1. Introduction
An electrical power system is mainly composed of thermal and hydro power plants connected via transmission lines in order to supply electricity to loads such as industrial zones or manufacturers, etc. For electrical generation, thermal plants use fossil fuel including gas, coal, and oil, which are very expensive, and will become exhausted in the near future, whereas taking water from natural rivers and discharging it via hydro turbines is considered negligible in terms of generation costs. In addition, comparing the response speed to electrical load changes, hydropower plants have advantages over thermal plants, because they can move from producing a very small amount of power to full power in several minutes, due to the quick water control. On the contrary, the startup and the response speed of thermal plants to load changes is very slow. Therefore, thermal plants need to run continuously for some hours once they start. Based on the advantages and disadvantages analyzed for thermal and hydropower plants, it is clear that the coordination of thermal and hydropower plants in electrical generation operations becomes more effective and economical. In summary, hydrothermal scheduling (HTS) aims to minimize the electricity generation fuel cost of thermal plants using fossil fuels, while all constraints from thermal plants, hydropower plants and the system are exactly met [
1]. With regard to this problem, the thermal power plant constraints are easily met, because only limitations on generation are taken into consideration and other constraints such as fossil fuel constraints and fuel costs for the start-up and shutdown processes are neglected. Among the optimization problems related to the optimal scheduling of hydrothermal systems, the fixed-head, short-term HTS problem has been widely and successfully studied so far [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29]. The fixed-head, short-term HTS problem has been classified into two sub-problems with different hydraulic constraints, namely the amount of discharged water available via the turbine [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17] and reservoir volume limits [
2,
3,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34]. In the two sub-problems, the water head of reservoirs is not supposed to be changed over the scheduled time, thus the water discharge function of the two problems has the same quadratic function model with respect to hydro generation and coefficients; however, the set of hydraulic constraints taken into account in the problems are almost completely different. The water volume, which is allowed to run the hydro turbines over the scheduled horizon, is constrained in the first problem, while the main constraints considered in the second problem are the reservoir volume at the beginning and the end of the scheduled horizon, the limitations of the reservoir volume and the water balance in each reservoir.
Several methods have been used to solve the first problem, such as Powell’s hybrid method [
1]; the Newton–Raphson method [
1,
2]; the lambda–gamma method (λ-γ method) [
2]; the Lagrange-multiplier, factorization-based, Newton–Raphson method [
3]; the Lagrange method based on the linearization of the coordination equation (LCEL) [
4]; the Lagrangian relaxation approach [
5]; Hopfield neural networks (HNN) [
6]; evolutionary programming (EP) [
7,
8]; the artificial immune system method (AIS) [
8]; particle swarm optimization (PSO) and the differential evolutionary method (DE) [
8]; the modified bacterial foraging algorithm (MBFA) [
9]; the optimal gamma-based genetic algorithm (OGB-GA) [
10]; fast genetic algorithm (FGA) [
11]; the predator–prey optimization technique (PPO) [
12]; improved genetic with multiplier updating (IGA-MU) [
13]; real-coded genetic algorithm (RCGA) [
14]; a Hopfield Lagrange network (HLN) [
15]; an augmented Hopfield Lagrange network (ALHN) [
15]; the Cuckoo search algorithm (CSA) [
16,
17]; and a modified cuckoo search algorithm (MCSA) [
17]. On the other hand, there has also been a number of methods proposed to solve the second problem, such as gradient search (GS) [
2]; Newton’s method [
3]; the simulated annealing approach (SA) [
18]; evolutionary programming (EP) [
19,
20,
21]; genetic algorithms (GA) [
22]; fast EP (FEP) [
23]; improved fast EP (IFEP) [
23]; hybrid EP (HEP) [
24]; PSO [
25]; the improved bacterial foraging algorithm (IBFA) [
26]; self-organizing, hierarchical PSO [
27]; running improved fast EP (RIFEP) [
28]; improved PSO [
29,
30]; a clonal selection algorithm (CS) [
31]; fully-informed particle swarm optimization (FIPSO) [
32]; a cuckoo search algorithm with Lévy distribution (CSA-Lévy) [
33]; a cuckoo search algorithm with Lévy Gaussian distribution (CSA-Gauss) [
33]; a cuckoo search algorithm with Cauchy distribution (CSA-Cauchy) [
33]; a one rank cuckoo search algorithm with Lévy distribution (ORCSA-Lévy) [
34]; and a one rank cuckoo search algorithm with Cauchy distribution (ORCSA-Cauchy) [
34].
Among the introduced methods, the methods in [
1,
2,
3,
4,
5,
6,
15] are in the family of deterministic algorithms and the others in [
7,
8,
9,
10,
11,
12,
13,
14,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34] are in the family of meta-heuristic algorithms. The first method group is mainly based on the gradient to find the optimal solution. Meanwhile the second method group searches for the optimal solution mainly based on the population. Moreover, the methods in the first group are defined as derivative-based optimization methods, finding the optimal solution by a single path search line and suffering from the drawback that they cannot deal with non-convex problems where the objective functions or constraints of the problems are non-differentiable or nonlinear. In addition, the conventional methods also suffer from difficulties when dealing with large-scale problems with complicated constraints. On the contrary, the meta-heuristic methods initialize a set of solutions at the beginning of the optimal solution search process. The solutions are newly generated in each iteration and the quality of these solutions is evaluated via a fitness function consisting of a penalty amount for constraint violation and an objective function that needs to be minimized. Unlike the deterministic algorithms, the entire computation procedure of many meta-heuristic methods will terminate based on a predetermined maximum number of iterations. The obtained solutions are capable of satisfying all constraints as the current iteration is much lower than the maximum number and the solution might be out of feasible operating zones even if the termination criteria has already been reached. The meta-heuristic algorithms are considered stronger and more effective than deterministic algorithms, because they can deal with problems where non-differentiable objective functions and many nonlinear constraints as well as large-scale systems are taken into consideration.
Among the deterministic methods, HLN and ALHN are considered the most effective methods, since they can obtain the global optimum solution with a very fast execution time and a low number of fitness evaluations. HLN is a developed version of HNN that combines the Hopfield network from the HNN method and the Lagrange optimization function of the λ-γ method. The search process of the HLN method is based on calculating the change of dynamic neurons, and the updating input and output of multiplier neurons and continuous neurons after establishing an energy function from the Lagrange optimization function. ALHN is also an improved version of HLN since the Lagrange optimization function is converted into an augmented Lagrange function. HLN can overcome several of the drawbacks of HNN, such as local optimum solutions, low convergence, and limited applications for large-scale systems. Compared to HLN, ALHN can obtain better optimum solutions. However, ALHN contains more control parameters due to its converting the Lagrange function into an augmented Lagrange function. In spite of the good performance, the application of the two methods must be stopped when facing problems with many considered constraints, since it has a high number of control parameters that are directly proportional to the number of considered constraints. Furthermore, there is a sensitive impact of the parameters on the results. Thus, if the value of a parameter is tuned, other parameters should also be changed. As a result, the selection of the parameters is the big challenge for the two methods.
Among the meta-heuristic algorithms, SA is the worst method for searching for the optimal solution for hydrothermal system scheduling problems. In fact, although SA can tackle the applicability limitations for non-differential objective functions that deterministic methods have coped with thus far, SA has not been widely applied because it requires a long simulation time and obtains a low quality solution. The applicability of SA is significantly dependent on the selection of the initial temperature and the cooling rate value. The optimal temperature is very hard to determine, since it has a very large range, from zero to infinite, while the cooling rate is used to decrease the temperature and is calculated based on the temperature. For the implementation of GA, the diversification of the offspring in the crossover operation and mutation operation must be performed to guarantee an optimal solution. This manner is regarded as an advantage of the EP method, as the main search operator generating new solutions is fulfilled by the mutation operation. Contrary to GA, EP is slow to obtain a near-optimal solution. However, the convergence speed of EP and GA can be improved by adding other techniques. In fact, there have been several improvements applied to these methods to enhance their search ability and speed up their convergence process. Several improved versions of GA and EP have been developed in [
10,
11,
13,
14,
23,
24,
28]. The reported results indicate that the improvements in the conventional EP and GA are successful and efficient. However, there are some weak points, such as the high number of iterations, long execution time, and low quality of optimal solutions. Aware of the drawbacks of GA, the authors in [
10] proposed the OGB-GA method by combining the Lagrange optimization function and GA in order to decrease the number of control variables for GA. Instead of having a large number of control variables, such as hydro generations and thermal generations, OGB-GA uses only one gamma variable from the Lagrange optimization function. Thus, GA is used in OGB-GA to determine gamma and then the coordination equation in the λ-γ method is applied to calculate the generation of hydro and thermal units. The result comparisons in [
10] illustrate the better performance of OGB-GA compared to GA. However, OGB-GA cannot deal with systems where the non-convex fuel cost function is taken into account. In [
11], FGA has been indicated as more efficient than GA in terms of higher solution quality and shorter computation times for solving large-scale systems via the result comparisons on four systems. Compared to GA, FGA has focused on decreasing the search space by collecting the minimum error and the maximum error of the best individual and the worst individual among the current population. As a result, FGA could carry on the search around the narrow zone and then an optimum could be obtained quickly, with a low maximum iteration number. However, if a global optimal solution was outside the limited narrow zone, FGA could converge to a local optimum due to the premature convergence. This disadvantage is evidence of the restricted application of FGA. Compared to FGA and OGB-GA, IGA-MU and RCGA show better performance and wider applications for optimization problems in electrical engineering.
