
An Online Learning Control Strategy for Hybrid Electric Vehicle Based on Fuzzy Q-Learning

Abstract
:1. Introduction
2. Problem Formulation


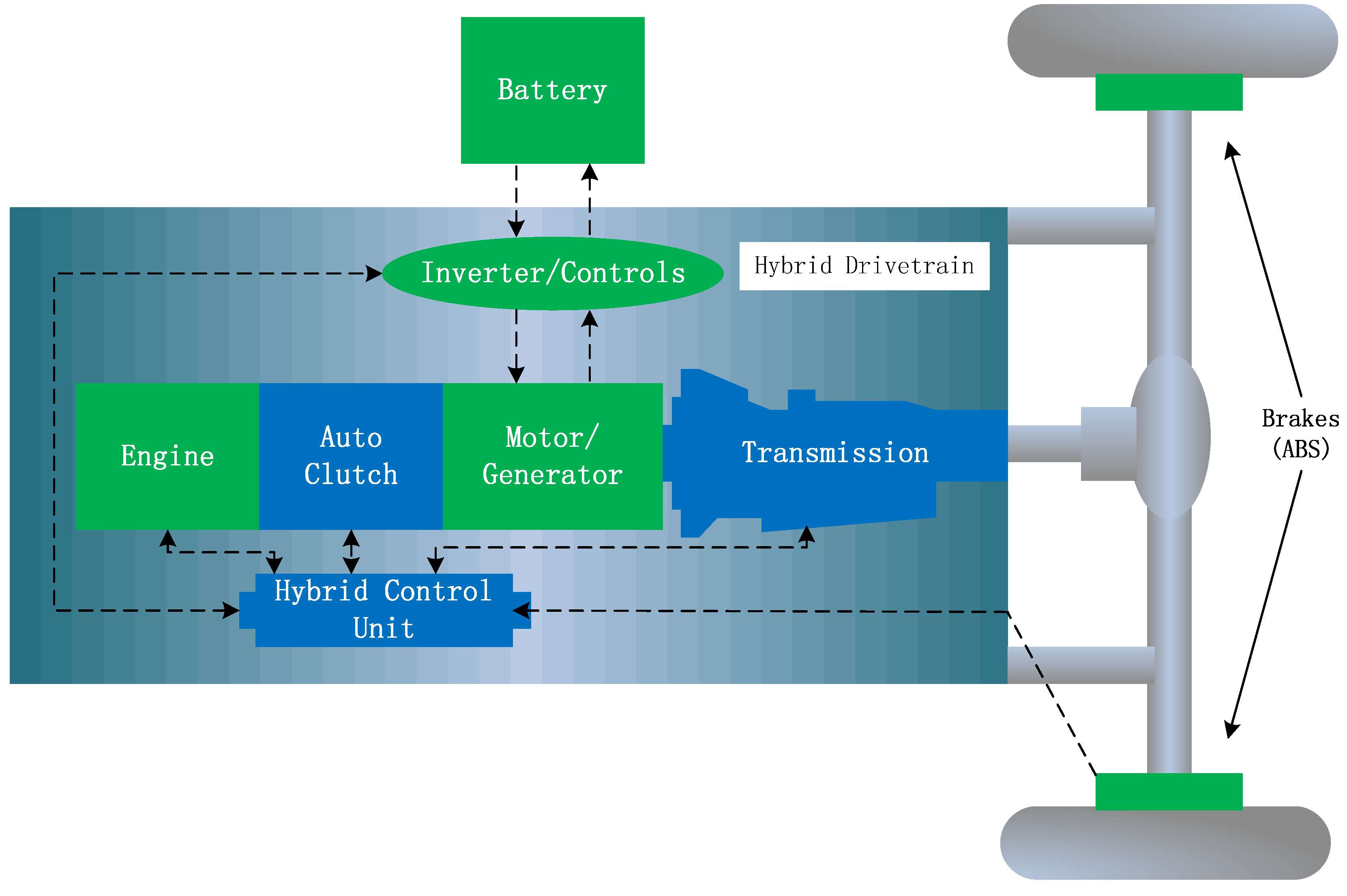{kind=link}
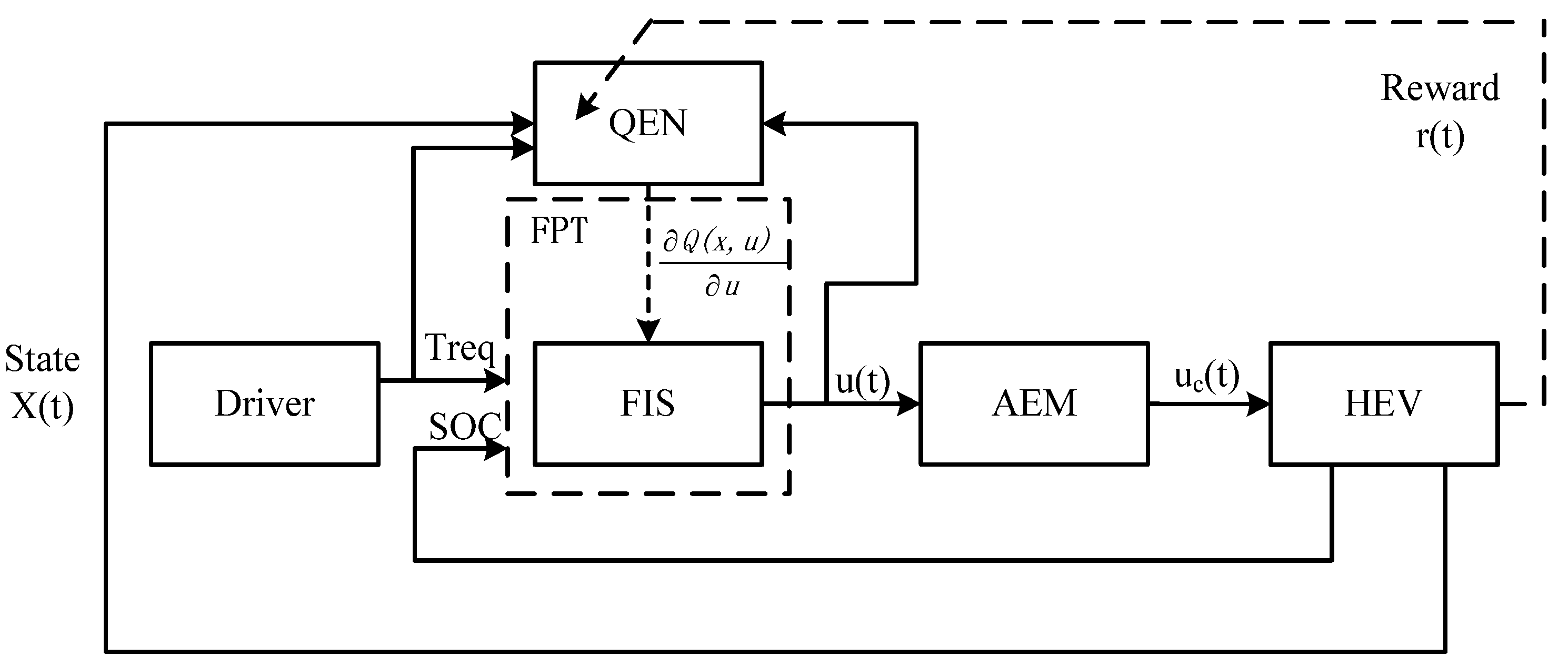{kind=link}
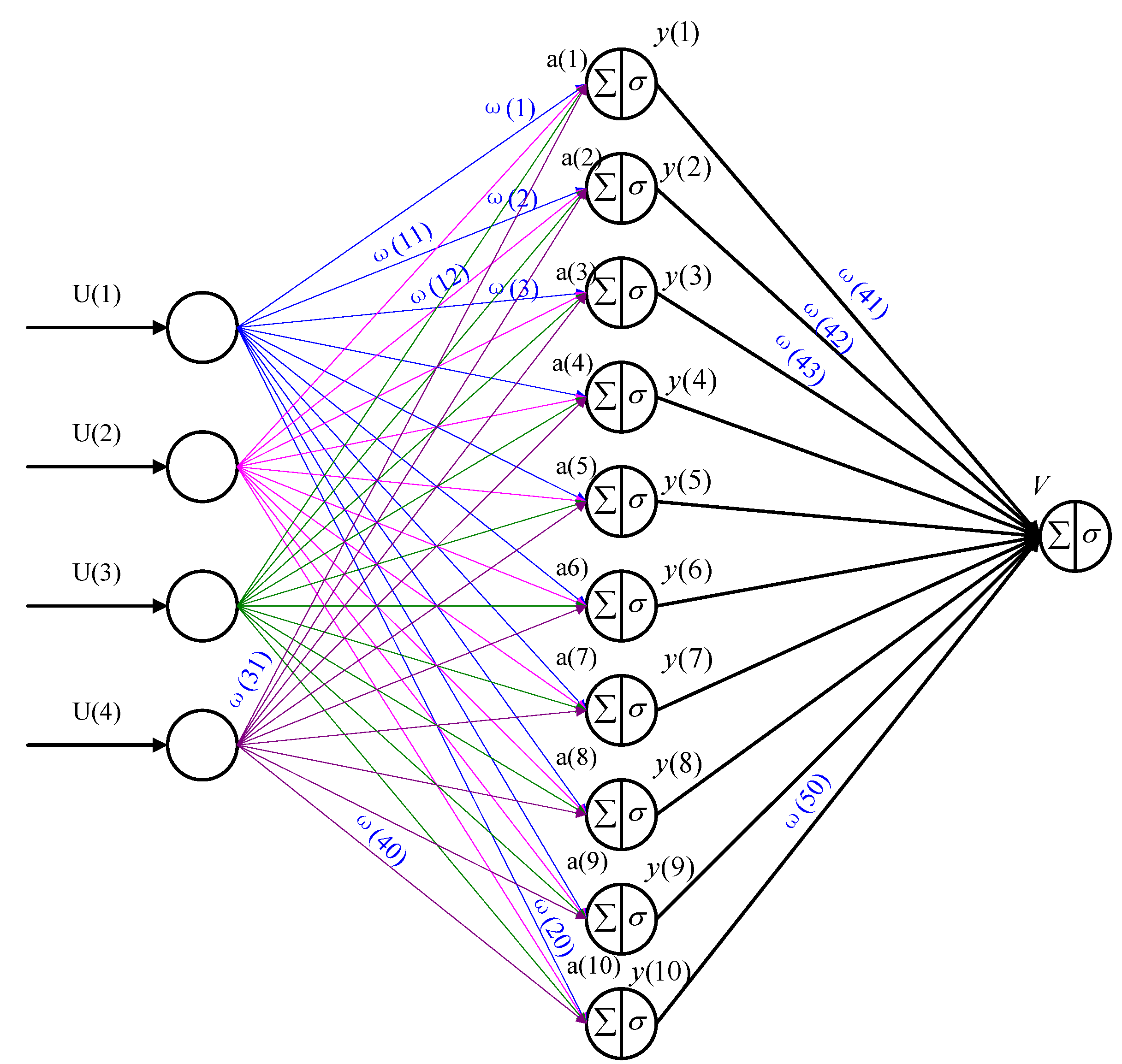{kind=link}
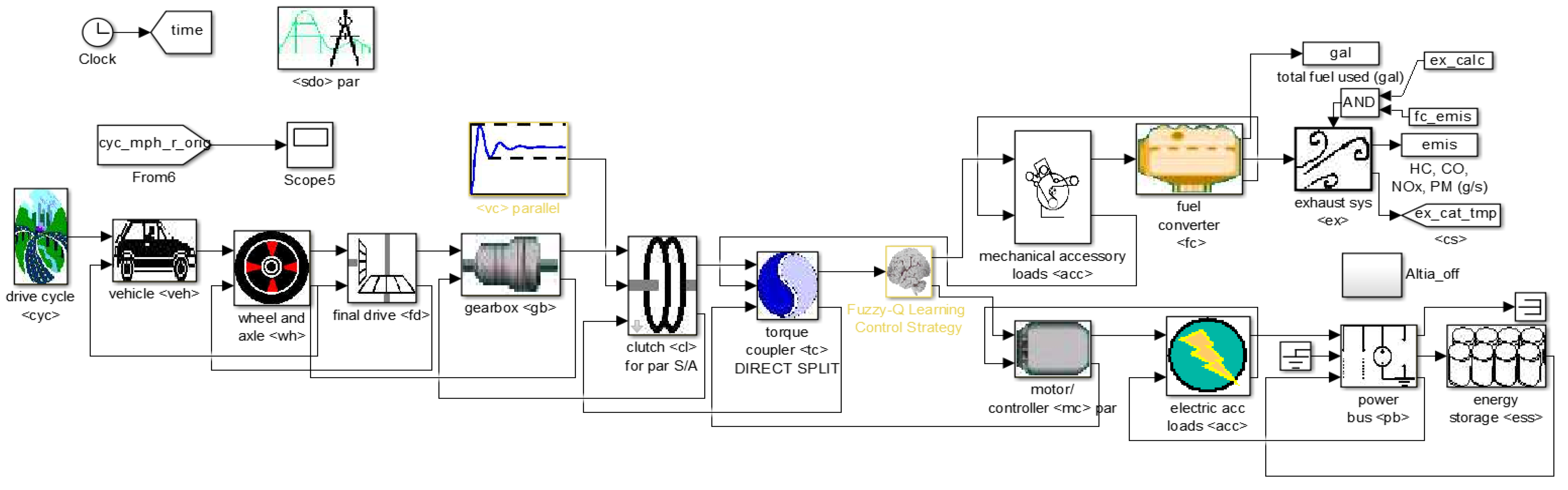{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Parameter |
|---|---|
| Spark ignition (SI) engine | Displacement: 1.0 L |
| Maximum power: 50 kW at 5700 r/min | |
| Maximum power: 89.5 N·m at 5600 r/min | |
| Permanent magnet motor | Maximum power: 10 kW |
| Maximum torque: 46.5 N·m | |
| Advanced Ni-MH battery | Capacity: 6.5 Ah |
| Nominal cell voltage: 1.2 V | |
| Total cells: 120 | |
| Automated manual transmission | 5 speed GR: 2.2791/2.7606/3.5310/5.6175/11.1066 |
| Vehicle | Curb weight: 1000 kg |
3. Fuzzy Q-Learning (FQL) Mechanism

3.1. Back Propagation (BP) Neural Network for Estimating Q*(x,u) (QEN)

- V is the summed input of the output node;
- ω(40 + i) is the weight between hidden node and the output node;
- y(i) is the output of the hidden node;
- a(i) is the summed input of ith hidden node;
- ω(j − 1,i) is the weight between input node and hidden node;
- U(i) is the input of QEN; and
- f is the activation function of the node.
