The goal of this section is to present a method to select a reduced number of sensors to be used in the fault detection method. Classical approaches to sensor or variable selection may be summarized in the following example. Let us assume that we have
N sensors or variables that are measuring during
seconds, where Δ is the sampling time and
. The discretized measures of each sensor can be arranged as a column vector
so we can build up a
matrix as follows:
It is worth noting that each column in matrix
X in Equation (
2) represents the measures of a single sensor or variable. In general, when some application of principal component analysis is used, and when a large number of variables or sensors is available, the results are usually slightly changed if just a subset of the sensors is used [
10]. Consequently, a simple approach is to calculate the subset of
σ sensors that maximizes the multiple correlation of the
non-selected sensors with respect to the
σ selected sensors. A similar approach, based on principal component analysis (PCA), that is also used in the field of feature extraction, is to compute the first principal components and observe the coefficients of the corresponding eigenvectors. More precisely, if the unit eigenvector related to the largest eigenvalue is
the sensor associated with the smallest coefficient
can be neglected. A comprehensive list of methods for deciding on which variables or sensors to reject can be found in [
10].
In this case, a column in matrix
in Equation (
3) no longer represents the values of a variable at different time instants but the measurements of a variable at one particular time instant in the whole set of experimental trials. Consequently, even though PCA can be applied to these kind of matrices as a way to reduce the dimensionality of the data and to create a new coordinates space where the data is best represented, the eigenvalues and eigenvectors of the covariance matrix
cannot be directly used to infer what variables or sensors could be neglected. In addition, we are not only interested in the sensors that best model the healthy wind turbine but the sensors that best discriminate the faulty wind turbine. This is one of the main differences between the work proposed by Wang et al. [
9] and the strategy presented in the present work: while in [
9] the authors use principal component analysis to reduce the number of inputs (sensors) to build the model of the active and reactive powers of a wind turbine as a multiple-input multiple-output linear system, in this paper, PCA is used to find the sensors that best separate the healthy and the faulty wind turbine with the purpose of fault detection.
The overall strategy to select the best subset of sensors that discriminate the healthy and the faulty wind turbine is to create a multiway PCA model measuring a healthy wind turbine. With the model, and for each fault scenario, we measure the Euclidean distance between the arithmetic mean of the projections into the PCA model that come from the healthy wind turbine and the mean of the projections that come from the faulty one. The subset of sensors related to the maximum distance between the means of each pair of projections will be the selected sensors. The detailed algorithmic procedure is described in the next subsection.
4.2. Results of the Sensor Selection
The results of the sensor selection are summarized in
Table 4 when the number of sensors to be combined is
and the number of principal components is
.
More precisely, with respect to
Table 4, it is worth noting that sensors 5, 6 and 7—corresponding to the first, second and third pitch angles—appear as selected in all of the eight fault scenarios. In this case, the sextuple of sensors is completed in fault scenarios 1, 2, 3 and 7 with sensors 9, 11 and 13 (side-to-side accelerations at tower bottom, mid-tower and tower top, respectively); in fault scenario 4 with sensors 1, 2 and 3 (generated electrical power, rotor speed and generator speed, respectively); in fault scenario 5 with sensors 1, 2 and 13 (generated electrical power, rotor speed and side-to-side acceleration at tower top, respectively); in fault scenario 6 with sensors 1, 3 and 13 (generated electrical power, generator speed and side-to-side acceleration at tower top, respectively); and finally, in fault scenario 8 with sensors 1, 11 and 13 (generated electrical power, side-to-side acceleration at mid-tower and tower top, respectively). From a physical point of view, when using
sensors, it is interesting to note that the three pitch angles and the side-to-side accelerations (and not the fore-aft accelerations that are in the same direction as the wind speed) are the most important signals to detect faults.
4.3. Fault Detection with a Reduced Number of Sensors
To analyze the effect on the overall performance of the fault detection strategy with a reduced number of sensors, we will study a total of 24 samples of
elements each, corresponding to the following distribution:
In this section, we will consider the following combination of
sensors:
sensors and 7, that is, we will measure and collect the information provided by the generated electrical power, rotor speed, generator torque and the first, second and third pitch angles.