In the EP methods introduced in [
19,
20,
21], only the Gauss random variable was used to generate offspring and the scaling factor was regarded as a constant. However, in the improved versions of EP [
23,
28], the number of offspring was generated by randomly generated initial parents using Gauss or Cauchy mutations in addition to using the scaling factor as a variable during the search process. The improved EP methods improved the solution and sped up convergence and were superior to conventional EP via only one test system. The improvement of HEP has not been validated, although the authors stated that their improved method was better than original one. In fact, only one system with one thermal unit and one hydro unit scheduled in six twelve-hour subintervals and quadratic fuel cost functions of thermal units were employed to run the proposed methods. Moreover, the optimal solutions for the simple system reported have indicated that the water discharge was lower than the minimum value predetermined in problem data.
Compared to GA and EP, PSO is more easily implemented for the HTS problem, since its feature is very simple, consisting of two updated factors, namely the velocity and position. Furthermore, the solution and the computation for PSO are more effective than those for GA and EP. Recently, several applications of CSA for HTS problems in [
16,
17] for the first problem and in [
33,
34] for the second problem have shown very good results with fast execution times compared to GA variants, EP variants, and other methods such as AIS, DE and deterministic methods. CSA methods construct their search strategy based on Lévy flights and the probability of alien egg identification. Lévy flights act as a global search tool, while the probability of alien egg identification acts as a local search tool. Thus, in each iteration, CSA methods have produced two new solution generations in which global search is the first generation and the probability of alien egg identification is the second generation. Compared to other mentioned methods, CSA methods can enlarge the global zone by using Lévy flights and then a local search around the solutions that have just been found by the global search could effectively exploit a narrow zone. As shown in [
33,
34], CSA could use three different distributions such as Lévy distribution, Gaussian distribution and Cauchy distribution, but the most appropriate distribution was Lévy distribution. Although the evidence indicates that a good evaluation of CSA has been clearly shown, the CSA methods used a high total number of fitness evaluations because they had two separate search strategies.
The CDE was developed by Storn and Price in 1997 [
35]. CDE, one of the most popular meta-heuristic algorithms, has been applied to solving different optimization problems in electrical engineering fields, such as hydrothermal scheduling [
8], large-scale distribution systems [
36], economic dispatch problems [
37], and optimal reactive power dispatching [
38]. CDE has been considered a simple meta-heuristic algorithm with two main advantages when compared to GA, and has been applied to optimization problems such as fast convergence and few control parameters [
39]. In spite of the advantages and the wide applicability of CDE, it has still coped with many other drawbacks, such as feeble local search ability, low convergence to the global optimum, and being easily trapped in local optima and less diversity [
40]. As is known, DE has three main operations, including mutation operation, crossover operation and selection operation. The mutation operation generates new solutions, the selection operation keeps the promising current solutions, and crossover mixes old solutions and new solutions to carry out the next mutation. Thus, many studies have pointed out the disadvantages of DE, mainly derived from the mutation and selection operations. In their study [
41], Qin et al. analyzed the mutation operation and pointed out the limits of the operation. It was shown that the mutation operation of CDE with the task of selection of mutation factor had a significant impact on the performance of DE. Thus, the implementation of CDE was time consuming due to the number of trials needed to select the mutation factor [
41]. In order to overcome disadvantages of CDE, Qin et al. suggested several improved versions of the mutation. Unlike the study in [
41], Padhye et al. [
42] focused on the selection operation and suggested the elitist selection operation because its performance influences the next mutation in the next generation. The selection of CDE may lead to missing some promising solutions, which are abandoned, and whose qualities would be better than other retained solutions. In fact, CDE selection is a comparison between the previous solution
Xd and the solution
Zd, which was chosen via crossover. Derived from the indication of the limitations of CDE, many DE variants have been constructed by modifying mutation and selection operation such as DE with the adaptive mutation [
40,
41], DE with elitist selection [
42], DE with ancestor tree [
43], DE with adaptive mutation and elitist selection [
44], DE with a penalty method [
45], and surrogate differential evolution (SDE) [
46]. DE variants with adaptive mutation and/or elitist selection can find better solutions than CDE; however, these methods have to cope with fundamental limitations such as spending a great deal of time tuning the crossover factor and several factors in the adaptive mutation operation, missing promising solutions of good quality, and keeping identical solutions in the current population.
The analysis of the good and bad properties of all mentioned methods identifies drawbacks that these methods have addressed, such as the:
- (i)
Restriction of applicability to complicated systems with non-differential objective functions and a high number of power plants,
- (ii)
Convergence to local optimal solutions or near-global optimal solutions with low quality and high objective functions, and
- (iii)
Limited time for searching for the optimal solution due to a high number of iterations and for tuning control parameters due to high number of control parameters and a large range of such control parameters.
In this study, we propose an efficient and new modified differential evolution (ENMDE) with two main modifications to the two operations, in which the first modification, self-tuned mutation, is constructed on the mutation operation, and the second modification, leading group selection, is carried out in the selection operation. The main contributions to the improvement of the proposed ENMDE method are as follows:
- (i)
Propose the cancelling of crossover operations in order to skip the task of tuning the crossover factor. This suggestion can enable the proposed method reduce the impact of parameter factors on the results and reduce the simulation time for the tuning crossover factor.
- (ii)
Propose a new formula for calculating the average fitness distance ratio in the mutation operation, which can balance the global search and local search for the proposed method effectively. In addition, the formula can reduce the selection of the average fitness distance ratio that most previous studies have coped with and the formula helps to reduce the simulation time for tuning good value.
- (iii)
Propose the leading group selection technique to keep the best solutions among old solutions and new solutions, where only one out of the identical good solutions is retained and solutions of worse quality are abandoned. The technique provides good opportunities to produce more new solutions of high quality.
In order to test the performance of the proposed ENMDE, we implement the ENMDE and two other versions of DE, including DE with self-tuned mutation (STMDE) and DE with the leading group selection (LGSDE) to solve two different fixed-head, short-term hydrothermal scheduling problems with six study cases. Between the two problems, the second problem is more complicated than the first, because reservoir constraints such as minimum limit, maximum limit, initial volume, end volume and water balance are considered. Four study cases, including two cases with convex objective functions and two cases with non-convex objective functions in the first problem, and one case with a convex objective function and one case with a non-convex objective function in the second problem, are the challenges that will result in evidence with which to evaluate the performance of the proposed ENMDE.
The remainder of this paper is organized as follow:
Section 2 analyzes methodologies relating to the HTS problem. The original differential evolution and proposed methods for the HTS problem are introduced in
Section 3. The application of the two considered hydrothermal scheduling problems, case studies, and the discussion of the results are found in
Section 4,
Section 5 and
Appendix A. Finally, the conclusions are stated in
Section 6.
5. Case Study and Discussion of the Results
In order to investigate the impact of the proposed self-tuned mutation technique and the proposed leading group selection technique on the obtained results, two other DE variants including STMDE and LGSDE, as well as ENMDE with both proposed techniques and CDE were tested on two HTS problems with different hydraulic constraints, and different objective function forms. The first is constrained by the available water constraints, while the second considers the different constraints in connection with the reservoir volumes, such as the initial volume, the end volume and limitations on the reservoir volume over the scheduled horizon. Four study cases for problem one and two study cases for problem two with information on the number of thermal units, the number of hydro units, valve point loading effects (VPLES) (the “yes” option corresponds to the nonconvex fuel cost function; the “no” option corresponds to the convex fuel cost function), and the number of subintervals are reported in
Table 1.
In addition, we also implemented other existing meta-heuristic algorithms, namely particle swarm optimization (PSO) [
51], the bat algorithm (BA) [
52] and the flower pollination algorithm (FPA) [
53] to solve four study cases for problem one and two study cases for problem two. For the implementation of BA, PSO and FPA, the population size
Np and the maximum iteration number
Gmax were also set to the same values as the proposed ENMDE. The selection was because there was the same total number of fitness evaluations (TNFES) between the proposed ENMDE and others. As mentioned in [
54,
55], the comparison of TNFES has been regarded as one more criterion for a fair comparison among the different methods implemented in the different studies. TNFES =
Np ×
Gmax is calculated for meta-heuristics with one generation per iteration, such as CDE, other DE variants, BA, PSO and FPA, but the value is twice as large, i.e., TNFES = 2 ×
Np ×
Gmax for meta-heuristics with two generations per iteration, such as CCSA and MCSA. In fact, BA has two new solution generations; however, only
Np new solutions were retained and other
Np new solutions were discarded by the comparison between the pulse rate and a random number. Consequently, there are only
Np fitness evaluations for each iteration and there are
Np ×
Gmax fitness evaluations for the whole search process. Similarly, FPA has the same scenario as BA, since there are two new solution generations, but only
Np solutions are kept and the other
Np solutions are abandoned through comparison between a random number and a probability. On the contrary, PSO only generates one new solution and all the new solutions are evaluated via calculation of the fitness function. Consequently, there are
Np ×
Gmax fitness evaluations in the whole search process of FPA, PSO and BA. Besides, the further selection of the parameters for these methods are as follows:
- (i)
PSO: The acceleration constants c1 and c2 are set to 2 while the weight factor ω is increased gradually from 0.1 to 1 with a step of 0.1.