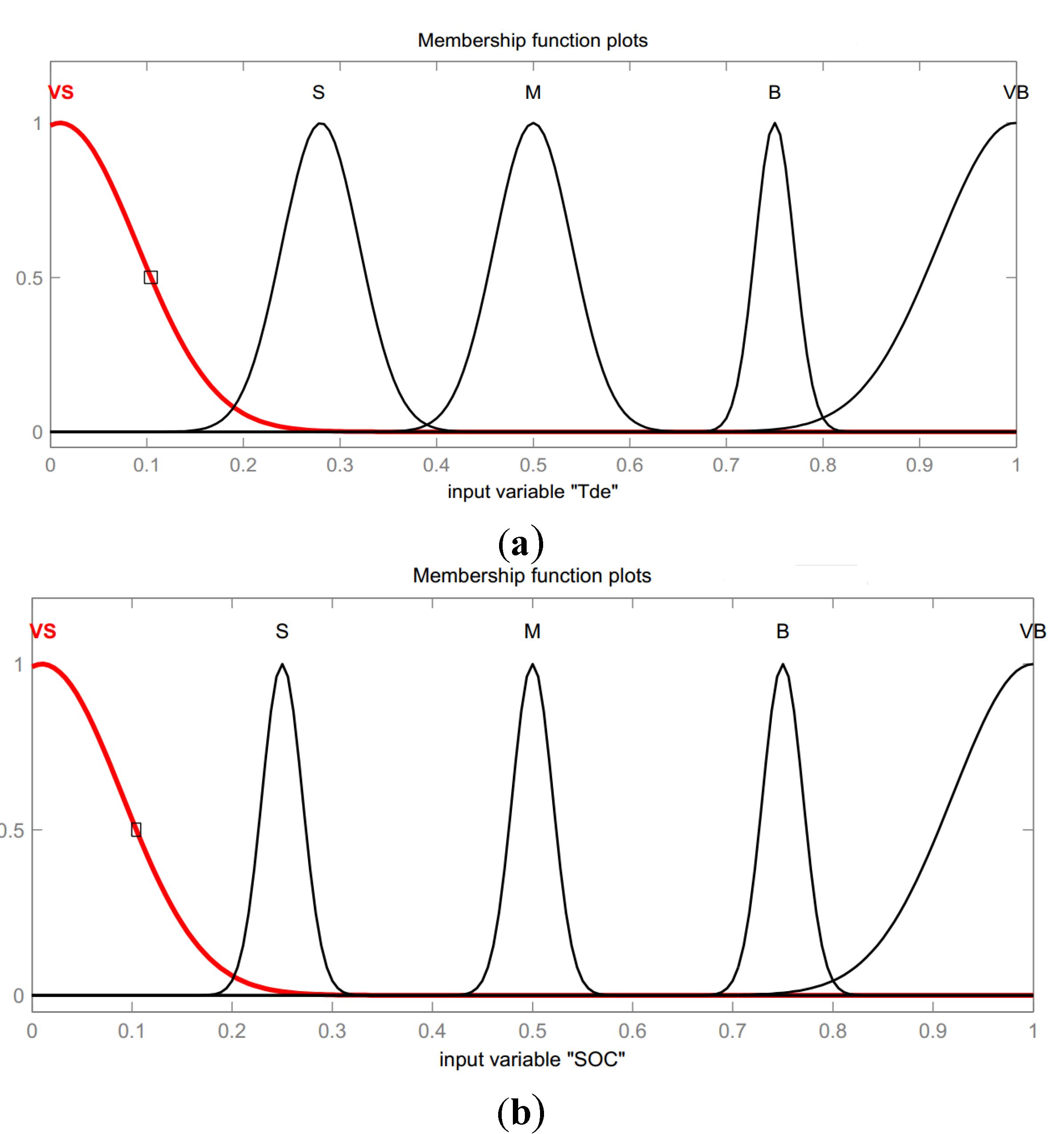
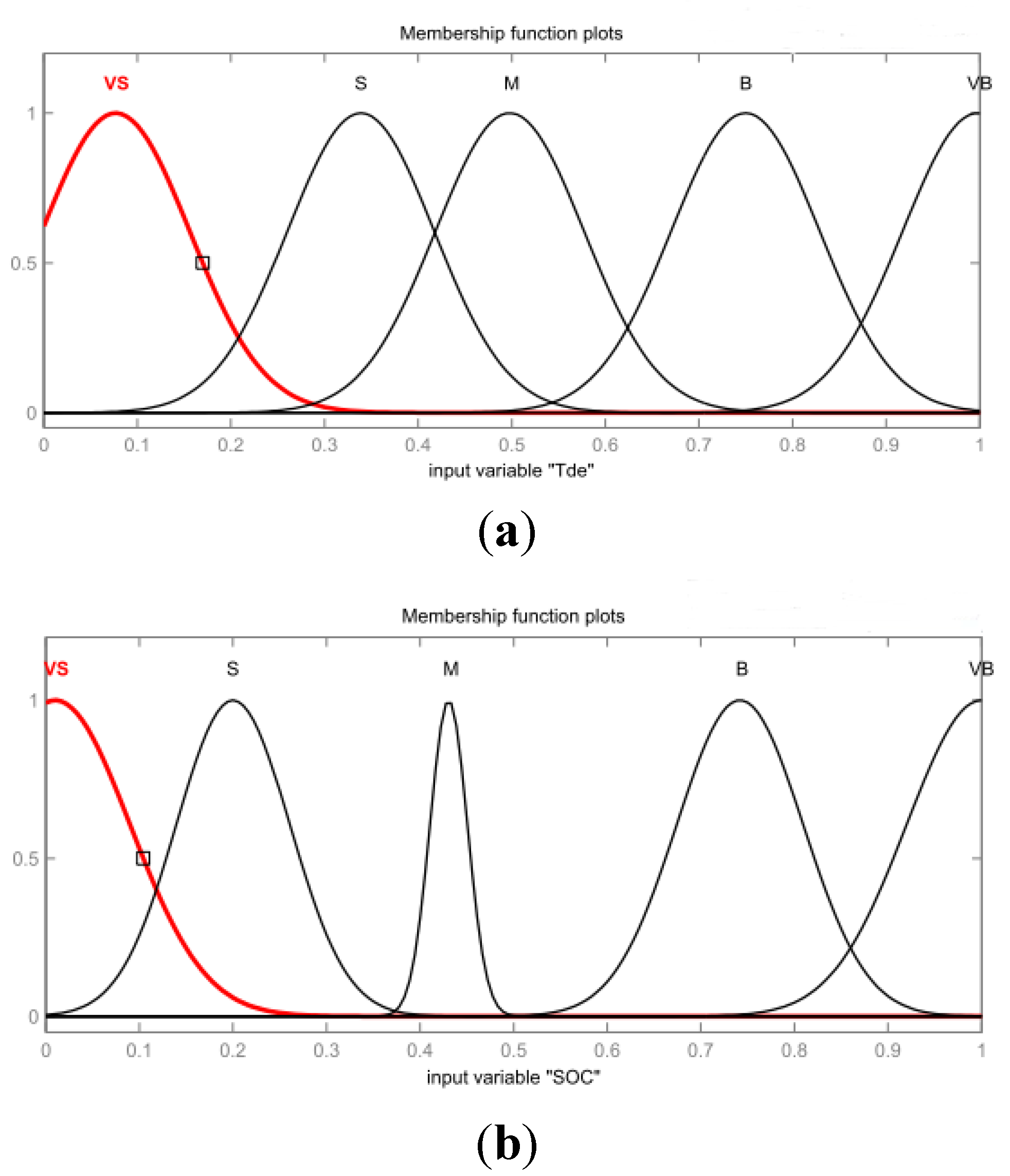
3.2. Fuzzy Interface System (FIS) Parameters Online Tuning-Based on Q*(x,u) (FPT)
3.3. Exploration Policy and Action Modifier
3.4. Overall Implementation Procedure
- 1)
- Initialize Q(xt,ut), the parameters (1)–(40), (41)–(50) of the QEN, and the parameters ξ of the FIS.
