revised IEEE 69-bus test system under Scenario B.

Figure 7.
The optimal dispatch scheme under Scenario B: (a) Evolution of the objective function; (b) Voltage profiles with and without the distributed optimization solution; (c) Capacitor bank control sequences; and, (d) Output of DGs.
Figure 7.
The optimal dispatch scheme under Scenario B: (a) Evolution of the objective function; (b) Voltage profiles with and without the distributed optimization solution; (c) Capacitor bank control sequences; and, (d) Output of DGs.

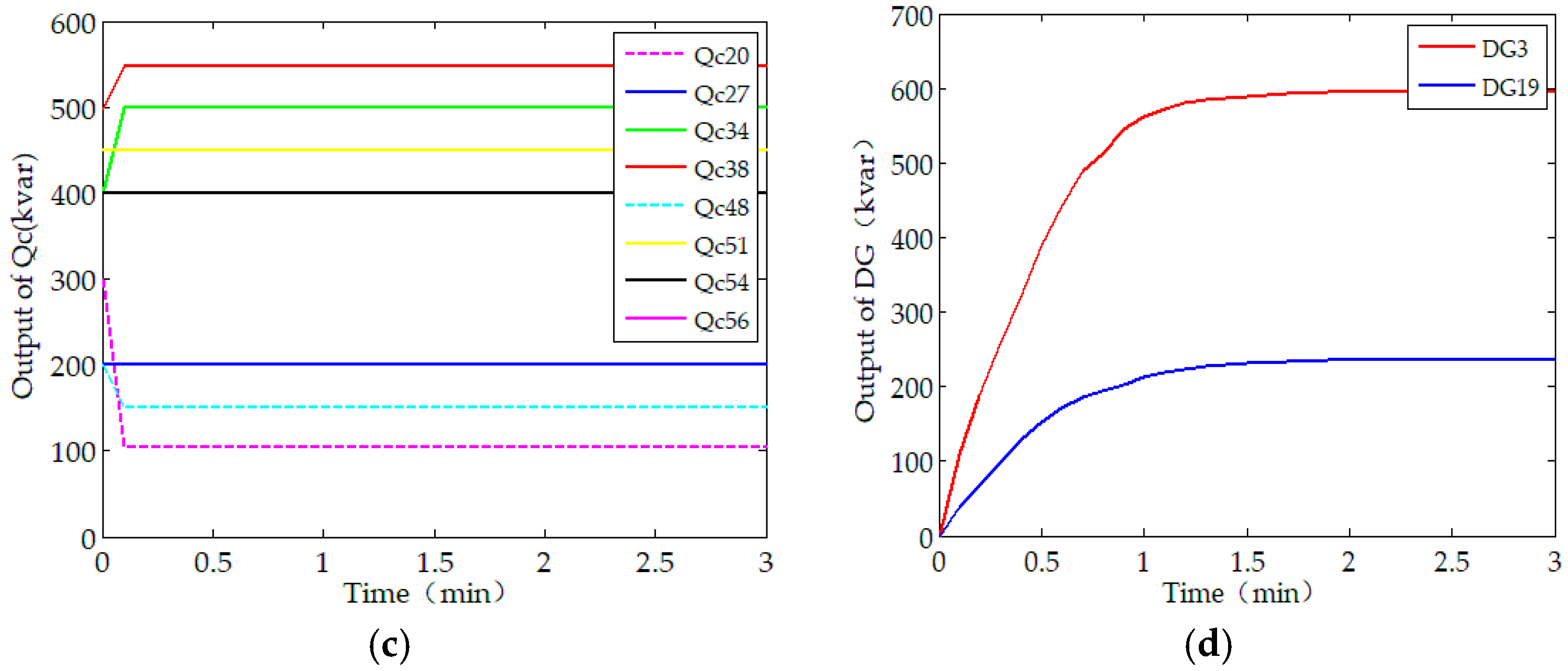
Figure 8.
The optimized dispatch scheme under Scenario C: (a) Evolution of the objective function; (b) Voltage profiles with and without the distributed optimization solution; (c) Capacitor bank control sequences; (d) Output of DGs.
Figure 8.
The optimized dispatch scheme under Scenario C: (a) Evolution of the objective function; (b) Voltage profiles with and without the distributed optimization solution; (c) Capacitor bank control sequences; (d) Output of DGs.
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Xie, J.; Liang, C.; Xiao, Y. Reactive Power Optimization for Distribution Network Based on Distributed Random Gradient-Free Algorithm. Energies 2018, 11, 534. https://doi.org/10.3390/en11030534
AMA Style
Xie J, Liang C, Xiao Y. Reactive Power Optimization for Distribution Network Based on Distributed Random Gradient-Free Algorithm. Energies. 2018; 11(3):534. https://doi.org/10.3390/en11030534
Chicago/Turabian StyleXie, Jun, Chunxiang Liang, and Yichen Xiao. 2018. "Reactive Power Optimization for Distribution Network Based on Distributed Random Gradient-Free Algorithm" Energies 11, no. 3: 534. https://doi.org/10.3390/en11030534
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.