A Regional Topic Model Using Hybrid Stochastic Variational Gibbs Sampling for Real-Time Video Mining

1
Key Laboratory of Educational Informatization for Nationalities Ministry of Education, Yunnan Normal University, Kunming 650500, China
2
School of Information, Yunnan Normal University, Kunming 650500, Yunnan, China
*
Author to whom correspondence should be addressed.
Algorithms 2018, 11(7), 97; https://doi.org/10.3390/a11070097
Submission received: 8 May 2018
/
Revised: 14 June 2018
/
Accepted: 21 June 2018
/
Published: 1 July 2018
(This article belongs to the Special Issue Discrete Algorithms and Discrete Problems in Machine Intelligence)
Abstract
:The events location and real-time computational performance of crowd scenes continuously challenge the field of video mining. In this paper, we address these two problems based on a regional topic model. In the process of video topic modeling, region topic model can simultaneously cluster motion words of video into motion topics, and the locations of motion into motion regions, where each motion topic associates with its region. Meanwhile, a hybrid stochastic variational Gibbs sampling algorithm is developed for inference of our region topic model, which has the ability of inferring in real time with massive video stream dataset. We evaluate our method on simulate and real datasets. The comparison with the Gibbs sampling algorithm shows the superiorities of proposed model and its online inference algorithm in terms of anomaly detection.
1. Introduction
Video mining is a hot topic that has attracted significant interests in recent years. Video mining is able to find the implicit, valuable, and understandable video patterns by analyzing visual features, time structure, event relationships, and semantic information of video data [1], which can be classified into video structure mining and video motion mining [2]. In particular, for poor structural videos such as traffic surveillance video, video motion mining can realize the applications of abnormal events detection or congestion analysis, and so on.
With the evolution of video mining technology, there has been an increasing number of research works focused on the use of topic models for video motion mining. Although probabilistic topic models were originally studied in the field of natural language processing [3,4], they also provide a way for discovering hidden pattern from images or document corpus. In the text mining, a topic model represents unlabeled documents as mixtures of topics where latent topics are distributions over observed words. In the video motion mining, full video is treated as document collection; a short video clip is treated as a document that divided from full video; the video features are considered as words. In this way, with the introduction of probabilitics topic model in video motion analysis, variety of latent motion patterns, and latent motions correlations were discovered, which are represented by topics. Figure 1 shows the diagram of video topic modeling.
Although several topic models have successfully applied in surveillance systems [5,6,7,8], there exist several premature phenomena in the procedure of video topic modeling—such as abnormal events locating and computational performance of real-time mining. In this paper, we focus on topic modeling with region information and uses it to automatically detect abnormal events from a complex video scene in real-time.
The rest of the paper is organized as follows. In the next section, we present a brief survey of the related works. In Section 3.1—Video Representation—the video representation is explained. In Section 3.2—Regional Topic Model and its Online Inference Algorithm, our regional topic model (RTM) and its hybrid stochastic variational Gibbs Sampling algorithm (HSVG) are presented. The datasets, evaluations and comparisons are discussed in detail, in Section 4. Our conclusions are presented in the last section.
2. Related Works
Recently, there has been a significant number of research works focused on the use of topic models for complex scene analysis. These methods have become quite popular due to their success in natural language processing, e.g., probabilistic latent semantic analysis (pLSA) [9] and latent Dirichlet allocation (LDA) [5]. Nevertheless, when there are lots of motions co-occurred, LDA has problems of low sensitivity, so it is unable to detect the abnormal event accurately. In addition, there is a problem with abnormal event localization in LDA: it can only detect which clip the abnormal event is in, but have no ability to determine where the event happened in. Therefore, several attempts have been made to model video data using LDA extensions.
X. Wang [10] adopted hierarchical variants of LDA, including a Hierarchical Dirichlet Processes (HDP) [7] mixture model and a Dual Hierarchical Dirichlet Processes (Dual-HDP) model, to connect three elements in visual surveillance: low-level visual features, simple atomic activities, and interactions. Thereafter, X. Wang [11] converted tracks into words, and applied a topic model to them. The words were the quantized positions and directions of motion, consequentially the topics would represent routes shared between objects. J. Li [12] proposed WS-JTM to address the typical topic model weakness of inference speed and exploited weak supervision. They fixed delta latent Dirichlet allocation (dLDA) in their extension, multi-class dLDA, which is also used to detect rare and subtle behavior. Thereafter, a two-staged cascaded LDA model was formulated by Li et al. in reference [13] where the first stage learns regional behavior and the second stage learns the global context over the regional models. Hospedales T.M. et al. [14] adopt a nonparametric Bayesian approach to automatically determine the number of topics shared by the documents and also when they appear in each temporal document. Emonet R. [15] proposed framework consists of an activity-based semantic scene segmentation model for learning behavior spatial context, and a cascaded probabilistic topic model for learning both behavior correlation context and behavior temporal context at multiple scales. Fu et al. [16] improved sparse topical coding (STC) to discover semantic motion patterns for a dynamic scene, which can be sparsely reconstructed. Yuan et al. [17] used a topic model to discover functional regions in a city using taxi probe data and point-of-interest information. Similarly, Farrahi and Gatica-Perez [18] used a topic model to discover human routines using mobile-phone location data. In [19], LDA was extended to model the flow of people entering or exiting a building. Yu et al. [20] proposed a topic model for detecting an anomalous group of individuals in a social network. Kinoshita et al. [21] introduced a traffic state model based on a probabilistic topic model to describe the traffic states for a variety of roads, the model can be learned using an expectation–maximization algorithm. Hospedales et al. [22] introduced a dynamic topic model named Markov clustering topic model (MCTM), and an approximation to online Bayesian inference was formulated to enable dynamic scene understanding and behavior mining in new video data online in real-time. In order to handle the temporal nature of the video data, Fan et al. [23] devised a dynamical causal topic model (DCTM) that can detect the latent topics and causal interactions between them.
Meanwhile, several attempts have also been made to find anomalies using topic models and surveillance cameras [24,25]. Jeong et al. [26] proposed a topic model for detecting anomalous trajectories of people or vehicles in surveillance-video images. Kaviani et al. [27] addressed the problem of abnormality detection based on a fully sparse topic models (FSTM). Isupova et al. [28] proposed a novel dynamic Bayesian nonparametric topic model and its Batch and online Gibbs samplers for anomaly detection in video.
In general, there were several key problems in existing studies about video mining using topic model: (1) model parameters increment leads to the increments of the model learning time, and then traditional off-line inference algorithm is not suitable for video monitoring system; (2) anomaly detection in a whole scene rather than in each region reduces the sensitivity of the anomaly detection.
To address the problem of motion region, Zou et al. [29] proposed a belief based on correlated topic model (BCTM) for the semantic region analysis of pedestrian motion patterns in the crowded scenes. Haines proposed regional LDA model (rLDA) [30], which not only can model activities in a complicated scene, but also realize a high sensitivity detection and the localization of motion topic (especially the abnormal event) by extracting spatial information ignored by LDA. Nonetheless, the inference algorithm of above studies still used the collapsed Gibbs sampling, which needs to scan the whole samples at each iteration. For huge data sets and data streams such as video, this way adopted by Gibbs sampling leads to high memory overhead, slow running speed, and judging convergence difficultly.
Classic approaches of inference algorithm in LDA are Gibbs sampling (GS) [31] and variational Bayesian (VB) batch inference [5]. In order to solve the problem of computational complexity, collapsed Gibbs sampling (CGS) [6] and collapsed VB batch inference (CVB) [32] were proposed. Nevertheless, for the purpose of LDA applied to video mining, we need to make the inference algorithm adapt to the characteristics of video streaming data set, it is better to a realize real-time and online processing quickly and efficiently. For text database which is huge or in the form of data stream, there have been developments of online LDA inference algorithm with less memory, faster running, and convergence speed. Hoffman proposed the stochastic gradient optimization algorithm (online LDA) [33], which repeatedly subsamples a small set of documents from the collection and then updates the topics from an analysis of the subsample. Since online LDA does not need to scan the entire samples for updating topic parameter matrix at each iteration, the updating of topic parameters is more frequently. The algorithm not only takes up less memory, faster running, and convergence speed, but also realizes online inference in real time for huge data sets or data stream. Nonetheless, the algorithm complexity linearly increased with the number of topics. Therefore, it is not suitable for large collection with many topics. On the basis of online LDA algorithm, Mimno proposed hybrid stochastic variational Gibbs sampling (HSVG) [34]. This algorithm introduced the second source of stochasticity by MCMC sampling, and taken advantage of sparse computation to make complexity sublinearly increased with the number of topics. It fits for a large collection with many topics. Besides, RLD (Riemannian Langevin dynamics) [35] algorithm was proposed by Girolami. It is a kind of Langevin dynamics algorithm based on Riemannian manifold of MH correction. Welling proposed SGLD (stochastic gradient Langevin dynamics) [36] algorithm, which reserved stochastic gradient optimization algorithm, and can sample from the posterior distribution. Patterson proposed SGRLD (stochastic gradient Riemannian Langevin dynamics) [37] by combining RLD and SGLD algorithm. In addition, Olga Isupova et al. [38] proposed new learning algorithms for activity analysis in video, which are based on the expectation maximization approach and variational Bayes inference.