For this combination of sensors, each sample of
elements is formed by the measures gathered from the sensors during
seconds, where
and the sampling rate
Hz. The fault detection strategy is based on the work by Pozo and Vidal [
5], where multiway principal component analysis (MPCA) is first applied and then the so-called Welch–Satterthwaite method [
19] to test for the equality of means. One of the key issues of the strategy presented in [
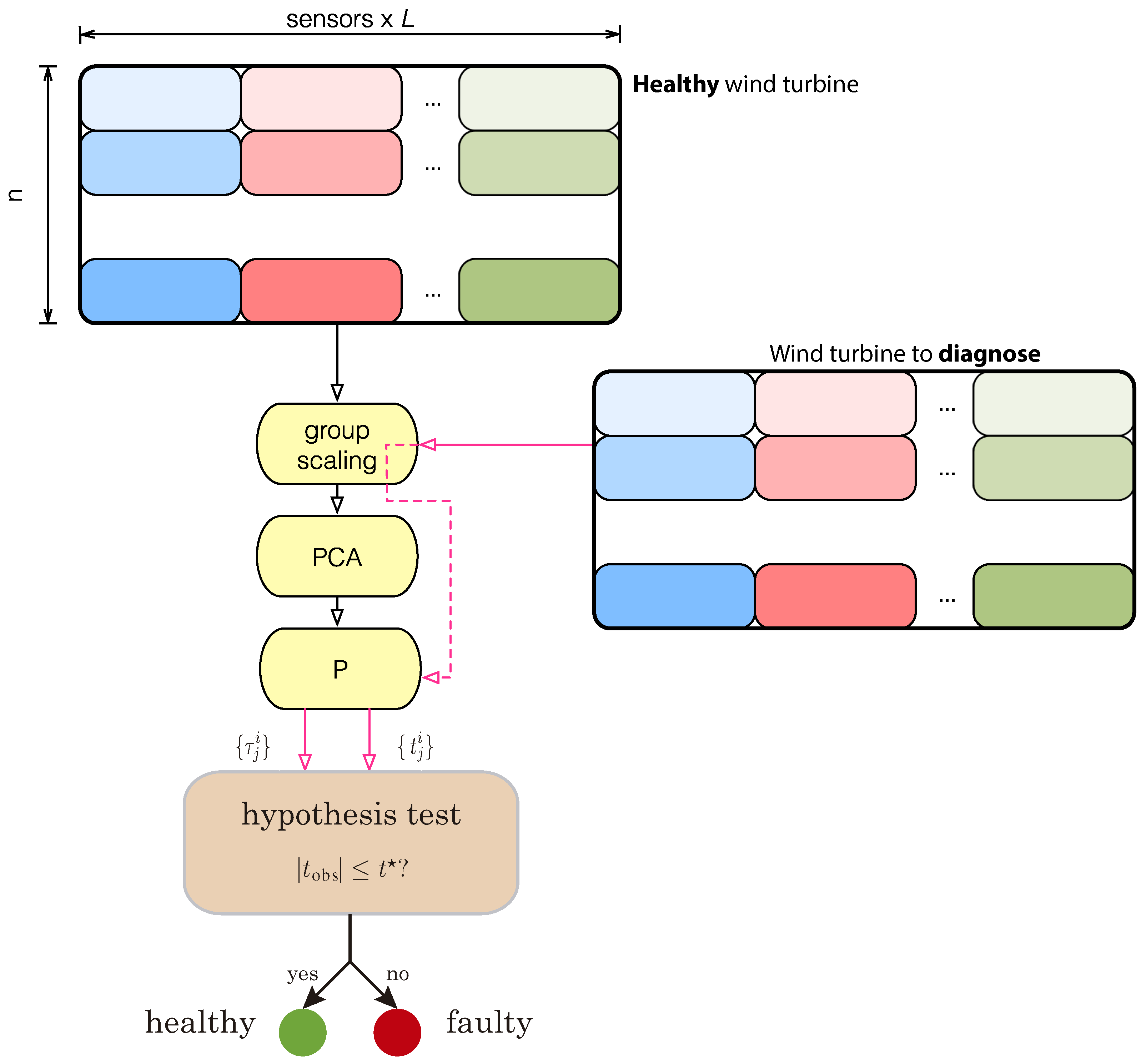
5] is the way the data is collected and arranged in a matrix. To create the baseline pattern or PCA model, we measure the
sensors from a healthy wind turbine and all the collected data is organized in a matrix
as follows:
where the superindex
of each element
in the matrix represents the number of sensors. For the sake of completeness, we summarize in the following itemized list the fault detection strategy presented in [
5], which is also illustrated in
Figure 1:
Sensor group-scaling is applied to matrix
in Equation (
7) so the mean of each column is 0 and the standard deviation of each sensor submatrix
is 1.
The covariance matrix
is computed according to the expression
The eigenvalues and eigenvectors of matrix are computed. The eigenvectors (principal components) constitute the columns of the transformation matrix —also called PCA model or baseline pattern— according to the eigenvalues in descending order.
With respect to the first principal component, for instance, the baseline sample is defined as the set of numbers , where is the first vector of the canonical basis.
When the measures of the
sensors are obtained from the current wind turbine to be diagnosed, a new matrix
Y has to be constructed as in Equation (
7):
Note that the number
ν of rows in matrix
in Equation (
8) is a natural number not necessarily equal to the number of rows
n in matrix
in Equation (
7).
Matrix
in Equation (
8) is scaled with respect to matrix
in Equation (
7), that is, we subtract to the
κ-th column of matrix
,
, the mean of the
κ-th column of matrix
. Likewise, each element in the submatrix
, is divided by the standard deviation of the submatrix
.
With respect to the first principal component, for instance, the sample of the current wind turbine to be diagnosed is defined as the set of numbers .
The Welch–Satterthwaite test for the equality of means [
19] is used with samples
and
to classify the current wind turbine to be diagnosed as
healthy or not.
As stated before, a particular configuration of
sensors has been considered.