- 2)
- Obtain the new control output ut based on (20) and input of the FIS.
- 3)
- Before it is fed to the actual system, u is processed by the action modifier according to uc = u + ud.
- 4)
- The action modifier provides uc, which acts as the control value of the system.
- 5)
- Based on our requirements for the system, we evaluate the performance of the controller as and obtain the states of the system.
- 6)
- Obtain the approximated Q(xt+1, ut+1) from the QEN based on the current control action, and current states, and some previous states.
- 7)
- From , Q(xt,ut), and Q(xt+1, ut+1), we can calculate the TD error δt based on Equation (11). Here, we assume Q(xt+1, ut+1) ≈ maxu’Q(xt+1, u’) because ut+1 is obtained from the FIS, which continuously maximizes Q(xt,ut) with respect to the control output .
- 8)
- Based on δt obtained from Step 7, we can update the parameters of the QEN according to Equations (14) and (15).
- 9)
- Tune the parameters of the FIS based on Equations (17)–(27).
- 10)
- Substitute with .
- 11)
- If the parameters of the QEN and the FIS are not changed any more or after predefined iterations, the learning procedure is terminated; otherwise, return to Step 2 after a fixed sampling time .
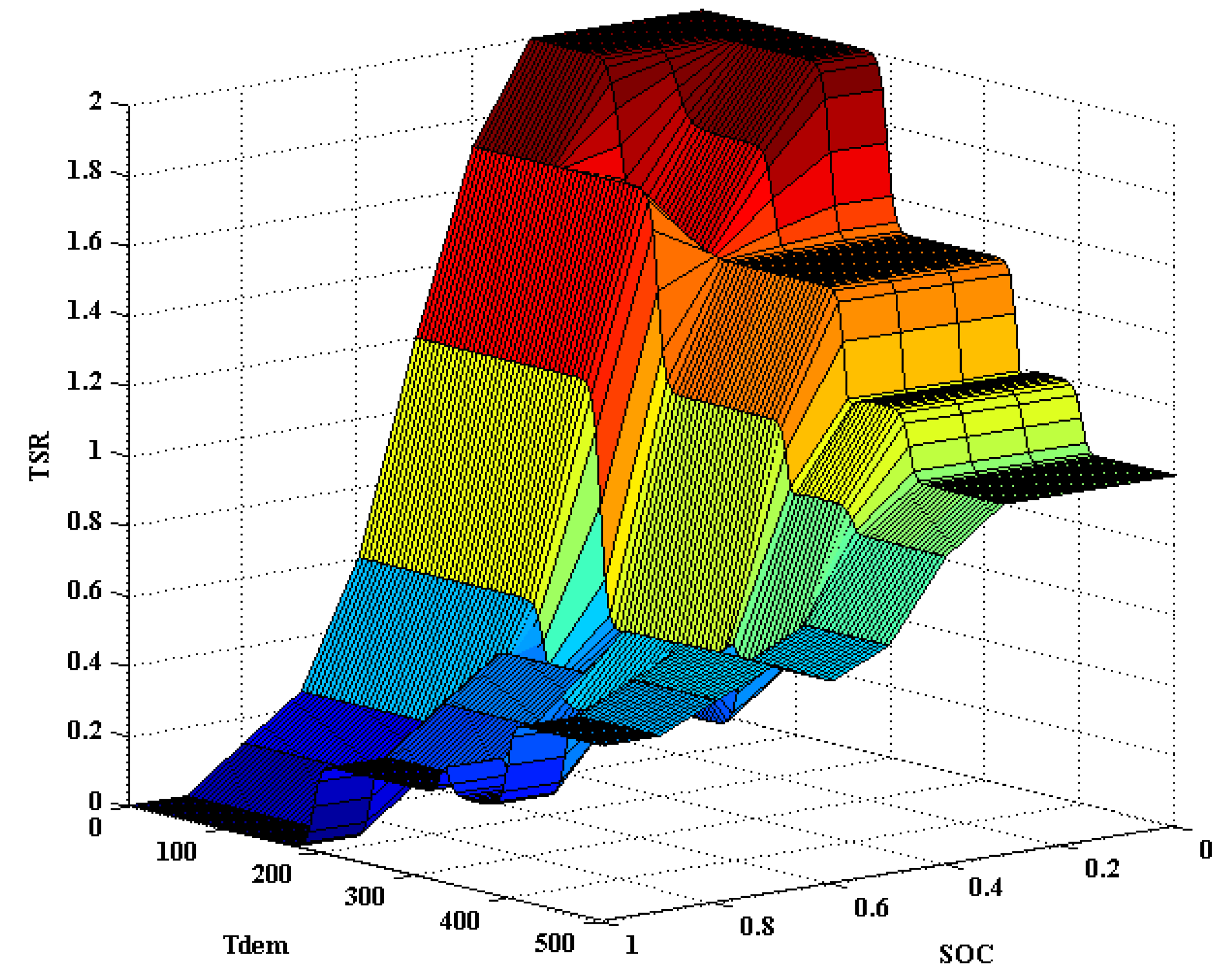
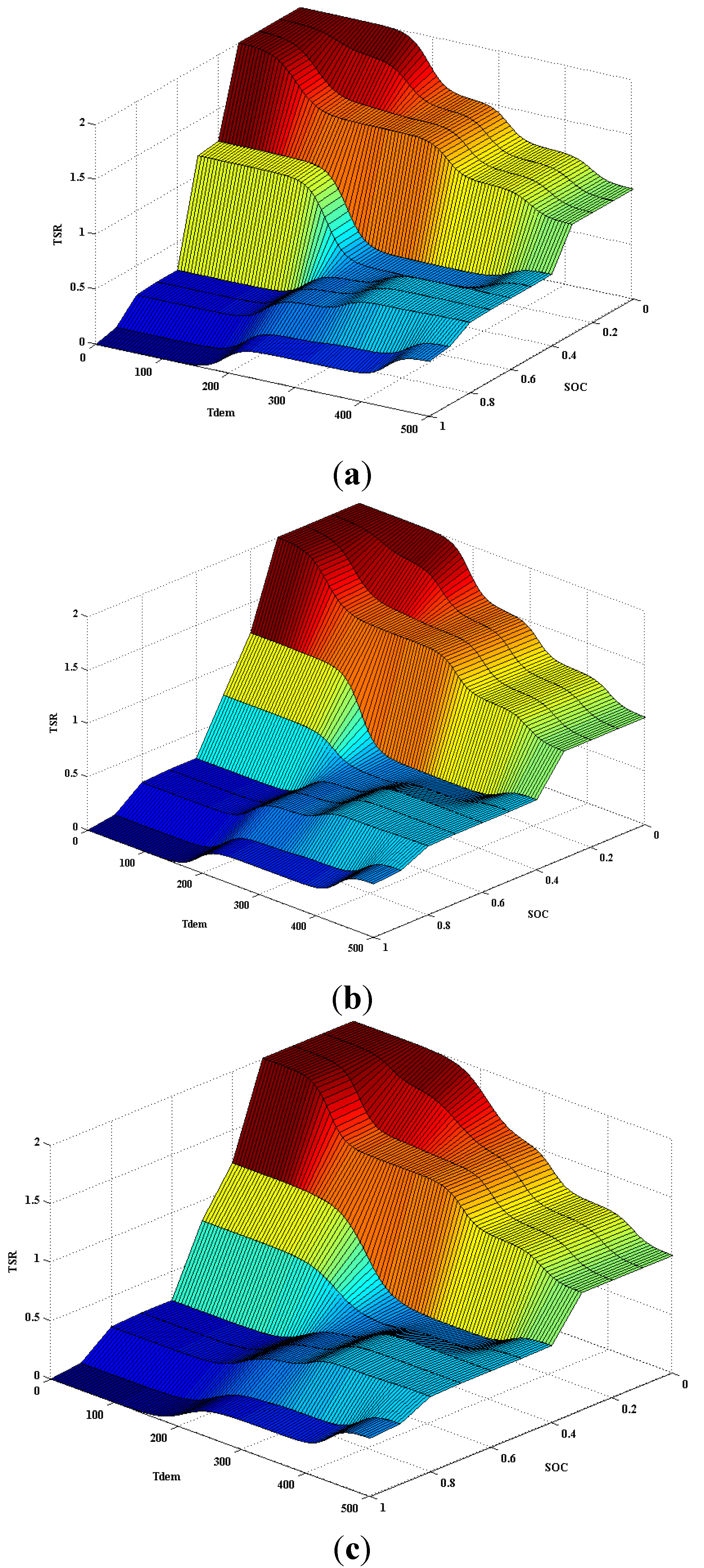
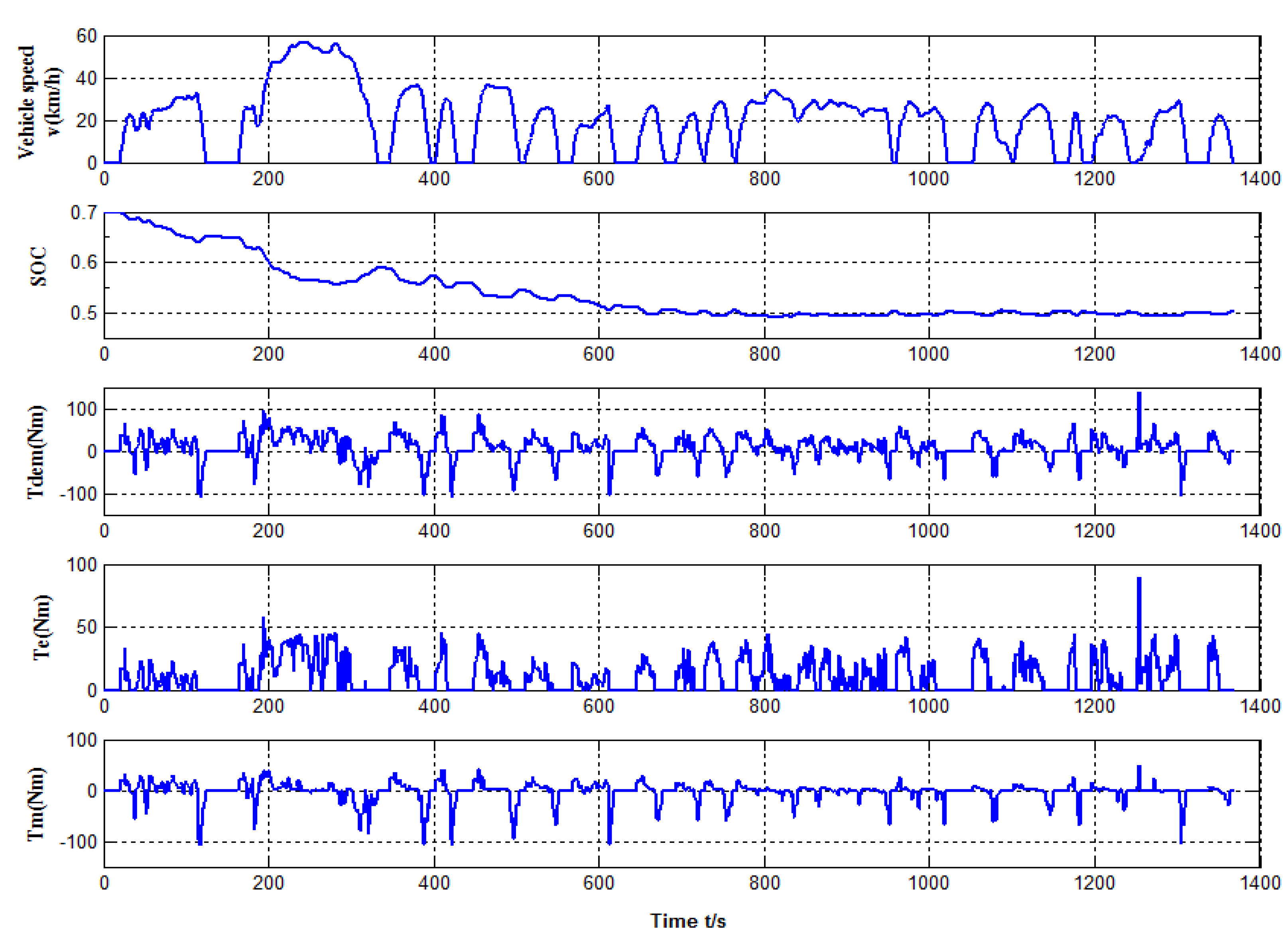
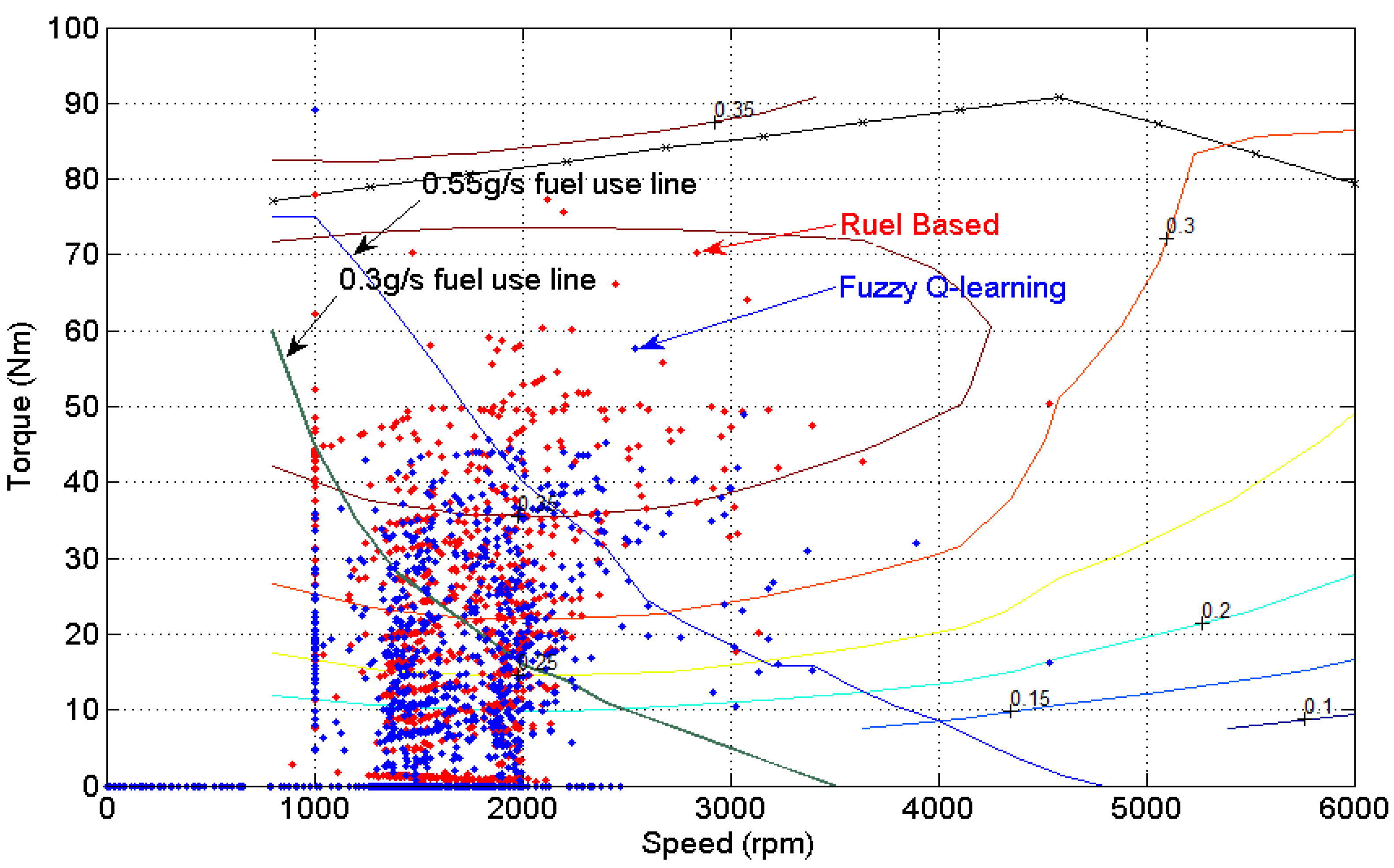
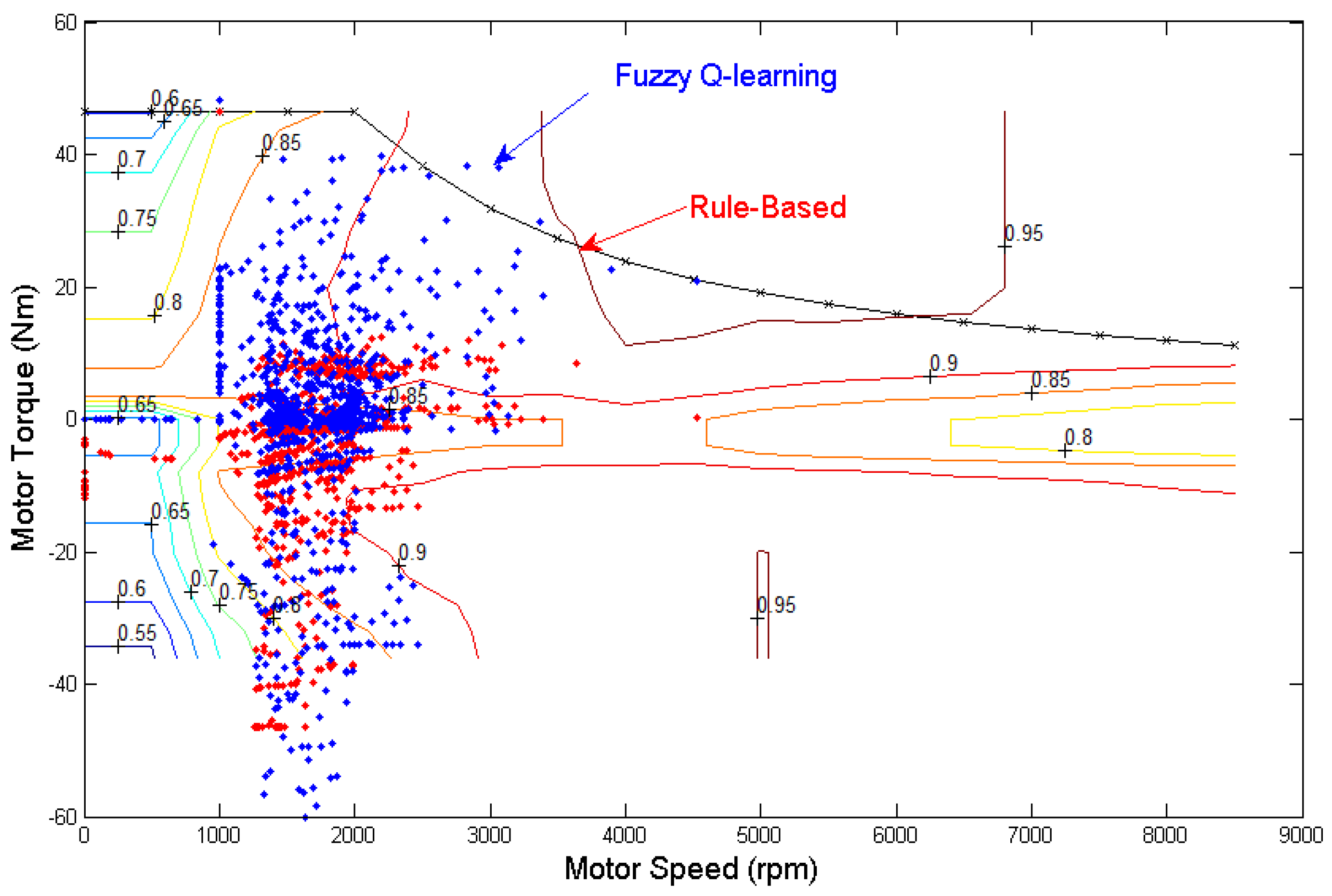
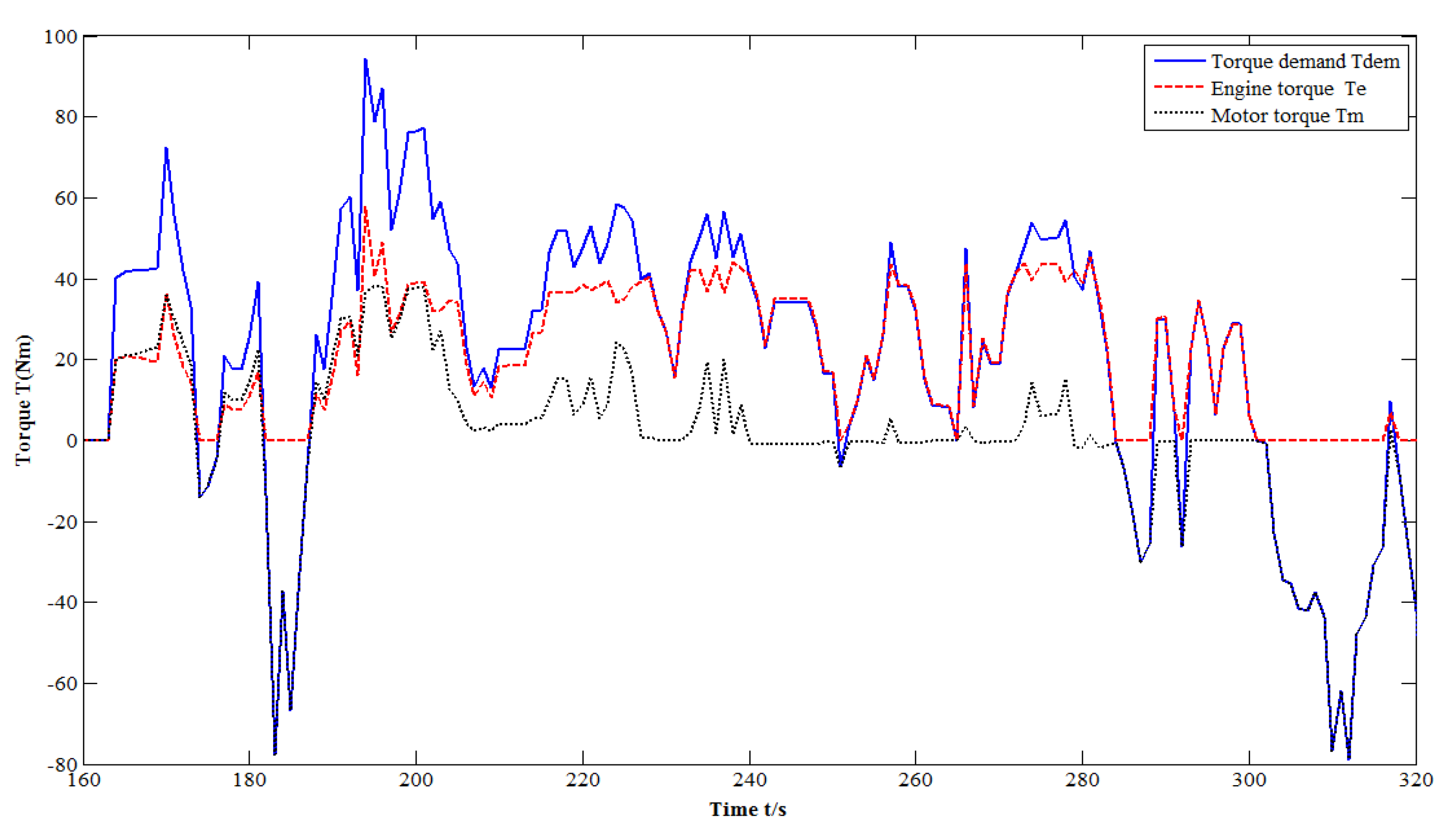
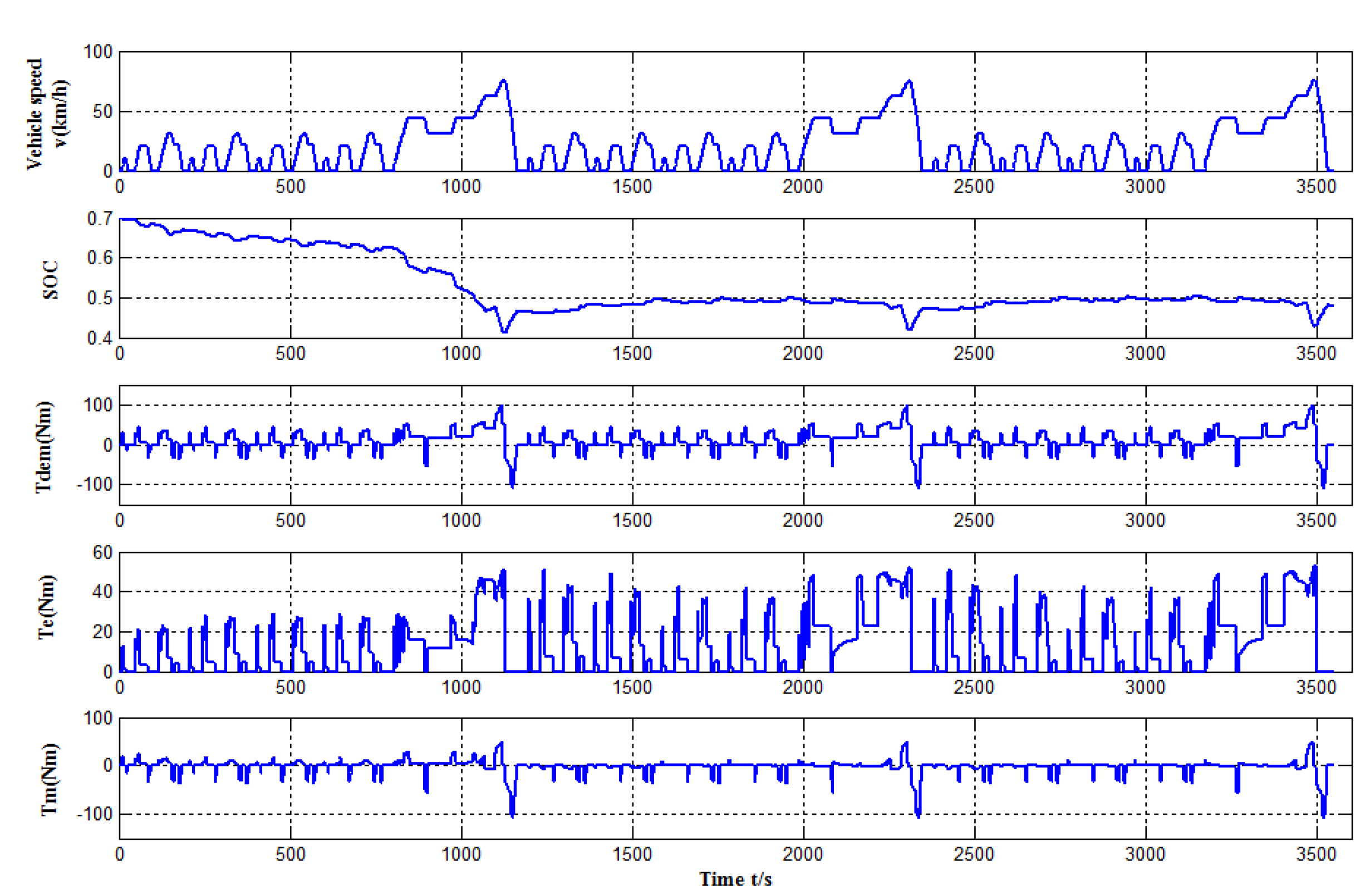
4. Simulation Results and Discussion

| Parameter | Value |
|---|---|
| Number of input nodes in QEN | 4 |