3. Materials and Methods
3.1. Video Representation
To discover motion patterns for video by topic modeling, the definitions of visual words and visual documents are essential for topic model applied to video analysis: given an input video, we first temporally segment the video into non-overlapping clips. Each clip is considered as a document. To create visual words, we segment a scene into sub-grid. Next, we compute optical flow field for motion object from foreground mask extracted in each frame, and then optical flow histograms are generated for one clip by counting grids accumulated over frames of this clip. After spatial and directional quantization, video motion word labeled in is split into grid position and motion direction . Finally, we select the largest optical flow histogram to generate a motion words sample . Then, for a visual word , the information of motion position and direction mix together to express a motion word , and all the motion words in a video clip constitute the bag of visual words (BOVW).
3.2. Regional Topic Model and Its Online Inference Algorithm
In our RTM, the goal is to discover a set of motions (topics) from video by learning the probability distributions of visual features over each topic and topics over each clip. These two probability distributions are represented as two co-occurring matrixes in Figure 1. Meanwhile, the location information of motion is discovered. Nonetheless, BOVW based on latent Dirichlet allocation (LDA) model presumes that the words are unordered and interchangeable in document, this hypothesis destroys the spatial information of motions or activities; we are unable to get the motion region from model learning.
In order to keep and use the spatial information of motion in video, we introduce RTM, in which each sample in a frame is not only labeled by its motion direction but also by a motion region label . It means that the latent motion topics in videos are associated with the regions where they occurred in.
Suppose that there are documents (video clips), each document contains observed samples . is the motion topic of each sample , and is its motion region label of region . Then, video sequence can be represented as , . The latent variables are motion topic and regional labels sets . From a global perspective, motion topic weight vector of document can be expressed as . When a symmetric Dirichlet prior distribution is applied on the topic weight vector , the hyperparameters of Dirichlet prior is , . From a local perspective, motion regional weight vector can be expressed as . When a symmetric Dirichlet prior distribution is applied on the regional weight vector, it means .
Document shares motion topics by local topic weight vector . In other words, the motion topic label subset obeys a multinomial distribution of dimension whose parameter is ,
Local motion topic weight vector obey a symmetric Dirichlet prior distribution whose parameter is
The corpus share motion regions by global region weight vector . In other words, motion region label set obeys a multinomial distribution of dimension whose parameter is ,
Likewise, global region weight obeys a symmetric Dirichlet prior distribution whose parameter is
Under the known motion topic label and known motion region label of sample , the sample subset allocated by document obeys a dimension multinomial distribution whose parameter is
The hybrid parameter obeys a symmetric Dirichlet prior distribution whose parameter is
The construction of RTM is summarized as that: the number of motion topics is ; the number of motion regions is ; the video sequence contains documents; the observed sample set is ; the corresponding latent variables set is . Then, the generative process of RTM is as follows, the corresponding graphical model is shown in Figure 2.
Generate
For each sample
Generate a regional label for its location
For each video clip
Generate a motion topic weight vector
For each sample
Generate motion topic label
Generate
Generate
As the generative process of RTM described above, the unknown parameters to be estimated are , and ; the known data are the observed samples and their joint distribution. As shown in Equation (7),
According to above construction of RTM, the model learning acts as clustering document sample subsets . The word samples not only can be clustered to motion topics, but also to motion regions. Each latent motion topic is inevitably correlated to a space region. It is worth noting that even though there have been several studies that introduce latent variables for merging various factors to jointly estimate document contents, which have the obvious differentiation with our RTM. For instance, in topic modeling of document, Rosen-Zvi et al. [39] introduced an author latent variable, and Bao et al. [40] introduced an emotion latent variable. Both of them first generated the introduced variables (emotion or author) from a specific distribution, then generated a latent topic from a multinomial distribution conditioned on generated variable, and finally generated document terms from another multinomial distribution based on latent topics. Whereas our RTM generates a introduced variable (region) and a latent topic in two independent steps respectively, and finally generates document terms from a multinomial distribution based on fixed latent region and topic. Therefore, a different generative process leads to different forms of joint distribution as well as inference algorithm.
As with traditional topic model, there are generally two kinds of inference methods for our RTM: MCMC sampling and VB inference. For realizing the real-time video mining, we proposed a hybrid stochastic variational Gibbs (HSVG) sampling algorithm for RTM. In comparison with HSVG sampling, the Gibbs sampling algorithm needs to scan the entire samples for at each iteration as a batch algorithm. Therefore, due to the huge memory (risk of overhead), slower running and difficultly determining convergence time, even collapsed Gibbs sampling algorithm is not suitable for huge data sets or data stream. The HSVG algorithm introduces the second source of stochasticity by MCMC sampling, and takes advantage of sparse computation to make complexity sublinearly increased with the number of topics, which fits for large collection with many topics. The inference process of our HSVG algorithm is formulated with more detail as follows.
Firstly, the motion region label is considered as a global latent variable. We eliminate the local motion topic weight by marginal computation, and obtain the local collapsed space of latent variable . Then the strong correlation between latent variable and local motion topic weight is retained. The joint distribution becomes Equation (8)
Next, for improving the inference accuracy by retaining weak correlation of local latent variables , we suppose that obeys an indecomposable variational distribution
Therefore, in the inference of semi-collapsed RTM, we just need to suppose that global latent variable , local latent variable , motion region weight and global hybrid parameters are independent. Then, the variational distribution of free variational parameters , , , and can be decomposed into Equation (10)
Then, the semi-collapsed ELBO (Evidence Lower Bound) of document collection is the global objective function
The motion topic weight in is eliminated by integrating
Then, Equation (13) is obtained
At this point, the local variational objective function of each document is
Next, the stochastic variational inference of global layer and the MCMC inference of local layer are as follows
1. Local MCMC Inference
Computing the first derivative of local objective function with respect to variational parameters
Set Equation (15) equals to zero, the optimal variational distribution is
Among Equation (16), the variational expectation of sufficient statistic respect to variational parameter is
The MCMC sampling method can be used to solve the estimation problem of optimal variational distribution without supposing the independent of local latent variables. Constructing a Markov chain whose stationary distribution is the optimal variational distribution local latent variables, the key problem of Gibbs sampling is computing the transition probability of Markov chain, which equals to the motion topic label ’s prediction probability of sample . Then, Equation (18) is obtained
In the Equation (18)
The prediction probability is iteratively learning in Markov chain, Markov chain is converged after times Gibbs sampling state transition in burn-in time. After Markov chain converged, the arithmetic average value of sample sufficient statistics is the estimation of
2. Global Stochastic Variational Inference
In the th stochastic iteration, the state space of Markov chain is constructed by the sample sufficient statistics of a stochastic small batch documents , the contribution of to natural gradient of global variational parameters is
At this point, the update amount , and of local small batch documents respect to global variational parameters is
Then, the variational expectation of or obtained from local MCMC inference respect to global variational parameters is that
When the number of motion topics , motion regions or words is large, observed samples of document is allocated to a large dimensions hybrid parameters matrix , which make sufficient statistics of many samples be zero. Then, estimated by MCMC sampling is a sparse matrix. Therefore, the amount of computations is decreased and computing speed is improved because of the sparsity.
Given the above description, the specific description of HSVG algorithm is shown in Algorithm 1.
| Algorithm 1. HSVG algorithm of RTM model |
| Initialize global variational parameters , and while the number of random iterations do |
| Update iteration step: |
| Import a small batch documents |
| Initialize from , from |
| for do |
| For a sample of document local MCMC inference is adopted |
| end_for |
| end_for |
| times iteration in burn-in time is not processed |
| For converged Markov chain do |
| end_for |
| , where |
| end_while |
4. Results
4.1. Evaluation Criterion
In the text mining and statistic inference of nature language, perplexity is always used to evaluate the performance of model, which is computed by . denotes the parametric estimation of trained model, and are test dataset and observed samples respectively. Perplexity is the negative log likelihood (NLL) divided by the number of observed samples . As described in above, the computation of perplexity is mainly the NLL computation of trained model, and NLL denotes the cross entropy of trained model and unknown testing data. Perplexity represents the uncertainty of trained model for unknown test set’s estimation. Therefore, the lower the NLL value is, the better the model performance is.
