A Modified Artificial Bee Colony Algorithm Based on the Self-Learning Mechanism


1
School of Control Science and Engineering, Shandong University, Jinan 250061, China
2
School of Mechanical, Electrical and Information Engineering, Shandong University at Weihai, Weihai 264209, China
*
Author to whom correspondence should be addressed.
Algorithms 2018, 11(6), 78; https://doi.org/10.3390/a11060078
Submission received: 26 April 2018
/
Revised: 18 May 2018
/
Accepted: 22 May 2018
/
Published: 24 May 2018
Abstract
:Artificial bee colony (ABC) algorithm, a novel category of bionic intelligent optimization algorithm, was achieved for solving complex nonlinear optimization problems. Previous studies have shown that ABC algorithm is competitive to other biological-inspired optimization algorithms, but there still exist several insufficiencies due to the inefficient solution search equation (SSE), which does well in exploration but poorly in exploitation. To improve accuracy of the solutions, this paper proposes a modified ABC algorithm based on the self-learning mechanism (SLABC) with five SSEs as the candidate operator pool; among them, one is good at exploration and two of them are good at exploitation; another SSE intends to balance exploration and exploitation; moreover, the last SSE with Lévy flight step-size which can generate smaller step-size with high frequency and bigger step-size occasionally not only can balance exploration and exploitation but also possesses the ability to escape from the local optimum. This paper proposes a simple self-learning mechanism, wherein the SSE is selected according to the previous success ratio in generating promising solutions at each iteration. Experiments on a set of 9 benchmark functions are carried out with the purpose of evaluating the performance of the proposed method. The experimental results illustrated that the SLABC algorithm achieves significant improvement compared with other competitive algorithms.
1. Introduction
In recent years, swarm intelligence algorithms have received a wide spread attention. The artificial bee colony (ABC) algorithm is a relatively new approach that was proposed by Karaboga [1,2], motivated by the collective foraging behavior of honey bees. In the process of foraging, the bees need to find the place of food source with the highest nectar amount. In ABC system, artificial bees search in the given search space and the food sources represent possible solutions for the optimisation problems. The bees update the candidate solutions by means of solution search equation (SSE) and if the new solution is better than the previous one in their memory, they memorize the new position and forget the previous one. Due to its simplicity and ease of implementation, the ABC algorithm has captured much attention and has been applied successfully to a variety of fields, such as classification and function approximation [3], feature selection [4], inverse modelling of a solar collector [5], electric power system optimization [6], multi-objective optimisation [7], complex network optimization [8], transportation energy demand [9], large-scale service composition for cloud manufacturing [10], job-shop scheduling problem with no-wait constraint [11], respiratory disease detection from medical images [12].
Although the ABC algorithm has been widely used in different fields, some researchers have also pointed out that the ABC algorithm suffers from low solution accuracy and poor convergence performance. To solve the optimization problem, the intelligent optimization algorithm should combine global search methods, used to locate the potential optimal regions, with local search methods, used to fine-tune the candidate solutions, to balance exploration and exploitation process. However, exploration strategies and exploitation strategies contradict each other and to achieve good performance, they should be well balanced. While the SSE of ABC, which is used to generate new candidate solutions based on the information of the present solutions, does well in exploration but poorly in exploitation, which results in the poor convergence rate. Thus, many related and improved ABC algorithms have been proposed [13,14,15,16].
Inspired by a operator of global best (gbest) solution in particle swarm optimization (PSO) algorithm [17], Zhu and Kwong proposed a modified ABC algorithm called gbest-guided ABC (GABC) algorithm to improve the exploitation [18]; the gbest term in the modified SSE can drive the new candidate solution towards the global best solution. Although the GABC algorithm accelerated the convergence rate, the exploration performance decreased. Therefore, how to balance exploration and exploitation has become the main goal in the ABC research. Inspired by differential evolution [19], Gao and Liu introduced a new initialization approach and proposed an improved SSE which is based on that the bee searches only around the best solution of the previous iteration to improve the exploitation; by hybridizing the original SSE and the improved SSE with the fixed selective probability, the new search mechanism obtains better performance [20]. After that, based on the two SSEs, Gao and Liu proposed the modified ABC (MABC) algorithm which excludes the onlooker and scout bee stage. In MABC, a selective probability was introduced to balance exploration of the original SSE and exploitation of the improved SSE [21]; if the new candidate solution obtained using the improved SSE is worse than the original one, the bee uses the original SSE to generate a new candidate solution with a certain probability. To well balance exploration and exploitation, Akay and Karaboga constructed an adaptive scaling factor (SF) which regulates the range of parameter in SSE by using Rechenberg’s 1/5 mutation rule; a smaller SF makes the candidate solution fine-tuned with a small steps while causing slow convergence rate and the bigger SF speeds up the search, but it reduces the exploitation performance [22]. In the original SSE in ABC algorithm, since the guidance of the last two term may be in opposite directions, it may cause an oscillation phenomenon. To overcome the oscillation phenomenon, Gao et al. presented a new SSE with two different candidate solutions selected from the solution space; moreover, an orthogonal learning strategy was developed to discover more effective information from the search experiences and to get more promising and efficient candidate solutions [23]. When the candidate solutions converge to the similar points, the SSE can cause a stagnation behavior during the search process, that means the value of the new candidate solution is the same with the value of the current solution. To overcome stagnation behavior of the algorithm, Babaoglu proposed a novel algorithm called distABC algorithm based on the distributed solution update rule, which uses the mean and standard deviation of the selected two solution to obtain a new candidate solution [24].
The above methods have achieved some progress, but there still exist some problems. The GABC algorithm improved the exploitation, but the exploration decreased. Even though MABC algorithm used two SSEs to balance exploration and exploitation, the selection mechanism and the fixed selective probability cannot adapt to the changing environment. Moreover, when the global best solution trapped in local optimum, GABC and MABC algorithm cannot escape from the local optimum effectively. The distABC algorithm overcame stagnation behavior, but distABC does poorly in exploitation. For population-based optimization methods, it is desirable to encourage the individuals to wander through the entire search space at the initial phase of the optimization; on the other hand, it is very important to fine-tune the candidate solutions in the succeeding phases of the optimization [25]. However, one SSE of original ABC algorithm cannot balance two aspects. Therefore, this paper proposes an achievable ABC algorithm which uses five SSEs as the candidate operator pool. The same with the SSE in ABC algorithm, the first SSE uses a solution selected randomly from the population to maintain population diversity and it emphasizes the exploration. Inspired by the PSO algorithm, the second SSE takes advantage of the information of the global best solution to guide the new candidate solution towards the global best solution. Therefore, the second SSE can improve the exploitation. To achieve good performance, the third SSE combines the above two SSEs which means that a randomly selected solution and the global best solution are all used in the SSE to balance exploration and exploitation. It seems that the global optimal solution is most likely around the best solution of the previous iteration. Therefore, the fourth SSE is the same with the one proposed in MABC algorithm which is based on that the bee searches only around the best solution of the previous iteration to improve the exploitation. When the candidate solutions trapped in local optimum, the above SSEs cannot escape from the local optimum effectively. To solve such problem, this paper proposes a novel SSE with Lévy flight step-size which can generate smaller step-size with high frequency and bigger step-size occasionally. The fifth SSE cannot only balance exploration and exploitation but also escape from the local optimum effectively. The five SSEs have both advantages and disadvantages and in order to make full use of the advantages of each SSE, this paper proposes a simple self-learning mechanism, wherein the SSE is selected according to the previous success ratio in generating promising solutions at each iteration. The SSE with a high success ratio means that the SSE can generate a better candidate solution with a large probability. Therefore, the self-learning mechanism cannot only select the appropriate SSE to generate new candidate solution but also adapt to the changing environment.
The following sections are organized as follows. Section 2 outlines the reviews of the classical ABC algorithm. Section 3 introduces the proposed self-learning mechanism (SLABC) algorithm. In Section 4, experiments are carried out to verify the effectiveness of SLABC algorithm based on nine benchmark functions in terms of t-test. Section 5 presents and discusses the experimental results. Finally, the conclusion is drawn in Section 6.
2. Classical ABC Algorithm
In the ABC algorithm, the colony of artificial bees contains three groups of bees: employed bees, onlooker bees and scouts bees [2]. Half of the colony consists of the employed bees, and another half consists of the onlooker bees. The scouts bees are transmuted from the inactive employed bees and then abandon their food source to search a new food source. Employed bees explore the food source in the search space and pass the food information to onlooker bees. Onlooker bees select the good food sources from those found by employed bees and further search the foods around the selected food source. The positions of the food sources are initialized in the search space and food sources present possible solutions for the optimization problem. There are solutions, where denotes the size of employed bees or onlooker bees. Suppose is the position of the ith solution and D is the number of dimension to be optimized. The flow of ABC algorithm is shown as follows.
2.1. Employed Bee Stage
At this stage, each employed bee search around the given solution and let . In the update process, the new candidate solution is produced by using SSE as follows:
where and are randomly chosen indexes; k has to be different from i; is a random number in the range . Then, a greedy selection mechanism is applied between and to select a better solution. After all the employed bees complete their searches, they share the solution information to the onlooker bees.
2.2. Onlooker Bee Stage
According to the fitness value of each solution, onlooker bees calculate the probability value associated with that solution,
where is the fitness value of solution i and is the number of solutions. Based on and roulette wheel selection method, an onlooker bee selects one solution to update. After selecting the solution , the onlooker bee update it by using Equation (1) and the greedy selection mechanism is also used to select a better solution. At this stage, only the selected solution can be updated and the better solutions may be updated many times.
2.3. Scouts Bee Stage
If a solution cannot be improved further at least times, this solution is assumed to be abandoned and a new solution will be produced randomly in the search space to replace the abandoned one. This operation can be defined as follows:
3. SLABC Algorithm
To improve the performance, the SLABC algorithm uses five SSEs as the candidate operator pool. One of the SSEs with Lévy flight step-size cannot only balance exploration and exploitation but also avoid trapping in the local optimum. This section first introduces the Lévy flight in detail.