Table 5 summarizes how the results in
Table 6 are organized. More precisely,
Table 6 includes—using the measures of sensors
and 7—the number of samples of the healthy wind turbine correctly classified by the test as healthy (correct decision); the number of samples of the faulty wind turbine correctly classified as faulty (correct decision); the number of samples of the faulty wind turbine wrongly classified as healthy (type II error or missing fault); and the number of samples of the healthy wind turbine wrongly classified as faulty (type I error or false alarm). It is worth noting that, for this configuration, type I errors (false alarms) and type II errors (missing faults) occur when we consider scores 2, 3 or 4, i.e., when the test is based purely on the first score all the classifications are accurate.
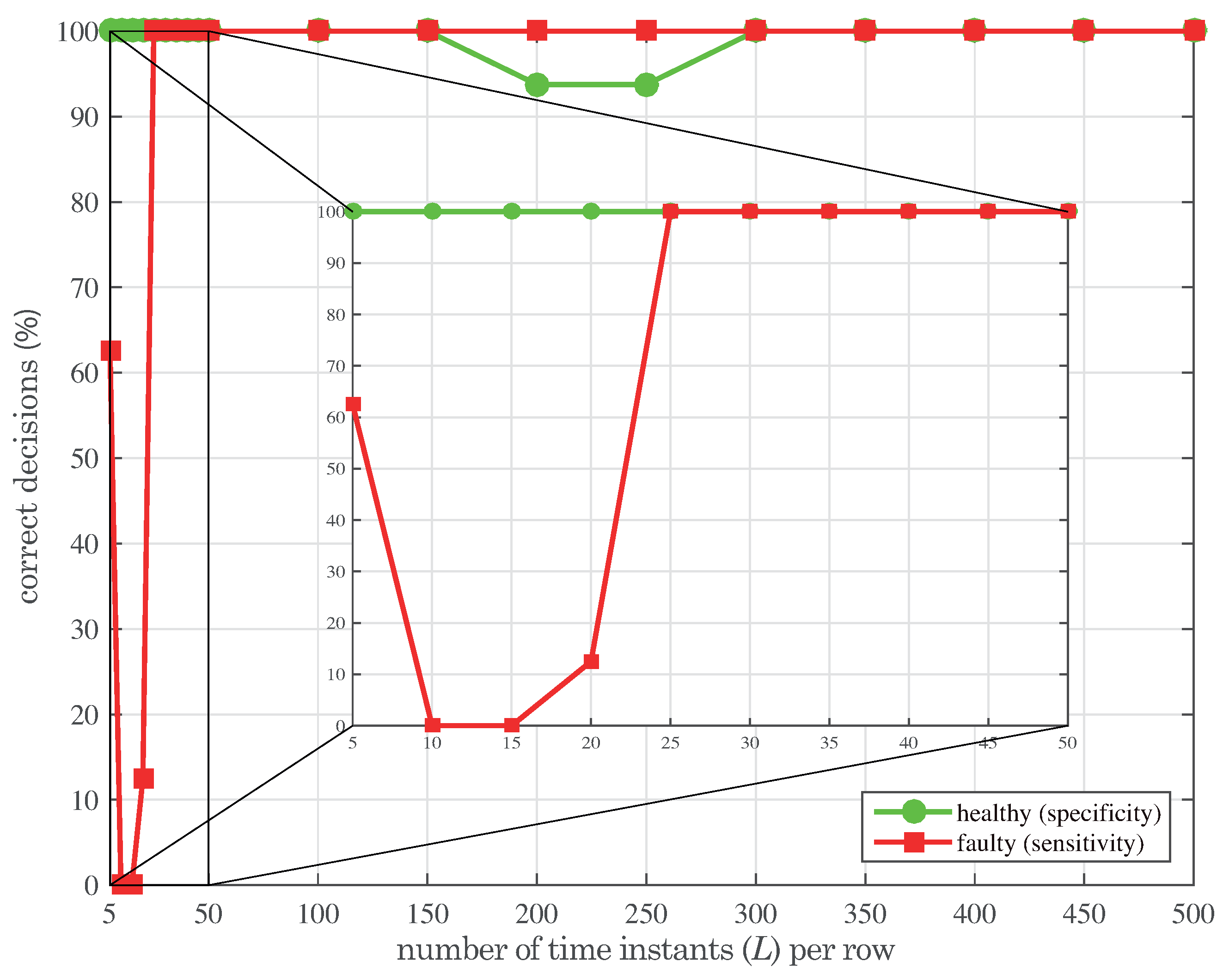
The sensitivity and specificity can also be used here as two statistical measures to analyze the performance of the test. On one hand, the sensitivity or power of the test is defined as the ratio of samples from the faulty wind turbine correctly classified. Therefore, if the false negative rate is defined as
γ, the sensitivity is computed as
. On the other hand, the specificity of the test can be defined as the percentage of samples from the healthy wind turbine correctly identified as such and is usually expressed as
, where
α is the false positive rate. These two measures are calculated—organized as detailed in
Table 7—in
Table 8 with respect to the 24 samples and for the first four scores. The results in
Table 8 show that the sensitivity
of the test is, on average,
, which is very close to
. Sensitivities of
are achieved when scores 1 and 3 are considered. The mean value of the the specificity is
, which is very close to the expected value of
, since the level of significance used in the test is
. The specificity when only score 1 is considered is increased to
.