In our RTM, NLL can be computed for motion topic and region of test video clip. The parameters estimation of trained model and a test video clip are learning in RTM, the learned local motion topic weight estimation and global parameter estimation , of original trained model is computed for NLL of test clips.
Besides, t_NLL and r_NLL are computed by:
t_NLL is used to evaluate the performance of learning motion topic by our model, and r_NLL is used to evaluate the performance of learning motion region. Meanwhile, because of the samples number difference between different regions, the abnormal events probabilities of the region including few samples is lower, so we add a sample number weight for each region. We regard the five most regions of r_NLL value as the most possible abnormal events regions. Furthermore, we utilize receiver operating characteristic curve (ROC) and AUC (area under ROC) to evaluate the abnormal detecting performance of our model, which are independent of threshold selection. Obviously, for ROC, the closer to the top left corner, the performance of abnormal detection is better. Similarly, the closer to 1 the AUC value is, the better the performance of abnormal detection. The running platform of experiment is shown in Table 1.
4.2. Datasets and Parameter Settings
In order to get the comprehensive evaluation of our model and its inference algorithm, we analyze the performance based on two types of dataset. The first one is a simulation video dataset constructed by specific steps, and the second one is a real video dataset.
4.2.1. Simulation Video Dataset
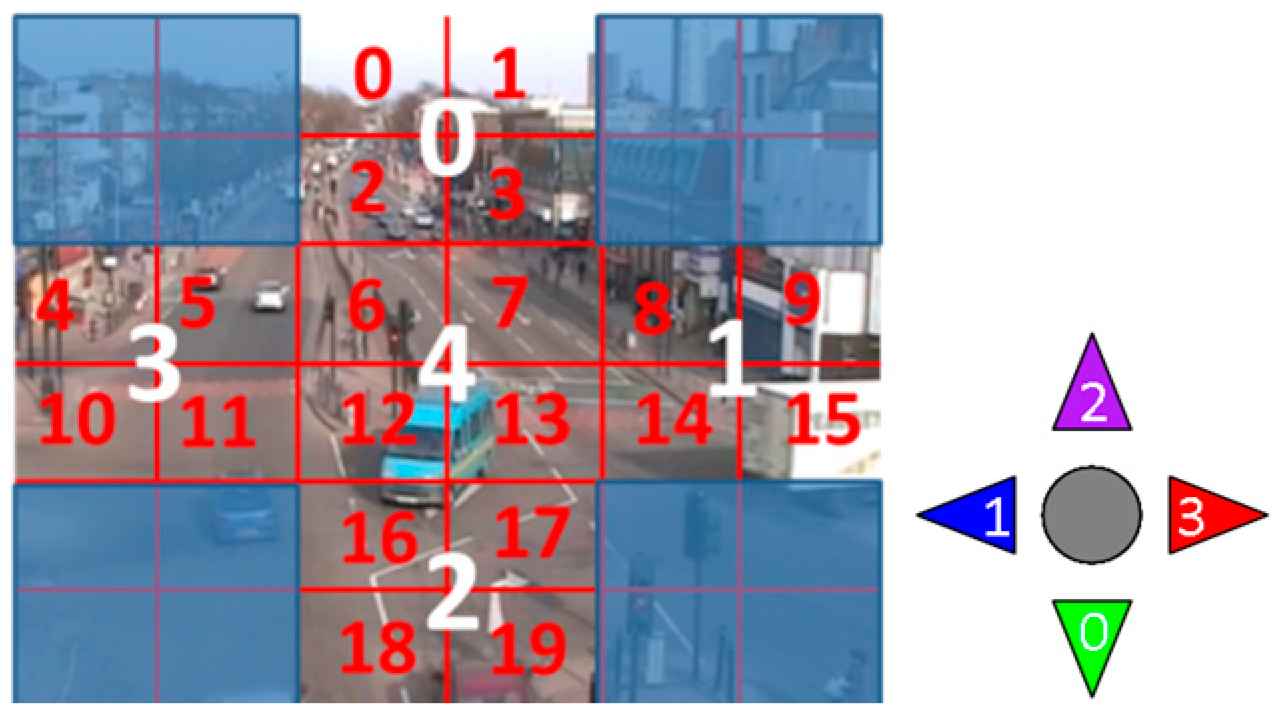
We make a simulation video dataset for simulating the traffic intersection. Each image of a frame was divided into a 6 by 6 grid (a total of 36 positions) and five valid regions (including the sides of up, middle, down, right, and left). Meanwhile, each valid region is composed by 4 grids, that there are in total of 4 × 5 = 20 locations to simulate one center and four directions of traffic intersection, as shown in Figure 3.
In Figure 3, white texts represent the valid region number , and red texts represent the valid location number . Four directions are represented as down (green), left (blue), up (purple) and right (red), whose number is . Then, the number of locations is , and the number of motion directions is . is used to denote a motion word, where ,, and the number of motion words is . The latent motion topic is constructed by combining region number and direction number . Regarding as an instance, it means that one location of region 0(that location number is one of ) is moving in direction 0(down). Then, normal and abnormal motions are able to be constructed by above way. There are five kinds of normal motion states and two kinds of abnormal motion states. The generative algorithm of simulation video is described below:
Generate an initial motion direction randomly.
Choose a motion topic, where the probability of abnormal motion topic is 5%, and the probability of abnormal motion topic is 95%.
Generate 100 samples by
Based on the chosen motion topic, choose a motion state randomly.
Based on the chosen motion state, generate an observed sample randomly.
Figure 4 shows the generated training set and test set by above steps. The color of arrow represents the direction, and the brightness represents the probability in motion topic.
4.2.2. Real Video Dataset
We use the QMUL street intersection dataset [41] for evaluating abnormality detection performance of this model. This standard video is 50 min in length, frame rates are 30 fps, resolution is 360 × 288, and there are 90,000 frames. Video codec is mpeg-4 compression encoding. The whole traffic light cycle is about 1.5 min; the average duration of abnormal event is 4.3 s (129 frames).
In our experiment, we divide whole video into 250 clips; each clip is 12 s (360 frames). The top 14.36 min (30 documents) is training dataset, and the last 10 min (50 documents) is test dataset. Each scene of a clip is first divided into a 4 by 4 grid (a total of 16 positions) and five valid regions. After cutting off the part of sky and generating motion code book for model training, RTM-HSVG (RTM is learned and inference by Hybrid Stochastic Variational Gibbs Sampling) and RTM-GS (RTM is learned and inference by Gibbs Sampling) then computes the negative loglikelihood of every region as a score in each test clip and abnormality clips are picked up while its abnormality score exceed 1.5 times of average. The parameter settings are shown in Table 2
4.3. Experimental Results
4.3.1. Simulation Experiment of Visualization Traffic Intersection
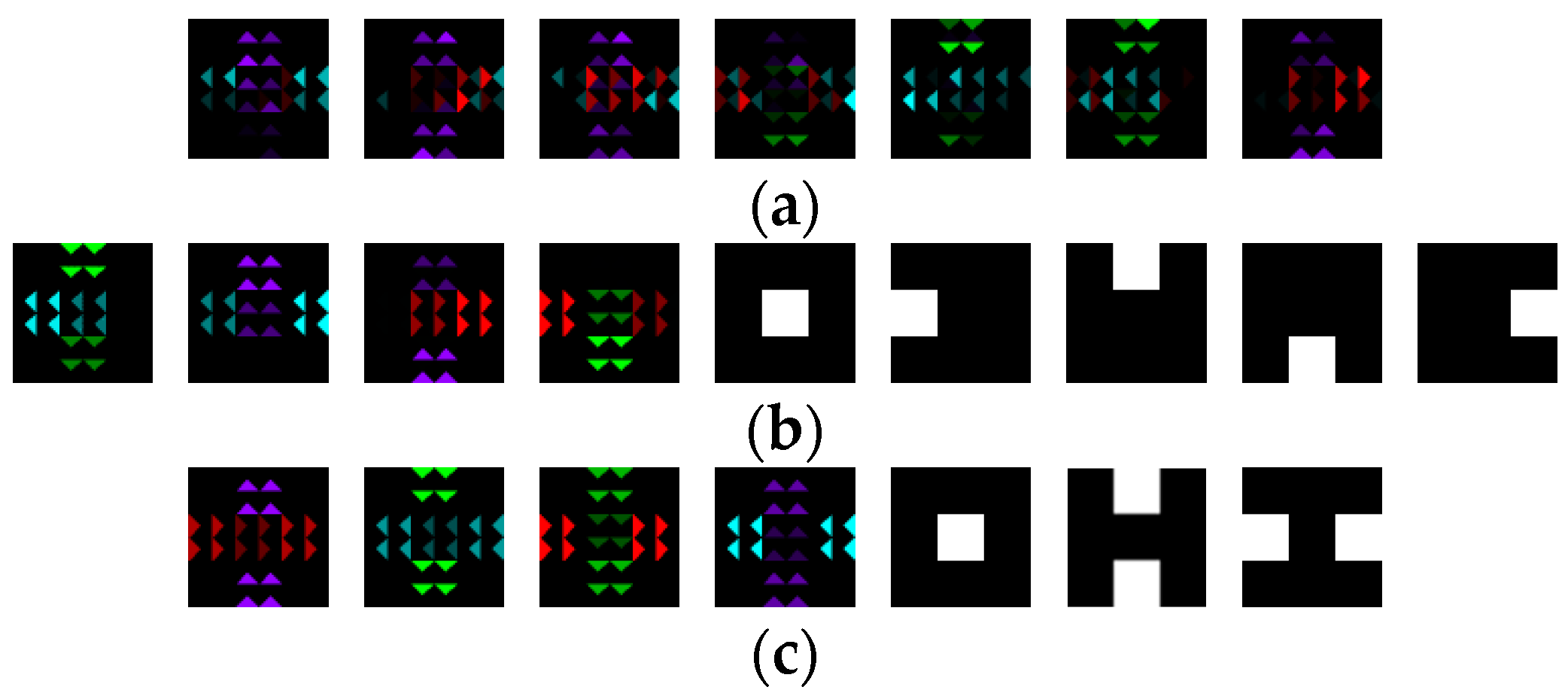
Firstly, the motion topics and regions discovered by RTM-GS and RTM-HSVG is shown in Figure 5, where Figure 5a shows the seven random simulated abnormal motions. The number of simulated training documents is same as the number of test set, which is 100.