3.1. Lévy Flight Step-Size
A Lévy flight is a random walk and the step-size satisfies a probability distribution which can be expressed as follows [26]:
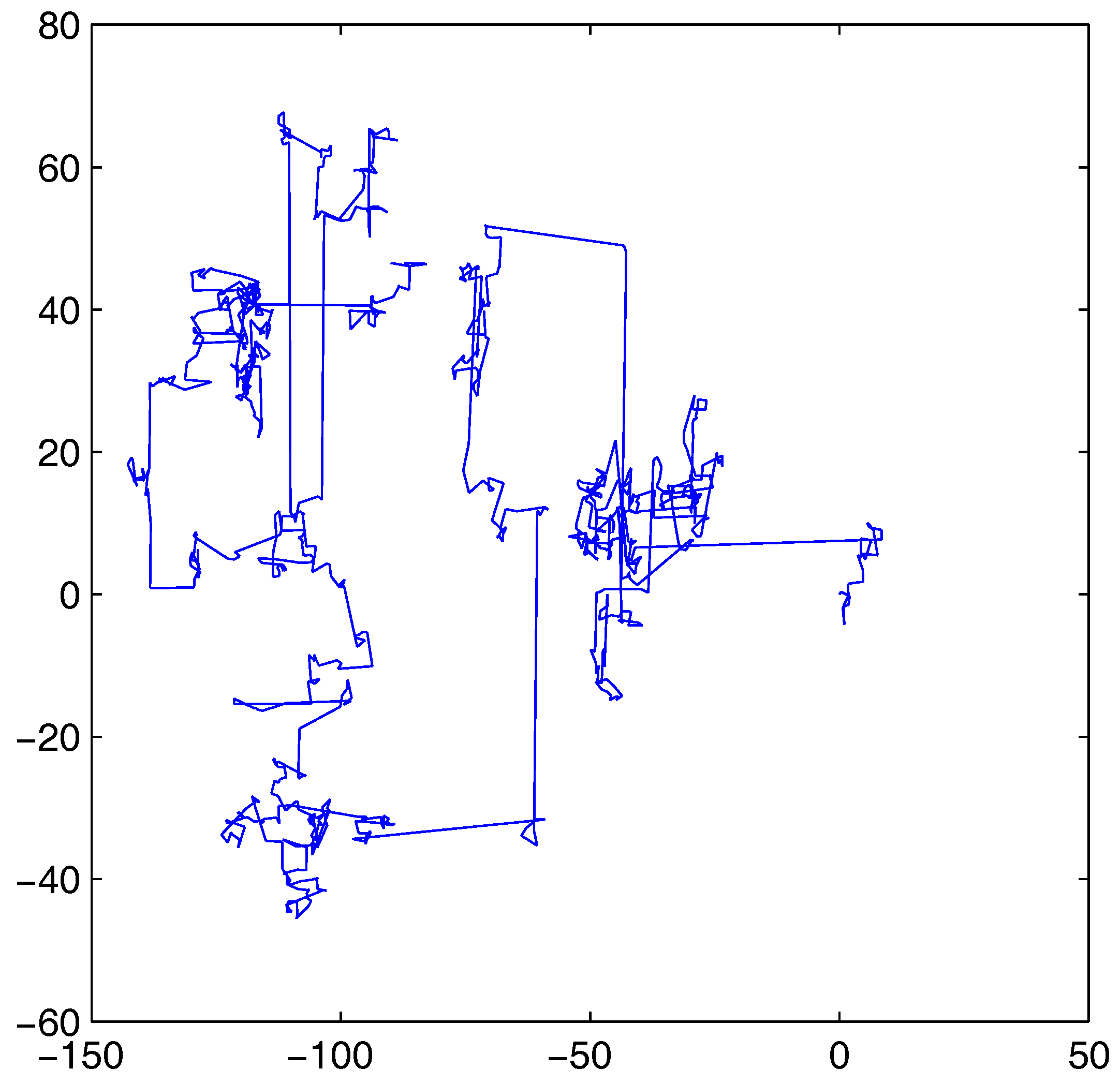
where s is the step-size with . Lévy flight can generate smaller step-size with high frequency and generate larger step-size occasionally. In the search process, the bee with a large step-size can reach anywhere of the entire search space to locate the potential optimal solution; when the bees are trapped in the local optimum, the large step-size can make the bees escape from the local optimum. The bees with a small step-size tend to fine-tune the current solution to obtain the optimal solution. The foraging behaviors of many creatures in nature satisfy Lévy flight, such as albatrosses’ foraging flight trajectory [27,28] and drosophilas’ intermittent foraging flight trajectory [29]. Viswanathan et al. suggest that Lévy flight is an optimal search strategy when the target sites are sparse and distributed randomly [26].
This paper uses the method proposed by [30] to calculate Lévy flight step-size:
where , u and v are two normal stochastic variables with standard deviation and .
where the notation is gamma function. If the real part of the complex number z is positive , then the integral
converges absolutely.
As shown in Figure 1, Lévy flight with a mix of large step-size and small step-size can balance exploration and exploitation. Therefore, SLABC introduces Lévy flight step-size to the modified SSEs to improve the performance.
3.2. The Modified Solution Search Equations
To solve the optimization problem, the intelligent optimization algorithm should combine global search methods with local search methods to balance exploration and exploitation. However, exploration strategies and exploitation strategies contradict each other and one SSE in ABC algorithm cannot balance two aspects. Therefore, this paper proposes an achievable ABC algorithm which uses five SSEs as the candidate operator pool.
Following the classical ABC algorithm, SLABC employs the original SSE as the first search equations to improve exploration of SLABC algorithm.
where and are randomly chosen indexes; is different with i; is a random number in the range .
To improve exploitation, the second SSE introduces the global best solution to guide the new candidate solutions towards the global best solution.
where is the global best solution. Generally speaking, there may be a better solution around the global best solution; therefore, we set random number in the range .
The Equation (9) is good at exploration and Equation (10) is good at exploitation, therefore to well balance exploration and exploitation, the third SSE combine the two equations as follows.
where are randomly chosen indexes and is different with i; and are random numbers.
It seems that the global optimal solution is most likely around the best solution of the previous iteration. Therefore, the fourth SSE is the same with the one proposed in MABC algorithm which is based on that the bee searches only around the best solution of the previous iteration to improve the exploitation.
where and are mutually different random integer indices selected from ; is a random number in the range .
Because the above four SSEs are based on the current solutions, when the present solutions converge to the similar point or are trapped in local optimum, the above SSEs cannot escape from the local minimum effectively. Therefore, this paper introduces Lévy flight step-size to the last SSE to solve this problem.
where s is the Lévy flight step-size which can be calculated in Equation (5).
Different from the GABC, MABC algorithm, the range of the weight , , in Equations (11) and (12) with the term are all reduced and the interval length are set to 1. Therefore, the new generated candidate solution can be in a smaller range and the accuracy of the solution will be improved. Moreover, to make the candidate solution nearer to the global best solution, the range of the weight in Equation (10) is further reduced and interval length are set to 0.5.
After all the employed (onlooker) bees produce the new candidate solutions using the improved SSEs, then, a greedy selection mechanism is used to select a better solution between and .
3.3. Self-Learning Mechanism
The five SSEs are regarded as the candidate operator pool and different operator is more effective at different stage. At each iteration, each employed (onlooker) bee will select a SSE from the candidate operator pool to update the corresponding solution. This paper proposes a simple self-learning mechanism to realize such optimal choice, wherein the SSE is selected according to the previous success ratio in generating promising solutions at each iteration.
In the self-learning mechanism, each SSE is assigned to a probability: success ratio. It is defined as
where denotes the counter that records the number of successful updating times of the k-th SSE, where the new candidate solution is better than the old one; is the total number of updating times of the k-th SSE is selected; is the success ratio of the k-th SSE. At each iteration, each SSE k is selected according to the success ratio through roulette wheel selection. The new candidate solutions are then produced by the selected SSE. In the initialization stage, each success ratio is given an equal selection probability.
It is well known that at the early stage of the optimization, the bees are inclined to locate the potential optimal regions by wandering through the entire search space. Conversely, most of the bees are apt to fine-tune the present solutions to obtain the global optimal solution at the latter stage of the optimization. Therefore, in order to avoid the interference between the early stage and the latter stage, this paper divides the whole optimization process into two stages. At each stage, , and the success ratio all will be initialized.
3.4. Description of the SLABC Algorithm
The pseudo code of the SLABC algorithm can be described as follows (Algorithm 1):
| Algorithm 1 |
| Initialize the population of the bees as N and ; set the number of trials as . |
| Randomly generate points in the search space to form an initial solution. |
| Find the global best solution and the its position from the points. |
| Set the maximum number of function evaluations, ; , and . |
| While |
| If |
| Initialize , and . |
| End If |
| Employed bee stage: |
| for to |
| Set the candidate solution and randomly choose j from . |
| Randomly choose a SSE k from the candidate strategy pool through roulette wheel selection |
| and count . |
| Update the candidate solution using the selected SSE. |
| If |
| , , . |
| Else |
| . |
| End If |
| End For |
| Update the and and calculate the probability value using Equation (2). |
| Onlooker bee stage: |
| for to |
| Select one solution to update based on and roulette wheel selection. |
| The update process is same as that in the employed bee stage. |
| End For |
| Update the and and calculate the probability value using Equation (2). |
| Scout stage: |
| If |
| Initialize with a new randomly generated point in the search space. |
| End If |
| End While |
4. Experiments and Results
4.1. Experimental Setup
To investigate the performance of the SLABC algorithm, 9 benchmark functions shown in Table 1 were used, including four unimodal functions () and five multimodal functions (). In Table 1, D denotes the dimensions of the solution space and 30, 60, and 100 dimensions are used in the present paper. The unimodal functions can be used to analyse the convergence rate of the algorithms. The multimodal functions are commonly used to show whether the algorithms can escape from the local optimum effectively.
The effectiveness of the proposed SLABC algorithm was evaluated by comparing its results with other related algorithms, such as ABC [2], GABC [20], MABC [21], and distABC [24]. To make a fair comparison among ABCs, all the algorithms were tested using the same parameters: the population size , , the maximum number of iterations, . Additionally, other specific parameters of each comparison algorithm are same as in ABC [2], GABC [20], MABC [21], and distABC [24]. In order to ensure the experiment results stability, we repeated each algorithm for 20 times and average the results.
4.2. Experimental Results
This paper uses five indexes to analysis the experimental results: the best solution (Best), median solution (Median), worst solution (Worst), average solution (Mean), and standard deviation (Std). Table 2, Table 3 and Table 4 show the experimental results obtained by each algorithm in the 20 independent runs. The results suggest that SLABC offers the higher solution accuracy on almost all the functions except function with . It can be seen from the formulation of Rosenbrock function () that the first term mainly influence the function value, which means that only the values among different dimensions in the candidate solutions are almost the same, the function value is smaller. Using the mean and standard deviation of the selected two solution, the distABC algorithm obtained the new candidate solutions, in which the values among different dimensions are of uniform size. Therefore, based on the distributed solution update rule, distABC algorithm gets the best results on Rosenbrock function ().
Moreover, in the case of functions , , with , the solution accuracy of SLABC are equal with the best of other algorithms. The Rastrigin function (), Griewank function () and Schwefel’s Problem 2.26 function () are multimodal functions and are easy to obtain the optimal solutions with . As the dimension gets higher, the difficulty of obtaining the optimal solution increases gradually. However, the solution accuracy of SLABC are better than the functions , , with and , which proves that SLABC algorithm outperforms the other algorithms.