- (ii)
BA: The pulse rate r is increased from 0.1 to 1 with a step of 0.1, while the loudness is fixed at 1.
- (iii)
FPA: The probability Pa is increased from 0.1 to 1, with a step of 0.1.
All demonstrations were implemented under the same conditions, such as coding in the same Matlab R2016a (The MathWorks, Natick, MA, USA) and running on the same PC with 2-GHz processor and 2-GB RAM for 50 independent trials for each study case.
5.1. The First Problem with Available Water Constraints
5.1.1. Study Cases 1 and 2 without Valve Point Loading Effects
In study cases one and two, two hydrothermal systems with the same structure, consisting of two thermal plants and two hydropower plants, were scheduled in three eight-hour subintervals for the first study case and four twelve-hour subintervals for the second study case. The data from the two systems were taken from [
6,
14]. To implement the proposed ENMDE method, two conventional DE factors, such as mutation factor F and crossover factor
CR, are advised to be in range [0, 1.2] and [0, 1] [
56]. However, the selection of
F is a simple task in the study, achieved by setting
F to 0.6;
CR is not used in the proposed ENMDE because it neglects the crossover operation.
For the implementation of STMDE, the mutation factor
MMF was also set to the same values as for ENMDE, but the crossover factor was set to the range from 0 to 1, as used for CDE. This is because the leading group selection is not performed for STMDE, so crossover is still effective for STMDE. On the contrary, the crossover factor is omitted for LGSDE. The compared results in terms of minimum cost, average cost, maximum cost, and standard deviation are reported in
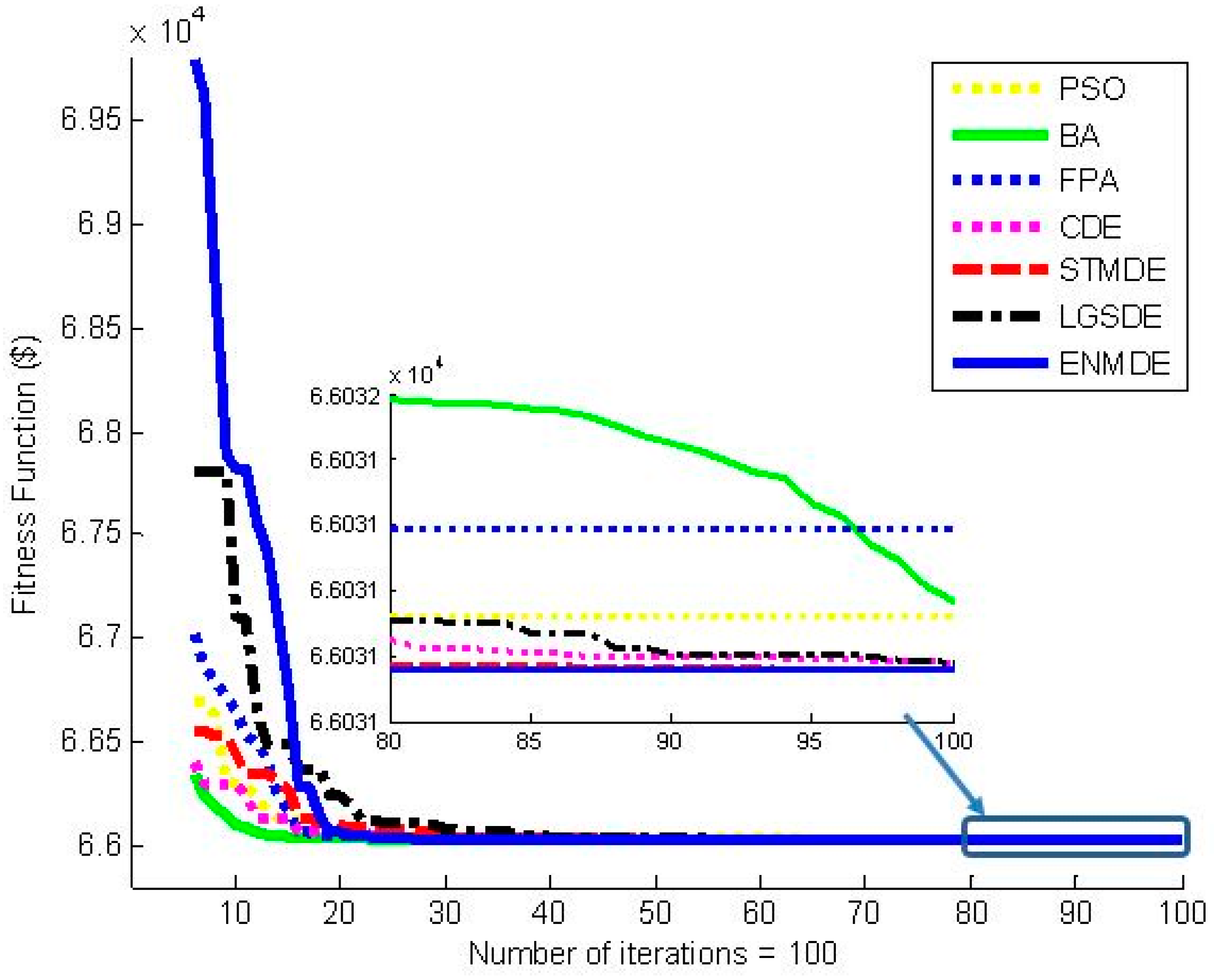
Table 2 for Case 1. Among the four considered DE variants, the proposed ENMDE can yield better costs than the three remaining ones. Two important costs, including minimum cost and standard deviation from ENMDE are
$66,030.7570 and
$30.8788, respectively; while these results were
$66,030.7781 and
$186.1825 for CDE,
$66,030.7590 and
$68.700 for STMDE, and
$66,030.7759 and
$131.4645 for LGSDE, respectively. The comparison indicates that the proposed ENMDE has the lowest minimum cost and lowest standard deviation, while CDE has the highest values. It is clear that the proposed self-tuned mutation technique (STMDE) and the proposed leading group selection technique (LGSDE) have a positive impact on the performance of DE, since the best cost and standard for STMDE and LGSDE are less than those for CDE. In fact, compared to CDE, STMDE obtains less cost and less standard deviation by
$0.0185 and
$40.1324, while LGSDE can reduce to
$0.0022 and
$54.718, respectively. Furthermore, the combination of the two proposed techniques shows more improvement in the performance, since the cost and standard deviation of ENMDE are lower than CDE by
$0.0207 and
$117.376.