As can be seen from Figure 5, although RTM-GS discovers more latent regions, a refined topic division is obtained by RTM-HSVG. Furthermore, in RTM-HSVG, the two roads with same direction are combined to a latent region, which is capable of moving crossroad. It is more reasonable that motions comply with traffic rules of a same road are the same.
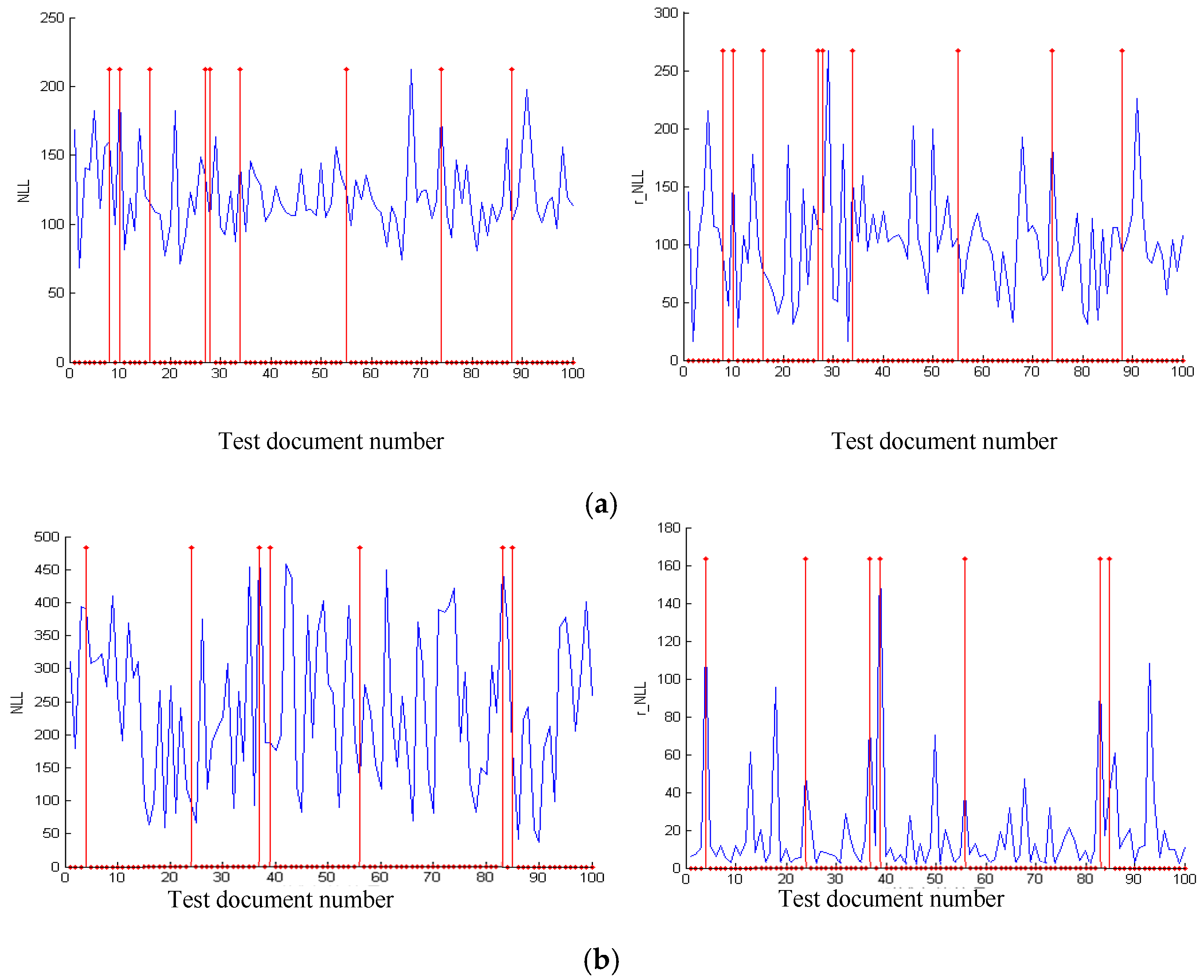
To compare the abilities of our model to discover abnormal motion, the NLL and r_NLL comparisons of our model and actual values is shown in Figure 6.
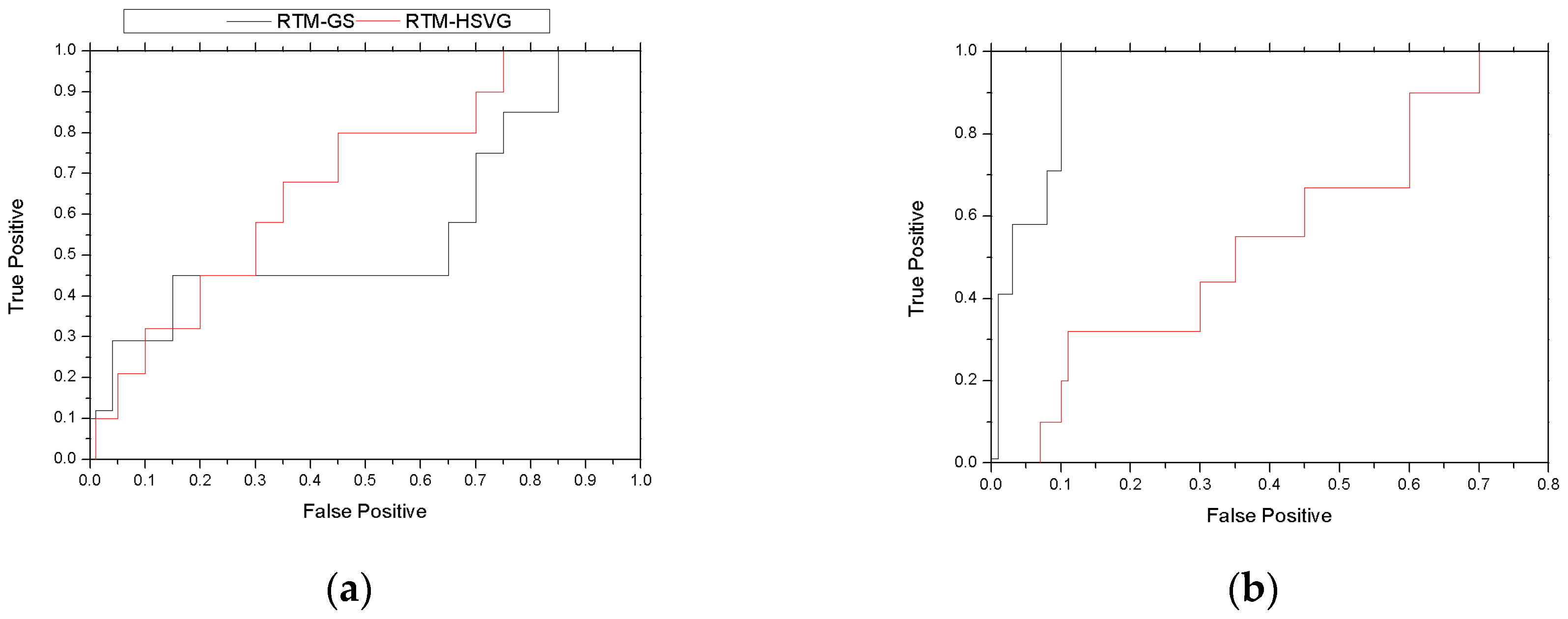
As shown in Figure 6, for r_NLL curve, the accuracy of RTM-GS seems to be higher than RTM-HSVG. Nonetheless, for NLL curve, RTM-HSVG obtained a higher accuracy. As HSVG is a kind of stochastic algorithm, it cause a volatile shocks in r_NLL curve. It also suggests that our stochastic online algorithm need to introduce more motion region information to acid early-warning. The difference between RTM-GS and RTM-HSVG is also able to be observed in their ROC and AUC, which is shown in Figure 7.