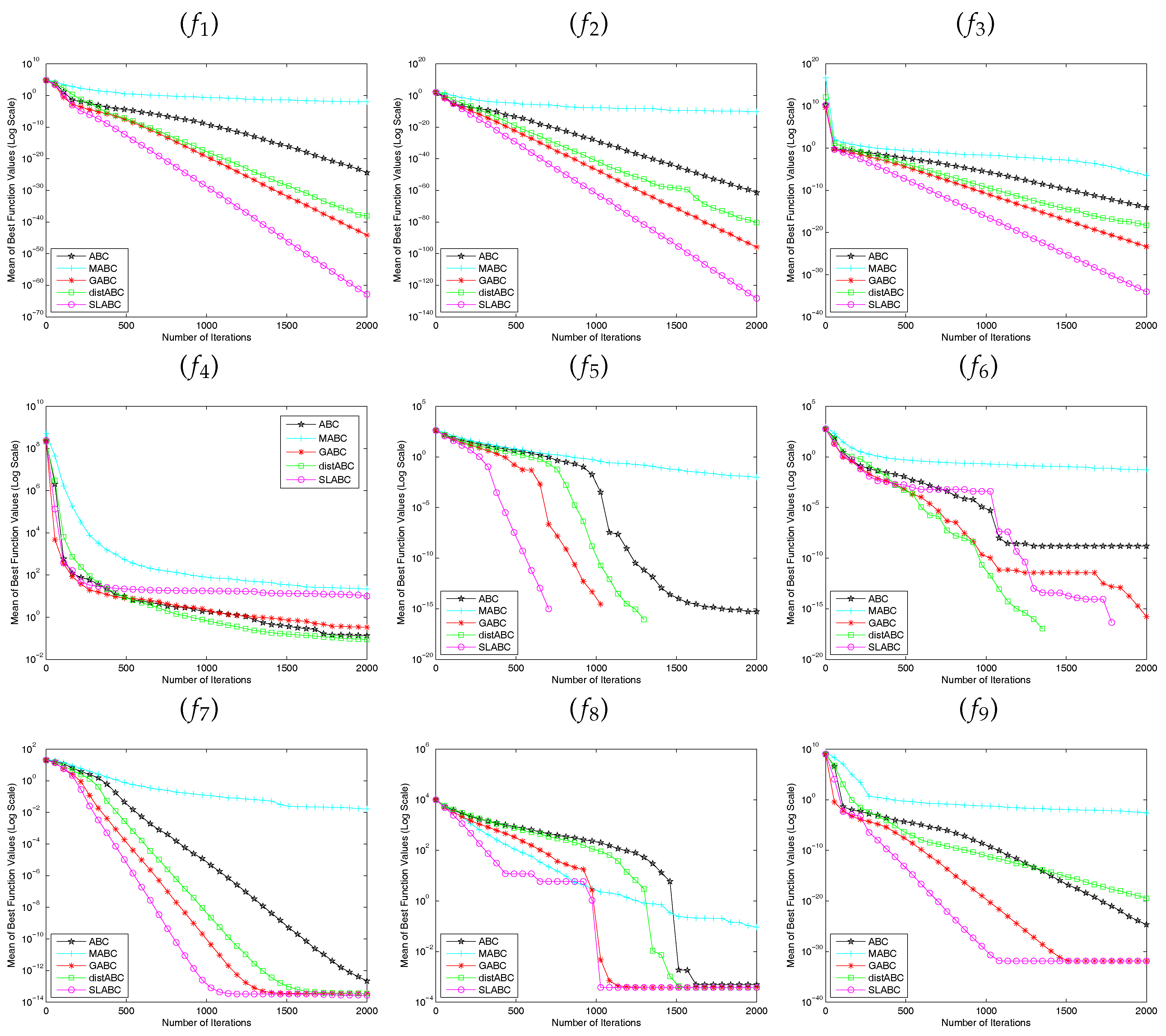
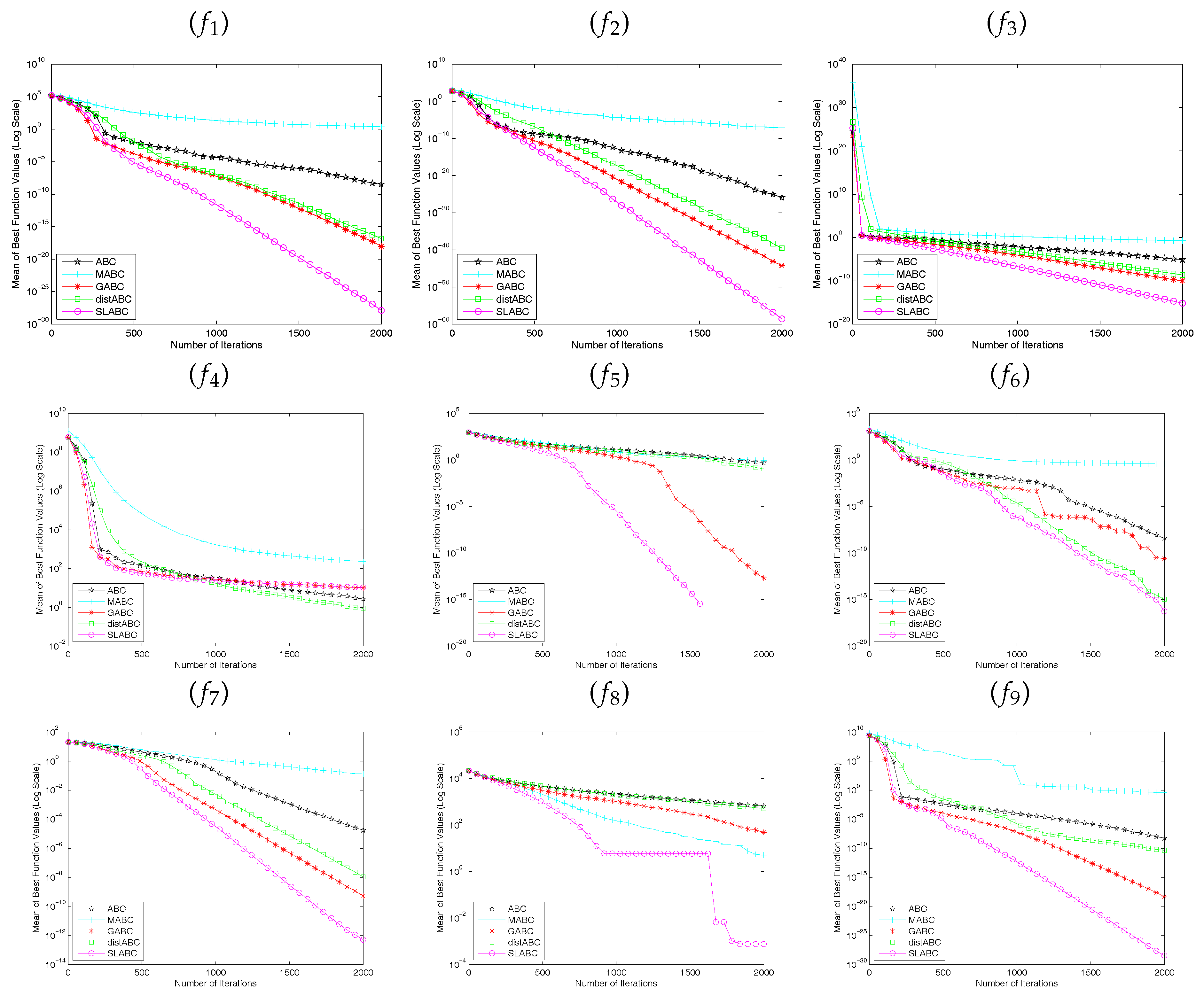
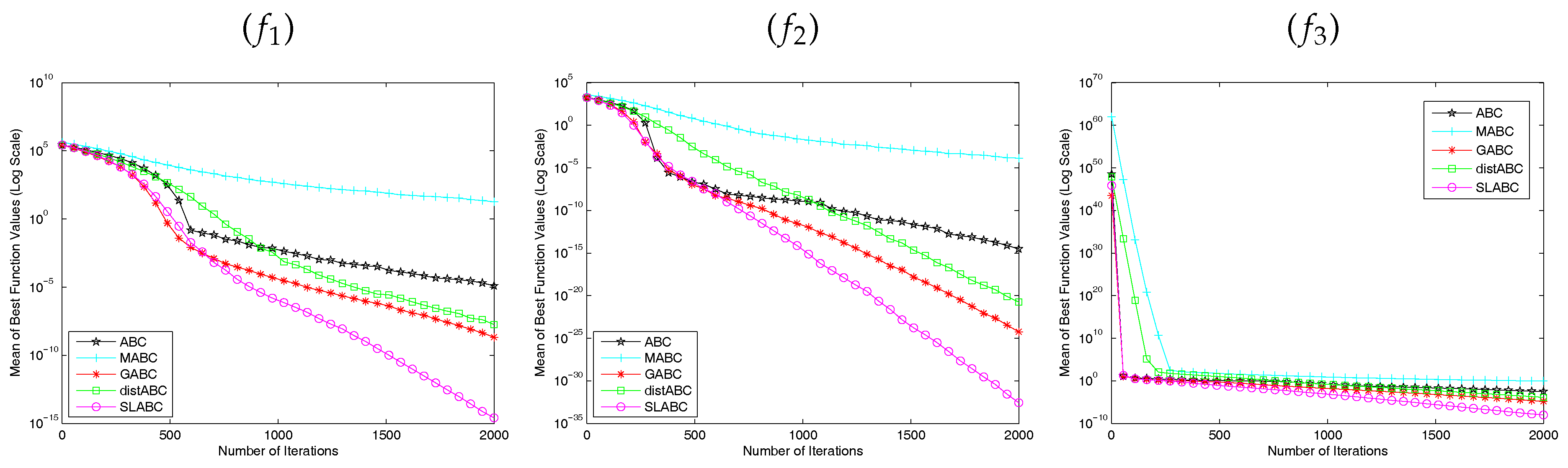
Figure 2, Figure 3 and Figure 4 show how the mean of the best solution for each algorithm changes with the number of iterations times. The lines that do not extend to the end of the experiments indicate that they have converged to 0 in the next calibration. As can be seen in the Figure 2, Figure 3 and Figure 4, the convergence rate of SLABC is faster than other algorithms except function with and function with . The distABC algorithm is better than SLABC algorithm on the convergence rate and the accuracy of the solution. Though functions , , with get the same solution, SLABC algorithm converges faster than other algorithm on , with and SLABC algorithm converges slower than distABC algorithm on with . According to the above analysis, it is obvious that the performance of SLABC is more superior to other algorithms except distABC algorithm on Rosenbrock function ().