On the other hand, when comparing the proposed ENMDE with RCGA [
14], BA, PSO, and FPA, the best cost from ENMDE was lower than that for RCGA [
14], BA, PSO, and FPA by
$0.2426,
$0.2096,
$0.1622, and
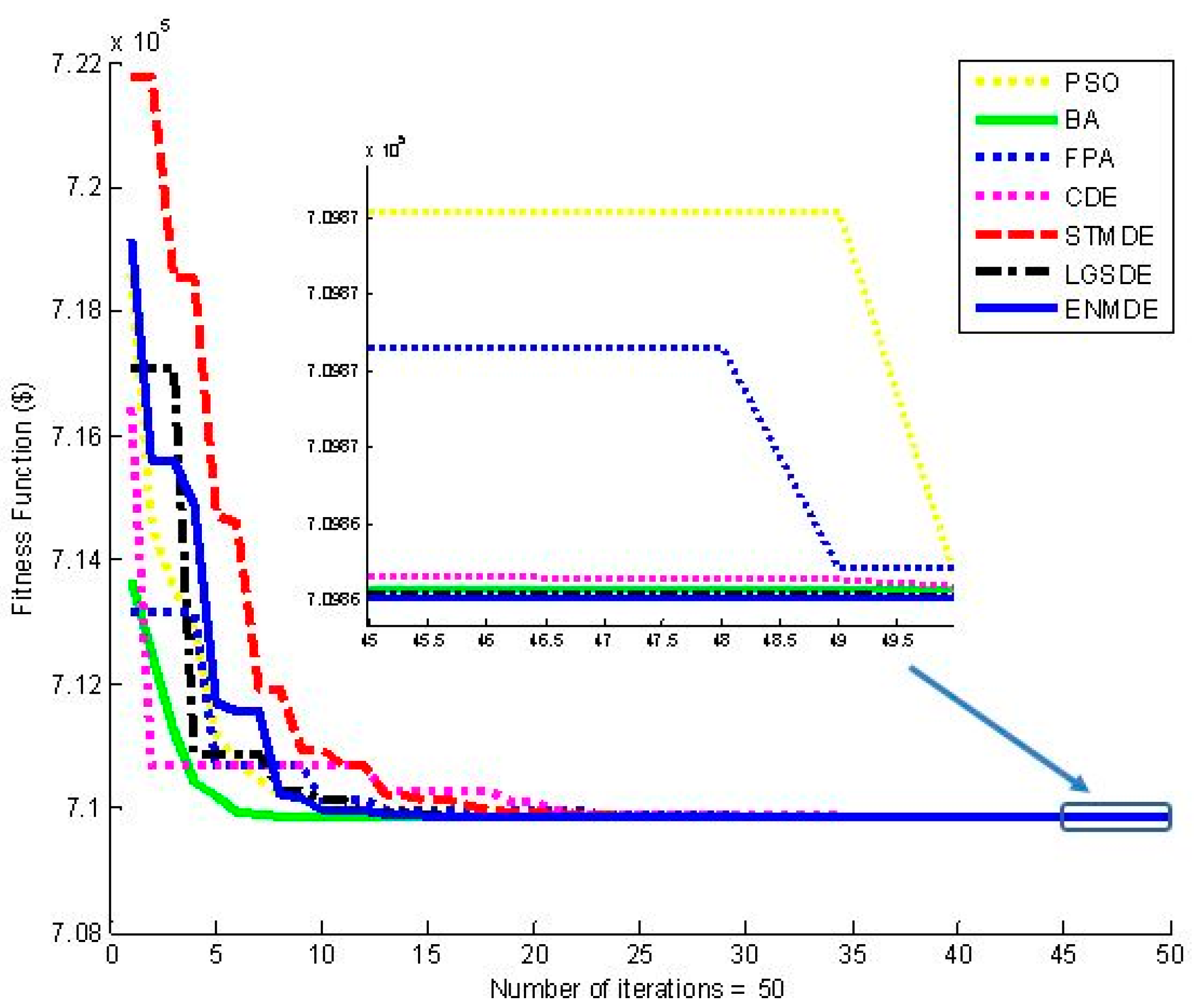
$0.4794, respectively. The lower cost indicates that ENMDE is more efficient than these methods in finding the best optimal solution. Furthermore, ENMDE used 2000, corresponding to an execution time of 0.66 s, while RCGA employed 5000m corresponding to 21.64 s. These values from the proposed method and the others are equal and approximately equal. The best fitness convergence characteristics obtained by these implemented methods, depicted in
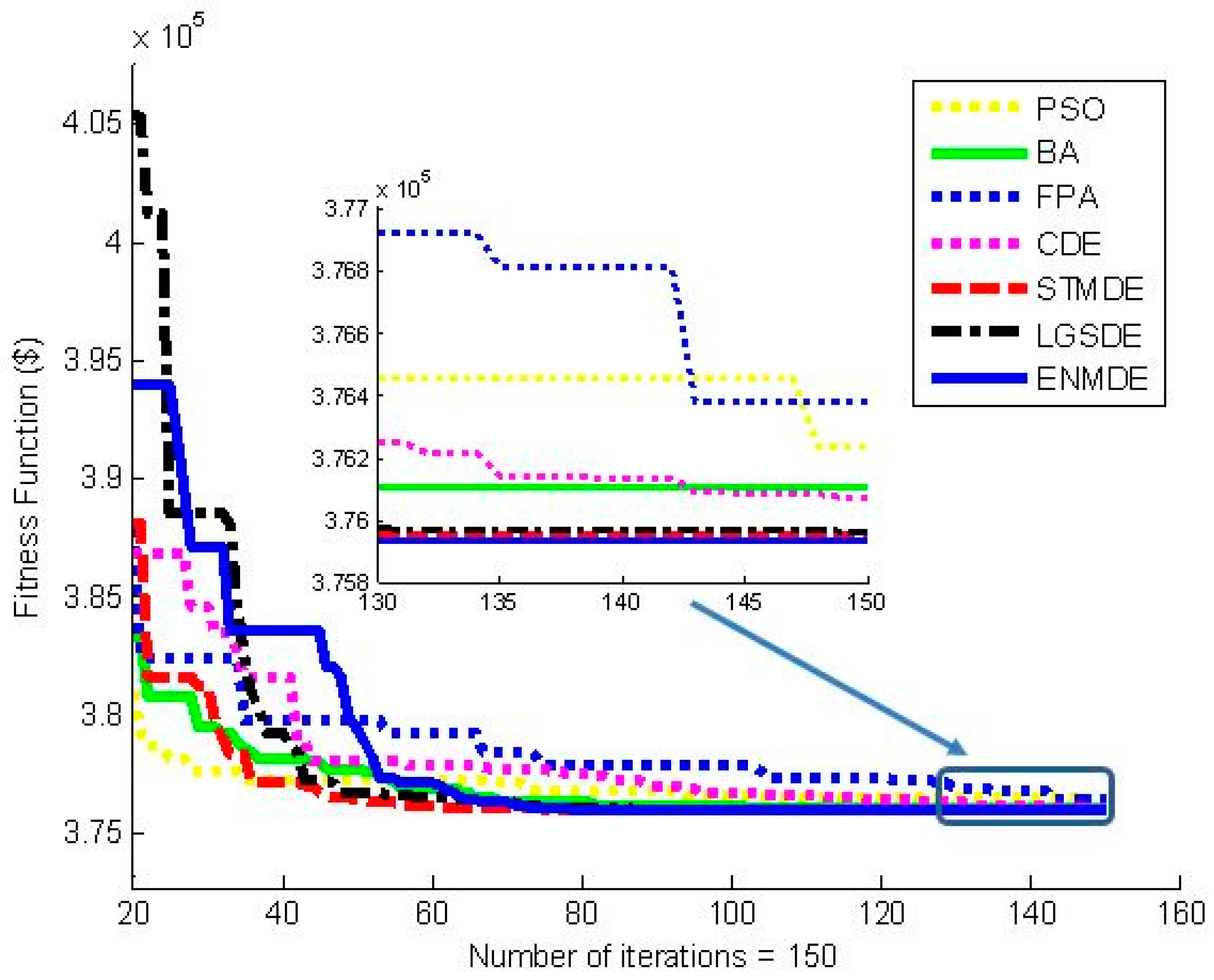
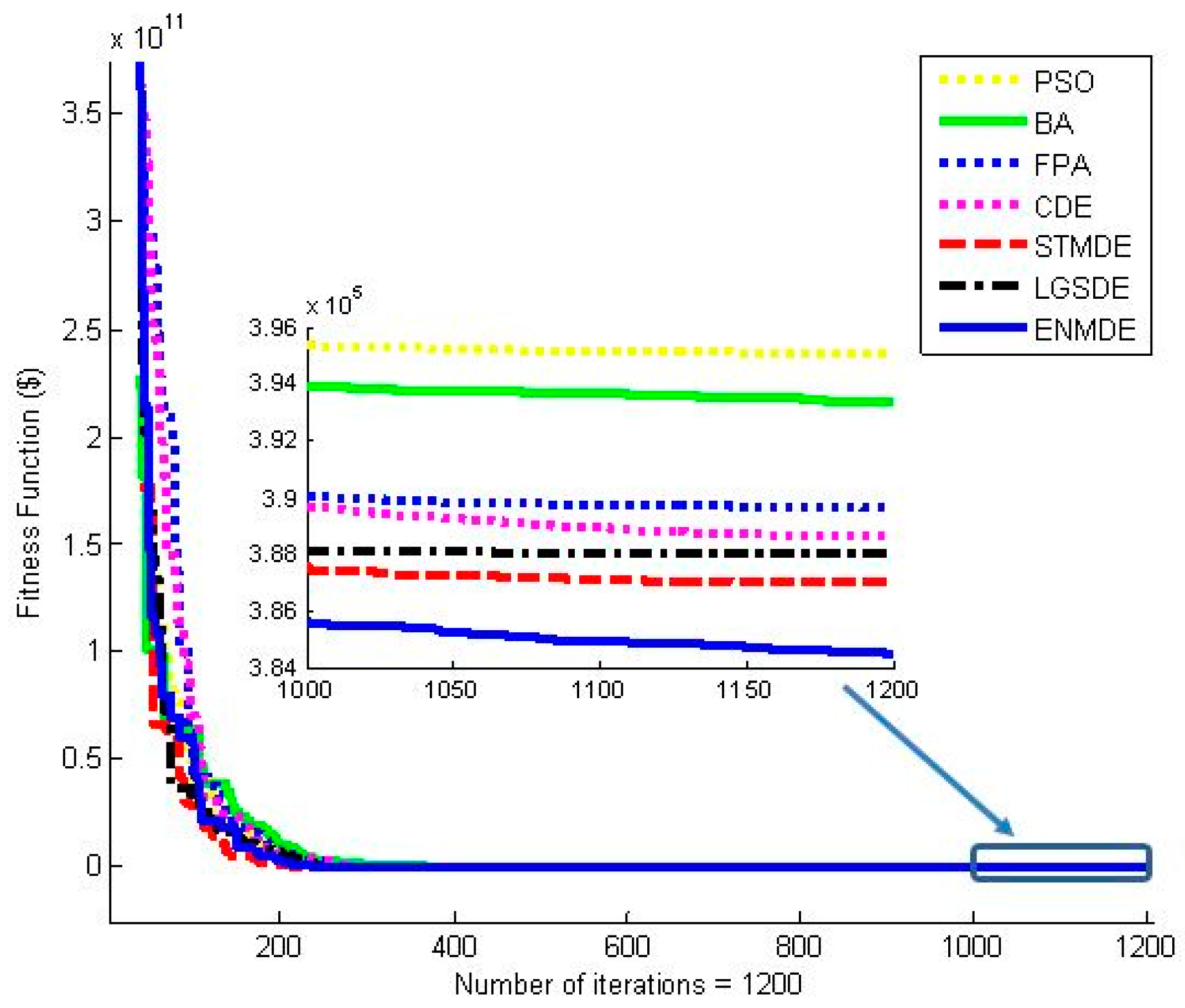
Figure 1, indicate that other methods tend to converge to local optimal solutions faster than the proposed ENMDE from the first iteration to the twentieth iteration, but these methods did not improve their fitness much from the eightieth to the last iteration. These methods are trapped into a local optimum and the jump out of the local zone was not carried out. It was clear that the search ability of the proposed ENMDE always improved when the iteration was increased. Consequently, it can be concluded that ENMDE is very effective for the study case of Problem 1.