As shown in Figure 7, the area under NLL ROC of RTM-HSVG is 0.68, and RTM-GS is 0.56. This result again explains that the comprehensive accuracy of RTM-HSVG is better than RTM-GS. On the other hand, the area under r_NLL ROC of RTM-HSVG is 0.64, and RTM-GS is 0.97, which illustrates that the performance of learning motion region of RTM-GS is better than RTM-HSVG. These simulated experimental results show the validity of RTM for discovering motion topic and motion region.
4.3.2. Real Video Experiment
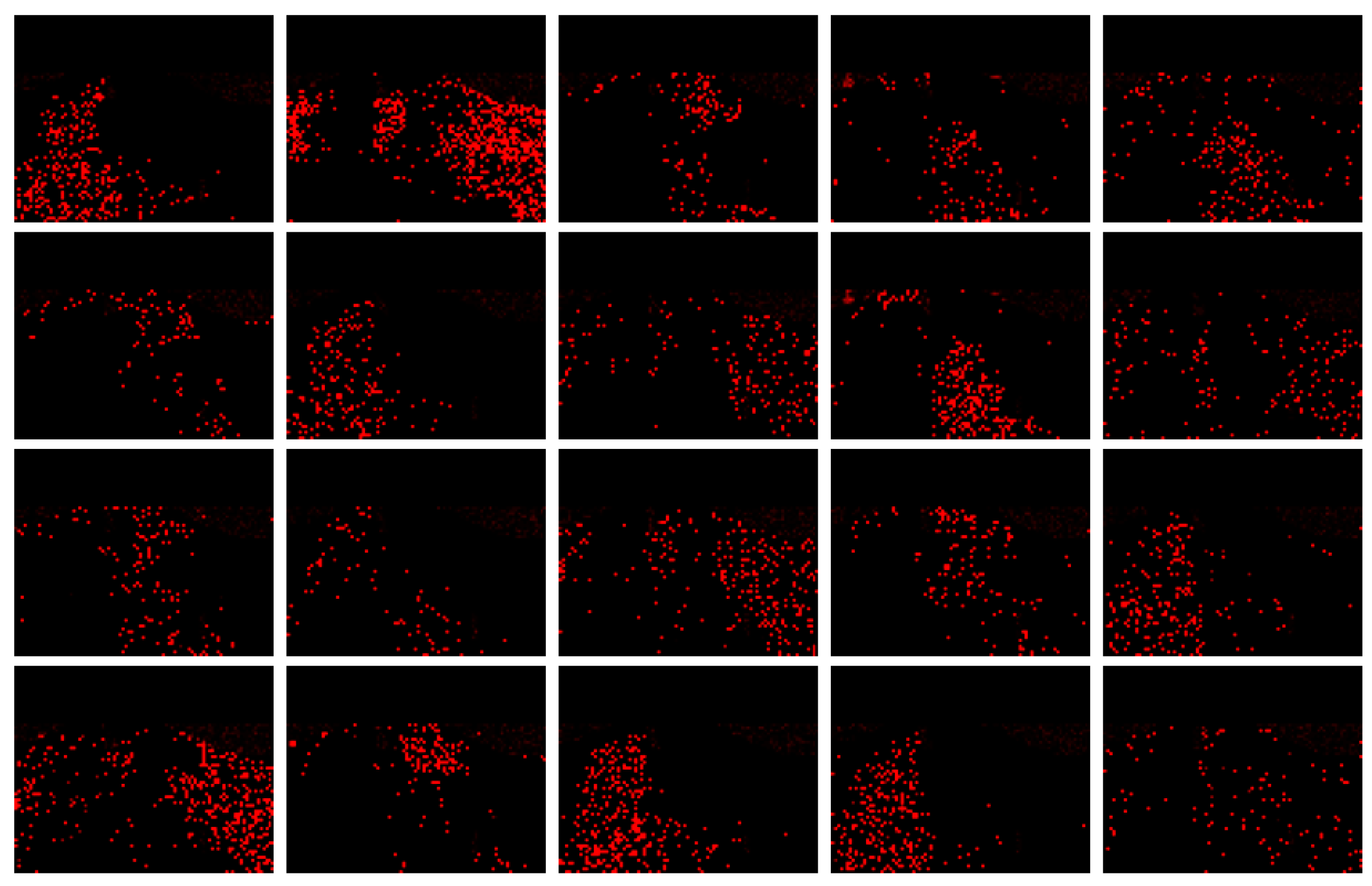
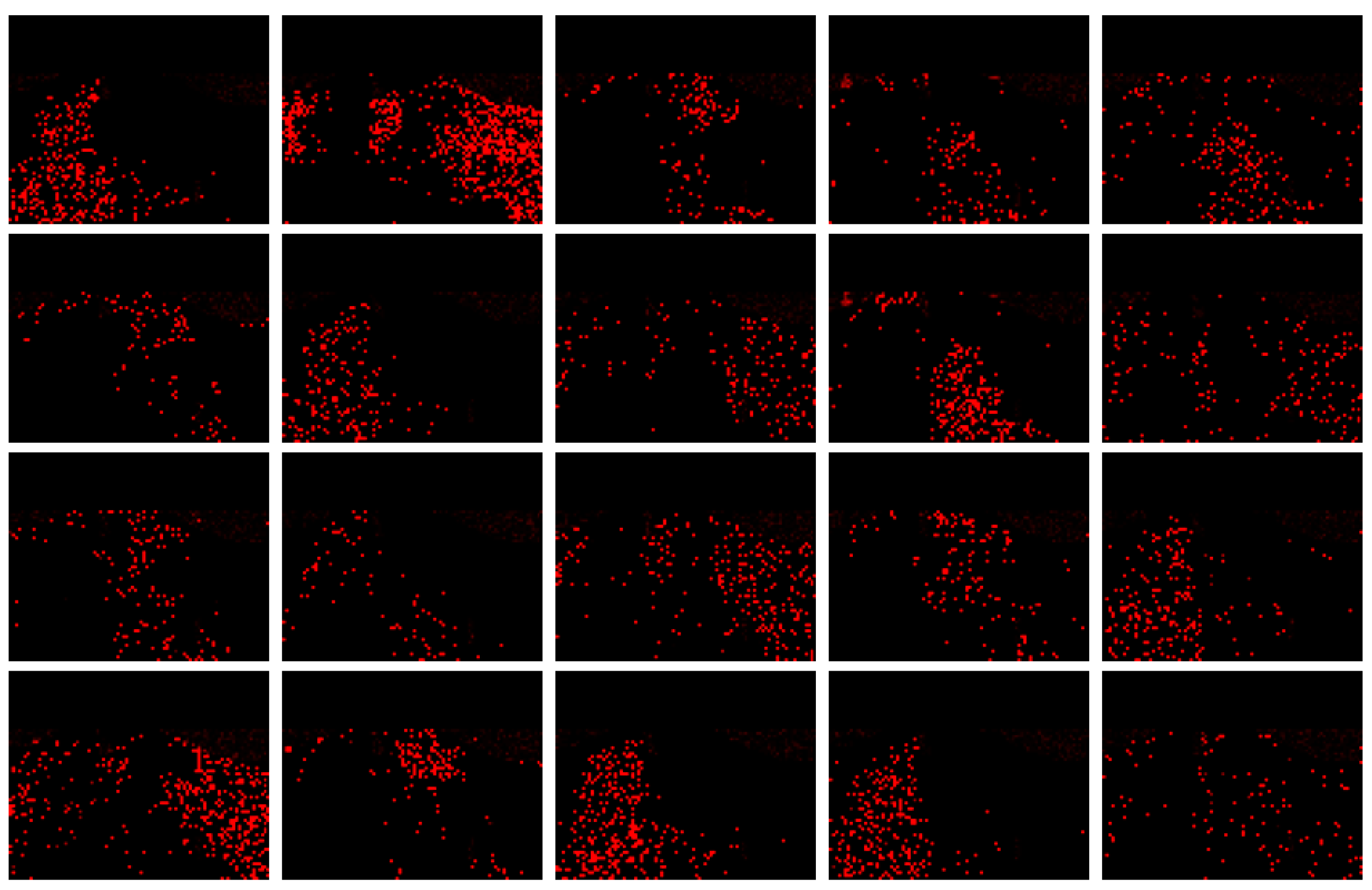
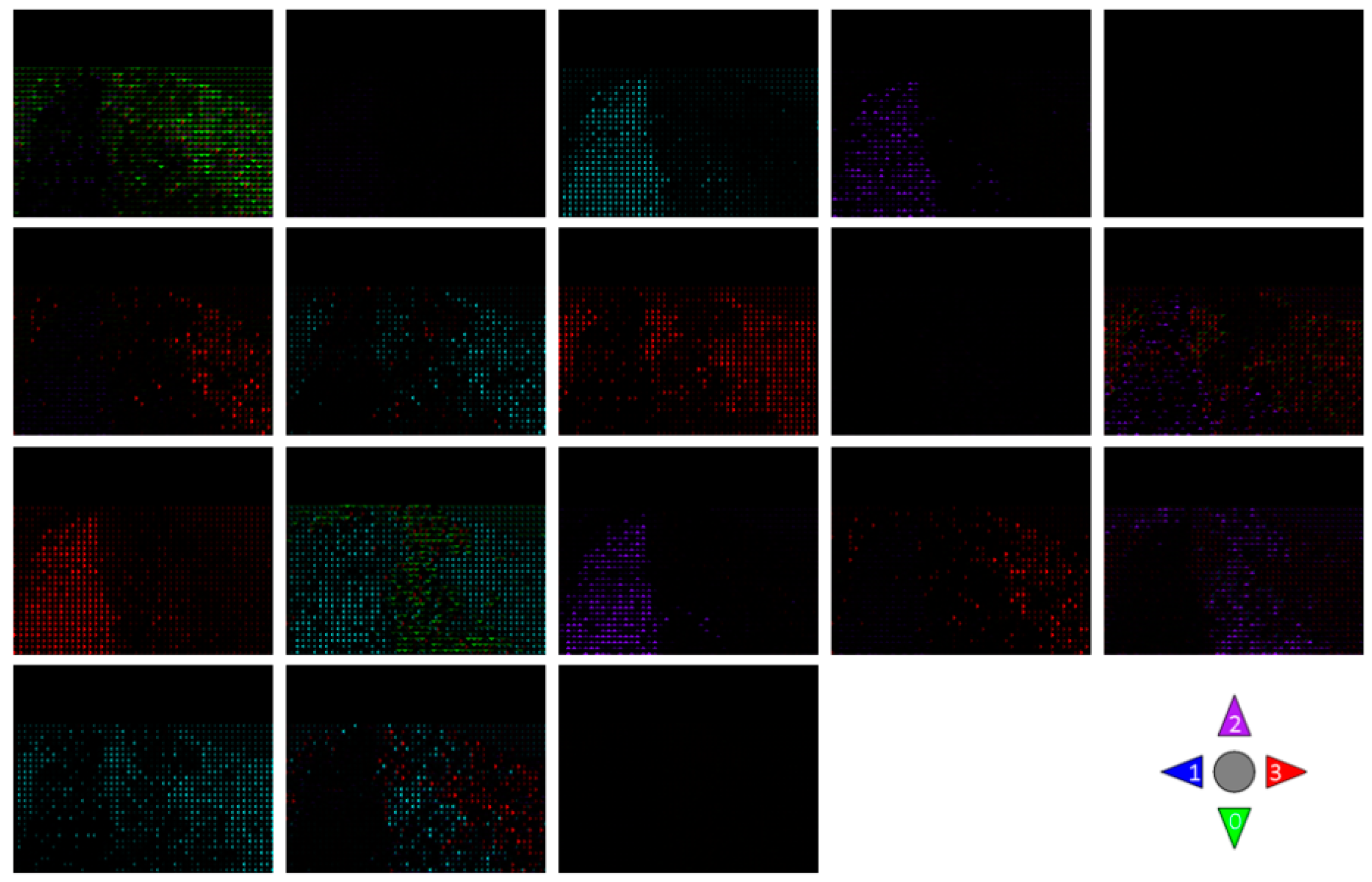
Likewise, for QUML dataset, the motion topics and regions discovered by RTM-GS and RTM-HSVG is shown in Figure 8, Figure 9, Figure 10 and Figure 11 respectively.
According to the comparisons of latent motion topic and motion regions discovered in above figures, RTM-GS obtained more clearly atomic motion patterns, which form the motion topic. Nevertheless, RTM-HSVG obtained a more focused clustering in both motion topic and region, and the direction representation of RTM-HSVG is richer (observed from the mixture of four directions). This is because the Markov chain state space of large-scale dataset is larger; it needs a longer burn-in time for Markov chain convergence. Even if RTM-HSVG has a shorter burn-in time, it also obtained a better performance than RTM-GS.