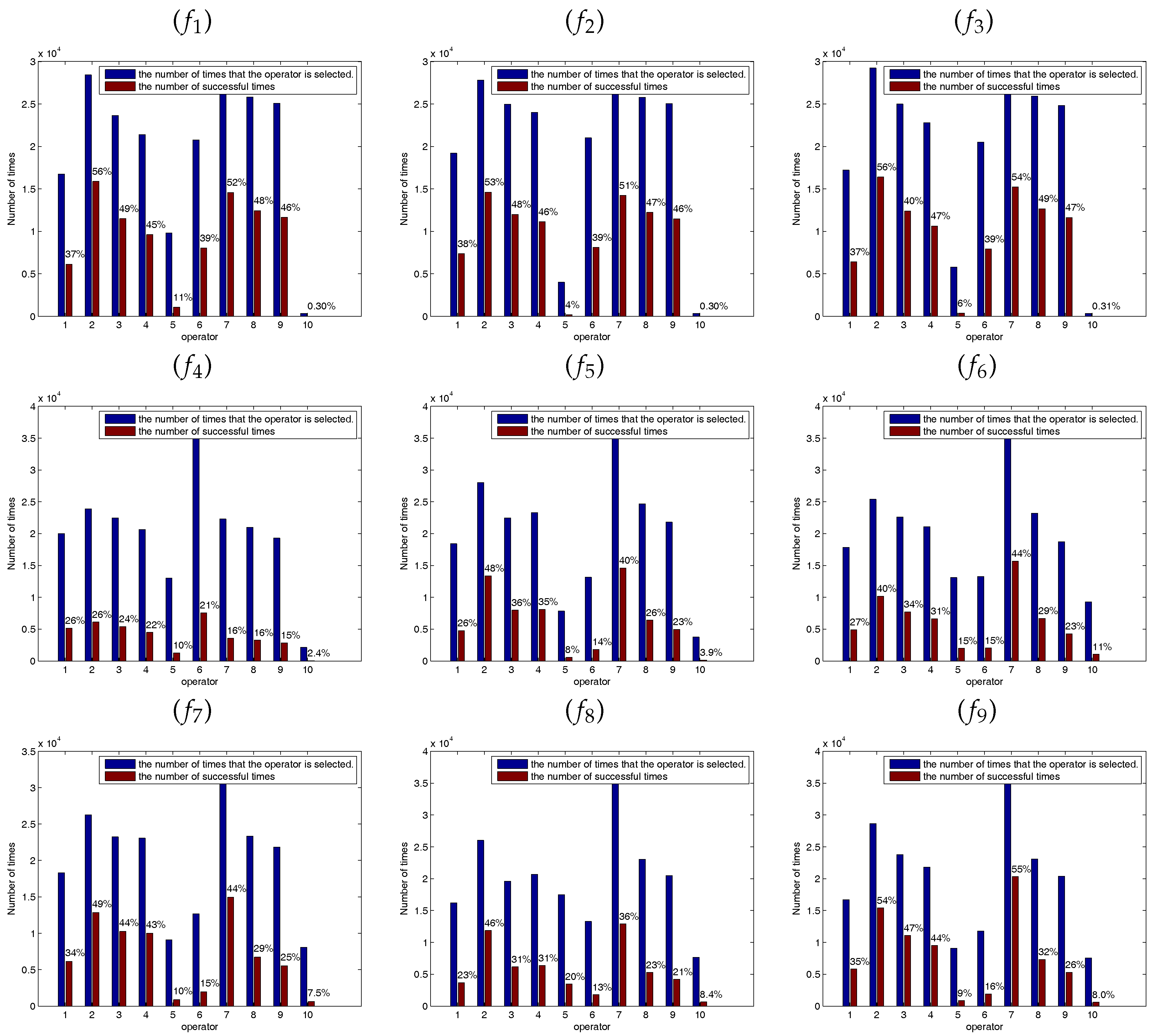
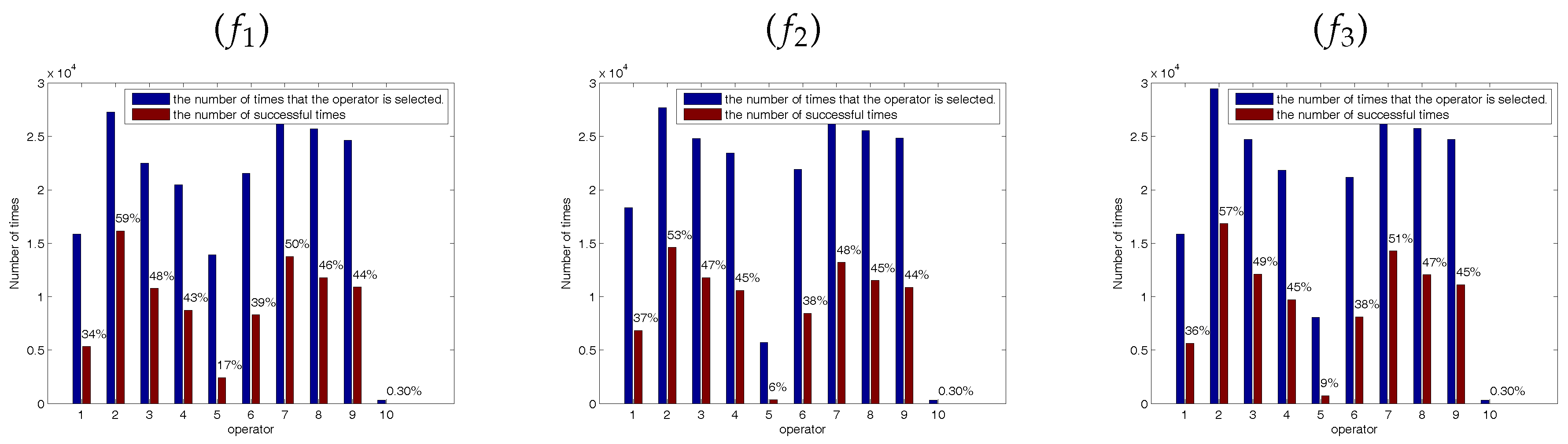
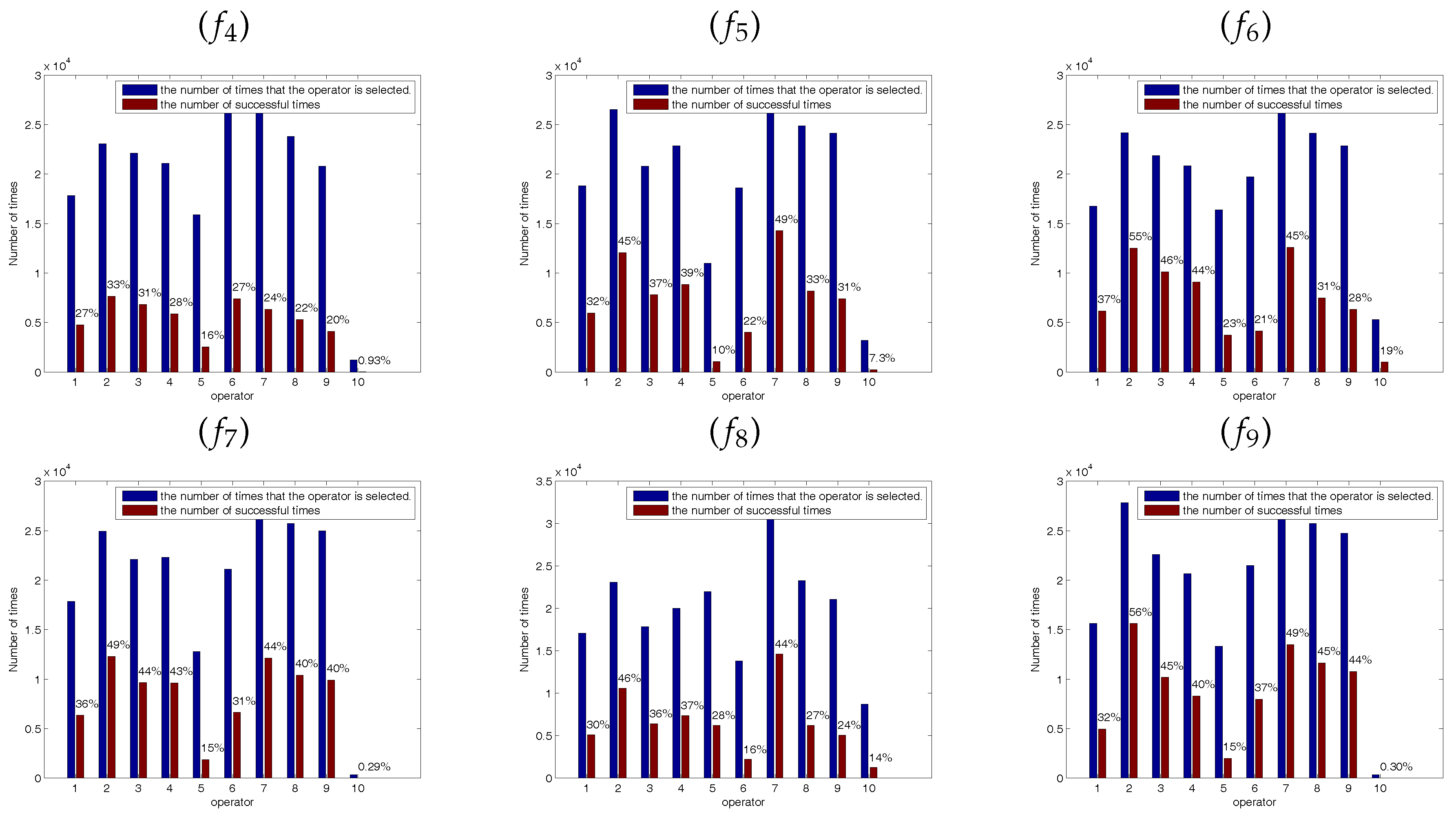
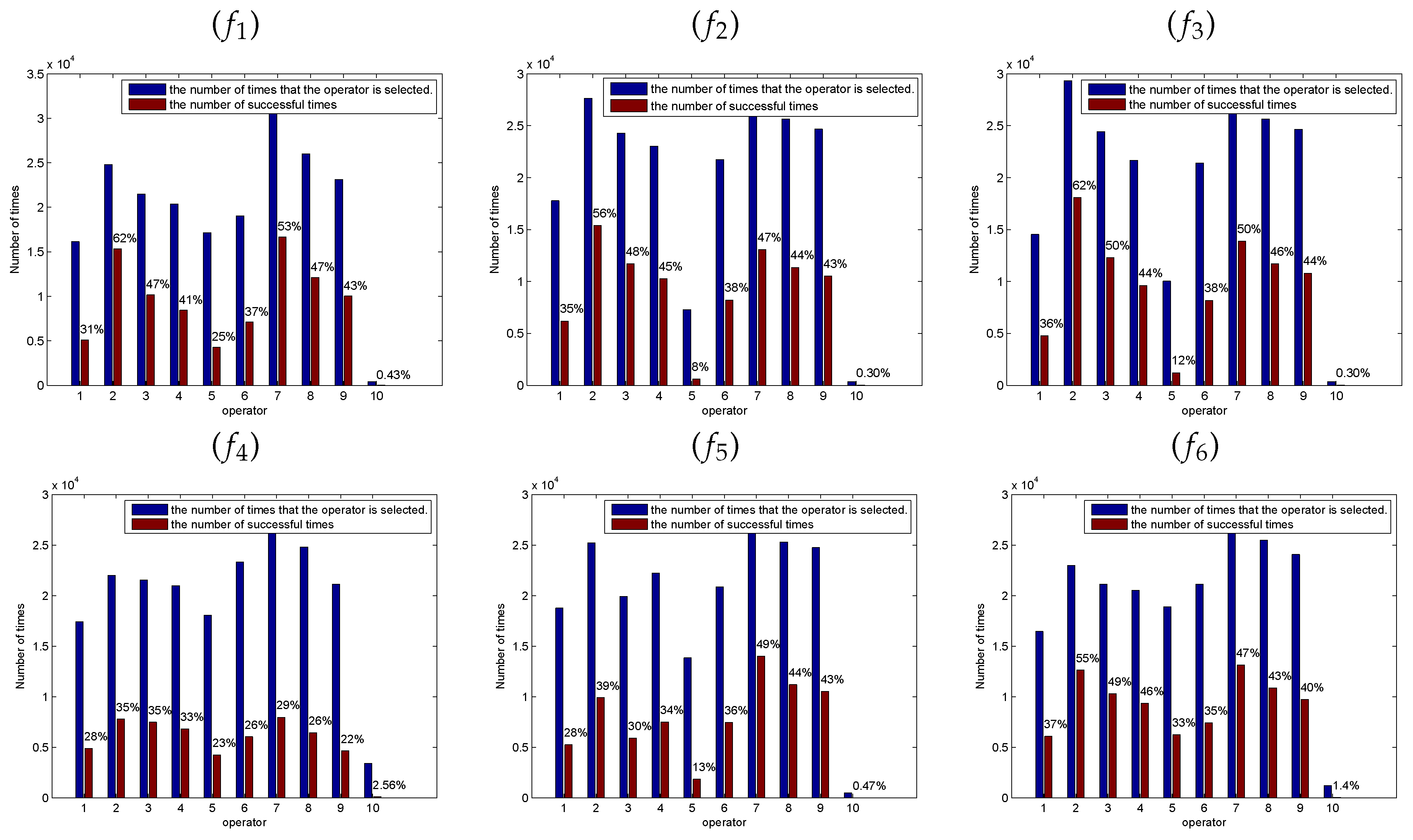
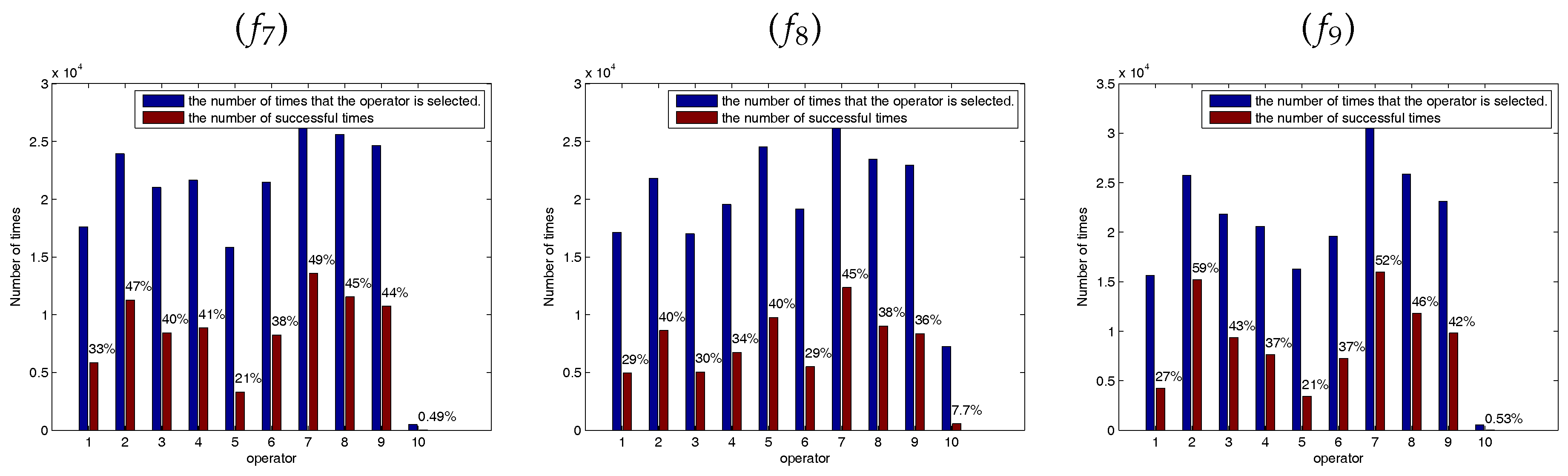
Figure 5, Figure 6 and Figure 7 show the success ratio of each SSE. The horizontal ordinate 1–5 correspond to the success ratio of each SSE () at the midpoint of the experiments () and 6–10 correspond to the success ratio of each SSE () at the end of the experiments (). As shown in these figures, the self-learning mechanism selected different SSE in solving different functions and different functions have different optimal combination of SSEs. In the figures, the coordinate 2 is corresponding to the second SSE at the early stage and the coordinate 7 is corresponding to the second SSE at the latter stage. In most of the functions, the second SSE (coordinate 2 and coordinate 7) has the highest success rate and the fifth SSE has the lowest success rate. The second SSE with the global best solution can improve exploitation. At the early stage of the optimization, the bees are inclined to locate the promising regions by wandering through the entire search space. At the latter stage, the bees are busy to fine-tune the present solutions to obtain the global optimal solution. Therefore, these solutions may trap in the local minimum at the latter stage of the optimization process. The fifth SSE is mainly to make the bees escape from the local minimum. Because functions – are unimodal functions, the fifth SSE with lévy flight step-size has a lower success ratio at the latter stage. However, functions – are multimodal functions which have many local minimum in the search space. The higher success ratio indicates that the SSE with lévy flight step-size can escape from the local optimum effectively to improve search efficiency.
4.3. Comparison Regarding the t-Test
This section mainly analyzes the experimental data and study whether the experimental results are statistically significantly different between SLABC and other algorithm. The F-test was used to analyze the homogeneity of variances and two-tailed t-test was used to determine if two sets of data are significantly different from each other. The sample size and number of degrees of freedom were set as 20 and 38, respectively. The confidence level was set to 95%. In the F-test, and if the F-value is larger than 2.17, the corresponding experimental results are heterogeneity of variance. If the p-value received in the t-test is less than 5%, it illustrates that the corresponding experimental results are significantly different. Table 5 lists the results of t-tests between SLABC and the best results of the other algorithms regarding the indexes “Mean” for different benchmark functions (listed are the F-value, p-value, and the significance of the results). “YES” indicates that the experimental results are significantly different between SLABC and the best one in other algorithms. “NO” suggests that no significant difference between the results of SLABC and of other algorithms.
From Table 2, Table 3, Table 4 and Table 5, although other algorithms (distABC) have higher solution accuracy on function with , there exist no significant difference between SLABC and distABC. The same as function with and function with , there exist no significant difference between SLABC and other algorithm. Moreover, SLABC and other algorithm obtain the same optimal solution on functions with .
Based on the results of statistical tests in Table 5, almost most of the results have obvious differences and it is clear that the results of SLABC algorithm are significantly better than the results of other algorithms.
5. Discussion
In the previous sections, comparative results of ABC, GABC, MABC and distABC were presented. In this section, we offer a thorough analysis on the proposed SLABC algorithm and all the algorithms were tested using the same parameters with Section 4.