The result obtained by the four DE variants and other methods for study case two are reported in
Table 3. Similar to the results yielded for case one, the two proposed techniques have a significant impact on the performance of DE since the lowest cost, mean cost, highest cost, and standard deviation cost for STMDE and LGSDE are better than those for CDE. In particular, all the costs from the proposed ENMDE are the lowest values when compared to those from CDE, STMDE, LGSDE, BA, PSO, and FPA. The best cost for ENMDE is lower than that for CDE, STMDE, LGSDE, BA, PSO, and FPA by
$136.54,
$18.76,
$31.84,
$170.64,
$293.25, and
$447.12, respectively. The convergence characteristics shown in
Figure 2 indicate that the other methods search very well at the beginning of the search process from the first iterations to the forty-fifth iteration, because their fitness functions were much lower than those of the proposed ENMDE. However, at the end of the search, from the 130th iteration to the last iteration, their fitness functions were much higher than those of the proposed ENMDE. Clearly, there are similarities between this scenario and scenario in case 1.
Compared to the others, the proposed ENMDE reveals its strongly highlighted search ability once its best cost is less than that of nearly all methods except HLN and ALHN in [
15]. The best cost for ENMDE is slightly higher than HLN and ALHN, by
$0.03 and
$0.06, respectively; while the cost for ENMDE is much lower than others, such as
$1621.23 compared to HNN,
$1440.96 compared to the Newton method,
$26.87 compared to CSA [
16],
$181.03 compared to CSA [
17], and
$56.76 compared to MCSA [
17]. Furthermore, the TNFES for the proposed ENMDE is 7500; whilst that for CSA [
16], and CSA and MCSA [
17] were 200,000, 500,000, and 72,000, respectively. With respect to the execution time, HLN and ALHN still perform best, with the fastest times. However, as pointed out in the introduction, the two methods suffer from a large limitation for the application to a large number of constraints and problems with non-convex objective functions. Overall, it can be concluded that the proposed ENMDE is very efficient for study case two. The optimal solutions obtained by ENMDE for the two cases are given in
Appendix A.
5.1.2 Study Cases 3 and 4 with Valve Point Loading Effects
In this section, a demonstration is implemented for two hydrothermal systems with a non-convex fuel cost function, for thermal units where the valve point loading effects of thermal generators are considered [