In order to test the impact of burn-in time on performance of our model, the burn-in time of RTM-GS is increasing to four times, and the iteration-times is set as 8000. Then, the motion topics and regions results are shown in Figure 12 and Figure 13.
In comparison with Figure 8 and Figure 12 as well as Figure 9 and Figure 13, we find that longer burn-in time makes a more focused clustering in both motion topic and region. Nevertheless, it is difficult to decide when Markov chain is convergent in Gibbs sampling, and longer burn-time is at the expense of time efficiency. Therefore, RTM-HSVG is more efficient than RTM-GS as an online algorithm. Meanwhile, we find that a larger number of topics can make more clear motion topics, which also makes more repeated latent topics. Therefore, it illustrates that the number of topics and regions are important aspects to decide performance of RTM.
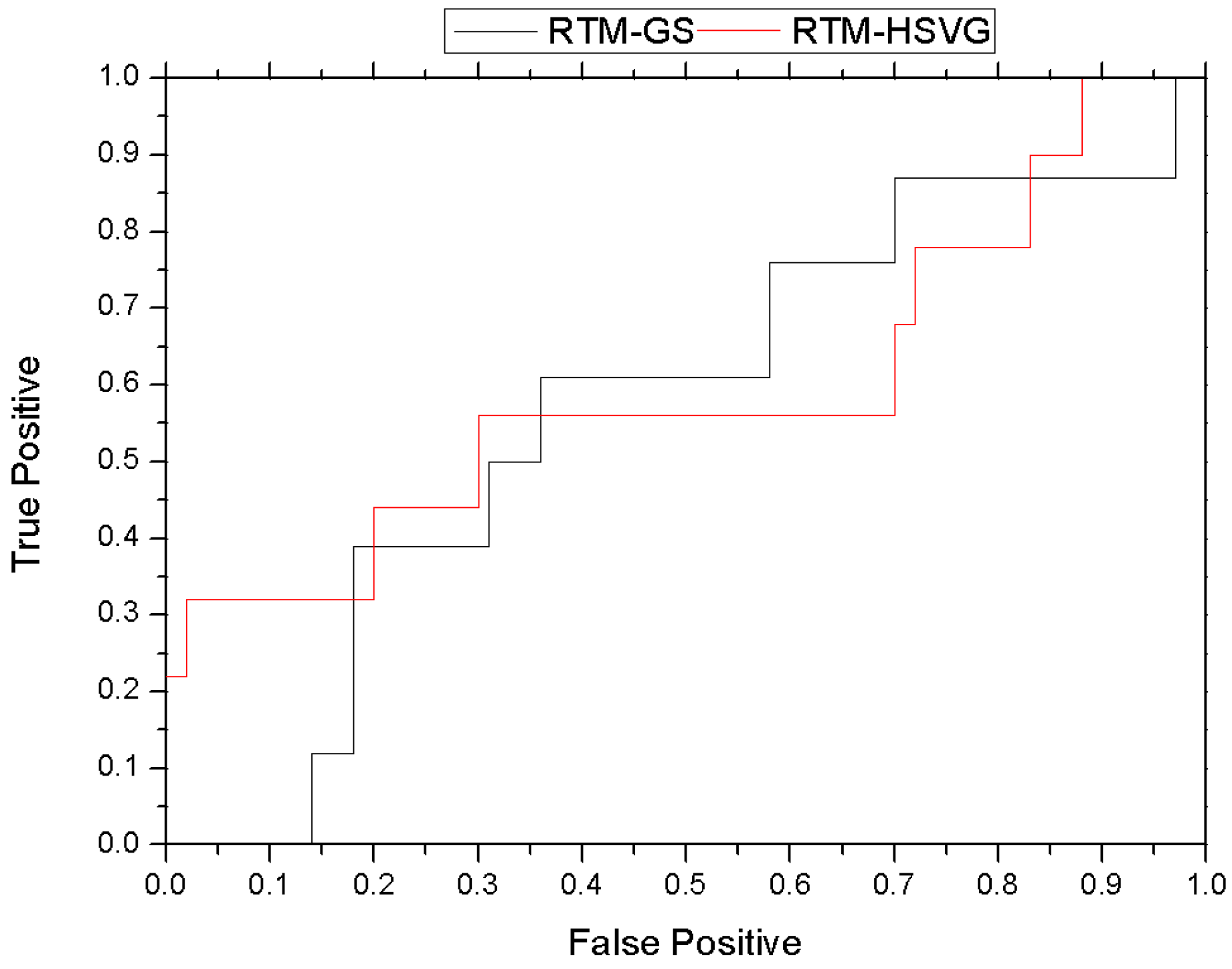
The ROC curve comparison of RTM-HSVG and RTM-GS is shown in the Figure 14. As shown in Figure 14, the area under ROC of RTM-HSVG is 0.59, and RTM-GS is 0.577. These results again indicate that RTM-HSVG can improve the accuracy of abnormal event detection in comparison with RTM-GS.