| Number of hidden nodes in QEN | 10 |
| Learning rate of QEN η | 0.34 |
| Rate of Gradient descent β | 0.32 |
| Coefficient of AEM | 0.40 |
| Discount factor γ | 0.90 |
| Emission cost weight a1 | 0 |
| SOC deviation cost weight a2 | 1 |
| Coefficient of σQ(t) | 0.41 |
| Te | Tdem | |||||
|---|---|---|---|---|---|---|
| VS | S | M | B | VB | ||
| SOC | VS | BC | BC | MC | SC | VB |
| S | BC | MC | MC | SC | VB | |
| M | SC | SC | M | M | B | |
| B | S | S | M | B | B | |
| VB | VS | VS | S | S | M | |





| Control strategy | Fuel consumption | Equivalent fuel consumption |
|---|---|---|
| Rule-based (L/100 km) | 3.88 | 3.87 |
| Fuzzy control (L/100 km) | 3.67 | 3.75 |
| FQL (L/100 km) | 3.48 | 3.65 |





| Control strategy | Fuel consumption | Equivalent fuel consumption |
|---|---|---|
| Rule-based (L/100 km) | 3.90 | 3.92 |
| Fuzzy control (L/100 km) | 3.67 | 3.79 |
| FQL (L/100 km) | 3.43 | 3.66 |
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Pisu, P.; Rizzoni, G. A comparative study of supervisory control strategies for hybrid electric vehicles. IEEE Trans. Control Syst. Technol. 2007, 15, 506–518. [Google Scholar] [CrossRef]
- Wirasingha, S.G.; Emadi, A. Classification and review of control strategies for plug-in hybrid electric vehicles. IEEE Trans. Veh. Technol. 2011, 60, 111–122. [Google Scholar] [CrossRef]
- Li, C.; Liu, G. Optimal fuzzy power control and management of fuel cell/battery hybrid vehicles. J. Power Sources 2009, 192, 525–533. [Google Scholar] [CrossRef]
- Odeim, F.; Roes, J.; Lars, W.; Angelika, H. Power management optimization of fuel cell/battery hybrid vehicles with experimental validation. J. Power Sources 2014, 252, 333–343. [Google Scholar] [CrossRef]