The reliability of the fault detection strategy can also be measured using the true rate of false negatives and the true rate of false positives. These two quantities are based on the Bayes theorem [
20]. On one hand, the true rate of false positives is defined as the proportion of samples from the faulty wind turbine with respect to the samples that have been classified by the test as healthy, that is,
On the other hand, the true rate of false negatives is defined as the proportion of samples from the healthy wind turbine with respect to those samples that have been classified by the test as faulty, that is,
For the sensor configuration proposed in this section, the results—organized as described in
Table 9—are summarized in
Table 10.
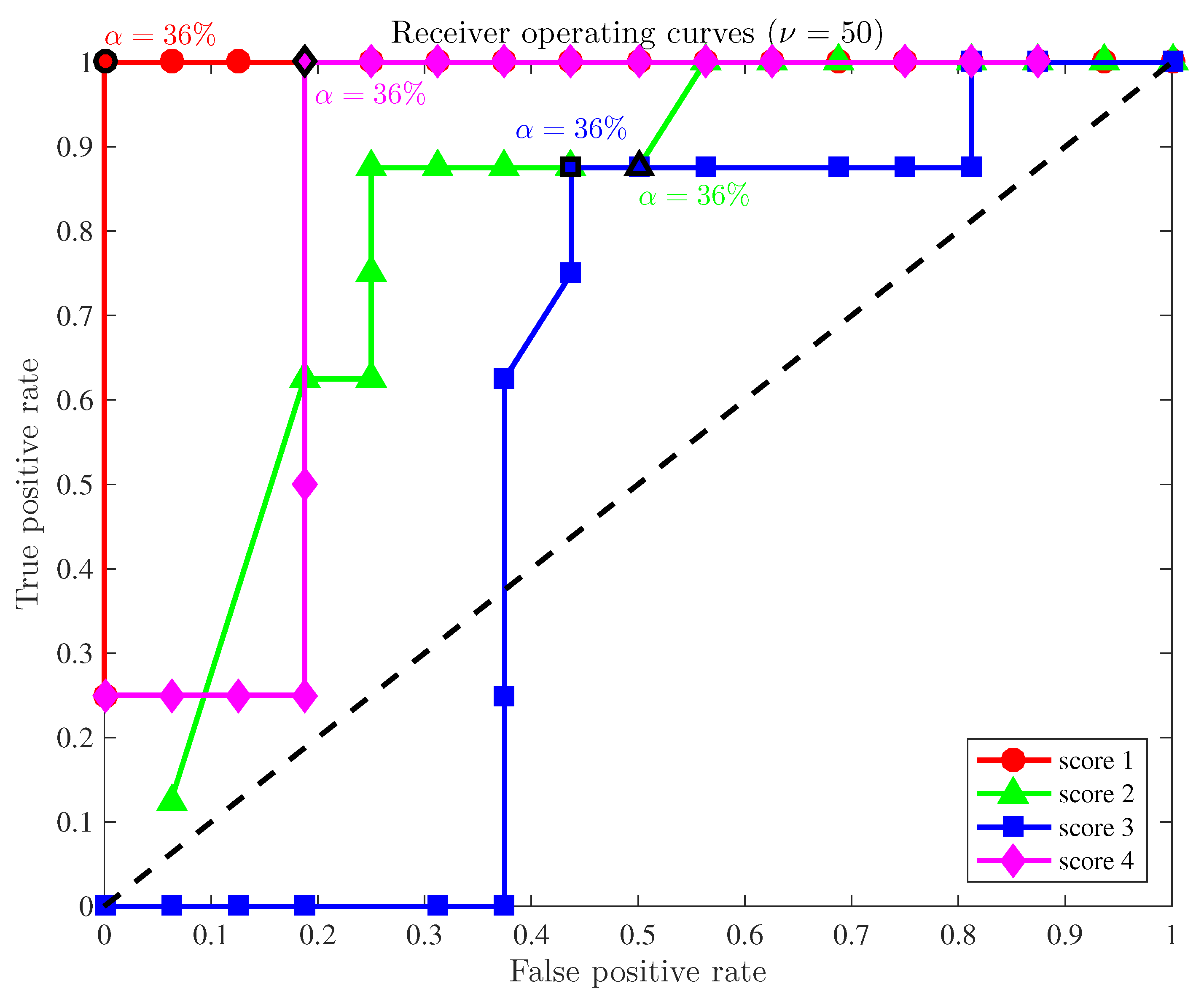
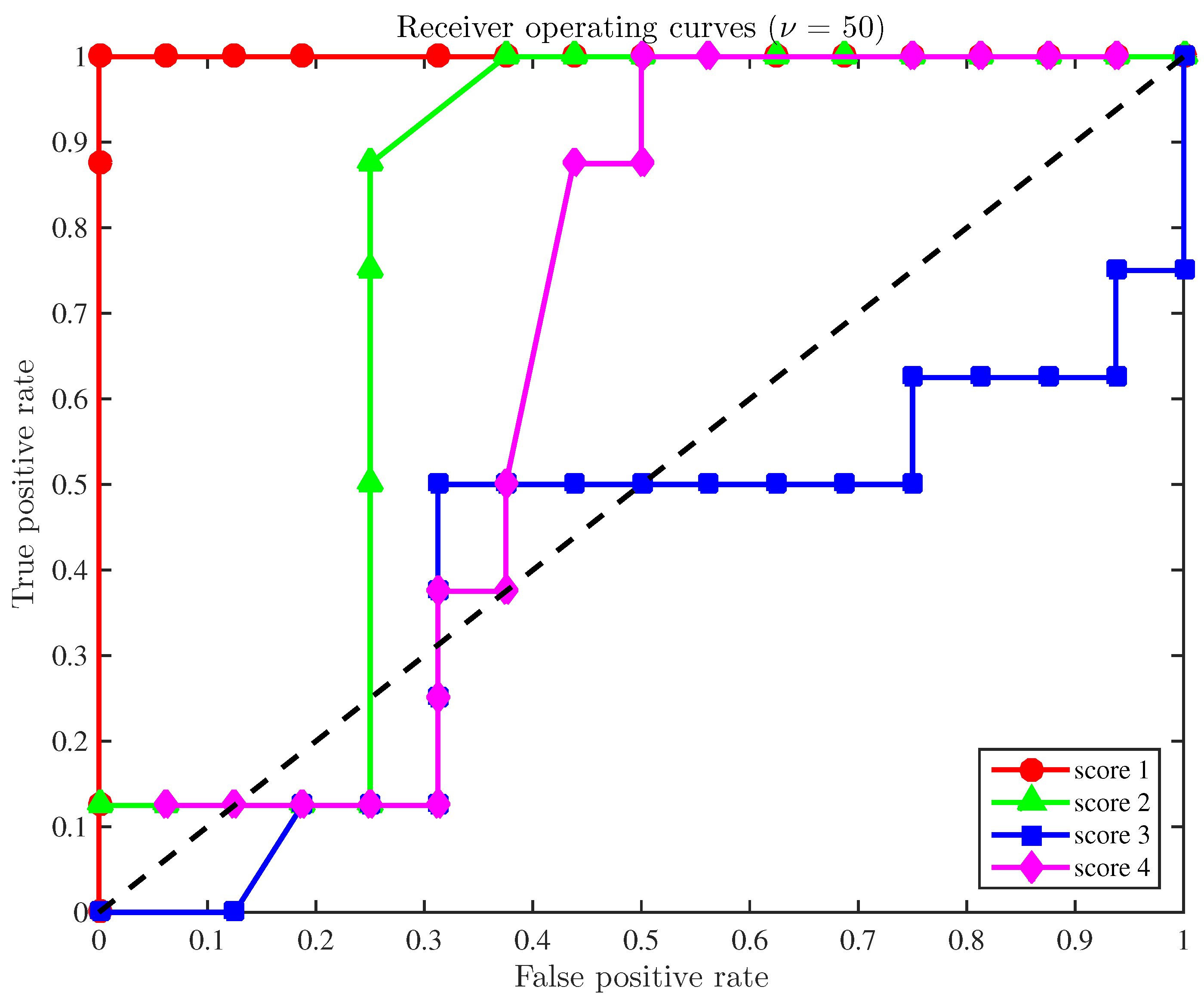
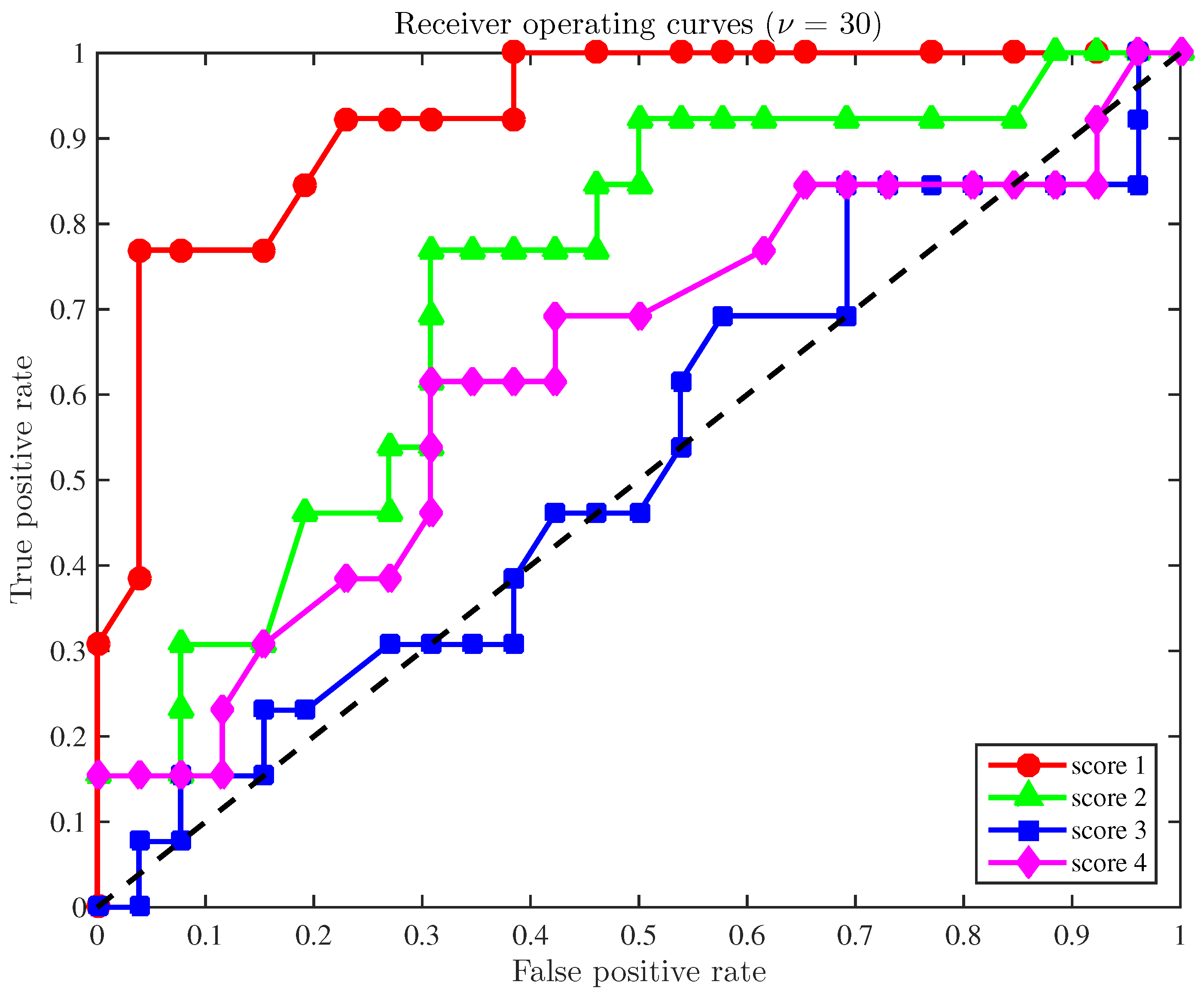
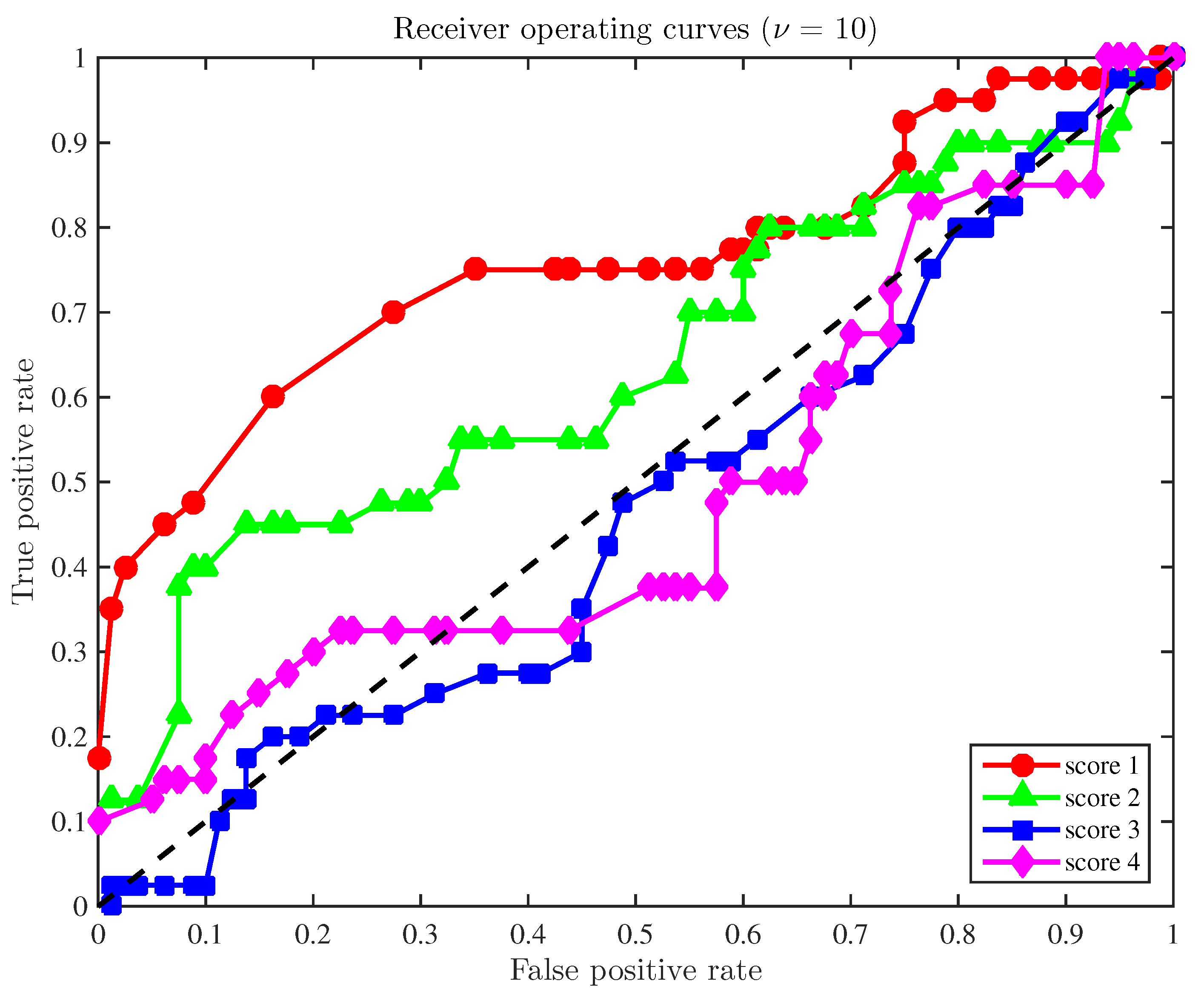
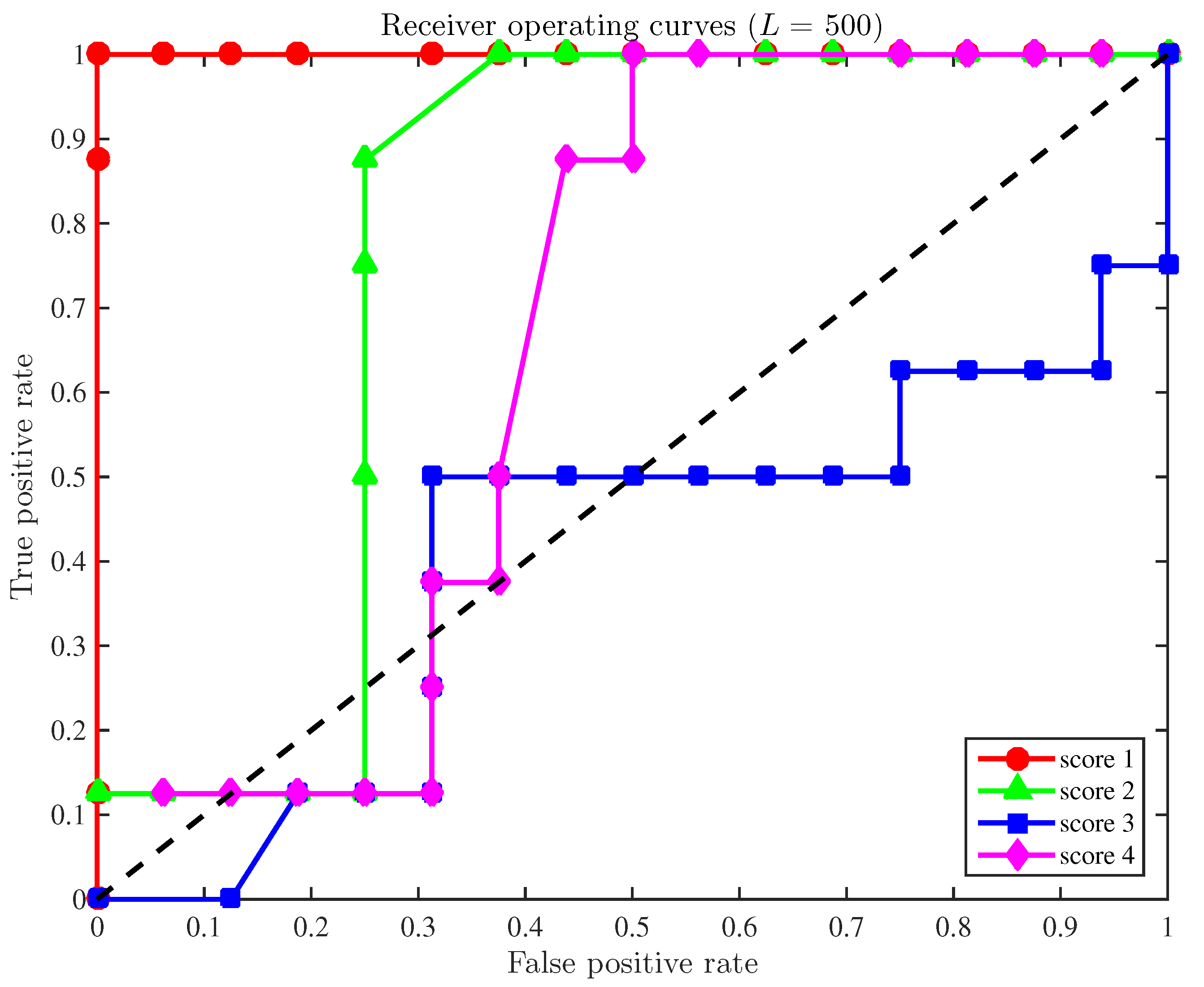
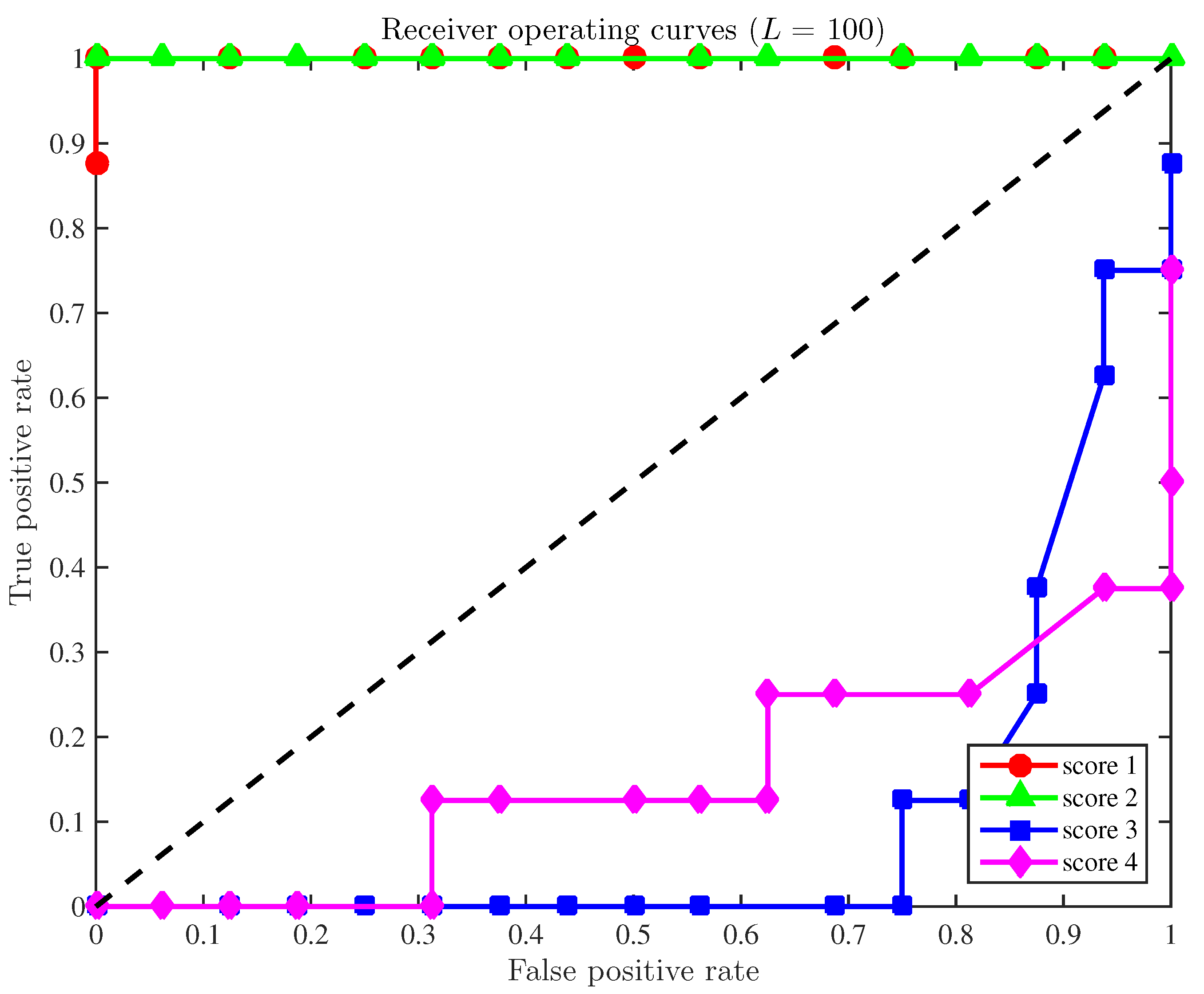
A final study is developed here based on the receiver operating curves (ROC) to demonstrate the overall accuracy of the fault detection strategy applied to a configuration with a reduced number of sensors. In general, these curves illustrate the compromise between the sensitivity and the false positive rate. More precisely, for a given level of significance and for each score, the pair of quantities
is represented on a plane. As in [
5], we have considered 49 levels of significance,
, within the range
, where
. The position of such points can be understood as follows. Since the ultimate goal is to reduce the quantity of false positives while the number of true positives is increased, these points must be ideally placed in the upper-left half plane. Therefore, a method is considered as satisfactory if those points lie within that upper-left half plane. In this sense,
Figure 2 illustrates the receiver operating curves for the four scores when the size of the samples to diagnose is
and the sensors used are numbers
and 7. The ROCs for score 1 (in red,
Figure 2) are particularly remarkable. The overall behavior of scores 2 and 4 are still acceptable, while the ROC for the third score must be considered as unsatisfactory.
The results of the fault detection strategy presented in this section, with respect to score 1 and using a reduced number of sensors (6 out of 13), when compared to the results in [
5]—when the 13 sensors are used—do not present any performance degradation. That is, in both cases, we have a
of accuracy in the detection of the 24 samples (healthy and faulty), but with about
less sensors.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}