At last, several abnormal events discovered by RTM-HSVG are shown in Figure 15, and the regions of abnormal motion are labeled by dark red.
Figure 15a shows an abnormal event in 33rd clips (37,410~37,769), its motion region is number 6, and NLL = 724,951.87. A fire vehicle is driving into the crossing from right and interrupting the vertical traffic.
Figure 15b shows an abnormal event in 25th clips (34,538~34,897), its motion region is number 9, and NLL = 753,774.17. A car is turning right illegally.
Figure 15c shows an abnormal event in 15th clips (30,948~31,307), its motion region is number 13, and NLL = 792,248.81. A car makes a U-turn illegally.
Figure 15d shows an abnormal event in 14th clips (30,589~30,948), its motion region is number 15, and NLL = 819,426.78. A fire vehicle is driving into the crossing from lift and interrupting the vertical traffic.
From the above experimental results, we can see that RTM is able to discover motion topics and motion regions efficiently. Specially, the HSVG inference algorithm designed for RTM is better than Gibbs sampling on accuracy and time efficiency. Therefore, we can anticipate that RTM-HSVG is a potential method for real-time video mining.
5. Conclusions
To solve the problem that traditional topic model is unable to process video in real-time and model motion regional information, we proposed a RTM and designed its hybrid stochastic variational Gibbs sampling algorithm. In RTM, observation data not only has the motion topic label but also has region label of its position. In our HSVG algorithm, the local weight is collapsed locally for retaining the high relativities between local latent variable set and local weight at first, and then local Gibbs sampling is introduced for retaining low relativities of local latent variable set . For global variational parameters , , and , the stochastic natural gradient methods are adopted, which make RTM capable of processing massive video dataset in real time. The experimental results on simulate and real dataset show that the proposed RTM-HSVG improves the anomaly detection performance in comparison to the RTM-GS.
Author Contributions
Conceptualization, L.T. and J.G.; Methodology, L.T.; Software, L.T. and L.L.; Validation, L.T. and L.L.; Formal Analysis, L.T.; Writing-Original Draft Preparation, L.T. and L.L.; Writing-Review & Editing, L.L.
Funding
This research was supported by the Doctor Science Foundation of Yunnan normal university (no. 2016zb009), the National Natural Science Foundation of China (grant number 61562093), the Key Project of Applied Basic Research Program of Yunnan Province (no. 2016FA024), and the MOE Key Laboratory of Educational Information for Nationalities (YNNU) Open Funding Project (no. EIN2017001).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Dai, K.; Zhang, J.; Li, G. Video mining: Concepts, approaches and applications. In Proceedings of the IEEE 12th International Multi-Media Modelling Conference Proceedings, Beijing, China, 4–6 January 2006. [Google Scholar]
- Chen, S.C.; Shyu, M.L.; Zhang, C.; Strickrott, J. A multimedia data mining framework: Mining information from traffic video sequences. Intell. Inf. Syst. 2002, 19, 61–77. [Google Scholar] [CrossRef]
- Blei, D.; Carin, L.; Dunson, D. Probabilistic topic models. IEEE Signal Process. Mag. 2010, 27, 55–65. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.H.; Zhao, G.G.; Sun, D.H. Modeling documents with event model. Algorithms 2015, 8, 562–572. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Griffiths, T.L.; Steyvers, M. Finding scientific topics. Proc. Natl. Acad. Sci. USA 2004, 101, 5228–5235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Teh, Y.W.; Jordan, M.I.; Beal, M.J.; Blei, D.M. Hierarchical dirichlet processes. Am. Stat. Assoc. 2006, 101, 1566–1581. [Google Scholar] [CrossRef]
- Larlus, D.; Verbeek, J. Category Level Object Segmentation by Combining Bag-of-Words Models with Dirichlet Processes and Random Fields. Int. J. Comput. Vis. 2010, 88, 238–253. [Google Scholar] [CrossRef]
- Hofmann, T. Probabilistic latent semantic analysis. In Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence, Stockholm, Sweden, 30 July–1 August 1999; pp. 289–296. [Google Scholar]
- Wang, X.; Ma, X.; Grimson, W.E.L. Unsupervised Activity Perception in Crowded and Complicated Scenes Using Hierarchical Bayesian Models. IEEE Trans. Pattern Anal. 2009, 31, 539–555. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.; Ma, K.T.; Ng, G.W. Trajectory analysis and semantic region modeling using a nonparametric Bayesian model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Li, J.; Gong, S.; Xiang, T. Scene segmentation for behaviour correlation. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 383–395. [Google Scholar]
- Li, J. Learning behavioural context. Int. J. Comput. Vis. 2012, 97, 276–304. [Google Scholar] [CrossRef]
- Hospedales, T.M.; Li, J.; Gong, S.; Xiang, T. Identifying rare and subtle behaviors: A weakly supervised joint topic model. Int. J. Comput. Vis. 2012, 33, 2451–2464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Emonet, R.; Varadarajan, J.; Odobez, J. Extracting and locating temporal motifs in video scenes using a hierarchical non parametric Bayesian model. Int. J. Comput. Vis. 2011, 32, 3233–3240. [Google Scholar]
- Fu, W.; Wang, J.; Lu, H.; Ma, S. Dynamic scene understanding by improved sparse topical coding. Pattern Recogn. 2013, 46, 1841–1850. [Google Scholar] [CrossRef]
- Yuan, J.; Zheng, Y.; Xie, X. Discovering regions of different functions in a city using human mobility and POIs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 186–194. [Google Scholar]
- Farrahi, K.; Gatica-Perez, D. Discovering routines from large-scale human locations using probabilistic topic models. ACM Trans. Intell. Syst. Technol. 2011, 2. [Google Scholar] [CrossRef]
- Zhao, Z.; Xu, W.; Chen, D. EM-LDA model of user behavior detection for energy efficiency. In Proceedings of the IEEE International Conference on System Science and Engineering, Shanghai, China, 11–13 July 2014; pp. 295–300. [Google Scholar]
- Yu, R.; He, X.; Liu, Y. GLAD: Group anomaly detection in social media analysis. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 372–381. [Google Scholar]
- Kinoshita, A.; Takasu, A.; Adachi, J. Real-time traffic incident detection using a probabilistic topic model. J. Intell. Inf. Syst. 2015, 54, 169–188. [Google Scholar] [CrossRef]
- Hospedales, T. Video behaviour mining using a dynamic topic model. Int. J. Comput. Vis. 2012, 98, 303–323. [Google Scholar] [CrossRef]
- Fan, Y.; Zhou, Q.; Yue, W.; Zhu, W. A dynamic causal topic model for mining activities from complex videos. Multimed. Tools Appl. 2017, 10, 1–16. [Google Scholar] [CrossRef]
- Hu, X.; Hu, S.; Zhang, X.; Zhang, H.; Luo, L. Anomaly detection based on local nearest neighbor distance descriptor in crowded scenes. Sci. World J. 2014, 2014, 632575. [Google Scholar] [CrossRef] [PubMed]
- Pathak, D.; Sharang, A.; Mukerjee, A. Anomaly localization in topic-based analysis of surveillance videos. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 389–395. [Google Scholar]
- Jeong, H.; Yoo, Y.; Yi, K.M.; Choi, J.Y. Two-stage online inference model for traffic pattern analysis and anomaly detection. Mach. Vis. Appl. 2014, 25, 1501–1517. [Google Scholar] [CrossRef]
- Kaviani, R.; Ahmadi, P.; Gholampour, I. Incorporating fully sparse topic models for abnormality detection in traffic videos. In Proceedings of the International Conference on Computer and Knowledge Engineering, Mashhad, Iran, 29–30 October 2014; pp. 586–591. [Google Scholar]
- Isupova, O.; Kuzin, D.; Mihaylova, L. Anomaly detection in video with Bayesian nonparametrics. arXiv, 2016arXiv:1606.08455v1.