8]. Study case three, including two hydropower plants and two thermal plants scheduled in three eight-hour subintervals, and study case four, including two hydropower plants and four thermal plants scheduled in four twelve-hour subintervals, are used to verify the performance of the proposed ENMDE method. The compared information reported in
Table 4 for case three and in
Table 5 for case four includes fuel costs, standard deviation, and computation time in addition to the population size, the maximum number of iterations and the total number of fitness evaluations. As seen from TNFES in
Table 4, the proposed ENMDE has the same value as the other implemented methods, such as BA, FPA, and DE variants, but the proposed ENMDE has much lower values than the other ones. In fact, the proposed ENMDE used 3500 fitness evaluations, while AIS, EP, PSO, and DE in [
8] used 10,000 fitness evaluations, especially CSA in [
16]; CSA and MCSA in [
17] used 150,000, 500,000, and 72,000 fitness evaluations, respectively. A similar scenario can be also seen in
Table 5, since the proposed ENMDE is in the group with the lowest TNFES of 20,000 fitness evaluations, while other methods used a very high number, such as CSA [
16] with 300,000 fitness evaluations, CSA [
17] with 700,000 fitness evaluations, and MCSA [
17] with 120,000 fitness evaluations. Comparing the best cost for case three and case four, the proposed ENMDE has a much lower cost than several methods with the same TNFES and have a slightly lower cost than several methods with a much higher TNFES. For case three, the cost obtained by ENMDE was less than BA and FPA by
$48.43 and
$42.552, respectively. Equally, ENMDE has a much lower cost than AIS, EP, PSO, and DE, being
$1.56,
$82.56,
$50.56, and
$5.56 lower, respectively. ENMDE has a slightly lower cost than CSA [
16] and CSA and MCSA [
17], being
$0.01,
$0.15 and
$0.01 lower, respectively. For case four, the cost obtained by ENMDE was
$1242.17 and
$848 lower than BA and FPA, respectively;
$1226.04,
$1526.04,
$1402.04, and
$1370.04 lower than AIS, EP, PSO, and DE [
8], respectively; and
$1.17,
$43.13, and
$17.94 lower than CSA [
16] and CSA and MCSA [
17], respectively. Similarly, the costs of the proposed ENMDE are also lower than CDE, STMDE and LGSDE.
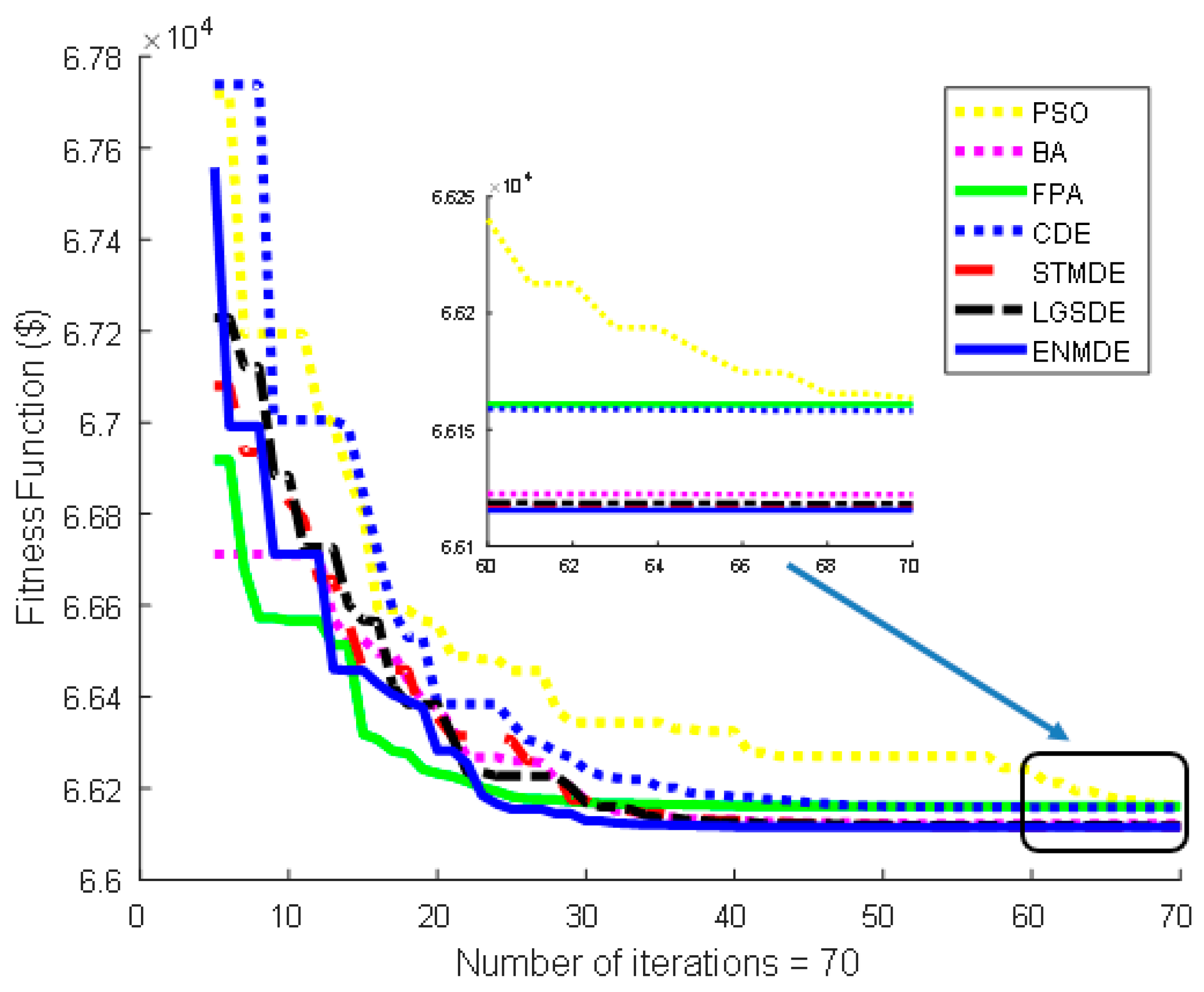
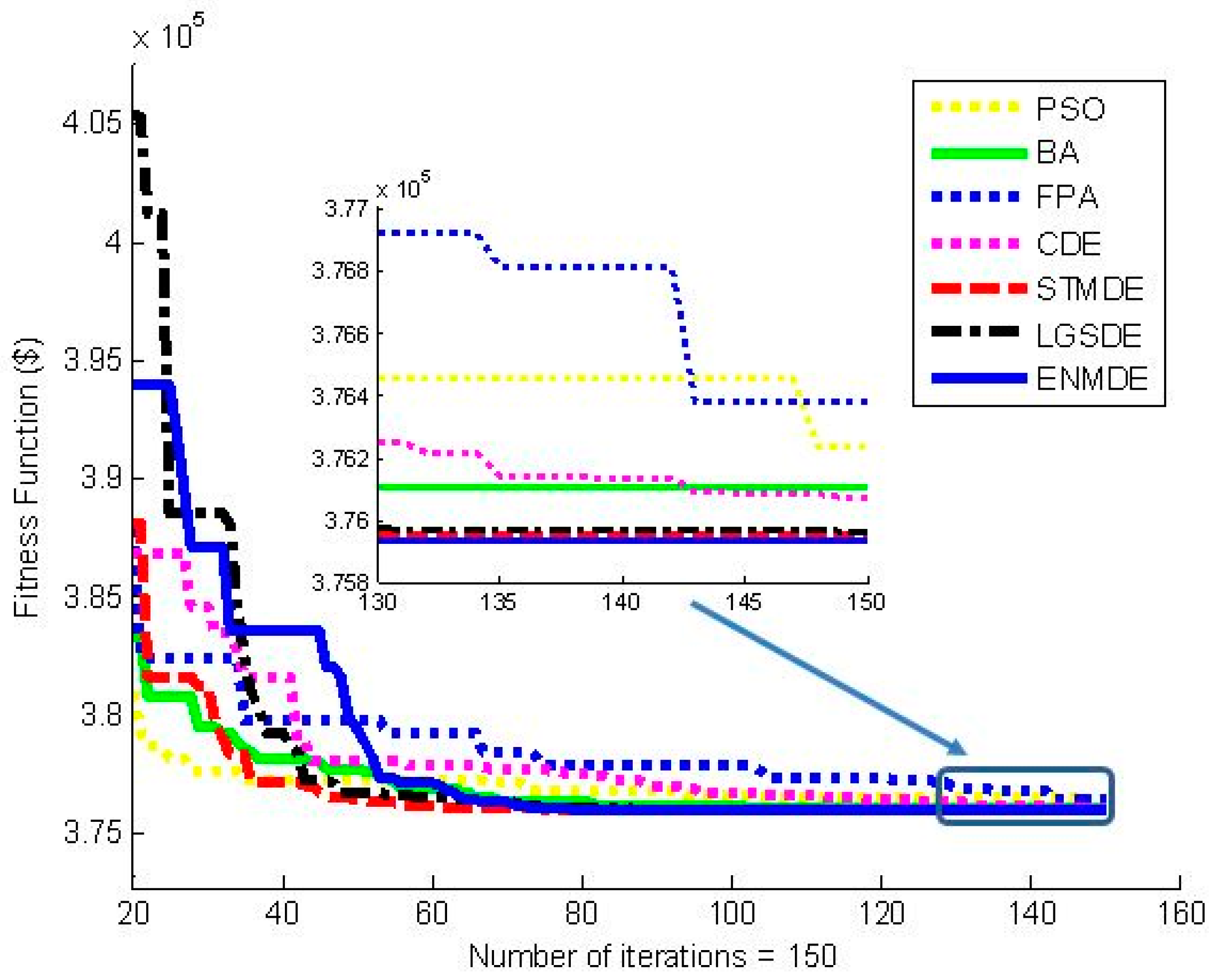
Figure 3 and
Figure 4 also show the better performance of the proposed ENMDE compared to other methods implemented in this paper. For the two cases with valve point loading effects, the application of HLN and ALHN in [
15] could not be performed. Therefore, there was no evaluation of their performance. In summary, the proposed ENMDE is very efficient compared to other methods for solving study cases three and four with a non-convex fuel cost function. The optimal solutions obtained by ENMDE are given in the