When constructing the SSE, the value range of the coefficients were adjusted to improve the performance of the SLABC algorithm. This section constructed two SLABC algorithm variants (SLABC1, SLABC2) and experiments on a set of 6 benchmark functions were carried out to clearly show how these coefficients influence the performance in various optimization problems. In SLABC1, the value range of the coefficient are reduced to half of the corresponding value range in SLABC. In SLABC2, the value range of the coefficient are increased to double of the corresponding value range in SLABC. The new generated candidate solutions can appear in a large range using the SLABC2 algorithm and can appear in a small range using the SLABC1 algorithm. From Table 6, the SLABC2 is worse than SLABC and SLABC1, which shows that the increased value range reduced the performance of the SLABC algorithm. Moreover, SLABC is better than SLABC1 except function , which means that too small value range can reduce solution accuracy. Through the analysis of experimental data, the changes of the value range can influence the performance of SLABC algorithm and only the appropriate value range can generate the better solutions.
Five SSEs are used to solve the optimization problem and each SSE has different effect. For example, the fifth SSE with Lévy flight step-size can help the artificial bees escape from the local optimum effectively. However, when solving the optimization problem of unimodal function, the fifth SSE is ineffective. This section constructed another SLABC algorithm variants (SLABC3 without the fifth SSEs) to illustrate the effect of such combination. As can be seen from Table 6, SLABC3 obtained the better solution than SLABC on the unimodal functions . Therefore, we can choose combination of different SSEs to solve different optimization problems in the future applications.
In order to avoid the interference between the early stage and the latter stage, SLABC algorithm divides the whole optimization process into two stages. We can divide the optimization process into much more stages to further reduce interference between each stage. To show the effect of such division, this section constructed another SLABC algorithm variants (SLABC4) which divides the whole optimization process into ten stages. As can be seen from Table 6, SLABC4 obtained the better solution than SLABC on most of the functions. Dividing the optimization process into several stages can improve the performance of SLABC algorithm and how to divide the optimization process remains to be a problem should be further studied.
This paper proposes a self-learning mechanism to select the appropriate SSE according to the previous success ratio. Such mechanism is a reinforcement mechanism and other optimization algorithms can construct novel algorithms variants to improve the performance by using the self-learning mechanism.
6. Conclusions
This paper proposes an improved ABC algorithm based on the self-learning mechanism with five SSEs as the candidate operator pool. Among them, one SSE is good at exploration; other two SSEs are good at exploitation; another SSE intends to balance the two aspects. The last SSE with Lévy flight step-size can avoid trapping in local optimal solution. Meanwhile, a simple self-learning mechanism is proposed, wherein the SSE is selected according to the previous success ratio in generating promising solutions at each iteration. Experiments verify that the proposed SLABC algorithm can improve search efficiency and speed up the convergence rate.
Author Contributions
B.P. conceived the experiments and wrote most of the paper. Y.S. performed the experiments and provided funding. C.Z. analyzed and processed the experimental data; H.W. and R.Y. helped with the data conversion and contributed several figures.
Funding
This research is supported by the NSFC under grant no. 61573213, 61473174, 61473179, by the Natural Science Foundation of Shandong Province under grant no. ZR2015PF009, ZR2014FM007, ZR2017PF008, by the China Postdoctoral Science Foundation under grant no. 2017M612270, by Shandong Province Science and Technology Development Program under grant no. 2014GGX103038, and Special Technological Program of Transformation of Initiatively Innovative Achievements in Shandong Province under grant no. 2014ZZCX04302.