- Zou, J.; Chen, X.; Wei, P.; Han, Z.; Jiao, J. A belief based correlated topic model for semantic region analysis in far-field video surveillance systems. In Proceedings of the Pacific-Rim Conference on Multimedia, Nanjing, China, 13–16 December 2013; pp. 779–790. [Google Scholar]
- Haines, T.S.F.; Xiang, T. Video topic modelling with behavioural segmentation. In Proceedings of the ACM International Workshop on Multimodal Pervasive Video Analysis, Firenze, Italy, 29 October 2010; pp. 53–58. [Google Scholar]
- Gasparini, M. Markov chain monte carlo in practice. Technometrics 1997, 39, 338. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.; Hofmann, T. A collapsed variational bayesian inference algorithm for latent dirichlet allocation. Adv. Neural Inf. Process. Syst. 2007, 19, 1353–1360. [Google Scholar]
- Hoffman, M.D.; Blei, D.M.; Bach, F. Online learning for latent dirichlet allocation. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; pp. 856–864. [Google Scholar]
- Mimno, D.; Hoffman, M.; Blei, D. Sparse stochastic inference for latent dirichlet allocation. arXiv, 2012arXiv:1206.6425.
- Girolami, M.; Calderhead, B. Riemann manifold langevin and hamiltonian monte carlo methods. J. R. Stat. Soc. 2015, 73, 123–214. [Google Scholar] [CrossRef]
- Welling, M.; Teh, Y.W. Bayesian learning via stochastic gradient langevin dynamics. In Proceedings of the International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 681–688. [Google Scholar]
- Patterson, S.; Teh, Y.W. Stochastic gradient riemannian langevin dynamics on the probability simplex. In Advances in Neural Information Processing Systems, Harrahs and Harveys, Lake Tahoe, 5–10 December 2013. 3102–3110.
- Isupova, O.; Kuzin, D.; Mihaylova, L. Learning methods for dynamic topic modeling in automated behavior analysis. IEEE Trans. Neural Netw. Learn. 2017, 99, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Rosen-Zvi, M.; Chemudugunta, C.; Griffiths, T.; Smyth, P.; Steyvers, M. Learning author-topic models from text corpora. ACM Trans. Inf. Syst. 2010, 28, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Bao, S.; Xu, S.; Zhang, L.; Yan, R.; Su, Z.; Han, D.; Yu, Y. Mining social emotions from affective text. IEEE Trans. Knowl. Data Eng. 2012, 24, 1658–1670. [Google Scholar] [CrossRef]
- Junction Dataset. Available online: http://www.eecs.qmul.ac.uk/~sgg/QMUL_Junction_Datasets/Junction/Junction.html (accessed on 29 May 2017).
Figure 1.
Diagram of video topic modeling.
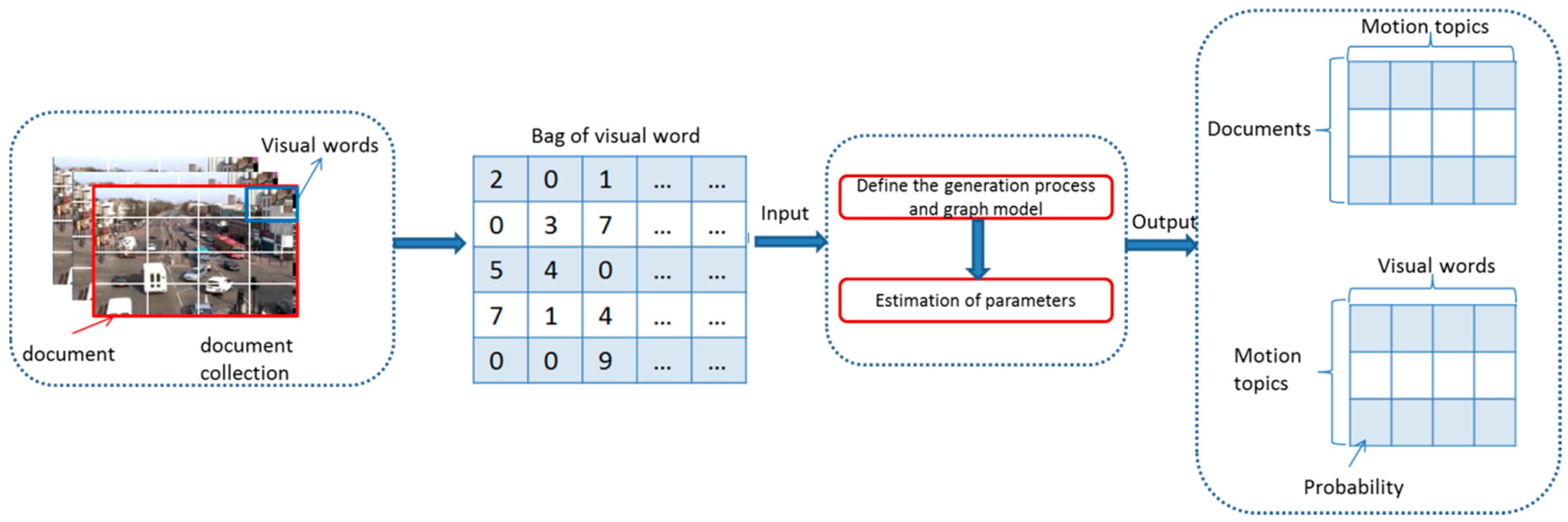
Figure 2.
Graphical model of RTM.

Figure 3.
Directions and regions of simulation video

Figure 4.
Generated simulation datasets. (a) Training set. (b) Test set.

Figure 5.
Motion topics and regions discovered by RTM-GS and RTM-HSVG in simulation dataset (a) The seven random simulate abnormal motions. (b) The four motion topics and five regions discovered by RTM-GS. (c) The four motion topics and three regions discovered by RTM-HSVG.
Figure 5.
Motion topics and regions discovered by RTM-GS and RTM-HSVG in simulation dataset (a) The seven random simulate abnormal motions. (b) The four motion topics and five regions discovered by RTM-GS. (c) The four motion topics and three regions discovered by RTM-HSVG.

Figure 6.
The NLL and r_NLL comparisons of our model and actual values. (a) NLL (left and blue) and r_NLL (right and blue) comparisons of RTM-HSVG. (b) NLL (left and blue) and r_NLL (right and blue) comparisons of RTM-GS.
Figure 6.
The NLL and r_NLL comparisons of our model and actual values. (a) NLL (left and blue) and r_NLL (right and blue) comparisons of RTM-HSVG. (b) NLL (left and blue) and r_NLL (right and blue) comparisons of RTM-GS.

Figure 7.
Comparative results of ROC. (a) Comparative results on NLL. (b) Comparative results on r_NLL.
Figure 7.
Comparative results of ROC. (a) Comparative results on NLL. (b) Comparative results on r_NLL.

Figure 8.
Twenty latent motion regions discovered by RTM-GS.

Figure 9.
Eighteen latent motion topics discovered by RTM-GS.

Figure 10.
Twenty latent motion regions discovered by RTM-HSVG.

Figure 11.
Thirty-six latent motion topics discovered by RTM-HSVG.

Figure 12.
Twenty latent motion regions discovered by RTM-GS on longer burn-in time.

Figure 13.
Eighteen latent motion topics discovered by RTM-GS on longer burn-in time.

Figure 14.
Comparative results of ROC on real video.

Figure 15.
Locating abnormal events by RTM-HSVG.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Software and hardware platform.
| CPU | Intel® Core(TM) 2 Duo CPU E8400 @ 3.00 GHz 3.00 GHz |
| Memory | 2.00 G |
| OS | Window7 |
| Programing platform | Python 2.7.5 |
Table 2.
Parameter settings of RTM-HSVG and RTM-GS.
| RTM-GS | RTM-HSVG |
|---|---|
| Burn-in time ; After Markov chain convergence, sampling at intervals of 100 times; the total number of sampling is ; ; ; The hyper parameter is ; ; | Burn-in time ; After Markov chain convergence, sampling at intervals of 10 times; the total number of sampling is ; ;; The hyper parameter is ; ; |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Tang, L.; Liu, L.; Gan, J. A Regional Topic Model Using Hybrid Stochastic Variational Gibbs Sampling for Real-Time Video Mining. Algorithms 2018, 11, 97. https://doi.org/10.3390/a11070097
AMA Style
Tang L, Liu L, Gan J. A Regional Topic Model Using Hybrid Stochastic Variational Gibbs Sampling for Real-Time Video Mining. Algorithms. 2018; 11(7):97. https://doi.org/10.3390/a11070097
Chicago/Turabian StyleTang, Lin, Lin Liu, and Jianhou Gan. 2018. "A Regional Topic Model Using Hybrid Stochastic Variational Gibbs Sampling for Real-Time Video Mining" Algorithms 11, no. 7: 97. https://doi.org/10.3390/a11070097
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.