Appendix A.
5.2. The Second Problem with Reservoir Volume Constraints
In
Section 5.1, a big effort was made to clarify the superiority of the proposed ENMDE over other algorithms, including conventional deterministic algorithms, original meta-heuristic algorithms and improved versions of original meta-heuristic algorithms, especially three other DE variants. In this section, the proposed ENMDE is tested on two other hydrothermal systems constrained by the reservoir volume, such as initial volume, end volume, and the limits on the volumes. The first system, called study case five, consists of one hydropower plant and one thermal plant, neglecting the valve point loading effects from [
2]. The second system, consisting of four hydro units and four thermal units considering valve point loading effects, is called study case six and is modified from study case five [
33].
5.2.1. Study Case 5 without Valve Point Loading Effects
The detailed results obtained by CDE, STMDE, LGSDE, ENMDE, and three additional methods, consisting of PSO, BA, and FPA, are shown in
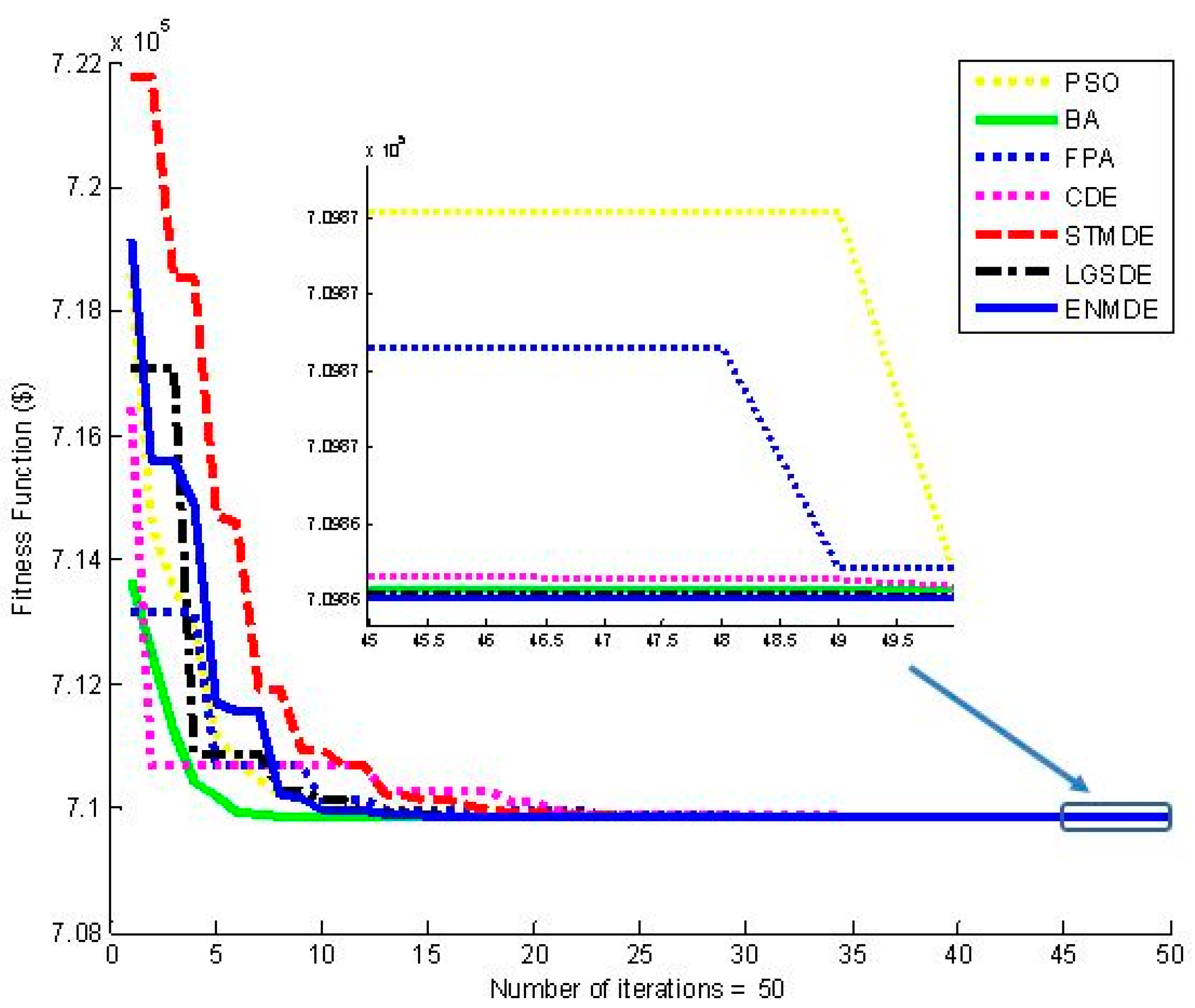
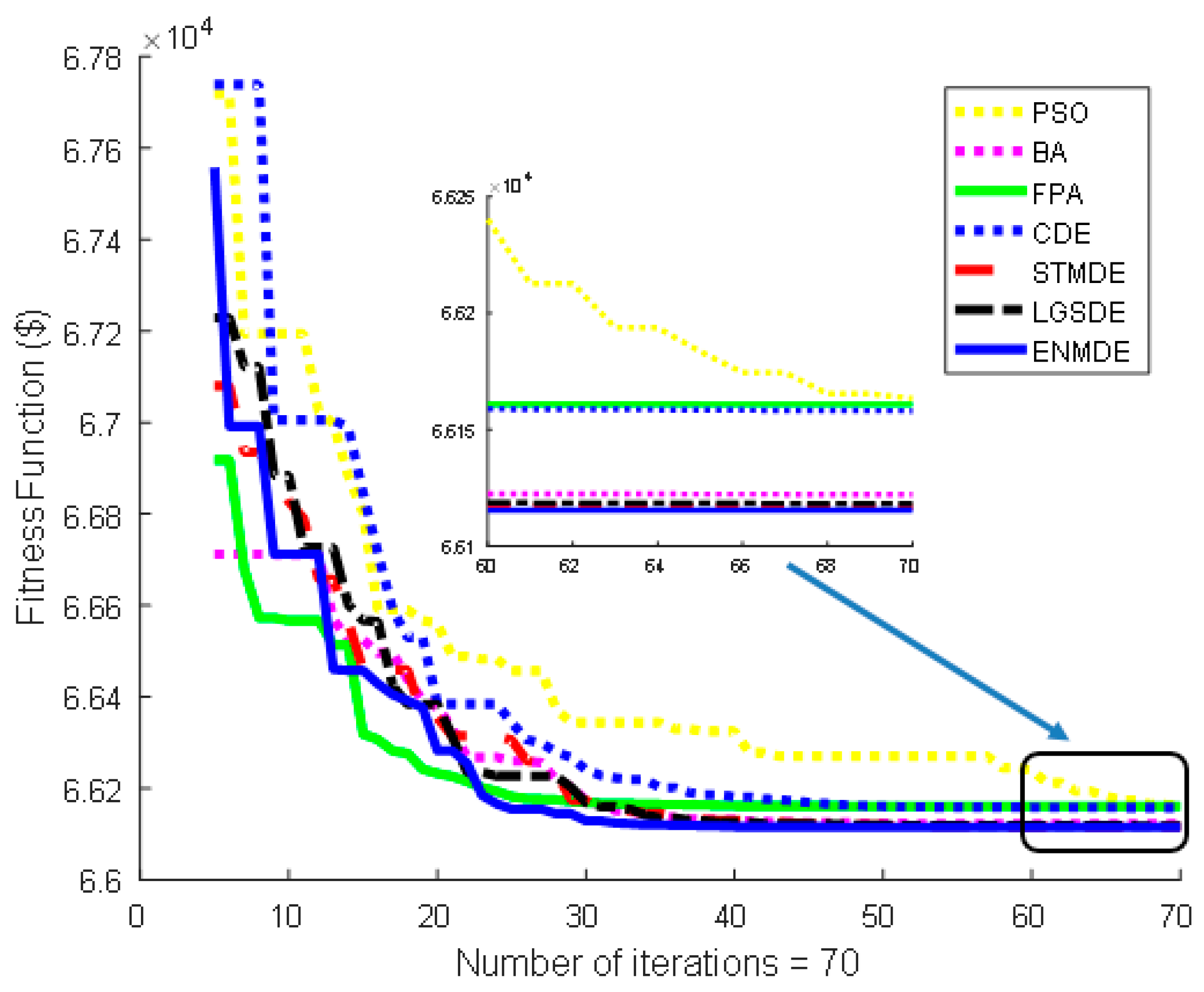
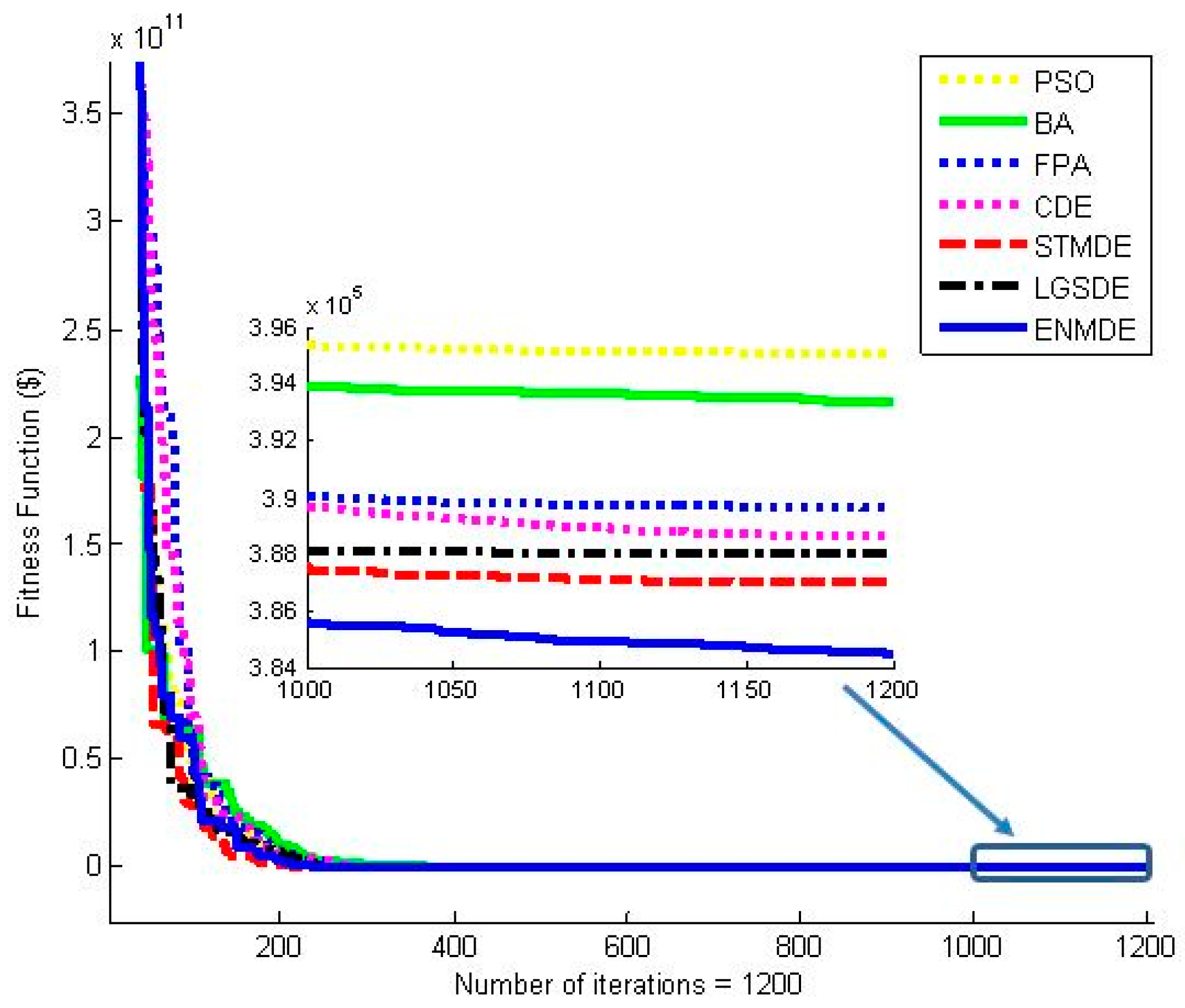
Table 6. The fitness convergence characteristics from the second iteration onwards yielded by these methods are depicted in
Figure 5. As seen from the
Table 6 and
Figure 5, the proposed ENMDE obtained the best minimum, average, maximum, and standard deviation cost and the fastest convergence compared to other methods. The performance of the proposed ENMDE method continued to compete with other methods and is presented in
Table 7. The best cost comparison reveals that the proposed ENMDE could find a high quality solution, which was as good as that of all methods excluding GS [
2], SA [
18], GA [
19], and EP [
20], the costs of which were much higher. Although the best cost cannot lead to a superiority of the proposed ENMDE over some methods, the TNFES value that the ENMDE used was much lower than all methods. In fact, ENMDE used only 1000 fitness evaluations, while the others used from 2100 to 24,000 fitness evaluations. This large difference justified the fastest execution time of the proposed ENMDE of 0.14 s, while other methods (excluding the CSA methods in the studies [
33,
34]) required from 4.54 s (CS [
31]) to 901 seconds (SA [
18]). Thus, it can be concluded that ENMDE is very efficient for study case five. The optimal solutions obtained by ENMDE are provided in the
Appendix A.