Acknowledgments
The authors also gratefully acknowledge the helpful comments and suggestions of the reviewers, which have improved the presentation.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Karaboga, D. An Idea Based on Honey Bee Swarm for Numerical Optimization; Technical Report TR06; Erciyes University: Kayseri, Turkey, 2005. [Google Scholar]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Glob. Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Let a biogeography-based optimizer train your Multi-Layer Perceptron. Inf. Sci. 2014, 269, 188–209. [Google Scholar] [CrossRef]
- Zorarpacı, E.; Özel, S.A. A hybrid approach of differential evolution and artificial bee colony for feature selection. Expert Syst. Appl. 2016, 62, 91–103. [Google Scholar] [CrossRef]
- Das, R.; Akay, B.; Singla, R.K.; Singh, K. Application of artificial bee colony algorithm for inverse modelling of a solar collector. Inverse Probl. Sci. Eng. 2016, 25, 887–908. [Google Scholar] [CrossRef]
- Marzband, M.; Azarinejadian, F.; Savaghebi, M.; Guerrero, J.M. An Optimal Energy Management System for Islanded Microgrids Based on Multiperiod Artificial Bee Colony Combined With Markov Chain. IEEE Syst. J. 2017, 11, 1712–1722. [Google Scholar] [CrossRef]
- Luo, J.; Liu, Q.; Yang, Y.; Li, X.; rong Chen, M.; Cao, W. An artificial bee colony algorithm for multi-objective optimisation. Appl. Soft Comput. 2017, 50, 235–251. [Google Scholar] [CrossRef]
- Lozano, M.; García-Martínez, C.; Rodríguez, F.J.; Trujillo, H.M. Optimizing network attacks by artificial bee colony. Inf. Sci. 2017, 377, 30–50. [Google Scholar] [CrossRef]
- Sonmez, M.; Akgüngör, A.P.; Bektaş, S. Estimating transportation energy demand in Turkey using the artificial bee colony algorithm. Energy 2017, 122, 301–310. [Google Scholar] [CrossRef]
- Zhou, J.; Yao, X. Multi-population parallel self-adaptive differential artificial bee colony algorithm with application in large-scale service composition for cloud manufacturing. Appl. Soft Comput. 2017, 56, 379–397. [Google Scholar] [CrossRef]
- Sundar, S.; Suganthan, P.N.; Jin, C.T.; Xiang, C.T.; Soon, C.C. A hybrid artificial bee colony algorithm for the job-shop scheduling problem with no-wait constraint. Soft Comput. 2017, 21, 1193–1202. [Google Scholar] [CrossRef]
- Woźniak, M.; Połap, D. Bio-inspired methods modeled for respiratory disease detection from medical images. Swarm Evol. Comput. 2018, in press. [Google Scholar] [CrossRef]
- Bansal, J.C.; Sharma, H.; Arya, K.V.; Nagar, A. Memetic search in artificial bee colony algorithm. Soft Comput. 2013, 17, 1911–1928. [Google Scholar] [CrossRef]
- Kang, F.; Li, J.; Li, H. Artificial bee colony algorithm and pattern search hybridized for global optimization. Appl. Soft Comput. 2013, 13, 1781–1791. [Google Scholar] [CrossRef]
- Gao, W.; Liu, S.; Huang, L. Enhancing artificial bee colony algorithm using more information-based search equations. Inf. Sci. 2014, 270, 112–133. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, H.; Wang, M.; Wan, J. Selection Mechanism in Artificial Bee Colony Algorithm: A Comparative Study on Numerical Benchmark Problems. In Neural Information Processing; Springer: Cham, Switzerland, 2017; pp. 61–69. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Zhu, G.; Kwong, S. Gbest-guided artificial bee colony algorithm for numerical function optimization. Appl. Math. Comput. 2010, 217, 3166–3173. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Gao, W.; Liu, S. Improved artificial bee colony algorithm for global optimization. Inf. Process. Lett. 2011, 111, 871–882. [Google Scholar] [CrossRef]
- Gao, W.; Liu, S. A modified artificial bee colony algorithm. Comput. Oper. Res. 2012, 39, 687–697. [Google Scholar] [CrossRef]
- Akay, B.; Karaboga, D. A modified Artificial Bee Colony algorithm for real-parameter optimization. Inf. Sci. 2012, 192, 120–142. [Google Scholar] [CrossRef]
- Gao, W.; Liu, S.; Huang, L. A Novel Artificial Bee Colony Algorithm Based on Modified Search Equation and Orthogonal Learning. IEEE Trans. Cybern. 2013, 43, 1011–1024. [Google Scholar] [PubMed]
- Babaoglu, I. Artificial bee colony algorithm with distribution-based update rule. Appl. Soft Comput. 2015, 34, 851–861. [Google Scholar] [CrossRef]
- Ratnaweera, A.; Halgamuge, S.K.; Watson, H.C. Self-organizing hierarchical particle swarm optimizer with time-varying acceleration coefficients. IEEE Trans. Evol. Comput. 2004, 8, 240–255. [Google Scholar] [CrossRef]
- Viswanathan, G.M.; Buldyrev, S.V.; Havlin, S.; Da, L.M.; Raposo, E.P.; Stanley, H.E. Optimizing the success of random searches. Nature 1999, 401, 911–914. [Google Scholar] [CrossRef] [PubMed]
- Viswanathan, G.M.; Afanasyev, V.; Buldyrev, S.V.; Murphy, E.J.; Prince, P.A.; Stanley, H.E. Lévy flight search patterns of wandering albatrosses. Nature 1996, 381, 413–415. [Google Scholar] [CrossRef]
- Edwards, A.M.; Phillips, R.A.; Watkins, N.W.; Freeman, M.P.; Murphy, E.J.; Afanasyev, V.; Buldyrev, S.V.; Da, L.M.; Raposo, E.P.; Stanley, H.E. Revisiting Lévy flight search patterns of wandering albatrosses, bumblebees and deer. Nature 2007, 449, 1044–1048. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reynolds, A.M.; Frye, M.A. Free-flight odor tracking in Drosophila is consistent with an optimal intermittent scale-free search. PLoS ONE 2007, 2, e354. [Google Scholar] [CrossRef] [PubMed]
- Mantegna, R.N. Fast, accurate algorithm for numerical simulation of Lévy stable stochastic processes. Phys. Rev. E 1994, 49, 4677–4683. [Google Scholar] [CrossRef]
Figure 1.
An example of 1000 steps of a Lévy flight in two dimensions. The origin of the motion is at [0,0], the step-size is generated according to Equation (5) with and the angular direction is uniformly distributed.
Figure 1.
An example of 1000 steps of a Lévy flight in two dimensions. The origin of the motion is at [0,0], the step-size is generated according to Equation (5) with and the angular direction is uniformly distributed.

Figure 2.
Comparison of the convergence results of the average best solution with 30 dimensions. () Sphere Function; () Quartic Function; () Schwefel’s Problem 2.22; () Rosenbrock Function; () Rastrigin Function; () Griewank Function; () Ackley Function; () Schwefel’s Problem 2.26; () Penalized Function.
Figure 2.
Comparison of the convergence results of the average best solution with 30 dimensions. () Sphere Function; () Quartic Function; () Schwefel’s Problem 2.22; () Rosenbrock Function; () Rastrigin Function; () Griewank Function; () Ackley Function; () Schwefel’s Problem 2.26; () Penalized Function.

Figure 3.
Comparison of the convergence results of the average best solution with 60 dimensions. () Sphere Function; () Quartic Function; () Schwefel’s Problem 2.22; () Rosenbrock Function; () Rastrigin Function; () Griewank Function; () Ackley Function; () Schwefel’s Problem 2.26; () Penalized Function.
Figure 3.
Comparison of the convergence results of the average best solution with 60 dimensions. () Sphere Function; () Quartic Function; () Schwefel’s Problem 2.22; () Rosenbrock Function; () Rastrigin Function; () Griewank Function; () Ackley Function; () Schwefel’s Problem 2.26; () Penalized Function.

Figure 4.
Comparison of the convergence results of the average best solution with 100 dimensions. () Sphere Function; () Quartic Function; () Schwefel’s Problem 2.22; () Rosenbrock Function; () Rastrigin Function; () Griewank Function; () Ackley Function; () Schwefel’s Problem 2.26; () Penalized Function.
Figure 4.
Comparison of the convergence results of the average best solution with 100 dimensions. () Sphere Function; () Quartic Function; () Schwefel’s Problem 2.22; () Rosenbrock Function; () Rastrigin Function; () Griewank Function; () Ackley Function; () Schwefel’s Problem 2.26; () Penalized Function.


Figure 5.
The success ratio of each SSE (operator). The horizontal ordinate denotes success ratio of each solution search equation at the midpoint of the experiments () and the end of the experiments () with 30 dimensions. () Sphere Function; () Quartic Function; () Schwefel’s Problem 2.22; () Rosenbrock Function; () Rastrigin Function; () Griewank Function; () Ackley Function; () Schwefel’s Problem 2.26; () Penalized Function.
Figure 5.
The success ratio of each SSE (operator). The horizontal ordinate denotes success ratio of each solution search equation at the midpoint of the experiments () and the end of the experiments () with 30 dimensions. () Sphere Function; () Quartic Function; () Schwefel’s Problem 2.22; () Rosenbrock Function; () Rastrigin Function; () Griewank Function; () Ackley Function; () Schwefel’s Problem 2.26; () Penalized Function.

Figure 6.
The success ratio of each SSE. The horizontal ordinate denotes success ratio of each solution search equation (operator) at the midpoint of the experiments () and the end of the experiments () with 60 dimensions. () Sphere Function; () Quartic Function; () Schwefel’s Problem 2.22; () Rosenbrock Function; () Rastrigin Function; () Griewank Function; () Ackley Function; () Schwefel’s Problem 2.26; () Penalized Function.
Figure 6.
The success ratio of each SSE. The horizontal ordinate denotes success ratio of each solution search equation (operator) at the midpoint of the experiments () and the end of the experiments () with 60 dimensions. () Sphere Function; () Quartic Function; () Schwefel’s Problem 2.22; () Rosenbrock Function; () Rastrigin Function; () Griewank Function; () Ackley Function; () Schwefel’s Problem 2.26; () Penalized Function.


Figure 7.
The success ratio of each SSE. The horizontal ordinate denotes success ratio of each solution search equation (operator) at the midpoint of the experiments () and the end of the experiments () with 100 dimensions. () Sphere Function; () Quartic Function; () Schwefel’s Problem 2.22; () Rosenbrock Function; () Rastrigin Function; () Griewank Function; () Ackley Function; () Schwefel’s Problem 2.26; () Penalized Function.
Figure 7.
The success ratio of each SSE. The horizontal ordinate denotes success ratio of each solution search equation (operator) at the midpoint of the experiments () and the end of the experiments () with 100 dimensions. () Sphere Function; () Quartic Function; () Schwefel’s Problem 2.22; () Rosenbrock Function; () Rastrigin Function; () Griewank Function; () Ackley Function; () Schwefel’s Problem 2.26; () Penalized Function.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Numerical benchmark functions.
| Type | Test Function | Formulation | Search Range | Minimum Value |
|---|---|---|---|---|
| Unimodal | Sphere | |||
| Quartic | ||||
| Schwefel’s Problem 2.22 | ||||
| Rosenbrock | ||||
| Multimodal | Rastrigin | |||
| Griewank | ||||
| Ackley | ||||
| Schwefel’s Problem 2.26 | ||||
| Penalized | ||||
| + |
Table 2.
Comparison between SLABC and other algorithms for 20 times independent runs tested on 9 basic benchmark functions with 30 dimensions.
Table 2.
Comparison between SLABC and other algorithms for 20 times independent runs tested on 9 basic benchmark functions with 30 dimensions.
| Functions | Metrics | ABC | MABC | GABC | distABC | SLABC |
|---|---|---|---|---|---|---|
| Best | 3.68 × 10 | 2.53 × 10 | 9.03 × 10 | 4.21 × 10 | 3.49 × 10 | |
| Median | 1.55 × 10 | 2.96 × 10 | 3.83 × 10 | 3.06 × 10 | 3.32 × 10 | |
| Worst | 2.91 × 10 | 2.23 × 10 | 1.89 × 10 | 1.82 × 10 | 1.25 × 10 | |
| Mean | 4.25 × 10 | 1.12 × 10 | 6.50 × 10 | 9.71 × 10 | 1.33 × 10 | |
| Std | 6.73 × 10 | 4.99 × 10 | 5.98 × 10 | 4.06 × 10 | 2.83 × 10 | |
| Best | 2.18 × 10 | 7.26 × 10 | 8.34 × 10 | 3.47 × 10 | 6.50 × 10 | |
| Median | 6.66 × 10 | 9.75 × 10 | 3.13 × 10 | 1.70 × 10 | 3.47 × 10 | |
| Worst | 4.85 × 10 | 1.21 × 10 | 9.61 × 10 | 7.77 × 10 | 6.18 × 10 | |
| Mean | 3.86 × 10 | 6.06 × 10 | 1.35 × 10 | 4.24 × 10 | 5.81 × 10 | |
| Std | 1.06 × 10 | 2.71 × 10 | 2.42 × 10 | 1.73 × 10 | 1.51 × 10 | |
| Best | 4.66 × 10 | 1.32 × 10 | 1.75 × 10 | 1.13 × 10 | 2.89 × 10 | |
| Median | 8.28 × 10 | 2.70 × 10 | 4.49 × 10 | 4.02 × 10 | 7.69 × 10 | |
| Worst | 1.46 × 10 | 5.83 × 10 | 8.59 × 10 | 7.47 × 10 | 2.50 × 10 | |
| Mean | 8.86 × 10 | 2.92 × 10 | 4.52 × 10 | 4.75 × 10 | 8.31 × 10 | |
| Std | 3.05 × 10 | 1.30 × 10 | 1.44 × 10 | 1.70 × 10 | 5.02 × 10 | |
| Best | 4.79 × 10 | 6.89 × 10 | 1.19 × 10 | 8.89 × 10 | 1.50 × 10 | |
| Median | 9.91 × 10 | 2.54× 10 | 9.07 × 10 | 6.26 × 10 | 1.09 × 10 | |
| Worst | 1.01 × 10 | 1.59 × 10 | 2.40 × 10 | 2.98 × 10 | 7.54 × 10 | |
| Mean | 1.34 × 10 | 2.16 × 10 | 3.32 × 10 | 8.84 × 10 | 9.87 × 10 | |
| Std | 2.10 × 10 | 4.19 × 10 | 5.44 × 10 | 8.88 × 10 | 2.24 × 10 | |
| Best | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Median | 0.00 × 10 | 6.21 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Worst | 3.55 × 10 | 1.15 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Mean | 5.33 × 10 | 9.82 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Std | 1.01 × 10 | 2.87 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Best | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Median | 3.00 × 10 | 1.94 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Worst | 3.08 × 10 | 5.47 × 10 | 1.55 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Mean | 1.54 × 10 | 5.47 × 10 | 1.67 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Std | 6.88 × 10 | 1.58 × 10 | 4.00 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Best | 1.21 × 10 | 2.13 × 10 | 3.20 × 10 | 3.20 × 10 | 2.49 × 10 | |
| Median | 2.13 × 10 | 2.96 × 10 | 3.73 × 10 | 3.91 × 10 | 2.84 × 10 | |
| Worst | 3.66 × 10 | 3.29 × 10 | 4.26 × 10 | 3.91 × 10 | 3.20 × 10 | |
| Mean | 2.15 × 10 | 1.70 × 10 | 3.66 × 10 | 3.59 × 10 | 2.81 × 10 | |
| Std | 6.17 × 10 | 7.34 × 10 | 3.66 × 10 | 3.63 × 10 | 1.96 × 10 | |
| Best | 3.82 × 10 | 3.82 × 10 | 3.82 × 10 | 3.82 × 10 | 3.82 × 10 | |
| Median | 3.82 × 10 | 3.82 × 10 | 3.82 × 10 | 3.82 × 10 | 3.82 × 10 | |
| Worst | 2.62 × 10 | 1.38 × 10 | 3.82 × 10 | 3.82 × 10 | 3.82 × 10 | |
| Mean | 4.94 × 10 | 9.12 × 10 | 3.82 × 10 | 3.82 × 10 | 3.82 × 10 | |
| Std | 5.00 × 10 | 3.17 × 10 | 2.83 × 10 | 1.44 × 10 | 7.46 × 10 | |
| Best | 1.29 × 10 | 1.35 × 10 | 1.35 × 10 | 4.47 × 10 | 1.35 × 10 | |
| Median | 1.20 × 10 | 5.23 × 10 | 1.35 × 10 | 2.83 × 10 | 1.35 × 10 | |
| Worst | 9.62 × 10 | 2.46 × 10 | 1.35 × 10 | 9.43 × 10 | 1.35 × 10 | |
| Mean | 2.20 × 10 | 2.67 × 10 | 1.35 × 10 | 3.38 × 10 | 1.35 × 10 | |
| Std | 2.51 × 10 | 6.79 × 10 | 2.81 × 10 | 2.68 × 10 | 2.81 × 10 |
Table 3.