- Zhang, C.; Vahidi, A.; Pisu, P.; Li, X.; Tennant, K. Role of terrain preview in energy management of hybrid electric vehicles. IEEE Trans. Veh. Technol. 2010, 59, 1139–1147. [Google Scholar] [CrossRef]
- Lu, S.; Hillmansen, S.; Roberts, C. A power-management strategy for multiple-unit railroad vehicles. IEEE Trans. Veh. Technol. 2011, 60, 406–420. [Google Scholar] [CrossRef]
- Zheng, C.; Chris, C.M.; Xiong, R.; Xu, J.; You, C. Energy management of a power-split plug-in hybrid electric vehicle based on genetic algorithm and quadratic programming. J. Power Sources 2014, 248, 416–426. [Google Scholar]
- Zhang, C.; Vahidi, A. Route preview in energy management of plug-in hybrid vehicles. IEEE Trans. Control Systems Technol. 2012, 20, 546–553. [Google Scholar] [CrossRef]
- Han, J.; Park, Y.; Kum, D. Optimal adaption of equivalent factor of equivalent consumption minimization strategy for fuel cell hybrid electric vehicles under active state inequality constraints. J. Power Sources 2014, 267, 491–502. [Google Scholar] [CrossRef]
- Ansarey, M.; Masoud, S.P.; Hussein, Z.; Mohammad, M. Optimal energy management in a dual-storage fuel-cell hybrid vehicle using multi-dimensional dynamic programming. J. Power Sources 2014, 250, 359–371. [Google Scholar] [CrossRef]
- Chen, H.; Wu, G.; Luo, L.; Tan, W. Simulation of hybrid electric vehicle control strategy based on compensation fuzzy neural network. In Proceedings of the 7th Intelligent Control and Automation World Congress, Chongqing, China, 25–27 June 2008; pp. 8697–8701.