5.2.2. Study Case 6 with Valve Point Loading Effects of Thermal Units
In order to clarify the performance of the proposed ENMDE, the largest system with four hydro units and four thermal units scheduled in six twelve hour subintervals considering the valve point loading effects was used. The results obtained by the CDE, STMDE, LGSDE, and ENMDE and the three additional methods, consisting of PSO, BA, and FPA accompanied by
Np,
Gmax and TNFES are compared and presented in
Table 8. The comparison of all the shown values implies that the proposed ENMDE is the most efficient method with the best costs and the lowest TNFES value. In fact, ENMDE, other DE variants, and PSO, BA and FPA used the same TNFES, with only 60,000, while the values for the CSA variants was very high and equal to 350,000. In addition, the best cost from the proposed ENMDE was respectively less than that of CSA-Lévy, CSA-Cauchy, CSA-Gauss, CDE, STMDE, LGSDE, BA, PSO, and FPA by
$3207.5,
$4369.6,
$4695.4,
$4143.7,
$2457.9,
$3500.8,
$8863.6,
$10,581.5, and
$5138.1, respectively.
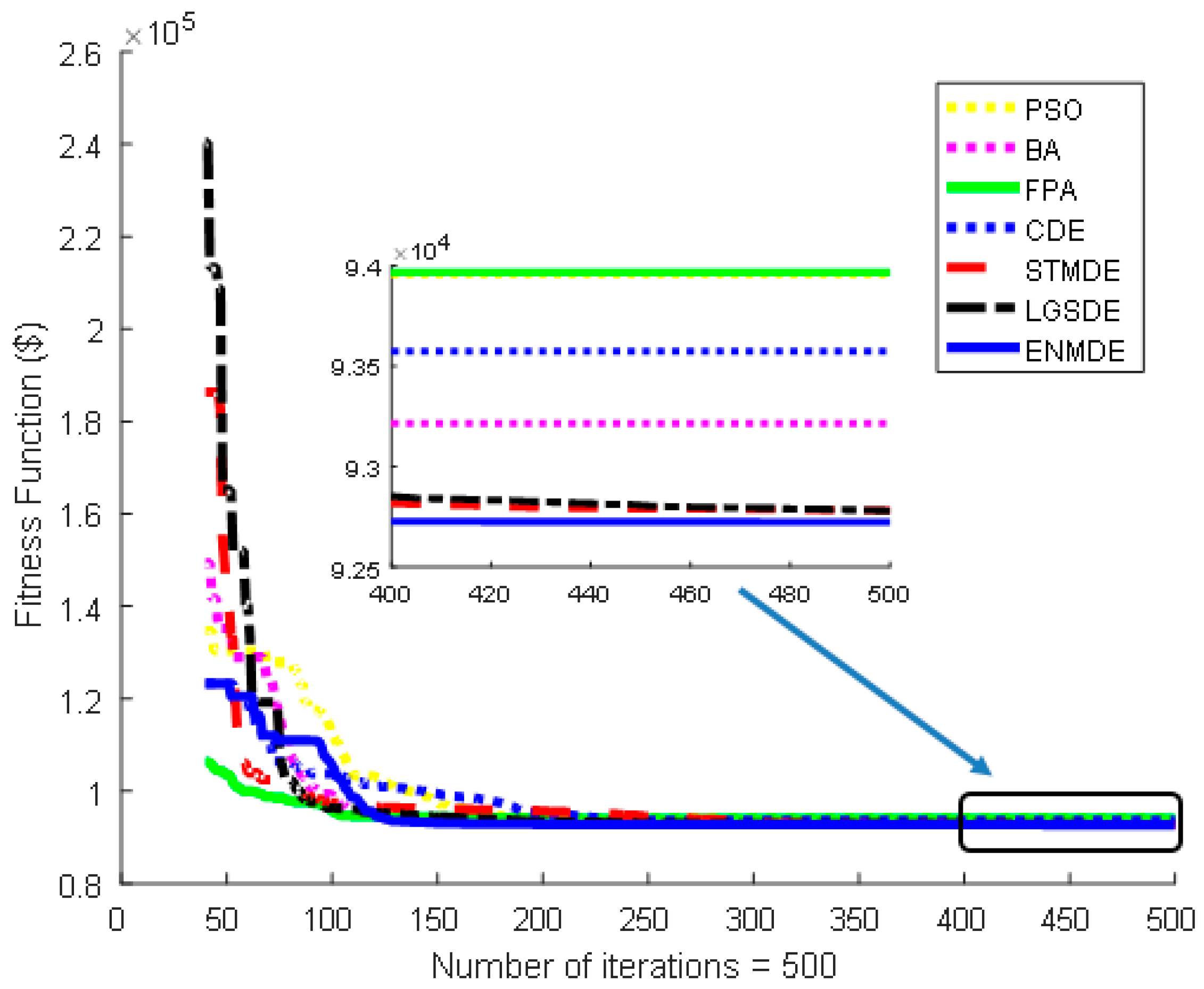
Figure 6 indicates the faster convergence of the proposed ENMDE than other DE variants, namely BA, PSO, and FPA. In summary, the proposed ENMDE can both obtain a better optimal solution and has faster convergence than all methods for the study case 5 with reservoir volume constraints and a non-convex fuel cost function. The optimal solutions obtained by ENMDE are given in
Appendix A.
5.3. Discussion of the Performance of the Proposed Method
In this work, we employed six benchmark systems and tried to demonstrate the effectiveness and robustness of the proposed method on the systems by adding a non-convex fuel cost function, increasing the number of power plants and changing the complex of set of constraints. We applied two different problems, where the first problem considers the constraint of available water and ignores the constraints related to reservoir volumes, such as reservoir volume limitation, the initial volume of reservoirs and the end volume of reservoirs, while the second problem ignores the constraints of available water but takes all constraints regarding the reservoir volume into account. For the challenge of searching for the global optimum solutions or near-global-optimum solutions, the valve point loading effects, which are represented as a non-convex fuel cost function form, were considered in study cases three and four in problem one and in study case six in problem two. Besides, the scale of the study cases also increased, such as the four power plants for cases one, two and three, six power plants for case four of problem one, two power plants for case five, and eight power plants for case six of problem two.
As observed from cost comparisons, the improvement of fuel cost obtained by the proposed method compared to the other methods is different for different study cases and the improvement is only significant for study case six. For a better performance evaluation between the proposed method and other methods, we supplemented cost saving and cost improvement in
Table 9,
Table 10 and
Table 11, in which cost saving in dollars and cost improvement in percent were calculated using Equation (37) and (38). Cost saving is the cost reduction of the proposed method compared to other methods, while cost improvement is the improvement of the proposed method over compared methods.
The cost improvement reported in these tables indicates that the highest cost improvements for cases 1–6 were 0.00073%, 0.382%, 0.1247%, 1.619%, 0.0017%, and 2.678%, respectively; while the lowest cost improvement for cases 1–5 was approximately 0%, excluding case six with a cost improvement of 0.635%. The difference among such numbers can be understood if the scale and the complex of the systems in
Table 1 are analyzed. It can be seen that the cost improvement for case two (0.382%) was higher than that for case one (0.00073%), because case two considers a scheduled period of two days with 48 hours, while case one considers the period of one day only. Similarly, the cost improvement for case four (1.619%) and case six (2.678%) are much higher than those for case three (0.1247%) and case five (0.0017%), respectively. The number of power plants for case three is four units and the scheduled period for case three is one day; while those for case four are six power plants and two days. Similarly, those for case five are two power plants and three days, but those for case six are eight power plants and three days. The analysis can send a message that a large-scale system can lead to better cost improvement. Besides, the cost improvement for the cases considering complex objective functions with VPLES is also better than the cases neglecting such VPLES. For instance, the improvement in case three with VPLES is 0.1247%, while that for case one without VPLES is 0.00073%, although these two cases consider the same number of power plants and the same scheduled period. Due to both the higher number of power plants and the much more complicated objective function with VPLES, the cost improvement for case four is 1.619%, that for case six is 2.678%, and that for case 2 is 0.382%.
With respect to the performance comparison, we have stated that the proposed method was more effective and robust than the other methods based on four comparison criteria consisting of the minimum fuel cost comparison, the standard deviation comparison, computational time comparison, and TNFES comparison. Among the four comparisons, the minimum fuel cost comparison reflects the quality of the optimal solutions and the standard deviation comparison points out the robustness of the methods, while the computational time and TNFES comparisons reflect the convergence speed. The proposed method obtained insignificantly lower fuel costs than most methods for cases 1–3 and five but for case four and case six, the lower cost is relatively high. The greater lower cost for cases four and six resulted in the evaluation that the optimal solutions for the proposed method for cases four and six are of higher quality than those of other methods. The slightly lower cost for cases 1–3 and five cannot result in the same conclusion as for cases four and six, but it can lead to the evaluation that these compared methods have not converged to the global optimum or the near-global optimum. In fact, these methods need more iterations to find the same global optimal solutions. Furthermore, the computational time and the TNFES value from the proposed method are also smaller or approximate to those from other methods, excluding deterministic methods such as ALHN and HLN.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}