Comparison between SLABC and other algorithms for 20 times independent runs tested on 9 basic benchmark functions with 60 dimensions.
Table 3.
Comparison between SLABC and other algorithms for 20 times independent runs tested on 9 basic benchmark functions with 60 dimensions.
| Functions | Metrics | ABC | MABC | GABC | distABC | SLABC |
|---|---|---|---|---|---|---|
| Best | 2.39 × 10 | 4.34 × 10 | 1.37 × 10 | 2.21 × 10 | 1.99 × 10 | |
| Median | 1.85 × 10 | 3.52 × 10 | 7.20 × 10 | 9.82 × 10 | 8.70 × 10 | |
| Worst | 1.50 × 10 | 2.36 × 10 | 3.13 × 10 | 4.51 × 10 | 4.59 × 10 | |
| Mean | 3.40 × 10 | 2.32 × 10 | 9.29 × 10 | 1.46 × 10 | 1.25 × 10 | |
| Std | 4.09 × 10 | 6.64 × 10 | 7.59 × 10 | 1.26 × 10 | 1.06 × 10 | |
| Best | 1.52 × 10 | 6.94 × 10 | 1.38 × 10 | 1.42 × 10 | 1.79 × 10 | |
| Median | 3.72 × 10 | 1.46 × 10 | 3.09 × 10 | 1.59 × 10 | 5.17 × 10 | |
| Worst | 7.55 × 10 | 1.22 × 10 | 2.74 × 10 | 2.23 × 10 | 2.17 × 10 | |
| Mean | 1.20 × 10 | 7.83 × 10 | 6.22 × 10 | 2.85 × 10 | 2.75 × 10 | |
| Std | 1.95 × 10 | 2.79 × 10 | 7.46 × 10 | 4.87 × 10 | 5.94 × 10 | |
| Best | 3.91 × 10 | 1.21 × 10 | 6.66 × 10 | 1.06 × 10 | 3.23 × 10 | |
| Median | 6.91 × 10 | 8.46 × 10 | 8.17 × 10 | 2.02 × 10 | 6.49 × 10 | |
| Worst | 1.27 × 10 | 1.31 × 10 | 1.65 × 10 | 4.96 × 10 | 1.24 × 10 | |
| Mean | 7.55 × 10 | 1.79 × 10 | 9.41 × 10 | 2.18 × 10 | 6.75 × 10 | |
| Std | 2.44 × 10 | 3.58 × 10 | 2.77 × 10 | 9.43 × 10 | 2.71 × 10 | |
| Best | 1.84 × 10 | 7.88 × 10 | 1.97 × 10 | 1.15 × 10 | 4.53 × 10 | |
| Median | 2.25 × 10 | 1.46 × 10 | 3.26 × 10 | 8.01 × 10 | 2.48 × 10 | |
| Worst | 8.50 × 10 | 7.63 × 10 | 8.43 × 10 | 2.17 × 10 | 8.20 × 10 | |
| Mean | 2.74 × 10 | 2.32 × 10 | 1.03 × 10 | 8.82 × 10 | 1.07 × 10 | |
| Std | 2.41 × 10 | 2.24 × 10 | 2.45 × 10 | 5.49 × 10 | 2.43 × 10 | |
| Best | 2.59 × 10 | 2.52 × 10 | 3.55 × 10 | 1.21 × 10 | 0.00 × 10 | |
| Median | 9.13 × 10 | 1.87 × 10 | 4.35 × 10 | 6.74 × 10 | 0.00 × 10 | |
| Worst | 1.99 × 10 | 1.46 × 10 | 1.03 × 10 | 9.95 × 10 | 0.00 × 10 | |
| Mean | 4.89 × 10 | 9.33 × 10 | 1.79 × 10 | 1.09 × 10 | 0.00 × 10 | |
| Std | 5.92 × 10 | 3.33 × 10 | 2.92 × 10 | 3.04 × 10 | 0.00 × 10 | |
| Best | 2.04 × 10 | 8.48 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Median | 1.51 × 10 | 9.96 × 10 | 2.78 × 10 | 1.67 × 10 | 0.00 × 10 | |
| Worst | 1.50 × 10 | 1.31 × 10 | 4.86 × 10 | 6.00 × 10 | 6.66 × 10 | |
| Mean | 3.98 × 10 | 3.71 × 10 | 2.64 × 10 | 7.94 × 10 | 5.55 × 10 | |
| Std | 4.92 × 10 | 5.00 × 10 | 1.08 × 10 | 1.48 × 10 | 1.75 × 10 | |
| Best | 6.89 × 10 | 1.14 × 10 | 3.31 × 10 | 7.60 × 10 | 3.73 × 10 | |
| Median | 1.50 × 10 | 6.23 × 10 | 5.25 × 10 | 1.04 × 10 | 5.17 × 10 | |
| Worst | 6.14 × 10 | 1.26 × 10 | 6.87 × 10 | 1.44e × 10 | 6.43 × 10 | |
| Mean | 1.72 × 10 | 1.31 × 10 | 5.11 × 10 | 1.07 × 10 | 5.08 × 10 | |
| Std | 1.16 × 10 | 3.21 × 10 | 9.52 × 10 | 2.16 × 10 | 7.29 × 10 | |
| Best | 3.57 × 10 | 7.64 × 10 | 7.64 × 10 | 2.41 × 10 | 7.64 × 10 | |
| Median | 6.26 × 10 | 7.64 × 10 | 2.84 × 10 | 5.61 × 10 | 7.64 × 10 | |
| Worst | 9.50 × 10 | 9.39 × 10 | 3.61 × 10 | 7.22 × 10 | 7.64 × 10 | |
| Mean | 6.75 × 10 | 5.13 × 10 | 4.86 × 10 | 5.20 × 10 | 7.64 × 10 | |
| Std | 2.01 × 10 | 2.10 × 10 | 9.68 × 10 | 1.31 × 10 | 1.43 × 10 | |
| Best | 9.97 × 10 | 5.76 × 10 | 9.00 × 10 | 9.85 × 10 | 2.44e × 10 | |
| Median | 4.95 × 10 | 1.70 × 10 | 3.15 × 10 | 4.72 × 10 | 2.89 × 10 | |
| Worst | 1.30 × 10 | 4.76 × 10 | 1.76 × 10 | 9.28 × 10 | 1.12 × 10 | |
| Mean | 5.43 × 10 | 3.70 × 10 | 4.55 × 10 | 4.45 × 10 | 3.45 × 10 | |
| Std | 3.24 × 10 | 1.08 × 10 | 4.09e × 10 | 1.83 × 10 | 2.84 × 10 |
Table 4.
Comparison between SLABC and other algorithms for 20 times independent runs tested on 9 basic benchmark functions with 100 dimensions.
Table 4.
Comparison between SLABC and other algorithms for 20 times independent runs tested on 9 basic benchmark functions with 100 dimensions.