- Meng, X.; Langlois, N. Optimized fuzzy logic control strategy of hybrid vehicles using ADVISOR. In Proceedings of the IEEE Computer, Mechatronics, Control and Electronic Engineering (CMCE) International Conference, Changchun, China, 24–26 August 2010; pp. 444–447.
- Chen, R.; Li, C.; Meng, X.; Yu, Y. The application of fuzzy-neural network on control strategy of hybrid vehicles. In Proceeding of the 27th Chinese Control Conference, Kunming, China, 16–18 July 2008; pp. 281–284.
- Bichi, M.; Ripaccioli, G.; Di, C.S.; Bemardini, D.; Bemporad, A.; Kolmanovsky, I.V. Stochastic model predictive control with driver behavior learning for improved powertrain control. In Proceeding of the 49th IEEE Decision and Control Conference, Atlanta, GA, USA, 15–17 December 2010; pp. 6077–6082.
- Borhan, H.; Vahidi, A.; Phillips, A.M.; Kuang, M.L.; Kolmanovsky, I.V.; Di, C.S. MPC-based energy management of a power-split hybrid electric vehicle. IEEE Trans. Control Syst. Technol. 2012, 20, 593–603. [Google Scholar] [CrossRef]
- Bubna, P.; Brunner, D.; Advani, S.G.; Prasad, A.K. Prediction-based optimal power management in a fuel cell/battery plug-in hybrid vehicle. J. Power Sources 2010, 195, 6699–6708. [Google Scholar] [CrossRef]
- Santucci, A.; Sorniotti, A.; Constantina, L. Power split strategies for hybrid energy storage systems for vehicular applications. J. Power Sources 2014, 258, 395–407. [Google Scholar] [CrossRef]
- Bordons, C.; Ridao, M.A.; Pérez, A.; Marcos, D. Model predictive control for power management in hybrid fuel cell vehicles. In Proceedings of the IEEE Vehicle Power and Propulsion Conference, Lille, France, 1–3 September 2010; pp. 1–6.
- Yan, Y.; Xie, H. Model predictive control for series-parallel plug-in hybrid electrical vehicle using GPS system. In Proceedings of Electrical and Control Engineering International Conference, Yichang, China, 16–18 September 2011; pp. 2334–2337.
- Li, W.; Xu, G.; Xu, Y. Online learning control for hybrid electric vehicle. Chin. J. Mech. Eng. 2012, 25, 98–106. [Google Scholar] [CrossRef]
- Dai, X.; Li, C.K.; Ahmad, B.R. An approach to tune fuzzy controllers based on reinforcement learning for autonomous vehicle control. IEEE Trans. Intell. Transp. Syst. 2005, 6, 285–293. [Google Scholar] [CrossRef]
- Watkins, C. Learning from delayed rewards. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 1989. [Google Scholar]
- Lin, C.C.; Peng, H.; Grizzle, J.M.; Kang, J.M. Power management strategy for a parallel hybrid electric truck. IEEE Trans. Control Syst. Technol. 2003, 11, 839–849. [Google Scholar]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Li, W.; Xu, H.; Xu, G. An Online Learning Control Strategy for Hybrid Electric Vehicle Based on Fuzzy Q-Learning. Energies 2015, 8, 11167-11186. https://doi.org/10.3390/en81011167
Hu Y, Li W, Xu H, Xu G. An Online Learning Control Strategy for Hybrid Electric Vehicle Based on Fuzzy Q-Learning. Energies. 2015; 8(10):11167-11186. https://doi.org/10.3390/en81011167
Chicago/Turabian StyleHu, Yue, Weimin Li, Hui Xu, and Guoqing Xu. 2015. "An Online Learning Control Strategy for Hybrid Electric Vehicle Based on Fuzzy Q-Learning" Energies 8, no. 10: 11167-11186. https://doi.org/10.3390/en81011167