| Functions | Metrics | ABC | MABC | GABC | distABC | SLABC |
|---|---|---|---|---|---|---|
| Best | 1.11 × 10 | 3.72 × 10 | 3.28 × 10 | 2.29 × 10 | 5.23 × 10 | |
| Median | 7.55 × 10 | 3.45 × 10 | 2.25 × 10 | 2.10 × 10 | 1.79 × 10 | |
| Worst | 4.46 × 10 | 1.12 × 10 | 4.01 × 10 | 2.71 × 10 | 7.16 × 10 | |
| Mean | 1.25 × 10 | 1.82 × 10 | 2.11 × 10 | 1.82 × 10 | 2.46 × 10 | |
| Std | 1.27 × 10 | 3.55 × 10 | 1.02 × 10 | 6.00 × 10 | 1.87 × 10 | |
| Best | 7.38 × 10 | 3.76 × 10 | 1.21 × 10 | 1.67 × 10 | 4.98 × 10 | |
| Median | 9.25 × 10 | 9.42 × 10 | 4.18 × 10 | 1.16 × 10 | 3.08 × 10 | |
| Worst | 1.84 × 10 | 1.48 × 10 | 2.23 × 10 | 5.76 × 10 | 2.10 × 10 | |
| Mean | 3.04 × 10 | 1.38 × 10 | 5.64 × 10 | 1.73 × 10 | 2.68 × 10 | |
| Std | 4.56 × 10 | 3.61 × 10 | 4.75 × 10 | 1.71 × 10 | 5.43 × 10 | |
| Best | 1.79 × 10 | 7.51 × 10 | 6.21 × 10 | 7.15 × 10 | 3.87 × 10 | |
| Median | 2.71 × 10 | 2.28 × 10 | 1.39 × 10 | 1.35 × 10 | 9.02 × 10 | |
| Worst | 5.86 × 10 | 8.83 × 10 | 3.36 × 10 | 1.70 × 10 | 2.08 × 10 | |
| Mean | 3.11 × 10 | 8.79 × 10 | 1.57 × 10 | 1.30 × 10 | 9.2 × 10 | |
| Std | 1.26 × 10 | 2.25 × 10 | 6.59 × 10 | 2.92 × 10 | 3.57 × 10 | |
| Best | 9.12 × 10 | 1.46 × 10 | 2.95 × 10 | 3.48 × 10 | 2.66 × 10 | |
| Median | 2.68 × 10 | 1.17 × 10 | 8.00 × 10 | 1.71 × 10 | 3.60 × 10 | |
| Worst | 8.31 × 10 | 1.14 × 10 | 1.88 × 10 | 4.78 × 10 | 1.45 × 10 | |
| Mean | 3.09 × 10 | 2.28 × 10 | 6.83 × 10 | 1.87 × 10 | 2.23 × 10 | |
| Std | 1.83 × 10 | 2.88 × 10 | 5.76 × 10 | 1.11 × 10 | 3.98 × 10 | |
| Best | 1.14 × 10 | 1.47 × 10 | 1.08 × 10 | 8.46 × 10 | 1.11 × 10 | |
| Median | 1.70 × 10 | 7.63 × 10 | 2.24 × 10 | 1.08 × 10 | 1.68 × 10 | |
| Worst | 2.24 × 10 | 6.76 × 10 | 4.04 × 10 | 1.30 × 10 | 2.98 × 10 | |
| Mean | 1.67 × 10 | 1.33 × 10 | 2.55 × 10 | 1.08 × 10 | 4.55 × 10 | |
| Std | 3.17 × 10 | 2.12 × 10 | 8.29 × 10 | 1.23 × 10 | 7.09 × 10 | |
| Best | 2.46 × 10 | 2.00 × 10 | 4.27 × 10 | 3.10 × 10 | 1.77 × 10 | |
| Median | 2.45 × 10 | 4.55 × 10 | 2.05 × 10 | 1.49 × 10 | 1.49 × 10 | |
| Worst | 9.39 × 10 | 2.44 × 10 | 6.47 × 10 | 2.27 × 10 | 1.18 × 10 | |
| Mean | 1.08 × 10 | 6.46 × 10 | 3.82 × 10 | 2.95 × 10 | 2.68 × 10 | |
| Std | 2.23 × 10 | 9.22 × 10 | 1.44 × 10 | 4.96 × 10 | 3.22 × 10 | |
| Best | 1.64 × 10 | 3.24 × 10 | 3.62 × 10 | 3.57 × 10 | 6.31 × 10 | |
| Median | 2.87 × 10 | 1.58 × 10 | 5.56 × 10 | 5.75 × 10 | 1.09 × 10 | |
| Worst | 4.93 × 10 | 4.17 × 10 | 8.04 × 10 | 1.26 × 10 | 1.56 × 10 | |
| Mean | 3.07 × 10 | 1.57 × 10 | 5.65 × 10 | 6.24 × 10 | 1.12 × 10 | |
| Std | 1.03 × 10 | 1.42 × 10 | 1.02 × 10 | 2.12 × 10 | 2.36 × 10 | |
| Best | 2.48 × 10 | 2.55 × 10 | 8.72 × 10 | 2.40 × 10 | 1.27 × 10 | |
| Median | 3.25 × 10 | 4.87 × 10 | 1.44 × 10 | 2.96 × 10 | 1.27 × 10 | |
| Worst | 3.63 × 10 | 4.30 × 10 | 1.77 × 10 | 3.36 × 10 | 1.18 × 10 | |
| Mean | 3.13 × 10 | 5.45 × 10 | 1.36 × 10 | 2.93 × 10 | 1.21 × 10 | |
| Std | 3.64 × 10 | 9.98 × 10 | 2.70 × 10 | 2.36 × 10 | 3.64 × 10 | |
| Best | 3.64 × 10 | 9.56 × 10 | 4.88 × 10 | 9.79 × 10 | 8.47 × 10 | |
| Median | 3.25 × 10 | 8.28 × 10 | 2.26 × 10 | 5.90 × 10 | 3.34 × 10 | |
| Worst | 4.98 × 10 | 4.75 × 10 | 6.97 × 10 | 1.29 × 10 | 3.16 × 10 | |
| Mean | 5.95 × 10 | 1.15 × 10 | 2.64 × 10 | 1.38 × 10 | 4.83 × 10 | |
| Std | 1.06 × 10 | 1.32 × 10 | 1.57 × 10 | 2.85 × 10 | 6.58 × 10 |
Table 5.
Results of t-tests between SLABC and the best results of the other algorithms regarding the indexes “Mean” for different benchmark functions.
Table 5.
Results of t-tests between SLABC and the best results of the other algorithms regarding the indexes “Mean” for different benchmark functions.
| Functions | Dim. | F-Value | p-Value | Significance | Two-Tailed P |
|---|---|---|---|---|---|
| D = 30 | 39.930 | 1.10 × 10 | YES | 0.05 | |
| D = 60 | 29.663 | 2.80 × 10 | YES | 0.05 | |
| D = 100 | 60.363 | 1.74 × 10 | YES | 0.05 | |
| D = 30 | 14.894 | 0.022 | YES | 0.05 | |
| D = 60 | 20.124 | 1.42 × 10 | YES | 0.05 | |
| D = 100 | 15.007 | 4.00 × 10 | YES | 0.05 | |
| D = 30 | 22.624 | 1.85 × 10 | YES | 0.05 | |
| D = 60 | 30.264 | 4.25 × 10 | YES | 0.05 | |
| D = 100 | 16.090 | 1.85 × 10 | YES | 0.05 | |
| D = 30 | 11.457 | 0.065 | NO | 0.05 | |
| D = 60 | 11.308 | 0.086 | NO | 0.05 | |
| D = 100 | 11.565 | 0.700 | NO | 0.05 | |
| D = 30 | - | - | SAME | 0.05 | |
| D = 60 | 23.119 | 0.013 | YES | 0.05 | |
| D = 100 | 70.236 | 2.52 × 10 | YES | 0.05 | |
| D = 30 | - | - | SAME | 0.05 | |
| D = 60 | 10.391 | 0.039 | YES | 0.05 | |
| D = 100 | 5.069 | 0.251 | NO | 0.05 | |
| D = 30 | 44.281 | 2.27 × 10 | YES | 0.05 | |
| D = 60 | 34.994 | 1.13 × 10 | YES | 0.05 | |
| D = 100 | 26.974 | 8.50 × 10 | YES | 0.05 | |
| D = 30 | - | - | SAME | 0.05 | |
| D = 60 | 4.813 | 0.288 | NO | 0.05 | |
| D = 100 | 14.296 | 0.028 | YES | 0.05 | |
| D = 30 | - | - | SAME | 0.05 | |
| D = 60 | 23.131 | 8.40 × 10 | YES | 0.05 | |
| D = 100 | 27.521 | 4.32 × 10 | YES | 0.05 |
Table 6.
Comparison between SLABC and other algorithms for 20 times independent runs tested on 6 basic benchmark functions with 60 dimensions.
Table 6.
Comparison between SLABC and other algorithms for 20 times independent runs tested on 6 basic benchmark functions with 60 dimensions.
| Functions | Metrics | SLABC1 | SLABC2 | SLABC3 | SLABC4 | SLABC |
|---|---|---|---|---|---|---|
| Best | 3.64 × 10 | 2.41 × 10 | 2.53 × 10 | 2.35 × 10 | 1.99 × 10 | |
| Median | 7.91 × 10 | 1.67 × 10 | 1.27 × 10 | 9.15 × 10 | 8.70 × 10 | |
| Worst | 1.45 × 10 | 8.14 × 10 | 1.85 × 10 | 3.80 × 10 | 4.59 × 10 | |
| Mean | 2.22 × 10 | 2.10 × 10 | 4.10 × 10 | 1.18 × 10 | 1.25 × 10 | |
| Std | 3.80 × 10 | 2.04 × 10 | 5.43 × 10 | 9.38 × 10 | 1.06 × 10 | |
| Best | 1.40 × 10 | 1.16 × 10 | 1.47 × 10 | 9.24 × 10 | 1.79 × 10 | |
| Median | 2.55 × 10 | 3.53 × 10 | 3.48 × 10 | 1.21 × 10 | 5.17 × 10 | |
| Worst | 2.09 × 10 | 8.46 × 10 | 1.04 × 10 | 3.52 × 10 | 2.17 × 10 | |
| Mean | 3.02 × 10 | 8.29 × 10 | 1.48 × 10 | 6.99 × 10 | 2.75 × 10 | |
| Std | 5.46 × 10 | 1.85 × 10 | 2.55 × 10 | 1.15 × 10 | 5.94 × 10 | |
| Best | 5.20 × 10 | 1.49 × 10 | 6.73 × 10 | 2.14 × 10 | 3.23 × 10 | |
| Median | 7.69 × 10 | 2.31 × 10 | 1.80 × 10 | 3.96 × 10 | 6.49 × 10 | |
| Worst | 1.83 × 10 | 3.98 × 10 | 3.25 × 10 | 6.87 × 10 | 1.24 × 10 | |
| Mean | 8.93 × 10 | 2.49 × 10 | 1.78 × 10 | 4.14 × 10 | 6.75 × 10 | |
| Std | 3.85 × 10 | 7.91 × 10 | 7.65 × 10 | 1.26 × 10 | 2.71 × 10 | |
| Best | 1.00 × 10 | 1.40 × 10 | 4.52 × 10 | 2.54 × 10 | 4.53 × 10 | |
| Median | 2.91 × 10 | 2.37 × 10 | 5.14 × 10 | 2.12 × 10 | 2.48 × 10 | |
| Worst | 7.04 × 10 | 1.06 × 10 | 1.43 × 10 | 8.68 × 10 | 8.20 × 10 | |
| Mean | 8.10 × 10 | 1.84 × 10 | 3.30 × 10 | 1.87 × 10 | 1.07 × 10 | |
| Std | 1.57 × 10 | 3.05 × 10 | 4.12 × 10 | 3.00 × 10 | 2.43 × 10 | |
| Best | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Median | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Worst | 0.00 × 10 | 0.00 × 10 | 9.95 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Mean | 0.00 × 10 | 0.00 × 10 | 4.97 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Std | 0.00 × 10 | 0.00 × 10 | 2.22 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Best | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Median | 2.00 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | 0.00 × 10 | |
| Worst | 1.35 × 10 | 6.66 × 10 | 8.99 × 10 | 1.11 × 10 | 6.66 × 10 | |
| Mean | 9.21 × 10 | 3.33 × 10 | 4.50 × 10 | 5.55 × 10 | 5.55 × 10 | |
| Std | 3.16 × 10 | 1.49 × 10 | 2.01 × 10 | 2.48 × 10 | 1.75 × 10 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Pang, B.; Song, Y.; Zhang, C.; Wang, H.; Yang, R. A Modified Artificial Bee Colony Algorithm Based on the Self-Learning Mechanism. Algorithms 2018, 11, 78. https://doi.org/10.3390/a11060078
AMA Style
Pang B, Song Y, Zhang C, Wang H, Yang R. A Modified Artificial Bee Colony Algorithm Based on the Self-Learning Mechanism. Algorithms. 2018; 11(6):78. https://doi.org/10.3390/a11060078
Chicago/Turabian StylePang, Bao, Yong Song, Chengjin Zhang, Hongling Wang, and Runtao Yang. 2018. "A Modified Artificial Bee Colony Algorithm Based on the Self-Learning Mechanism" Algorithms 11, no. 6: 78. https://doi.org/10.3390/a11060078
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.